1. Introduction
Mobile robot path planning is a crucial technique that enables robots to navigate through an environment while avoiding obstacles. This is achieved by planning a collision-free path [
1] from the robot’s current position to a desired destination based on environmental information obtained through sensors. Traditional path planning methods encompass a variety of algorithms with different principles and application scenarios. These methods can be classified into global and local path planning algorithms, including graph search methods, random sampling methods, bionic algorithms, artificial potential field methods, simulated annealing algorithms, neural network methods, and dynamic window methods.
Classical graph search algorithms include Dijkstra [
2], A* [
3], and D* [
4]. The Dijkstra algorithm solves the shortest path problem from a single point to all other vertices in a directed graph using a greedy algorithm. Although it can obtain the optimal path, it has a high computational cost and low efficiency. The A* algorithm, based on the Dijkstra algorithm, improves efficiency by adding the heuristic information, but its effectiveness in complex environments is not guaranteed. Moreover, this algorithm is only suitable for static environments and it performs poorly in dynamic environments. The D* algorithm is an improved version of the A* algorithm that can be applied in dynamically changing scenarios.
Classical random sampling methods such as Probabilistic Roadmap (PRM) [
5] and Rapidly Exploring Random Tree (RRT) [
6] have been widely used in robot path planning and motion control fields. The Lazy PRM [
7] algorithm is an improved version of the PRM algorithm that enhances efficiency by reducing the number of calls to the local planner. Liu et al. [
8] improved the RRT algorithm by using a goal-biased sampling strategy to determine the nodes and introduced an event-triggered step length extension based on the hyperbolic tangent function to improve node generation efficiency. Euclidean distance and angle constraints were used in the cost function of node connection optimization. Finally, the path was optimized further using path pruning and Bezier curve smoothing methods, leading to an improved convergence and accuracy.
Bionic algorithms are heuristic optimization algorithms based on the evolution and behavior of biological organisms in nature, mainly including genetic algorithms [
9] and ant colony algorithms [
10]. Liang et al. [
11] integrated the ant colony algorithm and genetic algorithm to propose a hybrid path planning algorithm, which used a genetic algorithm to generate initial paths and then used an ant colony algorithm to optimize them, significantly improving the accuracy and efficiency of path planning.
The artificial potential field method [
12] was first applied in the mobile robot path planning field in 1986. Zha et al. [
13] improved the artificial potential field method by adding a distance factor between the target point and the vehicle in the repulsive force function, and a safety distance within the influence range of obstacles. The experimental results showed that when the vehicle was driving within the safety distance of obstacles, it would be subject to increased repulsive force, ensuring the safety of the vehicle during driving. Zhao et al. [
14] proposed a multi-robot path planning method based on an improved artificial potential field and a fuzzy inference system, which overcame the problem of smooth path planning existing in traditional artificial potential field methods by using the incremental potential field calculation method.
Afifi et al. [
15] proposed a vehicle path planning method based on a simulated annealing algorithm, which solved the vehicle path planning problem under time window constraints, using the simulated annealing algorithm for path optimization and search. Jun et al. [
16] proposed a particle swarm optimization combined with simulated annealing (PSO-ICSA) to self-adaptively adjust the coefficients, enabling high-dimension objects to enhance the global convergence ability.
Zhang et al. [
17] proposed an indoor mobile robot path planning method based on deep learning. They used deep learning models to extract features from sensor data to predict the robot’s motion direction and speed, achieving good results in experiments. During robot path planning, when the environment changes, the robot re-executes the algorithm, significantly increasing the time to find the optimal path. Dimensionality reduction seems to be a solution to this problem. Ferreira et al. [
18] proposed a path planning algorithm based on a deep learning encoder model. They built a CNN encoder that uses nonlinear correlations to reduce data dimensions, eliminating unnecessary information and accelerating the efficiency of finding the shortest path.
Bai et al. [
19] combined a dynamic window algorithm with the A* algorithm to propose an unmanned aerial vehicle path planning method. Experiments proved that the improved algorithm significantly reduced both path planning length and time. Lee et al. [
20] proposed a dynamic window approach based on finite distribution estimation. Experimental results showed that this method could achieve a reliable obstacle avoidance effect for mobile robots and exhibited good performance in multiple scenarios.
Most of the above methods heavily rely on environmental map information. When faced with unknown environments, these methods may not achieve ideal results. When mobile robots are in unknown environments, due to the lack of environmental cognition, they must have certain exploration and autonomous learning abilities to efficiently complete path planning tasks. Therefore, studying mobile robot path planning algorithms that rely on little or no map information of the environment and have autonomous learning abilities has become one of the current key research topics.
Recently, artificial intelligence technologies represented by deep learning and reinforcement learning have developed rapidly. Reinforcement learning algorithms do not rely on map information and can learn path planning strategies in unknown environments by interacting with the environment through trial and error. However, reinforcement learning is prone to the problem of dimensionality disaster in the path planning process. Deep learning is an end-to-end model that can fit the mapping relationship between high-dimensional input and output data, and is suitable for dealing with high-dimensional data problems. Deep reinforcement learning combines the advantages of deep learning and reinforcement learning and has a huge advantage over other path planning methods when dealing with complex unknown environments. Nevertheless, path planning methods based on deep reinforcement learning still face problems such as sparse rewards, a slow learning rate, and difficult convergence in application process.
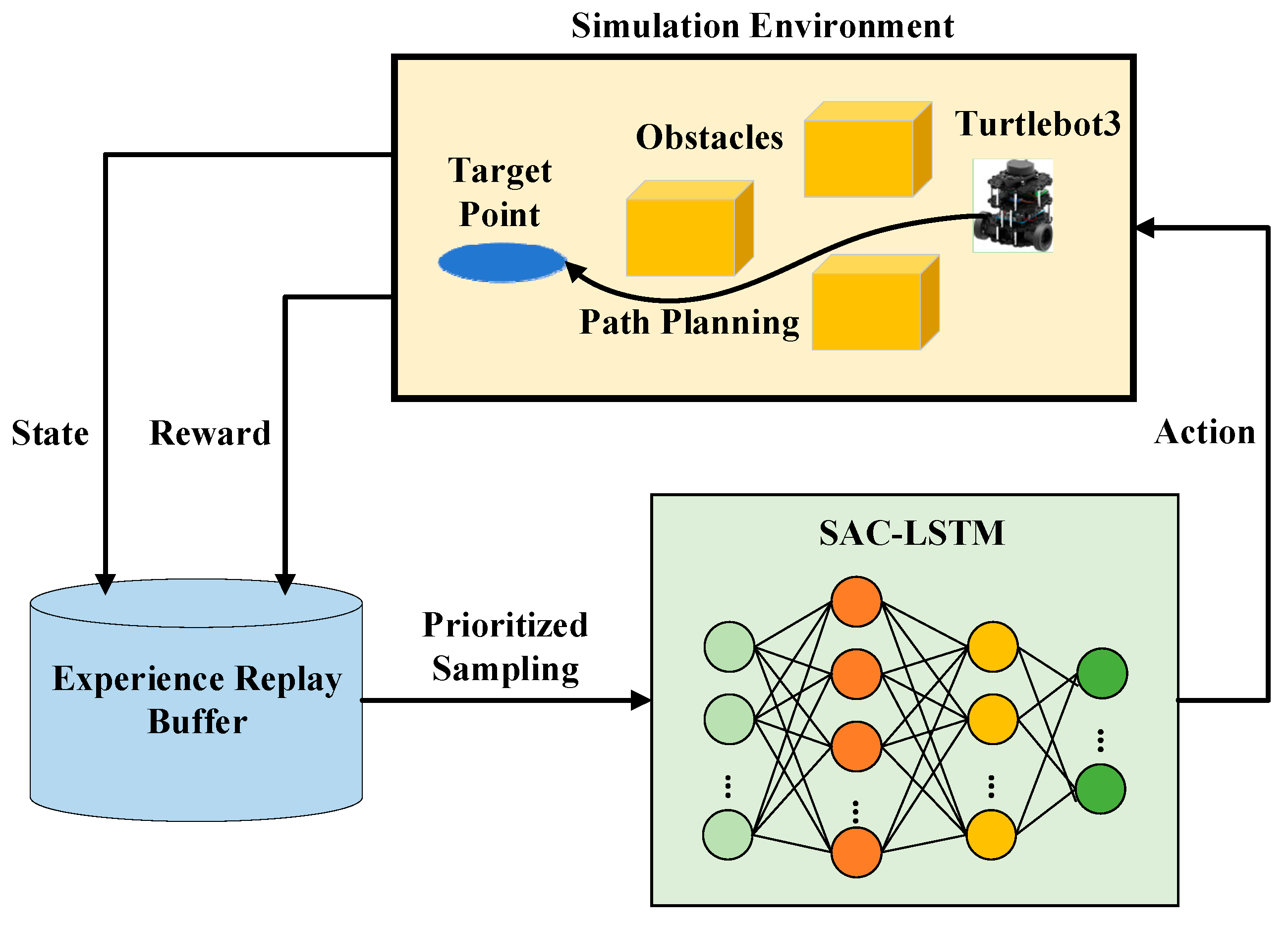
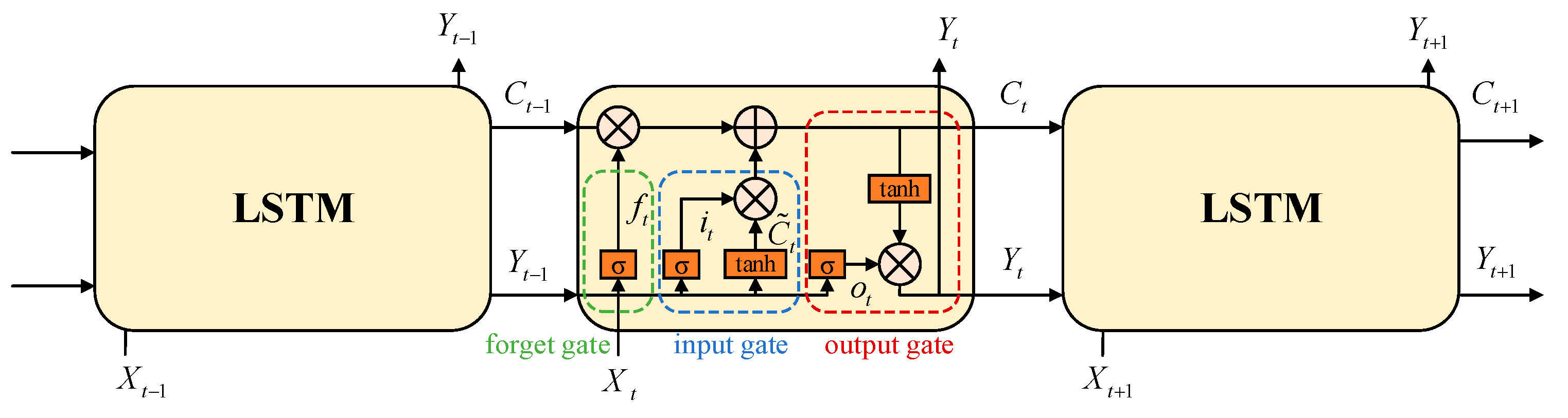
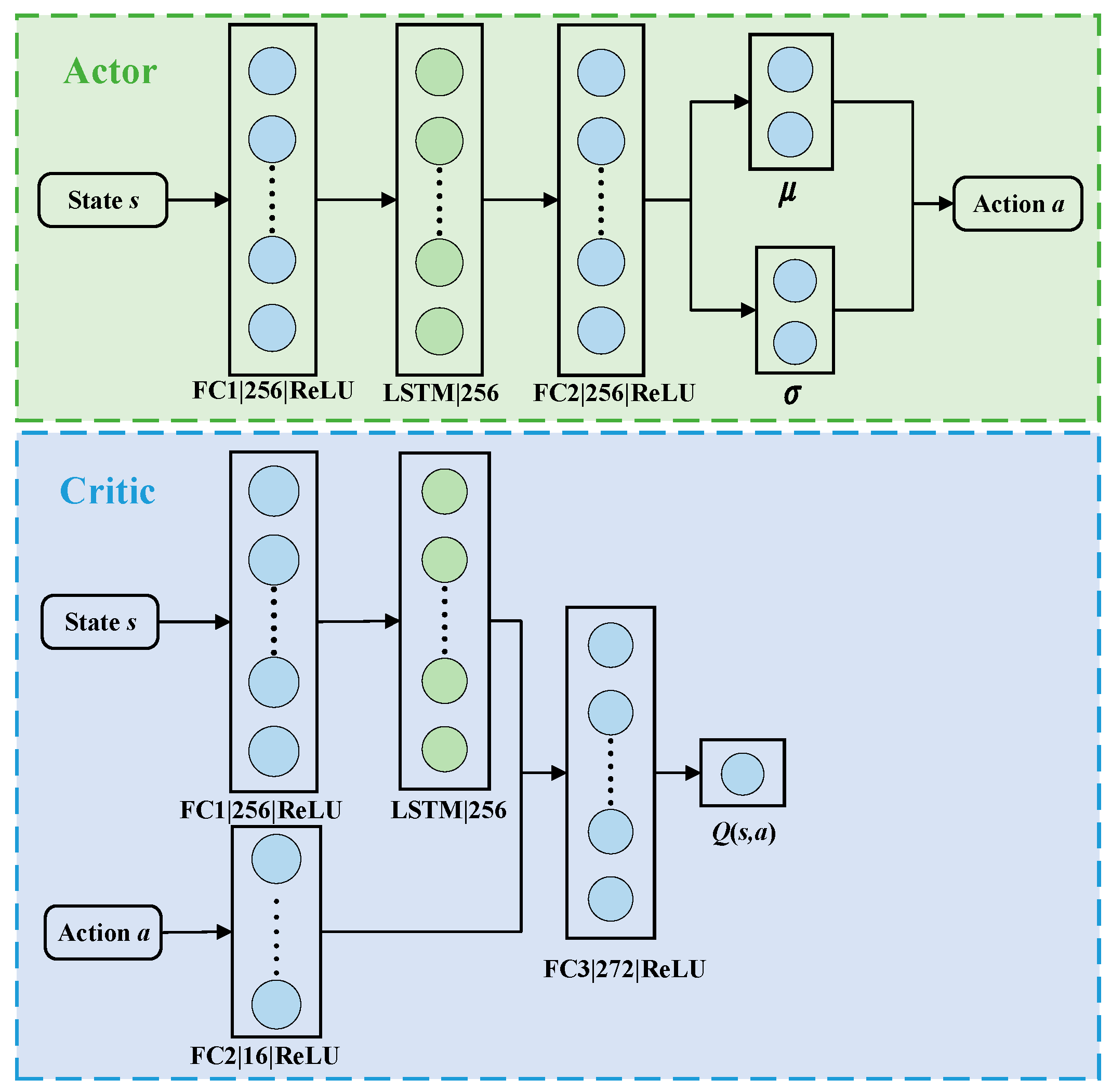
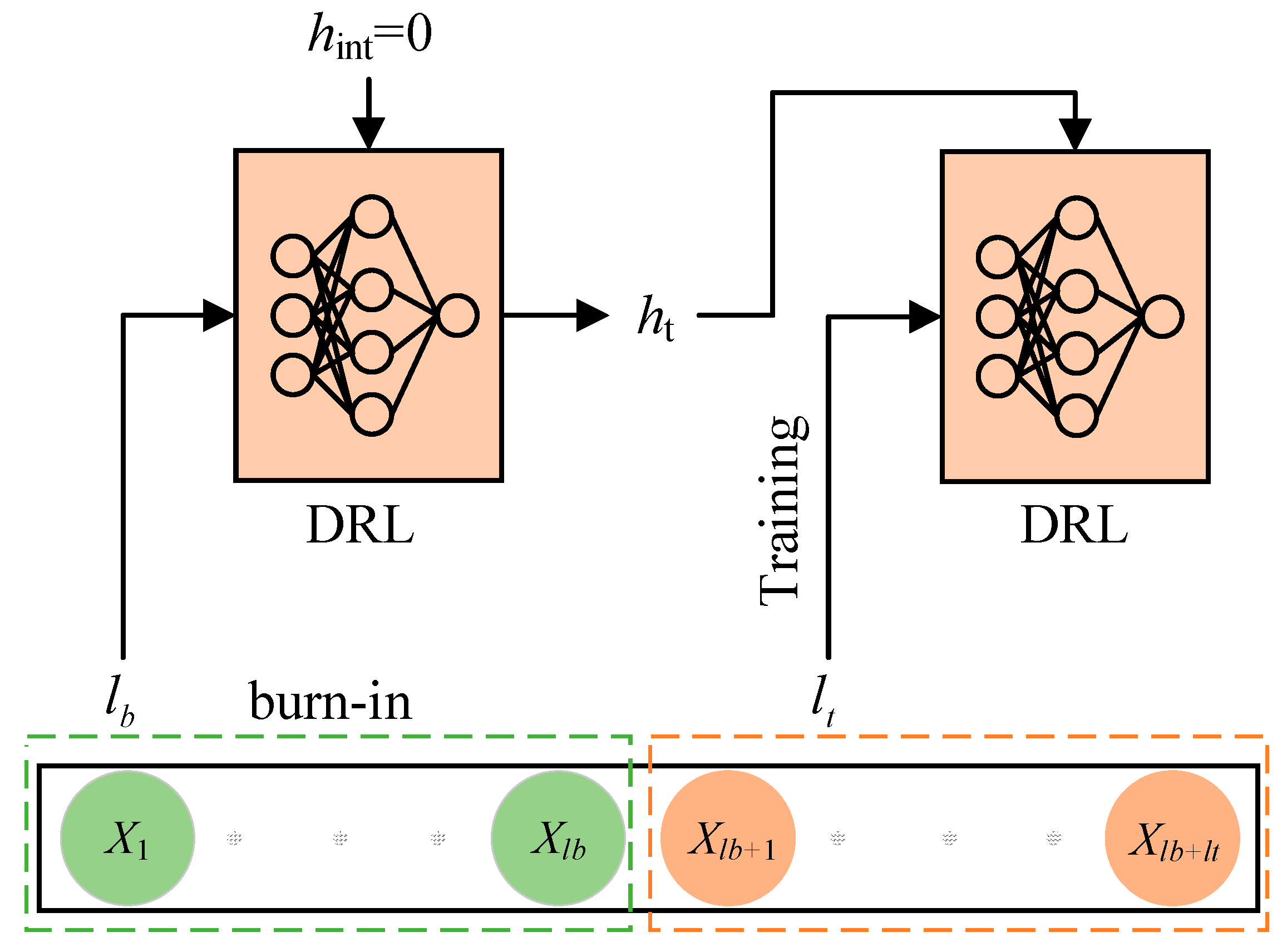
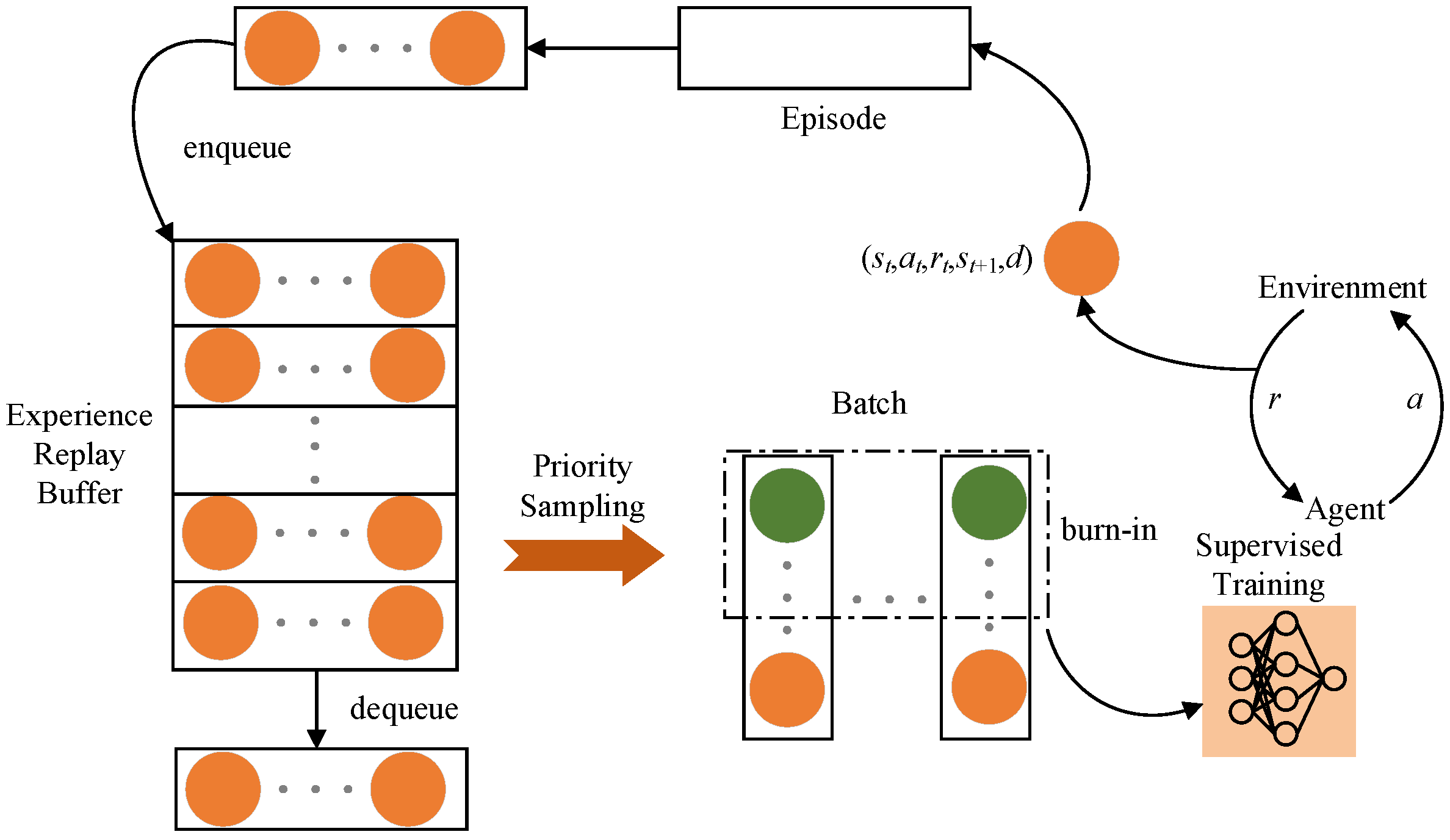
This paper focuses on the indoor mobile robot path planning problem in complex and unknown dynamic environments with several static and dynamic obstacles, using the Soft Actor–Critic (SAC) algorithm as the main method. The SAC algorithm, while powerful, exhibits certain limitations, namely (1) difficulty in processing complex or dynamic environmental information; (2) inadequacy in handling long-term dependencies in path planning; and (3) lack of predictive capability for future environmental states. To address these shortcomings, an improved SAC-LSTM algorithm is proposed. The main contributions of this paper are as follows. First, the LSTM network with memory capability is introduced into the SAC algorithm, allowing the agent to make more reasonable decisions by combining historical and current states and predict the dynamic changes in the environment, such as the future positions of moving obstacles. Second, the burn-in training mechanism is introduced to solve the problem of memory impairment caused by the hidden state being zeroed during the training process of the LSTM network, stabilizing the learning process, especially in the early stages of training. Third, by combining the prioritized experience replay mechanism, the problem of low sampling efficiency of the algorithm is solved, and the convergence speed of the algorithm is accelerated. Fourth, a complex dynamic test scenario is constructed for indoor mobile robots, featuring multiple stationary and moving obstacles of various sizes and shapes, as well as different motion trajectories, making the test scenario more realistic.
The rest of this paper is organized as follows:
Section 2 provides an overview of related works regarding path planning methods in dynamic environments.
Section 3 describes the proposed SAC-LSTM system framework and algorithms in detail.
Section 4 presents the experimental results and performance analysis. Finally,
Section 5 concludes the paper and discusses future research directions.
2. Related Work
In recent years, researchers have started to apply deep reinforcement learning (DRL) algorithms to the field of path planning to solve complex problems. In 2016, Tai et al. [
21] first applied the DQN algorithm to indoor mobile robots, which could complete path planning tasks in indoor scenarios, but the algorithm had low generalization. Wang et al. [
22] introduced an improved DQN algorithm combined with artificial potential field methods to design reward functions, improving the efficiency of mobile robot path planning. However, it could not achieve continuous action output for robots.
Lei et al. [
23] proposed a path planning algorithm using a DDQN framework with environment information obtained through LiDAR. It designed a new reward function to address the instability issue during training, improving algorithm stability, but its application was limited to simple scenarios with no guarantee of efficiency in complex situations. Tai et al. [
24] used an asynchronous deterministic policy gradient algorithm to build a mapless path planner with input from the mobile robot’s LiDAR-scanned environment information. After a period of training, the mobile robot could successfully reach the designated target, but the planned path was relatively tortuous.
In [
25], a deep reinforcement learning-based online path planning algorithm was proposed, successfully achieving path planning for drones in dynamic environments. Zhang et al. [
26] combined the advantages of DRL and interactive RL algorithms and proposed a deep interactive reinforcement method for autonomous underwater vehicle (AUV) path tracking, achieving path tracking in a Gazebo-simulated environment. In [
27], the DDPG algorithm was extended to a parallel deep deterministic policy gradient algorithm (PDDPG) and applied to multi-robot mapless collaborative navigation tasks.
Wang et al. [
28] proposed an end-to-end modular DRL architecture that decomposed navigation tasks in complex dynamic environments into local obstacle avoidance and global navigation subtasks, using DQN and dual-stream DQN algorithms to solve them, respectively. Experiments demonstrated that this modular architecture could efficiently complete navigation tasks. Gao et al. [
29] introduced an incremental training mode to address the low training efficiency in DRL path planning. In [
30], incorporating a curiosity mechanism into the A3C algorithm provided an additional reward for the exploration behavior of mobile robots, addressing the reward sparsity issue to some extent.
De Jesus et al. [
31] proposed a mobile robot path planning algorithm based on SAC, achieving path planning in different scenarios built on ROS. However, the algorithm still faced the problem of sparse environmental rewards. Park, K.-W. et al. [
32] employed the SAC algorithm to solve the path planning problem for multi-arm manipulators to avoid fixed and moving obstacles, and used the LSTM network to predict the position of the moving obstacles. The simulation and experimental results showed the optimal path and good prediction of obstacle position. Although the simulation and experimental scenario considered moving obstacles, there was only one moving obstacle, lacking verification for multiple obstacles. Additionally, the multi-arm manipulators used a camera in conjunction with the OpenCV vision algorithm to detect obstacles, which has limited effectiveness in detecting and predicting multiple moving obstacles.
In addition to LSTM, the metaheuristic-based recurrent neural network (RNN) [
33] has also been applied to control mobile robotic systems. The metaheuristic-based RNNs often integrate optimization algorithms (such as genetic algorithms and particle swarm optimization) with neural network characteristics. The Beetle Antennae Olfactory Recurrent Neural Network (BAORNN) [
34] is a metaheuristic-based control framework used for simultaneous tracking control and obstacle avoidance in redundant manipulators. A key feature of this framework is that it unifies tracking control and obstacle avoidance into a single constrained optimization problem, actively rewarding the optimizer to avoid obstacles by introducing a penalty term in the objective function. The distance calculation is based on the Gilbert–Johnson–Keerthi algorithm, which calculates the distance between the manipulator and obstacles by directly using their three-dimensional geometric shapes. In contrast, the RNN may offer more flexibility in solving specific control and optimization problems, but might not match the LSTM’s proficiency in handling complex sequential data and long-term dependencies.
As seen from the above literature, DRL-based path planning methods have the advantages of not relying on map information and autonomous learning capabilities, making them highly suitable for path planning tasks in unknown environments. However, during application, there are still issues such as sparse rewards, slow learning rates, and difficulty in converging the algorithm. In particular, in dynamic or complex environments, the SAC algorithm may require more accurate environmental models for effective learning. This could be difficult to achieve in practice, particularly in environments with high uncertainty or rapid changes. The SAC algorithm might be insufficient in effectively dealing with highly dynamic or non-stationary environments, where environmental states and dynamics can change rapidly.
4. Experiments and Discussion
4.1. Simulation Platform
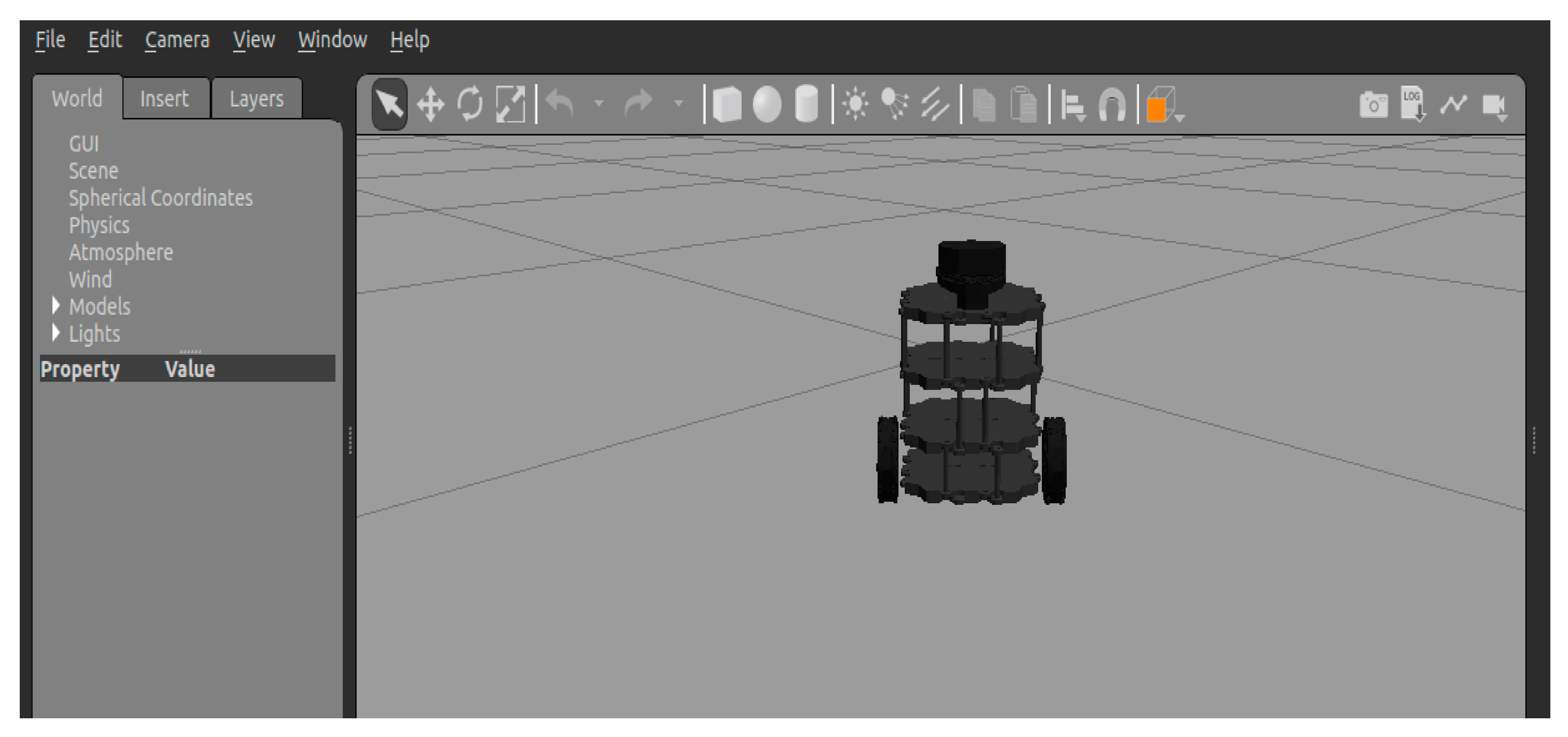
The experimental software environment for this paper included Ubuntu 18.04, CUDA 10.1, Pytorch 3.7, and ROS Kinetic. The hardware utilization comprised an AMD R7-5800H CPU and a GeForce GTX 3060 GPU with 6G of memory. The experiment employed the Turtlebot3 robot based on ROS, which obtains the environmental information around it with the help of laser radar. The 3D model of the mobile robot was loaded into the ‘empty.world’ in ROS, as depicted in
Figure 11.
This paper utilizes Gazebo9 software to set up experimental environments. Three experimental environments, depicted in
Figure 12, were built for testing the algorithm’s effectiveness in mobile robot path planning in indoor environments. These environments are an obstacle-free environment, a static obstacle environment, and a dynamic obstacle environment; all three are square areas measuring 8 m in length. The obstacle-free environment has only four surrounding walls. The static obstacle environment features twelve stationary obstacles, consisting of four cylinders with a diameter of 0.3 m and a height of 0.5 m, four small cubes measuring 0.5 m in edge-length, and four large cubes measuring 0.8 m in edge-length, which are added to the obstacle-free environment. In contrast, the dynamic obstacle environment features moving obstacles. The four cylinders rotate counterclockwise at a speed of 0.5 rad/s around the origin of the coordinate system (the center of the environment), as illustrated by the smaller white dashed circles in
Figure 12. Concurrently, four large cubes move clockwise at the same speed, following the trajectory shown by the larger white dashed circles with arrows in
Figure 12. Meanwhile, the four small cubes within this environment remain stationary.
Deep reinforcement learning involves agents gathering training data by interacting with their real-world environments. In a 3D experimental environment created by Gazebo, data acquisition can become a time-consuming and computationally expensive process. Consequently, this paper employs a time acceleration technique to reduce the duration of training. By default, Gazebo’s real-time update rate is 1000, and the max step size value is 0.001. When these settings are multiplied, the resulting ratio between the simulation time and the actual time is 1. However, in order to expedite simulations, the value for max step size is adjusted to 0.005, leading to a fivefold increase in simulation speed.
The specific experimental parameters are shown in
Table 1.
4.2. Computational Complexity
To quantify the computational complexity of SAC and SAC-LSTM algorithms, the contribution of each component to the overall computational load can be analyzed based on five key factors, as follows:
Due to the larger batch size (512) and experience buffer capacity (20,000), the SAC algorithm requires processing more data in the network training steps, leading to an increased computational load. When it comes to the SAC-LSTM algorithm, the inclusion of LSTM layers introduces additional time-dependency computations. A smaller batch size (32) might reduce the computational load per training iteration, but the burn-in process and LSTM’s time dependencies increase the computational load per batch.
- 2.
Prioritized Experience Replay
Prioritized experience replay requires additional computations to maintain a priority queue and update it after each learning step, increasing the computational load, especially with a larger experience buffer.
- 3.
Learning Parameters
The parameters, a learning rate of 0.001 and a discount factor of 0.99, mainly affect the convergence speed and stability of the algorithm, but have a relatively minor direct impact on computational load.
- 4.
Reward Mechanism
The reward coefficients and thresholds influence the efficiency of learning, but have a limited direct impact on computational load.
- 5.
Optimizer
The Adam optimizer is a computationally efficient optimizer but has a higher computational complexity compared to simpler ones such as SGD (Stochastic Gradient Descent).
Overall, the SAC-LSTM algorithm involves higher per-batch computational loads due to time-dependency processing with LSTM, smaller batch sizes, and burn-in processing. The SAC algorithm, although having larger data volumes per batch, might have a slightly lower per-batch computational load than SAC-LSTM, owing to the absence of complex time-series processing. When running both algorithms on the same computer platform, SAC-LSTM consumes approximately 10% more computation time per batch compared to SAC. This finding aligns closely with the qualitative analysis results mentioned above.
4.3. Experimental Results and Analysis
4.3.1. Obstacle-Free Experiment
In this paper, we chose the average reward as the evaluation metric for our algorithm. A higher value confirms better performance of the algorithm. The average reward is calculated from Equation (38). Within each episode,
represents the number of steps taken by the agent, and
r is the reward received for each step.
The robot’s starting point is the origin, and the target point is generated at random. During a single episode, once the robot reaches the target point, the environment generates a new target point randomly. As a result, the robot may reach multiple target points within a single episode.
Two reinforcement learning algorithms, SAC and SAC-LSTM, were trained for 1000 episodes in the obstacle-free environment. Their average reward curves are illustrated in
Figure 13. During the initial training phase, both algorithms demonstrated a decreasing trend in their average reward. This was attributed to the robot frequently circling in place or moving away from the target point, which was observed within the first 10 episodes. However, after that point, both algorithms exhibited a remarkable increase in their average reward. The SAC-LSTM algorithm reached its reward peak and convergence after 130 episodes, whereas the SAC algorithm achieved the same after 180 episodes. Notably, the average reward of the SAC-LSTM algorithm surpassed that of the SAC algorithm after convergence. This observation suggests that the SAC-LSTM algorithm enabled the robot to reach the target point more frequently during each episode’s path planning process, resulting in better path planning performance. Although both algorithms accomplished the task in the obstacle-free environment, the SAC-LSTM algorithm converged faster and yielded a higher average reward after convergence.
To further evaluate the model’s performance, the SAC and SAC-LSTM algorithms underwent 200 tests in the obstacle-free environment. For each test, the target points were randomly generated, and the results are presented in
Table 2. Our evaluation reveals that the path planning success rate for the SAC algorithm was 97%. In contrast, the proposed SAC-LSTM algorithm yielded better performance, achieving a success rate of 100%.
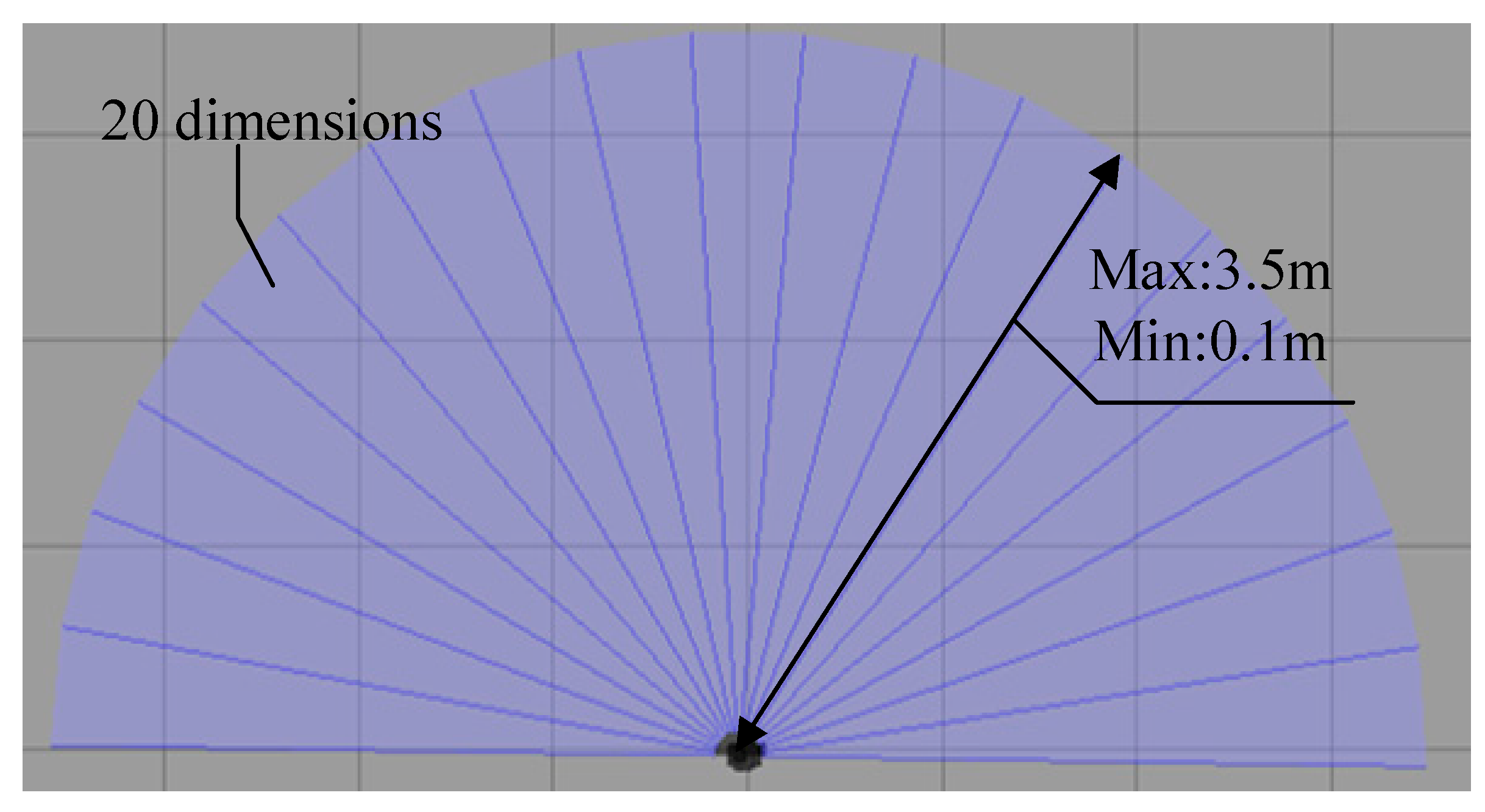
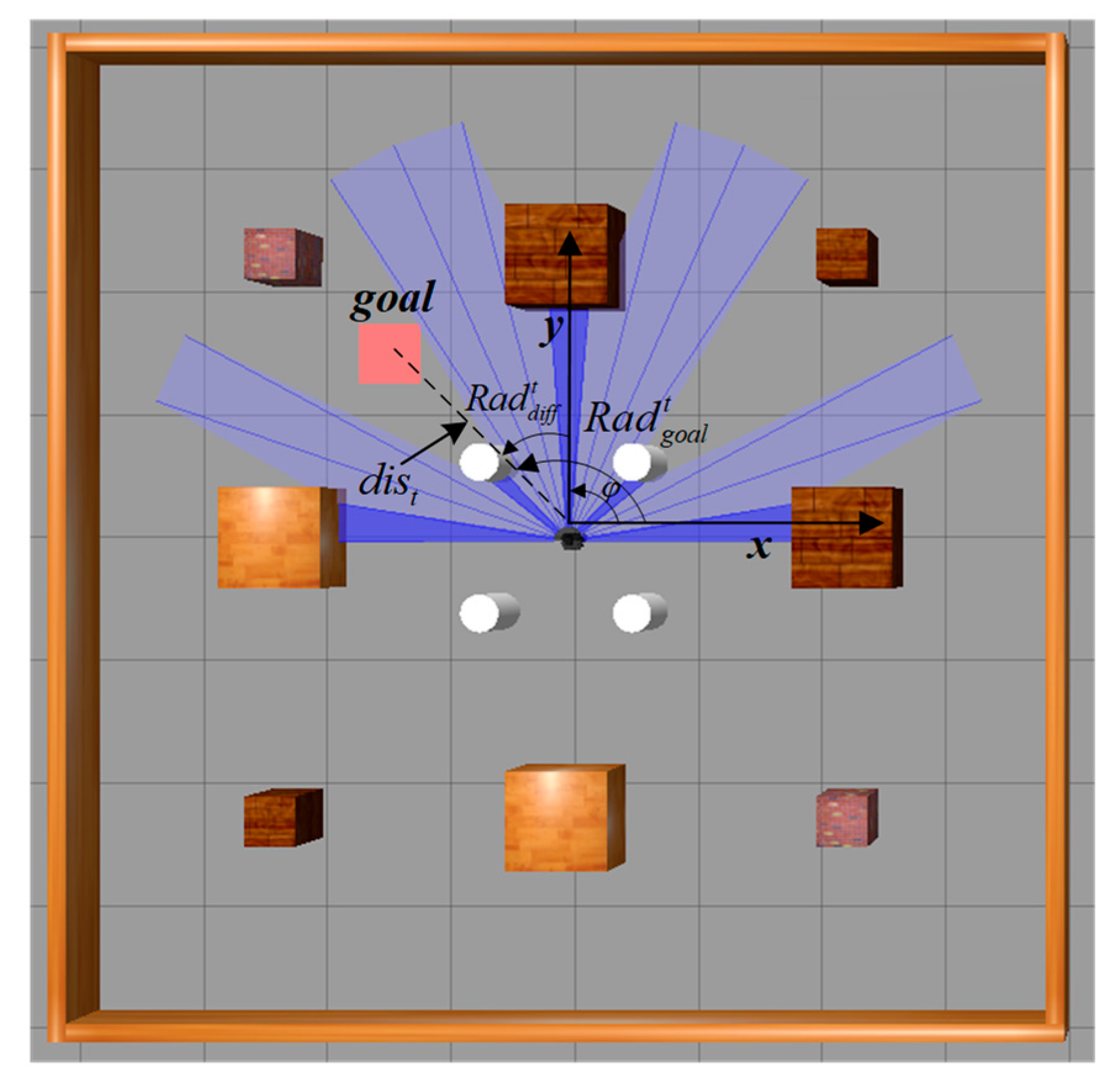
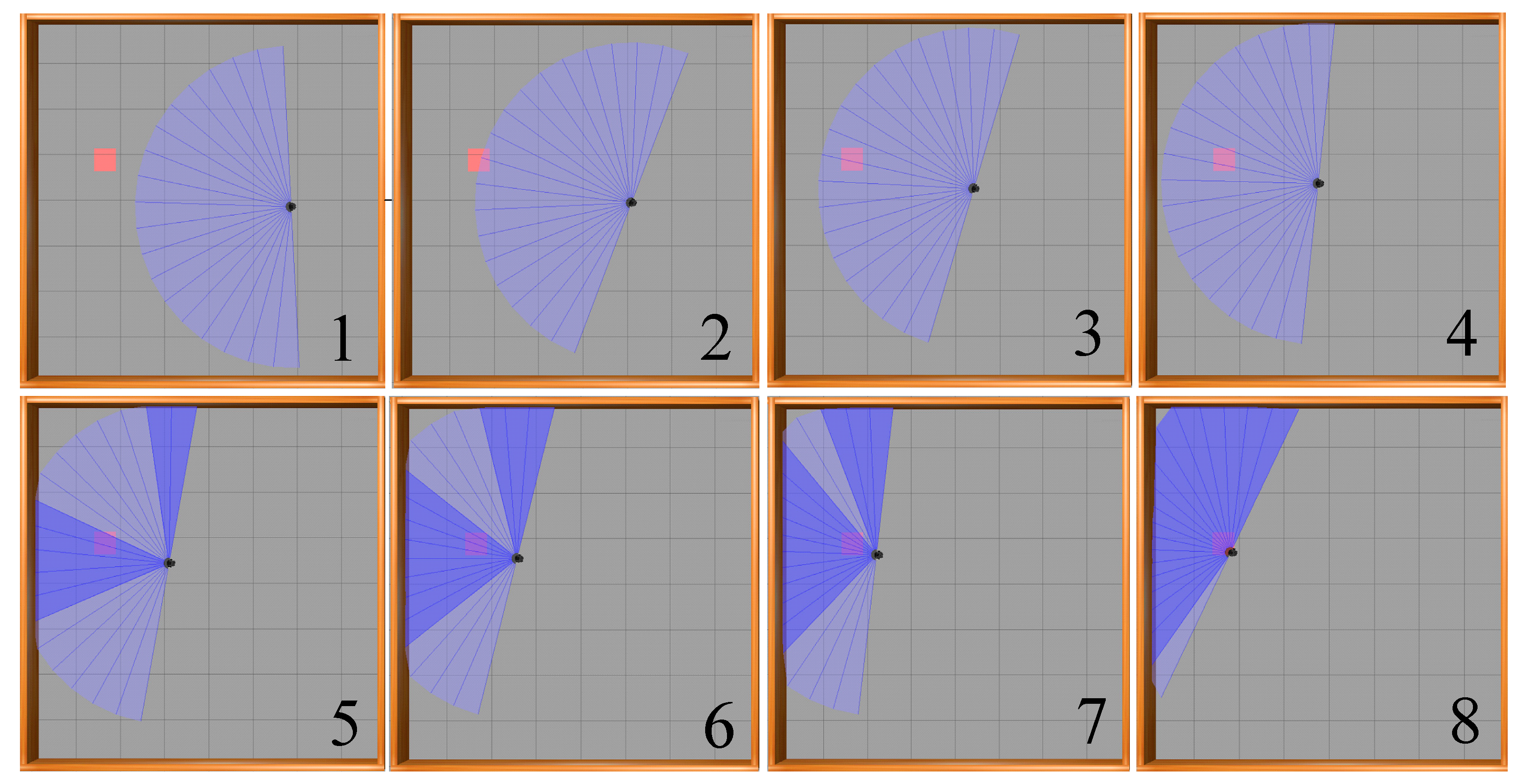
Illustrated in
Figure 14 is the motion process of the mobile robot towards the target point in the obstacle-free environment based on the SAC-LSTM algorithm. In the figure, the black dot represents the mobile robot, while the blue sector illustrates the range of the radar scan. The red square indicates the location of the target point. Notably, the mobile robot achieves optimal pathway and accurately reaches the target point from the starting point.
4.3.2. Static Obstacle Experiment
The two algorithms were trained for 1000 episodes in the obstacle environment illustrated in
Figure 12b. The plotted average reward curves of the two algorithms are depicted in
Figure 15. Notably, the static obstacle environment is significantly more complex than the obstacle-free environment since collision with the surrounding obstacles is more frequent during robot exploration. As expected, greater exploration time was required. The SAC-LSTM algorithm began to converge from the 20th episode. Interestingly, its converging process had a higher average reward than the SAC algorithm, finishing the process at the 380th episode. On the other hand, the SAC algorithm had reduced fluctuations and began to converge from the 30th episode, while the converging process completed at the 500th episode. Impressively, the SAC-LSTM algorithm yielded a faster convergence rate and a higher average reward after convergence than the SAC algorithm.
Two algorithms were tested 200 times in the static obstacle environment, where the target points were randomly generated. The test results are presented in
Table 3, indicating that the SAC algorithm’s success rate was only 88.5%, while the proposed SAC-LSTM algorithm achieved a success rate of 95.5%.
Figure 16 illustrates the movement process of a mobile robot based on the SAC-LSTM algorithm, from its starting point to the target point in the static obstacle environment. As shown, the mobile robot avoided the obstacles in the environment and reached the target point via the optimal path.
4.3.3. Dynamic Obstacle Experiment
The dynamic obstacle environment was constructed as shown in
Figure 12c to simulate a realistic path planning scenario. The SAC and SAC-LSTM algorithms underwent 1000 episodes of training, with the training results presented in
Figure 17. As shown in the figure, the difficulty of path planning increased due to the moving obstacles, resulting in significant fluctuations in the learning curves of both algorithms. The SAC-LSTM algorithm began to converge after the 75th episode when the fluctuations decreased, and it achieved convergence by the 510th episode. The SAC algorithm began to converge after the 95th episode and achieved convergence by the 710th episode. The proposed SAC-LSTM algorithm demonstrated a faster convergence rate than the SAC algorithm, with a slightly higher average reward after convergence.
A total of 200 tests were also conducted using both algorithms in the dynamic obstacle environment, with the target points generated randomly.
Table 4 shows the success rates of both algorithms, with the SAC algorithm achieving a success rate of only 78.5%, while the SAC-LSTM algorithm achieved a success rate of 89%.
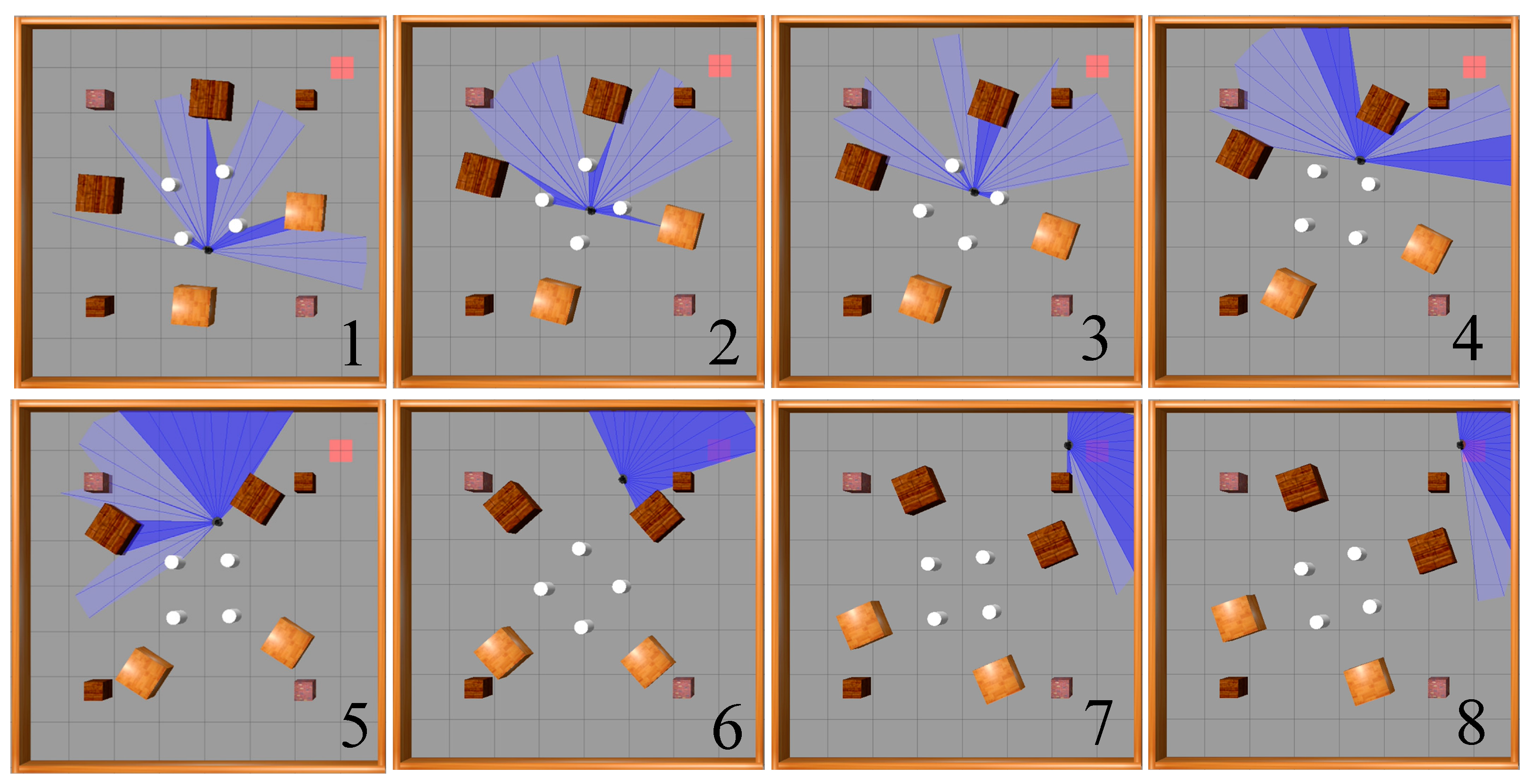
Figure 18 illustrates the movement process of a mobile robot driven by the SAC-LSTM algorithm, from its starting point to the target point in a dynamic obstacle environment. As shown, the mobile robot was able to avoid the moving obstacles and reach the target point via the optimal path.
As completing path planning tasks in dynamic environments is more challenging and requires higher performance from path planning algorithms, and as dynamic environments better reflect the actual work environment of mobile robots, in order to better test the performance of the two algorithms, an additional set of experiments was conducted on top of the initial experiment measuring success rate, which tested the path length, planning time, and number of times the robot reached the target point. Ten target points were randomly generated in the dynamic obstacle environment, all located near the moving obstacles at the periphery, so that each time the robot moved to a target point, interference from the moving obstacles was encountered, increasing the reliability of the experiment. The specific locations of the target points are illustrated in
Figure 19.
The target point numbers in
Figure 19 were sorted according to the Euclidean distance between each target point and the starting point of the mobile robot, which is set as the origin. Thirty experimental trials were conducted for each of the target points, with the path length, planning time, and success rates recorded. The path length and planning time were averaged from the successfully completed path planning tasks, and specific test results can be found in
Table 5 and
Table 6. Among the 10 target points tested, the SAC-LSTM algorithm achieved both shorter average path lengths and planning times, as well as higher success rates, compared to the SAC algorithm. This indicates that the path planning performance of the SAC-LSTM algorithm is superior to that of the SAC algorithm, enabling the mobile robot to reach its designated target point in less time and with a shorter route. Notably, for the 10th target point, the SAC algorithm was unable to guide the mobile robot to its target point based solely on the current state information, whereas the SAC-LSTM algorithm, which incorporates the LSTM network, has memory capability to consider both historical and current states to make better decisions, and thus guided the robot to complete its path planning task.
Based on the results of the three simulation experiments, the trained mobile robot was able to successfully complete the path planning task in all three environments, and the improved SAC-LSTM algorithm demonstrated significant enhancements in both path planning success rate and convergence speed. In particular, in dynamic and complex scenarios, the SAC-LSTM algorithm exhibited shorter planning time, shorter planning paths, and a higher number of instances where the target point was reached.
5. Conclusions
This paper presents the SAC-LSTM algorithm and develops a path planning algorithm framework for mobile robots, addressing the limitations of the SAC algorithm in path planning tasks. The proposed algorithm incorporates an LSTM network with memory capability, a burn-in mechanism, and a prioritized experience replay mechanism. By integrating historical and current states, the LSTM network enables more effective path planning decisions. The burn-in mechanism preheats the LSTM network’s hidden state before training, addressing memory depreciation and enhancing the algorithm’s performance. The prioritized experience replay mechanism accelerates algorithm convergence by emphasizing crucial experiences. A motion model for the Turtlebot3 mobile robot was established, and the state space, action space, reward function, and overall process of the SAC-LSTM algorithm were designed. To enhance the realism of the experimental scenarios, three environments were created, including obstacle-free, static obstacle, and dynamic obstacle scenarios. There are multiple stationary and moving obstacles of various sizes and shapes in the dynamic scenarios. The algorithm was subsequently trained and tested in these settings. The experimental results demonstrated that the SAC-LSTM algorithm outperformed the SAC algorithm in convergence speed and path planning success rate across all three scenarios with roughly the same computational cost. Furthermore, in an additional dynamic obstacle experiment, the SAC-LSTM algorithm exhibited shorter planning times, more efficient paths, and an increased number of instances where the target point was reached, indicating superior path planning performance.
Despite these advancements, certain limitations persist within this paper. The experiments relied solely on 2D lidar for environmental data, which may lead to inaccuracies when dealing with irregularly shaped obstacles. Future research could employ multi-sensor fusion to obtain more comprehensive environmental information. Additionally, the paper does not address the several sources of noise and uncertainty present in real-world environments, including sensor noise, environmental fluctuations, and uncertainty in obstacle movement. The algorithm needs sufficient robustness to handle these factors to perform well in practical settings. Moreover, the experiments were conducted exclusively in a simulated environment. To fully assess the effectiveness of the mobile robot in completing path planning tasks, it is essential to transfer the trained model to a real-world scenario.



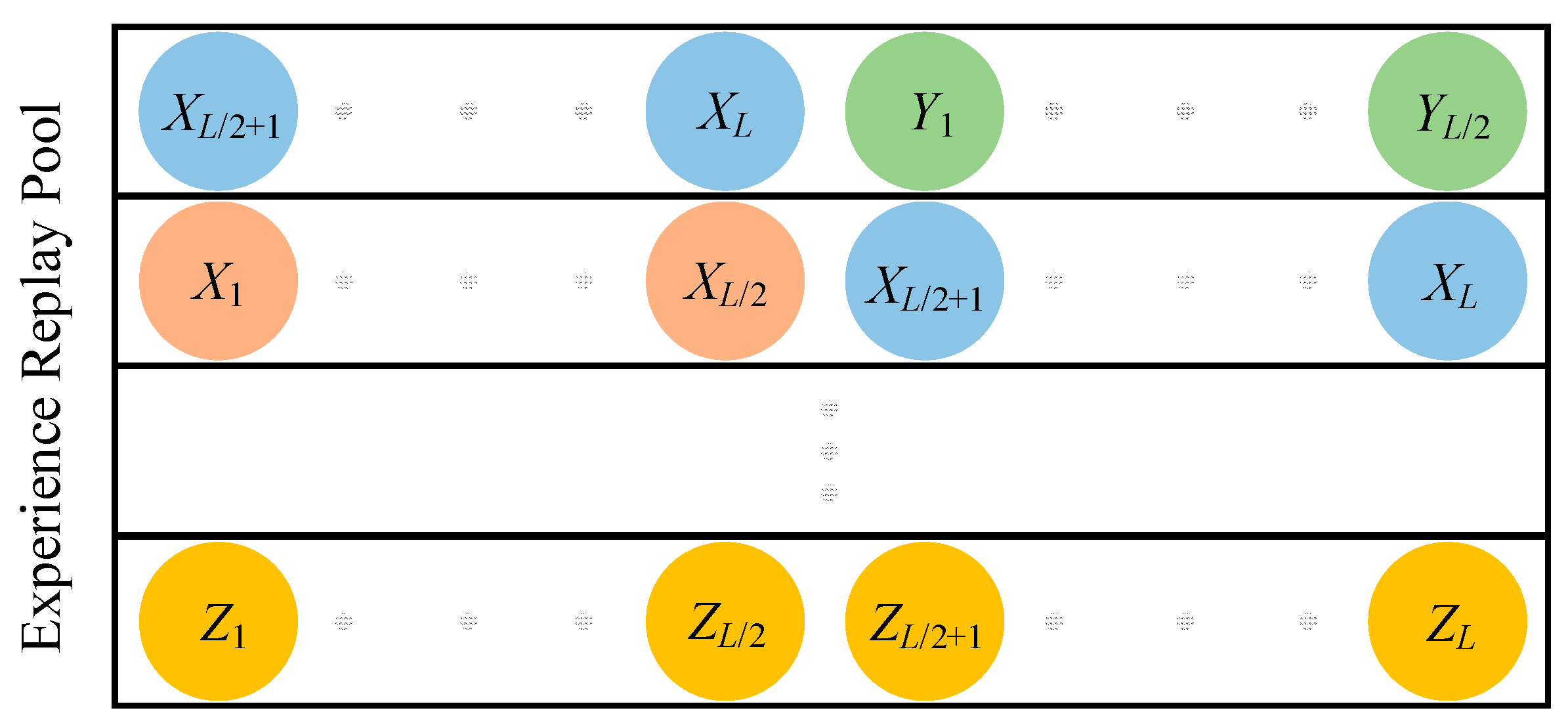








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}