6.2. System Loss Test
In order to compare the loss of the system caused by the increase in the system overhead after the addition of the protection measures, we tested the average upload speed of files uploaded through the SDK of the client (V) and the average upload speed of files uploaded directly through the HDFS API (V0).
We prepared a group of samples of typical files of different sizes, that is, randomly generated files of 1 MB, 5 MB, 10 MB, 20 MB, 40 MB, 50 MB, 70 MB, and 100 MB; the total size of each group of file samples is no less than 1 GB. We tested the data upload efficiency with protection measures (including ciphertext computing) and called the client SDK to upload the sample groups of different sizes. Each test uploads all files in the same group, and we recorded the total file size and time of the upload; furthermore, we calculated the upload velocity of the sample group.
For comparison, we directly called the API of the HDFS to upload the above test samples of different sizes (without protection measures). Similarly, we recorded the total file size and time and then calculated the average upload velocity of the sample groups. Finally, we compared the average upload velocity of calling the client SDK upload and HDFS API direct uploading.
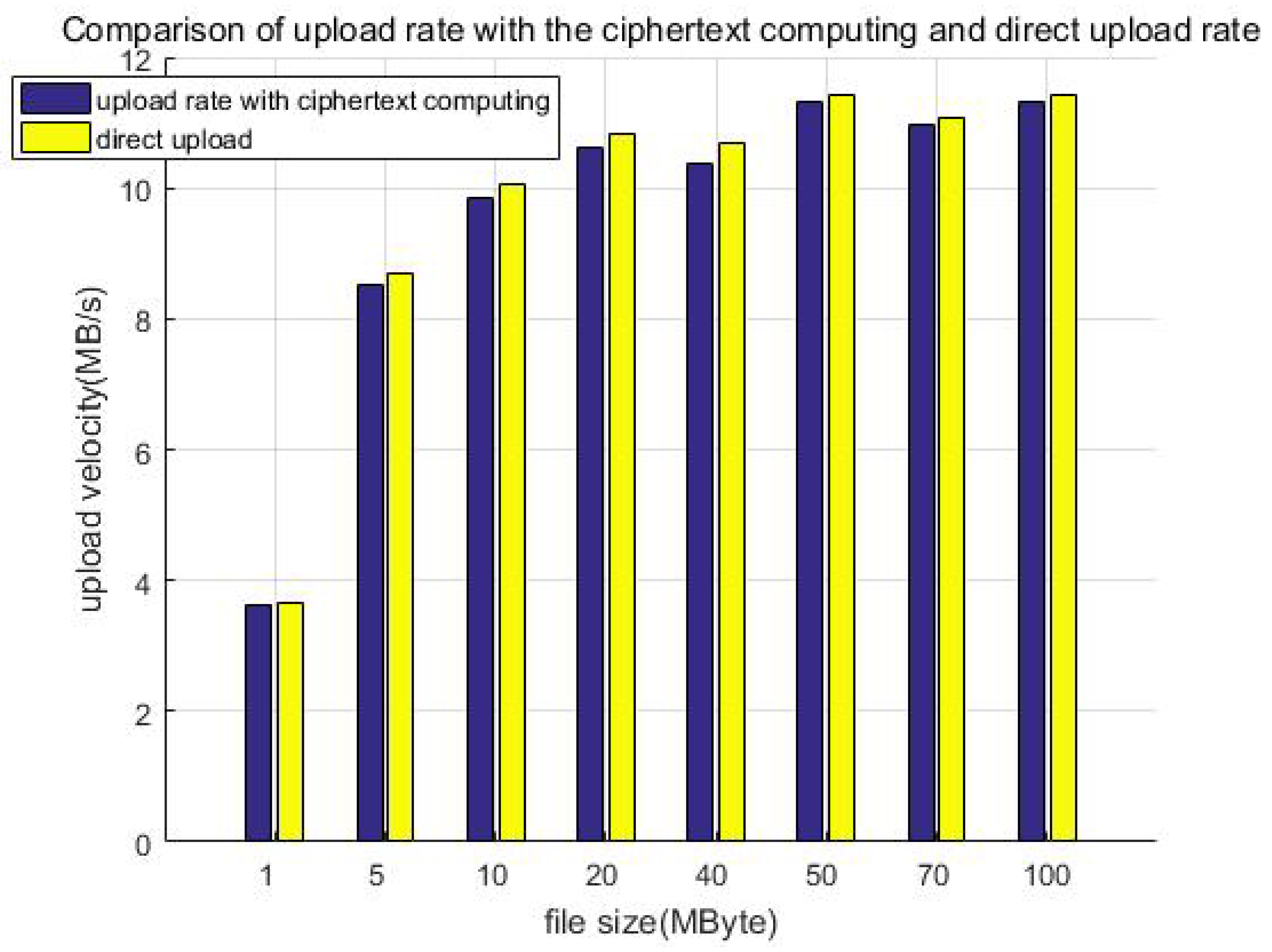
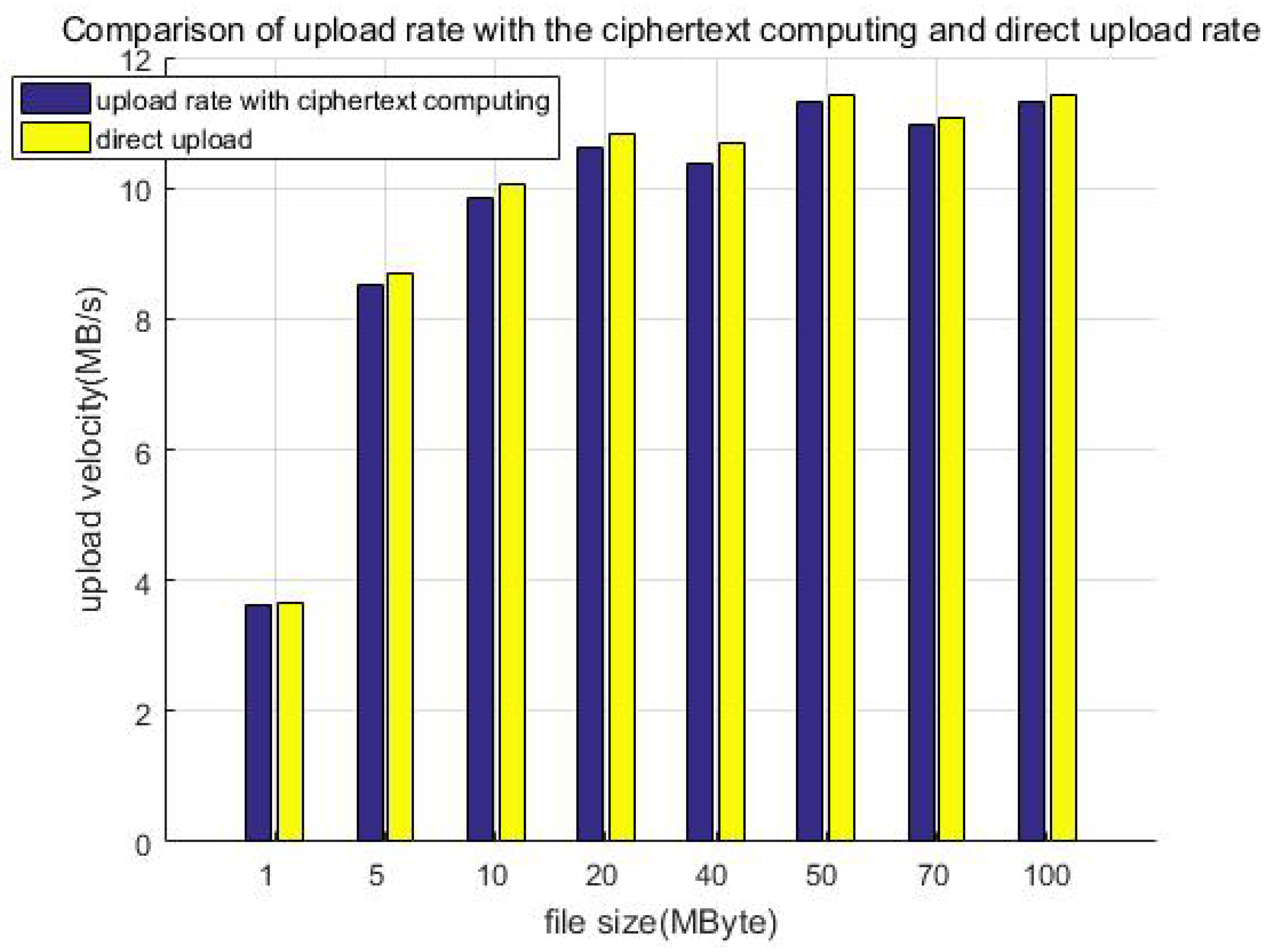
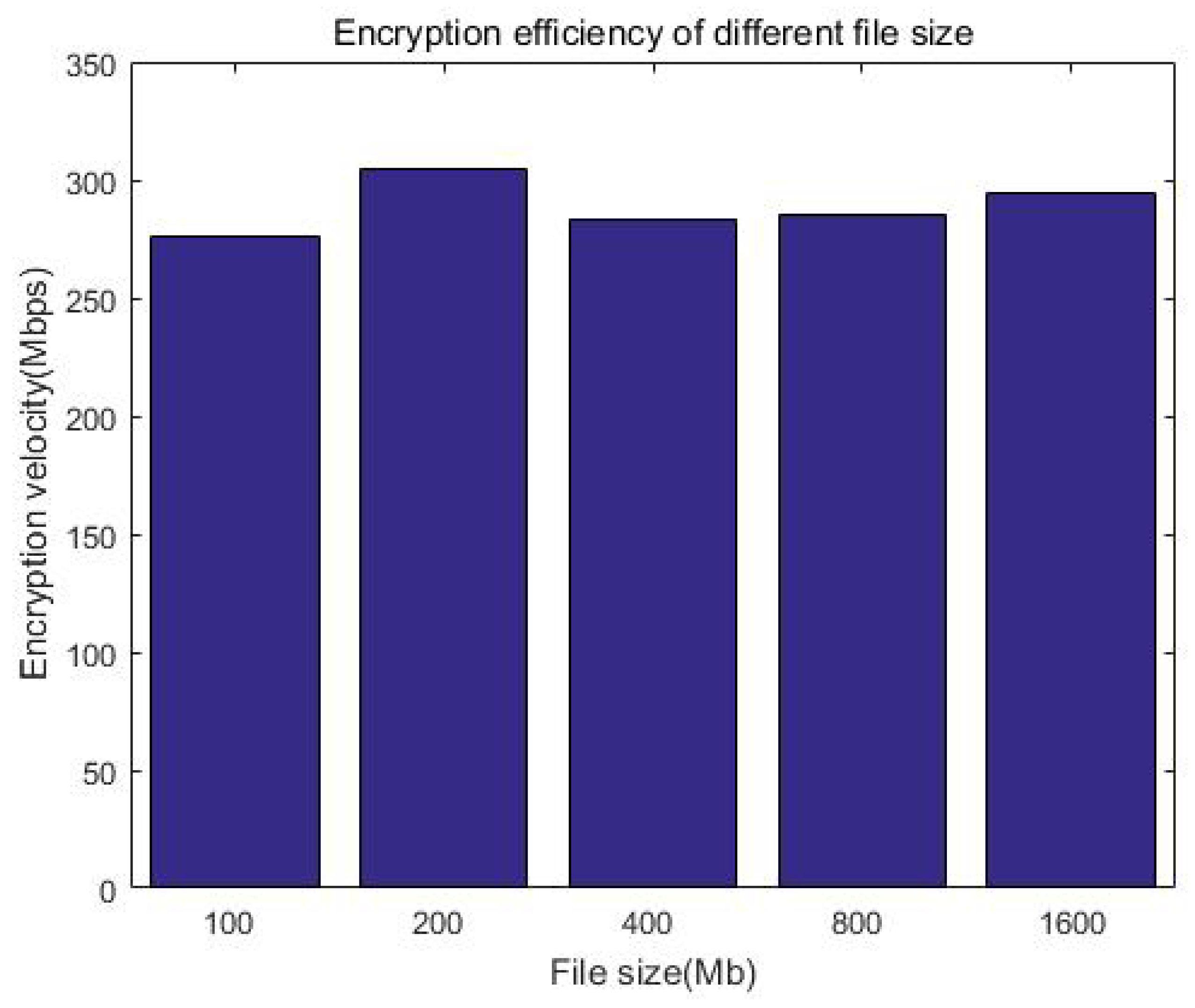
Figure 13 shows the comparison of the upload rate with the ciphertext computing and direct uploading. When the file size is less than 50 MB, the upload velocity gradually increases as the file size increases. When the file size exceeds 50 MB, the upload velocity is stable at about 11 MB/s as the file size increases, which is related to the network bandwidth of our equipment. This can be improved by adopting advanced equipment, for example, gigabit optical fibers. Furthermore, we can see that the direct upload is slightly faster than uploading with protection measures (ciphertext computing). This is because the client encryption procedure generates additional calculation overhead, which slows down the upload velocity. We call this part the system loss after adding the protection measures and define the loss as in Equation (
1), calculating the system efficiency:
Table 4 shows the upload velocity of the method with protection measures, direct uploading, and upload speed ratio. We constructed file data with different sizes but similar total data amount (1 GB) as test samples to test the upload velocity, for example building 1000 files of 1 MB in size, 200 files of 5 MB in size, or 100 files of 10 MB in size. Although the file size is different, it is multiplied by the corresponding number to make the total data amount of each test sample the same (about 1 GB in each column). It can be seen that the ratio of the upload speed is greater than 70%; that is, the system efficiency loss is less than 30%.
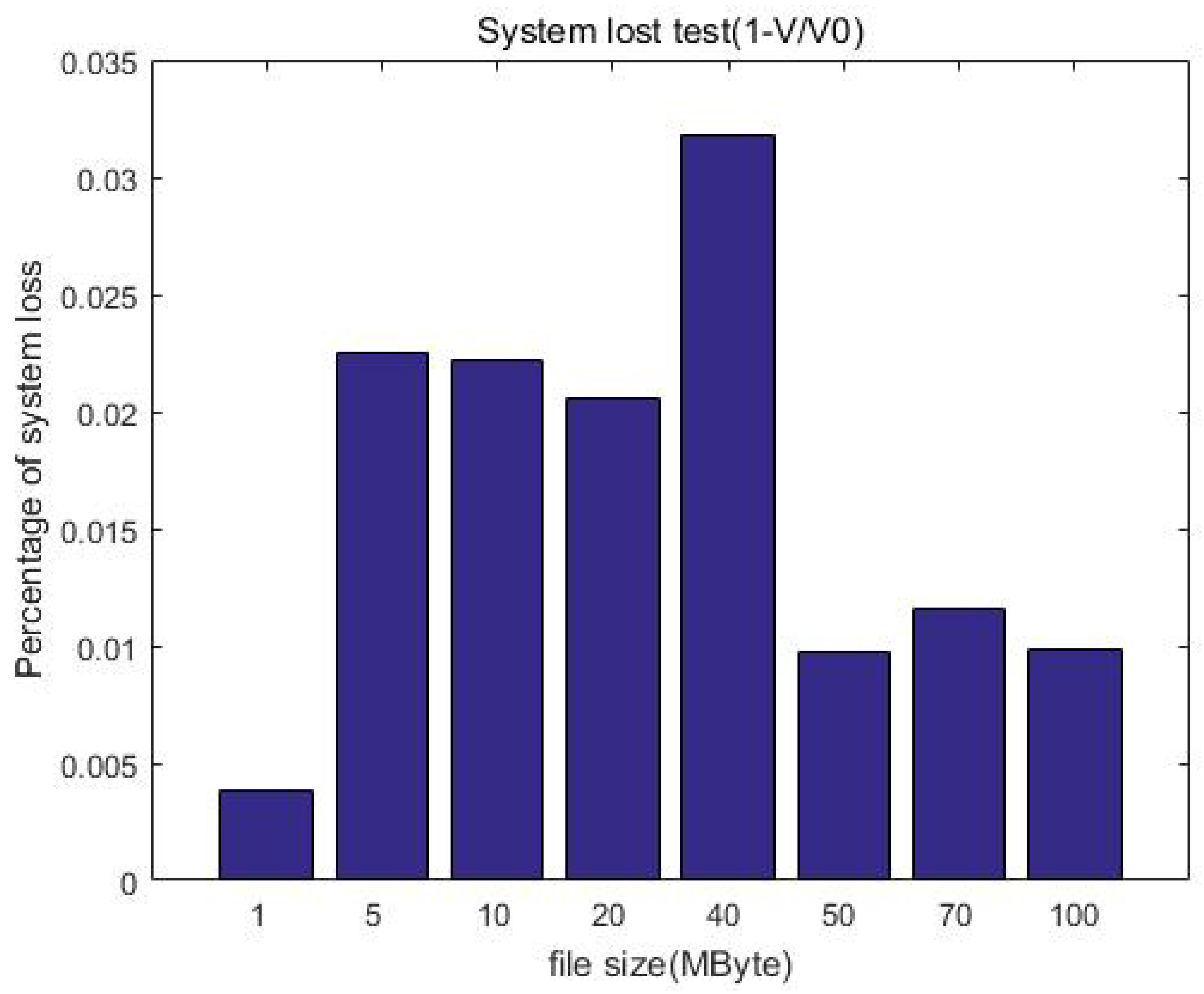
Figure 14 shows the changes in system loss with the increase in file size. Compared with the unprotected case, the increase in computational overhead for increasing the protection measures is constant (o(1)); this means the system loss is acceptable and will not affect the user experience when uploading.
6.3. Storage Redundancy Test
In order to compare the redundancy increase in ciphertext storage with ordinary storage, we uploaded files through the client software development kit (SDK) to obtain the total size of the ciphertext (S1) and compared the total size of corresponding uploaded plaintext in the pure HDFS (S0, ignoring the size of the HDFS metadata). Therefore, we can define the redundancy as Equation (
2), this denotes the size increase ratio of the uploaded data after the protection measures.
Table 5 shows the storage size of the ciphertext, plaintext, and their comparison, while
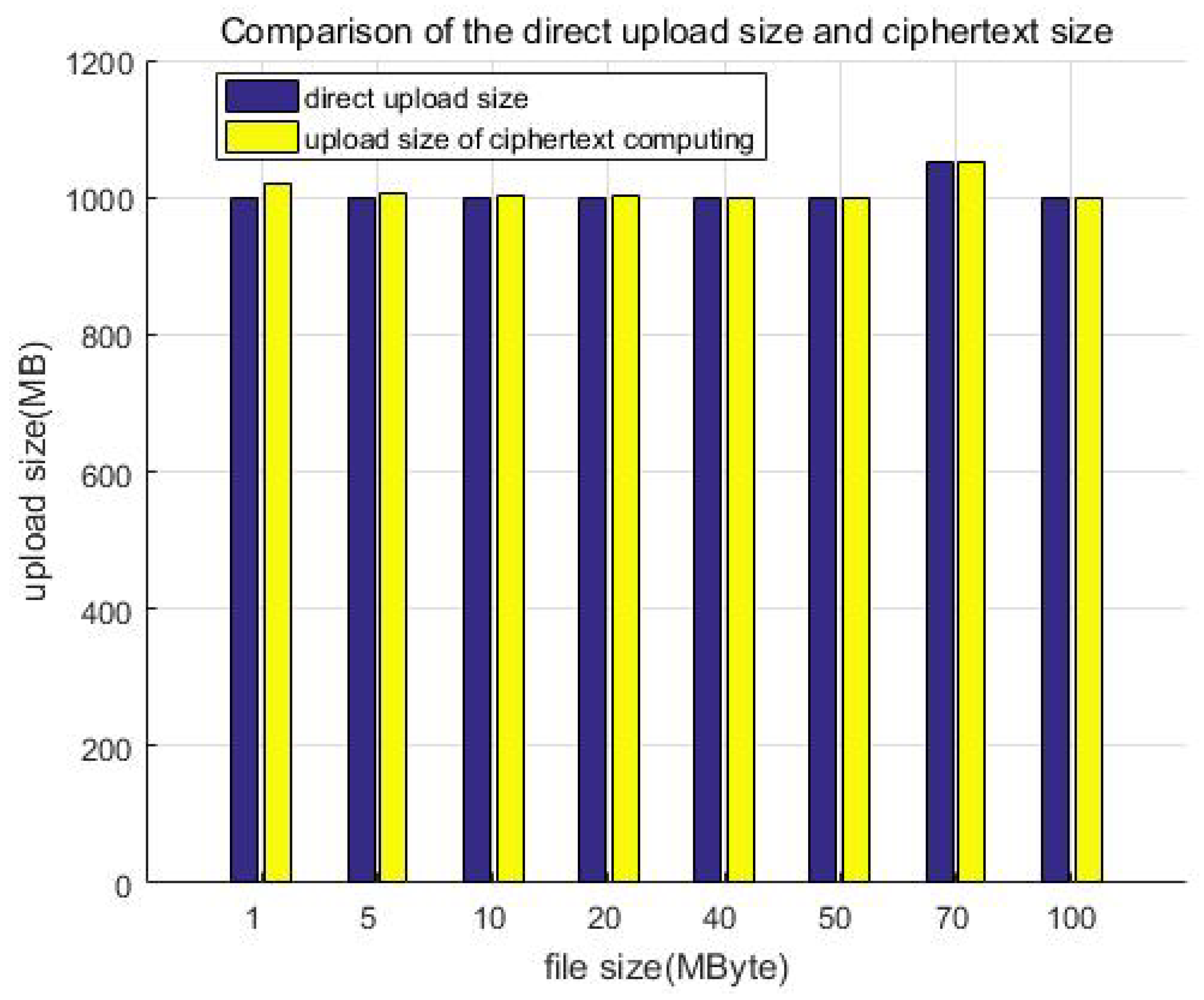
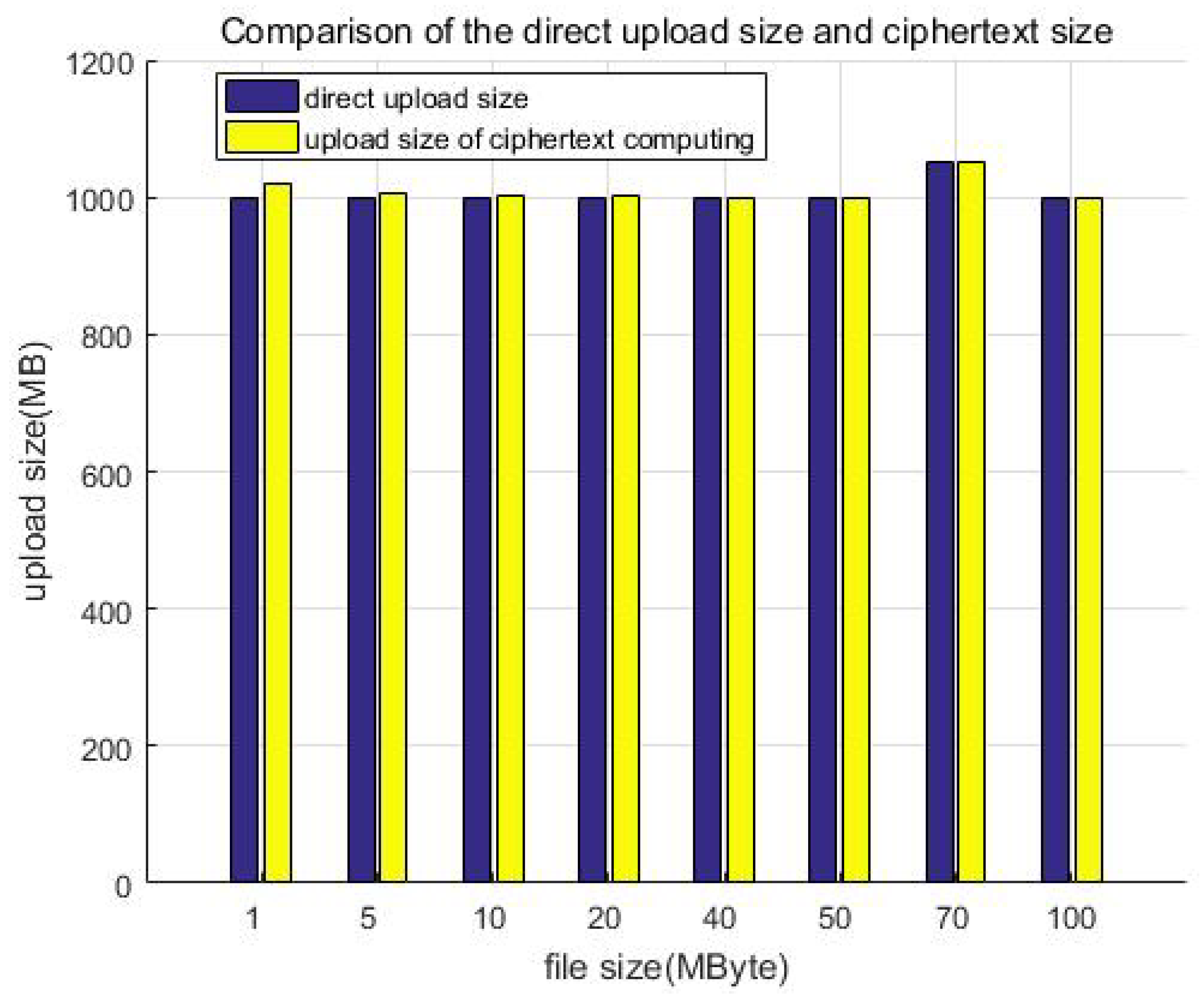
Figure 15 shows the comparison of the direct upload size and ciphertext size. Similarly, we constructed file data of different size but a similar total amount (about 1 GB) as test samples to test and compare the storage size. For example, building 1000 files of 1 MB in size, 200 files of 5 MB in size, or 100 files of 10 MB in size. Although the file size is different, it is multiplied by the corresponding number to make the total data amount of each test sample the same (about 1 GB in each column). It can be seen that the size increase ratio of the uploaded data is less than 10% after encryption; that is, the storage redundancy efficiency loss is less than 10%.
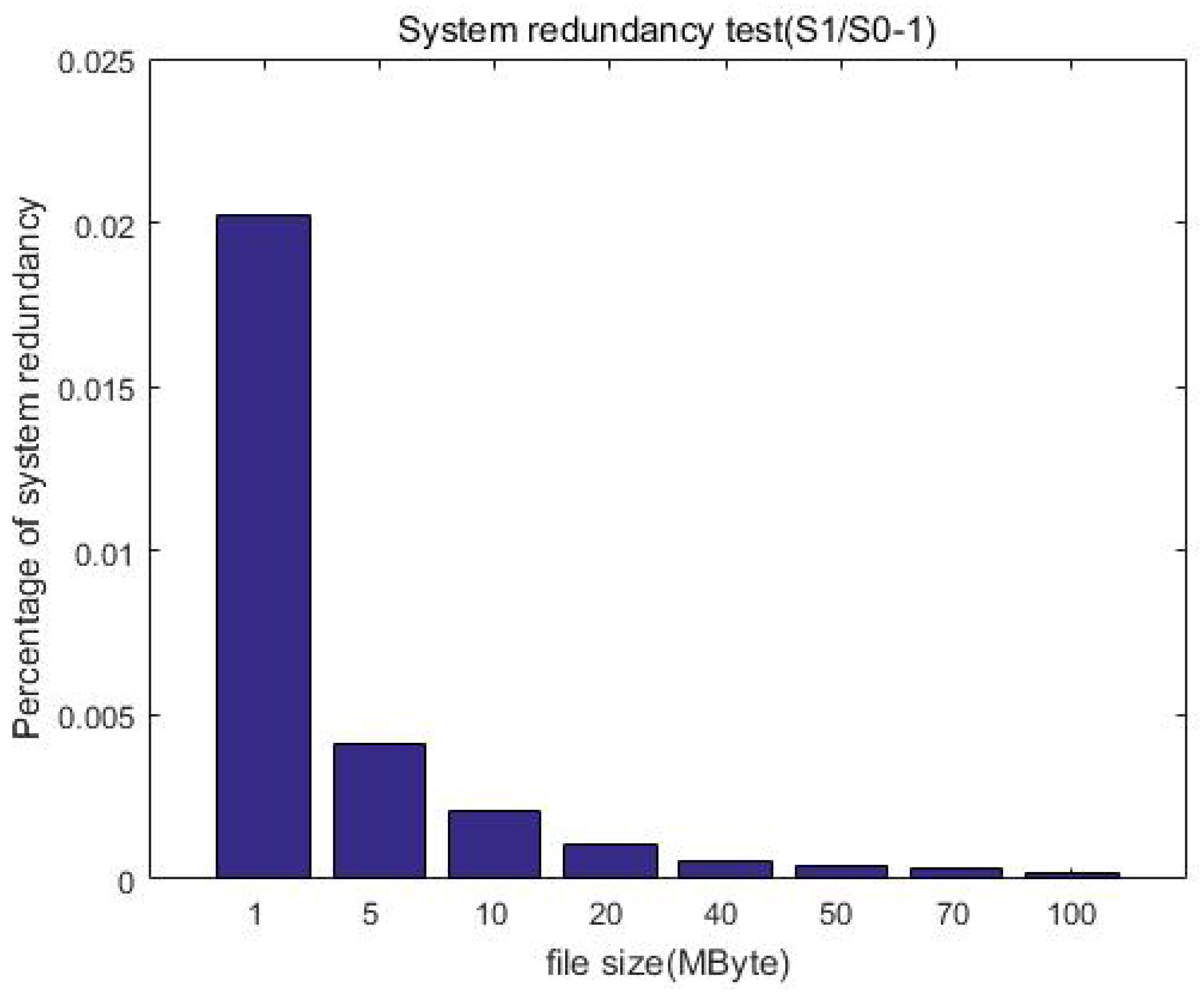
Figure 16 further shows that the redundancy gradually decreases with the increase in file size. This is expected because the file size before encryption is equivalent to that after encryption, and thus the redundancy is mainly the increase generated by the ciphertext index, that is, the metadata of the ciphertext. When the uploaded file is small, it may be equivalent to corresponding ciphertext metadata, and thus the redundancy is high. When the file size gradually increases, the generated ciphertext index size is unchanged, and thus the redundancy is reduced. Overall, the redundancy is constant (o(1)) after encryption when compared with the unprotected case, which is acceptable in the distributed file system.
6.5. Security Analysis
Mechanisms such as data encryption, message time stamping, sequence numbers, and signatures can effectively prevent typical protocol attacks, such as man-in-the-middle attacks (“MITM attacks”), replay attacks, tampering attacks, and type attacks. We analyze and demonstrate the security of the protocol against these attacks in the following.
6.5.1. Anti-MITM Attacks
Man-in-the-middle attacks (MITM attacks) mean that the attackers use various means to find and tamper with normal network communication data between participants. The participants generally cannot detect such attacks in these process.
There are many types of man-in-the-middle attacks, and there is still room for expansion, such as SMB session hijacking and DNS spoofing. MITM attacks include information theft, tampering and replay attacks, etc. This section mainly considers the prevention of information theft, while the other types can be found in subsequent subsections.
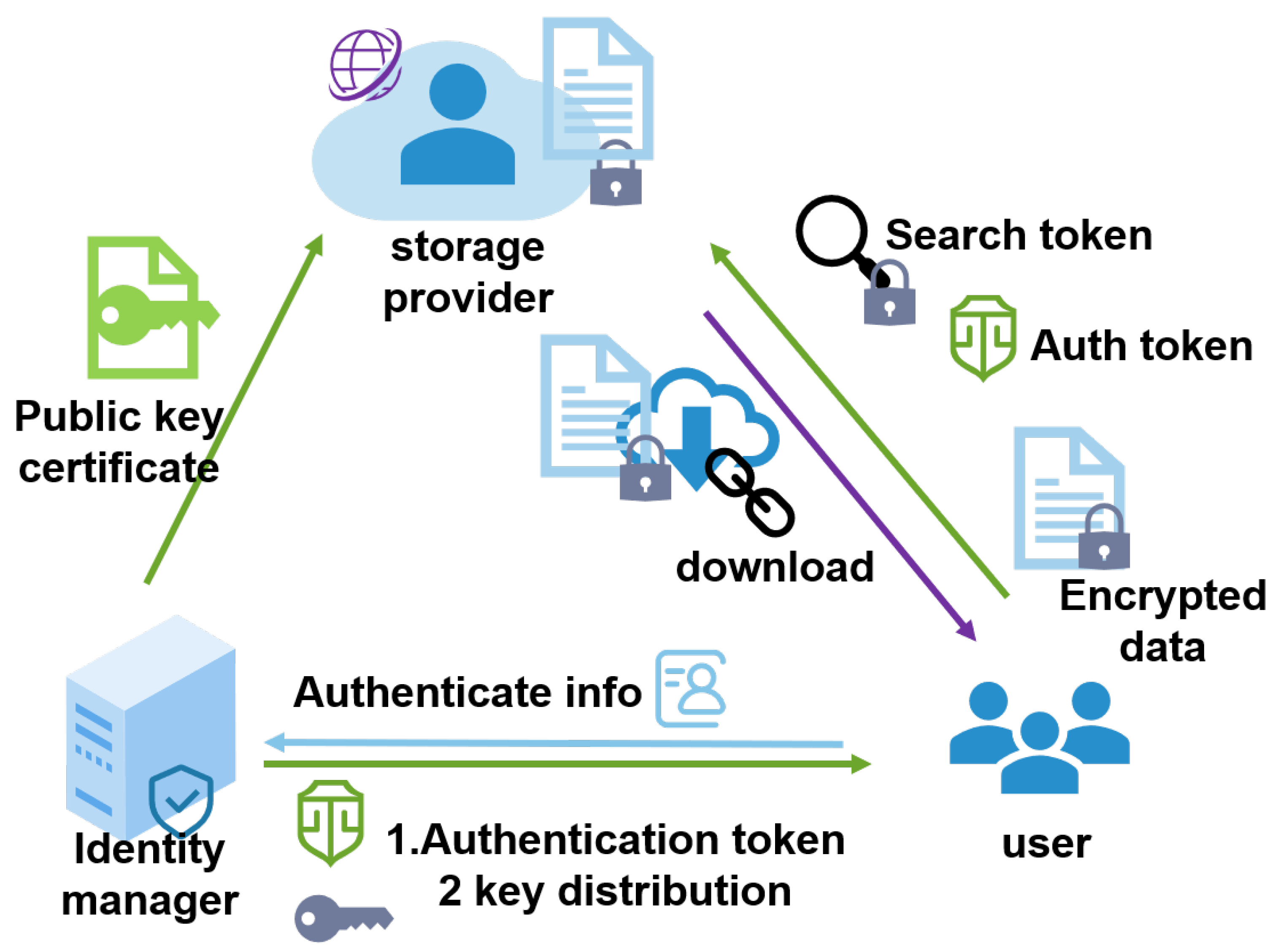
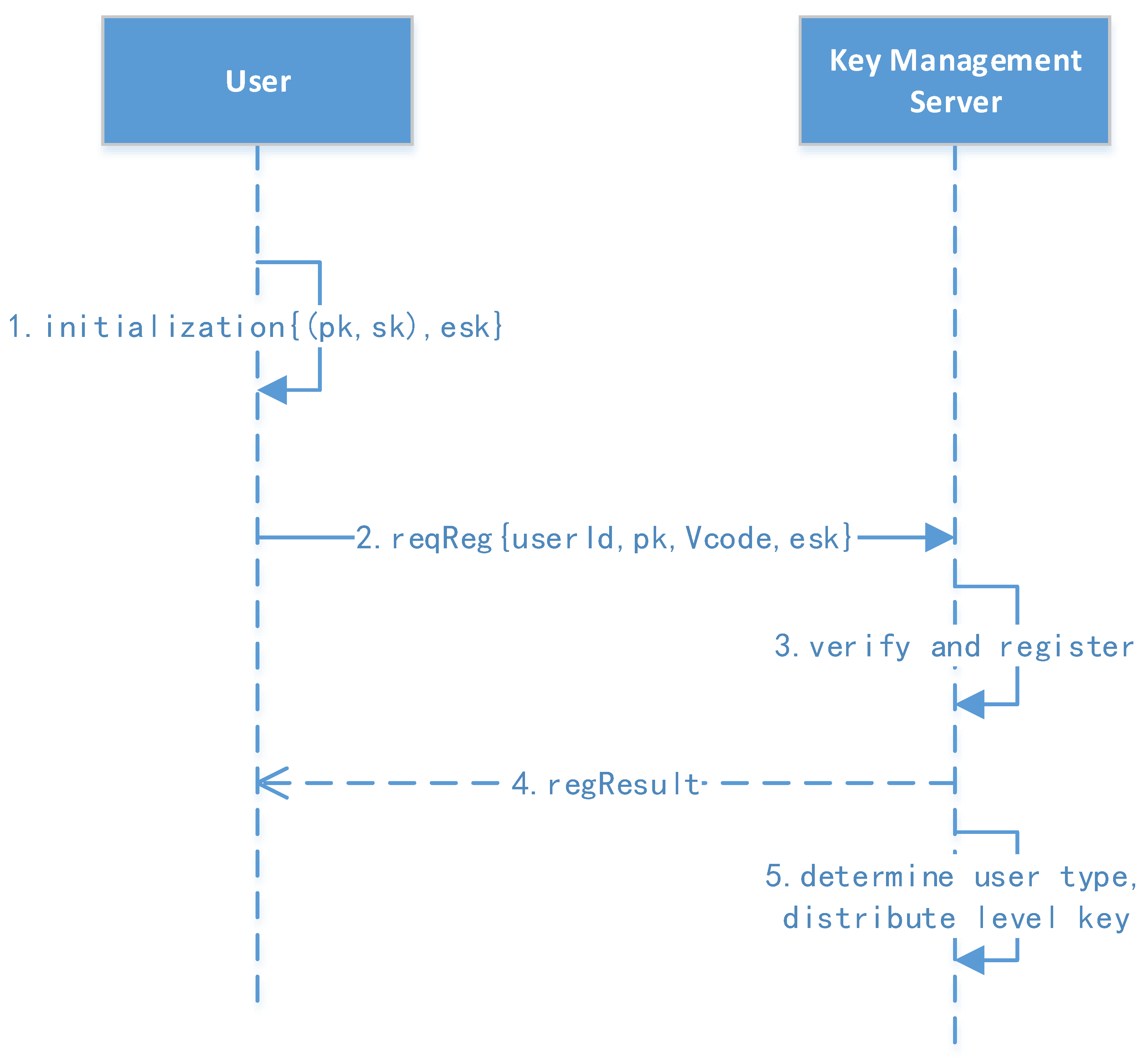
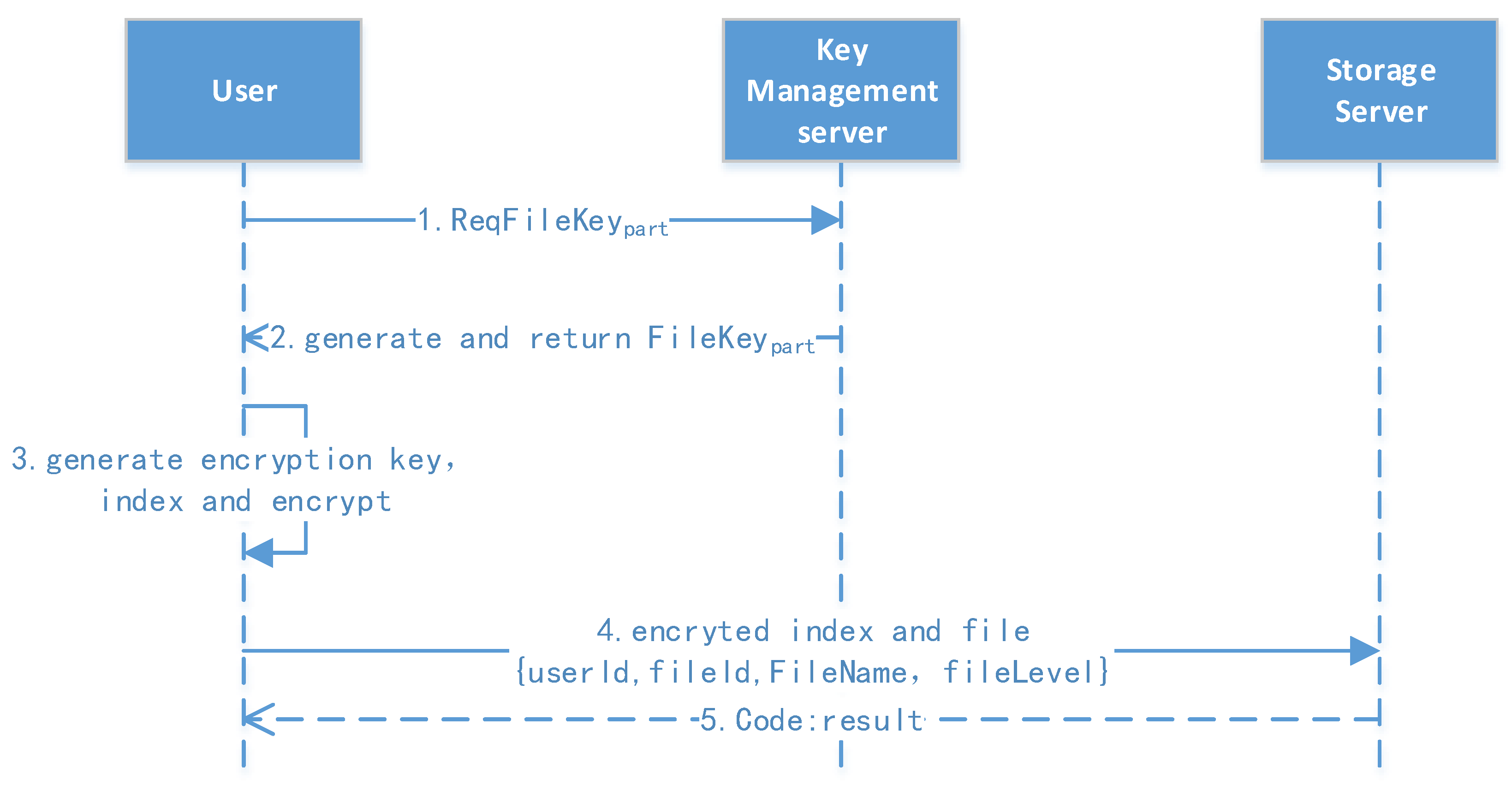
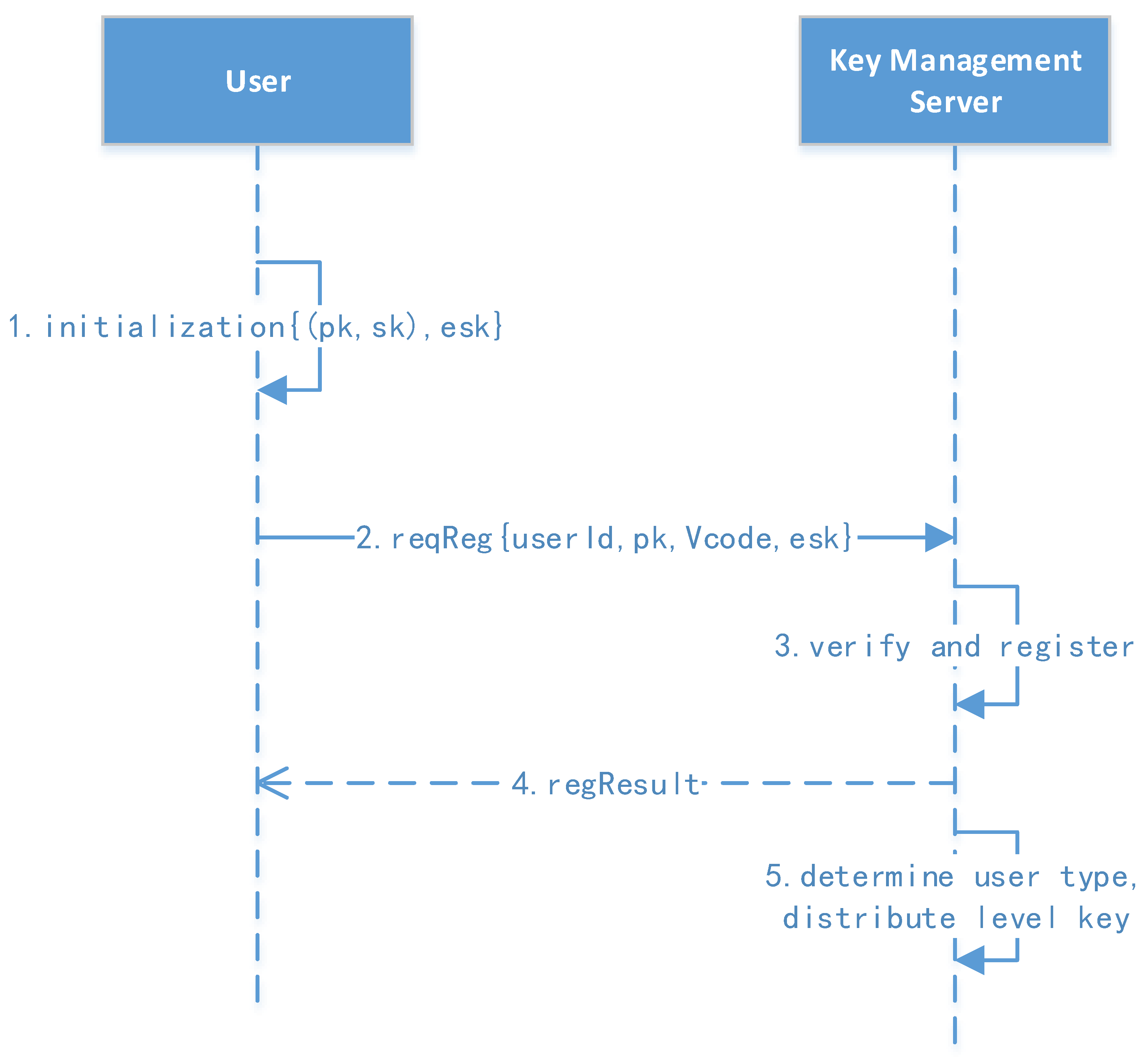
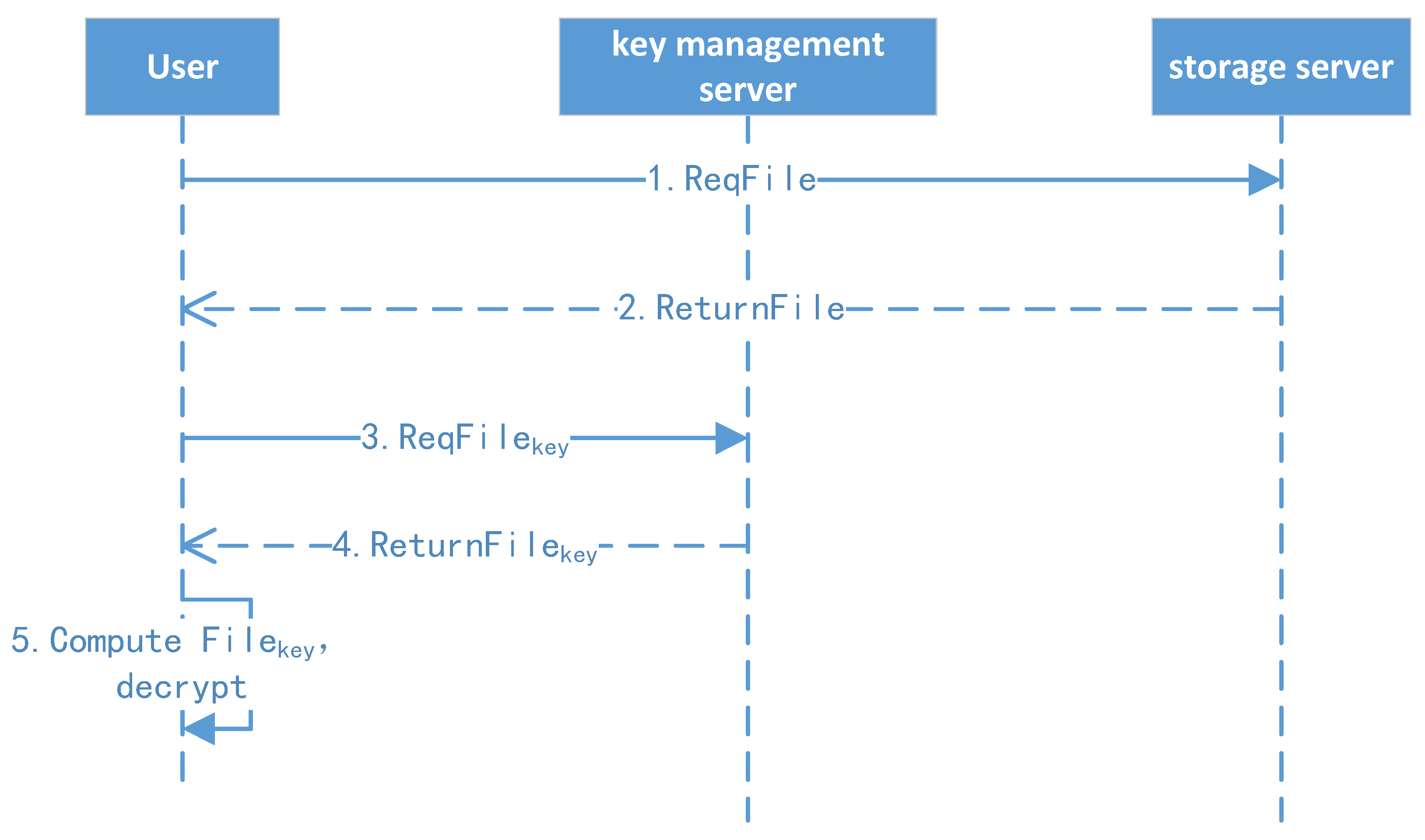
We use asymmetric encryption algorithms to encrypt the sensitive information in protocols between the client, storage services, key management, and other subsystems. For example, in user registration and authentication, the sender uses the receiver’s public key to encrypt sensitive information in the protocol; only the receiver who has the private key can decrypt it.
Attackers who intercept this communication link can only obtain the ciphertext. Relying on the secret key’s computation complexity, the protocol ensures that the sensitive information is not leaked. Further, we use HTTPS instead of HTTP to improve the system’s security and prevent attackers from stealing the protocol content.
6.5.2. Anti-Tampering Attacks
Tampering attacks mean that an attacker intercepts the protocol and tampers with the messages between the participants, so as to fake their identity or perform illegal operations.
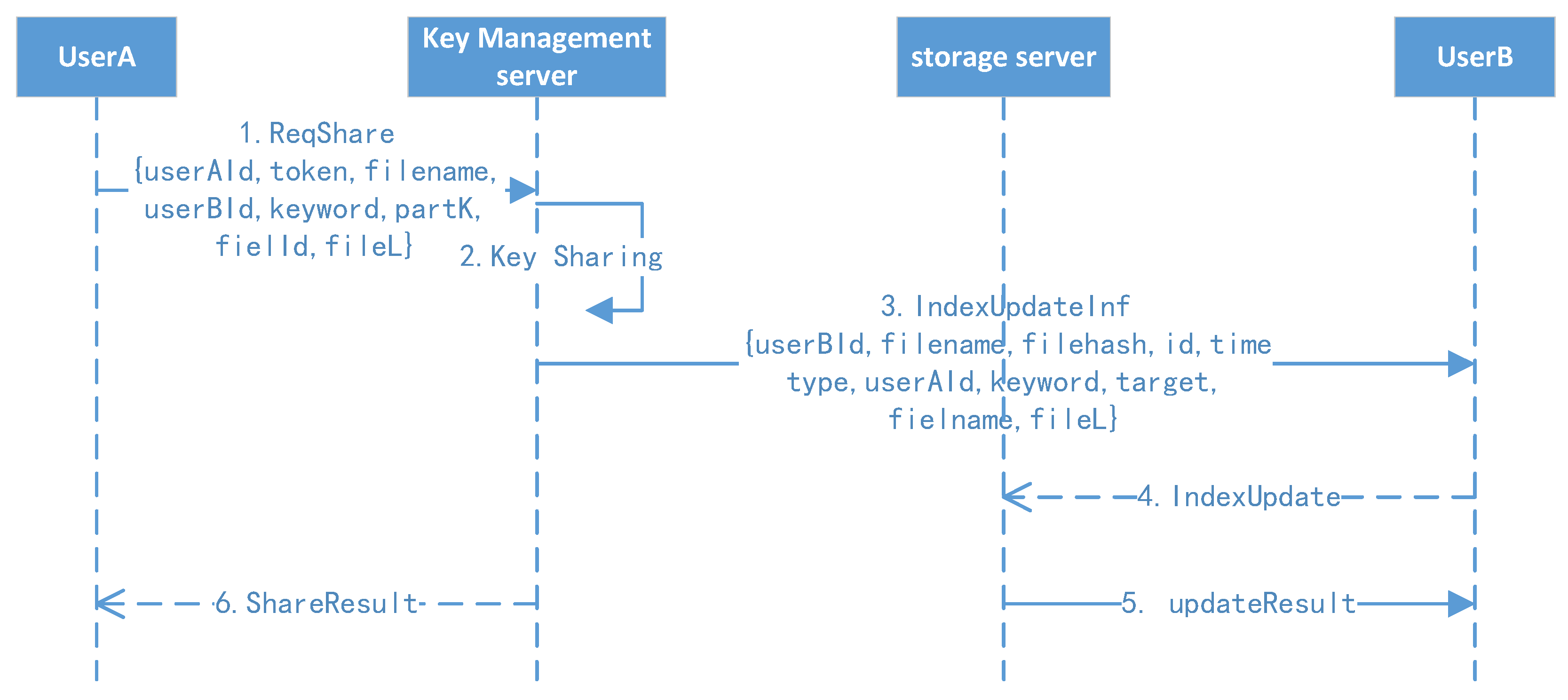
We introduced signatures in the messages between the client, storage service, key management, and other subsystems. When sending a message, a message digest is generated for the content, and the sender’s private key is used to generate a message signature. The receiver uses the sender’s public key to verify the signature after receiving the message. If the signature fails, the message is discarded. If the content has been tampered with, it will not pass the verification step, thus effectively preventing the tampering attack.
6.5.3. Anti-Replay Attacks
Replay attacks resend the eavesdropped data to the receiver. In some cases, the data transmitted are encrypted, ensuring that eavesdroppers cannot obtain the plaintext. However, if they know the accurate meaning of the data, they can fool the receiving end by sending the data again without knowing the content of the data. For example, some senders simply encrypt authentication information and then transmit it. At this time, although attackers cannot eavesdrop on the passwords, they may intercept the encrypted password and then replay it, thus achieving successful authentication. For another example, suppose a message indicates that the user has withdrawn a deposit. Attackers may intercept and resend this message to steal the deposit.
In the protocol design, we added timestamping and random serial numbers to the sending message, and the signature mechanism ensures that the content including the time and serial numbers cannot be falsified. After receiving the message, the receiver first verifies the signature to ensure that the data have not been falsified. Then, they check the timestamp. If it is not within a valid time range, it is discarded. If the time is valid, the user can check whether the message serial number is novel and if a message with a duplicate “sequence number” has been received, if so, this message will also be discarded. The receiver only saves recent sequence numbers, which are larger than the effective time range to ensure the efficiency of the protocol.
6.5.4. Anti-Type Flaw Attacks
Type flaw attacks attack the protocol by using the type of the protocol message domain, which is not clearly defined, or different domains are expressed in the same way in the implementation. This can destroy the authentication or secrecy of the protocols.
We take the Otway–Rees protocol as an example, which is a symmetric key protocol with a trusted third party. Its purpose is to assign a session key to users A and B. The details of the protocol are described as follows:
- 1.
: M, A, B,
- 2.
: M, A, B, ,
- 3.
: M, ,
- 4.
: M,
Among them, A and B represent the communication subject. S is the trusted third party, is the session key generated by S, and M represents the number of rounds in the protocol. and are random numbers used to ensure the freshness of the message through an inquiry/response mechanism. and are shared keys of A, B, and S.
One of the type flaw attacks is as follows:
- 1.
: M, A, B,
- 2.
: M, A, B, ,
- 3.
: M, ,
- 4.
: M,
Among them, IS means that the attacker is impersonating server S. Since is processed as a binary string, the attacker uses M,A,B to impersonate , which makes the receiver think that the binary string M,A,B is the session key , resulting in key leakage, and destroys the authentication of the protocol. In addition to directly using messages in one round of protocols, type flaw attacks can be implemented in parallel sessions of protocols.
There are two main ways to prevent type flaw attacks. One is to avoid similar types of encrypted messages in protocol design, such as changing the order of each field in the ciphertext to ensure that different encryption components have different forms. Another is to add additional information to the encrypted message to identify the type of each part of the message, which was proposed by J. Heather et al. [
42]. The additional identifiable information is called a tag.
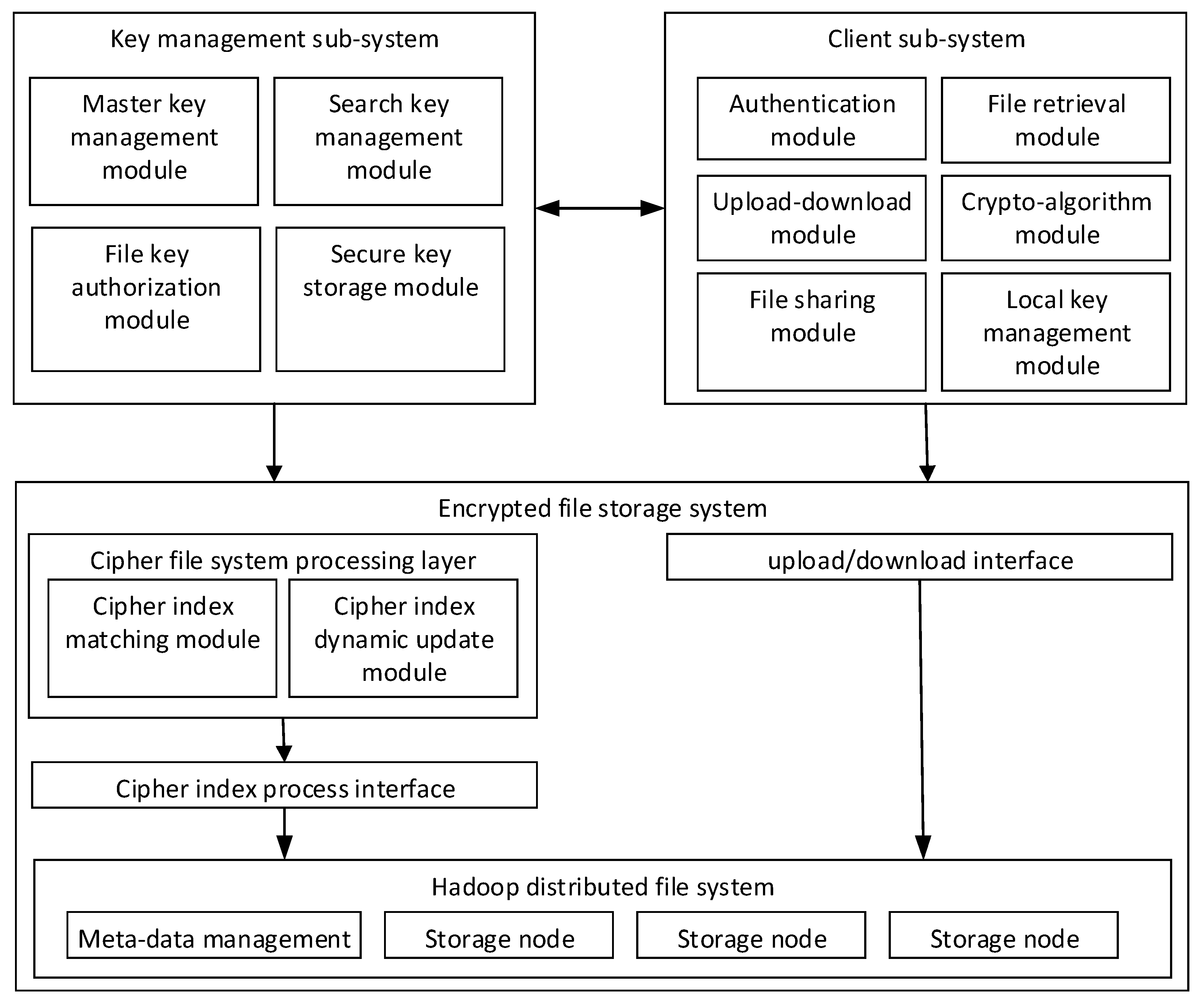
In our scheme, we use the RESTful API to realize communication between the client, key management, and cipher search server, and message data are in the JSON format, with key–value pairs.
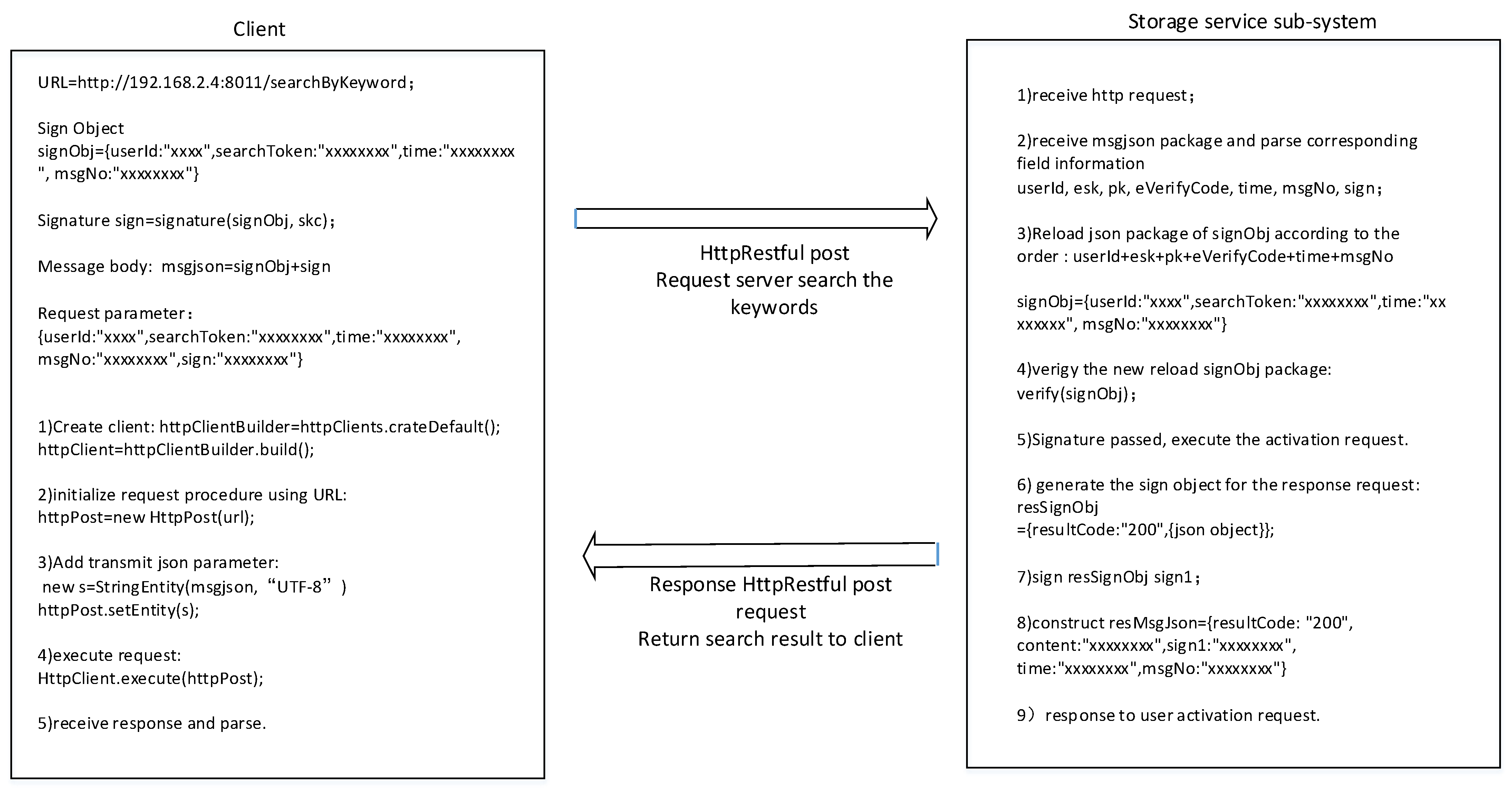
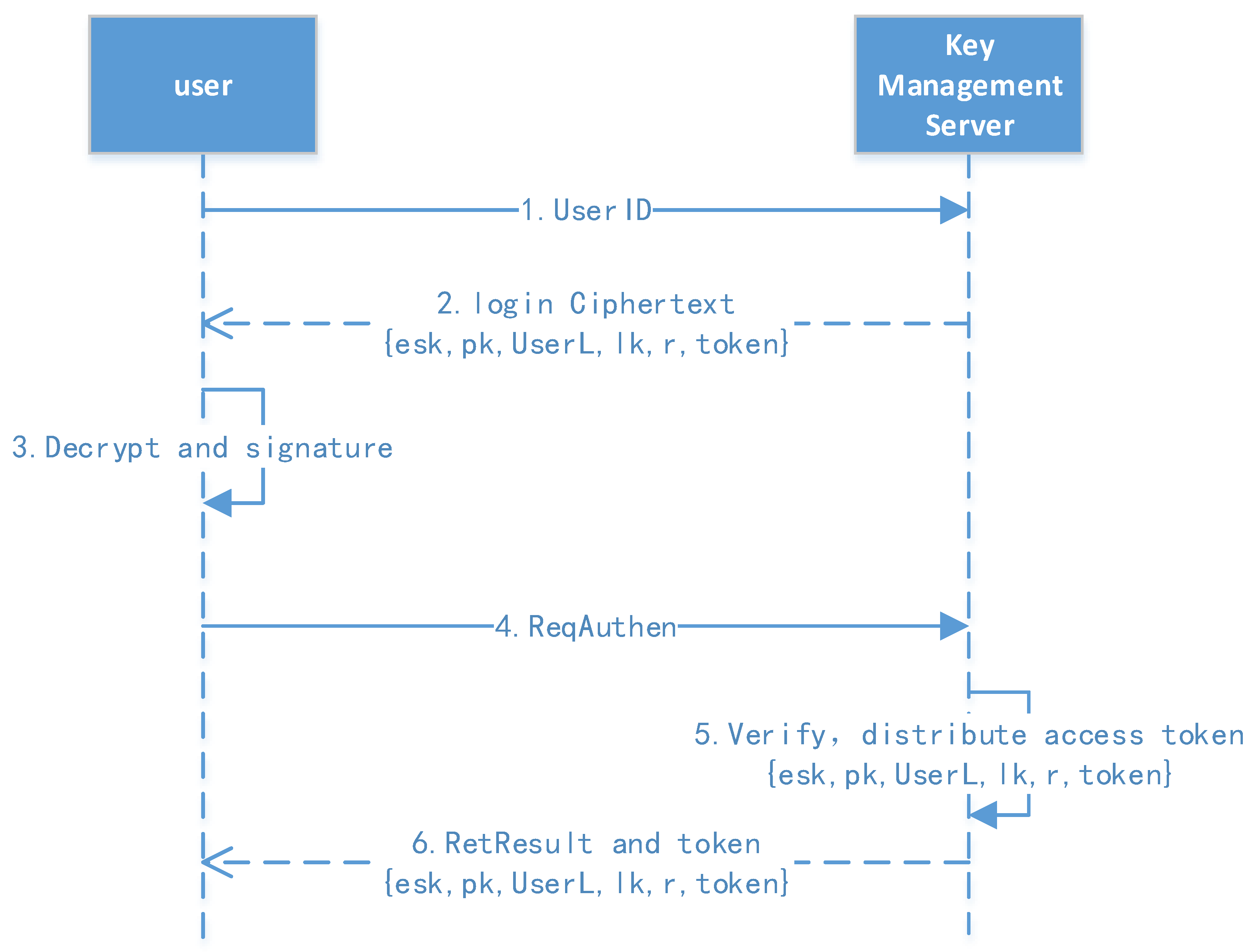
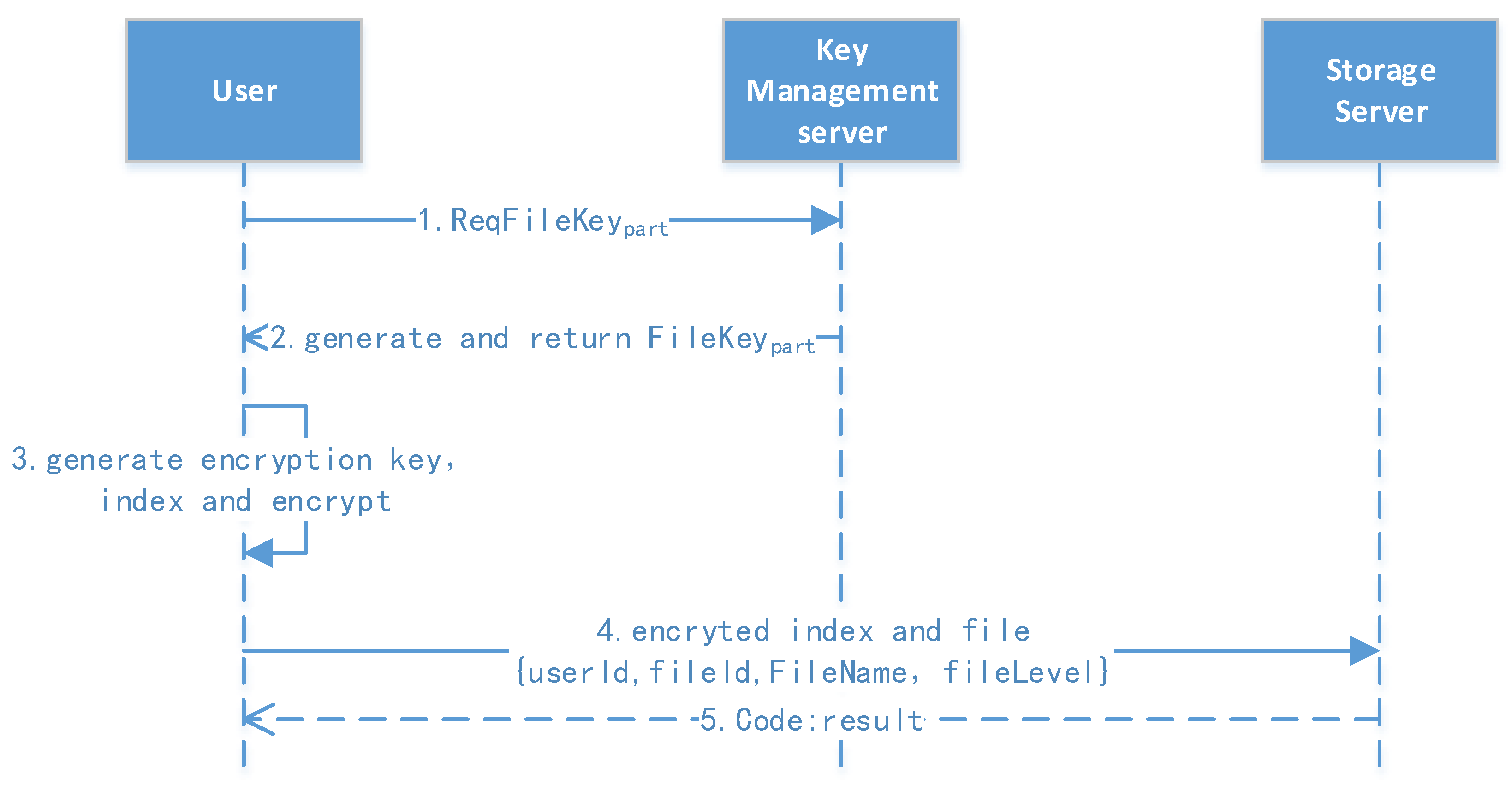
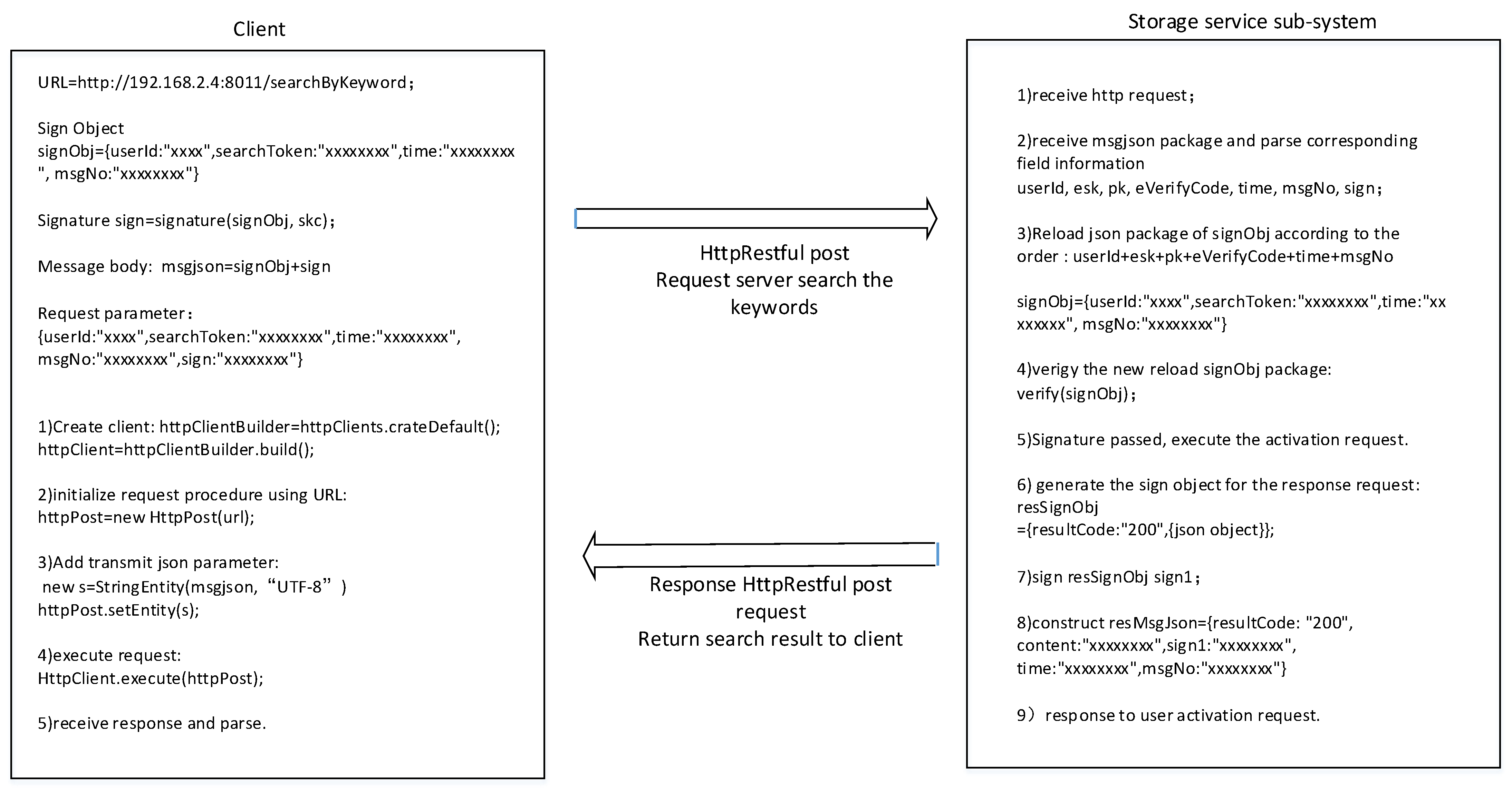
The cipher search protocol is an example, as shown in
Figure 19. Data field information is explicitly added to the message header and body, which is equivalent to adding message tags. At the same time, we encrypt the sensitive information in the message, and the request parameters of the user’s private key are signed so attackers cannot perform type attacks.
6.5.5. Anti-Internal Adversaries
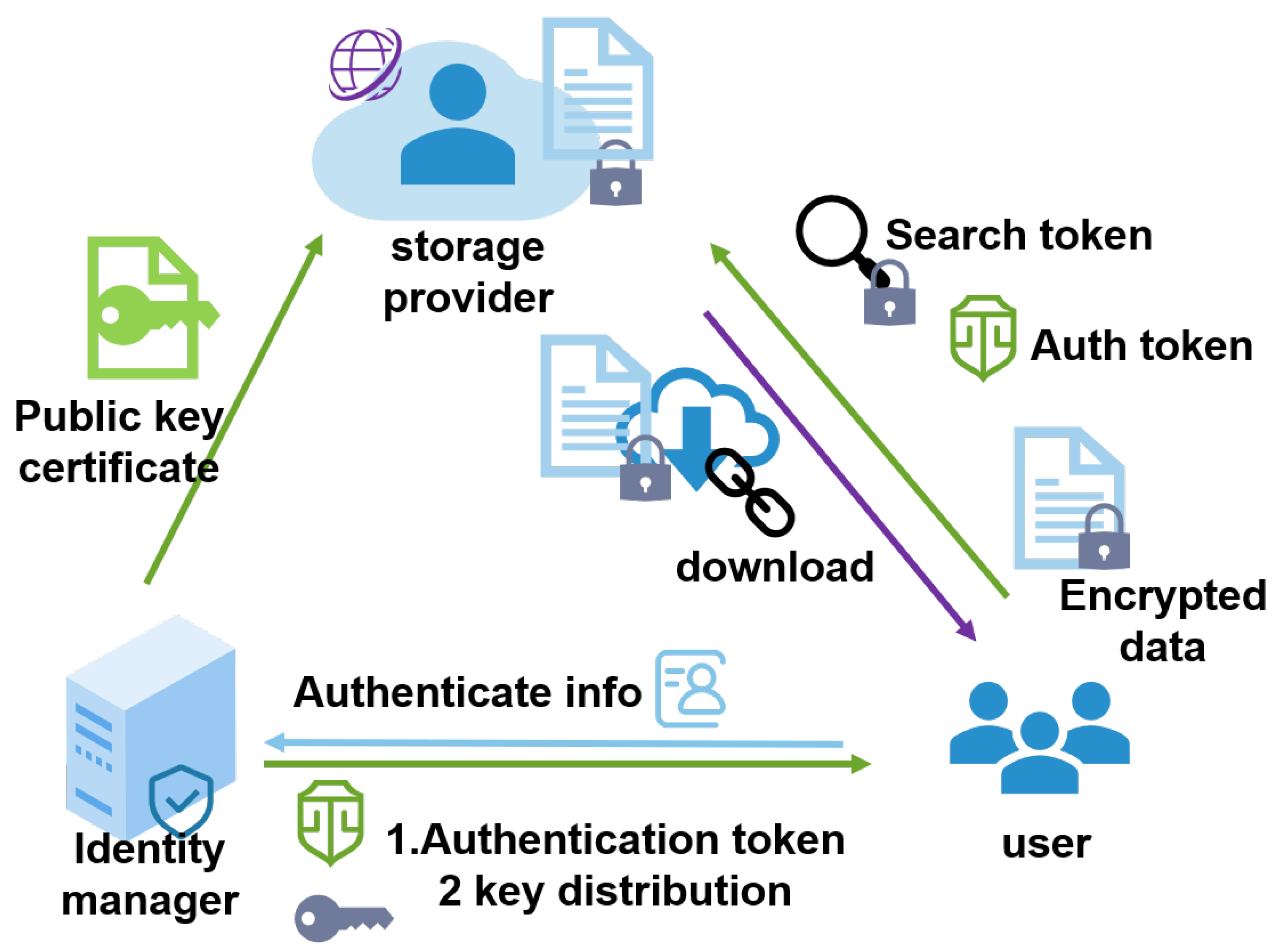
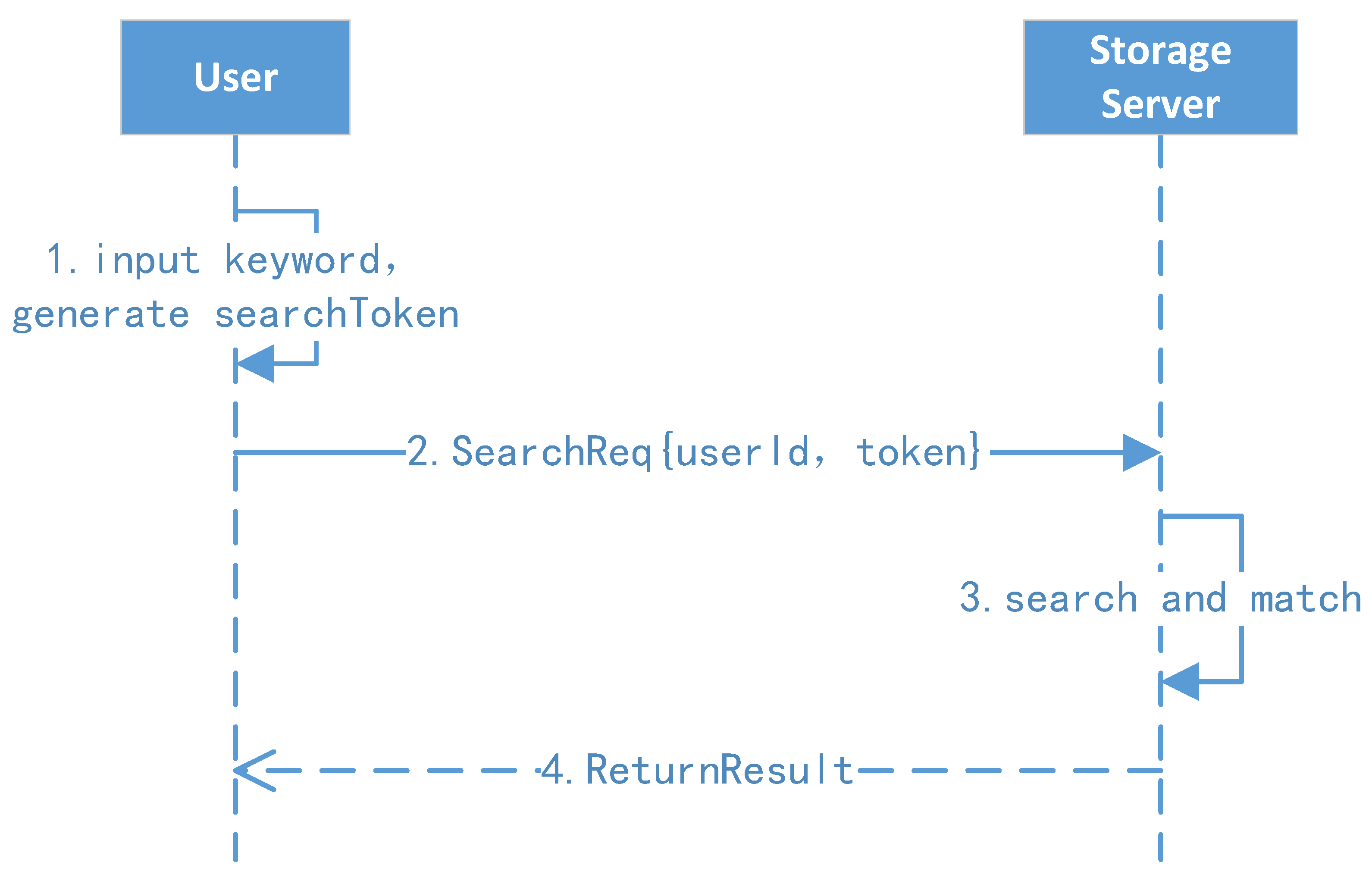
Our scheme supports users to store the ciphertext and directly query the ciphertext on the distributed file system. The cloud storage provider cannot know the user’s search keywords or the stored plaintext. The scheme allows the data owner to directly share their cloud-stored ciphertext data with others while ensuring data confidentially to service providers. Meanwhile, searchable encryption ensures that the storage provider cannot analyze the file content from user behavior associations. Users can completely master their cloud-stored ciphertext through private keys, and the storage end can only provide services according to the preset rules and not steal the users’ data.
6.6. Advantage Analysis
We chose a symmetric-based fine-grained encryption algorithm to deal with massive files compared with the research based on public key encryption. Attribute-based encryption (ABE) is a derivation of public key encryption, such as schemes based on elliptic curve cryptography (ECC) [
17,
43,
44] or the RSA algorithm [
45,
46]. Their key lengths are different at the same security level according to the National Institute of Standards and Technology (NIST) [
47]; for example, a 112-bit symmetrical encryption key has the same strength as a 2048-bit RSA key or a 224-bit ECC key, and thus our strategy is better than others in terms of security and key length.
Table 8 shows a comparison between our EStore and other schemes in terms of fine-grained encryption, fine-grained access control, collaboration, application of big data scenarios, and assumed attacker models. We comprehensively considered the use of a distributed file system, including the confidentiality of storage, accurate authorization, and secure cooperation between users. EStore improved the ability of the existing file system [
2,
6,
7]; further, we took into account both the confidentiality and usage of data and carried out a system evaluation, which has higher practical reference value than other schemes [
17,
19,
21].












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}