
Safety Helmet Detection Based on YOLOv5 Driven by Super-Resolution Reconstruction

Abstract
1. Introduction
- (1)
- (2)
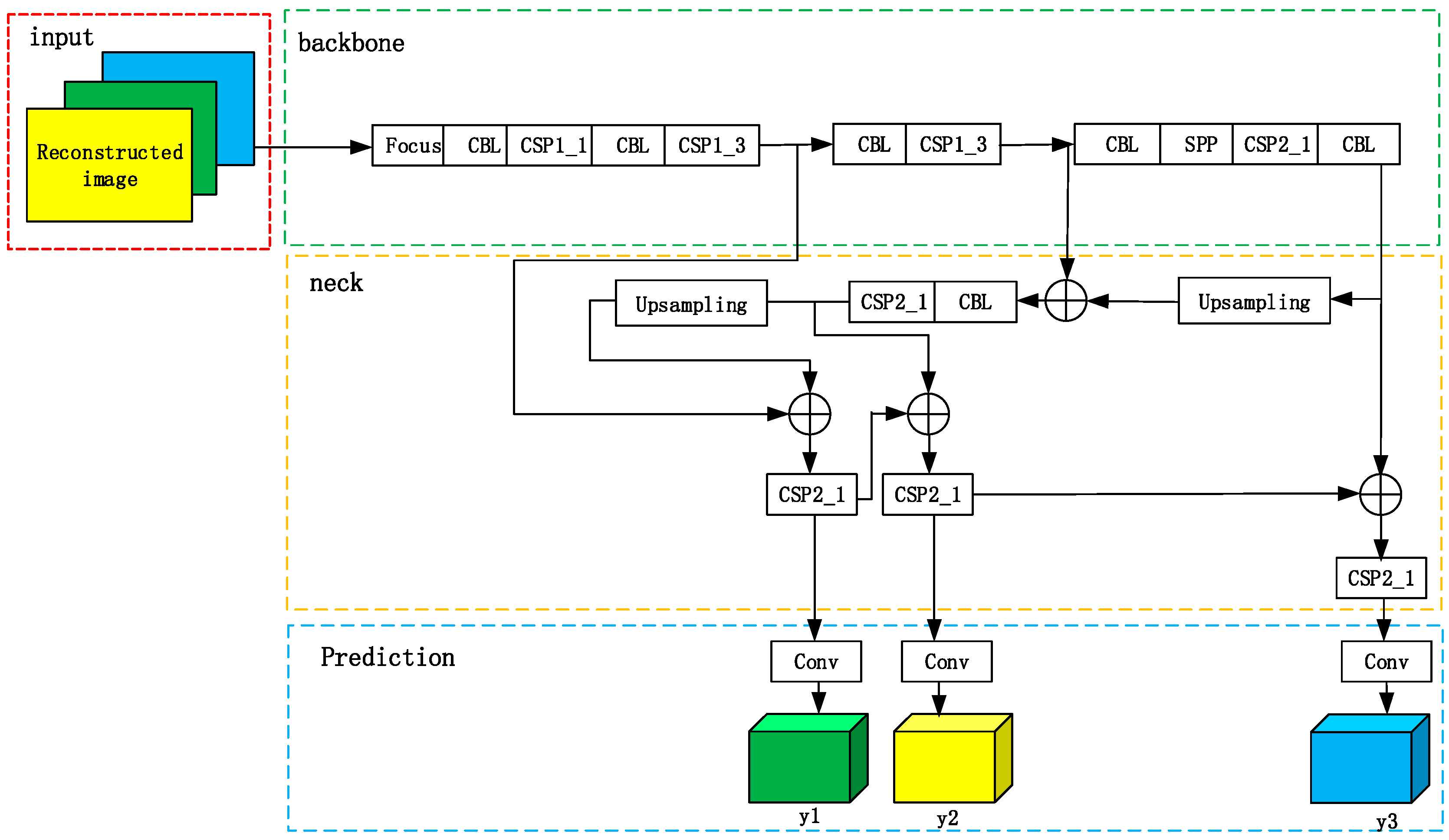
- A novel CSP (Cross Stage Partial) module of YOLO (You Only Look Once) v5 is presented to reduce the information loss and the gradient confusion.
- (3)
- Based on the proposed SR reconstruction network and YOLOv5 network, a novel end-to-end safety helmet detection model is proposed to make the proposed model reach an average precision (AP) of 79.1%.
- (4)
- More than 13,000 images are collected for safety helmet detection in construction sites.
2. Related Work
2.1. Target Detection
2.2. SR Reconstruction
3. Materials and Methods
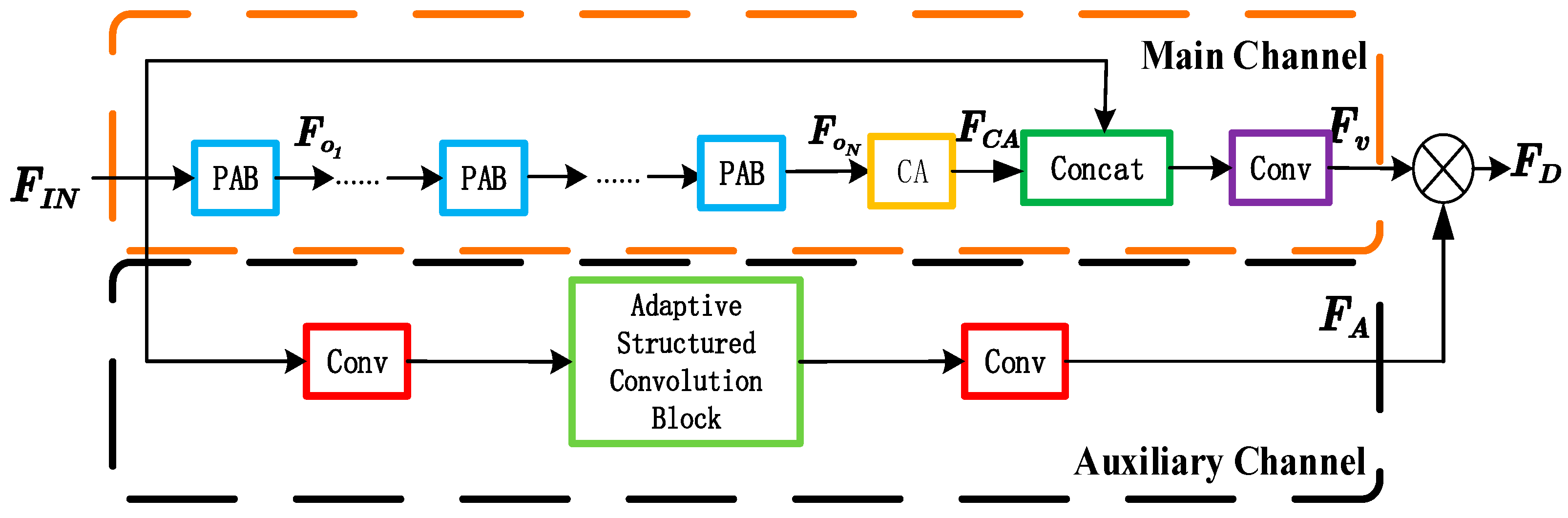
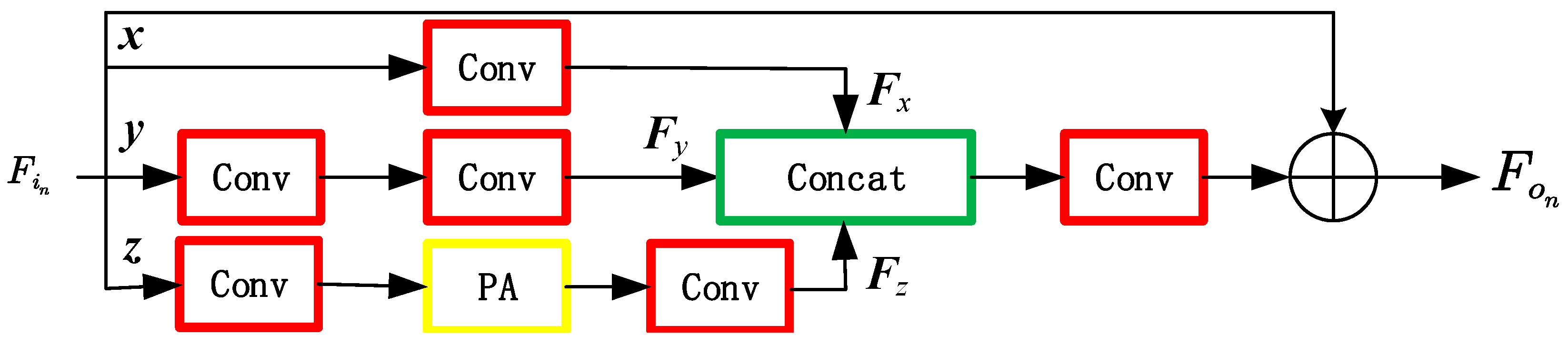
3.1. Dual-Channel Residual SR Reconstruction Module
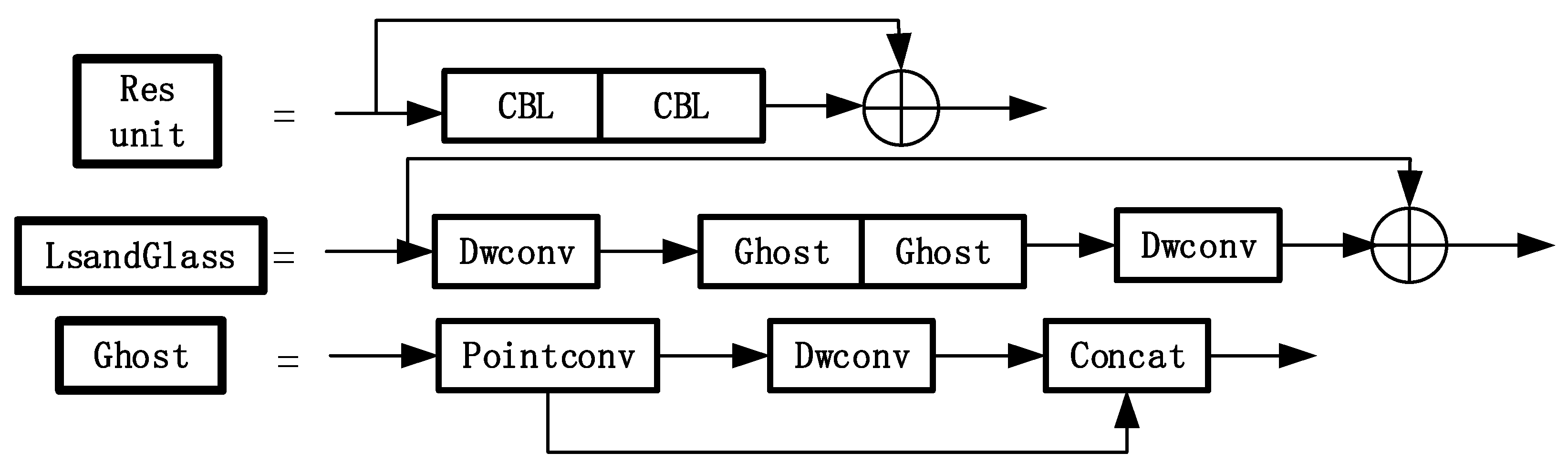
3.2. The Improved YOLOv5 Module
4. Results
4.1. Experimental Setup
4.2. Metrics
4.3. SR Reconstruction Experiments
4.4. Safety Helmet Detection Experiments
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Kurien, M.; Kim, M.K.; Kopsida, M.; Brilakis, I. Real-time simulation of construction workers using combined human body and hand tracking for robotic construction worker system. Autom. Constr. 2018, 86, 125–137. [Google Scholar] [CrossRef]
- Hao, Z.; Wei, Y. 448 cases of construction standard statistical characteristic analysis of inductrial injury accident. Stand. China 2017, 2, 245–247. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, J.; Chen, H.; Chen, J.; Li, Y.; Xu, J.; Deng, W. Intelligent diagnosis using continuous wavelet transform and gauss convolutional deep belief network. IEEE Trans. Reliab. 2022, 1–11. [Google Scholar] [CrossRef]
- Huang, C.; Zhou, X.; Ran, X.; Liu, Y.; Deng, W.; Deng, W. Co-evolutionary competitive swarm optimizer with three-phase for large-scale complex optimization problem. Inf. Sci. 2023, 619, 2–18. [Google Scholar] [CrossRef]
- Luo, X.; Wang, G.; Song, T.; Zhang, J.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. MIDeepSeg: Minimally interactive segmentation of unseen objects from medical images using deep learning. Med. Image Anal. 2021, 72, 102102. [Google Scholar] [CrossRef]
- Yan, W.; Liu, Y.; Lan, Q.; Zhang, T.; Tu, H. Trajectory planning and low-chattering fixed-time nonsingular terminal sliding mode control for a dual-arm free-floating space robot. Robotica 2022, 40, 625–645. [Google Scholar] [CrossRef]
- Yao, J.; Yan, W.; Lan, Q.; Liu, Y.; Zhao, Y. Parameter optimization of dsRNA splicing evolutionary algorithm based fixed-time obstacle-avoidance trajectory planning for space robot. Appl. Sci. 2021, 11, 8839. [Google Scholar] [CrossRef]
- Wu, D.; Luo, X.; Wang, G.; Shang, M.; Yuan, Y.; Yan, H. A highly accurate framework for self-labeled semisupervised classification in industrial applications. IEEE Trans. Ind. Inform. 2018, 14, 909–920. [Google Scholar] [CrossRef]
- Wu, D.; Luo, X.; He, Y.; Zhou, M. A prediction-sampling-based multilayer-structured latent factor model for accurate representation to high-dimensional and sparse data. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, P.; Zhang, R.; Yao, R.; Deng, W. A novel performance trend prediction approach using ENBLS with GWO. Meas. Sci. Technol. 2023, 34, 025018. [Google Scholar] [CrossRef]
- Deng, W.; Zhang, L.; Zhou, X.; Zhou, Y.; Sun, Y.; Zhu, W.; Chen, H.; Deng, W.; Chen, H.; Zhao, H. Multi-strategy particle swarm and ant colony hybrid optimization for airport taxiway planning problem. Inf. Sci. 2022, 612, 576–593. [Google Scholar] [CrossRef]
- Deng, W.; Liu, H.; Xu, J.; Zhao, H.; Song, Y. An improved quantum-inspired differential evolution algorithm for deep belief network. IEEE Trans. Instrum. Meas. 2020, 69, 7319–7327. [Google Scholar] [CrossRef]
- Song, Y.; Cai, X.; Zhou, X.; Zhang, B.; Chen, H.; Li, Y.; Deng, W.; Deng, W. Dynamic hybrid mechanism-based differential evolution algorithm and its application. Expert Syst. Appl. 2023, 213, 118834. [Google Scholar] [CrossRef]
- Luo, X.; Chen, J.; Song, T.; Wang, G. Semi-supervised medical image segmentation through dual-task consistency. Proc. AAAI Conf. Artif. Intell. 2021, 35, 8801–8809. [Google Scholar] [CrossRef]
- Luo, X.; Wang, G.; Liao, W.; Chen, J.; Song, T.; Chen, Y.; Zhang, S.; Metaxas, D.N.; Zhang, S. Semi-supervised medical image segmentation via uncertainty rectified pyramid consistency. Med. Image Anal. 2022, 80, 102517. [Google Scholar] [CrossRef]
- Li, J.; Qin, H.; Wang, J.; Li, J. OpenStreetMap-based autonomous navigation for the four wheel-legged robot via 3D-lidar and CCD camera. IEEE Trans. Ind. Electron. 2021, 69, 2708–2717. [Google Scholar] [CrossRef]
- Hale, A.R.; Heming, B.H.J.; Carthey, J.; Kirwan, B. Modelling of safety management systems. Saf. Sci. 1997, 26, 121–140. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale residual network for image super-resolution. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 527–542. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Long, Z.; Peng, Z. Based on dual channel residual network image super-resolution algorithm. J. Xi’an Jiaotong Univ. 2021, 1, 1–8. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Nishimura, K.; Mineeva, T.; Vilariño, R. Yolov5. [EB/OL]. Available online: https://github.com/ultralyc-s/yolov5 (accessed on 9 August 2020).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Lu, Y.; Zhou, Y.; Jiang, Z.; Guo, X.; Yang, Z. Channel attention and multi-level features fusion for single image super-resolution. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Liu, Y.; Wang, Y.; Li, N.; Cheng, X.; Zhang, Y.; Huang, Y.; Lu, G. An attention-based approach for single image super resolution. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2777–2784. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 294–310. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]











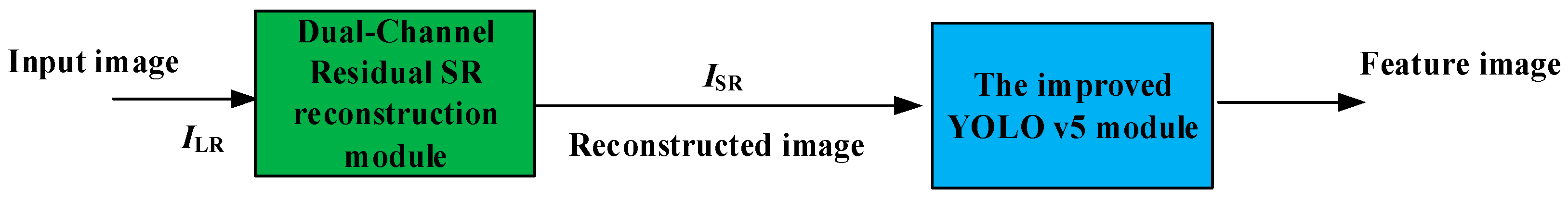{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Structure |
|---|---|
| SRCNN [19] | Three parts: input, non-linear mapping and output |
| SRGAN [35] | Two parts: generator network and discriminator network |
| Dual-Channel Residual SR Reconstruction model | Three parts: input, Dual-channel module and output |
| Model | SRCNN [19] | SRGAN [35] | Dual-Channel Residual SR Reconstruction Model | |
|---|---|---|---|---|
| Metrics | ||||
| PSNR | 25.313 | 27.923 | 29.420 | |
| SSIM | 0.779 | 0.820 | 0.855 | |
| Parameters’ number | 7,235,377 | 73,478,945 | 3,525,431 | |
| Model | Precision (%) | Recall (%) | AP (%) | |
|---|---|---|---|---|
| Metrics | ||||
| SRCNN [19]+YOLOv5 | 73.2 | 55.1 | 62.8 | |
| SRCNN+improved YOLOv5 | 74.1 | 58.3 | 64.3 | |
| SRGAN [35]+YOLOv5 | 81.3 | 61.1 | 71.2 | |
| SRGAN+improved YOLOv5 | 84.3 | 60.3 | 72.4 | |
| Dual-Channel Residual SR reconstruction module+YOLOv5 | 88.4 | 71.5 | 78.6 | |
| Dual-Channel Residual SR reconstruction module+improved YOLOv5 | 88.6 | 71.5 | 79.1 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, J.; Liu, Y.; Li, Z.; Liu, Y.; Zhan, B. Safety Helmet Detection Based on YOLOv5 Driven by Super-Resolution Reconstruction. Sensors 2023, 23, 1822. https://doi.org/10.3390/s23041822
Han J, Liu Y, Li Z, Liu Y, Zhan B. Safety Helmet Detection Based on YOLOv5 Driven by Super-Resolution Reconstruction. Sensors. 2023; 23(4):1822. https://doi.org/10.3390/s23041822
Chicago/Turabian StyleHan, Ju, Yicheng Liu, Zhipeng Li, Yan Liu, and Bixiong Zhan. 2023. "Safety Helmet Detection Based on YOLOv5 Driven by Super-Resolution Reconstruction" Sensors 23, no. 4: 1822. https://doi.org/10.3390/s23041822
APA StyleHan, J., Liu, Y., Li, Z., Liu, Y., & Zhan, B. (2023). Safety Helmet Detection Based on YOLOv5 Driven by Super-Resolution Reconstruction. Sensors, 23(4), 1822. https://doi.org/10.3390/s23041822