
Variational Regression for Multi-Target Energy Disaggregation


Abstract
:1. Introduction
2. Related Work on Multi Target NILM
3. Practical Challenges in NILM
4. Materials and Methods
4.1. Datasets
4.2. Data Preprocessing
- Mains and target time series were aligned in time;
- Empty or missing values were replaced with zeros;
- Time series were normalised using standardization, with the values transformed centered around the zero mean with the unit standard deviation:where Z is the standard score, x is the datapoint, and mean and std the average and the standard deviation of the time series, respectively;
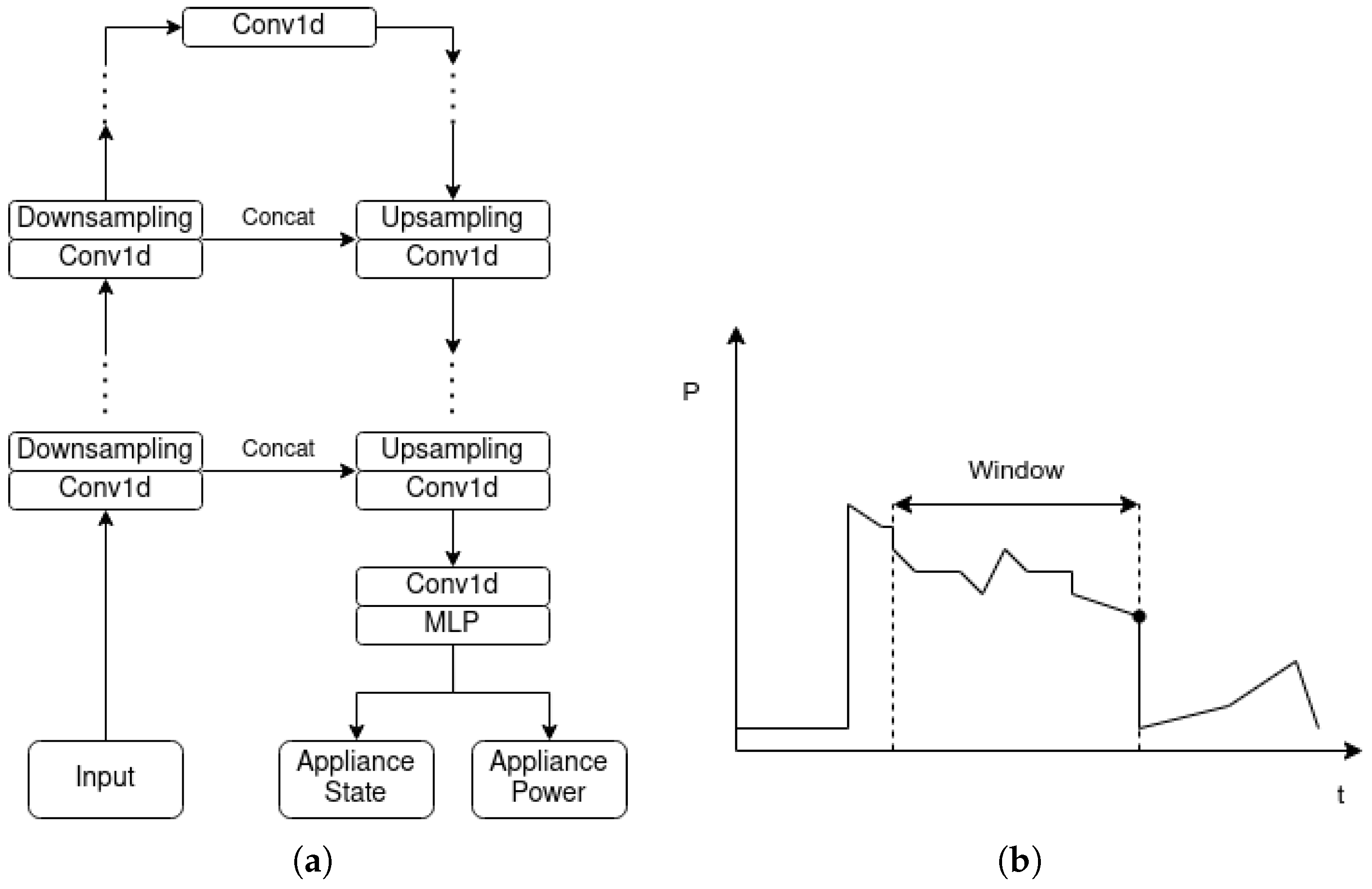
- The data were transformed in order to follow the sliding window method [27];
- The on/off states of the target appliances were calculated in each window. An appliance was considered to be working when its power level at the time of interest was above a predefined threshold. The power thresholds in this manuscript are drawn from the work of Kelly and Knottenbelt [23].
4.3. Methodology
4.4. Evaluation Metrics
5. Topology of Neural Networks
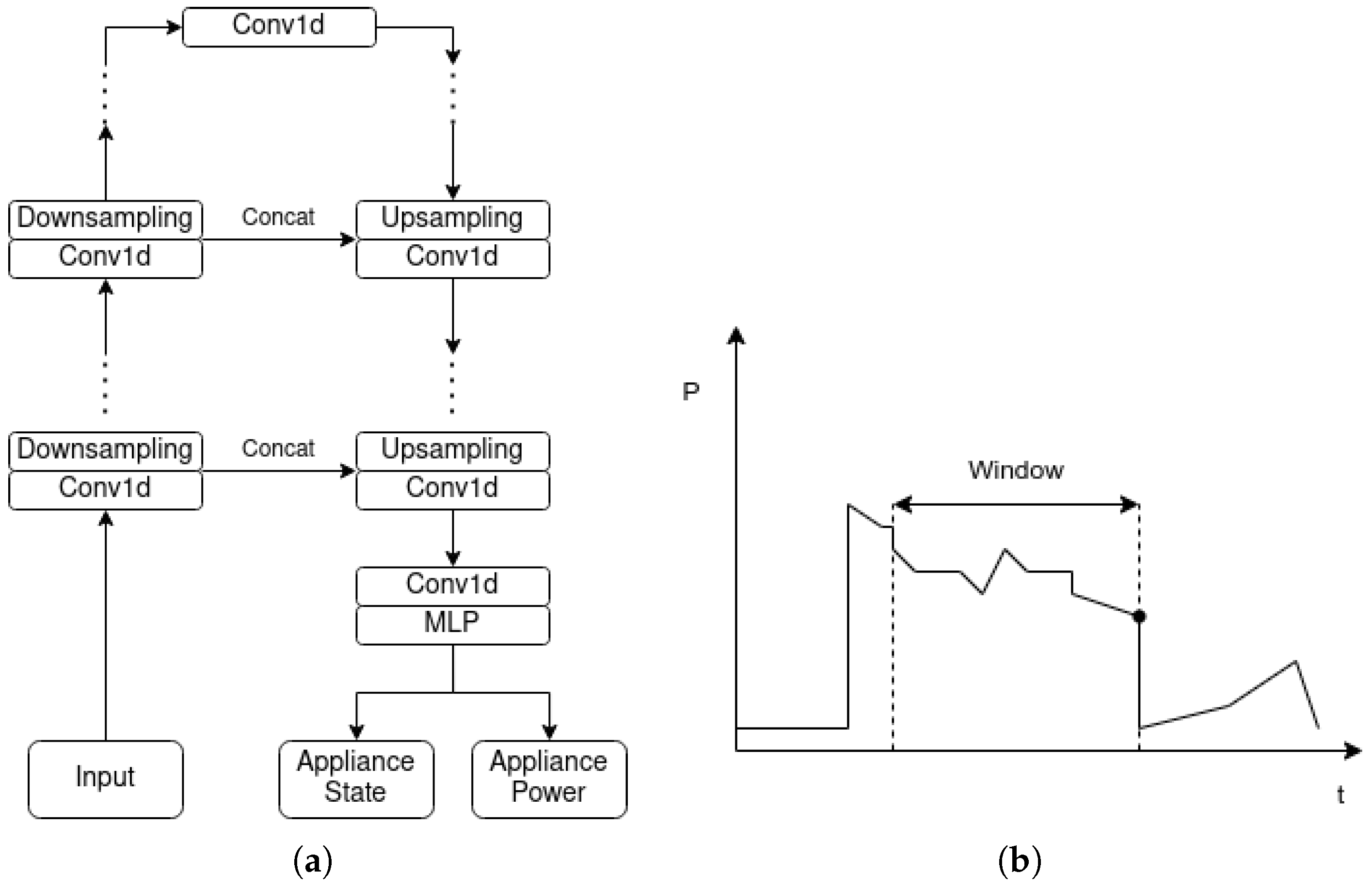
5.1. Single-Target Baseline Models
5.2. Multi-Target Baseline Models
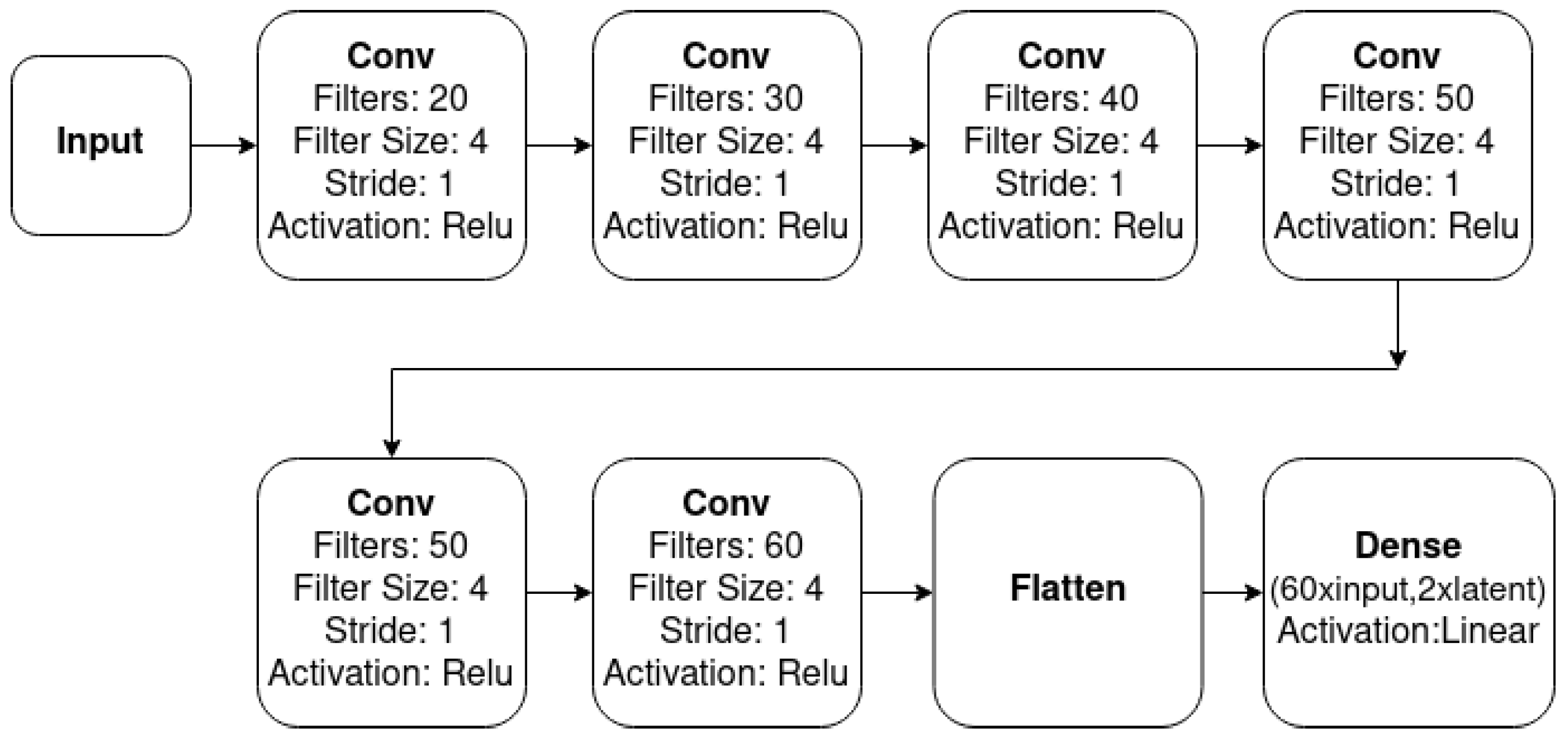
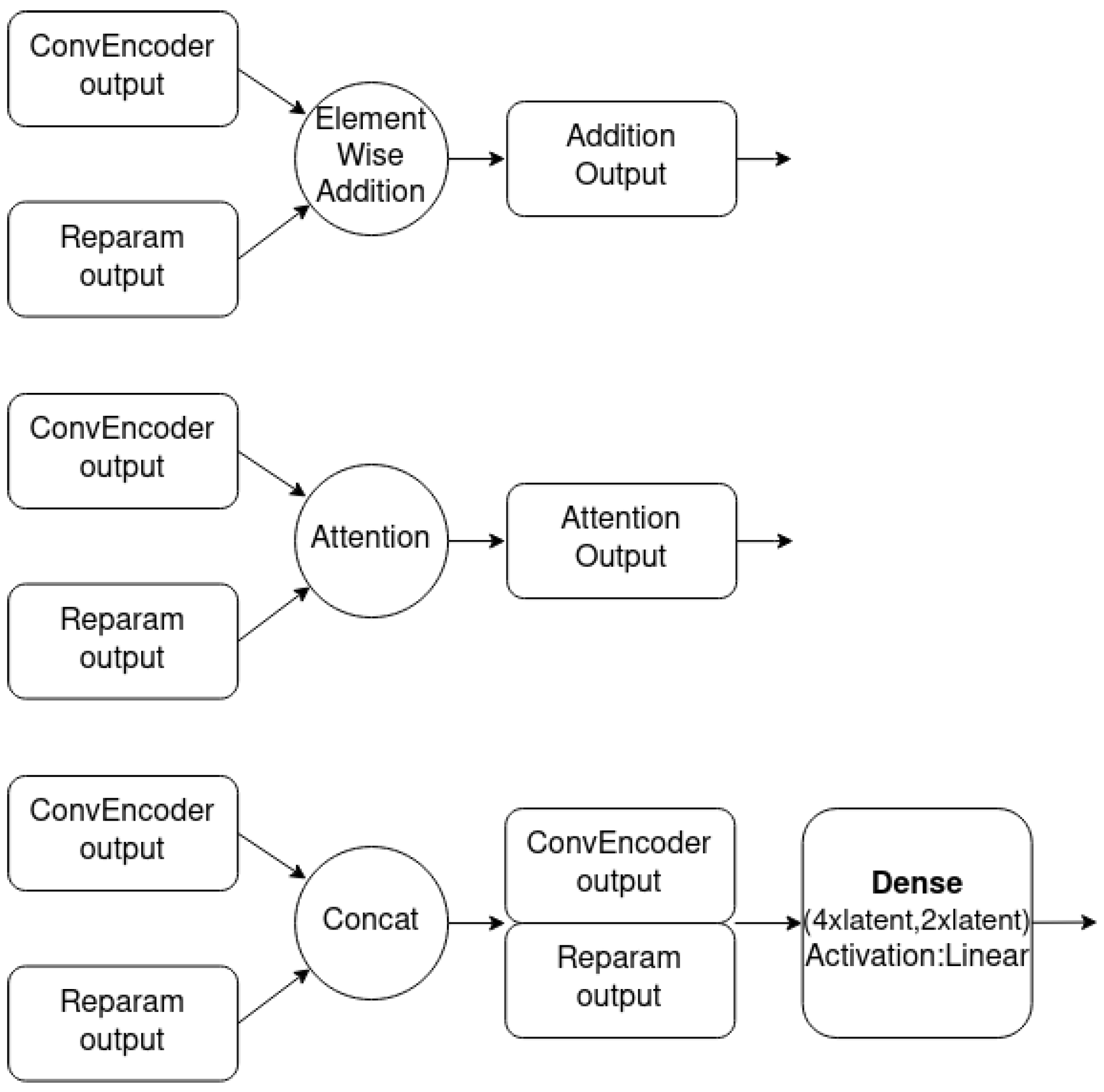
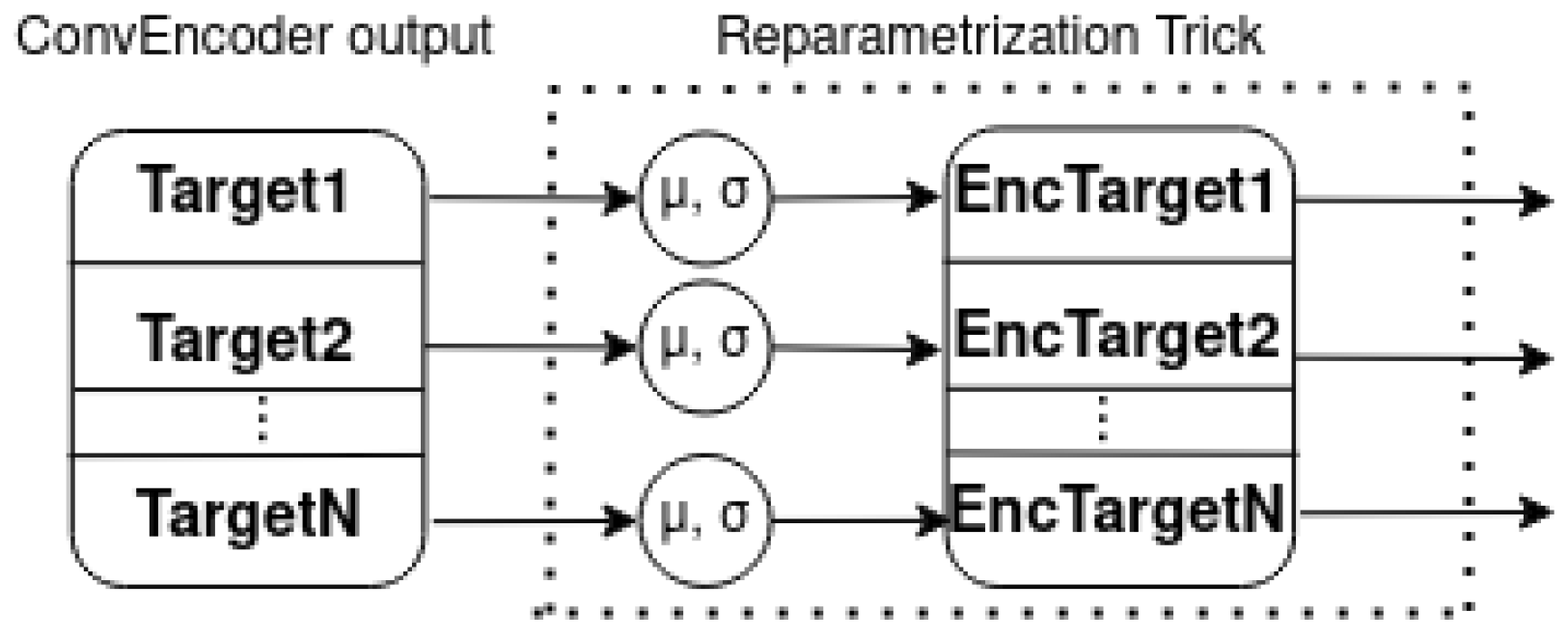
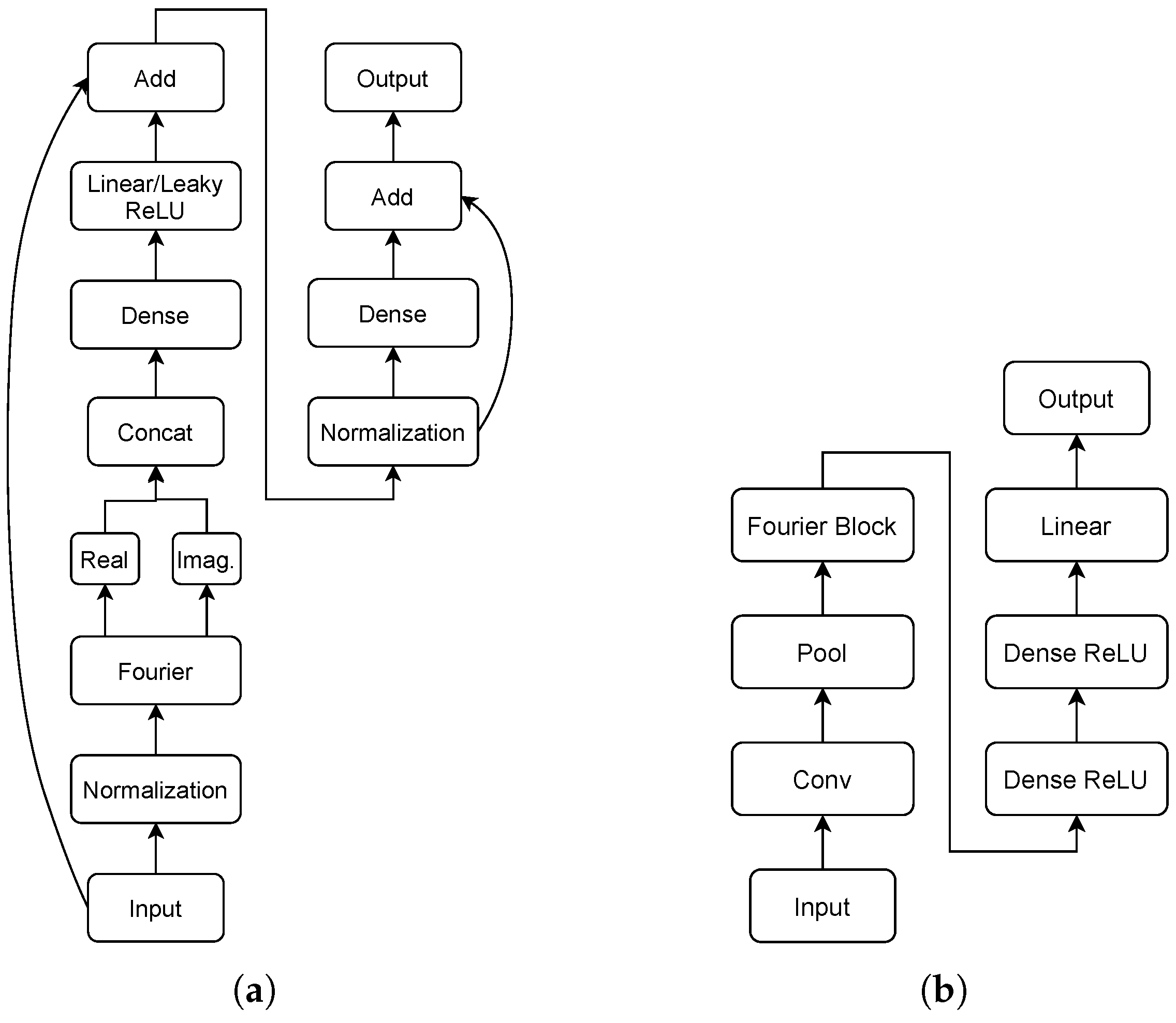
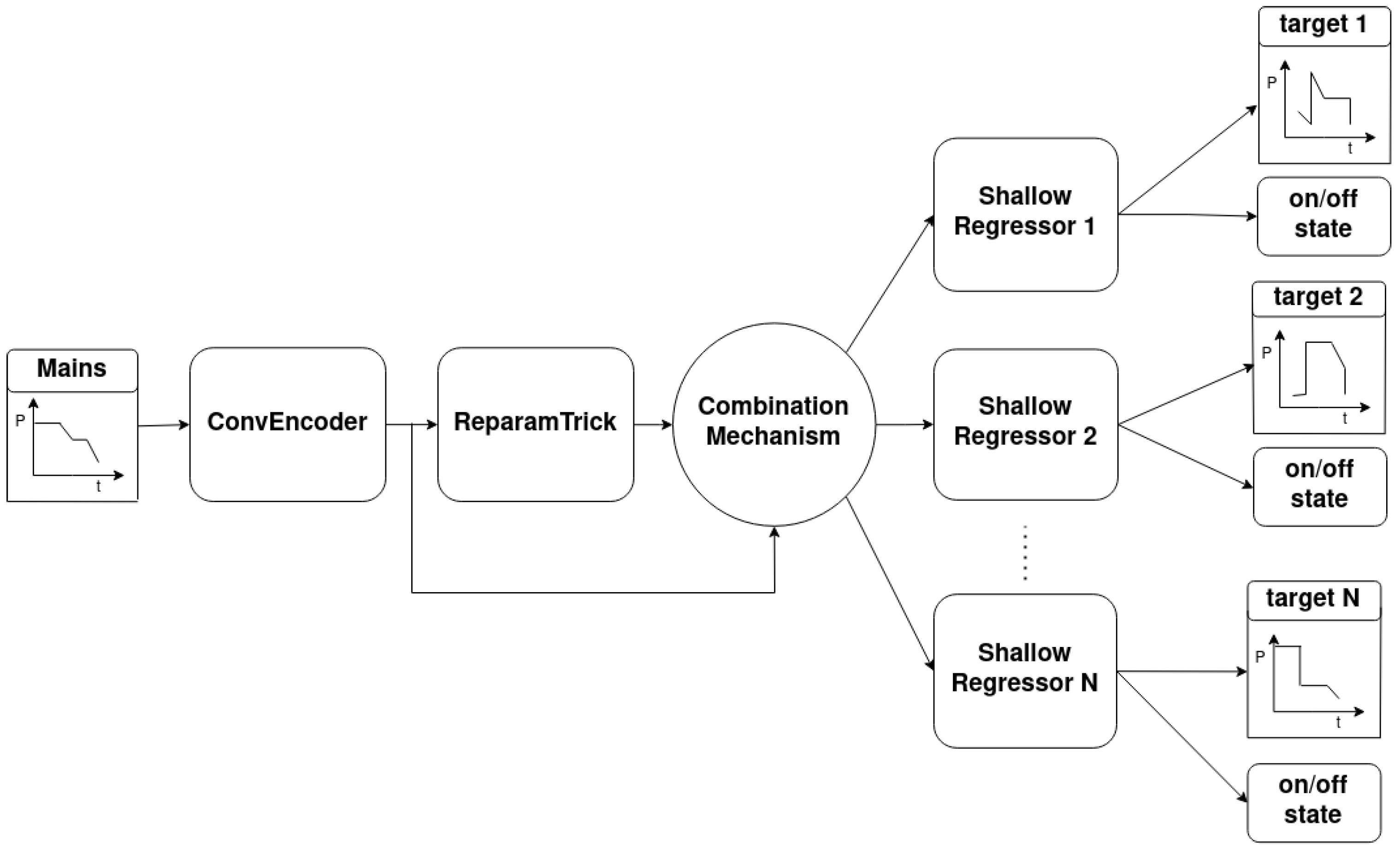
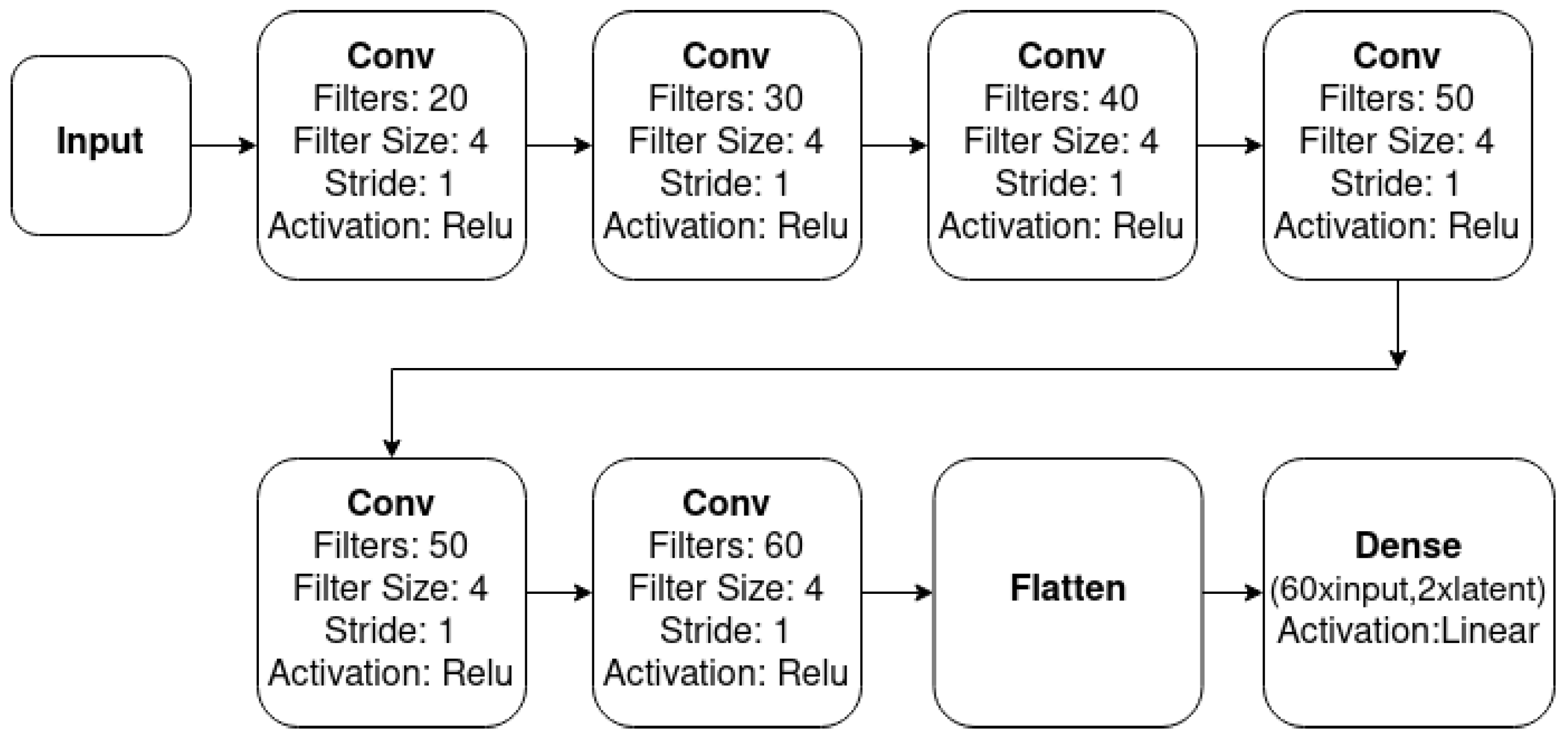
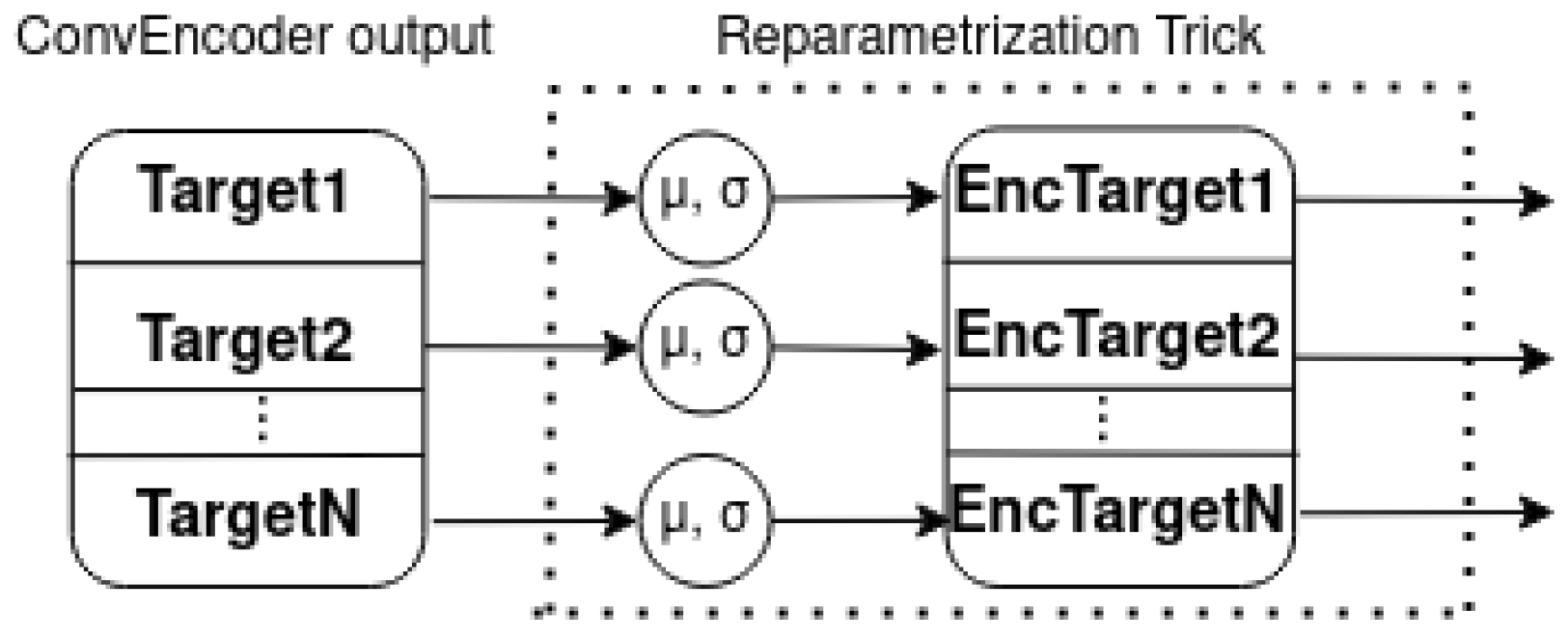
5.3. The Proposed Variational Multi-Target Regressor Architecture
5.4. Loss Function
6. Experimental Results and Discussion
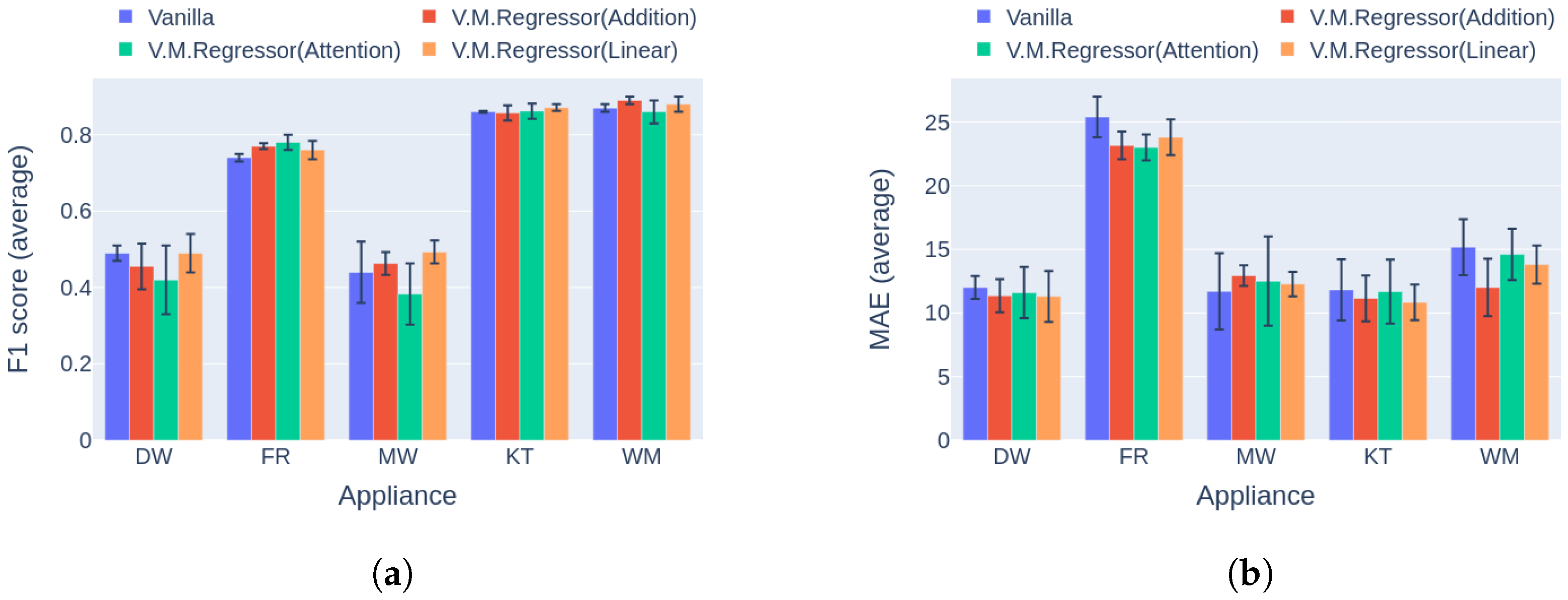
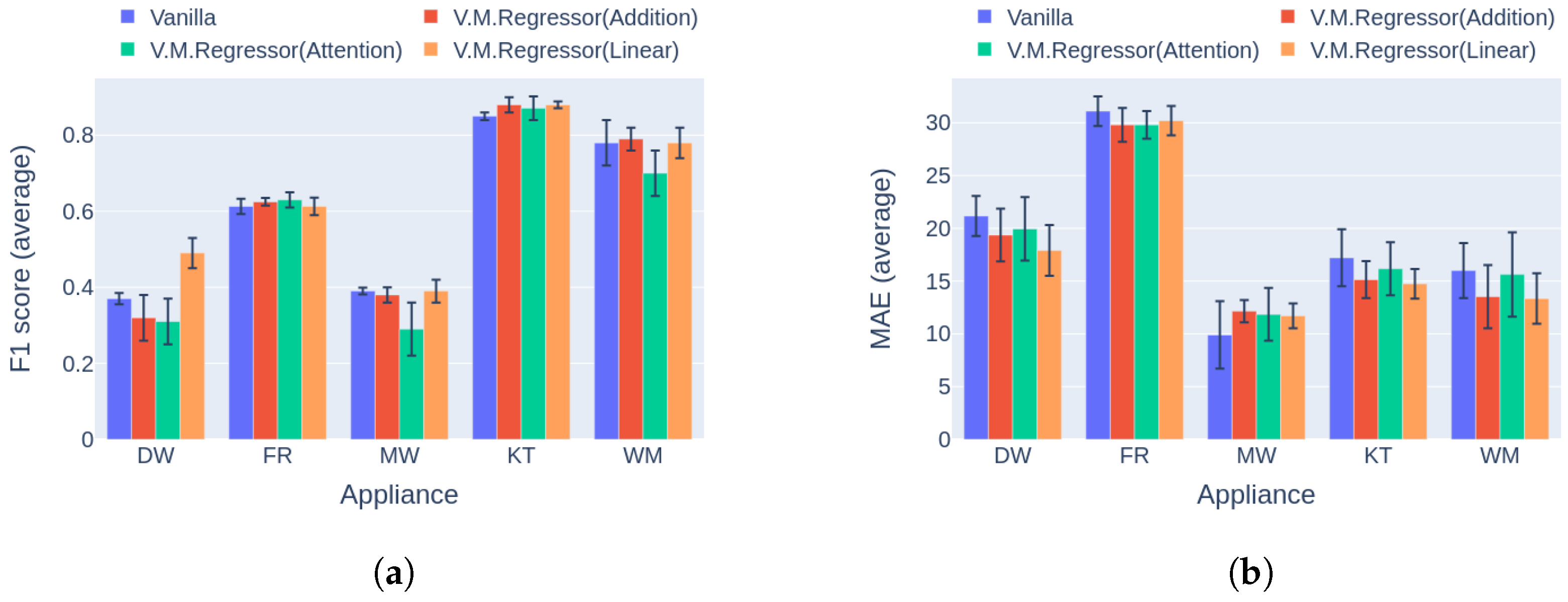
6.1. Ablation Study—Variational Inference
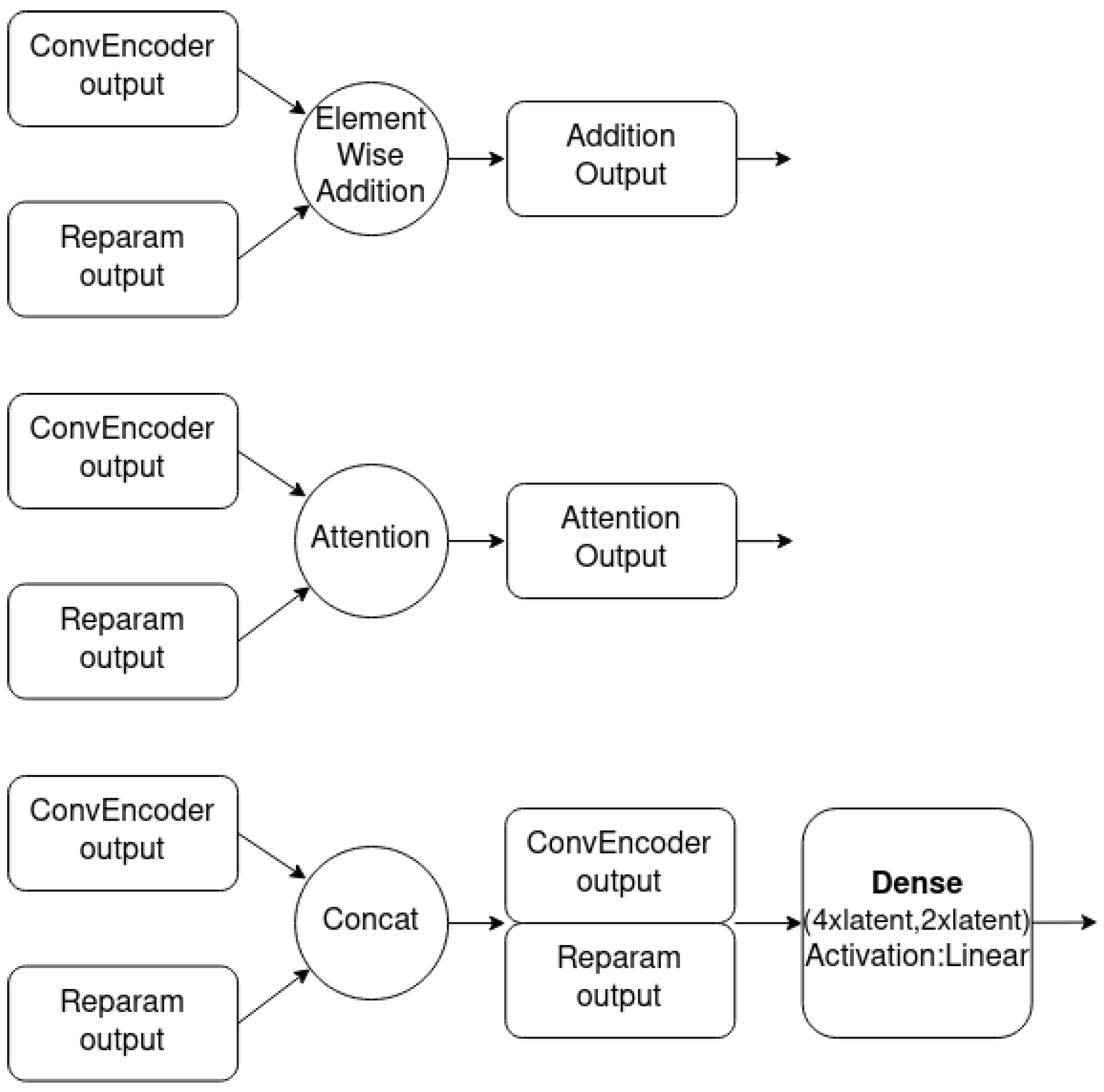
6.2. Combination Mechanism Selection
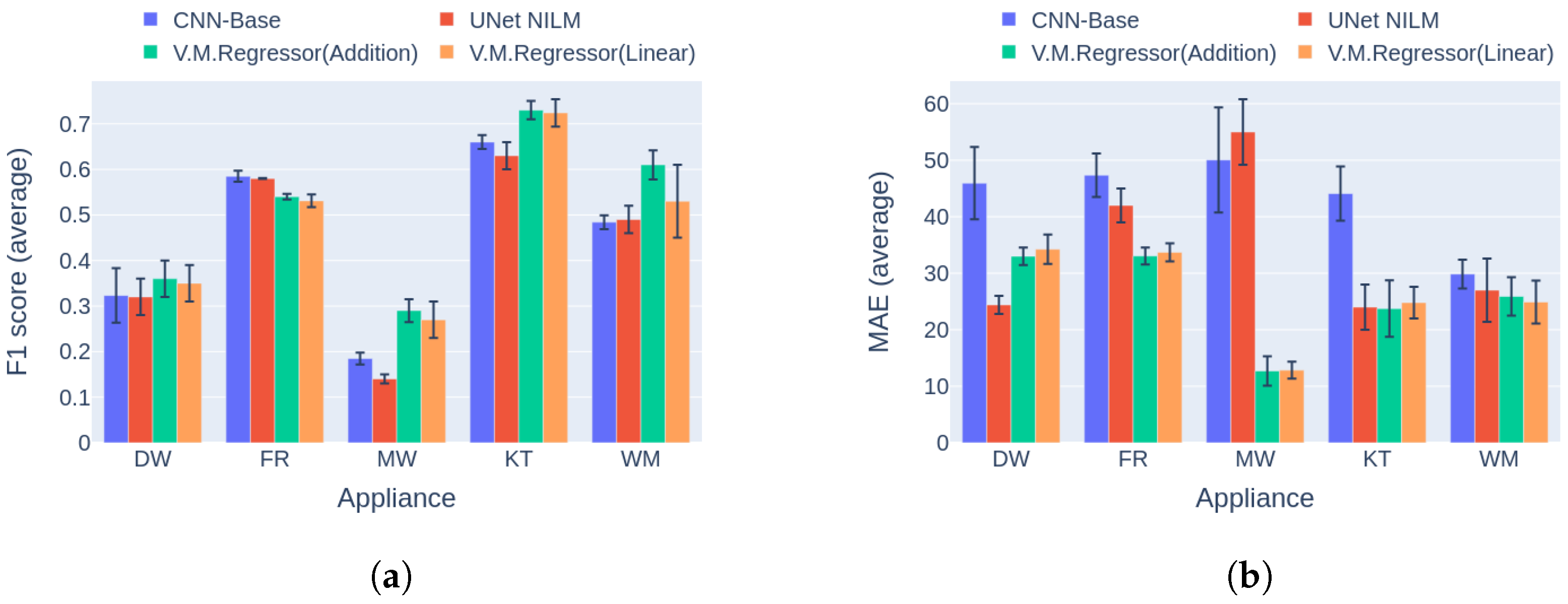
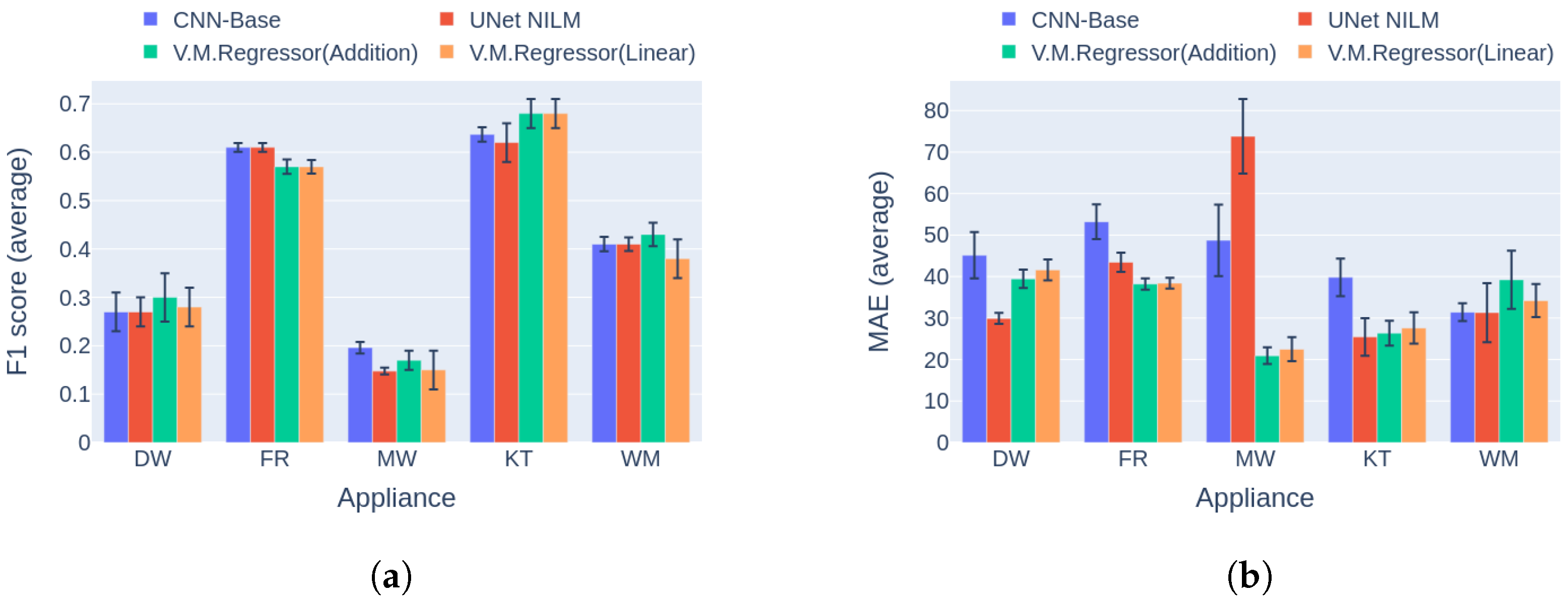
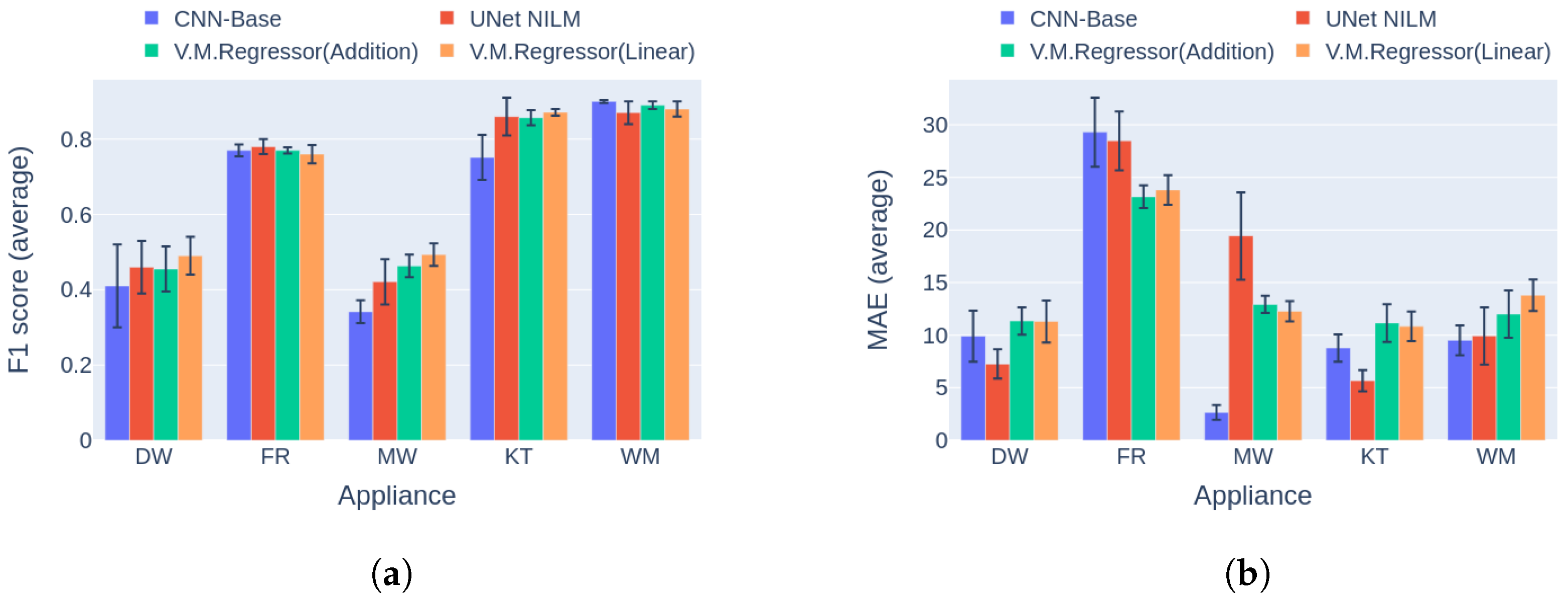
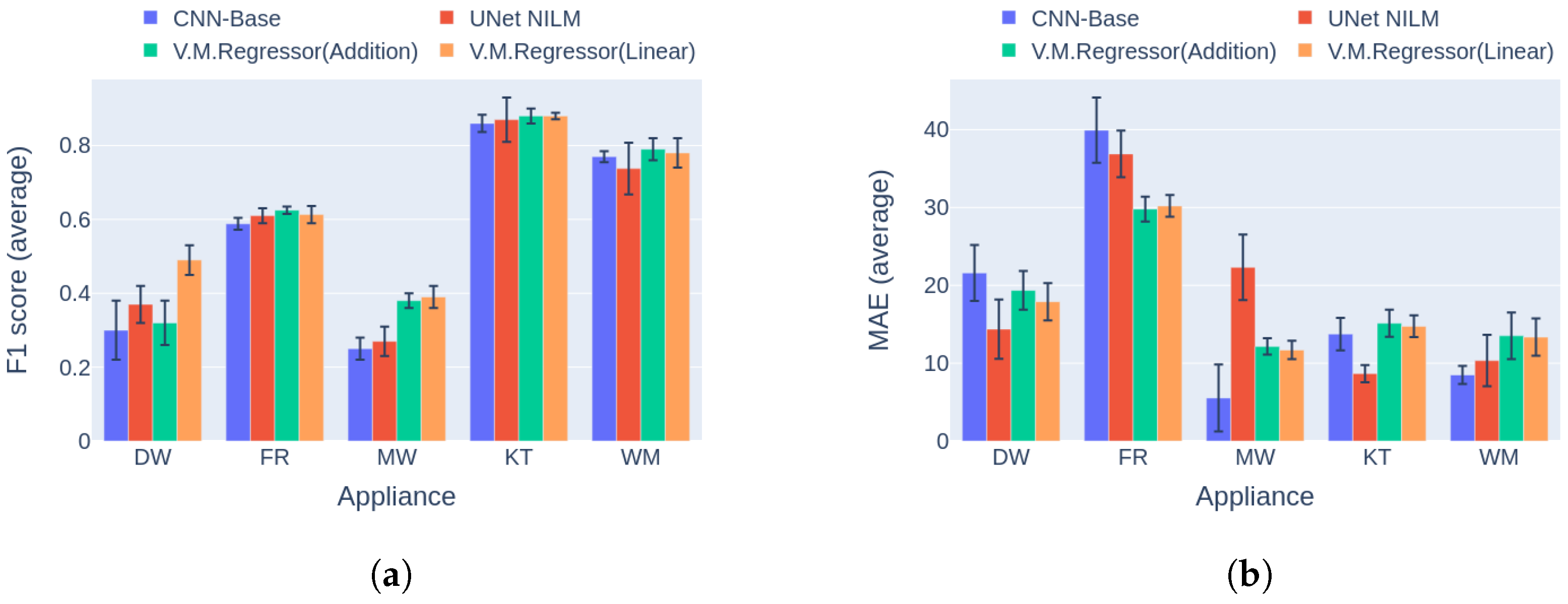
6.3. Comparison to Multi-Target Baseline
6.4. Comparison with Single-Target Models
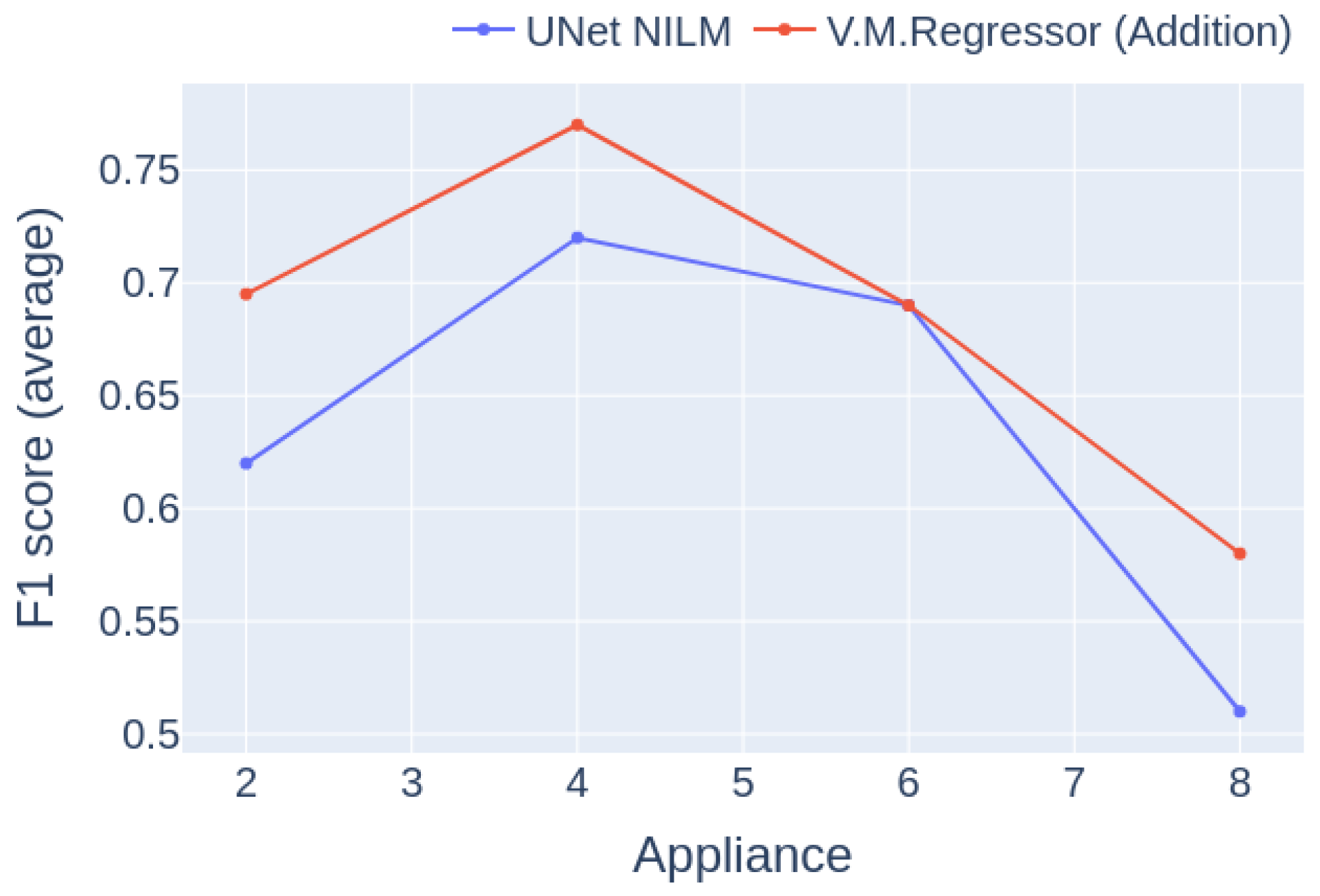
6.5. Performance for Different Numbers of Appliances
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hart, G.W. Nonintrusive appliance load monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Pal, M.; Roy, R.; Basu, J.; Bepari, M.S. Blind source separation: A review and analysis. In Proceedings of the 2013 International Conference Oriental COCOSDA Held Jointly with 2013 Conference on Asian Spoken Language Research and Evaluation (O-COCOSDA/CASLRE), Gurgaon, India, 25–27 November 2013; pp. 1–5. [Google Scholar] [CrossRef]
- Naghibi, B.; Deilami, S. Non-intrusive load monitoring and supplementary techniques for home energy management. In Proceedings of the 2014 Australasian Universities Power Engineering Conference (AUPEC), Perth, Australia, 28 September–1 October 2014; pp. 1–5. [Google Scholar]
- Mahapatra, B.; Nayyar, A. Home energy management system (HEMS): Concept, architecture, infrastructure, challenges and energy management schemes. Energy Syst. 2019, 13, 643–669. [Google Scholar] [CrossRef]
- Nalmpantis, C.; Vrakas, D. Machine learning approaches for non-intrusive load monitoring: From qualitative to quantitative comparation. Artif. Intell. Rev. 2019, 52, 217–243. [Google Scholar] [CrossRef]
- Lin, Y.H. A Parallel Evolutionary Computing-Embodied Artificial Neural Network Applied to Non-Intrusive Load Monitoring for Demand-Side Management in a Smart Home: Towards Deep Learning. Sensors 2020, 20, 1649. [Google Scholar] [CrossRef]
- Angelis, G.F.; Timplalexis, C.; Krinidis, S.; Ioannidis, D.; Tzovaras, D. NILM Applications: Literature review of learning approaches, recent developments and challenges. Energy Build. 2022, 261, 111951. [Google Scholar] [CrossRef]
- Alcalá, J.; Parson, O.; Rogers, A. Detecting Anomalies in Activities of Daily Living of Elderly Residents via Energy Disaggregation and Cox Processes. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, BuildSys ’15, Seoul, Republic of Korea, 4–5 November 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 225–234. [Google Scholar] [CrossRef]
- Bousbiat, H.; Klemenjak, C.; Leitner, G.; Elmenreich, W. Augmenting an Assisted Living Lab with Non-Intrusive Load Monitoring. In Proceedings of the 2020 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Dubrovnik, Croatia, 25–28 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Athanasiadis, C.L.; Pippi, K.D.; Papadopoulos, T.A.; Korkas, C.; Tsaknakis, C.; Alexopoulou, V.; Nikolaidis, V.; Kosmatopoulos, E. A Smart Energy Management System for Elderly Households. In Proceedings of the 2022 57th International Universities Power Engineering Conference (UPEC), Istanbul, Turkey, 30 August–2 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Donato, P.; Carugati, I.; Hernández, Á.; Nieto, R.; Funes, M.; Ureña, J. Review of NILM applications in smart grids: Power quality assessment and assisted independent living. In Proceedings of the 2020 Argentine Conference on Automatic Control (AADECA), Buenos Aires, Argentina, 28–30 October 2020. [Google Scholar] [CrossRef]
- Bucci, G.; Ciancetta, F.; Fiorucci, E.; Mari, S.; Fioravanti, A. State of art overview of Non-Intrusive Load Monitoring applications in smart grids. Meas. Sens. 2021, 18, 100145. [Google Scholar] [CrossRef]
- Massidda, L.; Marrocu, M. A Bayesian Approach to Unsupervised, Non-Intrusive Load Disaggregation. Sensors 2022, 22, 4481. [Google Scholar] [CrossRef]
- Kaur, D.; Islam, S.; Mahmud, M.A.; Haque, M.; Dong, Z. Energy forecasting in smart grid systems: Recent advancements in probabilistic deep learning. IET Gener. Transm. Distrib. 2022, 16, 4461–4479. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Mahdjoubi, L.; Gething, B.; Sierra, F. Disaggregating high-resolution gas metering data using pattern recognition. Energy Build. 2018, 176, 17–32. [Google Scholar] [CrossRef]
- Ellert, B.; Makonin, S.; Popowich, F. Appliance Water Disaggregation via Non-Intrusive Load Monitoring (NILM). In Smart City 360°. SmartCity 360 SmartCity 360 2016 2015. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Springer: Cham, Switzerland, 2016; Volume 166, pp. 455–467. [Google Scholar] [CrossRef]
- Pastor-Jabaloyes, L.; Arregui, F.J.; Cobacho, R. Water End Use Disaggregation Based on Soft Computing Techniques. Water 2018, 10, 46. [Google Scholar] [CrossRef]
- Gkalinikis, N.V.; Vrakas, D. Efficient Deep Learning Techniques for Water Disaggregation. In Proceedings of the 2022 2nd International Conference on Energy Transition in the Mediterranean Area (SyNERGY MED), Thessaloniki, Greece, 17–19 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Kim, H.; Marwah, M.; Arlitt, M.; Lyon, G.; Han, J. Unsupervised Disaggregation of Low Frequency Power Measurements. In Proceedings of the 2011 SIAM International Conference on Data Mining, Mesa, AZ, USA, 28–30 April 2011; pp. 747–758. [Google Scholar] [CrossRef]
- Kolter, J.Z.; Jaakkola, T. Approximate inference in additive factorial hmms with application to energy disaggregation. In Proceedings of the Fifteenth International Conference on Artificial Intelligence and Statistics, PMLR 22, La Palma, Spain, 21–23 April 2012; pp. 1472–1482. [Google Scholar]
- Parson, O.; Ghosh, S.; Weal, M.J.; Rogers, A.C. Non-Intrusive Load Monitoring Using Prior Models of General Appliance Types. In Proceedings of the AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012; AAAI Press: Palo Alto, CA, USA, 2012; Volume 26, pp. 356–362. [Google Scholar] [CrossRef]
- Fortuna, L.; Buscarino, A. Non-Intrusive Load Monitoring. Sensors 2022, 22, 6675. [Google Scholar] [CrossRef] [PubMed]
- Kelly, J.; Knottenbelt, W. Neural nilm: Deep neural networks applied to energy disaggregation. In Proceedings of the 2nd ACM International Conference on Embedded Systems for Energy-Efficient Built Environments, Seoul, Republic of Korea, 4–5 November 2015; pp. 55–64. [Google Scholar]
- Zhang, C.; Zhong, M.; Wang, Z.; Goddard, N.; Sutton, C. Sequence-to-point learning with neural networks for nonintrusive load monitoring. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Jia, Z.; Yang, L.; Zhang, Z.; Liu, H.; Kong, F. Sequence to point learning based on bidirectional dilated residual network for non-intrusive load monitoring. Int. J. Electr. Power Energy Syst. 2021, 129, 106837. [Google Scholar] [CrossRef]
- Mauch, L.; Yang, B. A new approach for supervised power disaggregation by using a deep recurrent LSTM network. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 63–67. [Google Scholar]
- Krystalakos, O.; Nalmpantis, C.; Vrakas, D. Sliding window approach for online energy disaggregation using artificial neural networks. In Proceedings of the 10th Hellenic Conference on Artificial Intelligence, Patras, Greece, 9–12 July 2018; pp. 1–6. [Google Scholar]
- Kaselimi, M.; Doulamis, N.; Doulamis, A.; Voulodimos, A.; Protopapadakis, E. Bayesian-optimized Bidirectional LSTM Regression Model for Non-intrusive Load Monitoring. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2747–2751. [Google Scholar] [CrossRef]
- Fang, Z.; Zhao, D.; Chen, C.; Li, Y.; Tian, Y. Non-Intrusive Appliance Identification with Appliance-Specific Networks. In Proceedings of the 2019 IEEE Industry Applications Society Annual Meeting, Baltimore, MD, USA, 29 September–3 October 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Moradzadeh, A.; Mohammadi-Ivatloo, B.; Abapour, M.; Anvari-Moghaddam, A.; Farkoush, S.G.; Rhee, S.B. A practical solution based on convolutional neural network for non-intrusive load monitoring. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 9775–9789. [Google Scholar] [CrossRef]
- Faustine, A.; Pereira, L.; Bousbiat, H.; Kulkarni, S. UNet-NILM: A Deep Neural Network for Multi-Tasks Appliances State Detection and Power Estimation in NILM. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, NILM’20, Virtual Event, 18 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 84–88. [Google Scholar] [CrossRef]
- Virtsionis-Gkalinikis, N.; Nalmpantis, C.; Vrakas, D. SAED: Self-attentive energy disaggregation. Mach. Learn. 2021, 1–20. [Google Scholar] [CrossRef]
- Langevin, A.; Carbonneau, M.A.; Cheriet, M.; Gagnon, G. Energy disaggregation using variational autoencoders. Energy Build. 2022, 254, 111623. [Google Scholar] [CrossRef]
- Piccialli, V.; Sudoso, A. Improving Non-Intrusive Load Disaggregation through an Attention-Based Deep Neural Network. Energies 2021, 14, 847. [Google Scholar] [CrossRef]
- Gkalinikis, N.V.; Nalmpantis, C.; Vrakas, D. Attention in Recurrent Neural Networks for Energy Disaggregation. In International Conference on Discovery Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 551–565. [Google Scholar]
- Yue, Z.; Witzig, C.R.; Jorde, D.; Jacobsen, H.A. BERT4NILM: A Bidirectional Transformer Model for Non-Intrusive Load Monitoring. In Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring, NILM’20, Virtual Event, 18 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 89–93. [Google Scholar] [CrossRef]
- Pan, Y.; Liu, K.; Shen, Z.; Cai, X.; Jia, Z. Sequence-To-Subsequence Learning With Conditional Gan For Power Disaggregation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3202–3206. [Google Scholar] [CrossRef]
- Bejarano, G.; DeFazio, D.; Ramesh, A. Deep latent generative models for energy disaggregation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 850–857. [Google Scholar]
- Sirojan, T.; Phung, B.T.; Ambikairajah, E. Deep neural network based energy disaggregation. In Proceedings of the 2018 IEEE International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–15 August 2018; pp. 73–77. [Google Scholar]
- Harell, A.; Jones, R.; Makonin, S.; Bajic, I.V. PowerGAN: Synthesizing Appliance Power Signatures Using Generative Adversarial Networks. arXiv 2020, arXiv:2007.13645. Available online: http://xxx.lanl.gov/abs/2007.13645 (accessed on 20 July 2020).
- Ahmed, A.M.A.; Zhang, Y.; Eliassen, F. Generative Adversarial Networks and Transfer Learning for Non-Intrusive Load Monitoring in Smart Grids. In Proceedings of the 2020 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Tempe, AZ, USA, 11–13 November 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Symeonidis, N.; Nalmpantis, C.; Vrakas, D. A Benchmark Framework to Evaluate Energy Disaggregation Solutions. In International Conference on Engineering Applications of Neural Networks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 19–30. [Google Scholar]
- Batra, N.; Kukunuri, R.; Pandey, A.; Malakar, R.; Kumar, R.; Krystalakos, O.; Zhong, M.; Meira, P.; Parson, O. Towards reproducible state-of-the-art energy disaggregation. In Proceedings of the 6th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, New York, NY, USA, 13–14 November 2019; pp. 193–202. [Google Scholar]
- Virtsionis Gkalinikis, N.; Nalmpantis, C.; Vrakas, D. Torch-NILM: An Effective Deep Learning Toolkit for Non-Intrusive Load Monitoring in Pytorch. Energies 2022, 15, 2647. [Google Scholar] [CrossRef]
- Klemenjak, C.; Makonin, S.; Elmenreich, W. Towards comparability in non-intrusive load monitoring: On data and performance evaluation. In Proceedings of the 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 17–20 February 2020; pp. 1–5. [Google Scholar]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2014, 61, 85–117. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Basu, K.; Debusschere, V.; Bacha, S. Load identification from power recordings at meter panel in residential households. In Proceedings of the 2012 XXth International Conference on Electrical Machines, Marseille, France, 2–5 September 2012; pp. 2098–2104. [Google Scholar]
- Basu, K.; Debusschere, V.; Bacha, S. Residential appliance identification and future usage prediction from smart meter. In Proceedings of the IECON 2013-39th Annual Conference of the IEEE Industrial Electronics Society, Vienna, Austria, 10–13 November 2013; pp. 4994–4999. [Google Scholar]
- Wittmann, F.M.; López, J.C.; Rider, M.J. Nonintrusive Load Monitoring Algorithm Using Mixed-Integer Linear Programming. IEEE Trans. Consum. Electron. 2018, 64, 180–187. [Google Scholar] [CrossRef]
- Dash, S.; Sodhi, R.; Sodhi, B. An Appliance Load Disaggregation Scheme Using Automatic State Detection Enabled Enhanced Integer Programming. IEEE Trans. Ind. Inform. 2021, 17, 1176–1185. [Google Scholar] [CrossRef]
- Balletti, M.; Piccialli, V.; Sudoso, A.M. Mixed-Integer Nonlinear Programming for State-Based Non-Intrusive Load Monitoring. IEEE Trans. Smart Grid 2022, 13, 3301–3314. [Google Scholar] [CrossRef]
- Tabatabaei, S.M.; Dick, S.; Xu, W. Toward non-intrusive load monitoring via multi-label classification. IEEE Trans. Smart Grid 2016, 8, 26–40. [Google Scholar] [CrossRef]
- Singhal, V.; Maggu, J.; Majumdar, A. Simultaneous Detection of Multiple Appliances From Smart-Meter Measurements via Multi-Label Consistent Deep Dictionary Learning and Deep Transform Learning. IEEE Trans. Smart Grid 2019, 10, 2969–2978. [Google Scholar] [CrossRef]
- Nalmpantis, C.; Vrakas, D. On time series representations for multi-label NILM. Neural Comput. Appl. 2020, 32, 17275–17290. [Google Scholar] [CrossRef]
- Athanasiadis, C.L.; Papadopoulos, T.A.; Doukas, D.I. Real-time non-intrusive load monitoring: A light-weight and scalable approach. Energy Build. 2021, 253, 111523. [Google Scholar] [CrossRef]
- Verma, S.; Singh, S.; Majumdar, A. Multi-label LSTM autoencoder for non-intrusive appliance load monitoring. Electr. Power Syst. Res. 2021, 199, 107414. [Google Scholar] [CrossRef]
- Kukunuri, R.; Aglawe, A.; Chauhan, J.; Bhagtani, K.; Patil, R.; Walia, S.; Batra, N. EdgeNILM: Towards NILM on Edge Devices. In Proceedings of the 7th ACM International Conference on Systems for Energy-Efficient Buildings, Cities, and Transportation, BuildSys ’20, Virtual Event, 18–20 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 90–99. [Google Scholar] [CrossRef]
- Jack, K.; William, K. The UK-DALE dataset domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar]
- Firth, S.; Kane, T.; Dimitriou, V.; Hassan, T.; Fouchal, F.; Coleman, M.; Webb, L. REFIT Smart Home Dataset, Provided by Loughborough University. 2017. Available online: https://repository.lboro.ac.uk/articles/dataset/REFIT_Smart_Home_dataset/2070091/1 (accessed on 20 June 2017).
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning, ICML ’08, Helsinki, Finland, 5–9 July 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 1096–1103. [Google Scholar] [CrossRef]
- Nalmpantis, C.; Virtsionis Gkalinikis, N.; Vrakas, D. Neural Fourier Energy Disaggregation. Sensors 2022, 22, 473. [Google Scholar] [CrossRef]
- Choromanski, K.M.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.Q.; Mohiuddin, A.; Kaiser, L.; et al. Rethinking Attention with Performers. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention. In Proceedings of the International Conference on Machine Learning (ICML), Virtual Event, 13–18 July 2020. [Google Scholar]
- Shen, Z.; Zhang, M.; Zhao, H.; Yi, S.; Li, H. Efficient Attention: Attention with Linear Complexities. arXiv 2018, arXiv:1812.01243. [Google Scholar]
- Kitaev, N.; Kaiser, L.; Levskaya, A. Reformer: The Efficient Transformer. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Lee-Thorp, J.; Ainslie, J.; Eckstein, I.; Ontanon, S. FNet: Mixing Tokens with Fourier Transforms. arXiv 2021, arXiv:2105.03824. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Monti, R.P.; Tootoonian, S.; Cao, R. Avoiding Degradation in Deep Feed-Forward Networks by Phasing Out Skip-Connections. In Artificial Neural Networks and Machine Learning—ICANN 2018; Kůrková, V., Manolopoulos, Y., Hammer, B., Iliadis, L., Maglogiannis, I., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 447–456. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational Inference: A Review for Statisticians. J. Am. Stat. Assoc. 2017, 112, 859–887. [Google Scholar] [CrossRef]
- Joyce, J.M. Kullback-Leibler Divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experiment | Environment Setup | Goal |
|---|---|---|
| Ablation study comparing the same network with and without variational inference. | Applied the first category of benchmarking [42], where training and inference happen during the same installation. | To highlight the performance boost due to the variational inference approach. |
| Performance comparison of three variations of the proposed network. | Applied the first two categories of benchmarking [42], where training and inference happen on installations from the same dataset. | To decide which combination method is the best. |
| Benchmark performance evaluation of multi-target models. | Executed the first three categories of benchmarking [42] for four installations from two different datasets. | For performance comparison of the novel model versus the baseline. |
| Performance comparison of multi-target models against single-target models. | Executed the first two categories of benchmarking [42], where training and inference happen on the same dataset. | For performance comparison of the novel multi-target model versus single-target baselines. |
| Performance comparison between multi-target models for different numbers of appliances. | Applied the first category of benchmarking [42], where training and inference happen on the same installation. | To highlight any performance boost or drop of the models. |
| Appliance | Category 1 | Category 2 | Category 3 | |||
|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | |
| Dishwasher | 1 | 1 | 1 | 2 | 1 | 2, 5 |
| Microwave | 1 | 1 | 1 | 2 | 1 | 2, 5 |
| Fridge | 1 | 1 | 1 | 2 | 1 | 2, 5 |
| Kettle | 1 | 1 | 1 | 2 | 1 | 2, 5 |
| Washing Machine | 1 | 1 | 1 | 2 | 1 | 2, 5 |
| Strategy | Appliances | Architecture | Params (Mil) | Size (MB) | Training GPU (it/s) | Inference GPU (it/s) |
|---|---|---|---|---|---|---|
| Single-Target | 1 | DAE | 2.9 | 11.540 | 102.13 | 139.20 |
| S2P | 10.3 | 41.160 | 18.390 | 78.16 | ||
| NFED | 4.7 | 18.956 | 20.220 | 44.93 | ||
| Multi-Target | 5 | CNN-base | 2.2 | 8.650 | 30.960 | 82.74 |
| UNet-NILM | 2.2 | 8.940 | 14.750 | 50.01 | ||
| V.M.Regressor (Linear) | 2.1 | 8.376 | 18.901 | 59.40 | ||
| V.M.Regressor (Addition) | 2.0 | 8.170 | 19.405 | 61.10 | ||
| V.M.Regressor (Attention) | 2.0 | 8.171 | 19.290 | 60.20 |
| Architecture | Parameters (millions) | Size on the Disk (MB) | Training GPU (it/s) | Inference GPU (it/s) |
|---|---|---|---|---|
| Vanilla | 2.0 | 8.170 | 19.8 | 62.2 |
| V.M.Regressor (Addition) | 2.0 | 8.170 | 19.4 | 61.1 |
| V.M.Regressor (Attention) | 2.0 | 8.171 | 19.3 | 60.2 |
| V.M.Regressor (Linear) | 2.1 | 8.376 | 18.9 | 59.4 |
| Category | Train | Test | Combination | F1 Macro | MAE Macro |
|---|---|---|---|---|---|
| 1 | UKDALE 1 | UKDALE 1 | Addition | 0.687 | 14.118 |
| Attention | 0.661 | 14.676 | |||
| Linear | 0.699 | 14.402 | |||
| 2 | UKDALE 1 | UKDALE 2 | Addition | 0.599 | 17.993 |
| Attention | 0.56 | 18.68 | |||
| Linear | 0.631 | 17.578 | |||
| 3 | UKDALE 1 | REFIT 2 | Addition | 0.506 | 25.678 |
| Attention | 0.446 | 29.402 | |||
| Linear | 0.481 | 26.098 | |||
| 4 | UKDALE 1 | REFIT 5 | Addition | 0.43 | 32.829 |
| Attention | 0.404 | 36.334 | |||
| Linear | 0.412 | 32.86 |
| Category | Addition (F1) | Linear (F1) | F1 Diff (%) | Addition (MAE) | Linear (MAE) | MAE Diff (%) |
|---|---|---|---|---|---|---|
| 1 & 2 | 0.643 | 0.665 | 3.364 | 16.055 | 15.99 | 0.405 |
| 3 | 0.493 | 0.484 | 1.843 | 29.254 | 29.479 | 0.766 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Virtsionis Gkalinikis, N.; Nalmpantis, C.; Vrakas, D. Variational Regression for Multi-Target Energy Disaggregation. Sensors 2023, 23, 2051. https://doi.org/10.3390/s23042051
Virtsionis Gkalinikis N, Nalmpantis C, Vrakas D. Variational Regression for Multi-Target Energy Disaggregation. Sensors. 2023; 23(4):2051. https://doi.org/10.3390/s23042051
Chicago/Turabian StyleVirtsionis Gkalinikis, Nikolaos, Christoforos Nalmpantis, and Dimitris Vrakas. 2023. "Variational Regression for Multi-Target Energy Disaggregation" Sensors 23, no. 4: 2051. https://doi.org/10.3390/s23042051
APA StyleVirtsionis Gkalinikis, N., Nalmpantis, C., & Vrakas, D. (2023). Variational Regression for Multi-Target Energy Disaggregation. Sensors, 23(4), 2051. https://doi.org/10.3390/s23042051