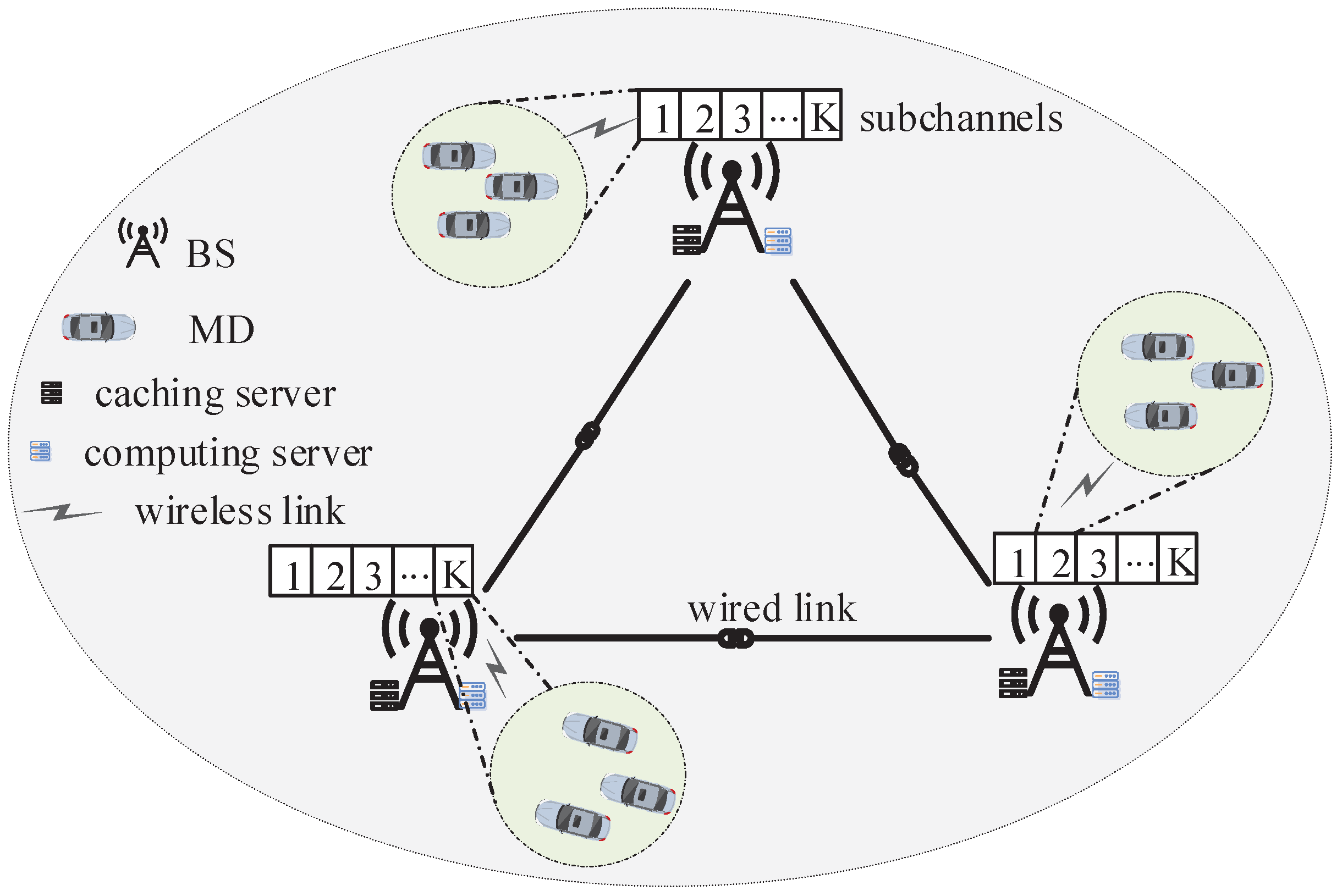
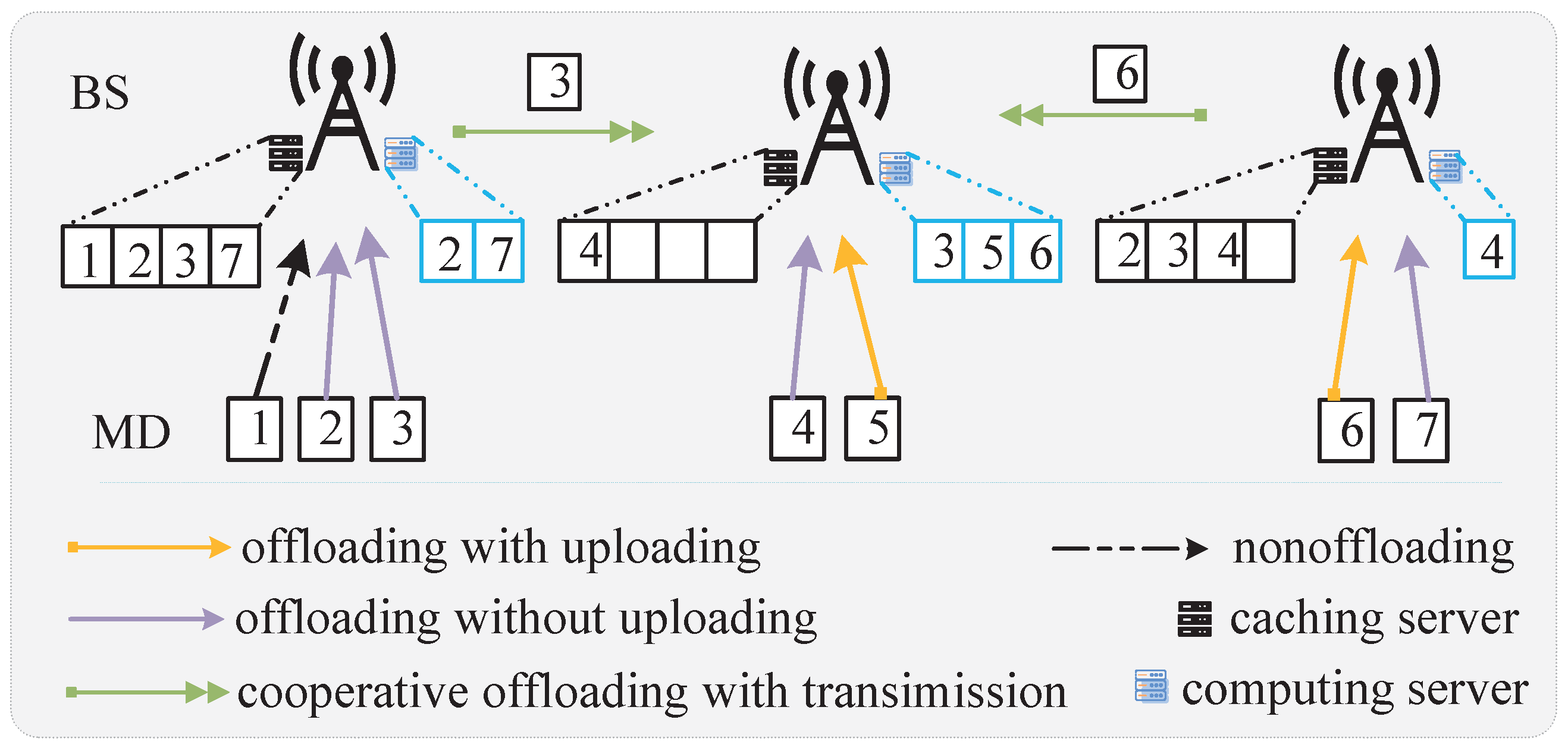
1. Introduction
With the rapid development of information and communication technologies, the data traffic generated by vehicles (mobile devices, MDs) has also significantly increased [
1]. For wireless communication networks, more spectrum resources are required for data traffic transmission [
2,
3,
4,
5]. In addition, higher computing power is required by MDs for supporting large amounts of task calculation. However, due to the limited battery capacity of MDs, it may be challenging to process these computation tasks for them. By deploying edge computing servers at base stations (BSs), mobile edge computing (MEC) can support MDs in processing tasks at the adjacent edge servers [
6,
7]. Compared with cloud computing (CC), which requires tasks to be uploaded to a remote cloud, MEC can provide additional computing resources for MDs within its coverage area and thus reduce their computing overhead [
8,
9,
10,
11,
12,
13,
14].
Although the edge servers can reduce the computing overhead of MDs by providing more computing resources, the extra time and energy consumption caused by offloading tasks through wireless channels cannot be ignored, especially for high-size computation tasks. In order to further reduce the time and energy consumption caused by offloading tasks, edge caching technology is also introduced into MEC networks. By caching tasks of MDs at edge servers in advance, the overhead caused by offloading tasks could be greatly reduced [
15,
16,
17,
18,
19].
To upload tasks from MDs to edge servers, orthogonal multiple access (OMA) is often used, but it may be greatly challenging to provide a high transmission rate and support massive connections. As another type of resource utilization management, non-orthogonal multiple access (NOMA) technologies can let multiple users share the same frequency bands, achieve higher spectral efficiency and support extensive connections [
20,
21,
22,
23]. It is evident that NOMA is a good type of resource utilization management for reducing the cost of task transmission in MEC networks.
Although the application of caching and NOMA technologies in MEC networks can reduce time and energy consumption, such a framework will make the design of computation offloading and edge caching schemes more complex. To the best of our knowledge, until now, how to jointly perform the device association, computation offloading, edge caching, subchannel selection and resource allocation is still an important and open topic in cache-assisted NOMA–MEC networks.
1.1. Related Work
So far, a lot of work has been conducted on joint computation offloading and resource optimization in NOMA–MEC networks. In [
20], joint radio and computation resource allocation was optimized to maximize the offloading energy efficiency in NOMA–MEC-enabled IoT networks, and a solution based on a multi-layer iterative algorithm was proposed. In [
21], local computation resource, offloading ratio, uplink transmission time and power and subcarrier assignment were jointly optimized to minimize the sum of weighted energy consumed by users in NOMA–MEC networks, and some effective iterative algorithms were designed for single-user and multi-user cases. In [
24], joint task offloading, power allocation and computing resource allocation were optimized to achieve delay minimization using a deep reinforcement learning (DRL) algorithm in NOMA–MEC networks. In [
25], the joint optimization of offloading decisions, local and edge computing resource allocation and power and subchannel allocation were realized to minimize energy consumption in heterogeneous NOMA–MEC networks, and an effective iterative algorithm was designed. In [
26], power and computation resource allocations were jointly optimized to minimize overall computation and transmission delay for massive MIMO and NOMA-assisted MEC systems, and a solution based on an interior-point algorithm was given. In [
27], the channel resource allocation and computation offloading policy were jointly optimized to minimize the sum of weighted energy and latency in NOMA–MEC networks, and some efficient solutions were found using a DRL algorithm based on actor–critic and deep Q-network (DQN) methods.
To further reduce the offloading time and energy consumption, edge caching technology is introduced into conventional MEC networks. Such a framework has attracted more and more attention. In [
28], the offloading and caching decisions, uplink power and edge computing resources were jointly optimized to minimize the sum of weighted local processing time and energy consumption in two-tier cache-assisted MEC networks, and a distributed collaborative iterative algorithm was proposed. In [
29], a problem of adaptive request scheduling and cooperative service caching was studied in cache-assisted MEC networks. After formulating the optimization problems as partially observable Markov decision process (MDP) problems, an online DRL algorithm was proposed to improve the service hitting ratio and latency reduction rate. In [
30], optimal offloading and caching strategies were established to minimize overall delay and energy consumption of all regions using a deep deterministic policy gradient (DDPG) framework in cache-assisted multi-region MEC networks. In [
31], joint MD association and resource allocation were performed to minimize the sum of MDs’ weighted delay in heterogeneous cellular networks with MEC and edge caching functions, and an effective iterative algorithm was developed using coalitional game and convex optimization theorems. In [
32], to minimize the content transmission delay in vehicular edge computing networks, a cooperative vehicular edge computing and caching scheme based on asynchronous federated and deep reinforcement learning was proposed to predict the popular content and the optimal cooperative caching location of the content. In [
33], to reduce the cost of the cloud service center through the asynchronous advantage actor–critic algorithm, the offloading decision, service caching and resource allocation strategies were jointly optimized in the three-tier mobile cloud–edge computing structure combining computation offloading and service caching mechanisms. In [
34], a logistic function-based service reliability probability (SRP) estimation model was built, and the average SRP maximization problem of a virtual machine-based edge computing server was studied for such a model. At last, a low-complexity heuristic alternative optimization algorithm was proposed.
To enhance spectral efficiency and support massive connections, NOMA technology has attracted increasing attention in cache-assisted MEC networks. In [
35], the multi-agent deep deterministic policy gradient method was used to dynamically optimize the user association, power control and cache placement of BSs and satellites to improve the network energy efficiency in a NOMA-enabled satellite integrated with a terrestrial network scenario. In [
36], joint optimization of offloading and caching decisions and computation resource allocation was performed to maximize long-term reward in cache-assisted NOMA–MEC networks under the predicted task popularity, and single-agent and multi-agent Q-learning algorithms were proposed to find feasible solutions. In [
37], joint optimization of offloading and caching decisions was performed to minimize the system delay in cache-assisted NOMA–MEC networks, and a multi-agent DQN algorithm was used for finding efficient solutions under the predicted popularity. In [
38], local task processing time was minimized by jointly optimizing offloading and caching decisions and the allocation of edge computing resources and uplink power in cache-assisted NOMA–MEC networks with single BS, and the blocking successive upper-bound minimization method was utilized to achieve efficient solutions.
Although the framework of cache-assisted (vehicular) NOMA–MEC networks can greatly reduce the task processing time and energy consumption and support massive connections, there exist very few relevant efforts. Unlike the above-mentioned work, we jointly optimize the edge computing resource allocation, subchannel selection, device association, offloading and caching decisions for the cache-assisted vehicular NOMA–MEC networks with multiple BSs, minimizing the energy consumed by MDs under time and resource constraints. In addition, unlike existing efforts, we develop an effective dynamic joint computation offloading and task-caching algorithm based on the twin-delayed deep deterministic policy gradient algorithm (TD3) to find efficient solutions, named the TD3-based offloading (TD3O) algorithm.
1.2. Contribution and Organization
In this paper, we jointly optimize the edge computing resource allocation, subchannel selection, device association, offloading and caching decisions in cache-assisted vehicular NOMA–MEC networks, minimizing the energy consumed by MDs under time and resource constraints. Specifically, the main contributions and work of this paper can be listed as follows.
Edge computing resource allocation, subchannel selection, device association, computation offloading and edge caching are jointly performed in cache-assisted vehicular NOMA–MEC networks. To the best of our knowledge, work that concerns subchannel selection is a new investigation for cache-assisted vehicular NOMA–MEC networks with multi-server scenarios. Meanwhile, as far as this problem is concerned, the goal is to minimize the energy consumed by MDs under the constraints of time, computing resources, caching capacity, the number of MDs associated with each BS and the number of MDs associated with each subchannel. As far as we know, such an optimization problem is a new concentration in cache-assisted vehicular NOMA–MEC networks.
We design effective algorithms to find feasible solutions to the formulated problem. Considering that the formulated problem is in a mixed-integer, nonlinear, multi-constraint form, a simple map between actions and actual policies in a conventional twin-delayed deep deterministic policy gradient (TD3) algorithm cannot be well applied. In addition, too large an action space will cause the TD3 algorithm to fail to search for correct actions and thus fail to converge. In view of these concerns, we develop an effective TD3O algorithm integrating with the AT algorithm to solve the formulated problem. Moreover, in order to solve this problem in a non-iterative manner, an effective heuristic algorithm (HA) is also designed.
Performance analyses of the designed algorithms. Some analyses are made for the computation complexity and convergence of the designed algorithms in detail. In addition, some meaningful simulation analyses are also made by introducing other benchmark algorithms for comparison, and some good results and insights are achieved.
The rest of the paper is organized as follows.
Section 2 introduces the system model.
Section 3 formulates a problem of minimizing local energy consumption in cache-assisted vehicular NOMA–MEC networks.
Section 4 designs the HA and TD3O algorithm.
Section 5 gives the computation complexity and convergence analyses for the designed algorithms.
Section 6 investigates the performance of the designed algorithms through simulation.
Section 7 gives conclusions and discussions.
4. Algorithm Design
As previously mentioned, the optimization problem P1 refers to minimizing local energy consumption within a given period. In view of this, we adopt the DRL algorithm to solve it. DRL is based on MDP, which implements the environment-based output of agent policy in MDP through neural networks, maximizing certain rewards. Considering that the overestimation of some conventional DRL algorithms (e.g., DQN and DDPG), the TD3 algorithm has been widely advocated because it can overcome well the problems of the above algorithms and achieve more stable output [
41,
42]. The main features of the TD3 algorithm are adding a new neural network and reducing the training frequency of the network based on DDPG.
The problem P1 has both continuous and discrete variables, and the solution space formed by the combination of all variables is very large, which is not a suitable scenario for the DQN algorithm to solve discrete space problems. Therefore, we use the TD3 algorithm, which can solve the continuous solution space problems. Considering that a simple mapping between only the decision of the algorithm and the actual strategy will fail to achieve convergence because of there being too many feasible strategies and the inability to search for the correct one, we develop an effective TD3O algorithm integrated with the AT algorithm to solve the problem P1.
4.1. MDP Used for Describing Problem P1
Considering that the optimization problem P1 needs to be tackled within a given period, in order to apply TD3O to the problem P1, such a period is divided into T timeslots and denoted as . Furthermore, the problem of joint computing offloading, task caching and resource allocation is described as a MDP, the state space, action space and reward function are defined as follows.
❶ State space: At each timeslot, the state space contains the information used for decisions made by the network. Here, the state at timeslot t can be denoted as . The detailed definitions can be found as follows.
are the standardized data sizes of tasks of MDs at timeslot
, where
is the minimum data size of the tasks of all MDs at timeslot t, and is the maximum data size of the tasks of all MDs at timeslot t.
are the task caching decision factors at BSs at timeslot t, where .
❷ Action space: At each timeslot, the action space refers to the decisions made by the network according to the state . The action at timeslot t can be denoted as . Specifically:
are the association decision factors of MDs at timeslot t, where .
are the caching decision factors at timeslot t for the next timeslot.
are the subchannel allocation decision factors of BSs at timeslot t, where .
are the offloading decision factors of MDs at timeslot t, where .
are the computing resource allocation factors of MDs at timeslot t, where .
It is noteworthy that the dimensions of the above-mentioned state and action spaces have been greatly reduced compared to the actual ones. The actual state and action spaces can be achieved by executing an AT algorithm in the following parts.
❸ Reward: Considering that the goal of problem P1 is to minimize local energy consumption and the constraints
and
cannot be strictly satisfied in the DRL-based iteration procedure, the reward
at timeslot
t is given by
where
is the penalty function added for guaranteeing the constraint
;
is the penalty function introduced for guaranteeing the constraint
;
is the energy-consumption discount factor;
and
are penalty coefficients.
When the network obtains action
according to the state
, the state space will obtain the next state
according to the action
. Specifically, the task-caching decisions of BSs can be directly achieved from
in
. Therefore, the total return of minimizing long-term local energy consumption within
T timeslots can be given by
where
is the reward discount factor satisfying
.
4.2. TD3O Algorithm
The TD3 algorithm is an actor-critic-based framework that comprises the policy (
) network, critic (Q) network and their corresponding target networks and updates the network parameters using gradient algorithms. It is characterized by using two critic networks and two critic target networks in the design of critic networks. The TD3 algorithm is often divided into two parts consisting of experience collection and training. In the phase of collecting experience, a new action
can be generated by adding random Gaussian noise into the output of the policy network at the state
, i.e.,
where
is the parameter of the policy network and
is the additive Gaussian noise.
After that, the environment is rewarded with and the next state can be achieved according to the state and action . To enable the algorithm to obtain better decisions through past experience-assisted training, we put the quadruple into the experience replay buffer as a historical experience. In the training process, a certain number of quadruples are randomly selected from the experience replay buffer for training. Since the TD3 algorithm consists of policy and critic networks, the training part of the network is relatively independent, so it is divided into the following two parts.
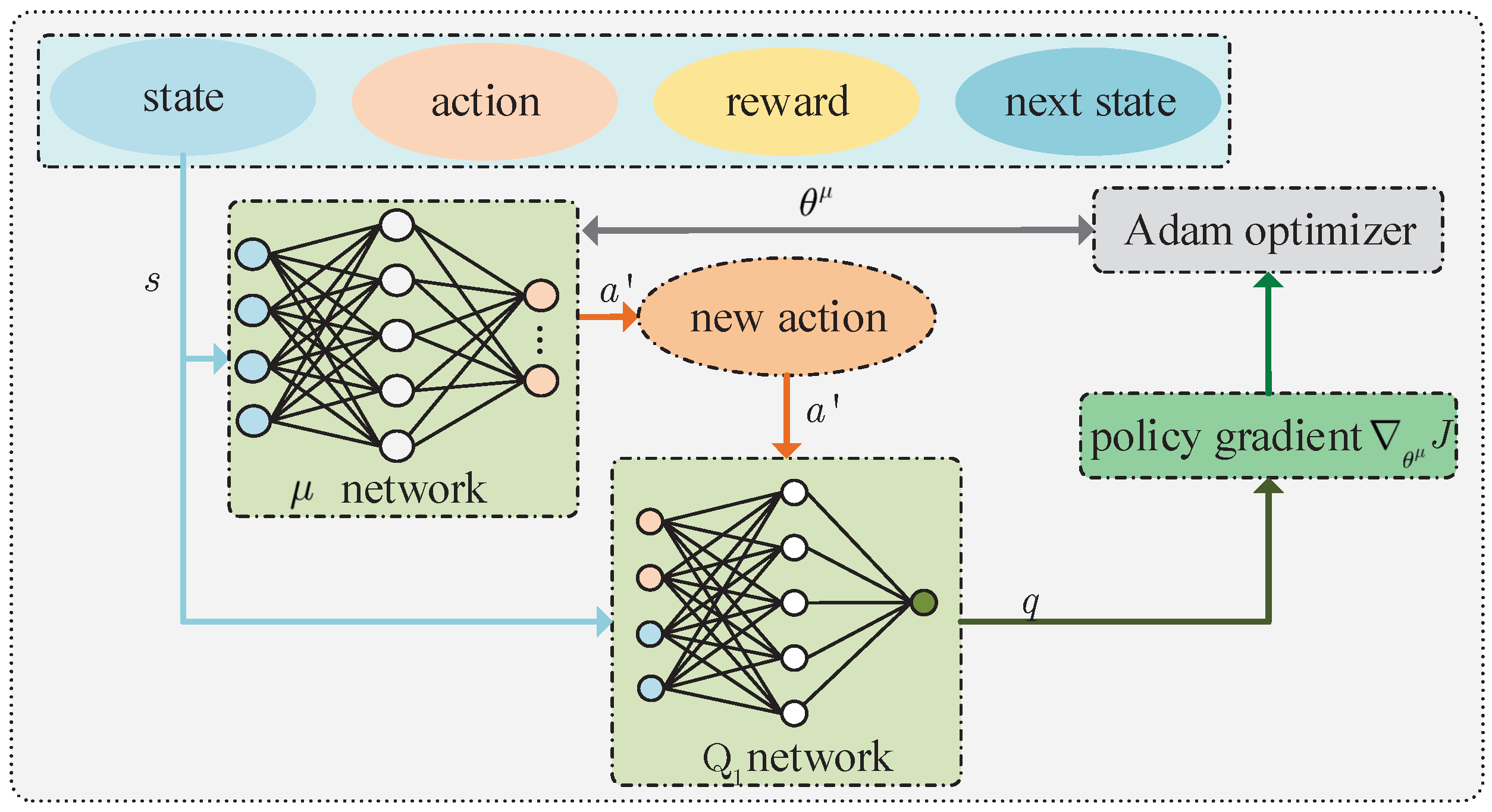
4.2.1. Training Policy Network
The training process of the policy network is shown in
Figure 3. In the training phase,
N quadruples are extracted from the experience replay buffer and denoted as
. For any quadruple
, the policy network outputs a new action
according to the state
. It should be noted that the policy
is different from
existing in the experience replay buffer. After
and
are inputted into any critic network (e.g., critic
network), such network outputs
, where
is the parameter of the critic
network. After achieving all
, their mathematical expectation is given by
where
. Then, the policy gradient of function
J with respect to
can be given by
where
.
Significantly, the calculated gradient requires gradient clipping, which can avoid skipping the optimal solution because the gradient is too large. The calculated policy gradients will be used to update the parameters of the policy networks. We assume that the learning rate of the policy network is
, and use the adaptive moment (Adam) estimation commonly used in DRL to obtain the optimal
[
43].
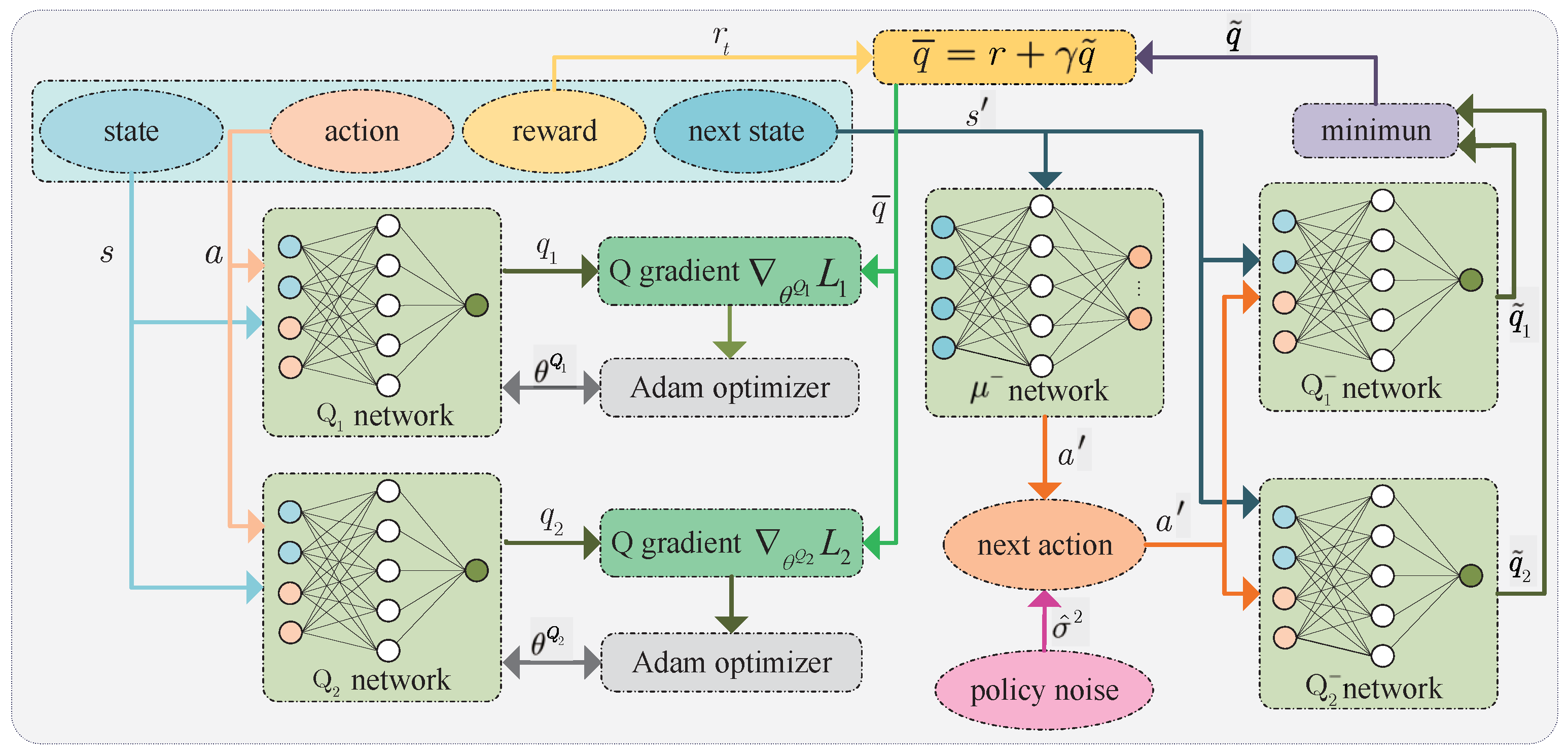
4.2.2. Training Critic Network
Figure 4 shows the training process of the critic network. During the critic network training, the policy at the next time is first estimated through the state at the next time by the policy target(
) network, i.e.,
, where
is policy noise, that is, trimmed additive Gaussian noise. Then, the action
and the state
are used as the input of the critic target (
network and critic target (
) network, where
and
are their parameters. After that, these two networks output
and
, respectively. Next, the approximation of Q value is
achieved using Behrman equation, where
. At the same time, the action
and the state
are used as the input of the critic
network and critic
network, where
and
are their parameters. After that, these two networks output
and
. At last, for all
, according to the theorem of mean squared error (MSE), the expectation function of the squared loss between
and
is
and the expectation function of the squared loss between
and
is given by
where
. Then, the gradient of the loss function
with respect to the parameter
is
and the gradient of the loss function
with respect to the parameter
is given by
Similar to calculating the policy gradient, the gradient clipping needs to be performed after calculating the gradients using (
19) and (
20). In addition,
is the learning rate of the critic network, and the parameters of the two critic networks are updated using the Adam algorithm. Certainly, the parameters of critic target networks also need to be updated using the soft update method, i.e.,
where
is the learning rate of target networks.
It is noteworthy that a lower network updating frequency is adopted in this paper. We assume that the update interval of the critic network is
and the update interval between the policy and critic networks is
. The critic networks are trained many times to ensure the stability of Q value. After that, the policy network can be updated. The detailed procedure of the TD3O algorithm is summarized in Algorithm 1, where
is the maximal number of epochs.
| Algorithm 1: TD3-based offloading (TD3O) |
| 1: Initialization: , , , , , , , . |
| 2: While |
| 3: Let , state and reward . |
| 4: While |
| 5: Generate action using (14). |
| 6: Achieve actual action by executing Algorithm 2. |
| 7: Calculate reward using (12) and obtain the state . |
| 8: If |
| 9: Replace the previous quadruple with . |
| 10: Else |
| 11: Put the quadruple into the queue. |
| 12: EndIf |
| 13: Update state . |
| 14: If and |
| 15: Extract N quadruples for training. |
| 16: For any sample n, and networks output and |
| 17: , respectively, and obtain the minimum value . |
| 18: Calculate and using (17) and (18), respectively. |
| 19: Calculate Q gradient using (19) and (20), and clip it. |
| 20: Find and using Adam optimizer. |
| 21: If |
| 22: Calculate q through . |
| 23: Calculate policy gradient using (16), and clip it. |
| 24: Find using Adam optimizer. |
| 25: EndIf |
| 26: Calculate , and using (21)–(23), respectively. |
| 27: EndIf |
| 28: . |
| 29: ; . |
| 30: EndWhile |
| 31: . |
| 32: EndWhile |
| Algorithm 2: Action transformation (AT) |
| 1: For each MD |
| 2: Achieve MD association matrix using discretization rule. |
| 3: Achieve task caching matrix using discretization rule. |
| 4: Achieve task offloading matrix using discretization rule. |
| 5: EndFor |
| 6: For each BS |
| 7: Returns the set of available subchannels and the set of |
| 8: offloading MDs. |
| 9: If |
| 10: associated MDs are randomly selected, disassociated |
| 11: and execute tasks locally. |
| 12: EndIf |
| 13: Achieve subchannel allocation matrix using discretization rule. |
| 14: EndFor |
| 15: For each MD |
| 16: If |
| 17: If |
| 18: Assign small enough computing capacity to MD m to avoid |
| 19: zero division. |
| 20: Else |
| 21: Allocate computing resources to MD m using (28). |
| 22: EndIf |
| 23: EndIf |
| 24: EndFor |
4.3. AT Algorithm
In order to apply the TD3O algorithm to solve the problem P1, it is necessary to convert the achieved continuous action
into a discrete one [
44]. To this end, we consider the following transformations for
.
4.3.1. The Discretization of Device Association Array
In
,
is the non-integer association index of MD
m, which is the continuous action achieved by the TD3 algorithm. Then, it is converted into an integer form, i.e.,
where
is an upward rounding function with respect to
b. Such a transformation can ensure that each MD can be associated with one BS.
4.3.2. The Discretization of Task-Caching Array
In
,
represents the non-integer caching index of MD
m, which is the continuous action achieved by the TD3 algorithm. Since each MD can store its task at all BSs, there exist
storage options for it. Consequently, in order to convert
into a discrete form, we first need to perform
where
is a downward rounding function with respect to
b. Then, in order to achieve the binary caching index, the decimal
needs to be converted into a binary number of
I 0–1 digits, which is given by
. In it,
is a function used for calculating the binary number of decimal
b. Then,
, where
represents the
i-th digit of the binary number
.
4.3.3. The Discretization of Task Offloading Array
In
,
is the non-integer offloading index of MD
m, which is the continuous action achieved by the TD3 algorithm. Considering that each MD can offload its task to at most one BS,
is converted into an integer form, i.e.,
4.3.4. The Discretization of Subchannel Allocation Array
In
,
is the non-integer index of the subchannels allocated by BS
i to its associated MDs who need to offload tasks, which is the continuous action achieved by the TD3 algorithm. To achieve the integer form of
, we first need to perform
where
is the number of MDs that are associated with BS
i and need to offload tasks;
is the number of available subchannels at BS
i;
is a function with respect to
and
and is used for calculating the number of feasible subchannel allocation policies between
MDs and
subchannels at BS
i;
is a factorial function with respect to
b;
shall be satisfied.
Then, we assume that
is the set of
feasible subchannel allocation policies between
MDs and
subchannels at BS
i. After that, the subchannel allocation policy
in the set
is selected according to the Equation (
27). It is noteworthy that
feasible subchannel allocation policies are generated in advance. That is to say, in the policy
, we can easily know the utilized indices of
subchannels for
MDs. According to these rules, we can easily find the subchannel allocation index
.
4.3.5. The Transformation of Computing Resource Allocation Array
In
,
represents the computing resource score of MD
m at the target BS that is executing its task. If
is satisfied between MD
m and BS
i, according to the proportional allocation of computing resources, the computing resources allocated to MD
m by BS
i can be given by
Based on the above-mentioned operations, the output action of the TD3O algorithm can be effectively converted into an actual decision, which is summarized as Algorithm 2.
4.4. HA
To solve the problem P1 in a non-iterative manner, we design an effective heuristic algorithm, which is summarized in Algorithm 3. In such an algorithm, to reduce the uplink transmission time and energy consumption, some MDs are associated with the nearest BSs, and the BSs randomly cache the tasks of their associated MDs until the cache space cannot cache more tasks. Then, the uncached MDs randomly select a BS as the offloading target, and to guarantee time constraints, the BS will evenly distribute the computing resources according to the computation amount of the task. Finally, a part of the MDs are disassociated from BSs without sufficient subchannels and execute tasks by themselves.
| Algorithm 3: Heuristic algorithm (HA) |
| 1: Initialization: energy consumption . |
| 2: Each MD selects (is associated with) the nearest BS. |
| 3: For each BS |
| 4: If |
| 5: associated MDs are randomly selected, disassociated |
| 6: and execute tasks locally. |
| 7: EndIf |
| 8: Randomly select the tasks of MDs associated with BS i for caching |
| 9: until the caching space is full. |
| 10: EndFor |
| 11: For |
| 12: Randomly select a target BS for each MD without cached task. |
| 13: Randomly allocate subchannels to MDs associated with each BS. |
| 14: If subchannels are insufficient |
| 15: Extra MDs are randomly selected to execute tasks locally. |
| 16: EndIf |
| 17: Proportionally allocate computing resources to MDs associated with |
| 18: each BS according to the CPU cycles required by tasks. |
| 19: Calculate the total local energy consumption . |
| 20: . |
| 21: EndFor |
6. Performance Evaluation
In order to verify the performance of the designed algorithms, we introduce the following algorithms for comparison.
DDPG-based offloading (DDPGO): DDPG is a classical DRL algorithm [
45]. Compared with the TD3 algorithm, the DDPG algorithm reduces the critic network and the critic target network. In addition, both the critic network and policy network are updated at each timeslot in the DDPG algorithm. In this paper, the DDPG algorithm used to solve the problem P1 is named the DDPG-based offloading (DDPGO) algorithm. The difference between the two algorithms is that the state input and action output are the same as the mode used by TD3O, and it also uses the AT algorithm to convert continuous actions.
Completely offloading (CO): In the CO algorithm, the task of each MD is offloaded to the nearest BS for computing. Such BS proportionally allocates the computing capacity to its associated MDs according to the CPU cycles required by the tasks of these MDs.
Completely local executing (CLE): In the CLE algorithm, the tasks of all MDs can be executed by themselves.
In this paper, we consider that each BS is deployed in a non-overlapping area with a radius of 400 m and a power spectral density of −174 dBm/Hz. In addition, , , , , , ∼, , , , , , , , , and . In the DRL algorithm, we consider that both the policy network and the critic network are composed of three-layer fully connected neural networks, where the numbers of neurons in three-layer neural networks in the policy network are 300, 200 and 128, respectively, and the corresponding target network has the same structure with this policy network; the number of neurons in three-layer neural networks in the critic network are 300, 128 and 32, respectively, and the corresponding target network has the same structure as this critic network. Significantly, the first-layer fully connected neural network of the policy network and the critic network utilizes the rectified linear unit 6 (RELU6), which suppresses the maximum value as the activation function, while other layers use RELU as the activation function.
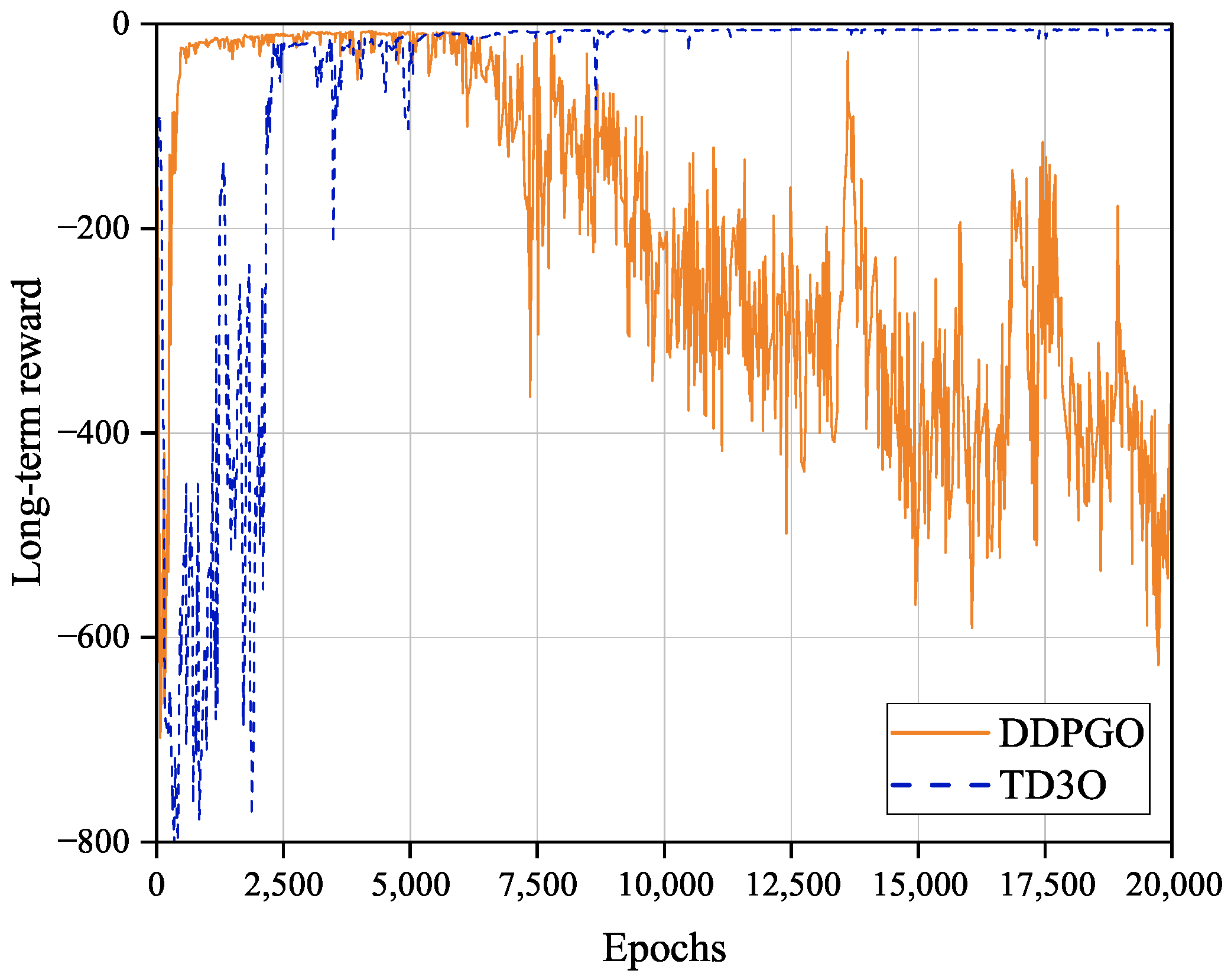
Figure 5 shows the convergence of the TD3O and DDPGO algorithms. As shown in
Figure 5, DDPGO may have a higher convergence rate than TD3O, but the former may have worse convergence stability than the latter. The reason for this may be that the critic network and the policy network are updated synchronously in DDPGO. In DDPGO, the network parameters are updated in each training phase, which speeds up the convergence. Synchronously, the policy network parameters are updated in the training, which results in the instability of the long-term reward value and training bias. As we know, TD3O is composed of two sets of critic networks. Consequently, it could be trained in a relatively stable Q value so that the algorithm can converge stably. In the simulation, it is also easy to find that TD3O could achieve a more stable and better solution to the problem P1 than DDPGO in general.
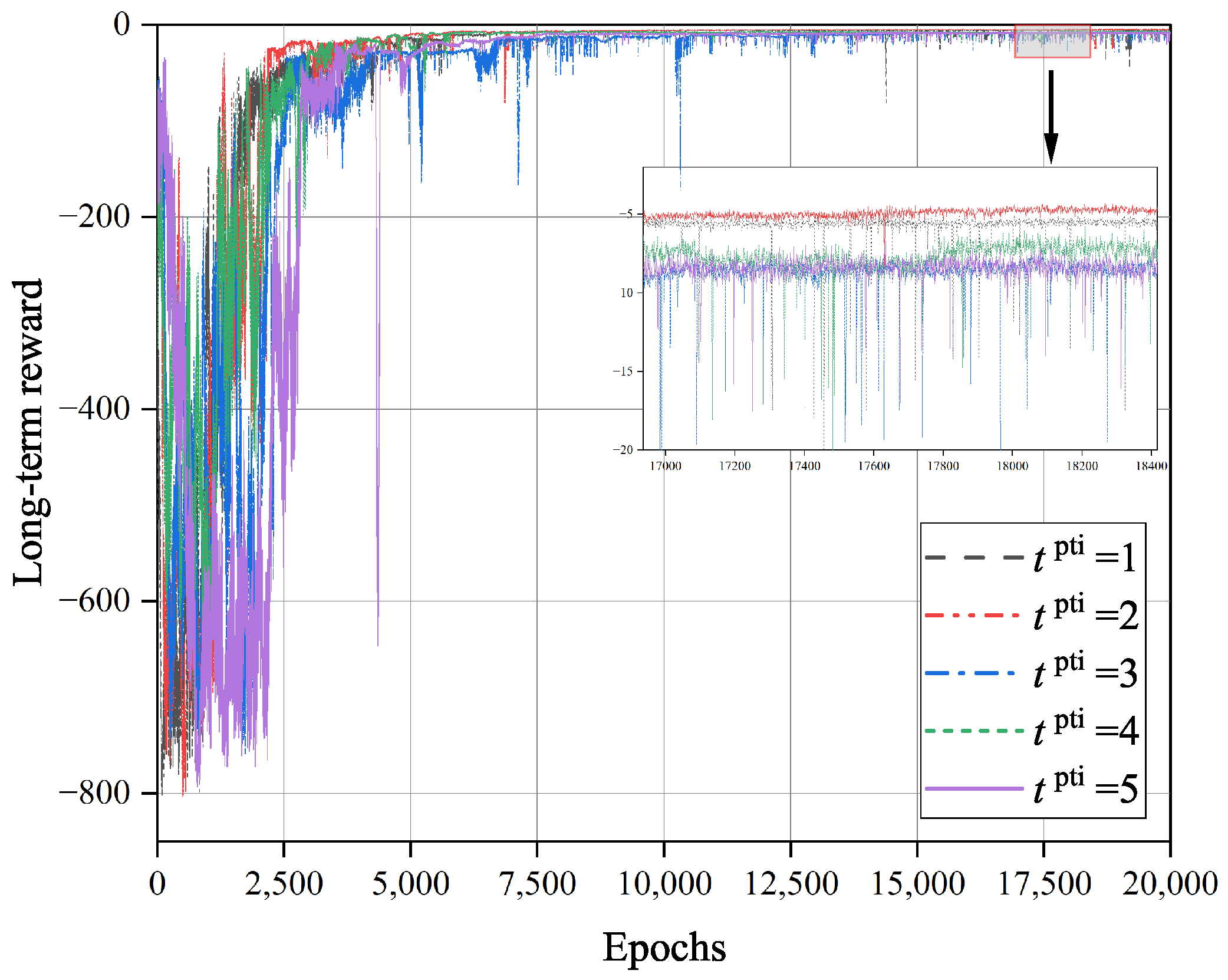
Figure 6 shows the impact of the training interval
on the convergence of the TD3O algorithm. As we know, under the same number of iterations, a larger
can effectively reduce the overall training time of the network. However, it will reduce the total learning times of the policy network and its target network. As illustrated in
Figure 6, the convergence rate of TD3O may decrease with
in general.
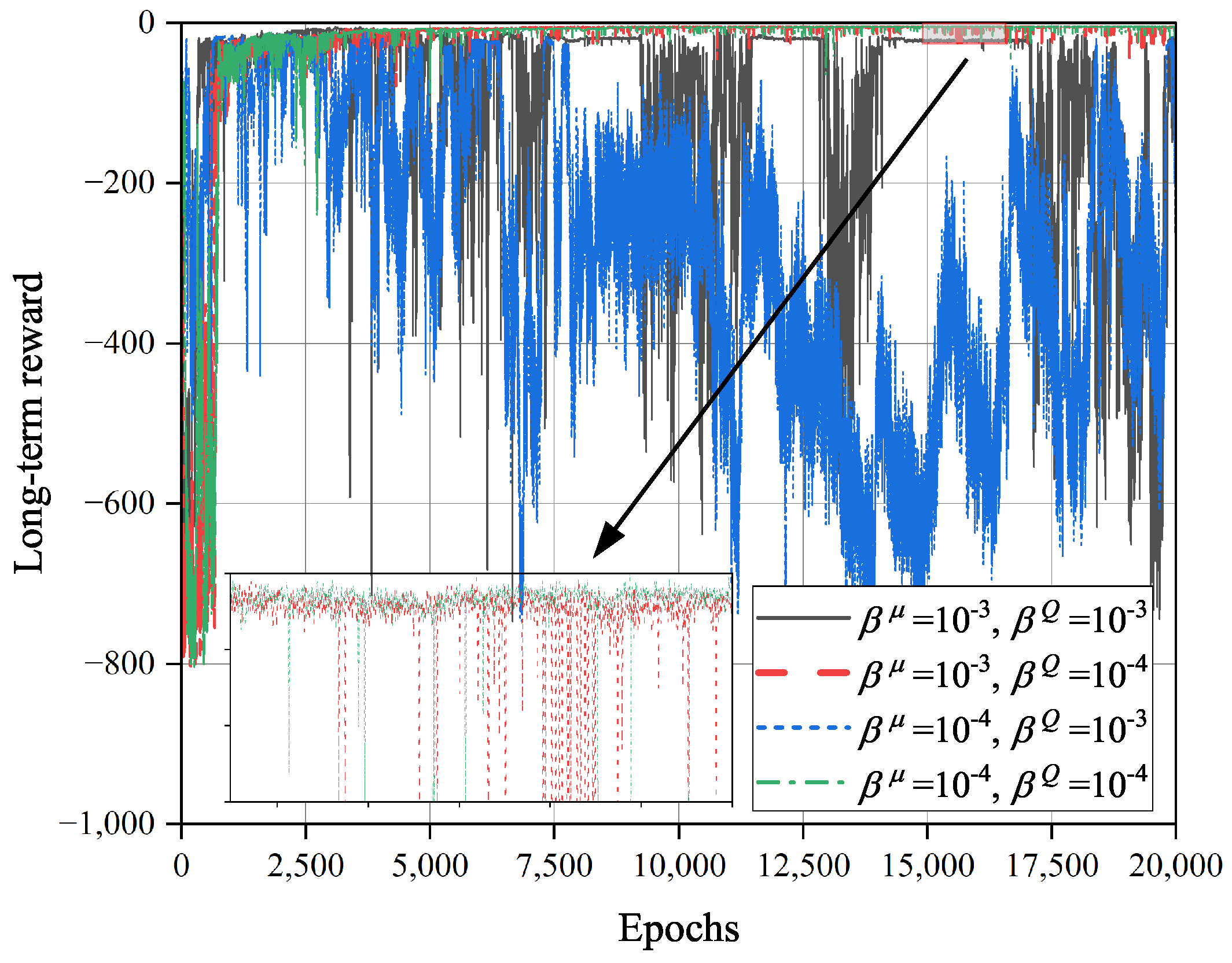
Figure 7 shows the impacts of learning rates
and
on the convergence of the TD3O algorithm. As we know, when the learning rate
of the critic network increases, the parameters of such network will be updated at a larger scale, which speeds up the convergence of TD3O. However, it may lead to the failure of stable evaluation of environmental information, which weakens the convergence stability of TD3O. As illustrated in
Figure 7, when
, the convergence rate of TD3O is relatively high, but the achieved long-term reward dramatically fluctuates at this moment. On the other hand, the learning rate
of the policy network can affect the optimization capability of TD3O. Specifically, a lower
means a smaller amplitude of updating the policy network, which is better for finding better solutions. As seen from
Figure 7, TD3O can achieve a better long-term reward when
and
.
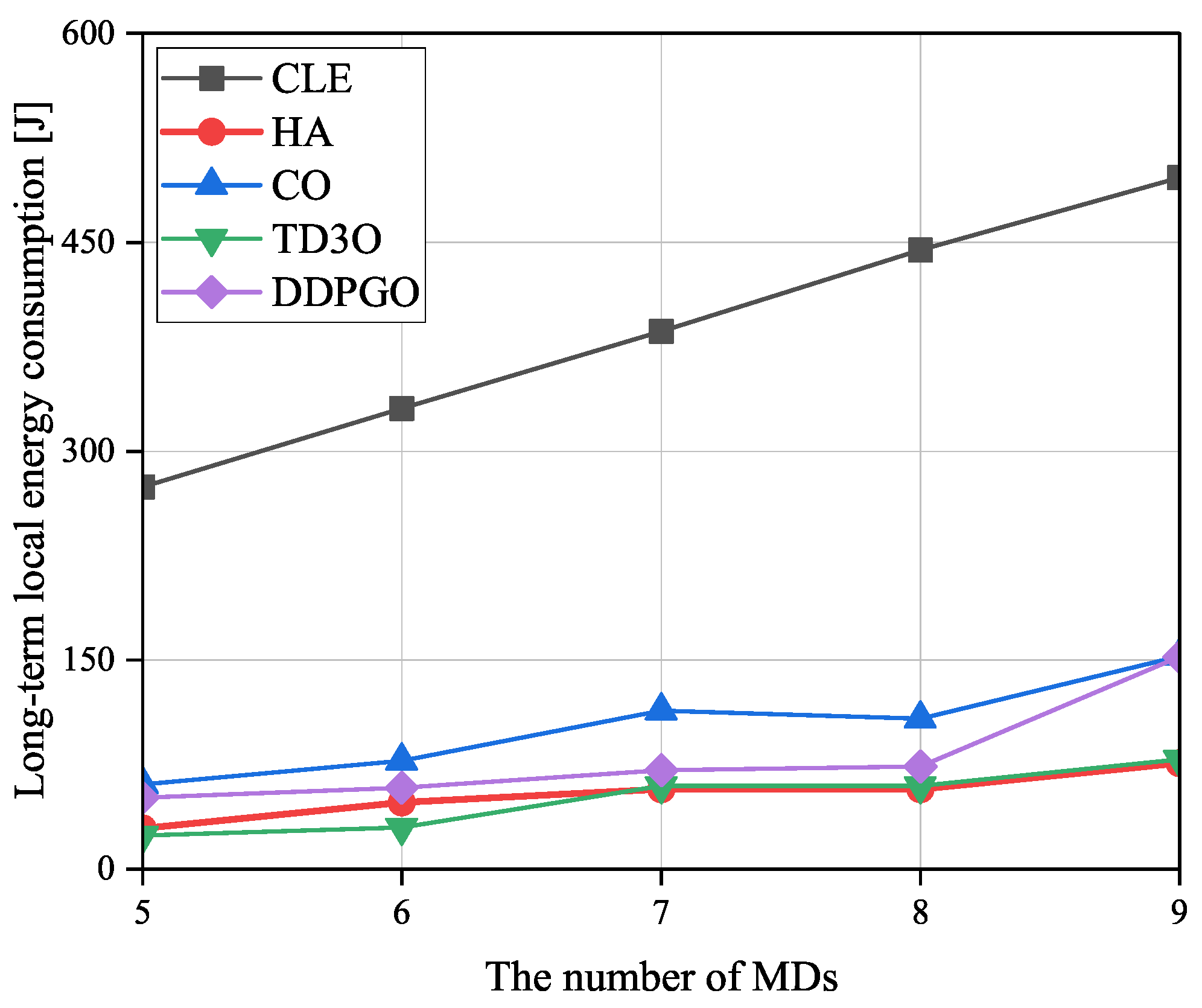
Figure 8 shows the impact of the number of MDs on the long-term local energy consumption
, where
is the sum of the total local energy consumption in
T timeslots. In general, the
increases with the number of MDs since a greater energy consumption is used when tackling more tasks of more MDs. Since CLE executes tasks in maximal computation capacity, it could achieve the highest
among all algorithms. In CO, MDs are associated with the nearest BSs, which may result in a relatively imbalanced load distribution. Then, some overloaded BSs cannot provide good services for their associated MDs because of limited resources, which may result in high
. Consequently, CO could achieve higher
than other algorithms excluding CLE. As illustrated in
Figure 8, TD3O could achieve lower
than DDPGO since the former can effectively mitigate the overestimation existing in the latter. Although HA lets MDs be associated with the nearest BSs, some MDs associated with overloaded BSs will disassociate and execute tasks locally. Such an operation may result in relatively low
.
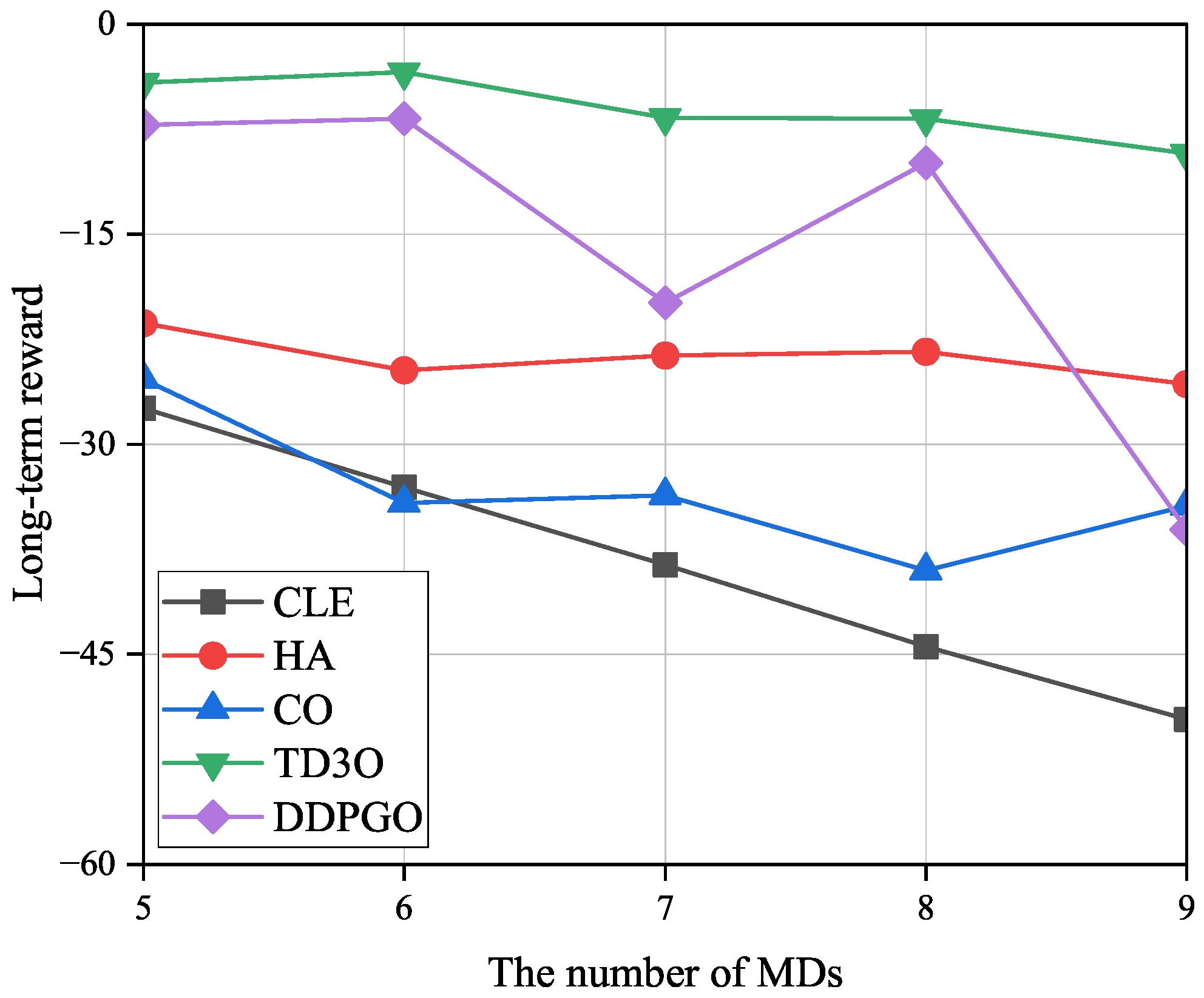
Figure 9 shows the impacts of the number of MDs on the long-term reward (
R). As illustrated in
Figure 9,
R may decrease with the number of MDs since more MDs result in a higher energy consumption. Since both TD3O and DDPGO try to maximize the reward but in other algorithms this is not the case, the former could achieve higher
R than other algorithms in general. Since TD3O could achieve lower
than DDPGO, the former could achieve a higher
R than the latter. In view of the unstable convergence of DDPGO, its reward may dramatically fluctuate. Since CLE could achieve the highest
among all algorithms, it could achieve the lowest
R in general. In addition, CO could achieve a lower
R than HA since the former consumes more energy than the latter.
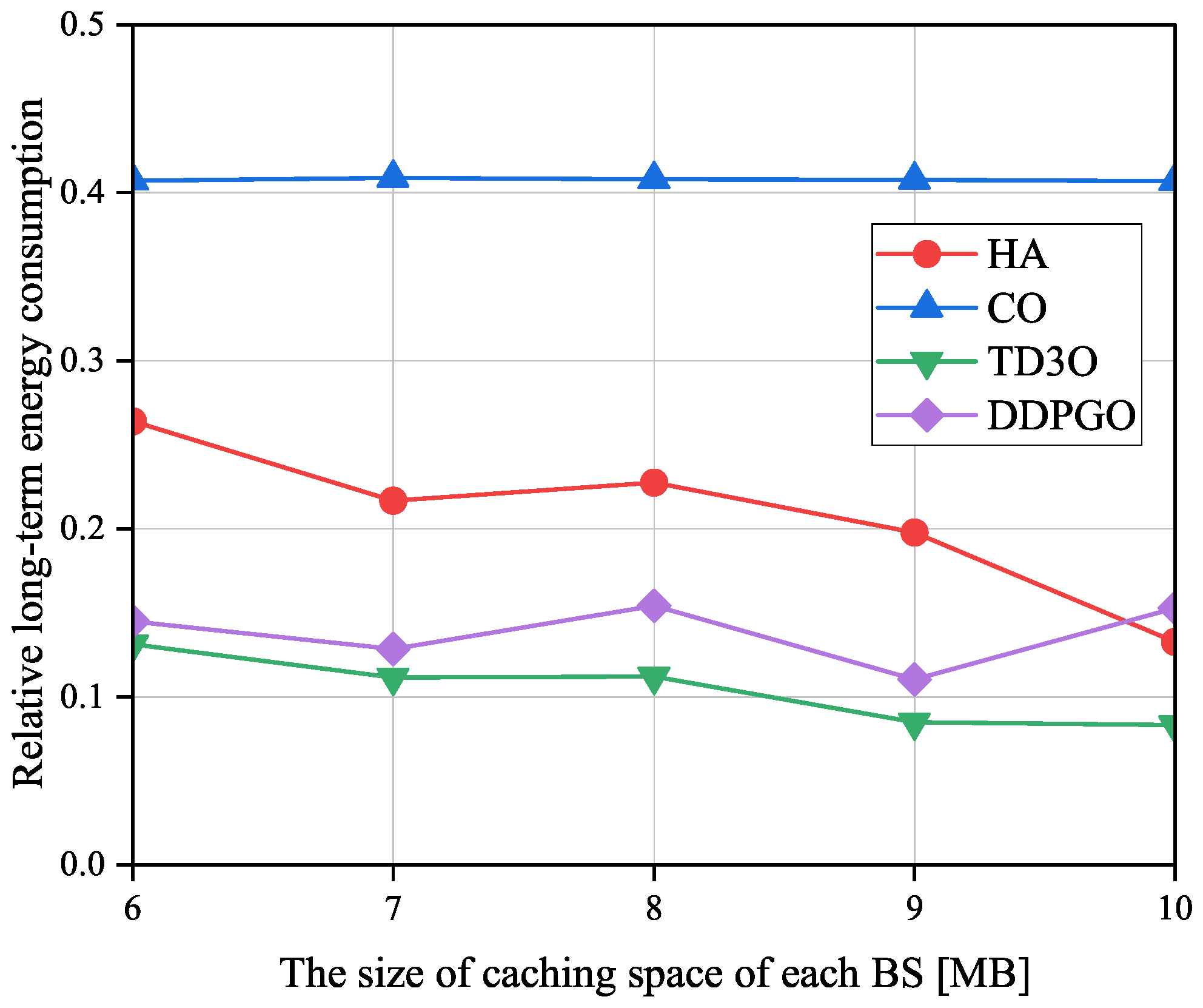
Figure 10 shows the impacts of the size of caching space of each BS on the relative long-term energy consumption
denoted as the ratio of
achieved by an offloading algorithm to the one attained by CLE. Evidently, a smaller
means a higher energy gain caused by offloading tasks. As illustrated in
Figure 10, in addition to DDPGO and CO,
in other algorithms decreases with the size of the caching space of each BS in general. The reason for this may be that a larger caching space can hold more tasks to reduce the transmission energy consumption. However, as revealed in
Figure 5 and
Figure 9, the unstable convergence of DDPGO may result in a dramatically fluctuating performance. Therefore,
in DDPGO may evidently be fluctuating. In addition,
in CO may not change with the size of caching space of each BS since it does not utilize caching space. By minimizing the
, TD3O and DDPGO could achieve a lower
than other algorithms in general. In addition, TD3O could achieve a lower
than DDPGO since the former mitigates the overestimation existing in DDPGO. As seen from
Figure 10, CO could achieve the highest
among all algorithms since it has no sufficient resources to provide for MDs associated with overloaded BSs.
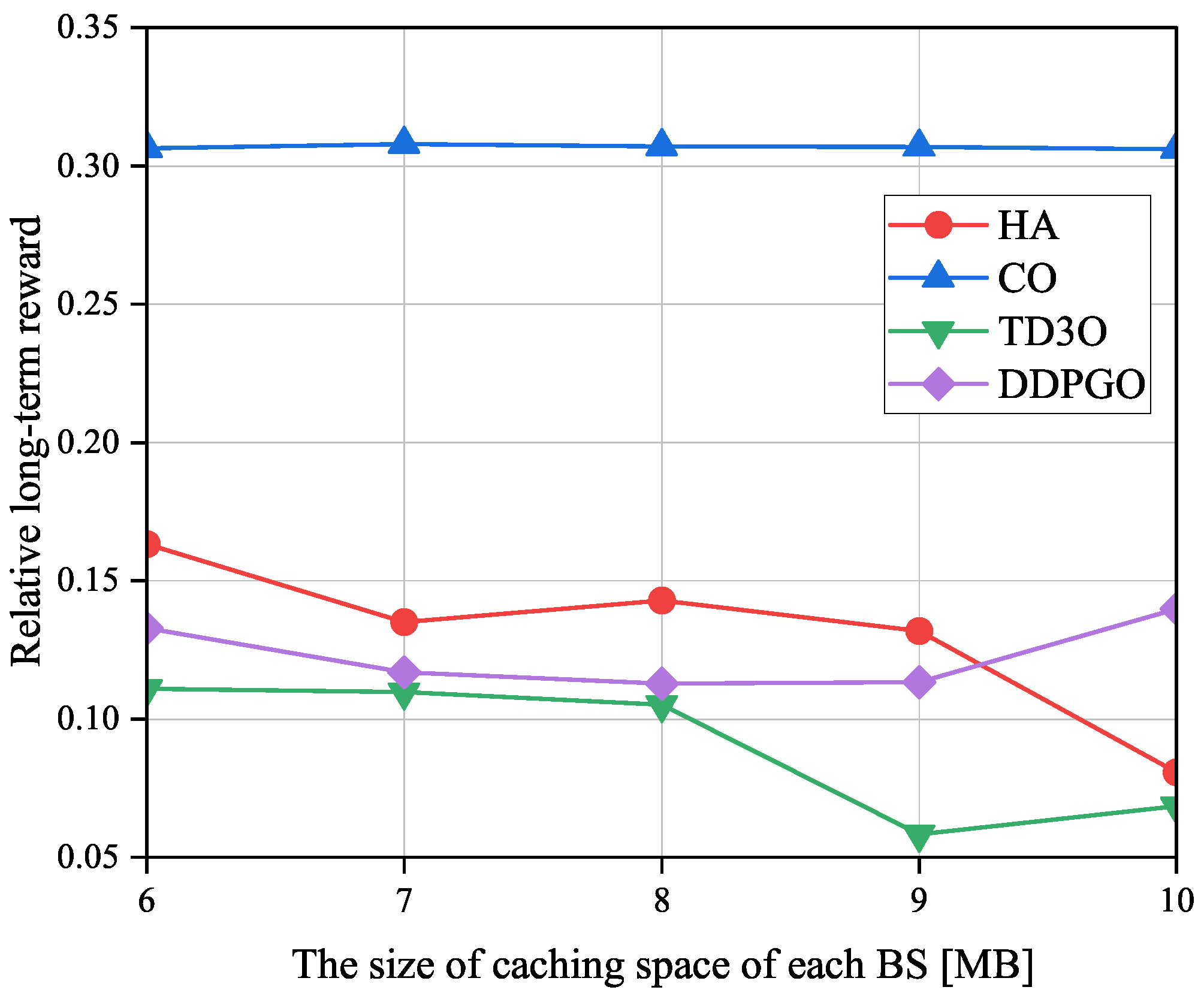
Figure 11 shows the impacts of the size of the caching space of each BS on the relative long-term reward
denoted as the ratio of the long-term reward achieved by an offloading algorithm to the one attained by CLE. Evidently, a smaller
means a higher reward gain caused by offloading tasks. As illustrated in
Figure 11,
in TD3O and HA decreases with the size of the caching space of each BS in general. The reason for this may be that a larger caching space can hold more tasks to reduce the transmission energy consumption, and then bring a higher reward. However, due to the unstable convergence of DDPGO,
in DDPGO may be fluctuating. Moreover,
in CO may not change with the size of caching space of each BS since it does not utilize caching space. By minimizing the
and thus increasing the reward, TD3O and DDPGO could achieve a lower
than other algorithms in general. In addition, TD3O could achieve a lower
than DDPGO since the former mitigates the overestimation existing in DDPGO. As can be seen from
Figure 11, CO could achieve the highest
because of the high energy consumed by MDs associated with overloaded BSs.
As seen from the above-mentioned simulation figures, although HA is a non-iterative algorithm, it could sometimes achieve better performance than DDPGO. In addition, it may always achieve fairly better performance than CO and CLE.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}