

Multi-Dimensional Anomaly Detection and Fault Localization in Microservice Architectures: A Dual-Channel Deep Learning Approach with Causal Inference for Intelligent Sensing

Abstract
1. Introduction
- We design a dual-channel architecture that combines the temporal modeling capabilities of TCNs with the latent representation power of VAEs, enabling effective anomaly detection across diverse metrics and service types.
- We develop a contrastive learning approach that creates unified representations of heterogeneous monitoring data, addressing the challenge of correlating metrics with different statistical properties and scales.
- We propose a causal inference mechanism that models the dependencies between services and traces fault propagation patterns, significantly improving the precision of root cause localization.
- We conducted extensive experiments on the public MultiDimension-Localization dataset, demonstrating that our framework outperformed state-of-the-art methods in both anomaly detection and fault localization tasks.
- We analyzed the computational efficiency and scalability of our approach, showing that it maintains real-time performance, even with large numbers of services and metrics.
2. Related Works
2.1. Traditional Anomaly Detection Methods
2.2. Deep Learning for Anomaly Detection
2.3. Fault Localization and Root Cause Analysis
3. Preliminaries
3.1. Problem Formulation
- Anomaly Detection: Identify timestamps t where the system exhibits anomalous behavior, represented by a binary indicator function , where 1 indicates an anomaly.
- Fault Localization: For each detected anomaly at time t, identify the specific service(s) that represent the root cause of the anomaly through a function .
3.2. Key Technical Concepts
3.2.1. Temporal Convolutional Networks
3.2.2. Variational Autoencoders
3.2.3. Causal Inference
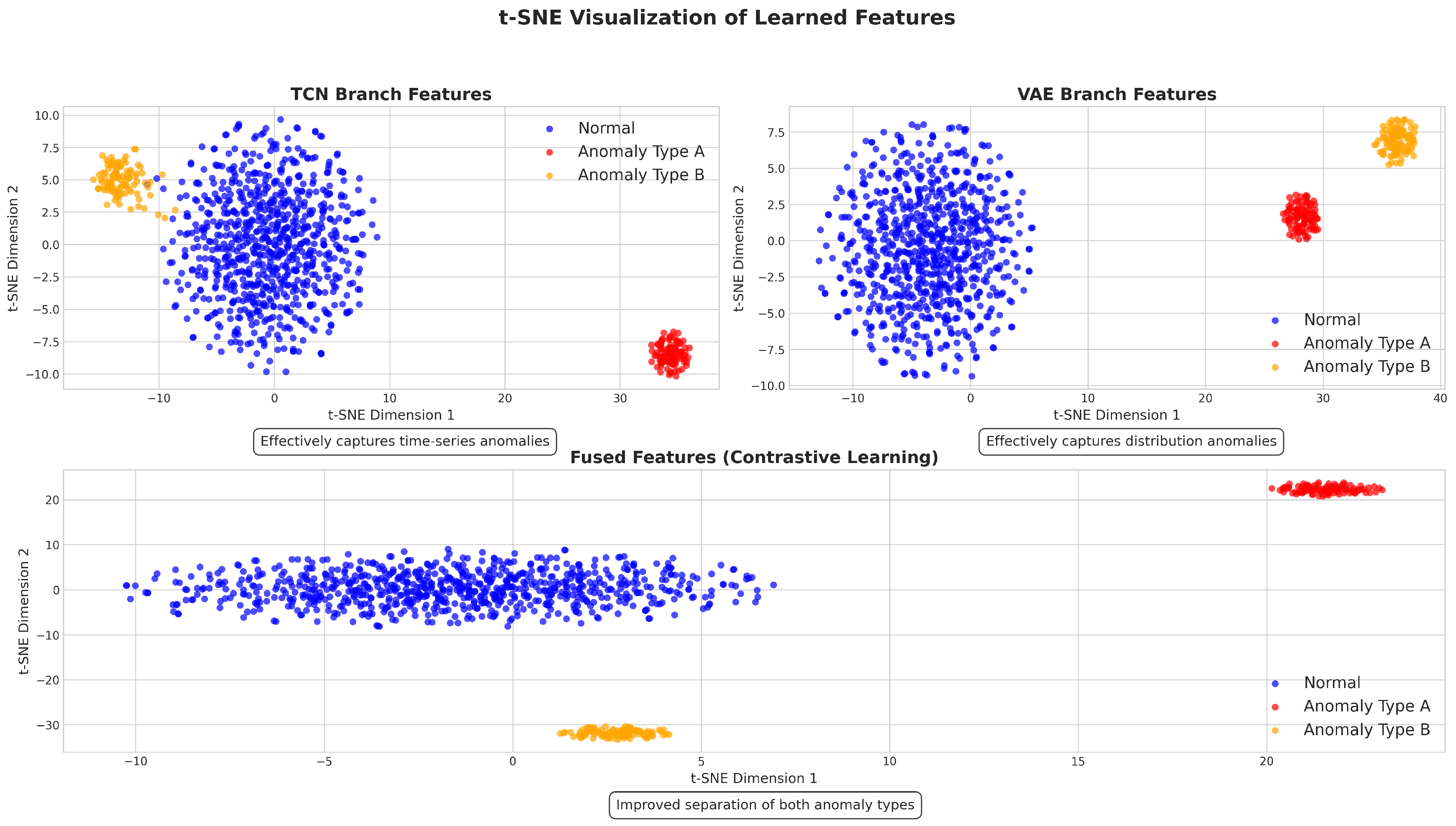
3.2.4. Contrastive Learning
4. Methodology
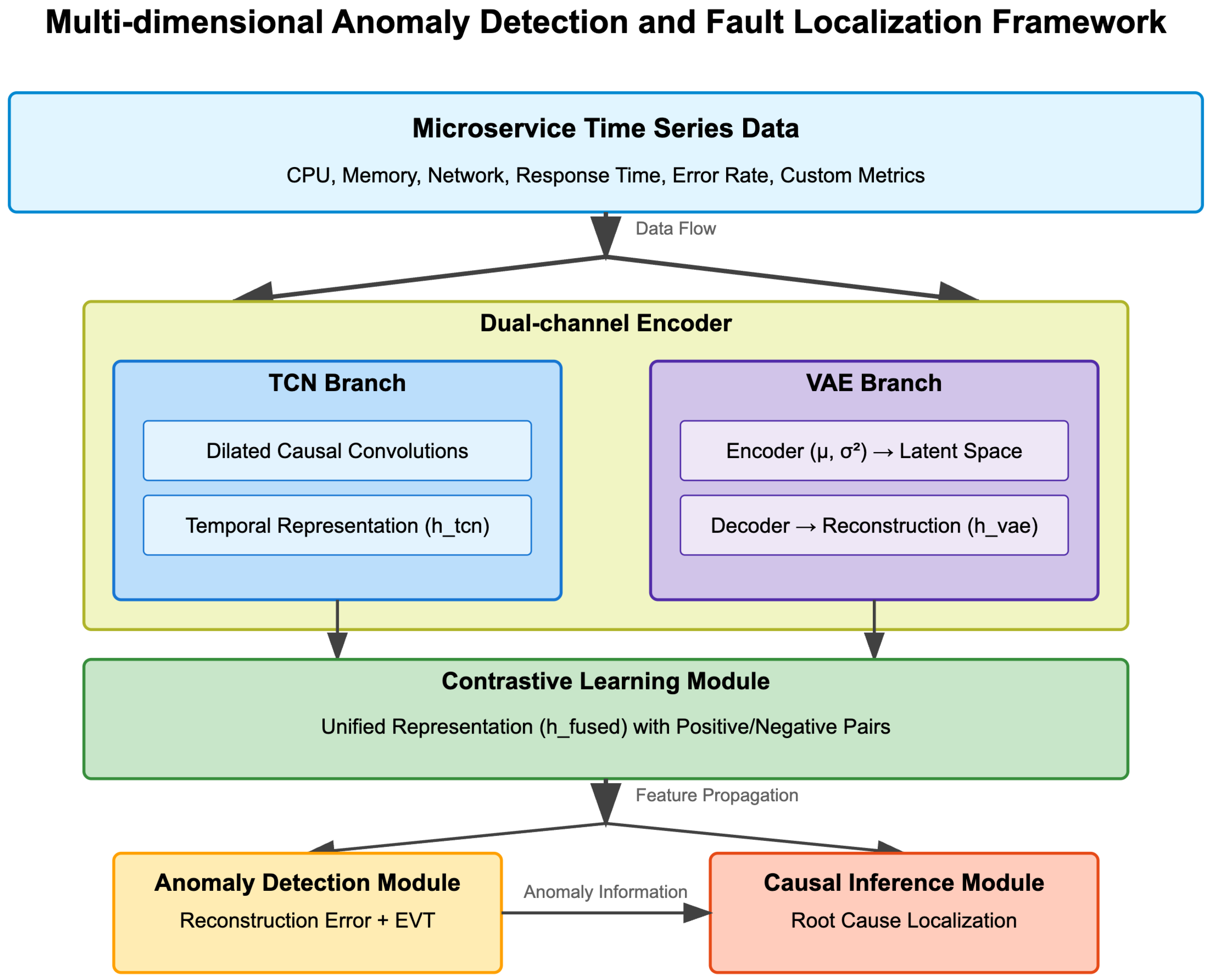
4.1. Framework Overview
4.2. Dual-Channel Encoder for Sensed Time Series
4.2.1. TCN Branch
4.2.2. VAE Branch
4.3. Contrastive Learning for Heterogeneous Sensed Metric Fusion
4.4. Anomaly Detection
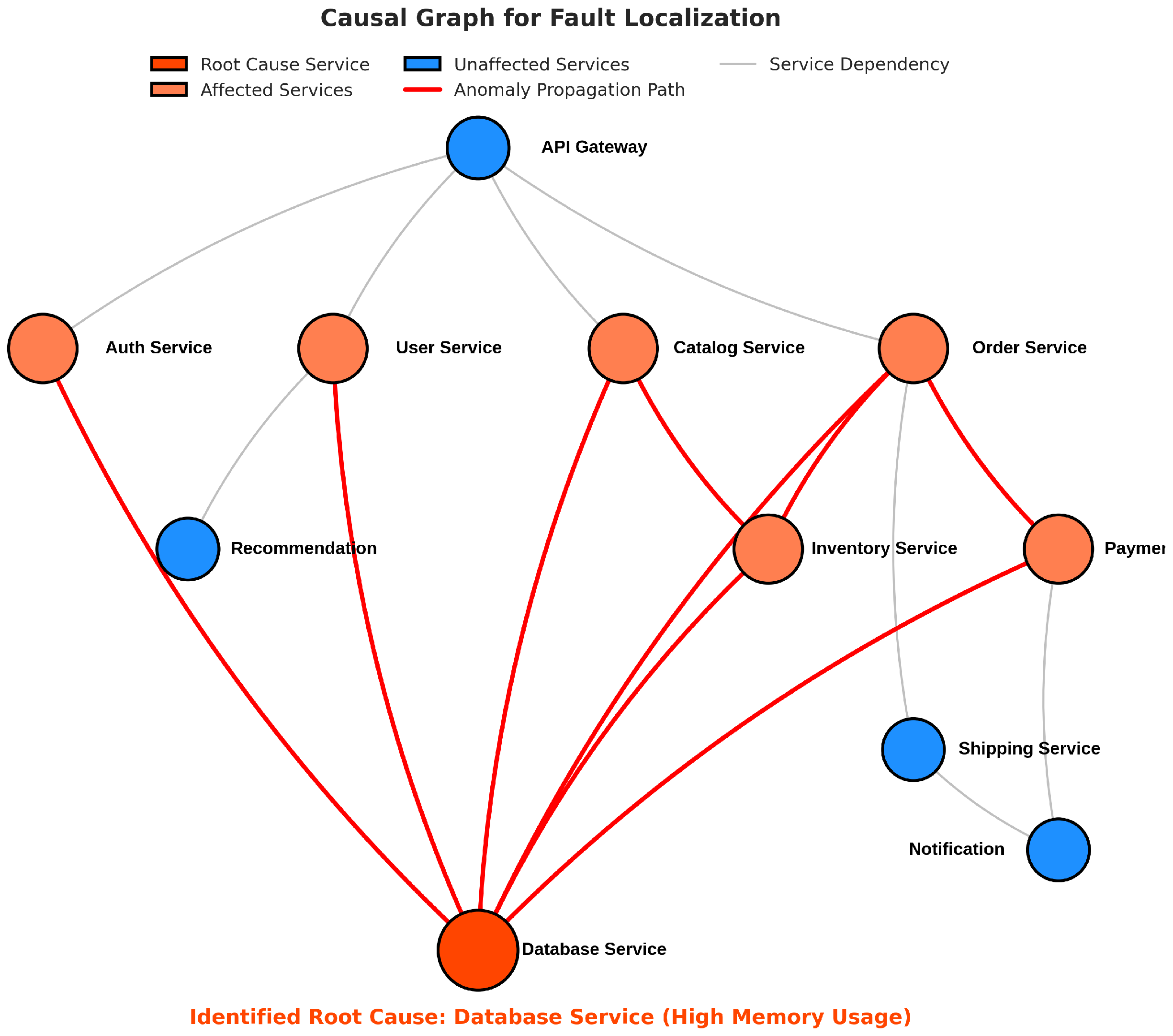
4.5. Causal Inference for Fault Localization
4.5.1. Causal Structure Learning
- Start with the prior dependency graph (which may be incomplete or contain errors).
- For each pair of services , test their conditional independence given increasing sets of conditioning variables using partial correlation tests with a significance level = 0.05.
- Remove edges between i and j if they are conditionally independent given any subset of other variables, effectively filtering out spurious dependencies.
- Add edges between previously unconnected services i and j if they show a strong conditional dependence that cannot be explained by existing connections.
- Orient the remaining edges based on statistical tests for v-structures and acyclicity constraints.
4.5.2. Causal Effect Estimation
4.6. Training Procedure
- Pretraining: We first pretrain the TCN and VAE branches separately on normal data to learn baseline representations of system behavior.
- Contrastive Learning: Next, we train the contrastive learning module to fuse the embeddings from both branches, using augmented views of the same service’s metrics as positive pairs.
- Joint Optimization: Finally, we jointly optimize the entire framework using a combined loss function:where is the mean squared error for the TCN’s prediction, is a structure learning loss that encourages sparse and interpretable causal graphs, and are hyperparameters that control the contribution of each loss term.
5. Experiments
5.1. Experimental Setup
5.1.1. Dataset
5.1.2. Baseline Methods
- LSTM-VAE [43]: Combines LSTM networks with variational autoencoders to model temporal dependencies and reconstruct normal patterns.
- MSCRED [24]: Uses convolutional networks to capture spatial and temporal correlations in multivariate time series through signature matrices.
- OmniAnomaly [29]: Integrates stochastic recurrent neural networks with planar normalizing flows for multivariate time series anomaly detection.
- InterFusion [44]: Employs a Transformer-based architecture to model intra-metric and inter-metric correlations for multivariate time series anomaly detection.
- TranAD [45]: Utilizes an adversarial framework with Transformer-based architecture for real-time anomaly detection.
- MicroCause [46]: Builds causal graphs from service dependencies and trace data to identify the root causes of anomalies.
- CloudRanger [31]: Uses statistical correlation analysis and graph-based propagation to trace the root cause of performance anomalies.
- MicroRCA [7]: Combines random forest classifiers with service topology information for root cause analysis.
- MIDAS [32]: Employs autoencoders with attention mechanisms to identify anomalous services and localize faults.
- CausalRCA [33]: Applies causal discovery algorithms to infer causal relationships between metrics and identify root causes.
- TCN-only: Used only the TCN branch for anomaly detection and a simplified causal model for fault localization.
- VAE-only: Used only the VAE branch for anomaly detection and a simplified causal model for fault localization.
- No-Contrastive: Used both TCN and VAE branches but without the contrastive learning module for feature fusion.
- No-Causal: Used the full anomaly detection component but replaced the causal inference module with a simple correlation-based approach.
5.1.3. Evaluation Metrics
5.1.4. Implementation Details
5.2. Experimental Results
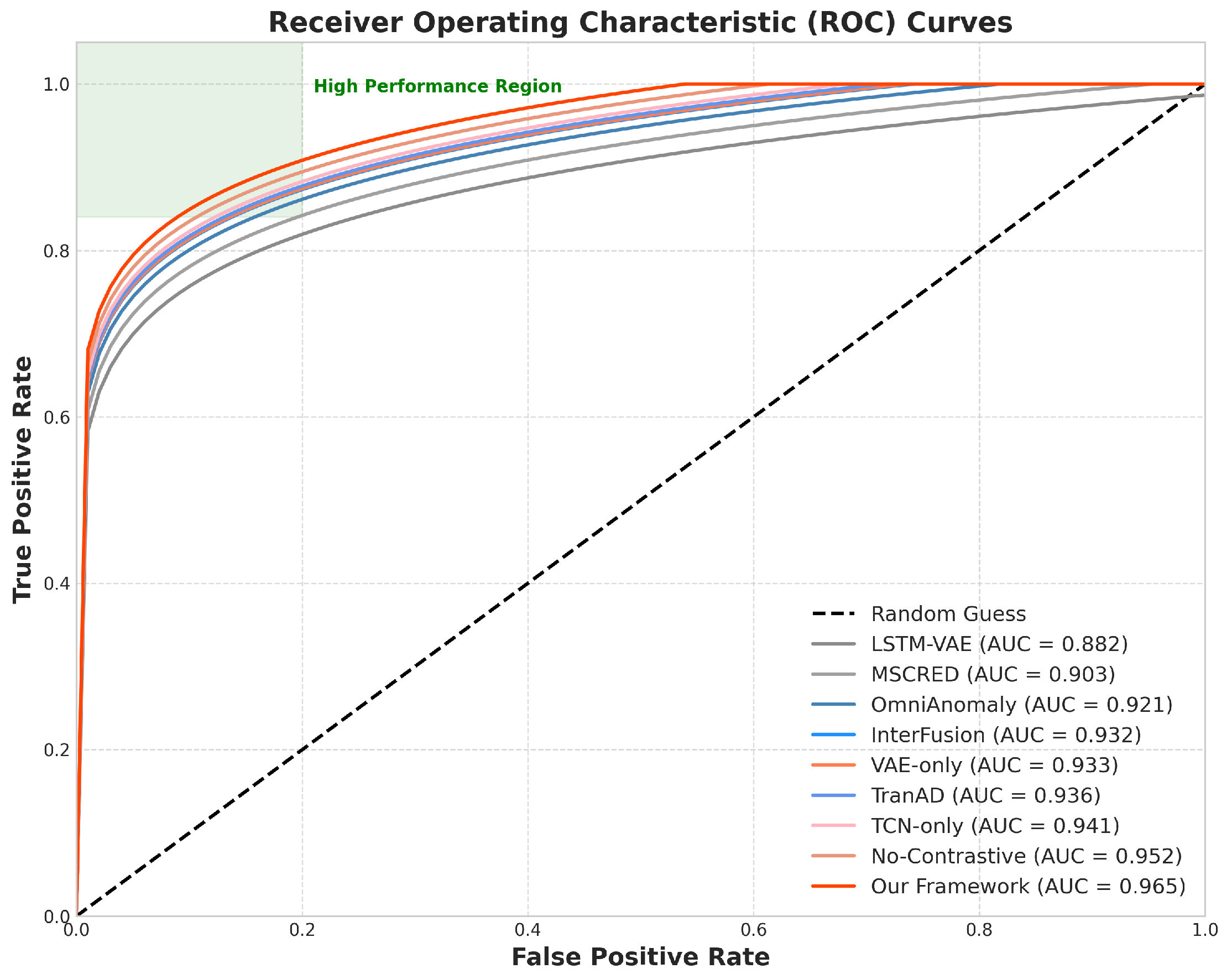
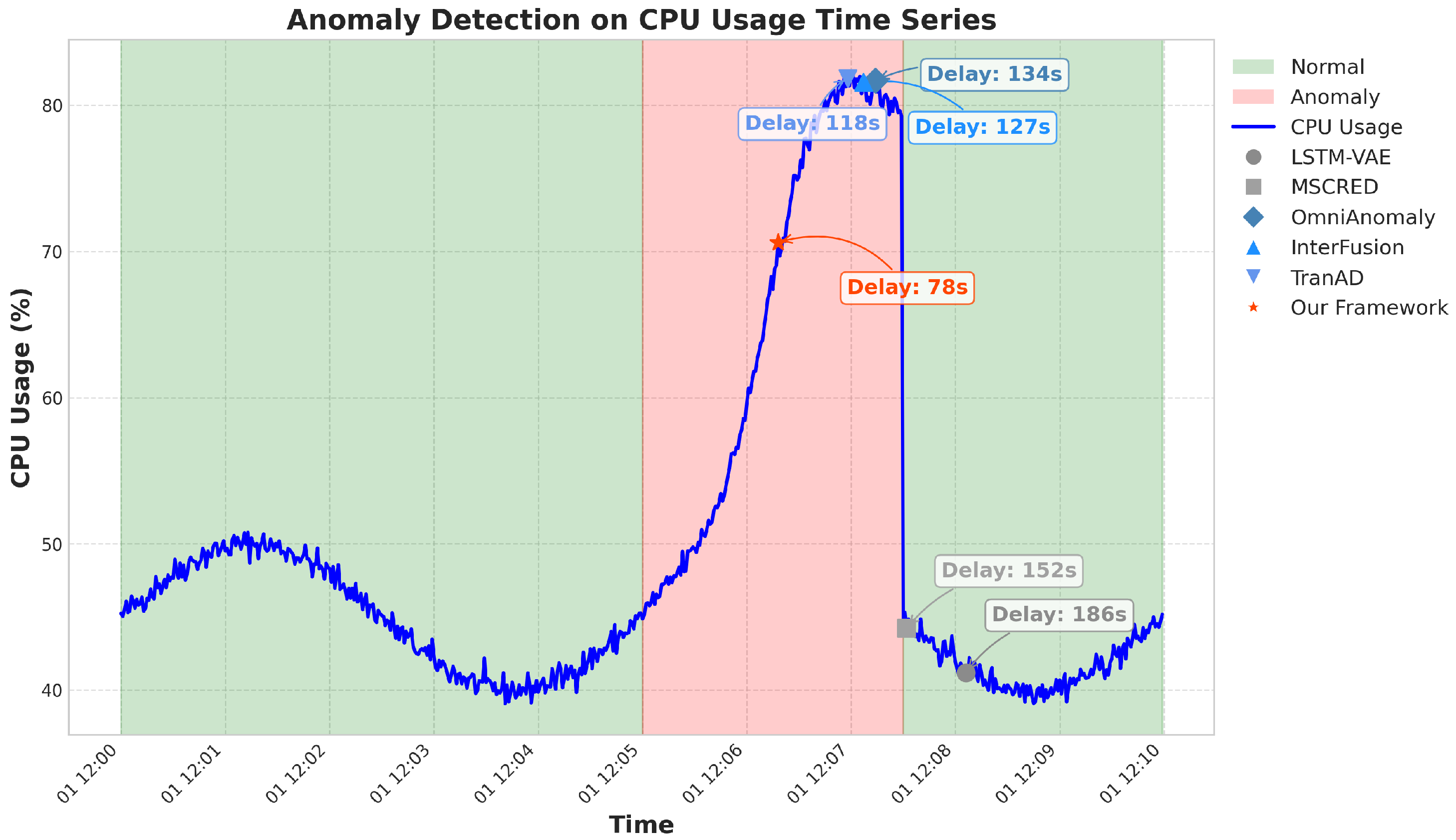
5.2.1. Anomaly Detection Performance
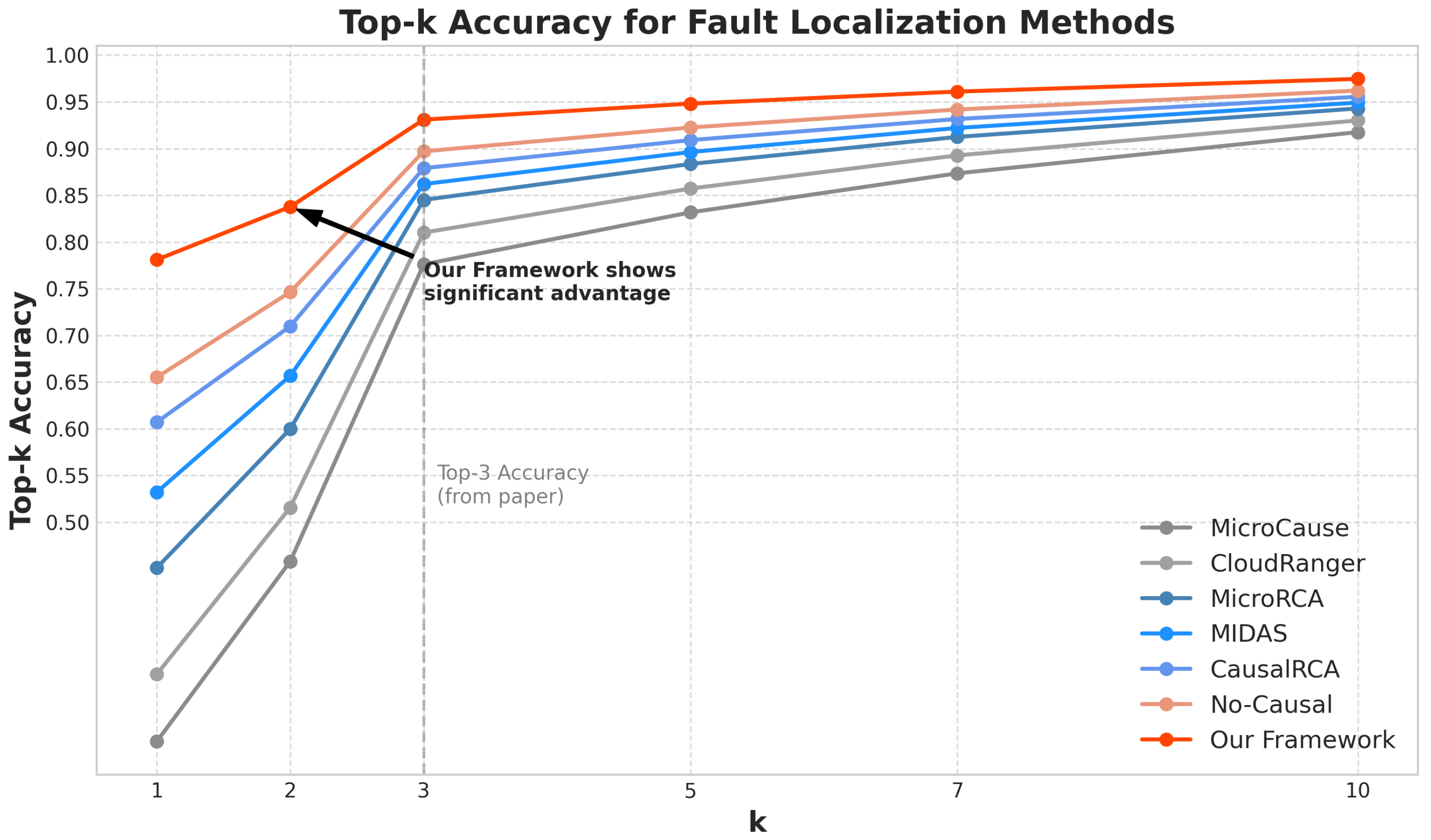
5.2.2. Fault Localization Performance
5.2.3. Ablation Study
5.2.4. Hyperparameter Sensitivity Analysis
5.2.5. Feature Visualization
5.2.6. Computational Efficiency
5.2.7. Robustness Analysis of Causal Module
5.2.8. Cross-Dataset Generalization Analysis
5.2.9. Data Preprocessing Strategy Analysis
5.2.10. Dynamic Topology Evaluation
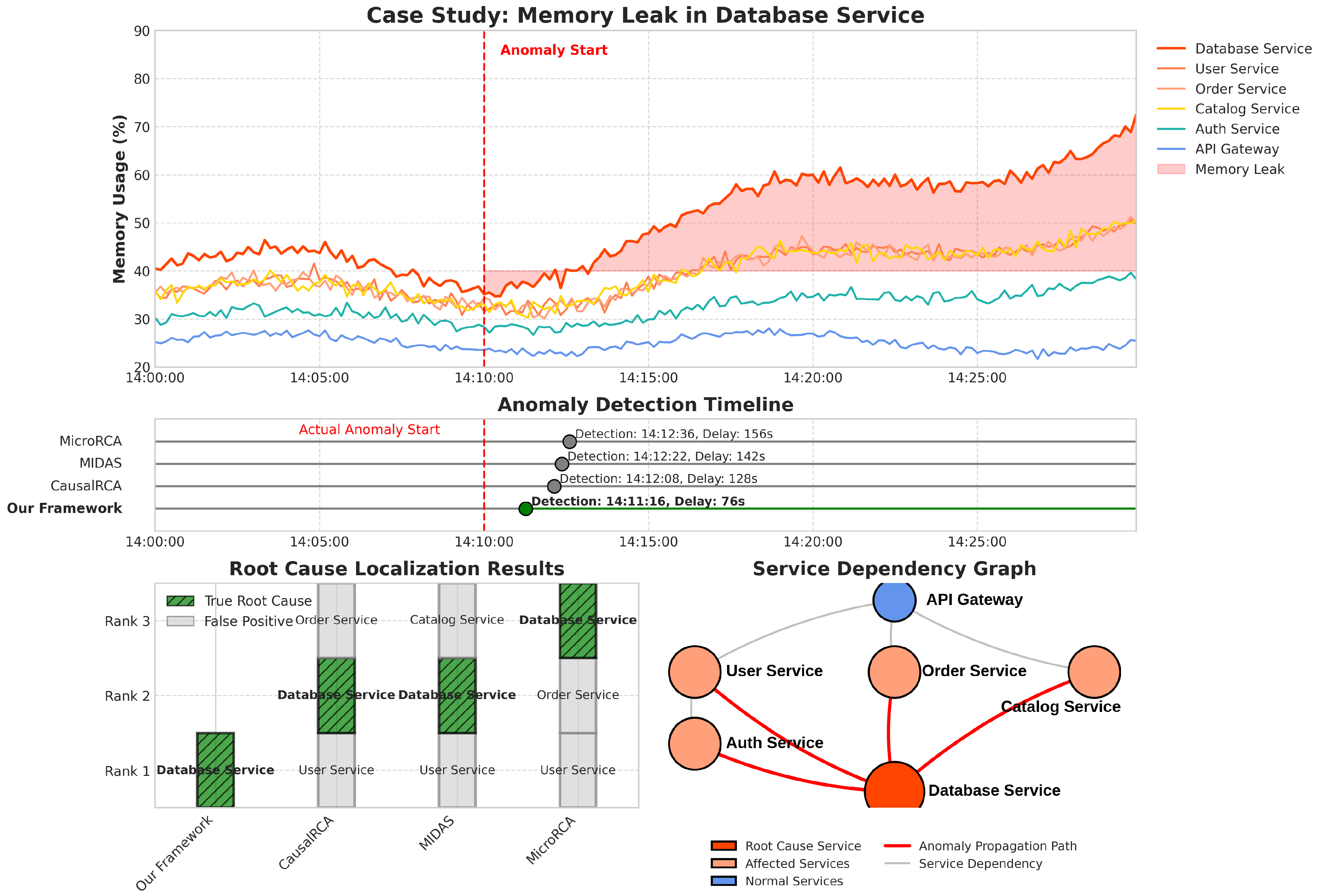
5.3. Case Study
5.4. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dragoni, N.; Giallorenzo, S.; Lafuente, A.L.; Mazzara, M.; Montesi, F.; Mustafin, R.; Safina, L. Microservices: Yesterday, today, and tomorrow. In Present and Ulterior Software Engineering; Springer: Cham, Switzerland, 2017; pp. 195–216. [Google Scholar]
- Zhou, X.; Peng, X.; Xie, T.; Sun, J.; Ji, C.; Li, W.; Ding, D. Fault analysis and debugging of microservice systems: Industrial survey, benchmark system, and empirical study. IEEE Trans. Softw. Eng. 2018, 47, 243–260. [Google Scholar] [CrossRef]
- Ma, M.; Xu, J.; Wang, Y.; Chen, P.; Zhang, Z.; Wang, P. Automap: Diagnose your microservice-based web applications automatically. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 246–258. [Google Scholar]
- Lin, J.; Chen, P.; Zheng, Z. Microscope: Pinpoint performance issues with causal graphs in micro-service environments. In Proceedings of the International Conference on Service-Oriented Computing, Hangzhou, China, 12–15 November 2018; Springer International Publishing: Cham, Switzerland, 2018; pp. 3–20. [Google Scholar]
- Drayer, E.; Routtenberg, T. Detection of false data injection attacks in power systems with graph fourier transform. In Proceedings of the 2018 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, 26–28 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 890–894. [Google Scholar]
- Yu, G.; Chen, P.; Chen, H.; Guan, Z.; Huang, Z.; Jing, L.; Weng, T.; Sun, X.; Li, X. Microrank: End-to-end latency issue localization with extended spectrum analysis in microservice environments. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3087–3098. [Google Scholar]
- Wu, L.; Tordsson, J.; Elmroth, E.; Kao, O. MicroRCA: Root cause localization of performance issues in microservices. In Proceedings of the NOMS 2020-2020 IEEE/IFIP Network Operations and Management Symposium, Budapest, Hungary, 20–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–9. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 413–422. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.; Smola, A.J.; Williamson, R.C. Estimating the support of a high-dimensional distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly detection: A survey. Acm Comput. Surv. (CSUR) 2009, 41, 1–58. [Google Scholar] [CrossRef]
- Malhotra, P.; Vig, L.; Shroff, G.; Agarwal, P. Long short term memory networks for anomaly detection in time series. In Proceedings of the 23rd European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 22–24 April 2015; Volume 89, p. 94. [Google Scholar]
- Xu, H.; Chen, W.; Zhao, N.; Li, Z.; Bu, J.; Li, Z.; Liu, Y.; Zhao, Y.; Pei, D.; Feng, Y.; et al. Unsupervised anomaly detection via variational auto-encoder for seasonal kpis in web applications. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 187–196. [Google Scholar]
- Li, Z.; Zhao, Y.; Liu, R.; Pei, D. Robust and rapid clustering of kpis for large-scale anomaly detection. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–10. [Google Scholar]
- Kulkarni, S.G.; Liu, G.; Ramakrishnan, K.K.; Wood, T. Living on the edge: Serverless computing and the cost of failure resiliency. In Proceedings of the 2019 IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), Paris, France, 1–3 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Bogner, J.; Wagner, S.; Zimmermann, A. Automatically measuring the maintainability of service-and microservice-based systems: A literature review. In Proceedings of the 27th International Workshop on Software Measurement and 12th International Conference on Software Process and Product Measurement, Gothenburg, Sweden, 25–27 October 2017; pp. 107–115. [Google Scholar]
- Hellerstein, J.M.; Koutsoupias, E.; Papadimitriou, C.H. On the analysis of indexing schemes. In Proceedings of the Sixteenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Tucson, Arizona, 12–14 May 1997; pp. 249–256. [Google Scholar]
- Brutlag, J.D. Aberrant behavior detection in time series for network service monitoring. In Proceedings of the 14th Systems Administration Conference (LISA 2000), New Orleans, LA, USA, 3–8 December 2000. [Google Scholar]
- Cleveland, R.B.; Cleveland, W.; McRae, J.; Terpenning, I. STL: A seasonal-trend decomposition procedure based on loess. J. Off. Stat. 1990, 6, 3–73. [Google Scholar]
- Hodge, V.; Austin, J. A survey of outlier detection methodologies. Artif. Intell. Rev. 2004, 22, 85–126. [Google Scholar] [CrossRef]
- Wang, C.; Viswanathan, K.; Choudur, L.; Talwar, V.; Satterfield, W.; Schwan, K. Statistical techniques for online anomaly detection in data centers. In Proceedings of the 12th IFIP/IEEE International Symposium on Integrated Network Management (IM 2011) and Workshops, Dublin, Ireland, 23–27 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 385–392. [Google Scholar]
- Soldani, J.; Tamburri, D.A.; Van Den Heuvel, W.J. The pains and gains of microservices: A systematic grey literature review. J. Syst. Softw. 2018, 146, 215–232. [Google Scholar] [CrossRef]
- Ma, M.; Lin, W.; Pan, D.; Wang, P. Ms-rank: Multi-metric and self-adaptive root cause diagnosis for microservice applications. In Proceedings of the 2019 IEEE International Conference on Web Services (ICWS), Milan, Italy, 8–13 July 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 60–67. [Google Scholar]
- Du, M.; Li, F.; Zheng, G.; Srikumar, V. Deeplog: Anomaly detection and diagnosis from system logs through deep learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 1285–1298. [Google Scholar]
- Zhang, C.; Song, D.; Chen, Y.; Feng, X.; Lumezanu, C.; Cheng, W.; Ni, J.; Zong, B.; Chen, H.; Chawla, N.V. A deep neural network for unsupervised anomaly detection and diagnosis in multivariate time series data. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 1409–1416. [Google Scholar]
- Munir, M.; Siddiqui, S.A.; Dengel, A.; Ahmed, S. DeepAnT: A deep learning approach for unsupervised anomaly detection in time series. IEEE Access 2018, 7, 1991–2005. [Google Scholar] [CrossRef]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the MLSDA 2014 2nd Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, Australia, 2 December 2014; pp. 4–11. [Google Scholar]
- An, J.; Cho, S. Variational autoencoder based anomaly detection using reconstruction probability. Spec. Lect. IE 2015, 2, 1–18. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Su, Y.; Zhao, Y.; Niu, C.; Liu, R.; Sun, W.; Pei, D. Robust anomaly detection for multivariate time series through stochastic recurrent neural network. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2828–2837. [Google Scholar]
- Chen, P.; Qi, Y.; Zheng, P.; Hou, D. Causeinfer: Automatic and distributed performance diagnosis with hierarchical causality graph in large distributed systems. In Proceedings of the IEEE INFOCOM 2014-IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1887–1895. [Google Scholar]
- Wang, P.; Xu, J.; Ma, M.; Lin, W.; Pan, D.; Wang, Y.; Chen, P. Cloudranger: Root cause identification for cloud native systems. In Proceedings of the 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Washington, DC, USA, 1–4 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 492–502. [Google Scholar]
- Bhatia, S.; Hooi, B.; Yoon, M.; Shin, K.; Faloutsos, C. Midas: Microcluster-based detector of anomalies in edge streams. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 3242–3249. [Google Scholar]
- Xin, R.; Chen, P.; Zhao, Z. Causalrca: Causal inference based precise fine-grained root cause localization for microservice applications. J. Syst. Softw. 2023, 203, 111724. [Google Scholar] [CrossRef]
- Tunde-Onadele, O.; Qin, F.; Gu, X.; Lin, Y. ClearCausal: Cross Layer Causal Analysis for Automatic Microservice Performance Debugging. In Proceedings of the 2024 IEEE International Conference on Autonomic Computing and Self-Organizing Systems (ACSOS), Aarhus, Denmark, 16–20 September 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 175–180. [Google Scholar]
- Zhu, Y.; Wang, J.; Li, B.; Zhao, Y.; Zhang, Z.; Xiong, Y.; Chen, S. Microirc: Instance-level root cause localization for microservice systems. J. Syst. Softw. 2024, 216, 112145. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Pearl, J. Understanding propensity scores. Causality Model. Reason. Inference 2009, 2, 348–352. [Google Scholar]
- Spirtes, P.; Glymour, C.N.; Scheines, R. Causation, Prediction, and Search; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Chickering, D.M. Optimal structure identification with greedy search. J. Mach. Learn. Res. 2002, 3, 507–554. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Online, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Siffer, A.; Fouque, P.A.; Termier, A.; Largouet, C. Anomaly detection in streams with extreme value theory. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 1067–1075. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Park, D.; Hoshi, Y.; Kemp, C.C. A multimodal anomaly detector for robot-assisted feeding using an lstm-based variational autoencoder. IEEE Robot. Autom. Lett. 2018, 3, 1544–1551. [Google Scholar] [CrossRef]
- Li, D.; Chen, D.; Jin, B.; Shi, L.; Goh, J.; Ng, S.K. MAD-GAN: Multivariate anomaly detection for time series data with generative adversarial networks. In Proceedings of the International Conference on Artificial Neural Networks, Munich, Germany, 17–19 September 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 703–716. [Google Scholar]
- Tuli, S.; Casale, G.; Jennings, N.R. Tranad: Deep transformer networks for anomaly detection in multivariate time series data. arXiv 2022, arXiv:2201.07284. [Google Scholar] [CrossRef]
- Meng, Y.; Zhang, S.; Sun, Y.; Zhang, R.; Hu, Z.; Zhang, Y.; Jia, C.; Wang, Z.; Pei, D. Localizing failure root causes in a microservice through causality inference. In Proceedings of the 2020 IEEE/ACM 28th International Symposium on Quality of Service (IWQoS), Hangzhou, China, 15–17 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–10. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristic | MultiDimension | AIOps-2020 | MicroSim |
|---|---|---|---|
| Number of services | 21 | 26 | 10/30/50 |
| Metrics per service | 19 | 15 | 12 |
| Total time series | 399 | 390 | 120/360/600 |
| Monitoring period | 2 weeks | 3 weeks | 4 weeks |
| Sampling interval | 1 min | 2 min | 1 min |
| Anomaly cases | 58 | 72 | 150 |
| Anomaly types | 4 types | 5 types | 4 types |
| System domain | General | E-commerce | Simulated |
| Data source | Real production | Real production | Synthetic |
| Method | Precision | Recall | F1-Score | AUC-ROC | Delay (s) |
|---|---|---|---|---|---|
| LSTM-VAE | |||||
| MSCRED | |||||
| OmniAnomaly | |||||
| InterFusion | |||||
| TranAD | |||||
| TCN-only (ours) | |||||
| VAE-only (ours) | |||||
| No-Contrastive (ours) | |||||
| Our Framework |
| Method | Precision | Recall | F1-Score | Top-3 Acc. | Mean Rank |
|---|---|---|---|---|---|
| MicroCause | |||||
| CloudRanger | |||||
| MicroRCA | |||||
| MIDAS | |||||
| CausalRCA | |||||
| No-Causal (ours) | |||||
| Our Framework |
| Configuration | Detection F1 | Detection Delay | Local. F1 | Mean Rank |
|---|---|---|---|---|
| Full Framework | s | |||
| TCN-only | s | |||
| VAE-only | s | |||
| No-Contrastive | s | |||
| No-Causal | s | |||
| No-Adaptive Threshold | s | |||
| No-EVT | s |
| Window Length | Detection F1 | Detection Delay (s) | Localization F1 | Training Time (h) | Memory (GB) |
|---|---|---|---|---|---|
| 10 | 7.23 | 3.84 | |||
| 20 | 8.12 | 4.21 | |||
| 30 | 9.34 | 4.92 | |||
| 40 | 11.47 | 6.15 | |||
| 50 | 14.28 | 7.83 |
| Dilation Factors | Detection F1 | Detection Delay (s) | Localization F1 | Receptive Field | Params (M) |
|---|---|---|---|---|---|
| [1] | 3 | 2.1 | |||
| [1,2] | 7 | 4.2 | |||
| [1,2,4] | 15 | 6.3 | |||
| [1,2,4,8] | 31 | 8.4 | |||
| [2,4,8] | 28 | 6.3 |
| Latent Dim | Detection F1 | Detection Delay (s) | Localization F1 | Reconstruction Loss | KL Divergence |
|---|---|---|---|---|---|
| 8 | |||||
| 16 | |||||
| 32 | |||||
| 64 | |||||
| 128 |
| Temperature | Detection F1 | Detection Delay (s) | Localization F1 | Contrastive Loss | Training Stability |
|---|---|---|---|---|---|
| 0.01 | Unstable | ||||
| 0.05 | Stable | ||||
| 0.07 | Stable | ||||
| 0.1 | Stable | ||||
| 0.2 | Stable | ||||
| 0.5 | Stable |
| Method | Training Time (h) | Inference Time (ms) | Memory (GB) |
|---|---|---|---|
| LSTM-VAE | 5.23 | 28.4 | 3.86 |
| MSCRED | 6.78 | 34.2 | 4.12 |
| OmniAnomaly | 7.42 | 32.1 | 4.35 |
| InterFusion | 8.15 | 37.6 | 4.67 |
| TranAD | 6.92 | 25.8 | 3.98 |
| MicroCause | – | 45.3 | 2.76 |
| CloudRanger | – | 38.7 | 2.45 |
| MicroRCA | 3.56 | 42.1 | 3.12 |
| MIDAS | 4.87 | 40.5 | 3.65 |
| CausalRCA | 5.12 | 43.8 | 3.42 |
| Our Framework | 9.34 | 46.2 | 4.92 |
| Missing Edges | Localization F1 | Localization Precision | Localization Recall | Top-3 Accuracy | Mean Rank |
|---|---|---|---|---|---|
| 0% (Complete) | |||||
| 10% | |||||
| 20% | |||||
| 30% | |||||
| 40% | |||||
| 50% |
| False Edges | Localization F1 | Localization Precision | Localization Recall | Top-3 Accuracy | Mean Rank |
|---|---|---|---|---|---|
| 0% (Clean) | |||||
| 5% | |||||
| 10% | |||||
| 15% | |||||
| 20% | |||||
| 25% |
| Dependency Age | Localization F1 | Localization Precision | Localization Recall | Top-3 Accuracy | Mean Rank |
|---|---|---|---|---|---|
| Current (0 days) | |||||
| 1 day | |||||
| 3 days | |||||
| 7 days | |||||
| 14 days |
| Scenario | Missing | Noise | Age | Localization F1 |
|---|---|---|---|---|
| Perfect Graph | 0% | 0% | 0 days | |
| Mild Degradation | 10% | 5% | 1 day | |
| Moderate Degradation | 20% | 10% | 3 days | |
| Severe Degradation | 30% | 15% | 7 days | |
| Extreme Degradation | 40% | 20% | 14 days |
| Method | Transfer Type | AIOps-2020 | MicroSim-30 | ||
|---|---|---|---|---|---|
| Detection F1 | Local. F1 | Detection F1 | Local. F1 | ||
| LSTM-VAE | Same-dataset | ||||
| Direct transfer | |||||
| Fine-tuned | |||||
| OmniAnomaly | Same-dataset | ||||
| Direct transfer | |||||
| Fine-tuned | |||||
| CausalRCA | Same-dataset | ||||
| Direct transfer | |||||
| Fine-tuned | |||||
| Same-dataset | |||||
| Our Framework | Direct transfer | ||||
| Fine-tuned | |||||
| Services | Detection F1 | Detection Delay (s) | Localization F1 | Training Time (h) | Inference Time (ms) |
|---|---|---|---|---|---|
| 10 | 4.23 | 28.4 | |||
| 30 | 9.34 | 46.2 | |||
| 50 | 16.78 | 72.6 |
| Configuration | Detection F1 | Localization F1 |
|---|---|---|
| Full Framework (Direct) | ||
| TCN-only (Direct) | ||
| VAE-only (Direct) | ||
| No-Contrastive (Direct) | ||
| No-Causal (Direct) | ||
| Full Framework (Fine-tuned) | ||
| No-Contrastive (Fine-tuned) |
| Strategy | 5% Missing | 10% Missing | 15% Missing | 20% Missing | ||||
|---|---|---|---|---|---|---|---|---|
| Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | |
| No Imputation | ||||||||
| Forward Fill | ||||||||
| Backward Fill | ||||||||
| Linear Interp. | ||||||||
| Mean Imputation | ||||||||
| Median Imputation | ||||||||
| KNN Imputation | ||||||||
| Strategy | SNR: 40 dB | SNR: 30 dB | SNR: 20 dB | SNR: 10 dB | ||||
|---|---|---|---|---|---|---|---|---|
| Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | |
| No Filtering | ||||||||
| Gaussian Filter | ||||||||
| Moving Average | ||||||||
| Savitzky–Golay | ||||||||
| Median Filter | ||||||||
| Wavelet Denoising | ||||||||
| Imputation | Denoising | Detection F1 | Localization F1 | Processing Time (ms) |
|---|---|---|---|---|
| Forward Fill | Gaussian Filter | |||
| Forward Fill | Moving Average | |||
| Forward Fill | Savitzky–Golay | |||
| Linear Interp. | Gaussian Filter | |||
| KNN | Gaussian Filter | |||
| KNN | Wavelet Denoising | |||
| Mean | Gaussian Filter | |||
| No Imputation | No Filtering |
| Strategy | Processing Time (ms) | Memory Overhead (%) | CPU Usage (%) | Scalability |
|---|---|---|---|---|
| Imputation Methods: | ||||
| Forward Fill | Excellent | |||
| Backward Fill | Excellent | |||
| Linear Interpolation | Good | |||
| Mean Imputation | Good | |||
| KNN Imputation | Moderate | |||
| Denoising Methods: | ||||
| Gaussian Filter | Excellent | |||
| Moving Average | Excellent | |||
| Savitzky–Golay | Good | |||
| Median Filter | Good | |||
| Wavelet Denoising | Moderate |
| Change Rate | Detection Performance | Localization Performance | Adaptation Time | |||
|---|---|---|---|---|---|---|
| F1-Score | Delay (s) | F1-Score | Mean Rank | Detection (min) | Localization (min) | |
| Static Baseline | N/A | N/A | ||||
| Low (1/day) | ||||||
| Moderate (3/day) | ||||||
| High (5/day) | ||||||
| Rewiring % | 6-h Interval | 12-h Interval | 24-h Interval | |||
|---|---|---|---|---|---|---|
| Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | |
| 0% (Static) | ||||||
| 10% | ||||||
| 20% | ||||||
| 30% | ||||||
| Change Type | During Transition | Post-Adaptation | Recovery Time | |||
|---|---|---|---|---|---|---|
| Det. F1 | Loc. F1 | Det. F1 | Loc. F1 | Detection | Localization | |
| Service Addition: | ||||||
| Gradual (6 h) | min | min | ||||
| Abrupt | min | min | ||||
| Service Removal: | ||||||
| Gradual (6 h) | min | min | ||||
| Abrupt | min | min | ||||
| Dependency Rewiring: | ||||||
| Gradual (6 h) | min | min | ||||
| Abrupt | min | min | ||||
| Detection Mechanism | Detection Rate | False Positive | Trigger Delay | Adaptation Trigger | Effectiveness |
|---|---|---|---|---|---|
| Correlation Pattern Change | min | High sensitivity | Good | ||
| New Metric Signatures | min | Service addition | Excellent | ||
| Prediction Error Spike | min | All change types | Good | ||
| Causal Graph Likelihood | min | Dependency changes | Excellent | ||
| Combined Indicators | min | All types | Outstanding |
| Approach | During Transition | Retraining Required | Downtime | |||
|---|---|---|---|---|---|---|
| Det. F1 | Loc. F1 | Time (hours) | Data Required | Detection | Localization | |
| Our Adaptive Framework | 0.891 ± 0.015 | 0.816 ± 0.019 | 0 | None | 0 min | 0 min |
| LSTM-VAE (Static) | 0.623 ± 0.034 | 0.487 ± 0.041 | 8–12 | Full dataset | 480–720 min | 480–720 min |
| OmniAnomaly (Static) | 0.651 ± 0.031 | 0.509 ± 0.038 | 6–10 | Full dataset | 360–600 min | 360–600 min |
| CausalRCA (Static) | 0.587 ± 0.037 | 0.441 ± 0.044 | 10–15 | Full dataset | 600–900 min | 600–900 min |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, S.; Wang, Y.; Liu, W. Multi-Dimensional Anomaly Detection and Fault Localization in Microservice Architectures: A Dual-Channel Deep Learning Approach with Causal Inference for Intelligent Sensing. Sensors 2025, 25, 3396. https://doi.org/10.3390/s25113396
Xing S, Wang Y, Liu W. Multi-Dimensional Anomaly Detection and Fault Localization in Microservice Architectures: A Dual-Channel Deep Learning Approach with Causal Inference for Intelligent Sensing. Sensors. 2025; 25(11):3396. https://doi.org/10.3390/s25113396
Chicago/Turabian StyleXing, Suchuan, Yihan Wang, and Wenhe Liu. 2025. "Multi-Dimensional Anomaly Detection and Fault Localization in Microservice Architectures: A Dual-Channel Deep Learning Approach with Causal Inference for Intelligent Sensing" Sensors 25, no. 11: 3396. https://doi.org/10.3390/s25113396
APA StyleXing, S., Wang, Y., & Liu, W. (2025). Multi-Dimensional Anomaly Detection and Fault Localization in Microservice Architectures: A Dual-Channel Deep Learning Approach with Causal Inference for Intelligent Sensing. Sensors, 25(11), 3396. https://doi.org/10.3390/s25113396