1. Introduction
The task of detecting and regressing the keypoint positions of multiple individuals on data coming from camera sensors is known as multi-person pose estimation. Considerable progress has been made in multi-person pose estimation over the last few years. Methods are generally divided into two categories: non-end-to-end and end-to-end. Top-down [
1,
2,
3,
4,
5,
6], bottom-up [
7,
8,
9,
10], and one-stage model [
11,
12,
13,
14] approaches are examples of non-end-to-end methods.
Top-down methods, which are based on a highly accurate person detector, identify people in an image first and then estimate their poses. Bottom-up methods are effective in crowded environments, as they predict all keypoints in the image and then associate them into individual poses, thus removing the need for explicit detection. One-stage methods predict keypoints and their associations directly, simplifying the process by combining pose estimation and detection into a single step.
Transformers were originally introduced by Vaswani et al. [
15] for machine translation. One of the main advantages of transformers is their global computations and perfect memory, which makes them more suitable than RNNs for long sequences. Using this ability to handle sequences, DETR [
16] modeled the object detection problem as generating a sequence of rectangles, one for each identified object. The same DETR paradigm was then extended to pose estimation, where the four-dimensional representation of the detection box becomes a sequence of joint positions. PRTR [
17] and TFPose [
18] are two seminal examples to which the reader can refer for further details. Inspired by the success of DETR, end-to-end methods use transformers to improve accuracy and performance by integrating the entire process into a single framework.
By treating object detection as a direct prediction of a set of objects, these techniques transform multi-person pose estimation and eliminate the need for post-processing steps such as non-maximum suppression. GroupPose [
19] optimizes the pose estimation pipeline and achieves superior performance by using group-specific attention mechanisms to refine interactions between keypoint and instance queries.
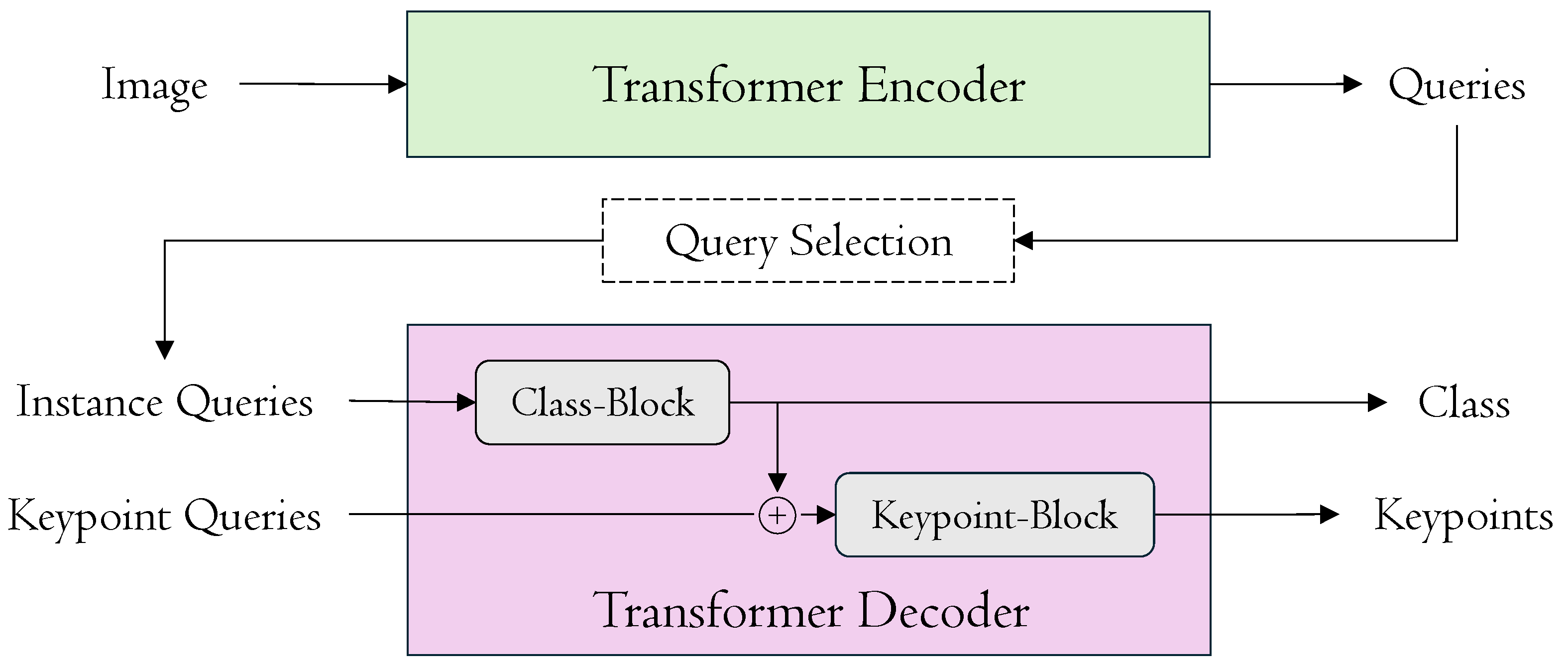
We build on this line of work and introduce a new and effective framework for end-to-end multi-person pose estimation called DualPose, as depicted in
Figure 1. DualPose presents significant innovations that improve computational effectiveness and accuracy. First, we modify the transformer decoder architecture by employing two distinct blocks: one for processing class prediction and the other for keypoint localization. Inspired by GroupPose [
19], we use
keypoint queries to regress
positions and
N class queries to categorize human poses. For class queries, the Class-Block transformer accurately identifies and categorizes the people in the input image. The output of this Class-Block transformer is then added to the Keypoint-Block transformer, providing more comprehensive contextual information. Furthermore, in comparison to conventional sequential processing, we introduce an improved strategy within the Keypoint-Block by employing a novel parallel computation technique for self-attentions to enhance both efficiency and accuracy.
To stabilize training and improve effectiveness, DualPose also includes a contrastive denoising (CDN) mechanism [
20]. This contrastive method improves the model’s ability to differentiate real and false keypoints. We use two hyperparameters to control the noise scale, generating positive samples with lower noise levels (to reconstruct their corresponding ground-truth keypoint positions) and negative samples with heavily distorted poses, which the model learns to predict as “no pose”. Both types of samples are generated based on ground-truth data. Furthermore, we present a novel adaptation, inherited from object detection [
20], by combining both L1 and object keypoint similarity (OKS) as reconstruction losses. The L1 loss ensures fine-grained accuracy in keypoint localization, while the OKS loss accounts for variations in human pose structure and aligns the predicted keypoints with ground-truth annotations.
Experimental results demonstrate that our novel approach, DualPose, outperforms recent end-to-end methods on both MS COCO [
21] and CrowdPose [
22] datasets. Specifically, DualPose achieves an AP of 71.2 with ResNet-50 [
5] and 73.4 with Swin-Large [
23] on the MS COCO
val2017 dataset.
In this work, we introduce key innovations that improve the accuracy and effectiveness of multi-person pose estimation: nolistsep
DualPose uses a dual-block decoder to separate class prediction from keypoint localization, reducing task interference.
Parallel self-attention in the keypoint block improves effectiveness and precision.
A contrastive denoising mechanism enhances robustness by helping the model distinguish between real and noisy keypoints.
L1 and OKS losses are applied exclusively for keypoint reconstruction, rather than for bounding boxes as in object detection.
2. Related Work
Multi-person pose estimation has seen substantial advances, with methodologies commonly divided into non-end-to-end and end-to-end approaches. Non-end-to-end methods include top-down and bottom-up strategies, as well as one-stage models. End-to-end methods integrate the entire process into a single streamlined framework.
2.1. Non-End-to-End Methods
Non-end-to-end approaches for multi-person pose estimation encompass both top-down [
1,
2,
3,
4,
6,
24] and bottom-up [
7,
8,
9,
10] methods.
Top-down methods identify individual subjects in an image and then estimate their poses. However, the accuracy of person detection is a major factor in how effectively they perform especially in busy or obscure environments. The two-step procedure also amplifies the risk of error propagation and increases processing complexity.
Bottom-up methods detect all keypoints first and then associate them to form poses. This approach is more efficient in crowded scenes, but adds complexity during keypoint association, often resulting in reduced accuracy in challenging scenarios.
We also include in this section the recent methods that make use of diffusion models, such as DiffusionRegPose [
25],
Di2Pose [
26]: the best performances are in fact obtained by exploiting their iterative capacity for continuous improvement of the result. Therefore, they are not able to produce the final results in a single step. Moreover, they require an initial (random) seed posture as a first step for each detected person, falling in the top-down category. However, we believe they are of great importance, especially for their ability to generate multiple hypotheses, thus exploiting all the potential of probabilistic methods.
One-stage methods [
11,
12,
13,
14,
27] streamline pose estimation by combining detection and pose estimation into a single step. These models directly predict keypoints and their associations from the input image, eliminating intermediate stages such as person detection or keypoint grouping.
2.2. End-to-End Methods
End-to-end methods [
19,
28,
29,
30] revolutionize multi-person pose estimation by integrating the entire pipeline into a single, unified model. Inspired by detection transformer (DETR) [
16], which pioneered the use of transformers for object detection, along with its variants [
20,
31,
32,
33,
34,
35], these methods streamline the process and improve accuracy.
PETR [
28] employs a transformer-based architecture to solve multi-person pose estimation as a hierarchical set prediction problem, first regressing poses using a pose decoder and then refining keypoints using a keypoint decoder. QueryPose [
29] adopts a sparse query-based framework to perform human detection and pose estimation, eliminating the need for dense representations and complex post-processing. ED-Pose [
30] integrates explicit keypoint box detection to unify global (human-level) and local (keypoint-level) information, enhancing both efficiency and accuracy through a dual-decoder architecture. GroupPose [
19] uses group-specific attention to refine keypoint and instance query interactions, optimizing the process and achieving superior performance with one simple transformer decoder.
These methods have limitations: PETR struggles with keypoint precision and high computational costs, ED-Pose adds complexity with its dual-decoder, and QueryPose falters with occlusions.
GroupPose still employs a single decoder that mixes classification and keypoint regression, causing task interference in crowded scenes, and its within/across attentions are executed sequentially, adding latency and increasing FLOPs compared with our parallel dual-block design.
Our model addresses these issues with a dual-block transformer that separates class and keypoint predictions, enhancing precision and effectiveness, while the contrastive denoising mechanism improves robustness without added complexity.
Finally, we reiterate that DualPose is currently developed to work on traditional RGB images. Architectures that operate on depth sensors [
36,
37] or on data from radar sensors [
38] have not been taken into consideration.
3. Proposed Method
We propose DualPose, a novel and effective framework for end-to-end multi-person pose estimation. Building on previous end-to-end frameworks [
19,
28,
29,
30], we formulate the multi-person pose estimation task as a set prediction problem. DualPose employs a more advanced dual-block transformer decoder compared to previous approaches, which only use a basic transformer decoder [
31]. This improves accuracy and computational efficiency. In the following sections, we detail the core components of DualPose.
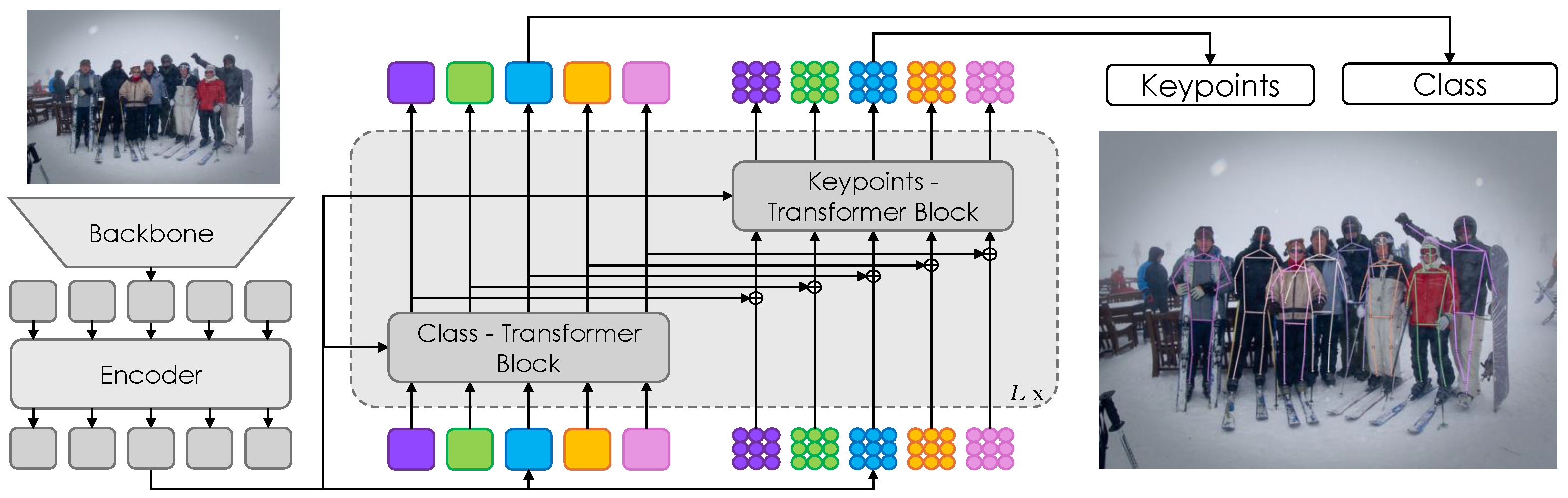
3.1. Overall
The DualPose model consists of four primary components: a backbone [
5,
23], a transformer encoder [
15], a transformer decoder, and task-specific prediction heads. This architecture is designed to simultaneously compute
K keypoints (e.g.,
on MS COCO) for
N human instances in the input image coming from an RGB sensor. Refer to
Figure 2 for the complete model architecture.
3.1.1. Backbone and Transformer Encoder
We follow the DETR framework [
31] to build the transformer encoder and backbone. The model processes an input image and generates multi-level features using six deformable transformer layers [
31]. These features are then sent to the following transformer decoder.
3.1.2. Transformer Decoder
We introduce a dual-query system for the transformer decoder, where N instance queries and keypoint queries are generated. The instance queries classify each person in the image, while the keypoint queries predict the positions of the keypoints for each detected individual. By treating each keypoint independently, these keypoint queries allow for precise regression of the keypoint positions. This separation of tasks enables the model to handle instance detection and keypoint localization more effectively.
Each decoder layer follows the design of previous DETR frameworks, incorporating self-attention, cross-attention implemented with deformable attention, and a feed-forward network (FFN). However, each decoder layer architecture has been extended to include two distinct blocks: one for class prediction and one for keypoint prediction. Unlike GroupPose [
19], where two group self-attentions are computed sequentially, our method computes them in parallel.
3.1.3. Prediction Heads
Following GroupPose [
19], we employ two lightweight three-layer feed-forward heads (hidden width 256) for human classification and key-point regression. The classification head converts each instance query into a soft-max confidence for the human class plus a background label, while the regression head projects the same query embedding to a
-dimensional vector containing the normalized
coordinates of the
K joints. During inference DualPose outputs, for every one of the
N instance queries, both its classification score and the full set of
K keypoint locations; a simple confidence threshold is then applied to discard low-quality poses.
3.1.4. Losses
The loss function in DualPose addresses the assignment of predicted poses to their corresponding ground-truth counterparts using the Hungarian matching algorithm [
16], ensuring a one-to-one mapping between predictions and ground-truth poses. It includes classification loss (
) and keypoint regression loss (
), without additional supervisions such as those in QueryPose [
29] or ED-Pose [
30]. The keypoint regression loss (
) combines
loss and object keypoint similarity (OKS) [
28]. The cost coefficients and loss weights from ED-Pose [
30] are used in Hungarian matching and loss calculation.
The overall loss is then computed as following:
where
and
are the predicted and ground-truth coordinates of joint
j, and
are the weights as defined by Yang et al. [
30].
3.2. Queries
In multi-person pose estimation, the objective is to predict N human poses, each with K keypoint positions for every input image. To achieve this, we use keypoint queries, where each set of K keypoints represents a single pose. Furthermore, N instance queries are used to classify and score the predicted poses, ensuring accurate identification and assessment of each human instance.
3.3. Query Construction
The process begins by identifying human instances and predicting poses using the output memory of the transformer encoder, following previous frameworks [
19,
28,
30]. We select
N instances based on classification scores, resulting in
memory features.
For keypoint queries, each content part () is constructed by combining randomly initialized learnable keypoint embeddings with corresponding memory features. The position part is initialized based on the predicted human poses. Instance queries use randomly initialized learnable instance embeddings () for classification tasks, without explicit position information.
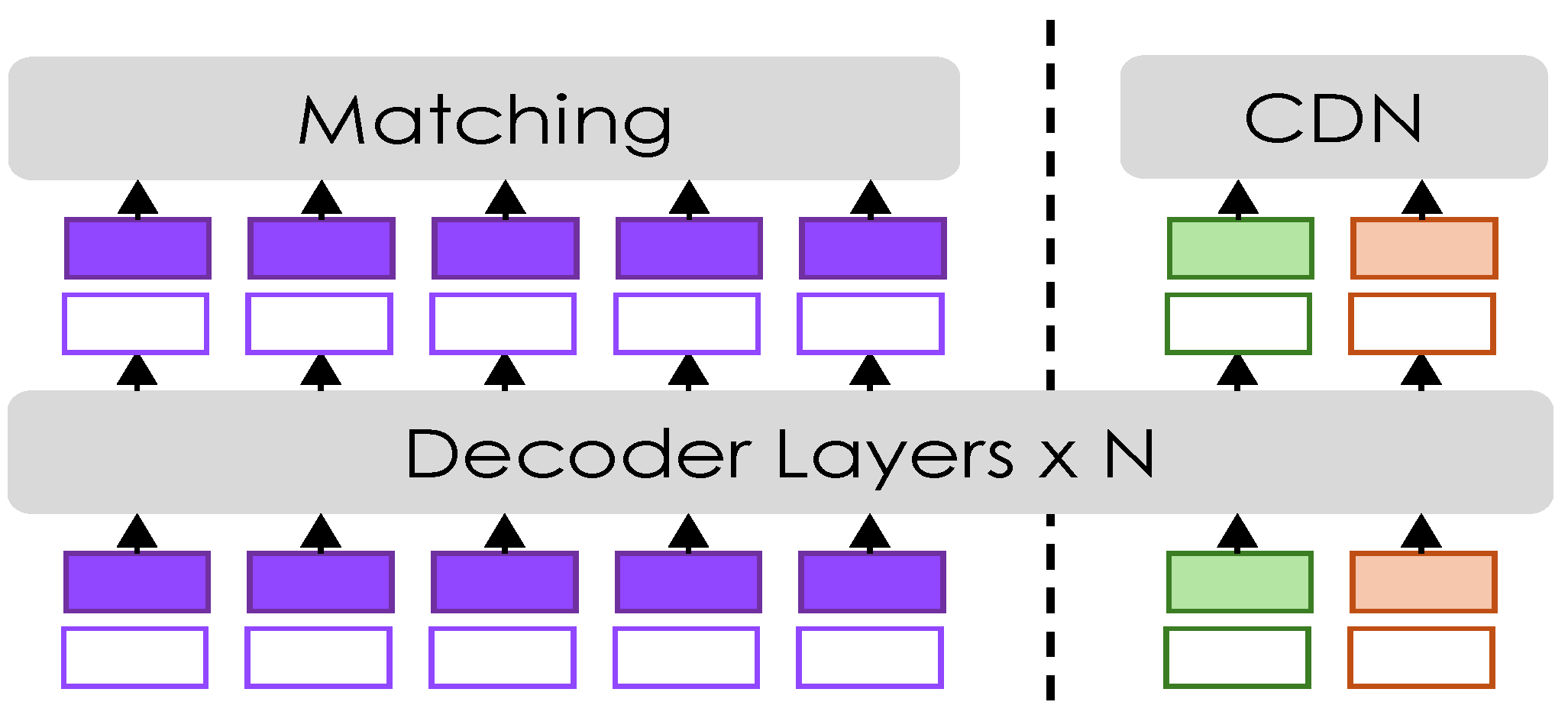
3.4. Contrastive Denoising
In this work, we improve training stability and performance by integrating a contrastive denoising (CDN) mechanism into the transformer decoder. During training, CDN adds controlled noise to the ground-truth labels and poses, helping the model to better distinguish between true and false keypoints. Our approach is inspired by the work of Zhang [
20], which applies CDN to object detection. However, we have adapted it to suit the context of pose estimation, allowing our model to achieve greater robustness in discerning accurate poses from noisy data. A summary schema is shown in
Figure 3.
To this end, we use two different hyperparameters, and , to control the noise scale for keypoints in pose estimation. Here, , ensuring a hierarchy in noise levels. Positive queries are designed to closely reconstruct ground-truth (GT) keypoints and are generated within an inner boundary defined by . Negative queries are meant to predict “no pose”, simulating difficult scenarios that force the model to distinguish between true and false positives. They are placed between the inner and outer boundaries (, ).
Let
be a ground-truth keypoint. We sample
and generate
Positive and negative queries are organized into CDN groups. If the input image contains n ground-truth (GT) poses, each CDN group generates queries, with each GT pose yielding a positive and a negative query. The reconstruction losses are and OKS for keypoint regression, and focal loss for classification. An additional focal loss is used to label negative samples as background.
This contrastive denoising method greatly enhances the model’s performance in multi-person pose estimation by improving its ability to accurately identify keypoints despite varying degrees of noise.
3.5. Dual-Block Decoder
In DETR frameworks [
16,
31,
32], the self-attention of the transformer decoder captures interactions between queries, but processing keypoint regression and class predictions simultaneously can lead to inefficiencies and interference between tasks. This often results in reduced accuracy and precision when handling complex scenes with multiple individuals or occlusions.
To address these issues, we propose a new transformer decoder architecture in DualPose that decouples the computation of keypoints and class predictions into two distinct blocks, allowing each one to process the queries independently and more effectively. This division allows a more specialized handling of the corresponding task, with the Class-Block focused on class prediction and the Keypoint-Block on keypoint localization. This dual-block structure minimizes interference between the different query types, improving accuracy and effectiveness in multi-person pose estimation.
3.5.1. Class-Block
The Class-Block transformer processes class queries independently from keypoint-queries for class prediction. As a result, it can focus on accurately identifying individuals across the image. The output of the Class-Block is then added to the input of the Keypoint-Block, providing richer contextual information.
3.5.2. Keypoint-Block
The Keypoint-Block transformer is designed to handle the prediction of body joints. We incorporate the group self-attention mechanism from GroupPose [
19], but we introduce a new enhancement by processing these self-attentions in parallel. Specifically, the queries, keys, and values are split into two halves, each processed by a separate self-attention mechanism simultaneously. This design boosts effectiveness and accuracy in predicting keypoints, while leveraging the refined contextual information from the Class-Block.
3.5.3. Parallel Group Self-Attention
Let
be the keypoint query matrix (
N people,
K joints each, model width
d). We first split the feature dimension into two equal halves:
For each sub-matrix we build its own triplet () using the same feature for queries, keys and values, as customary in self-attention: . We decompose the full self-attention map into two parallel group-attentions:
Within-group attention: a block of size repeated for every person, so that each K keypoint queries for one instance attend only to each other. This captures the kinematic relations inside one human pose.
Across-group attention: a block of size repeated for every keypoint type. It lets equal-type queries exchange information across different people, enabling duplicate suppression and global context.
Their outputs are concatenated and projected back to the original width:
5. Conclusions
In this paper, we present DualPose, a framework for multi-person pose estimation based on a dual-block transformer decoder architecture. The main contribution is related to the new transformer decoder architecture proposed, which decouples the computation of keypoints and class predictions into two distinct blocks, allowing each one to process the queries independently and more effectively. DualPose enhances accuracy and precision by implementing parallel group self-attentions and distinguishing class from keypoint predictions. Furthermore, training robustness and stability are improved through a contrastive denoising mechanism. These improvements make DualPose an excellent human pose estimation system applicable in all real cases, from industrial to surveillance applications, further enhancing the skills of smart sensors. Comprehensive experiments on MS COCO and CrowdPose demonstrate that DualPose outperforms state-of-the-art techniques.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}