
The Influence of a Coherent Annotation and Synthetic Addition of Lung Nodules for Lung Segmentation in CT Scans




Abstract
:1. Introduction
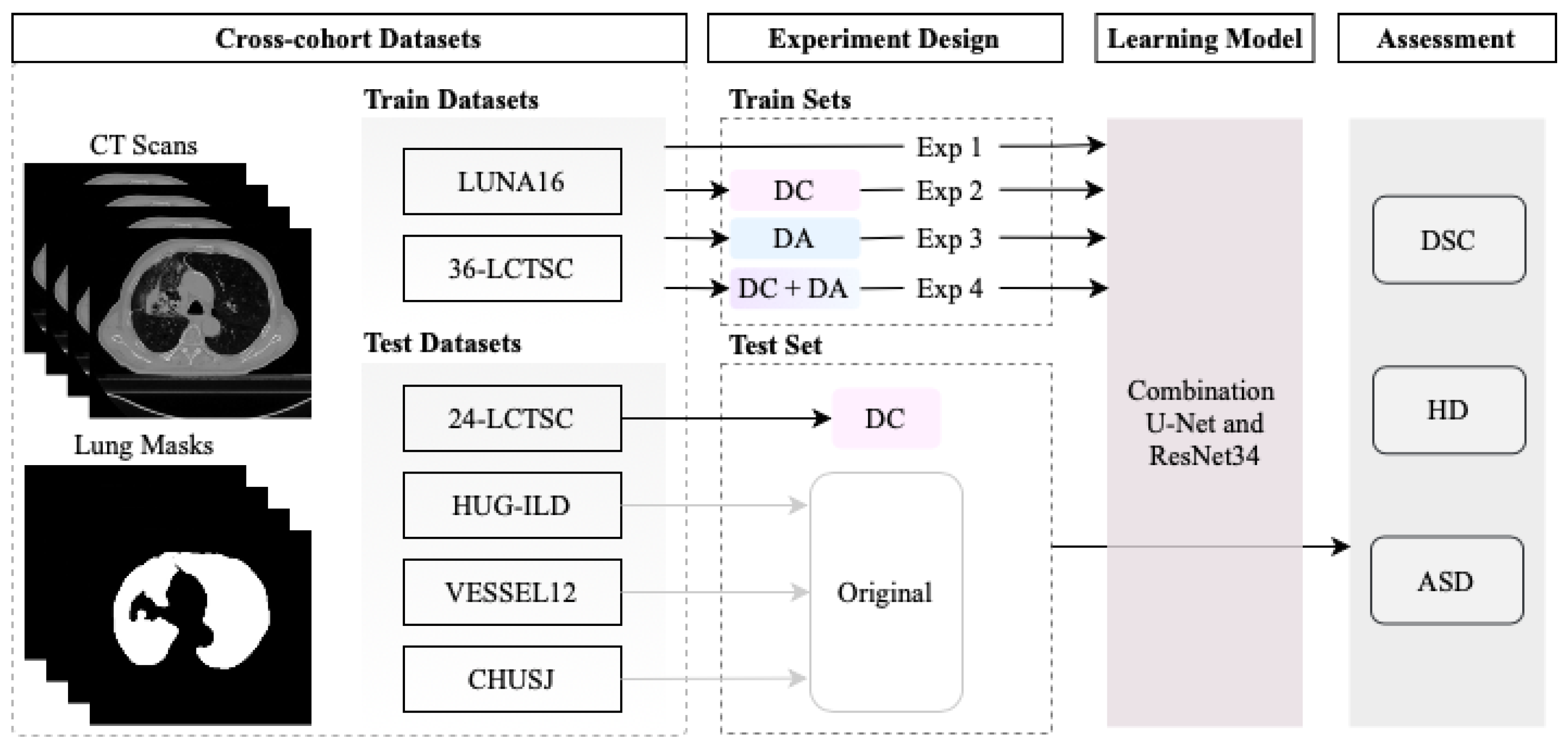
2. Materials and Methods
2.1. Datasets
2.2. Mask Segmentation
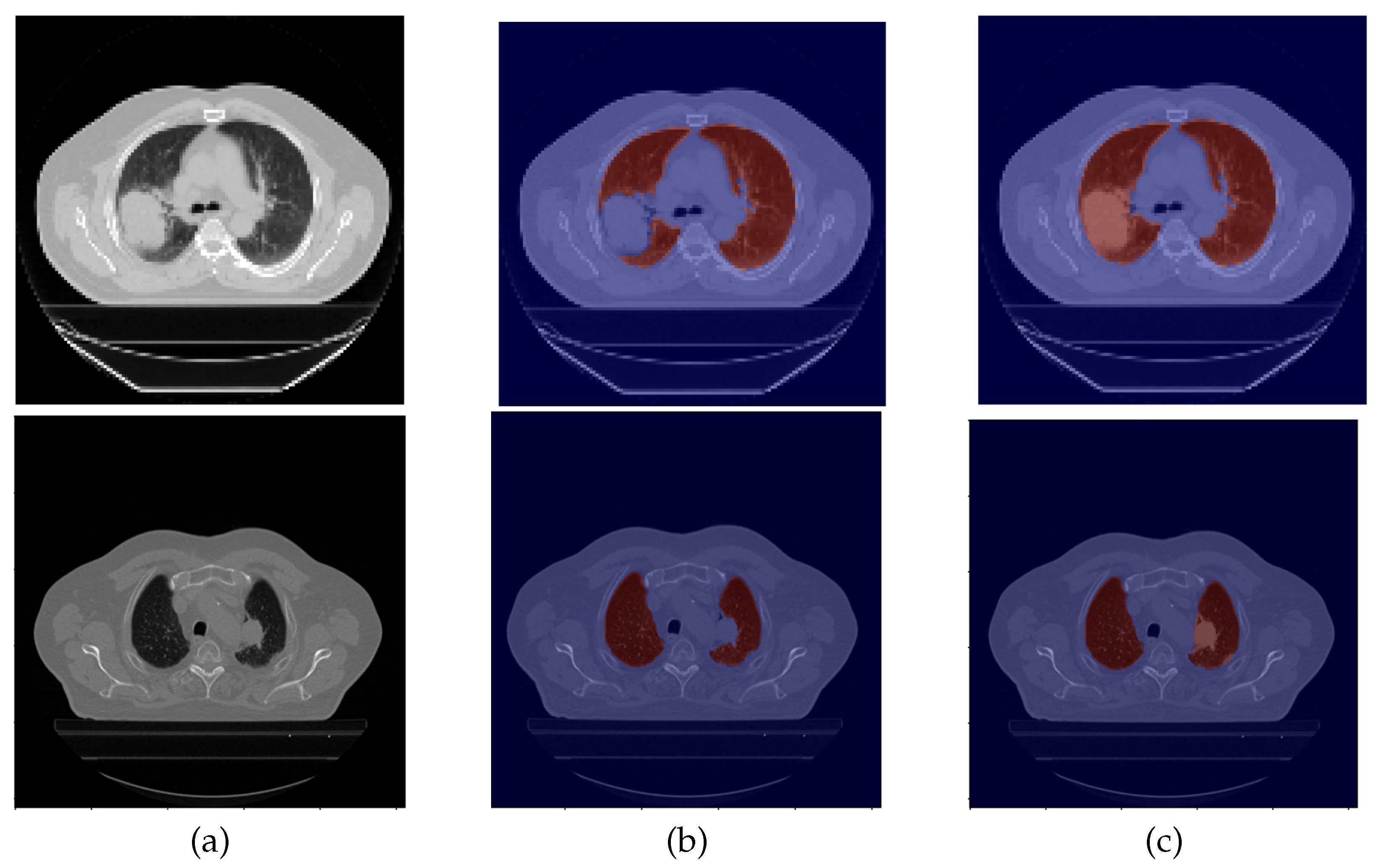
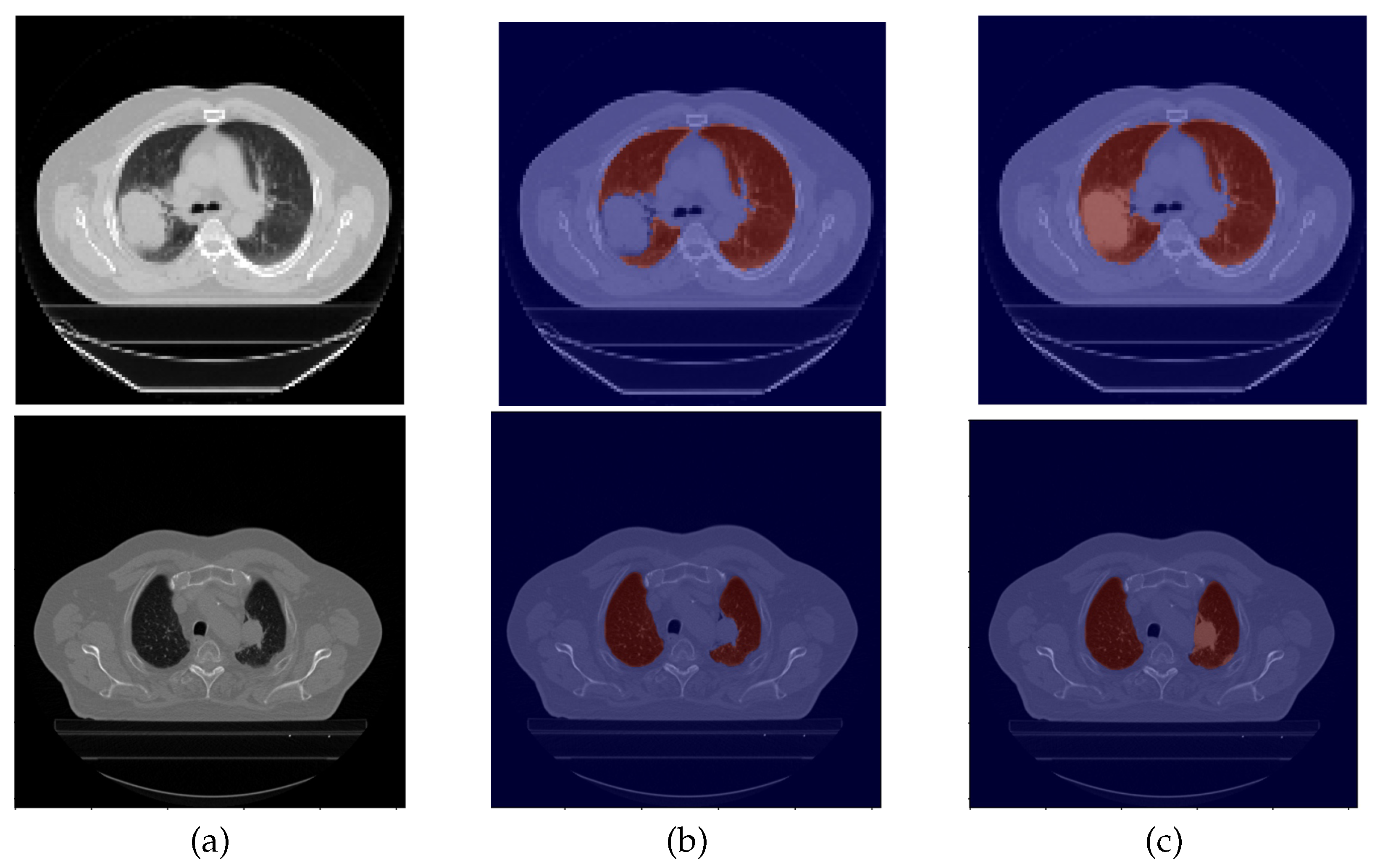
2.2.1. Original Masks
2.2.2. Mask Correction Protocol
- The lung is surround by the bones (clavicle, sternum, ribs, and vertebra) and muscles of the chest wall, the pleura, and the mediastinum (trachea, esophagus, pericardium, heart, and main vessels);
- On CT scans, airways are characterized as low density, whereas all the other structures are observed in variable higher densities;
- The apex and base of the lung are harder to define due to the overlapping of other structures, such as the abdominal organs. Key factors to differentiate were the pleura and the low density of the lung in contrast to the subcutaneous tissue near the lung apex and the abdominal organs distal to the lung base.
- Excluding the upper airways, such as the trachea;
- Excluding the main bronchi;
- Defining the hilum, which contains structures such as the bronchi and pulmonary and systemic vessels. It is contiguous to the mediastinum and, for that reason, it can be harder to define. The main characteristic was to acknowledge the hilum as the root of the lung and, for that reason, the hilum structures were surrounded by lung tissue;
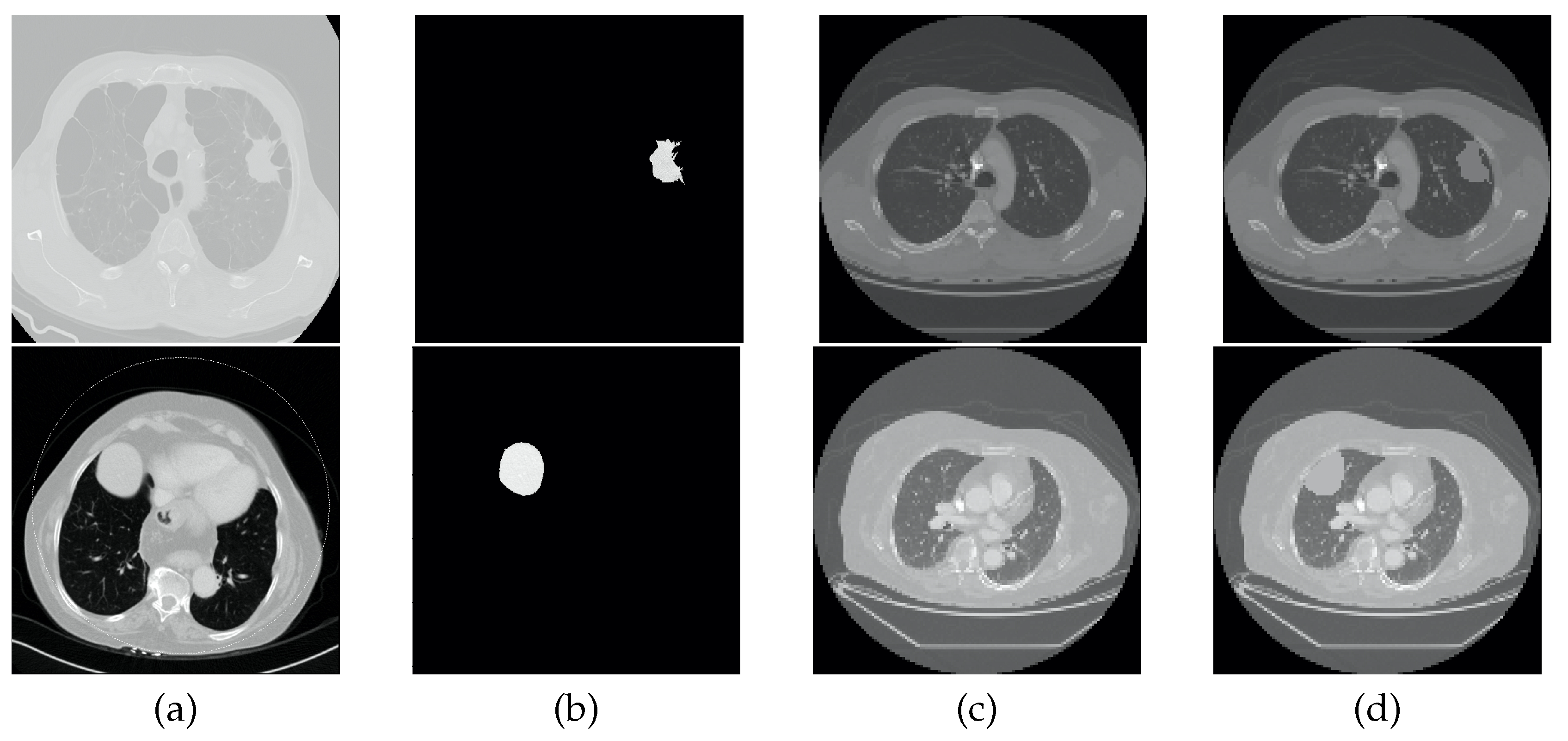
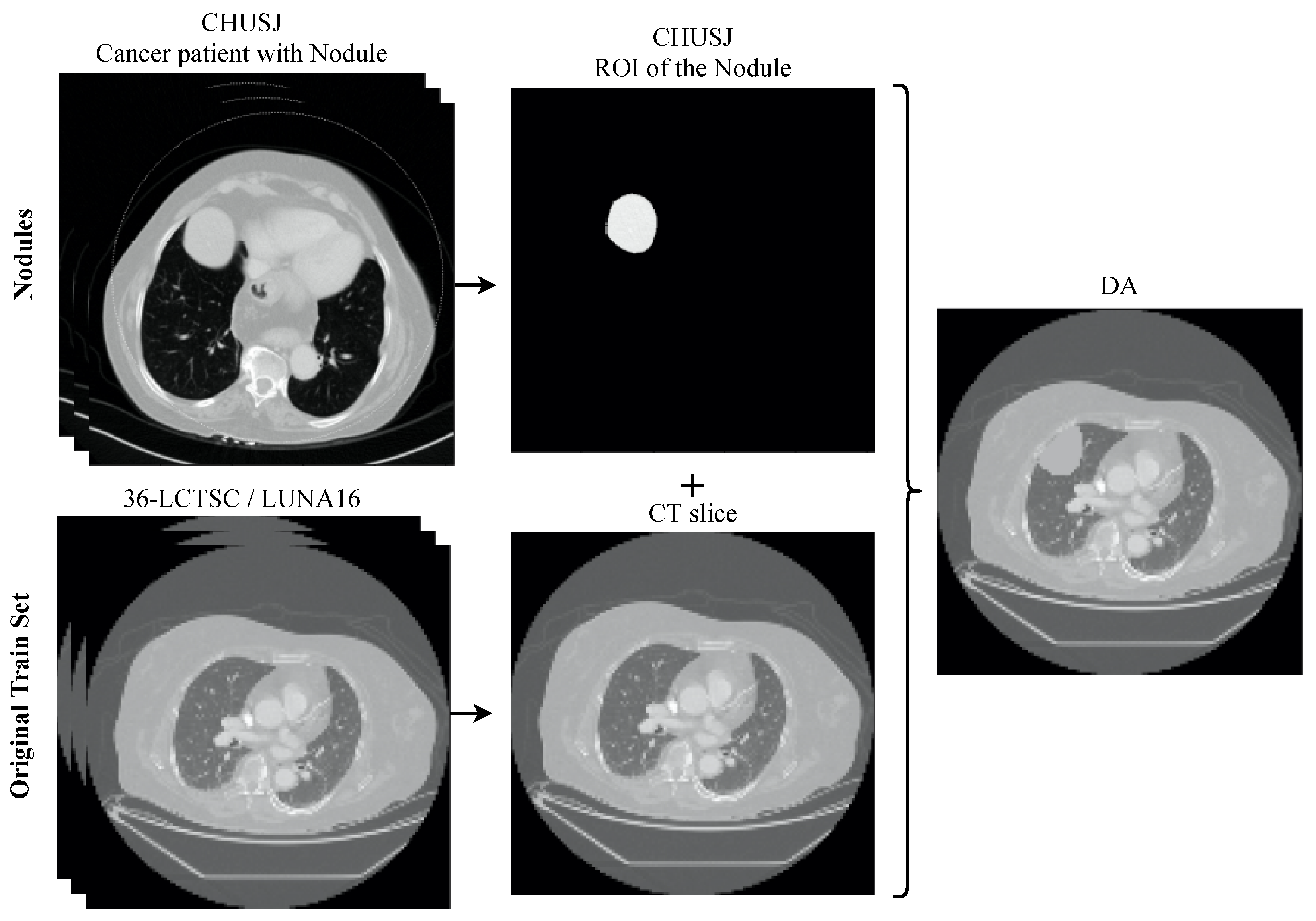
- Including the lung nodules, which, in the majority of cases, appear as a well defined higher density area. Peripheral lung nodules constitute a harder group of nodules to define and, in this case, the key factors were to evaluate the different densities between the chest wall and the nodule, as well to find the fine well-defined line that characterizes the pleura.
2.3. Pre-Processing
2.4. Segmentation Model
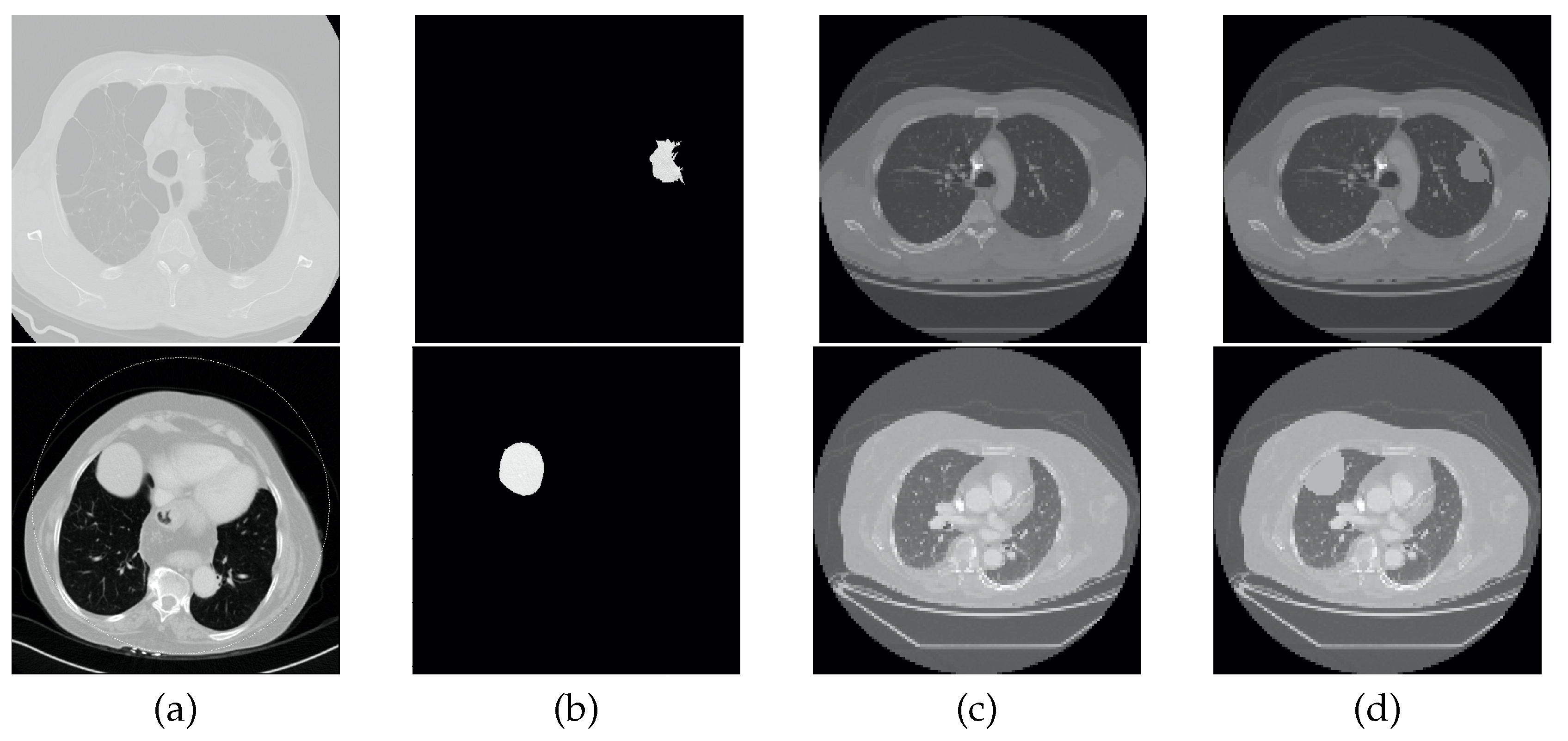
2.5. Data Augmentation
2.6. Experiment Design
2.7. Performance Metrics
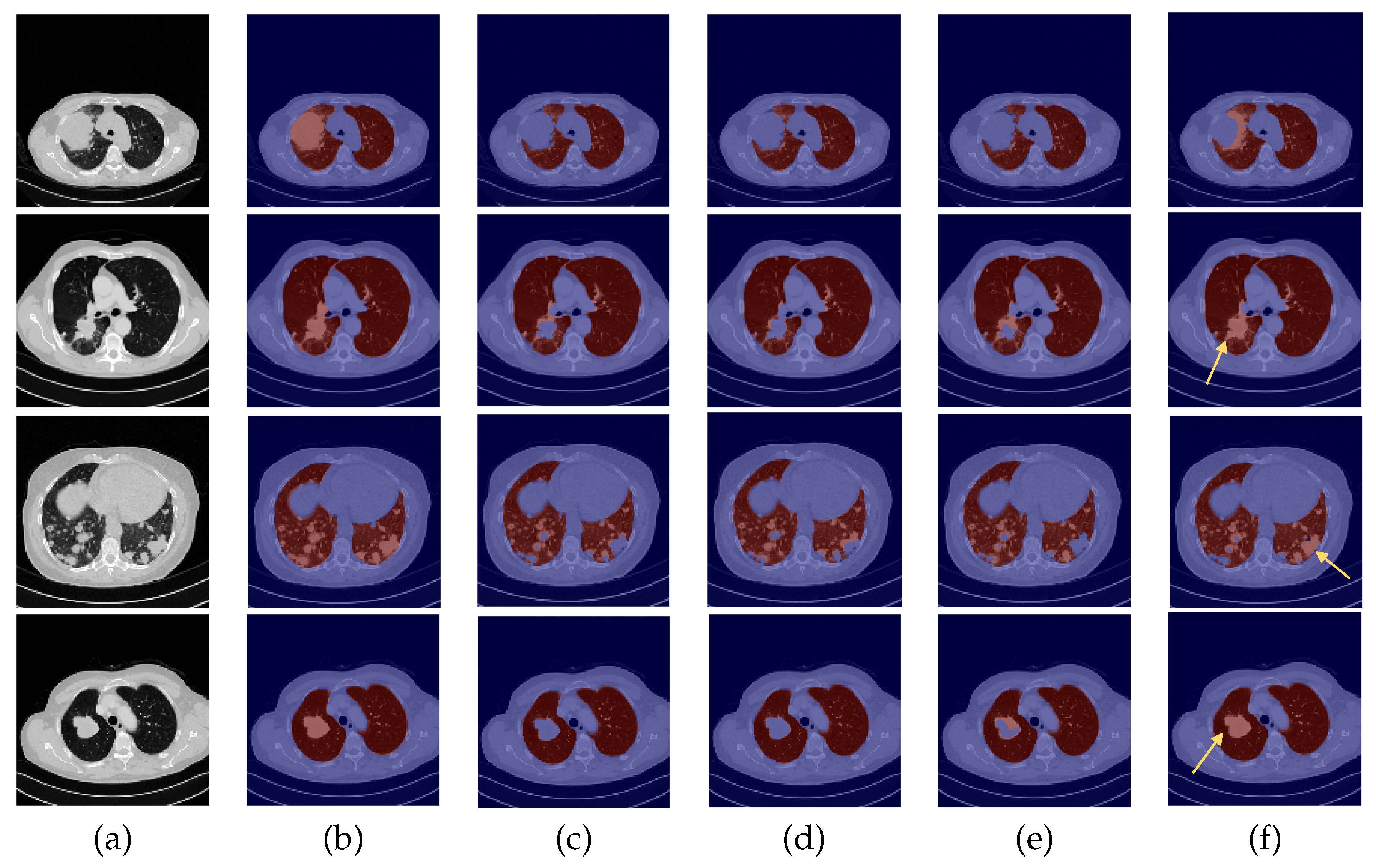
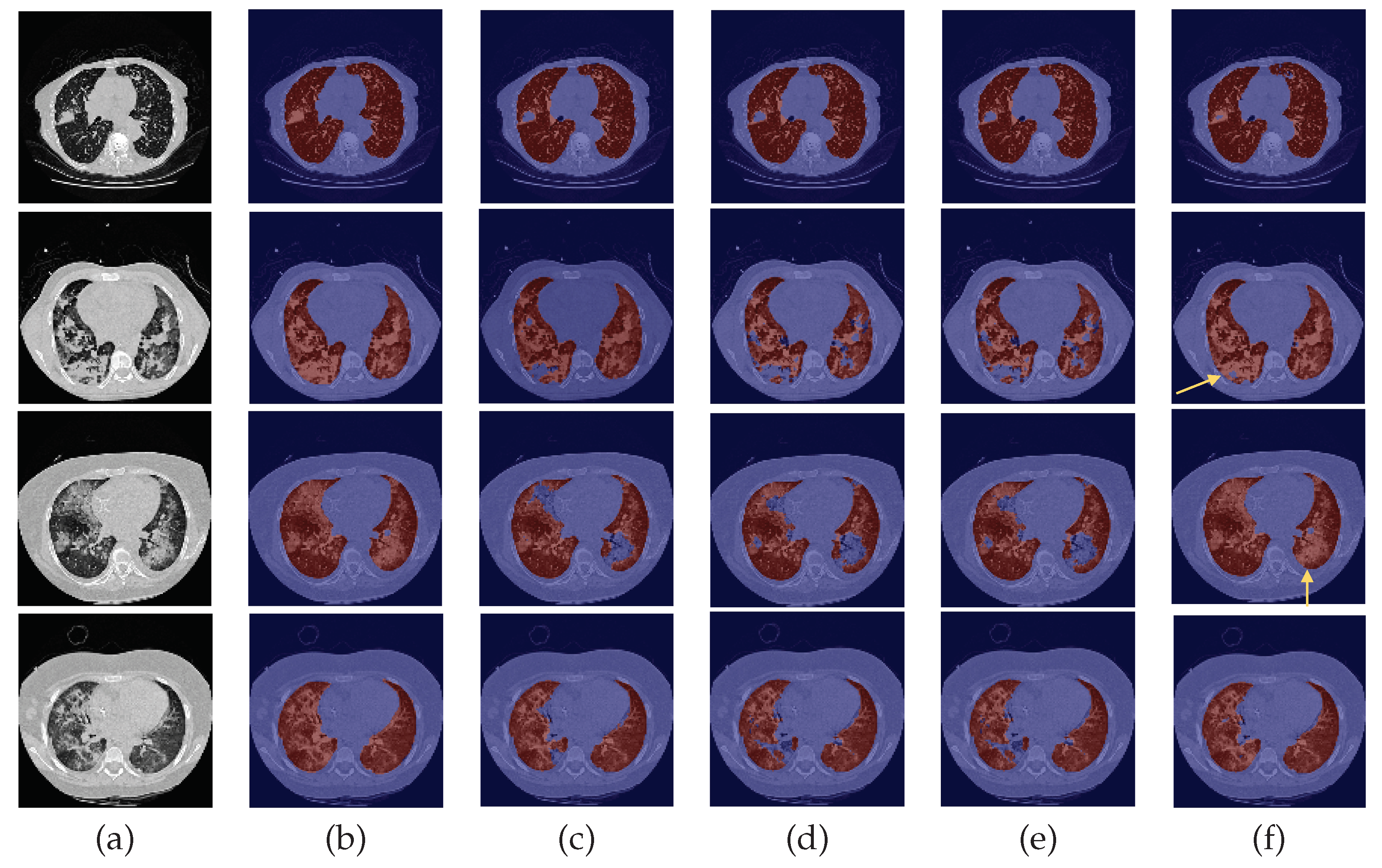
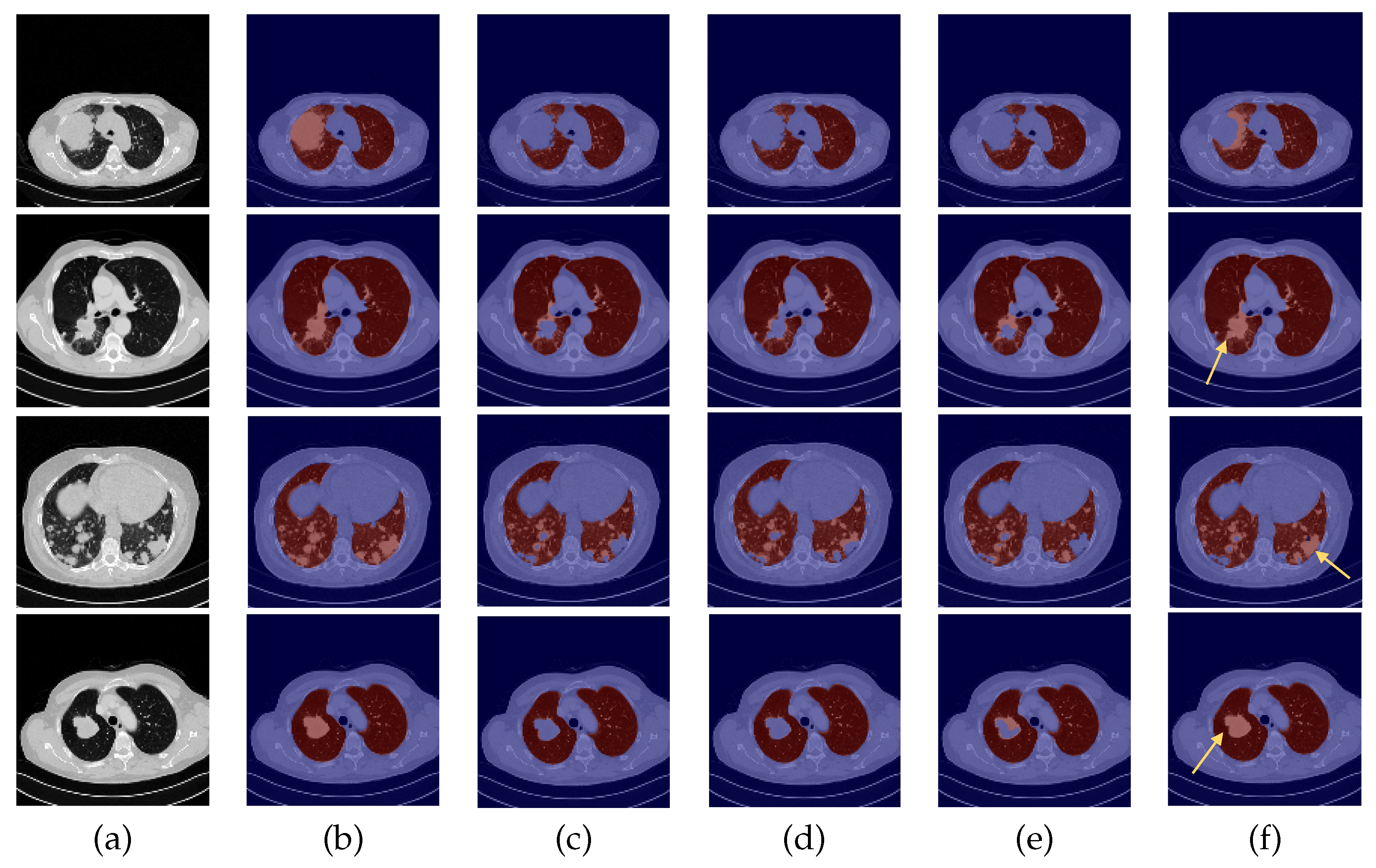
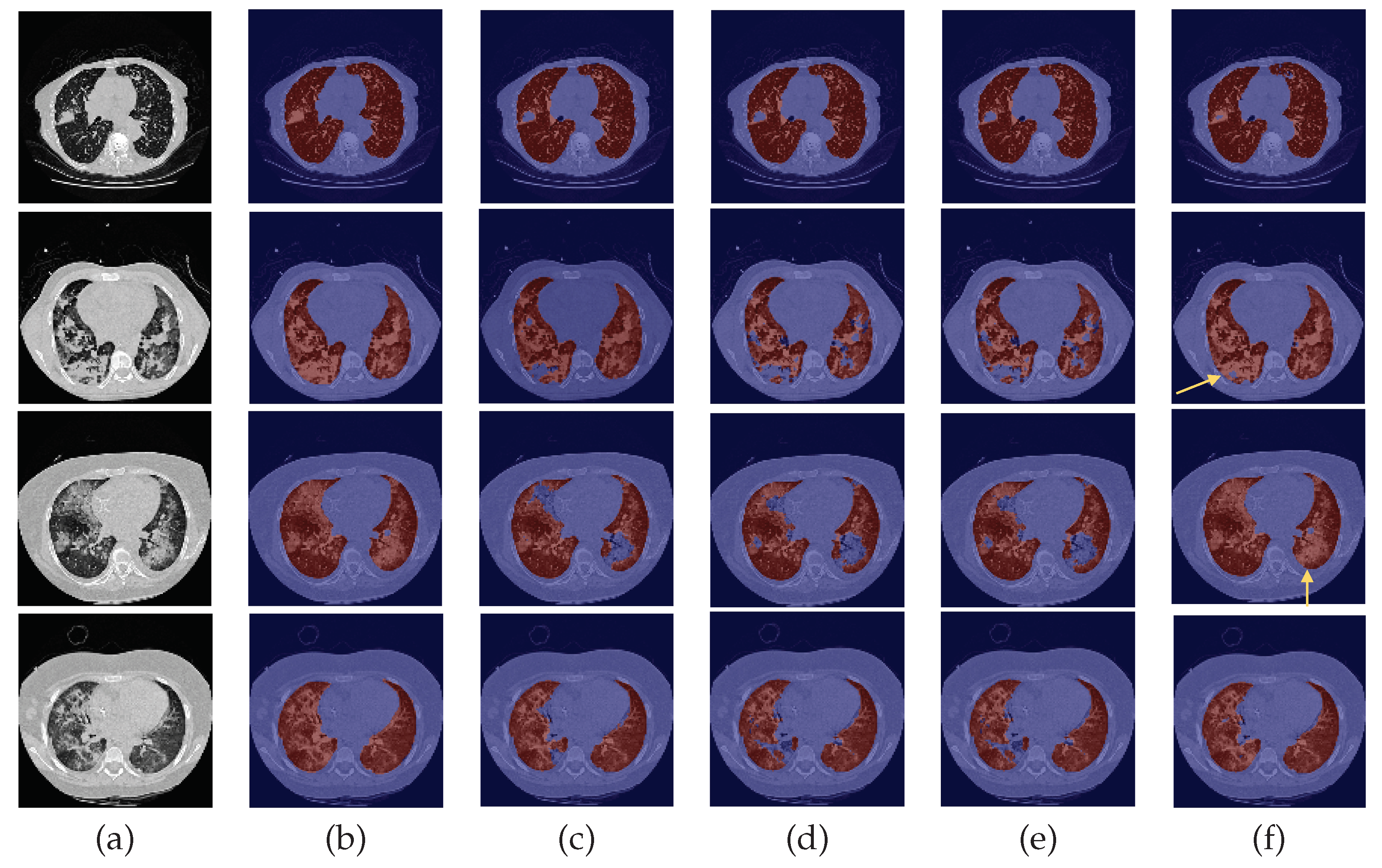
3. Results and Discussion
3.1. Experiment with DC and DA
3.2. Baseline Experiment: No DC nor DA
3.3. Experiment with DC but No DA
3.4. Experiment with DA but No DC
4. Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Durham, A.L.; Adcock, I.M. The relationship between COPD and lung cancer. Lung Cancer 2015, 90, 121–127. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Silva, F.; Pereira, T.; Neves, I.; Morgado, J.; Freitas, C.; Malafaia, M.; Sousa, J.; Fonseca, J.; Negrão, E.; Flor de Lima, B.; et al. Towards Machine Learning-Aided Lung Cancer Clinical Routines: Approaches and Open Challenges. J. Pers. Med. 2022, 12, 480. [Google Scholar] [CrossRef] [PubMed]
- Firmino, M.; Angelo, G.; Morais, H.; Dantas, M.; Valentim, R. Computer-aided detection (CADe) and diagnosis (CADx) system for lung cancer with likelihood of malignancy. BioMed. Eng. OnLine 2016, 15, 2. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khanna, A.; Londhe, N.D.; Gupta, S.; Semwal, A. A deep Residual U-Net convolutional neural network for automated lung segmentation in computed tomography images. Biocybern. Biomed. Eng. 2020, 40, 1314–1327. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015. [Google Scholar] [CrossRef] [Green Version]
- Tan, J.; Jing, L.; Huo, Y.; Li, L.; Akin, O.; Tian, Y. LGAN: Lung segmentation in CT scans using generative adversarial network. Comput. Med. Imaging Graph. 2021, 87, 101817. [Google Scholar] [CrossRef] [PubMed]
- Sousa, J.; Pereira, T.; Silva, F.; Silva, M.; Vilares, A.; Cunha, A.; Oliveira, H. Lung Segmentation in CT Images: A Residual U-Net Approach on a Cross-Cohort Dataset. Appl. Sci. 2022, 12, 1959. [Google Scholar] [CrossRef]
- Karimi, D.; Dou, H.; Warfield, S.K.; Gholipour, A. Deep learning with noisy labels: Exploring techniques and remedies in medical image analysis. Med. Image Anal. 2020, 65, 101759. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Jeyaseelan, L.; Li, Q.; Chiang, J.; Wu, Z.; Ding, X. Embracing Imperfect Datasets: A Review of Deep Learning Solutions for Medical Image Segmentation. Med. Image Anal. 2020, 63, 101693. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hofmanninger, J.; Prayer, F.; Pan, J.; Röhrich, S.; Prosch, H.; Langs, G. Automatic lung segmentation in routine imaging is primarily a data diversity problem, not a methodology problem. Eur. Radiol. Exp. 2020, 4, 50. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.; Sharp, G.; Veeraraghavan, H.; van Elmpt, W.; Dekker, A.; Lustberg, T.; Gooding, M. Data from Lung CT Segmentation Challenge; The Cancer Imaging Archive: Frederick Nat. Lab for Cancer Research, Frederick, MD, USA, 2017. [Google Scholar] [CrossRef]
- Setio, A.A.A.; Traverso, A.; de Bel, T.; Berens, M.S.; van den Bogaard, C.; Cerello, P.; Chen, H.; Dou, Q.; Fantacci, M.E.; Geurts, B.; et al. Validation, comparison, and combination of algorithms for automatic detection of pulmonary nodules in computed tomography images: The LUNA16 challenge. Med. Image Anal. 2017, 42, 1–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Depeursinge, A.; Vargas, A.; Platon, A.; Geissbuhler, A.; Poletti, P.A.; Müller, H. Building a Reference Multimedia Database for Interstitial Lung Diseases. Comput. Med. Imaging Graph. 2012, 36, 227–238. [Google Scholar] [CrossRef] [PubMed]
- Rudyanto, R.D.; Kerkstra, S.; van Rikxoort, E.M.; Fetita, C.; Brillet, P.Y.; Lefevre, C.; Xue, W.; Zhu, X.; Liang, J.; Öksüz, İ.; et al. Comparing algorithms for automated vessel segmentation in computed tomography scans of the lung: The VESSEL12 study. Med. Image Anal. 2014, 18, 1217–1232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bryant, J.; Drage, N.; Richmond, S. CT number definition. Radiat. Phys. Chem. 2012, 81, 358–361. [Google Scholar] [CrossRef]
- Yeghiazaryan, V.; Voiculescu, I. Family of boundary overlap metrics for the evaluation of medical image segmentation. J. Med. Imaging 2018, 5, 015006. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | # CTs | Number of Slices | Slice Spacing (mm) | Slice Thickness (mm) |
|---|---|---|---|---|
| LCTSC [13] | 60 | 5858 | 1.02 ± 0.11 | 2.65 ± 0.38 |
| LUNA16 [14] | 176 | 44,098 | 0.69 ± 0.09 | 1.60 ± 0.74 |
| HUG-ILD [15] | 112 | 2978 | 0.70 ± 0.10 | 1.00 ± 0.00 |
| VESSEL12 [16] | 10 | 4279 | 0.74 ± 0.09 | 0.88 ± 0.15 |
| CHUSJ | 27 | 3349 | 0.71 ± 0.08 | 3.07 ± 0.38 |
| Dataset | Pathologies Diagnosed | Original Mask Protocol |
|---|---|---|
| LCTSC [13] | Multiple pathologies of the thoracic region. | Inclusion of emphysematic, inflated, fibrotic, and collapsed (this last case can be excluded in some images) lungs, and small vessels that go outside the region of the hilum. Exclusion of main bronchus and tumor masses. |
| LUNA16 [14] | Lung cancer. | Masks automatically generated. |
| HUG-ILD [15] | Interstitial lung diseases. | Not disclosed. |
| VESSEL12 [16] | Alveolar inflammation, diffuse interstitial lung disease, and emphysema. | Automatically generated and manually revised when needed. |
| CHUSJ | Lung cancer. | Exclusion of upper airways and main bronchi. Inclusion of lung nodules. |
| # | DC | DA | 24-LCTSC | HUG-ILD | VESSEL12 | CHUSJ |
|---|---|---|---|---|---|---|
| Mean ± Std | Mean ± Std | Mean ± Std | Mean ± Std | |||
| 1 | x | x | 0.9417 ± 0.1133 | 0.9334 ± 0.1609 | 0.9778 ± 0.0726 | 0.9339 ± 0.1129 |
| 2 | √ | x | 0.9458 ± 0.1029 | 0.9311 ± 0.1594 | 0.9785 ± 0.0625 | 0.9364 ± 0.1115 |
| 3 | x | √ | 0.9253 ± 0.1251 | 0.9270 ± 0.1622 | 0.9809 ± 0.0569 | 0.9271 ± 0.1196 |
| 4 | √ | √ | 0.9412 ± 0.1088 | 0.9352 ± 0.1654 | 0.9767 ± 0.0630 | 0.9360 ± 0.1121 |
| # | DC | DA | 24-LCTSC | HUG-ILD | VESSEL12 | CHUSJ |
|---|---|---|---|---|---|---|
| Mean ± Std | Mean ± Std | Mean ± Std | Mean ± Std | |||
| 1 | x | x | 3.1614 ± 3.7081 | 5.1783 ± 5.3090 | 1.9395 ± 3.8953 | 4.0943 ± 6.9651 |
| 2 | √ | x | 4.8517 ± 6.4032 | 5.2617 ± 5.4048 | 1.9858 ± 3.9991 | 3.8958 ± 6.4470 |
| 3 | x | √ | 4.3834 ± 5.5277 | 5.4314 ± 5.7357 | 1.9028 ± 3.6274 | 4.2868 ± 7.0384 |
| 4 | √ | √ | 4.8844 ± 6.3457 | 5.4441 ± 6.2199 | 1.9438 ± 3.7094 | 3.9945 ± 6.7283 |
| # | DC | DA | 24-LCTSC | HUG-ILD | VESSEL12 | CHUSJ |
|---|---|---|---|---|---|---|
| Mean ± Std | Mean ± Std | Mean ± Std | Mean ± Std | |||
| 1 | x | x | 0.3816 ± 1.2082 | 0.4381 ± 1.4125 | 0.1167 ± 0.5317 | 0.4639 ± 1.5110 |
| 2 | √ | x | 0.4036 ± 1.6168 | 0.4429 ± 1.2223 | 0.1121 ± 0.2732 | 0.4483 ± 1.6712 |
| 3 | x | √ | 0.8286 ± 2.6559 | 0.5473 ± 2.1692 | 0.1115 ± 0.5858 | 0.4741 ± 1.2826 |
| 4 | √ | √ | 0.3870 ± 1.2582 | 0.5643 ± 2.3712 | 0.1167 ± 0.2921 | 0.4947 ± 2.3349 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sousa, J.; Pereira, T.; Neves, I.; Silva, F.; Oliveira, H.P. The Influence of a Coherent Annotation and Synthetic Addition of Lung Nodules for Lung Segmentation in CT Scans. Sensors 2022, 22, 3443. https://doi.org/10.3390/s22093443
Sousa J, Pereira T, Neves I, Silva F, Oliveira HP. The Influence of a Coherent Annotation and Synthetic Addition of Lung Nodules for Lung Segmentation in CT Scans. Sensors. 2022; 22(9):3443. https://doi.org/10.3390/s22093443
Chicago/Turabian StyleSousa, Joana, Tania Pereira, Inês Neves, Francisco Silva, and Hélder P. Oliveira. 2022. "The Influence of a Coherent Annotation and Synthetic Addition of Lung Nodules for Lung Segmentation in CT Scans" Sensors 22, no. 9: 3443. https://doi.org/10.3390/s22093443
APA StyleSousa, J., Pereira, T., Neves, I., Silva, F., & Oliveira, H. P. (2022). The Influence of a Coherent Annotation and Synthetic Addition of Lung Nodules for Lung Segmentation in CT Scans. Sensors, 22(9), 3443. https://doi.org/10.3390/s22093443