
Polarized Object Surface Reconstruction Algorithm Based on RU-GAN Network


Abstract
1. Introduction
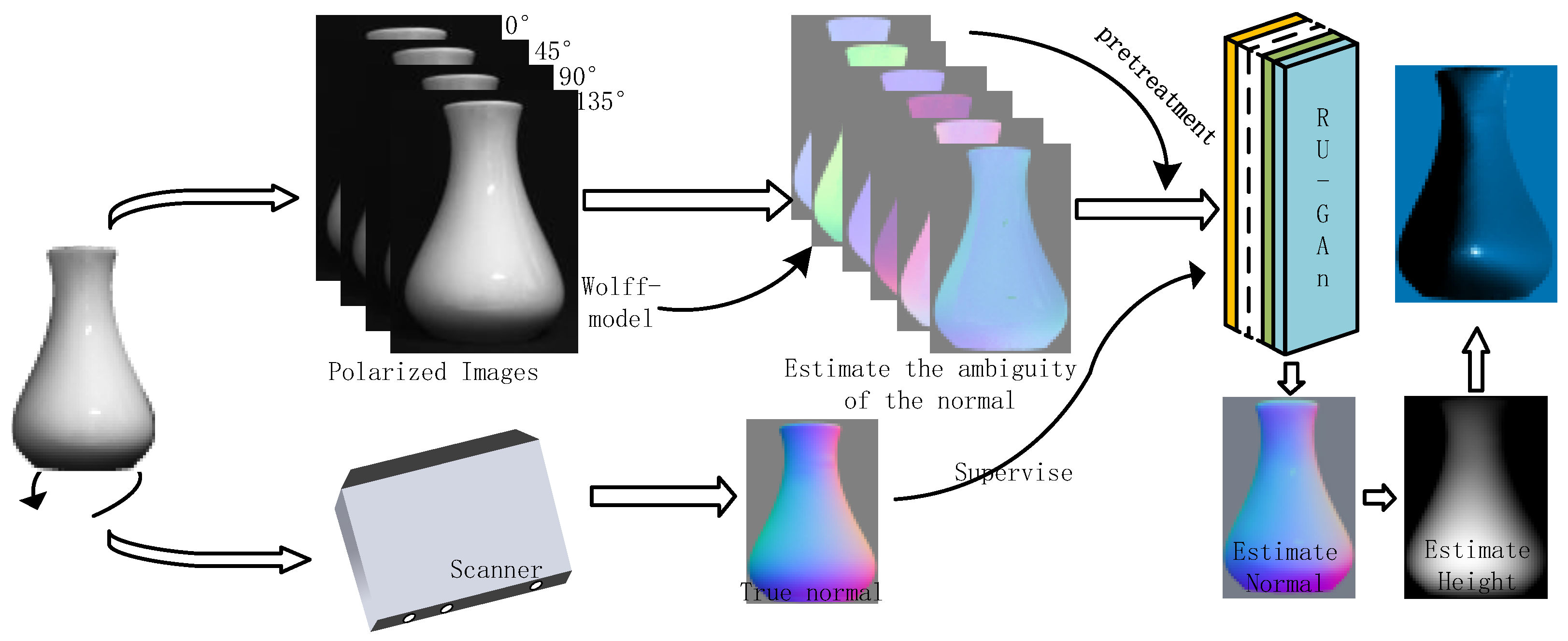
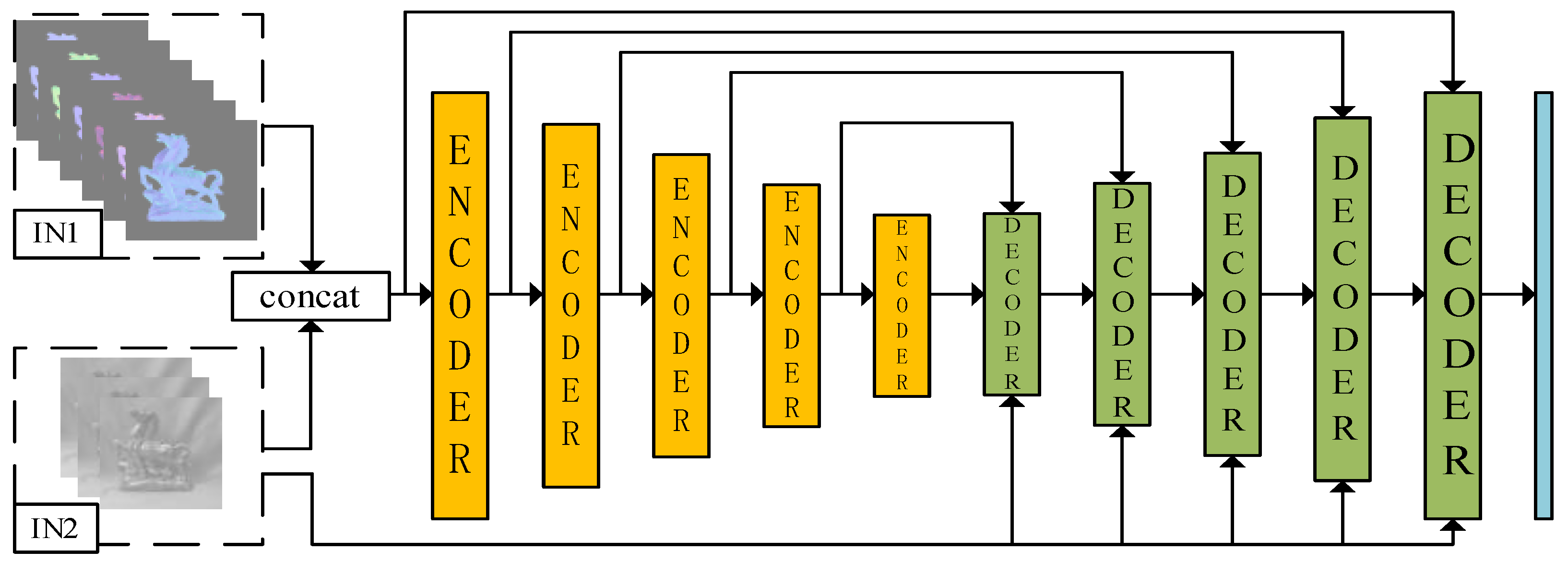
- A set of frameworks is proposed to reconstruct the surface of an object from polarized images only, as shown in Figure 1. First, six feasible solutions for zenith and azimuth angles are obtained using the physical model, and six polarized surface normal vector maps are reconstructed. Secondly, the RU-GAN model proposed in this paper is used for the normal vector estimation task, and then the height map of the object surface is obtained from the energy function. Finally, the object surface is constructed from the height map.
- The use of the spectral properties under the specular reflection model is proposed to achieve reflective localization on the surface of an object. Further, data preprocessing using bilinear interpolation optimizes the neural network model input and narrows the range of reflective region in the image.
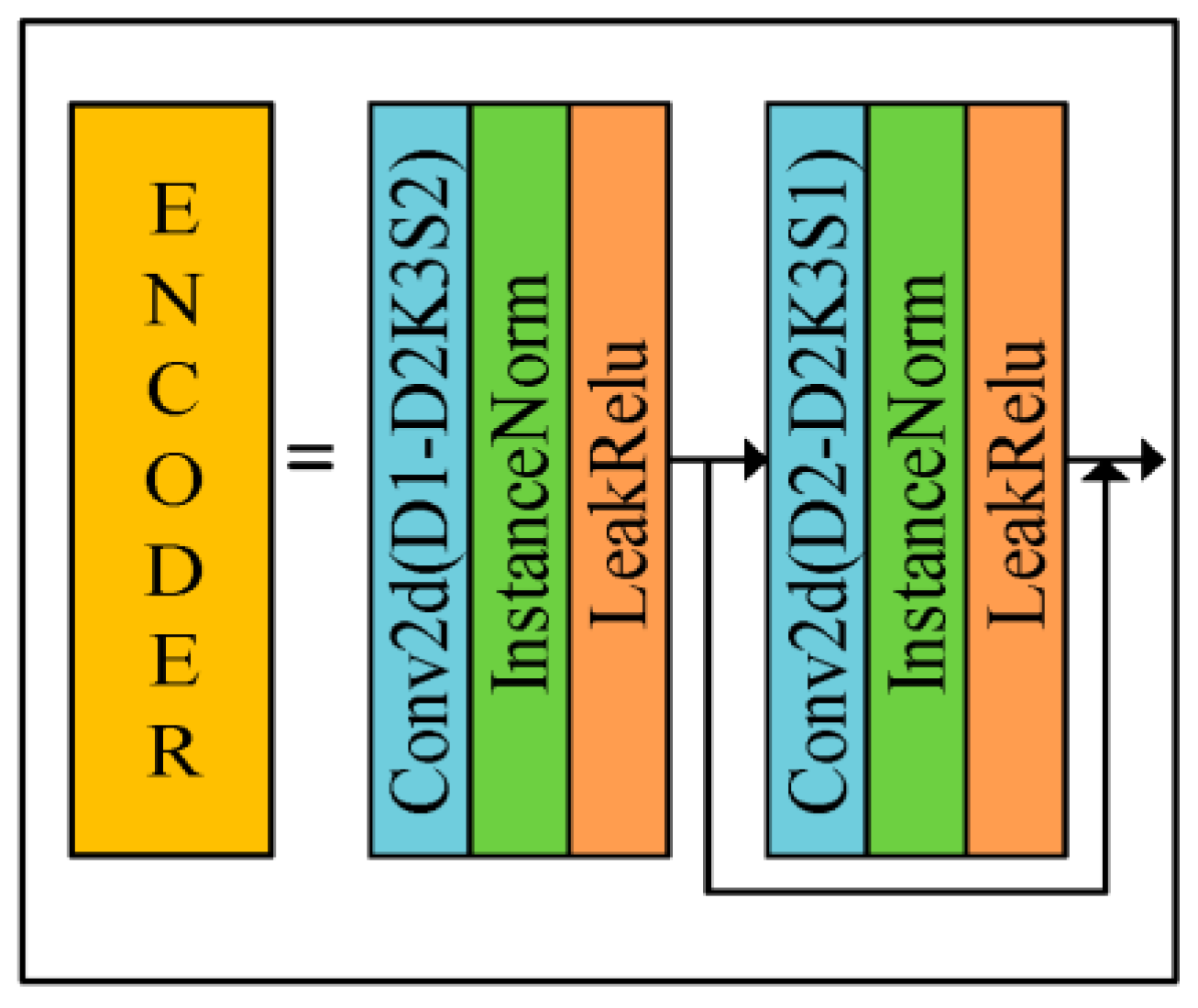
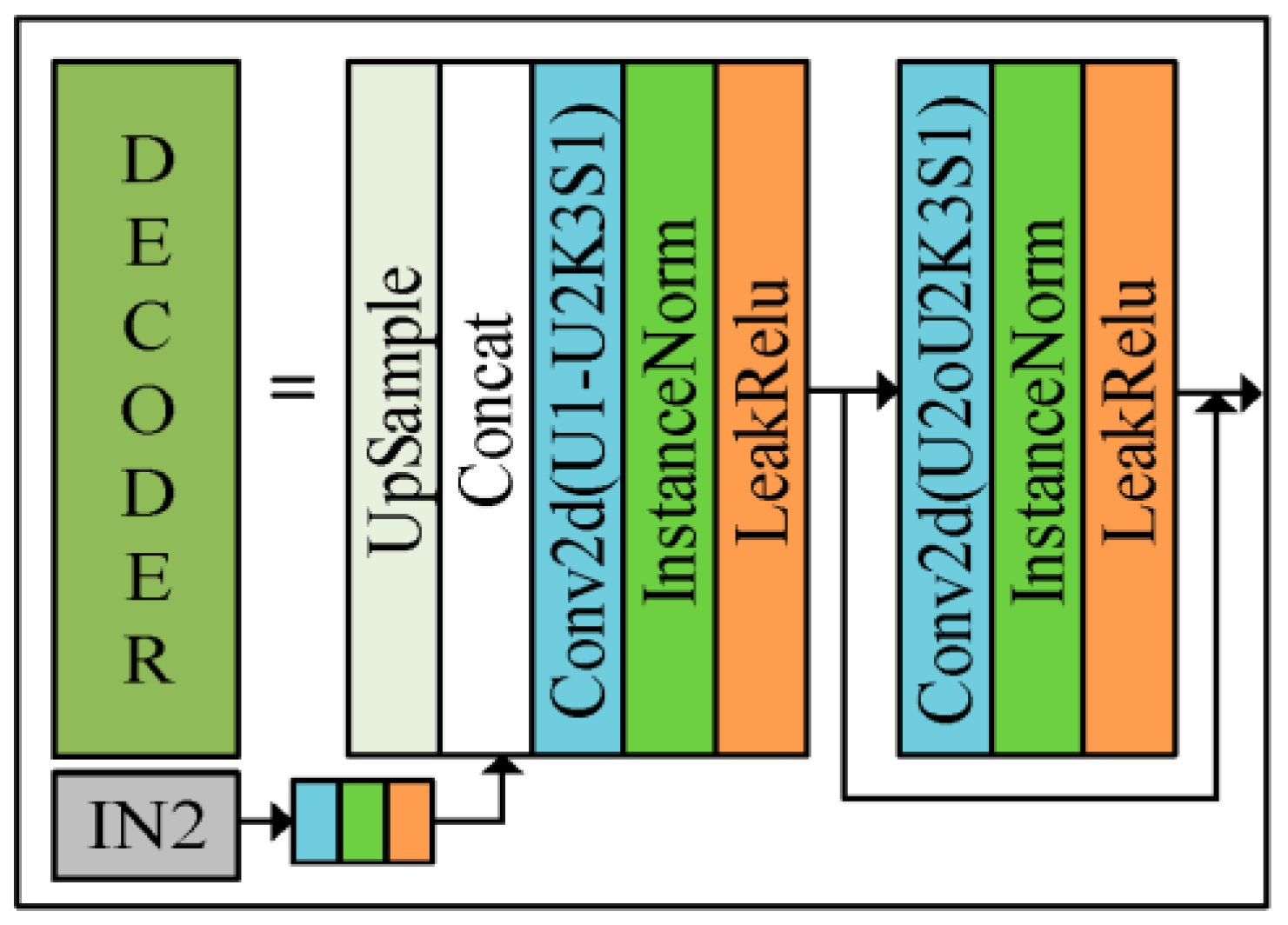
- The uncertainty of the zenith angle and azimuth angle is solved using a neural network. Six polarized surface normal vectors are introduced into the RU-Gan network to realize the real normal vector estimation task. Since the six polarized surface normal vectors are enriched with six feasible solutions for zenith angle and azimuth angle, so the estimated normal vector obtained by using them as network inputs is more accurate. The RU-Gan network proposed in this paper uses jump compensation in the generator part, which greatly reduces the information loss during the learning process. The content loss functions reconstructed in this paper include cosine loss and mean squared loss, which enhance the ability of the network to learn texture information and numerical fitting information, respectively.
2. Fundamentals
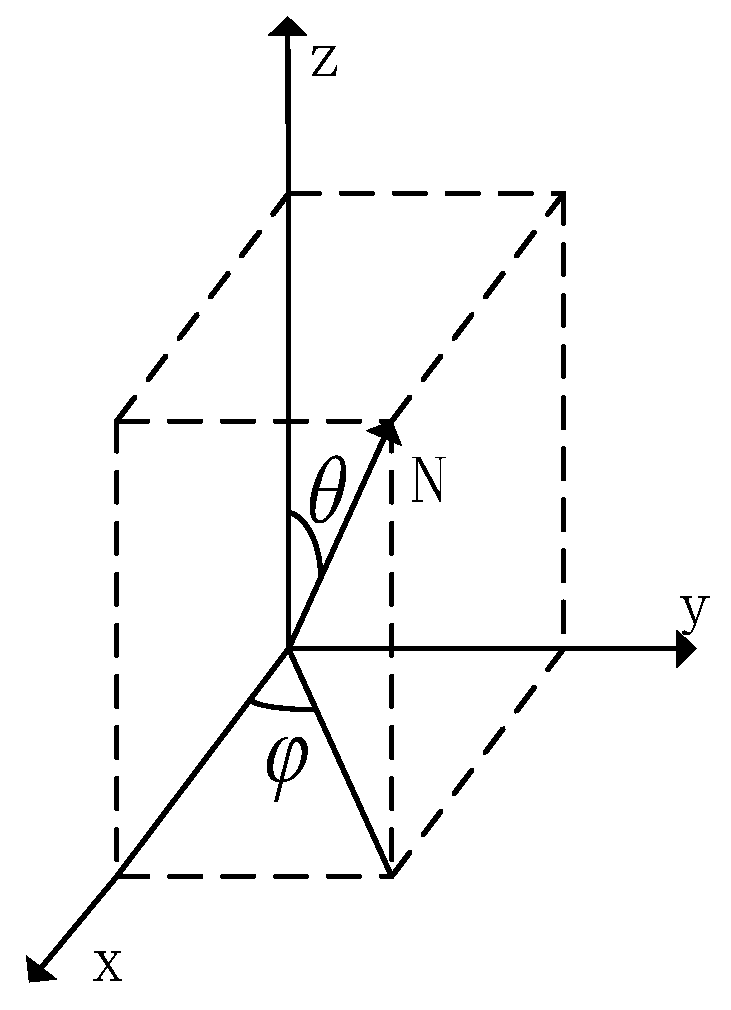
2.1. Polar Coordinate Representation of Surface Normal Vector
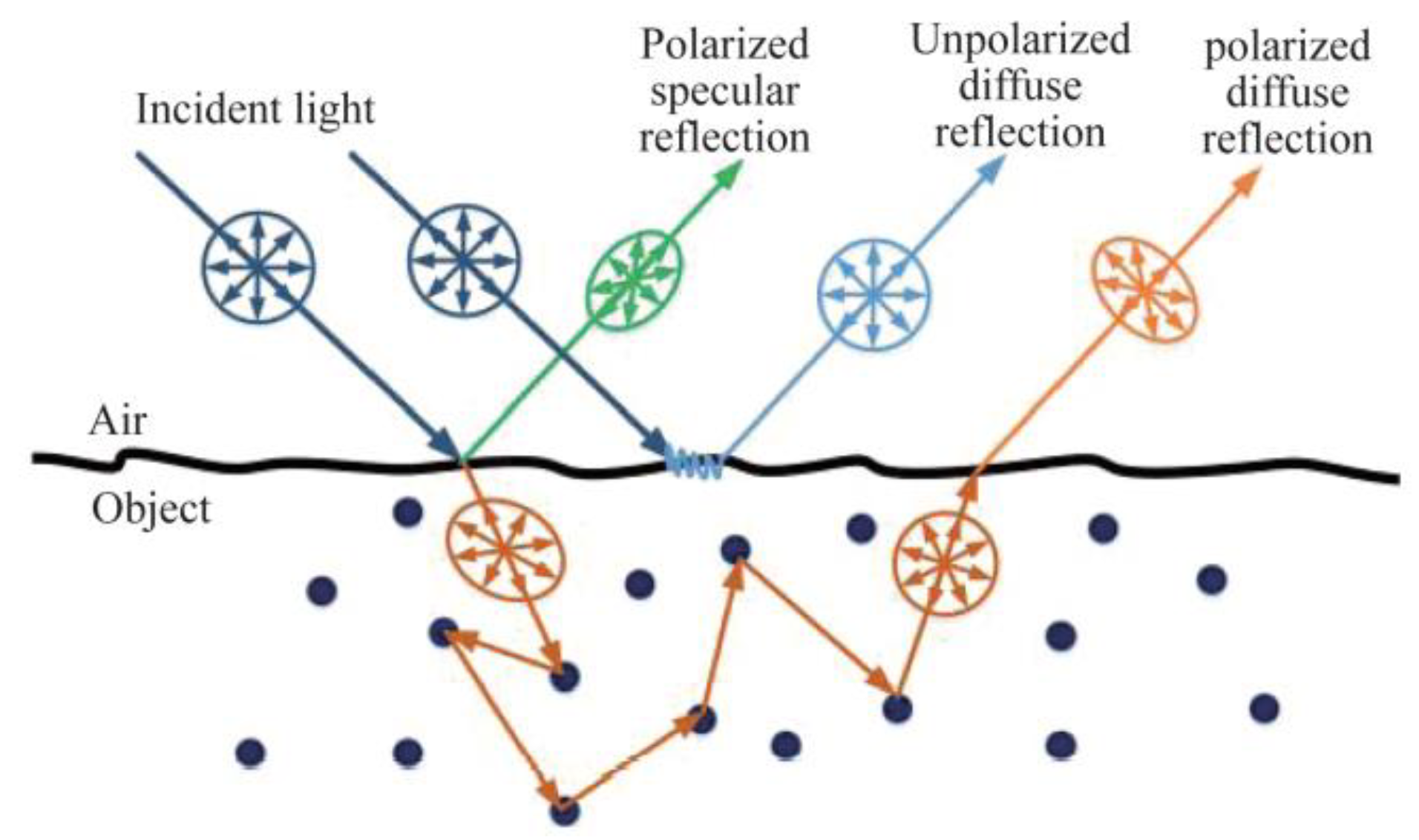
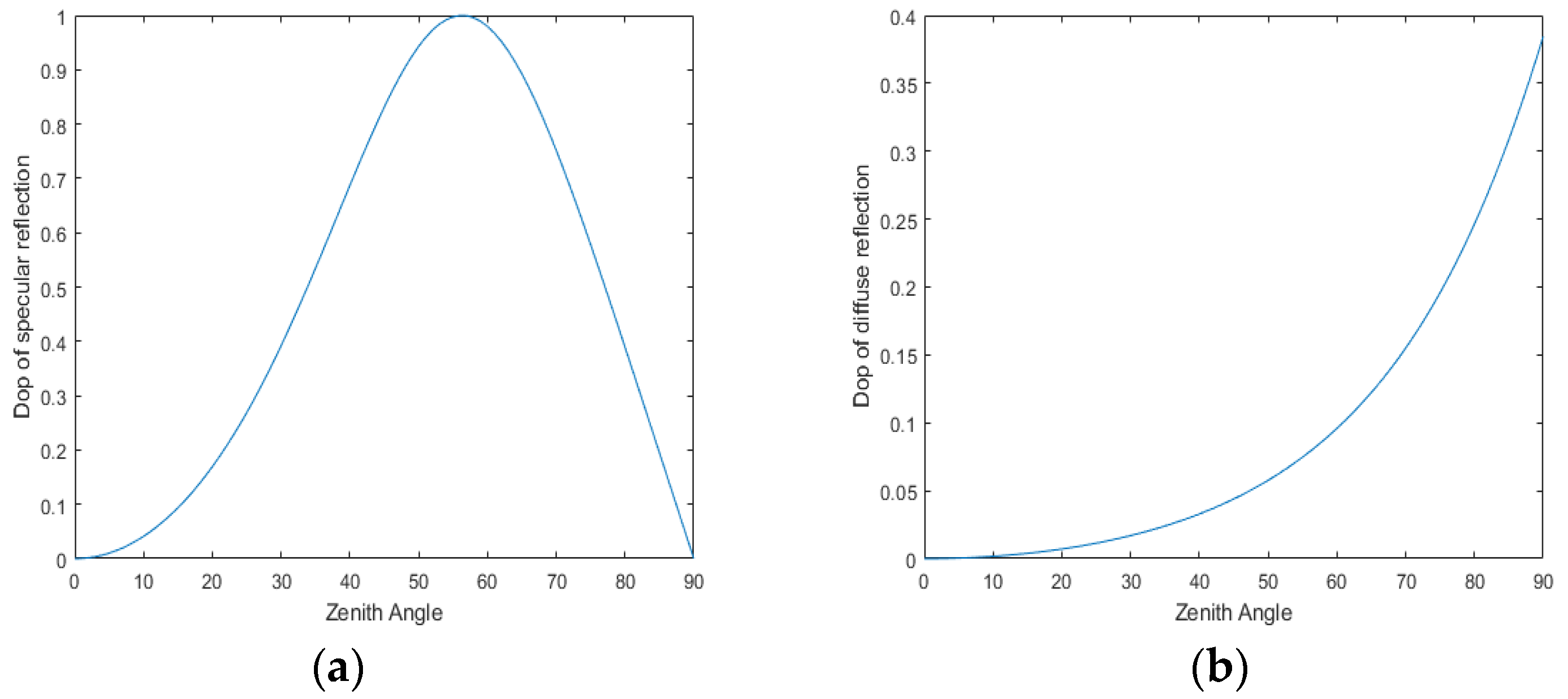
2.2. Light Reflection Model
2.3. Reflective Area Correction
3. Proposed Method
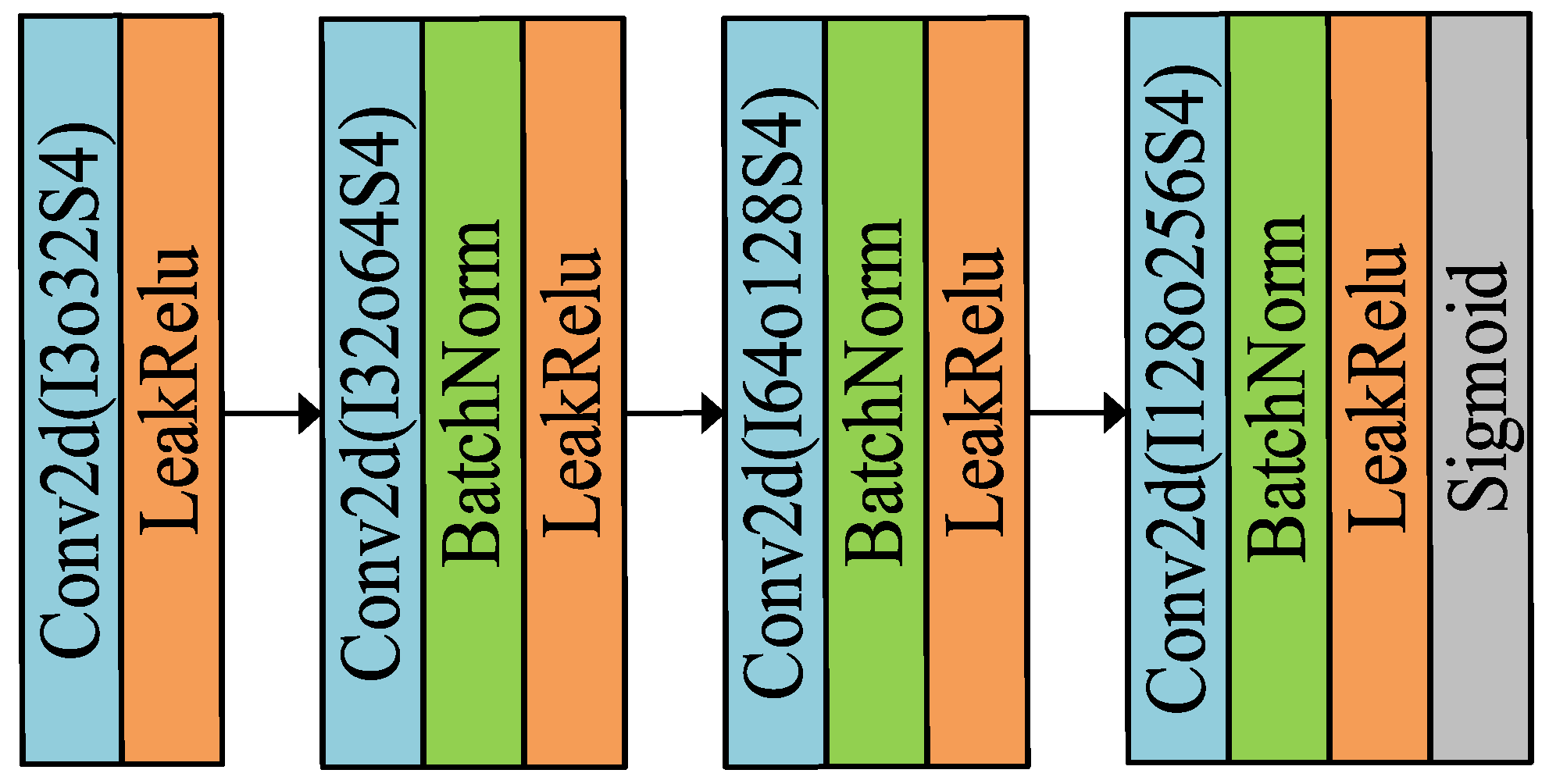
3.1. Neural Network Model
3.2. Loss Function and Training Parameters
3.3. Object Surface Reconstruction
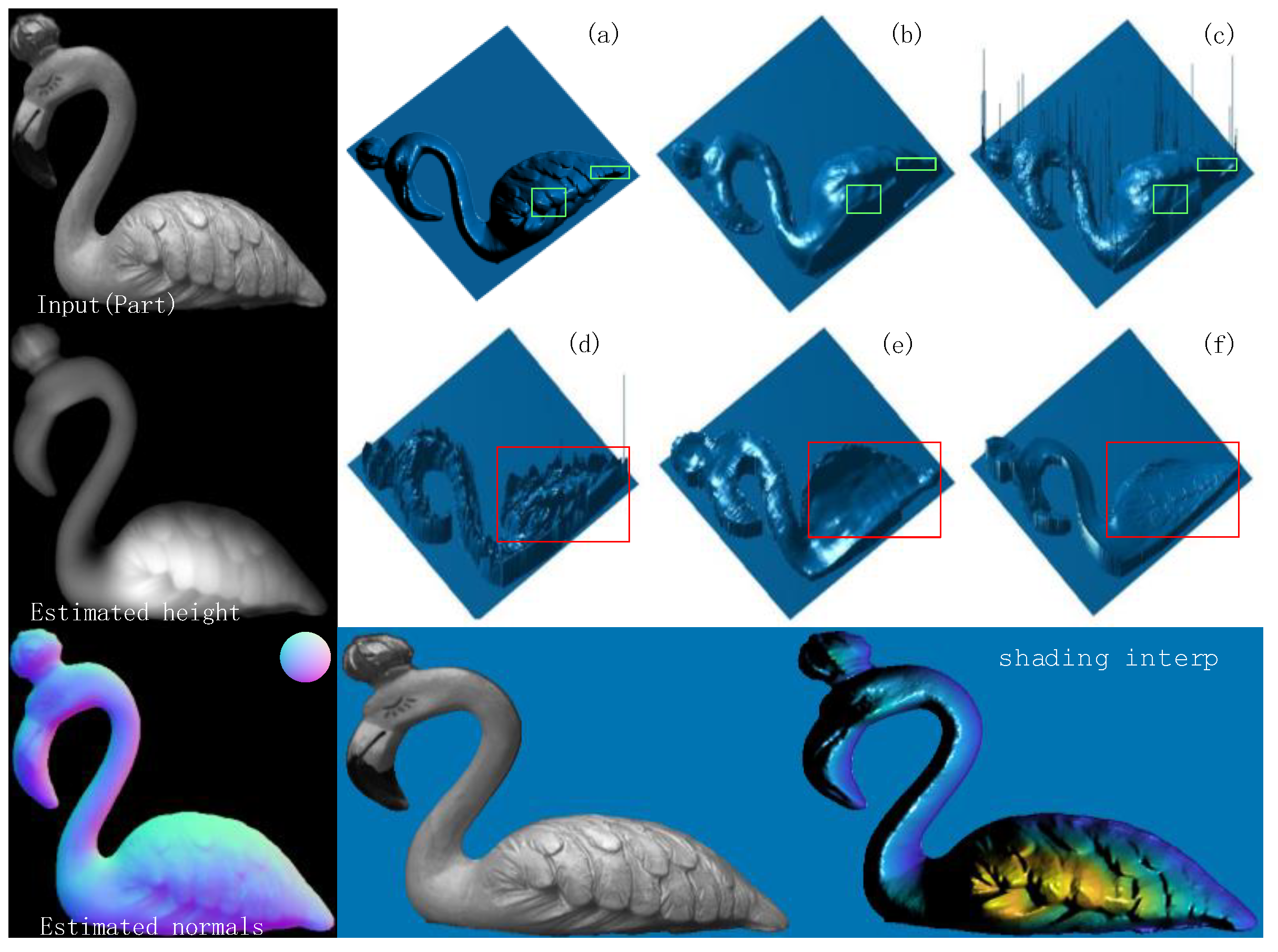
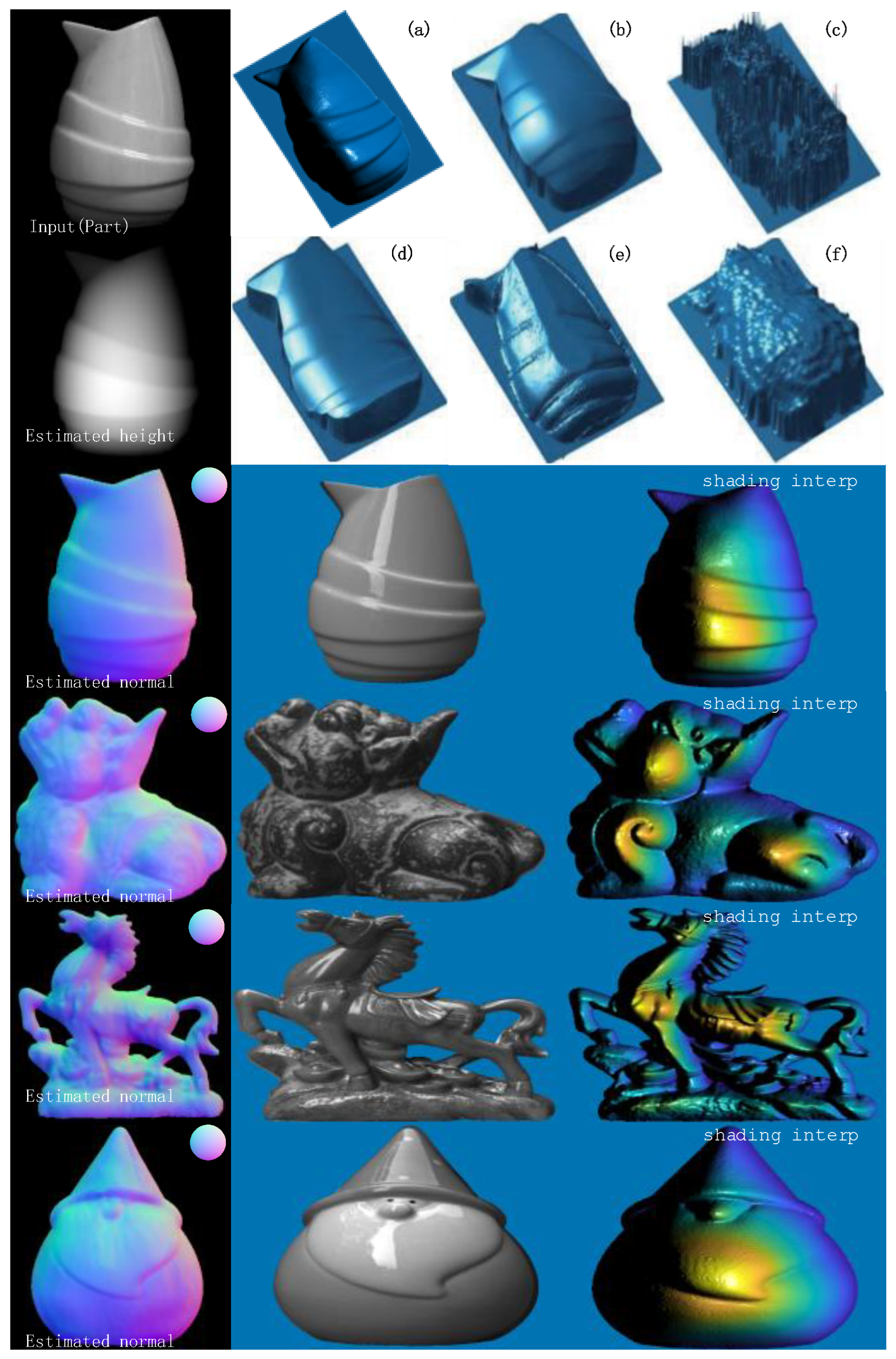
4. Experimental Results and Analysis
4.1. Experimental Results and Analysis
4.1.1. Experimental Validation of Resnet
4.1.2. Experimental Verification of Content Loss
4.2. Analysis of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, X.; Liu, F.; Shao, X. The principle and research progress of polarization three-dimensional imaging technology. J. Infrared Millim. Waves 2021, 40, 248–262. [Google Scholar]
- Li, S.; Jiang, H.; Zhu, J.; Duan, J.; Fu, Q.; Fu, Y. Dong Scientific Research. Development Status and Key Technologies of Polarization Imaging Detection Technology. China Opt. 2013, 6, 803–809. [Google Scholar]
- Aharchi, M.; Ait Kbir, M. A review on 3D reconstruction techniques from 2D images. In Proceedings of the Third International Conference on Smart City Applications, Casablanca, Morocco, 2–4 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 510–522. [Google Scholar]
- Koshikawa, K. A polarimetric approach to shape understanding of glossy objects. In Proceedings of the International Conference on Artificial Intelligence, Tokyo, Japan, 20–23 August 1979; pp. 493–495. [Google Scholar]
- Wolff, L.B.; Boult, T.E. Constraining Object Features using a Polarization Reflectance Model. Phys. Based Vis. Princ. Pract. Radiom 1993, 1, 167. [Google Scholar] [CrossRef]
- Wolff, L.B. Surface Orientation from Polarization Images. Optics, Illumination, and Image Sensing for Machine Vision II. Int. Soc. Opt. Photonics 1988, 850, 110–121. [Google Scholar]
- Atkinson, G.A.; Hancock, E.R. Recovery of Surface Orientation from Diffuse Polarization. IEEE Trans. Image Process. 2006, 15, 1653–1664. [Google Scholar] [CrossRef]
- Smith, W.A.P.; Ramamoorthi, R.; Tozza, S. Height-from-polarisation with Unknown Lighting or Albedo. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2875–2888. [Google Scholar] [CrossRef] [PubMed]
- Mahmoud, A.H.; El-Melegy, M.T.; Farag, A.A. Direct Method for Shape Recovery from Polarization and Shading. In Proceedings of the 19th IEEE International Conference on Image Processing, Orlando, FL, USA, 30 September–3 October 2012; pp. 1769–1772. [Google Scholar]
- Miyazaki, D.; Tan, R.T.; Hara, K.; Ikeuchi, K. Polarization-based Inverse Rendering from a Single View. In Proceedings of the Computer Vision, IEEE International Conference on IEEE Computer Society, Nice, France, 13–16 October 2003; Volume 3, p. 982. [Google Scholar]
- Bajcsy, R.; Sang, W.L.; Leonardis, A. Detection of diffuse and specular interface reflections interreflections by color image segmentation. Int. J. Comput. Vis. 1996, 17, 241–272. [Google Scholar] [CrossRef]
- Zhang, R.; Shi, B.; Yang, J.; Zhao, H.; Zuo, Z. Polarized multi view 3D reconstruction based on parallax angle and zenith angle optimization. J. Infrared Millim. Waves 2021, 40, 133–142. [Google Scholar]
- Yang, J.; Yan, L.; Zhao, H.; Chen, R.; Zhang, R.; Shi, B. Polarization 3D reconstruction of low texture objects with rough depth information. J. Infrared Millim. Wave 2019, 38, 819–827. [Google Scholar]
- Ba, Y.; Chen, R.; Wang, Y.; Yan, L.; Shi, B.; Kadambi, A. Physics-based Neural Networks for Shape from Polarization. arXiv 2019, preprint. arXiv:1903.10210. [Google Scholar]
- Chen, C. Estimation of Surface Normals Based on Polarization Information. Master’s Thesis, Guangdong University of Technology, Guangzhou, China, 2021. [Google Scholar] [CrossRef]
- Wang, K.; Gou, C.; Duan, Y.; Lin, Y.; Zheng, X.; Wang, F. Research progress and prospect of generative countermeasure network GAN. J. Autom. 2017, 43, 321–332. [Google Scholar] [CrossRef]
- Jiang, L.; Zhang, D.; Pan, B.; Zheng, P.; Che, L. Multi focus image fusion based on generation countermeasure network. J. Comput. Aided Des. Graph. 2021, 33, 1715–1725. [Google Scholar] [CrossRef]
- Waghule, D.R.; Ochawar, R.S. Overview on Edge Detection Methods. In Proceedings of the 2014 International Conference on Electronic Systems, Signal Processing and Computing Technologies, Nagpur, India, 9–11 January 2014; pp. 151–155. [Google Scholar] [CrossRef]
- Wang, S.; Yang, K. Research and implementation of image scaling algorithm based on bilinear interpolation. Autom. Technol. Appl. 2008, 27, 44–45+35. [Google Scholar]
- Hudon, M.; Lutz, S. Augmenting Hand-Drawn Art with Global Illumination Effects through Surface Inflation. In Proceedings of the European Conference on Visual Media Production, London, UK, 17–18 December 2019. [Google Scholar] [CrossRef]
- Hochreiter, S.; Younger, A.S.; Conwell, P.R. Learning to learn using gradient descent. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; pp. 87–94. [Google Scholar] [CrossRef]
- Agrawal, A.; Raskar, R.; Chellappa, R. What is the range of surface reconstructions from a gradient field? In European Conference on Computer Vision, Proceedings of the 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 578–591. [Google Scholar]
- Kovesi, P. Shapelets correlated with surface normals produce surfaces. In Proceedings of the IEEE International Conference on Computer Vision, Beijing, China, 17–21 October 2005; Volume 2, pp. 994–1001. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MAE | Ours | Ba [14] | Zhang [12] | Yang [13] | Smith [8] | Mahm [9] | Miya [10] |
|---|---|---|---|---|---|---|---|
| Monster | 20.05 | 21.55 | 30.21 | 28.21 | 45.25 | 70.16 | 51.45 |
| Flamingo | 18.75 | 20.19 | 25.86 | 24.92 | 34.54 | 41.25 | 42.42 |
| Vase1 | 9.96 | 10.32 | 17.68 | 16.91 | 34.11 | 50.21 | 42.95 |
| Vase2 | 11.80 | 12.30 | 16.68 | 16.82 | 40.21 | 44.70 | 50.00 |
| Horse | 21.83 | 22.27 | 33.48 | 31.72 | 42.76 | 47.79 | 47.95 |
| Christmas | 12.70 | 13.50 | 23.56 | 22.87 | 43.62 | 65.38 | 42.38 |
| Indicators | Ours | Ba [14] | Zhang [12] | Smith [8] | Mahm [9] | Miya [10] |
|---|---|---|---|---|---|---|
| MAE | 0.0643 | 0.0685 | 0.1152 | 0.1641 | 0.1931 | 0.1917 |
| MSE | 0.0121 | 0.0139 | 0.0237 | 0.0474 | 0.0569 | 0.0620 |
| SSIM | 0.9350 | 0.8379 | 0.7940 | 0.7450 | 0.7157 | 0.6562 |
| PSNR | 69.0172 | 69.3922 | 64.4152 | 61.5412 | 60.6321 | 60.4009 |
| CC | 0.9294 | 0.9193 | 0.8318 | 0.6441 | 0.5220 | 0.5432 |
| SCD | 0.0196 | 0.0224 | 0.0638 | 0.0662 | 0.0930 | 0.0941 |
| AG | 0.0536 | 0.0544 | 0.0926 | 0.1326 | 0.1591 | 0.1589 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Cheng, C.; Duan, J.; Hao, Y.-F.; Zhu, Y.; Zhang, H. Polarized Object Surface Reconstruction Algorithm Based on RU-GAN Network. Sensors 2023, 23, 3638. https://doi.org/10.3390/s23073638
Yang X, Cheng C, Duan J, Hao Y-F, Zhu Y, Zhang H. Polarized Object Surface Reconstruction Algorithm Based on RU-GAN Network. Sensors. 2023; 23(7):3638. https://doi.org/10.3390/s23073638
Chicago/Turabian StyleYang, Xu, Cai Cheng, Jin Duan, You-Fei Hao, Yong Zhu, and Hao Zhang. 2023. "Polarized Object Surface Reconstruction Algorithm Based on RU-GAN Network" Sensors 23, no. 7: 3638. https://doi.org/10.3390/s23073638
APA StyleYang, X., Cheng, C., Duan, J., Hao, Y.-F., Zhu, Y., & Zhang, H. (2023). Polarized Object Surface Reconstruction Algorithm Based on RU-GAN Network. Sensors, 23(7), 3638. https://doi.org/10.3390/s23073638