Abstract
Federated learning (FL) enables distributed model training across sensor-equipped edge devices while preserving data privacy. However, its performance is often hindered by statistical heterogeneity among clients and system heterogeneity in dynamic wireless networks. To address these challenges, we propose TCS-FEEL, a topology-aware client selection framework that jointly considers user distribution, device-to-device (D2D) communication, and statistical similarity of client data. The proposed approach integrates randomized client sampling with an adaptive tree-based communication structure, where user devices not only participate in local model training but also serve as relays to exploit efficient D2D transmission. TCS-FEEL is particularly suited for sensor-driven edge intelligence scenarios such as autonomous driving, smart city monitoring, and the Industrial IoT, where real-time performance and efficient resource utilization are crucial. Extensive experiments on MNIST and CIFAR-10 under various non-IID data distributions and mobility settings demonstrated that TCS-FEEL consistently reduced the number of training rounds and shortened per-round wall-clock time compared with existing baselines while maintaining model accuracy. These results highlight that integrating topology control with client selection provides an effective solution for accelerating privacy-preserving and resource-efficient FL in dynamic, sensor-rich edge environments.
1. Introduction
The Internet of Things (IoT) is reshaping the landscape of global connectivity. With the increasing proliferation of interconnected IoT devices, numerous benefits are being introduced into everyday life. The IoT has been widely adopted in diverse domains such as smart homes, smart cities, the Industrial Internet of Things (IIoT) [1], and smart healthcare [2]. However, the explosive growth of IoT devices has posed significant challenges to conventional cloud computing paradigms, where vast volumes of raw data have to be transmitted to centralized servers for processing [3]. This approach has led to substantial latency, congestion, and scalability issues, undermining real-time responsiveness in latency-critical applications.
Edge computing addresses these limitations by processing data closer to their source, thereby significantly reducing latency [4]. This feature makes it particularly suitable for latency-sensitive IoT scenarios such as virtual reality, augmented reality [5], and autonomous driving [6]. In autonomous driving, for instance, real-time obstacle classification on sensor-equipped vehicles imposes stringent computational and communication requirements, necessitating highly efficient distributed intelligence at the network edge. Such edge devices, equipped with heterogeneous sensing and communication capabilities, further emphasize the need for scalable, secure, and resource-efficient distributed learning solutions.
When integrated with the IoT, edge computing offers multiple advantages, including high QoS, low latency, reduced energy consumption, and improved scalability [7]. However, it also introduces new challenges in terms of privacy and data security, as many devices collect sensitive personal or environmental information. Federated learning (FL) has emerged as a promising distributed intelligence paradigm in this context, enabling collaborative model training directly on devices without sharing raw sensor data [8]. This property is particularly critical in sensor-based systems such as autonomous vehicles, smart surveillance, and industrial monitoring, where privacy-preserving, real-time intelligence is essential.
Despite these advantages, FL performance in edge environments is often constrained by system heterogeneity (i.e., differences in computing, memory, and bandwidth capabilities) and statistical heterogeneity (i.e., non-identically and independently distributed data) [9]. System heterogeneity introduces straggler effects, where faster clients idle while waiting for slower ones, while statistical heterogeneity leads to biased global models and slower convergence. Moreover, traditional FL frameworks typically rely on star topologies, where direct device-to-server communication can incur high latency, particularly for resource-constrained or distant devices.
To mitigate these challenges, recent works have explored device-to-device (D2D) communication to complement device-to-server (D2S) links, thereby forming semi-decentralized FL architectures [10,11,12]. D2D communication can reduce energy consumption, enable localized model synchronization, and enhance fault tolerance in dynamic networks—characteristics that are essential to sensor-driven applications with mobile or intermittently connected nodes. Moreover, adaptive topology control further enhances robustness by accommodating device mobility and availability fluctuations [13].
On the other hand, client sampling strategies that jointly consider statistical and system heterogeneity have been developed to accelerate convergence [14]. Integrating such strategies with dynamic topology optimization is particularly critical to federated sensor networks, where both communication efficiency and learning performance need to be co-optimized.
Figure 1 illustrates the main challenges in achieving communication-efficient FL in a general mobile edge environment. In this work, we address these challenges by introducing TCS-FEEL, a topology-aware client selection framework specifically designed for sensor-driven federated edge learning. By jointly optimizing communication topology and client selection, TCS-FEEL enables secure, low-latency, and resource-efficient collaborative intelligence directly at the sensing edge. This contribution closely aligns with the goals of sensor-based computational intelligence by facilitating privacy-preserving, adaptive, and scalable machine learning across distributed sensor networks.
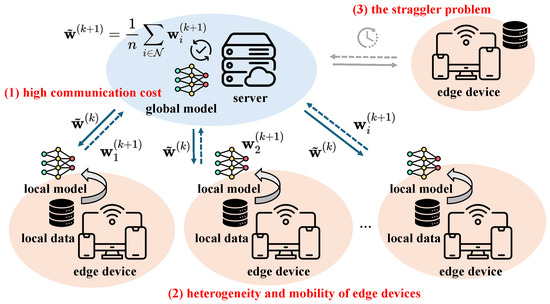
Figure 1.
Main challenges in achieving communication-efficient FL in mobile edge environments, highlighted in red in the figure, include: (1) high communication cost arising from the frequent exchange of model parameters and increase in model size; (2) dynamic communication topology due to the heterogeneity and mobility of edge devices; (3) the straggler problem owing to the lack of joint optimization of communication and computation.
For example, in autonomous driving scenarios, real-time obstacle classification tasks performed by on-vehicle edge devices involve substantial computational demand and require frequent model updates to adapt to rapidly changing environments. FL in such settings faces unique challenges, including dynamic topology changes resulting from high mobility and scenario-dependent non-IID data distributions. Therefore, the design of an efficient communication topology is essential to supporting such real-world applications, as it can significantly reduce communication latency, accelerate model updates, and ensure reliable coordination among mobile devices. The proposed TCS-FEEL framework is specifically designed to address these challenges by jointly optimizing communication topology and client selection, thereby enabling more efficient and robust FL in highly dynamic and heterogeneous environments.
In summary, the key contributions of this paper are as follows:
- We propose a topology-aware FL framework that leverages D2D communication to dynamically construct tree-based topologies, thereby reducing model transmission latency and improving communication efficiency. Furthermore, we develop a low-complexity algorithm to efficiently solve the topology optimization problem.
- We design a stochastic client selection strategy that evaluates client importance by jointly considering data volume, statistical distribution, and communication delay, effectively mitigating the adverse effects of non-IID data on convergence performance.
- We conduct extensive simulations in dynamic wireless edge networks with heterogeneous data distributions. The results demonstrate that the proposed TCS-FEEL framework achieves faster convergence and significantly lower communication time compared with state-of-the-art approaches.
The remainder of this paper is organized as follows: Section 2 reviews the related work. Section 3 introduces the system model, including the FL objective and the considered network model. Section 4 presents the proposed TCS-FEEL framework, formulates the optimization objective, and describes the integration of stochastic client selection and dynamic tree topology. Section 5 details the Monte Carlo-based Gradient Descent (MCGD) algorithm for solving the client selection problem. Section 6 presents the experimental setup and results, while Section 7 provides an in-depth discussion of the findings. Finally, Section 8 concludes the paper and outlines future research directions.
2. Related Work
The exploration and enhancement of communication efficiency in FL over dynamic edge wireless networks has become a rapidly growing research field. This section reviews existing studies, focusing on two major aspects: network topology designs and client sampling strategies for optimizing FL communication and convergence.
2.1. Network Topologies
In FL, the network topology defines how edge devices communicate with each other and ultimately with the central server. The highly dynamic link conditions in edge networks require FL frameworks to adopt adaptive and fault-tolerant topologies for model aggregation. Several survey papers provide comprehensive overviews of topology optimization in dynamic edge networks [13,15].
Hierarchical FL has demonstrated significant advantages in reducing communication overhead [16,17,18]. A tree topology is formed when additional layers are introduced between the server and devices, with the central server as the root node and edge devices as the leaf nodes. Zhang et al. [19] proposed a two-tier FL scheme where local D2D groups aggregate their results before transmitting them to the server, thereby reducing the communication overhead.
Huang et al. [20] further advanced hierarchical FL by enabling any device to serve as both an aggregation and relay node, thereby constructing a more flexible and adaptive tree topology. In their approach, devices with weak channel conditions to the server can offload their model updates to nearby devices with stronger connectivity, thereby mitigating high transmission delays. Moreover, by jointly optimizing both the communication topology and computation speed, their method employs a trained deep neural network (DNN) to infer the optimal topology dynamically.
Xu et al. [21] proposed a dynamic tree construction approach by leveraging D2D communication. Their method forms and optimizes a local communication graph in each round by using a minimum spanning tree algorithm, significantly reducing communication costs. However, this approach focuses solely on communication optimization and does not account for disparities in local training time, which limits its applicability in heterogeneous environments.
2.2. Client Sampling Strategies
Client selection plays a critical role in accelerating FL convergence. The total FL time depends on both the number of training rounds required to achieve the target accuracy and the wall-clock time per round [22].
Importance-based sampling has been widely adopted to mitigate the impact of statistical heterogeneity. In these approaches, clients are selected in each round based on their statistical characteristics, such as data quality and dataset size [23,24], or based on local gradient and loss information [25,26], thereby reducing the number of rounds needed to achieve the target accuracy.
Luo et al. [27] developed a stochastic sampling strategy that optimizes selection probabilities to jointly address both system and statistical heterogeneity, ensuring that the global model remains an unbiased weighted estimate of all local models while mitigating non-IID effects and maintaining fairness.
Chen et al. [28] proposed a latency-aware client selection framework that jointly optimizes client selection probabilities, the number of participating clients, and the total training rounds to minimize the overall latency of FL under data and system heterogeneity. Specifically, their method formulates a mixed-integer nonlinear optimization problem that incorporates both data size and communication delay and derives the optimal client participation probabilities by using grid search and polyhedral active set algorithms. However, this approach performs offline optimization based on static network conditions and does not adapt to time-varying topologies or dynamic communication states, limiting its applicability in highly mobile edge environments.
Xu et al. [21] further introduced a gradient-based client selection approach that assigns participation probabilities based on local gradient information. However, because this method requires all clients to complete local training before selection, it may exacerbate the impact of system heterogeneity.
While the above studies have advanced client selection strategies from different perspectives, most focus on either statistical heterogeneity or communication efficiency in isolation. This leaves an open problem of jointly considering both communication dynamics and system constraints in client selection, an aspect that motivates the design of the framework proposed in this paper.
3. System Model
This section presents the system model and key assumptions underlying the proposed TCS-FEEL framework. We consider a federated edge learning scenario consisting of a set of user devices (UDs) and a base station (BS) interconnected via device-to-server (D2S) and device-to-device (D2D) communication links. The proposed model is structured into three core components. Specifically, we first define the FL objective and client sampling mechanism, which govern distributed model training and aggregation across UDs. Next, we introduce the network model, which characterizes communication properties and captures topology dynamics under device mobility. Finally, we present the computation model, which quantifies local training time based on device processing capabilities. Key notations and definitions are summarized in Table 1.

Table 1.
Key notations and definitions.
3.1. Federated Learning Objective
We consider a collaborative learning environment that consists of a set of UDs indexed by and a single BS indexed by . We refer to all UDs and the BS collectively as nodes. Each UD is assumed to store a local dataset of size . Let and denote the feature vector and label of the t-th sample on UD i, respectively, and let represent the model parameters belonging to the parameter space .
We define the loss function as a function that quantifies the prediction error of a model parameterized by on sample t. We define the local loss on UD i as the empirical mean of the sample-wise losses:
We define a coefficient that quantifies the proportion of a local dataset size over the global dataset size as which denotes the relative weight of UD i’s data in the global dataset. To avoid bias toward UDs with smaller datasets, the FL framework minimizes the following weighted global loss:
All UDs cooperate to learn a single global model that minimizes the global loss:
Throughout this work, we assume a standard synchronous FL workflow, where each communication round consists of local training on the UDs followed by model aggregation at the BS.
3.2. Client Sampling
In each FL round, only a subset of UDs participate in training. Let denote the set of UDs selected in round k. UD i is independently included with probability . The sampling process is repeated until becomes a non-empty subset. Let
The conditional inclusion probability of UD i is given by
Let denote the global model available to the UDs at the start of round k, and let denote UD i’s local model after E local epochs in round k (initialized from ). The BS updates the global model via inverse-probability weighting:
The factor ensures unbiasedness with respect to client selection, i.e.,
3.3. Network Model
We consider two communication modes: (i) access links between UDs and the BS, comprising uplink and downlink transmissions, and (ii) D2D links between nearby UDs. To improve reliability and efficiency, we adopt dedicated bandwidth for each mode: Hz for D2D, Hz for uplink, and Hz for downlink. This orthogonal allocation prevents bandwidth contention across communication types and stabilizes channel conditions.
Directed link rates are estimated in each FL round via periodic probe packets. Let denote the measured average throughput of directed link in round k (including D2D links , uplinks , and downlinks ). The BS collects these measurements from UDs and maintains global knowledge of .
At round k, the network is modeled as a weighted directed graph
where represents the set of nodes (i.e., the UDs and the BS) and a directed edge is assigned the latency weight
with M denoting the model size in bits. We define a directed path from node i to j in round k as a finite ordered sequence of vertices:
Therefore, the transmission time equals the sum of edge weights:
Each UD downloads and uploads the model along the shortest directed paths in . In case multiple shortest paths exist, ties are broken deterministically. First, paths with fewer hops are preferred. If a tie remains, the lexicographically smallest next hop is selected. Under this rule, each node has a unique parent, and the selected paths form a tree topology rooted in the BS.
3.4. Computation Model
In round k, each UD performs E local epochs of mini-batch stochastic gradient descent (SGD) on its dataset . Let denote the average processing time per sample on UD i in round k. The local training time is
4. Our Framework
Building on the system model defined in Section 3, we present the design of the proposed TCS-FEEL framework, which aims to minimize the total wall-clock training time by jointly leveraging the latency and computation models as optimization variables. Specifically, the network latency model guides dynamic topology construction, while the computation model informs client selection strategies.
This section is organized as follows: First, we provide an overview of the overall workflow of TCS-FEEL, outlining the key stages of the training and communication process. Next, we describe the optimization of communication topology, which exploits D2D relaying to reduce transmission latency and improve network efficiency. Then, we present the formulation of client selection criteria, which jointly consider system and statistical heterogeneity to accelerate convergence. Finally, we define the overall optimization objective of TCS-FEEL, aiming to minimize the total training time while maintaining high model accuracy.
4.1. Workflow Overview
Figure 2 illustrates the overall workflow of the proposed TCS-FEEL framework. In each FL round, the system dynamically computes the shortest communication paths in real time based on the current network topology and channel conditions, thereby ensuring that routing decisions adapt to mobility and link variations. The overall process is summarized as follows:
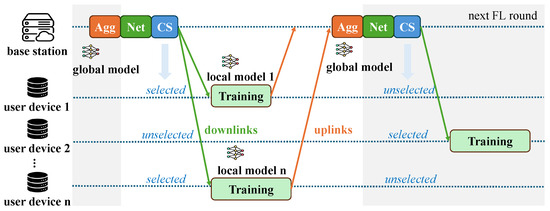
Figure 2.
Overall workflow of the proposed TCS-FEEL framework. As illustrated, each round consists of network topology optimization (Net), client selection (CS), local training, and model aggregation (Agg).
- The system first performs real-time topology construction by computing the shortest upload and download paths for all UDs based on the current network state. It then calculates their selection probabilities by jointly considering transmission latency, dataset size, and data distribution similarity.
- A subset of UDs is sampled according to these probabilities to participate in the current round, with the constraint that at least one UD is selected.
- The global model maintained at the BS is transmitted to the selected UDs along the shortest download paths.
- Each selected UD performs local model training on its local dataset.
- The locally updated models are uploaded to the BS along the shortest upload paths. Since the network topology may change during local training due to device mobility, the shortest paths are recomputed in real time before the upload phase. If a selected UD also acts as a relay, it aggregates received updates with its own before forwarding.
- Finally, the BS aggregates all received updates to generate the new global model, which is distributed in the next round.
4.2. Network Topology Optimization
Efficient communication topology construction is essential to minimizing transmission latency in federated edge learning, particularly under dynamic network conditions caused by device mobility. In the proposed TCS-FEEL framework, the communication topology is dynamically optimized in each FL round to establish low-latency routes between UDs and the BS by leveraging D2D relaying opportunities.
At time instant t, the network environment is modeled as a weighted directed graph , where denotes the set of nodes (UDs and the BS), represents the set of directed links, and denotes the latency weight of edge . For each selected UD , two routing problems must be solved: (i) the uplink problem, which seeks the shortest directed path from UD i to the BS (0), and (ii) the downlink problem, which seeks the shortest directed path from the BS (0) to UD i.
These routing tasks are formulated as classical single-source or single-destination shortest-path problems on a non-negatively weighted directed graph. Therefore, we employ the Dijkstra algorithm, which guarantees the optimal solution in polynomial time and has been widely used in network optimization [29,30,31]. The shortest-path computation is highly efficient and incurs negligible overhead relative to the total round duration. Once the shortest paths for all participating UDs are determined, the resulting routing structure naturally forms a tree topology rooted at the BS, enabling multi-hop model uploading and downloading while minimizing per-round communication delay.
Let s be the source and g the target. The Dijkstra algorithm maintains, for each node v, a tentative distance , a hop count , and a predecessor . A min-priority queue is keyed lexicographically by the tuple to obtain deterministic results: first minimize distance; if equal, prefer fewer hops; if still equal, use the node index to break ties.
For uploads, we set and run the Dijkstra algorithm on for each or equivalently perform a single Dijkstra run from 0 on the reverse graph with to obtain all distances and next hops simultaneously. For downloads, we perform one Dijkstra run from on to recover every path.
Let () denote the selected shortest upload (download, respectively) path. We define the routing function as the next hop toward the BS on . The predecessor map returned by the Dijkstra algorithm induces a BS-rooted shortest-path tree for uploads (and, analogously, for downloads). Algorithm 1 computes the shortest upload path for every UD i and the corresponding minimum transmission time:
The shortest download paths and their times are obtained analogously by running the Dijkstra algorithm from the BS on :
With a binary heap, the Dijkstra algorithm runs in time per execution. Equivalently, performing a single Dijkstra run from the BS on the reverse graph yields all upload shortest paths within the same bound per round.
| Algorithm 1 Dijkstra-based upload routing in time instant t. |
|
4.3. Client Selection Strategy
Let the expected number of participating UDs per round be K. To improve training efficiency and reduce the overall wall-clock time, UDs with lower transmission latency, larger local dataset sizes, and data distributions closer to the global distribution are assigned higher participation probabilities. The total time for UD i in round k is expressed as
where and represent the model download and upload transmission times, respectively. Importantly, both terms are estimated during the client selection stage, i.e., prior to the start of round k, based on the current network topology and channel conditions. This enables the server to anticipate the communication cost of each candidate UD before selection, thereby facilitating informed decision making that jointly accounts for communication delay, computation time, and statistical contribution.
We define a normalized latency factor, where a smaller corresponds to a larger :
The normalized dataset size is given by
Let be the global data distribution. We quantify the mismatch between the local distribution and by using the Jensen–Shannon (JS) divergence, which is defined as a symmetric and bounded measure derived from the Kullback–Leibler divergence:
where . For discrete labels , this can be expressed as
We then map this divergence to a similarity score:
where is a scaling coefficient that controls the sensitivity of the similarity score to distribution mismatch.
Let denote the utility score of client i, which is designed to increase with lower total delay, larger dataset size, and higher similarity between the local and global data distributions. We define as
where are weighting coefficients that control the relative importance of the three factors.
4.4. Optimization Objective
Given an expected number K of participating clients per round, our goal is to determine a probability distribution that maximizes the expected utility of the selected clients while maintaining a certain level of randomness in the selection process. To formalize the trade-off between utility maximization and probability dispersion, we formulate the following entropy-regularized optimization problem:
where is a temperature coefficient that controls the trade-off between exploitation of high-utility clients and exploration across all clients.
The first term in (20) encourages assigning higher probabilities to clients with larger values, while the second term serves as an entropy regularizer to avoid deterministic or overly skewed selections. The constraint ensures that the expected number of participating clients per round equals K.
By applying the method of Lagrange multipliers, the optimal solution is obtained in closed form as
This allocation ensures that clients with smaller delay, larger dataset size, and more globally representative data distributions have a higher probability of being selected.
5. Monte Carlo-Based Gradient Descent for Client Selection
In our design, the utility scores of clients dynamically vary across rounds due to changes in network conditions. To efficiently solve the optimization problem defined in Equation (20), we employ a low-complexity Monte Carlo-Based Gradient Descent (MCGD) approach. The detailed procedure is summarized in Algorithm 2, which iteratively updates the selection probabilities based on sampled gradients and converges to an optimal client selection strategy with low computational overhead.
| Algorithm 2 MCGD for client selection in round k. |
|
Given the client utility score , the entropy-regularized objective in round k is defined as
where controls the trade-off between utility maximization and probability dispersion and K denotes the expected number of selected clients per round. When is computed from stochastic measurements (e.g., probe-based throughput or empirical data distribution), we denote , where represents the random state in round k. The optimization target then becomes
The partial derivative with respect to is
and a Monte Carlo mini-batch unbiased estimator over a batch is given by
Let denote the feasible set,
and let represent the Euclidean projection onto , which can be implemented via capped-simplex water filling (clipping and renormalization).
A projected softmax initialization is adopted to provide an effective warm start, which consistently accelerates convergence in practice. Step sizes follow a diminishing schedule (e.g., ), guaranteeing convergence under standard stochastic approximation theory. The projection operator is implemented via a capped-simplex water-filling algorithm with complexity, while each gradient update step after aggregation requires time. Because varies in every round, the algorithm is executed at each FL round to ensure that the selection probabilities are continuously and optimally adapted to the prevailing network and data conditions.
6. Evaluation
This section evaluates the performance of the proposed TCS-FEEL framework through extensive simulations. We first describe the experimental setup, including datasets, model configurations, network parameters, and baseline schemes. Next, we present results on key performance metrics such as per-round latency, convergence speed, communication energy consumption, and topology dynamics.
6.1. Experimental Setup
An illustrative example of the simulated system layout is shown in Figure 3. The values of the parameters that we used for simulations are summarized in Table 2.
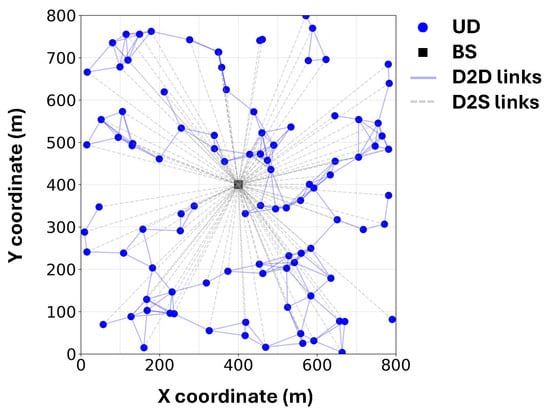
Figure 3.
An example of the simulated system.
Table 2.
Experimental parameters and implementation details.
UD distribution and mobility: We simulate the FL process within an m2 square area, where a single BS is deployed at the center and 100 UDs are uniformly distributed across the area. The Random Direction Mobility Model [32] is adopted to emulate the mobility of UDs. Specifically, at each second, every UD moves in a randomly chosen direction with an average speed of v m/s. We assume that two UDs can establish a D2D link if their distance does not exceed 100 m, which reflects a realistic upper bound for D2D connectivity in urban and vehicular scenarios [21,33].
Network: Network probes are simulated by applying Shannon’s capacity formula under Rayleigh fading for each D2D, uplink, and downlink connection, given the distance and channel conditions at each time snapshot. The throughput of D2D links, uplinks, and downlinks is modeled using Shannon’s formula:
where C is the channel capacity utilization rate, is the transmission power of node i, denotes the Euclidean distance between nodes i and j, is the path-loss exponent, and represents the background noise. The channel gain follows a zero-mean unit-variance Rayleigh distribution when UD i transmits to UD j. We assume orthogonal resource allocation among D2D, uplink, and downlink links based on a TDMA scheme, following widely adopted modeling practices in the D2D communication literature [33]. Specifically, we set when both i and j are UDs, when j is the BS, and when i is the BS. This orthogonality assumption simplifies interference modeling and enables a focused analysis of the impact of topology optimization and client selection on system performance. However, we acknowledge that this stylized assumption neglects potential co-channel interference effects present in real-world deployment, which may lead to slightly optimistic estimates of achievable throughput.
Model and datasets: Each UD trains a ResNet-9 architecture consisting of four convolutional blocks and two residual blocks, followed by a global average pooling layer and a fully connected output layer. The input channels are set to one for MNIST and three for CIFAR-10, with 10 output classes. The model contains approximately million parameters and a total size of Mb.
We adopt stochastic gradient descent (SGD) as the local optimizer, with a momentum of and a weight decay of . The initial learning rate is set to and decayed following a cosine annealing schedule. Each client trains its local model for epochs per round using a batch size of 64 and a cross-entropy loss function.
We adopted the widely used MNIST and CIFAR-10 datasets for evaluation. The MNIST dataset consists of grayscale images of size across 10 classes. The CIFAR-10 dataset contains color images of size across 10 classes. To simulate varying degrees of data heterogeneity, we partition the training data across UDs using a Dirichlet distribution [34]. A smaller value of (e.g., ) leads to highly skewed data distributions, where each UD may only possess samples from a limited number of classes. In contrast, larger values of (e.g., ) produce more balanced data distributions across UDs, thereby reducing the degree of non-IID.
Hardware and implementation details: All experiments were conducted on a workstation equipped with an Intel® CoreTM i9-10850K CPU running at 3.60 GHz with 20 logical cores, 32 GB RAM, and the Ubuntu 20.04.4 LTS (64-bit) operating system. All programs were implemented in Python 3.10 using the NumPy and NetworkX libraries. To ensure consistent single-threaded execution and accurate measurement of the control-plane overhead, all tests were run with OMP_NUM_THREADS=1 and MKL_NUM_THREADS=1.
Each experiment was repeated five times with different random seeds controlling data partitioning, client sampling, model initialization, and mobility patterns. All reported improvements were statistically validated using pair-wise Mann–Whitney U tests between TCS-FEEL and other baseline methods across five independent runs. Statistical significance is denoted as and .
Wall-clock time measurements: The total per-round wall-clock time consists of two components: (i) local computation time, which is proportional to the number of local epochs and the size of the local dataset, and (ii) communication time, including model uploading and potential D2D relaying. Fixing enables us to isolate the effects of topology optimization and client selection on communication latency and overall training time.
Baselines: We compare TCS-FEEL with three baseline policies under different scenarios, described as follows:
- FedAvg (Star) [35]: In this scheme, a subset of UDs is randomly selected in each round, where each UD is chosen with probability . The selected UDs directly send their local models to the BS for aggregation, following a star topology.
- CSTAR [21]: In CSTAR, the selection probability of each UD in each round is determined by both latency and the contribution of its model update. Different from our TCS-FEEL, only the selected UDs participate in model transmission, while unselected UDs do not take part in training or forwarding.
- LACS (Latency-Aware Client Selection) [28]: In this method, client selection is formulated as an offline optimization problem to minimize overall training latency under data and system heterogeneity. Unlike our TCS-FEEL, LACS assumes a static star network. The optimal selection probabilities are obtained via grid search and polyhedral active set algorithms based on the initial network conditions. For a fair comparison, we compute the latency in LACS using the initial communication parameters of the network.
- FedAvg (Tree): The client selection strategy is the same as FedAvg (Star), where each UD is randomly selected with probability in each round. Meanwhile, the model transmission is consistent with our TCS-FEEL, where all UDs in the system are used to construct a dynamic tree topology.
- TCS-FEEL (Star): This variant applies the proposed stochastic client selection strategy while maintaining a static star topology for communication, where all selected UDs transmit their local models directly to the BS without D2D relaying.
6.2. Model Convergence Evaluation
We compared TCS-FEEL with baseline schemes on the CIFAR-10 and MNIST datasets in terms of model convergence speed. Specifically, we measured the validation accuracy of the aggregated model, as well as the number of rounds required to reach target accuracies on the two datasets under different non-IID settings.
Figure 4 illustrates the global model accuracy achieved by different FL schemes on the MNIST dataset under different non-IID settings. The curves represent the average validation accuracy, while the shaded areas denote the standard deviation across multiple runs. Table 3 shows the number of rounds required to achieve a validation accuracy level of on MNIST under different non-IID settings. Obviously, our TCS-FEEL consistently outperforms all baseline schemes across all scenarios. Specifically, when , TCS-FEEL reduces the number of convergence rounds by compared with CSTAR and by more than compared with LASC and FedAvg (Star). When , TCS-FEEL reduces the number of convergence rounds by compared with CSTAR and by more than compared with LASC and FedAvg (Star) (). When , TCS-FEEL requires 11.1% fewer convergence rounds than CSTAR and over 21.7% fewer than both LASC and FedAvg (Star) ().
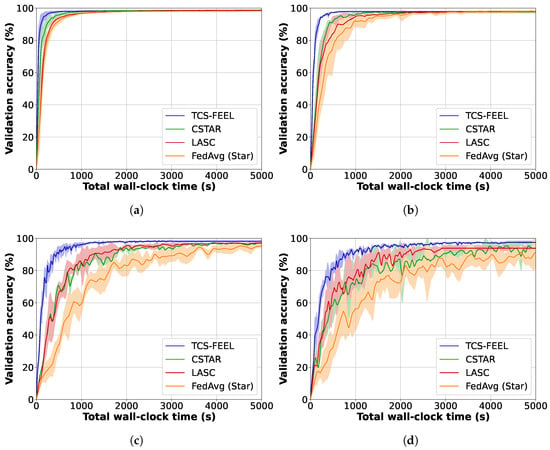
Figure 4.
Model convergence speed and wall-clock training time for our method and baseline schemes on MNIST dataset under different non-IID settings (runs ): (a) , (b) , (c) , and (d) .
Table 3.
Number of rounds required to achieve 95% accuracy on MNIST under different non-IID settings (runs , mean ± std).
Similarly, Figure 5 shows the global model accuracy achieved by different FL schemes on the CIFAR-10 dataset under different non-IID settings. The curves represent the average validation accuracy, while the shaded areas denote the standard deviation across multiple runs. Table 4 shows the number of rounds required to achieve a validation accuracy level of on CIFAR-10 under different non-IID settings. The results show that TCS-FEEL converges in fewer rounds than the random selection baseline. Specifically, when , TCS-FEEL reduces the number of convergence rounds by more than compared with FedAvg (Star) (). When , TCS-FEEL achieves over fewer convergence rounds than FedAvg (Star) (). When , TCS-FEEL achieves more than fewer convergence rounds than FedAvg (Star) (). The model did not reach accuracy on all methods when .
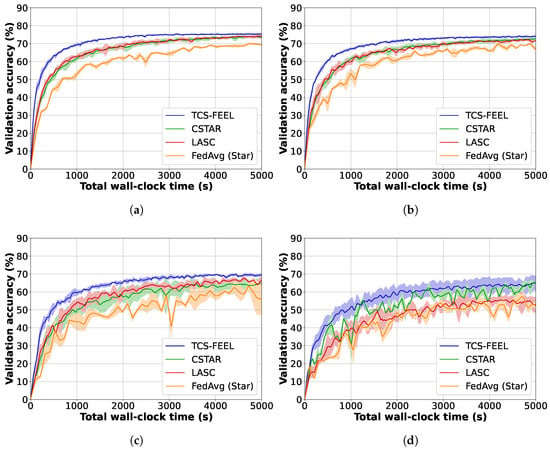
Figure 5.
Model convergence speed and wall-clock training time for our method and baseline schemes on CIFAR-10 dataset under different non-IID settings (runs ): (a) , (b) , (c) , and (d) .
Table 4.
Number of rounds required to achieve 70% accuracy on CIFAR-10 under different non-IID settings (runs , mean ± std).
6.3. Per-Round Latency Analysis
To provide an intuitive understanding of the different communication structures, we visualize the topologies of FedAvg (Star), CSTAR, and TCS-FEEL in Figure 6. In the star topology adopted by FedAvg, all selected UDs communicate directly with the BS, which often creates a communication bottleneck and leads to higher latency, especially in dense networks. In contrast, the tree-based topology leverages D2D communication, allowing UDs to relay model updates through intermediate devices. Compared with CSTAR, which relies only on those selected UDs for transmission, our TCS-FEEL further enhances efficiency by effectively utilizing the available D2D communication opportunities. As a result, TCS-FEEL achieves shorter time per round, leading to faster convergence and lower latency in dynamic edge environments.
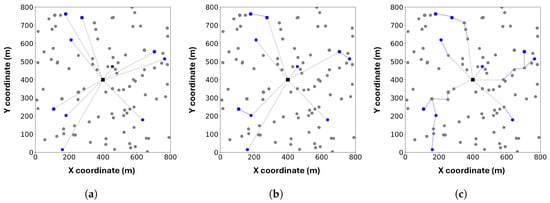
Figure 6.
Visualization of three topologies: (a) Star, (b) CSTAR, (c) TCS-FEEL. Gray circles represent unselected UDs, and blue circles represent selected UDs. Gray dashed lines denote D2S links, and blue solid lines denote D2D links.
Next, we compare the average per-round latency of TCS-FEEL with the baseline schemes. Figure 7 illustrates the average time per round required by different FL methods on the MNIST dataset under varying degrees of non-IID data distributions. Specifically, when , the proposed tree-based topology reduces the per-round latency by compared with CSTAR, by compared with LASC (), and by compared with FedAvg (Star) (). When , TCS-FEEL reduces the per-round latency by compared with CSTAR, by compared with LASC, and by compared with FedAvg (Star) (). When , TCS-FEEL reduces the per-round latency by compared with CSTAR (), by compared with LASC, and by compared with FedAvg (Star) (). When , TCS-FEEL reduces the per-round latency by compared with CSTAR, by compared with LASC, and by compared with FedAvg (Star) ().
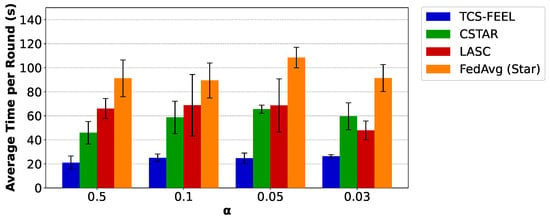
Figure 7.
The average time per round for our method and baseline schemes on the MNIST dataset under different non-IID settings (runs , mean ± std).
Similarly, Figure 8 presents the results on the CIFAR-10 dataset. Consistent with the observations on MNIST, when , the proposed tree-based topology reduces the per-round latency by compared with CSTAR (), by compared with LASC (), and by compared with FedAvg (Star) (). When , TCS-FEEL reduces the per-round latency by compared with CSTAR (), by compared with LASC (), and by compared with FedAvg (Star) (). When , TCS-FEEL reduces the per-round latency by compared with CSTAR (), by compared with LASC (), and by compared with FedAvg (Star) (). When , TCS-FEEL reduces the per-round latency by compared with CSTAR, by compared with LASC (), and by compared with FedAvg (Star) ().
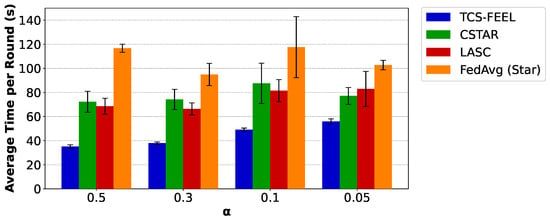
Figure 8.
The average time per round for our method and baseline schemes on the CIFAR-10 dataset under different non-IID settings (runs , mean ± std).
These results demonstrate that our design not only accelerates convergence in terms of rounds but also significantly shortens the time of each training round, leading to faster FL training.
6.4. Ablation Study
To evaluate the contribution of individual components in the proposed framework, we compared four schemes: TCS-FEEL, TCS-FEEL (Star), FedAvg (Tree), and FedAvg (Star). The ablation experiments were conducted on both the MNIST and CIFAR-10 datasets under various non-IID levels.
As shown in Figure 9 and Figure 10, data heterogeneity significantly influences model convergence and training efficiency. When decreases, the convergence speed of all methods decreases. Nevertheless, TCS-FEEL consistently achieves higher accuracy and shorter wall-clock training time across all values, demonstrating robustness under highly heterogeneous conditions.
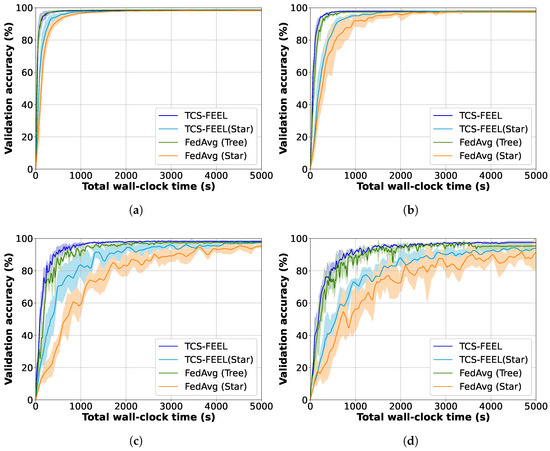
Figure 9.
Ablation study on the impact of data heterogeneity (non-IID level ) on model convergence and wall-clock training time using the MNIST dataset (runs ): (a) , (b) , (c) , and (d) .
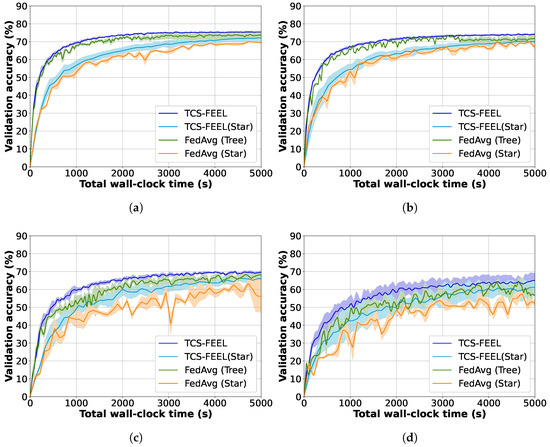
Figure 10.
Ablation study on the impact of data heterogeneity (non-IID level ) on model convergence and wall-clock training time using the CIFAR-10 dataset (runs ): (a) , (b) , (c) , and (d) .
Figure 11 and Figure 12 further analyze the contribution of the key modules, including the topology construction and client selection mechanisms. Among them, TCS-FEEL and FedAvg (Tree) adopt a tree-based topology construction mechanism (Topo), while the remaining two employ a star-shaped network (No Topo). Similarly, TCS-FEEL and TCS-FEEL (Star) include the client selection module (Select), whereas the other two baselines operate without selection (No Select).
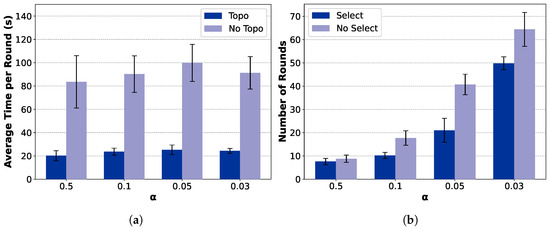
Figure 11.
Ablation study on MNIST dataset (runs , mean ± std): (a) comparison between topology-aware and topology-free settings in terms of wall-clock training time and (b) comparison between selection-based and non-selection schemes in terms of convergence speed.
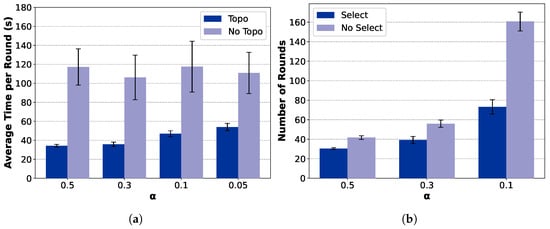
Figure 12.
Ablation study on CIFAR-10 dataset (runs , mean ± std): (a) comparison between topology-aware and topology-free settings in terms of wall-clock training time and (b) comparison between selection-based and non-selection schemes in terms of convergence speed.
Impact of Network Topology Optimization: As illustrated in Figure 11a and Figure 12a, the proposed tree-based topology significantly reduces the per-round latency compared with the star topology. The topology construction module yields over lower per-round latency on the MNIST dataset and lower latency on the CIFAR-10 dataset (). This confirms that adaptive topology formation effectively mitigates communication bottlenecks by enabling multi-hop routing and D2D relaying, thereby accelerating aggregation and enhancing scalability in dynamic edge networks.
Impact of Client Selection: As shown in Figure 11b and Figure 12b, the client selection module further accelerates model convergence by prioritizing high-quality and well-connected clients, particularly under highly non-IID conditions. Specifically, when , it reduces the number of convergence rounds by on MNIST () and, when , by on CIFAR-10 (). This demonstrates that intelligent selection not only shortens the convergence process but also complements topology adaptation in minimizing total wall-clock time.
Overall, both components contribute distinct yet complementary benefits. Topology optimization reduces intra-round latency by improving connectivity, while client selection decreases the number of rounds required for convergence. Their integration in TCS-FEEL leads to substantial end-to-end performance improvements, achieving superior scalability and robustness across diverse non-IID scenarios.
6.5. Control-Plane Overhead Analysis
In addition to evaluating the per-round latency from the data plane, we further analyzed the control-plane overhead, which primarily includes the shortest-path computation (Algorithm 1) and the client selection procedure (Algorithm 2) executed in each training round. The CPU execution time required for these two operations for different numbers of clients is summarized in Table 5. The implementation for measuring the control-plane overhead is provided in the Supplementary Material (benchmark_control_plane.py).
Table 5.
Control-plane overhead per round for different numbers of clients (milliseconds, runs , mean ± std).
The results reveal that the control-plane overhead grows sublinearly with the number of clients, which aligns with the theoretical complexity of the underlying algorithms. Importantly, even at a large scale with clients, the total control-plane overhead remains below s per round, whereas the average time per round for local training and communication typically ranges from several tens to hundreds of seconds.
This comparison demonstrates that the optimization cost introduced by our control plane is negligible relative to the overall per-round latency. Therefore, the proposed TCS-FEEL framework maintains scalability and efficiency even in large-scale FL deployment, and the control procedures do not become the bottleneck of the system.
6.6. Energy Efficiency Analysis
In this section, we evaluate the communication energy consumption of the proposed TCS-FEEL framework and compare it against two baseline topologies: STAR, where each selected UD directly uploads to the BS without D2D links, and CSTAR, where only the selected UDs can serve as relays. To evaluate the energy efficiency of the proposed framework, we model the per-client communication energy consumption by decomposing it into two components: transmission energy and relay energy.
The transmission energy represents the energy consumed by a UD when transmitting model parameters either directly to the BS or to a neighboring node in a D2D link. It is given by
where is the transmission power of the UD and denotes the total transmission time. The transmission time depends on the model size M and the achievable throughput and is given by
where is determined by the Shannon’s capacity of the wireless link, as expressed in Equation (27).
The relay energy accounts for the additional energy consumed by intermediate UDs that receive and forward data during multi-hop D2D communication. It is defined as
where and denote the reception and transmission power of the relay device, respectively. Here, is the total reception time required for the relay to receive the model update from the previous hop, and is the forwarding transmission time needed to forward the received data to the next hop. Both and are determined by the model size and the achievable throughput of the corresponding D2D links. Specifically, they can be expressed as
where denotes the achievable throughput of the incoming D2D link and denotes the achievable throughput of the outgoing D2D link at the relay.
Finally, the total communication energy consumption per client is the sum of the transmission and relay components:
For communication energy modeling, the transmit and receive power of UDs are set to and , respectively. These values are commonly adopted in prior studies [33] and reflect the typical power levels of short-range radios operating in urban and vehicular scenarios. To ensure a fair comparison across all schemes, in each training round, of the UDs are randomly selected to participate in local training. For the energy consumption metrics, we report the average values computed over all UDs, including those not selected as active clients.
Table 6 presents the per-client average transmission energy (), relay energy (), and total communication energy () under the three schemes. The results are obtained by averaging over 20 independent simulation runs with UDs. From the results, we observe that the proposed TCS-FEEL achieves the lowest total communication energy consumption among the three schemes. Specifically, the total per-client communication energy is reduced from J in the STAR topology to J in TCS-FEEL, corresponding to a reduction of approximately . This improvement arises from the utilization of multi-hop D2D relaying, which shortens the transmission distance and reduces transmission power while maintaining efficient data delivery. Although the relay energy consumption slightly increases compared with STAR, the significant decrease in direct transmission energy leads to a lower overall energy cost.
Table 6.
Per-client average communication energy consumption (Joule, runs , mean ± std).
Furthermore, TCS-FEEL outperforms CSTAR by leveraging the forwarding capability of all participating clients, instead of restricting relaying to selected UDs only. This broader relay participation improves energy efficiency while ensuring robust data delivery paths in dynamic topologies. These results confirm that D2D-assisted topology-aware client selection not only enhances model convergence but also achieves superior energy efficiency in federated edge learning systems.
6.7. Sensitivity Analysis Under Bandwidth Scaling
To evaluate the robustness of TCS-FEEL under more realistic communication conditions, we performed a sensitivity analysis that relaxes the orthogonal-link assumption for D2D communication. In the baseline configuration, all D2D and D2S links were assumed to be orthogonal; i.e., each link operated on an independent frequency band without interference. To approximate bandwidth sharing and contention among concurrent D2D links, we introduced an effective bandwidth scaling factor , where the effective bandwidth for each D2D link is given by
with B being the nominal channel bandwidth. The D2S links were kept orthogonal and unaffected by bandwidth scaling, maintaining their original bandwidth B.
When decreases, only the D2D links experience proportionally reduced transmission rates, emulating the impact of spectrum reuse or interference-limited D2D communication. The per-round communication latency was then recalculated as
where and denote the sets of D2S and D2D links, respectively. The rest of the training and aggregation pipeline remained unchanged, and each experiment was repeated five times with different random seeds to ensure statistical reliability.
As illustrated in Figure 13, the overall per-round communication time of both TCS-FEEL and CSTAR increases as the effective bandwidth scaling factor decreases, which is expected since a lower limits the available transmission capacity. When , TCS-FEEL achieves and lower per-round communication time than CSTAR and FedAvg (Star), respectively (). Even under the most constrained condition (), TCS-FEEL still maintains substantial advantages, achieving and lower per-round communication time compared with CSTAR and FedAvg (Star), respectively ().
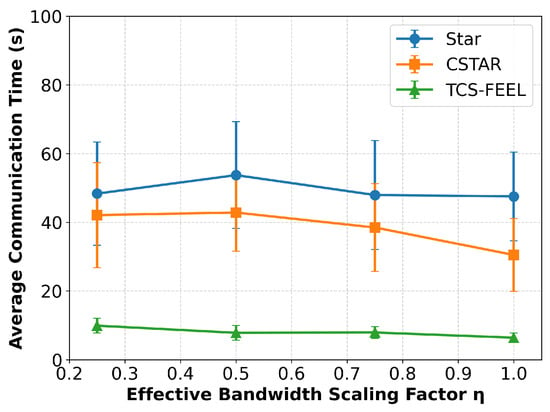
Figure 13.
Sensitivity analysis of per-round communication latency under different effective bandwidth scaling factors (runs , mean ± std). Lower values represent stronger bandwidth contention among D2D links.
6.8. Topological Dynamics Analysis
To evaluate the robustness of the proposed TCS-FEEL framework under device mobility, we analyze the topological dynamics of the D2D communication graph over time using the link change ratio (LCR). The LCR is defined as the proportion of links that differ from the initial topology and serves as an indicator of topology stability in dynamic environments. A higher LCR indicates more frequent changes in network topology. Formally, the LCR at time t is expressed as
where denotes the set of communication links in the initial topology at , is the set of links at time t, and Δ represents the symmetric difference between the two sets. A higher indicates that a larger fraction of links have changed compared with the initial topology.
We simulate UDs with random initial positions and evaluate three time snapshots s relative to the baseline at s, at three different mobility speeds: , , and . In each round, 10% of the UDs are randomly selected as participating clients for a fair comparison. We compare the LCR evolution for our TCS-FEEL and CSTAR.
Figure 14 shows the evolution of the LCR for both methods. As expected, the LCR increases with mobility speed due to more frequent link formation and breakage events. It is important to note that a higher LCR itself does not directly indicate greater robustness; rather, it reflects a more dynamic communication environment that poses greater challenges for maintaining stable connectivity and low latency. However, TCS-FEEL consistently exhibits a higher LCR than CSTAR across all speeds and time snapshots while still maintaining stable communication performance, demonstrating its stronger robustness against topology dynamics. This is because allowing all UDs to participate in relaying provides more redundant communication paths, thereby mitigating the impact of node mobility on network connectivity.
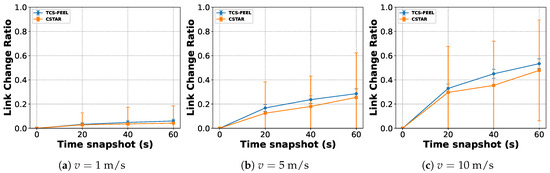
Figure 14.
Link change ratio evolution at different mobility speeds (runs , mean ± std): (a) , (b) , and (c) .
7. Discussion
This section discusses the comparative performance and robustness of the proposed TCS-FEEL framework. We first compare TCS-FEEL with representative communication-efficient FL approaches to highlight its advantages in dynamic edge environments. We then examine its robustness when relaxing modeling assumptions such as link orthogonality, showing that the proposed framework maintains stable performance even under bandwidth-limited and interference-prone conditions.
7.1. Comparison with Related Works
While numerous studies have investigated communication-efficient FL, most differ from our work in assumptions, problem settings, or design objectives. For instance, hierarchical FL approaches such as [16,17,18,19] assume static two-tier structures with fixed relay nodes, which fail to capture the rapid topology variations caused by device mobility in edge environments. Similarly, deep learning-based topology optimization [20] relies on global topology collection for training, introducing high latency and making it impractical for dynamic edge scenarios.
Chen et al. [28] proposed a latency-aware client selection framework (LACS) that jointly optimizes client participation probabilities and total training rounds to mitigate system heterogeneity. While effective under static network conditions, LACS performs offline optimization and assumes fixed links, preventing real-time adaptation to mobility or fluctuating link quality. In contrast, our TCS-FEEL performs online topology adaptation and stochastic client selection in each round, allowing it to dynamically respond to topology and bandwidth variations.
Experimental results strongly validate the effectiveness of this design. As shown in Figure 4 and Table 3, TCS-FEEL achieves the fastest convergence on MNIST across all non-IID settings. When , it reduces convergence rounds by compared with CSTAR and by more than compared with LACS and FedAvg (Star); at , these reductions reach and (), respectively. On the CIFAR-10 dataset (Figure 5, Table 4), TCS-FEEL achieves up to fewer rounds than FedAvg (Star) and maintains comparable or better performance than LACS under moderate heterogeneity (). These results confirm that jointly optimizing topology and client selection effectively accelerates convergence under heterogeneous and dynamic conditions.
In terms of per-round latency, Figure 7 and Figure 8 further demonstrate that TCS-FEEL consistently outperforms existing methods. On MNIST, when , TCS-FEEL reduces per-round latency by compared with CSTAR, by compared with LACS, and by compared with FedAvg (Star) (). On CIFAR-10, the reductions reach , , and , respectively (). These improvements arise because TCS-FEEL’s dynamic tree-based topology enables multi-hop D2D relaying and adaptive link selection, reducing bottlenecks inherent in the star topology and improving bandwidth utilization.
Overall, compared with CSTAR, LACS, and FedAvg (Star), TCS-FEEL advances the state of the art in topology- and client selection-aware FL. By integrating adaptive topology construction with stochastic client selection, TCS-FEEL achieves both faster convergence (a reduction in rounds of up to ) and lower communication latency (a reduction of up to per round) across diverse datasets and non-IID levels. These results highlight its robustness and scalability for real-world mobile edge learning scenarios.
7.2. Discussion on Interference and Robustness
It is important to note that our throughput model initially assumed orthogonal spectrum allocation and neglected inter-link interference for analytical tractability. To examine the robustness of this assumption, we conducted a sensitivity analysis under bandwidth scaling, where only D2D links experienced effective bandwidth reduction to emulate interference and spectrum contention effects.
As shown in Figure 13, the per-round latency of CSTAR increases markedly as the effective bandwidth scaling factor decreases, whereas the increase for TCS-FEEL remains relatively minor. Even under the most constrained condition (), TCS-FEEL consistently outperforms all baseline methods, with statistically significant gains (). These results demonstrate that the communication efficiency advantages introduced by the topology construction and client selection modules remain robust even when the orthogonal-link assumption is relaxed.
Therefore, although the original analytical model may slightly overestimate the absolute throughput, the relative performance superiority of TCS-FEEL persists in interference-limited or bandwidth-constrained scenarios. Incorporating interference-aware scheduling and adaptive spectrum allocation into TCS-FEEL represents a promising direction for future research, further enhancing its scalability and practicality in dense wireless environments.
8. Conclusions
This paper presented TCS-FEEL, a novel FL framework tailored to dynamic edge networks, which integrates stochastic client selection with adaptive network topology optimization. The proposed approach jointly addresses both system and statistical heterogeneity. Extensive simulations on widely used datasets under diverse non-IID scenarios demonstrate that TCS-FEEL consistently outperforms existing baselines. Specifically, it requires fewer communication rounds to reach target accuracy levels and significantly reduces the per-round wall-clock time, thereby accelerating global model convergence. Moreover, these improvements become more pronounced under severe data heterogeneity, underscoring the robustness and scalability of the framework. TCS-FEEL provides an intelligent and privacy-preserving solution for sensor-driven edge networks, enabling efficient FL in latency-sensitive and mobility-intensive applications such as autonomous driving, smart city sensing, and the Industrial IoT.
In future work, we aim to broaden the applicability and impact of TCS-FEEL in several directions. First, we plan to integrate advanced privacy-preserving techniques, such as differential privacy and secure aggregation, to further enhance data confidentiality. Second, we will investigate adaptive spectrum sharing and interference-aware communication models to bridge the gap between the current orthogonal bandwidth assumption and real-world wireless environments. Finally, we plan to evaluate TCS-FEEL in real-world testbeds and cross-domain applications, paving the way for its large-scale deployment in sensor-rich edge networks.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/s25216534/s1.
Author Contributions
Conceptualization, H.C. and H.L.; literature review, H.C. and H.L.; methodology, H.C. and H.L.; formal analysis, H.C. and H.L.; writing—original draft preparation, H.C. and H.L.; writing—review and editing, H.C. and H.L.; visualization, H.C. and H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by JSPS KAKENHI grant number JP23K11063 from the Japan Society for the Promotion of Science.
Data Availability Statement
The data presented in this article are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Peter, O.; Pradhan, A.; Mbohwa, C. Industrial internet of things (IIoT): Opportunities, challenges, and requirements in manufacturing businesses in emerging economies. Procedia Comput. Sci. 2023, 217, 856–865. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pham, Q.V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.J. Federated learning for smart healthcare: A survey. ACM Comput. Surv. (Csur) 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Botta, A.; De Donato, W.; Persico, V.; Pescapé, A. Integration of cloud computing and internet of things: A survey. Future Gener. Comput. Syst. 2016, 56, 684–700. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Fahim, M.; Ouchao, B.; Jakimi, A.; El Bermi, L. Application of a non-immersive VR, IoT based approach to help moroccan students carry out practical activities in a personal learning style. Future Internet 2019, 11, 11. [Google Scholar] [CrossRef]
- Liu, S.; Liu, M.; Wu, Y.; Li, Z.; Xiao, Y. A Multi-Scale Model Based on Squeeze and Excitation Network for Classifying Obstacles in Front of Vehicles in Autonomous Driving. IEEE Internet Things J. 2025, 12, 14219–14228. [Google Scholar] [CrossRef]
- Kong, L.; Tan, J.; Huang, J.; Chen, G.; Wang, S.; Jin, X.; Zeng, P.; Khan, M.; Das, S.K. Edge-computing-driven internet of things: A survey. ACM Comput. Surv. 2022, 55, 1–41. [Google Scholar] [CrossRef]
- Zhang, Z.; Wu, L.; Ma, C.; Li, J.; Wang, J.; Wang, Q.; Yu, S. LSFL: A lightweight and secure federated learning scheme for edge computing. IEEE Trans. Inf. Forensics Secur. 2022, 18, 365–379. [Google Scholar] [CrossRef]
- Almanifi, O.R.A.; Chow, C.O.; Tham, M.L.; Chuah, J.H.; Kanesan, J. Communication and computation efficiency in federated learning: A survey. Internet Things 2023, 22, 100742. [Google Scholar] [CrossRef]
- Xing, H.; Simeone, O.; Bi, S. Decentralized federated learning via SGD over wireless D2D networks. In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Hosseinalipour, S.; Azam, S.S.; Brinton, C.G.; Michelusi, N.; Aggarwal, V.; Love, D.J.; Dai, H. Multi-stage hybrid federated learning over large-scale D2D-enabled fog networks. IEEE/ACM Trans. Netw. 2022, 30, 1569–1584. [Google Scholar] [CrossRef]
- Parasnis, R.; Hosseinalipour, S.; Chu, Y.W.; Chiang, M.; Brinton, C.G. Energy-efficient connectivity-aware learning over time-varying D2D networks. IEEE J. Sel. Top. Signal Process. 2024, 18, 242–258. [Google Scholar] [CrossRef]
- Yuan, L.; Wang, Z.; Sun, L.; Yu, P.S.; Brinton, C.G. Decentralized federated learning: A survey and perspective. IEEE Internet Things J. 2024, 11, 34617–34638. [Google Scholar] [CrossRef]
- Jia, C.; Hu, M.; Chen, Z.; Yang, Y.; Xie, X.; Liu, Y.; Chen, M. AdaptiveFL: Adaptive heterogeneous federated learning for resource-constrained AIoT systems. In Proceedings of the 61st ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 23–27 June 2024; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, J.; Dong, F.; Leung, H.; Zhu, Z.; Zhou, J.; Drew, S. Topology-aware federated learning in edge computing: A comprehensive survey. ACM Comput. Surv. 2024, 56, 1–41. [Google Scholar] [CrossRef]
- Deng, Y.; Lyu, F.; Ren, J.; Zhang, Y.; Zhou, Y.; Zhang, Y.; Yang, Y. SHARE: Shaping data distribution at edge for communication-efficient hierarchical federated learning. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Washington, DC, USA, 7–10 July 2021; pp. 24–34. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-edge-cloud hierarchical federated learning. In Proceedings of the ICC 2020-2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Wen, W.; Chen, Z.; Yang, H.H.; Xia, W.; Quek, T.Q. Joint scheduling and resource allocation for hierarchical federated edge learning. IEEE Trans. Wirel. Commun. 2022, 21, 5857–5872. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Y.; Liu, J.; Argyriou, A.; Han, Y. D2D-assisted federated learning in mobile edge computing networks. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Huang, S.; Zhang, Z.; Wang, S.; Wang, R.; Huang, K. Accelerating federated edge learning via topology optimization. IEEE Internet Things J. 2022, 10, 2056–2070. [Google Scholar] [CrossRef]
- Xu, Z.; Di Maio, A.; Samikwa, E.; Braun, T. CSTAR-FL: Stochastic Client Selection for Tree All-Reduce Federated Learning. IEEE Trans. Mob. Comput. 2024, 24, 3110–3129. [Google Scholar] [CrossRef]
- Reisizadeh, A.; Tziotis, I.; Hassani, H.; Mokhtari, A.; Pedarsani, R. Straggler-resilient federated learning: Leveraging the interplay between statistical accuracy and system heterogeneity. IEEE J. Sel. Areas Inf. Theory 2022, 3, 197–205. [Google Scholar] [CrossRef]
- Taïk, A.; Mlika, Z.; Cherkaoui, S. Data-aware device scheduling for federated edge learning. IEEE tRansactions Cogn. Commun. Netw. 2021, 8, 408–421. [Google Scholar] [CrossRef]
- Rai, S.; Kumari, A.; Prasad, D.K. Client selection in federated learning under imperfections in environment. AI 2022, 3, 124–145. [Google Scholar] [CrossRef]
- Chen, W.; Horvath, S.; Richtarik, P. Optimal client sampling for federated learning. arXiv 2020, arXiv:2010.13723. [Google Scholar] [CrossRef]
- Rizk, E.; Vlaski, S.; Sayed, A.H. Federated learning under importance sampling. IEEE Trans. Signal Process. 2022, 70, 5381–5396. [Google Scholar] [CrossRef]
- Luo, B.; Xiao, W.; Wang, S.; Huang, J.; Tassiulas, L. Tackling system and statistical heterogeneity for federated learning with adaptive client sampling. In Proceedings of the IEEE INFOCOM 2022-IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 1739–1748. [Google Scholar] [CrossRef]
- Chen, X.; Zhou, X.; Zhang, H.; Sun, M.; Poor, H.V. Client selection for wireless federated learning with data and latency heterogeneity. IEEE Internet Things J. 2024. [Google Scholar] [CrossRef]
- Regilan, S.; Hema, L.; Jenitha, J. Energy-aware adaptive Dijkstra: A robust routing algorithm for wireless sensor networks in dynamic environments. In Proceedings of the 2024 Third International Conference on Intelligent Techniques in Control, Optimization and Signal Processing (INCOS), Tamil Nadu, India, 14–16 March 2024; pp. 1–5. [Google Scholar] [CrossRef]
- Freschi, V.; Lattanzi, E. A Prim–Dijkstra Algorithm for Multihop Calibration of Networked Embedded Systems. IEEE Internet Things J. 2021, 8, 11320–11328. [Google Scholar] [CrossRef]
- Adiyanto, E.K.; Wahjuni, S.; Rahmawan, H. Modification of load calculation in the Dijkstra algorithm to achieve high throughput and low latency on 5G networks. J. Appl. Eng. Technol. Sci. (JAETS) 2024, 5, 1182–1198. [Google Scholar] [CrossRef]
- Camp, T.; Boleng, J.; Davies, V. A survey of mobility models for ad hoc network research. Wirel. Commun. Mob. Comput. 2002, 2, 483–502. [Google Scholar] [CrossRef]
- Asadi, A.; Wang, Q.; Mancuso, V. A survey on device-to-device communication in cellular networks. IEEE Commun. Surv. Tutor. 2014, 16, 1801–1819. [Google Scholar] [CrossRef]
- Hsu, T.M.H.; Qi, H.; Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv 2019, arXiv:1909.06335. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics. PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar] [CrossRef]














Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).