
Deep Reinforcement Learning-Based Energy Consumption Optimization for Peer-to-Peer (P2P) Communication in Wireless Sensor Networks
Abstract
1. Introduction
1.1. Background Description
1.2. Related Works
1.3. Contribution of This Work
2. Overview of WSN and DRL
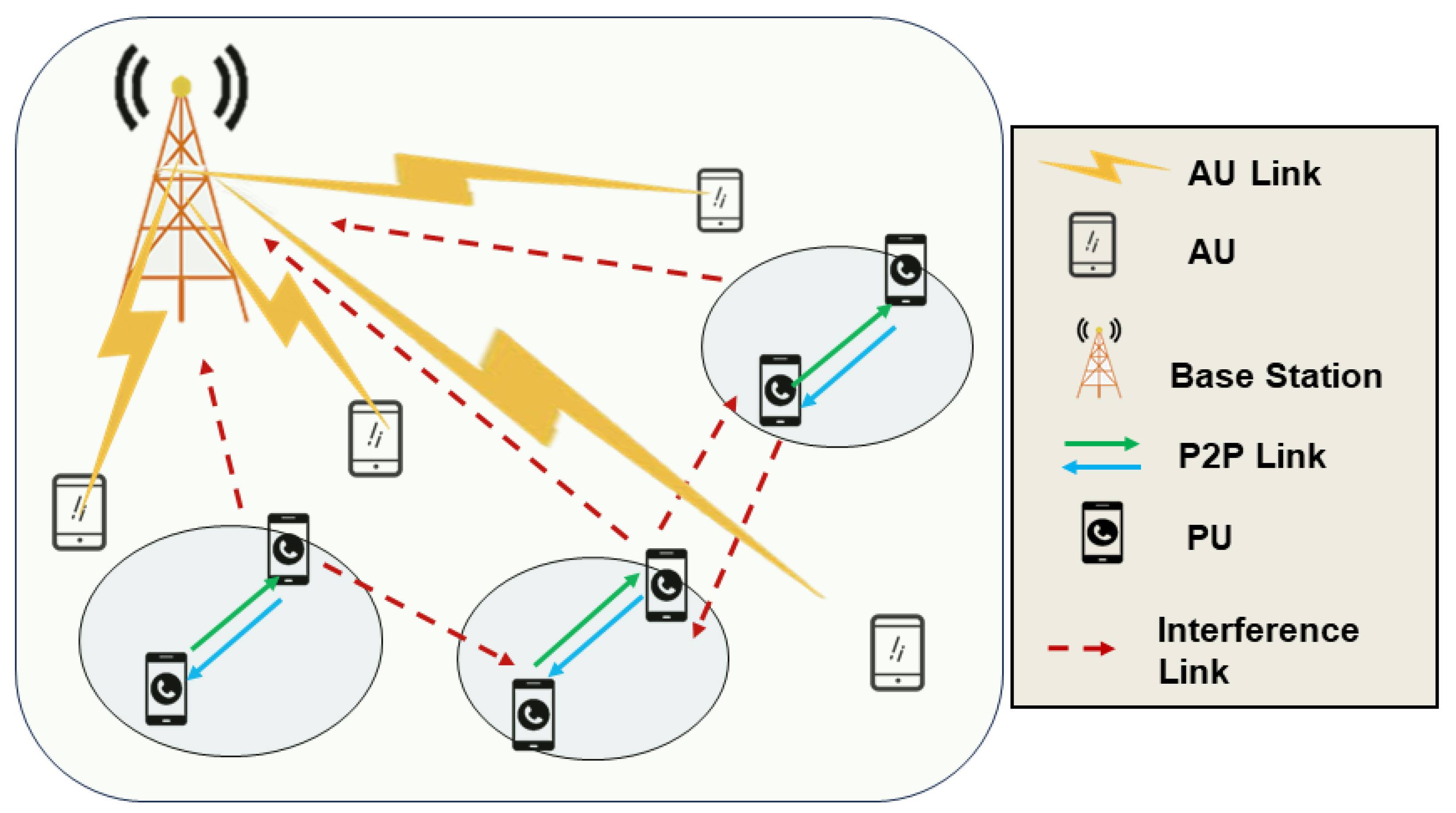
2.1. The New Suture of WSN
2.2. The Basic Theory of DRL
- The agent selects an action to interact with the external environment;
- After the agent performs an action, the system transitions from the current state to another state;
- The system provides the agent with a reward based on the action taken;
- Based on the received reward, the agent learns whether the action is advantageous or detrimental;
- If the action is advantageous, meaning that the intelligent agent receives positive reinforcement, it will tend to select and execute that action. Otherwise, the intelligent agent will attempt to choose alternative actions to obtain positive reinforcement.
- Certain states that the agent can occupy;
- Actions that the agent can choose to transition from the current state to another state;
- Transition probabilities, representing the likelihood of transitioning from the current state to another state based on the chosen action;
- Reward probabilities, indicating the likelihood of transitioning to another state and receiving a reward after the agent takes an action;
- Discount factor, which alters the importance of current and future rewards and will be explained in detail later.
3. System Model
4. Analysis and Problem Formulation
4.1. Analysis of P2P Communication
4.2. Problem Formulation
4.3. DRL-Based Energy Consumption for P2P Communication
5. Distributed Algorithm Based on DDQN
| Algorithm 1: Training process based on DDQN distributed algorithm |
| Input: |
| Environment simulator, DDQN neural network structure. |
| 1: Start: |
| Initialize the model to generate sersors, AUs, and PUs; |
| Random initialization of deep neural networks as a function of Q. |
| Cycle: |
| 2: for epoch |
| 3: Generate state . |
| 4: for step |
| 5: Select the P2P pair in the system. For the agent, the action |
| (transmission power and spectrum resources) is selected based on the policy. |
| 6: The environment generates reward and next state . |
| 7: Collect experience (,,,) and store it in the experience pool. |
| 8: if mod K |
| 9: Generate random numbers and then sample. |
| 10: Select the experience corresponding to the serial number to |
| train the neural network . |
| 11: end if |
| 12: end for |
| 13: end for |
| Output: Well-trained neural network model |
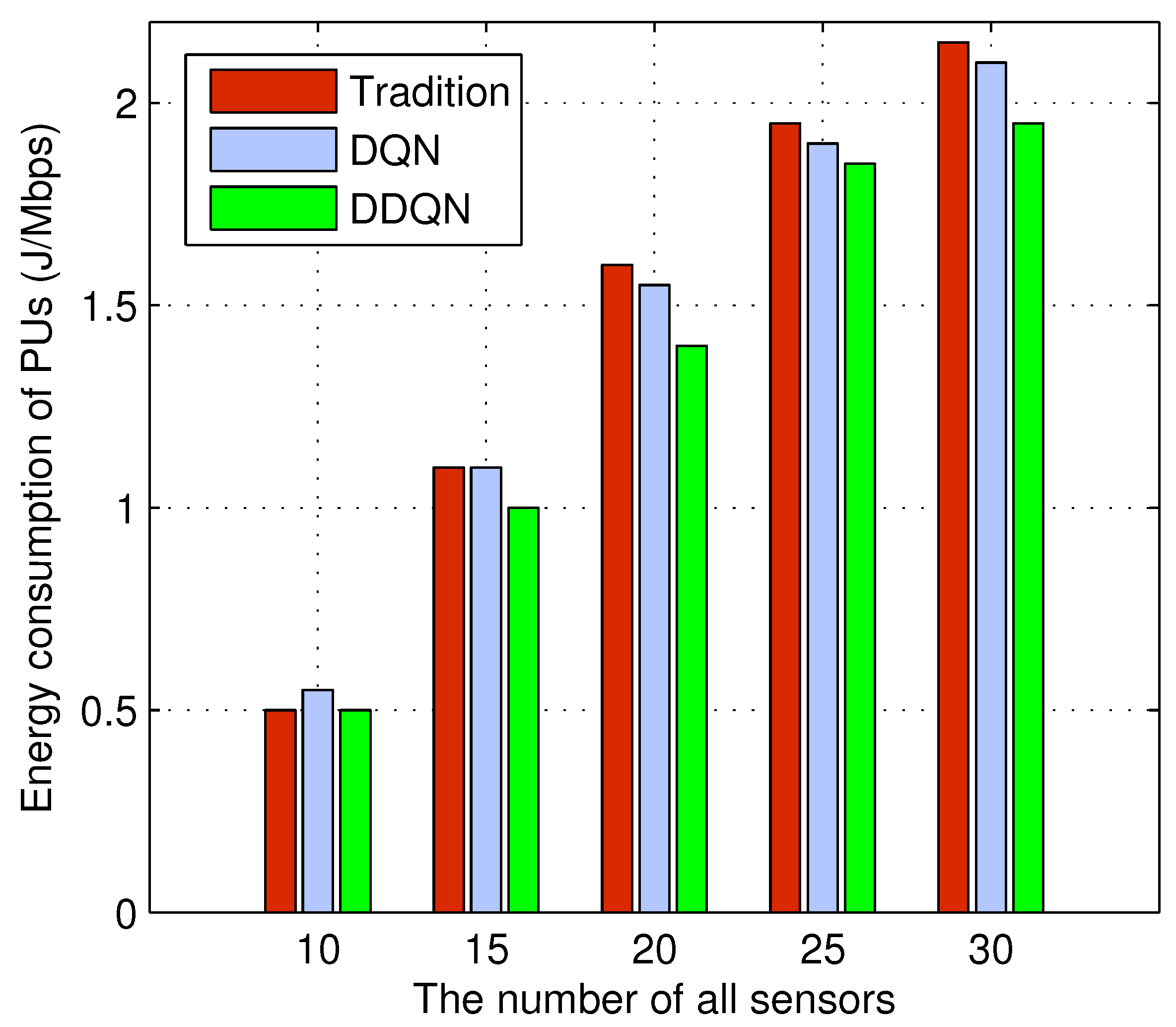
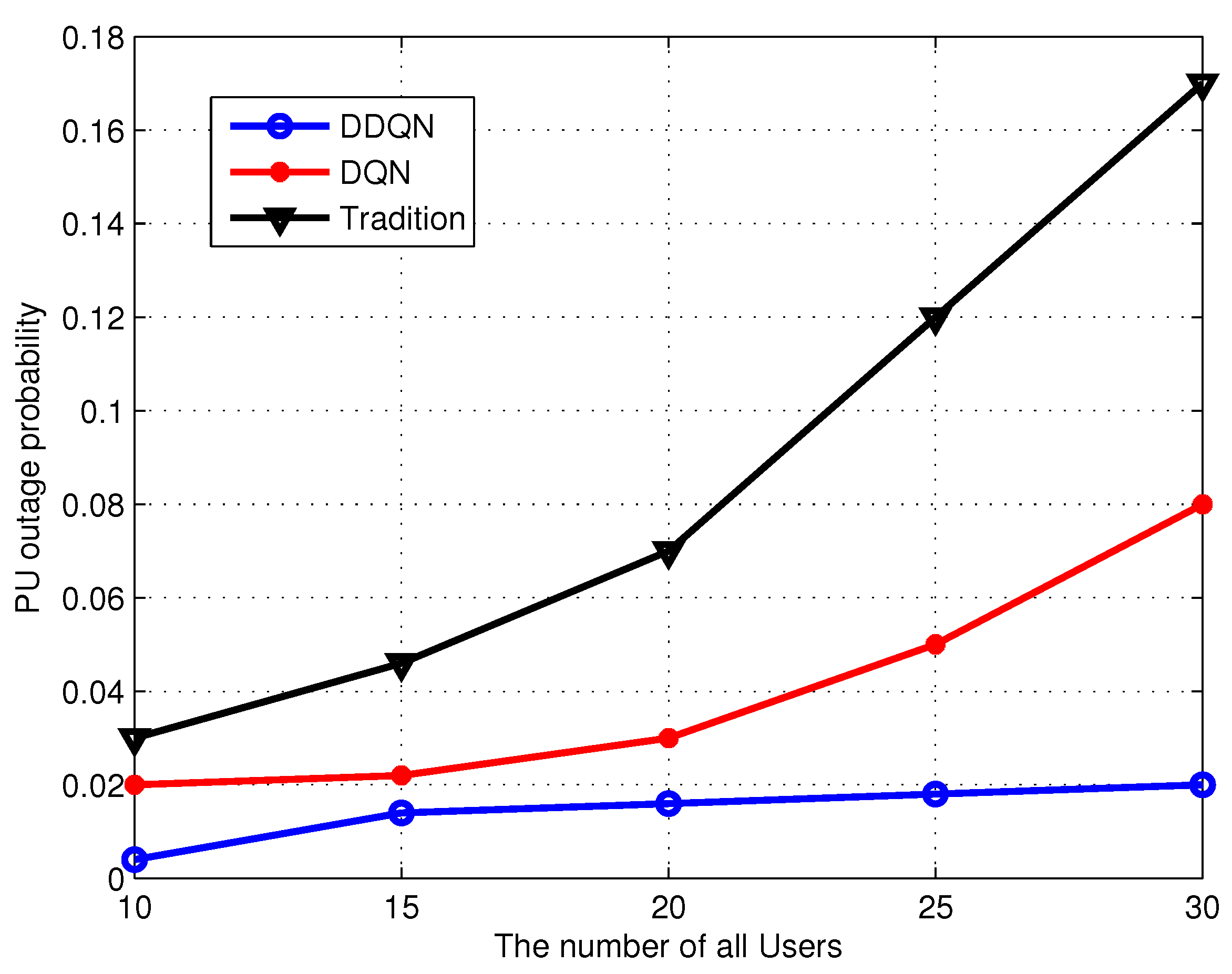
6. Experiment Results and Evaluation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Younus, M.U.; Khan, M.K.; Bhatti, A.R. Improving the Software-Defined Wireless Sensor Networks Routing Performance Using Reinforcement Learning. IEEE Internet Things J. 2022, 9, 3495–3508. [Google Scholar] [CrossRef]
- Xu, F.; Yang, H.C.; Alouini, M.S. Energy Consumption Minimization for Data Collection from Wirelessly-Powered IoT Sensors: Session-Specific Optimal Design with DRL. IEEE Sens. J. 2022, 22, 19886–19896. [Google Scholar] [CrossRef]
- Kang, J.M.; Chun, C.J.; Kim, I.M.; Kim, D.I. Deep RNN-Based Channel Tracking for Wireless Energy Transfer System. IEEE Syst. J. 2020, 14, 4340–4343. [Google Scholar] [CrossRef]
- Yu, L.; Xie, W.; Xie, D.; Zou, Y.; Zhang, D.; Sun, Z.; Zhang, L.; Zhang, Y.; Jiang, T. Deep Reinforcement Learning for Smart Home Energy Management. IEEE Internet Things J. 2020, 7, 2751–2762. [Google Scholar] [CrossRef]
- Brik, B.; Ksentini, A.; Bouaziz, M. Federated Learning for UAVs-Enabled Wireless Networks: Use Cases, Challenges, and Open Problems. IEEE Access 2020, 8, 53841–53849. [Google Scholar] [CrossRef]
- Wang, Z.; Li, T.; Ge, L.; Zhou, Y.; Zhang, G.; Tang, W. Learn from Optimal Energy-Efficiency Beamforming for SWIPT-Enabled Sensor Cloud System Based on DNN. IEEE Access 2021, 9, 60841–60852. [Google Scholar] [CrossRef]
- Su, X.; Ren, Y.; Cai, Z.; Liang, Y.; Guo, L. A Q-Learning-Based Routing Approach for Energy Efficient Information Transmission in Wireless Sensor Network. IEEE Trans. Netw. Serv. Manag. 2023, 20, 1949–1961. [Google Scholar] [CrossRef]
- Hameed, I.; Tuan, P.V.; Koo, I. Deep Learning–Based Energy Beamforming with Transmit Power Control in Wireless Powered Communication Networks. IEEE Access 2021, 9, 142795–142803. [Google Scholar] [CrossRef]
- Peng, Y.; Xue, X.; Bashir, A.K.; Zhu, X.; Al-Otaibi, Y.D.; Tariq, U.; Yu, K. Securing Radio Resources Allocation with Deep Reinforcement Learning for IoE Services in Next-Generation Wireless Networks. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2991–3003. [Google Scholar] [CrossRef]
- Li, J.; Xing, Z.; Zhang, W.; Lin, Y.; Shu, F. Vehicle Tracking in Wireless Sensor Networks via Deep Reinforcement Learning. IEEE Sens. Lett. 2020, 4, 1–4. [Google Scholar] [CrossRef]
- Kim, T.; Vecchietti, L.F.; Choi, K.; Lee, S.; Har, D. Machine Learning for Advanced Wireless Sensor Networks: A Review. IEEE Sens. J. 2021, 21, 12379–12397. [Google Scholar] [CrossRef]
- Zhao, B.; Zhao, X. Deep Reinforcement Learning Resource Allocation in Wireless Sensor Networks with Energy Harvesting and Relay. IEEE Internet Things J. 2022, 9, 2330–2345. [Google Scholar] [CrossRef]
- Barat, A.; Prabuchandran, K.J.; Bhatnagar, S. Energy Management in a Cooperative Energy Harvesting Wireless Sensor Network. IEEE Commun. Lett. 2024, 28, 243–247. [Google Scholar] [CrossRef]
- Matar, M.; Xia, T.; Huguenard, K.; Huston, D.; Wshah, S. Anomaly Detection in Coastal Wireless Sensors via Efficient Deep Sequential Learning. IEEE Access 2023, 11, 110260–110271. [Google Scholar] [CrossRef]
- Guo, H.; Wu, R.; Qi, B.; Xu, C. Deep-q-Networks-Based Adaptive Dual-Mode Energy-Efficient Routing in Rechargeable Wireless Sensor Networks. IEEE Sens. J. 2022, 22, 9956–9966. [Google Scholar] [CrossRef]
- Li, M.; Sun, Y.; Lu, H.; Maharjan, S.; Tian, Z. Deep Reinforcement Learning for Partially Observable Data Poisoning Attack in Crowdsensing Systems. IEEE Internet Things J. 2020, 7, 6266–6278. [Google Scholar] [CrossRef]
- Gong, S.; Cui, L.; Gu, B.; Lyu, B.; Hoang, D.T.; Niyato, D. Hierarchical Deep Reinforcement Learning for Age-of-Information Minimization in IRS-Aided and Wireless-Powered Wireless Networks. IEEE Trans. Wirel. Commun. 2023, 22, 8114–8127. [Google Scholar] [CrossRef]
- Oubbati, O.S.; Lakas, A.; Guizani, M. Multiagent Deep Reinforcement Learning for Wireless-Powered UAV Networks. IEEE Internet Things J. 2022, 9, 16044–16059. [Google Scholar] [CrossRef]
- Zhu, B.; Bedeer, E.; Nguyen, H.H.; Barton, R.; Henry, J. UAV Trajectory Planning in Wireless Sensor Networks for Energy Consumption Minimization by Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2021, 70, 9540–9554. [Google Scholar] [CrossRef]
- Lu, H.; Jin, C.; Helu, X.; Du, X.; Guizani, M.; Tian, Z. DeepAutoD: Research on Distributed Machine Learning Oriented Scalable Mobile Communication Security Unpacking System. IEEE Trans. Netw. Sci. Eng. 2022, 9, 2052–2065. [Google Scholar] [CrossRef]
- Jia, R.; Zhang, X.; Feng, Y.; Wang, T.; Lu, J.; Zheng, Z.; Li, M. Long-Term Energy Collection in Self-Sustainable Sensor Networks: A Deep Q-Learning Approach. IEEE Internet Things J. 2021, 8, 14299–14307. [Google Scholar] [CrossRef]
- Yang, M.; Liu, N.; Feng, Y.; Gong, H.; Wang, X.; Liu, M. Dynamic Mobile Sink Path Planning for Unsynchronized Data Collection in Heterogeneous Wireless Sensor Networks. IEEE Sens. J. 2023, 23, 20310–20320. [Google Scholar] [CrossRef]
- Fu, S.; Tang, Y.; Wu, Y.; Zhang, N.; Gu, H.; Chen, C.; Liu, M. Energy-Efficient UAV-Enabled Data Collection via Wireless Charging: A Reinforcement Learning Approach. IEEE Internet Things J. 2021, 8, 10209–10219. [Google Scholar] [CrossRef]
- Kumar, M.; Mukherjee, P.; Verma, K.; Verma, S.; Rawat, D.B. Improved Deep Convolutional Neural Network Based Malicious Node Detection and Energy-Efficient Data Transmission in Wireless Sensor Networks. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3272–3281. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, J.; Zhao, X. Deep-Reinforcement-Learning-Based Optimal Transmission Policies for Opportunistic UAV-Aided Wireless Sensor Network. IEEE Internet Things J. 2022, 9, 13823–13836. [Google Scholar] [CrossRef]
- Huang, R.; Ma, L.; Zhai, G.; He, J.; Chu, X.; Yan, H. Resilient Routing Mechanism for Wireless Sensor Networks with Deep Learning Link Reliability Prediction. IEEE Access 2020, 8, 64857–64872. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Noise | −114 dBm |
| Reward function weights , , | 0.1, 0.9, 1 |
| Maximum tolerable transmission time | 100 ms |
| P2P transmission power | 30 dBm, 24 dBm, 16 dBm, 8 dBm |
| Carrier frequency | 2 GHz |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, J.; Peng, J.; Yan, Q.; He, G.; Xiang, H.; Liu, Z. Deep Reinforcement Learning-Based Energy Consumption Optimization for Peer-to-Peer (P2P) Communication in Wireless Sensor Networks. Sensors 2024, 24, 1632. https://doi.org/10.3390/s24051632
Yuan J, Peng J, Yan Q, He G, Xiang H, Liu Z. Deep Reinforcement Learning-Based Energy Consumption Optimization for Peer-to-Peer (P2P) Communication in Wireless Sensor Networks. Sensors. 2024; 24(5):1632. https://doi.org/10.3390/s24051632
Chicago/Turabian StyleYuan, Jinyu, Jingyi Peng, Qing Yan, Gang He, Honglin Xiang, and Zili Liu. 2024. "Deep Reinforcement Learning-Based Energy Consumption Optimization for Peer-to-Peer (P2P) Communication in Wireless Sensor Networks" Sensors 24, no. 5: 1632. https://doi.org/10.3390/s24051632
APA StyleYuan, J., Peng, J., Yan, Q., He, G., Xiang, H., & Liu, Z. (2024). Deep Reinforcement Learning-Based Energy Consumption Optimization for Peer-to-Peer (P2P) Communication in Wireless Sensor Networks. Sensors, 24(5), 1632. https://doi.org/10.3390/s24051632