

Hybrid Deep Learning Framework for Continuous User Authentication Based on Smartphone Sensors



Abstract
1. Introduction
2. Related Work
3. Dataset Information
3.1. Data Collection and Preprocessing
3.1.1. MotionSense Dataset
- Accelerometer: captures acceleration (including gravity);
- Attitude: measures orientation angles (pitch, roll, and yaw);
- Gyroscope: records angular velocity.
3.1.2. Human Activity Recognition (HAR) Using Smartphones (UCI)
3.1.3. Overall Preprocessing Workflow for Both Datasets
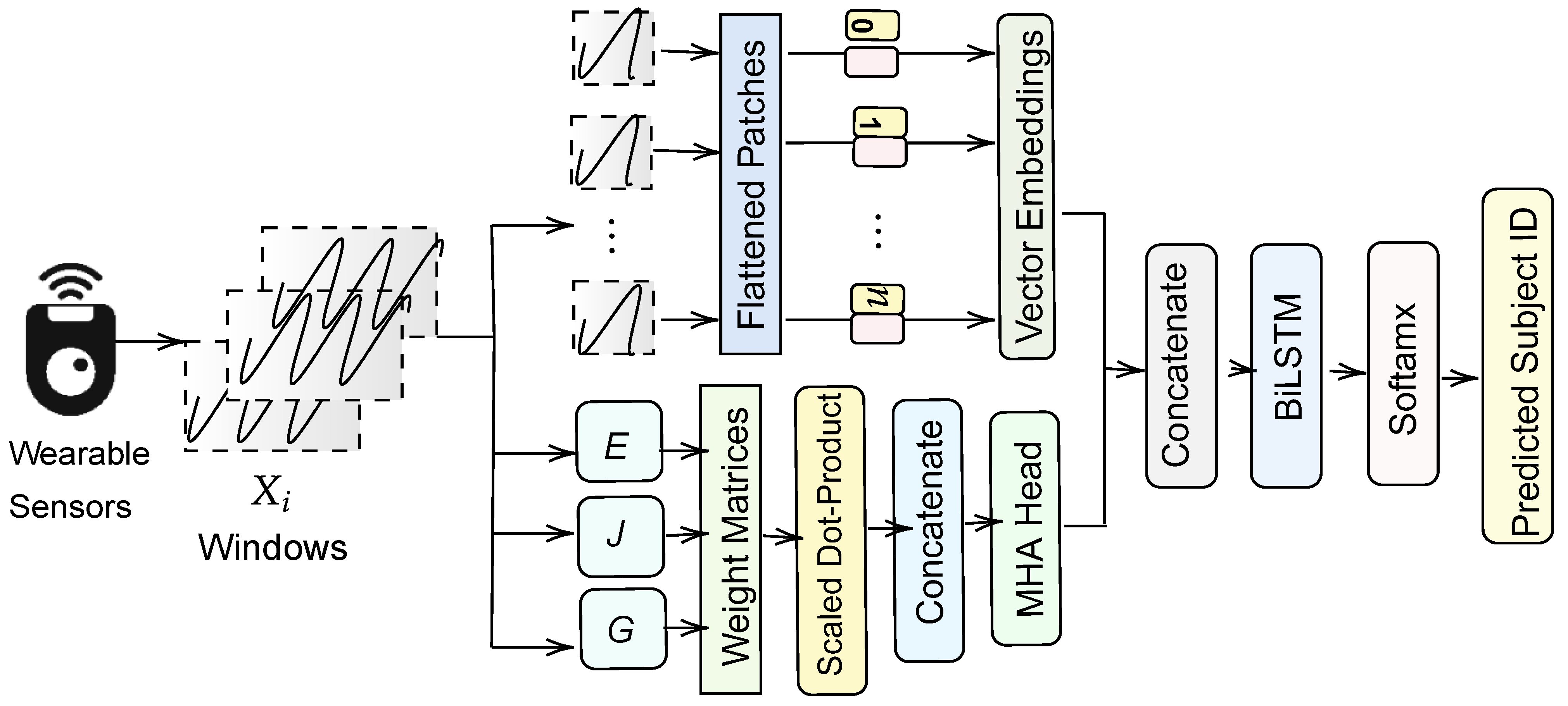
4. Proposed Method
4.1. Notation
4.2. Problem Formulation
4.3. Vision-Transformer-like Feature Extraction
4.4. Multi-Head Attention for Temporal Modeling
4.5. Bidirectional LSTM and Final Classification
4.6. Loss Function and Optimization
4.7. Key Implementation Details
4.8. Hyperparameter Optimization
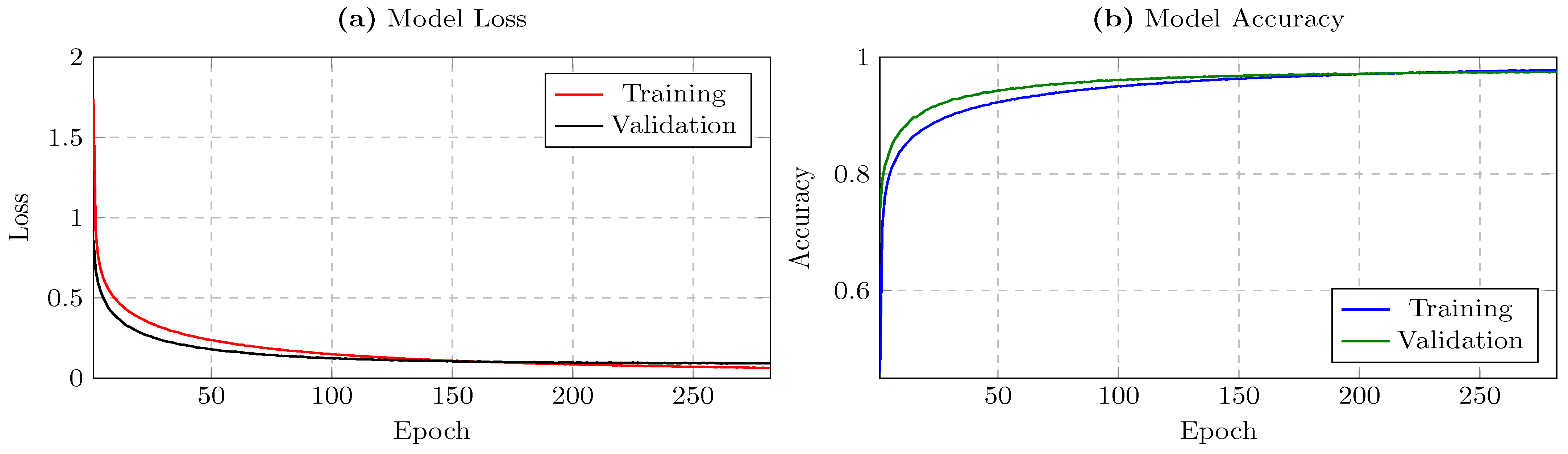
5. Evaluation and Validation
5.1. Metrics
5.2. Experimental Protocol
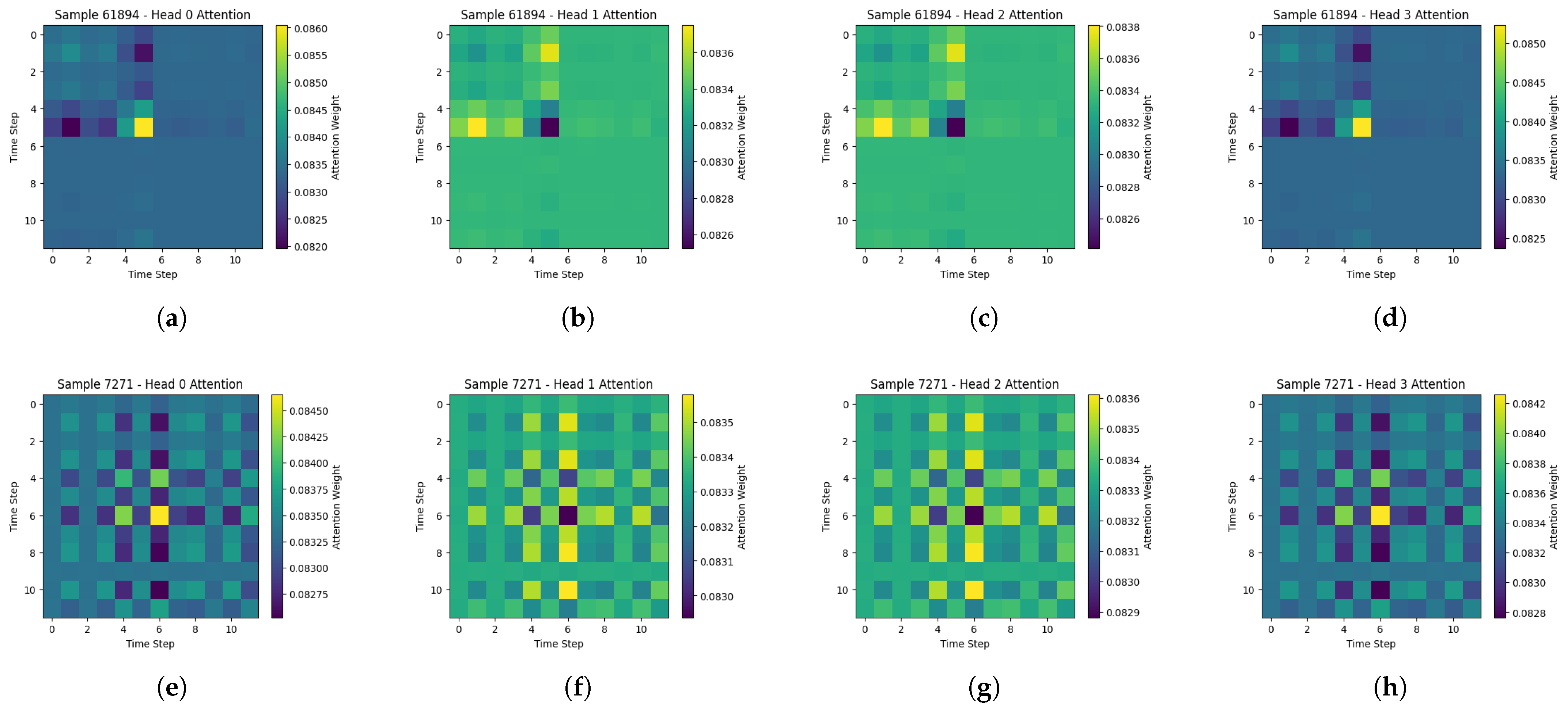
5.3. Results
Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Musa, H.S.; Krichen, M.; Altun, A.A.; Ammi, M. Survey on blockchain-based data storage security for android mobile applications. Sensors 2023, 23, 8749. [Google Scholar] [CrossRef] [PubMed]
- Malhotra, P.; Singh, Y.; Anand, P.; Bangotra, D.K.; Singh, P.K.; Hong, W.C. Internet of things: Evolution, concerns and security challenges. Sensors 2021, 21, 1809. [Google Scholar] [CrossRef] [PubMed]
- Baig, A.F.; Eskeland, S. Security, privacy, and usability in continuous authentication: A survey. Sensors 2021, 21, 5967. [Google Scholar] [CrossRef] [PubMed]
- Al-Naji, F.H.; Zagrouba, R. CAB-IoT: Continuous authentication architecture based on Blockchain for internet of things. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 2497–2514. [Google Scholar] [CrossRef]
- Ayeswarya, S.; Singh, K.J. A comprehensive review on secure biometric-based continuous authentication and user profiling. IEEE Access 2024, 12, 82996–83021. [Google Scholar] [CrossRef]
- Murmuria, R.; Stavrou, A.; Barbará, D.; Fleck, D. Continuous authentication on mobile devices using power consumption, touch gestures and physical movement of users. In Proceedings of the Research in Attacks, Intrusions, and Defenses: 18th International Symposium, RAID 2015, Kyoto, Japan, 2–4 November 2015; Proceedings 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 405–424. [Google Scholar]
- Incel, Ö.D.; Günay, S.; Akan, Y.; Barlas, Y.; Basar, O.E.; Alptekin, G.I.; Isbilen, M. DAKOTA: Sensor and touch screen-based continuous authentication on a mobile banking application. IEEE Access 2021, 9, 38943–38960. [Google Scholar] [CrossRef]
- Mekruksavanich, S.; Jitpattanakul, A. Deep learning approaches for continuous authentication based on activity patterns using mobile sensing. Sensors 2021, 21, 7519. [Google Scholar] [CrossRef] [PubMed]
- Stylios, I.; Kokolakis, S.; Thanou, O.; Chatzis, S. Behavioral biometrics & continuous user authentication on mobile devices: A survey. Inf. Fusion 2021, 66, 76–99. [Google Scholar]
- Gupta, S.; Maple, C.; Crispo, B.; Raja, K.; Yautsiukhin, A.; Martinelli, F. A survey of human-computer interaction (HCI) & natural habits-based behavioural biometric modalities for user recognition schemes. Pattern Recognit. 2023, 139, 109453. [Google Scholar]
- Nóbrega, M.L. Explainable and Interpretable Face Presentation Attack Detection Methods. Master’s Thesis, Universidade do Porto, Porto, Portugal, 2021. [Google Scholar]
- Parmar, V.; Sanghvi, H.A.; Patel, R.H.; Pandya, A.S. A comprehensive study on passwordless authentication. In Proceedings of the 2022 International Conference on Sustainable Computing and Data Communication Systems (ICSCDS), Erode, India, 7–9 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1266–1275. [Google Scholar]
- Han, A.H.; Lee, D.H. Detecting Risky Authentication Using the OpenID Connect Token Exchange Time. Sensors 2023, 23, 8256. [Google Scholar] [CrossRef] [PubMed]
- Sağbaş, E.A.; Ballı, S. Machine learning-based novel continuous authentication system using soft keyboard typing behavior and motion sensor data. Neural Comput. Appl. 2024, 36, 5433–5445. [Google Scholar] [CrossRef]
- Alzahrani, S.; Alderaan, J.; Alatawi, D.; Alotaibi, B. Continuous mobile user authentication using a hybrid cnn-bi-lstm approach. Comput. Mater. Contin. 2023, 75, 651–667. [Google Scholar] [CrossRef]
- Aleissaee, A.A.; Kumar, A.; Anwer, R.M.; Khan, S.; Cholakkal, H.; Xia, G.S.; Khan, F.S. Transformers in remote sensing: A survey. Remote Sens. 2023, 15, 1860. [Google Scholar] [CrossRef]
- Mienye, I.D.; Swart, T.G.; Obaido, G. Recurrent neural networks: A comprehensive review of architectures, variants, and applications. Information 2024, 15, 517. [Google Scholar] [CrossRef]
- Ali, A.M.; Benjdira, B.; Koubaa, A.; El-Shafai, W.; Khan, Z.; Boulila, W. Vision transformers in image restoration: A survey. Sensors 2023, 23, 2385. [Google Scholar] [CrossRef]
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Centeno, M.P.; Guan, Y.; van Moorsel, A. Mobile based continuous authentication using deep features. In Proceedings of the 2nd International Workshop on Embedded and Mobile Deep Learning, Munich, Germany, 15 June 2018; pp. 19–24. [Google Scholar]
- Abuhamad, M.; Abuhmed, T.; Mohaisen, D.; Nyang, D. AUToSen: Deep-learning-based implicit continuous authentication using smartphone sensors. IEEE Internet Things J. 2020, 7, 5008–5020. [Google Scholar] [CrossRef]
- Cao, Q.; Xu, F.; Li, H. User authentication by gait data from smartphone sensors using hybrid deep learning network. Mathematics 2022, 10, 2283. [Google Scholar] [CrossRef]
- Centeno, M.P.; van Moorsel, A.; Castruccio, S. Smartphone continuous authentication using deep learning autoencoders. In Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST), Calgary, AB, Canada, 28–30 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 147–1478. [Google Scholar]
- Wang, T.; Wang, Y. A Low-memory Mobile Phone Continuous Authentication Scheme Based on Multimodal Biometric Information. In Proceedings of the 2024 2nd International Conference On Mobile Internet, Cloud Computing and Information Security (MICCIS), Changsha, China, 11–14 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 148–154. [Google Scholar]
- Li, Y.; Sun, X.; Yang, Z.; Huang, H. SNNAuth: Sensor-Based Continuous Authentication on Smartphones Using Spiking Neural Networks. IEEE Internet Things J. 2024, 11, 15957–15968. [Google Scholar] [CrossRef]
- Shen, Z.; Li, S.; Zhao, X.; Zou, J. MMAuth: A continuous authentication framework on smartphones using multiple modalities. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1450–1465. [Google Scholar] [CrossRef]
- Li, Y.; Luo, J.; Deng, S.; Zhou, G. CNN-based continuous authentication on smartphones with conditional Wasserstein generative adversarial network. IEEE Internet Things J. 2021, 9, 5447–5460. [Google Scholar] [CrossRef]
- Ehatisham-ul-Haq, M.; Azam, M.A.; Loo, J.; Shuang, K.; Islam, S.; Naeem, U.; Amin, Y. Authentication of smartphone users based on activity recognition and mobile sensing. Sensors 2017, 17, 2043. [Google Scholar] [CrossRef] [PubMed]
- Sánchez, P.M.S.; Maimó, L.F.; Celdrán, A.H.; Pérez, G.M. AuthCODE: A privacy-preserving and multi-device continuous authentication architecture based on machine and deep learning. Comput. Secur. 2021, 103, 102168. [Google Scholar] [CrossRef]
- Cariello, N.; Levine, S.; Zhou, G.; Hoplight, B.; Gasti, P.; Balagani, K.S. SMARTCOPE: Smartphone change of possession evaluation for continuous authentication. Pervasive Mob. Comput. 2024, 97, 101873. [Google Scholar] [CrossRef]
- Lee, W.; Lee, R. Implicit Authentication with Smartphone Sensors Using Machine Learning. arXiv 2017, arXiv:1708.09754. [Google Scholar]
- Malekzadeh, M.; Clegg, R.G.; Cavallaro, A.; Haddadi, H. Protecting sensory data against sensitive inferences. In Proceedings of the 1st Workshop on Privacy by Design in Distributed Systems, Porto, Portugal, 23–26 April 2018; pp. 1–6. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the ESANN 2013 Proceedings, European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 5–7 October 2022; Volume 3, p. 3. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Data / Features | Classification | Method | Strengths (+) and Limitations (−) |
|---|---|---|---|---|
| Sagbas and Balli [14] | 59 participants; 125 features (accel., gyro, typing) | Multi-class (59 distinct users) | RF, kNN, SLR + CFS (feature selection) | +
Up to 93% accuracy; very fast (0.03 ms). − Accuracy is moderate compared to modern deep learning (which can be more than 93%). Classical ML may miss subtle temporal/contextual cues. |
| Alzahrani et al. [15] | Accelerometer, gyroscope data (raw sensor streams) | Multi-class | CNN and BiLSTM (no patching or advanced attention) | +
Significant improvement over classical ML; integrated deep approach. − No specialized segmentation or multi-head attention; may underutilize key sensor segments if user activities vary. |
| Centeno et al. [20] | Public human activity dataset; Siamese embeddings | Binary (pairs of sequences) | Siamese CNN (measures similarity between motion samples) | +
Up to 97.8% accuracy; robust to frequency/length changes. − Pairwise verification less scalable for large multi-class user sets. |
| Abuhamad et al. [21] | Behavioral data: accel., gyro, magnetometer | Binary (one user vs. others) | Deep pipeline (implicit user patterns) | +
98% F1-score, low rejection. − Not multi-class; only legitimate vs. others approach. |
| Mekruksavanich and Jitpattanakul [8] | Accel., gyro, magnet. for activity-based auth | Binary (owner vs. impostor) | Deep learning classifiers (no advanced attention) | +
Effective multi-sensor integration. − No multi-class discrimination among multiple valid users. |
| Cao et al. [22] | Gait data from smartphone sensors | Multi-class (user identification) | Hybrid CNN and LSTM (for gait patterns) | +
Higher performance than classical gait methods. − Focus on gait alone; may ignore other daily user activities. |
| Centeno et al. [23] | Smartphone sensors; autoencoder-based | Binary (anomaly detection) | Deep autoencoders (legit vs. fraudulent) | +
High accuracy, minimal overhead. − Framed as anomaly detection, not a full multi-class user ID. |
| Wang et al. [24] | Multimodal (touch and motion); CNN–LSTM–Attention | Multi-class | Memory-efficient CNN–LSTM–Attention (no multi-head or patch-based) | +
Robust performance combining multiple data sources. − Limited segmentation detail; lacks advanced multi-head attention for local/global dependencies. |
| Li et al. [25] (SNNAuth) | Accel., gyro + spiking neural networks (SNNs) | Binary (one user vs. impostor) | SNN-based energy-efficient approach | +
Low power usage,
high discrimination. − Not designed for multi-user classification; focus on single user. |
| Shen et al. [26] | Multimodal sensor data (CNN and LSTM), final one-class classifier | One-class (legitimate vs. impostor) | CNN–LSTM and deep one-class (DeSVDD style) | +
Accurate single-user verification
(multiple data sources). − Does not handle multi-subject classification; no patch-based attention. |
| Yantao et al. [27] (CAGANet) | CNN-extracted features and CWGAN for augmentation | One-class (OC-SVM, LOF, IF, EE) | Data augmentation (Wasserstein GAN); CNN feature extraction | +
Robustness via CWGAN;
strong performance
for single-user profile. − Not multi-class ID; verifies “one user vs. all” scenario only. |
| Muaaz et al. [28] | Accel., gyro, magnet.; 6 daily activities and 5 phone positions | Multi-class | Classical ML (time+frequency features); variable usage context | +
Covers diverse real behaviors and phone positions;
multi-class. − Conventional feature engineering; only well-known classifiers, no end-to-end deep approach. |
| Sánchez et al. [29] | Behavioral data from multiple devices (smart office) | Multi-device (multi-class context) | Machine/deep learning with privacy focus | +
Privacy-preserving analytics
across heterogeneous devices. − Less emphasis on specialized time-series extraction for single smartphone sensors. |
| Cariello et al. [30] (SMARTCOPE) | Accel., gyro for change-of-possession (grab, give, rest) | Event-based trigger (then re-auth) | Detect short, discrete transitions and re-auth invocation | +
Reduces false prompts,
shortens attacker window
by event-driven checks. − Focus on discrete transitions; no advanced segmentation/attention for continuous or subtle behaviors. |
| Lee and Lee [31] | Behavioral signals (accel., gyro), private dataset | Implicit continuous | Machine learning (∼98.1% accuracy) | +
High background auth accuracy;
user convenience. − Smaller private dataset, simpler ML pipelines. |
| Our Proposed Hybrid Approach | Time-series data (advanced patch extraction, multi-head attention, BiLSTM) | Multi-class (user ID) | Patch-based segmentation and multi-head attention and BiLSTM | +
on MotionSense;
on UCI HAR;
outperforms Transformer, Informer, CNN and LSTM. − More complex architecture (i.e., higher computation). |
| Dataset | Participants | Activities | Features | Sampling Rate | Notes/Window Setup |
|---|---|---|---|---|---|
| MotionSense | 24 (14 M, 10 F) | 6 | 12 | 50 Hz | 15 trials per participant a |
| UCI HAR | 30 (ages 19–48) | 6 | 561 b | 50 Hz | 2.56 s windows (50% overlap) |
| Model | MotionSense Accuracy | UCI HAR Accuracy |
|---|---|---|
| Logistic regression | 0.5743 | 0.8229 |
| K-nearest neighbors | 0.9384 | 0.8100 |
| Naive Bayes | 0.3866 | 0.3060 |
| LSTM | 0.9374 | 0.7649 |
| CNN | 0.9251 | 0.8019 |
| Informer | 0.6719 | 0.8374 |
| Transformer | 0.9177 | 0.7939 |
| Our Hybrid Model | 0.9751 | 0.8937 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, B.; Alotaibi, M. Hybrid Deep Learning Framework for Continuous User Authentication Based on Smartphone Sensors. Sensors 2025, 25, 2817. https://doi.org/10.3390/s25092817
Alotaibi B, Alotaibi M. Hybrid Deep Learning Framework for Continuous User Authentication Based on Smartphone Sensors. Sensors. 2025; 25(9):2817. https://doi.org/10.3390/s25092817
Chicago/Turabian StyleAlotaibi, Bandar, and Munif Alotaibi. 2025. "Hybrid Deep Learning Framework for Continuous User Authentication Based on Smartphone Sensors" Sensors 25, no. 9: 2817. https://doi.org/10.3390/s25092817
APA StyleAlotaibi, B., & Alotaibi, M. (2025). Hybrid Deep Learning Framework for Continuous User Authentication Based on Smartphone Sensors. Sensors, 25(9), 2817. https://doi.org/10.3390/s25092817