
An Ensemble Learning Based Classification Approach for the Prediction of Household Solid Waste Generation

 ,
,  ,
,  , ,
, ,
Abstract
:1. Introduction
1.1. Motivations
- Poor use of smart waste management solutions in municipalities: in numerous urban cities around the world, the acceptance and use rate of new technologies (e.g., ML) that assist in the management of solid waste (e.g., waste collection, recycling) is still low.
- Inefficient and expensive IoT devices: transforming any city into a smart city, sadly, comes with a high financial and environmental cost. The practical challenge for municipalities is to reduce the reliance and installment of IoT sensors and devices while augmenting the waste management sector. ML techniques might offer the necessary escape route.
- Unoptimized use of waste management resources: legacy computer systems burden the capacity and resources (e.g., collection trucks, human capital) of waste management authorities. Examples of disadvantages include, but are not limited to, the inefficient waste bin collection routes and failure to meet the expectations and needs of the citizens.
- Lack of predictive analytics for waste management (SWM): municipalities are required to monitor in real-time and predict the waste of their cities (e.g., waste containers fill levels) during the season and thereby deploy the necessary infrastructure to accommodate the changing demands of the city households.
- Upgradation of waste management solutions with smart IoT architectures: waste management authorities that are using legacy platforms are in dire need to modernize their infrastructure to incorporate smart waste sensors to supply predictive models with the necessary waste data.
- Need for sustainable waste management attitudes and behaviors: there is an urging need to innovate intelligent waste management solutions that promote sustainable waste disposal practices and engage households in the reduction and recycling of their solid waste.
1.2. Main Contributions
- We proposed designing and training an ensemble model that can predict solid waste produced by the citizens/households of an actual city.
- We employed the Optuna algorithm, which uses an efficient sampling and pruning strategy to optimize the hyperparameter configurations to maximize the predictions of waste generation for all single ML models.
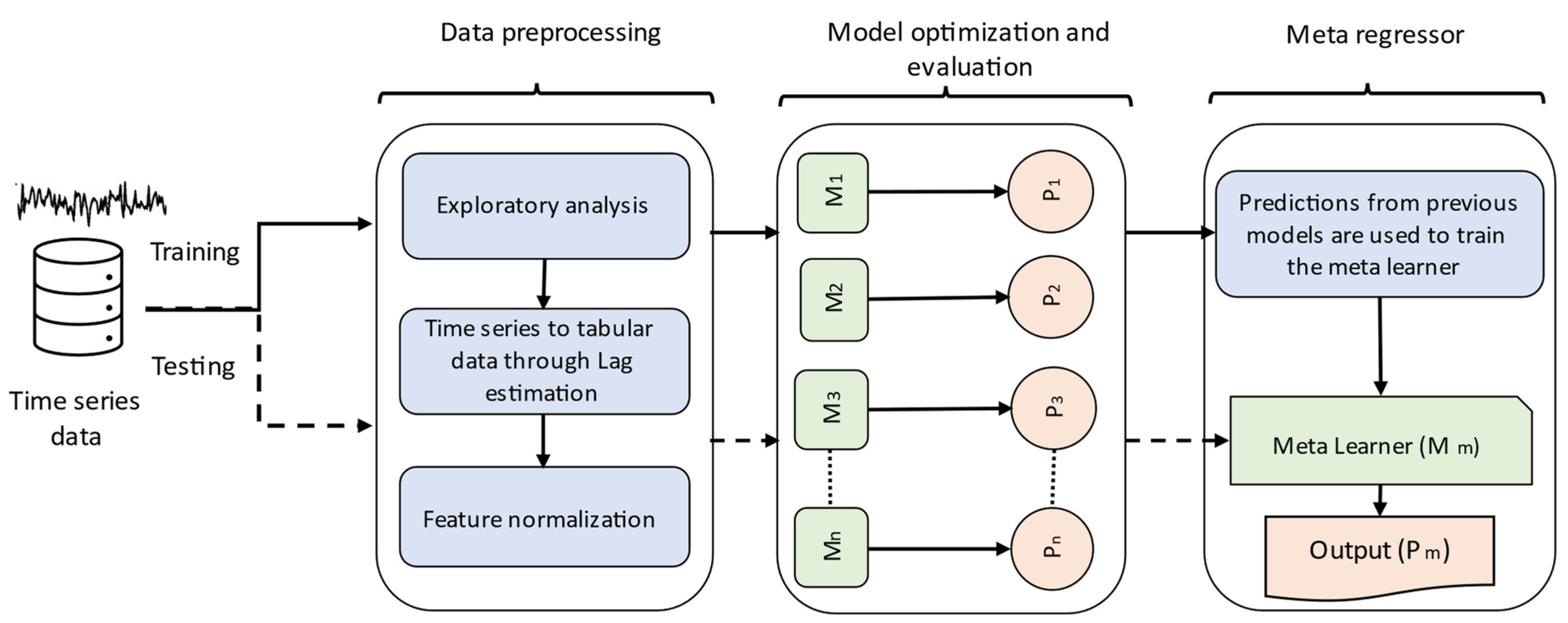
- To the best of our knowledge, we are the first study to introduce a meta regressor as an ensemble technique that learns from the predictions of the optimized machine learning models for forecasting household waste generation.
- We validated our ensemble meta learner model using a real dataset with limited features to make significant time-series predictions.
- We compared the proposed method and benchmarked it against existing state-of-the-art methods for predicting household waste generation.
1.3. Article Structure
2. Related Works
3. Materials and Methods
| Algorithm 1. Pseudocode for training the meta classifier |
| Input: Training Dataset |
| Output: An ensemble classifier C for weekly waste generation |
|
3.1. Solid Waste Dataset
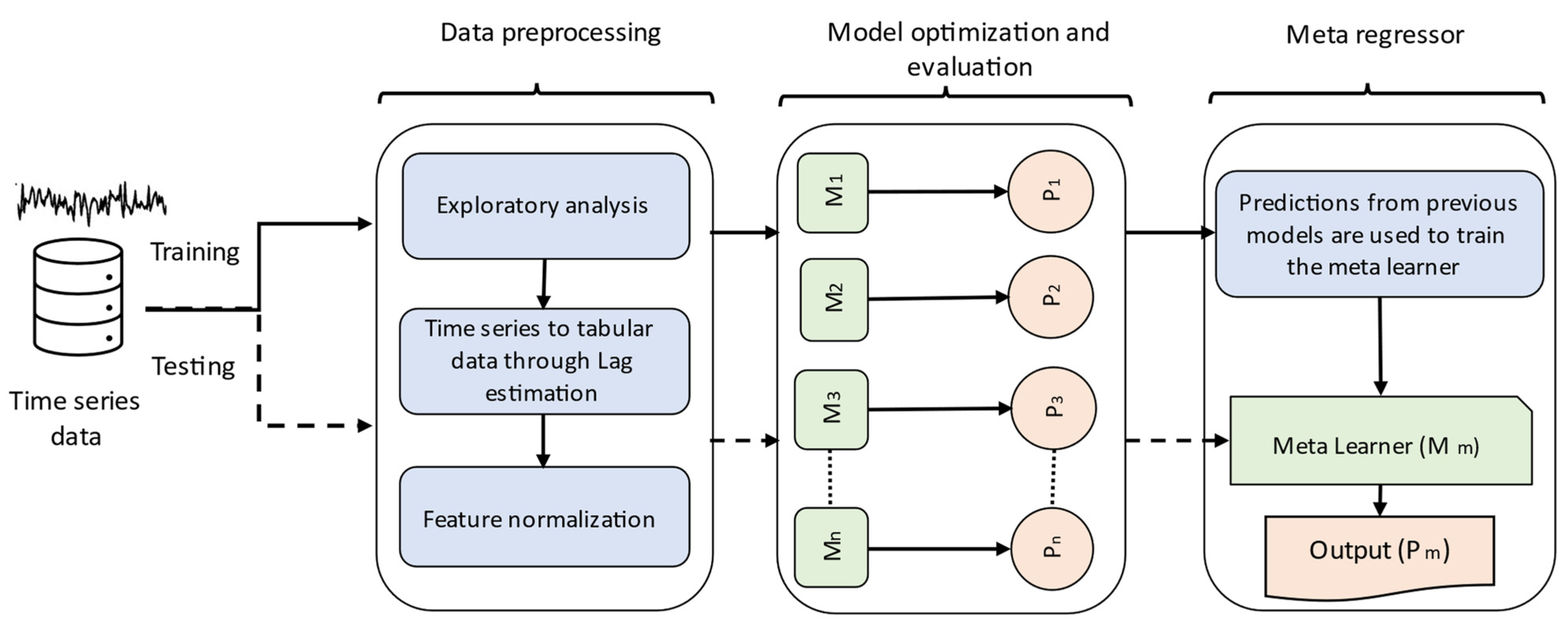
3.2. Data Preprocessing
3.3. Machine Learning Algorithms
3.4. Model Hyperparameter Optimization
3.5. Meta Regressor
3.6. Model Evaluation
3.6.1. Mean Absolute Error (MAE)
3.6.2. Mean Squared Error (MSE)
3.6.3. Mean Absolute Percentage Error (MAPE)
3.6.4. Coefficient of Determination (R2 score)
4. Results and Discussion
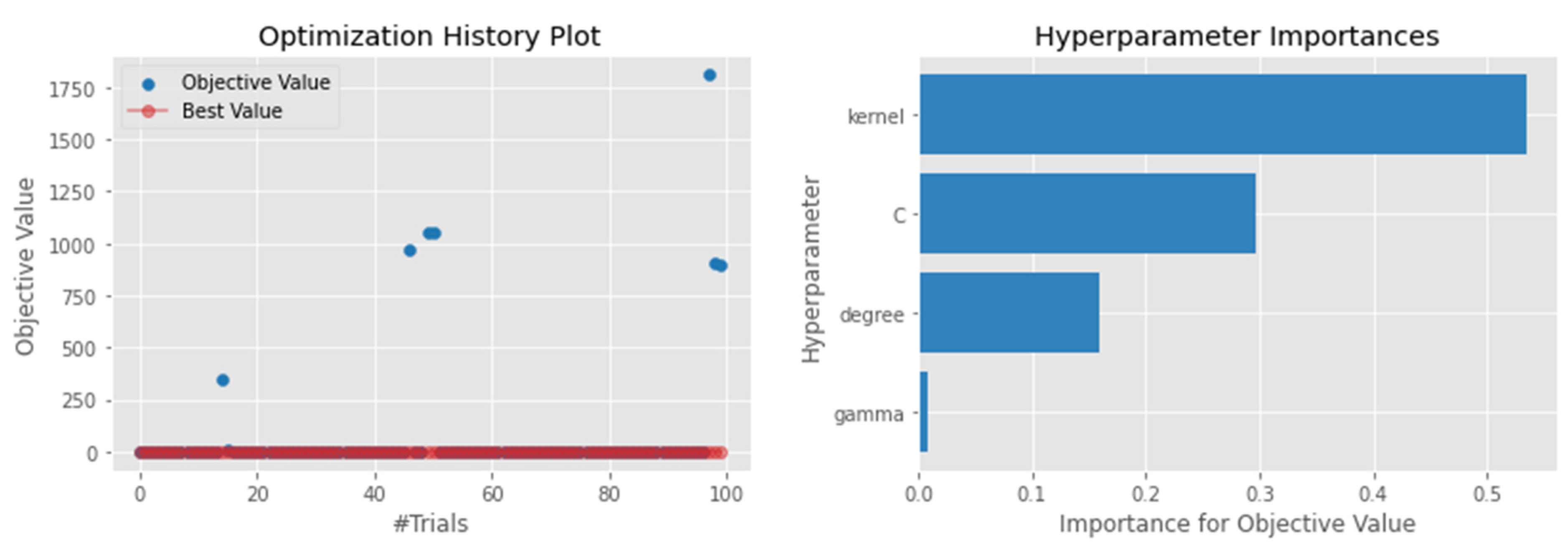
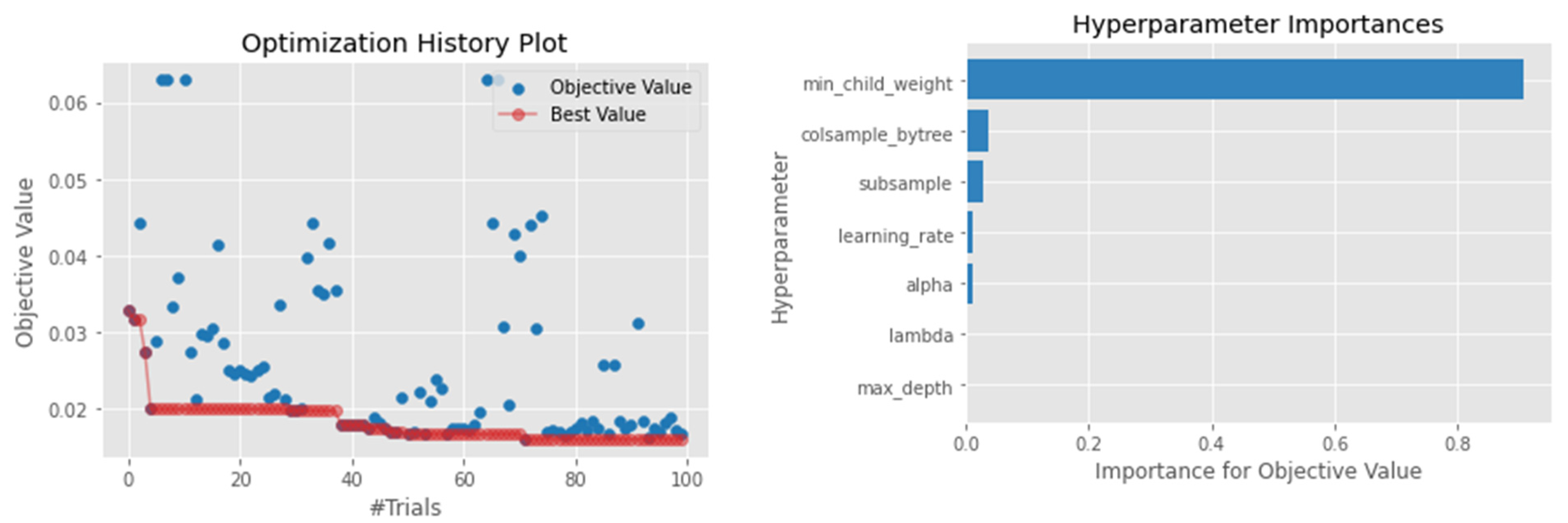
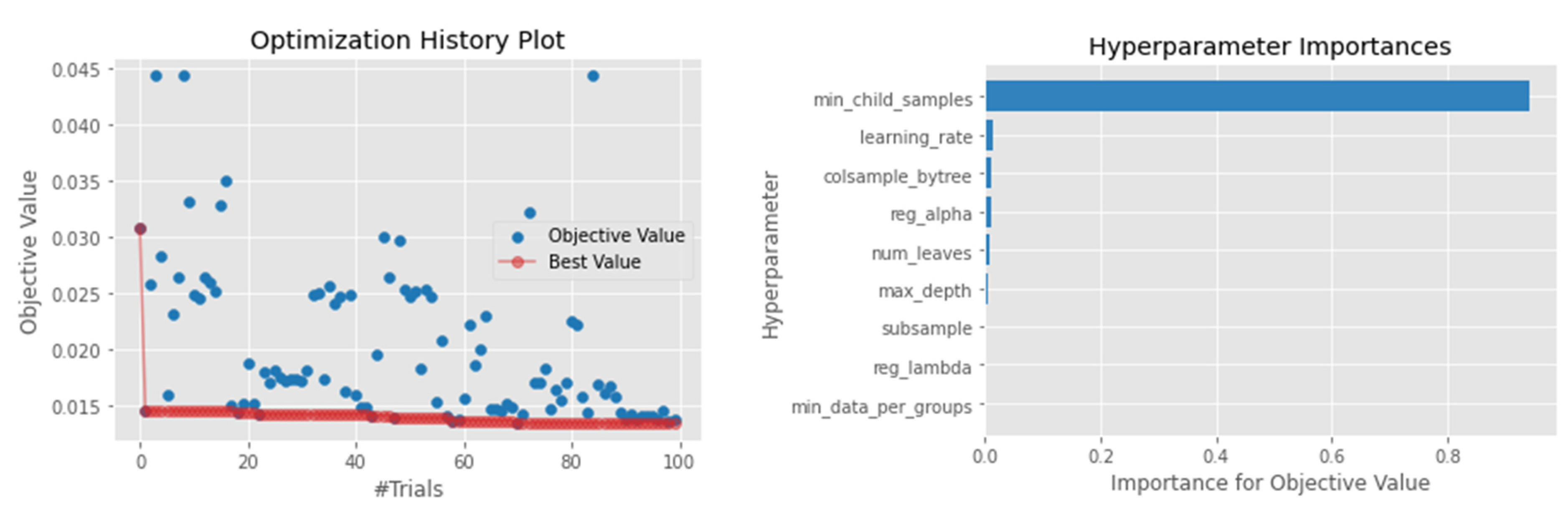
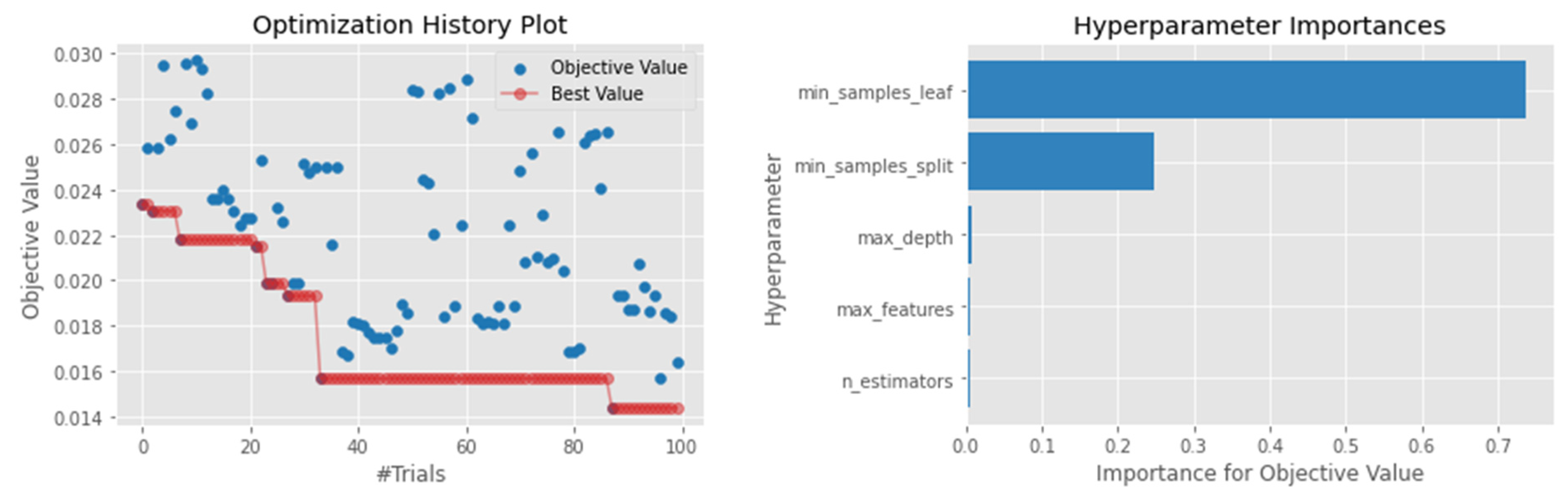
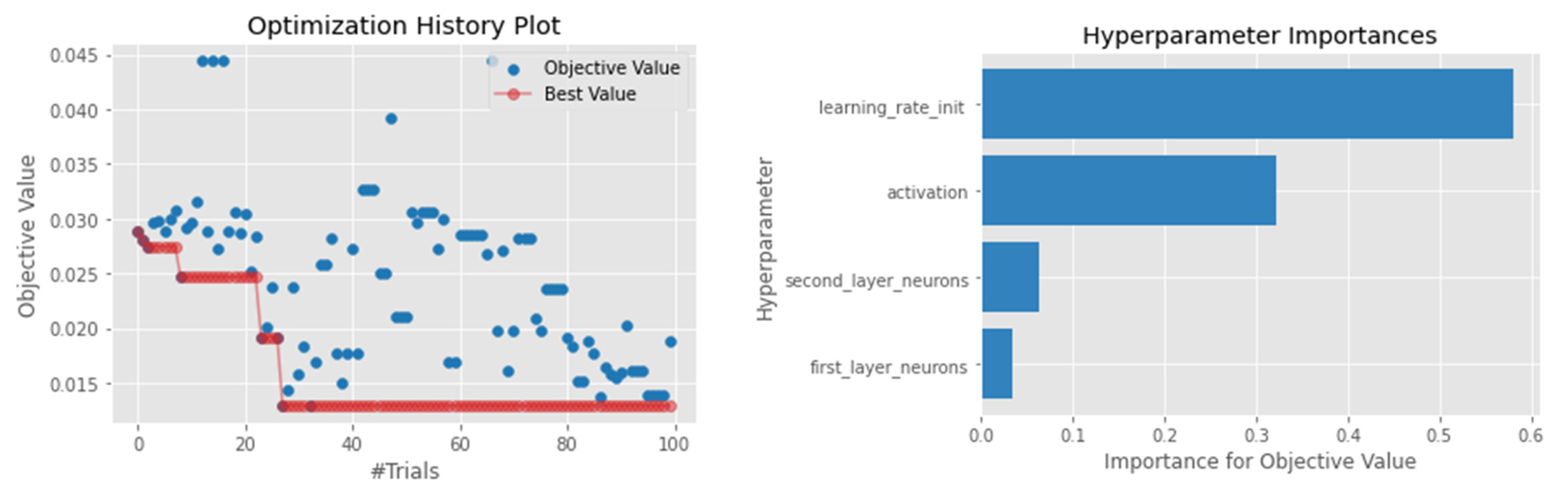
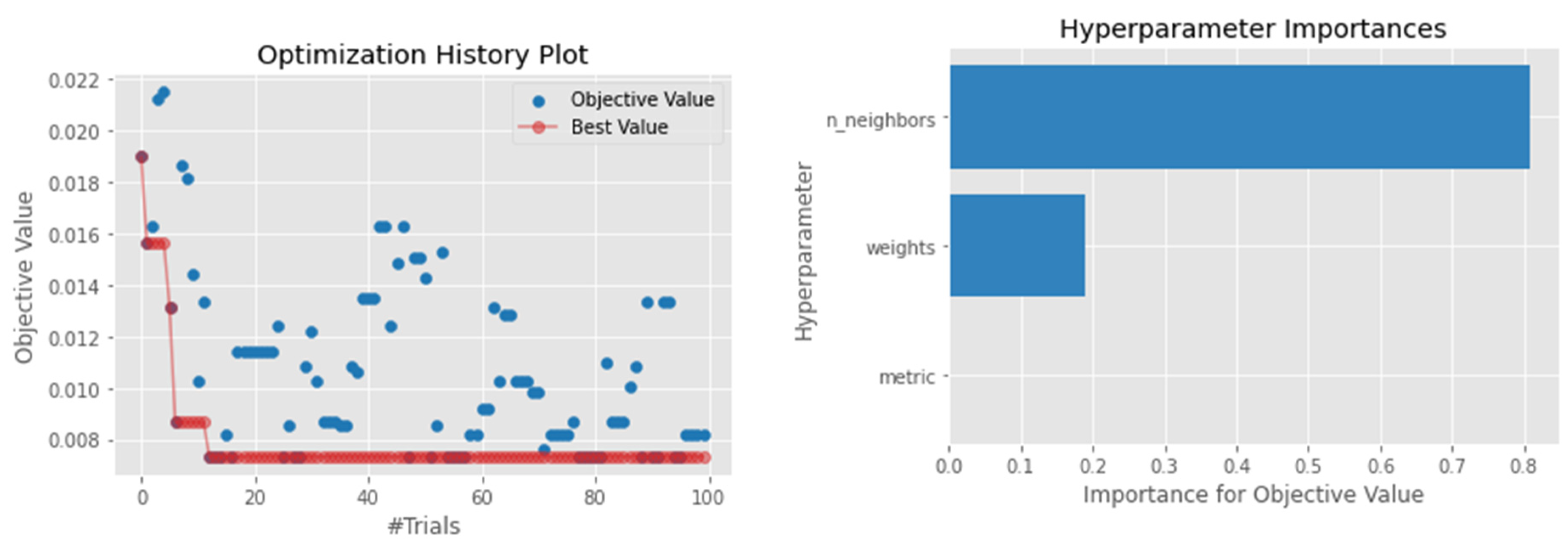
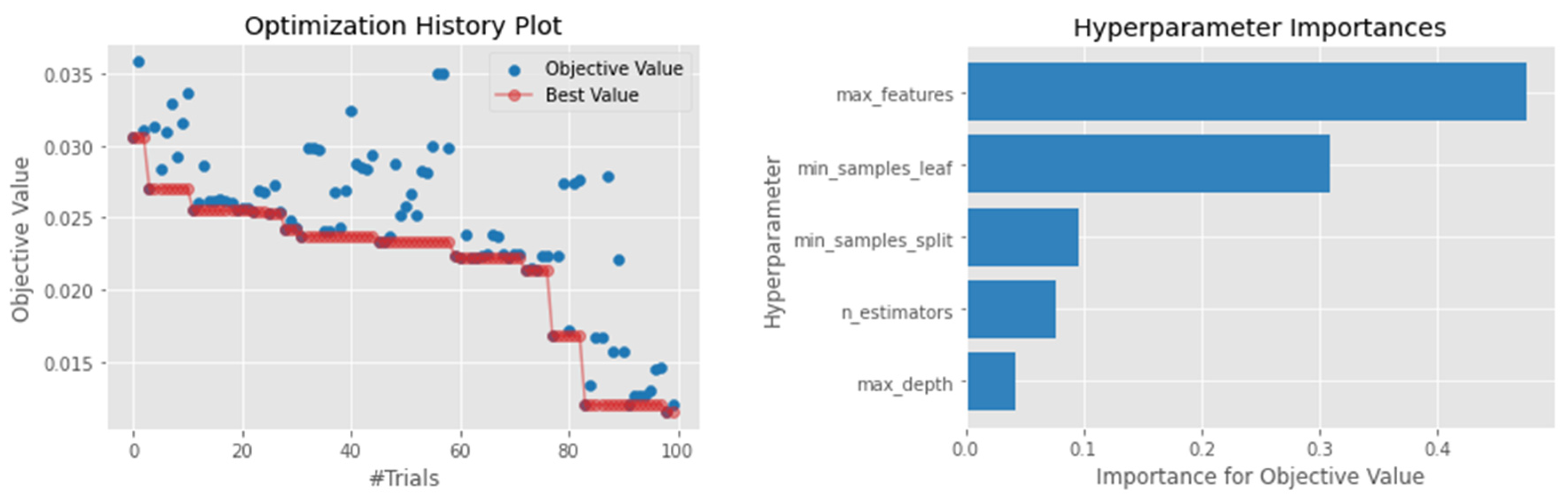
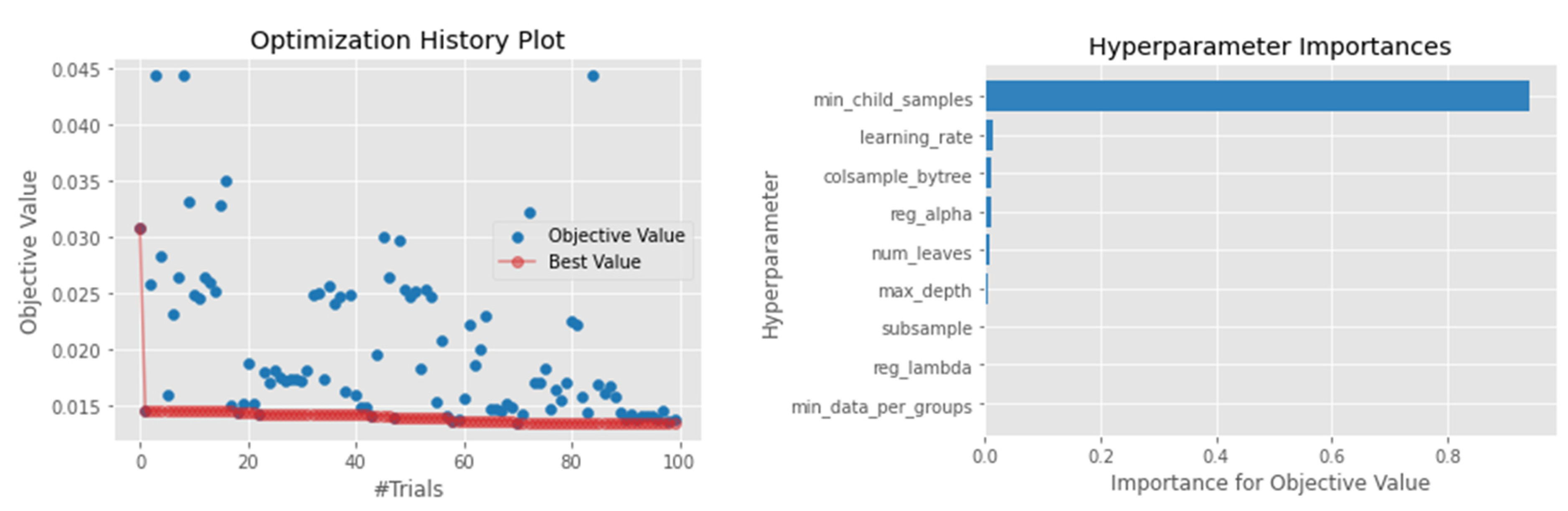
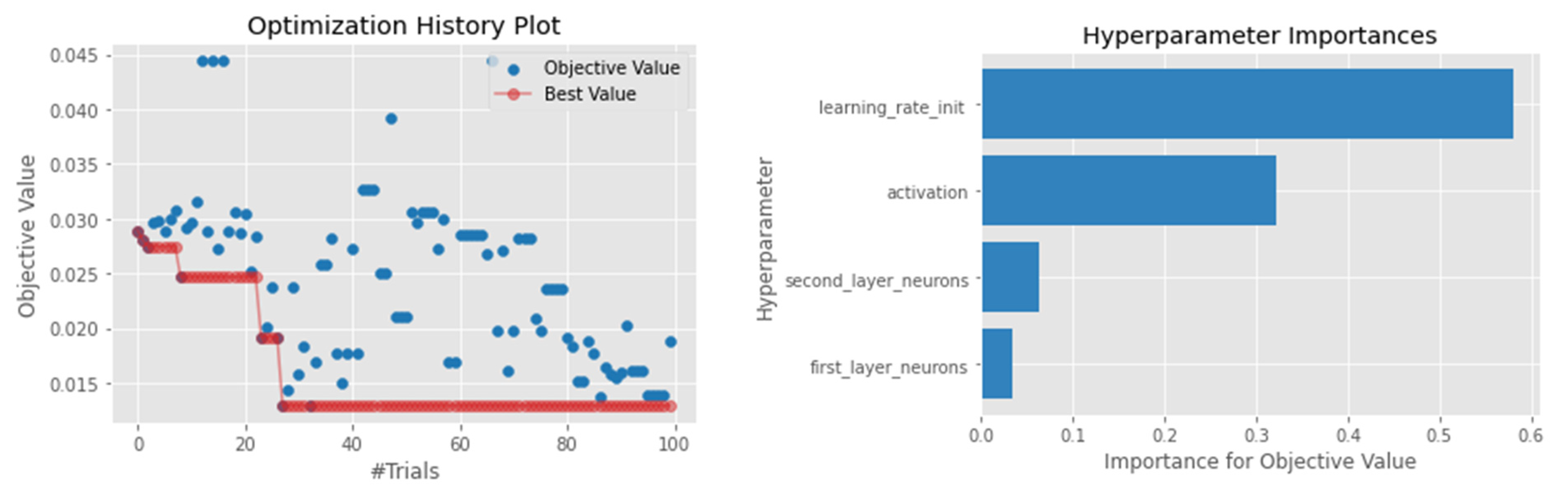
4.1. Hyperparameter Optimization
4.2. Prediction of Waste Generation Using ARIMA Model
4.3. Prediction of Waste Generation Using NARX Model
4.4. Prediction of Daily Waste Generation Using Machine Learning Algorithms
4.4.1. Support Vector Regressor
4.4.2. XGBoosting
4.4.3. LightGBM
4.4.4. Random Forest (RF)
4.4.5. Artificial Neural Network
4.4.6. K-Nearest Neighbors
4.4.7. ExtraTrees (ETS)
4.5. Prediction of Daily Waste Generation Using the Proposed Ensemble Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MAE | MSE | RMSE | MAPE | R2 Score |
|---|---|---|---|---|---|
| SARIMA [15] | 0.191 | 0.061 | 0.247 | 0.99 | −0.708 |
| NARX neural network [75] | 0.0850 | 0.014 | 0.119 | 0.834 | 0.612 |
| LightGBM [73] | 0.0796 | 0.0114 | 0.1066 | 0.3557 | 0.7462 |
| KNN [76] | 0.0652 | 0.0112 | 0.1060 | 0.2816 | 0.7489 |
| SVR [77] | 0.0927 | 0.0138 | 0.1174 | 0.4015 | 0.6918 |
| ETS [33] | 0.0817 | 0.0118 | 0.1085 | 0.3490 | 0.7368 |
| RF [78] | 0.0850 | 0.0128 | 0.1131 | 0.3822 | 0.7143 |
| XGBoosting [79] | 0.0898 | 0.0148 | 0.1215 | 0.4044 | 0.6700 |
| ANN [80] | 0.0895 | 0.0141 | 0.1186 | 0.3784 | 0.6854 |
| Ensemble (Average ensemble) | 0.073 | 0.010 | 0.098 | 0.331 | 0.787 |
| Proposed Ensemble (Meta model) | 0.059 | 0.009 | 0.094 | 0.263 | 0.802 |
5. Theoretical and Managerial Implications
6. Conclusions and Future Works
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Worldbank. Urban Population. Available online: https://data.worldbank.org/indicator/SP.URB.TOTL.IN.ZS (accessed on 8 April 2022).
- United Nations. Available online: https://www.un.org/development/desa/en/news/population/2018-revision-of-world-urbanization-prospects.html (accessed on 8 April 2022).
- Worldbank. Trends in Solid Waste Management. Available online: https://datatopics.worldbank.org/what-a-waste/trends_in_solid_waste_management.html (accessed on 8 April 2022).
- Zanella, A.; Bui, N.; Castellani, A.; Vangelista, N.; Zorzi, M. Internet of Things for smart cities. IEEE Internet Things J. 2014, 1, 22–32. [Google Scholar] [CrossRef]
- Pardini, K.; Rodrigues, J.J.; Diallo, O.; Das, A.K.; de Albuquerque, V.H.C.; Kozlov, S.A. A Smart Waste Management Solution Geared towards Citizens. Sensors 2020, 20, 2380. [Google Scholar] [CrossRef] [Green Version]
- Mdukaza, S.; Isong, B.; Dladlu, N.; Abu-Mahfouz, A.M. Analysis of IoT-enabled solutions in smart waste management. In Proceedings of the IECON 2018—44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018. [Google Scholar]
- Wu, H.; Yang, B.; Tao, F. Optimization of vehicle routing for waste collection and transportation. Int. J. Environ. Res. Public Health 2020, 17, 4963. [Google Scholar] [CrossRef] [PubMed]
- Pardini, K.; Rodrigues, J.J.P.C.; Kozlov, S.A.; Kumar, N.; Furtado, V. IoT-Based Solid Waste Management Solutions: A Survey. J. Sens. Actuator Netw. 2019, 8, 5. [Google Scholar] [CrossRef] [Green Version]
- Ali, T.; Irfan, M.; Alwadie, A.S.; Glowacz, A. IoT-Based Smart Waste Bin Monitoring and Municipal Solid Waste Management System for Smart Cities. Arab. J. Sci. Eng. 2020, 45, 10185–10198. [Google Scholar] [CrossRef]
- Folianto, F.; Low, Y.S.; Yeow, W.L. Smartbin: Smart waste management system. In Proceedings of the 2015 IEEE Tenth International Conference on Intelligent Sensors, Sensor Networks and Information Processing (ISSNIP), Singapore, 7–9 April 2015; pp. 1–2. [Google Scholar]
- Shyam, G.K.; Manvi, S.S.; Bharti, P. Smart waste management using Internet-of-Things (IoT). In Proceedings of the 2nd International Conference on Computing and Communications Technologies, Kaushambi, India, 22–24 September 2017. [Google Scholar]
- Mahajan, S.A.; Kokane, A.; Shewale, A.; Shinde, M.; Ingale, S. Smart waste management system using IoT. Int. J. Adv. Eng. Res. Sci. 2017, 4, 237122. [Google Scholar] [CrossRef]
- Gupta, P.K.; Shree, V.; Hiremath, L.; Rajendran, S. The Use of Modern Technology in Smart Waste Management and Recycling: Artificial Intelligence and Machine Learning. In Advances in Intelligent Information and Database Systems; Springer Science and Business Media LLC: Berlin, Germany, 2019; Volume 823, pp. 173–188. [Google Scholar]
- Bakhshi, T.; Ahmed, M. Iot-Enabled Smart City Waste Management Using Machine Learning Analytics. In Proceedings of the 2018 2nd International Conference on Energy Conservation and Efficiency (ICECE), Lahore, Pakistan, 16–17 October 2018; pp. 66–71. [Google Scholar]
- Kannangara, M.; Dua, R.; Ahmadi, L.; Bensebaa, F. Modeling and prediction of regional municipal solid waste generation and diversion in Canada using machine learning approaches. Waste Manag. 2017, 74, 3–15. [Google Scholar] [CrossRef]
- Medvedev, A.; Fedchenkov, P.; Zaslavsky, A.; Anagnostopoulos, T.; Khoruzhnikov, S. Waste management as an IoT-enabled service in smart cities. In Proceedings of the 15th International Conference, NEW2AN 2015, and 8th Conference ruSMART 2015, St. Petersburg, Russia, 26–28 August 2015; pp. 104–115. [Google Scholar]
- Fatimah, Y.A.; Govindan, K.; Murniningsih, R.; Setiawan, A. Industry 4.0 based sustainable circular economy approach for smart waste management system to achieve sustainable development goals: A case study of Indonesia. J. Clean. Prod. 2020, 269, 122263. [Google Scholar] [CrossRef]
- Anagnostopoulos, T.; Zaslavsky, A.; Kolomvatsos, K.; Medvedev, A.; Amirian, P.; Morley, J.; Hadjiefthymiades, S. Challenges and Opportunities of Waste Management in IoT-enabled Smart Cities: A Survey. IEEE Trans. Sustain. Comput. 2017, 2, 275–289. [Google Scholar] [CrossRef]
- Fallavi, K.N.; Kumar, V.R.; Chaithra, B.M. Smart waste management using Internet of Things: A survey. In Proceedings of the 2017 International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 10–11 February 2017; pp. 60–64. [Google Scholar]
- Londres, G.; Filipe, N.; Gama, J. Optimizing Waste Collection: A Data Mining Approach. In ECML PKDD 2019: Machine Learning and Knowledge Discovery in Databases, Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Würzburg, Germany, 16–20 September 2019; Cellier, P., Driessens, K., Eds.; Springer Science and Business Media LLC: Berlin, Germany, 2019; Volume 1167, pp. 570–578. [Google Scholar]
- Camero, A.; Toutouh, J.; Ferrer, J.; Alba, E. Waste generation prediction in smart cities through deep neuroevolution. In Ibero-American Congress on Information Management and Big Data; Springer Science and Business Media LLC: Berlin, Germany, 2018; Volume 978, pp. 192–204. [Google Scholar]
- Sheng, T.J.; Islam, M.S.; Misran, N.; Baharuddin, M.H.; Arshad, H.; Islam, M.R.; Chowdhury, M.E.H.; Rmili, H.; Islam, M.T. An internet of things based smart waste management system using LoRa and tensorflow deep learning model. IEEE Access 2020, 8, 148793–148811. [Google Scholar] [CrossRef]
- Ahmed, N.; Atiya, A.; Gayar, N.; El-Shishiny, H. An Empirical Comparison of Machine Learning Models for Time Series Forecasting. Econom. Rev. 2010, 29, 594–621. [Google Scholar] [CrossRef]
- Ferrer, J.; Alba, E. BIN-CT: Urban waste collection based on predicting the container fill level. Biosystems 2019, 186, 103962. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Camero, A.; Toutouh, J.; Ferrer, J.; Alba, E. Waste generation prediction under uncertainty in smart cities through deep neuroevolution. Rev. Fac. Ing. Univ. Antioq. 2019, 93, 128–138. [Google Scholar] [CrossRef]
- Fan, Y.V.; Jiang, P.; Tan, R.R.; Aviso, K.B.; You, F.; Zhao, X.; Lee, C.T.; Klemeš, J.J. Forecasting plastic waste generation and interventions for environmental hazard mitigation. J. Hazard. Mat. 2021, 424, 127330. [Google Scholar] [CrossRef] [PubMed]
- Jassim, M.S.; Coskuner, G.; Zontul, M. Comparative performance analysis of support vector regression and artificial neural network for prediction of municipal solid waste generation. Waste Manag. Res. 2022, 40, 195–204. [Google Scholar] [CrossRef] [PubMed]
- Kontokosta, C.E.; Hong, B.; Johnson, N.E.; Starobin, D. Using machine learning and small area estimation to predict building-level municipal solid waste generation in cities. Comput. Environ. Urban Syst. 2018, 70, 151–162. [Google Scholar] [CrossRef]
- Yang, L.; Zhao, Y.; Niu, X.; Song, Z.; Gao, Q.; Wu, J. Municipal Solid Waste Forecasting in China Based on Machine Learning Models. Front. Energy Res. 2021, 9, 1–13. [Google Scholar] [CrossRef]
- Kulisz, M.; Kujawska, J. Prediction of municipal waste generation in Poland using neural network modeling. Sustainability 2020, 12, 10088. [Google Scholar] [CrossRef]
- Flores, C.A.R.; da Cunha, A.C.; Cunha, H.F.A. Solid waste generation indicators, per capita, in Amazonian countries. Environ. Sci. Pollut. Res. 2022, 18509–3, 1–14. [Google Scholar] [CrossRef]
- Elshaboury, N.; Mohammed Abdelkader, E.; Al-Sakkaf, A.; Alfalah, G. Predictive Analysis of Municipal Solid Waste Generation Using an Optimized Neural Network Model. Processes 2021, 9, 2045. [Google Scholar] [CrossRef]
- Rathod, T.; Hudnurkar, M.; Ambekar, S. Use of Machine Learning in Predicting the Generation of Solid Waste. Pjaee 2020, 17, 4323–4335. [Google Scholar]
- Meza, J.K.S.; Yepes, D.O.; Rodrigo-Ilarri, J.; Cassiraga, E. Predictive analysis of urban waste generation for the city of Bogotá, Colombia, through the implementation of decision trees-based machine learning, support vector machines and artificial neural networks. Heliyon 2019, 5, e02810. [Google Scholar] [CrossRef] [PubMed]
- Abbasi, M.; El Hanandeh, A. Forecasting municipal solid waste generation using artificial intelligence modelling approaches. J. Waste Manag. 2016, 56, 13–22. [Google Scholar] [CrossRef] [PubMed]
- Kumar, S.; Kumar, R. Forecasting of municipal solid waste generation using non-linear autoregressive (NAR) neural models. Waste Manag. 2021, 121, 206–214. [Google Scholar]
- Ali, S.; Ahmad, A. Forecasting MSW generation using artificial neural network time series model: A study from metropolitan city. SN Appl. Sci. 2019, 1, 1–16. [Google Scholar] [CrossRef] [Green Version]
- Baldo, D.; Mecocci, A.; Parrino, S.; Peruzzi, G.; Pozzebon, A. A Multi-Layer LoRaWAN Infrastructure for Smart Waste Management. Sensors 2021, 21, 2600. [Google Scholar] [CrossRef]
- Vishnu, S.; Ramson, S.; Senith, S.; Anagnostopoulos, T.; Abu-Mahfouz, A.; Fan, X.; Srinivasan, S.; Kirubaraj, A. IoT-Enabled Solid Waste Management in Smart Cities. Smart Cities 2021, 4, 53. [Google Scholar] [CrossRef]
- Balaji, S.; Nathani, K.; Santhakumar, R. IoT Technology, Applications and Challenges: A Contemporary Survey. Wirel. Pers. Commun. 2019, 108, 363–388. [Google Scholar] [CrossRef]
- Razmjoo, A.; Gandomi, A.; Mahlooji, M.; Astiaso Garcia, D.; Mirjalili, S.; Rezvani, A.; Ahmadzadeh, S.; Memon, S. An Investigation of the Policies and Crucial Sectors of Smart Cities Based on IoT Application. Appl. Sci. 2022, 12, 2672. [Google Scholar] [CrossRef]
- Salehi-Amiri, A.; Akbapour, N.; Hajiaghaei-Keshteli, M.; Gajpal, Y.; Jabbarzadeh, A. Designing an effective two-stage, sustainable, and IoT based waste management system. Renew. Sustain. Energy Rev. 2022, 157, 112031. [Google Scholar] [CrossRef]
- Claire, N.U.M.; Ngend, L. IOT Based Waste Management for Smart City, Case of Musanze City. Int. J. Progress. Sci. Tech. 2022, 30, 537–542. [Google Scholar]
- Shukla, S.; Hait, S. Smart waste management practices in smart cities: Current trends and future perspectives. In Advanced Organic Waste Management: Sustainable Practices and Approaches; Elsevier: Amsterdam, The Netherlands, 2022; pp. 407–424. [Google Scholar]
- John, J.; Varkey, M.S.; Podder, R.S.; Sensarma, N.; Selvi, M.; Santhosh Kumar, S.V.N.; Kannan, A. Smart Prediction and Monitoring of Waste Disposal System Using IoT and Cloud for IoT Based Smart Cities. Wirel. Pers. Com. 2022, 122, 243–275. [Google Scholar] [CrossRef]
- Tasnim, R.S. Ensemble Classifiers and Their Applications: A Review. Int. J. Comput. Trends Technol. 2014, 10, 31–35. [Google Scholar]
- Chongomweru, H.; Kasem, A. A novel ensemble method for classification in imbalanced datasets using split balancing technique based on instance hardness (sBal_IH). Neural Comput. Appl. 2021, 33, 11233–11254. [Google Scholar] [CrossRef]
- GitHub. Smart Waste Generation. Available online: https://github.com/anamoun/smartwastegeneration (accessed on 15 March 2022).
- Caiafa, C.F.; Sun, Z.; Tanaka, T.; Marti-Puig, P.; Solé-Casals, J. Machine Learning Methods with Noisy, Incomplete or Small Datasets. Appl. Sci. 2021, 11, 4132. [Google Scholar] [CrossRef]
- Brownlee, J. Basic Feature Engineering with Time Series Data in Python. Machine Learning Mastery. 2019. Available online: https://machinelearningmastery.com/basic-feature-engineering-time-series-data-python (accessed on 5 February 2022).
- Masini, R.P.; Medeiros, M.C.; Mendes, E.F. Machine learning advances for time series forecasting. J. Econ. Sur. 2021, 3, 1–44. [Google Scholar]
- Surakhi, O.; Zaidan, M.A.; Fung, P.L.; Hossein Motlagh, N.; Serhan, S.; AlKhanafseh, M.; Ghoniem, R.M.; Hussein, T. Time-Lag Selection for Time-Series Forecasting Using Neural Network and Heuristic Algorithm. Electronics 2021, 10, 2518. [Google Scholar] [CrossRef]
- Xia, W.; Jiang, Y.; Chen, X.; Zhao, R. Application of machine learning algorithms in municipal solid waste management: A mini review. Waste Manag. Res. 2021, 40, 609–624. [Google Scholar] [CrossRef]
- Fernandez-Delgado, M.; Cernadas, E.; Barro, S. Do we Need Hundreds of Classifiers to Solve Real World Classification Problems? J. Mach. Learn. 2014, 15, 3133–3181. [Google Scholar]
- Sami, K.N.; Amin, Z.M.A.; Hassan, R. Waste Management Using Machine Learning and Deep Learning Algorithms. Int. J. Perceptive Cogn. Comput. 2020, 6, 97–106. [Google Scholar] [CrossRef]
- Cubillos, M. Multi-site household waste generation forecasting using a deep learning approach. Waste Manag. 2020, 115, 8–14. [Google Scholar] [CrossRef] [PubMed]
- Kumar, A.; Samadder, S.R.; Kumar, N.; Singh, C. Estimation of the Generation Rate of Different Types of Plastic Wastes and Possible Revenue Recovery from Informal Recycling. Waste Manag. 2018, 79, 781–790. [Google Scholar] [CrossRef] [PubMed]
- Abbasi, M.; Rastgoo, M.N.; Nakisa, B. Monthly and seasonal modeling of municipal waste generation using radial basis function neural network. Env. Prog. Sust. Energy 2019, 38, 13033. [Google Scholar] [CrossRef]
- Fernández-Delgado, M.; Sirsat, M.S.; Cernadas, E.; Alawadi, S.; Barro, S.; Febrero-Bande, M. An extensive experimental survey of regression methods. Neural Netw. 2019, 111, 11–34. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. On hyperparameter optimization of machine learning algorithms: Theory and practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Wu, J.; Chen, X.Y.; Zhang, H.; Xiong, L.D.; Lei, H.; Deng, S.H. Hyperparameter optimization for machine learning models based on bayesian optimization. J. Electron. Sci. Technol. 2019, 17, 26–40. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A next-generation hyperparameter optimization framework. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2623–2631. [Google Scholar]
- Schütt, M. Systematic Variation in Waste Site Effects on Residential Property Values: A Meta-Regression Analysis and Benefit Transfer. Env. Res. Econ. 2021, 78, 381–416. [Google Scholar] [CrossRef]
- Zheng, D.; Shen, J.; Li, R.; Jian, B.; Zeng, J.; Mao, Y.; Zhaang, X.; Halder, P.; Qu, M. Understanding the key factors determining rural domestic waste treatment behavior in China: A meta-analysis. Envi. Sci. Pollut. Res. 2022, 29, 11076–11090. [Google Scholar] [CrossRef]
- Funch, O.I.; Marhaug, R.; Kohtala, S.; Steinert, M. Detecting glass and metal in consumer trash bags during waste collection using convolutional neural networks. Waste Manag. 2021, 119, 30–38. [Google Scholar] [CrossRef]
- Zhao, L.; Pan, Y.; Wang, S.; Zhang, L.; Islam, M.S. Skip-YOLO: Domestic Garbage Detection Using Deep Learning Method in Complex Multi-scenes. Res. Sq. 2021. preprint. [Google Scholar] [CrossRef]
- Karunasingha, D.S.K. Root mean square error or mean absolute error? Use their ratio as well. Inf. Sci. 2022, 585, 609–629. [Google Scholar] [CrossRef]
- Kim, T.; Oh, J.; Kim, N.; Cho, S.; Yun, S.Y. Comparing Kullback-Leibler Divergence and Mean Squared Error Loss in Knowledge Distillation. arXiv 2021, arXiv:2105.08919. [Google Scholar]
- Morresi, N.; Casaccia, S.; Sorcinelli, M.; Arnesano, M.; Uriarte, A.; Torrens-Galdiz, J.I.; Revel, G.M. Sensing Physiological and Environmental Quantities to Measure Human Thermal Comfort Through Machine Learning Techniques. IEEE Sens. J. 2021, 21, 12322–12337. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Marandi, F.; Ghomi, S.M.T.F. Time series forecasting and analysis of municipal solid waste generation in Tehran city. In Proceedings of the 2016 12th International Conference on Industrial Engineering (ICIE), Tehran, Iran, 25–26 January 2016. [Google Scholar]
- Carbonera, L.F.B.; Pinheiro, B.D.; Karnikowski, D.D.C.; Alberto, F.F. The non-linear autoregressive network with exogenous inputs (NARX) neural network to damp power system oscillations. Int. Trans. Electr. Energy Syst. 2021, 31, e12538. [Google Scholar] [CrossRef]
- Guo, H.-N.; Wu, S.-B.; Tian, Y.-J.; Zhang, J.; Liu, H.-T. Application of machine learning methods for the prediction of organic solid waste treatment and recycling processes: A review. Bioresour. Technol. 2021, 319, 124114. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely Randomized Trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef] [Green Version]
- Boussaada, Z.; Curea, O.; Remaci, A.; Camblong, H.; Mrabet Bellaaj, N. A nonlinear autoregressive exogenous (narx) neural network model for the prediction of the daily direct solar radiation. Energies 2018, 11, 620. [Google Scholar] [CrossRef] [Green Version]
- Dubey, S.; Singh, P.; Yadav, P.; Singh, K.K. Household Waste Management System Using IoT and Machine Learning. Procedia Comput. Sci. 2020, 167, 1950–1959. [Google Scholar] [CrossRef]
- Oguz-Ekim, P. Machine Learning Approaches for Municipal Solid Waste Generation Forecasting, Environ. Eng. Sci. 2021, 38, 489–499. [Google Scholar]
- Ghanbari, F.; Kamalan, H.; Sarraf, A. An evolutionary machine learning approach for municipal solid waste generation estimation utilizing socioeconomic components. Arab. J. Geosci. 2021, 14, 1–16. [Google Scholar] [CrossRef]
- Jayaraman, V.; Parthasarathy, S.; Lakshminarayanan, A.R.; Singh, H.K. Predicting the Quantity of Municipal Solid Waste using XGBoost Model. In Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2–4 September 2021; pp. 148–152. [Google Scholar]
- Vu, H.L.; Ng, K.T.W.; Bolingbroke, D. Time-lagged effects of weekly climatic and socioeconomic factors on ANN municipal yard waste prediction models. Waste Manag. 2018, 84, 129–140. [Google Scholar] [CrossRef] [PubMed]





| Article | Strengths | Weaknesses |
|---|---|---|
| A multi-layer LoRaWAN infrastructure [38] |
|
|
| Use of IoT to enable solid waste management [39] |
|
|
| Prediction of plastic waste generation using SHAP [26] |
|
|
| Forecasting of regional waste generation [15] |
|
|
| Application of deep neuroevolution for the prediction of waste generation [25] |
|
|
| Algorithm | Advantages | Disadvantages | |
|---|---|---|---|
| LightGBM | Family of gradient boosting framework that uses a tree-based algorithm |
|
|
| KNN | Selects k-closest examples from the dataset |
|
|
| SVR | Selects the best hyperplane that maximizes separability between classes |
|
|
| ETS | An ensemble of decision trees that performs a random split of the node |
|
|
| RF | An ensemble of decision trees that uses a greedy approach to achieve the best split |
|
|
| XGBoosting | An ensemble of decision trees that uses a gradient boosting framework |
|
|
| ANN | Inspired by the human brain, ANN consists of several input and output layers that can extract patterns from given data |
|
|
| Algorithm | Search Space |
|---|---|
| SVR | Kernel = [‘rbf’,’poly’,’linear’,’sigmoid’] C = float (0.1, 3.0) Gamma = [‘auto’,’scale’] Degree = int (1, 3) |
| XGboost | max_depth = int (4, 12) learning_rate = log uniform (0.005, 0.05) colsample_bytree = log uniform (0.2, 0.6) subsample = log uniform (0.4, 0.8) alpha = log uniform (0.01, 10.0) lambda = log uniform (1 × 10−8, 10.0) gamma = log uniform (1 × 10−8, 10.0) min_child_weight = log uniform (10, 1000) |
| LightGBM | reg_alpha = log uniform (1 × 10−3, 10.0) reg_lambda = log uniform (1 × 10−3, 10.0) colsample_bytree = [0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0] subsample = [0.4, 0.5, 0.6, 0.7, 0.8, 1.0] learning_rate = [0.006, 0.008, 0.01, 0.014, 0.017, 0.02] max_depth = [10, 20, 100] num_leaves = int (1, 1000) min_child_samples = int (1, 300) cat_smooth = int (1, 100) |
| RF | n_estimators =_int (low = 100, high = 1000) max_depth = float (4, 50) min_samples_split = int (2.0, 150.0) min_samples_leaf = int (2.0, 60.0) max_features = [“auto”, “sqrt”, “log2”] |
| ANN | learning_rate_init = float (0.0001, 0.1, step = 0.005) first_layer_neurons = int (10, 100, step = 10) activation = [‘identity’, ‘tanh’, ‘relu’] |
| KNN | n_neighbors = int (1, 30) weights = [‘uniform’, ‘distance’] metric = [‘euclidean’, ‘manhattan’, ‘minkowski’] |
| Extreme Trees | n_estimators = int (low = 100, high = 1000) max_depth = float (4, 50) min_samples_split = int (2.0, 150.0) min_samples_leaf = int (2.0, 60.0) max_features = [“auto”, “sqrt”, “log2”] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Namoun, A.; Hussein, B.R.; Tufail, A.; Alrehaili, A.; Syed, T.A.; BenRhouma, O. An Ensemble Learning Based Classification Approach for the Prediction of Household Solid Waste Generation. Sensors 2022, 22, 3506. https://doi.org/10.3390/s22093506
Namoun A, Hussein BR, Tufail A, Alrehaili A, Syed TA, BenRhouma O. An Ensemble Learning Based Classification Approach for the Prediction of Household Solid Waste Generation. Sensors. 2022; 22(9):3506. https://doi.org/10.3390/s22093506
Chicago/Turabian StyleNamoun, Abdallah, Burhan Rashid Hussein, Ali Tufail, Ahmed Alrehaili, Toqeer Ali Syed, and Oussama BenRhouma. 2022. "An Ensemble Learning Based Classification Approach for the Prediction of Household Solid Waste Generation" Sensors 22, no. 9: 3506. https://doi.org/10.3390/s22093506
APA StyleNamoun, A., Hussein, B. R., Tufail, A., Alrehaili, A., Syed, T. A., & BenRhouma, O. (2022). An Ensemble Learning Based Classification Approach for the Prediction of Household Solid Waste Generation. Sensors, 22(9), 3506. https://doi.org/10.3390/s22093506