

Integrating Reinforcement Learning into M/M/1/K Retry Queueing Models for 6G Applications


Abstract
1. Introduction
1.1. Context & Motivation
1.2. Research Gap
1.3. Contributions of the Research Study
- Introduction of the 6G retrial queueing system: We develop a code that simulates a simple example of the RQS to address the challenges.
- Integration of RL in the 6G-RQS: We propose an RL-based decision-making model that dynamically adapts to the nature of the 6G-RQS environment and tries to adapt the service and retrial policies for optimization purposes.
- Comprehensive performance evaluation: We simulate many different scenarios across varying parameters to see the ability of the model in enhancing the service and the system efficiency.
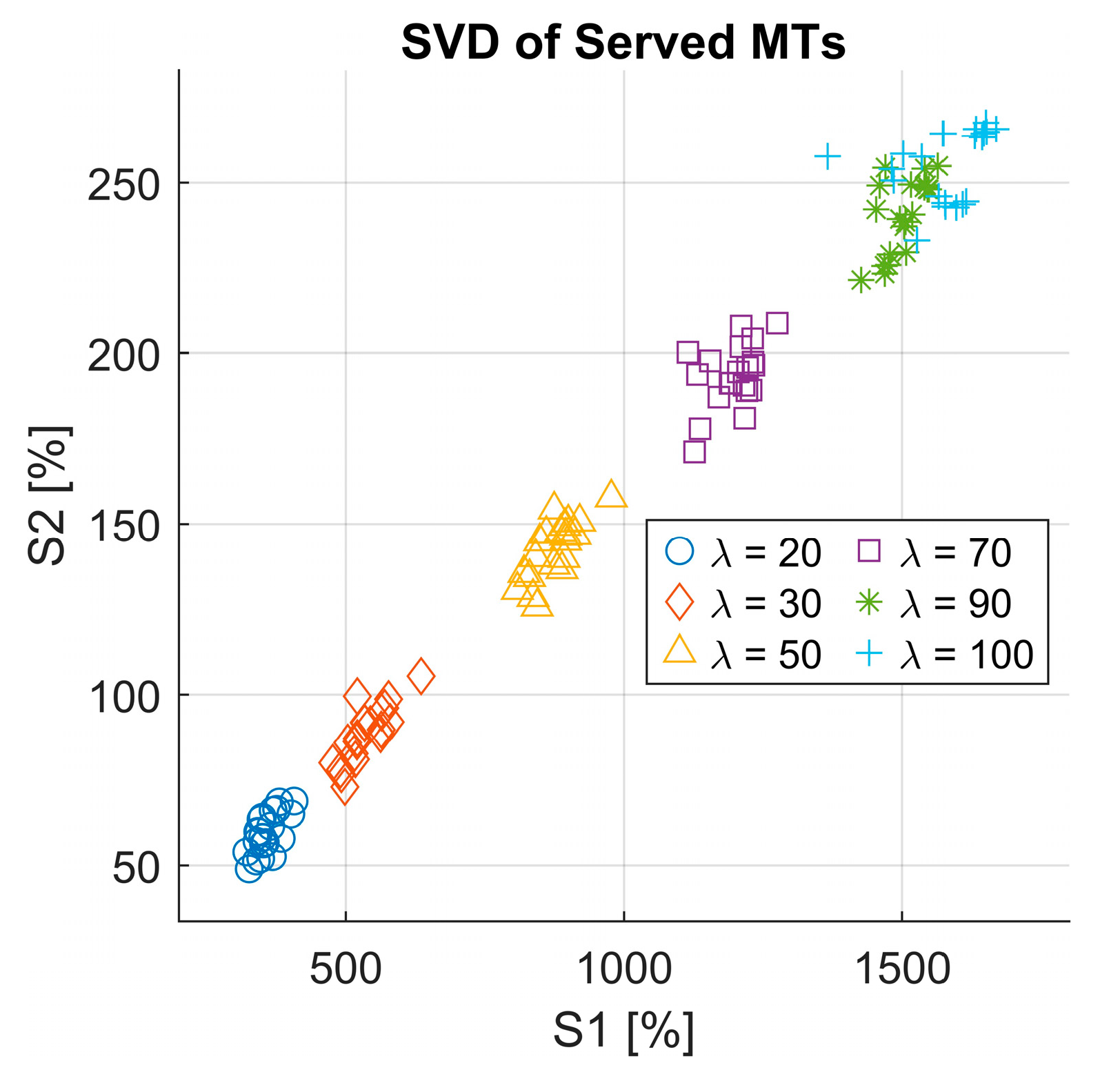
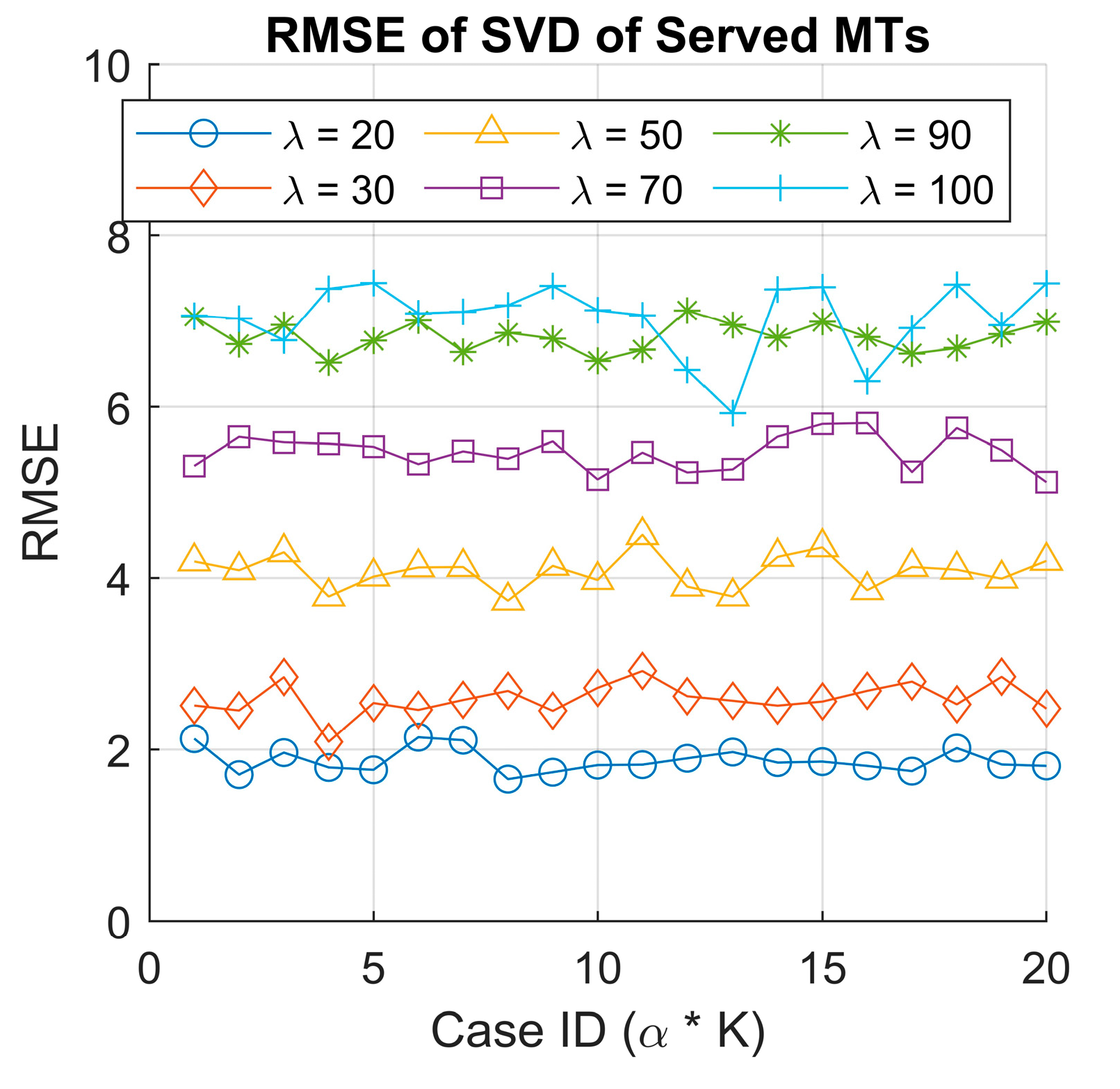
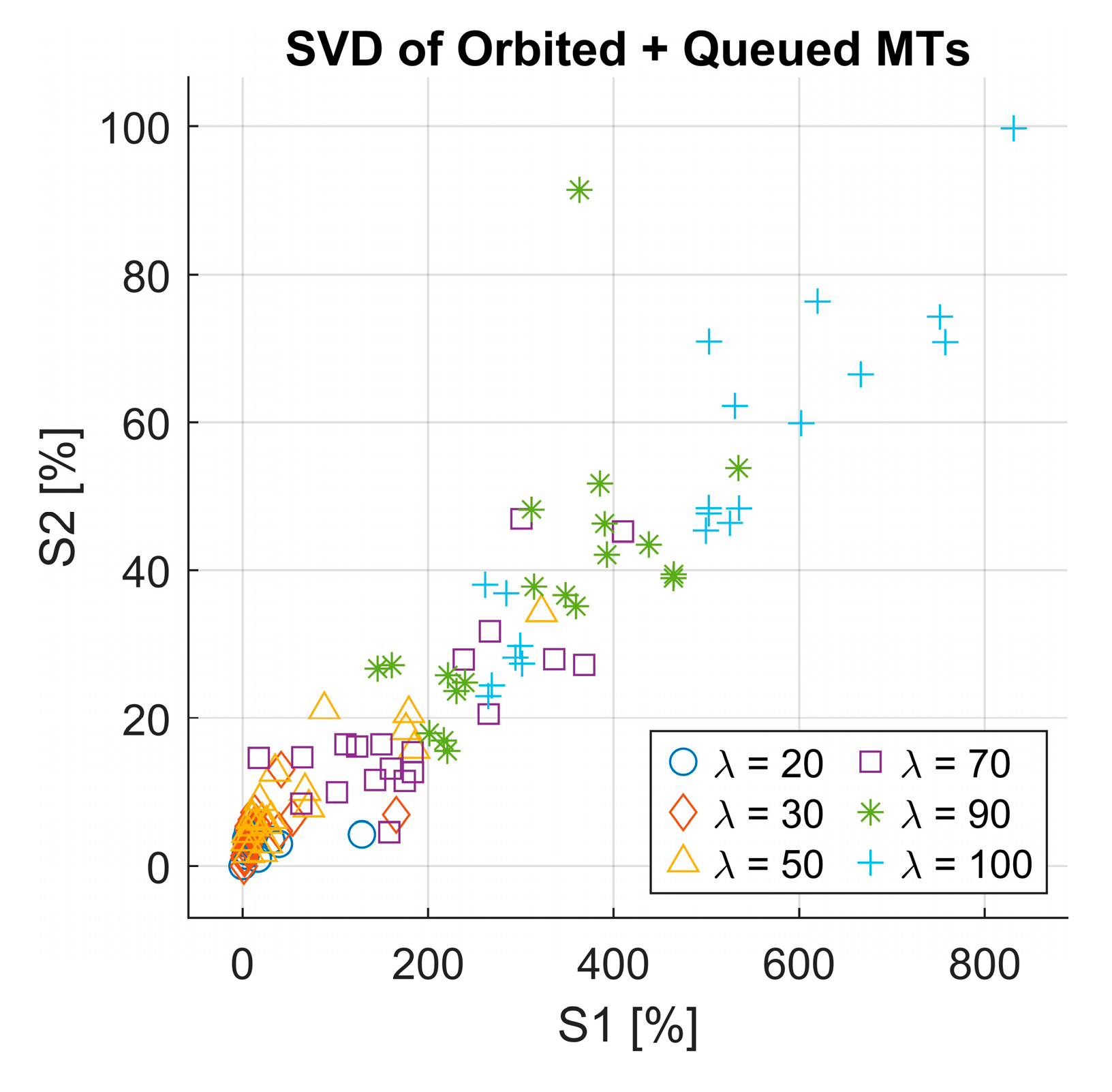
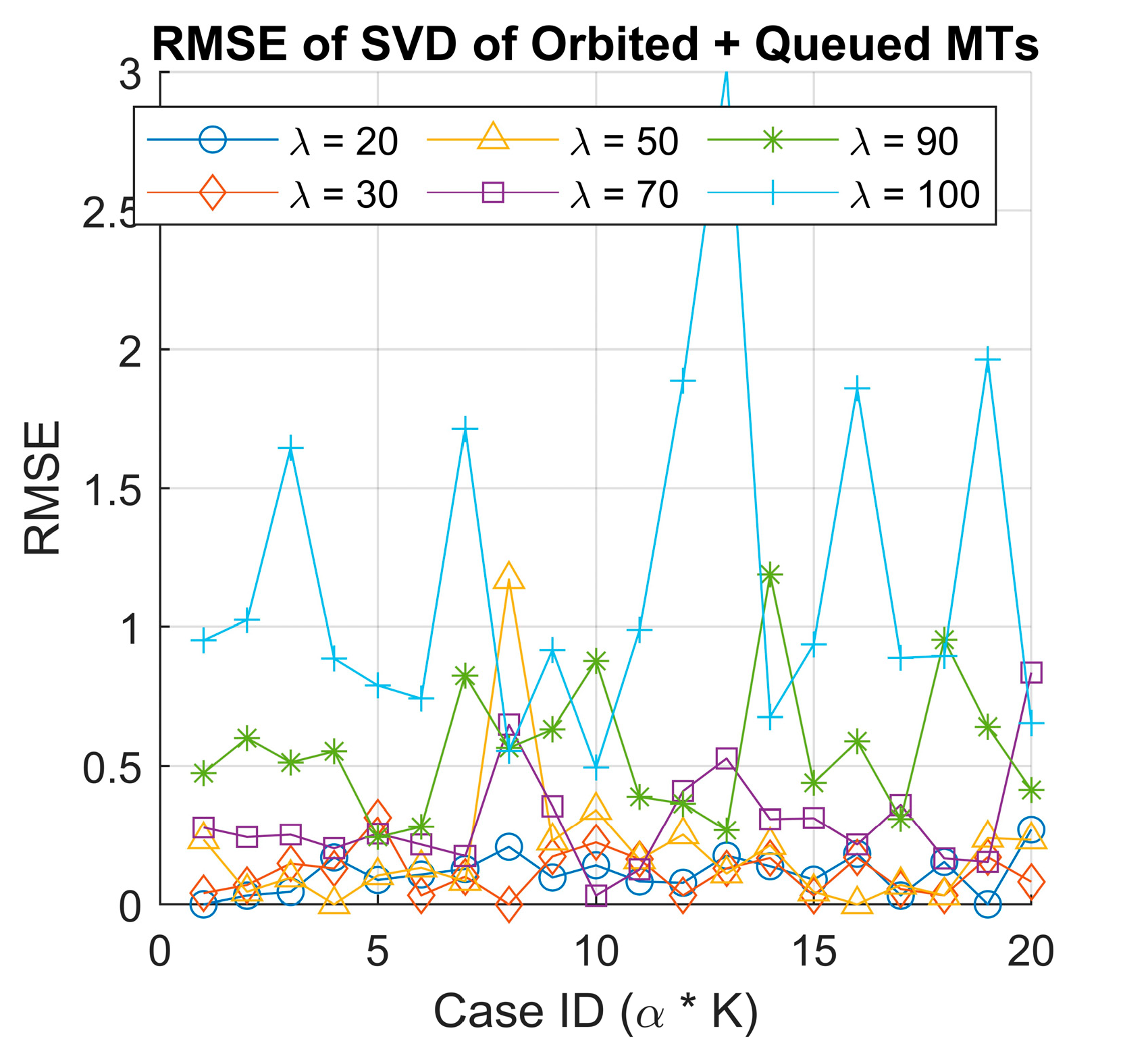
- Singular Value Decomposition (SVD) analysis: We employ SVD to extract existing latent patterns in queue behavior that could influence RL decisions.
- Implications for future 6G and THz networks: We demonstrate how RL manages the proposed model and check how it could contribute to scalable, fair, and energy-efficient scheduling in ultra-dense 6G and for communicating over THz spectrums.
2. Related Work
2.1. Queueing Theory in the Next-Generation Networks
2.2. Reinforcement Learning for Sustainable Networking
2.3. 6G Promising Technologies
2.4. Fundamentals of Queueing Theory and Its Applications in Wireless Networks
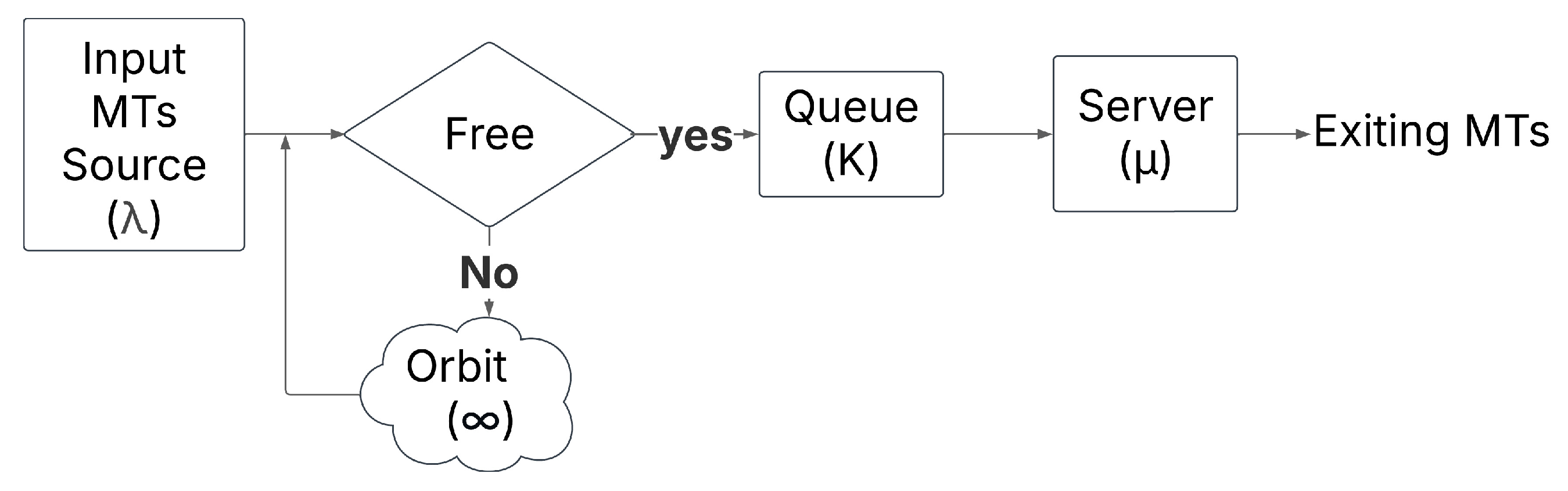
3. Methodology of the Retrial Queueing Systems M/M/1/K Model
3.1. General Concept of the Model
3.2. Orbit and Retrial Mechanism
3.3. Performance Metrics
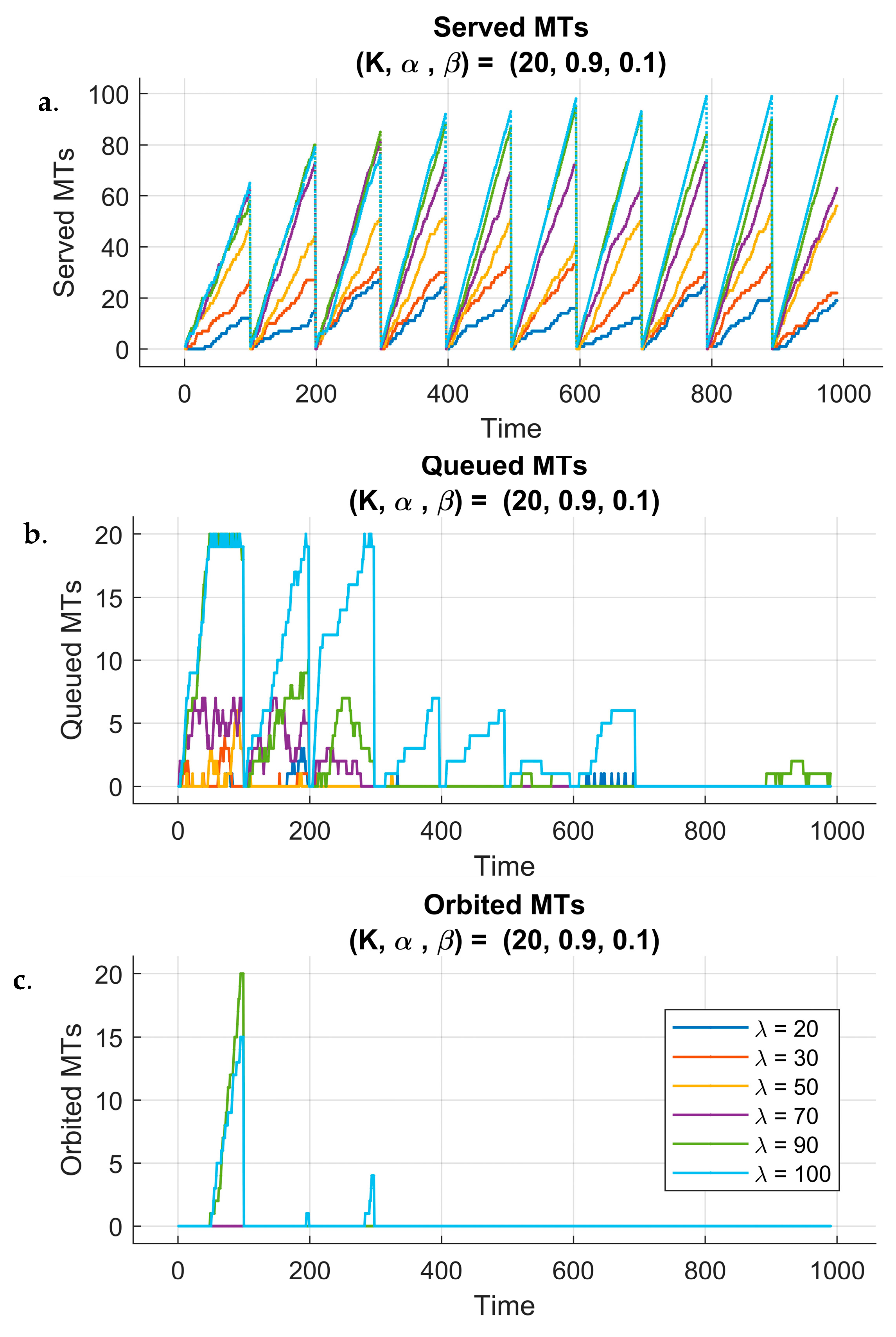
3.4. Implementation of the RQS Model and Simulation Results
| Algorithm 1. Retrial queueing system pseudocode. |
| 1. // Input |
| : Retry rate, |
| : Total simulation time, |
| = Maximum queue length |
| 5. // Initialize the Simulation |
| 6. Initialize to zero: |
| 7. MTs_in_queue, MTs_served |
| 8. MTs_in_orbit, AP_busy |
| to time_sim |
| 10. // MTs arrival based on Poisson process |
| ) |
| 12. if AP_busy = False |
| 13. // AP is free, serve the MT |
| 14. AP_busy = True |
| 15. MTs_served = MTs_served + 1 |
| 16. elseif MTs_in_queue < k |
| 17. // AP is busy, add MT to the queue |
| 18. MTs_in_queue = MTs_in_queue + 1 |
| 19. else |
| 20. // Queue is full, MT go to the orbit |
| 21. MTs_in_orbit = MTs_in_orbit + 1 |
| 22. // Service completion |
| 23. if AP_busy = True and rand() < (μ/time_sim) |
| 24. AP_busy = False |
| 25. if MTs_in_queue > 0 |
| 26. // Serve an MT from the queue |
| 27. MTs_in_queue = MTs_in_queue − 1 |
| 28. AP_busy = True |
| 29. MTs_served = MTs_served + 1 |
| 30. // MTs retry from orbit |
| 31. if rand() < (θ/time_sim) & MTs_in_orbit > 0 |
| 32. if AP_busy = False |
| 33. AP_busy = True |
| 34. MTs_served = MTs_served + 1 |
| 35. MTs_in_orbit = MTs_in_orbit − 1 |
| 36. elseif MTs_in_queue < k |
| 37. // Move MT from orbit to queue |
| 38. MTs_in_queue = MTs_inqueue + 1 |
| 39. MTs_in_orbit = MTs_in_orbit − 1 |
| 40. else |
| 41. // MTs remain in orbit (queue is full) |
| 42. end for |
4. Methodology of Reinforcement Learning for Efficient Queue Management
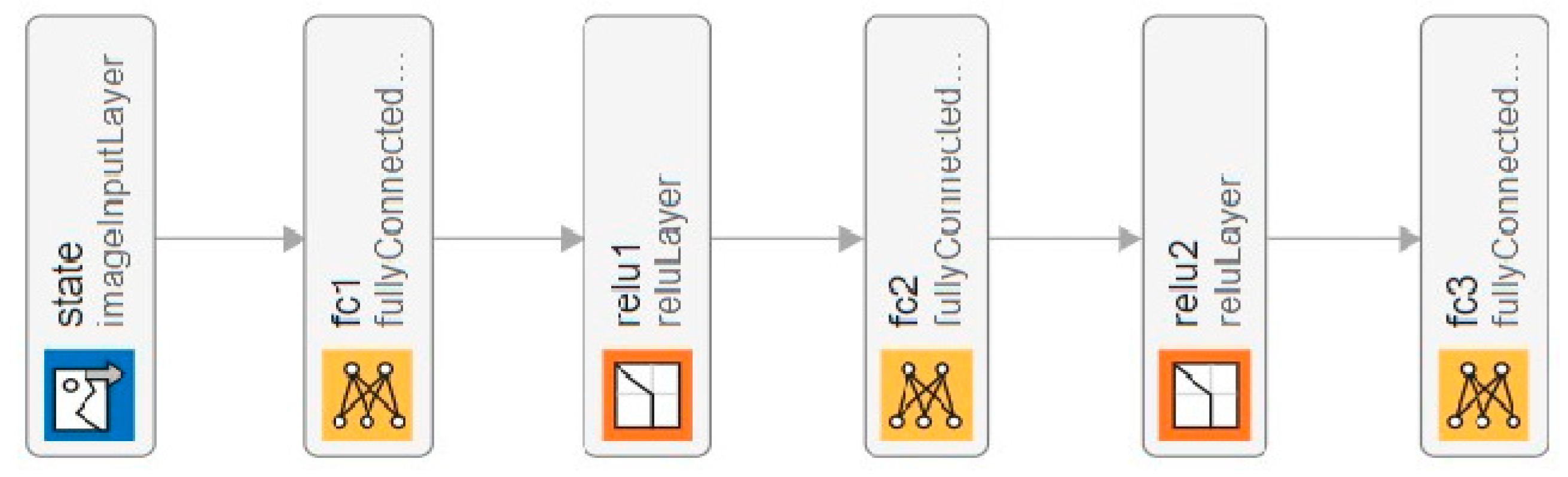
4.1. RL Q-Learning and Deep Q-Network
4.1.1. RL Q-Learning and Q-Table
4.1.2. Deep RL for Queue Optimization and Critic-Based Methods
4.2. Integrating RL Framework into the RQS Model
- : Do nothing, let the system operate normally.
- : Force the AP to serve one MT.
| Algorithm 2. Reinforcement learning integration pseudocode. | |
| 1. | // Define Environment // contains the RQS simulation-based inputs, state, and reward |
| 2. | // 1. Simulation-based Input |
| 3. | : Retry rate, |
| 4. | time_sim: Total simulation time, |
| 5. | K = Maximum queue length |
| 6. | // 2. State (2D vector) |
| 7. | Number of MTs in the queue |
| 8. | AP status (busy/free) |
| 9. | // 3. Reward |
| 10. | |
| 11. | // Define observation |
| 12. | Number of MTs in the queue |
| 13. | AP status (busy/free) |
| 14. | // Define Action |
| 15. | if Action = 0 |
| 16. | Agent does nothing |
| 17. | else |
| 18. | Agent forces AP to serve one MT |
| // Update State | |
| 19. | if MT arrives: |
| 20. | if AP free |
| 21. | AP serves MT |
| 22. | elseif queue < K |
| 23. | MT joins queue |
| 24. | else |
| 25. | MT lost |
| 26. | if AP finishes serving |
| 27. | AP becomes free |
| 28. | If queue not empty |
| 29. | Serve next MT from queue |
| 30. | if retry occurs and lost MTs > 0 |
| 31. | if queue < K |
| 32. | Move one lost MT to queue |
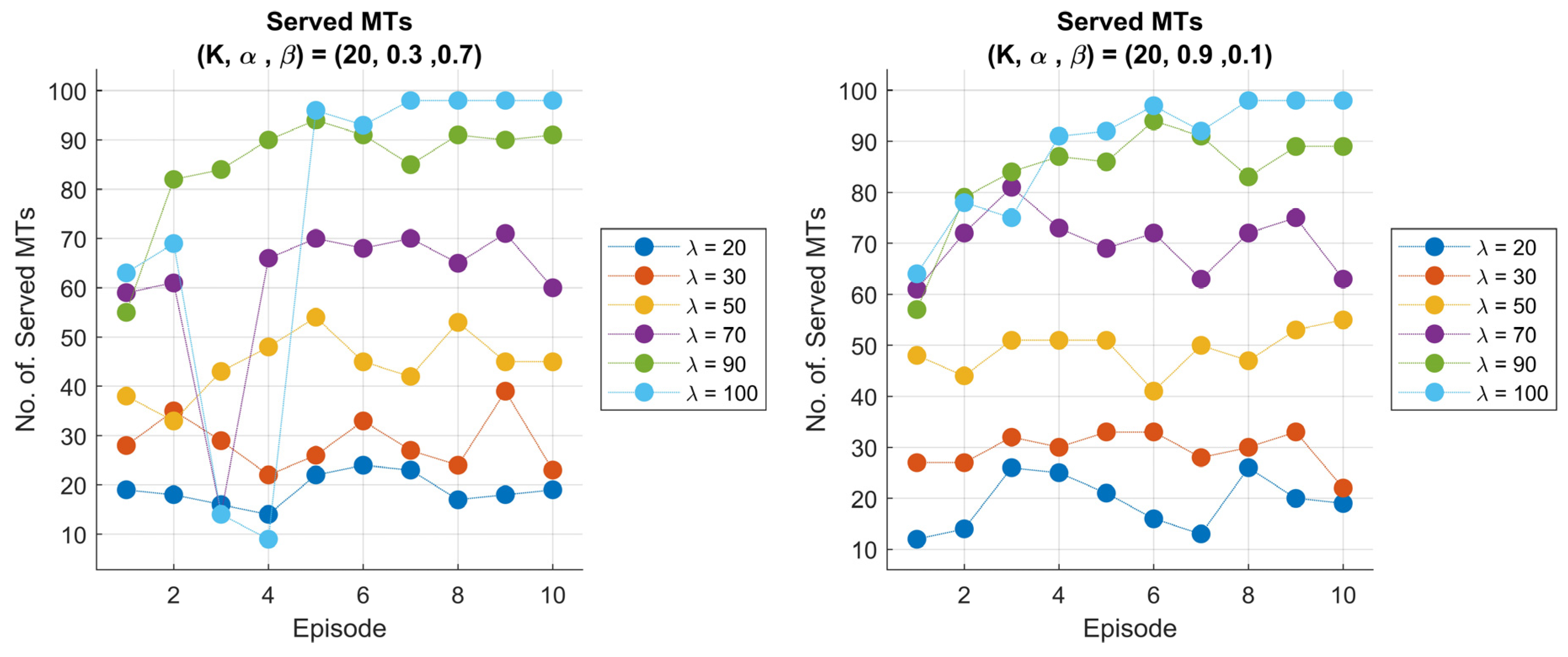
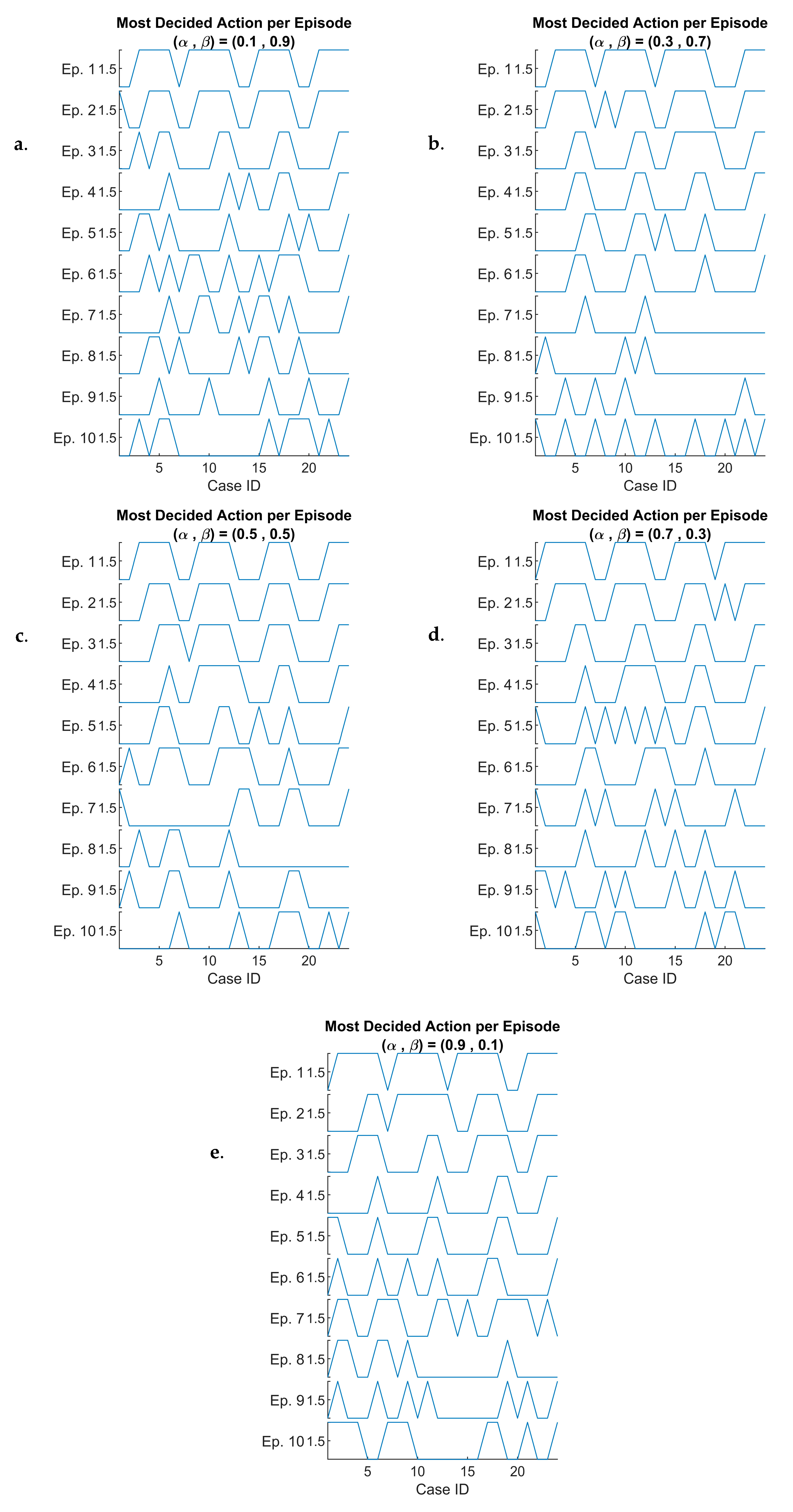
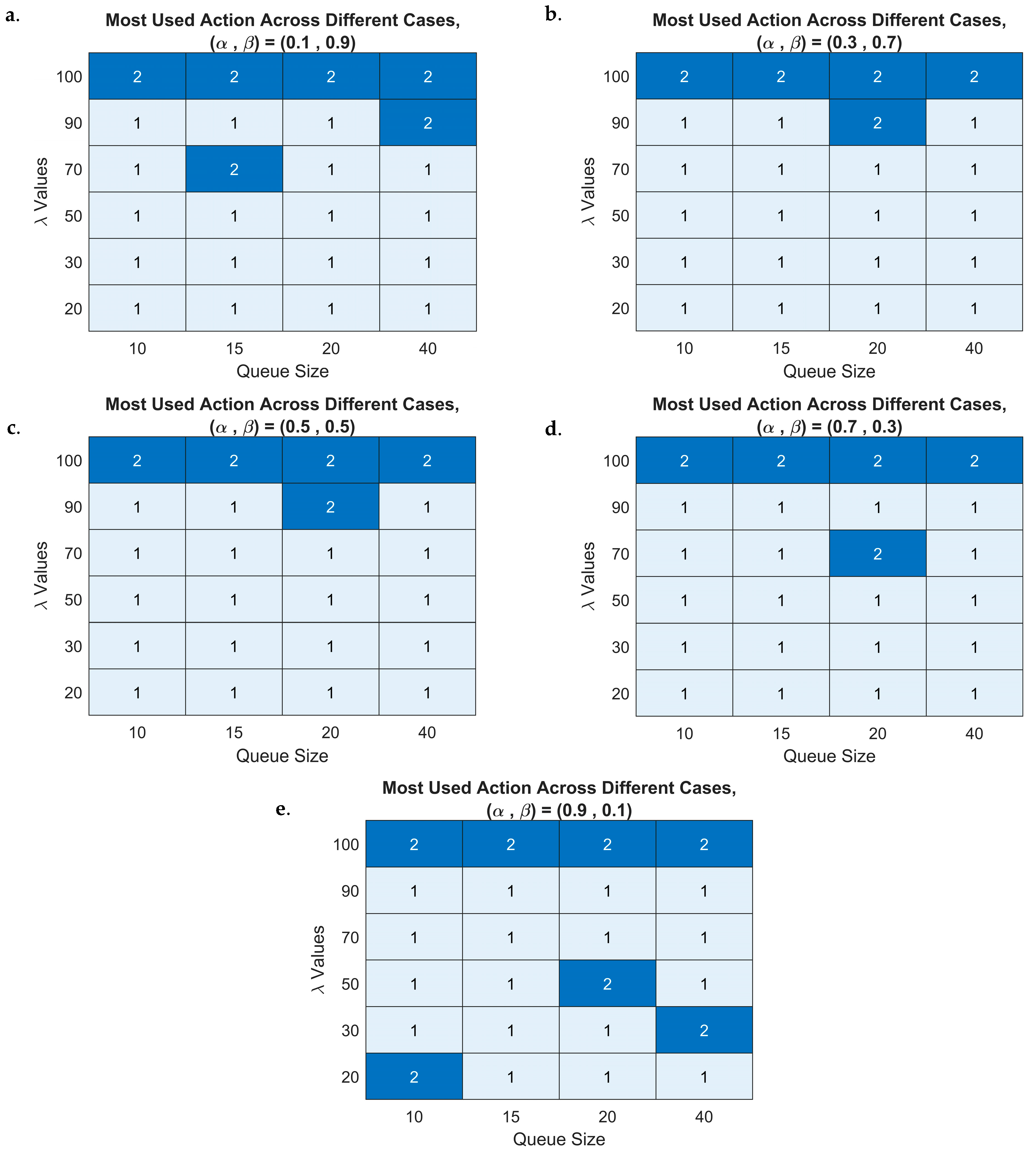
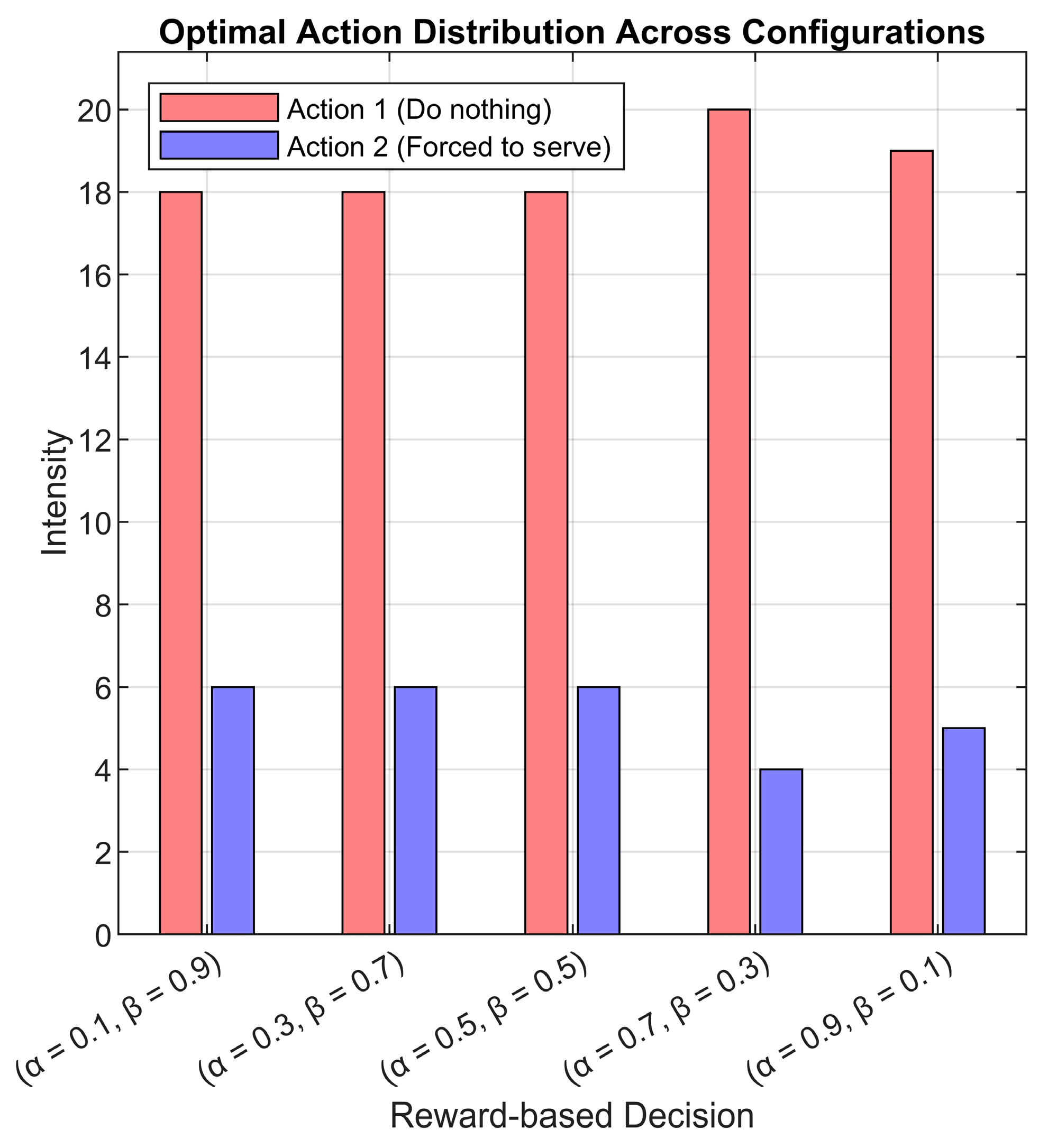
4.3. Implementation of the RL-6G-RQS Model, Simulation and Performance Evaluation
4.4. DQN Performance Evaluation in 6G-RQS Environment
4.5. Discussion of the RL DQN Simulation Findings
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mas, L.; Vilaplana, J.; Mateo, J.; Solsona, F. A queuing theory model for fog computing. J. Supercomput. 2022, 78, 11138–11155. [Google Scholar] [CrossRef]
- Katayama, Y.; Tachibana, T. Optimal task allocation algorithm based on queueing theory for future internet application in mobile edge computing platform. Sensors 2022, 22, 4825. [Google Scholar] [CrossRef] [PubMed]
- Rodrigues, T.K.; Liu, J.; Kato, N. Application of cybertwin for offloading in mobile multiaccess edge computing for 6G networks. IEEE Internet Things J. 2021, 8, 16231–16242. [Google Scholar] [CrossRef]
- Roy, A.; Pachuau, J.L.; Saha, A.K. An overview of queuing delay and various delay-based algorithms in networks. Computing 2021, 103, 2361–2399. [Google Scholar] [CrossRef]
- Najim, A.H.; Mansour, H.S.; Abbas, A.H. Characteristic analysis of queue theory in Wi-Fi applications using OPNET 14.5 modeler. East.-Eur. J. Enterp. Technol. 2022, 2, 116. [Google Scholar] [CrossRef]
- Mazhar, T.; Malik, M.A.; Mohsan, S.A.H.; Li, Y.; Haq, I.; Ghorashi, S.; Karim, F.K.; Mostafa, S.M. Quality of service (QoS) performance analysis in a traffic engineering model for next-generation wireless sensor networks. Symmetry 2023, 15, 513. [Google Scholar] [CrossRef]
- Phung-Duc, T.; Akutsu, K.; Kawanishi, K.; Salameh, O.; Wittevrongel, S. Queueing models for cognitive wireless networks with sensing time of secondary users. Ann. Oper. Res. 2022, 310, 641–660. [Google Scholar] [CrossRef]
- Adamu, A.; Surajo, Y.; Jafar, M.T. SARED: Self-adaptive active queue management scheme for improving quality of service in network systems. Comput. Sci. 2021, 22, 251–266. [Google Scholar] [CrossRef]
- Akar, N.; Dogan, O. Discrete-time queueing model of age of information with multiple information sources. IEEE Internet Things J. 2021, 8, 14531–14542. [Google Scholar] [CrossRef]
- Meng, T.; Zhao, Y.; Wolter, K.; Xu, C.-Z. On consortium blockchain consistency: A queueing network model approach. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 1369–1382. [Google Scholar] [CrossRef]
- Liu, B.; Xie, Q.; Modiano, E. RL-QN: A reinforcement learning framework for optimal control of queueing systems. ACM Trans. Model. Perform. Eval. Comput. Syst. 2022, 7, 1–35. [Google Scholar] [CrossRef]
- Raeis, M.; Tizghadam, A.; Leon-Garcia, A. Queue-learning: A reinforcement learning approach for providing quality of service. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; pp. 461–468. [Google Scholar]
- Dai, J.G.; Gluzman, M. Queueing network controls via deep reinforcement learning. Stoch. Syst. 2022, 12, 30–67. [Google Scholar] [CrossRef]
- Tam, P.; Ros, S.; Song, I.; Kang, S.; Kim, S. A survey of intelligent end-to-end networking solutions: Integrating graph neural networks and deep reinforcement learning approaches. Electronics 2024, 13, 994. [Google Scholar] [CrossRef]
- Kim, M.; Jaseemuddin, M.; Anpalagan, A. Deep reinforcement learning based active queue management for iot networks. J. Netw. Syst. Manag. 2021, 29, 34. [Google Scholar] [CrossRef]
- Du, H.; Zhang, R.; Liu, Y.; Wang, J.; Lin, Y.; Li, Z.; Niyato, D.; Kang, J.; Xiong, Z.; Cui, S.; et al. Enhancing deep reinforcement learning: A tutorial on generative diffusion models in network optimization. IEEE Commun. Surv. Tutor. 2024, 26, 2611–2646. [Google Scholar] [CrossRef]
- Walton, N.; Xu, K. Learning and information in stochastic networks and queues. In Tutorials in Operations Research: Emerging Optimization Methods and Modeling Techniques with Applications; INFORMS: Maryland, MD, USA, 2021; pp. 161–198. [Google Scholar]
- Zhang, C.; Zhang, W.; Wu, Q.; Fan, P.; Fan, Q.; Wang, J.; Letaief, K.B. Distributed deep reinforcement learning based gradient quantization for federated learning enabled vehicle edge computing. IEEE Internet Things J. 2024, 12, 4899–4913. [Google Scholar] [CrossRef]
- Patil, A.; Iyer, S.; Pandya, R.J. A survey of machine learning algorithms for 6G wireless networks. arXiv 2022, arXiv:2203.08429. [Google Scholar]
- Alhammadi, A.; Shayea, I.; El-Saleh, A.A.; Azmi, M.H.; Ismail, Z.H.; Kouhalvandi, L.; Saad, S.A. Artificial intelligence in 6G wireless networks: Opportunities, applications, and challenges. Int. J. Intell. Syst. 2024, 2024, 8845070. [Google Scholar] [CrossRef]
- Mekrache, A.; Bradai, A.; Moulay, E.; Dawaliby, S. Deep reinforcement learning techniques for vehicular networks: Recent advances and future trends towards 6G. Veh. Commun. 2022, 33, 100398. [Google Scholar] [CrossRef]
- Saleh, A.M.; Omar, S.S.; Abd El-Haleem, A.M.; Ibrahim, I.I.; Abdelhakam, M.M. Trajectory optimization of UAV-IRS assisted 6G THz network using deep reinforcement learning approach. Sci. Rep. 2024, 14, 18501. [Google Scholar] [CrossRef]
- Mageed, I.A. The entropian threshold theorems for the steady state probabilities of the stable M/G/1 Queue with Heavy Tails with Applications of Probability Density Functions to 6G networks. Electron. J. Comput. Sci. Inf. Technol. 2023, 9, 24–30. [Google Scholar]
- Shi, Y.; Lian, L.; Shi, Y.; Wang, Z.; Zhou, Y.; Fu, L.; Bai, L.; Zhang, J.; Zhang, W. Machine learning for large-scale optimization in 6g wireless networks. IEEE Commun. Surv. Tutor. 2023, 25, 2088–2132. [Google Scholar] [CrossRef]
- Noman, H.M.F.; Hanafi, E.; Noordin, K.A.; Dimyati, K.; Hindia, M.N.; Abdrabou, A.; Qamar, F. Machine learning empowered emerging wireless networks in 6G: Recent advancements, challenges and future trends. IEEE Access 2023, 11, 83017–83051. [Google Scholar] [CrossRef]
- Ali, R.; Ashraf, I.; Bashir, A.K.; Bin Zikria, Y. Reinforcement-learning-enabled massive Internet of Things for 6G wireless communications. IEEE Commun. Stand. Mag. 2021, 5, 126–131. [Google Scholar] [CrossRef]
- Tao, Z.; Xu, W.; Huang, Y.; Wang, X.; You, X. Wireless network digital twin for 6g: Generative ai as a key enabler. IEEE Wirel. Commun. 2024, 31, 24–31. [Google Scholar] [CrossRef]
- Kalor, A.E.; Durisi, G.; Coleri, S.; Parkvall, S.; Yu, W.; Mueller, A.; Popovski, P. Wireless 6g connectivity for massive number of devices and critical services. Proc. IEEE 2024, 1–23. [Google Scholar] [CrossRef]
- Talbi, D.; Gal, Z. AI-Driven Insights into B5G/6G MAC Mechanisms: A Comprehensive Analysis. Internet Things 2025, 31, 101571. [Google Scholar] [CrossRef]
- Talbi, D.; Gal, Z. Decomposition Based Congestion Analysis of the Communication in B5G/6G TeraHertz High-Speed Networks. Infocommunications J. A Publ. Sci. Assoc. Infocommunications (HTE) 2023, 15, 43–48. [Google Scholar] [CrossRef]
- Sztrik, J. Queueing theory and its Applications, a personal view. In Proceedings of the 8th international conference on applied informatics, Ben Guerir, Morocco, 8–11 October 2025; Vol. 1. [Google Scholar]
- Moltchanov, D.; Sopin, E.; Begishev, V.; Samuylov, A.; Koucheryavy, Y.; Samouylov, K. A tutorial on mathematical modeling of 5G/6G millimeter wave and terahertz cellular systems. IEEE Commun. Surv. Tutor. 2022, 24, 1072–1116. [Google Scholar] [CrossRef]
- Walraevens, J.; Bruneel, H.; Fiems, D.; Wittevrongel, S. Delay analysis of multiclass queues with correlated train arrivals and a hybrid priority/FIFO scheduling discipline. Appl. Math. Model. 2017, 45, 823–839. [Google Scholar] [CrossRef]
- Han, B.; Sciancalepore, V.; Feng, D.; Costa-Perez, X.; Schotten, H.D. A utility-driven multi-queue admission control solution for network slicing. In Proceedings of the IEEE Infocom 2019-IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019. [Google Scholar]
- Sztrik, J. Basic Queueing Theory; University of Debrecen: Faculty of Informatics: Debrecen, Hungary, 2011. [Google Scholar]
- Avgouleas, I.; Pappas, N.; Angelakis, V. A wireless caching helper system with heterogeneous traffic and random availability. EURASIP J. Wirel. Commun. Netw. 2021, 2021, 69. [Google Scholar] [CrossRef]
- Ajah, S.; Achumba, I.E.; Chukwuchekwa, N.; Onyebuchi, N.; Osuji, L. Performance analysis of the queuing methodologies in cognitive radio for optimal 5G networks-review. In Proceedings of the School of Engineering and Technology Conference and Exhibition (SETCONF), AIFPU, Ebonyi State, 10–12 May 2023; Volume 4. [Google Scholar]
- Moltchanov, D.; Sopin, E.; Begishev, V.; Samuylov, A.; Koucheryavy, Y.; Samouylov, K. A tutorial on mathematical modeling of millimeter wave and terahertz cellular systems. arXiv 2021, arXiv:2109.08651. [Google Scholar] [CrossRef]
- Koda, Y.; Ouyang, R.; Ohmi, N.; Harada, H. Survey, taxonomy, and unification of standard mmWave channel models for WPAN, WLAN, and cellular systems in 6G. IEEE Commun. Stand. Mag. 2024, 8, 44–52. [Google Scholar] [CrossRef]
- Golos, E.; Daraseliya, A.; Sopin, E.; Begishev, V.; Gaidamaka, Y. Optimizing service areas in 6 G mmwave/thz systems with dual blockage and micromobility. Mathematics 2023, 11, 870. [Google Scholar] [CrossRef]
- Wang, J.; Wang, C.-X.; Huang, J.; Wang, H.; Gao, X.; You, X.; Hao, Y. A novel 3D non-stationary GBSM for 6G THz ultra-massive MIMO wireless systems. IEEE Trans. Veh. Technol. 2021, 70, 12312–12324. [Google Scholar] [CrossRef]
- Sopin, E.; Begishev, V.; Prosvirov, V.; Samouylov, K.; Koucheryavy, Y. The Impact of Traffic Characteristics on System and User Performance in 5G/6G Cellular Systems. arXiv 2024, arXiv:2411.04474. [Google Scholar]
- Blaszczyszyn, B.; Keeler, H.P. Studying the SINR process of the typical user in Poisson networks using its factorial moment measures. IEEE Trans. Inf. Theory 2015, 61, 6774–6794. [Google Scholar] [CrossRef]
- Morales, D.; Jornet, J.M. ADAPT: An Adaptive Directional Antenna Protocol for medium access control in Terahertz communication networks. Ad Hoc Netw. 2021, 119, 102540. [Google Scholar] [CrossRef]
- O’Donoghue, B.; Osband, I.; Munos, R.; Mnih, V. The uncertainty bellman equation and exploration. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Meyn, S. The projected Bellman equation in reinforcement learning. IEEE Trans. Autom. Control 2024, 69, 8323–8337. [Google Scholar] [CrossRef]
- Yadav, R.; Zhang, W.; Elgendy, I.A.; Dong, G.; Shafiq, M.; Laghari, A.A.; Prakash, S. Smart healthcare: RL-based task offloading scheme for edge-enable sensor networks. IEEE Sens. J. 2021, 21, 24910–24918. [Google Scholar] [CrossRef]
- Ghorrati, Z.; Shahnazari, K.; Esmaeili, A.; Matson, E.T. Fuzzy Q-Table Reinforcement Learning for continues State Spaces: A Case Study on Bitcoin Futures Trading. In Proceedings of the 2024 10th International Conference on Control, Decision and Information Technologies (CoDIT), Valletta, Malta, 1–4 July 2024. [Google Scholar]
- Padhye, V.; Lakshmanan, K. A deep actor critic reinforcement learning framework for learning to rank. Neurocomputing 2023, 547, 126314. [Google Scholar] [CrossRef]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| ) | 45 |
| ) | 40 |
| ) | 20 |
| ) | 5 |
| ) | 1000 |
| Parameter | Value | Description |
|---|---|---|
| Gradient Threshold | 1 | Limits the magnitude of a gradient to prevent instability. |
| Learn Rate | Controls the step size in weight updates, ensuring smooth convergence. | |
| Target Smooth Factor | Determines the smoothing factor for updating the target network for stable learning. | |
| Experience Buffer Length [Bytes] | Defines the size of the replay buffer used for experience replay, improving sample efficiency. | |
| Discount Factor | 0.99 | Ensures future rewards are considered. |
| Mini Batch Size | 64 | Specified the number of samples used per training step for gradient update. |
| Number of Episodes | 10 | Defines the number of training episodes used for learning the policy. |
| Parameter | Value |
|---|---|
| Arrival rate λ) | [20, 30, 50, 70, 90, 100] |
| Service rate () | 0.5 |
| Retry rate () | 1 |
| Queue size () | [10, 15, 20, 40] |
| Scaling factor () | [0.1, 0.3, 0.5, 0.7, 0.9] |
| Weight () | 1 − |
| Simulation time | 100 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Talbi, D.; Gal, Z. Integrating Reinforcement Learning into M/M/1/K Retry Queueing Models for 6G Applications. Sensors 2025, 25, 3621. https://doi.org/10.3390/s25123621
Talbi D, Gal Z. Integrating Reinforcement Learning into M/M/1/K Retry Queueing Models for 6G Applications. Sensors. 2025; 25(12):3621. https://doi.org/10.3390/s25123621
Chicago/Turabian StyleTalbi, Djamila, and Zoltan Gal. 2025. "Integrating Reinforcement Learning into M/M/1/K Retry Queueing Models for 6G Applications" Sensors 25, no. 12: 3621. https://doi.org/10.3390/s25123621
APA StyleTalbi, D., & Gal, Z. (2025). Integrating Reinforcement Learning into M/M/1/K Retry Queueing Models for 6G Applications. Sensors, 25(12), 3621. https://doi.org/10.3390/s25123621