

A Deep Reinforcement Learning Strategy for Surrounding Vehicles-Based Lane-Keeping Control



Abstract
:1. Introduction
2. Related Work
2.1. Traditional Lateral Controller for Autonomous Vehicle
2.2. Autonomous Fault-Tolerant System
2.3. Application of Deep Learning Technology in AVs
2.3.1. Object Detection Using Deep Learning
2.3.2. Vehicle Control Technology Using RL
3. LKS Method Based on DDPG
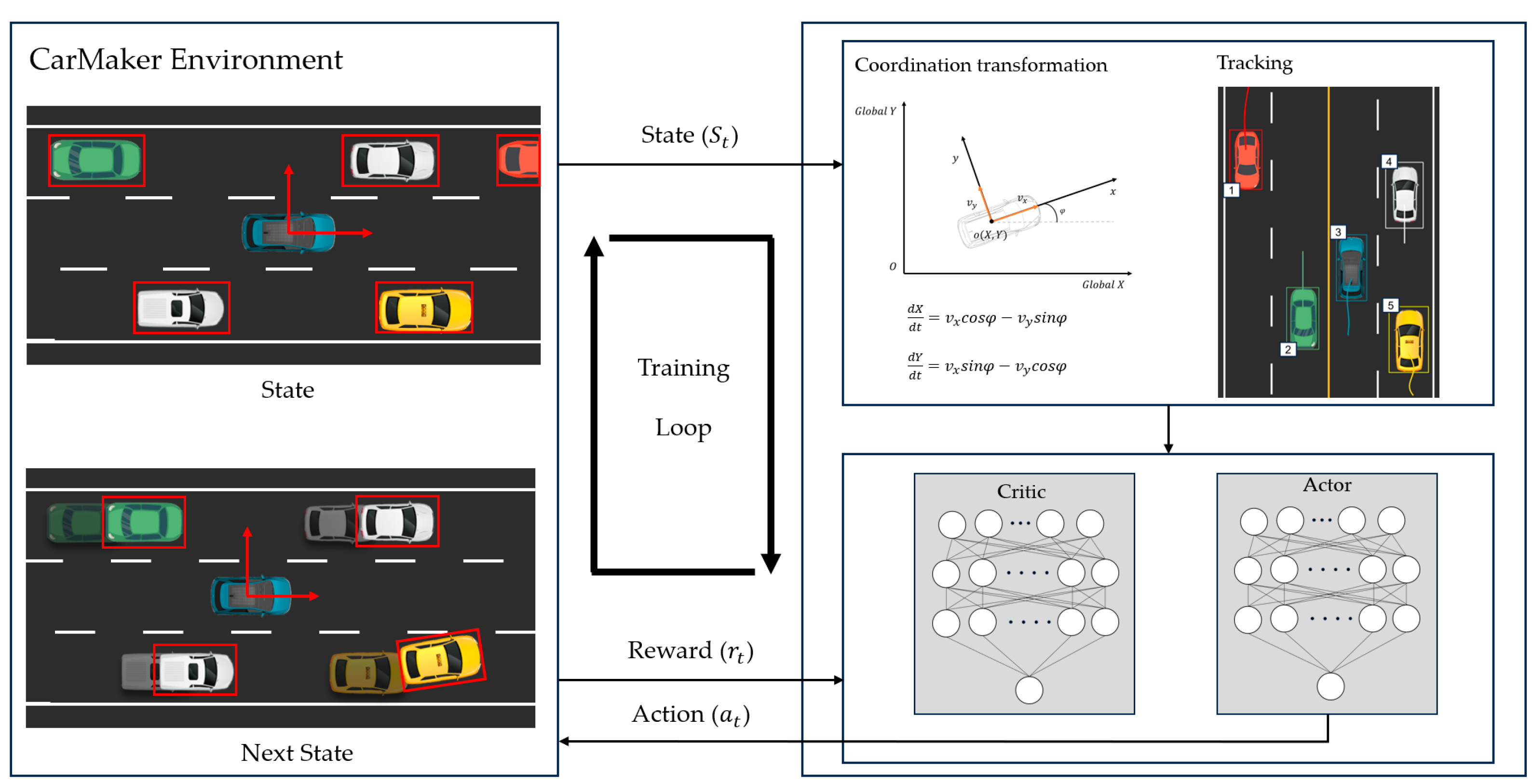
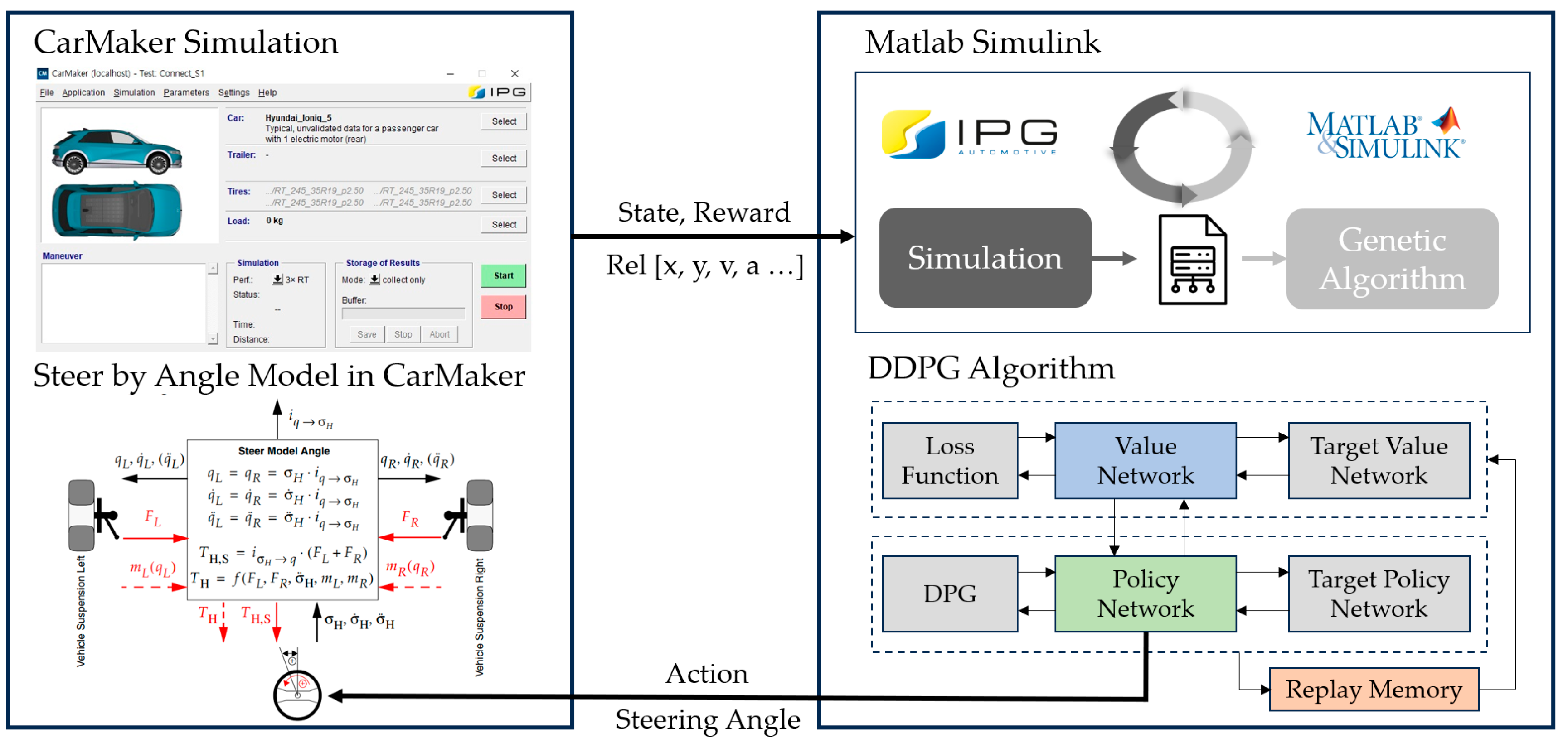
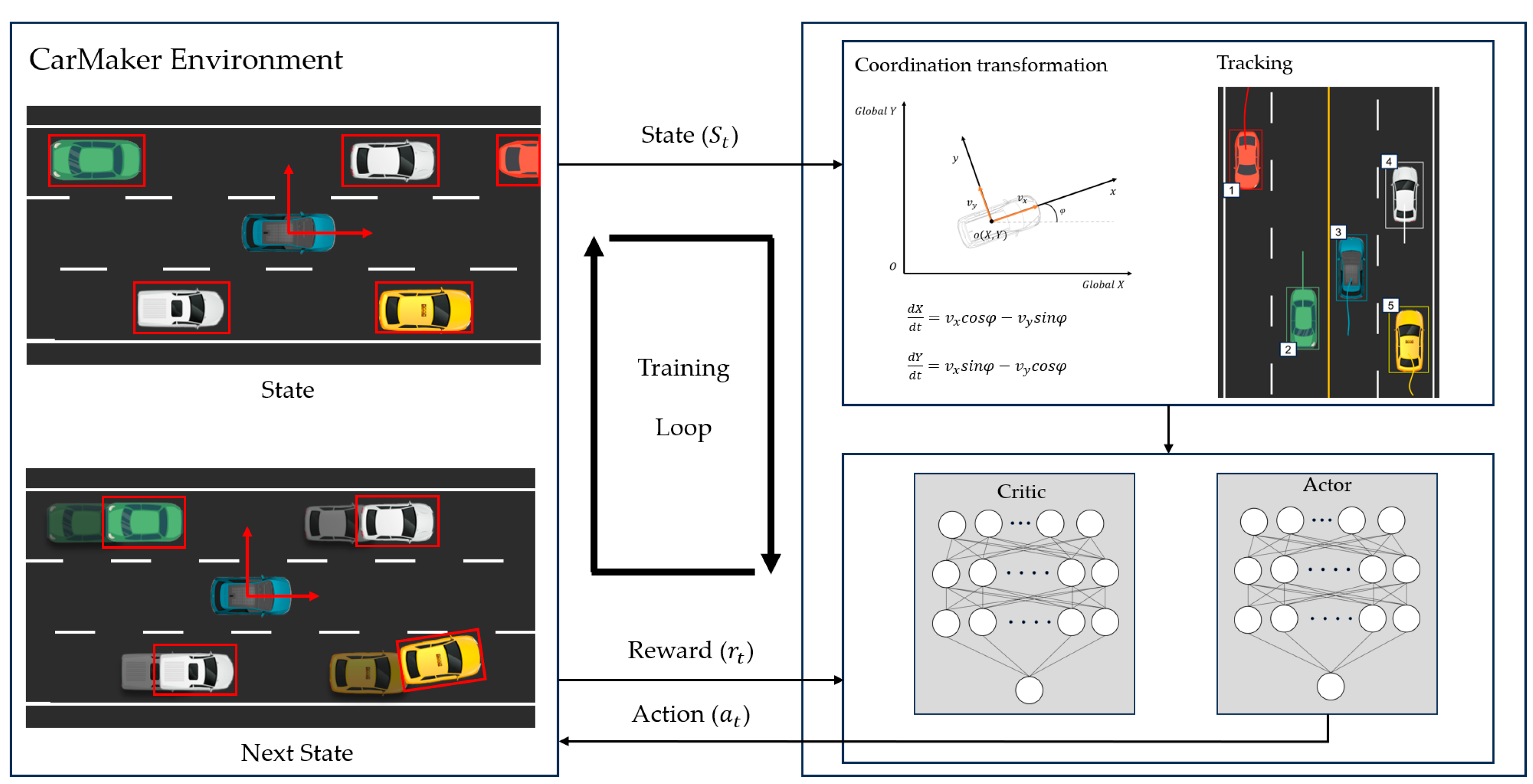
3.1. Proposed Method for LKS Using RL
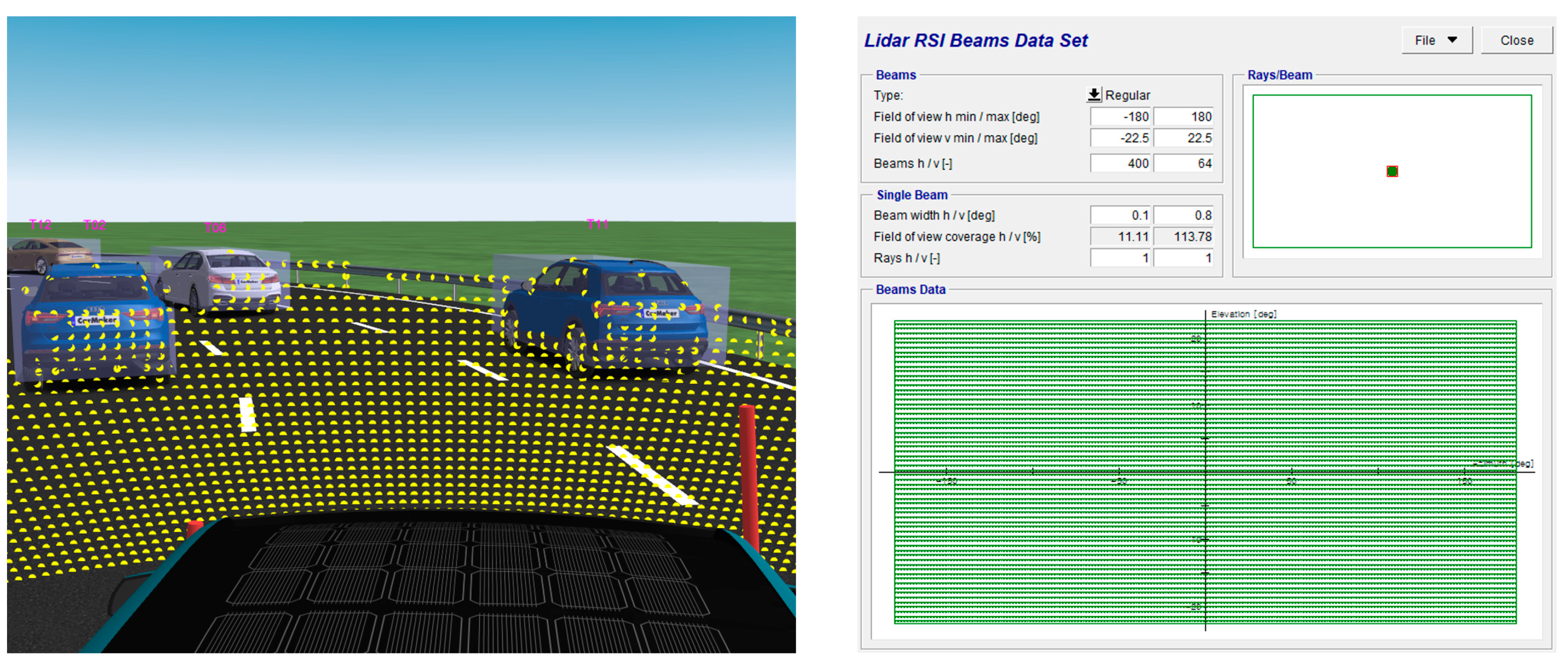
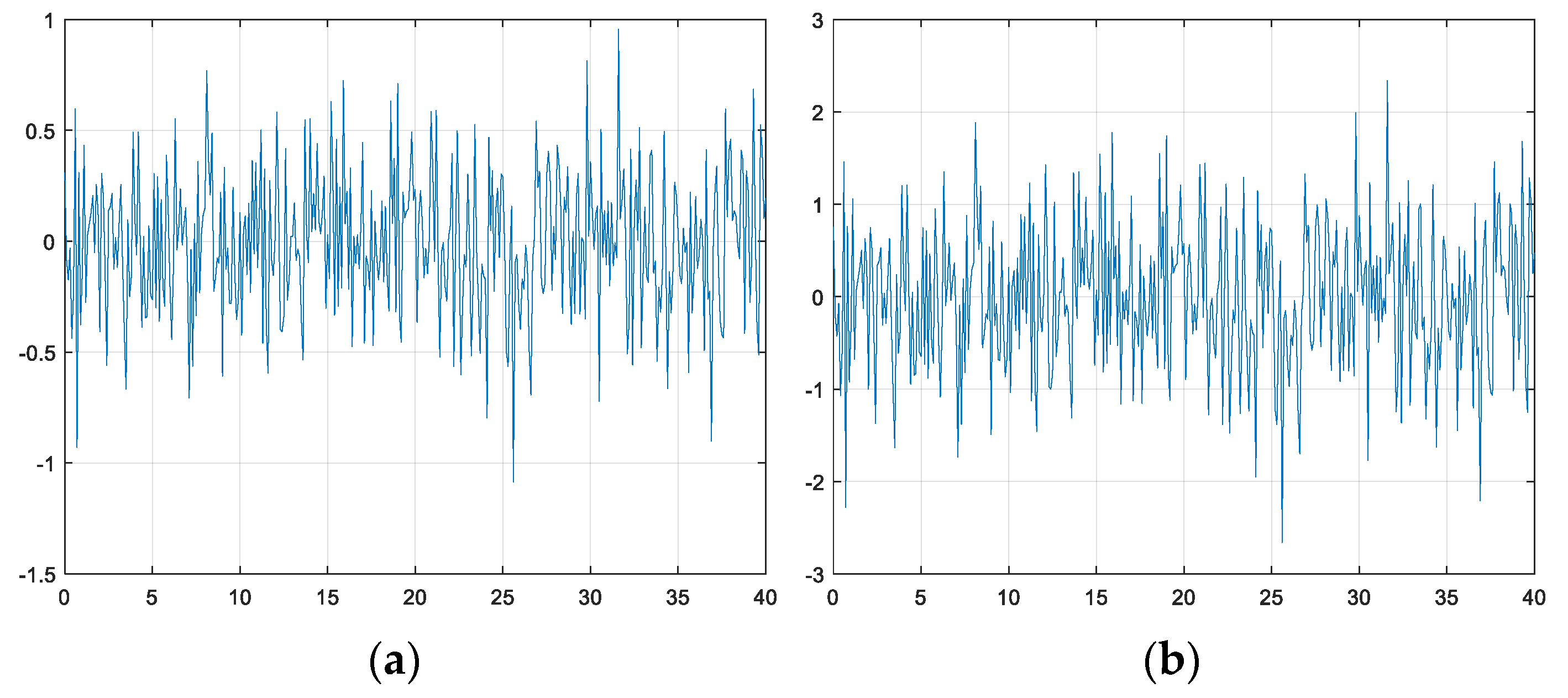
3.2. Training Environment
3.3. DDPG Algorithm
- Randomly initialize the critic Q(S,A;) and actor π(S;θ) with parameter values and , respectively.
- Utilize Equation (1) to determine the action to take based on the current observation S, where N represents the stochastic noise component of the noise model defined via NoiseOptions:
- Take action A, and then observe the reward R and subsequent observation S′.
- Store the experience (S,A,R,S′) in the experience buffer.
- Randomly select a mini-batch of M experiences () from the experience buffer, where M is determined by the value assigned to the MiniBatchSize option.
- If is a terminal state, set the value function target yi to Ri:
- Optimize the critic parameters by minimizing the loss L calculated using Equation (3) over all the sampled experiences:
- Optimize the actor parameters using Equation (4):
- Update the target actor and critic parameters depending on the target update method.
3.4. DDPG Actor–Critic Network
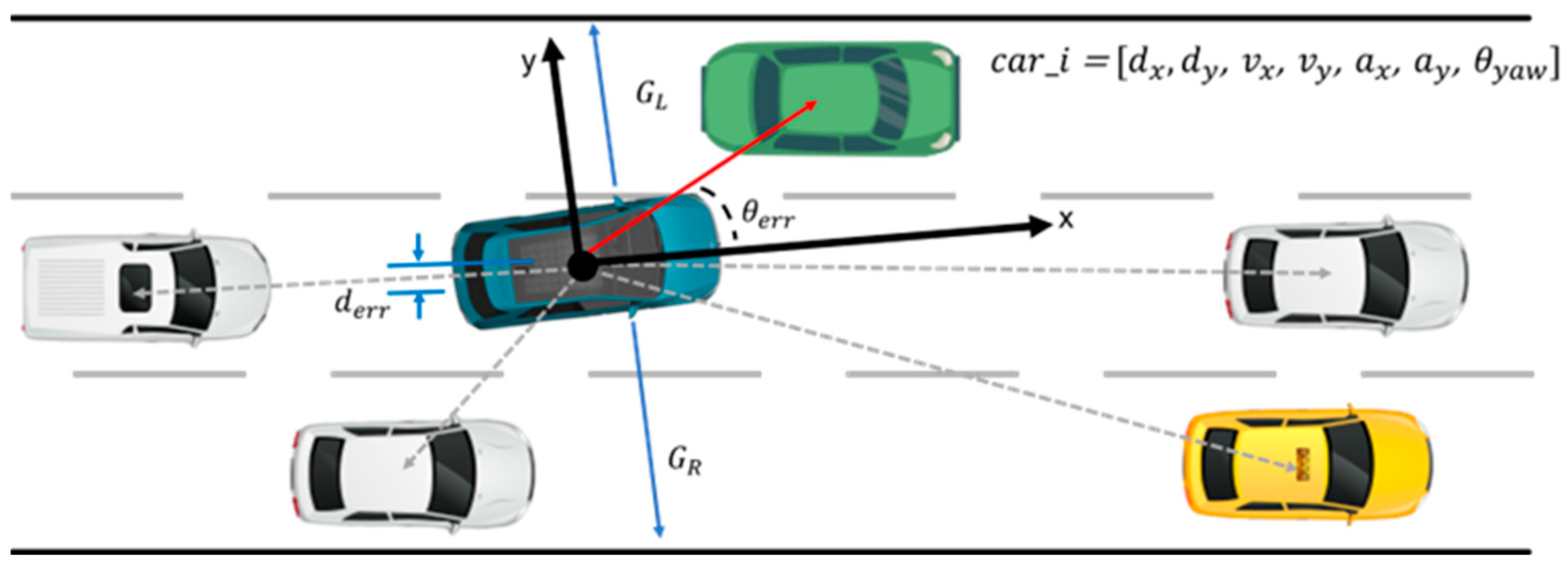
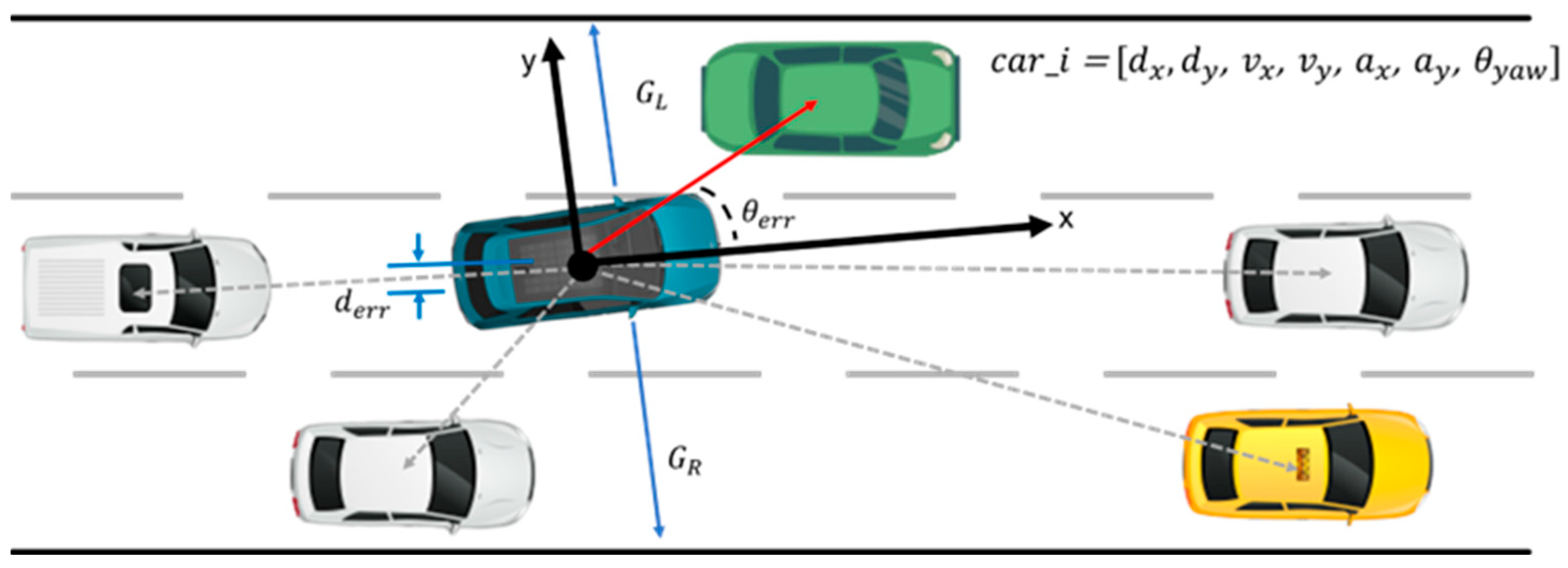
3.5. State Space
3.6. Observation Space
3.7. Action Space
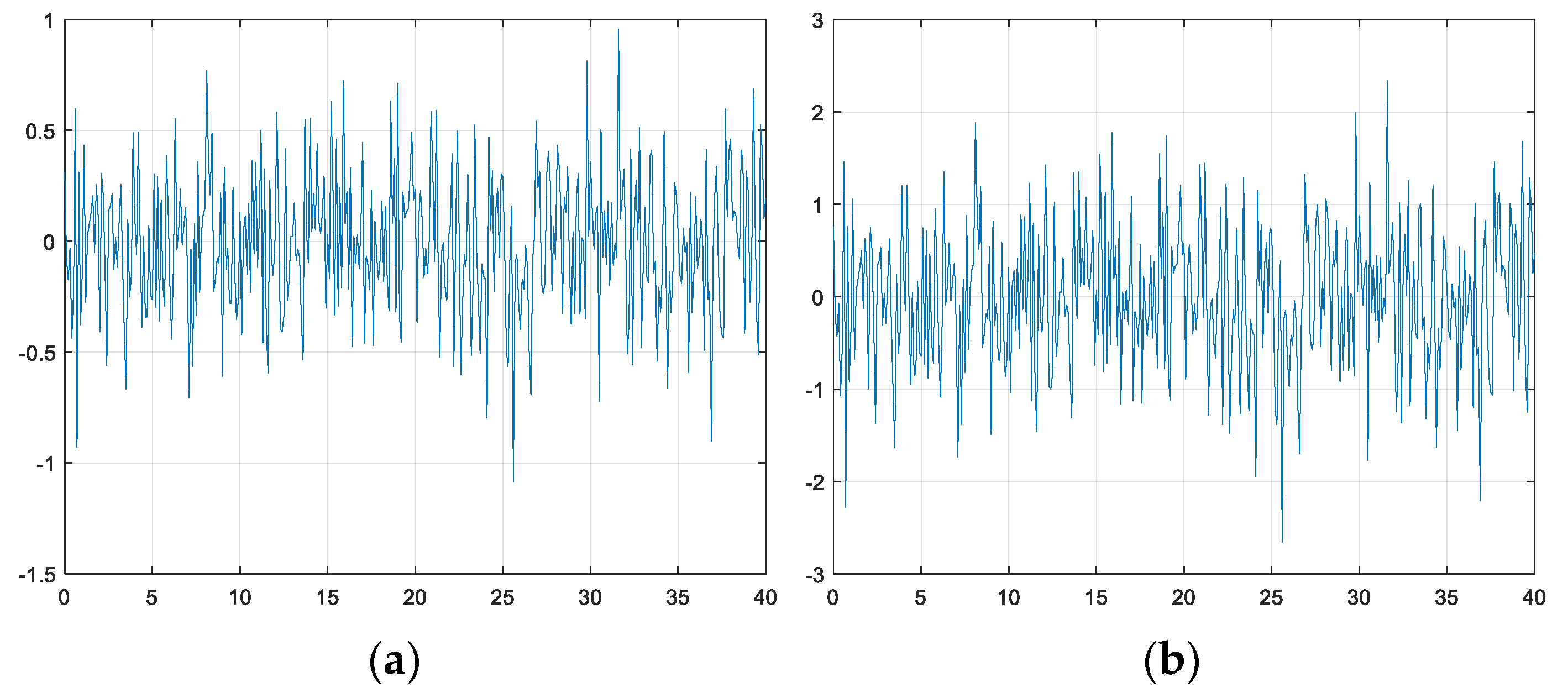
3.8. Reward Function
3.9. Termination States
- If the ego vehicle deviates from the intended path or angle by more than a specified threshold:().
- If there is a collision between the ego vehicle and surrounding vehicles or obstacles:().
- If the learning score meets the satisfactory performance criterion and intervals of performance decline are identified afterward.
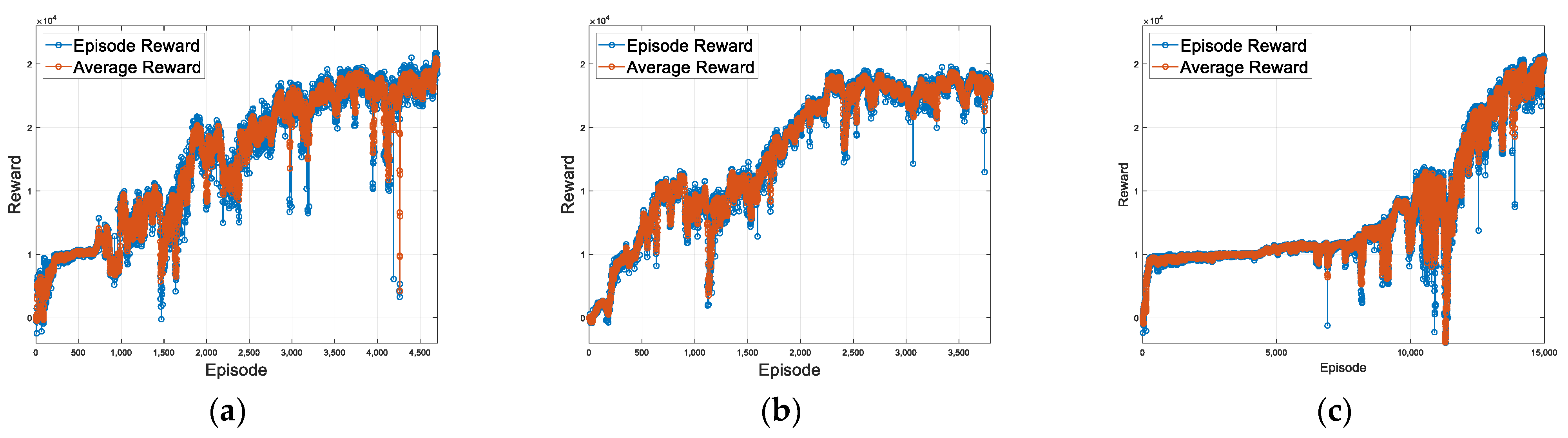
4. Results
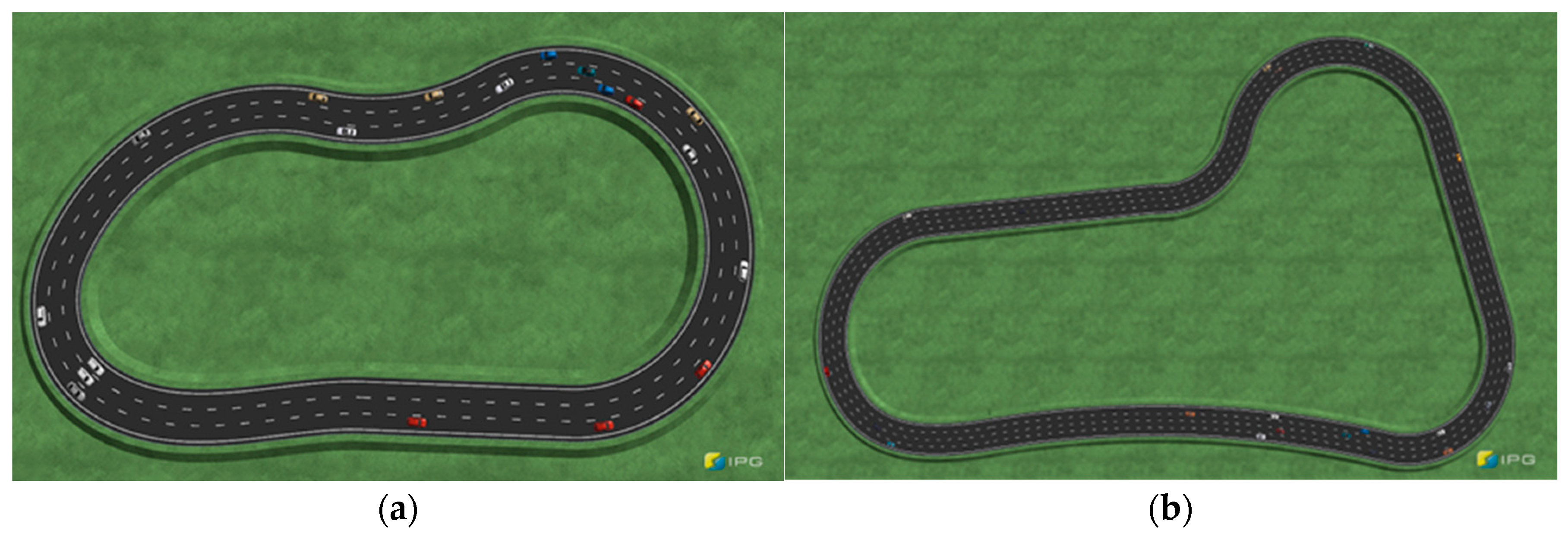
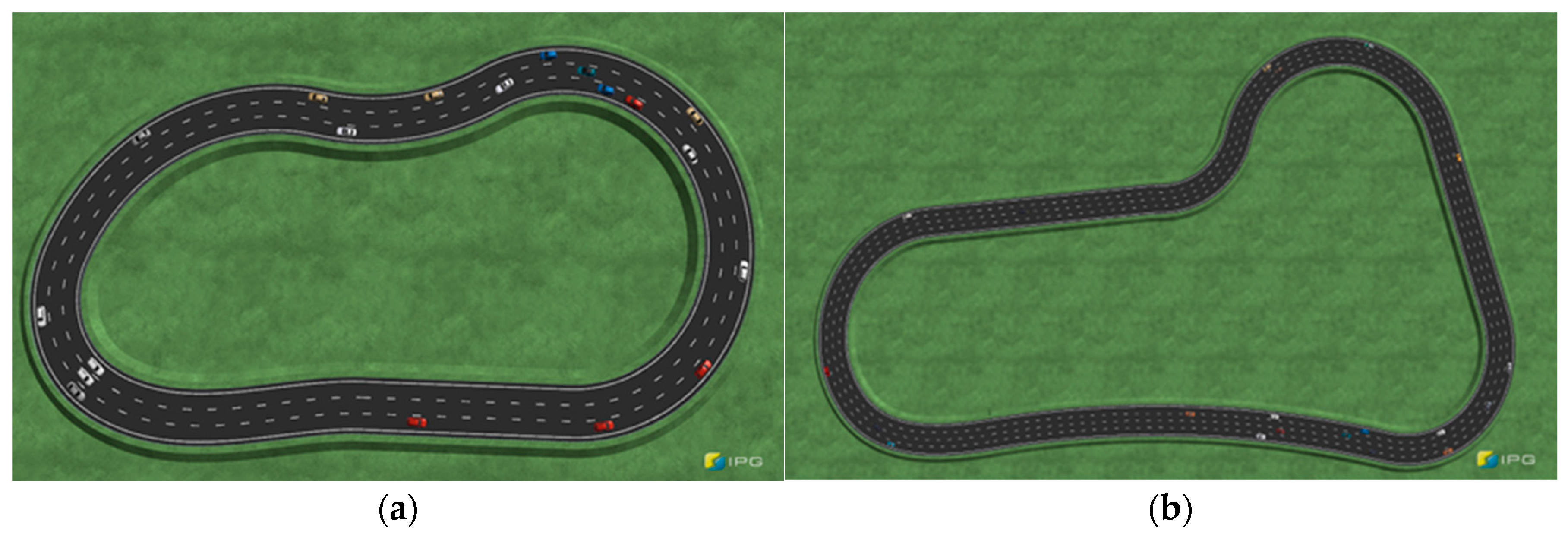
4.1. Simulation Scenario
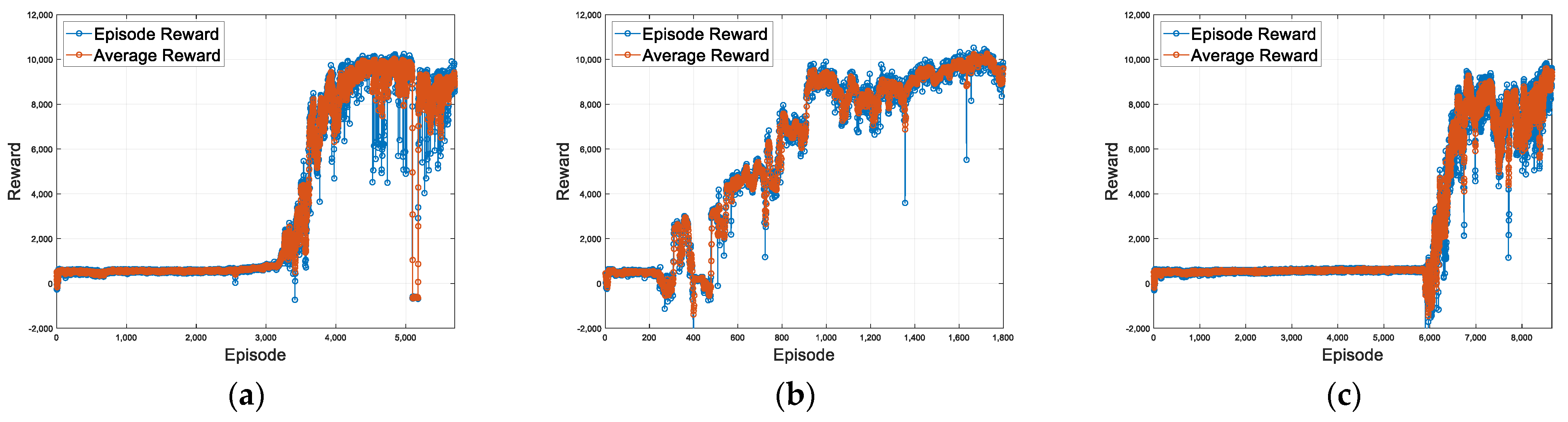
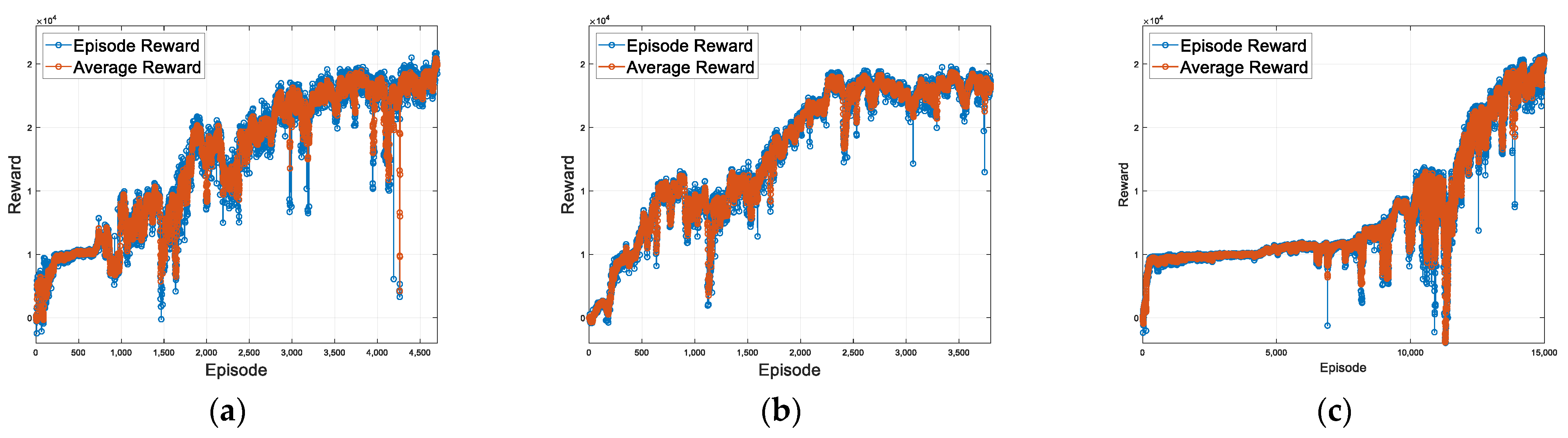
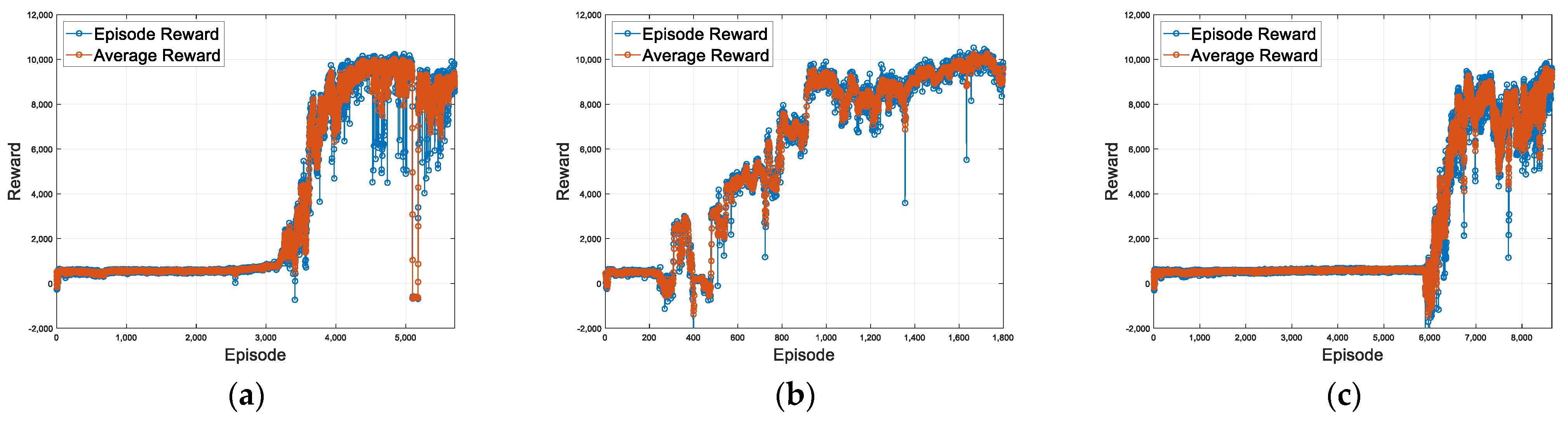
4.2. Proposed Method for Fault-Tolerant System Using RL
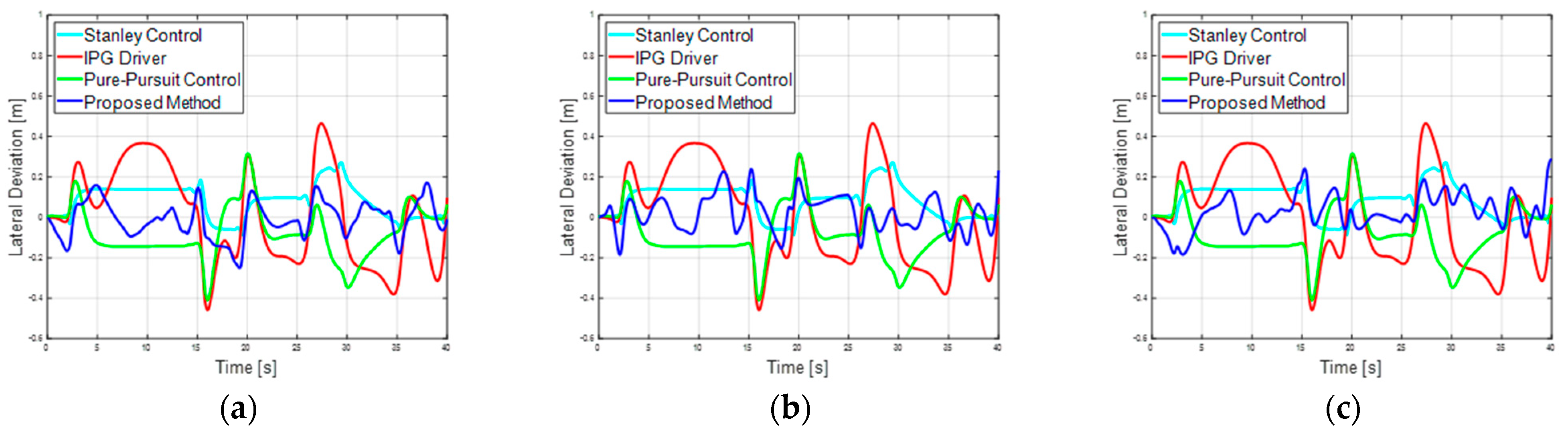
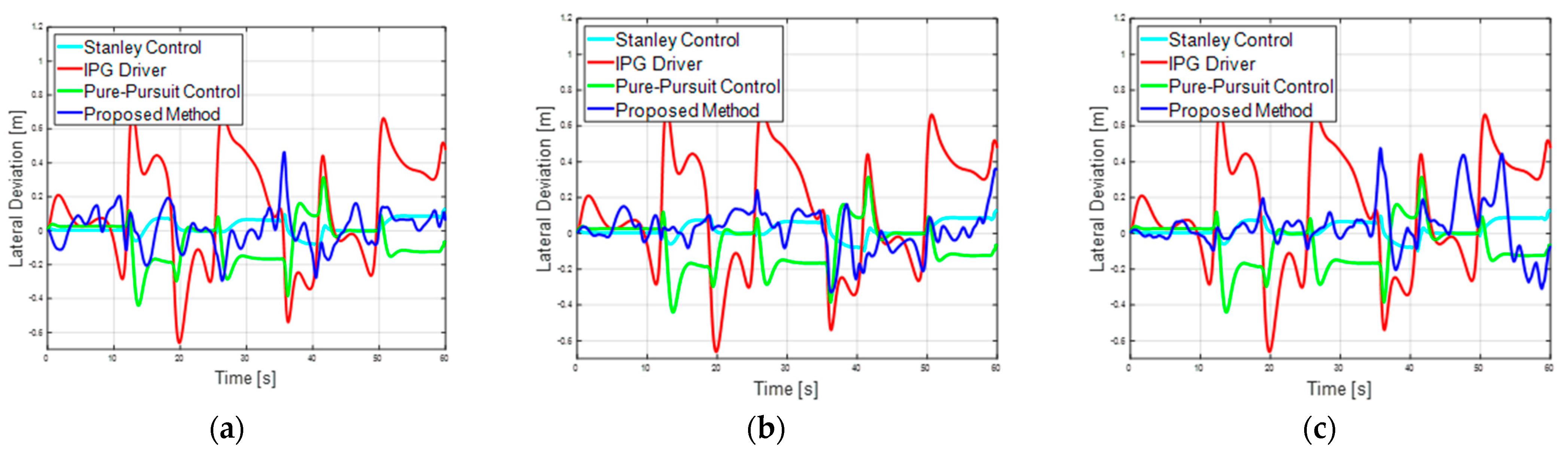
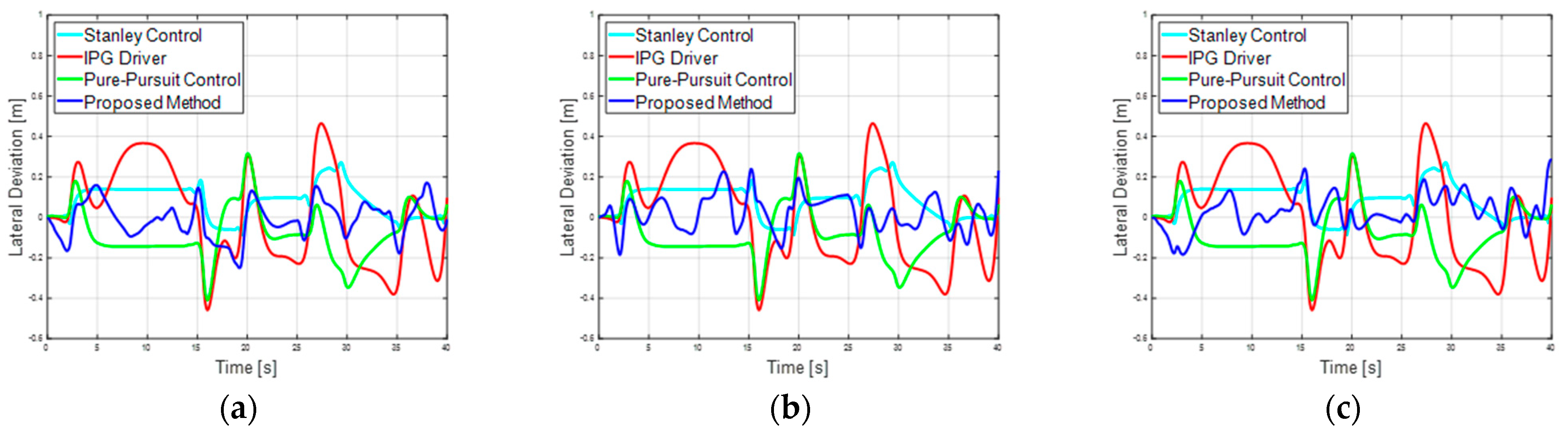
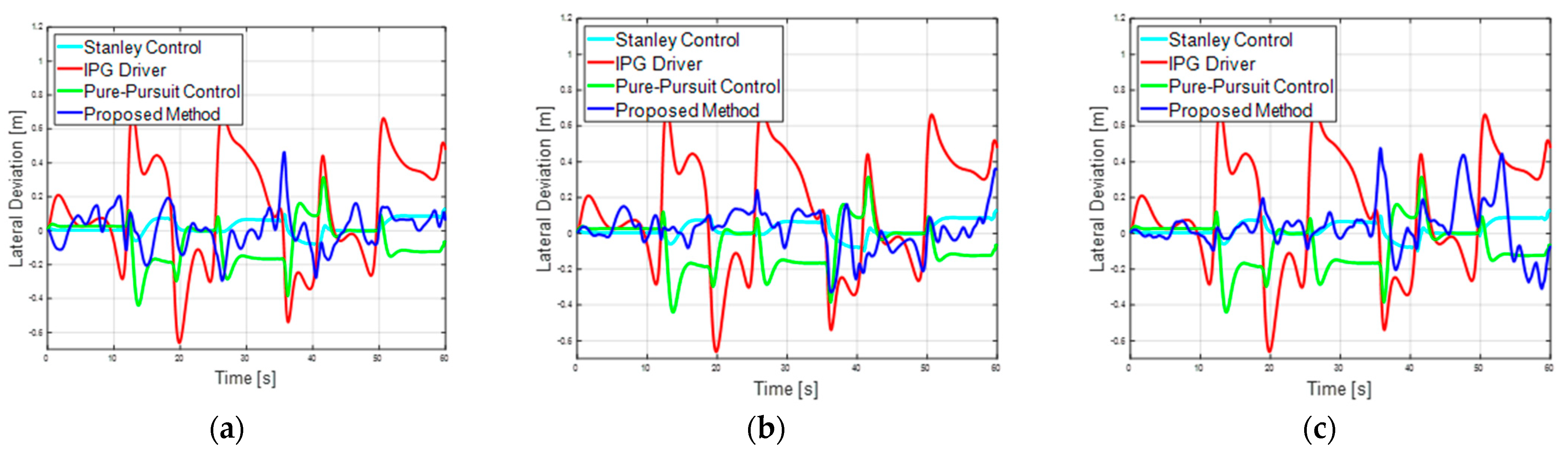
4.3. Comparison with Traditional Controllers
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Biggi, G.; Stilgoe, J. Artificial intelligence in self-driving cars research and innovation: A scientometric and bibliometric analysis. SSRN Electron. J. 2021. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A survey of deep learning techniques for autonomous driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Behringer, R.; Sundareswaran, S.; Gregory, B.; Elsley, R.; Addison, B.; Guthmiller, W.; Daily, R.; Bevly, D. The DARPA grand challenge-development of an autonomous vehicle. In Proceedings of the IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; IEEE: Piscataway, NJ, USA, 2004. [Google Scholar]
- Chan, C.-Y. Advancements, prospects, and impacts of automated driving systems. Int. J. Transp. Sci. Technol. 2017, 6, 208–216. [Google Scholar] [CrossRef]
- Hemphill, T.A. Autonomous vehicles: US regulatory policy challenges. Technol. Soc. 2020, 61, 101232. [Google Scholar] [CrossRef]
- ISO 26262-10:2012; Road Vehicles—Functional Safety—Part 10: Guideline on ISO 26262. ISO: Geneva, Switzerland, 2012.
- Chen, J.; Zhang, S.; Zhou, S. Analysis of automatic emergency braking system performance insufficiency based on system theory process analysis. In Proceedings of the 2023 IEEE International Conference on Industrial Technology (ICIT), Orlando, FL, USA, 4–6 April 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- ISO DIS 11270; Intelligent Transport Systems–Lane Keeping Assistance Systems (LKAS)–Performance Requirements and Test Procedures. ISO: Geneva, Switzerland, 2013.
- Son, W.-I.; Oh, T.-Y.; Park, K.-H. Development of Lidar-based MRM algorithm for LKS systems. Korean ITS J. 2021, 20, 174–192. [Google Scholar] [CrossRef]
- UNECE. Available online: http://www.unece.org/trans/main/wp29/faq.html (accessed on 15 December 2023).
- GRVA-06-02-Rev.4 Proposal for a New UN Regulation on ALKS; GRVA: Geneva, Switzerland, 2020; pp. 3–10.
- Kim, H.J.; Yang, J.H. Takeover requests in simulated partially autonomous vehicles considering human factors. IEEE Trans. Hum.-Mach. Syst. 2017, 47, 735–740. [Google Scholar] [CrossRef]
- Magdici, S.; Matthias, A. Fail-safe motion planning of autonomous vehicles. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Heo, J.; Lee, H.; Yoon, S.; Kim, K. Responses to take-over request in autonomous vehicles: Effects of environmental conditions and cues. IEEE Trans. Intell. Transp. Syst. 2022, 23, 23573–23582. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wasala, A.; Byrne, D.; Miesbauer, P.; O’Hanlon, J.; Heraty, P.; Barry, P. Trajectory based lateral control: A reinforcement learning case study. Eng. Appl. Artif. Intell. 2020, 94, 103799. [Google Scholar] [CrossRef]
- Fehér, Á.; Aradi, S.; Bécsi, T. Online trajectory planning with reinforcement learning for pedestrian avoidance. Electronics 2022, 11, 2346. [Google Scholar] [CrossRef]
- Elmquist, A.; Negrut, D. Methods and models for simulating autonomous vehicle sensors. IEEE Trans. Intell. Veh. 2020, 5, 684–692. [Google Scholar] [CrossRef]
- Pérez-Gil, Ó.; Barea, R.; López-Guillén, E.; Bergasa, L.M.; Gomez-Huelamo, C.; Gutiérrez, R.; Diaz-Diaz, A. Deep reinforcement learning based control for Autonomous Vehicles in CARLA. Multimed. Tools Appl. 2022, 81, 3553–3576. [Google Scholar] [CrossRef]
- Lee, H.; Kim, T.; Yu, D.; Hwang, S.H. Path-following correction control algorithm using vehicle state errors. Trans. Korean Soc. Automot. Eng. 2022, 30, 123–131. [Google Scholar] [CrossRef]
- Samuel, M.; Hussein, M.; Mohamad, M.B. A review of some pure-pursuit based path tracking techniques for control of autonomous vehicle. Int. J. Comput. Appl. 2016, 135, 35–38. [Google Scholar] [CrossRef]
- Rokonuzzaman, M.; Mohajer, N.; Nahavandi, S.; Mohamed, S. Review and performance evaluation of path tracking controllers of autonomous vehicles. IET Intell. Transp. Syst. 2021, 15, 646–670. [Google Scholar] [CrossRef]
- Isermann, R. Fault-Diagnosis Applications: Model-Based Condition Monitoring: Actuators, Drives, Machinery, Plants, Sensors, and Fault-tolerant Systems; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Realpe, M.; Vintimilla, B.X.; Vlacic, L. A fault tolerant perception system for autonomous vehicles. In Proceedings of the 2016 35th Chinese Control Conference (CCC), Chengdu, China, 27–29 July 2016; IEEE: Piscataway, NJ, USA, 2016. [Google Scholar]
- Kang, C.M.; Lee, S.H.; Kee, S.C.; Chung, C.C. Kinematics-based fault-tolerant techniques: Lane prediction for an autonomous lane keeping system. Int. J. Control. Autom. Syst. 2018, 16, 1293–1302. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Jin, Y.; Barber, P.; Fallah, S. A survey of deep learning applications to autonomous vehicle control. IEEE Trans. Intell. Transp. Syst. 2020, 22, 712–733. [Google Scholar] [CrossRef]
- Kuutti, S.; Bowden, R.; Fallah, S. Weakly supervised reinforcement learning for autonomous highway driving via virtual safety cages. Sensors 2021, 21, 2032. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Alaba, S.Y.; Ball, J.E. Ball. A survey on deep-learning-based lidar 3d object detection for autonomous driving. Sensors 2022, 22, 9577. [Google Scholar] [CrossRef]
- Mock, J.W.; Muknahallipatna, S.S. A comparison of ppo, td3 and sac reinforcement algorithms for quadruped walking gait generation. J. Intell. Learn. Syst. Appl. 2023, 15, 36–56. [Google Scholar] [CrossRef]
- Riedmiller, M.; Montemerlo, M.; Dahlkamp, H. Learning to drive a real car in 20 minutes. In Proceedings of the 2007 Frontiers in the Convergence of Bioscience and Information Technologies, Jeju, Republic of Korea, 11–13 October 2007; IEEE: Piscataway, NJ, USA, 2007. [Google Scholar]
- IPG Automotive GmbH. Carmaker: Virtual Testing of Automobiles and Light-Duty Vehicles. 2017. Available online: https://ipg-automotive.com/en/products-solutions/software/carmaker/#driver%20 (accessed on 13 March 2019).
- Cao, Y.; Ni, K.; Jiang, X.; Kuroiwa, T.; Zhang, H.; Kawaguchi, T.; Hashimoto, S.; Jiang, W. Path following for Autonomous Ground Vehicle Using DDPG Algorithm: A Reinforcement Learning Approach. Appl. Sci. 2023, 13, 6847. [Google Scholar] [CrossRef]
- DDPG Agents—MATLAB & Simulink. MathWorks. 2023. Available online: https://kr.mathworks.com/help/reinforcement-learning/ug/ddpg-agents.html?lang=en (accessed on 11 November 2023).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Discount factor (γ) | 0.99 |
| Target smooth factor | 0.001 |
| Mini-batch size | 64 |
| Target network update frequency | 100 |
| Replay memory size | 107 |
| Noise variance | 0.6 |
| Noise variance decay rate | 106 |
| Neurons | Name | |
|---|---|---|
| Feature input layer | 35, 37 | Observation |
| Fully connected layer | 100 | ActorFC1 |
| Rectified linear unit | Relu1 | |
| Fully connected layer | 100 | ActorFC2 |
| Rectified linear unit | Relu2 | |
| Fully connected layer | 100 | ActorFC3 |
| Rectified linear unit | Relu3 | |
| Fully connected layer | 1 | ActorFC4 |
| Hyperbolic tangent layer | Than1 | |
| Scaling layer | Actorscaling1 |
| State Path | ||
|---|---|---|
| Neurons | Name | |
| Feature input layer | 35, 37 | Observation |
| Fully connected layer | 100 | CriticFC1 |
| Rectified linear unit | Relu1 | |
| Fully connected layer | 100 | CriticFC2 |
| Addition layer | 2 | Add |
| Rectified linear unit | Relu2 | |
| Fully connected layer | 1 | CriticFC3 |
| Action path | ||
| Feature input layer | 1 | Action |
| Fully connected layer | 100 | CriticActionFC1 |
| State (i = 0,1,2,3,4) | Meaning |
|---|---|
| Object relative distance, | |
| Object relative velocity, | |
| Object relative acceleration, | |
| Object relative heading, | |
| S36 | Ego vehicle lateral offset, |
| S37 | Ego vehicle heading offset, |
| S38 | Collision status |
| S39 | Longitudinal velocity, |
| S40 | Simulation time, |
| S41 | Steering angle, |
| S42,S43 | Guard rail distance, |
| Observation (i = 0,1,2,3,4) | Meaning |
|---|---|
| Object relative distance, | |
| Object relative velocity, | |
| Object relative acceleration, | |
| Object relative heading angle, | |
| Guard rail distance, |
| State | Description | Min | Max |
|---|---|---|---|
| δ | Steering angle | −180° | 180° |
| k1 | k2 | k3 | k4 | k5 |
|---|---|---|---|---|
| 1 | 40 | 1 | 300 |
| Proposed Method RL Controller | Scenario 1 | Scenario 2 | ||
|---|---|---|---|---|
| Max_Deviation [m] | Deviation RMS | Max_Deviation [m] | Deviation RMS | |
| Basic | 0.2507 | 0.0904 | 0.4641 | 0.1121 |
| Guard rail | 0.2387 | 0.0889 | 0.3617 | 0.1067 |
| Gaussian noise | 0.2850 | 0.0908 | 0.4764 | 0.1412 |
| Controller | Scenario 1 | Scenario 2 | |||
|---|---|---|---|---|---|
| Max_Deviation [m] | RMS Error | Max_Deviation [m] | RMS Error | ||
| Traditional Control | Pure pursuit | 0.3154 | 0.1487 | 0.3149 | 0.1398 |
| Stanley | 0.2716 | 0.1151 | 0.1308 | 0.0494 | |
| IPG Driver | 0.4646 | 0.2376 | 0.7095 | 0.3398 | |
| RL Control | TD3 | 0.2421 | 0.0903 | 0.3648 | 0.1147 |
| Ours | 0.2387 | 0.0889 | 0.3617 | 0.1067 | |
| Controller | Scenario 1 | Scenario 2 | |||
|---|---|---|---|---|---|
| Max_Heading [deg] | RMS Error | Max_Heading [deg] | RMS Error | ||
| Traditional Control | Pure pursuit | 3.9086 | 3.1578 | 4.7712 | 1.9117 |
| Stanley | 2.3507 | 2.2792 | 3.1480 | 1.7052 | |
| IPG Driver | 4.7928 | 3.2544 | 6.7176 | 2.1671 | |
| RL Control | TD3 | 2.3418 | 2.1798 | 4.8529 | 1.8653 |
| Ours | 2.2531 | 2.1546 | 4.7953 | 1.8295 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.; Park, S.; Kim, J.; Yoo, J. A Deep Reinforcement Learning Strategy for Surrounding Vehicles-Based Lane-Keeping Control. Sensors 2023, 23, 9843. https://doi.org/10.3390/s23249843
Kim J, Park S, Kim J, Yoo J. A Deep Reinforcement Learning Strategy for Surrounding Vehicles-Based Lane-Keeping Control. Sensors. 2023; 23(24):9843. https://doi.org/10.3390/s23249843
Chicago/Turabian StyleKim, Jihun, Sanghoon Park, Jeesu Kim, and Jinwoo Yoo. 2023. "A Deep Reinforcement Learning Strategy for Surrounding Vehicles-Based Lane-Keeping Control" Sensors 23, no. 24: 9843. https://doi.org/10.3390/s23249843
APA StyleKim, J., Park, S., Kim, J., & Yoo, J. (2023). A Deep Reinforcement Learning Strategy for Surrounding Vehicles-Based Lane-Keeping Control. Sensors, 23(24), 9843. https://doi.org/10.3390/s23249843