

A Survey of the Multi-Sensor Fusion Object Detection Task in Autonomous Driving


Abstract
1. Introduction
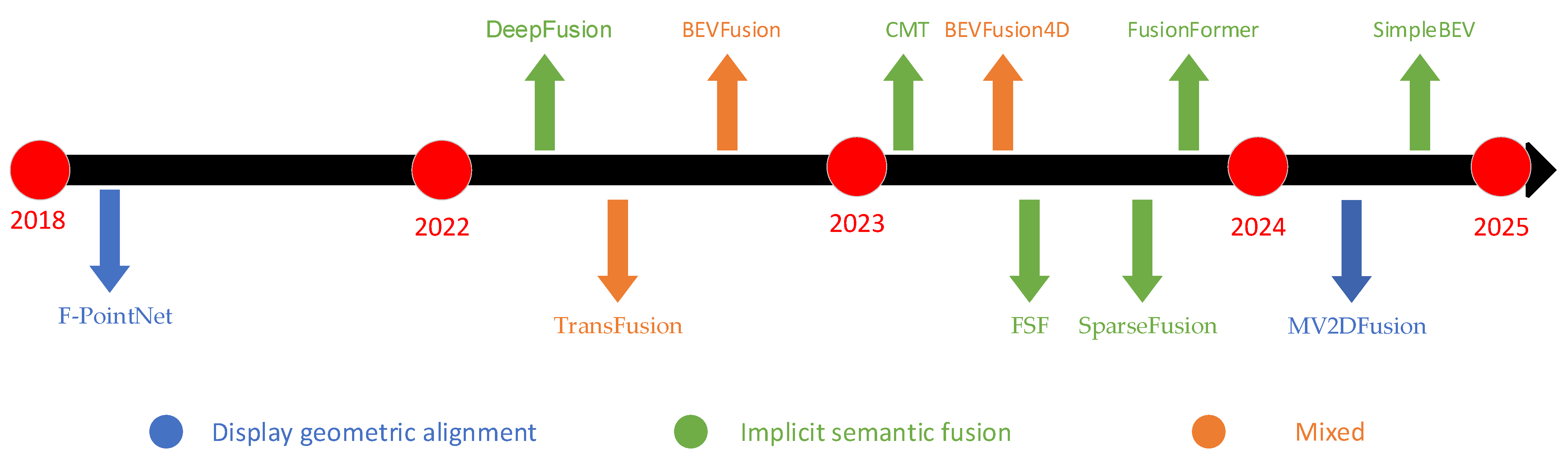
2. The Origin and Development of Multi-Sensor Fusion Object Detection
3. Characteristics of Three Sensors
3.1. Camera
3.2. LiDAR
3.3. Millimeter-Wave Radar
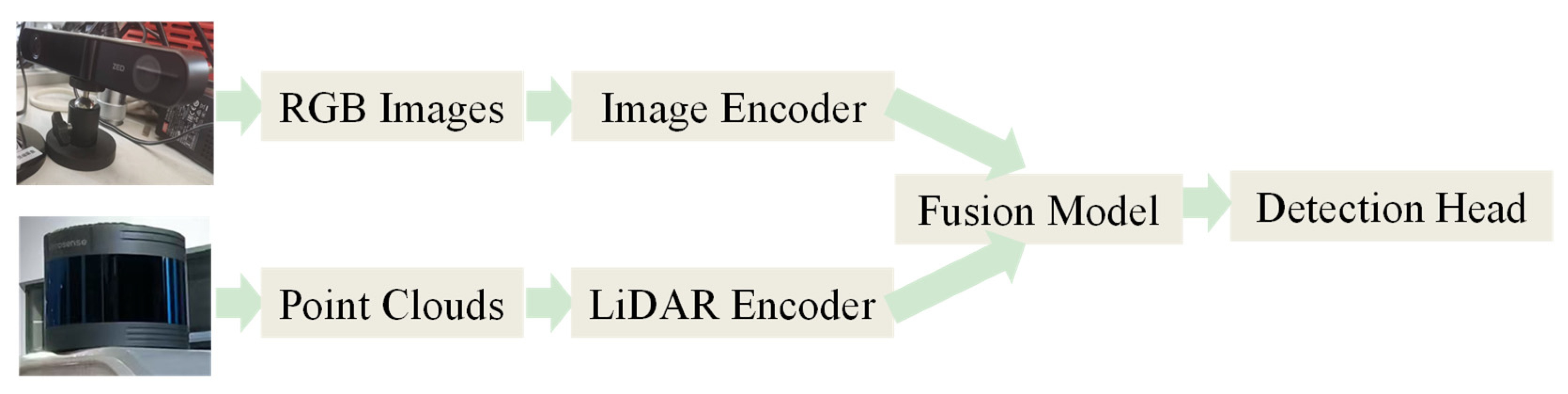
4. Multi-Sensor Feature Fusion Object Detection
4.1. Feature-Level Fusion
4.2. Proposal-Level Fusion
5. Datasets and Evaluation Metrics
5.1. Datasets
5.2. Evaluation Metrics
6. Multi-Task Applications of Multi-Sensor Fusion Target Detection Algorithms
6.1. Segmentation
6.2. Tracking and Path Planning
6.3. Lane Detection
6.4. Traffic Flow Analysis
6.5. Dynamic Scene Understanding
7. Summary and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Nemati, M.; Ding, J.; Choi, J. Short-Range Ambient Backscatter Communication Using Reconfigurable Intelligent Surfaces. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference (WCNC), Seoul, Republic of Korea, 25–28 May 2020; pp. 1–6. [Google Scholar]
- Wang, L.; Zhang, X.; Song, Z.; Bi, J.; Zhang, G.; Wei, H.; Tang, L.; Yang, L.; Li, J.; Jia, C.; et al. Multi-Modal 3D Object Detection in Autonomous Driving: A Survey and Taxonomy. IEEE Trans. Intell. Veh. 2023, 8, 3781–3798. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Gupta, H.; Kotlyar, O.; Andreasson, H.; Lilienthal, A.J. Robust Object Detection in Challenging Weather Conditions. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3 January 2024; pp. 7508–7517. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Deng, D. DBSCAN Clustering Algorithm Based on Density. In Proceedings of the 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 25–27 September 2020; pp. 949–953. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhou, Q.; Yu, C. Point RCNN: An Angle-Free Framework for Rotated Object Detection. Remote Sens. 2022, 14, 2605. [Google Scholar] [CrossRef]
- Ghiasi, G.; Lin, T.-Y.; Pang, R.; Le, Q.V. NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, X.; Li, K.; Chehri, A. Multi-Sensor Fusion Technology for 3D Object Detection in Autonomous Driving: A Review. IEEE Trans. Intell. Transport. Syst. 2024, 25, 1148–1165. [Google Scholar] [CrossRef]
- Li, L.; Xie, S.; Ning, J.; Chen, Q.; Zhang, Z. Evaluating Green Tea Quality Based on Multisensor Data Fusion Combining Hyperspectral Imaging and Olfactory Visualization Systems. J. Sci. Food Agric. 2019, 99, 1787–1794. [Google Scholar] [CrossRef]
- Guo, W.; Wang, J.; Wang, S. Deep Multimodal Representation Learning: A Survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Cheng, J.; Sun, J.; Shi, L.; Dai, C. An Effective Method Fusing Electronic Nose and Fluorescence Hyperspectral Imaging for the Detection of Pork Freshness. Food Biosci. 2024, 59, 103880. [Google Scholar] [CrossRef]
- Khaleghi, B.; Khamis, A.; Karray, F.O.; Razavi, S.N. Multisensor Data Fusion: A Review of the State-of-the-Art. Inf. Fusion. 2013, 14, 28–44. [Google Scholar] [CrossRef]
- Dubertrand, R.; Hubert, M.; Schlagheck, P.; Vandewalle, N.; Bastin, T.; Martin, J. Scattering Theory of Walking Droplets in the Presence of Obstacles. New J. Phys. 2016, 18, 113037. [Google Scholar] [CrossRef]
- Ji, T.; Sivakumar, A.N.; Chowdhary, G.; Driggs-Campbell, K. Proactive Anomaly Detection for Robot Navigation With Multi-Sensor Fusion. IEEE Robot. Autom. Lett. 2022, 7, 4975–4982. [Google Scholar] [CrossRef]
- Ren, Y.; Huang, X.; Aheto, J.H.; Jiang, L.; Qian, C.; Wang, Y.; Zhang, X.; Yu, S.; Wang, L. Development and Test of a Smart Multisensory Device for Preserved Eggs. J. Food Process Eng. 2022, 45, e14093. [Google Scholar] [CrossRef]
- Han, F.; Zhang, D.; Aheto, J.H.; Feng, F.; Duan, T. Integration of a Low-cost Electronic Nose and a Voltammetric Electronic Tongue for Red Wines Identification. Food Sci. Nutr. 2020, 8, 4330–4339. [Google Scholar] [CrossRef]
- Xu, S.; Xu, X.; Zhu, Q.; Meng, Y.; Yang, G.; Feng, H.; Yang, M.; Zhu, Q.; Xue, H.; Wang, B. Monitoring Leaf Nitrogen Content in Rice Based on Information Fusion of Multi-Sensor Imagery from UAV. Precis. Agric. 2023, 24, 2327–2349. [Google Scholar] [CrossRef]
- Grewal, M.S.; Andrews, A.P. Kalman Filtering: Theory and Practice Using MATLAB®, 4th ed.; Wiley: Hoboken, NJ, USA, 2015; ISBN 978-1-118-85121-0. [Google Scholar]
- Buch, J.R.; Kakad, Y.P.; Amengonu, Y.H. Performance Comparison of Extended Kalman Filter and Unscented Kalman Filter for the Control Moment Gyroscope Inverted Pendulum. In Proceedings of the 2017 25th International Conference on Systems Engineering (ICSEng), Las Vegas, NV, USA, 22–24 August 2017; pp. 57–62. [Google Scholar]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Zhu, X.; Chikangaise, P.; Shi, W.; Chen, W.-H.; Yuan, S. Review of Intelligent Sprinkler Irrigation Technologies for Remote Autonomous System. Int. J. Agric. Biol. Eng. 2018, 11, 23–30. [Google Scholar] [CrossRef]
- Xiang, H.; Tian, L. Development of a Low-Cost Agricultural Remote Sensing System Based on an Autonomous Unmanned Aerial Vehicle (UAV). Biosyst. Eng. 2011, 108, 174–190. [Google Scholar] [CrossRef]
- Ouyang, Q.; Zhao, J.; Pan, W.; Chen, Q. Real-Time Monitoring of Process Parameters in Rice Wine Fermentation by a Portable Spectral Analytical System Combined with Multivariate Analysis. Food Chem. 2016, 190, 135–141. [Google Scholar] [CrossRef]
- Liu, J.; Abbas, I.; Noor, R.S. Development of Deep Learning-Based Variable Rate Agrochemical Spraying System for Targeted Weeds Control in Strawberry Crop. Agronomy 2021, 11, 1480. [Google Scholar] [CrossRef]
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep Learning for Image and Point Cloud Fusion in Autonomous Driving: A Review. IEEE Trans. Intell. Transport. Syst. 2022, 23, 722–739. [Google Scholar] [CrossRef]
- Sun, J.; Wang, P.; Qin, Z.; Qiao, H. Overview of Camera Calibration for Computer Vision. In Proceedings of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 29 June–4 July 2014; pp. 86–92. [Google Scholar]
- Sim, S.; Sock, J.; Kwak, K. Indirect Correspondence-Based Robust Extrinsic Calibration of LiDAR and Camera. Sensors 2016, 16, 933. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Zhang, L.; Xing, C.; Xie, P.; Cao, Y. Target Three-Dimensional Reconstruction From the Multi-View Radar Image Sequence. IEEE Access 2019, 7, 36722–36735. [Google Scholar] [CrossRef]
- De Silva, V.; Roche, J.; Kondoz, A. Robust Fusion of LiDAR and Wide-Angle Camera Data for Autonomous Mobile Robots. Sensors 2018, 18, 2730. [Google Scholar] [CrossRef]
- Fiddian-Green, R.G.; Silen, W. Mechanisms of Disposal of Acid and Alkali in Rabbit Duodenum. Am. J. Physiol. 1975, 229, 1641–1648. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Niu, Q. Multi-Sensor Fusion in Automated Driving: A Survey. IEEE Access 2020, 8, 2847–2868. [Google Scholar] [CrossRef]
- Roriz, R.; Cabral, J.; Gomes, T. Automotive LiDAR Technology: A Survey. IEEE Trans. Intell. Transport. Syst. 2022, 23, 6282–6297. [Google Scholar] [CrossRef]
- Yaopeng, L.; Xiaojun, G.; Shaojing, S.; Bei, S. Review of a 3D Lidar Combined with Single Vision Calibration. In Proceedings of the 2021 IEEE International Conference on Data Science and Computer Application (ICDSCA), Dalian, China, 29 October 2021; pp. 397–404. [Google Scholar]
- Chang, J.; Hu, R.; Huang, F.; Xu, D.; Hsu, L.-T. LiDAR-Based NDT Matching Performance Evaluation for Positioning in Adverse Weather Conditions. IEEE Sens. J. 2023, 23, 25346–25355. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Liu, A.; Yuan, L. A Review of Image and Point Cloud Fusion-Based 3D Object Detection for Autonomous Driving. In Proceedings of the 2023 China Automation Congress (CAC), Chongqing, China, 17 November 2023; pp. 7828–7833. [Google Scholar]
- Hussain, M.; O’Nils, M.; Lundgren, J.; Mousavirad, S.J. A Comprehensive Review on Deep Learning-Based Data Fusion. IEEE Access 2024, 12, 180093–180124. [Google Scholar] [CrossRef]
- Yang, W.; Bu, Y.; Li, D.; Xu, W. MCSGCalib: Multi-Constraint-Based Extrinsic Calibration of Solid-State LiDAR and GNSS/INS for Autonomous Vehicles. IEEE Trans. Intell. Transport. Syst. 2024, 25, 18791–18804. [Google Scholar] [CrossRef]
- Huang, Y.; Lan, L.; Yang, Y.; Liu, J.; Deng, K.; Liu, Y.; Zheng, K. Automotive Millimeter Wave Radar Imaging Techniques. In Proceedings of the 2023 International Conference on Microwave and Millimeter Wave Technology (ICMMT), Qingdao, China, 14 May 2023; pp. 1–2. [Google Scholar]
- Shen, X.; Shao, J.; Zhang, X.; Zhao, C.; Wang, K.; Luo, L.; Ouyang, B. Research on Automatic Calibration Method of Transmission Loss for Millimeter-Wave Radar Testing System in Intelligent Vehicle. In Proceedings of the 2023 IEEE International Workshop on Metrology for Automotive (Metro Automotive), Modena, Italy, 28 June 2023; pp. 223–227. [Google Scholar]
- Cao, J.; Fang, Y.; Xu, J.; Ling, Q. Feature Fusion and Interaction Network for 3D Object Detection Based on 4D Millimeter Wave Radars. In Proceedings of the 2024 43rd Chinese Control Conference (CCC), Kunming, China, 28–31 July 2024; pp. 8876–8881. [Google Scholar]
- Bruder, J.A.; Brinkmann, M.C.; Whitley, G.R.; Lane, T.L. Testing of MMW Radar Performance in Adverse Weather Conditions and Clutter Backgrounds. In Proceedings of the RADAR 2002, Edinburgh, UK, 22–25 April 2002; pp. 547–551. [Google Scholar]
- Su, Z.; Ming, B.; Hua, W. An Asymmetric Radar-Camera Fusion Framework for Autonomous Driving. In Proceedings of the 2023 IEEE Sensors, Vienna, Austria, 29 October 2023; pp. 1–4. [Google Scholar]
- Yang, H.; Meng, Y.; Chen, B.; Li, J.; Chen, G.; Qing, A. Hardware and Software Co-Processing Acceleration Architecture of Range Migration Algorithm for 3-D Millimeter-Wave Imaging. In Proceedings of the 2024 IEEE International Conference on Computational Electromagnetics (ICCEM), Nanjing, China, 15–17 April 2024; pp. 1–3. [Google Scholar]
- Fan, L.; Wang, J.; Chang, Y.; Li, Y.; Wang, Y.; Cao, D. 4D mmWave Radar for Autonomous Driving Perception: A Comprehensive Survey. IEEE Trans. Intell. Veh. 2024, 9, 4606–4620. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Advances in Neural Information Processing Systems 30 (NIPS 2017); Curran Associates: Montreal, QC, Canada, 2017. [Google Scholar]
- Zhu, W.; Sun, J.; Wang, S.; Shen, J.; Yang, K.; Zhou, X. Identifying Field Crop Diseases Using Transformer-Embedded Convolutional Neural Network. Agriculture 2022, 12, 1083. [Google Scholar] [CrossRef]
- Ji, W.; Wang, J.; Xu, B.; Zhang, T. Apple Grading Based on Multi-Dimensional View Processing and Deep Learning. Foods 2023, 12, 2117. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Guo, Y.; Zhang, L.; Ding, Y.; Zhang, G.; Zhang, D. Improved Lightweight Zero-Reference Deep Curve Estimation Low-Light Enhancement Algorithm for Night-Time Cow Detection. Agriculture 2024, 14, 1003. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Wang, Y.; Guizilini, V.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. DETR3D: 3D Object Detection from Multi-View Images via 3D-to-2D Queries 2021. In Proceedings of the 5th Conference on Robot Learning, Auckland, New Zealand, 14–18 December 2022. [Google Scholar]
- Li, Y.; Yu, A.W.; Meng, T.; Caine, B.; Ngiam, J.; Peng, D.; Shen, J.; Wu, B.; Lu, Y.; Zhou, D.; et al. DeepFusion: Lidar-Camera Deep Fusion for Multi-Modal 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Besl, P.J.; McKay, N.D. A Method for Registration of 3-D Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 239–256. [Google Scholar] [CrossRef]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.; Han, S. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation, London, UK, 29 May–2 June 2023. [Google Scholar]
- Cai, H.; Zhang, Z.; Zhou, Z.; Li, Z.; Ding, W.; Zhao, J. BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird’s-Eye-View via Cross-Modality Guidance and Temporal Aggregation. arXiv 2023, arXiv:2303.17099. [Google Scholar]
- Zhao, Y.; Gong, Z.; Zheng, P.; Zhu, H.; Wu, S. SimpleBEV: Improved LiDAR-Camera Fusion Architecture for 3D Object Detection. arXiv 2024, arXiv:2411.05292. [Google Scholar]
- Hu, C.; Zheng, H.; Li, K.; Xu, J.; Mao, W.; Luo, M.; Wang, L.; Chen, M.; Peng, Q.; Liu, K.; et al. FusionFormer: A Multi-Sensory Fusion in Bird’s-Eye-View and Temporal Consistent Transformer for 3D Object Detection. arXiv 2023, arXiv:2309.05257. [Google Scholar]
- Yan, J.; Liu, Y.; Sun, J.; Jia, F.; Li, S.; Wang, T.; Zhang, X. Cross Modal Transformer: Towards Fast and Robust 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 1–6 October 2023. [Google Scholar]
- Philion, J.; Fidler, S. Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D 2020. In Computer Vision–ECCV 2020, Proceedings of the 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16; Springer International Publishing: Cham, Switzerland, 2020. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2019, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Huang, J.; Huang, G. BEVDet4D: Exploit Temporal Cues in Multi-Camera 3D Object Detection. arXiv 2022, arXiv:2203.17054. [Google Scholar]
- Sabater, A.; Montesano, L.; Murillo, A.C. Event Transformer. A Sparse-Aware Solution for Efficient Event Data Processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum PointNets for 3D Object Detection from RGB-D Data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Li, Y.; Fan, L.; Liu, Y.; Huang, Z.; Chen, Y.; Wang, N.; Zhang, Z. Fully Sparse Fusion for 3D Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 7217–7231. [Google Scholar] [CrossRef] [PubMed]
- Xie, Y.; Xu, C.; Rakotosaona, M.-J.; Rim, P.; Tombari, F.; Keutzer, K.; Tomizuka, M.; Zhan, W. SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 1–6 October 2023. [Google Scholar]
- Wang, Z.; Huang, Z.; Gao, Y.; Wang, N.; Liu, S. MV2DFusion: Leveraging Modality-Specific Object Semantics for Multi-Modal 3D Detection. arXiv 2024, arXiv:2408.05945. [Google Scholar]
- Zhou, C.; Yu, L.; Babu, A.; Tirumala, K.; Yasunaga, M.; Shamis, L.; Kahn, J.; Ma, X.; Zettlemoyer, L.; Levy, O. Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model. arXiv 2024, arXiv:2408.11039. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Wang, Z.; Jia, K. Frustum ConvNet: Sliding Frustums to Aggregate Local Point-Wise Features for Amodal 3D Object Detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-View 3D Object Detection Network for Autonomous Driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. PointPillars: Fast Encoders for Object Detection from Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, H.; Liang, L.; Zeng, P.; Song, X.; Wang, Z. SparseLIF: High-Performance Sparse LiDAR-Camera Fusion for 3D Object Detection. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 109–128. [Google Scholar]
- Zhang, Y.; Wang, Z.; Wang, H.; Blaabjerg, F. Artificial Intelligence-Aided Thermal Model Considering Cross-Coupling Effects. IEEE Trans. Power Electron. 2020, 35, 9998–10002. [Google Scholar] [CrossRef]
- Wang, S.; Feng, L.; Xiao, D.; Hu, Y. Human-in-the-Loop Assisted Trafficability Prediction for Planetary Rover on Soft Dangerous Terrains. IEEE Trans. Automat. Sci. Eng. 2025, 22, 4651–4660. [Google Scholar] [CrossRef]
- Feng, L.; Wang, S.; Shi, J.; Xiong, P.; Chen, C.; Xiao, D.; Song, A.; Liu, P.X. An Interpretable Nonlinear Decoupling and Calibration Approach to Wheel Force Transducers. IEEE Trans. Intell. Transport. Syst. 2024, 25, 225–236. [Google Scholar] [CrossRef]
- Feng, L.; Miao, T.; Jiang, X.; Cheng, M.; Hu, Y.; Zhang, W.; Song, A. An Instrumented Wheel to Measure the Wheel–Terrain Interactions of Planetary Robotic Wheel-on-Limb System on Sandy Terrains. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar] [CrossRef]
- Wang, Y.; Han, Z.; Xing, Y.; Xu, S.; Wang, J. A Survey on Datasets for Decision-Making of Autonomous Vehicle. IEEE Intell. Transp. Syst. Mag. 2024, 16, 23–40. [Google Scholar] [CrossRef]
- Awais, M.; Li, W.; Hussain, S.; Cheema, M.J.M.; Li, W.; Song, R.; Liu, C. Comparative Evaluation of Land Surface Temperature Images from Unmanned Aerial Vehicle and Satellite Observation for Agricultural Areas Using In Situ Data. Agriculture 2022, 12, 184. [Google Scholar] [CrossRef]
- Laflamme, C.-É.N.; Pomerleau, F.; Giguère, P. Driving Datasets Literature Review. arXiv 2019, arXiv:1910.11968. [Google Scholar]
- Yu, J.; Zhangzhong, L.; Lan, R.; Zhang, X.; Xu, L.; Li, J. Ensemble Learning Simulation Method for Hydraulic Characteristic Parameters of Emitters Driven by Limited Data. Agronomy 2023, 13, 986. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhao, Y.; Zhang, X.; Sun, J.; Yu, T.; Cai, Z.; Zhang, Z.; Mao, H. Low-Cost Lettuce Height Measurement Based on Depth Vision and Lightweight Instance Segmentation Model. Agriculture 2024, 14, 1596. [Google Scholar] [CrossRef]
- Kim, T.; Jeon, H.; Lim, Y. Challenges of YOLO Series for Object Detection in Extremely Heavy Rain: CALRA Simulator Based Synthetic Evaluation Dataset. arXiv 2023, arXiv:2312.07976. [Google Scholar]
- Ma, J.; Zhao, Y.; Fan, W.; Liu, J. An Improved YOLOv8 Model for Lotus Seedpod Instance Segmentation in the Lotus Pond Environment. Agronomy 2024, 14, 1325. [Google Scholar] [CrossRef]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The ApolloScape Open Dataset for Autonomous Driving and Its Application. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2702–2719. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Barnes, D.; Gadd, M.; Murcutt, P.; Newman, P.; Posner, I. The Oxford Radar RobotCar Dataset: A Radar Extension to the Oxford RobotCar Dataset. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6433–6438. [Google Scholar]
- Wilson, B.; Qi, W.; Agarwal, T.; Lambert, J.; Singh, J.; Khandelwal, S.; Pan, B.; Kumar, R.; Hartnett, A.; Pontes, J.K.; et al. Argoverse 2: Next Generation Datasets for Self-Driving Perception and Forecasting. arXiv 2023, arXiv:2301.00493. [Google Scholar]
- Xiao, P.; Shao, Z.; Hao, S.; Zhang, Z.; Chai, X.; Jiao, J.; Li, Z.; Wu, J.; Sun, K.; Jiang, K.; et al. PandaSet: Advanced Sensor Suite Dataset for Autonomous Driving. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021. [Google Scholar]
- Geyer, J.; Kassahun, Y.; Mahmudi, M.; Ricou, X.; Durgesh, R.; Chung, A.S.; Hauswald, L.; Pham, V.H.; Mühlegg, M.; Dorn, S.; et al. A2D2: Audi Autonomous Driving Dataset. arXiv 2020, arXiv:2004.06320. [Google Scholar]
- Patil, A.; Malla, S.; Gang, H.; Chen, Y.-T. The H3D Dataset for Full-Surround 3D Multi-Object Detection and Tracking in Crowded Urban Scenes. In Proceedings of the 2019 International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Bhattacharyya, A.; Reino, D.O.; Fritz, M.; Schiele, B. Euro-PVI: Pedestrian Vehicle Interactions in Dense Urban Centers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. KAIST Multi-Spectral Day/Night Data Set for Autonomous and Assisted Driving. IEEE Trans. Intell. Transport. Syst. 2018, 19, 934–948. [Google Scholar] [CrossRef]
- Feng, G.; Wang, C.; Wang, A.; Gao, Y.; Zhou, Y.; Huang, S.; Luo, B. Segmentation of Wheat Lodging Areas from UAV Imagery Using an Ultra-Lightweight Network. Agriculture 2024, 14, 244. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, A.; Liu, J.; Faheem, M. A Comparative Study of Semantic Segmentation Models for Identification of Grape with Different Varieties. Agriculture 2021, 11, 997. [Google Scholar] [CrossRef]
- Tang, S.; Xia, Z.; Gu, J.; Wang, W.; Huang, Z.; Zhang, W. High-Precision Apple Recognition and Localization Method Based on RGB-D and Improved SOLOv2 Instance Segmentation. Front. Sustain. Food Syst. 2024, 8, 1403872. [Google Scholar] [CrossRef]
- Zhu, J.; Sun, B.; Cai, J.; Xu, Y.; Lu, F.; Ma, H. Inspection and Classification of Wheat Quality Using Image Processing. Qual. Assur. Saf. Crops Foods 2023, 15, 43–54. [Google Scholar] [CrossRef]
- Zhuang, Z.; Li, R.; Jia, K.; Wang, Q.; Li, Y.; Tan, M. Perception-Aware Multi-Sensor Fusion for 3D LiDAR Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 16260–16270. [Google Scholar]
- Gao, J.; Qi, H. Soil Throwing Experiments for Reverse Rotary Tillage at Various Depths, Travel Speeds, and Rotational Speeds. Trans. ASABE 2017, 60, 1113–1121. [Google Scholar] [CrossRef]
- Ye, T.; Jing, W.; Hu, C.; Huang, S.; Gao, L.; Li, F.; Wang, J.; Guo, K.; Xiao, W.; Mao, W.; et al. FusionAD: Multi-Modality Fusion for Prediction and Planning Tasks of Autonomous Driving. arXiv 2023, arXiv:2308.01006. [Google Scholar]
- Sun, J.; Wang, Z.; Ding, S.; Xia, J.; Xing, G. Adaptive Disturbance Observer-Based Fixed Time Nonsingular Terminal Sliding Mode Control for Path-Tracking of Unmanned Agricultural Tractors. Biosyst. Eng. 2024, 246, 96–109. [Google Scholar] [CrossRef]
- Wang, Q.; Qin, W.; Liu, M.; Zhao, J.; Zhu, Q.; Yin, Y. Semantic Segmentation Model-Based Boundary Line Recognition Method for Wheat Harvesting. Agriculture 2024, 14, 1846. [Google Scholar] [CrossRef]
- Li, J.; Shang, Z.; Li, R.; Cui, B. Adaptive Sliding Mode Path Tracking Control of Unmanned Rice Transplanter. Agriculture 2022, 12, 1225. [Google Scholar] [CrossRef]
- Guo, N.; Zhang, X.; Zou, Y. Real-Time Predictive Control of Path Following to Stabilize Autonomous Electric Vehicles Under Extreme Drive Conditions. Automot. Innov. 2022, 5, 453–470. [Google Scholar] [CrossRef]
- He, X.; Lv, C. Towards Safe Autonomous Driving: Decision Making with Observation-Robust Reinforcement Learning. Automot. Innov. 2023, 6, 509–520. [Google Scholar] [CrossRef]
- Fahrenkrog, F.; Reithinger, S.; Gülsen, B.; Raisch, F. European Research Project’s Contributions to a Safer Automated Road Traffic. Automot. Innov. 2023, 6, 521–530. [Google Scholar] [CrossRef]
- Liu, W.; Zhou, J.; Liu, Y.; Zhang, T.; Yan, M.; Chen, J.; Zhou, C.; Hu, J.; Chen, X. An Ultrasonic Ridge-Tracking Method Based on Limiter Sliding Window Filter and Fuzzy Pure Pursuit Control for Ridge Transplanter. Agriculture 2024, 14, 1713. [Google Scholar] [CrossRef]
- Zhang, X.; Gong, Y.; Li, Z.; Liu, X.; Pan, S.; Li, J. Multi-Modal Attention Guided Real-Time Lane Detection. In Proceedings of the 2021 6th IEEE International Conference on Advanced Robotics and Mechatronics (ICARM), Chongqing, China, 3 July 2021; pp. 146–153. [Google Scholar]
- Li, W.; Wang, X.; Zhang, Y.; Wu, Q. Traffic Flow Prediction over Muti-Sensor Data Correlation with Graph Convolution Network. Neurocomputing 2021, 427, 50–63. [Google Scholar] [CrossRef]
- Yuanyuan, Z.; Bin, Z.; Cheng, S.; Haolu, L.; Jicheng, H.; Kunpeng, T.; Zhong, T. Review of the Field Environmental Sensing Methods Based on Multi-Sensor Information Fusion Technology. Int. J. Agric. Biol. Eng. 2024, 17, 1–13. [Google Scholar] [CrossRef]
- Zhu, W.; Chen, X.; Jiang, L. PV-LaP: Multi-Sensor Fusion for 3D Scene Understanding in Intelligent Transportation Systems. Signal Process. 2025, 227, 109749. [Google Scholar] [CrossRef]
- Tao, K.; Wang, A.; Shen, Y.; Lu, Z.; Peng, F.; Wei, X. Peach Flower Density Detection Based on an Improved CNN Incorporating Attention Mechanism and Multi-Scale Feature Fusion. Horticulturae 2022, 8, 904. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | Camera | LiDAR | Millimeter-Wave Radar |
|---|---|---|---|
| Data Type | 2D RGB/grayscale images | 3D point clouds | 1D/2D range-velocity |
| Resolution | High (texture/color) | High (spatial) | Low (spatial), high (velocity) |
| Detection Range | Tens to hundreds of meters | Tens to hundreds of meters | Hundreds of meters |
| Environmental Robustness | Lighting-dependent | Lighting-insensitive | All-weather robustness |
| Output Information | Semantic features | Distance and shape data | Distance and velocity data |
| Advantages | Cost-effective, rich texture details | High-precision ranging | All-weather capability, superior speed measurement |
| Limitations | Lighting-sensitive, no direct ranging | High cost, large data volume | Low spatial resolution, limited geometric details |
| Algorithm | Advantages | Limitations |
|---|---|---|
| DeepFusion | Effectively integrates data from different sensors, improving accuracy. | High computational complexity, potentially compromising real-time performance. |
| BEVFusion | Provides more intuitive spatial information, aiding in complex scene processing. | High dependency on sensor position and orientation, potentially affecting fusion quality. |
| BEVFusion4D | Captures temporal changes, enhancing detection capability for dynamic objects. | Increased model complexity and higher computational resource requirements. |
| SimpleBEV | Simple structure, easy to implement and deploy. | Detection performance in complex scenes may lag behind more sophisticated models. |
| FusionFormer | Self-attention mechanism enhances global context modeling. | High computational overhead during training and inference, potentially impacting real-time applications. |
| CMT | Flexibly handles information interaction between different modalities. | High demands on model design and hyperparameter tuning, increasing complexity |
| Algorithm | Advantages | Limitations |
|---|---|---|
| F-PointNet | Efficient point cloud processing with strong robustness. | High computational complexity may hinder real-time applications. |
| FSF | Adaptive feature selection enhances fusion effectiveness and flexibility. | Complex implementation of adaptive mechanisms depends on feature quality. |
| SparseFusion | Sparse data specialization reduces computational burden and improves efficiency. | Potential information loss in sparse scenarios may degrade fusion performance. |
| MV2DFusion | Effective multimodal integration enhances contextual understanding in dynamic scenes. | High computational demands due to multi-view processing and view dependency. |
| TransFusion | Enables robust occlusion handling via dynamic feature–proposal alignment in an end-to-end framework. | Transformer-based cross-attention scales quadratically with the number of proposals, posing challenges for deployment on edge devices. |
| Dataset Name | Total Images | Total Size | Label Categories |
|---|---|---|---|
| KITTI | 15,000 | 1242 × 375 | 11 |
| nuScenes | 40,000 | 1600 × 900 | 10 |
| Waymo Open Dataset | 2,000,000 | 1280 × 720 | 6 |
| ApolloScape [93] | 20,000 | 1280 × 720 | 5 |
| Cityscape [94] | 5000 | 2048 × 1024 | 30 |
| Oxford RobotCar [95] | 2,000,000 | 1280 × 960 | - |
| Argoverse2 [96] | 500,000 | 1920 × 1200 | 10 |
| PandaSet [97] | 48,000 | 1920 × 1080 | 10 |
| A2D2 [98] | 246,000 | 1920 × 1080 | 10 |
| H3D (Honda) [99] | 100,000 | 1920 × 1080 | 5 |
| Euro-PVI [100] | 20,000 | 640 × 480 | 2 |
| KAIST Multi-Spectral [101] | 50,000 | 640 × 480 | 2 |
| Type | Model | mAP | NDS |
|---|---|---|---|
| Feature-Level Fusion Methods | BEVFusion | 70.2% | 72.9% |
| BEVFusion4D | 73.3% | 74.7% | |
| SimpleBEV | 75.7% | 77.6% | |
| FusionFormer | 72.6% | 75.1% | |
| CMT | 72.0% | 74.1% | |
| Proposal-Level Fusion Methods | FSF | 70.4% | 74.0% |
| SparseFusion | 72.0% | 73.8% | |
| MV2DFusion | 74.5% | 76.7% | |
| Transfusion | 68.9% | 71.7% |
| Related Literature | Application Domain | Application of Multi-Sensor Target Detection Algorithms |
|---|---|---|
| Perception-Aware Multi-Sensor Fusion for 3D LiDAR Semantic Segmentation. | Segmentation | Proposed a network incorporating two workflows (LiDAR and camera) to leverage information from both modalities. |
| FusionAD: Multimodality Fusion for Prediction and Planning Tasks of Autonomous Driving. | Tracking and Path Planning | Constructed a Transformer-based multimodal fusion network to effectively generate fusion-based features. |
| Multi-Modal Attention-Guided Real-Time Lane Detection. | Lane Detection | Utilized multi-frame input and long short-term memory networks to address vehicle occlusion, lane line detection, and marking degradation issues. |
| Traffic Flow Prediction Over Multi-Sensor Data Correlation with Graph Convolution Network. | Traffic Flow Analysis | Introduced a novel model capable of eliminating differences in periodic data while effectively capturing inter-traffic pattern relationships. |
| PV-LaP: Multi-Sensor Fusion for 3D Scene Understanding in Intelligent Transportation Systems. | Dynamic Scene Understanding | Enhanced environmental perception accuracy by integrating camera and LiDAR data. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Liu, J.; Dong, H.; Shao, Z. A Survey of the Multi-Sensor Fusion Object Detection Task in Autonomous Driving. Sensors 2025, 25, 2794. https://doi.org/10.3390/s25092794
Wang H, Liu J, Dong H, Shao Z. A Survey of the Multi-Sensor Fusion Object Detection Task in Autonomous Driving. Sensors. 2025; 25(9):2794. https://doi.org/10.3390/s25092794
Chicago/Turabian StyleWang, Hai, Junhao Liu, Haoran Dong, and Zheng Shao. 2025. "A Survey of the Multi-Sensor Fusion Object Detection Task in Autonomous Driving" Sensors 25, no. 9: 2794. https://doi.org/10.3390/s25092794
APA StyleWang, H., Liu, J., Dong, H., & Shao, Z. (2025). A Survey of the Multi-Sensor Fusion Object Detection Task in Autonomous Driving. Sensors, 25(9), 2794. https://doi.org/10.3390/s25092794