1. Introduction
The weak target detection algorithm in infrared is an important technology for infrared warning and guidance. In real-world scenarios, the imaging distance of the target is far, the imaging area is small, and the radiation energy is low, which makes the target easily affected by noise and clutter interference. Therefore, how to separate weak targets from complex backgrounds is a challenging research topic, and many scholars have conducted in-depth research on this issue [
1,
2].
Traditional spatial–temporal filtering methods are one of the mainstream weak target detection algorithms in infrared, which separate the target and the background by local feature information of the image in the spatial–temporal domain. There are two methods of temporal filtering: single-frame detection algorithms and multi-frame detection algorithms. Multi-frame detection algorithms are mainly three-dimensional matching filtering algorithm, projection transformation algorithm, dynamic programming algorithm, pipeline filtering algorithm, etc. Common single-frame detection algorithms include top-hat filtering algorithm, gradient reciprocal filtering algorithm, etc. The principle of three-dimensional matching filtering is to set a three-dimensional filter on all possible motion trajectories of the target, and then analyze and judge the collection results of the filter. The three-dimensional filter with the highest signal-to-noise ratio is determined as the weak target and motion trajectory. However, for motion-mismatched targets, multiple velocity filters need to be set to capture the target trajectory, which leads to an increase in the computational complexity of the detection algorithm [
3]. The projection transformation projects multidimensional data into a low-dimensional space, and obtain the motion trajectory of the target from the low-dimensional data. Since this algorithm appears to reduce the dimensionality of the data during the calculation, the data of the samples to be processed and the suspicious target signals are greatly reduced, which simplifies the computation. Compared with the multidimensional matching filtering, reduced computation is accompanied by poorer target detection result [
4,
5]. In the study of small target detection, Wang et al. [
6] first used feature triangles to perform registration on infrared images and reduced the computation by using the star point coordinate matrix method. Then, the maximum value projection transformation method was used to process the sequence images and, therefore, obtain the result. The idea based on dynamic programming is to equivalently treat the accumulated energy of the detected small target on a certain trajectory as the decision function in the theory of dynamic programming. The motion range of the target at different stages is regarded as the decision space. Then, by recursive methods, the motion trajectory that can make the decision function achieve global optimization is found [
7]. Guo et al. [
8] proposed a dynamic programming method based on parallel computing, which performs a parallel search on the suspicious candidate target area to obtain the candidate target points. This method effectively improves the detection efficiency, but its detection performance decreases as the target signal-to-noise ratio gradually decreases. The principle of the pipeline filtering algorithm is that when the target signal is sampled at an appropriate frequency, the motion characteristics of the target signal in space are continuous in time, while random noise does not have continuity. Dong et al. [
9] proposed a method that combines a modified visual attention model (VAM) with anti-jitter pipeline filtering algorithm. In this method, the best mode is adaptively selected to calculate the saliency map. Then, a local saliency singularity evaluation strategy is designed to automatically extract suspicious targets and suppress background clutter. Finally, the real target is distinguished by anti-vibration pipe filtering. This method can improve the efficiency of target detection in infrared imaging under different weather conditions. Although many improved pipeline methods have been proposed, it is difficult to achieve good detection performance when the motion of small targets has complex and varied characteristics. The top-hat filtering algorithm models the background of the image by using a structural element as a template for opening and closing operations on the image, and obtains the final difference map. Bai et al. [
10] combined multi-scale operations with structural elements, which predict the image background by different scale structural elements. The top-hat filtering algorithm causes a loss of target energy intensity during opening and closing operations, resulting in poor detection in scenes with low target energy. Li et al. [
11] established a correlation coefficient function based on the local feature information of the image, and introduced it into the gradient reciprocal filter algorithm, which can obtain an improved background estimation. Due to the complex and variable gray-scale characteristics of the image background, the filtering template of the gradient reciprocal filter algorithm cannot completely match the background features, resulting in a large number of edge residues in the detection results. Most real-world scenarios contain a lot of noise and clutter, and the noise signal is only slightly different from the weak target in terms of texture and energy. It is difficult to fully distinguish noise from the target based on only local feature information in the image. Therefore, traditional spatio-temporal filtering algorithms are easily interfered by noise and clutter, leading to low detection rates.
In the study of infrared faint target detection with deep learning, in order to effectively improve the generalization ability of the deep neural network detection model, Dai et al. proposed a special ACM detection model based on the construction of a high-quality annotation data set. There is an asymmetric upper and lower information modulation model for small infrared target detection [
12]. This model not only realizes forward and backward information transfer to fusion, but also supplements a top-down information modulation module based on point-oriented channel attention, which enhances the fusion of target signals. The DNAnet network proposed by Li et al. completes the feature fusion of the target through the repeated use of image features [
13], making full use of the weak information of the target. In addition, the model also includes the constructed dense interaction module and channel-attention module, which realizes the fusion of target features and the enhancement of adaptive features, and has achieved remarkable results in the detection of small infrared targets. In order to solve the problems of detection loss (MD) and false alarm (FA) more effectively, Wang et al. proposed an adversarial network consisting of two generators and one discriminator to extract target feature information [
14]. This model distributes detection tasks to different training models, which improves the overall detection efficiency of the model. To sum up, the weak and small target detection model of deep learning has achieved remarkable results, but considering the limitations of the generalization ability of the model brought about by the multiple changes in the air and space detection environment, it is necessary to start from the data set construction and model construction. From the perspective of research, increase the practical application of deep learning detection models in the detection of small and weak infrared targets.
In recent years, scholars have paid more attention to the information about the entire image. They have transformed the problem of detecting targets into the matrix reconstruction problem through machine learning theories, and solved this problem using the overlapping direction multiplier method to obtain the detect result. Gao et al. [
15] proposed an infrared patch-image (IPI) model that utilizes the correlation characteristics of non-local image background. Wang et al. [
16] suppressed strong background edge contours by combining anisotropy and L1 norm on the basis of the IPI model. Xue et al. [
17] suppressed strong background edge contours by combining anisotropy and the L1 norm. Xue et al. used the weighted L1 norm to constrain the target and added constraints on the noise using L1,1 and L2,1 norms to eliminate the background residue. However, in a complex background, the simple nuclear norm cannot fully constrain the background. These methods are unable to fully recover the background image, causing unsatisfactory detection results. Compared with two-dimensional data, high-dimensional data have more structural information, making it easier for us to explore hidden relationships between data. Therefore, Dai et al. [
18] proposed an infrared patch tensor (IPT) model to extend the two-dimensional image matrix to three-dimensional, fully exploring the spatial correlation of non-local areas of the image, and using the prior information to constrain sparse targets through re-weighting. Zhang et al. [
19] further suppressed the background using partial sum of the tensor nuclear norm (PSTNN), and then used the corner descriptor function and the background descriptor function to obtain prior information of the image to jointly constrain the target using the L1 norm. Wang et al. [
20] constructed a new spatio-temporal tensor model, non-overlapping patch spatial–temporal tensor (NPSTT) model, based on the IPT model to avoid redundant information. The method also obtains better target constraint results with the help of tensor upper bound nuclear norm. Kong et al. [
21] approximated the non-convex tensor fiber rank using Log tensor fibered nuclear norm (LogTFNN) on the basis of the IPT model, and then used hypertotal variation (HTV) to suppress noise. Cao et al. [
22] defined a mode-k1k2 extension tensor tubal rank (METTR) and fully preserve the spatial correlation of non-local areas in images by METTR-norm.
During the actual process of target detection, the background is complex, often accompanied by strong edge contours and strong noise. Merely using the information about the entire image cannot completely suppress the strong edges, leading to residual background in the detection results. The IPT model constructs background weight function based on the characteristics of the structural tensor, but ignores the information of the target, leading to excessive contraction of the target. The PSTTN model proposes a structural tensor descriptor function for both the background and the corner points based on the RIPT model, while retaining the prior information of both the background and the target. However, because the prior information related to the background is only based on the maximum value of the eigenvalues, it cannot completely suppress the contours of strong edge contours, resulting in some edge contours being retained in the final local feature prior information.
In summary, in order to solve the limitations of existing detection models, we propose a low-rank sparse inversion method for detecting small targets by combining a new norm with self-attention mechanisms.
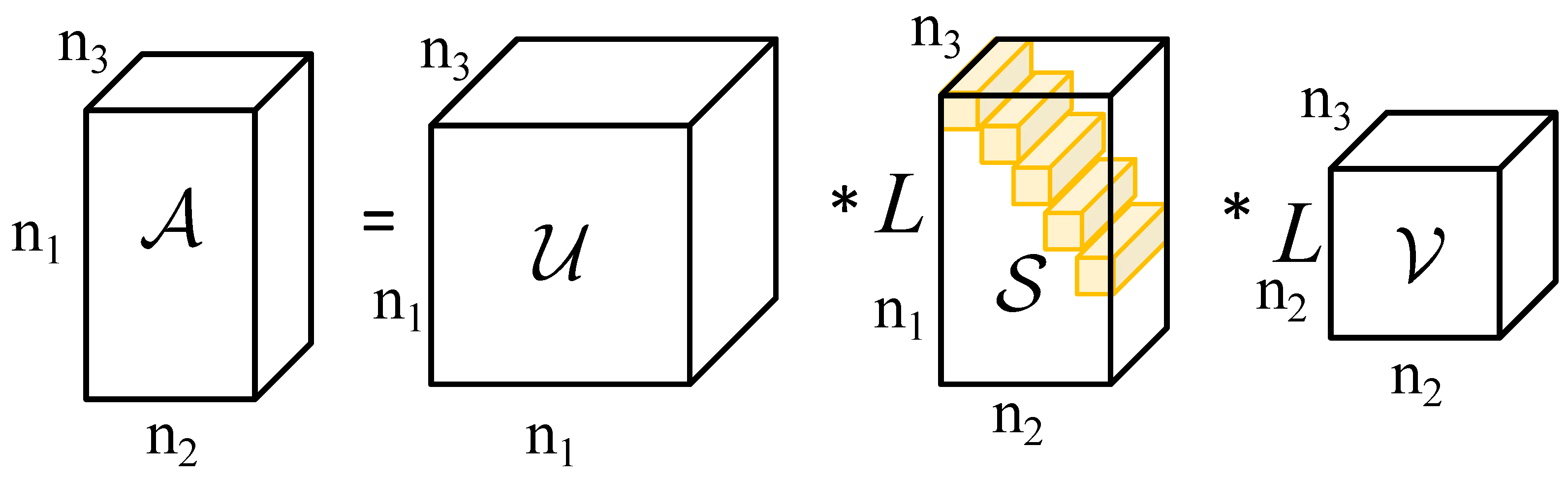
To better constrain the low-rank tensor, we approximate the tensor rank using a new tensor nuclear norm that is non-convex. The new tensor nuclear norm preserves the structural information between the various slices of the tensor and can accurately recover low-rank backgrounds under certain interference. Moreover, the high-order tensor is reduced during the operation, reducing the computational complexity of the algorithm.
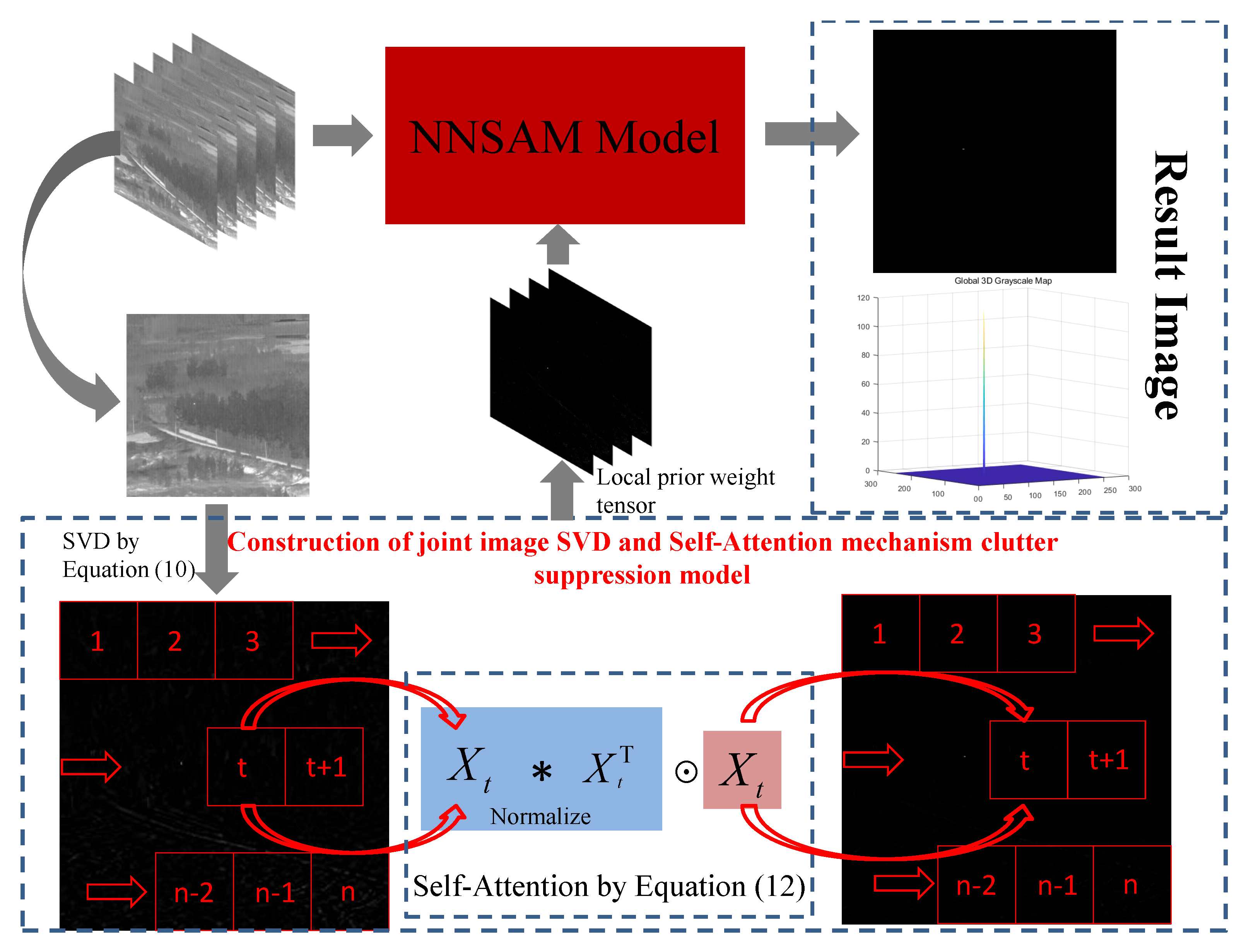
We construct a self-attention mechanism model to constrain the sparse characteristics of the target. This model obtains local feature information of the image to suppress strong edge contours and strong noise and transforms the local feature information into a weight matrix to introduce the constraint of the sparse component of the infrared small target detection model.
We design an overlapping direction multiplier method to solve the infrared small target detection model and obtain the target image. In the solving process, we use a re-weighting strategy to accelerate the convergence speed and accuracy of the model.
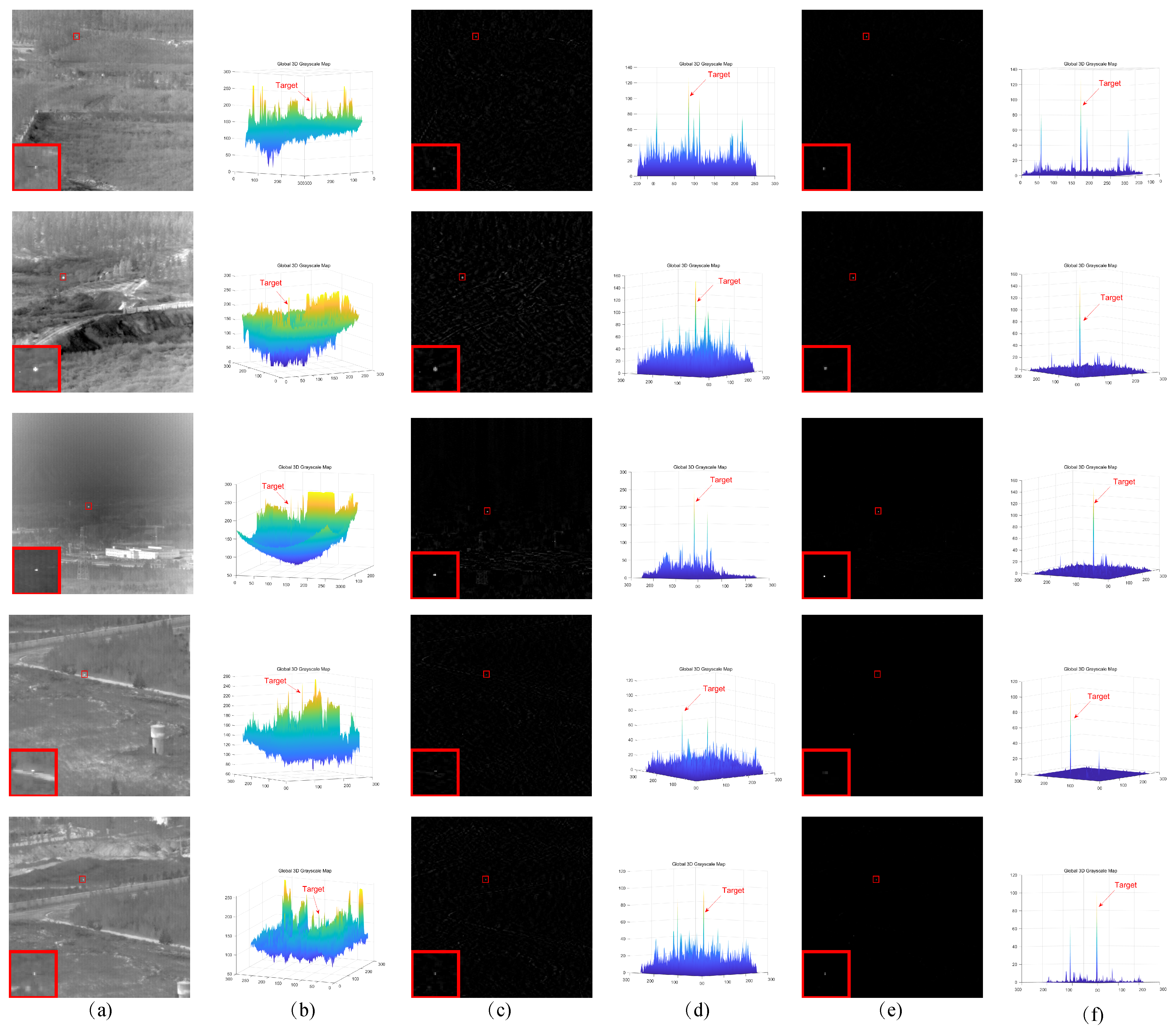
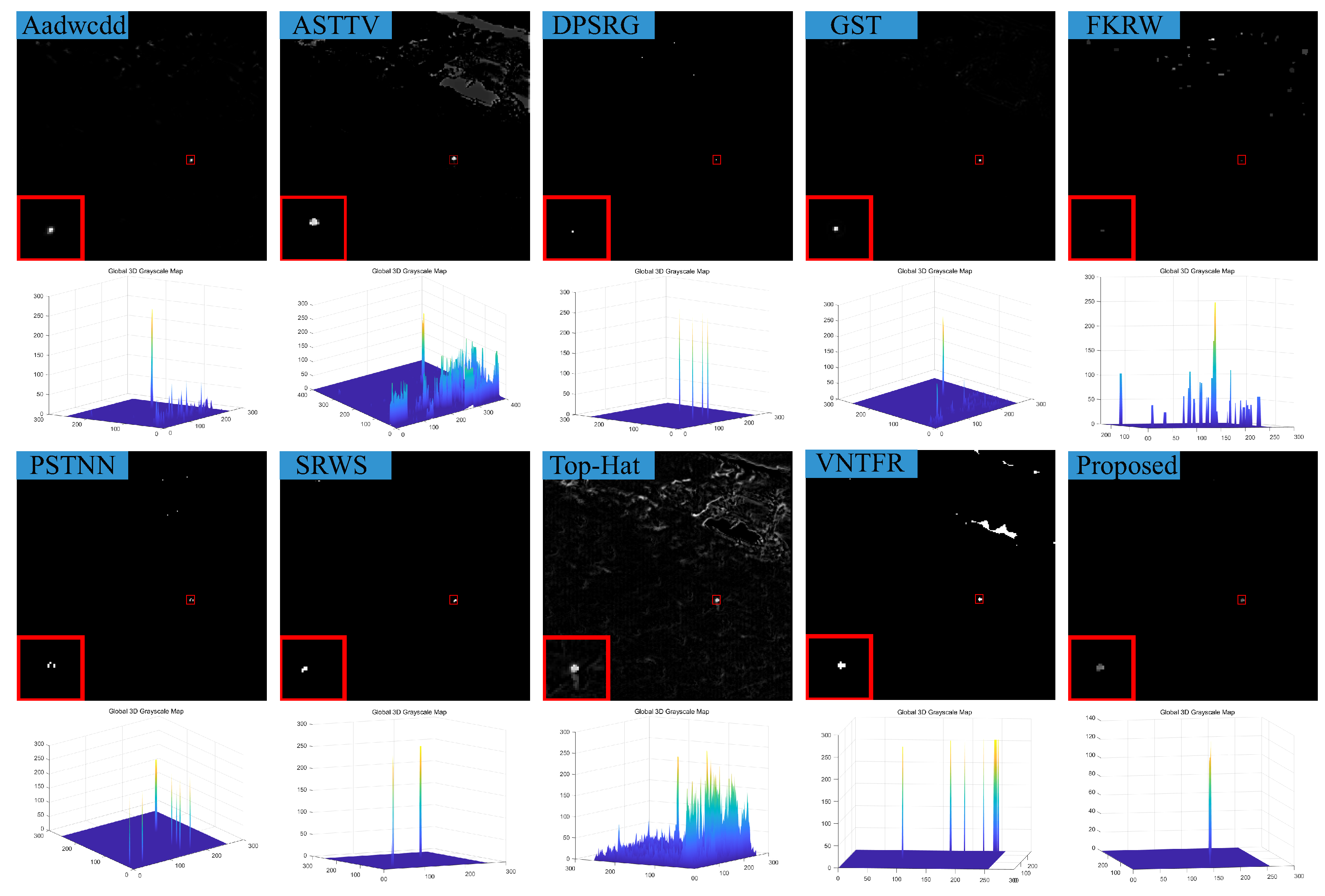
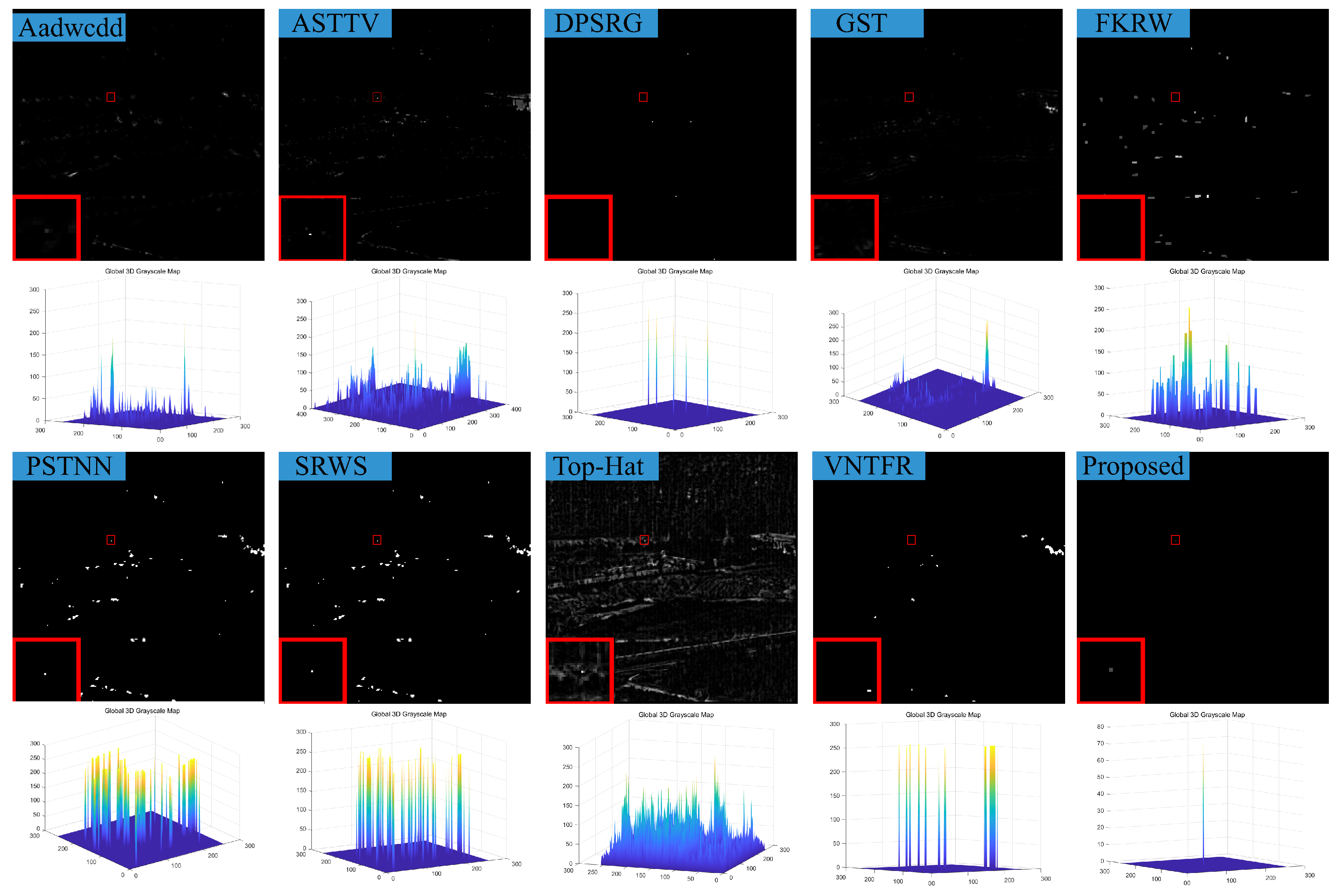
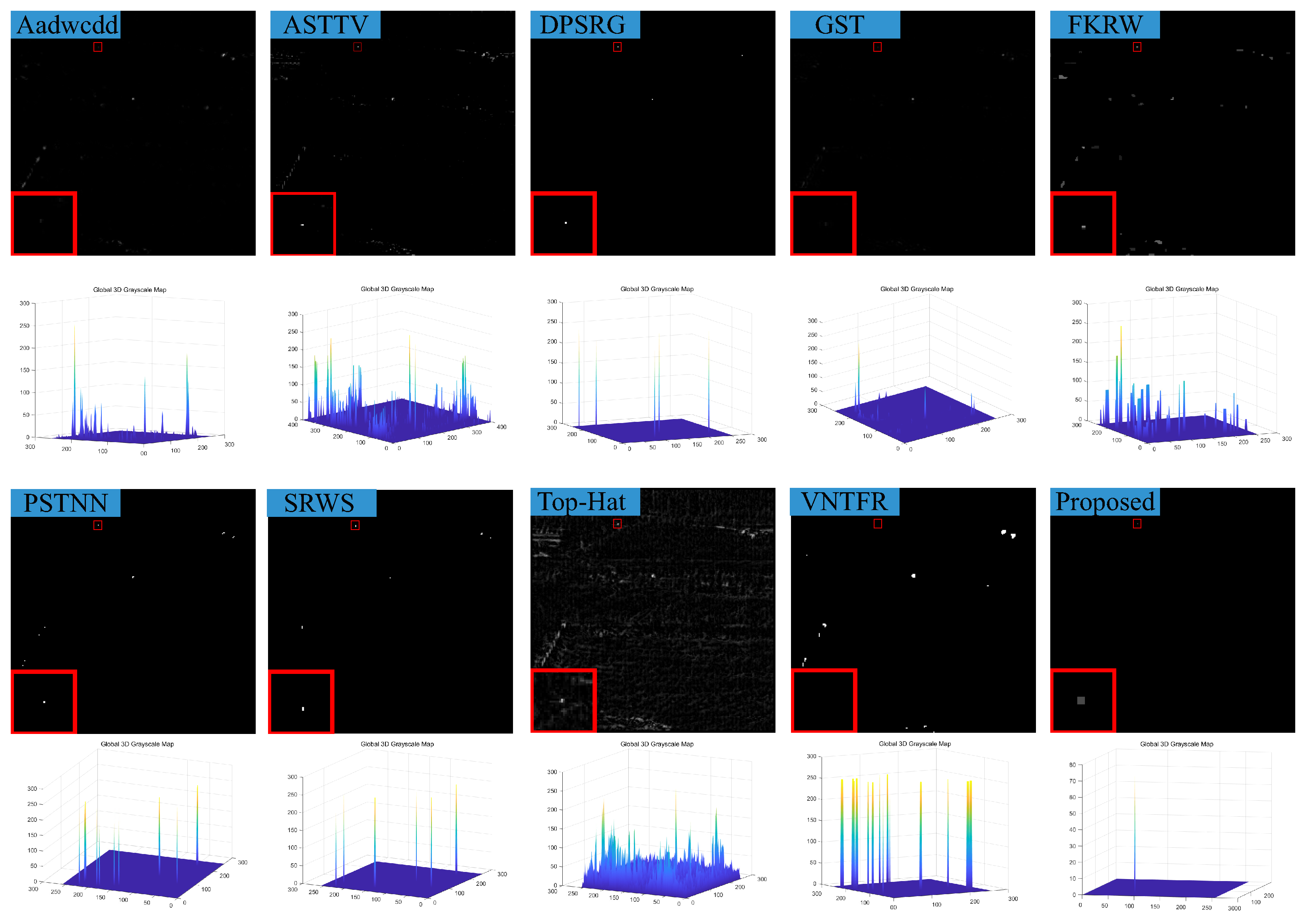
5. Conclusions
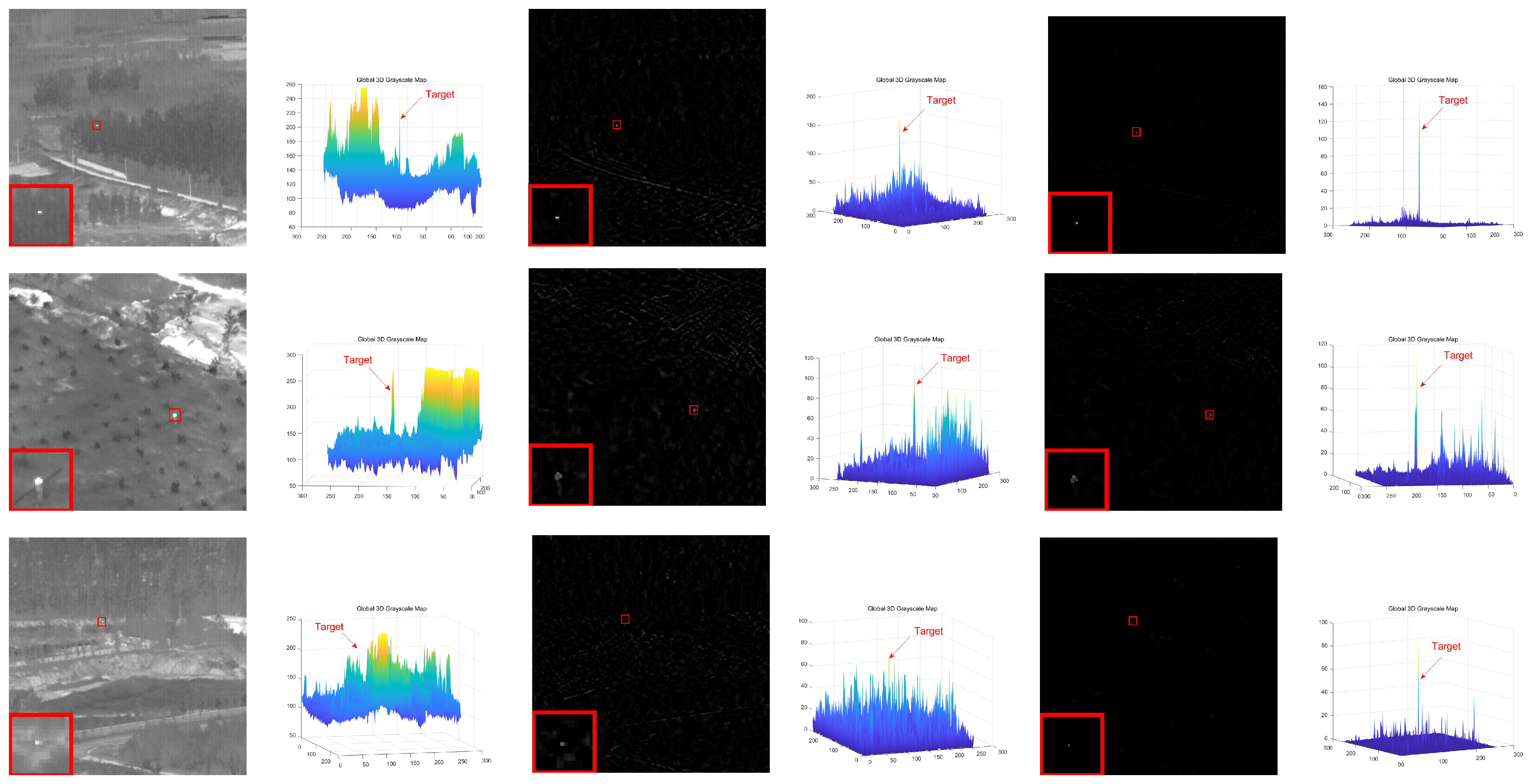
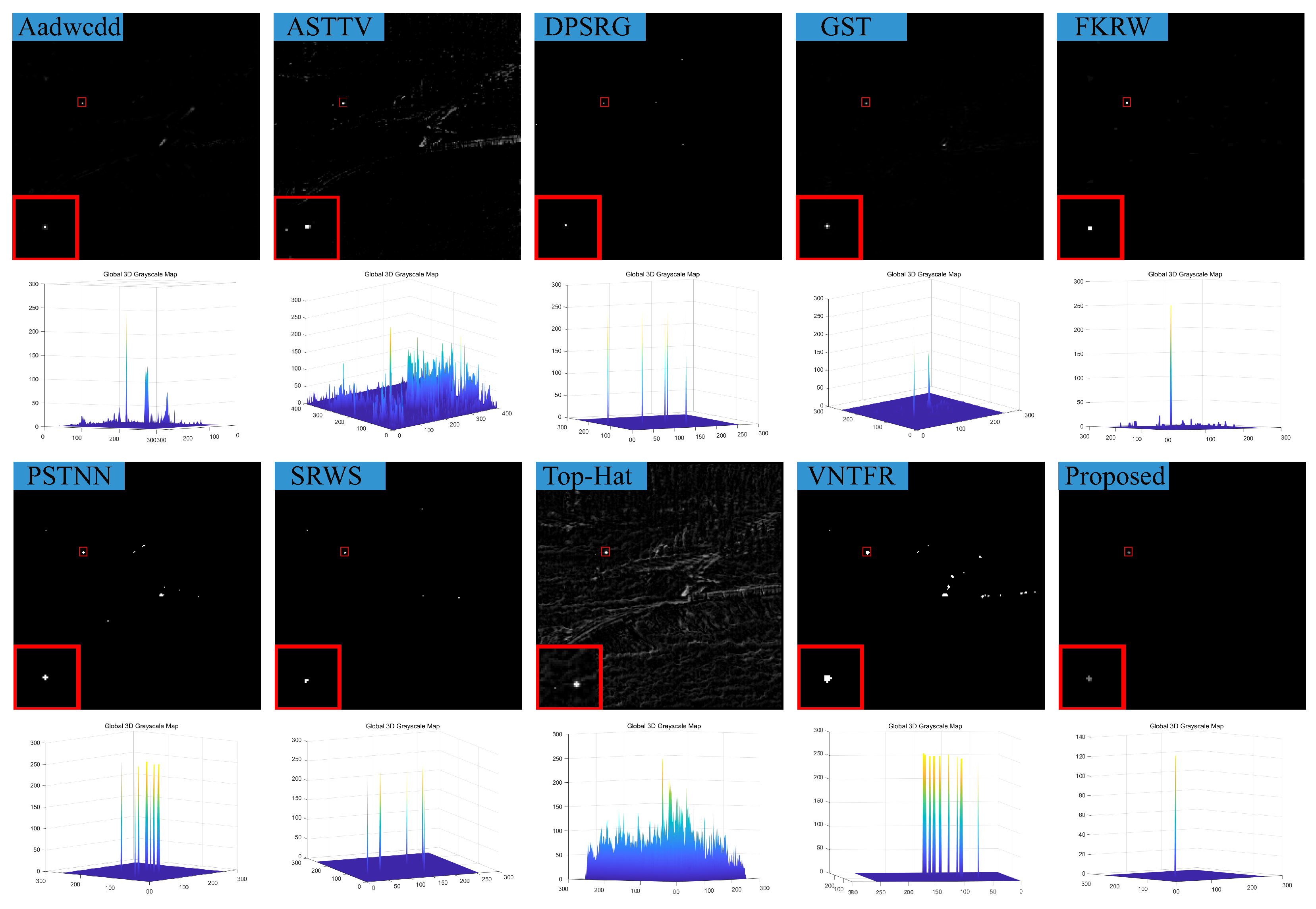
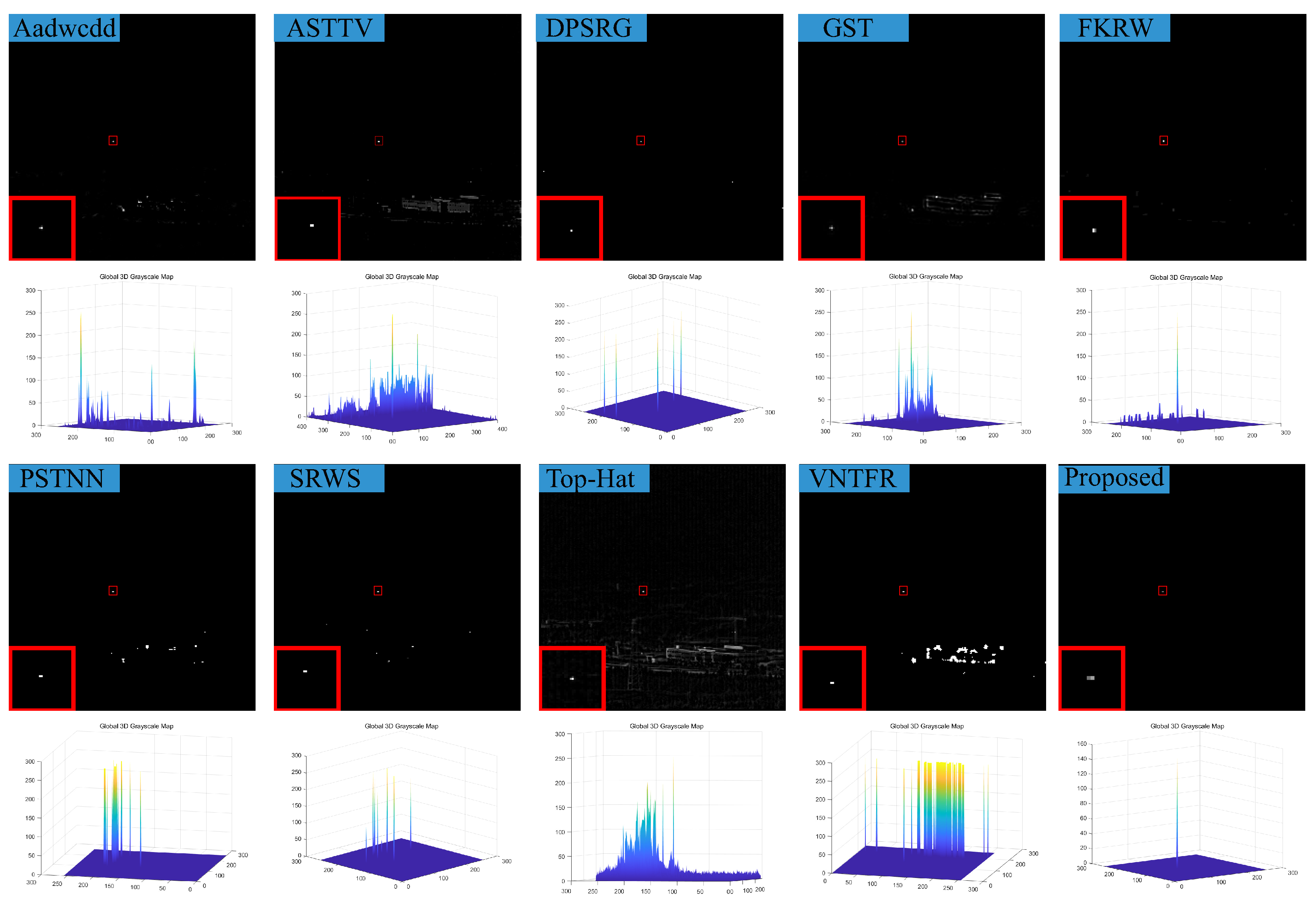
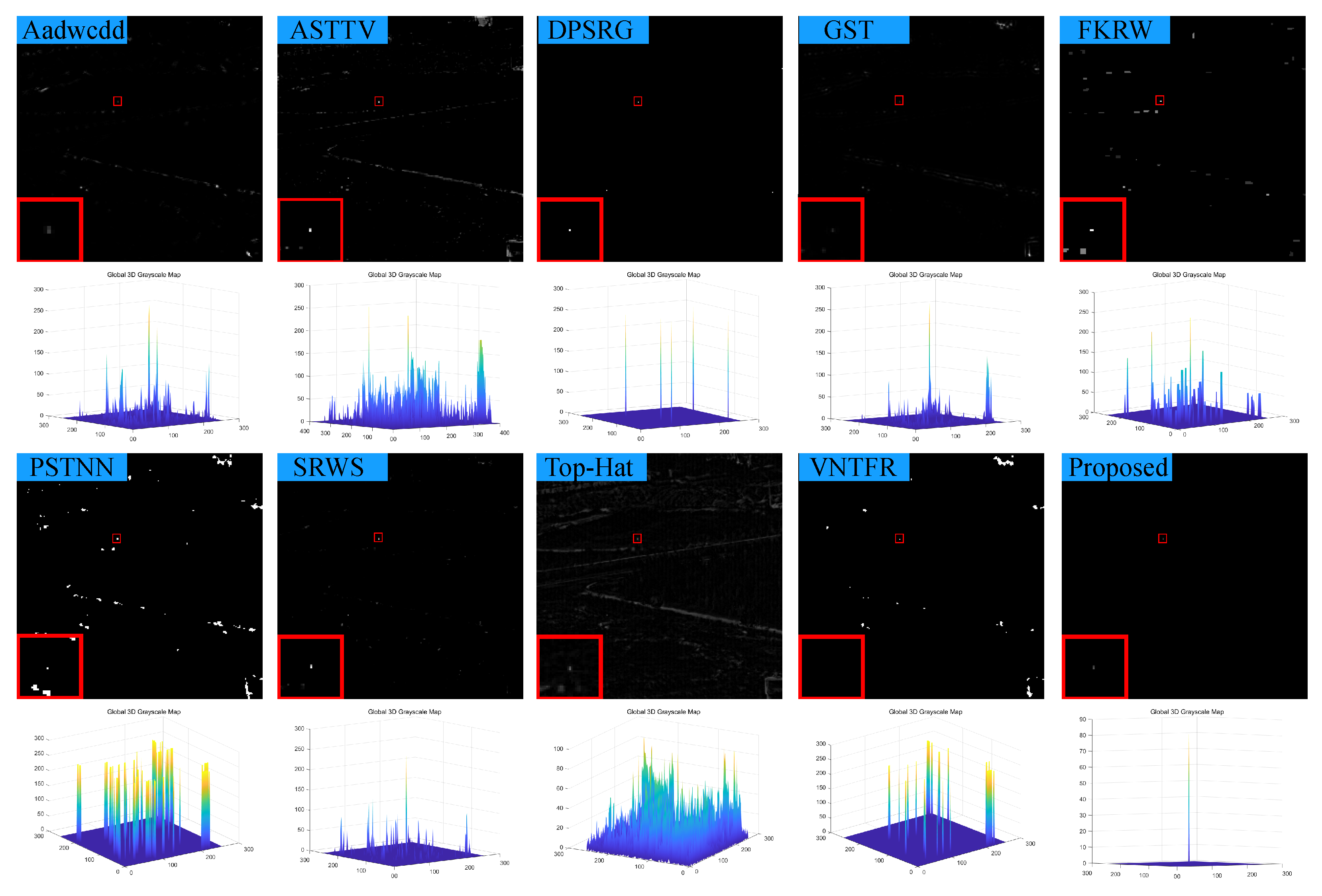
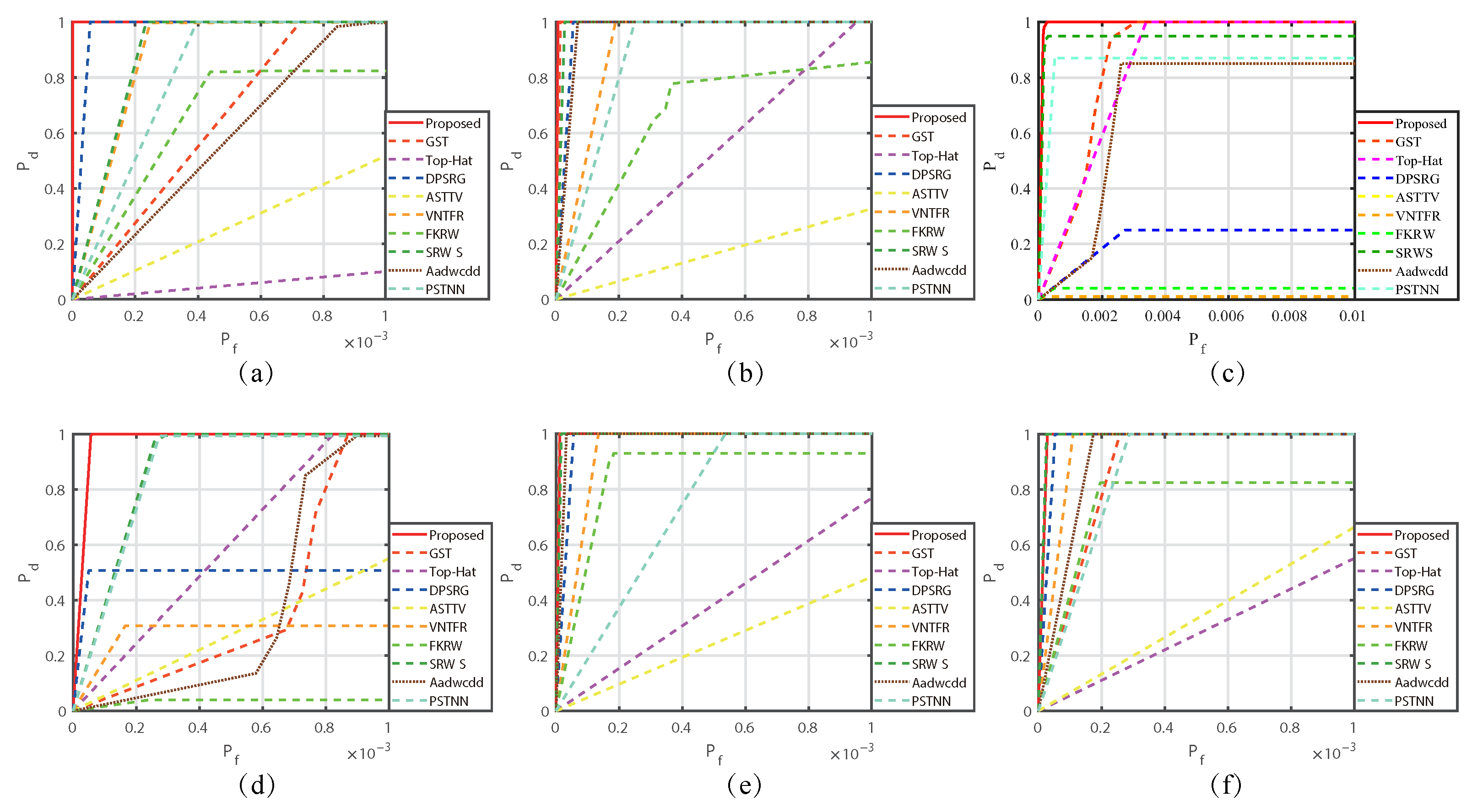
In response to the shortcomings of existing weak target algorithms in an intricate environment, such as low noise robustness, weak background suppression capability, and a high false alarm rate, we propose a low-rank sparse inversion weak target detection method using a joint new paradigm and attention mechanism. In this method, we use an improved tensor nuclear norm to explore the hidden structural information between various modes of the tensor, which can better approximate the tensor rank while reducing time and computational complexity compared to PSTNN, SNN, TNN, etc. We also establish a target sparse constraint algorithm based on self-attention mechanism as a prior information constraint model for target components to achieve better background and target separation and reduce noise and residual background in detection results. Finally, we use optimization algorithms based on ADMM and linear transformation T-SVD to solve the detection model. Based on extensive experimental results in various scenarios, our method demonstrates robustness and outperforms other algorithms in evaluation metrics such as BSF, SSIM, SNR, ROC, etc.
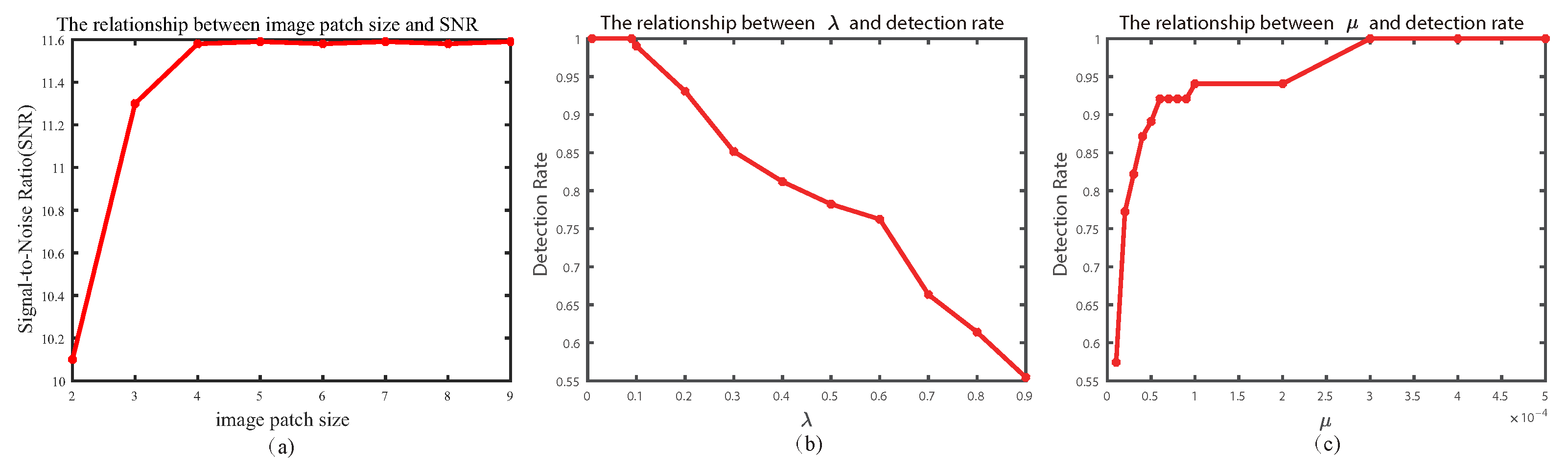
In the sparse target-constrained algorithm based on self-attention mechanism, the image patch size used in this paper is fixed, which has certain limitations when dealing with targets of different sizes. Therefore, if a method can be established to adaptively adjust the image patch size, it will lead to more exciting results. At the same time, we will explore the application of attention mechanism in the time domain and establish a target sparse constraint method based on image temporal–spatial information, which will be integrated into TRPCA model to further improve target detection performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}