Abstract
The development of Facial Expression Recognition (FER) technology has significantly enhanced the naturalness and intuitiveness of human-robot interaction. In the field of service robots, particularly in applications such as production assistance, caregiving, and daily service communication, efficient FER capabilities are crucial. However, existing Convolutional Neural Network (CNN) models still have limitations in terms of feature representation and recognition accuracy for facial expressions. To address these challenges, we propose CAGNet, a novel network that combines multiscale feature aggregation and attention mechanisms. CAGNet employs a deep learning-based hierarchical convolutional architecture, enhancing the extraction of features at multiple scales through stacked convolutional layers. The network integrates the Convolutional Block Attention Module (CBAM) and Global Average Pooling (GAP) modules to optimize the capture of both local and global features. Additionally, Batch Normalization (BN) layers and Dropout techniques are incorporated to improve model stability and generalization. CAGNet was evaluated on two standard datasets, FER2013 and CK+, and the experiment results demonstrate that the network achieves accuracies of 71.52% and 97.97%, respectively, in FER. These results not only validate the effectiveness and superiority of our approach but also provide a new technical solution for FER. Furthermore, CAGNet offers robust support for the intelligent upgrade of service robots.
1. Introduction
With the rapid advancement of artificial intelligence, service robots are becoming increasingly prevalent across various domains, including companionship, daily life assistance, communication, and many others, thus becoming an integral part of human daily life [1]. For example, in healthcare settings, service robots can adapt their interaction strategies by recognizing changes in human facial expressions, providing better support to patients [2]. Similarly, in educational environments, these robots can optimize teaching strategies based on students’ facial feedback, ultimately enhancing the learning experience [3]. Consequently, to more effectively understand and respond to human emotional needs, it is essential for service robots to possess efficient Facial Expression Recognition (FER) capabilities, which enables robots to accurately capture and interpret the emotional cues conveyed through facial expressions to offer the user more personalized and empathetic services [4,5].
FER methods generally consist of three key stages: face detection, feature extraction, and classification. Among these, feature extraction is the most critical step. Accurately extracting features that genuinely reflect expression-related information is essential to improve the accuracy of FER [6]. In recent years, the extensive application of deep learning technology has greatly promoted the progress of this field. In particular, the advantages of Convolutional Neural Networks (CNNs) in automatic feature extraction have significantly improved the recognition performance [7].
Although deep learning has made remarkable progress in the field of FER, the recognition accuracy of many existing models on standard datasets still has room for improvement, especially in the recognition of complex expression changes and subtle emotional differences. Some current mainstream network structures often struggle to fully integrate local details and global information during the feature extraction process, resulting in insufficiently comprehensive expression feature representation. Therefore, how to design a network structure that can effectively enhance feature expression and improve recognition accuracy has become an important direction in current research.
To address the above issues, this paper proposes a new FER network, CAGNet. It enhances the model’s ability to recognize subtle expression changes through multi-scale feature fusion and attention mechanisms, and introduce attention mechanisms to strengthen the expressive power of key facial regions. Experimental results show that the network achieves recognition accuracy superior to existing methods on two public datasets, providing technical support for service robots to achieve more precise emotional perception.
The structure of this paper is organized as follows. Section 2 reviews relevant research works in the field of FER. Section 3 introduces the methodology and the proposed network architecture. Section 4 presents the experimental results. Section 5 discusses the experimental outcomes and their applications in robotics. Finally, Section 6 concludes the paper and outlines future research directions.
2. State-of-the-Art
Traditional FER algorithms typically rely on manually designed feature extractors including Local Binary Patterns (LBPs) [8], Histogram of Oriented Gradients (HOGs) [9], Gabor wavelet transforms [10], Haar-like features [11], and others. Researchers [12] introduced a face detection method based on Haar-like features combined with an AdaBoost cascade classifier, demonstrating relatively good detection performance for frontal face images under well-lit conditions. However, due to its dependence on manually designed features, the method’s ability to effectively capture facial expressions from multiple viewpoints requires further enhancement. Zhang et al. [13] proposed a method for multi-scale and multi-directional filtering of images. At each scale, the maximum pixel values across eight directions at each coordinate are fused to form a new feature map. Subsequently, classification was performed using histogram-based block statistics, which integrated richer features while reducing computational complexity. Traditional facial recognition research methods, although capable of achieving good results in recognition and classification, were highly dependent on handcrafted features. This not only consumed a significant amount of time and effort but also made the system’s performance heavily reliant on the choice of features. The reliance on handcrafted features led to poor system stability, as these features were susceptible to interference from external factors.
To overcome these limitations, deep learning techniques have been widely adopted in the field of FER in recent years. Deep learning simplifies the feature extraction process and removes the need for manual features design by automating the process of learning high-level feature representations from raw data. In particular, CNN is capable of automatically capturing both local and global features in images [14]. Through multiple layers of convolution and pooling operations, CNN progressively extracts more abstract feature representations. Examples of deep neural network models that have been widely used include AlexNet [15], VGGNet [16], GoogLeNet [17], ResNet [18], and DenseNet [19]. Furthermore, the introduction of Batch Normalization (BN) layers, dropout layers [20,21], and regularization techniques into the CNN architecture can further enhance the model’s performance and generalization capabilities, making it better suited for complex application scenarios. Zhang et al. [22] proposed a novel FER algorithm based on an improved residual neural network. By designing a residual neural network and introducing the Mish activation function and Inception module to extract deep features, significant performance improvements have been achieved on multiple datasets. Xie et al. [23] introduced a deep residual network model that combined attention mechanisms with deformable convolutions. The model embedded position-aware attention mechanisms within residual blocks and incorporated deformable convolutions at both input and output layers, enhancing the capability to extract features from different positions in the image. Liang et al. [24] proposed a lightweight FER method that combined an improved CNN with channel weighting. The method used a neural network architecture that combined standard and depthwise separable convolutions, and employed a Global Average Pooling (GAP) layer as the output layer. By introducing the Squeeze-and-Excitation (SE) module for channel weighting, the accuracy of the network model was enhanced. Zhang et al. [25] enhanced the traditional VGG network by adding BN layers to accelerate convergence and improve generalization. The model was validated on four datasets and achieved excellent results. Zhao et al. [26] presented a lightweight FER model based on knowledge distillation. This model greatly increased the accuracy of the lightweight student model by optimizing the distillation loss function. Guo et al. [27] proposed an efficient self-healing network model, which performed linear gather classification for label rectification after fusing features by using a multi-scale attention method and capturing and weighting facial expression regions. Yang et al. [28] proposed a robust driver emotion recognition method based on feature separation. This method can effectively overcome the influence of individual differences and light changes through partial feature exchange and multi-loss constraint mechanisms, and has performed excellently on both self-built and public datasets. Chudasama et al. [29] presented a multimodal fusion network for dialog emotion recognition, which integrates text, audio, and visual features through a multi-head attention fusion layer, introduces a novel feature extractor and adaptive margin triplet loss to optimize feature learning, and designs a weighted facial expression model to combine scene and facial information. On multimodal datasets, the weighted average F1 score of this model outperforms the existing methods.
Although deep learning has made remarkable progress in the field of FER, such as improving feature extraction and classification effects through models like CNN and Recurrent Neural Networks (RNNs), these technologies still face problems such as complex models and low accuracy. Meanwhile, simple cascade structures may ignore the complex interactions between high-level and low-level features, making it difficult to capture subtle differences in expressions. Therefore, exploring more efficient network structures and optimization strategies to overcome these limitations has become an important direction in current research [30].
This paper introduces CAGNet, a novel network that combines multiscale feature aggregation and attention mechanisms to enhance FER. CAGNet employs a hierarchical convolutional architecture to effectively extract multi-scale features from input images. By integrating Convolutional Block Attention Module (CBAM) and GAP modules, it optimizes the capture of both local and global features, improving sensitivity to subtle expression differences. BN layers and Dropout techniques are also incorporated to enhance model stability and generalization, preventing overfitting.On the FER Challenge 2013 (FER2013) and Extended Cohn-Kanade dataset (CK+) standard datasets, CAGNet achieves recognition accuracies of 71.52% and 97.97%, respectively, outperforming traditional network models and other related methods.Furthermore, the FER algorithm has been deployed on service robots, enabling them to perceive users’ emotional states. Combined with the MediaPipe Pose [31] algorithm for real-time human posture detection, this system enables intelligent control of robotic movement.
3. Methodology
3.1. CBAM Attention Mechanism
When observing objects, humans tend to selectively focus on more important information while ignoring less relevant parts, a phenomenon known as attention. In deep learning, the introduction of attention mechanisms allows models to concentrate on key information and ignore less important details, thereby emphasizing and retaining the features that are crucial for the task. This paper primarily adopts a hybrid attention mechanism in computer vision, where the CBAM is one of the most representative [32]. CBAM integrates channel attention and spatial attention mechanisms in a sequential manner, allowing for a comprehensive analysis of the input feature maps across both channel and spatial dimensions. This ensures that feature regions receive thorough attention. The network architecture is depicted in Figure 1. where “Input Feature” and “Refined Feature” represent the input feature map and the refined feature map, respectively.
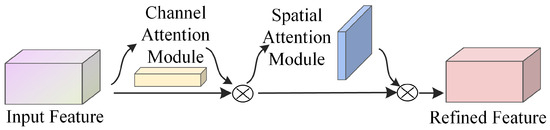
Figure 1.
CBAM network structure.
The channel attention mechanism operates by assigning varying weights to individual channels, with higher weights signifying greater importance for a given channel. As shown in the structure of the channel attention mechanism in Figure 2, an input feature map A of dimensions is compressed along the spatial dimensions using both Average Pooling (AvgPool) and Maximum Pooling (MaxPool), resulting in two spatial descriptor features, and , each of size . Following dimensionality reduction and expansion, these compressed feature descriptors are input into a single hidden layer Multilayer Perceptron (MLP) to extract weight vectors that represent the relative relevance of each channel. The two feature vectors processed by the MLP are summed up, and the resulting vector is passed through a Sigmoid activation function (denoted as for the Sigmoid operation) to produce the channel attention weight coefficients . The channel-attended feature map is then created by multiplying these channel attention weight coefficients element-wise by the original input feature map.
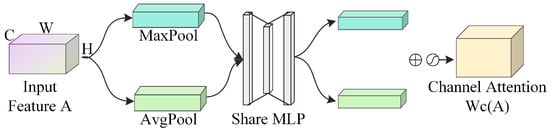
Figure 2.
Channel attention mechanism network structure.
In the FER task, employing a spatial attention mechanism can effectively retain the key information in facial expression images that are affected by rotation, distortion, and scale changes, thereby mitigating the negative impacts brought about by these transformations. As depicted in Figure 3, the network structure of the spatial attention mechanism processes the input feature map through Avgpool and Maxpool operations along the channel dimension, generating two efficient feature descriptors, and . These descriptors are then concatenated horizontally and subjected to a convolution operation using a kernel f to capture spatial contextual information. The output after convolution is passed through a Sigmoid activation function (denoted as for the Sigmoid operation), producing the spatial attention weight coefficients . Lastly, the input feature map is multiplied by the spatial attention weight coefficients to produce the spatial attention feature map .
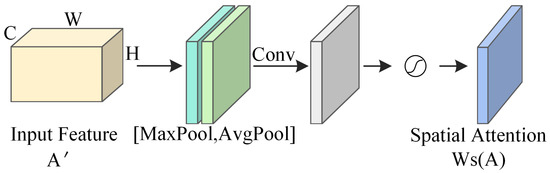
Figure 3.
Network architecture of the spatial attention mechanism.
3.2. Global Average Pooling
In CNNs, GAP is a technique that effectively reduces model parameters, avoids overfitting, and improves generalization ability [33]. Different from traditional Fully Connected Layers (FC), GAP generates a fixed-length vector by calculating the pixel average value of each feature map channel. It not only retains key feature information, but also makes the model more lightweight and easier to train. Its parameters are adaptively determined by the spatial dimensions of input feature maps, eliminating the need for manual setting of H and W, which shows good structural simplicity and generalization performance [34]. As shown in Figure 4, when a feature map of size is input into the network, GAP computes the average of all pixel values for each channel, resulting in a vector. Tasks like image classification, object identification, and semantic segmentation are made easier by the fact that this vector can be used directly for classification tasks or routed through an FC or Softmax layer to obtain the final classification output.
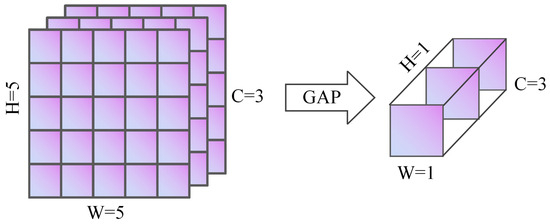
Figure 4.
Schematic Diagram of global average pooling.
3.3. The Proposed Network
Every convolutional module in CAGNet uses a multi-layered structure, with a stack of two convolutional layers coming first, followed right away by a BN layer and a ReLU non-linear activation function. This architecture improves the model’s capacity for learning while guaranteeing that the data stays stable throughout transmission. L2 regularization, which lessens the size of the model’s weights and avoids overfitting, is integrated into both the convolutional and FC to enhance the model’s capacity for generalization. The data undergoes pooling operations after the two convolutional layers, batch normalization, and activation, which helps reduce computational complexity while retaining essential features. The CBAM attention mechanism is introduced after the first and fourth convolutional modules. This mechanism assigns weights to feature maps along both the spatial and channel dimensions, enabling the model to focus on emotion classification while filtering out irrelevant background information or distracting factors. Subsequently, global average pooling is applied to the feature maps, followed by FC and Dropout layers to refine feature extraction and classification. The Dropout rate is set to 0.1 after the activation function and 0.5 after the FC. The extracted features are then passed through a Softmax layer, which converts the features into probability distributions for each emotion category. Through the Softmax transformation, the model produces a probability vector, where each element represents the confidence level for the corresponding emotion category. Accurate facial emotion identification and classification are achieved by using the index of the maximum value in the output vector to determine the emotion state conveyed by the input facial image. Figure 5 depicts the architecture of CAGNet.
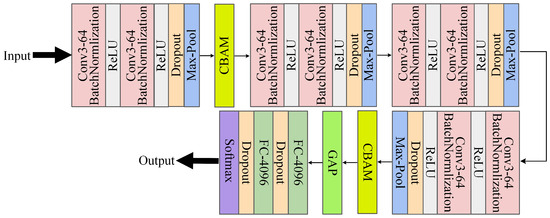
Figure 5.
Architecture of CAGNet.
In this architecture, multi-layer convolution and pooling are applied to process 48 × 48 grayscale input images. After each 3 × 3 convolutional layer and 2 × 2 pooling layer, the feature map size is halved sequentially. Following multiple convolution and pooling operations, the feature map dimensions are reduced from 48 × 48 to 24 × 24, then to 12 × 12, followed by 6 × 6, and finally to 3 × 3. GAP compresses the 3 × 3 feature map into a one-dimensional vector, which serves as input to the FC. The final emotion category probabilities are output through the Softmax layer. Table 1 provides a detailed breakdown of the entire processing flow from the input data to the final probability predictions of the emotion category in CAGNet.

Table 1.
Detail structure of CAGNet.
4. Results
4.1. Experimental Data
To validate the effectiveness of the proposed CAGNet, which is a FER model based on multiscale feature aggregation and attention mechanisms, this study conducted experiments using the public datasets FER2013 [35] and CK+ [36].
The images in the FER2013 dataset were obtained through Google and consist of facial images captured in natural settings, which were then uploaded to the internet. Consequently, the images may have issues such as occlusions, watermarks, variations in pose, and class imbalance. Using these datasets can demonstrate the robustness of the model. There are 35,887 photos of facial expressions in the FER2013 dataset, of which 28,709 are in the training set and 3589 are in each of the validation and test sets. As shown in Figure 6, it includes seven different types of facial expressions: Anger, Neutral, Sad, Disgust, Happy, Fear, and Surprise.

Figure 6.
Examples from the FER2013 Dataset. Adapted the permission from ref. [35].
The CK+ dataset is widely utilized and consists of images captured in a controlled laboratory setting, ensuring minimal interference from external factors. It contains 593 image sequences from 123 individuals, with 327 sequences labeled according to facial expressions. For this study, the last three frames from each sequence were selected, yielding a total of 981 expression images, which were subsequently resized to 48 × 48 pixels. The CK+ dataset includes seven expression labels: Anger, Disgust, Sad, Surprise, Fear, Happy, and Contempt, as shown in Figure 7.

Figure 7.
Examples from the CK+ Dataset. Adapted the permission from ref. [36].
Image preprocessing was employed on both datasets to improve the trained model’s capacity for generalization and reduce the possibility of overfitting brought on by insufficient data. The images from the FER2013 and CK+ datasets were normalized to 48 × 48 pixel grayscale images, and the labels were one-hot encoded. Data augmentation techniques, including random scaling, horizontal and vertical translations, random rotations, and horizontal flipping, were applied to the images. The specific data augmentation strategies and their parameter configurations are shown in Table 2.
Table 2.
Data augmentation strategies and their parameter configurations.
4.2. Experimental Procedure
The experiments in this study were conducted on a 64-bit Windows 10 operating system, using the deep learning framework TensorFlow-GPU 2.6.2 and the Python 3.7.16 interpreter. The hardware environment consisted of an AMD Ryzen Threadripper PRO 3945WX 12-Core CPU, an NVIDIA RTX A6000 GPU, and 64GB of RAM.
A batch size of 128 was used for training on the FER2013 dataset, and the model was trained across 300 epochs. The Stochastic Gradient Descent (SGD) optimizer with momentum was used to update the network parameters, and a value of 0.9 for momentum was chosen. A basic learning rate scheduler with an initial learning rate of 0.01 was incorporated into the Reduce Learning Rate on Plateau (RLRP) approach. For five consecutive epochs, the learning rate was lowered by a factor of 0.75 if the validation accuracy did not increase. In order to stop training if the validation loss did not improve after ten consecutive epochs, an EarlyStopping callback was also added. A batch size of 32 was employed for training on the CK+ dataset, and the model was trained across 200 epochs. An 8:2 ratio was used to randomly divide the dataset into training and testing sets. Additionally, the SGD optimizer with momentum was used, keeping the initial learning rate at 0.01 and the momentum value at 0.9.
4.3. Experimental Analysis and Comparison
Experimental Evaluation
The confusion matrix is used to assess CAGNet’s capacity to recognize different kinds of facial expressions. This matrix displays the expected labels on the horizontal axis and the actual labels on the vertical axis, while other cells show misclassifications between distinct expressions, the value at the intersection of a predicted and a true label represents the accuracy for that specific label. Therefore, the values along the main diagonal of the confusion matrix correspond to the correct classification rates for each expression. To enhance visual clarity, the depth of the blue color is used to represent the level of accuracy, with darker shades indicating higher accuracy. In general, higher values along the diagonal suggest lower recognition errors, while higher values off the diagonal indicate greater misclassification and higher recognition errors by the model.
Based on the FER2013 dataset, this study compares the FER outcomes of CAGNet with those of the traditional VGG16 network, as illustrated in Figure 8. The results indicate that while the VGG16 network achieved an overall recognition accuracy of 67.93%, CAGNet reached an accuracy of 71.52%. Through this comparison, it is evident that the recognition accuracy for four categories of expressions Disgust, Fear, Sad, and Surprise have been notably improved. Specifically, the improvements for Disgust, Fear, Sad, and Surprise expressions are 18%, 8%, 13%, and 10%, respectively, while the accuracy for the Happy expression remains consistent. Furthermore, Angry expressions are prone to being misclassified as Sad, Netural or Fear. Disgust expressions tend to be misclassified as Angry. Fear expressions are likely to be incorrectly identified as Sad, Angry or Netural. Happy expressions have a tendency to be misrecognized as Neutral. Sad expressions can be misinterpreted as Neutral or Fear. Surprise expressions are often misclassified as Fear. Lastly, Neutral expressions are susceptible to being misidentified as Sad. In summary, CAGNet not only enhances the overall recognition accuracy but also reduces confusion errors for specific expression categories, namely Disgust, Fear, Sad, and Surprise, thereby demonstrating superior performance over the VGG16 network.
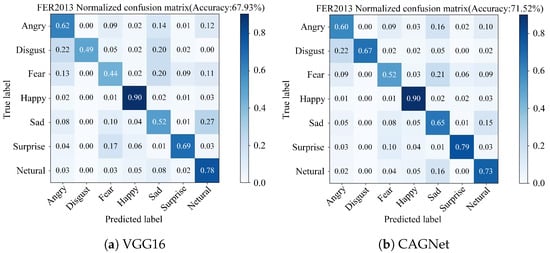
Figure 8.
Confusion matrix for the FER2013 dataset. (a) VGG16. (b) CAGNet.
Based on the CK+ dataset, the traditional VGG16 network achieved an overall recognition accuracy of 94.24%, whereas CAGNet reached an accuracy of 97.97%. As illustrated in Figure 9, the comparison reveals improvements in the recognition accuracy for Fear, Happy, Sad, Surprise, and Contempt expressions. Notably, the highest increases were observed for Sad and Contempt expressions, both of which improved by 20%. Meanwhile, the accuracy for Angry and Disgust expressions remained consistent. In terms of confusion across different expressions, Angry expressions are prone to being misclassified as Sad or Contempt, and Fear expressions are likely to be misclassified as either Contempt. Importantly, there are no confusion errors for Disgust, Fear, Happy, Sad, Surprise and Contempt expressions, indicating perfect classification within these categories. In summary, the proposed network not only enhances the overall recognition accuracy but also significantly reduces confusion errors for specific expression categories, namely Fear, Happy, Sad, Surprise and Contempt. This demonstrates the superior performance of CAGNet over the VGG16 network in terms of both accuracy and reduced misclassification rates across key expression categories.
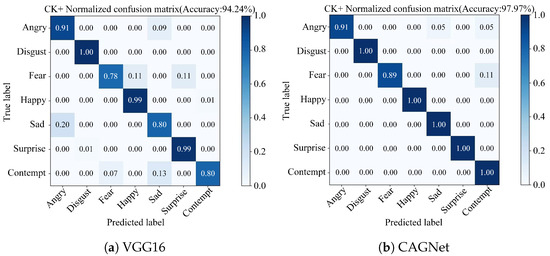
Figure 9.
Confusion matrix for the CK+ dataset. (a) VGG16. (b) CAGNet.
5. Discussion
On the FER2013 dataset, the recognition accuracy for Happy expressions reaches as high as 90%, whereas the accuracy for Fear expressions is only 52%. This disparity is primarily attributed to the imbalance in the number of data samples within the test set and the lower quality of some samples. For instance, categories such as Happy and Neutral have significantly more samples compared to other categories. Additionally, the similarity between different expressions further complicates the model’s prediction performance. On the CK+ dataset, the highest recognition accuracies are achieved for Disgust, Happy, Sad, Surprise, and Contempt expressions, while the recognition performance for Angry and Fear expressions remains relatively poor. The subtle differences between these expressions make them difficult to distinguish, and potential imbalances or variations in sample quality within the dataset also impact the model’s performance.Overall, CAGNet consistently outperforms the traditional VGG16 network. This significant improvement can be attributed to several key enhancements: the introduction of an attention mechanism to focus on the most relevant features, the incorporation of BN layers to stabilize and accelerate the training process, and the addition of Dropout layers to reduce dependency on individual neurons and prevent overfitting, thereby enhancing the model’s generalization ability. Furthermore, GAP is employed to effectively reduce the number of model parameters, avoid overfitting, and strengthen the model’s generalization capability.
5.1. Comparison of Different Attention Mechanisms
Employing experiments on both the FER2013 and CK+ datasets, we performed a comparison study employing a consistent baseline network design to better examine the effects of various attention processes on model performance. We evaluated the performance of four attention mechanisms: Efficient Channel Attention Network (ECANet) [37], ClassAgnostic Segmentation Networks (CANet) [38], Squeeze-and-Excitation Networks (SENet) [39], and CBAM. The accuracy rates of these attention mechanisms on the two datasets are presented in Table 3. The experimental results show that ECANet achieved accuracy rates of 68.20% on FER2013 and 96.27% on CK+, CANet achieved accuracy rates of 67.98% on FER2013 and 95.93% on CK+, SENet achieved accuracy rates of 68.54% on FER2013 and 96.95% on CK+, and CBAM achieved accuracy rates of 71.52% on FER2013 and 97.97% on CK+. Although ECANet, CANet, and SENet also demonstrate good performance, they primarily enhance features in a single dimension (such as channel or spatial), and thus fail to fully exploit the interplay between different dimensions. In contrast, CBAM extracts complementary information among channels through global average pooling and max pooling operations in the channel dimension, and learns channel-wise weights using a shared network structure. In the spatial dimension, it compresses the channel information to generate a spatial attention map that highlights important regions in the image. By collaboratively enhancing feature responses in both the channel and spatial dimensions, CBAM can more comprehensively identify and strengthen semantic information in key facial regions, thereby improving the model’s ability to capture critical facial features. This leads to higher recognition accuracy, with outstanding performance on both the FER2013 and CK+ datasets.
Table 3.
Accuracy Rates of different attention mechanisms on FER2013 and CK+ datasets.
5.2. Performance of the Proposed Network Model
To validate the effectiveness and superiority of CAGNet, a comparative study was conducted on the FER2013 and CK+ datasets with current mainstream FER methods. Li et al. [40] proposed an enhanced YOLOv8 algorithm to address challenges such as the difficulty of traditional convolutional operations in capturing subtle features and the effective fusion of multi-scale features. Kumar et al. [41] proposed a Cross-Connected Convolutional Neural Network (CC-CNN) for facial feature extraction. Lin et al. [42] proposed a FER method that combines an attention mechanism with the ShuffleNetV2 network. Boughida et al. [43] used Gabor filters and a genetic algorithm for expression recognition. Zhang et al. [22] proposed a novel FER algorithm based on an improved residual neural network. The comparison results are shown in Table 4. The model performance on the FER2013 dataset is generally lower than that on the CK+ dataset. This is mainly due to the fact that FER2013 contains low-resolution images, which may lack sufficient detail to distinguish subtle expression changes. Additionally, the FER2013 dataset suffers from class imbalance, with some categories having significantly more samples than others, which can lead to the model being biased towards the majority classes during training. In contrast, the CK+ dataset provides higher-resolution images and has a more balanced distribution across categories, resulting in generally better performance on these dataset.
Table 4.
Comparison results of different facial expression recognition methods.
5.3. Expression Recognition Application
The integration of FER technology with service robots can significantly enhance the quality of human-robot interaction. By recognizing users’ facial expressions, service robots can gain a better understanding of human emotional states, enabling them to provide more empathetic and personalized services. Users communicate emotional information through their facial expressions, which are captured by cameras or other sensors and processed by the system. The system then uses interactive cognitive mechanisms to interpret the user’s emotions and respond accordingly, fostering dynamic interaction. Throughout this process, the system continuously refines its accuracy and intelligence in FER through autonomous learning and adaptive growth, ultimately achieving a more natural, efficient, and personalized collaborative experience. The relationship between FER and robot collaboration is illustrated in Figure 10.
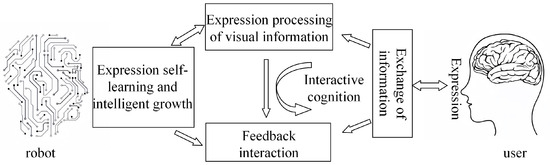
Figure 10.
This relationship diagram of FER and robot collaboration.
To enable service robots to understand and respond to users’ emotional states, this paper deploys FER algorithms onto a service robot platform and integrates them with a human pose perception module, thereby constructing an intelligent interactive system capable of both emotion perception and behavioral response. The service robot platform consists of an industrial control computer and a display terminal, serving as the core processing unit and human-machine interface. Environmental visual data captured by the camera is transmitted to the industrial computer for analysis and processing.
The system employs the MediaPipe Pose algorithm for real-time detection of human posture, extracting normalized coordinates of key body joints from the image and mapping them into the physical image space. Subsequently, a geometric averaging method is used to compute the central coordinate of the human posture, which helps determine the person’s spatial position within the image. When the horizontal offset between the human center point and the image center is less than a predefined threshold (50 pixels), the target is considered to be in the central region, and the robot receives a stop command. If the horizontal offset exceeds the threshold, left or right turning commands are generated based on the direction of the offset, enabling lateral following behavior. In the case of vertical offset beyond the threshold, a forward command is issued to guide the robot toward the user. All control instructions are transmitted to the robot’s lower-level control system via a serial communication protocol, enabling real-time parameter updates and action execution. This allows the robot to dynamically track the user’s position and perform autonomous motion control. A flowchart of the robot’s tracking control algorithm is shown in Figure 11.
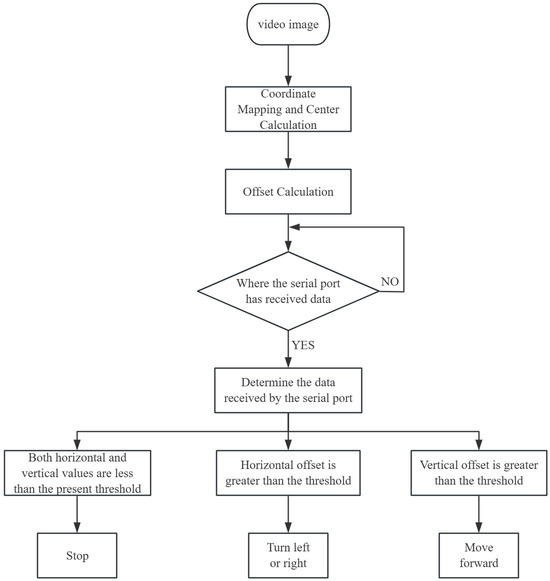
Figure 11.
Robot tracking and control algorithm flowchart.
When the service robot detects a user’s facial expressions, it can perceive the user’s emotional state based on the recognition results. By integrating this capability with a human posture perception module for real-time localization and tracking, it further enhances the intelligence and humanization of human-robot interaction. Figure 12 showcases the tracking detection effect diagram of the service robot platform. The FER algorithm proposed in this paper cannot directly participate in the underlying force control of physical human-computer interaction, but it can serve as a high-level emotional auxiliary signal to enhance the system’s ability to understand users’ emotions. During the trajectory learning process based on Dynamic Movement Primitives, inputting emotional features as contextual information helps robots formulate differentiated response strategies according to different emotional states, thereby improving the interaction experience and safety in human-robot collaboration.The recognition performance of the current model may degrade under complex lighting conditions or partial facial occlusions. Meanwhile, its computational requirements also impose higher demands on resource-constrained edge devices.

Figure 12.
Tracking detection effect diagram of the service robot platform.
6. Conclusions
In summary, this paper proposes CAGNet, a novel network that integrates visual techniques and combines multiscale feature aggregation with attention mechanisms, aiming to meet the demand for efficient expression recognition in service robots for production, companionship, and daily life service interactions. CAGNet employs a hierarchical convolutional structure, optimizing the capture of both local and global features through the integration of CBAM and GAP modules. Additionally, CAGNet incorporates BN layers and Dropout techniques to enhance its stability and generalization capabilities. Through rigorous evaluation on the FER2013 and CK+ standard datasets, the experimental results confirm the effectiveness of CAGNet, achieving recognition accuracies of 71.52% and 97.97%, respectively. This not only contributes a novel technical solution to the field of FER but also lays a solid technological foundation for the intelligent upgrade of service robots. In the future, more lightweight network architectures can be designed to adapt to embedded robotic platforms. Additionally, introducing multimodal information (such as speech and posture) can enhance the depth of emotional understanding and improve the model’s adaptability to complex scenarios with lighting changes and facial occlusions.
Author Contributions
All authors contributed to the conception and design of the study. Material preparation, data collection, and analysis were carried out by D.Z., W.M. and Q.M. The first draft of the manuscript was written by W.M., and all authors provided comments on earlier versions of the manuscript. The final manuscript was reviewed and approved by D.Z. and Z.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Henan Provincial Science and Technology Project (NO. 242102211043).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the findings of this study, including the CK+ and FER2013 datasets, are openly available at http://www.jeffcohn.net/Resources/ (for CK+, accessed on 15 May 2023) and https://www.kaggle.com/datasets/msambare/fer2013 (for FER2013, accessed on 17 August 2023).
Acknowledgments
This work was supported by the Henan Provincial Science and Technology Key Project: “User Personality Recognition Technology Based on Multi-Modal Nonverbal Feature Fusion in Human-Robot Interaction for Home Service Robots” (Project No.: 242102211043). The authors express their sincere gratitude for the support provided by this project.Additionally, to improve the linguistic fluency of this manuscript, the authors utilized AI-assisted editing tools to ensure clearer and more accurate expression.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Li, H.; Xiao, X.; Liu, X.; Guo, J.; Wen, G.; Liang, P. Heuristic objective for facial expression recognition. Vis. Comput. 2023, 39, 4709–4720. [Google Scholar] [CrossRef]
- Hosney, R.; Talaat, F.M.; El-Gendy, E.M.; Saafan, M.M. AutYOLO-ATT: An attention-based YOLOv8 algorithm for early autism diagnosis through facial expression recognition. Neural. Comput. Appl. 2024, 36, 1–21. [Google Scholar] [CrossRef]
- Geng, Y.; Meng, H.; Dou, J. FEAIS: Facial emotion recognition enabled education aids IoT system for online learning. In Proceedings of the ICALT, Bucharest, Romania, 1–4 July 2022; pp. 403–407. [Google Scholar]
- Chen, L.; Wu, M.; Pedrycz, W.; Hirota, K.; Chen, L.; Wu, M.; Pedrycz, W.; Hirota, K. Weight-Adapted Convolution Neural Network for Facial Expression Recognition. In Emotion Recognition and Understanding for Emotional Human-Robot Interaction Systems; Springer: Berlin/Heidelberg, Germany, 2021; pp. 57–75. [Google Scholar]
- Putro, M.D.; Nguyen, D.L.; Jo, K.H. A fast CPU real-time facial expression detector using sequential attention network for human–robot interaction. IEEE Trans. Industr. Inform. 2022, 18, 7665–7674. [Google Scholar] [CrossRef]
- Li, J.; Jin, K.; Zhou, D.; Kubota, N.; Ju, Z. Attention mechanism-based CNN for facial expression recognition. Neurocomputing 2020, 411, 340–350. [Google Scholar] [CrossRef]
- Ge, H.; Zhu, Z.; Dai, Y.; Wang, B.; Wu, X. Facial expression recognition based on deep learning. Comput. Methods Programs Biomed. 2022, 215, 106621. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern. Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the CVPR, San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Niu, L.; Zhao, Z.; Zhang, S. Extraction method for facial expression features based on Gabor feature fusion and LBP histogram. J. Shenyang Univ. Technol 2016. [Google Scholar]
- Whitehill, J.; Omlin, C.W. Haar features for FACS AU recognition. In Proceedings of the FGR, Southampton, UK, 10–12 April 2006; p. 5. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, S.; Zhang, H.; Tong, X. Expression Recognition Based on Feature Fusion Method forDimensionality Reduction. Comput. Digit. Eng. 2015, 43, 396–399. [Google Scholar]
- Lee, D.H.; Yoo, J.H. CNN Learning Strategy for Recognizing Facial Expressions. IEEE Access 2023, 1, 70865–70872. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the CVPR, Honolulu, HI, USA, 21-26 July 2017; pp. 6526–6534. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the ICML, Lille, France, 7–9 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. JMLR 2014, 15, 1929–1958. [Google Scholar]
- Zhang, W.; Zhang, X.; Tang, Y. Facial expression recognition based on improved residual network. IET Image Process 2023, 17, 2005–2014. [Google Scholar] [CrossRef]
- Xie, S.; Li, M.; Liu, S.; Tang, X. ResNet with attention mechanism and deformable convolution for facial expression recognition. In Proceedings of the ICICSP, Shanghai, China, 24–26 September 2021; pp. 389–393. [Google Scholar]
- Liang, H.; Ying, B.; Lei, Y.; Yu, Z.; Liu, L. A CNN-improved and channel-weighted lightweight human facial expression recognition method. J. Image Graph. 2022, 27, 3491–3502. [Google Scholar] [CrossRef]
- Zhang, S.; Wang, W. Research on Facial Expression Recognition Based on Improved VGG Model. Mod. Inf. Technol. 2021, 5, 100–103. [Google Scholar] [CrossRef]
- Zhao, J.; Feng, X.; Cao, W.; Pei, T.; Jia, W.Z.; Wang, R. T-SNet:Lightweight Facial Expression Recognition Based on Knowledge Distillation. Microelectron. Comput. 2025, 42, 38–47. [Google Scholar] [CrossRef]
- Guo, X.; Ma, N.; Liu, W.; Sun, F.; Zhang, J.; Chen, Y.; Zang, G. Expression Recognition and Interaction of Pharyngeal Swab Collection Robot. Comput. Eng. Appl. 2022, 58, 125. [Google Scholar]
- Yang, L.; Yang, H.; Hu, B.B.; Wang, Y.; Lv, C. A robust driver emotion recognition method based on high-purity feature separation. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15092–15104. [Google Scholar] [CrossRef]
- Chudasama, V.; Kar, P.; Gudmalwar, A.; Shah, N.; Wasnik, P.; Onoe, N. M2fnet: Multi-modal fusion network for emotion recognition in conversation. In Proceedings of the CVPR, New Orleans, LA, USA, 19–24 June 2022; pp. 4652–4661. [Google Scholar]
- Zhang, S.; Yang, Y.; Chen, C.; Zhang, X.; Leng, Q.; Zhao, X. Deep learning-based multimodal emotion recognition from audio, visual, and text modalities: A systematic review of recent advancements and future prospects. Expert. Syst. Appl. 2024, 237, 121692. [Google Scholar] [CrossRef]
- Sánchez-Brizuela, G.; Cisnal, A.; de la Fuente-López, E.; Fraile, J.C.; Pérez-Turiel, J. Lightweight real-time hand segmentation leveraging MediaPipe landmark detection. Virtual Real. 2023, 27, 3125–3132. [Google Scholar] [CrossRef]
- Liao, L.; Wu, S.; Song, C.; Fu, J. PH-CBAM: A parallel hybrid CBAM network with multi-feature extraction for facial expression recognition. Electronics 2024, 13, 3149. [Google Scholar] [CrossRef]
- Liu, C.; Liu, X.; Chen, C.; Wang, Q. Soft thresholding squeeze-and-excitation network for pose-invariant facial expression recognition. Vis. Comput. 2023, 39, 2637–2652. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network In Network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. Neural Netw. 2015, 64, 59–63. [Google Scholar] [CrossRef] [PubMed]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the CVPR, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the CVPR, Seattle, WA, USA, 14–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhang, C.; Lin, G.; Liu, F.; Yao, R.; Shen, C. Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning. In Proceedings of the CVPR, Long Beach, CA, USA, 16–20 June 2019; pp. 5217–5226. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the CVPR, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, W.; Wang, J.; Zhang, L.; Zeng, X.; Chen, G.; Long, H. Research on facial expression recognition based on improved YOLOv8. In Proceedings of the MVAID 2024, SPIE, Kunming, China, 26–28 April 2024; Volume 13230, pp. 323–329. [Google Scholar]
- Kumar Tataji, K.N.; Kartheek, M.N.; Prasad, M.V. CC-CNN: A cross connected convolutional neural network using feature level fusion for facial expression recognition. Multimed Tools Appl. 2024, 83, 27619–27645. [Google Scholar] [CrossRef]
- Lin, E.; Wang, F.; Tan, X. Facial expression recognition of ShuffleNetV2 combined withultra-lightweight dual attention modules. Electron. Meas. Technol. 2024, 47, 168–174. [Google Scholar] [CrossRef]
- Boughida, A.; Kouahla, M.N.; Lafifi, Y. A novel approach for facial expression recognition based on Gabor filters and genetic algorithm. Evol. Syst. Ger. 2022, 13, 331–345. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).