Abstract
With the rapid development of 3D sensor technology, point cloud semantic segmentation has found widespread applications in autonomous driving, remote sensing, mapping, and industrial manufacturing. However, outdoor traffic scenes present significant challenges: point clouds are inherently disordered, unevenly distributed, and unstructured. As a result, traditional point cloud semantic segmentation methods often suffer from low accuracy and unstable performance in complex tasks such as semantic segmentation and object detection. To address these limitations, this paper proposes an improved point cloud semantic segmentation method based on Cylinder3D. The proposed approach integrates the PointMamba and MS3DAM modules, which enhance the model’s ability to capture global features while preserving local details, thereby improving adaptability and recognition across multiple feature scales. Furthermore, leveraging the linear computational complexity of Mamba enables the method to maintain high efficiency when processing large-scale point cloud data. In addition, incorporating the KAT module into the encoder improves the model’s perceptual capacity and robustness in handling point clouds. Experimental results on the SemanticKITTI dataset demonstrate that the proposed method achieves a mean Intersection over Union (mIoU) of 64.98%, representing a 2.81% improvement over Cylinder3D, thereby confirming its superior segmentation accuracy compared with existing models.
1. Introduction
With the advancement of sensor technology, the performance of LiDAR, a key sensor for acquiring point cloud data, has continuously improved [1,2]. Three-dimensional LiDAR sensors have become indispensable components of autonomous driving systems [3], and the progress in 3D sensing has facilitated the widespread use of point clouds in diverse fields, including autonomous driving, mapping, and industrial manufacturing [4]. Point cloud data represent spatial geometry and object surfaces through collections of 3D points [5]. Compared with traditional 2D image data, point clouds offer richer information and a more comprehensive representation of complex scenes [6]. However, their inherent disorder, uneven distribution, and unstructured characteristics pose significant challenges for traditional convolutional neural networks, which struggle to efficiently and accurately perform segmentation on 3D point clouds. In traffic environments, these challenges result in reduced accuracy and unstable segmentation performance. To address this, recent studies have proposed various deep learning frameworks for 3D point cloud segmentation [7], aiming to enhance segmentation accuracy by exploiting the unique characteristics of point cloud data. In traffic scenarios, the design of accurate and efficient algorithms, along with optimized network architectures, can improve the speed and precision of segmenting moving vehicles, pedestrians, and other dynamic objects, thereby contributing to traffic safety on railways and highways.
Current approaches to 3D point cloud processing can be broadly categorized into three types [8]: projection-based, voxel-based, and point-based methods. Projection-based methods map 3D scenes onto 2D planes, thereby transforming 3D problems into 2D ones and enabling the use of well-established 2D convolutional neural networks, such as SqueezeNet [9]. However, this projection inevitably results in information loss. Voxel-based [10] methods partition 3D point cloud data into fixed voxels, creating a structured representation that allows the application of 3D convolutional neural networks. Despite this advantage, voxelization often leads to information loss and high computational complexity. In contrast, point-based methods operate directly on raw point cloud data, preserving fine-grained structural details and minimizing information loss.
In recent years, Transformer-based architectures have emerged as a prominent research focus for point cloud understanding. Guo et al. [11] proposed a Transformer-based approach incorporating an attention mechanism, which, while effective for global modeling, substantially increases computational complexity and model parameters. Stratified Transformer further enhances the modeling of local geometric details and long-range contextual dependencies through a hierarchical attention mechanism. Meanwhile, state-space sequence models (SSMs), such as S4 and its recent variant Mamba, have demonstrated the capacity to model long sequences with linear complexity. These approaches address the quadratic complexity limitation of standard Transformers and offer potential efficiency advantages for high-resolution point clouds.
Despite these advances, the direct application of existing Transformer or SSM frameworks to outdoor traffic scenes remains challenging. LiDAR data in traffic environments are more complex than indoor scans or object-level datasets: point cloud distributions are highly inhomogeneous, object scales vary significantly, and scenes contain both dynamic and static targets. Moreover, autonomous driving imposes strict latency and memory constraints, necessitating segmentation models that are both accurate and real-time capable.
Cylinder3D effectively addresses the challenge of uneven point distribution in outdoor LiDAR scenes through a cylindrical partitioning strategy, enabling better geometric representation of objects. However, it still struggles to capture multi-scale contextual relationships and fine-grained local details, leading to unstable segmentation results in complex traffic scenes.
To overcome these limitations, this study proposes CMPNet, which builds upon the Cylinder3D [12] framework and proposes a novel Multi-Scale 3D Attention Module (MS3DAM) to enhance both local feature extraction and global context modeling. By integrating features across multiple spatial scales, CMPNet achieves more accurate segmentation of objects with varying sizes, thus improving the robustness and accuracy of semantic segmentation in real-world traffic environments.
2. Related Work
2.1. Traditional Point Cloud Semantic Segmentation Methods
2.1.1. Point-Based Methods
The point-based approach uses raw point cloud data as input to deep learning models. While this method preserves data integrity, it is insufficient for learning local features and cannot effectively address the uneven point cloud density in complex scenes. To address this limitation, Qi et al. proposed PointNet++ [13], an extension of PointNet [14] that introduces a hierarchical feature learning framework to capture local point cloud information. PointNet++ aggregates local features through farthest point sampling and progressively constructs global feature representations, demonstrating strong generalization across varying densities and resolutions. However, for large-scale outdoor point cloud data, its multi-scale grouping and recursive aggregation operations result in high computational complexity and memory consumption. To address these issues, RangeNet++ [15] projects 3D point clouds onto 2D images via spherical projection, segments the resulting depth maps using 2D convolutional neural networks, and maps the results back to 3D space using a KNN-based post-processing algorithm. This approach enables fast and accurate semantic segmentation suitable for autonomous driving applications. Nevertheless, semantic segmentation of small targets remains imprecise, and differentiating similar parts of distinct objects remains challenging. For large-scale point clouds, RandLA-Net [16] significantly reduces computational complexity and memory usage by introducing random local regions and a local feature aggregation mechanism. Additionally, it enhances the understanding of complex geometric structures through multi-scale feature fusion and extracts global contextual information using a global feature extraction module, which is then integrated with local features to improve overall segmentation performance.
Point-based methods effectively preserve the structure of the original point cloud. However, they often emphasize either global or local feature extraction while neglecting the correlations among points, which leads to lower accuracy when segmenting adjacent objects in a scene.
2.1.2. Voxel-Based Methods
Voxel-based methods for point cloud semantic segmentation convert point cloud data into structured 3D grids and leverage established 3D convolutional neural networks for feature extraction, enabling efficient semantic segmentation. By structuring the inherently irregular and sparse point cloud data, these methods allow traditional 2D and 3D convolutional networks to be directly applied to point cloud processing tasks. For large-scale point cloud data, the SPVCNN [17] model introduces 3D-NAS, demonstrating significant improvements in mean Intersection over Union (mIoU). However, voxelization methods exhibit limited effectiveness for outdoor point clouds. To address this limitation, Cylinder3D [18] replaces traditional voxelization with cylindrical partitioning, which better accommodates the sparsity and varying density of large-scale point clouds. Cylinder3D also incorporates two asymmetric residual blocks to preserve features of cuboid-shaped objects while reducing computational cost and memory usage. MinkUNet [19] introduces a 4D spatio-temporal convolutional neural network for processing 3D videos, which in some cases outperforms conventional 3D CNNs in speed. Furthermore, it proposes a generalized sparse convolution algorithm for high-dimensional point cloud data, effectively enhancing computational efficiency and overall model performance through the use of sparse tensors. MSF-CSCNet [20] builds upon Cylinder3D by incorporating multi-scale voxel feature fusion and channel context modeling, thereby substantially enhancing both the accuracy and robustness of point cloud semantic segmentation. However, this approach exhibits a higher dependency on computational resources, and its adaptability across diverse scenes remains constrained.
2.2. Channel Attention and Spatial Attention Features
Different channels in a feature map correspond to different objects. Channel attention [21] explicitly models the dependencies between channels, adaptively determines the importance of each channel, and assigns different weights to enhance important features while suppressing less relevant features. Channel attention was first introduced by SENet [22], which aggregates global spatial information through two operations, Squeeze and Excitation, to learn channel importance, significantly improving image classification performance. Building on this, CBAM [23] enhances convolutional neural network feature representations by incorporating both channel and spatial attention mechanisms. Coordinate Attention [24] further combines positional information with channel attention through a coordinate attention module, enabling the model to more accurately locate and recognize objects of interest while maintaining low computational overhead.
The attention mechanism [25] aims to enhance a model’s representational capacity and overall performance by learning the relative importance of different parts of the input data and dynamically adjusting its focus accordingly. Spatial attention [26], in particular, captures relationships among different spatial locations within the input, and has been widely applied in domains such as image analysis, natural language processing, and video understanding. It improves the model’s ability to interpret and represent complex data. However, most existing designs apply self-attention directly to 2D feature maps, generating attention matrices based on isolated query–key pairs at each spatial location, without fully leveraging the rich contextual information surrounding the key. To address this limitation, the Contextual Transformer module (CoT) [27] incorporates contextual information into the key representation to learn a dynamic attention matrix, thereby enhancing the model’s representational power effectively. DANet [28] incorporates a spatial attention mechanism to model the contextual information surrounding each pixel, thereby enhancing its ability to capture the shape and edge characteristics of objects. By effectively modeling rich contextual dependencies within local features, the method leads to substantial improvements in segmentation performance.
2.3. Multi-Scale Dilated Convolution and Receptive Field
Dilated convolution [29] is primarily used to enlarge the receptive field, enabling segmentation tasks to capture broader context without increasing the number of parameters [30]. However, in practice, it often suffers from the grid effect, which leads to the loss of local information and limits the relevance of features captured from distant regions. To address these issues, this study adopts multi-scale dilated convolution, where each convolution branch employs a distinct dilation rate. This strategy enables the model to effectively capture information at multiple scales, thereby broadening the receptive field and improving the extraction of spatial information across diverse ranges. By setting varied dilation rates, the model is able to enhance its perception of spatial structures at different levels, ensuring both comprehensive feature representation and stronger contextual awareness.
By employing different expansion rates, the model can capture spatial structures at multiple scales, enabling both global feature representation and enhanced contextual modeling. In practice, smaller expansion rates emphasize local geometric details, whereas larger rates facilitate the capture of long-range dependencies in sparse traffic scenarios; medium rates provide a balance between these extremes. Although inflated convolutions can expand the receptive field without increasing the number of parameters, excessively large expansion rates may compromise local accuracy and reduce computational efficiency due to sparse sampling. Such trade-offs have been investigated in previous semantic segmentation studies, including DeepLab’s multiscale approach for 2D images, and have proven effective in 3D point cloud segmentation. To achieve a reasonable balance between accuracy and efficiency, we evaluated several combinations of expansion rates and determined that the combination of 3, 12, and 39 yields optimal multiscale feature modeling. This empirical selection was further validated through ablation experiments, where alternative configurations consistently resulted in reduced segmentation performance.
Although extensive research has been conducted on point cloud semantic segmentation, many algorithms still rely on a single channel output and lack effective information exchange between channel groups, which limits the expressive power of neural networks. To address this limitation, this paper integrates channel attention and spatial attention mechanisms into Cylinder3D, enhancing feature representation in key regions and improving overall model accuracy.
3. Methodology
3.1. CMPNet
Cylinder3D serves as the baseline architecture for this study. It projects irregular LiDAR point clouds into a cylindrical coordinate system to mitigate the uneven point density problem and employs voxel-based feature encoding and 3D sparse convolution to perform semantic segmentation. However, the original Cylinder3D framework faces three main limitations: (1) its voxel feature encoder, built upon standard MLPs, struggles to capture complex local spatial relationships; (2) it lacks an effective mechanism for multi-scale feature extraction and long-range dependency modeling; and (3) its normalization scheme exhibits limited robustness when handling sparse or highly unstructured outdoor scenes. To address these issues, we propose an improved point cloud semantic segmentation framework named CMPNet, which systematically enhances the feature representation capability and robustness of the Cylinder3D architecture. As shown in Figure 1, CMPNet retains the cylindrical partitioning strategy of Cylinder3D while integrating three functional modules: PointMamba [31], KAT [32] and MS3DAM.
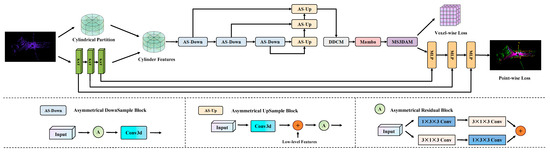
Figure 1.
The CMPNet network structure.
Specifically, the input raw point cloud is first processed by the KAT encoder, which replaces the conventional Voxel Feature Encoder (VFE) in Cylinder3D. The KAT module introduces the GR-KAN mechanism to replace standard multilayer perceptrons (MLPs) with group rational functions, allowing it to capture intricate local spatial dependencies that conventional VFEs fail to model effectively. GR-KAN employs rational functions instead of B-splines, making it more compatible with GPU architectures and improving computational efficiency. In addition, GR-KAN reduces the number of model parameters and computational cost through parameter sharing, while its variance-preserving initialization enhances training stability. Within the KAT module, layer normalization is applied to stabilize the input distribution and maintain consistent feature scaling, thereby preserving the spatial structure of point cloud features during training.
After feature encoding, the processed features are redistributed through cylindrical partitioning to achieve a balanced spatial distribution. Next, an asymmetric 3D sparse convolutional network is employed to extract local geometric structures. Within this network, we introduce the MS3DAM, a newly designed component that applies multi-scale dilated convolutions and attention fusion to capture both fine-grained local details and global contextual cues, compensating for the limited multi-scale modeling capability of the original Cylinder3D.
Finally, to enhance global context perception and computational efficiency, the PointMamba module is incorporated. Its sequence-based feature aggregation enables long-range dependency modeling with linear complexity, significantly reducing the computational cost in large-scale outdoor traffic scenes.
Through these targeted enhancements, CMPNet effectively addresses the architectural limitations of Cylinder3D, achieving superior segmentation accuracy, robustness, and efficiency.
3.2. MS3DAM
In point cloud semantic segmentation tasks, objects often appear in various sizes and shapes. Conventional convolutional layers employ a fixed receptive field, which substantially restricts their ability to capture multi-scale features. To address this limitation, we design the MS3DAM that applies multiple dilation rates in parallel and integrates channel and spatial attention mechanisms to enhance feature representation [33].
First, MS3DAM enlarges the receptive field. Traditional convolutional networks expand the receptive field by stacking multiple convolutional layers, which significantly increases computational cost and may dilute important information. In contrast, dilated convolution, particularly with varying dilation rates, effectively enlarges the receptive field without reducing resolution, thereby enabling the model to capture broader contextual information.
Second, MS3DAM enhances the capture of multi-scale information. In tasks such as semantic segmentation and object detection, where objects differ greatly in size and shape, parallelizing convolutions with multiple dilation rates allows the network to simultaneously extract features at different scales. This improves the model’s adaptability and recognition of features across diverse spatial ranges.
Global average pooling [34] effectively captures the global features of an entire image, which is crucial for understanding the overall scene structure. Integrating this global information with local features enables the network to better interpret the relationship between individual image regions and the whole, thereby facilitating more accurate predictions.
In convolutional neural networks, different channels typically represent distinct features or patterns. However, when processing complex images, some channels contain more useful information than others, and conventional convolutional operations cannot dynamically adjust their importance. Similarly, spatial locations vary in significance; for instance, regions containing target objects are more critical than background areas. Traditional convolutions, however, treat all spatial locations equally and fail to emphasize key regions. To address these limitations, channel attention is introduced to evaluate and adjust the importance of each channel, thereby strengthening informative feature channels and suppressing less relevant ones. In addition, spatial attention is applied to highlight crucial regions within the image, enabling the model to focus on local areas that exert the greatest influence on the task outcome.
Finally, to enhance overall model performance, multi-scale features must be effectively integrated with the attention mechanism, as using either technique alone is insufficient. By concatenating the output features of multi-scale dilated convolutions along the channel dimension and applying both channel and spatial attention mechanisms for weighting, the module fuses features from multiple perspectives. Combining different dilated convolution layers with global features ensures that the network captures both local details and global context. This design produces more comprehensive network outputs and improves the model’s generalization across diverse scenarios. Additionally, feature dimensionality reduction via the final 1 × 1 × 1 convolution reduces computational cost and integrates information from different branches, generating a more effective feature representation for the downstream task.
The MS3DAM module, as illustrated in Figure 2, is designed to enhance feature representation by integrating multiple dilation rates and combining channel and spatial attention mechanisms. This architectural design effectively addresses the requirement to capture both fine-grained local information and broad contextual information within an image, which is essential for tackling complex visual tasks, including semantic segmentation in outdoor traffic scenarios and object detection applications.
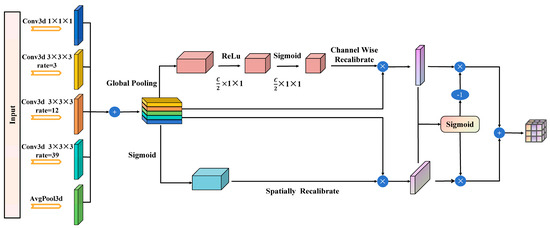
Figure 2.
MS3DAM frame diagram.
This module represents an integrated combination of multi-scale dilated convolutions with channel and spatial attention mechanisms. It performs feature extraction across multiple scales through five parallel convolutional branches, each configured with distinct dilation rates to expand the receptive field and capture spatial information at varying ranges. The first branch employs a 1 × 1 × 1 convolutional kernel to directly extract features without altering spatial resolution. The second branch uses a 3 × 3 × 3 convolutional kernel with a dilation rate of 3, moderately enlarging the receptive field. The third branch applies a 3 × 3 × 3 convolutional kernel with a dilation rate of 12, further expanding the receptive field to capture a broader range of contextual information. The fourth branch achieves the widest receptive field using a 3 × 3 × 3 convolutional kernel with a dilation rate of 39. Finally, the fifth branch incorporates a global average pooling operation to extract global contextual features, thereby enhancing the model’s comprehension of the overall scene layout.
Subsequently, the multi-scale features extracted from the five distinct branches are concatenated along the channel dimension to form a unified feature map [35]. This combined feature map is then simultaneously refined using both the channel attention mechanism and the spatial attention mechanism. Within the channel attention module, global average pooling is applied to the synthesized feature map to obtain channel-wise global features. The importance weights for each channel are then learned through two fully connected layers employing ReLU and Sigmoid activation functions, respectively. These weights are finally multiplied by the original feature map in a channel-wise manner to implement channel weighting. In the spatial attention module, the combined feature map is globally pooled along the channel dimension to generate a spatial feature map. The importance weights for each spatial location are subsequently learned using a 1 × 1 × 1 convolution followed by a Sigmoid activation function. These weights are applied to the original feature map in an element-wise manner to achieve spatial weighting.
Finally, the output feature maps obtained from the channel attention and spatial attention mechanisms are fused through an element-wise addition operation to produce the enhanced feature maps. At this stage, the feature maps calibrated by the channel and spatial attention mechanisms are each combined with the original merged feature map via element-wise addition to integrate and reinforce the relevant features. The resulting enhanced feature maps are subsequently passed through a 1 × 1 × 1 convolutional layer for dimensionality reduction and feature integration, generating the final output feature representations.
By combining multi-scale dilated convolutions with channel and spatial attention, MS3DAM effectively captures both local details and global contextual information. This design addresses the limitations of Cylinder3D in multi-scale feature extraction and global perception, providing more comprehensive and robust features for semantic segmentation in complex outdoor traffic scenarios.
3.3. PointMamba
Cylinder3D employs cylindrical partitioning and 3D sparse convolutions to extract local geometric features from point clouds. However, it lacks an efficient mechanism for modeling long-range dependencies across large-scale point cloud sequences, which limits its capability to capture global contextual information in complex outdoor scenarios. To address this limitation, we introduce PointMamba, which offers linear computational complexity while maintaining the ability to model long sequences, as illustrated in Figure 3. Mamba [36] is based on a state space model [37] (SSM) that incorporates a selectivity mechanism, enabling the model to capture contextual information relevant to the inputs. The formulation of SSM is defined as follows:
where denotes the state matrix, and and represent the mapping parameters. Both and are determined using the zero-order hold (ZOH) rule:
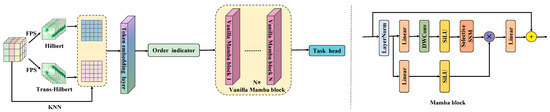
Figure 3.
PointMamba frame diagram.
Building on SSM, the SelectiveSSM (S6) framework makes the parameters , and functions of the inputs, effectively converting the SSM into a time-varying model and allowing the network to selectively focus on or filter out information. However, due to the inherent irregularity and sparsity of point clouds, Mamba’s unidirectional modeling encounters difficulties when processing point cloud data. These challenges can be effectively mitigated through the reordering strategy implemented in PointMamba.
When processing 3D point cloud data, PointMamba employs two types of space-filling curves, Hilbert [38] and Trans-Hilbert, to scan the key points, thereby preserving spatial localization effectively. Based on this, K-nearest neighbors (KNN) is applied to generate point patches, which are subsequently fed into the token embedding layer to produce serialized point tokens. To efficiently handle the inherently disordered structure of point clouds, a reordering strategy is applied to the point tokens, providing a more geometrically coherent scanning order. The reordered tokens are then input into an encoder composed of stacked Mamba modules [39], where feature extraction is performed via selective state-space modeling. This approach enhances the model’s global modeling capability and significantly reduces computational resource consumption, while retaining linear computational complexity.
Within CMPNet, PointMamba works synergistically with the KAT encoder and the MS3DAM module to complement local geometric feature extraction with global sequence modeling, forming an integrated and improved point cloud semantic segmentation framework based on Cylinder3D.
3.4. KAT
Traditional Voxel Feature Encoders (VFE) employ standard multilayer perceptron (MLP) in point cloud segmentation tasks, but they often struggle to capture the intricate spatial relationships inherent within point clouds, thereby limiting the model’s feature representation capability. Furthermore, conventional normalization methods exhibit limited robustness when applied to sparse point clouds. To address these limitations, we introduce the KAT module and replace the traditional MLP with the GR-KAN [40] module, as illustrated in Figure 4. GR-KAN utilizes rational functions in place of the B-splines [41] employed in the conventional KAN [42], which more effectively aligns with GPU architectures and enhances both computational efficiency and compatibility. In addition, GR-KAN [43] substantially reduces the number of model parameters and computational requirements through parameter sharing. Concurrently, variance-preserving initialization within GR-KAN further improves the stability of model training. The formula of GR-KAN is defined as follows:
where denotes the index of the input channel. With groups, each group contains channels, where represents the group index. After transformation, the above equation can be rewritten as:
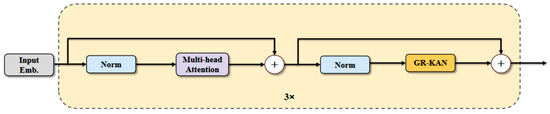
Figure 4.
KAT frame diagram.
In this form, the parameters can be shared across input channels. Consequently, the rational function can be directly applied to the input vectors, that is, to each grouped edge.
Within the KAT module, layer normalization is applied to stabilize the input distribution of each layer, preserving the spatial structure of the point cloud features while maintaining consistent feature scaling during training. Compared to standard MLPs, KAT can effectively capture local spatial dependencies in point clouds, thereby enhancing feature representation and reducing computational cost.
4. Experiment and Analysis
4.1. Experimental Setup
4.1.1. Experimental Environment
The experimental setup employed in this study consists of an Intel Core i7-14700KF processor (Intel, Santa Clara, CA, USA) with 32 GB of RAM, an NVIDIA GeForce RTX 4070 Ti SUPER graphics card (NVIDIA, Santa Clara, CA, USA), and CUDA 11.8-enabled GPU acceleration. The deep learning framework is based on Python 3.8 and utilizes PyTorch version 2.0.0+cu118. Detailed parameter configurations are presented in Table 1.

Table 1.
Experimental Hyperparameter Settings.
All experiments were conducted three times using different random seeds (1643723704, 1919680557, 1995020035), and the mean and standard deviation of the results were computed. The Adam optimizer was employed with an initial learning rate of 0.001 and a weight decay coefficient of 0.01. A linear warm-up strategy was applied during the first 1000 iterations, followed by a multi-stage decay of the learning rate by a factor of 0.1 at the 30th epoch. Training continued for 36 epochs with a batch size of 2. Data augmentation was performed using the GlobalRotScaleTrans and RandomFlip3D strategies to improve the model’s generalization capability in complex traffic scenarios.
4.1.2. Evaluation Metrics and Datasets
To evaluate the effectiveness of the CMPNet model, experiments were conducted on the SemanticKITTI [44] and nuScenes [45] datasets. The SemanticKITTI dataset is a widely recognized large-scale benchmark for point cloud semantic segmentation, specifically designed for scene understanding in autonomous driving. It comprises point cloud sequences collected from 22 real-world road scenes, which are further subdivided into 43,552 detailed scenes, encompassing a total of over 4.5 billion 3D points. Following the official dataset partitioning guidelines, sequences 00–07 and 09–10 are designated for training, sequence 08 serves as the validation set, and sequences 11–21 constitute the test set. The nuScenes dataset includes a test set containing 8130 samples, a validation set comprising 6019 samples, and an additional independent test set of 6008 samples.
To comprehensively assess the performance of the proposed model in point cloud semantic segmentation tasks, this study employs mean Intersection over Union (mIoU), Accuracy (acc), and Accuracy per Class (acc_cls) as the primary evaluation metrics. The integration of these metrics enables a thorough quantification of the model’s overall performance in point cloud segmentation, while also providing a robust foundation for an in-depth analysis of the network’s accuracy and generalization capabilities across diverse scenarios.
- 1.
- The mean Intersection over Union (mIoU) denotes the average Intersection over Union (IoU) computed for each class within the dataset and is widely employed to evaluate the extent of overlap between the predicted results and the corresponding ground truth. It is calculated by averaging the IoU values across all classes in the entire dataset. The specific formula for this computation is presented as follows:where C is the number of point cloud semantic categories, TP denotes the number of correctly predicted as belonging to the current category, FP indicates the number of incorrectly predicted as current category point clouds, and FN denotes the number of incorrectly predicted as belonging to other categories.
- 2.
- Accuracy (ACC) represents the proportion of correctly predicted samples relative to the total number of samples and is commonly utilized to evaluate the overall classification performance of the model. The calculation formula is provided as follows:
- 3.
- ACC_cls denotes the mean accuracy computed across all categories and is employed to evaluate the model’s prediction performance for each individual category. By analyzing the accuracy of each category separately, it is possible to more comprehensively assess the model’s predictive capability for different types of samples.
4.1.3. Loss Function
The loss function employed in this study comprises two components: voxel loss and point loss. The overall loss function can be formally expressed as follows:
For the voxel loss component , this study utilizes a combination of weighted cross-entropy loss and Lovasz-Softmax loss to simultaneously optimize point-wise accuracy and IoU scores. For the point loss component , only the weighted cross-entropy loss is employed to supervise model training.
4.2. Comparative Experiment
4.2.1. Results on SemanticKITTI
To establish the baseline model for this study, we conducted experiments on all mainstream algorithms supported by the MMDetection3D framework that are suitable for outdoor point cloud semantic segmentation, including MinkUNetW16, MinkUNetW20, MinkUNetW32, Cylinder3D, SPVCNNW16, SPVCNNW20, SPVCNNW32, RangeNet++ and SalsaNext. All experiments were performed using the default configurations provided by the MMDetection3D framework and executed on the SemanticKITTI dataset within a standardized experimental environment.
The experimental results demonstrate that the Cylinder3D model achieves superior segmentation accuracy under identical experimental conditions, significantly outperforming the majority of comparison models with a mean Intersection over Union (mIoU) of 62.17%. Although its mIoU (62.17%) is marginally lower than that of MinkUNetW32 (62.30%), improving MinkUNet’s performance requires adjusting its network width, which incurs higher computational costs. Moreover, while the overall accuracy of Cylinder3D is slightly lower than some comparison models, this metric is sensitive to category imbalance. In contrast, mIoU offers a more comprehensive assessment of segmentation capability and is therefore more informative for evaluating performance in point cloud segmentation tasks. Consequently, Cylinder3D is selected as the baseline model for this study.
The results, summarized in Table 2, indicate that CMPNet outperforms several state-of-the-art models. Specifically, the proposed CMPNet model achieves the highest mean Intersection over Union (mIoU) of 64.98%, representing an improvement of 2.81% over the previously optimal Cylinder3D model, which relies on cylindrical partitioning of the point cloud. This result demonstrates that CMPNet possesses a stronger capability to capture semantic boundaries of diverse objects in complex scenes. In the acc_cls metric, which evaluates category discrimination ability, CMPNet also attains superior performance, outperforming Cylinder3D and other comparison models. Although CMPNet exhibits slightly lower overall accuracy (acc) than MinkUNet and SPVCNN, it still surpasses the Cylinder3D model in this metric. The substantial lead of CMPNet in mIoU and acc_cls, particularly mIoU as a comprehensive metric reflecting balanced segmentation across categories, provides strong evidence that CMPNet excels in segmenting small objects, edge regions, and non-dominant categories, thereby achieving the most comprehensive and balanced segmentation performance. As detailed in Table 2, CMPNet demonstrates significant improvements over the original Cylinder3D model across multiple categories. CMPNet achieves remarkable advances in the segmentation of small and challenging objects, such as bicycles, motorcycles, and bicyclists, while simultaneously attaining optimal performance in critical road infrastructure categories, including road, sidewalk, and traffic signs.
Table 2.
Comparison of recognition accuracy.
To more intuitively demonstrate the segmentation performance, Figure 5 visualizes the segmentation results on the SemanticKITTI dataset. Specifically, Figure 5a,c illustrate the segmentation outputs of the Cylinder3D model and the CMPNet model, respectively, whereas Figure 5e depicts the ground truth segmentation. It is evident that the CMPNet model achieves higher semantic segmentation accuracy across most regions. In contrast, Cylinder3D tends to misclassify parts of parking areas as sidewalks and certain portions of buildings as fences. The CMPNet model, however, performs particularly well in accurately recognizing categories such as roads, trees, and roadside buildings. It not only effectively delineates various regions but also correctly distinguishes between different object classes. To provide a more direct comparison of model performance, Figure 5b,d present point cloud segmentation results using a two-color visualization scheme: red regions indicate discrepancies between the predicted results and the ground truth, whereas green regions represent areas of agreement. These visualization results clearly demonstrate that the proposed CMPNet model (Figure 5d) exhibits substantial advantages in point cloud semantic segmentation relative to the baseline model (Figure 5b). Although our method achieves strong overall performance, it may produce inaccurate segmentation results for distant objects. For instance, as shown on the rightmost side of Figure 5d, the CMPNet model fails to clearly distinguish the ground from the surrounding trees.
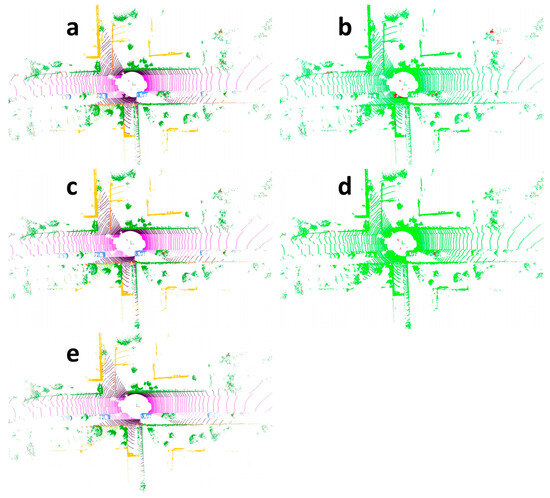
Figure 5.
Point cloud semantic segmentation result visualization. (a) Visualization of Cylinder3D point cloud segmentation. (b) Two-color visualization of Cylinder3D point cloud segmentation. (c) Visualization of CMPNet point cloud segmentation. (d) Two-color visualization of CMPNet point cloud segmentation. (e) The ground truth segmentation.
Figure 6 presents a comparison of semantic segmentation results for traffic signs in the same scene using Cylinder3D and CMPNet, alongside the corresponding ground-truth labels. Specifically, Figure 6a depicts the ground-truth segmentation, while Figure 6b,c show the segmentation results produced by CMPNet and Cylinder3D, respectively. As illustrated, CMPNet demonstrates superior accuracy in recognizing traffic signs, exhibiting finer segmentation and enhanced robustness compared to Cylinder3D. This visual result is consistent with the quantitative experimental results on the SemanticKITTI dataset, where CMPNet achieves a mean Intersection over Union (mIoU) of 50.95% for the traffic sign category, demonstrating its enhanced capability in segmenting small and challenging objects.
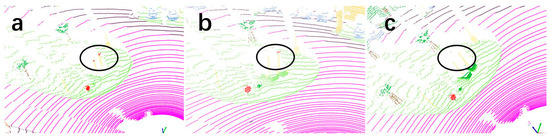
Figure 6.
Visualization of CMPNet and Cylinder3D for Traffic Sign Recognition. (a) The ground truth segmentation. (b) Visualization of CMPNet point cloud segmentation. (c) Visualization of Cylinder3D point cloud segmentation.
4.2.2. Results on nuScenes
To further validate the effectiveness of CMPNet, this study conducts generalization experiments on nuScenes [45], a publicly available large-scale dataset widely used for autonomous driving research. The results are summarized in Table 3. Despite the inherent complexity of the nuScenes dataset, which poses substantial challenges for point cloud segmentation, CMPNet continues to demonstrate outstanding performance. Specifically, the experimental results indicate that CMPNet achieves a mean Intersection over Union (mIoU) of 73.9%, corresponding to a 3.1% improvement over the Cylinder3D model. These findings not only further corroborate CMPNet’s performance superiority in point cloud semantic segmentation for outdoor traffic scenarios but also highlight its robust stability across different datasets.
Table 3.
Results of different methods on the nuScenes dataset.
To ensure the statistical reliability of our experimental results and mitigate the influence of randomness in training, each model was trained three times using different random seeds (1643723704, 1919680557, 1995020035). Table 2 and Table 3 indicate that CMPNet achieved an average mIoU of 64.98 ± 0.5 on the SemanticKITTI dataset and 73.9 ± 0.5 on the nuScenes dataset, demonstrating consistent model performance. Furthermore, a paired t-test comparing CMPNet with the baseline model Cylinder3D yielded p < 0.05, confirming that the observed performance improvement is unlikely to result from random variation.
4.3. Ablation Experiment
4.3.1. Ablation Studies Between Different Modules
To evaluate the contribution of each module to the overall performance of CMPNet, this study employs the Cylinder3D model as the baseline and conducts a series of ablation experiments on the SemanticKITTI dataset. The results of these experiments are presented in Table 4. When the MS3DAM module is incorporated, the model’s mean Intersection over Union (mIoU) increases substantially to 64.04%, indicating that MS3DAM possesses a significant advantage in capturing both global features and complex spatial relationships within the point cloud. In contrast, adding only the PointMamba module raises the mIoU to 63.44%. Although this improvement is smaller than that achieved by MS3DAM, the PointMamba module’s strength lies in its state-space model with linear computational complexity, which enables efficient handling of large-scale point cloud data. Additionally, the use of the KAT module alone results in a 1.58% increase in mIoU. When modules are combined, further gains are observed. As both the PointMamba and MS3DAM modules are integrated simultaneously, the mIoU further rises to 64.31%, demonstrating that the synergistic combination of these two modules enhances the model’s feature extraction capability. When the KAT module is combined individually with either the PointMamba or MS3DAM modules, the mIoU improves further, with both combinations surpassing 64%. Ultimately, the complete CMPNet model, integrating all three modules, achieves an mIoU of 64.98%, corresponding to a 2.81% increase over the baseline. These findings fully substantiate both the effectiveness of each module and the synergistic benefits of their combined application in addressing complex point cloud semantic segmentation tasks.
Table 4.
Ablation experiment results.
4.3.2. Multi-Scale Dilation Branch Ablation Experiment
To verify the effectiveness of the multi-scale dilation branches within the MS3DAM module, ablation experiments were conducted on its three individual dilation branches, and the results are presented in Table 5. Utilizing the CMPNet model as the baseline, the dilation rate of each branch was reduced independently, and experiments are conducted with various combinations of these rates. The experimental results indicate that the existing configuration of dilation rates in the MS3DAM module yields the optimal model performance, while modifying the dilation rate of any branch results in a significant decline in performance. These findings conclusively demonstrate that the synergistic interaction of the multi-scale branches plays a crucial role in enhancing the overall performance of the model.
Table 5.
Multi-scale dilation branch ablation experiment.
4.3.3. Attention Mechanism Ablation Experiment
To further analyze the contribution of the attention mechanisms in the MS3DAM module, we performed ablation experiments based on CMPNet. The model performance was evaluated using only channel attention, using only spatial attention, and disabling both attention mechanisms (No Attention), respectively, while keeping the multiscale expansion branch constant. The experimental results are shown in Table 6. The experimental results show that disabling both channel attention and spatial attention (No Attention) leads to a significant performance degradation (61.65%), while the performance improves to 64.24% and 64.15% when using only channel attention or only spatial attention, respectively. The best performance is achieved only when both channel and spatial attention are used (64.98%). This fully demonstrates that both channel attention and spatial attention contribute positively to the model performance, and their combination can achieve the optimal feature representation effect.
Table 6.
Attention mechanism ablation experiment.
4.3.4. Training Stability and Robustness Analysis
To further verify the robustness and generalization ability of the proposed CMP-Net, the training and validation processes were analyzed, as shown in Figure 7. The training loss exhibits a continuous downward trend, while both validation mIoU and accuracy remain stable and high throughout the training process. This indicates that CMPNet achieves steady convergence without significant overfitting. The close alignment between the training and validation curves demonstrates the model’s robust learning behavior and stable optimization across epochs. These observations further confirm that CMPNet maintains consistent performance under complex outdoor scenes, effectively mitigating overfitting while preserving high segmentation accuracy.
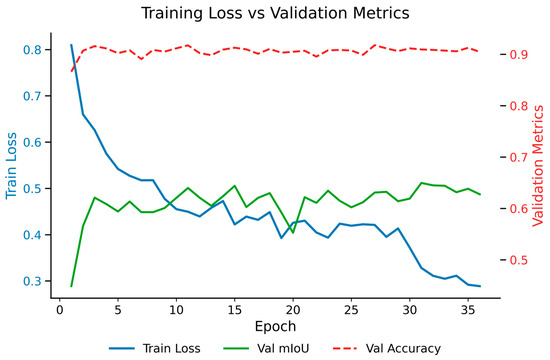
Figure 7.
Training loss and validation performance metrics of CMPNet.
4.4. Computational Efficiency Analysis
To assess CMPNet’s computational efficiency, we evaluate its complexity in terms of the number of model parameters and compare it with the widely adopted baseline model, Cylinder3D. As presented in Table 7, CMPNet contains substantially fewer parameters than Cylinder3D, demonstrating that our design effectively reduces model redundancy while preserving robust representational capacity, and meanwhile attains the highest mIoU performance.
Table 7.
Comparison of model efficiency and segmentation performance on the SemanticKITTI.
5. Discussion
In this paper, to address the limitations of the Cylinder3D algorithm, including erroneous segmentation, limited recognition capability, and low computational efficiency during the segmentation process, we propose an innovative semantic segmentation method for point clouds, CMPNet, which achieves high segmentation accuracy on the SemanticKITTI dataset through integrating the PointMamba, MS3DAM, and KAT modules. During the study, we observed that combining multi-scale dilated convolution with channel and spatial attention effectively expands the receptive field and captures spatial information at multiple scales. Consequently, the MS3DAM module was designed to enhance feature representation and strengthen the model’s ability to extract global features. The incorporation of the PointMamba module improves both segmentation accuracy and computational efficiency in point cloud semantic segmentation tasks. Moreover, experimental results indicate that introducing the KAT module at the head of the encoder allows CMPNet to exhibit superior perceptual capability and robustness when processing point clouds. Therefore, in comparison with the Cylinder3D algorithm, CMPNet demonstrates enhanced performance in recognizing complex scene structures and achieves overall improved robustness. The experimental results demonstrate that CMPNet outperforms advanced models such as Cylinder3D, MinkUNet, SPVCNN, and RangeNet++ in overall segmentation performance, achieving more comprehensive and balanced results.
Although CMPNet demonstrates strong segmentation accuracy on the SemanticKITTI dataset, several limitations were observed during the experiments. In particular, CMPNet tends to underperform in scenarios involving distant objects, where the MS3DAM module struggles to capture sufficient multi-scale contextual information in low-density regions, leading to fragmented or missing segmentation results. These failure cases indicate that further improvements in feature aggregation and attention calibration are needed to better handle irregular point cloud distributions. Moreover, while CMPNet improves segmentation accuracy, it also increases model complexity and computational overhead. Future research will continue to explore model lightweighting strategies to reduce computational costs while maintaining segmentation performance, thereby enhancing the practical applicability of CMPNet in traffic scene understanding. It should be noted that the current experiments may involve certain dataset-specific biases. To further assess and improve CMPNet’s generalization capability, future work will evaluate the model on a wider variety of datasets.
6. Conclusions
This study proposes CMPNet, an improved point cloud semantic segmentation framework built upon the Cylinder3D architecture, systematically addressing its limitations in multi-scale feature extraction, long-range dependency modeling, and robustness under sparse point cloud conditions. CMPNet integrates a newly designed Multi-Scale 3D Attention Module (MS3DAM) to enhance local and global feature representation, a KAT encoder to replace the traditional voxel feature encoder for improved geometric preservation, and the PointMamba module to efficiently model long sequences with linear computational complexity. Experimental results demonstrate that CMPNet attains robust segmentation performance on the publicly available SemanticKITTI dataset. Ablation studies further confirm the contribution of each individual module in enhancing model performance. The results indicate that CMPNet exhibits superior capability in recognizing complex scene structures and achieves greater overall robustness compared to the Cylinder3D algorithm. Future research will continue to focus on enhancing computational efficiency and improving the model’s ability to process sparse data, thereby enabling it to handle a broader range of real-world application scenarios.
Author Contributions
Conceptualization, Y.B.; Methodology, X.Z.; Software, X.Z. and Y.G.; Validation, Y.G.; Writing—original draft, X.Z.; Writing—review and editing, X.Z. and Y.G.; Supervision, Y.B., Y.G. and Y.H.; Project administration, Y.B.; Funding acquisition, Y.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Inner Mongolia Education Department Project (Grant No. JY20230118), the Key R&D and Achievement Transformation Program in the Public Welfare Field during the 14th Five-Year Plan of Inner Mongolia (Grant No. 2023YFSH0003), the Scientific Research Project of Colleges and Universities in Inner Mongolia Autonomous Region (Grant No. NJZY22387), and the Scientific Research Project of Inner Mongolia University of Technology (Grant No. ZY202018). The APC was funded by these projects.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, N.; Kähler, O.; Pfeifer, N. A Comparison of Deep Learning Methods for Airborne Lidar Point Clouds Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6467–6486. [Google Scholar] [CrossRef]
- Zhao, J.; Zhao, W.; Deng, B.; Wang, Z.; Zhang, F.; Zheng, W.; Cao, W.; Nan, J.; Lian, Y.; Burke, A.F. Autonomous driving system: A comprehensive survey. Expert Syst. Appl. 2024, 242, 122836. [Google Scholar] [CrossRef]
- Kim, C.-J.; Lee, M.-J.; Hwang, K.-H.; Ha, Y.-G. End-to-end deep learning-based autonomous driving control for high-speed environment. J. Supercomput. 2022, 78, 1961–1982. [Google Scholar] [CrossRef]
- Cui, Y.; Chen, R.; Chu, W.; Chen, L.; Tian, D.; Li, Y.; Cao, D. Deep learning for image and point cloud fusion in autonomous driving: A review. IEEE Trans. Int. Trans. Sys. 2021, 23, 722–739. [Google Scholar] [CrossRef]
- Wang, R.; Peethambaran, J.; Chen, D. Lidar point clouds to 3-D urban models, A review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 606–627. [Google Scholar] [CrossRef]
- Liu, W.; Lai, B.; Wang, C.; Bian, X.; Yang, W.; Xia, Y.; Lin, X.; Lai, S.-H.; Weng, D.; Li, J. Learning to match 2d images and 3d lidar point clouds for outdoor augmented reality. In Proceedings of the 2020 IEEE Conference on Virtual Reality and 3D User Interfaces, Atlanta, GA, USA, 22–26 March 2020; pp. 654–655. [Google Scholar]
- Guo, Y.; Wang, H.; Hu, Q.; Liu, H.; Liu, L.; Bennamoun, M. Deep learning for 3d point clouds: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4338–4364. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zhao, X.; Chen, Z.; Lu, Z. A review of deep learning-based semantic segmentation for point cloud. IEEE Access 2019, 7, 179118–179133. [Google Scholar] [CrossRef]
- Su, H.; Maji, S.; Kalogerakis, E.; Learned-Miller, E. Multi-view convolutional neural networks for 3d shape recognition. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 945–953. [Google Scholar]
- Mao, J.; Xue, Y.; Niu, M.; Bai, H.; Feng, J.; Liang, X.; Xu, H.; Xu, C. Voxel transformer for 3d object detection. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 1578–1587. [Google Scholar]
- Guo, M.-H.; Cai, J.-X.; Liu, Z.-N.; Mu, T.-J.; Martin, R.R.; Hu, S.-M. Pct: Point cloud transformer. Comput. Vis. Media 2021, 7, 187–199. [Google Scholar] [CrossRef]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3d: An effective 3d framework for driving-scene lidar semantic segmentation. arXiv 2008, arXiv:2008.01550. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Garcia-Garcia, A.; Gomez-Donoso, F.; Garcia-Rodriguez, J.; Orts-Escolano, S.; Cazorla, M.; Azorin-Lopez, J. Pointnet: A 3d convolutional neural network for real-time object class recognition. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1578–1585. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. Rangenet++: Fast and accurate lidar semantic segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 4213–4220. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11108–11117. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching efficient 3d architectures with sparse point-voxel convolution. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 685–702. [Google Scholar]
- Choy, C.; Gwak, J.; Savarese, S. 4d spatio-temporal convnets: Minkowski convolutional neural networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3075–3084. [Google Scholar]
- Bai, Y.; Gong, Y.; Wang, J.; Wei, F. MSF-CSCNet: A supercomputing-ready 3D semantic segmentation network for urban point clouds via multi-scale fusion and context-aware channel modeling. J. Supercomp. 2025, 81, 1–27. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; p. 30. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Li, Y.; Yao, T.; Pan, Y.; Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1489–1500. [Google Scholar] [CrossRef] [PubMed]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 3146–3154. [Google Scholar]
- Wang, P.; Chen, P.; Yuan, Y.; Liu, D.; Huang, Z.; Hou, X.; Cottrell, G. Understanding convolution for semantic segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the 15th European Conference on Computer Vision(ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liang, D.; Zhou, X.; Xu, W.; Zhu, X.; Zou, Z.; Ye, X.; Tan, X.; Bai, X. Pointmamba: A simple state space model for point cloud analysis. Adv. Neural Inf. Process. Syst. 2024, 37, 32653–32677. [Google Scholar]
- Yang, X.; Wang, X. Kolmogorov-arnold transformer. arXiv 2024, arXiv:2409.10594. [Google Scholar] [PubMed]
- Sun, L.; Dong, J.; Tang, J.; Pan, J. Spatially-adaptive feature modulation for efficient image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 13190–13199. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar] [PubMed]
- Xie, L.; Li, C.; Wang, Z.; Zhang, X.; Chen, B.; Shen, Q.; Wu, Z. SHISRCNet: Super-resolution and classification network for low-resolution breast cancer histopathology image. In Proceedings of the 26th International Conference on Medical Image Computing and Computer Assisted Intervention, Vancouver, BC, Canada, 8–12 October 2023; pp. 23–32. [Google Scholar]
- Gu, A.; Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. arXiv 2023, arXiv:2312.00752. [Google Scholar] [CrossRef]
- Gu, A.; Goel, K.; Ré, C. Efficiently modeling long sequences with structured state spaces. arXiv 2021, arXiv:2111.00396. [Google Scholar]
- Hilbert, D. Über die Stetige Abbildung Einer Linie auf ein Flächenstück; Springer: Berlin, Germany, 1935. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time Series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Unser, M.; Aldroubi, A.; Eden, M. B-spline signal processing. I. Theory. IEEE Trans. Sig. Proc. 2002, 41, 821–833. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. Kan: Kolmogorov-arnold networks. arXiv 2024, arXiv:2404.19756. [Google Scholar] [PubMed]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, South Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Zhu, X.; Zhou, H.; Wang, T.; Hong, F.; Ma, Y.; Li, W.; Li, H.; Lin, D. Cylindrical and asymmetrical 3d convolution networks for lidar segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 9939–9948. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).