
A Review of Vision-Based Multi-Task Perception Research Methods for Autonomous Vehicles


Abstract
1. Introduction
2. Relevant Technical Background
2.1. Classification of Perception Tasks
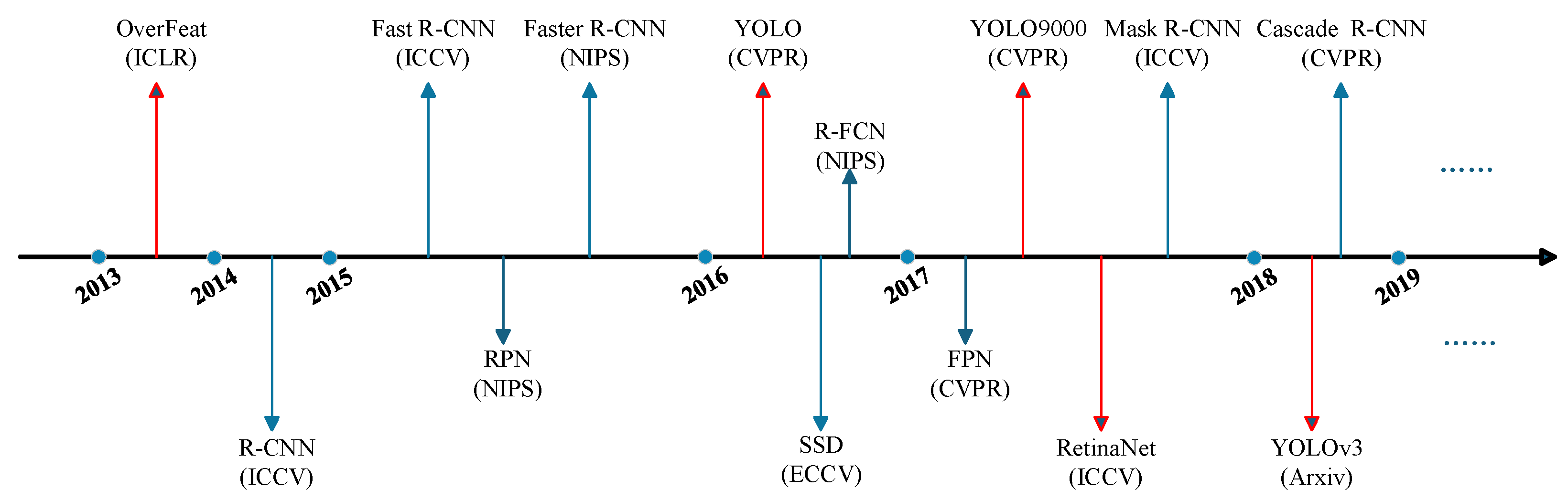
2.2. Traffic Object Detection
2.2.1. Two-Stage Object Detectors
2.2.2. One-Stage Object Detectors
2.3. Drivable Area Segmentation
2.3.1. CNN-Based Methods
2.3.2. Transformer-Based Methods
2.3.3. Hybrid Architectures
2.3.4. Novel Architectures
2.4. Lane Detection
2.4.1. Segmentation-Based Method
2.4.2. Anchor-Based Method
2.4.3. Row Classification-Based Method
2.4.4. Key Point-Based Method
2.4.5. Parametric Curve-Based Method
3. Multi-Task Perception
3.1. Multi-Task Learning
3.2. Environment Perception Technology Based on Multi-Task Network
4. Multi-Task Perception for Autonomous Driving
4.1. Classic Network Framework
4.2. Loss Function
4.3. Emerging Architecture
4.3.1. Global Dependency Modeling with Transformers
4.3.2. Sequence Perception and Multi-Task Processing with Mamba
4.3.3. Neural Architecture Search (NAS) in Multi-Task Learning
4.3.4. AutoMTL: An Operator-Level Dynamic Sharing Framework for Multi-Task Learning
5. Evaluation
5.1. Datasets
- Detailed data collection methods (sensors, environments, and conditions).
- Comprehensive annotation details (label types and guidelines).
- Clear information on data splits (training, validation, and testing).
- Ethical considerations.
- Accessibility and licensing information.
5.2. Evaluation Metrics
6. Challenges and Opportunities
6.1. Challenges
6.2. Opportunities
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Liang, J.; Li, Y.; Yin, G.; Xu, L.; Lu, Y.; Feng, J.; Shen, T.; Cai, G. A MAS-Based Hierarchical Architecture for the Cooperation Control of Connected and Automated Vehicles. IEEE Trans. Veh. Technol. 2023, 72, 1559–1573. [Google Scholar] [CrossRef]
- Liu, H.; Yan, S.; Shen, Y.; Li, C.; Zhang, Y.; Hussain, F. Model Predictive Control System Based on Direct Yaw Moment Control for 4WID Self-Steering Agriculture Vehicle. Int. J. Agric. Biol. Eng. 2021, 14, 175–181. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Sallab, A.A.A.; Yogamani, S.; Perez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transport. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Wang, H.; Gu, J.; Wang, M. A Review on the Application of Computer Vision and Machine Learning in the Tea Industry. Front. Sustain. Food Syst. 2023, 7, 1172543. [Google Scholar] [CrossRef]
- Wei, L.; Jianping, H.; Jiaxin, L.; Rencai, Y.; Tengfei, Z.; Mengjiao, Y.; Jing, L. Method for the Navigation Line Recognition of the Ridge without Crops via Machine Vision. Int. J. Agric. Biol. Eng. 2024, 17, 230–239. [Google Scholar] [CrossRef]
- Zhou, X.; Sun, J.; Tian, Y.; Lu, B.; Hang, Y.; Chen, Q. Hyperspectral Technique Combined with Deep Learning Algorithm for Detection of Compound Heavy Metals in Lettuce. Food Chem. 2020, 321, 126503. [Google Scholar] [CrossRef]
- Chen, C.; Zhu, W.; Steibel, J.; Siegford, J.; Han, J.; Norton, T. Classification of Drinking and Drinker-Playing in Pigs by a Video-Based Deep Learning Method. Biosyst. Eng. 2020, 196, 1–14. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; NeurIPS: San Diego, CA, USA, 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Volume 8691, pp. 346–361. [Google Scholar]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Ji, W.; Gao, X.; Xu, B.; Pan, Y.; Zhang, Z.; Zhao, D. Apple Target Recognition Method in Complex Environment Based on Improved YOLOv4. J. Food Process Eng. 2021, 44, e13866. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, Z.; Zhang, K.; Yang, L.; Zhang, D.; Yu, Y. Research on the Visual Location Method for Strawberry Picking Points under Complex Conditions Based on Composite Models. J. Sci. Food Agric. 2024, 104, 8566–8579. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Gao, Z.; Zhang, Y.; Zhou, J.; Wu, J.; Li, P. Real-Time Detection and Location of Potted Flowers Based on a ZED Camera and a YOLO V4-Tiny Deep Learning Algorithm. Horticulturae 2021, 8, 21. [Google Scholar] [CrossRef]
- Ji, W.; Zhang, T.; Xu, B.; He, G. Apple Recognition and Picking Sequence Planning for Harvesting Robot in a Complex Environment. J. Agric. Eng. 2023, 55, 1549. [Google Scholar] [CrossRef]
- Xu, Z.; Liu, J.; Wang, J.; Cai, L.; Jin, Y.; Zhao, S.; Xie, B. Realtime Picking Point Decision Algorithm of Trellis Grape for High-Speed Robotic Cut-and-Catch Harvesting. Agronomy 2023, 13, 1618. [Google Scholar] [CrossRef]
- Chen, T.; Qi, X.; Lu, D.; Chen, B. Gas Chromatography-Ion Mobility Spectrometric Classification of Vegetable Oils Based on Digital Image Processing. Food Meas. 2019, 13, 1973–1979. [Google Scholar] [CrossRef]
- Tang, N.; Sun, J.; Yao, K.; Zhou, X.; Tian, Y.; Cao, Y.; Nirere, A. Identification of Lycium barbarum Varieties Based on Hyperspectral Imaging Technique and Competitive Adaptive Reweighted Sampling—Whale Optimization Algorithm—Support Vector Machine. J. Food Process Eng. 2021, 44, e13603. [Google Scholar] [CrossRef]
- Chen, J.; Lian, Y.; Zou, R.; Zhang, S.; Ning, X.; Han, M. Real-Time Grain Breakage Sensing for Rice Combine Harvesters Using Machine Vision Technology. Int. J. Agric. Biol. Eng. 2020, 13, 194–199. [Google Scholar] [CrossRef]
- Yang, N.; Qian, Y.; EL-Mesery, H.S.; Zhang, R.; Wang, A.; Tang, J. Rapid Detection of Rice Disease Using Microscopy Image Identification Based on the Synergistic Judgment of Texture and Shape Features and Decision Tree–Confusion Matrix Method. J. Sci. Food Agric. 2019, 99, 6589–6600. [Google Scholar] [CrossRef]
- Chen, J.; Song, J.; Guan, Z.; Lian, Y. Measurement of the Distance from Grain Divider to Harvesting Boundary Based on Dynamic Regions of Interest. Int. J. Agric. Biol. Eng. 2021, 14, 226–232. [Google Scholar] [CrossRef]
- Luo, Y.; Wei, L.; Xu, L.; Zhang, Q.; Liu, J.; Cai, Q.; Zhang, W. Stereo-Vision-Based Multi-Crop Harvesting Edge Detection for Precise Automatic Steering of Combine Harvester. Biosyst. Eng. 2022, 215, 115–128. [Google Scholar] [CrossRef]
- Liu, X.; Jia, W.; Ruan, C.; Zhao, D.; Gu, Y.; Chen, W. The Recognition of Apple Fruits in Plastic Bags Based on Block Classification. Precis. Agric. 2018, 19, 735–749. [Google Scholar] [CrossRef]
- Wu, X.; Wu, B.; Sun, J.; Yang, N. Classification of Apple Varieties Using Near Infrared Reflectance Spectroscopy and Fuzzy Discriminant C-Means Clustering Model. J. Food Process Eng. 2017, 40, e12355. [Google Scholar] [CrossRef]
- Wu, X.; Zhou, J.; Wu, B.; Sun, J.; Dai, C. Identification of Tea Varieties by Mid-infrared Diffuse Reflectance Spectroscopy Coupled with a Possibilistic Fuzzy C-means Clustering with a Fuzzy Covariance Matrix. J. Food Process Eng. 2019, 42, e13298. [Google Scholar] [CrossRef]
- Peng, Y.; Wang, A.; Liu, J.; Faheem, M. A Comparative Study of Semantic Segmentation Models for Identification of Grape with Different Varieties. Agriculture 2021, 11, 997. [Google Scholar] [CrossRef]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision–ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tang, S.; Xia, Z.; Gu, J.; Wang, W.; Huang, Z.; Zhang, W. High-Precision Apple Recognition and Localization Method Based on RGB-D and Improved SOLOv2 Instance Segmentation. Front. Sustain. Food Syst. 2024, 8, 1403872. [Google Scholar] [CrossRef]
- Zhu, W.; Sun, J.; Wang, S.; Shen, J.; Yang, K.; Zhou, X. Identifying Field Crop Diseases Using Transformer-Embedded Convolutional Neural Network. Agriculture 2022, 12, 1083. [Google Scholar] [CrossRef]
- Ji, W.; Wang, J.; Xu, B.; Zhang, T. Apple Grading Based on Multi-Dimensional View Processing and Deep Learning. Foods 2023, 12, 2117. [Google Scholar] [CrossRef]
- Sharma, G.; Liu, D.; Maji, S.; Kalogerakis, E.; Chaudhuri, S.; Měch, R. ParSeNet: A Parametric Surface Fitting Network for 3D Point Clouds. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Paramesh, G.; Narayana, G.V.S. Tomato Leaf Disease Diagnosis Based on Improved Convolution Neural Network. In Proceedings of the 2022 Second International Conference on Computer Science, Engineering and Applications (ICCSEA), Gunupur, India, 8 September 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–6. [Google Scholar]
- Zuo, X.; Chu, J.; Shen, J.; Sun, J. Multi-Granularity Feature Aggregation with Self-Attention and Spatial Reasoning for Fine-Grained Crop Disease Classification. Agriculture 2022, 12, 1499. [Google Scholar] [CrossRef]
- Tao, K.; Wang, A.; Shen, Y.; Lu, Z.; Peng, F.; Wei, X. Peach Flower Density Detection Based on an Improved CNN Incorporating Attention Mechanism and Multi-Scale Feature Fusion. Horticulturae 2022, 8, 904. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, Y.; Liu, S.; Shi, J.; Loy, C.C.; Lin, D.; Jia, J. PSANet: Point-Wise Spatial Attention Network for Scene Parsing. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2018; Volume 11213, pp. 270–286. ISBN 978-3-030-01239-7. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA; pp. 8759–8768. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083v2. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H.S. Conditional Random Fields as Recurrent Neural Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. (ViT) An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Yuan, Y.; Fu, R.; Huang, L.; Lin, W.; Zhang, C.; Chen, X.; Wang, J. HRFormer: High-Resolution Transformer for Dense Prediction. arXiv 2021, arXiv:2110.09408. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. MetaFormer Is Actually What You Need for Vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. TransUNet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Cui, Y.; Jiang, C.; Wang, L.; Wu, G. MixFormer: End-to-End Tracking with Iterative Mixed Attention. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4129–4146. [Google Scholar] [CrossRef] [PubMed]
- Tolstikhin, I.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J.; et al. MLP-Mixer: An All-MLP Architecture for Vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Chen, S.; Xie, E.; Ge, C.; Chen, R.; Liang, D.; Luo, P. CycleMLP: A MLP-like Architecture for Dense Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 14284–14300. [Google Scholar] [CrossRef]
- Lian, D.; Yu, Z.; Sun, X.; Gao, S. AS-MLP: An Axial Shifted MLP Architecture for Vision. arXiv 2021, arXiv:2107.08391. [Google Scholar]
- Zhang, T.; Zhou, J.; Liu, W.; Yue, R.; Shi, J.; Zhou, C.; Hu, J. SN-CNN: A Lightweight and Accurate Line Extraction Algorithm for Seedling Navigation in Ridge-Planted Vegetables. Agriculture 2024, 14, 1446. [Google Scholar] [CrossRef]
- Ma, Z.; Yang, S.; Li, J.; Qi, J. Research on SLAM Localization Algorithm for Orchard Dynamic Vision Based on YOLOD-SLAM2. Agriculture 2024, 14, 1622. [Google Scholar] [CrossRef]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial As Deep: Spatial CNN for Traffic Scene Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.; Yang, Z.; Liu, H.; Cai, D. RESA: Recurrent Feature-Shift Aggregator for Lane Detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 3547–3554. [Google Scholar] [CrossRef]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; De Souza, A.F.; Oliveira-Santos, T. Keep Your Eyes on the Lane: Real-Time Attention-Guided Lane Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 294–302. [Google Scholar]
- Qin, Z.; Wang, H.; Li, X. Ultra Fast Structure-Aware Deep Lane Detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. CondLaneNet: A Top-to-down Lane Detection Framework Based on Conditional Convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar] [CrossRef]
- Wang, J.; Ma, Y.; Huang, S.; Hui, T.; Wang, F.; Qian, C.; Zhang, T. A Keypoint-Based Global Association Network for Lane Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1382–1391. [Google Scholar]
- Feng, Z.; Guo, S.; Tan, X.; Xu, K.; Wang, M.; Ma, L. Rethinking Efficient Lane Detection via Curve Modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Han, L.; Mao, H.; Kumi, F.; Hu, J. Development of a Multi-Task Robotic Transplanting Workcell for Greenhouse Seedlings. Appl. Eng. Agric. 2018, 34, 335–342. [Google Scholar] [CrossRef]
- Cheng, J.; Sun, J.; Yao, K.; Xu, M.; Dai, C. Multi-Task Convolutional Neural Network for Simultaneous Monitoring of Lipid and Protein Oxidative Damage in Frozen-Thawed Pork Using Hyperspectral Imaging. Meat Sci. 2023, 201, 109196. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Ni, L.; Bai, X.; Jiang, H.; Xu, L. Simultaneous Analysis of Mildew Degree and Aflatoxin B1 of Wheat by a Multi-Task Deep Learning Strategy Based on Microwave Detection Technology. LWT 2023, 184, 115047. [Google Scholar] [CrossRef]
- Wu, D.; Liao, M.; Zhang, W.; Wang, X.; Bai, X.; Cheng, W.; Liu, W. YOLOP: You Only Look Once for Panoptic Driving Perception. Mach. Intell. Res. 2022, 19, 550–562. [Google Scholar] [CrossRef]
- Vu, D.; Ngo, B.; Phan, H. HybridNets: End-to-End Perception Network. arXiv 2022, arXiv:2203.09035. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: High Quality Object Detection and Instance Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1483–1498. [Google Scholar] [CrossRef]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kumar, V.R.; Yogamani, S.; Rashed, H.; Sistu, G.; Witt, C.; Leang, I.; Milz, S.; Mäder, P. OmniDet: Surround View Cameras Based Multi-Task Visual Perception Network for Autonomous Driving. IEEE Robot. Autom. Lett. 2021, 6, 2830–2837. [Google Scholar] [CrossRef]
- Heuer, F.; Mantowsky, S.; Bukhari, S.S.; Schneider, G. MultiTask-CenterNet (MCN): Efficient and Diverse Multitask Learning Using an Anchor Free Approach. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 997–1005. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 19–20 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2636–2645. [Google Scholar]
- Liu, B.; Chen, H.; Wang, Z. LSNet: Extremely Light-Weight Siamese Network For Change Detection in Remote Sensing Image. In Proceedings of the IGARSS 2022–2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. PVT v2: Improved Baselines with Pyramid Vision Transformer. Comp. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Li, W.; Wang, X.; Xia, X.; Wu, J.; Li, J.; Xiao, X.; Zheng, M.; Wen, S. SepViT: Separable Vision Transformer. arXiv 2022, arXiv:2203.15380. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, NT, USA, 11–15 June 2025. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-Time Joint Semantic Reasoning for Autonomous Driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26–30 June 2018. [Google Scholar]
- Qian, Y.; Dolan, J.M.; Yang, M. DLT-Net: Joint Detection of Drivable Areas, Lane Lines, and Traffic Objects. IEEE Trans. Intell. Transport. Syst. 2020, 21, 4670–4679. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Wang, J.; Wu, Q.M.J.; Zhang, N. You Only Look at Once for Real-Time and Generic Multi-Task. IEEE Trans. Veh. Technol. 2024, 73, 12625–12637. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Han, C.; Zhao, Q.; Zhang, S.; Chen, Y.; Zhang, Z.; Yuan, J. YOLOPv2: Better, Faster, Stronger for Panoptic Driving Perception. arXiv 2022, arXiv:2208.11434. [Google Scholar]
- Yu, F.; Chen, H.; Wang, X.; Xian, W.; Chen, Y.; Liu, F.; Madhavan, V.; Darrell, T. BDD100K: A Diverse Driving Dataset for Heterogeneous Multitask Learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 18–22 June 2023. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning Lightweight Lane Detection CNNs by Self Attention Distillation. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–3 November 2019. [Google Scholar]
- Li, J.; Ke, X.; Wang, Z.; Wan, J.; Tan, G. Cutransnet: Transformers to Make Strong Encoders for Multi-Task Vision Perception of Autonomous Driving. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Korea, Republic of Korea, 14 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 7385–7389. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Yu, Q.; Dai, J. BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers. arXiv 2022, arXiv:2203.17270. [Google Scholar]
- Lin, B.; Jiang, W.; Chen, P.; Zhang, Y.; Liu, S.; Chen, Y.-C. MTMamba: Enhancing Multi-Task Dense Scene Understanding by Mamba-Based Decoders. In Proceedings of the Computer Vision–ECCV 2024: 18th European Conference, Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- You, Z.; Wang, N.; Wang, H.; Zhao, Q.; Wang, J. MambaBEV: An Efficient 3D Detection Model with Mamba2. arXiv 2024, arXiv:2410.12673. [Google Scholar]
- Xu, X.; Jiang, Y.; Chen, W.; Huang, Y.; Zhang, Y.; Sun, X. DAMO-YOLO: A Report on Real-Time Object Detection Design. arXiv 2022, arXiv:2211.15444. [Google Scholar]
- Li, Z.; Xi, T.; Zhang, G.; Liu, J.; He, R. AutoDet: Pyramid Network Architecture Search for Object Detection. Int. J. Comput. Vis. 2021, 129, 1087–1105. [Google Scholar] [CrossRef]
- Nekrasov, V.; Chen, H.; Shen, C.; Reid, I. Fast Neural Architecture Search of Compact Semantic Segmentation Models via Auxiliary Cells. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 9118–9127. [Google Scholar]
- Liu, C.; Chen, L.-C.; Schroff, F.; Adam, H.; Hua, W.; Yuille, A.L.; Fei-Fei, L. Auto-DeepLab: Hierarchical Neural Architecture Search for Semantic Image Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 82–92. [Google Scholar]
- Liu, H.; Li, D.; Peng, J.; Zhao, Q.; Tian, L.; Shan, Y. MTNAS: Search Multi-Task Networks for Autonomous Driving. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, T.; Liu, H. Multi-Task Neural Architecture Search Using Architecture Embedding and Transfer Rank. arXiv 2025, arXiv:2504.00772. [Google Scholar]
- Dong, X.; Yang, Y. NAS-Bench-201: Extending the Scope of Reproducible Neural Architecture Search. arXiv 2020, arXiv:2001.00326. [Google Scholar]
- Sharifi, A.A.; Zoljodi, A.; Daneshtalab, M. TrajectoryNAS: A Neural Architecture Search for Trajectory Prediction. Sensors 2024, 24, 5696. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Z.; Feng, L.; Liu, S.; Wong, K.-C.; Tan, K.C. Toward Evolutionary Multitask Convolutional Neural Architecture Search. IEEE Trans. Evol. Computat. 2024, 28, 682–695. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, X.; Guan, H. AutoMTL: A Programming Framework for Automating Efficient Multi-Task Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 34216–34228. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision Meets Robotics: The KITTI Dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Advantages | Disadvantages |
|---|---|---|
| MultiNet [98] | 1. Shared feature extractor, inference speed <45 ms 2. ROI alignment technique to improve detection accuracy 3. No need for explicit proposal generation network | 1. Independent decoders which limit co-optimization of tasks 2. Fixed input size 3. Lack of multi-scale detection capability 4. Segmentation computing redundancy |
| DLT-Net [99] | 1. Context tensor for cross-task feature fusion 2. High multi-task precision balance 3. Strong robustness in sparse scenarios | 1. Limited performance on Jetson TX2 (<15 FPS) 2. Complex models and high consumption of training resources 3. Poor generalization on long-tailed data |
| YOLOP [82] | 1. Real-time triple-task processing on Jetson TX2 (23 FPS) 2. Lightweight design for edge deployment 3. Adaptive cascade module optimizes segmentation | 1. Delay introduced by multi-tasking module 2. Accuracy fluctuations in complex scenes 3. The need to trade off between accuracy and real time |
| A-YOLOM [101] | 1. Ultra-lightweight architecture (<3 MB) 2. Adaptive multi-task weight allocation 3. Supporting dynamic resolution input | 1. Limited performance on Jetson TX2 (<15 FPS) 2. Complex models and high consumption of training resources 3. Poor generalization on long-tailed data |
| HybridNets [83] | 1. Hybrid CNN–Transformer architecture 2. Multi-modal fusion 3. End-to-end multi-task optimization | 1. High computational requirements (>16 GB VRAM) 2. Difficult to deploy on edge devices 3. Slow training convergence |
| Model | Recall (%) | mAP (%) | Speed (fps) | Image Size | Backbone+Neck |
|---|---|---|---|---|---|
| MultiNet [98] | 81.3 | 60.2 | 8.6 | 224 × 224 | VGG/Resnet |
| DLT-Net [99] | 89.4 | 68.4 | 9.3 | 1280 × 720 | VGG16 FPN |
| FasterR-CNN [10] | 81.2 | 64.9 | 8.8 | 1000 × 600 | VGG16/Resnet RPN |
| YOLOv5s | 86.8 | 77.2 | 82 | 640 × 640 | CSPDarknet53 FPN, PAN |
| YOLOv8n(det) | 82.2 | 75.1 | - | 640 × 640 | CSPDarknet FPN, PAN |
| YOLOP [82] | 89.2 | 76.5 | 41 | 640 × 384 | CSPDarknet SPP, FPN |
| A-YOLOM(n) [101] | 85.3 | 78.0 | - | 640 × 640 | CSPDarknet FPN, PAN |
| A-YOLOM(s) [101] | 86.9 | 81.1 | - | 640 × 640 | CSPDarknet FPN, PAN |
| HybridNets [83] | 92.8 | 77.3 | 28 | 640 × 384 | EfficientNet-B3 BiFPN |
| YOLOPv2 [103] | 83.4 | 91.1 | 91 | 640 × 384 | E-ELAN SPP, FPN |
| Model | mIoU (%) | Speed (fps) | Image Size | Backbone+Neck |
|---|---|---|---|---|
| MultiNet [98] | 71.6 | 8.6 | 224 × 224 | VGG/Resnet |
| DLT-Net [99] | 71.3 | 9.3 | 1280 × 720 | VGG16 FPN |
| PSPNet [45] | 89.6 | 11.1 | 473 × 473 | ResNet PPM |
| YOLOv8n(seg) | 78.1 | - | 640 × 640 | CSPDarknet FPN, PAN |
| YOLOP [82] | 91.6 | 41 | 640 × 384 | CSPDarknet SPP, FPN |
| A-YOLOM(n) [101] | 90.5 | - | 640 × 640 | CSPDarknet FPN, PAN |
| A-YOLOM(s) [101] | 91.0 | - | 640 × 640 | CSPDarknet FPN, PAN |
| HybridNets [83] | 90.5 | 28 | 640 × 384 | EfficientNet-B3 BiFPN |
| YOLOPv2 [103] | 93.2 | 91 | 640 × 384 | E-ELAN SPP, FPN |
| Model | Accuracy (%) | LaneLineIoU (fps) | Image Size | Backbone+Neck |
|---|---|---|---|---|
| Enet [53] | 34.12 | 14.64 | 640 × 360 | - |
| SCNN [72] | 35.79 | 15.84 | 512 × 512 | - |
| Enet-SAD [107] | 36.56 | 16.02 | 360 × 640 | - |
| YOLOP [82] | 70.50 | 26.2 | 640 × 384 | CSPDarknet SPP, FPN |
| HybridNets [83] | 85.40 | 31.60 | 640 × 384 | EfficientNet-B3 BiFPN |
| YOLOPv2 [103] | 87.31 | 27.25 | 640 × 384 | E-ELAN SPP, FPN |
| Dataset | Year | Data Amount | Tag Categories | Scenarios |
|---|---|---|---|---|
| KITTI [123] | CVPR2012 | 150 K | 11 | urban and rural roads |
| MSCOCO [106] | ECCV2014 | 164 K | 80 | urban streets and natural landscapes |
| Cityscapes [124] | CVPR2016 | 25 K | 30 | urban street scenes |
| BDD100K [104] | CVPR2018 | 100 K | 10/8/2 | multiple cities and surrounding areas |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Li, J.; Dong, H. A Review of Vision-Based Multi-Task Perception Research Methods for Autonomous Vehicles. Sensors 2025, 25, 2611. https://doi.org/10.3390/s25082611
Wang H, Li J, Dong H. A Review of Vision-Based Multi-Task Perception Research Methods for Autonomous Vehicles. Sensors. 2025; 25(8):2611. https://doi.org/10.3390/s25082611
Chicago/Turabian StyleWang, Hai, Jiayi Li, and Haoran Dong. 2025. "A Review of Vision-Based Multi-Task Perception Research Methods for Autonomous Vehicles" Sensors 25, no. 8: 2611. https://doi.org/10.3390/s25082611
APA StyleWang, H., Li, J., & Dong, H. (2025). A Review of Vision-Based Multi-Task Perception Research Methods for Autonomous Vehicles. Sensors, 25(8), 2611. https://doi.org/10.3390/s25082611