

Facial Landmark-Driven Keypoint Feature Extraction for Robust Facial Expression Recognition


Abstract
Highlights
- We proposed Keypoint Features, a novel approach for feature representation based on facial landmarks, and NKF, a framework for robust FER, which was designed for clear component analysis.
- We demonstrated state-of-the-art FER performance on benchmark datasets and performed a rigorous analysis of component contributions via ablation studies, and demonstrated strong generalization.
- This work demonstrates the significant potential of keypoint-based FER, paving the way for its application in real-world scenarios and potential extension to other landmark-driven tasks.
- This work provides a strong empirical foundation and performs an analysis of the components that can guide the future research in developing highly accurate and computationally efficient FER systems for unconstrained environments.
Abstract

1. Introduction
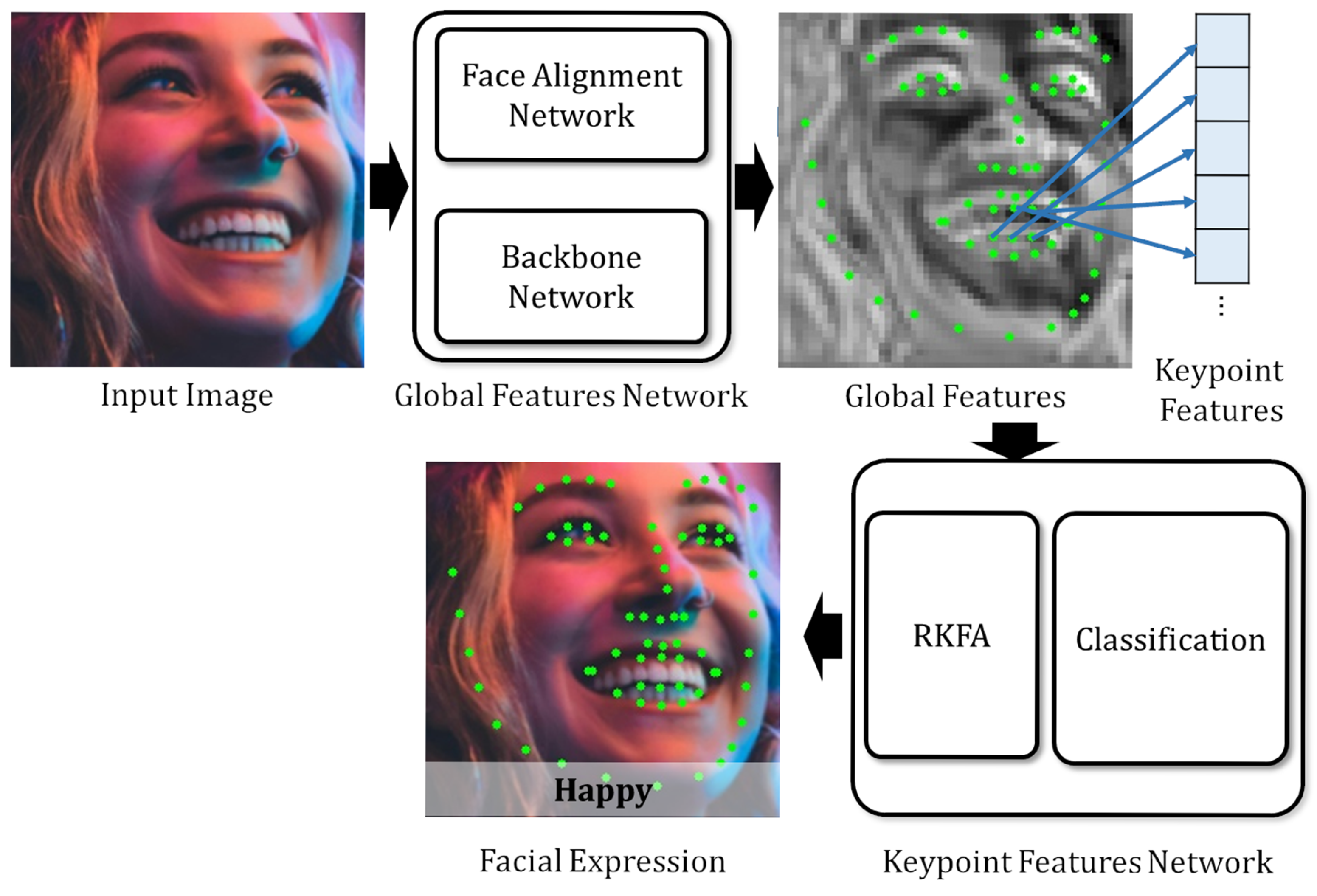
- We propose a novel type of feature called Keypoint Features, which are extracted from feature maps at the coordinates of facial landmarks predicted by a face alignment network. This feature enables a more effective utilization of information from specific facial regions.
- To enhance the quality of the extracted Keypoint Features, we introduce two methods: (i) Keypoint Feature regularization, which aims to reduce the negative effect of incorrectly predicted facial landmarks; and (ii) Representative Keypoint Feature Attention (RKFA), which uses a nasal base Keypoint Feature that includes whole-face information to improve FER performance.
- We designed a deliberately simple network, excluding other advanced structures, to clearly analyze the effects of the proposed components. We empirically validated their contributions through experiments on multiple benchmark datasets and ablation studies.
2. Related Work
2.1. FER with Face Alignment as a Preprocessing Step
2.2. FER with Face Alignment for Feature Extraction
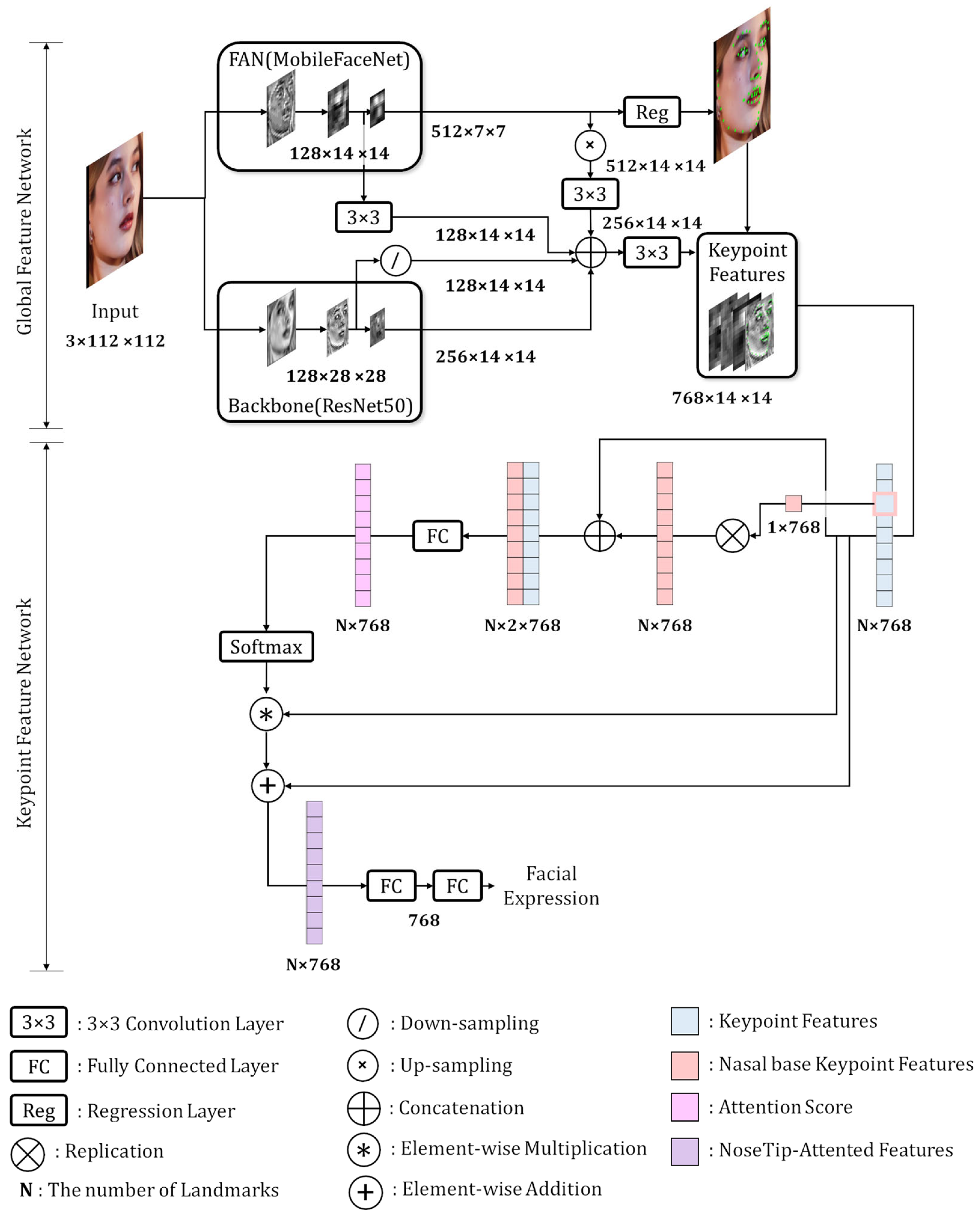
3. Proposed Method
3.1. Global Feature Network
3.2. Keypoint Features
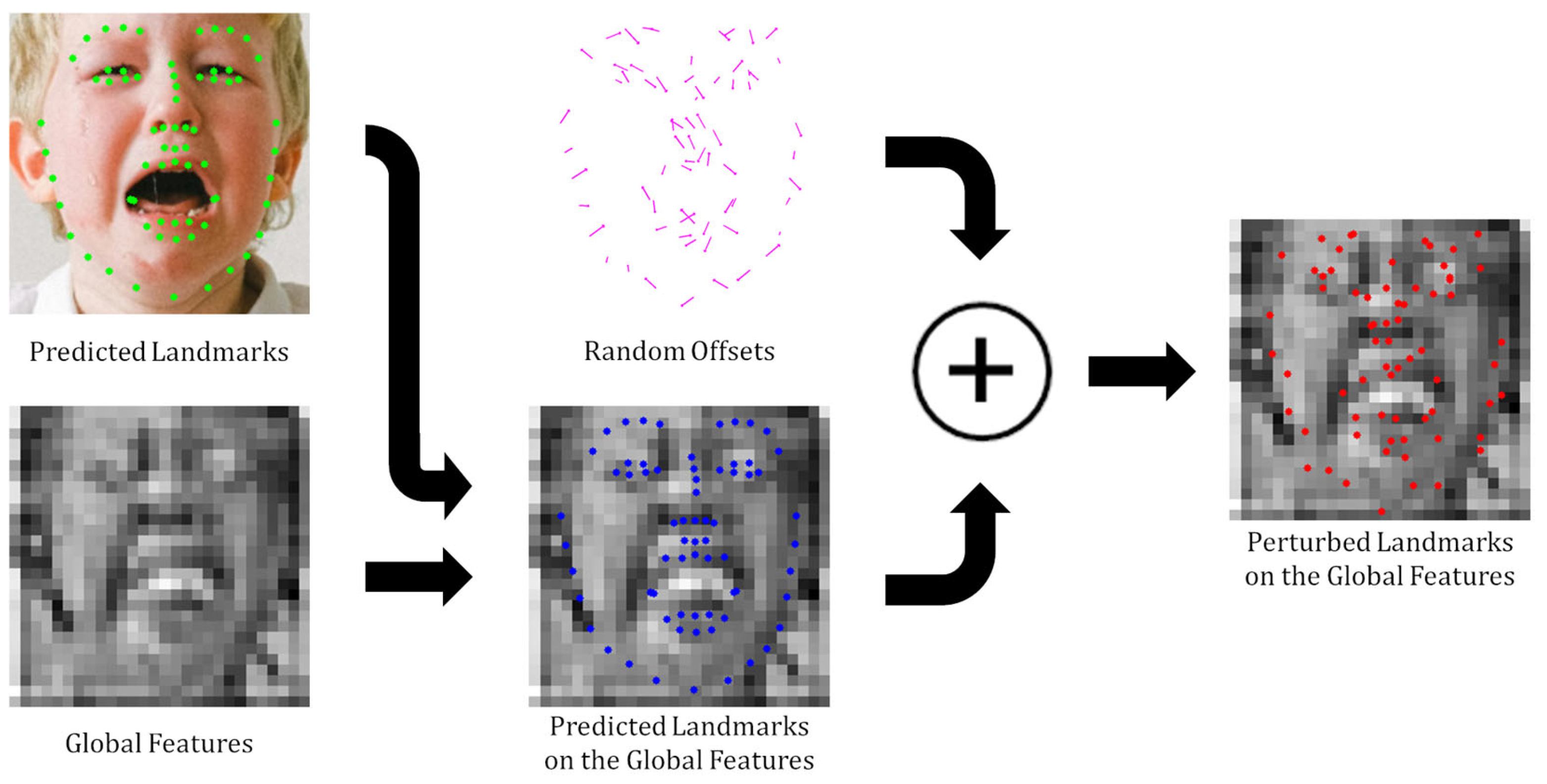
3.3. Keypoint Feature Regularization
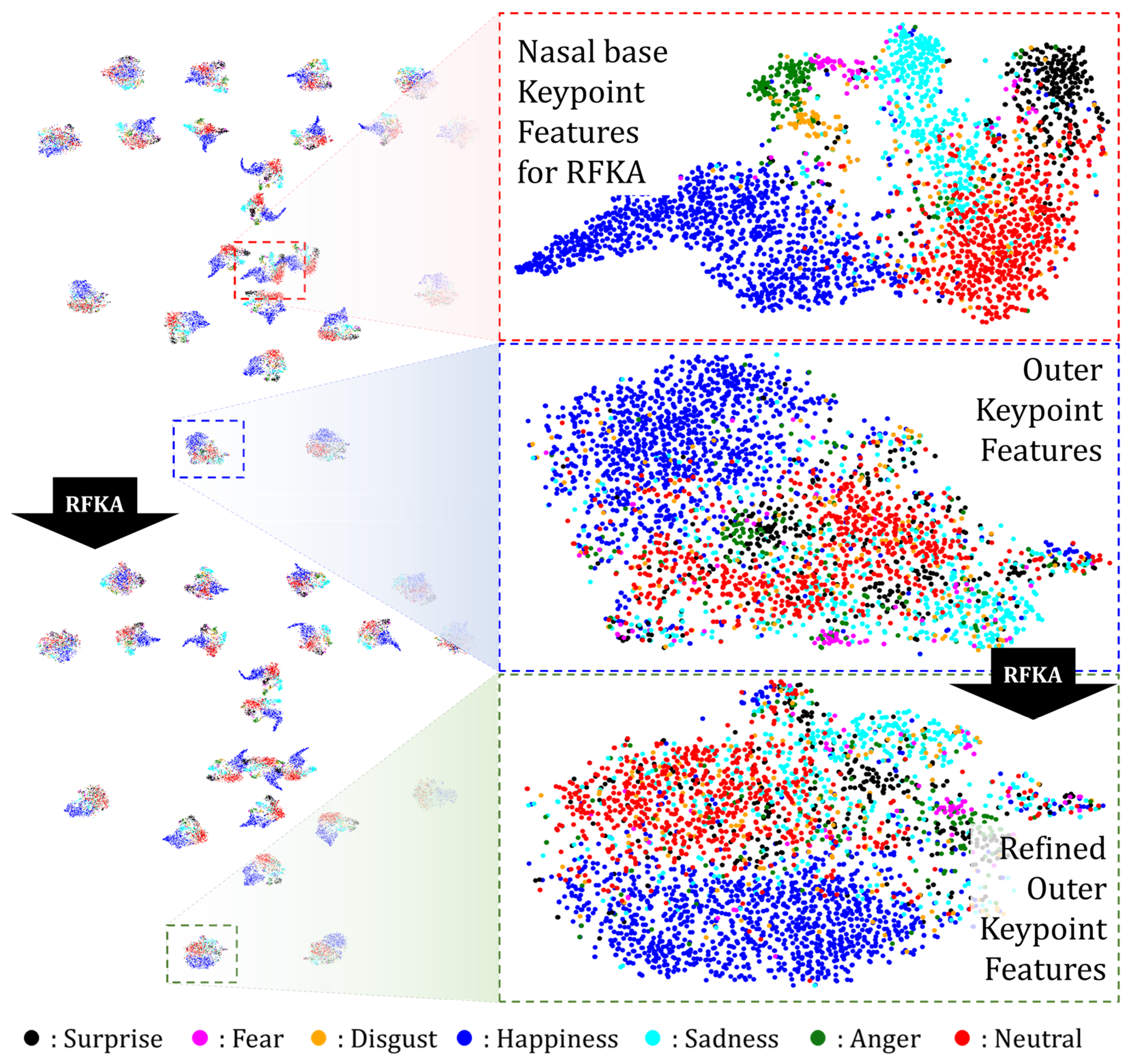
3.4. Representative Keypoint Feature Attention Using the Nasal Base Landmark
4. Experiments
4.1. Dataset
4.2. Implementation Details
4.3. Evaluation
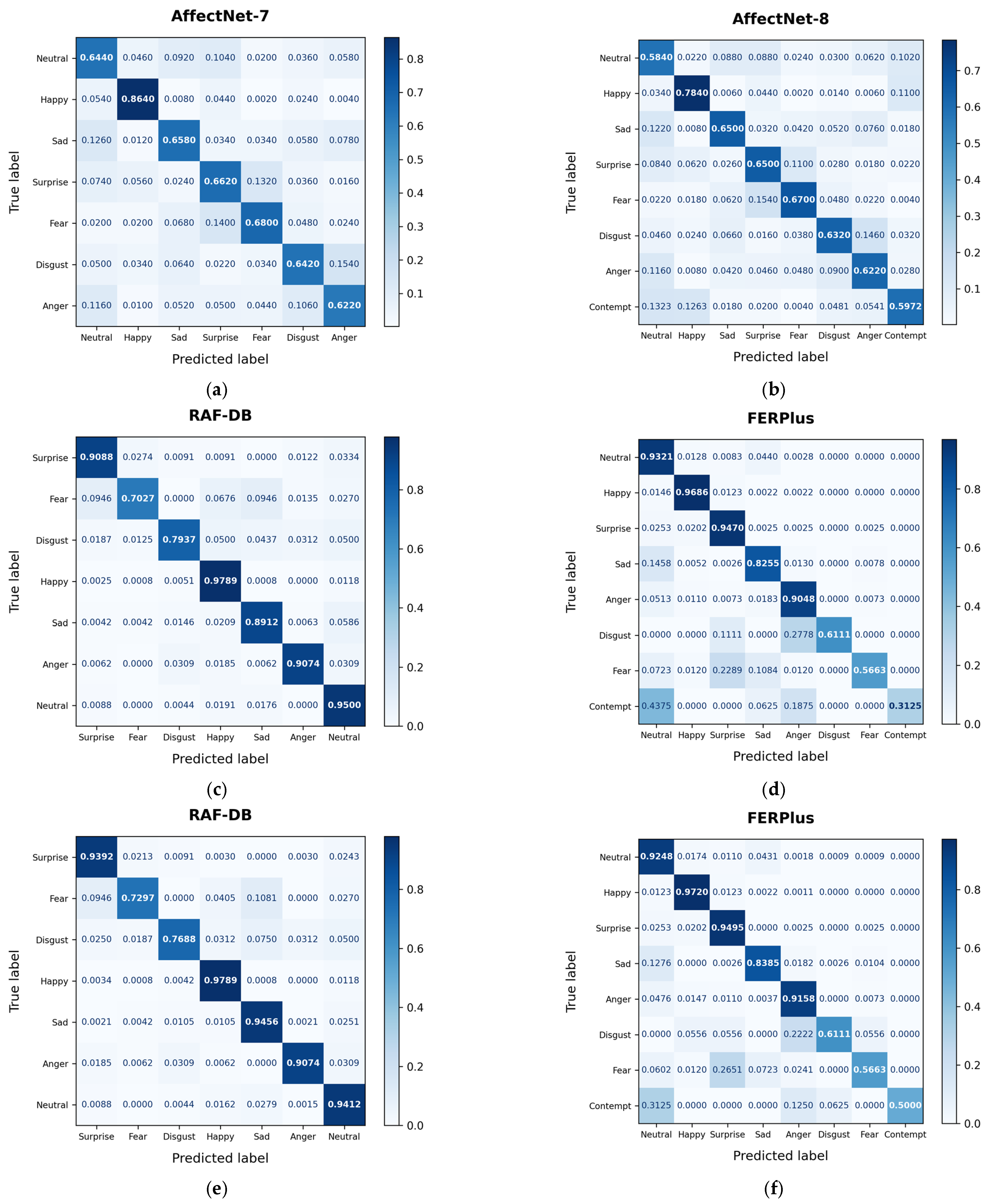
4.3.1. Comparison with State-of-the-Art Methods
4.3.2. Ablation Study
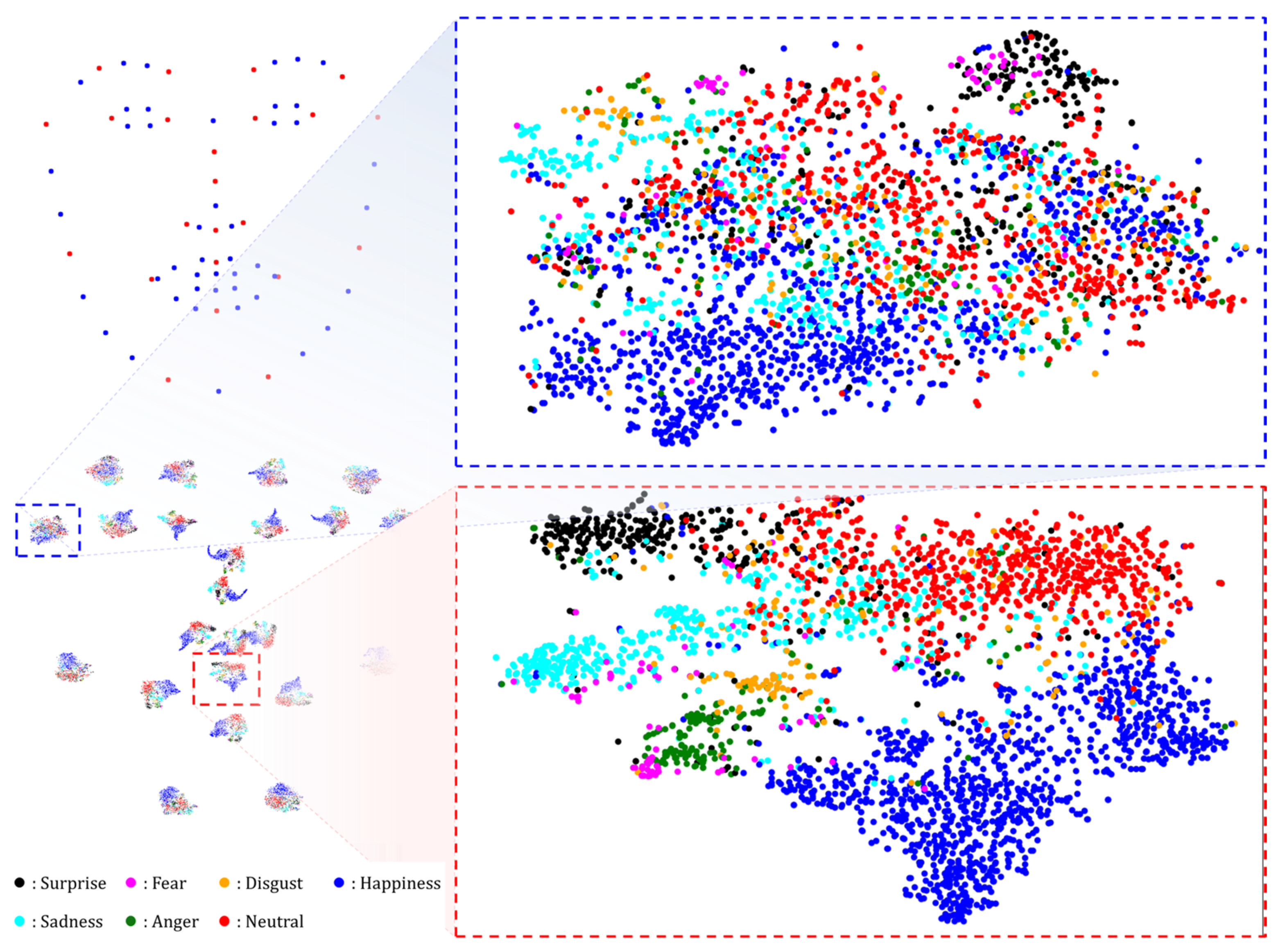
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, C.; Mendieta, M.; Chen, C. POSTER: A Pyramid Cross-Fusion Transformer Network for Facial Expression Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Paris, France, 2–6 October 2023; pp. 3146–3155. [Google Scholar]
- Mao, J.; Xu, R.; Yin, X.; Chang, Y.; Nie, B.; Huang, A.; Wang, Y. Poster++: A simpler and stronger Facial Expression Recognition network. Pattern Recognit. 2024, 148, 110951. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Ling, X.; Deng, W. Learn from all: Erasing attention consistency for noisy label facial expression recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022; pp. 418–434. [Google Scholar]
- Zhao, Z.; Liu, Q.; Zhou, F. Robust lightweight Facial Expression Recognition network with label distribution training. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), Online, 2–9 February 2021; Volume 35, pp. 3510–3519. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef]
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2852–2861. [Google Scholar]
- Barsoum, E.; Zhang, C.; Ferrer, C.C.; Zhang, Z. Training deep networks for Facial Expression Recognition with crowd-sourced label distribution. In Proceedings of the 18th ACM International Conference on Multimodal Interaction (ICMI), Tokyo, Japan, 12–16 November 2016; pp. 279–283. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Wang, J.; Feng, Z.; Ning, X.; Lin, Y.; Chen, B.; Jia, Z. Two-stream Dynamic Heterogeneous Graph Recurrent Neural Network for Multi-label Multi-modal Emotion Recognition. IEEE Trans. Affect. Comput. 2025, 1–14. [Google Scholar] [CrossRef]
- Li, Y.; Wang, M.; Gong, M.; Lu, Y.; Liu, L. FER-former: Multimodal Transformer for Facial Expression Recognition. IEEE Trans. Multimed. 2024, 27, 2412–2422. [Google Scholar] [CrossRef]
- Li, H.; Niu, H.; Zhu, Z.; Zhao, F. Cliper: A unified vision-language framework for in-the-wild facial expression recognition. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME), Niagara Falls, ON, Canada, 15–19 July 2024; pp. 1–6. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 3–7 May 2021. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Liu, X.; Vijaya Kumar, B.V.K.; You, J.; Jia, P. Adaptive deep metric learning for identity-aware facial expression recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Honolulu, HI, USA, 21–26 July 2017; pp. 20–29. [Google Scholar]
- Meng, Z.; Liu, P.; Cai, J.; Han, S.; Tong, Y. Identity-aware convolutional neural network for facial expression recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 558–565. [Google Scholar]
- Cai, J.; Meng, Z.; Khan, A.S.; Li, Z.; O’Reilly, J.; Tong, Y. Island loss for learning discriminative features in facial expression recognition. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 302–309. [Google Scholar]
- Li, Y.; Lu, Y.; Li, J.; Lu, G. Separate loss for basic and compound Facial Expression Recognition in the wild. In Proceedings of the Asian Conference on Machine Learning (ACML), Nagoya, Japan, 17–19 November 2019; pp. 897–911. [Google Scholar]
- Farzaneh, A.H.; Qi, X. Discriminant distribution-agnostic loss for Facial Expression Recognition in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Online, 14–19 June 2020; pp. 406–407. [Google Scholar]
- Farzaneh, A.H.; Qi, X. Facial expression recognition in the wild via deep attentive center loss. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Online, 5–9 January 2021; pp. 2402–2411. [Google Scholar]
- Xuefeng, C.; Huang, L. A Lightweight Model Enhancing Facial Expression Recognition with Spatial Bias and Cosine-Harmony Loss. Computation 2024, 12, 201. [Google Scholar] [CrossRef]
- Zeng, J.; Shan, S.; Chen, X. Facial expression recognition with inconsistently annotated datasets. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 222–237. [Google Scholar]
- Wang, K.; Peng, X.; Yang, J.; Lu, S.; Qiao, Y. Suppressing uncertainties for large-scale facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 14–19 June 2020; pp. 6897–6906. [Google Scholar]
- Otberdout, N.; Kacem, A.; Daoudi, M.; Ballihi, L.; Berretti, S. Deep Covariance Descriptors for Facial Expression Recognition. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; p. 159. [Google Scholar]
- Fan, Y.; Lam, J.C.K.; Li, V.O.K. Video-based emotion recognition using deeply-supervised neural networks. In Proceedings of the 20th ACM International Conference on Multimodal Interaction (ICMI), Boulder, CO, USA, 16–20 October 2018; pp. 584–588. [Google Scholar]
- Yang, H.; Ciftci, U.; Yin, L. Facial expression recognition by de-expression residue learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2168–2177. [Google Scholar]
- Acharya, D.; Huang, Z.; Pani Paudel, D.; Van Gool, L. Covariance pooling for facial expression recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR Workshops), Salt Lake City, UT, USA, 18–22 June 2018; pp. 367–374. [Google Scholar]
- Chen, Y.; Wang, J.; Chen, S.; Shi, Z.; Cai, J. Facial motion prior networks for facial expression recognition. In Proceedings of the 2019 IEEE Visual Communications and Image Processing (VCIP), Taipei, Taiwan, 1–4 December 2019; pp. 1–4. [Google Scholar]
- Fu, Y.; Wu, X.; Li, X.; Pan, Z.; Luo, D. Semantic neighborhood-aware deep facial expression recognition. IEEE Trans. Image Process. 2020, 29, 6535–6548. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Pang, C.; Zhang, B. FaceCaps for facial expression recognition. Comput. Animat. Virtual Worlds 2021, 32, e2021. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, Y.; Zhang, Y.; Wang, Y.; Song, Z. A dual-direction attention mixed feature network for facial expression recognition. Electronics 2023, 12, 3595. [Google Scholar] [CrossRef]
- Wang, K.; Peng, X.; Yang, J.; Meng, D.; Qiao, Y. Region attention networks for pose and occlusion robust facial expression recognition. IEEE Trans. Image Process. 2020, 29, 4057–4069. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 14–16 June 2020. [Google Scholar]
- Kazemi, V.; Sullivan, J. One millisecond face alignment with an ensemble of regression trees. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–27 June 2014; pp. 1867–1874. [Google Scholar]
- Kollias, D.; Cheng, S.; Ververas, E.; Kotsia, I.; Zafeiriou, S. Deep neural network augmentation: Generating faces for affect analysis. Int. J. Comput. Vis. 2020, 128, 1455–1484. [Google Scholar] [CrossRef]
- Blanz, V.; Vetter, T. Face recognition based on fitting a 3D morphable model. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1063–1074. [Google Scholar] [CrossRef]
- Chen, S.; Wang, J.; Chen, Y.; Shi, Z.; Geng, X.; Rui, Y. Label distribution learning on auxiliary label space graphs for facial expression recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 14–16 June 2020; pp. 13984–13993. [Google Scholar]
- Liu, H.; An, R.; Zhang, Z.; Ma, B.; Zhang, W.; Song, Y.; Hu, Y.; Chen, W.; Ding, Y. Norface: Improving facial expression analysis by identity normalization. In Proceedings of the European Conference on Computer Vision (ECCV), Milan, Italy, 29 September–4 October 2024; pp. 293–314. [Google Scholar]
- Ding, H.; Zhou, P.; Chellappa, R. Occlusion-adaptive deep network for robust facial expression recognition. In Proceedings of the 2020 IEEE International Joint Conference on Biometrics (IJCB), Houston, TX, USA, 28 September–1 October 2020; pp. 1–9. [Google Scholar]
- Chen, Y.; Li, J.; Shan, S.; Wang, M.; Hong, R. From static to dynamic: Adapting landmark-aware image models for Facial Expression Recognition in videos. IEEE Trans. Affect. Comput. 2024, 15, 4589–4599. [Google Scholar] [CrossRef]
- Chen, C. PyTorch Face Landmark: A Fast and Accurate Facial Landmark Detector. 2021. Available online: https://github.com/cunjian/pytorch_face_landmark (accessed on 24 October 2023).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.-H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the 20th International Conference of the Neural Information Processing (ICONIP 2013), Daegu, Republic of Korea, 3–7 November 2013; Proceedings, Part III 20. Springer: Daegu, Republic of Korea, 2013; pp. 117–124. [Google Scholar]
- So, J.; Han, Y. 3D face alignment through fusion of head pose information and features. Image Vis. Comput. 2024, 151, 105253. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In Proceedings of the 14th European Conference of the Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Amsterdam, The Netherlands, 2016; pp. 87–102. [Google Scholar]
- Foret, P.; Kleiner, A.; Mobahi, H.; Neyshabur, B. Sharpness-aware Minimization for Efficiently Improving Generalization. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, 3–7 May 2021. [Google Scholar]
- Kwon, J.; Kim, J.; Park, H.; Choi, I.K. ASAM: Adaptive Sharpness-Aware Minimization for Scale-Invariant Learning of Deep Neural Networks. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual Event, 18–24 July 2021; pp. 5905–5914. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations (ICLR)—Poster Session, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Li, H.; Wang, N.; Ding, X.; Yang, X.; Gao, X. Adaptively learning facial expression representation via cf labels and distillation. IEEE Trans. Image Process. 2021, 30, 2016–2028. [Google Scholar] [CrossRef] [PubMed]
- Wen, Z.; Lin, W.; Wang, T.; Xu, G. Distract your attention: Multi-head cross attention network for facial expression recognition. Biomimetics 2023, 8, 199. [Google Scholar] [CrossRef] [PubMed]
- Shi, J.; Zhu, S.; Wang, D.; Liang, Z. ARM: A lightweight module to amend facial expression representation. Signal Image Video Process. 2023, 17, 1315–1323. [Google Scholar] [CrossRef]
- Xue, F.; Wang, Q.; Guo, G. Transfer: Learning relation-aware facial expression representations with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Online, 10 March 2021; pp. 3601–3610. [Google Scholar]
- Bohi, A.; Boudouri, Y.E.; Sfeir, I. A novel deep learning approach for facial emotion recognition: Application to detecting emotional responses in elderly individuals with Alzheimer’s disease. Neural Comput. Appl. 2024, 36, 8483–8501. [Google Scholar] [CrossRef]
- Fölster, M.; Hess, U.; Werheid, K. Facial age affects emotional expression decoding. Front. Psychol. 2014, 5, 30. [Google Scholar] [CrossRef] [PubMed]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Ridnik, T.; Ben-Baruch, E.; Noy, A.; Zelnik, L. ImageNet-21K Pretraining for the Masses. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, Virtual Event, 22–29 September 2021; Volume 1. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | AffectNet | RAF-DB | FERPlus |
|---|---|---|---|
| Initial Learning Rate | 1.0 × 10−6 | 5.0 × 10−6 | 5.0 × 10−6 |
| Epoch | 50 | 200 | 200 |
| Landmark Perturbation | 0.05 | 0.10 | 0.5 |
| Random Erasing Scale | (0.05, 0.05) | (0.02, 0.1) | (0.05, 0.05) |
| Method | Accuracy (%) | |||
|---|---|---|---|---|
| AffectNet-7 | AffectNet-8 | RAF-DB | FERPlus | |
| KTN [53] | 63.97 | - | 88.07 | 90.49 |
| DAN [54] | 65.69 | 62.09 | 89.70 | - |
| EAC [3] | 65.32 | - | 90.35 | 89.64 |
| ARM [55] | 65.20 | 61.33 | 90.42 | - |
| TransFER [56] | 66.23 | - | 90.91 | 90.83 |
| LFNSB [20] | 66.57 | 63.12 | 91.07 | - |
| S2D [40] | 66.42 | 63.76 | 92.21 | 91.01 |
| EmoNeXt [57] | 67.46 | 64.13 | - | - |
| POSTER++ [2] | 67.49 | 63.77 | 92.21 | - |
| DDAMFN [30] | 67.03 | 64.25 | 91.35 | 90.74 |
| Norface [38] | 68.69 | - | 92.97 | - |
| NKF(Ours) | 68.17 | 64.87 | 93.16 | 91.44 |
| S2D † [40] | - | - | 92.57 (+0.36) | 91.17 (+0.16) |
| NKF † (Ours) | - | - | 94.04 (+0.88) | 91.66 (+0.22) |
| Data | Method | Accuracy (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Neu | Hap | Sad | Sur | Fea | Dis | Ang | Con | Avg | ||
| Aff7 | KTN [53] | 66.60 | 86.80 | 60.80 | 55.20 | 64.00 | 60.00 | 54.40 | - | 63.97 |
| ARM [55] | 65.00 | 87.00 | 64.00 | 61.00 | 62.00 | 53.00 | 64.00 | - | 65.20 | |
| LFNSB [20] | 68.79 | 87.50 | 69.44 | 66.67 | 60.71 | 50.00 | 57.89 | - | 65.86 | |
| POSTER++ [2] | 65.40 | 89.40 | 68.00 | 66.00 | 64.20 | 55.40 | 65.00 | - | 67.45 | |
| DDAMFN [30] | 66.20 | 87.20 | 66.40 | 63.80 | 66.00 | 56.60 | 63.00 | - | 67.03 | |
| NKF (Ours) | 64.40 | 86.40 | 65.80 | 66.20 | 68.00 | 64.20 | 62.20 | - | 68.17 | |
| Aff8 | ARM [55] | 63.00 | 86.00 | 64.00 | 61.00 | 62.00 | 52.00 | 63.00 | 40.00 | 61.33 |
| LFNSB [20] | 52.38 | 82.35 | 68.75 | 80.00 | 62.50 | 44.44 | 46.15 | 57.14 | 61.71 | |
| POSTER++ [2] | 60.60 | 76.40 | 66.80 | 65.60 | 63.00 | 58.00 | 60.20 | 59.52 | 63.76 | |
| DDAMFN [30] | 57.80 | 81.80 | 63.00 | 65.60 | 64.20 | 60.00 | 62.00 | 59.60 | 64.25 | |
| NKF (Ours) | 58.40 | 78.40 | 65.00 | 65.00 | 67.00 | 63.20 | 62.20 | 59.72 | 64.87 | |
| RAF | KTN [53] | 88.53 | 94.60 | 87.24 | 83.28 | 68.92 | 65.62 | 81.48 | - | 81.38 |
| ARM [55] | 97.90 | 95.40 | 83.90 | 90.30 | 70.30 | 64.40 | 77.20 | - | 82.77 | |
| LFNSB [20] | 92.79 | 96.71 | 87.24 | 87.84 | 67.57 | 74.38 | 87.65 | - | 84.88 | |
| POSTER++ [2] | 92.06 | 97.22 | 92.89 | 90.58 | 68.92 | 71.88 | 88.27 | - | 85.97 | |
| DDAMFN [30] | 92.49 | 96.60 | 89.55 | 91.03 | 65.75 | 72.33 | 84.57 | - | 84.62 | |
| NKF(Ours) | 95.00 | 97.89 | 89.12 | 90.88 | 70.27 | 79.37 | 90.74 | - | 87.61 | |
| NKF † (Ours) | 94.12 | 97.89 | 94.56 | 93.92 | 72.97 | 76.88 | 90.74 | - | 88.73 | |
| FERPlus | KTN [48] | 92.07 | 95.85 | 81.38 | 92.96 | 57.69 | 53.33 | 90.41 | 30.77 | 74.31 |
| DDAMFN [30] | 92.77 | 96.40 | 79.42 | 92.86 | 55.29 | 62.50 | 93.23 | 26.67 | 74.89 | |
| NKF (Ours) | 93.21 | 96.86 | 82.55 | 94.70 | 56.63 | 61.11 | 90.48 | 31.25 | 75.85 | |
| NKF † (Ours) | 92.48 | 97.20 | 83.85 | 94.95 | 56.63 | 61.11 | 91.58 | 50.00 | 78.48 | |
| Attribute | Method | Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Gender | - | Male | Female | Unsure | - | - |
| NKF (Ours) | 91.83 | 93.77 | 95.98 | - | - | |
| NKF † (Ours) | 92.87 | 94.51 | 96.98 | - | - | |
| Race | - | Caucasian | African American | Asian | - | - |
| NKF (Ours) | 92.64 | 95.73 | 94.20 | - | - | |
| NKF † (Ours) | 93.32 | 97.01 | 95.86 | - | - | |
| Age | - | 0–3 | 4–19 | 20–39 | 40–69 | 70+ |
| NKF (Ours) | 96.96 | 94.24 | 92.36 | 93.23 | 86.52 | |
| NKF † (Ours) | 98.18 | 95.68 | 92.84 | 94.22 | 89.89 | |
| Method | #Param(M) | #FLOPs(G) | Accuracy (%) | ||||
|---|---|---|---|---|---|---|---|
| RAF | Aff7 | Aff8 | |||||
| TransFER [56] | 65.20 | 15.30 | 90.91 | 66.23 | - | ||
| DAN [54] | 19.72 | 2.23 | 89.70 | 65.69 | 62.09 | ||
| POSTER++ [2] | 43.70 | 8.40 | 92.21 | 67.49 | 63.77 | ||
| DDAMFN [30] | 4.11 | 0.55 | 91.35 | 67.03 | 64.25 | ||
| LFNSB [20] | 2.68 | 0.38 | 91.07 | 66.57 | 63.12 | ||
| NKF † (Ours) | Global Net. | 25.24 | 7.01 | - | - | - | |
| KF Net. | Penultimate Layer | 40.11 | 0.04 | - | - | - | |
| Others | 1.19 | 0.08 | - | - | - | ||
| All | 66.54 | 7.13 | 94.04 † | 68.17 | 64.87 | ||
| Component | Choice | |||||||
|---|---|---|---|---|---|---|---|---|
| Input | Original | ✓ | ✓ | - | - | - | - | - |
| Accurately Aligned Image | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | |
| Network | Keypoint Features | - | ✓ | - | ✓ | ✓ | ✓ | ✓ |
| KF Regularization | - | ✓ | - | - | ✓ | - | ✓ | |
| RKFA | - | ✓ | - | - | - | ✓ | ✓ | |
| Accuracy (%) | 62.94 | 64.39 | 63.97 | 64.44 | 64.59 | 64.57 | 64.87 | |
| Landmark Type | Accuracy (%) |
|---|---|
| Half, 34 landmarks | 64.51 |
| Inner, 51 landmarks | 64.52 |
| Full, 68 landmarks | 64.87 |
| Attention Type | Accuracy (%) |
|---|---|
| Without RKFA | 64.59 |
| Center point of the Feature Map | 64.69 |
| Nasal base | 64.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
So, J.; Han, Y. Facial Landmark-Driven Keypoint Feature Extraction for Robust Facial Expression Recognition. Sensors 2025, 25, 3762. https://doi.org/10.3390/s25123762
So J, Han Y. Facial Landmark-Driven Keypoint Feature Extraction for Robust Facial Expression Recognition. Sensors. 2025; 25(12):3762. https://doi.org/10.3390/s25123762
Chicago/Turabian StyleSo, Jaehyun, and Youngjoon Han. 2025. "Facial Landmark-Driven Keypoint Feature Extraction for Robust Facial Expression Recognition" Sensors 25, no. 12: 3762. https://doi.org/10.3390/s25123762
APA StyleSo, J., & Han, Y. (2025). Facial Landmark-Driven Keypoint Feature Extraction for Robust Facial Expression Recognition. Sensors, 25(12), 3762. https://doi.org/10.3390/s25123762