

Digital Twin Network-Based 6G Self-Evolution

Abstract
1. Introduction
- First, an architecture is proposed for the DT-native network to realize 6G self-evolution, which includes a new concept of “future shot” for predicting future states and evolution strategy performance.
- Second, we propose a full-scale network prediction method for requirement predictions and strategy validations, which include a CTHGAM model for generating predicting strategy and an LTHCGAM for generating predicting results.
- Third, a method for generating an evolution strategy is proposed, which incorporates a conditional hierarchical Graph Neural Network (GNN) for selecting evolution elements and Large Language Model (LLM) for giving evolution strategy models. In addition, we design efficient hierarchical virtual–physical interaction strategies.
- Finally, we analyze four potential applications of the proposed DT-native network.
2. Architecture of DT-Native Network
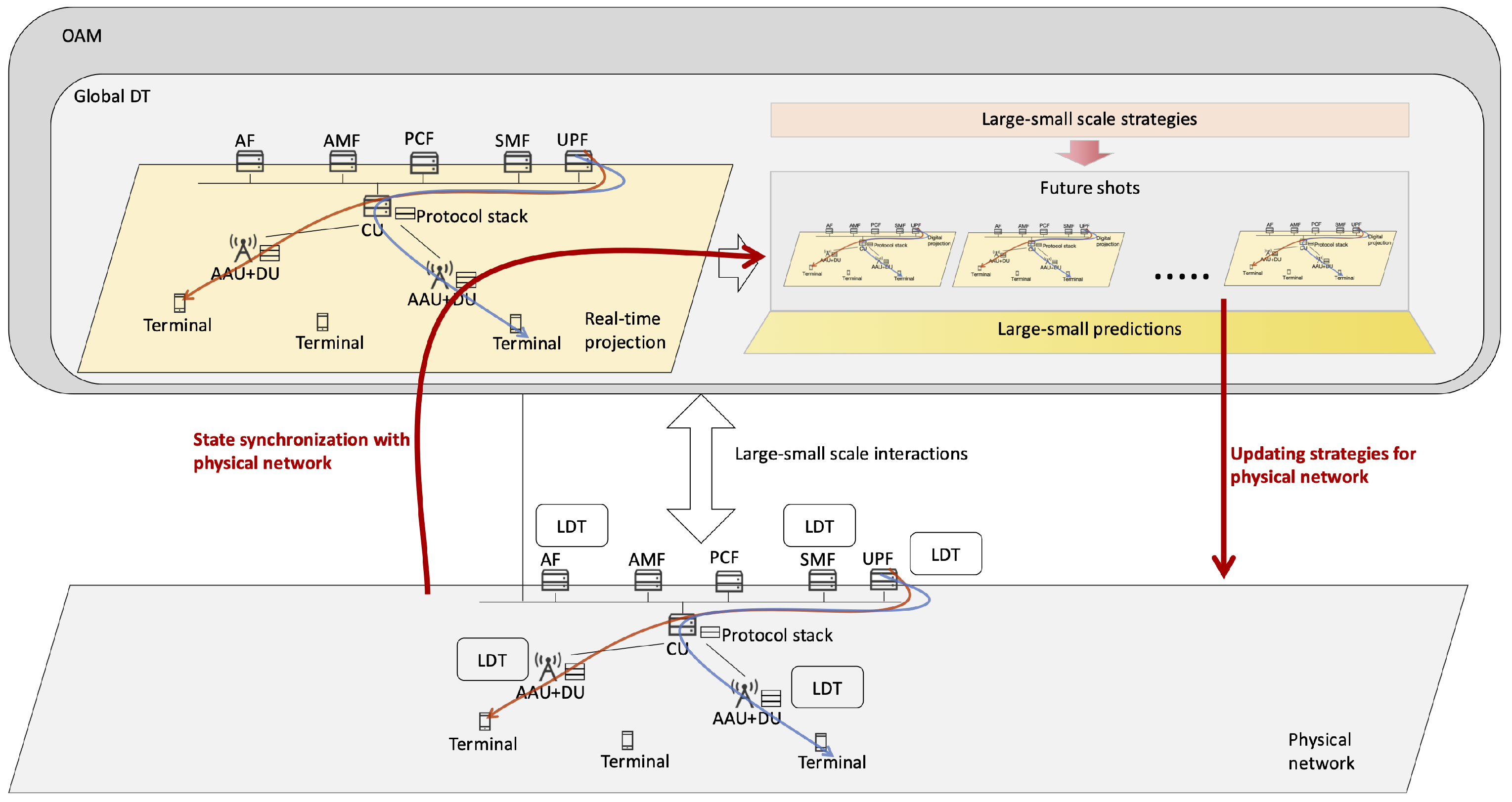
2.1. Overview
2.2. Future Shot
2.3. Hybrid Centralized–Distributed Autonomy
3. Key Technologies of DT-Native Network
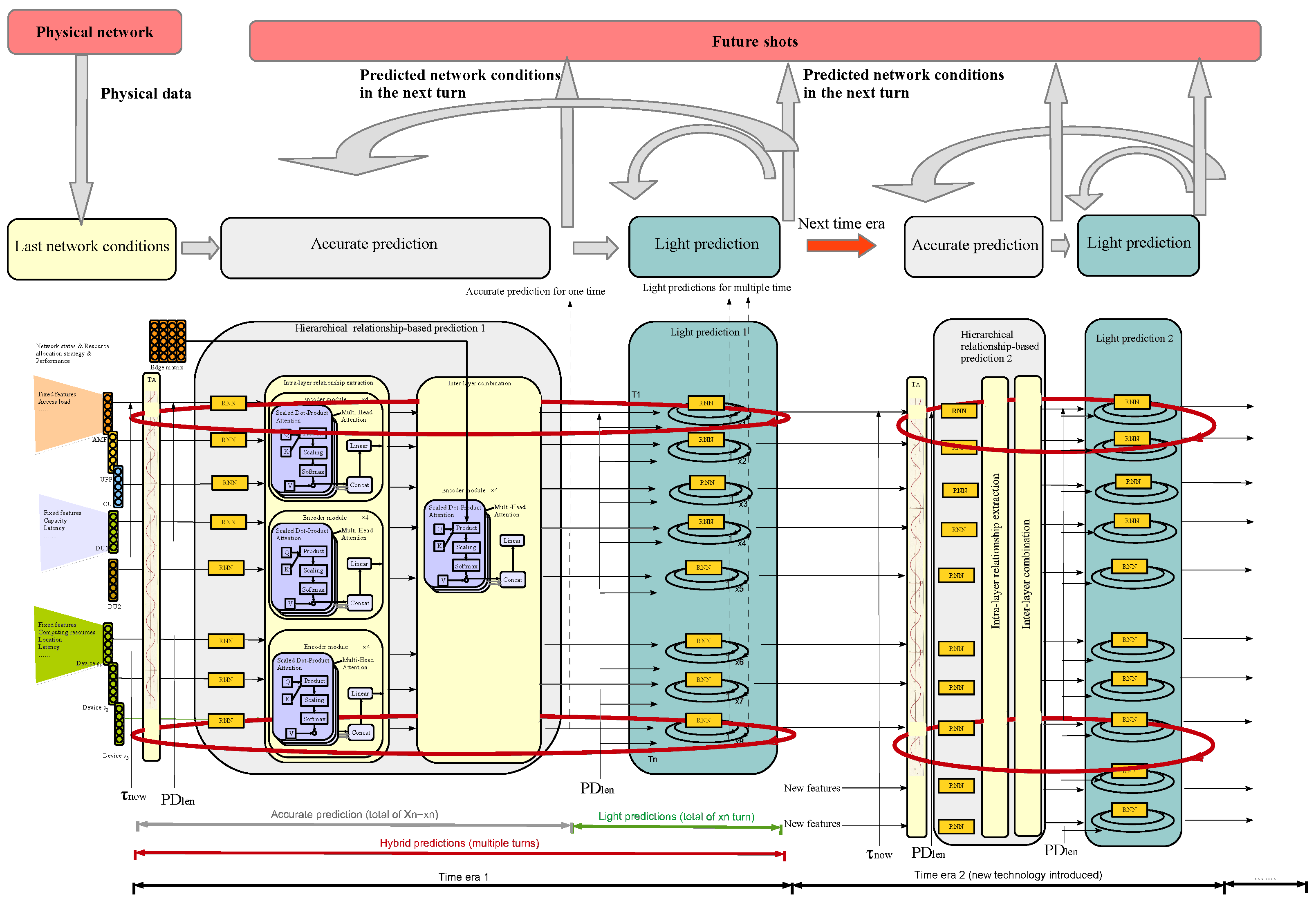
3.1. Differentiating Long–Short-Term Prediction
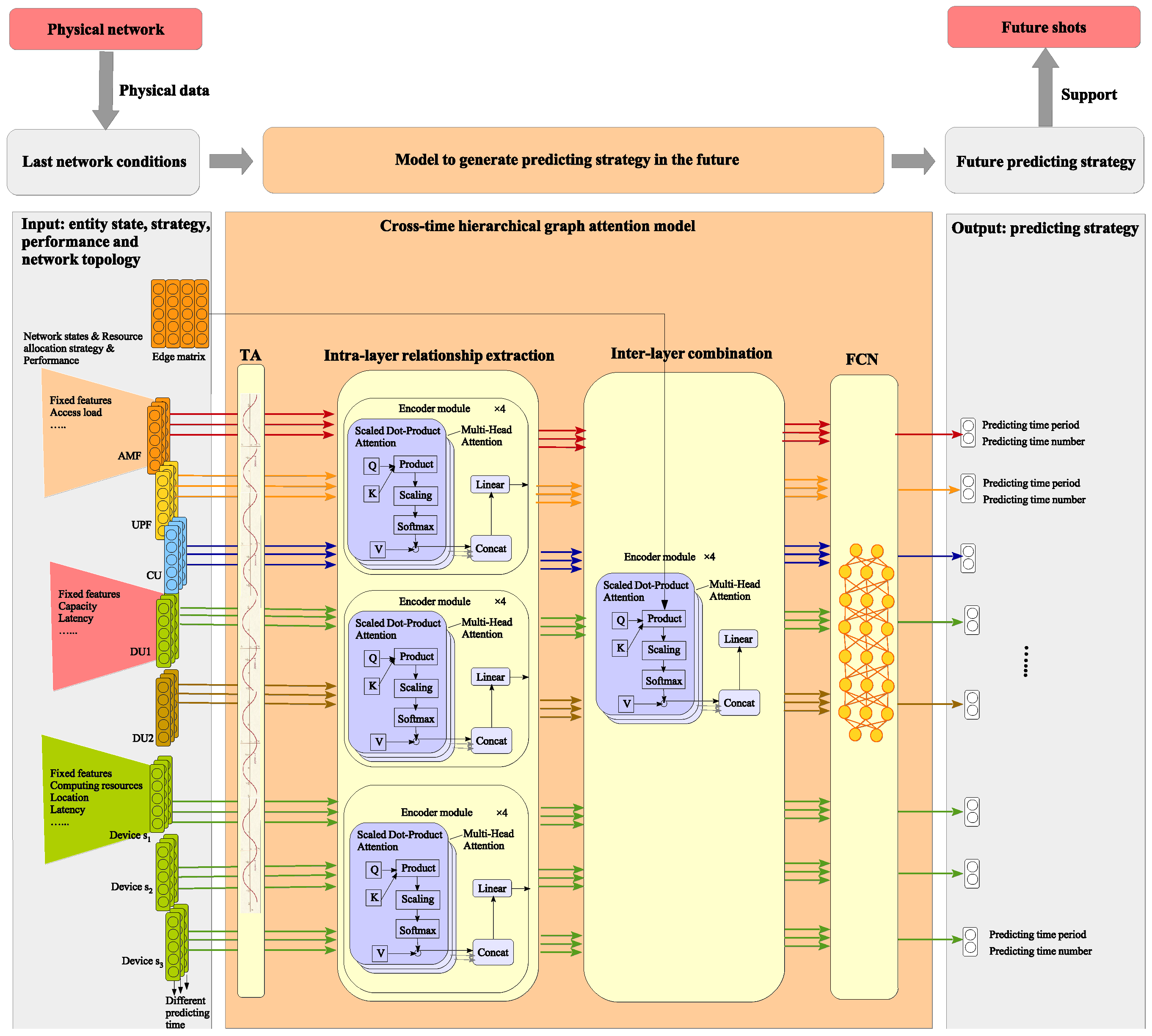
3.1.1. Determining Predicting Strategies
| Algorithm 1 Cross-Time Hierarchical Graph Attention Model (CTHGAM) |
|
3.1.2. Giving Predicting Results
| Algorithm 2 Long-Term Hierarchical Convolutional Graph Attention Model (LTHCGAM) |
|
3.2. Autonomous Large–Small-Scale Strategy Generation
- Large-scope self-awareness: For example, it may be demand self-awareness on an OAM platform, which can be implemented in three steps. First, it can identify a time point after which performance falls below a certain threshold. Then, it can use an LLM model to provide recommendations on which technology should be employed for optimization or evolution. The LLM’s foundation model can be trained on extensive datasets comprising historical network data, laboratory data, and standardized communication protocols, which had been used by researchers to develop network large models [15]. The LLM can be further fine-tuned using supervised learning on labeled datasets derived from historical network optimization scenarios and reinforcement learning with a reward function that prioritizes KPIs such as reduced latency, increased throughput, and enhanced reliability, ensuring alignment with the network’s self-evolution objectives. Finally, the heterogeneous graph, formed by the heterogeneous performance of various network elements with their connecting topology, and the optimization method suggested by the LLM are input into a conditional-heterogeneous graph neural network (Conditional-HGNN) to output a prioritized ranking of network nodes recommended for optimization, as depicted in Figure 4.
- Small-scope self-awareness: For example, it may be demand self-awareness on a single network element, which is implemented in two steps. First, it can identify a point in time after which performance falls below a certain threshold. Then, it uses an LLM to suggest which technology should be used for optimization or evolution.
- Large magnitude: If the improvement approach is significant and requires introducing new technology, it involves two steps. First, it initializes configuration parameters for the new technology. If a flexible, intelligent, and dynamic configuration scheme based on AI is needed, an LLM can be used to define the AI model’s structure and initial parameters. If AI-based configuration is not required, a preset template can be used for initialization. Second, it performs the adaptive optimization of the initial configuration. Concretely, it can build a performance pre-validation environment based on the APIs of different network elements to train AI-based configuration strategies or optimize non-AI configuration schemes based on templates.
- Small magnitude: If the improvement approach is minor and only requires optimizing the configuration parameters of existing technology, proceed directly with the second step above.
3.3. Large–Small Time-Scale Controls
- On a small time scale, an NDT quickly interacts with the physical network to continuously optimize the physical network. By deploying distributed NDT modules on its physical counterpart, it can timely update network AI algorithms via inner physical–virtual interfaces to quickly adapt to the changing physical environments, ensuring precise and efficient strategies for resource allocation, mobility management, and other network operational states.
- On a large time scale, an NDT periodically interacts with its physical network to facilitate its gradual evolution. Many network evolution strategies require long-term, incremental progression and directional transitions. For instance, a cell-free network might begin with pilot deployments in areas with fewer users and then progressively expand to densely populated regions until the entire network is fully upgraded. By deploying a central NDT module on an OAM, CU or other centralized operation places, it can have an overview of the whole network and gradually emit controls over it on a large time scale.
- At the smallest time scale, an network element DT is deployed alongside its physical counterpart, performing real-time status monitoring and closed-loop control of the equipment.
- At the largest time scale, a DT is deployed within an operation and maintenance administration system, enabling large time-scale optimization and control across the entire network.
4. Use Cases
4.1. Large Language Models and AGI
4.2. Transportation and Driving
4.3. Industrial Internet
4.4. Low Altitude Airspace Economy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Time Alignment Based on Positional Encoding
References
- Cui, Q.; You, X.; Wei, N.; Nan, G.; Zhang, X.; Zhang, J.; Lyu, X.; Ai, M.; Tao, X.; Feng, Z.; et al. Overview of AI and Communication for 6G Network: Fundamentals, Challenges, and Future Research Opportunities. arXiv 2024, arXiv:2412.14538. [Google Scholar] [CrossRef]
- Cui, Y.; Liu, J.; Yu, M.; Jiang, J.; Zhang, L.; Lu, L. Network Digital Twin. IEEE Netw. 2024, 38, 5–6. [Google Scholar] [CrossRef]
- Hakiri, A.; Gokhale, A.; Yahia, S.B.; Mellouli, N. A comprehensive survey on digital twin for future networks and emerging Internet of Things industry. Comput. Netw. 2024, 244, 110350. [Google Scholar] [CrossRef]
- Jang, S.; Jeong, J.; Lee, J.; Choi, S. Digital twin for intelligent network: Data lifecycle, digital replication, and AI-based optimizations. IEEE Commun. Mag. 2023, 61, 96–102. [Google Scholar] [CrossRef]
- Masaracchia, A.; Van Huynh, D.; Alexandropoulos, G.C.; Canberk, B.; Dobre, O.A.; Duong, T.Q. Toward the metaverse realization in 6G: Orchestration of RIS-enabled smart wireless environments via digital twins. IEEE Internet Things Mag. 2024, 7, 22–28. [Google Scholar] [CrossRef]
- Liu, H.; Su, W.; Li, T.; Huang, W.; Li, Y. Digital Twin Enhanced Multi-Agent Reinforcement Learning for Large-Scale Mobile Network Coverage Optimization. ACM Trans. Knowl. Discov. Data 2024, 19, 1–23. [Google Scholar] [CrossRef]
- Lai, J.; Chen, Z.; Zhu, J.; Ma, W.; Gan, L.; Xie, S.; Li, G. Deep learning based traffic prediction method for digital twin network. Cogn. Comput. 2023, 15, 1748–1766. [Google Scholar] [CrossRef] [PubMed]
- Xun, Z.; Zhang, S.; Xun, Y.; Mu, D.; Mao, B.; Guo, H. An Adaptive Vehicle Trajectory Prediction Scheme Based on Digital Twin Platform. IEEE Internet Things J. 2025, 12, 16204–16213. [Google Scholar] [CrossRef]
- Cheng, N.; Wang, X.; Li, Z.; Yin, Z.; Luan, T.; Shen, X. Toward Enhanced Reinforcement Learning-Based Resource Management via Digital Twin: Opportunities, Applications, and Challenges. arXiv 2024, arXiv:2406.07857. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, Y.; Zhang, C.; Zheng, Q.; Yang, L.; You, X. Digital twin-enhanced deep reinforcement learning for resource management in networks slicing. IEEE Trans. Commun. 2024, 72, 6209–6224. [Google Scholar] [CrossRef]
- Consul, P.; Budhiraja, I.; Garg, D.; Kumar, N.; Singh, R.; Almogren, A.S. A Hybrid Task Offloading and Resource Allocation Approach for Digital Twin-Empowered UAV-Assisted MEC Network Using Federated Reinforcement Learning for Future Wireless Network. IEEE Trans. Consum. Electron. 2024, 70, 3120–3130. [Google Scholar] [CrossRef]
- Wang, J.; Li, J.; Liu, J. Digital twin-assisted flexible slice admission control for 5G core network: A deep reinforcement learning approach. Future Gener. Comput. Syst. 2024, 153, 467–476. [Google Scholar] [CrossRef]
- Liu, G.; Zhu, Y.; Kang, M.; Yue, L.; Zheng, Q.; Li, N.; Wang, Q.; Huang, Y.; Wang, X. Native Design for 6G Digital Twin Network: Use Cases, Architecture, Functions and Key Technologies. IEEE Internet Things J. 2025. early access. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Y.; Wang, L.; Duan, X.; Lu, L.; Hu, Y.; Zhan, Y.; Lian, Y.; Sun, T. Native Network Digital Twin Architecture for 6G: From Design to Practice. IEEE Commun. Mag. 2024, 63, 24–31. [Google Scholar] [CrossRef]
- Zhou, H.; Hu, C.; Yuan, Y.; Cui, Y.; Jin, Y.; Chen, C.; Wu, H.; Yuan, D.; Jiang, L.; Wu, D.; et al. Large language model (llm) for telecommunications: A comprehensive survey on principles, key techniques, and opportunities. IEEE Commun. Surv. Tutor. 2024. early access. [Google Scholar] [CrossRef]
- Tao, Z.; Xu, W.; Huang, Y.; Wang, X.; You, X. Wireless Network Digital Twin for 6G: Generative AI as a Key Enabler. IEEE Wirel. Commun. 2024, 31, 24–31. [Google Scholar] [CrossRef]
- Shu, M.; Sun, W.; Zhang, J.; Duan, X.; Ai, M. Digital-twin-enabled 6G network autonomy and generative intelligence: Architecture, technologies and applications [version 3; peer review: 3 approved with reservations, 1 not approved]. Digit. Twin 2025, 2, 16. [Google Scholar] [CrossRef]
- Long, S.; Tang, F.; Li, Y.; Tan, T.; Jin, Z.; Zhao, M.; Kato, N. 6G comprehensive intelligence: Network operations and optimization based on Large Language Models. IEEE Netw. 2024. early access. [Google Scholar] [CrossRef]
- Xu, M.; Niyato, D.; Kang, J.; Xiong, Z.; Mao, S.; Han, Z.; Kim, D.I.; Letaief, K.B. When Large Language Model Agents Meet 6G Networks: Perception, Grounding, and Alignment. IEEE Wirel. Commun. 2024, 31, 63–71. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, S.; Feng, O.; Tian, T.; Huang, Y.; Zhong, G. Research on Demand-Based Scheduling Scheme of Urban Low-Altitude Logistics UAVs. Appl. Sci. 2023, 13, 5370. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Full Form |
|---|---|
| AAU | Active Antenna Unit |
| AGI | Artificial General Intelligence |
| ALSSSG | Autonomous Large–Small-Scale Strategy Generation |
| AMF | Access and Mobility Management Function |
| CTHGAM | Cross-Time Hierarchical Graph Attention Model |
| CU | Centralized Unit |
| DLSTP | Differentiating Long–Short-Term Prediction |
| DT | Digital Twin |
| DU | Distributed Unit |
| FCN | Fully Connected Network |
| GNN | Graph Neural Network |
| HGNN | Heterogeneous Graph Neural Network |
| KPI | Key Performance Indicator |
| LDT | Local Digital Twin |
| LLM | Large Language Model |
| LSTSC | Large–Small Time-Scale Controls |
| LTHCGAM | Long-Term Hierarchical Convolutional Graph Attention Model |
| NDT | Network Digital Twin |
| OAM | Operations, Administration, and Maintenance |
| RAN | Radio Access Network |
| RIS | Reconfigurable Intelligent Surface |
| RL | Reinforcement Learning |
| RNN | Recurrent Neural Network |
| SON | Self-Organizing Network |
| THz | Terahertz |
| UAV | Unmanned Aerial Vehicle |
| UPF | User Plane Function |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.; Kang, M.; Zhu, Y.; Li, N.; Liu, G.; Wang, Q. Digital Twin Network-Based 6G Self-Evolution. Sensors 2025, 25, 3543. https://doi.org/10.3390/s25113543
Huang Y, Kang M, Zhu Y, Li N, Liu G, Wang Q. Digital Twin Network-Based 6G Self-Evolution. Sensors. 2025; 25(11):3543. https://doi.org/10.3390/s25113543
Chicago/Turabian StyleHuang, Yuhong, Mancong Kang, Yanhong Zhu, Na Li, Guangyi Liu, and Qixing Wang. 2025. "Digital Twin Network-Based 6G Self-Evolution" Sensors 25, no. 11: 3543. https://doi.org/10.3390/s25113543
APA StyleHuang, Y., Kang, M., Zhu, Y., Li, N., Liu, G., & Wang, Q. (2025). Digital Twin Network-Based 6G Self-Evolution. Sensors, 25(11), 3543. https://doi.org/10.3390/s25113543