
LPCF-YOLO: A YOLO-Based Lightweight Algorithm for Pedestrian Anomaly Detection with Parallel Cross-Fusion


Abstract
1. Introduction
- Lightweight and Efficiency-Oriented.
- 2.
- Heterogeneous Feature Synergy Enhancement.
- 3.
- Deployment-Friendly Optimization.
- In the backbone network, an FPC-F (Fast Parallel Cross-Fusion) module based on PConv and a S-EMCP (Space-efficient Merging Convolution Pooling) module have been designed to replace the original C2F and SPPF modules, respectively. Additionally, an ADown module has been introduced at the third layer to reduce floating-point computations.
- In the neck network, the CSPPC module has been designed to replace the C2F module in HSFPN, thus forming the L-HSFPN (Lightweight High-level Screening-feature Pyramid) module.
- In the bounding box loss function, the Wise-IoU Loss is utilized to replace the CIoU Loss.
2. Related Work
3. Methodology
3.1. Backbone
3.2. Neck
3.3. Wise-IoU
4. Experiments and Results
4.1. Dataset
4.2. Experimental Environment and Training Parameter Settings
4.3. Evaluation Indicators
4.4. Comparative Experimental Results and Analysis
4.4.1. Comparison Results and Analysis of LPCF-YOLO and SOTA Algorithms
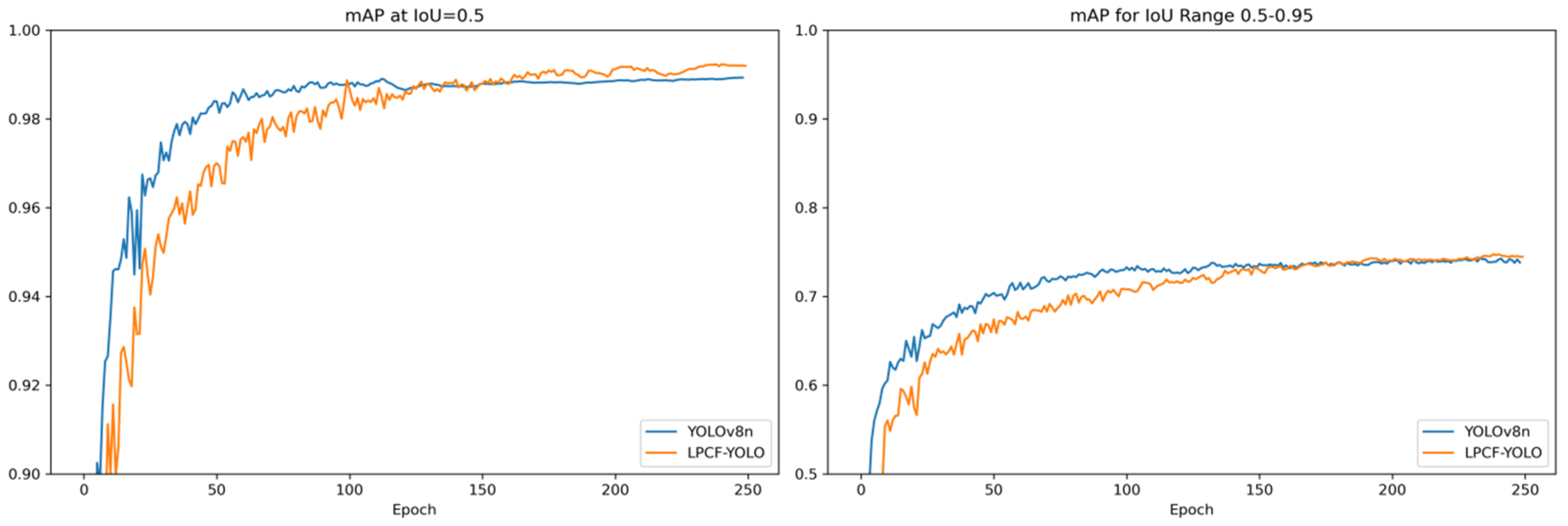
4.4.2. Comparison and Visualization Analysis of Evaluation Metrics Between LPCF-YOLO and YOLOv8n in the UCSD-Ped1 and UCSD-Ped2 Datasets
4.5. Results and Analysis of Ablation Experiments
4.5.1. The Overall Ablation Experiment of LPCF-YOLO
4.5.2. Ablation Experiment Focused on the Internal Structure of the LPCF-YOLO-Backbone
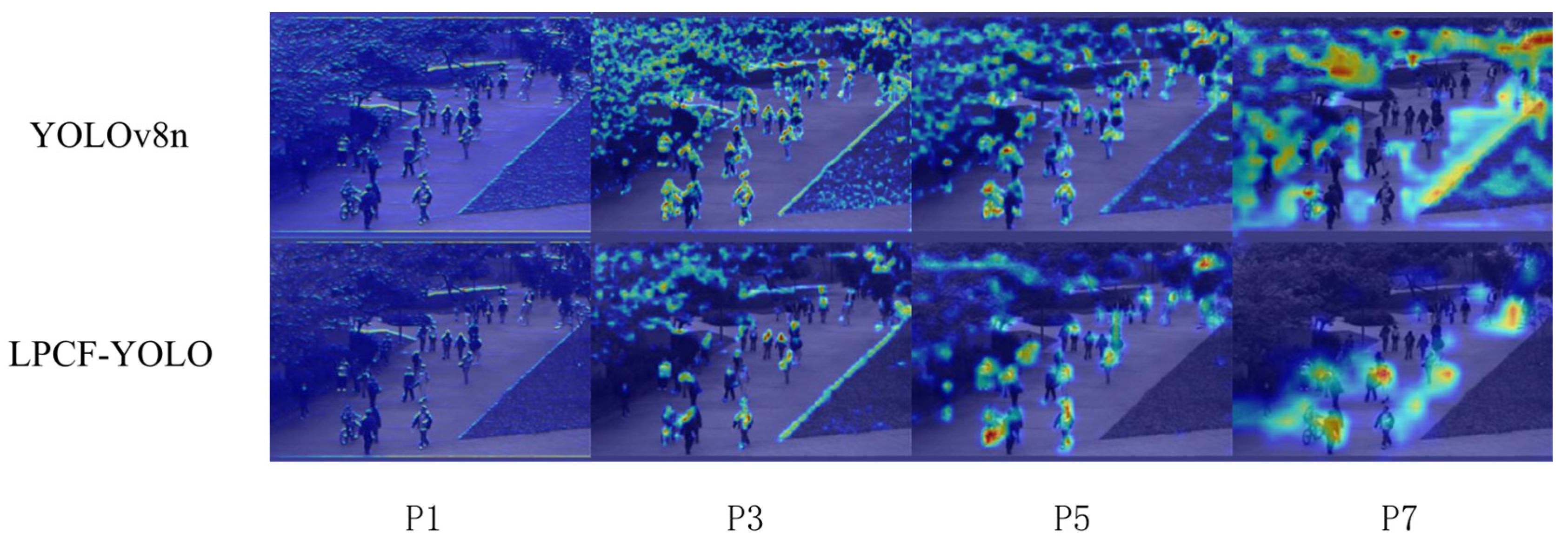
4.5.3. Comparison of Heatmap Results Across Different Network Layers Between YOLOV8n and LPCF-YOLO
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Pang, G.; Shen, C.; Cao, L.; Hengel, A.V.D. Deep learnin g for anomaly detection: A review. ACM Comput. Surv. 2021, 54, 38. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep learning for anomaly detection: A survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Ristea, N.C.; Madan, N.; Ionescu, R.T.; Nasrollahi, K.; Khan, F.S.; Moeslund, T.B. Self-supervised predictive convolutional attentive block for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 13576–13586. [Google Scholar]
- Liu, W.; Chang, H.; Ma, B.; Shan, S.; Chen, X. Diversity-measurable anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12147–12156. [Google Scholar]
- Bera, A.; Kim, S.; Manocha, D. Real-time anomaly detection using trajectory-level crowd behavior learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 50–57. [Google Scholar]
- Bertini, M.; Del Bimbo, A.; Seidenari, L. Multi-scale and real-time non-parametric approach for anomaly detection and localiz- ation. Comput. Vis. Image Underst. 2012, 116, 320–329. [Google Scholar] [CrossRef]
- Cong, Y.; Yuan, J.; Liu, J. Abnormal event detection in crowded scenes using sparse representation. Pattern Recognit. 2013, 46, 1851–1864. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Hu, J. A survey of network anomaly detection techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Kim, J.; Grauman, K. Observe locally, infer globally: A space-time MRF for detecting abnormal activities with incremental updates. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 2921–2928. [Google Scholar]
- Chauhan, S.; Vig, L. Anomaly detection in ECG time signals via deep long short-term memory networks. In Proceedings of the IEEE International Conference on Data Science and Advanced Analytics (DSAA), Paris, France, 19–21 October 2015; pp. 1–7. [Google Scholar]
- Malhotra, P.; Ramakrishnan, A.; Anand, G.; Vig, L.; Agarwal, P.; Shroff, G. LSTM-based encoder-decoder for multi-sensor anomaly detection. arXiv 2016, arXiv:1607.00148. [Google Scholar]
- Tay, N.C.; Connie, T.; Ong, T.S.; Teoh, A.B.J.; Teh, P.S. A review of abnormal behavior detection in activities of daily living. IEEE Access 2023, 11, 5069–5088. [Google Scholar] [CrossRef]
- Ravanbakhsh, M.; Nabi, M.; Sangineto, E.; Marcenaro, L.; Regazzoni, C.; Sebe, N. Abnormal event detection in videos using generative adversarial nets. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1577–1581. [Google Scholar]
- Xu, D.; Yan, Y.; Ricci, E.; Sebe, N. Detecting anomalous events in videos by learning deep representations of appearance and motion. Comput. Vis. Image Underst. 2017, 156, 117–127. [Google Scholar] [CrossRef]
- Park, H.; Noh, J.; Ham, B. Learning memory-guided normality for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 14372–14381. [Google Scholar]
- Gong, D.; Liu, L.; Le, V.; Saha, B.; Mansour, M.R.; Venkatesh, S. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1705–1714. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the 14th European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Zhao, Z.; Qin, Y.; Qian, Y.; Wu, Y.; Qin, W.; Zhang, H.; Wu, X. Automatic potential safety hazard evaluation system for environment around high-speed railroad using hybrid U-shape learning architecture. IEEE Trans. Intell. Transp. Syst. 2025, 26, 1071–1087. [Google Scholar] [CrossRef]
- Jocher, G. YOLOv5 by Ultralytics (Version 5.0). 2020. Available online: https://github.com/ultralytics/ultralytics (accessed on 20 April 2025).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO (Version 8.0.0). 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 20 April 2025).
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. YOLOv9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Jocher, G.; Qiu, J.; Chaurasia, A. Ultralytics YOLO (Version 11.0.0). 2024. Available online: https://github.com/ultralytics/ultralytics (accessed on 20 April 2025).
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zhou, T.; Zheng, L.; Peng, Y.; Jiang, R. A survey of research on crowd abnormal behavior detection algorithm based on YOLO network. In Proceedings of the 2nd International Conference on Consumer Electronics and Computer Engineering (ICCECE), Guangzhou, China, 14–16 January 2022; pp. 783–786. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Chen, Y.; Zhang, C.; Chen, B.; Huang, Y.; Sun, Y.; Wang, C.; Fu, X.; Dai, Y.; Qin, F.; Peng, Y.; et al. Accurate leukocyte detection based on deformable-DETR and multi-level feature fusion for aiding diagnosis of blood diseases. Comput. Biol. Med. 2024, 170, 107917. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Tong, Z.; Chen, Y.; Xu, Z.; Yu, R. Wise-IoU: Bounding box regression loss with dynamic focusing mechanism. arXiv 2023, arXiv:2301.10051. [Google Scholar]
- Li, Y.; Dong, Z. Abnormal behavior detection in crowd scene using YOLO and Conv-AE. In Proceedings of the 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 1720–1725. [Google Scholar]
- Li, Z.; Zhang, J.; Wen, Y.; Dong, Y.; Xu, W. A multiscale fusion YOLOV3-based model for human abnormal behavior detection in special scenarios. J. Transp. Eng. Part A Syst. 2023, 149, 04022150. [Google Scholar] [CrossRef]
- Yuan, P.; Fan, C.; Zhang, C. YOLOv5s-MEE: A YOLOv5-based Algorithm for Abnormal Behavior Detection in Central Control Room. Inf. Technol. Control 2024, 53, 220–236. [Google Scholar] [CrossRef]
- Ganagavalli, K.; Santhi, V. YOLO-based anomaly activity detection system for human behavior analysis and crime mitigation. Signal Image Video Process. 2024, 18, 417–427. [Google Scholar] [CrossRef]
- Chen, Z.; Guo, H.; Yang, J.; Jiao, H.; Feng, Z.; Chen, L.; Gao, T. Fast vehicle detection algorithm in traffic scene based on improved SSD. Measurement 2022, 201, 111655. [Google Scholar] [CrossRef]
- Kong, Y.; Shang, X.; Jia, S. Drone-DETR: Efficient small object detection for remote sensing image using enhanced RT-DETR model. Sensors 2024, 24, 5496. [Google Scholar] [CrossRef] [PubMed]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.-C.; Tan, M. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Qiao, S.; Chen, L.C.; Yuille, A. DetectoRS: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 10213–10224. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Zhang, Y.F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Gevorgyan, Z. SIoU loss: More powerful learning for bounding box regression. arXiv 2022, arXiv:2205.12740. [Google Scholar]
- Ma, S.; Xu, Y. MPDIoU: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| UCSD | Label Category | Quantity |
|---|---|---|
| Ped1 | Bike | 2405 |
| Through the lawn | 349 | |
| Skateboard | 1474 | |
| Cart | 685 | |
| Wheelchair | 328 | |
| Pushcart | 129 | |
| Ped2 | Bike | 1159 |
| Skateboard | 290 | |
| Cart | 115 |
| Item | Parameter |
|---|---|
| Operating System | Windows 10 |
| Programming Language | Python 3.9 |
| CPU | 12thGen Intel(R) Core(TM) i9-12900H |
| GPU | NVIDIA RTX A2000 8 GB Laptop GPU |
| VRAM | 8 GB |
| Algorithm Framework | PyTorch 2.5.0 |
| Method | Bike (%) | Skateboard (%) | Cart (%) | Wheelchair (%) | Through the Lawn (%) | Pushcart (%) | mAP @0.5 (%) | mAP @0.5:0.95(%) | Params/M | GFLO-Ps |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5n [20] | 99.13 | 99.15 | 99.39 | 99.5 | 96.59 | 99.5 | 98.87 | 76.05 | 2.51 | 7.1 |
| YOLOv7-tiny [21] | 99.07 | 98.96 | 99.32 | 99.5 | 94.81 | 99.5 | 98.53 | 73.96 | 6.02 | 13.2 |
| YOLOv8n [22] | 99.41 | 99.08 | 99.38 | 99.5 | 95.17 | 99.5 | 98.67 | 75.74 | 3.00 | 8.1 |
| YOLOv9t [23] | 99.18 | 99.44 | 99.43 | 99.5 | 94.61 | 99.5 | 98.61 | 74.31 | 2.01 | 7.6 |
| YOLOv10n [24] | 99.20 | 99.22 | 99.43 | 99.5 | 95.81 | 99.5 | 98.76 | 75.12 | 2.70 | 8.2 |
| YOLOv11n [25] | 99.49 | 99.41 | 99.49 | 99.5 | 96.49 | 99.5 | 98.98 | 77.49 | 2.58 | 6.3 |
| LPCF-YOLO | 99.27 | 99.58 | 99.54 | 99.5 | 96.12 | 99.5 | 98.92 | 75.83 | 2.09 | 1.7 |
| Method | Bike (%) | Skateboard (%) | Cart (%) | mAP @0.5 (%) | mAP @0.5:0.95 (%) | Params/M | GFLOPs |
|---|---|---|---|---|---|---|---|
| YOLOv5n [20] | 99.5 | 99.5 | 99.5 | 99.5 | 77.61 | 2.51 | 7.1 |
| YOLOv7-tiny [21] | 99.45 | 99.5 | 99.5 | 99.49 | 76.32 | 6.02 | 13.2 |
| YOLOv8n [22] | 99.49 | 99.5 | 99.5 | 99.5 | 76.85 | 3.01 | 8.1 |
| YOLOv9t [23] | 99.46 | 99.5 | 99.5 | 99.49 | 75.49 | 2.01 | 7.6 |
| YOLOv10n [24] | 99.48 | 99.5 | 99.5 | 99.49 | 76.53 | 2.7 | 8.2 |
| YOLOv11n [25] | 99.5 | 99.5 | 99.5 | 99.5 | 77.47 | 2.58 | 6.3 |
| LPCF-YOLO | 99.47 | 99.5 | 99.5 | 99.49 | 76.77 | 2.09 | 1.7 |
| LPCF-YOLO-Backbone | L-HSFPN | WIOU | UCSD-Ped1 mAP @0.5(%) | UCSD-Ped2 mAP @0.5(%) | Params/M | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|
| 98.67 | 99.5 | 3.00 | 8.1 | 15.7 | |||
| √ | 98.71 | 99.48 | 3.19 | 2.1 | 44.3 | ||
| √ | 98.87 | 99.5 | 1.91 | 6.7 | 15.3 | ||
| √ | 98.65 | 99.5 | 3.00 | 8.1 | 15.7 | ||
| √ | √ | 98.64 | 99.5 | 2.09 | 1.7 | 42.9 | |
| √ | √ | 98.95 | 99.5 | 1.91 | 6.7 | 15.3 | |
| √ | √ | 98.72 | 99.49 | 3.19 | 2.1 | 44.5 | |
| √ | √ | √ | 98.92 | 99.49 | 2.09 | 1.7 | 43.9 |
| FPC-F | S-EMCP | ADown | UCSD-Ped1 mAP @0.5(%) | UCSD-Ped2 mAP @0.5(%) | Params/M | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|
| 98.67 | 99.5 | 3.00 | 8.1 | 15.7 | |||
| √ | 98.98 | 99.5 | 3.36 | 7.8 | 16.2 | ||
| √ | 98.78 | 99.5 | 2.84 | 8.0 | 15.9 | ||
| √ | 98.33 | 99.39 | 3.00 | 2.2 | 43.5 | ||
| √ | √ | 98.79 | 99.5 | 3.19 | 7.7 | 16.5 | |
| √ | √ | √ | 98.71 | 99.48 | 3.19 | 2.1 | 44.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, P.; Sheng, H.; Jia, S. LPCF-YOLO: A YOLO-Based Lightweight Algorithm for Pedestrian Anomaly Detection with Parallel Cross-Fusion. Sensors 2025, 25, 2752. https://doi.org/10.3390/s25092752
Jia P, Sheng H, Jia S. LPCF-YOLO: A YOLO-Based Lightweight Algorithm for Pedestrian Anomaly Detection with Parallel Cross-Fusion. Sensors. 2025; 25(9):2752. https://doi.org/10.3390/s25092752
Chicago/Turabian StyleJia, Peiyi, Hu Sheng, and Shijie Jia. 2025. "LPCF-YOLO: A YOLO-Based Lightweight Algorithm for Pedestrian Anomaly Detection with Parallel Cross-Fusion" Sensors 25, no. 9: 2752. https://doi.org/10.3390/s25092752
APA StyleJia, P., Sheng, H., & Jia, S. (2025). LPCF-YOLO: A YOLO-Based Lightweight Algorithm for Pedestrian Anomaly Detection with Parallel Cross-Fusion. Sensors, 25(9), 2752. https://doi.org/10.3390/s25092752