1. Introduction
In the context of today’s rapid development of intelligent and automation technologies, path planning algorithms, as core technologies in the fields of autonomous navigation, intelligent transportation, and robotic systems, are gradually becoming the core focus of research in multiple fields. The main task of path planning algorithms is to generate feasible paths from the starting point to the end point for various types of mobile entities (e.g., robots, self-driving vehicles, and unmanned aerial vehicles) in complex and changing environments while meeting the key requirements of safety, high efficiency, and dynamic adaptability. Currently, path planning algorithms are widely used in many fields, including driverless vehicles [
1,
2], additive manufacturing [
3,
4], and biology [
5]. With the increasing complexity of application scenarios, the performance of path planning algorithms must also improve.
A significant amount of research has been devoted to the path planning problem. Commonly used path planning methods include artificial potential field-based methods [
6], geometric-based methods [
7], learning-based methods [
8,
9], and sampling-based methods [
10,
11]. However, each of these methods has inherent limitations. Field-based potential artificial methods may encounter issues with local minima in complex environments, leading to inaccurate path planning. Geometric-based methods, such as A* [
12] and Dijkstra [
13], perform poorly in complex and high-dimensional spaces with limited processing capabilities. Improved A* [
14] optimizes the path planning problem of the A* algorithm in large scenes by leveraging the connectivity relationships of nodes in the topological map, thereby enhancing the planning efficiency of the algorithm. Dynamic A* [
15] incorporates a distance constraint and dynamically selects checkpoints to replan the path, thereby enabling the mobile robot to dynamically plan a feasible path to the destination within a limited distance while approaching the shortest path as closely as possible. Learning-based methods require large amounts of training data and computational resources, which can significantly limit their practical application. Intelligent optimization algorithms include Genetic Algorithms [
16,
17], Particle Swarm Optimization [
18], Ant Colony Algorithms [
19], and path planning algorithms based on reinforcement learning. The Adaptive Genetic Algorithm [
20] is an improvement over the basic genetic algorithm, which greatly improves the convergence accuracy and accelerates the convergence speed.
In contrast, sampling-based methods offer broad applicability and high search efficiency. They can quickly find feasible paths, even in high-dimensional spaces, and perform exceptionally well in large environments. These advantages render sampling-based algorithms particularly prominent in various application scenarios. Rapid-exploring Random Tree (RRT) [
21] is a typical representative of sampling-based algorithms and is known for its ability to quickly generate feasible paths. Rapid-exploring Random Tree Star (RRT*) [
22] represents a milestone variant of the RRT algorithm. It introduces the ChooseParent and Rewire processes on the basis of the RRT. In the ChooseParent phase, RRT* selects a parent node from the neighbors of the new node, and the Rewire process optimizes and rewires the path, providing probabilistic completeness and asymptotic optimality. Although RRT* theoretically guarantees an optimal solution, its slow convergence speed makes it challenging to compute the optimal path within a finite time. Numerous variants of RRT* have been developed to address this issue. Ran et al. proposed a path planning algorithm based on the Rapidly-exploring Random Tree Star (RRT*) algorithm [
23] for mobile robots under kinematic constraints. An improved RRT*(IBPF-RRT*) [
24] guides the random tree towards the target point by optimizing the sampling part to enhance planning speed and proposes a path optimization strategy to reduce redundant inflection points and path cost. Goal-oriented RRT* (GRRT*) [
25] and Dynamic Environment RRT* (ED-RRT*) [
26] reduce the sampling process time through goal-oriented sampling strategies. However, both methods suffer from local optima. The Fast-RRT* [
27] algorithm employs a Hybridsampling strategy that combines goal-oriented sampling with constraint sampling during the Sampling phase, which reduces the ambiguity of the sampling process. However, this algorithm performs poorly in concave-map environments. S. Huang [
28] proposed an improved algorithm that integrates the artificial potential field method with the Rapidly-exploring Random Tree algorithm. This approach utilizes the gravitational and repulsive fields of the artificial potential field to reduce the randomness inherent in the path planning process, thereby enhancing the search efficiency of the RRT algorithm. Q. Zhang [
29] proposed a novel hybrid path planning algorithm based on the Rapidly-exploring Random Tree algorithm. By incorporating heuristic search principles into the random extension process of RRT, the algorithm is able to plan more efficient paths in a reduced time frame. H. Yang [
30]. proposed an improved RRT-Connect algorithm that incorporates a target bias strategy into the traditional RRT-Connect framework. This enhancement allows the algorithm to outperform conventional methods in terms of both path length and execution time. However, despite these improvements that enhance the traditional RRT algorithm and demonstrate its superiority, some disadvantages and limitations remain, particularly in scenarios involving multiple obstacles or dynamic environments. RRT*-Normal (RRT*N) [
31] was proposed to improve the speed of finding the target path, which generates new nodes through a probability distribution such that nodes close to the target have a higher probability. Faster RRT* (F-RRT*) [
32] introduced the concept of creating parent nodes for the sampling points. The ChooseParent phase incorporates the FindReachest and CreateNode processes to generate new nodes as parent nodes for the sampling points to improve the path quality. However, the high cost associated with creating new nodes and the issue of creating redundant nodes hinder the speed of the algorithm in obtaining an initial solution. The Fast Forward-RRT* (FF-RRT*) [
33] algorithm improves upon the Hybridsampling strategy of Fast-RRT* and addresses its application limitations. In the ChooseParent phase, FF-RRT* fully inherits its strategy from F-RRT*. The performance benefits obtained from the enhanced sampling strategy offset the performance associated with the ChooseParent phase. However, FF-RRT* cannot resolve the fundamental shortcomings of F-RRT*. More Quickly-RRT* (MQ-RRT*) [
34] introduces a new hybrid sampling strategy that combines a sparse sampling mechanism with a dynamic goal-biased strategy. This approach provides guidance during the sampling process while avoiding repeated sampling in the same space. MQ-RRT* also proposes a method for creating new nodes and improving path quality in environments with circular obstacles. However, the algorithm performs poorly in narrow spaces.
In the field of path planning, sensor technology plays a crucial role. Sensors can provide mobile robots with environmental information, including the location, shape of obstacles, and dynamic changes in the environment, thereby providing necessary input data for path planning algorithms. During the path planning process, the acquisition and processing of sensor data are crucial steps. Typically, mobile robots are equipped with various types of sensors, such as LiDAR, cameras, and ultrasonic sensors. These sensors can obtain environmental information in real time and convert it into data that can be used for path planning. For example, LiDAR can provide high-precision environmental distance information, while cameras can capture visual information of the environment to identify the shape and texture of obstacles. In this paper, the proposed algorithm assumes that sensor data has been preprocessed to extract obstacle and free space information from the environment, which is then used as input for the path planning algorithm. More attention is focused on the path planning itself.
Inspired by the aforementioned algorithms, a new path planning algorithm, FHQ-RRT*, is proposed on the basis of F-RRT* and MQ-RRT*. It can acquire high-quality paths at a faster speed and solve the pathfinding failure issue of MQ-RRT* in narrow-map environments. The main contributions of this paper are as follows:
1. Dynamic Sparse Sampling Strategy: A strategy is proposed that dynamically adjusts the exploration speed and precision of the algorithm on the basis of the growth rate of the random tree, enhancing the adaptability of the algorithm to the environment.
2. New Node Creation Method and KeyPoints Concept: The new algorithm actively creates parent nodes for the sampling points through dichotomy and collision detection instead of choosing from existing nodes. The newly created parent nodes are closer to obstacles and can effectively reduce the path cost. All newly created parent nodes are defined as KeyPoints, and no new parent nodes must be created when the temporary parent node of a new sampling point is a key point. This improvement reduced the number of parent node creations and increased the efficiency of the algorithm.
3. New Rewire Strategy: A strategy that focuses the rewire operation on more valuable nodes, thereby improving the efficiency of rewiring.
The rest of this paper is organized as follows.
Section 2 presents the necessary background for this paper, including the relevant definitions of path planning and the principles of reference algorithms. The proposed FHQ-RRT* method is introduced in
Section 3.
Section 4, and
Section 5 describes the simulation environment and results with a comparative analysis of RRT*, F-RRT*, and MQ-RRT*.
Section 6 concludes the paper and presents possible future research directions.
2. Preliminaries
This section formalizes the motion planning problem and introduces the F-RRT* and MQ-RRT* algorithms, which inspire the proposal of the FHQ-RRT* algorithm.
2.1. Problem Definition
Let define the configuration space in which is the obstacle region and where = / is the obstacle-free region. (, , ) defines a path planning problem, where ∈ denotes the initial state and where denotes the goal area. Let a continuous function : [0,1] → of the bounded variation be path. Path is collision-free if [0,1] and (τ) ∈ .
Feasible path planning. For the path planning problem (, , ), any solution corresponding to a feasible path such that is collision-free, (0) = , and (1) = . If no solution exists, then a failure is reported.
Map Information Acquisition. Spatial data and obstacles are obtained through radar, sensors, or other devices, and input into the path planning algorithm.
Additionally, the relevant definitions of the concepts involved in the algorithm are as follows:
SampleFree: Sample point is randomly selected from the map space. If is within , then . Otherwise, the sample is regenerated until the condition is satisfied.
CollisionFree: Given two points and , check that the local path σ from to is collision-free on the map.
CollisionNode: Given two points and , return the closest collision point to among the intersections of the path from to and the obstacle.
Create: Given three points, , , and . Create a node in the direction of to in terms of the length of the local path from to , and return that node .
Cost: Given point of V, it returns the full length of the path from to .
Classify: Given point of V, return all nodes in whose parent is not .
Distance: Given two points and , the Euclidean distance between and .
Parent: Given point of V, it returns the parent vertex of .
Nearest: Returns the point to in the Euclidean distance.
Nears: Return the set of points contained in a hypersphere of a specific radius centered at .
InitialPathFound: Determines if an initial solution has been found.
2.2. F-RRT*
Algorithm 1 describes the execution process of the F-RRT*. The authors of F-RRT* reported that the parameter significantly affects the computation time for path planning. They also discovered that nodes close to obstacles could offer better paths.
To reduce the impact of on the computation time, F-RRT* omits the parameter during the ChooseParent phase. Instead, it selects a parent node for in two steps: FindReachest (described in Algorithm 2) and CreateNode (described in Algorithm 3). FindReachest selects the reachable node from the ancestors of . becomes the candidate parent node of . It is obvious that connecting and makes the cost of the path from to lower than connecting and . CreateNode then creates a new node via the dichotomy method, which can connect to both and the parent node of , thereby improving the quality of the path. During this process, the parameter serves as the terminating criterion for the dichotomy.
Although this method improves path quality, the frequent use of dichotomy in the CreateNode process leads to a high number of collision-detection operations, increasing the cost of creating new nodes. In addition, because F-RRT* does not recognize previously created nodes, many repeated operations are needed to create the same node.
| Algorithm1 F-RRT* |
Require
Ensure: G = (V, E)
1: ,
do
3:·······
4:·······
5:········
6:··············
7:··············
8:··············
9:··············
10:···················
11:···················
12:············else
13:···················V ← V ∪ {}
14:···················
15:············end if
16:············ then
17: ···················Return
18:·············end if
19:·······end if
20:·······
21: end for |
| Algorithm 2 FindReachest |
Require
Ensure:
1
do
3:········then
4:··············
5:········else
6:···············
7:········end if
8: end while
9: Return |
| Algorithm 3 CreateNode |
Require:
Ensure:
1
then
3:·········
4:········· do
5:···············
6:··············· then
7:······················
8:···············else
9:······················
10:·············end if
11:·······end while
12:·······
13: ······do
14:··············
15:·············· then
16:····················
17:··············else
18:·····················
19:··············end if
20: ·······
then
23:········
24: else
25:········
26: end if
27: Return |
2.3. MQ-RRT*
The MQ-RRT* algorithm introduces a new hybrid sampling strategy that combines a sparse sampling mechanism and a dynamic goal-biased mechanism. The sparse sampling mechanism effectively avoids repeated sampling within the same space by limiting the minimum distance between the random tree nodes. The goal-biased mechanism allows the algorithm to dynamically adjust the probability of selecting a goal node as a sample point on the basis of the growth speed of the random tree. Specifically, as the growth speed of the random tree increases, the probability of selecting the goal node as a sample point also increases, increasing the growth of the random tree to a certain degree of directionality, which helps accelerate the path search. In addition, MQ-RRT* introduces a new node creation method that improves the path quality of the algorithm in environments with circular obstacles.
3. Proposed Algorithm: FHQ-RRT*
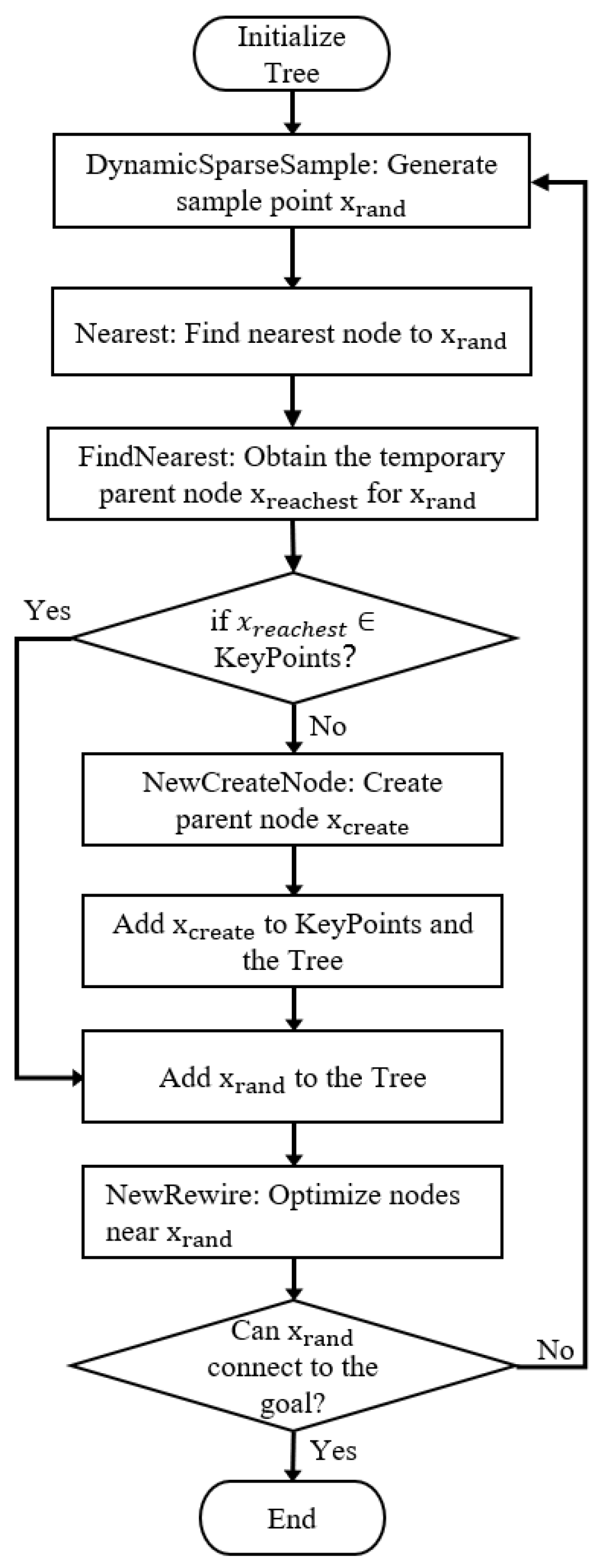
In this section, we introduce the basic principles of the FHQ-RRT* algorithm. First, the algorithm proposes a dynamic sparse sampling strategy for the sampling phase that controls the density of the random tree node by dynamically adjusting the spacing between them, thereby achieving a balance between the exploration speed and accuracy of the algorithm. Second, the algorithm introduces a new node creation method and the concept of KeyPoints, aiming to reduce the cost and frequency of node creation while improving path quality. Finally, the algorithm presents a new rewiring strategy that focuses on the scope of the rewire in areas of higher value, thus improving the efficiency of rewiring. The pseudocode for the FHQ-RRT* algorithm is presented in Algorithm 4.
Figure 1 illustrates the flowchart of FHQ-RRT*.
| Algorithm 4 F HQ-RRT* |
Require
Ensure:
1:
2: for do
3:········
4:········
4:········
4:········ is not None then
5:··············· then
6:······················
7:······················
8:···············else
9:······················
10:····················
11:····················
12:····················
13:············end if
14:············then
15:····················Return
16:············end if
17:·······end if
18:·······
19: end for
20: Return |
3.1. Dynamic Sparse Sampling Strategy
The sparse sampling strategy of MQ-RRT* effectively avoids the repeated sampling of the explored space. However, owing to its limitation of the minimum distance between random tree nodes, this strategy lacks sufficient adaptability in response to environmental changes. In particular, maps with narrow spaces may fail to generate feasible paths. To overcome this limitation, this paper proposes a dynamic sparse sampling strategy that dynamically adjusts the distance between random tree nodes on the basis of the tree growth rate, thereby improving the adaptability of the algorithm to environmental changes. The core concept of the dynamic sparse sampling strategy is as follows.
When the growth speed of a random tree is fast, the environment is relatively simple. In this case, the algorithm selects a larger sparse distance, reducing the density of random tree nodes and thus accelerating the algorithm’s exploration speed.
When the growth speed of the random tree slows down, the environment becomes more complex. At this point, the algorithm selects a smaller sparse distance to increase the density of random tree nodes, thereby improving its ability to explore environmental details.
In extreme environments, especially those with narrow spaces, the algorithm completely eliminates the limitation of sparse distance and reverts to a random sampling strategy, allowing for the full release of the algorithm’s ability to explore environmental details.
The growth rate of a random tree (
is defined as the reciprocal of the number of iterations (
) required for the algorithm to successfully expand a new node. Its mathematical expression is as follows:
These operations are represented by a DynamicSparseSample function in Algorithm 5.
| Algorithm 5 DynamicSparseSample |
Require
Ensure
1:
do
3:········
4:········
7: Continue
8:········end if
9:········
10:······
11:······ < 1 then
12:············· then
13:·····················
14:·····················
15:·············end if
16:······then
17:············· < then
18:·····················
19:·····················
20:·············end if
21:······end if
22:······
23: end for
24: Return |
3.2. Improved Choose Parent Strategy
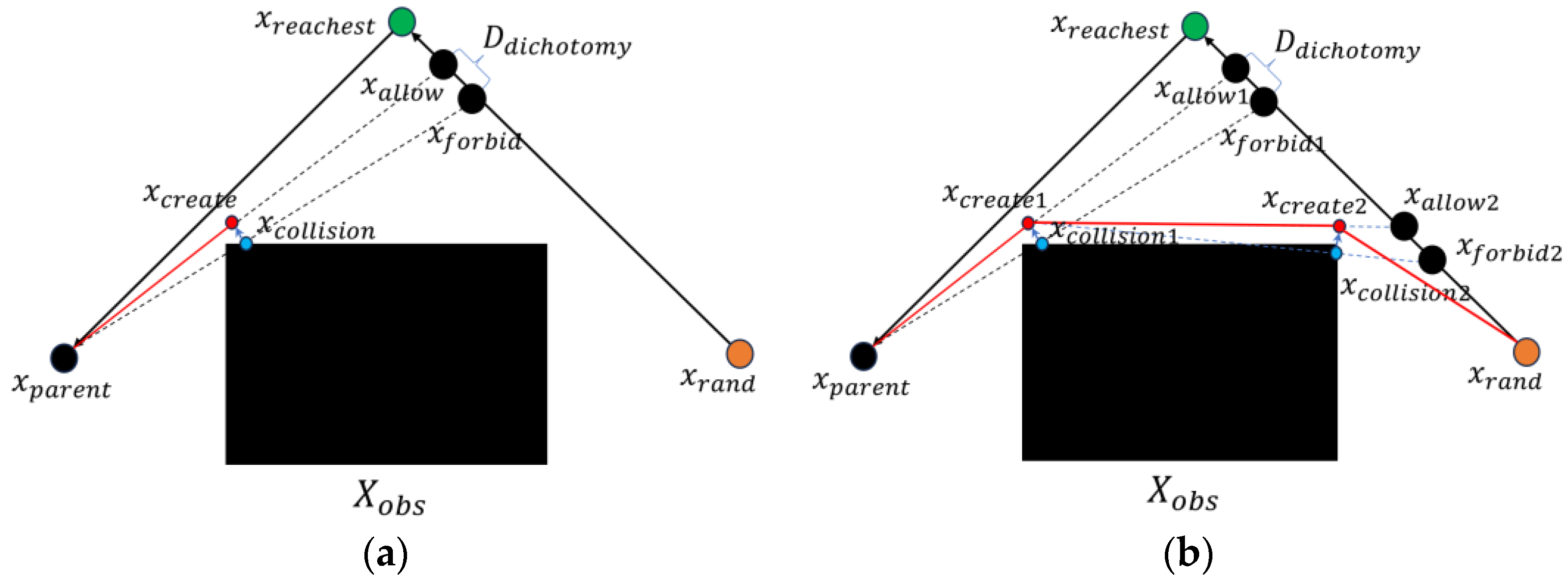
The processes of creating new nodes in both F-RRT* and MQ-RRT* are computationally expensive. To address these issues, this paper proposes a new node creation method called NewCreateNode, which reduces the cost of creating nodes. Algorithm 6 describes the execution process of NewCreateNode, the main principle of which is shown in
Figure 2a, which uses a binary search to find a passable path and a collision path on the obstacle side. The CollisionNode process computes the collision point between the collision path and obstacle and returns the farthest collision point
from
. The Create process then generates a new node
on the passable path on the basis of the distance from
to
.
Compared with the method used in F-RRT*, NewCreateNode reduces the cost of node creation by nearly half. Additionally, the new method supports recursive calls, allowing the algorithm to generate paths that are closer to obstacles.
Figure 2b illustrates the effects of path generation through recursive calls.
The three algorithms mentioned in the background (F-RRT* and MQ-RRT*) frequently call the CreateNode process to create a new parent node whenever a new random sample point is added, thereby replacing the candidate parent node for . This approach leads to the generation of many new parent nodes, especially at the corners of obstacles, where the new parent nodes are very close to each other and consume significant computational resources but actually contribute little to path optimization.
To address this issue, this paper introduced the concept of KeyPoints. The nodes created by the NewCreateNode process were marked as KeyPoints. When the algorithm detects that the candidate parent node of
belongs to KeyPoints, it directly adds
to the tree structure without creating a new parent node. This improvement aims to reduce unnecessary consumption of computational resources and enhance the efficiency of the algorithm.
| Algorithm 6 NewCreateNode |
Require
Ensure:
1
then
3:········
4:········ do
5:················
6:················ then
7:························
8:················else
9:························
10:·············end if
11:······end while
12:······
13:······
14:······ then
15:············ ∪ }
16:·············
17:·············
18:······end if
19:······ then
20:·············Return
21:······end if
22: end if
23: Return |
3.3. Newrewire
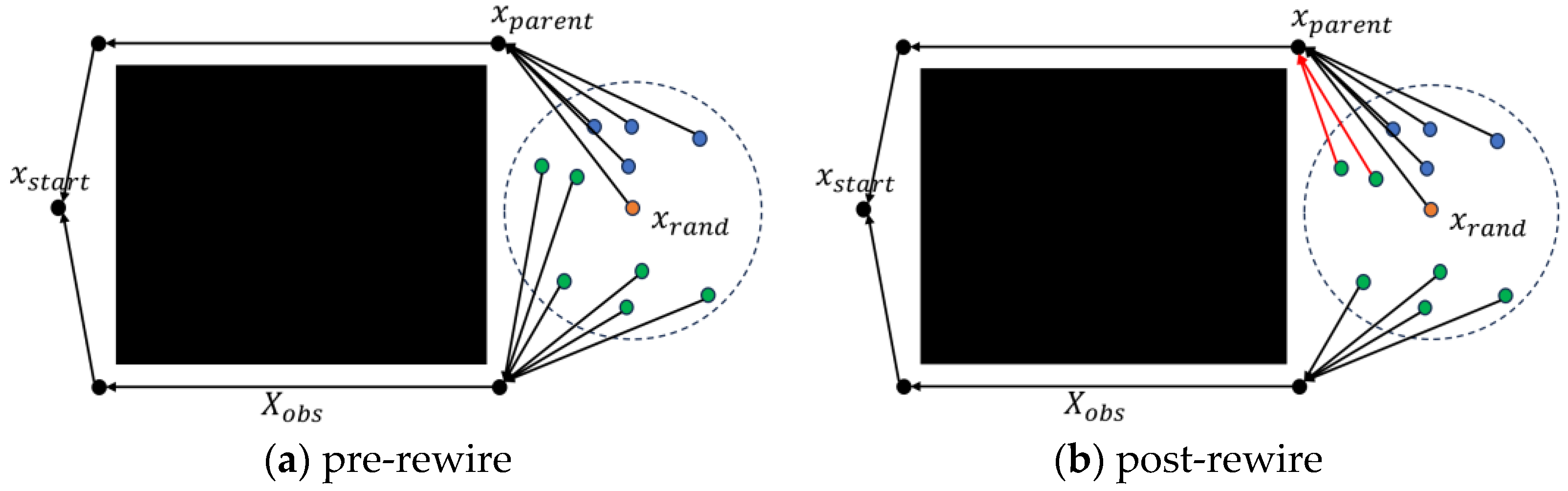
In the Rewire phase, this paper proposes a new rewire strategy. Before rewiring the path, the algorithm introduces a Classification process to divide the nodes near
(denoted as
) into two categories: co-origin nodes and non-co-origin nodes. The co-origin nodes refer to the nodes that share the same parent as
, whereas the non-co-origin nodes are the other nodes excluding the co-origin nodes, as shown in
Figure 3a. This classification aims to prevent the algorithm from processing co-origin nodes, as they share the same parent with
, and processing them does not improve path quality. On the other hand, focusing on the rewiring operation on non-co-origin nodes can effectively improve the efficiency of path rewiring.
In addition, a path-rewire strategy for non-co-origin nodes was introduced. Specifically, for any node
in the set of non-co-origins, if it is connected to the parent node of
and the path cost of
is reduced, then the parent node of
is updated to the parent node of
. This improvement improved the quality of the path, as shown in
Figure 3b. These operations are represented via the NewRewire function in Algorithm 7.
| Algorithm 7 NewRewire |
Require
Ensure:
1
2
do
4:·······then
5:·············· then
6:·····················
7:··············end if
8:·······end if
9: end for
10: Return |
4. Experimentation
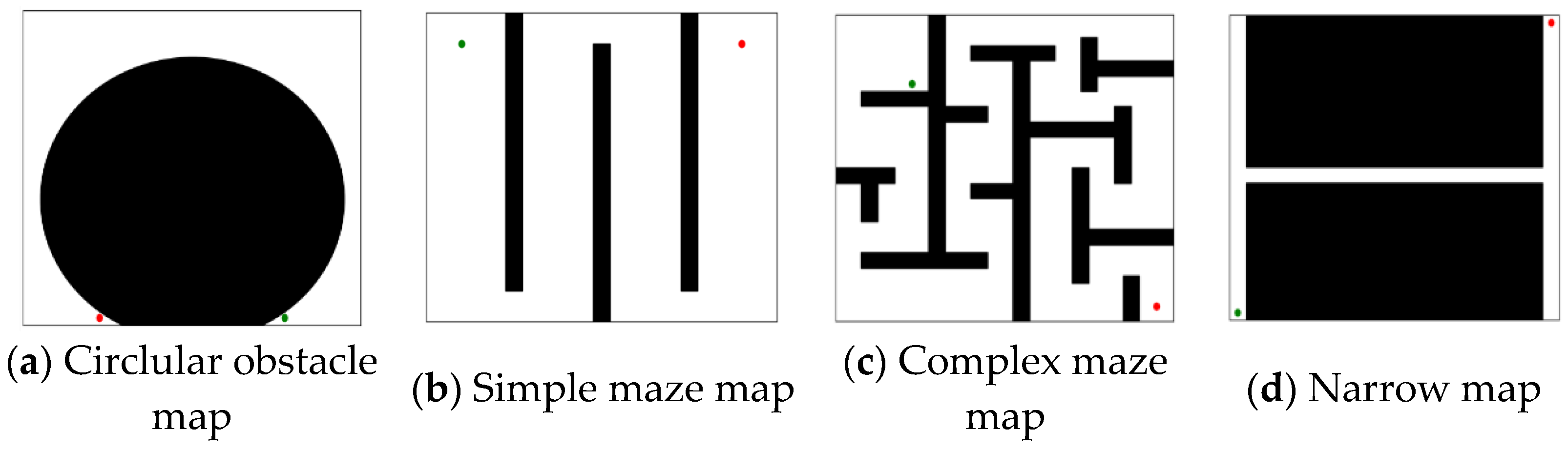
In this section, we conduct simulations of the FHQ-RRT* algorithm and compare its performance with those of three other algorithms—RRT*, F-RRT*, and MQ-RRT*—in four 2D map environments: the circular obstacle map, simple maze map, complex maze map, and narrow map. Each map was 200 × 200 units in size; the simulation environments are shown in
Figure 4.
RRT* was chosen as the baseline algorithm, and FHQ-RRT* was compared with MQ-RRT* and F-RRT* because these two algorithms are all path planning algorithms based on triangle inequality, with MQ-RRT* being the latest representative of this class of algorithms. To minimize the effect of randomness, each algorithm was run 100 times during the simulation, and the experimental data were averaged to ensure the reliability of the comparison results.
The basic performance of the four algorithms was evaluated via the following three fundamental indicators:
: Represents the time required for algorithm to generate a feasible path.
: Represents the total number of nodes in the random tree when algorithm generates a feasible path.
: Represents the cost of the feasible path generated by algorithm .
Additionally, to show the effective improvement brought by the enhancements proposed in FHQ-RRT*, we introduce four additional indicators for comparison (it is important to note that RRT* is not involved in the comparison of these additional indicators because it is not an optimization algorithm based on the triangle inequality).
: Represents the frequency with which algorithm invokes the CreateNode process. This frequency is measured as the ratio of the total number of times the CreateNode process is called during the generation of feasible paths to the total number of iterations performed by algorithm . This parameter reflects the impact of the KeyPoints concept on the performance of the algorithm.
: Represents the cost of executing the CreateNode process in algorithm . Specifically, it is measured by the number of collision checks required during the execution of the CreateNode process.
: Represents the cost of rewiring the path via the Rewire process in algorithm . This cost is measured by the number of nodes that must be rewired during the execution of the Rewire process. Because the number of nodes processed in the Rewire process is related to the density of the random tree nodes, indirectly reflects the impact of the sparse sampling mechanism on the algorithm’s performance.
: To demonstrate the advantages of the proposed NewRewire process, we define as the execution cost of the NewRewire process in FHQ-RRT*.
The algorithm terminates when either a feasible path is found or the maximum number of iterations is reached. All the simulations were performed on a computer equipped with a Core i7-12800X CPU and 16 GB of RAM.
4.1. Parameter Selection
In the simulation process, the following parameters need to be identified: the query radius , maximum iteration number , binary search parameter , and parameters related to the dynamic sparse sampling strategy: . The parameter of the sparse sampling distance for MQ-RRT* is .
Hu et al. [
33] demonstrated in their paper that as
increases, the path cost rises while the time cost decreases. A larger
will lead to an increase in the number of nodes processed during the rewiring phase, thereby increasing the time cost. The parameters
and
control the sparsity of the sampling points, directly affecting the algorithm’s exploration efficiency. In simple obstacle maps, larger values of
and
can accelerate the exploration speed. However, in complex obstacle maps, excessively large
and
values can increase the sampling failure rate, thereby slowing down the path planning speed. Therefore, it is advisable to set smaller
and larger
values to achieve rapid exploration in simple obstacle maps and reduce the sampling failure rate while maintaining a certain exploration speed in complex obstacle maps. The parameters
and
influence the growth rate of the random tree and its sensitivity to environmental complexity. Larger
and
values can enhance the algorithm’s sensitivity to complex environments, enabling it to adjust the sparse distance
or abandon the sparsity constraint earlier, thereby ensuring successful path planning. However, excessively large
values can make the algorithm overly sensitive, slowing down the exploration of the environment and increasing the planning time. Overall, it is recommended to select smaller
and
values and larger
and
values to balance the algorithm’s performance across different environments.
A larger and a smaller increase the algorithm’s computation time but can yield more optimal paths. Therefore, we set = 25 and = 1. To accommodate the environmental complexity in the four maps, we set = 0.2, = 0.1, = 10, and = 15. Additionally, we set = 10 and = 10000.
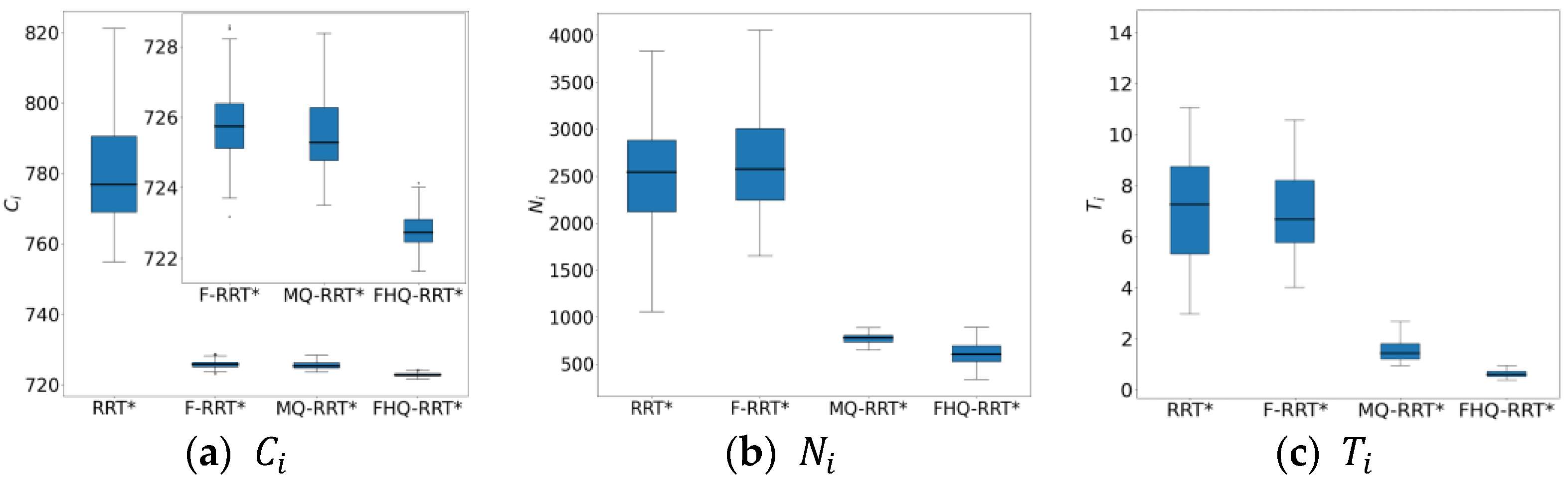
4.2. Circular Obstacles Map
Figure 5 shows the simulation results of the four algorithms in the circular obstacle map, where the red line represents the feasible path. As shown in the figure, both MQ-RRT* and FHQ-RRT* generate shorter and smoother paths. This demonstrates that, like MQ-RRT*, FHQ-RRT* has the ability to generate more optimal paths around arc-shaped obstacles. This is mainly due to the recursive calls of NewCreateNode, which enable the algorithm to generate a series of nodes that closely follow the obstacles’ surfaces. Compared with MQ-RRT*, FHQ-RRT* reduces the path cost by 1.2%. As can be seen from the data in
Table 1, the nodes generated by NewCreateNode in FHQ-RRT* are closer to the obstacles, thereby reducing the path cost.
In terms of time cost
, FHQ-RRT* reduces it by 40% compared with other algorithms, mainly due to the synergistic optimization of the dynamic sparse sampling strategy, key point identification, and rewiring mechanism. In the circular obstacle map, the random tree grows rapidly. FHQ-RRT* dynamically adjusts the sparse sampling to select a larger sparse distance, reducing the node density and accelerating the exploration of the environment. The
value of FHQ-RRT* is 39.5% lower than that of MQ-RRT*, which also proves the effectiveness of the dynamic sparse sampling strategy in improving the algorithm’s performance. In addition, key point identification reduces the frequency of calling the node creation program, lowering the computational overhead. According to the data in
Table 2, the
indicator shows that the number of nodes that FHQ-RRT*’s NewRewire process needs to handle is 86% less than that of other algorithms’ Rewire process. This is because the NewRewire process does not need to process co-origin nodes. Moreover, the
indicator shows that the execution cost of FHQ-RRT*’s NewCreateNode is 50.1% lower than that of other algorithms. This further proves the effectiveness of the relevant improvements in the node creation program.
Figure 6 shows the box plots of the basic indicator data for the four algorithms, further demonstrating FHQ-RRT*’s advantage in data stability and indicating better consistency in its performance.
4.3. Simple Maze Map
Figure 7 shows the simulation results of the four algorithms in the simple maze map. Except for RRT*, the path costs generated by the other algorithms are very close, as their planned paths are near-optimal. However, according to the data in
Table 3, the path cost indicator
shows that FHQ-RRT* still achieves a lower path cost than the other algorithms, primarily due to its generation of nodes closer to obstacles, which further reduces the path cost in path planning.
In terms of time cost
, FHQ-RRT* reduces it by 77% compared with other algorithms. This is because, in the simple maze map, the rapid growth of the random tree prompts FHQ-RRT*’s dynamic sparse sampling strategy to select a larger sparse distance, thereby reducing the sampling density and accelerating the exploration of the environment. In comparison of the number of nodes
, the FHQ-RRT* algorithm reduces them by 55.5% relative to other algorithms, thereby further substantiating the efficacy of the dynamic sparse sampling strategy in reducing the number of nodes. Additionally, according to the data in
Table 4, the
indicator shows that FHQ-RRT*’s NewRewire process reduces the number of processed nodes by 96.5% by focusing the rewiring operation on more valuable areas, thereby reducing computational overhead. Meanwhile, FHQ-RRT* reduces computational cost by identifying key points to avoid frequent calls to the node creation process. The combined effect of these improvements gives FHQ-RRT* a significant advantage in terms of time cost compared with other algorithms.
The box plots of the basic indicator data for FHQ-RRT* in
Figure 8 further confirm its superiority in terms of data stability, thereby verifying its excellent performance in path planning.
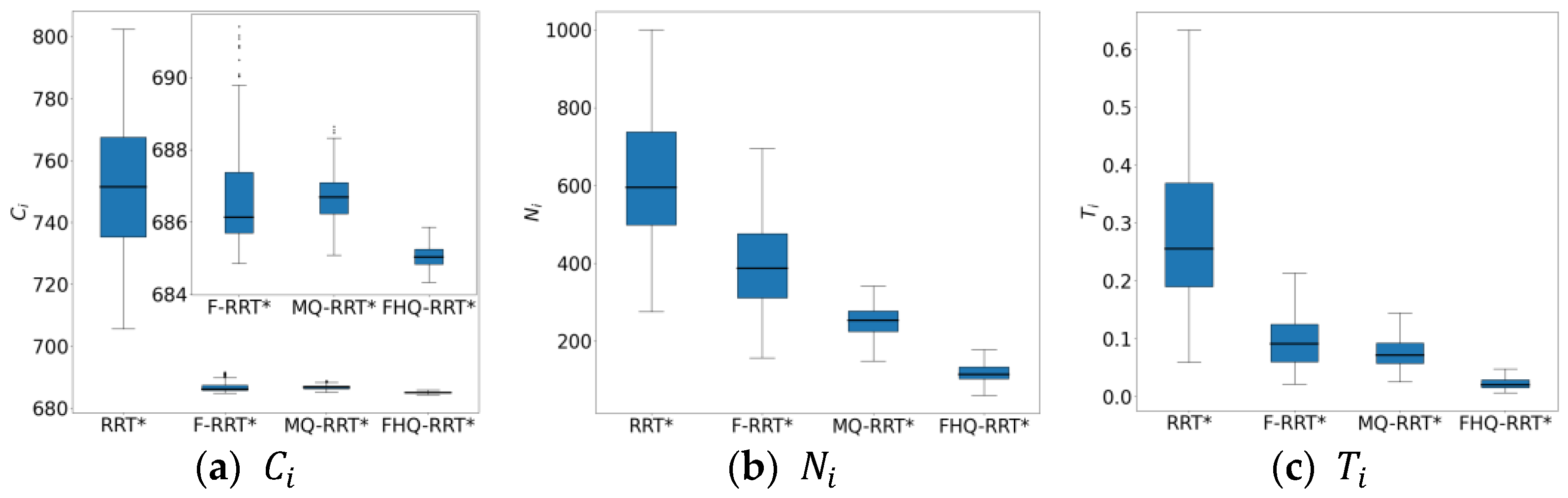
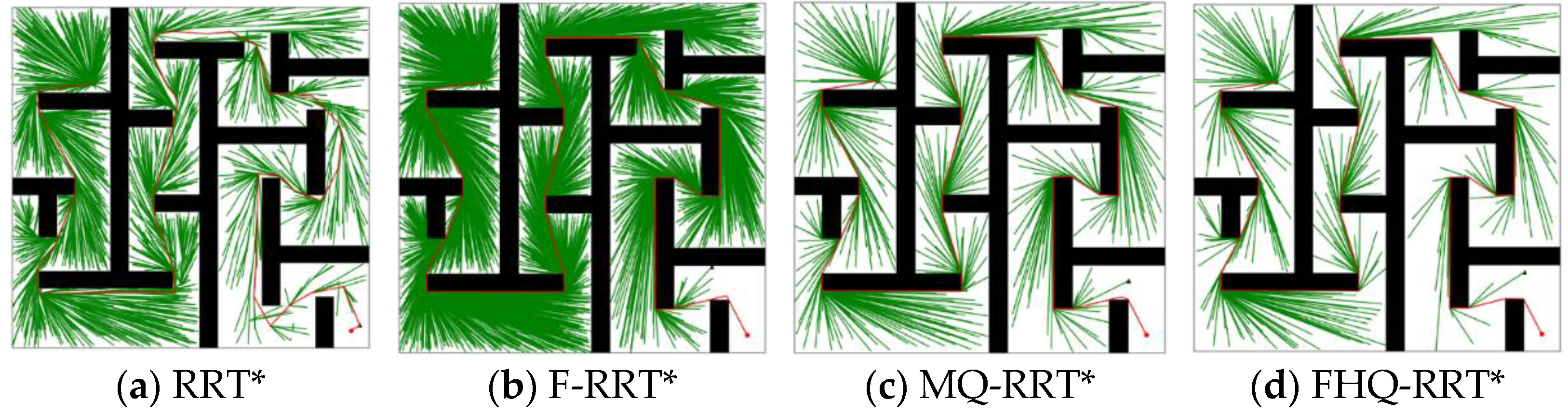
4.4. Complex Maze Map
Figure 9 shows the simulation results of the four algorithms in the complex maze map. According to the data in
Table 5, except for RRT*, the paths generated by the other algorithms are close to the optimal solution, leading to closely matched
values. However, the nodes created by the NewCreateNode process of FHQ-RRT* are closer to the obstacles, thereby achieving the lowest path cost.
FHQ-RRT* and MQ-RRT* both employ sparse sampling strategies to reduce node density, resulting in significantly lower compared with F-RRT* and RRT*. The value of FHQ-RRT* is 30% lower than that of MQ-RRT*, as the slower tree growth rate in the complex maze map causes FHQ-RRT*’s dynamic sparse sampling strategy to select smaller sparse distances more frequently. However, when the tree growth rate increases, it switches to larger sparse distances, thereby further reducing the number and density of nodes.
In terms of time cost, FHQ-RRT* reduces it by 56.6%, 90.8%, and 91.8% compared with MQ-RRT*, F-RRT*, and RRT*, respectively. This advantage is mainly attributed to two factors: First, the dynamic sparse sampling strategy accelerates the algorithm’s exploration of the environment, thereby reducing time overhead. Second, according to the data in
Table 6, the low computational cost and low invocation frequency of NewCreateNode, along with the improved rewiring efficiency of the NewRewire process due to fewer processed nodes, collectively reduce the computation time.
The box plots of the basic indicators for the four algorithms in
Figure 10 further confirm the advantage of FHQ-RRT* in terms of data stability.
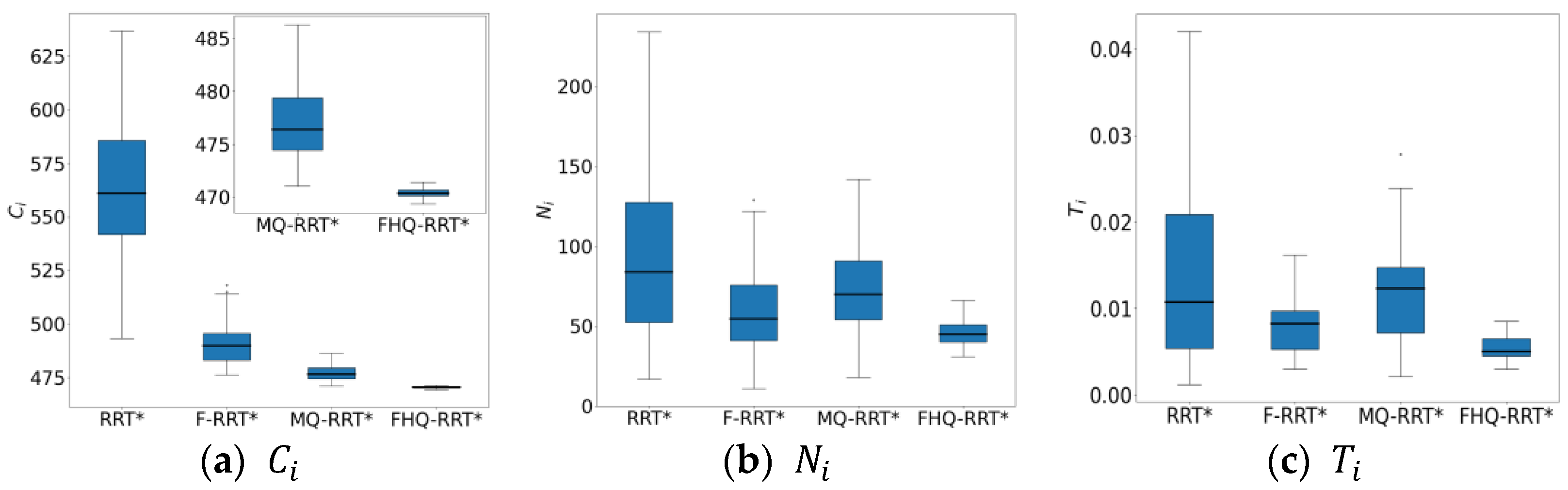
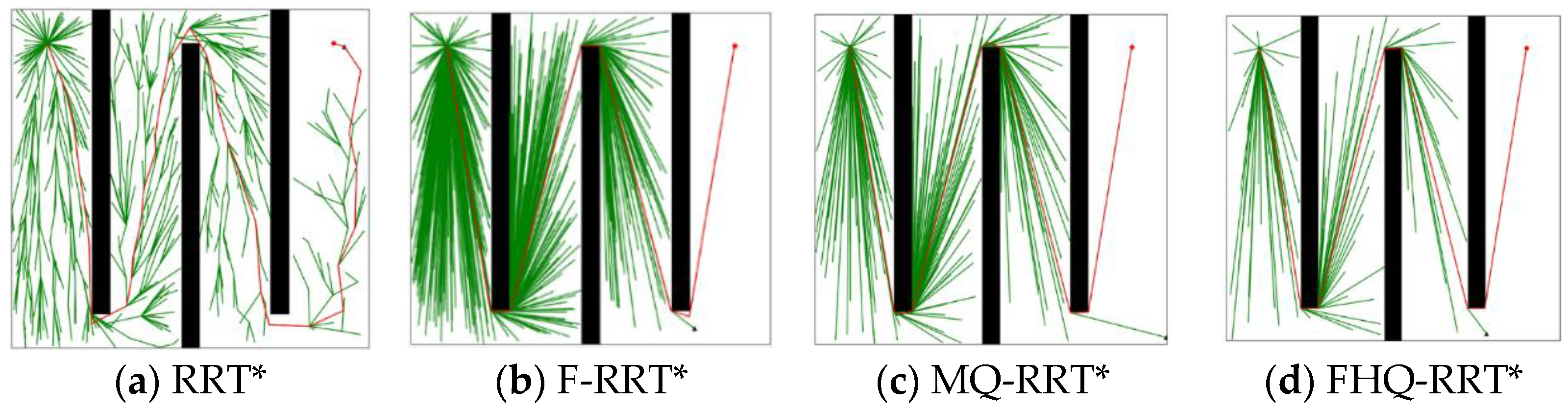
4.5. Narrow Map
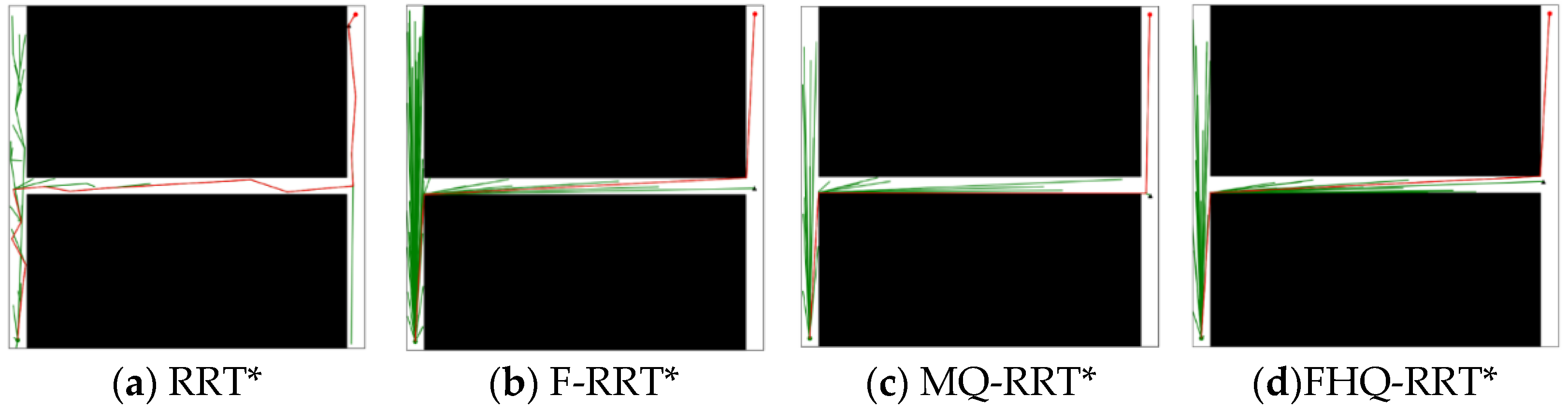
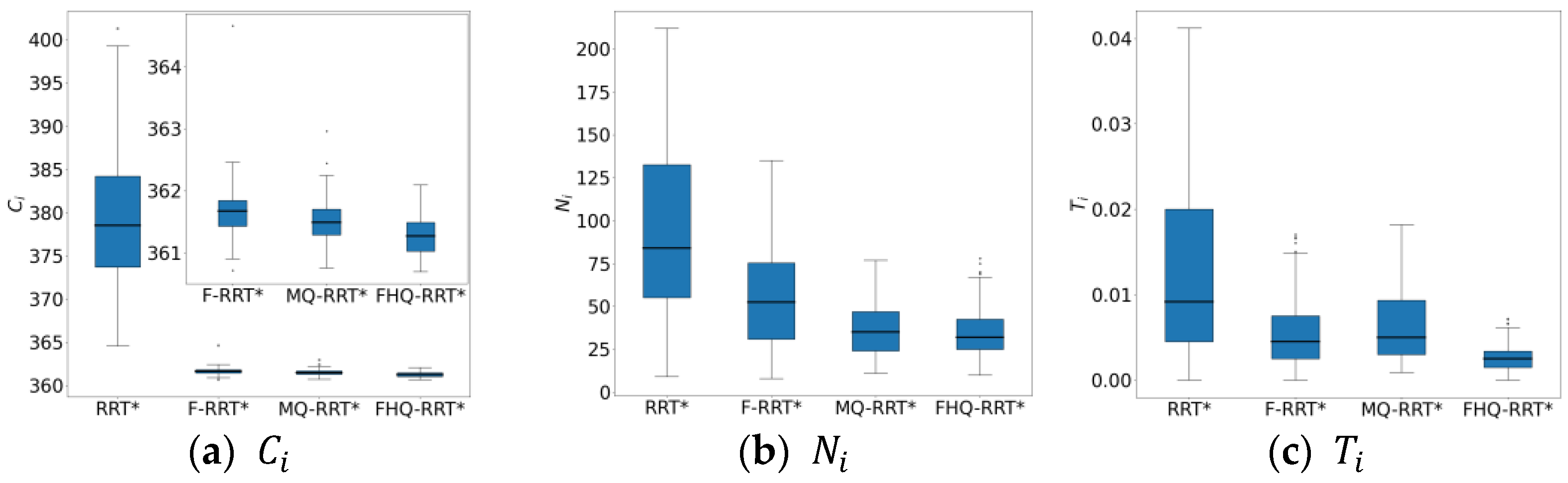
During the experiments, the narrower the gap in tight spaces was, the higher the failure rate of the MQ-RRT* algorithm. However, the FHQ-RRT* algorithm, which employs a dynamic sparse sampling strategy, did not encounter this issue. Specifically, when the navigable gap is excessively narrow, the dynamic sparse sampling strategy of FHQ-RRT* abandons the sparse distance constraint and reverts to random sampling, thereby ensuring the successful acquisition of a feasible path. To ensure that the sparse sampling strategy of MQ-RRT* could obtain sampling points and complete the planning task, the width of the narrow gap was set to 10 units.
Figure 11 shows the simulation results of the four algorithms in the narrow map environment. According to the data in
Table 7, except for RRT*, the paths planned by the other three algorithms are close to the optimal solution, resulting in similar
values. However, due to the closer proximity of nodes created by the NewCreateNode process of FHQ-RRT* to the obstacles, the
value of FHQ-RRT* remains the lowest.
In terms of node count
, the sparse sampling strategy, which limits node density, results in lower node counts for FHQ-RRT* and MQ-RRT* compared with the other two algorithms. Regarding time cost
, F-RRT* reduces it by 42.8% compared with MQ-RRT*, as the sparse distance constraint in MQ-RRT* lowers the sampling success rate in the narrow map, thereby increasing the algorithm’s runtime. Although FHQ-RRT* is also subject to the sparse distance constraint, according to the data in
Table 8, its low computational cost and low invocation frequency of the NewCreateNode process, along with the improved rewiring efficiency of the NewRewire process due to fewer processed nodes, significantly reduce the runtime, making it 50% lower than that of F-RRT*.
Figure 12 shows the box plots of the basic indicator data for the four algorithms, further demonstrating FHQ-RRT*’s advantage in data stability and indicating better consistency in its performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}