1. Introduction
Emotions play a crucial role in human communication and cognition, which makes comprehending them significant to understanding human behavior [
1]. The field of affective computing strives to give emotional intelligence to machines that can recognize and interpret human affects [
1,
2], offering exciting possibilities for education, entertainment, and healthcare. Early detection and prediction of (mental) diseases or their symptoms can be facilitated, since specific emotional and affective states are often indicators thereof [
3]. Moreover, long-term stress is one of today’s significant factors causing health problems, including high blood pressure, cardiac diseases, and anxiety [
4]. Notably, some patients with epilepsy (PWE) report premonitory symptoms or auras as specific affective states, stress, or mood changes, enabling them to predict an oncoming seizure [
5]. This association of premonitory symptoms and seizure counts has been analyzed and validated from patient-reported diaries [
6], and non-pharmacological interventions were proven to reduce the seizure rate [
7]. However, many PWE cannot consistently identify their prodromal symptoms, and many do not perceive prodromes [
8], emphasizing the necessity of objective prediction of epileptic seizures. In a previous work, the authors proposed developing a system to predict seizures by continuously monitoring their affective states [
9]. Therefore, identifying pre-ictal states by measuring and predicting affective states in real-time through neurophysiological data could aid in finding pre-emptive therapies for PWE. That would be incredibly beneficial, especially to people with drug-resistant epilepsy, and would improve their quality of life [
3,
8]. Consequently, emotion detection in this paper is motivated by the idea that allowing computers to perceive and understand human emotions could improve human–computer interactions (HCI) and enhance their ability to make decisions by adapting their reactions accordingly.
Since emotional reactions are seemingly subjective experiences, neurophysiological biomarkers, such as heart rate, respiration, or brain activity [
10,
11], are inevitable. Additionally, for continuous monitoring of affective states and thus detecting or predicting stress-related events reliably, low-cost, consumer-grade devices rather than expensive and immobile hospital equipment would be more meaningful [
12]. This is an important area of interest in cognitive science and affective computing, with use cases varying from designing brain–computer interfaces [
13,
14] to improving healthcare for patients suffering from neurological disorders [
15,
16]. Among these, electroencephalography (EEG) has proven to be an accurate and reliable modality without needing external annotation [
17,
18]. Since clinical EEG is the gold standard for epileptic seizure detection [
19], utilizing EEG-based emotion classification in detection systems could potentially predict seizures by knowing the affective states. Moreover, with recent advancements in wearable technology, consumer-grade EEG devices have become more accessible and reliable, opening possibilities for countless real-life applications. Wearable EEG devices such as the
Emotiv EPOC headset or the
Muse S headband have become quite popular tools in emotion recognition [
20,
21,
22]. The Muse S headband has also been used for event-related potential (ERP) research [
12] and for the challenge of affect recognition in particular. More specifically, Muse S has already been used in experimental setups to obtain EEG data from which the mental state (relaxed/concentrated/neutral) [
13] and the emotional state (using the valence-arousal space) [
23] could be reliably inferred through the use of a properly trained classifier.
1.1. Problem Statement
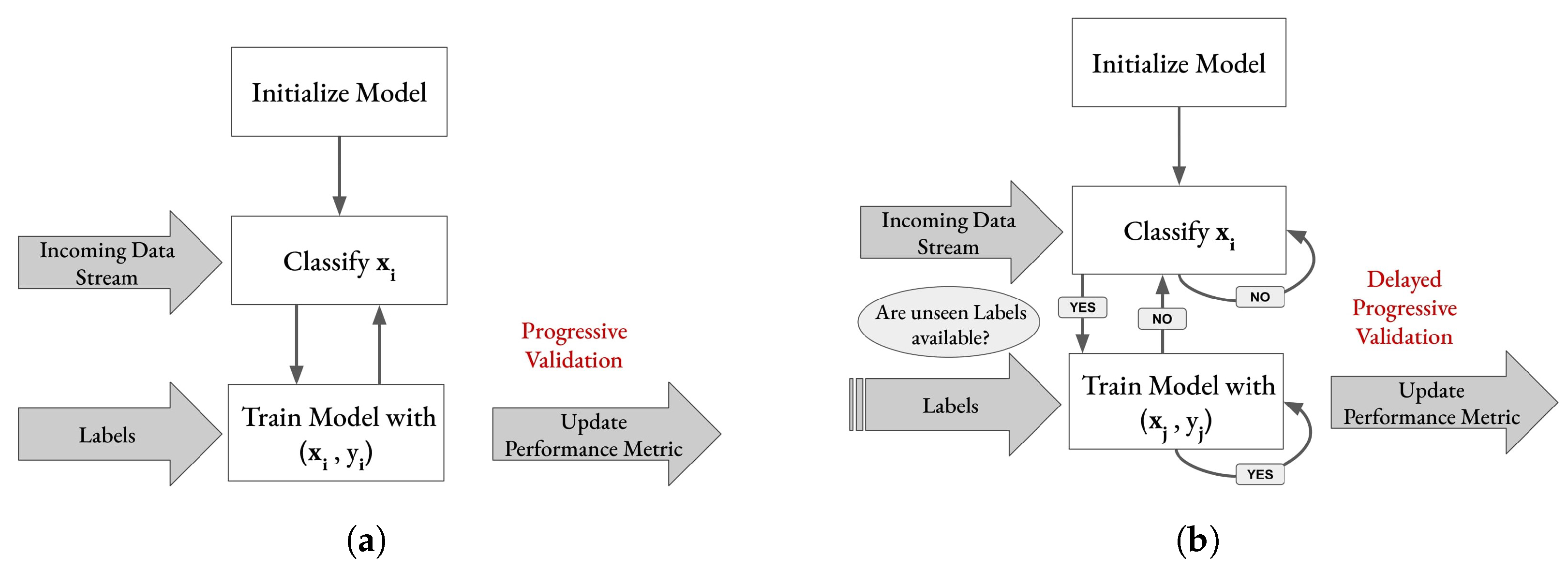
A challenging but essential step to identifying stress-related events or improving HCI in real-life settings is to recognize changes in peoples’ affect by leveraging live data. The EEG-based emotion classifications mentioned in the literature have nearly exclusively been employed in traditional machine learning strategies, i.e., offline classifiers, and are often combined with complex data pre-processing techniques on static datasets [
24,
25]. Such cases expect the whole dataset, including labels, to be present for model training, unlike real application scenarios, where the data source is primarily a live data stream and classification results are required in real-time. Moreover, a live data stream from a non-stationary EEG data source presents challenges associated with, for example, the online arrival of data, the velocity of data, the data volume over time, and the dynamic nature of data [
26]. The training and classification time for the offline models and the static behavior dealing with upcoming data streams makes real-time classification of affective states infeasible. Therefore, for live emotion classification, employing online learning by updating a pre-trained model continuously on new data is inevitable. Additionally, to ensure the usability of such a system in daily life, it is necessary to classify the data from a portable EEG device. Furthermore, the existing methodologies in the literature have primarily been developed and evaluated on curated EEG datasets, which need more reproducibility to apply to live data from real applications.
Regarding the mentioned problems, the primary goal of this paper is to answer the research question of how reliably an online classifier classifies emotion from state-of-the-art AMIGOS data [
22] and how accurately the classifier can perform affective state prediction while curating EEG data from wearable EEG devices in live settings.
1.2. Key Contributions
Therefore, firstly, the key contribution of this paper is the establishment of a lightweight emotion classification pipeline that can classify a person’s affective state based on an incoming EEG data stream in real-time, efficiently enough to be used in real applications, e.g., for seizure prediction. The developed pipeline leverages online learning to train subject-specific models on data streams by implementing binary classifiers for the affect dimensions: Valence and Arousal. The pipeline is validated by streaming an existing dataset of established quality, AMIGOS, with better classification performance than state-of-the-art contributions.
Secondly, an experimental framework is developed, similar to the AMIGOS dataset, which can collect neurophysiological data from a wide range of commercially available EEG devices and show live prediction results of the subjects’ affective states even when labels arrive with a delay. Data from 15 participants were captured by using two consumer-grade EEG devices.
Thirdly, the most novel contribution of this paper is to validate the pipeline on the curated dataset by wearable EEG devices in the first experiment with consistent classification performance on the AMIGOS dataset. Following this, live emotion prediction was performed successfully on an incoming data stream in the second experiment with delayed incoming labels.
The curated data from the experiments and metadata are accessible to the designated researchers as per the participants’ consent. Therefore, the dataset is available upon request for scientific use via a contact form on Zenodo:
https://doi.org/10.5281/zenodo.7398263 (accessed on 18 February 2023). The Python code for loading the dataset and implementations of the developed pipeline have been made available on GitHub:
https://github.com/HPI-CH/EEGEMO (accessed on 18 February 2023). The next section will explain the related works, material, and methods utilized within this paper following the results and discussion sections.
1.3. Related Work
Recent review papers from Dadebayev et al. [
24] and Suhaimi et al. [
25] mention several articles on EEG-based emotion recognition using various affect dimension scales, EEG devices, machine learning algorithms, and performance matrices. However, only a few research works have mentioned
real-time emotion classification. Müller et al. [
27] proposed an online linear discriminate analysis (LDA) classifier by utilizing spectral features in the EEG data obtained from a brain–computer interface (BCI) device. However, while demonstrating the application of real-time arousal monitoring, the researchers used data from one participant to train an offline LDA classifier. Moreover, the data acquisition took place utilizing a 128-channel BCI, and applying the methodology to the data from wearable EEG devices was mentioned in their future work, which already falls into the scope of this paper.
Liu et al. [
28,
29] showed promising results on emotion recognition using the fractal dimension (FD) model on a 14-channel EEG headset. The applied methodology in real-time application was reflected as computer avatars demonstrating a person’s emotion based on live data. The fractal algorithm required 1024 samples at a time, obtained by the device’s buffer function. The buffer function may not be useful for general applications and EEG devices. A follow-up work was proposed by Lan et al. [
30,
31], analyzing the stable features of the previously mentioned application. Hou et al. [
32] further developed a meter to visualize the intensity of the felt emotion. However, the mentioned live emotion classification was based on a static model and was not updated during prediction. We propose a general emotion classification pipeline that deals with a selection of consumer-grade EEG devices and general applications, which can be validated on the published dataset from the researchers mentioned above [
33].
Additionally, Javaid et al. [
34] reported a 25.44% higher accuracy while switching from eight to three wet electrodes of an openBCI Kit while quantifying four basic emotions using an FD threshold-based classifier similar to [
28]. However, the authors also mentioned incorporating an Emotiv EPOC device in a second session of their proposed method, but the follow-up research still needs to be reported.
Sarno et al. [
35] used power features in the K-nearest neighbor (KNN) classifier to train 14-channel EEG data offline and predict binary and tertiary emotion in an online stage. An evaluation only of accuracy was reported, which is compatible with our results, given that the F1-Score reported in our paper is relatively high. Moreover, our paper uses fewer electrodes and multiple algorithms and develops and publishes the data collection framework.
Very recently, Bajada et al. [
36] built an emotion classification pipeline incorporating discrete wavelet transforms (DWT) features into a 3D convolutional neural network (3D CNN) and support vector machine (SVM) classifiers from pre-recorded and pre-trained data from the state-of-the-art DEAP [
37] dataset. They proposed using the proposed algorithm for real-time monitoring because it maintains a high accuracy of up to 92%, reducing from 32 channels to 5 channels. Li et al. [
38] addressed the challenge of when a model can see the data only once by leveraging cross-subject and cross-session data by implementing the
Fast Online Instance Transfer (FOIT) algorithm. They validated their methodology on two state-of-the-art datasets: SEED [
39] and SEED-IV [
40]. However, these mentioned studies need to apply live incoming data streams similar to our approach, which pose challenges such as velocity, veracity, and concept drift. To the best of our knowledge, only Nandi et al. [
41] have employed online learning to classify emotions from an EEG data stream from the DEAP dataset and proposed an application scenario in e-learning, but have yet to report undertaking any such live experiments. They compared the performance of different state-of-the-art online classifiers, such as adaptive random forest (ARF) [
26] and Hoeffding adaptive tree (HAT) [
42], against their own real-time emotion classification system (RECS) on the DEAP dataset.
Indeed, more research is needed on using online machine learning for emotion recognition.
Moreover, multi-modal labeled data for the classification of affective states have been made freely available through annotated affective databases, such as DEAP [
37], DREAMER [
43], ASCERTAIN [
44], SAFE [
33], and AMIGOS [
22], which play a significant role in further enhancing the research of this field. They include diverse data from experimental setups using differing emotional stimuli such as music, videos, pictures, or cognitive load tasks in an isolated or social setting. Such databases enable the development and improvement of frameworks and model architectures with existing data of ensured quality. However, none of these published datasets include the data collection framework to be reused in curating the data from wearable EEG devices in live settings.
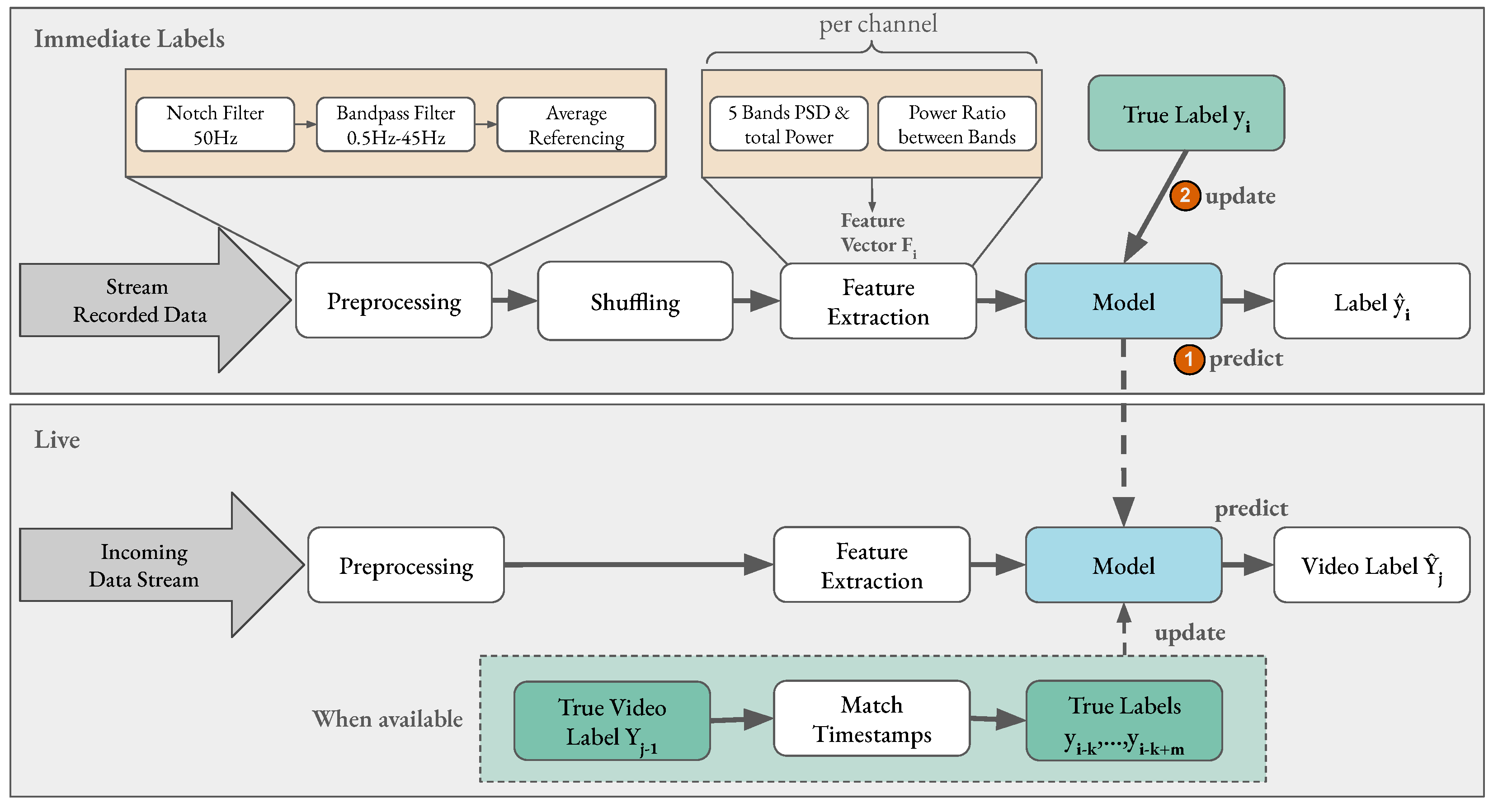
2. Materials and Methods
2.1. Dataset I: AMIGOS Dataset
The developed emotion classification pipeline in this paper was evaluated on the state-of-art dataset for affect, personality, and mood research on individuals and groups (AMIGOS) published by Miranda-Correa et al. [
22], which is further referred to as
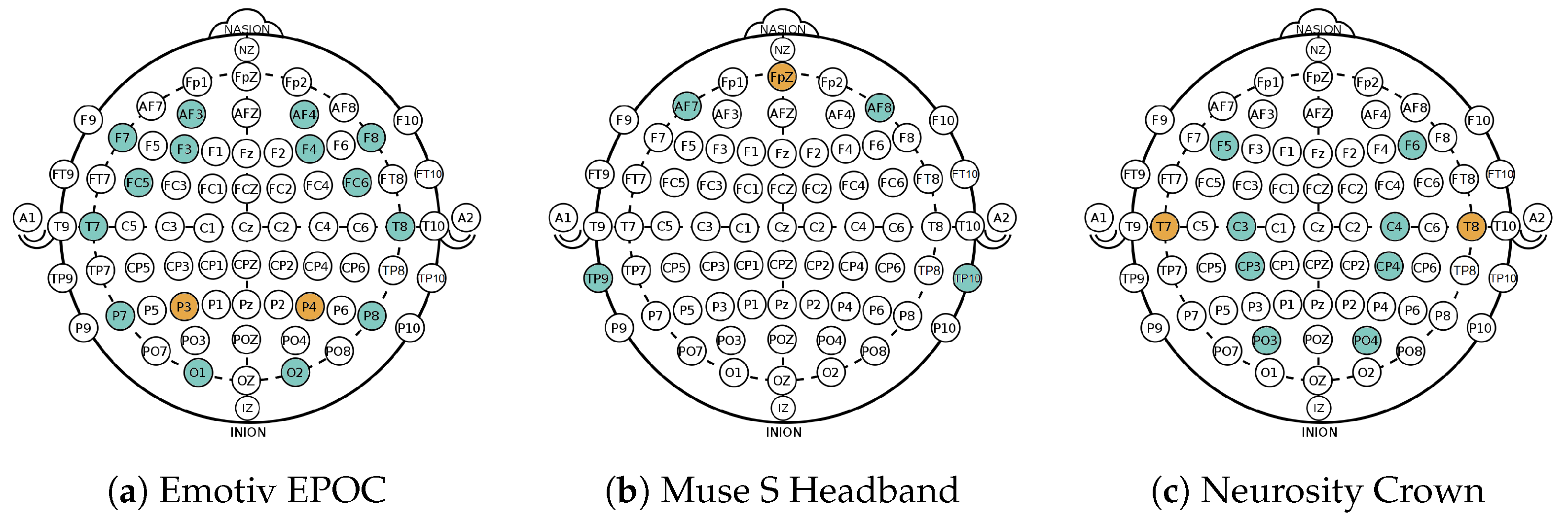
Dataset I. Upon following the data receiving protocol, all data from the AMIGOS dataset that are used in this work stem from short video individual experiments where 40 healthy participants (13 female) aged between 21 and 40 (mean age 28.3) were asked to watch 16 videos from defined movie clips. The EEG data were recorded using the Emotiv EPOC headset (
https://www.emotiv.com/epoc-x/ (accessed on 20 February 2023)) with a sampling frequency of 128 Hz and a 14 bit resolution. This device records EEG data from 14 channels (AF3, F7, F3, FC5, T7, P7, O1, O2, P8, T8, FC6, F4, F8, and AF4) of the brain according to the 10–20 system as depicted in
Figure 1a.
Additionally, Dataset I reports the Self-Assessment Manikin [
45] with a scale from 1 to 9 as recording participants’ affect ratings of the dimensions valence, arousal, and dominance. The participants were also asked to rate their familiarity with the videos and whether they liked them, and had to select at least one option from a list of basic emotions felt after watching each video. However, only the obtained valence and arousal ratings were considered the ground truth for this paper. Furthermore, the participants answered the Positive and Negative Affect Schedules (PANAS) [
46] questionnaire at the beginning and end of the experiment; only one overall calculated PANAS score is reported. Pre-processed data files were used for classification, where the EEG data were down-sampled to 128 Hz, averaged to a common reference, and a band pass filter was applied from 4.0–45.0 Hz as described in the description on the website (
http://www.eecs.qmul.ac.uk/mmv/datasets/amigos/readme.html (accessed on 20 February 2023)). The files containing electrocardiogram (ECG) and galvanic skin response (GSR) data were removed for the analysis of this paper.
To validate the established pipeline in daily life and live setup, two different datasets with individual experimental protocols, named Dataset II and Dataset III, were curated with the description of participants, data acquisition, and experimental protocols mentioned in the following sections.
2.2. Participants
For Dataset II, eleven participants were recruited (six females and five males) between the ages of 25 and 42 (, years). Data from two participants had to be discarded for further analysis. Dataset III was made with data from four participants (one female and three males) between the ages of 25 and 34 (, years). People who were pregnant, older than 65 years, and had taken part in one of the experiments were excluded from participation. All participants had normal or corrected vision and reported no history of neurological or mental illnesses or head injuries.
2.3. Data Acquisition
Hardware: During the experiments, two consumer-grade devices,
Muse S Headband Gen 1 (
https://choosemuse.com/compare/ (accessed on 20 February 2023)) and
Neurosity Crown (
https://neurosity.co/crown (accessed on 20 February 2023)), were used to collect the EEG data from the participants, as depicted in
Figure 2. Both devices operated with a sampling rate of 256 Hz and the EEG data were collected with four and eight channels, respectively.
According to the international10–20 system [
47], the channels on the Muse S Headband correspond to AF7, AF8, TP9, and TP10 (see
Figure 1b), with a reference electrode at Fpz [
12]. The channel locations of Neurosity Crown are C3, C4, CP3, CP4, F5, F6, PO3, and PO4, with reference sensors located at T7 and T8, as shown in
Figure 1c. Using the Mind Monitor App (
https://mind-monitor.com/ (accessed on 20 February 2023)), the raw EEG data were streamed from Muse to a phone via Bluetooth. The app sends the data to a laptop via the open sound control (OSC) protocol and the python-osc library (
https://pypi.org/project/python-osc/ (accessed on 20 February 2023)) on the receiving end. As the incoming data tuples from the Muse Monitor App did not include timestamps, they were added by the pipeline upon arrival of each sample. Similarly, the Crown uses the python-osc library to stream the raw EEG data to a laptop without enabling any pre-processing settings. In contrast to the Muse Headband, the Crown includes a timestamp when sending data.
Software: In this paper, the experiment was implemented using the software PsychoPy (v 2021.2.3) [
48] in a way that guided the participants through instructions, questionnaires, and stimuli. The participants were allowed to go at their own pace by clicking on the “Next” (“Weiter” in German) button, as shown in the screenshots of PsychoPy in
Figure 3.
2.4. Stimuli Selection
Inducing specific emotional reactions is a challenge, even in a fully controlled experimental setting. Several datasets have tried to solve this issue with different modalities such as pictures [
49,
50,
51], music [
52,
53], music videos [
37,
54,
55], or combinations of them [
56]. In this work, videos depicting short movie scenes were used as stimuli, based on the experimental setup of Dataset I [
22]. Therefore, 16 short clips (51–150 s long,
s,
s) depicting scenes from 15 different movies were used for emotion elicitation. Twelve of these videos stem from the DECAF dataset [
54], and four movie scenes were taken from the MAHNOB-HCI [
55] dataset. According to Miranda-Correa et al., these specific clips were chosen because they “lay further to the origin of the scale” than all other tested videos. This means they represent the most extreme ratings in their respective category according to the labels provided by 72 volunteers. The labels were provided in the two-dimensional plane spanned by the two dimensions
Valence and
Arousal according to Russell’s circumplex model of affect [
57]. Valence, the dimension describing one’s level of pleasure, ranges from sad (unpleasant and stressed) to happy (pleasant and content), and Arousal ranges from sleepy (bored and inactive) to excited (alert and active). Therefore, the four category labels are High Arousal, Low Valence (HALV); High Arousal, High Valence (HAHV); Low Arousal, High Valence (LAHV); and Low Arousal, Low Valence (LALV). The selected movie scenes described in
Table 1 are balanced between each of the valence–arousal space quadrants (HVHA, HVLA, LVHA, and LVLA). The video ID 19 corresponded to a scene from the movie
Gandhi, which differs from the AMIGOS dataset but falls into the same LALV quadrant.
2.5. Behavioral Data
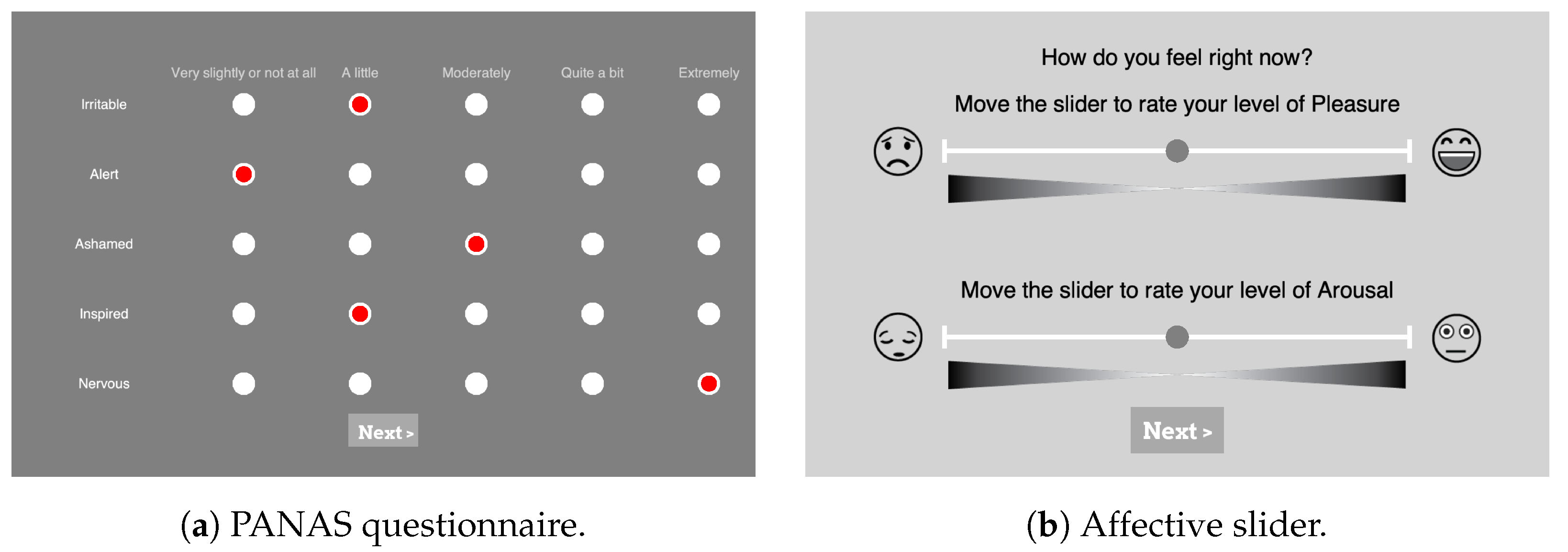
PANAS: During the experiments, participants were asked to assess their baseline levels of affect in the PANAS scale. As depicted in
Figure 3a, in total 20 questions (10 questions from each of the Positive Affect (PA) and Negative Affect (NA) dimensions) were answered using a 5-point Likert scale with the options ranging from “very slightly or not at all” (1) to “extremely” (5). To see if the participants’ moods generally changed over the course of the experiments, they were asked to answer the PANAS once at the beginning and once again at the end. For the German version of the PANAS questionnaire, the translation of Breyer and Bluemke [
58] was used.
Affect Self-Assessment: The Affective Slider (AS) [
59] was used in the experiment to capture participants’ emotional self-assessment after presenting each stimulus, as depicted in the screenshot in
Figure 3b (
https://github.com/albertobeta/AffectiveSlider (accessed on 20 February 2023)). The AS is a digital self-reporting tool composed of two slider controls for the quick assessment of pleasure and arousal. The two sliders show emoticons at their ends to represent the extreme points of their respective scales, i.e., unhappy/happy for pleasure (valence) and sleepy/wide awake for arousal. For the experiments, AS was designed in a continuous normalized scale with a step size of 0.01 (i.e., a resolution of 100), and the order of the two sliders was randomized each time.
Figure 3.
Screenshots from the PsychoPy [
48] setup of self-assessment questions. (
a) Partial PANAS questionnaire with five different levels represented by clickable radio buttons (in red) with the levels’ explanation on top, (
b) AS for valence displayed on top and the slider for arousal on the bottom.
Figure 3.
Screenshots from the PsychoPy [
48] setup of self-assessment questions. (
a) Partial PANAS questionnaire with five different levels represented by clickable radio buttons (in red) with the levels’ explanation on top, (
b) AS for valence displayed on top and the slider for arousal on the bottom.
2.6. Dataset II
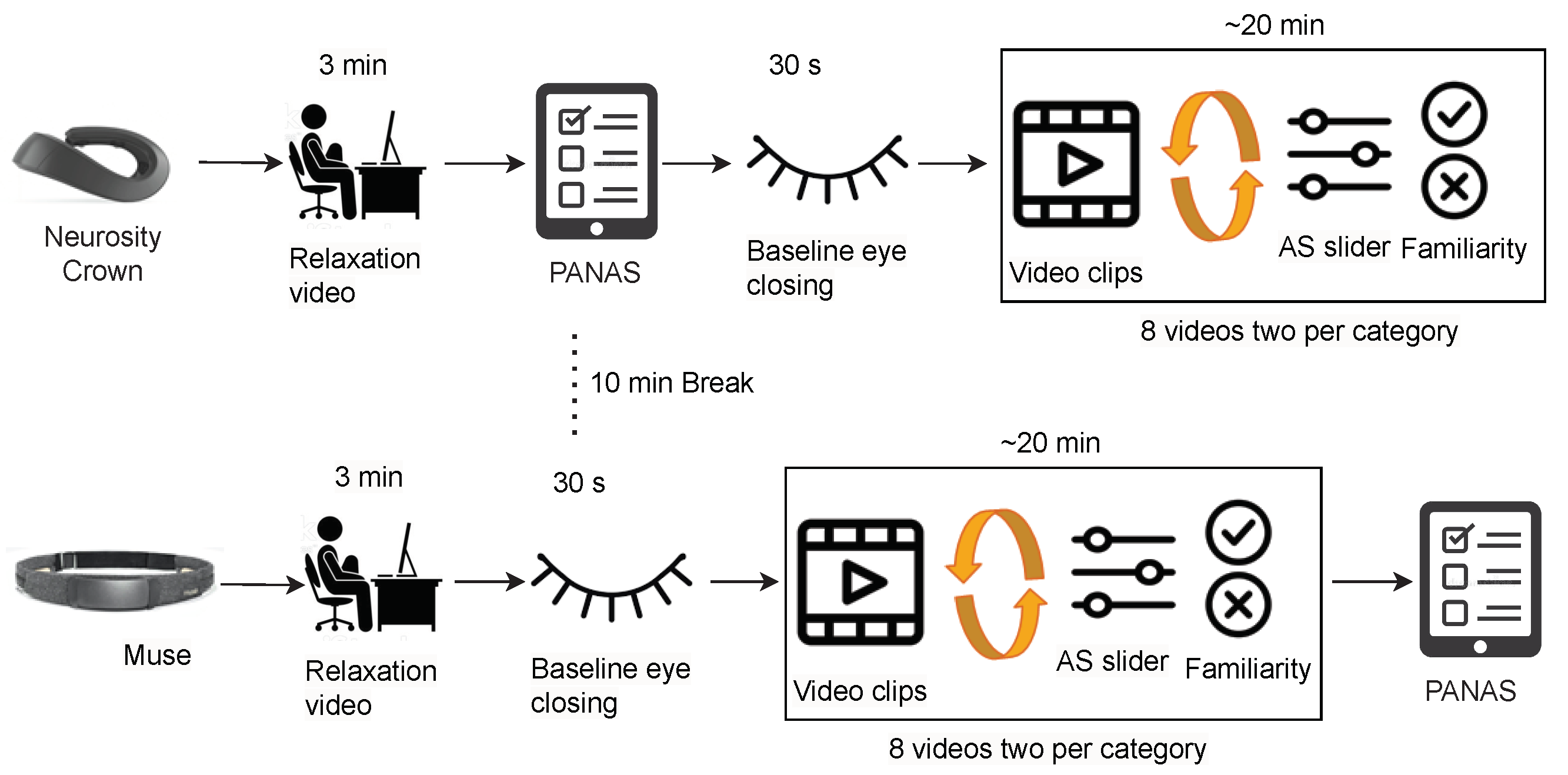
Briefing Session: In the beginning, each participant went through a pre-experimental briefing where the experimenter explained the study procedure and informed the participant of the experiment’s duration, i.e., two parts of approximately 20 min each with a small intermediate break. The participant then received and read the data information sheet, filled out the personal information sheet, and signed the consent to participate. Personal information included age, nationality, biological sex, handedness (left- or right-handed), education level, and neurological- or mental health-related problems. The documents and the study platform (i.e., PsychoPy) were provided according to the participant’s choice of study language between English and German. Afterward, the experimenter explained the three scales mentioned in and allowed the participant to accustom to the PsychoPy platform. This ensured the understanding of the different terms and scales used for the experiment without having to interrupt the experiment afterwards. The participant could refrain from participating at any moment during the experiment.
Data Collection: After the briefing, the experimenter put either the Muse headband or the Crown on the participant by a random choice. Putting headphones over the device, the participant was asked to refrain from strong movements, especially of the head. The experimenter then checked the incoming EEG data and let the participant begin the experiment. After greeting the participant with a welcome screen, a relaxation video was shown to the participant (
https://www.youtube.com/watch?v=S6jCd2hSVKA (accessed on 20 February 2023)) for 3 min. They answered the PANAS questionnaire to rate their current mood and closed eyes for half a minute to get a baseline measure of EEG data. Afterwards, they were asked to initially rate the valence and arousal state with the AS. Following this, an instruction about watching eight short videos was provided. Each of those was preceded by a video counter and followed by two questionnaires: the AS and the familiarity. The order of the videos and the order of the two sliders of AS were randomized over both parts of the experiments, fulfilling the condition that the labels of the videos are balanced. The first part of the experiment ended after watching eight videos and answering the corresponding questionnaire. The participant was allowed a short break after taking the EEG device and the headphones off.
In the second part of the experiment, the experimenter put the device that had not been used in the first part (Muse or Crown, respectively) and the headphones on the participant. Subsequently, the experimenter started the second part of the experiment, again after ensuring that the data collection was running smoothly. The participant followed the exact same protocol: watching the relaxation video, closing their eyes, and watching eight more movie scenes with the AS and familiarity questions in between. Lastly, they were asked for a final mood self-assessment via a second PANAS questionnaire to capture differences before and after the experiment. The experimental setup for curating Dataset II is depicted in
Figure 4.
In this experiment, one PC (with a 2.4 to 3.0 GHz Dual Intel Core i5-6300U and 12 GB RAM) was used to present the stimuli and store EEG data to be used only after the experiment session.
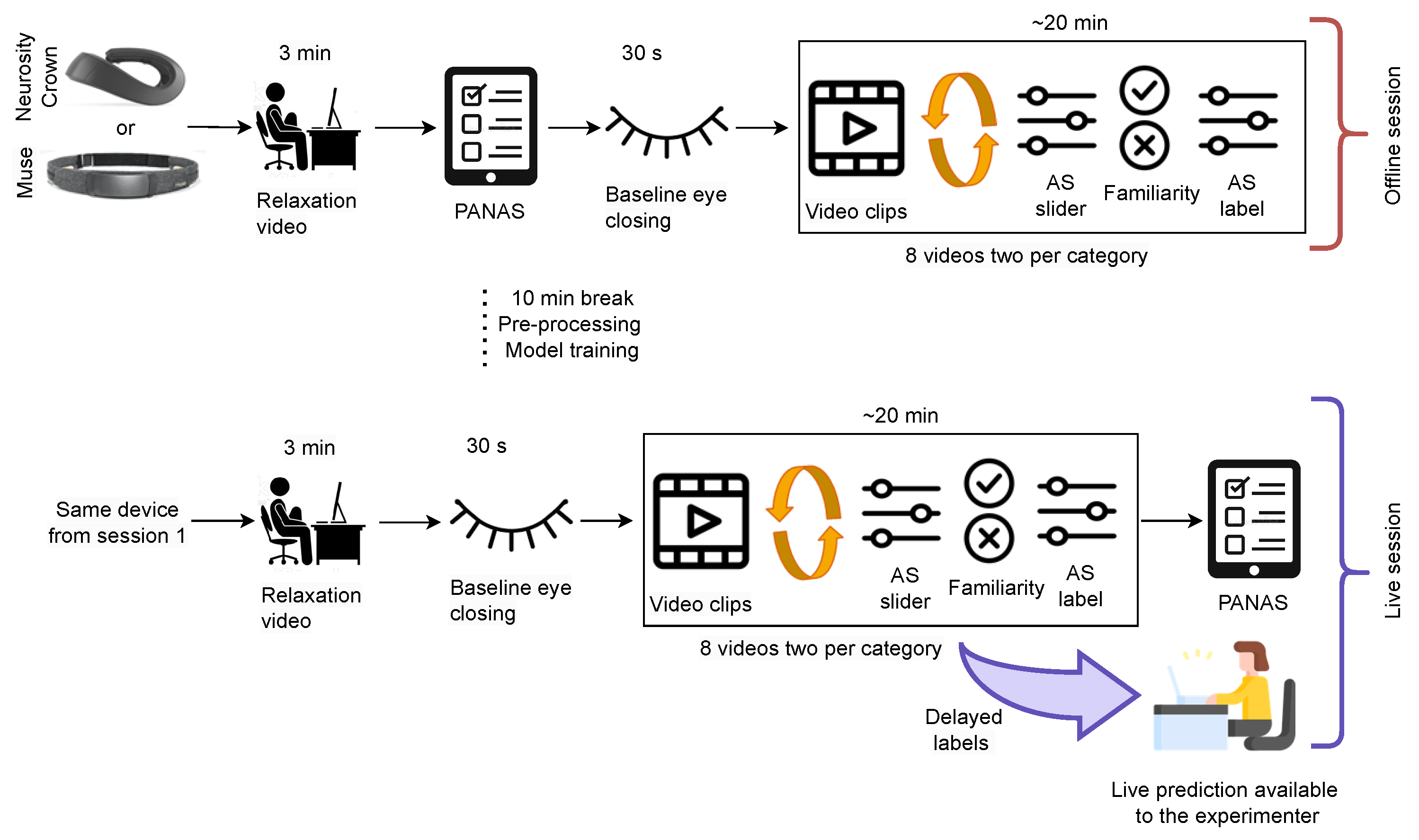
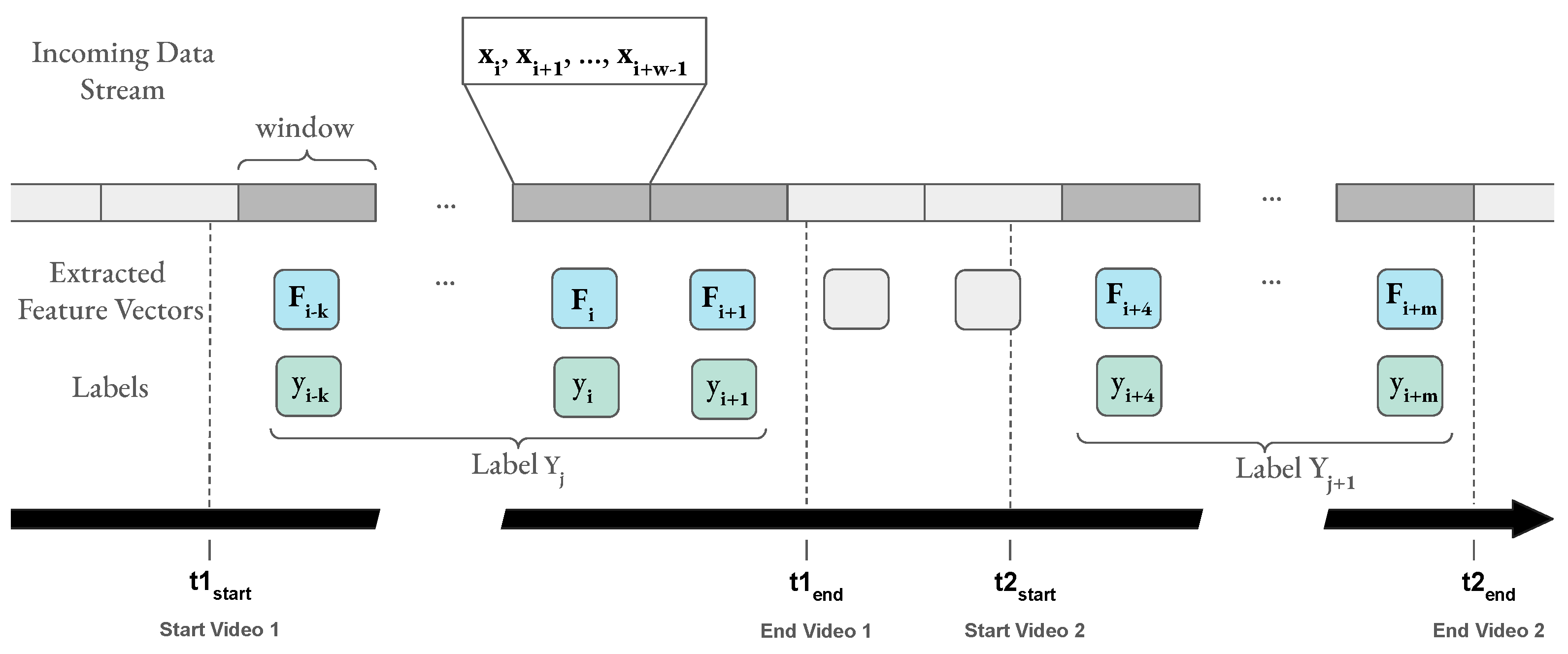
2.7. Dataset III: Live Training and Classification
The experimental setup for curating Dataset III is depicted in
Figure 5. The participants received the same briefing as mentioned in
Section 2.6. For both parts of the experiment, the same device was used. The protocol for the stimuli presentation in the first part (before the break) was the same as that as for the experiment with Dataset II, i.e., a relaxation video, PANAS, eye closing, eight video stimuli, and the AS and familiarity questions. One additional instruction after each AS was shown, which includes the original label of the videos. This additional information was given to the participant since the arousal ratings given in Dataset II were very imbalanced. During the break, the recorded EEG data were pre-processed and used to train an initial model in an online way. This initial model training was necessary because the data needed to be shuffled, as explained in
Section 3.2. The initial model was continuously trained and updated during the second part of the experiment where a live prediction of affect is performed. The second part of the experiment was conducted similar to the first part: a relaxation video, eye closing, eight video stimuli, and the AS and familiarity questions. However, one additional prediction was performed and was available to the experimenter before the AS label from the participant. Furthermore, the AS label was used to update the model training and the prediction was running in parallel.
Figure 6 displays the initialized model in the bottom gray rectangle that performed live emotion classification on the incoming EEG data stream. However, the prediction results were only displayed to the experimenter to avoid additional bias. Since the objective of this experiment was
live online learning and classification, the data were coming in an online stream; however, the data were also stored for later evaluation and reproducibility.
In this experiment, the same PC from the previous experiment was again used to present the stimuli. Additionally, the AS label was sent to a second machine (MacBook Pro (2019) with a 2.8 GHz Quad-Core (Intel Core i7) and 16 GB). It also received EEG data, and performed data pre-processing, online model training, and live emotion classification.
5. Discussion
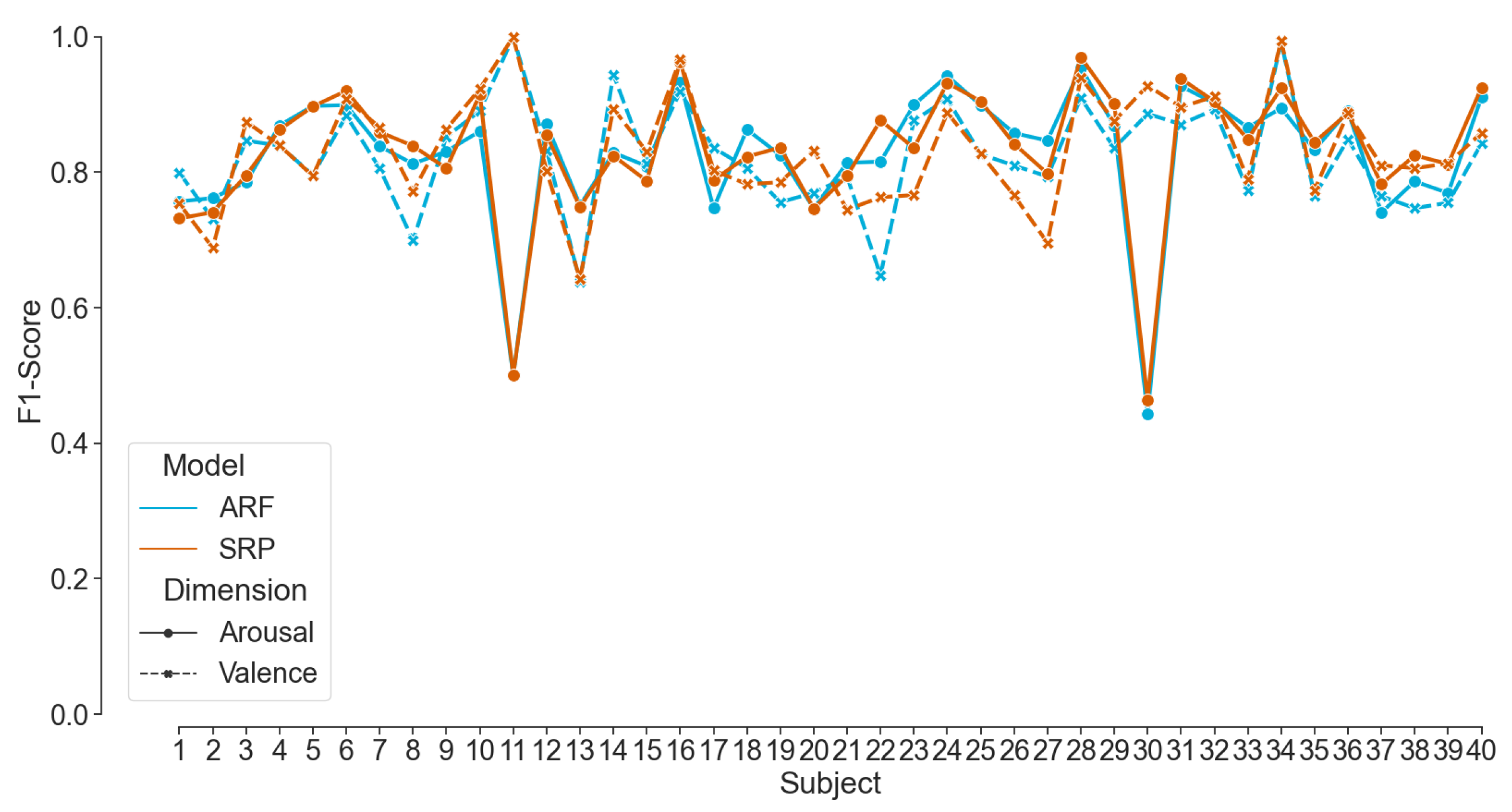
In this paper, firstly, a real-time emotion classification pipeline was built for binary classification (high/low) of the two affect dimensions:
Valence and
Arousal. Adaptive random forest (ARF), streaming random patches (SRP), and logistic regression (LR) classifiers with 10-fold cross-validation were applied to the EEG data stream. The subject-dependent models were evaluated with progressive and delayed validation, respectively, when immediate and delayed labels were available. The pipeline was validated on existing data of ensured quality from the state-of-the-art AMIGOS [
22] dataset. By streaming the recorded data to the pipeline, the mean F1-Scores were more than 80% for both ARF and SRP models. The results outperform the authors’ baseline results by approximately 25% and are also slightly better than the work reported in [
73] using the same dataset. The results of Topic et al. [
74] showed a better performance; however, due to the reported complex setup and computationally expensive methods, the system is unsuitable for real-time emotion classification. Nevertheless, the results mentioned in the related work apply offline classifiers with a hold-out or a k-fold cross-validation technique. In contrast, our pipeline applies an online classifier by employing progressive validation. To the best of our knowledge, no other work has tested and outperformed our online EEG-based emotion classification framework on the published AMIGOS dataset.
Secondly, a similar framework to the AMIGOS dataset, Dataset II, was established within this paper, which can collect neurophysiological data from a wide range of neurophysiological sensors. In this paper, two consumer-grade EEG devices were used to collect data from 15 participants while watching 16 emotional videos. The framework available in the mentioned repository can be adapted for similar experiments.
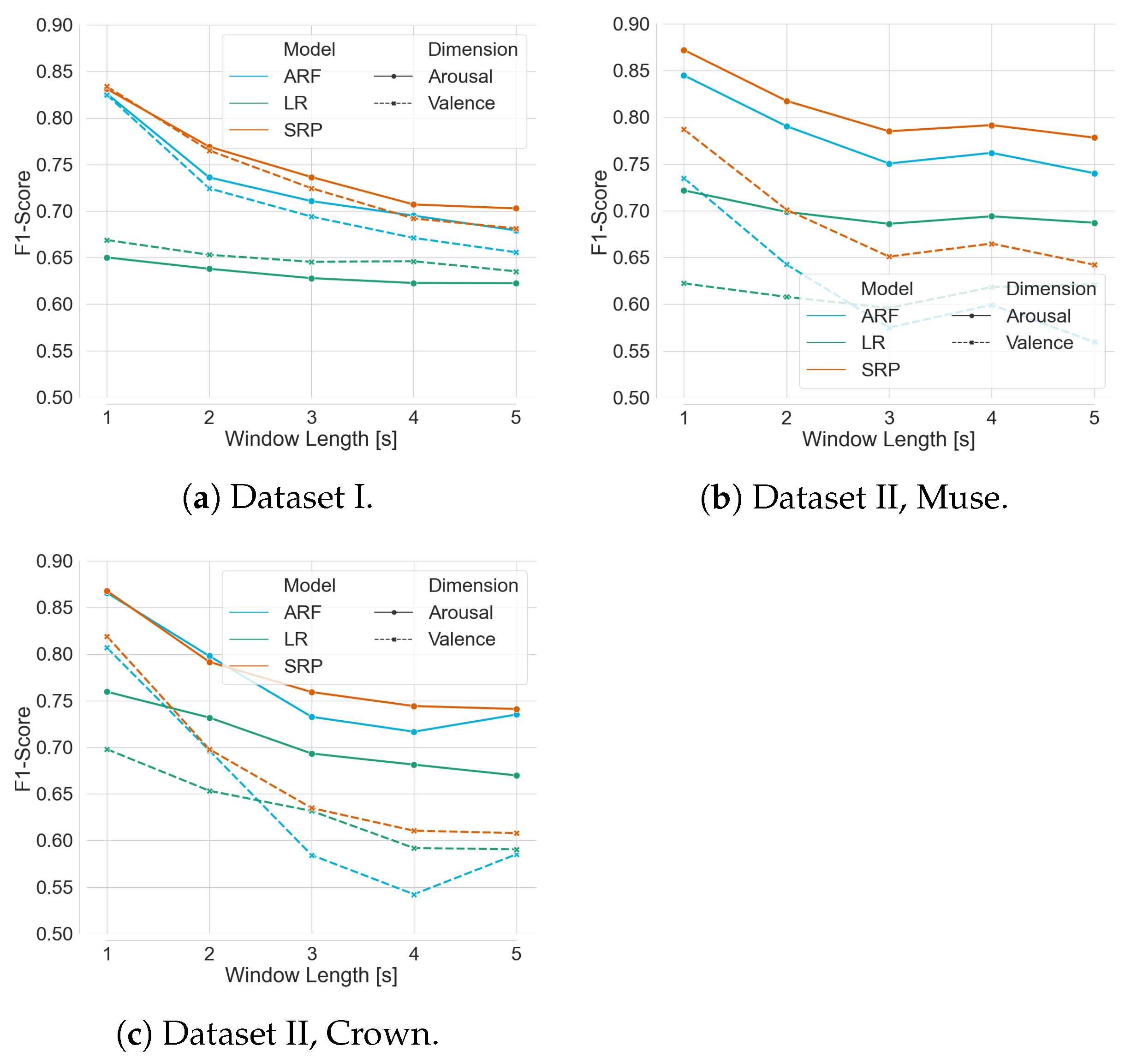
Thirdly, and most importantly, we curated data in two experiments to validate our classification pipeline using the mentioned framework. Eleven participants took part in acquiring th data for Dataset II, where EEG data were recorded while watching 16 emotion elicitation videos. The pre-recorded data were streamed to the pipeline and showed a mean F1-Score of more than 82% with ARF and SRP classifiers using progressive validation. This finding validates the competence of the pipeline on the challenging dataset from consumer-grade EEG devices. Additionally, the online classifiers consistently showed better performance for ARF and SRP than LR on all compared modalities. However, internal testing verified that the run-time of the training step of the pipeline of ARF is less than that of SRP, concluding that ARF should be used in live prediction. The analysis on window length shows a clear trend of increasing performance scores with decreasing window length; therefore, a window length of 1 s was chosen for live prediction. Although the two employed consumer-grade devices have a different number of sensors at contrasting positions, there were no statistically significant differences between the achieved performance scores found for their respective data. Therefore, we used both devices for live prediction, and the pipeline was applied to a live incoming data stream in the experiment of Dataset III with the above-mentioned features of the model. In the first part of the experiment, the model was trained with the immediate labels from the EEG data stream. In the second part, the model was used to predict affect dimensions while the labels were available after a delay of the video length. The model was continuously updated whenever a new label is available. The performance scores achieved during the live classification with delayed labels were much lower than those with immediate labels, motivating us to induce an artificial delay to stream Dataset II. The results are compatible with live prediction. The literature reports better results for real-time emotion classification frameworks [
29,
30,
36] with the assumption of knowing the true label immediately after a prediction. The novelty of this paper is to present a real-time emotion classification pipeline close to a realistic production scenario from daily life with the possibility of including further modifications in future work.
In future work, the selected stimuli can be shortened to reduce the delay of the incoming labels so that the model can be updated more frequently. Otherwise, multiple intermediate labels can also be included in the study design to ensure the inclusion of short-term emotions felt while watching the movies. Furthermore, more dynamic pre-processing of the data can be included with feature selection algorithms for better classification and prediction in live settings. Moreover, the collected data from the experiments reveal a strong class imbalance in the self-reported affect ratings for arousal, with high arousal ratings making up 82.96% of all ratings in that dimension. This general trend towards higher arousal ratings is also visible in Dataset I, albeit not as intensely (62.5% high arousal ratings). In contrast, Betella et al. [
59] found “a general desensitization towards highly arousing content” in participants. The underrepresented class can be up-sampled in the model training in the future, or basic emotions can be classified instead of arousal and valance dimensions, solving the multi-class problem [
75,
76]. By including more participants in the future for live prediction, the prediction can be visible to the participant as well to include neuro-feedback. It will also be interesting to see if the predictive performance improves by utilizing additional modalities other than EEG, for example, heart rate and electrodermal activity [
20,
23,
37].

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}