Abstract
Insulator defect detection in power inspection tasks faces significant challenges due to the large variations in defect sizes and complex backgrounds, which hinder the accurate identification of both small and large defects. To overcome these issues, we propose a novel dual-branch YOLO-based algorithm (DB-YOLO), built upon the YOLOv11 architecture. The model introduces two dedicated branches, each tailored for detecting large and small defects, respectively, thereby enhancing robustness and precision across multiple scales. To further strengthen global feature representation, the Mamba mechanism is integrated, improving the detection of large defects in cluttered scenes. An adaptive weighted CIoU loss function, designed based on defect size, is employed to refine localization during training. Additionally, ShuffleNetV2 is embedded as a lightweight backbone to boost inference speed without compromising accuracy. We evaluate DB-YOLO on the following three datasets: the open source CPLID, a self-built insulator defect dataset, and GC-10. Experimental results demonstrate that DB-YOLO achieves superior performance in both accuracy and real-time efficiency compared to existing state-of-the-art methods. These findings suggest that the proposed approach offers strong potential for practical deployment in real-world power inspection applications.
1. Introduction
In recent years, the need for a reliable and safe power supply has grown rapidly with societal development. Insulators, as essential components of power transmission systems, are critical for maintaining line stability and safety. However, prolonged exposure to harsh outdoor conditions—such as extreme temperatures, intense UV radiation, and environmental pollution—can cause various defects, including cracks, breakages, deformations, and contamination. Such defects may compromise both electrical insulation and mechanical integrity, potentially resulting in flashovers, line trips, or large-scale power outages. Consequently, the accurate and efficient detection of insulator defects is of paramount importance [1].
Recent studies have increasingly focused on small-scale defects, also known as incipient faults, which are subtle yet often precede severe failures. Detecting such early-stage defects requires sensitive and robust methods. Some data-driven techniques have been explored in some engineering fields to capture the weak signals of incipient faults [2,3,4]. However, these methods are primarily designed for mechanical or control systems using residual analysis, and they cannot be directly applied to image-based insulator defect detection. The key distinction of this work is that we propose a vision-based deep learning approach specifically tailored to detect fine defects in insulator images. By incorporating the concept of early-stage sensitivity into the network design, our method achieves high-precision recognition of small-scale defects. Compared with traditional approaches and existing residual-based methods, our approach is better suited to handle complex backgrounds and diverse defect patterns in visual data.
Currently, insulator defect detection methods can be broadly divided into traditional image processing- and deep learning-based approaches. Traditional techniques usually rely on handcrafted features combined with classical classifiers such as Support Vector Machines (SVMs) [5] or Random Forests [6]. For example, Guo et al. [7] proposed an automated detection method based on Principal Component Analysis (PCA), while Luo [8] combined SVM with Quantum Particle Swarm Optimization (SVM-QPSO) to enhance classification accuracy.
However, due to the complex backgrounds and diverse shapes of defects in insulator images, it is difficult to extract effective features using handcrafted methods. This complexity limits the performance of traditional recognition algorithms and often leads to low detection accuracy. In contrast, deep learning methods, especially convolutional neural networks (CNNs) [9], can directly learn hierarchical features from raw images, enabling end-to-end defect detection without the need for manual feature design. Compared with traditional approaches, deep learning offers better accuracy, faster inference, and improved generalization. Ferguson et al. [10] explored the effectiveness of feature extractors like VGG-16 and ResNet-101 in defect detection tasks. Xu et al. [11] enhanced defect detection performance by leveraging feature cascades within VGG-16. Li et al. [1] proposed a Two-Stage Defect Detection Framework based on Improved-YOLOv5 and Optimized-Inception-ResNetV2, which improves the accuracy of small defect localization through architectural enhancements and attention mechanisms.
Despite these advancements, deep learning-based models still face challenges in detecting small-scale or irregularly shaped insulator defects, particularly when real-time performance is required in practical applications. Many existing networks are computationally intensive and structurally redundant, making them unsuitable for deployment on lightweight edge devices such as drones used in power line inspections. Moreover, the variation in defect sizes and patterns further complicates detection. To overcome these limitations, researchers have explored multi-branch and multi-scale YOLO models that explicitly enhance feature representation across different object sizes. For example, MAF-YOLO [12] integrates multi-branch auxiliary fusion to improve small-object perception, UAV-YOLOv8 [13] rethinks multi-scale representation learning to achieve a better balance between accuracy and speed, and RDS-YOLO [14] introduces multi-scale feature fusion tailored for dense small targets. These studies highlight the importance of designing detection frameworks that adapt to varying target scales while ensuring computational efficiency.
In this study, we aim to address these challenges by introducing a dual-branch object detection framework tailored for insulator defect detection. Our method is designed to accurately recognize defects of different sizes and appearances by explicitly incorporating a large-defect detection branch and a small-defect detection branch, thus enhancing robustness across scales. At the same time, we optimize the architecture to maintain real-time performance suitable for aerial inspection scenarios using unmanned aerial vehicles (UAVs), ensuring both detection accuracy and deployment feasibility.
To address the challenges of detecting insulator defects with varying sizes, this paper introduces an enhanced detection algorithm based on YOLOv11, incorporating a dual-branch architecture. The model is designed with the following two specialized detection branches: one focusing on large-scale defects and the other on small-scale defects. This targeted approach allows the network to more effectively handle multi-scale defect features, significantly improving overall detection accuracy without compromising the lightweight and efficient nature of the original YOLO framework. To further enhance global perception, we incorporate the Mamba mechanism, which improves contextual feature extraction, particularly in cluttered scenes where large defects may be missed. Additionally, we introduce an adaptive weighted CIoU loss that dynamically adjusts parameters based on defect size, promoting better convergence during training and enabling precise localization of both small and large defects. This approach enhances model robustness and accuracy while reducing training complexity. Compared with existing state-of-the-art methods, the proposed network delivers higher detection accuracy without compromising inference speed, demonstrating strong potential for real-time insulator inspection and large-scale industrial applications.
- This study presents a dual-branch insulator defect detection method built on YOLOv11, which enhances detection accuracy while retaining the model’s lightweight characteristics. The approach adopts a dual-branch design, comprising separate branches for large and small defects, allowing the network to specialize in detecting targets of varying sizes.
- To better detect large-scale defects, the Mamba algorithm is incorporated to strengthen the network’s global feature extraction. By capturing more comprehensive contextual information, the Mamba mechanism enables the accurate identification of extensive defect regions, even in complex scenes with cluttered backgrounds and local interference.
- To optimize detection performance across various defect scales, an adaptive weighted CIoU loss function is designed. The loss parameters are dynamically adjusted based on the size of the defect, which facilitates model convergence during training and enhances detection accuracy for both large and small defects.
- Compared with current state-of-the-art detection models, the proposed network delivers superior accuracy while sustaining high inference speed, making it well-suited for real-time insulator inspection and practical industrial deployment.
2. Related Works
2.1. Object Detection
Over the past decades, numerous strategies for object detection have been proposed from different perspectives. Early approaches mainly relied on handcrafted feature design [15], often combined with classifiers such as SVMs [5] for recognition. With the rise of deep learning in computer vision, fully convolutional network (FCN)-based detection frameworks [16] have become mainstream, and these methods are generally categorized into two-stage and one-stage paradigms [17].
Two-stage detection is exemplified by the Faster R-CNN family [18], where the first stage generates feature representations and regions of interest (ROIs), followed by classification and regression in the second stage. Although this architecture achieves high accuracy, it suffers from considerable inference latency.
In contrast, one-stage detectors, such as the YOLO series [19], directly divide the feature map into grids, each responsible for predicting object categories and bounding boxes. Anchor-based detectors including RetinaNet [20] and EfficientDet [21] follow a similar design principle. Owing to their efficiency, one-stage methods are widely applied in industrial defect detection tasks. The one-stage object detection network consists of the following three parts: backbone, neck, and detector. The backbone is responsible for feature extraction. The neck is used to fuse features. The detector is used for object detection. We designed a dual-branch YOLO algorithm based on YOLOv11, which takes advantage of YOLO’s lightweight architecture while significantly enhancing detection accuracy. The dual-branch structure allows the model to specialize in detecting different types of targets—one branch focuses on large targets and the other on small targets. This specialization enables the model to better handle a wider range of object sizes, ensuring more accurate detections. By combining the efficiency of YOLO’s lightweight design with a more focused detection strategy through the dual-branch approach, we were able to strike a balance between speed and precision, making the algorithm both fast and highly accurate.
2.2. Vision in Mamba
Based on the study of SSM [22], Mamba [23] exhibits linear complexity in input size, addressing the computational efficiency issue of the Transformer on long sequences of modeling state space.
Within the development of general-purpose visual backbones, Vision Mamba [24] introduced the first pure vision-oriented backbone based on selective SSM, marking the initial application of Mamba in computer vision. Building on this, VMamba [25] proposed the Cross-Scan mechanism, enabling 2D selective scanning to enhance visual representation and achieving strong results in image classification. LocalMamba [26] adopts a window-based scanning strategy, refining local dependency modeling while incorporating dynamic scanning to adaptively select optimal configurations across layers. To alleviate the heavy computational cost of self-attention in Transformer-based detectors, Mamba YOLO integrates an ODMamba backbone with a State Space Model (SSM), thereby reducing complexity [27].
We designed a branch specifically for large targets, leveraging the advantages of the Mamba algorithm to enhance global feature extraction, thereby improving detection accuracy. The Mamba algorithm allows the network to better capture and utilize global contextual information, which is crucial for accurately identifying large targets. By focusing on global features, we are able to ensure that the network not only detects the target but also distinguishes it from the surrounding environment more effectively. This results in a more robust detection performance, especially in complex or cluttered backgrounds where large targets might otherwise be missed.
2.3. IoU Loss
The regression loss of bounding boxes plays a pivotal role in determining object localization accuracy. To overcome the limitation of zero gradients when the predicted and ground truth boxes do not overlap, Rezatofighi et al. [28] proposed the GIoU Loss. Building upon this, Zheng et al. [29] introduced the DIoU Loss, which incorporates not only overlap but also center distance and aspect ratio consistency, and later extended it to CIoU Loss. Subsequently, Zhang et al. [30] refined CIoU by replacing aspect ratio consistency with independent penalties on length and width, resulting in the EIoU Loss.
However, prior studies have largely neglected the imbalance in loss across objects of different scales. Such bias can misguide the network’s focus, hindering effective weight updates [31]. To address this, we designed adaptive weighted CIoU loss functions with scale-specific parameters, significantly reducing training difficulty and enhancing accuracy. By dynamically adjusting IoU loss according to object size, the model achieves better precision in detecting both small and large targets. This tailored design improves sensitivity to small objects while maintaining robustness for larger ones, ultimately leading to faster convergence and superior detection performance.
3. Materials and Methods
3.1. Overview
The overall framework of the proposed network is shown in Figure 1. In practical insulator defect detection, defect sizes vary significantly, from tiny flaws spanning only a few pixels to large defects covering substantial portions of the image. Such scale variation presents a major challenge for conventional detectors, which often fail to achieve balanced performance across small and large targets. To address this issue, we propose DB-YOLO, a dual-branch YOLO-based model tailored for multi-scale defect detection.
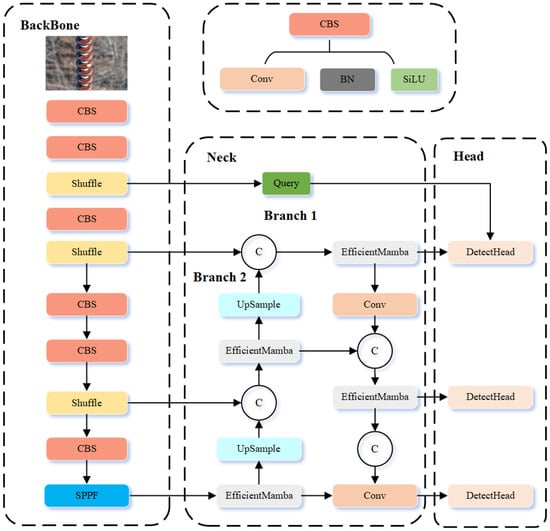
Figure 1.
Structure of our method.
The key idea of DB-YOLO is its dual-branch design, where two specialized branches are optimized for different defect sizes. Specifically, the large-defect branch focuses on wide-area flaws, while the small-defect branch emphasizes fine-grained target recognition. This structure effectively mitigates the scale imbalance problem, yielding improved detection accuracy across diverse defect categories.
To further boost performance, several architectural enhancements are introduced. First, the YOLOv11 backbone is replaced with ShuffleNetV2, a lightweight alternative that reduces parameters and accelerates inference while preserving accuracy, enabling real-time deployment. Second, the large-defect branch integrates the Mamba module, which strengthens global feature extraction and enhances contextual perception. In parallel, the small-defect branch employs the QueryDet mechanism, which improves the detection of small targets by focusing on fine-grained representations. The synergy of these modules enhances both efficiency and detection precision.
In addition, an adaptive weighted CIoU-based loss is designed to tackle optimization difficulties arising from scale variation. By dynamically adjusting according to defect size, the loss function enables balanced optimization for both small and large targets. This adaptive design not only improves detection accuracy but also accelerates model convergence.
The following sections provide detailed discussions of the Efficient Mamba Block, the Cascaded Query Mechanism, and the Adaptive Weighted CIoU Loss.
3.2. Efficient Mamba Block
In insulator defect detection, one of the major challenges is the efficient detection of large defects, which often occupy a significant portion of the image. Traditional detection methods often perform poorly when dealing with large-scale defects, as they may fail to capture the broad contextual information necessary for accurate detection. This leads to computational bottlenecks, where the model either sacrifices speed or detection accuracy when processing larger defects.
Traditional State Space Models (SSMs) face limitations in handling large-scale visual tasks due to their global information extraction complexity of , where N is the spatial resolution dimension of the input feature map (e.g., ).
To reduce this computational complexity, EMB introduces a selective scanning strategy that combines dilated convolution with an efficient skipping sampling mechanism. This module is shown in Figure 2, where (a) represents the Mamba Block, (b) illustrates the EMB, and the overall implementation is also depicted. Specifically, EMB divides the input feature map into multiple blocks and performs scanning with a stride p, effectively skipping positions in the spatial dimension. Instead of scanning every spatial location, EMB selects sparse key points where the following hold:
This reduces the number of tokens to be processed and lowers the complexity to , significantly reducing computational cost while preserving a global receptive field.
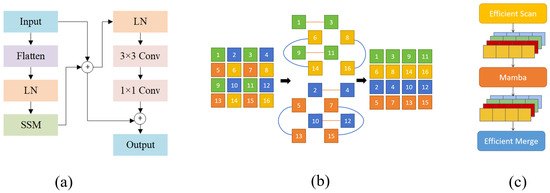
Figure 2.
(a) Mamba Block. (b) Description of EMB. (c) Implementation of EMB.
After scanning, EMB reconstructs the global structure of the feature map by merging these blocks, enabling the model to capture more comprehensive contextual information—a crucial factor in detecting large-area defects.
Furthermore, the Mamba Block enhances the capability of SSMs through the Selective State Space (S6) mechanism, in which the parameters dynamically adapt to the input. The state update function is defined as follows:
Here, is the output vector at step t, is the previous hidden state, and is the current input feature vector. The transformation matrices and bias vectors are functions of the current input, expressed as follows:
where and denote lightweight parameterized functions ( convolutions) and are learnable parameters. This design allows state to adapt dynamically to the input context, selectively emphasizing informative features while efficiently propagating information from previous states.
Finally, these features are fed into a Selective State Intermediate Layer, where the extracted representations more effectively reflect relevant information. This enables efficient and accurate large-defect detection without sacrificing real-time performance.
3.3. Cascaded Query Mechanism Based on QueryDet
In FPN-based detectors, small objects are typically detected using high-resolution feature maps with weak semantic information. However, such small objects only occupy a small portion of the image, and their localization performance tends to degrade significantly. This issue becomes more pronounced in insulator defect detection tasks, where defects are often sparsely distributed across the image and vary in size. Directly adding a layer dedicated to small-object detection in the network would significantly increase the computational cost, severely affecting real-time processing capabilities and making it difficult to balance accuracy and speed.
To address this, we introduce the QueryDet [32] module in the small-defect detection branch of the proposed DB-YOLO model. For the preprocessed and layers (as shown in Figure 3), we construct query (Query), key (Key), and value (Value) feature sets, and we perform sparse query operations using attention mechanisms to obtain enhanced feature maps for small object regions. These are then combined with the high-resolution spatial information from the layer to accurately detect small objects.
Figure 3.
Structure of QueryDet.
The Query-block converts the feature maps from and into query-key-value triplets, which are used in subsequent attention operations. The image first passes through the backbone and feature pyramid network to extract multi-scale features, with the highest resolution layer chosen as the primary feature layer. Subsequently, the Query-block utilizes high-confidence indexes from and to perform sparse queries on and generate fine-grained feature maps for high-resolution detection.
This encoding strategy is used to generate target maps for small objects and is involved in IoU calculations, non-maximum suppression (NMS), and the optimization of the regression loss function.
Figure 4 provides a simplified diagram where the left input is the processed fine-grained feature map, and the right input is the key region index map obtained via coarse querying. The query module extracts these high-confidence regions from the fine-grained feature map, and then high-resolution detection is applied to these regions, improving the detection performance for small defects.
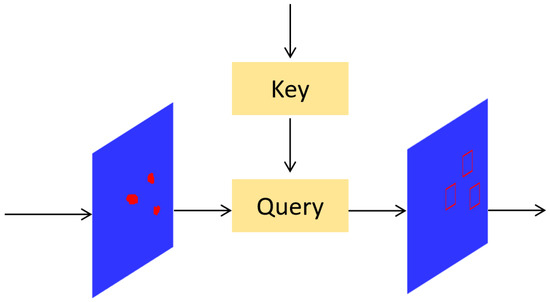
Figure 4.
Structures of Query-block. The red regions represent the feature map of the target.
Unlike traditional methods that add a separate layer for small-object detection, QueryDet leverages existing multi-scale features and introduces attention mechanisms to intelligently filter key detection regions. This approach improves small-object detection accuracy without adding computational overhead. It effectively enhances small-defect detection capabilities while maintaining high real-time performance.
3.4. Adaptive Weighted CIoU Loss
In YOLOv11, the default bounding box regression relies on the standard Intersection over Union (IoU) loss. Although widely used, IoU-based losses often suffer from limitations such as inaccurate localization for highly overlapping boxes and insensitivity to aspect ratio or scale variations. These shortcomings are particularly problematic in industrial defect detection, where object sizes and shapes vary considerably.
To overcome these issues, we replace the standard box loss with an adaptive weighted Complete IoU (CIoU) loss. CIoU [33] extends traditional IoU by incorporating both aspect ratio and center distance, offering a more comprehensive measure for localization accuracy. Beyond this, we further enhance CIoU by introducing an adaptive confidence weighting strategy, which dynamically adjusts confidence penalties according to the detection difficulty of individual objects. This mechanism ensures that the network allocates greater attention to hard-to-detect instances, thereby improving robustness in defect detection.
For single-class detection, the weight adjustment depends on the predicted confidence score as follows: predictions with lower confidence are penalized more heavily, forcing the network to refine uncertain regions. This adaptive design effectively mitigates the challenges posed by scale variation, ensuring balanced optimization across both small and large targets. The formulation of the weighted CIoU loss is presented in Equation (4).
where denotes the intersection over the union between the predicted box and ground truth box , is the squared Euclidean distance between their centers, c is the diagonal length of the minimum enclosing box covering both, and preserve aspect ratio consistency, and is a size-dependent weight that emphasizes low-confidence predictions. This adaptive design forces the network to refine uncertain regions, effectively mitigating challenges from scale variation and improving the detection of difficult, low-contrast defects while maintaining stability for high-confidence predictions.
4. Results
4.1. Datasets
To validate the effectiveness of the proposed insulator defect detection algorithm, we conducted experiments separately on two publicly available datasets and one self-constructed dataset from the Lijiang Power Grid in Yunnan Province. The detailed descriptions of the three datasets are provided in Table 1. We briefly introduce the datasets, evaluation metrics, and training setup, and we finally present experimental results with comparisons to existing methods.

Table 1.
Summary of insulator defect detection datasets.
The Chinese Power Line Insulator Dataset (CPLID) [34] consists of 600 real-world images of intact insulators and 248 synthetically generated images of defective ones. All images were acquired using UAVs and are provided by the State Grid Corporation of China. Representative samples are illustrated in Figure 5.

Figure 5.
Chinese Power Line Insulator Dataset.
The Lijiang dataset, collected in collaboration with Yunnan Power Grid Co., Ltd., Kunming, China, consists of 4000 high-resolution images taken under real-world conditions using UAV-mounted cameras. It covers diverse scenarios including strong lighting, occlusion, and background interference. It contains six label categories, namely, Crack (Cr), Contamination (Co), Broken (Br), Burn (Bu), Rust (Ru), and Missing Cap (Mc). All defect regions were annotated by experts in YOLO format. The dataset is split into training, validation, and test sets (70%/15%/15%) and augmented with random cropping, flipping, and brightness adjustments. Representative samples are illustrated in Figure 6.

Figure 6.
Yunnan Lijiang Power Line Insulator Dataset.
This IFDD dataset focuses on various types of insulator defect detection and contains nine label categories, namely, Glassdirty, Glassloss, Polymer, Polymerdirty, Two glass, Broken disc, Insulator, Pollution-flashover, and Snow. The dataset consists of 1607 images, which are split into a training set (1285 images), test set (162 images), and validation set (160 images) in an approximate 8:1:1 ratio. Representative samples are shown in Figure 7.

Figure 7.
IDFF Dataset.
4.2. Quantitative Metrics
To comprehensively evaluate the performance of the proposed DB-YOLO model in insulator defect detection, multiple quantitative metrics are employed. Conventional studies often rely on Precision, Recall, and mean Average Precision (mAP), which provide useful but limited insights into model behavior. In this work, we extend the evaluation to include additional indicators, such as F1-Score, False Positive Rate (FPR), and True Negative Rate (TNR), so as to ensure a more rigorous and balanced assessment.
Precision is defined as the ratio of true positive predictions to the sum of true positives and false positives, which can be expressed as follows:
where and denote true positives and false positives, respectively. Recall measures the ability of the model to detect actual defects and is given by the following:
where represents false negatives. To balance Precision and Recall, the F1-Score is introduced as their harmonic mean, expressed as follows:
To further examine the diagnostic reliability in engineering applications, we introduce FPR and TNR. The False Positive Rate quantifies the probability of misclassifying non-defect samples as defects and is expressed as follows:
while the True Negative Rate measures the proportion of correctly identified non-defect samples, expressed as follows:
where denotes true negatives. Furthermore, this study adopts as the standard metric for defect detection evaluation, which corresponds to the mean of average precision across all classes at an IoU threshold of 0.5 as follows:
where denotes the average precision of class i at = 0.5, and N is the number of defect categories. It should be emphasized that all reported mAP values in this study refer to . Inference speed is reported in terms of FPS, which allows the assessment of the model’s practical efficiency. A higher FPS indicates shorter processing time per image, providing a direct measure of suitability for real-time or near real-time engineering inspection tasks.
4.3. Model Training
The proposed framework is implemented in PyTorch 2.1 and executed on a workstation equipped with an NVIDIA RTX 3090 GPU. Training is performed in GPU mode with CUDA 11.3.1 and cuDNN 8.2.1. Model parameters are optimized using the stochastic gradient descent (SGD) algorithm, with the detailed training configurations summarized in Table 2.
Table 2.
Experimental parameter settings.
4.4. Comparison with State-of-the-Art Methods
The experimental results on the China Power Line Insulator dataset are presented in Table 3. The proposed method achieves the highest mAP50 (99.6%) and an accuracy of 91.2% while maintaining a recall of 100%. The F1-score reaches 95.3%, with the FPR reduced to 4.0% and the TNR improved to 96.0%, indicating strong robustness.
Table 3.
Comparison of different methods on the Chinese Power Line Insulator Dataset.
In terms of efficiency, the proposed method reaches 60 FPS, corresponding to approximately 16.7 ms per image. Although this speed is lower than FCOS (125 FPS, 8.0 ms) and YOLOv4 (91 FPS, 11.0 ms), it still satisfies the near real-time requirements of UAV inspection. Compared with YOLOv11, the second-best model, our method improves mAP50 by 0.1%, accuracy by 4.4%, and F1-score by 2.3%. Relative to YOLOv5, the accuracy gain reaches 5.1%. These results demonstrate that the slight sacrifice in inference speed is compensated by substantial improvements in accuracy and robustness, which are more valuable for engineering applications.
On the IFDD dataset (Table 4), the proposed method achieves 92.2% accuracy, 89.5% recall, 93.1% mAP50, and 90.8% F1-score, with an FPR of 3.8% and a TNR of 96.2%, outperforming all comparison models. The inference speed is 58 FPS (17.2 ms per image), slightly slower than FCOS (121 FPS, 8.3 ms) and several YOLO variants, but still within a practical range for engineering deployment.
Table 4.
Comparison of different methods on the IFDD Dataset.
On the Yunnan Lijiang Power Line Insulator dataset (Table 5), the proposed method achieves the highest mAP50 (81.4%) across all categories and shows superior performance in multiple defect types, including cracks, contamination, rust, and missing caps. The inference speed reaches 78 FPS (12.8 ms per image), which is lower than FCOS (130 FPS, 7.7 ms) and some YOLO models, yet it remains sufficient for UAV inspection tasks.
Table 5.
Comparison of different methods and their performance on the Yunnan Lijiang Power Line Insulator Dataset.
In addition to the quantitative results, qualitative comparisons are presented in Figure 8, Figure 9 and Figure 10. On the China Power Line Insulator dataset (Figure 8), the proposed method effectively identifies small-scale defects under complex backgrounds and significantly reduces false detections compared with baseline models. On the IFDD dataset (Figure 9), the proposed method demonstrates higher localization accuracy for small targets or partially occluded defects while maintaining robustness against background interference. On the Yunnan Lijiang dataset (Figure 10), the proposed method exhibits strong adaptability to various defect types and is capable of accurately detecting defects of different scales even in complex scenarios. These qualitative results further confirm that the proposed model not only surpasses comparison methods in numerical metrics but also provides reliable detection performance in real-world engineering environments.

Figure 8.
Results from the Chinese Power Line Insulator Dataset.

Figure 9.
Result from the IDFF Dataset.

Figure 10.
Result from the Yunnan Lijiang Power Line Insulator Dataset.
Overall, the proposed method demonstrates clear advantages in accuracy and robustness while maintaining competitive diagnostic efficiency. Although it is not the fastest model, its balance between inference speed and detection performance makes it highly suitable for real-world engineering applications, ensuring reliability, safety, and operational efficiency.
4.5. Ablation Experiment
To evaluate the contributions of each module, we conducted ablation experiments on the following three datasets: CPLID, IFDD, and the Yunnan Lijiang Power Line Insulator Dataset, using YOLOv11 as the baseline. Table 6 presents the precision, recall, F1-score, and FPS for each module combination. Introducing the SHUFFLE module led to a notable increase in inference speed, with CPLID FPS rising from 62 to 66 (+4) and Lijiang dataset FPS from 80 to 84 (+4). However, the precision and F1-score slightly decreased, with CPLID F1 dropping from 93.0% to 91.8% (−1.2%), IFDD F1 from 89.9% to 88.8% (−1.1%), and Lijiang F1 from 78.4% to 77.1% (−1.3%). This indicates that while SHUFFLEBone improves computational efficiency, it introduces minor information loss, which is particularly evident in the CPLID dataset dominated by small targets.
Table 6.
Ablation study on the three datasets.
After incorporating the EMB, the performance was substantially recovered and further enhanced. The F1-score increased to 93.4% for CPLID (+1.6% relative to SHUFFLEBone), 90.4% for IFDD (+1.6%), and 79.4% for Lijiang (+2.3%), demonstrating that EMB effectively enhances multi-scale feature representation and is especially crucial for small-target detection in CPLID. The improvements on the IFDD and Lijiang datasets further show that EMB also benefits medium- and large-target detection, confirming its key role in overall model accuracy.
Adding the Query Block (QB) module further improved detection performance, with F1-scores reaching 94.4% for CPLID (+1.0%), 90.6% for IFDD (+0.2%), and 80.5% for Lijiang (+1.1%). QB enhances feature selection and boundary localization, leading to more robust detection in complex backgrounds. Finally, integrating AWCIOU loss with the complete Mamba mechanism yielded F1-scores of 95.3% for CPLID (+0.9%), 90.8% for IFDD (+0.2%), and 81.2% for Lijiang (+0.7%), representing improvements of +2.3%, +0.9%, and +2.8% points relative to the baseline, respectively. These results highlight that EMB is the primary contributor for small-target performance in CPLID, while the combination of QB and AWCIOU ensures balanced gains for medium and large targets in the IFDD and Lijiang datasets.
Overall, the ablation study clearly quantifies the contributions of each module. SHUFFLE improves inference speed but slightly reduces F1-score; EMB is critical for enhancing small-target and multi-scale feature representation; and QB and AWCIOU further refine feature selection and localization, yielding consistent improvements across all datasets.
5. Discussion
5.1. Lightweight Comparison Experiment
We conducted comparative experiments using several mainstream lightweight backbones, including MobileNetV3 [49], GhostNet [50], and ShuffleNetV2 [51], as the convolutional modules for YOLOv11. A detailed comparison with the baseline YOLOv11s is presented in Table 7.
Table 7.
Effectiveness comparison of Shufflebone with different backbones.
As shown in Table 7, ShuffleNetV2 (referred to as “shuffle”) achieved the highest F1-score of 76.2% among the evaluated lightweight networks and a competitive mAP50 of 77.4%, while significantly reducing computational cost, with only 2.45 G FLOPs and a model size of 2.3 M parameters. In comparison, YOLOv11s + MobileNetV3 obtained an F1-score of 70.5% and mAP50 of 72.1% with 3.3 G FLOPs and 7.3 M parameters, while YOLOv11s + GhostNet achieved 71.0% F1 and 72.7% mAP50 with 5.4 G FLOPs and 6.7 M parameters. These results demonstrate that ShuffleNetV2 not only maintains relatively high detection accuracy but also substantially improves efficiency in terms of FLOPs, model size, and computational cost, highlighting its excellent lightweight characteristics and validating the effectiveness of our proposed backbone modifications.
5.2. Curve-Based Comparison
To comprehensively evaluate the performance of our proposed method against the baseline YOLOv11, we conducted curve-based comparisons on the Yunnan Lijiang Power Line Insulator Dataset using Precision–Recall (PR) and Precision–Confidence (PC) curves (Figure 11). The blue curve represents the average performance across all defect categories, while the colored curves correspond to individual defect types. On the PR curve, our method consistently outperforms YOLOv11 across the full recall range. Notably, it maintains higher precision at high recall levels, demonstrating superior accuracy and robustness for multi-category defect detection, while still achieving high precision at low recall levels, indicating a low false positive rate.
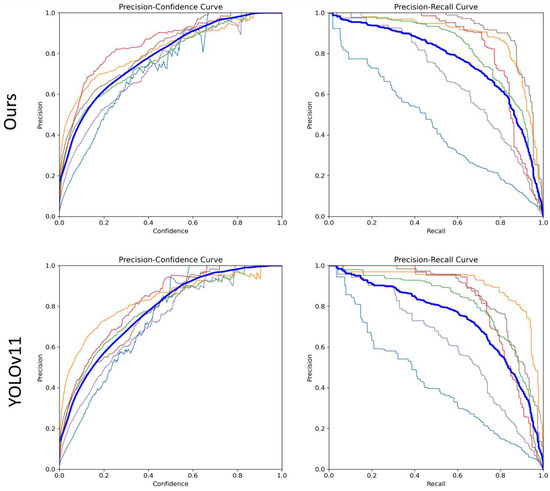
Figure 11.
Model curves of different metrics. The blue curve represents the mean curve across all classes, while the other colored curves correspond to different individual classes.
On the PC curve, the proposed method shows a stabler and slower decline in precision at low confidence thresholds, whereas YOLOv11’s precision drops more rapidly, indicating less reliable predictions at lower confidence levels. This highlights the stronger confidence calibration of our model, which helps reduce false alarms in automated inspection scenarios.
Overall, the curve-based analysis demonstrates that the proposed method not only improves detection accuracy over YOLOv11 but also maintains reliable performance under high-recall and low-confidence conditions, illustrating its advantages for practical engineering applications.
5.3. Comparison with Multi-Branch YOLO Models
To further evaluate the effectiveness of the proposed dual-branch detection framework, we conducted a comparative study with several recently proposed multi-branch YOLO models, including UAV-YOLOv8, RDS-YOLO, and MAF-YOLO. These models are specifically designed to improve detection performance for objects of varying scales, particularly focusing on small targets. The comparison was performed on the following three widely used insulator defect datasets: CPLID, IFDD, and Lijiang. The evaluation metrics include Precision, Recall, model parameters (Params), computational complexity (FLOPs), and inference speed (FPS), providing a comprehensive assessment of both detection accuracy and efficiency. The results are summarized in Table 8.
Table 8.
Performance comparison of different algorithms on the three datasets.
The experimental results on the CPLID, IFDD, and Lijiang datasets show that on the CPLID dataset, our proposed method achieves the highest precision of 91.2% and maintains a recall of 100%, outperforming UAV-YOLOv8, RDS-YOLO, and MAF-YOLO. In addition, our model achieves the best trade-off between accuracy and efficiency, with only 7.1 M parameters and 6.8 G FLOPs, while running at 60 FPS. These results indicate that our dual-branch framework can effectively capture both large- and small-scale defect features without introducing excessive computational overhead.
For the IFDD dataset, our method again achieves the best overall performance, reaching 92.2% precision and 89.5% recall. Compared to UAV-YOLOv8, which requires more than 31 G FLOPs, our approach significantly reduces computational cost to 6.8 G while preserving competitive accuracy. Compared to lightweight models such as RDS-YOLO and MAF-YOLO, our framework demonstrates higher detection accuracy while maintaining similar real-time performance, confirming its superiority in balancing effectiveness and efficiency.
On the Lijiang dataset, which contains more challenging conditions with smaller defects and complex backgrounds, our approach consistently demonstrates some advantages. The proposed method achieves 82.3% precision and 80.1% recall, outperforming other multi-branch YOLO variants by a clear margin. In addition, the FPS of our method remains at 78, which is higher than UAV-YOLOv8 and comparable to other lightweight competitors, further validating its suitability for deployment in real-world UAV-based inspection tasks.
Overall, these results demonstrate that the proposed dual-branch framework effectively addresses the challenges of insulator defect detection across different datasets. By explicitly incorporating small-defect and large-defect detection branches, the model achieves superior accuracy across scales, while its optimized architecture ensures low computational complexity and real-time inference.
6. Conclusions
In this paper, we proposed a novel dual-branch YOLO algorithm based on YOLOv11 to address the challenge of detecting insulator defects of varying sizes in real-world power line inspection scenarios. By introducing a dual-branch structure that separately focuses on large and small defects, the proposed method ensures more accurate and effective detection across a wide range of defect scales. Additionally, the integration of the Mamba algorithm for enhanced global feature extraction, combined with an adaptive weighted CIoU loss function tailored to different defect sizes, further optimizes detection performance while reducing training complexity. To improve efficiency, we adopt the lightweight ShuffleNetV2 as the backbone network, enabling real-time inference without compromising accuracy.
Experimental results on three insulator-related datasets—the CPLID, IFDD, and Lijiang dataset—demonstrate that our approach achieves superior performance in both detection accuracy and processing speed. This makes it highly applicable to real-world inspection tasks such as UAV-based automatic insulator defect detection.
Although the proposed dual-branch YOLO algorithm shows strong performance in insulator defect detection, several limitations remain. First, while the adaptive weighted CIoU loss improves detection across different defect sizes, the model’s robustness may still be challenged in complex backgrounds such as occlusion by trees or interference from wires. Second, although we evaluated the model on multiple datasets, the current data still covers a limited range of scenarios. Future work could explore the expansion of dataset diversity—across various climates, viewing angles, and operational environments—to further enhance the model’s generalizability and robustness.
Author Contributions
Conceptualization, Y.Z. and Z.F.; methodology, Z.F., Y.Z., C.L. and J.Q.; software, Y.Z. and Z.F.; validation, Z.F., Y.Z., C.L. and J.Q.; formal analysis, Z.F., Y.Z., C.L. and J.Q.; investigation, Y.Z. and Z.F.; resources, Z.F., Y.Z. and C.L.; data curation, Z.F. and C.L.; writing—original draft preparation, Z.F., Y.Z., C.L. and J.Q.; writing—review and editing, Y.Z., C.L. and J.Q.; visualization, Z.F.; supervision, Y.Z.; project administration, C.L. and J.Q.; funding acquisition, Y.Z. and C.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding. The APC was funded by Yan Zhao and Chaofu Liu.
Data Availability Statement
All data supporting the reported results in this study are available from the corresponding author upon reasonable request, due to privacy and ethical restrictions.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Li, Z.; Tian, X.; Liu, X.; Liu, Y.; Shi, X. A two-stage industrial defect detection framework based on improved-yolov5 and optimized-inception-resnetv2 models. Appl. Sci. 2022, 12, 834. [Google Scholar] [CrossRef]
- Feng, K.; Wu, Y.; Zhou, Y.; Lian, Z. Data-Driven ToMFIR-based Active Incipient Fault Detection for the Suspension System of High-Speed Trains. IEEE Access, 2025; early access. [Google Scholar] [CrossRef]
- Wu, Y.; Su, Y.; Wang, Y.L.; Shi, P. Fuzzy Data-Driven ToMFIR With Application to Incipient Fault Detection and Isolation for High-Speed Rail Vehicle Suspension Systems. IEEE Trans. Intell. Transp. Syst. 2024, 25, 7921–7932. [Google Scholar] [CrossRef]
- Tang, Y.; Ma, P.; Li, L.; Liu, X.; Liu, Y.; Wang, Q. Incipient fault detection based on double Kullback–Leibler divergence and self-attention. Reliab. Eng. Syst. Saf. 2025, 264, 111247. [Google Scholar] [CrossRef]
- Wu, W.-J.; Lin, S.-W.; Moon, W.K. Combining support vector machine with genetic algorithm to classify ultrasound breast tumor images. Comput. Med. Imaging Graph. 2012, 36, 627–633. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Zhang, X.; Yu, S.; Chen, Q.; Liu, W. A random forest classification algorithm for polarized SAR images with comprehensive multi-features. J. Remote Sens. 2019, 23, 685–694. [Google Scholar]
- Guo, Y.-C.; Deng, X.-F.; Gao, C. Surface defect automatic detection algorithm based on principal component analysis. Comput. Eng. 2013, 39, 2. [Google Scholar]
- Luo, X.-C. A hybrid SVM-QPSO model based ceramic tube surface defect detection algorithm. In Proceedings of the Fifth International Conference on Intelligent Systems Design and Engineering Applications, Zhangjiajie, China, 15–16 June 2014; pp. 28–31. [Google Scholar]
- Wang, J.; Luo, L.; Ye, W.; Zhu, S. A defect-detection method of split pins in the catenary fastening devices of high-speed railway based on deep learning. IEEE Trans. Instrum. Meas. 2020, 69, 9517–9525. [Google Scholar] [CrossRef]
- Ferguson, M.; Ak, R.; Lee, Y.-T.T.; Law, K.H. Automatic localization of casting defects with convolutional neural networks. In Proceedings of the IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 1726–1735. [Google Scholar]
- Xu, X.; Lei, Y.; Yang, F. Railway Subgrade Defect Automatic Recognition Method Based on Improved Faster R-CNN. Sci. Program. 2018, 2018, 4832972. [Google Scholar] [CrossRef]
- Yang, Z.; Guan, Q.; Zhao, K.; Yang, J.; Xu, X.; Long, H.; Tang, Y. Multi-branch auxiliary fusion YOLO with re-parameterization heterogeneous convolutional for accurate object detection. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Urumqi, China, 18–20 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 492–505. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Yang, T.; Zhang, R. Enhanced receptive field and multi-branch feature extraction in YOLO for bridge surface defect detection. Electronics 2025, 14, 989. [Google Scholar] [CrossRef]
- Dornaika, F.; Bosaghzadeh, A.; Salmane, H.; Ruichek, Y. A graph construction method using LBP self-representativeness for outdoor object categorization. Eng. Appl. Artif. Intell. 2014, 36, 294–302. [Google Scholar] [CrossRef]
- Gao, Y.; Li, X.; Wang, X.V.; Wang, L.; Gao, L. A review on recent advances in vision-based defect recognition towards industrial intelligence. J. Manuf. Syst. 2022, 62, 753–766. [Google Scholar] [CrossRef]
- Villa, M.; Dardenne, G.; Nasan, M.; Letissier, H.; Hamitouche, C.; Stindel, E. FCN-based approach for the automatic segmentation of bone surfaces in ultrasound images. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 1707–1716. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar] [CrossRef]
- Cheng, X.; Yu, J. RetinaNet with difference channel attention and adaptively spatial feature fusion for steel surface defect detection. IEEE Trans. Instrum. Meas. 2020, 70, 2503911. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Gu, A.; Johnson, I.; Goel, K.; Saab, K.; Dao, T.; Rudra, A.; Ré, C. Combining recurrent, convolutional, and continuous-time models with linear state space layers. In Advances in Neural Information Processing Systems, Proceedings of the Conference and Workshop on Neural Information Processing Systems 2021, New Orleans, LA, USA, 10–16 December 2021; NeurIPS Foundation: La Jolla, CA, USA, 2021; Volume 34, pp. 572–585. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Zhu, L.; Liao, B.; Zhang, Q.; Wang, X.; Liu, W.; Wang, X. Vision mamba: Efficient visual representation learning with bidirectional state space model. arXiv 2024, arXiv:2401.09417. [Google Scholar] [CrossRef]
- Shi, Y.; Dong, M.; Xu, C. Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model. arXiv 2024, arXiv:2405.14174. [Google Scholar] [CrossRef]
- Huang, T.; Pei, X.; You, S.; Wang, F.; Qian, C.; Xu, C. Localmamba: Visual state space model with windowed selective scan. arXiv 2024, arXiv:2403.09338. [Google Scholar] [CrossRef]
- Wang, Z.; Li, C.; Xu, H.; Zhu, X. Mamba YOLO: SSMs-Based YOLO For Object Detection. arXiv 2024, arXiv:2406.05835. [Google Scholar] [CrossRef]
- Union, G.I.O. A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, M.; Wan, H.; Li, M.; Li, G.; Han, D. IDD-Net: Industrial defect detection method based on deep-learning. Eng. Appl. Artif. Intell. 2023, 123, 106390. [Google Scholar] [CrossRef]
- Yang, C.; Huang, Z.; Wang, N. QueryDet: Cascaded Sparse Query for Accelerating High-Resolution Small Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 13668–13677. [Google Scholar]
- Du, S.; Zhang, B.; Zhang, P.; Xiang, P. An improved bounding box regression loss function based on CIOU loss for multi-scale object detection. In Proceedings of the IEEE 2nd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 16–18 July 2021; pp. 92–98. [Google Scholar]
- Tao, X.; Zhang, D.; Wang, Z.; Liu, X.; Zhang, H.; Xu, D. Detection of power line insulator defects using aerial images analyzed with convolutional neural networks. IEEE Trans. Syst. Man Cybern. Syst. 2018, 50, 1486–1498. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. Fcos: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9627–9636. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Borovec, J.; Liu, C.; Hogan, A.; Diaconu, L.; Poznanski, J.; Yu, L.; Rai, P.; Ferriday, R.; et al. ultralytics/yolov5: V3.0. Zenodo. 2020. Available online: https://zenodo.org/records/3983579 (accessed on 13 August 2020).
- Sohan, M.; Thotakura, S.R.; Venkata, C.R.R. A review on yolov8 and its advancements. In Proceedings of the International Conference on Data Intelligence and Cognitive Informatics, Tirunelveli, India, 18–20 November 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 529–545. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H.-Y.M. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–21. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 821–830. [Google Scholar]
- Paz, D.; Zhang, H.; Christensen, H.I. TridentNet: A Conditional Generative Model for Dynamic Trajectory Generation. In Proceedings of the International Conference on Intelligent Autonomous Systems, Wuhan, China, 22–25 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 403–416. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhang, H.; Dong, Y.; Wei, S. Automatic Ship Detection Based on RetinaNet Using Multi-Resolution Gaofen-3 Imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Zhao, W.; Chen, F.; Huang, H.; Li, D.; Cheng, W. A New Steel Defect Detection Algorithm Based on Deep Learning. Comput. Intell. Neurosci. 2021, 2021, 5592878. [Google Scholar] [CrossRef]
- Sinha, D.; El-Sharkawy, M. Thin MobileNet: An Enhanced MobileNet Architecture. In Proceedings of the 2019 IEEE 10th Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 10–12 October 2019; pp. 280–285. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. Shufflenet v2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).