1. Introduction
In the field of Prognostics and Health Management (PHM) [
1], real-time prediction of equipment degradation is crucial as it serves as an important basis for developing Condition-Based Maintenance (CBM) strategies [
2]. However, in most cases, the data measured by the monitoring system cannot track the degradation status of the system. Therefore, a model that can predict system degradation or a quantifiable indicator is needed to evaluate the health status of the system, such as the system health indicator (HI). HI reflects the current health status of the system and is an important basis for predicting the trend of system fault development and performance degradation, which can be used to estimate the time when the system reaches failure [
3]. Therefore, constructing a reasonable and accurate system HI is an important foundation for developing CBM strategies. For example, HI plays an important role in anomaly detection [
4], remaining useful life (RUL) prediction [
5], and health state prediction [
6], and the effectiveness of the implementation in these fields heavily depends on HI construction [
7].
The construction of HI can be divided into two types: model-based methods and data-driven methods, or directly using parameters with clear physical meanings in the system, such as the crack length of mechanical devices and the vibration amplitude of rotating machinery. Among these, model-based methods require in-depth analysis of system characteristics and the establishment of physical failure models based on this, which usually requires rich domain knowledge [
8]. Currently, with the development of data collection and storage technology, data-driven methods have become the mainstream method for constructing HI. The core idea is to fuse multiple measurement data to obtain the comprehensive HI of the system.
The evaluation of system health status can be summarized into two questions: what data to use, and how to process and analyze the data. Usually, the most easily obtained data for a system are its monitoring data, which are typically time series data. The monitoring data of the system actually reflect many characteristics of the system, and by deeply mining the system monitoring data, a large amount of relevant information about the system’s health status can be obtained. For example, in [
9], several data-driven models have been proposed and applied for diagnostics and prognostics purposes in complex systems based on monitoring data. In [
10], a PHM model for the prediction of component failures and the system lifetime is proposed by combining monitoring data, time-to-failure data, and background engineering knowledge of the systems. Likewise, in [
11], the degradation index of a rolling bearing is constructed based on the monitoring data.
Regarding the issue of HI construction, a certain number of researchers have adopted traditional machine learning methods such as principal component analysis [
12], quantitative programming [
13], support vector machines [
14], hidden Markov model [
15], and Bayesian linear regression [
16]. In recent years, with the massive accumulation of data and the development of computer hardware, as an important branch of machine learning, deep learning technology has been rapidly developed. Currently, deep learning techniques have been applied to HI construction in relevant literature; these techniques include vanilla neural networks [
17], recurrent neural networks (RNNs) [
18], long short-term memory networks [
19,
20], convolutional neural networks [
21,
22], and generative adversarial networks [
23].
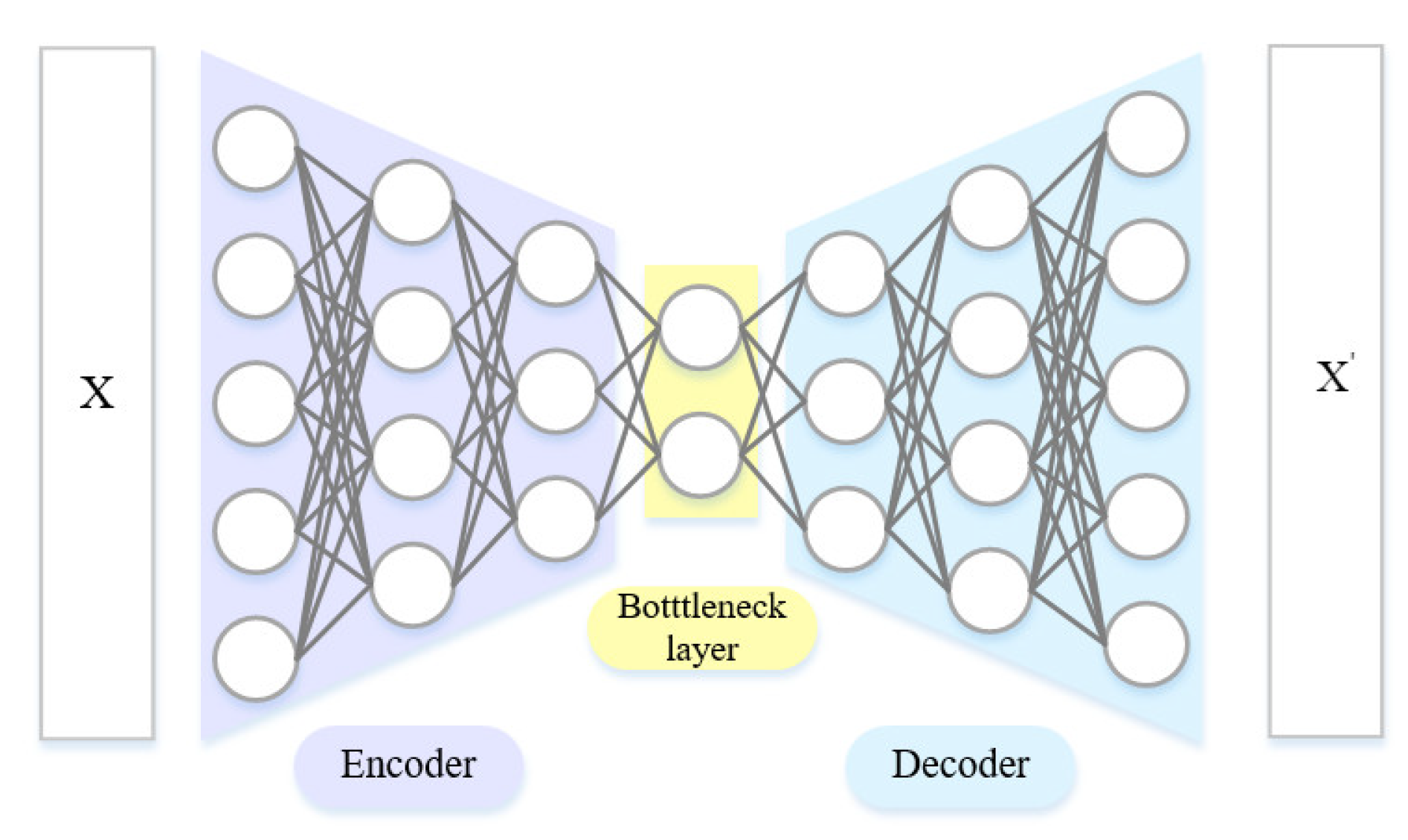
Among the current numerous deep learning methods, an autoencoder is a kind of unsupervised learning method, which is essentially a custom-built neural network architecture. The architecture of the autoencoder consists of a decoder and an encoder. It was first proposed by Rumelhart et al. and is mainly used for data dimension reduction [
24]. A deep autoencoder is a multi-layer feedforward neural network with narrow middle and wide ends. It compresses the input data into a low dimensional projection through the encoder, and then reconstructs the output data through the decoder, trying to make them similar enough. Thus, the dimension of input data can be reduced in a hierarchical manner, achieving high-quality data reconstruction. With the development of autoencoder methods, derivative methods such as the denoising autoencoder [
25], sparse autoencoder [
26], and stacked autoencoder [
27] have been invented. In the field of PHM research, the autoencoder has also been gradually applied to anomaly detection [
28,
29], RUL prediction [
30], fault diagnosis [
31,
32], and health status assessment [
33].
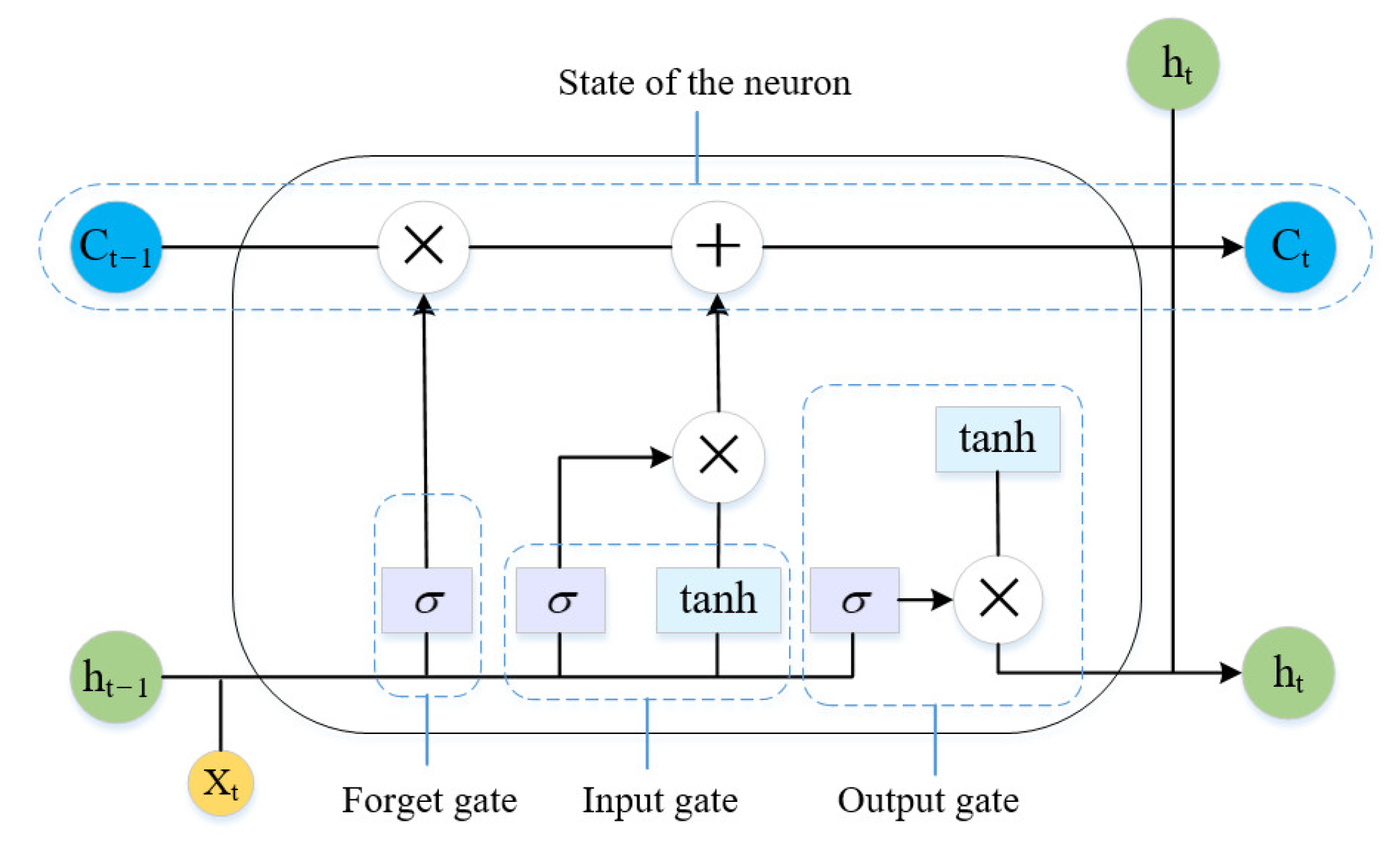
For HI construction, we use a basic assumption that when the system’s health status deteriorates, the monitoring data of the system will gradually deviate from the range of normal data, and the more the system performance degrades, the greater the degree of deviation. Therefore, the autoencoder can successfully reconstruct normal data samples after training, but for the abnormal data of the system and the monitoring data after system degradation, an autoencoder model is expected to obtain a large reconstruction error, and the more serious the system degradation, the larger the reconstruction error should be. Based on this, it is reasonable to use autoencoder to build a system HI based on system monitoring data. However, as mentioned earlier, the monitoring data of the system are typically time series data, and methods mentioned above do not fully consider the time series characteristics of monitoring data and the correlation between variables. The LSTM neural network is a kind of recurrent neural network that is specially designed to solve the vanishing gradient problem existing in general RNNs. It can learn the relationship between variables in time series, capture the time series characteristics of monitoring data, and better realize the encoding and decoding of time series data.
By comparison, for time series analysis, sensor selection, also known as feature selection, is one of the important factors that determine the final effect, which plays a vital role in the quantitative analysis of data. At present, for the feature analysis of the time series of the HI, in most cases, the selection of variables is mainly undertaken manually by observing the trend, amplitude, noise, and other characteristics of the variables. This approach has problems such as strong subjectivity, inability to conduct quantitative analysis, and inaccuracy [
34]. To solve these problems, a sensor selection method based on mutual information (MI) is proposed to determine the input data of the autoencoder. Mutual information is a measure of the interdependence between two variables, and indicates how much information is shared between two variables [
35]. The greater the mutual information between two variables, the stronger their correlation [
36]. It has become one of the important methods in feature selection for calculating and analyzing the mutual information of features, judging the correlation between features, and then selecting the features with strong correlations with target variables [
37]. However, for feature extraction and analysis of time series, one of the main problems of mutual information-based methods is identifying suitable target variables; that is, the key to mutual information-based methods is to identify appropriate target data. In most cases, there is no intuitive and directly available target information and the existing literature and research are mainly focused on the improvement in the feature extraction algorithm based on mutual information itself. To solve the above problems, we propose a target information extraction method based on PCA dimensionality reduction. On this basis, a mutual information method coupled with target variables is constructed to distinguish and extract applicable monitoring sensor data.
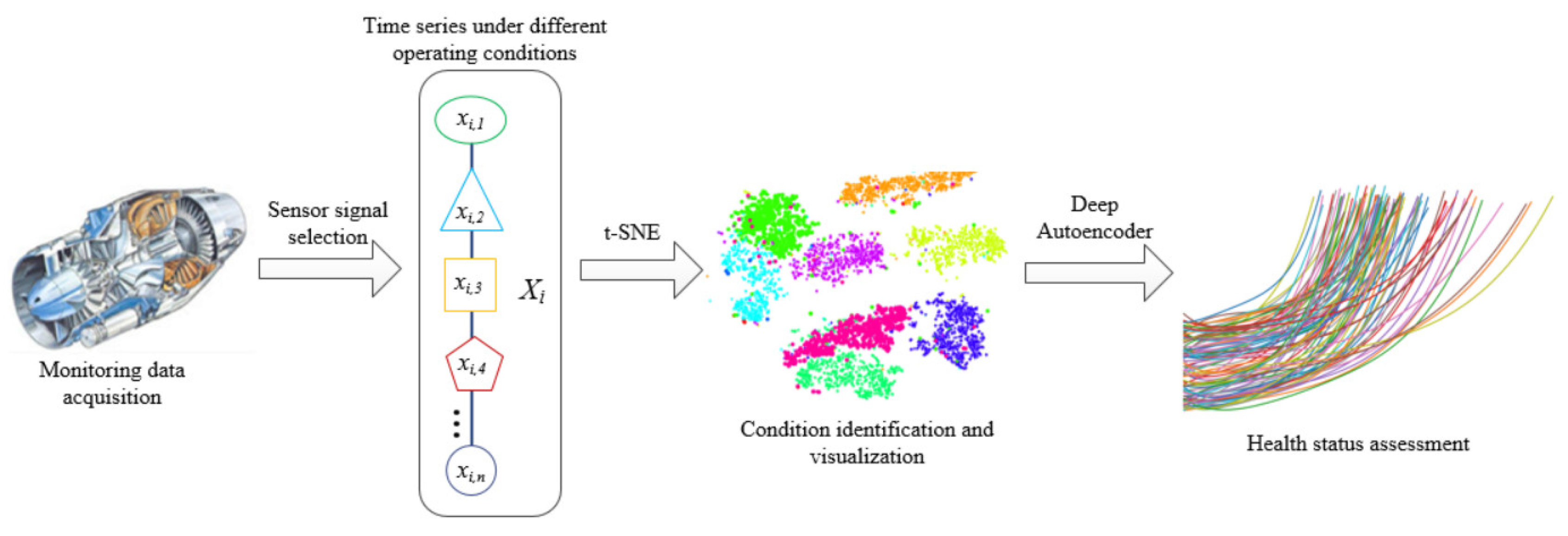
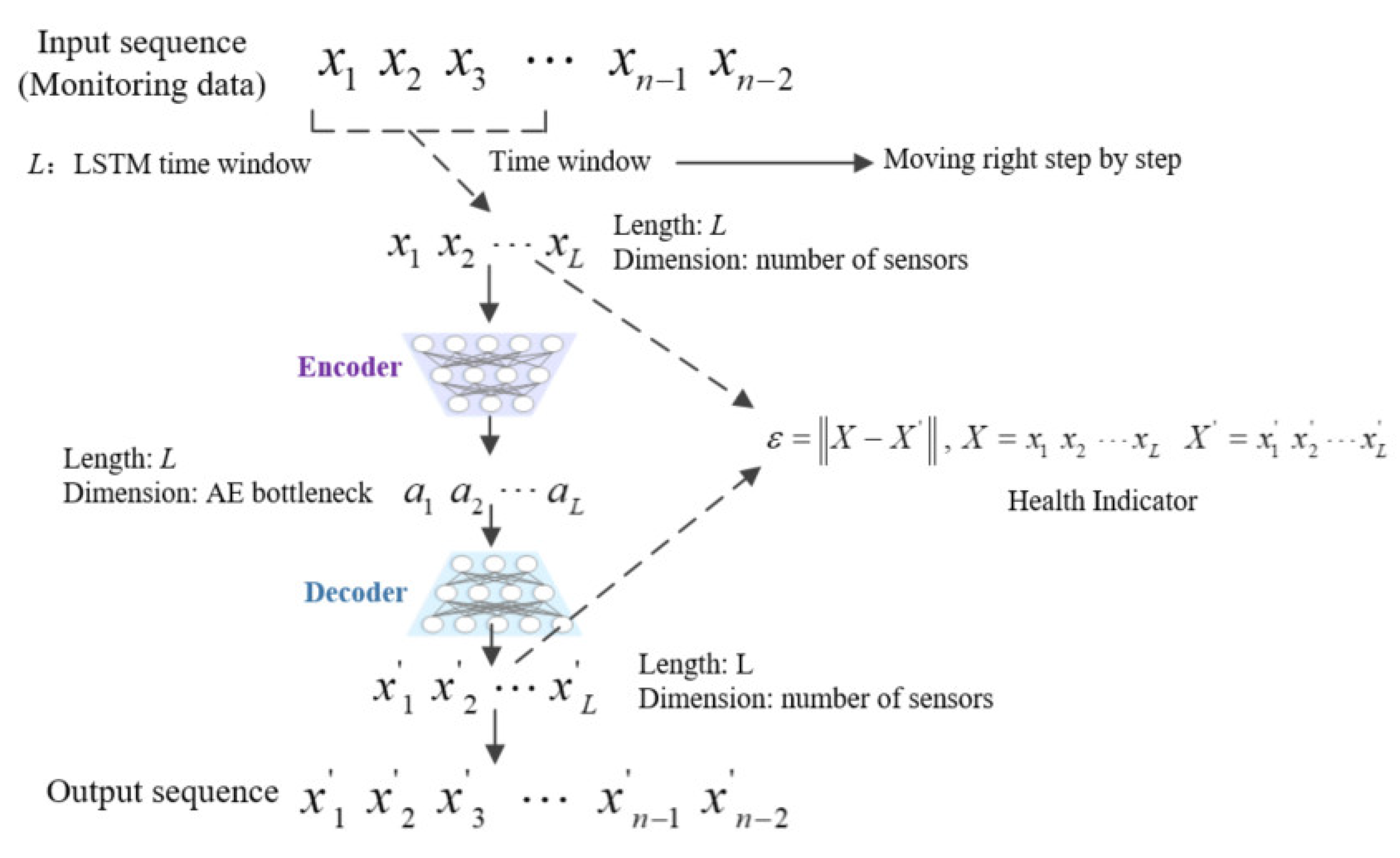
In view of the above situation, we propose an HI construction method based on a deep autoencoder, which is used to assess system health status based on high-dimensional monitoring time series data. The model is composed of a neural network composed of an encoder and a decoder, and LSTM is used to optimize the autoencoder network structure. While extracting the information of monitoring time series data, the method can complete the bidirectional mapping of data between the high-dimensional feature space and the low-dimensional latent space. The autoencoder compresses the time series into a low-dimensional space, and then uses the decoder to reconstruct the compressed data, minimize the reconstruction error, and construct the HI of the system by the degree of the reconstruction error.
1.1. Highlight and Contribution
To summarize, we propose an HI construction method based on LSTM and autoencoder neural networks for the health assessment of complex systems. This method is a data-driven approach that uses system health operating data to train neural networks, and uses the reconstruction error of the decoder as the basis for HI construction. To verify the effectiveness of the method, we conduct HI construction experiments based on the CMAPSS dataset and compared with the most widely used PCA dimensionality reduction method for extracting HI from multiple metrics. In summary, the contributions of this research are as follows:
(1) We propose a construction method for a system HI based on an autoencoder and LSTM neural network. As the system gradually degrades and reaches failure, the monitoring data will gradually deviate from the normal range. Based on this assumption, the LSTM neural network is used to obtain the data series characteristics of the system monitoring data, and the system health index is constructed according to the reconstruction error of the autoencoder.
(2) We design a specific technical process for implementing HI construction based on the above theoretical methods. In this process, we focus on data processing of sensor selection and operating condition identification, and propose a sensor selection method based on mutual information and operating condition identification method based on t-distributed stochastic neighbor embedding.
(3) The effectiveness of the proposed method is verified based on a publicly available aviation engine operation dataset. The experimental results are compared with other methods to verify the feasibility of the proposed method. Through qualitative and quantitative analysis, it is shown that the proposed method does not require the establishment of an accurate mathematical model for the system, and can effectively achieve the health status assessment of the system.
1.2. Organization
The remainder of this paper is organized as follows. In
Section 2, we describe the architecture of the proposed system and introduce the theoretical foundation of the methodology. Results of the experiments are presented and discussed in
Section 3. Finally, the conclusions and future work are set out in
Section 4.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}