
Performance of Deep Learning Models in Forecasting Gait Trajectories of Children with Neurological Disorders


Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
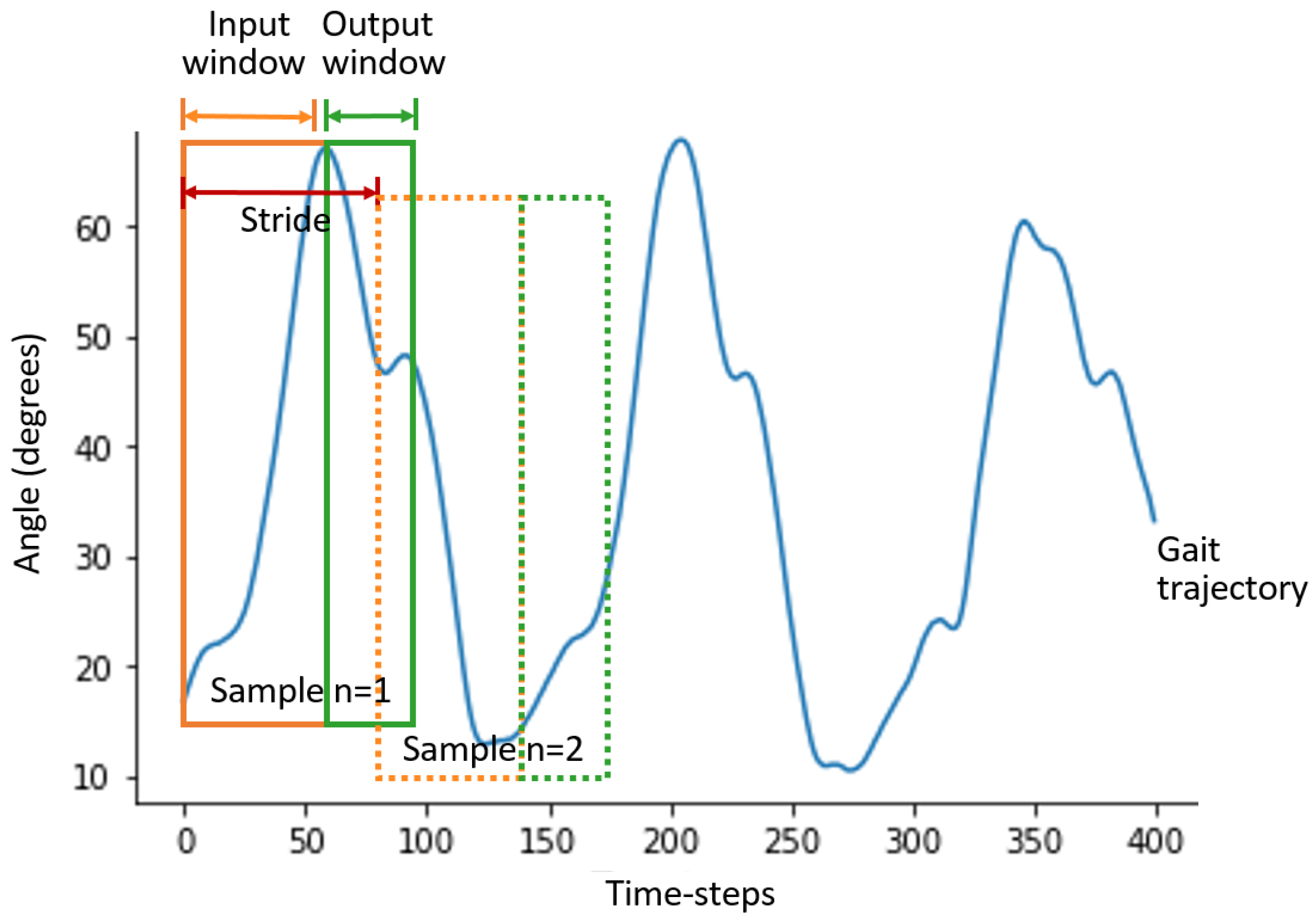
2.2. Data Processing
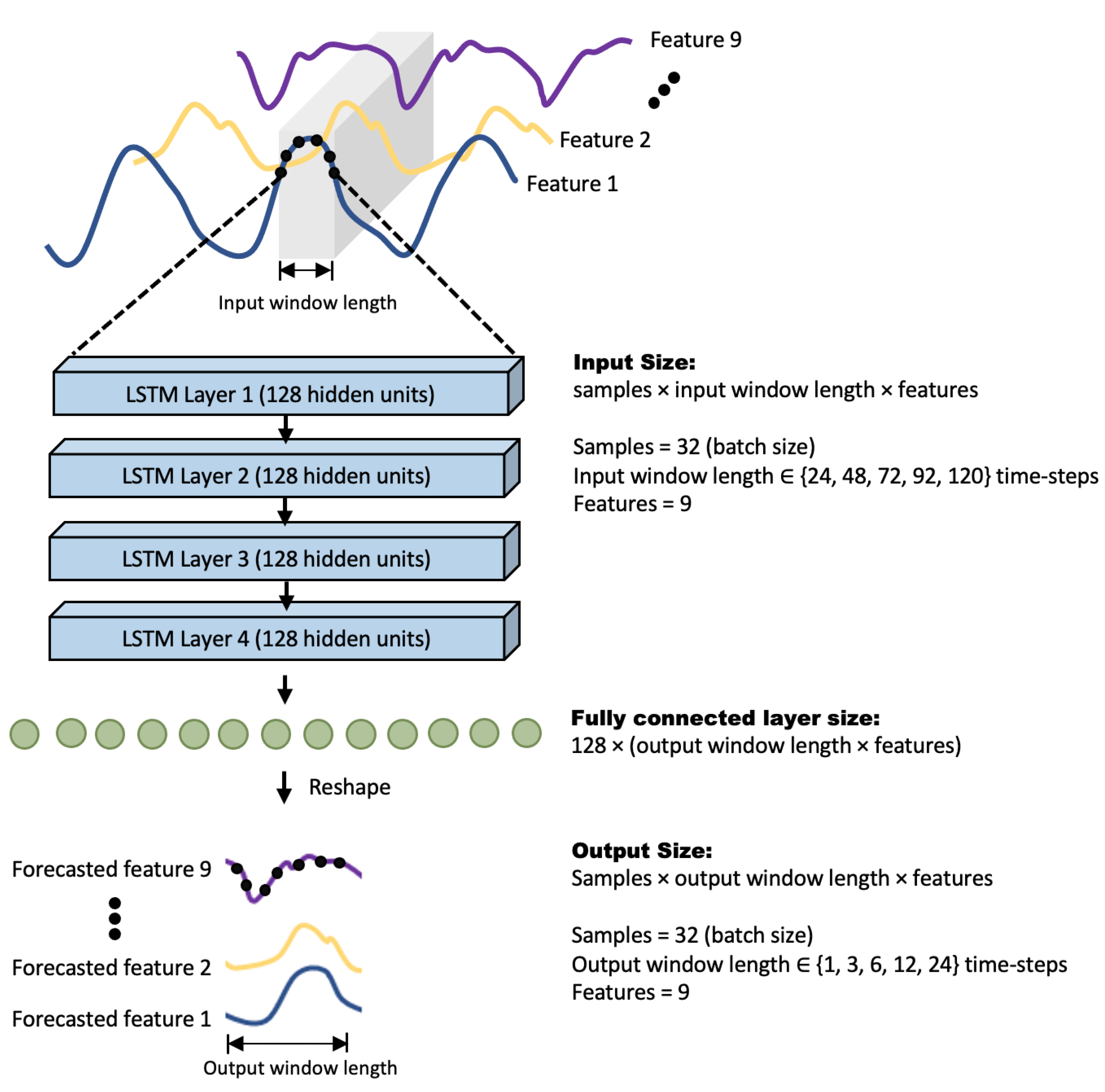
2.3. Long Short-Term Memory (LSTM) Architecture
2.4. Convolutional Neural Network (CNN) Architecture
2.5. Baseline Methods
2.6. Details of Network Implementation
2.7. Evaluation Metrics
3. Results
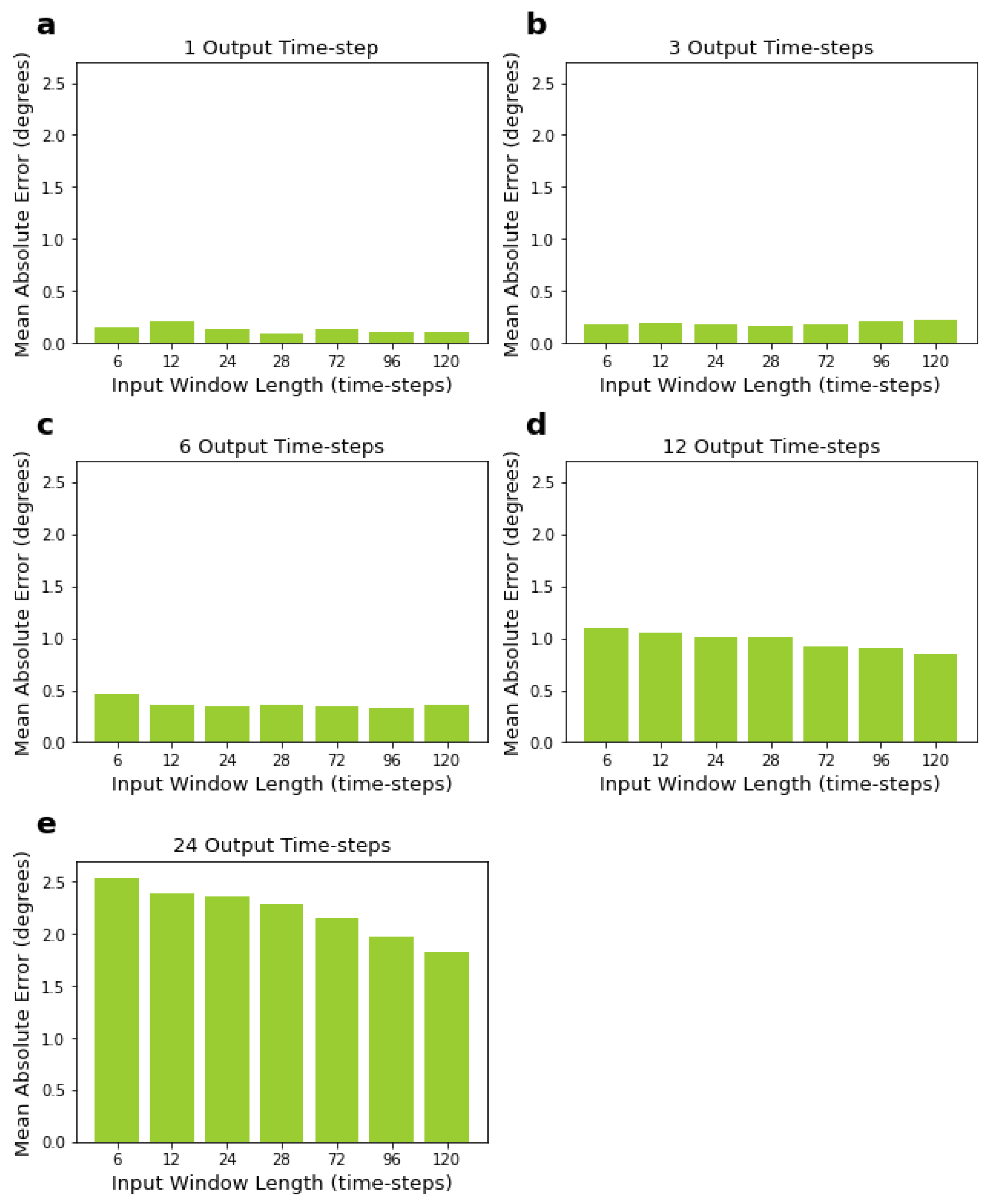
3.1. LSTM Network Performance for Varying Input and Output Window Sizes
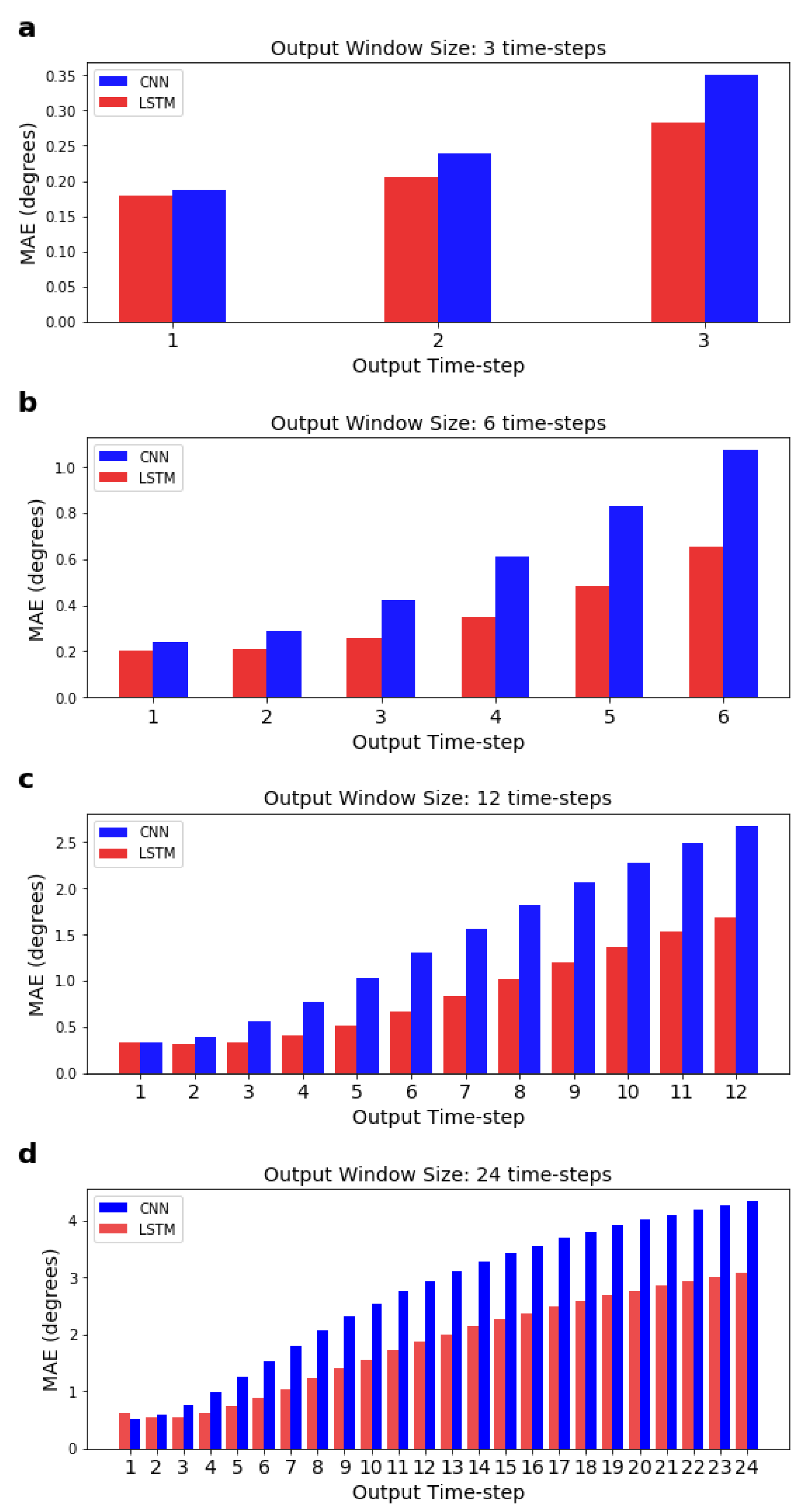
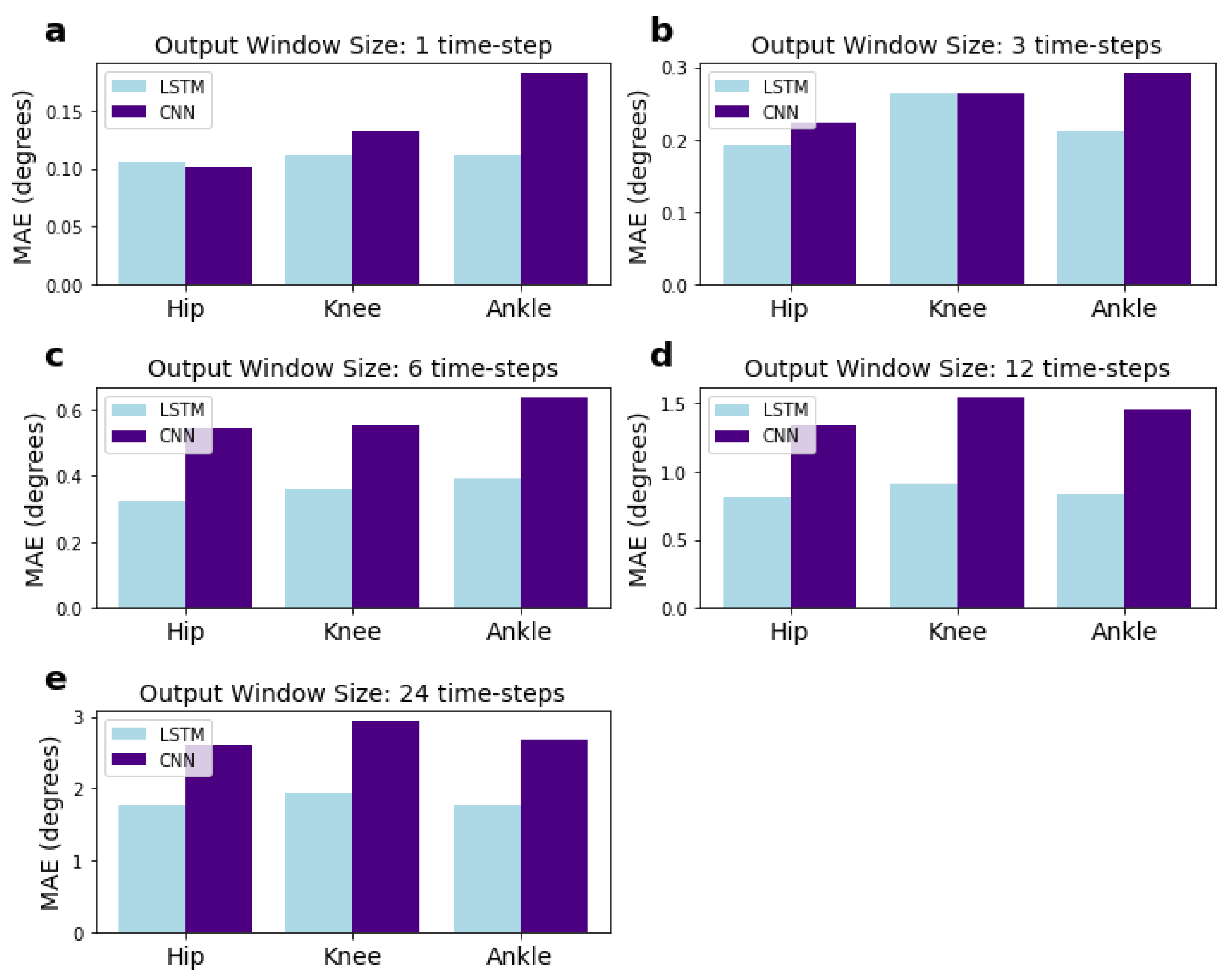
3.2. Performance of the CNN and Comparisons with LSTM Network
3.3. Benchmarking Performance of Deep Learning Models
3.4. Accuracy of the Models across the Different Time-Steps
3.5. Performance of the Models for Each Joint
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| LSTM | Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| FCN | Fully Connected Network |
| MAE | Mean Absolute Error |
| MSE | Mean Squared Error |
References
- Webster, J.B. Introduction. In Atlas of Orthoses and Assistive Devices, 5th ed.; Webster, J.B., Murphy, D.P., Eds.; Elsevier: Philadelphia, PA, USA, 2019; p. 376. [Google Scholar] [CrossRef]
- Makinson, B.J. Research and Development Prototype for Machine Augmentation of Human Strength and Endurance Hardiman I Project; General Electric: Schenectady, NY, USA, 1971. [Google Scholar]
- Kumar, V.; Hote, Y.V.; Jain, S. Review of Exoskeleton: History, Design and Control. In Proceedings of the 2019 3rd International Conference on Recent Developments in Control, Automation Power Engineering (RDCAPE), Noida, India, 10–11 October 2019; pp. 677–682. [Google Scholar] [CrossRef]
- Bosch, T.; van Eck, J.; Knitel, K.; de Looze, M. The effects of a passive exoskeleton on muscle activity, discomfort and endurance time in forward bending work. Appl. Ergon. 2016, 54, 212–217. [Google Scholar] [CrossRef]
- Bai, S.; Virk, G.S.; Sugar, T.G. (Eds.) Wearable Exoskeleton Systems: Design, Control and Applications; Control, Robotics & Sensors; Institution of Engineering and Technology: London, UK, 2018. [Google Scholar]
- Chen, B.; Ma, H.; Qin, L.Y.; Gao, F.; Chan, K.M.; Law, S.W.; Qin, L.; Liao, W.H. Recent developments and challenges of lower extremity exoskeletons. J. Orthop. Transl. 2016, 5, 26–37. [Google Scholar] [CrossRef] [Green Version]
- Riener, R.; Lunenburger, L.; Jezernik, S.; Anderschitz, M.; Colombo, G.; Dietz, V. Patient-cooperative strategies for robot-aided treadmill training: First experimental results. IEEE Trans. Neural Syst. Rehabil. Eng. 2005, 13, 380–394. [Google Scholar] [CrossRef] [PubMed]
- Høyer, E.; Opheim, A.; Jørgensen, V. Implementing the exoskeleton Ekso GTTM for gait rehabilitation in a stroke unit—Feasibility, functional benefits and patient experiences. Disabil. Rehabil. Assist. Technol. 2020, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Winfree, K.N.; Stegall, P.; Agrawal, S.K. Design of a minimally constraining, passively supported gait training exoskeleton: ALEX II. In Proceedings of the 2011 IEEE International Conference on Rehabilitation Robotics, Zurich, Switzerland, 29 June–1 July 2011; pp. 1–6. [Google Scholar] [CrossRef]
- Gorgey, A.S. Robotic exoskeletons: The current pros and cons. World J. Orthop. 2018, 9, 112–119. [Google Scholar] [CrossRef] [PubMed]
- Quintero, H.A.; Farris, R.J.; Goldfarb, M. A Method for the Autonomous Control of Lower Limb Exoskeletons for Persons with Paraplegia. J. Med. Devices Trans. ASME 2012, 6, 041003. [Google Scholar] [CrossRef]
- Zoss, A.; Kazerooni, H.; Chu, A. Biomechanical design of the Berkeley lower extremity exoskeleton (BLEEX). IEEE/ASME Trans. Mechatron. 2006, 11, 128–138. [Google Scholar] [CrossRef]
- Sankai, Y. HAL: Hybrid Assistive Limb Based on Cybernics. In Robotics Research; Kaneko, M., Nakamura, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 25–34. [Google Scholar]
- Baud, R.; Manzoori, A.R.; Ijspeert, A.; Bouri, M. Review of control strategies for lower-limb exoskeletons to assist gait. J. NeuroEng. Rehabil. 2021, 18, 119. [Google Scholar] [CrossRef]
- Al-Shuka, H.F.N.; Song, R.; Ding, C. On high-level control of power-augmentation lower extremity exoskeletons: Human walking intention. In Proceedings of the 2018 Tenth International Conference on Advanced Computational Intelligence (ICACI), Xiamen, China, 29–31 March 2018; pp. 169–174. [Google Scholar] [CrossRef]
- Kolaghassi, R.; Al-Hares, M.K.; Sirlantzis, K. Systematic Review of Intelligent Algorithms in Gait Analysis and Prediction for Lower Limb Robotic Systems. IEEE Access 2021, 9, 113788–113812. [Google Scholar] [CrossRef]
- Xiong, B.; Zeng, N.; Li, H.; Yang, Y.; Li, Y.; Huang, M.; Shi, W.; Du, M.; Zhang, Y. Intelligent Prediction of Human Lower Extremity Joint Moment: An Artificial Neural Network Approach. IEEE Access 2019, 7, 29973–29980. [Google Scholar] [CrossRef]
- Song, J.; Zhu, A.; Tu, Y.; Wang, Y.; Arif, M.A.; Shen, H.; Shen, Z.; Zhang, X.; Cao, G. Human Body Mixed Motion Pattern Recognition Method Based on Multi-Source Feature Parameter Fusion. Sensors 2020, 20, 537. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Laschowski, B.; McNally, W.; Wong, A.; McPhee, J. Environment Classification for Robotic Leg Prostheses and Exoskeletons Using Deep Convolutional Neural Networks. Front. Neurorobot. 2022, 15, 730965. [Google Scholar] [CrossRef] [PubMed]
- Al-Shuka, H.F.N.; Song, R. On low-level control strategies of lower extremity exoskeletons with power augmentation. In Proceedings of the 2018 Tenth International Conference on Advanced Computational Intelligence (ICACI), Xiamen, China, 29–31 March 2018; pp. 63–68. [Google Scholar] [CrossRef]
- Vantilt, J.; Tanghe, K.; Afschrift, M.; Bruijnes, A.K.; Junius, K.; Geeroms, J.; Aertbeliën, E.; De Groote, F.; Lefeber, D.; Jonkers, I.; et al. Model-based control for exoskeletons with series elastic actuators evaluated on sit-to-stand movements. J. NeuroEng. Rehabil. 2019, 16, 65. [Google Scholar] [CrossRef] [PubMed]
- Vallery, H.; Van Asseldonk, E.H.; Buss, M.; Van Der Kooij, H. Reference trajectory generation for rehabilitation robots: Complementary limb motion estimation. IEEE Trans. Neural Syst. Rehabil. Eng. 2009, 17, 23–30. [Google Scholar] [CrossRef] [Green Version]
- Tanghe, K.; De Groote, F.; Lefeber, D.; De Schutter, J.; Aertbeliën, E. Gait Trajectory and Event Prediction from State Estimation for Exoskeletons During Gait. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 211–220. [Google Scholar] [CrossRef]
- Liu, D.X.; Wu, X.; Wang, C.; Chen, C. Gait trajectory prediction for lower-limb exoskeleton based on Deep Spatial-Temporal Model (DSTM). In Proceedings of the 2017 2nd International Conference on Advanced Robotics and Mechatronics (ICARM), Hefei and Tai’an, China, 27–31 August 2017; pp. 564–569. [Google Scholar] [CrossRef]
- Zaroug, A.; Lai, D.T.H.; Mudie, K.; Begg, R. Lower Limb Kinematics Trajectory Prediction Using Long Short-Term Memory Neural Networks. Front. Bioeng. Biotechnol. 2020, 8, 362. [Google Scholar] [CrossRef]
- Su, B.; Gutierrez-Farewik, E.M. Gait Trajectory and Gait Phase Prediction Based on an LSTM Network. Sensors 2020, 20, 7127. [Google Scholar] [CrossRef]
- Hernandez, V.; Dadkhah, D.; Babakeshizadeh, V.; Kulić, D. Lower body kinematics estimation from wearable sensors for walking and running: A deep learning approach. Gait Posture 2021, 83, 185–193. [Google Scholar] [CrossRef]
- Jia, L.; Ai, Q.; Meng, W.; Liu, Q.; Xie, S.Q. Individualized Gait Trajectory Prediction Based on Fusion LSTM Networks for Robotic Rehabilitation Training. In Proceedings of the 2021 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Delft, The Netherlands, 12–16 July 2021; pp. 988–993. [Google Scholar] [CrossRef]
- Zaroug, A.; Garofolini, A.; Lai, D.T.H.; Mudie, K.; Begg, R. Prediction of gait trajectories based on the Long Short Term Memory neural networks. PLoS ONE 2021, 16, e0255597. [Google Scholar] [CrossRef]
- Zhu, C.; Liu, Q.; Meng, W.; Ai, Q.; Xie, S.Q. An Attention-Based CNN-LSTM Model with Limb Synergy for Joint Angles Prediction. In Proceedings of the 2021 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Delft, The Netherlands, 12–16 July 2021; pp. 747–752. [Google Scholar] [CrossRef]
- Kirtley, C. Clinical Gait Analysis: Theory and Practice; Churchill Livingstone Elsevier: Edinburgh, UK, 2006. [Google Scholar]
- Steinwender, G.; Saraph, V.; Scheiber, S.; Zwick, E.B.; Uitz, C.; Hackl, K. Intrasubject repeatability of gait analysis data in normal and spastic children. Clin. Biomech. 2000, 15, 134–139. [Google Scholar] [CrossRef]
- Moon, Y.; Sung, J.; An, R.; Hernandez, M.E.; Sosnoff, J.J. Gait variability in people with neurological disorders: A systematic review and meta-analysis. Hum. Mov. Sci. 2016, 47, 197–208. [Google Scholar] [CrossRef] [PubMed]
- Automatic Real-Time Gait Event Detection in Children Using Deep Neural Networks. Available online: https://simtk.org/frs/?group_id=1946 (accessed on 1 October 2021).
- Kidzinski, L.; Delp, S.; Schwartz, M. Automatic real-time gait event detection in children using deep neural networks. PLoS ONE 2019, 14, e0211466. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 2 February 2022).
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Gieysztor, E.; Kowal, M.; Paprocka-Borowicz, M. Gait Parameters in Healthy Preschool and School Children Assessed Using Wireless Inertial Sensor. Sensors 2021, 21, 6423. [Google Scholar] [CrossRef] [PubMed]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Moreira, L.; Figueiredo, J.; Vilas-Boas, J.P.; Santos, C.P. Kinematics, Speed, and Anthropometry-Based Ankle Joint Torque Estimation: A Deep Learning Regression Approach. Machines 2021, 9, 154. [Google Scholar] [CrossRef]
- Molinaro, D.D.; Kang, I.; Camargo, J.; Gombolay, M.C.; Young, A.J. Subject-Independent, Biological Hip Moment Estimation During Multimodal Overground Ambulation Using Deep Learning. IEEE Trans. Med Robot. Bionics 2022, 4, 219–229. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper-Parameter | Search Space | Selected Value | |
|---|---|---|---|
| LSTM | learning rate | [0.1, 0.01, 0.001, 0.0001, 0.00001] | 0.001 |
| number of LSTM layers | [1, 2, 3, 4] | 4 | |
| number of LSTM hidden units | [16, 32, 64, 100, 128] | 128 | |
| CNN | learning rate | [0.1, 0.01, 0.001, 0.0001, 0.00001] | 0.0001 |
| conv1D layer 1 channels | [16, 32, 48] | 32 | |
| conv1D layer 2 channels | [32, 48, 64] | 48 | |
| conv1D layer 3 channels | [64, 128, 256] | 256 | |
| conv1D layer 4 channels | [128, 256, 512] | 512 | |
| kernel size for layers 1, 2 | [1, 2, 3, 4, 5, 6, 7] | 7 | |
| kernel size for layers 3, 4 | [1, 2, 3, 4, 5, 6, 7] | 7 | |
| padding | [0, 1, 2, 3, 4, 5] | 4 | |
| conv1D stride | [1, 2, 3, 4, 5] | 1 | |
| dilation | [1, 2, 4] | 1 | |
| FCN | learning rate | [0.1, 0.01, 0.001, 0.0001, 0.00001] | 0.001 |
| hidden layers | [1, 2, 3, 4, 6, 8, 10] | 3 | |
| nodes per layer | [10, 20, 40, 60, 100, 140, 160, 200] | 200 |
| Input Window Size (ms) | Input Time- Steps | Output Window Size (ms) | Output Time- Steps | MSE (Degrees) | MSE std (Degrees) | MAE (Degrees) | MAE std (Degrees) | Mean Pearson Correlation Coefficient |
|---|---|---|---|---|---|---|---|---|
| 50 | 6 | 8.33 | 1 | 0.034 | 0.065 | 0.143 | 0.115 | 1.000 |
| 100 | 12 | 8.33 | 1 | 0.077 | 0.130 | 0.214 | 0.177 | 1.000 |
| 200 | 24 | 8.33 | 1 | 0.027 | 0.055 | 0.126 | 0.105 | 1.000 |
| 400 | 48 | 8.33 | 1 | 0.019 | 0.161 | 0.095 | 0.099 | 1.000 |
| 600 | 72 | 8.33 | 1 | 0.030 | 0.266 | 0.126 | 0.119 | 1.000 |
| 800 | 96 | 8.33 | 1 | 0.020 | 0.125 | 0.107 | 0.092 | 1.000 |
| 1000 | 120 | 8.33 | 1 | 0.022 | 0.318 | 0.109 | 0.098 | 1.000 |
| 50 | 6 | 25 | 3 | 0.079 | 0.526 | 0.175 | 0.220 | 1.000 |
| 100 | 12 | 25 | 3 | 0.077 | 0.474 | 0.187 | 0.206 | 1.000 |
| 200 | 24 | 25 | 3 | 0.079 | 0.793 | 0.176 | 0.218 | 1.000 |
| 400 | 48 | 25 | 3 | 0.080 | 3.068 | 0.169 | 0.227 | 1.000 |
| 600 | 72 | 25 | 3 | 0.092 | 2.597 | 0.173 | 0.250 | 1.000 |
| 800 | 96 | 25 | 3 | 0.104 | 1.279 | 0.200 | 0.252 | 1.000 |
| 1000 | 120 | 25 | 3 | 0.117 | 2.028 | 0.223 | 0.261 | 1.000 |
| 50 | 6 | 50 | 6 | 0.614 | 4.115 | 0.461 | 0.633 | 0.998 |
| 100 | 12 | 50 | 6 | 0.422 | 3.956 | 0.365 | 0.537 | 0.998 |
| 200 | 24 | 50 | 6 | 0.416 | 4.416 | 0.350 | 0.541 | 0.998 |
| 400 | 48 | 50 | 6 | 0.381 | 2.773 | 0.356 | 0.505 | 0.998 |
| 600 | 72 | 50 | 6 | 0.426 | 7.653 | 0.352 | 0.550 | 0.998 |
| 800 | 96 | 50 | 6 | 0.363 | 3.377 | 0.332 | 0.502 | 0.998 |
| 1000 | 120 | 50 | 6 | 0.405 | 5.414 | 0.359 | 0.526 | 0.998 |
| 50 | 6 | 100 | 12 | 3.548 | 15.749 | 1.104 | 1.526 | 0.984 |
| 100 | 12 | 100 | 12 | 3.310 | 15.545 | 1.058 | 1.480 | 0.985 |
| 200 | 24 | 100 | 12 | 3.200 | 14.790 | 1.008 | 1.478 | 0.985 |
| 400 | 48 | 100 | 12 | 3.279 | 30.567 | 1.007 | 1.505 | 0.985 |
| 600 | 72 | 100 | 12 | 2.723 | 14.993 | 0.927 | 1.365 | 0.987 |
| 800 | 96 | 100 | 12 | 2.524 | 13.366 | 0.906 | 1.305 | 0.988 |
| 1000 | 120 | 100 | 12 | 2.157 | 9.940 | 0.847 | 1.200 | 0.990 |
| 50 | 6 | 200 | 24 | 16.981 | 57.084 | 2.531 | 3.252 | 0.928 |
| 100 | 12 | 200 | 24 | 15.025 | 49.937 | 2.383 | 3.057 | 0.935 |
| 200 | 24 | 200 | 24 | 15.114 | 55.836 | 2.357 | 3.091 | 0.934 |
| 400 | 48 | 200 | 24 | 14.058 | 50.333 | 2.282 | 2.975 | 0.937 |
| 600 | 72 | 200 | 24 | 12.617 | 48.434 | 2.158 | 2.821 | 0.945 |
| 800 | 96 | 200 | 24 | 10.389 | 38.372 | 1.973 | 2.549 | 0.955 |
| 1000 | 120 | 200 | 24 | 8.971 | 36.862 | 1.828 | 2.373 | 0.961 |
| Input Window Size (ms) | Input Time- Steps | Output Window Size (ms) | Output Time- Steps | MSE (Degrees) | MSE std (Degrees) | MAE (Degrees) | MAE std (Degrees) | Mean Pearson Correlation Coefficient |
|---|---|---|---|---|---|---|---|---|
| 50 | 6 | 8.33 | 1 | 0.069 | 0.960 | 0.129 | 0.229 | 1.000 |
| 50 | 6 | 25 | 3 | 0.184 | 1.699 | 0.234 | 0.360 | 0.999 |
| 50 | 6 | 50 | 6 | 0.891 | 4.685 | 0.552 | 0.766 | 0.996 |
| 50 | 6 | 100 | 12 | 5.265 | 20.277 | 1.358 | 1.850 | 0.977 |
| 50 | 6 | 200 | 24 | 20.437 | 65.596 | 2.840 | 3.517 | 0.913 |
| 1000 | 120 | 8.33 | 1 | 0.061 | 0.709 | 0.138 | 0.203 | 1.000 |
| 1000 | 120 | 25 | 3 | 0.216 | 2.020 | 0.259 | 0.386 | 0.999 |
| 1000 | 120 | 50 | 6 | 0.994 | 4.966 | 0.576 | 0.814 | 0.995 |
| 1000 | 120 | 100 | 12 | 5.496 | 18.724 | 1.440 | 1.850 | 0.975 |
| 1000 | 120 | 200 | 24 | 18.007 | 54.453 | 2.738 | 3.242 | 0.926 |
| Input Window Size (ms) | Input Time- Steps | Output Window Size (ms) | Output Time- Steps | LSTM MAE (Degrees) | CNN MAE (Degrees) | FCN MAE (Degrees) | Naïve Method 1 MAE (Degrees) | Naïve Method 2 MAE (Degrees) |
|---|---|---|---|---|---|---|---|---|
| 50 | 6 | 8.33 | 1 | 0.143 * | 0.129 * | 0.195 * | 0.449 | 1.513 * |
| 50 | 6 | 25 | 3 | 0.175 * | 0.234 * | 0.294 * | 0.888 | 1.916 * |
| 50 | 6 | 50 | 6 | 0.461 * | 0.552 * | 0.568 * | 1.517 | 2.486 * |
| 50 | 6 | 100 | 12 | 1.104 * | 1.358 * | 1.336 * | 2.640 | 3.494 * |
| 50 | 6 | 200 | 24 | 2.531 * | 2.840 * | 2.489 * | 4.417 | 5.096 * |
| 1000 | 120 | 8.33 | 1 | 0.109 * | 0.138 * | 0.369 * | 0.448 | 6.090 * |
| 1000 | 120 | 25 | 3 | 0.223 * | 0.259 * | 0.594 * | 0.888 | 6.121 * |
| 1000 | 120 | 50 | 6 | 0.359 * | 0.576 * | 0.902 * | 1.520 | 6.167 * |
| 1000 | 120 | 100 | 12 | 0.847 * | 1.440 * | 1.454 * | 2.651 | 6.254 * |
| 1000 | 120 | 200 | 24 | 1.828 * | 2.738 * | 2.320 * | 4.448 | 6.385 * |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kolaghassi, R.; Al-Hares, M.K.; Marcelli, G.; Sirlantzis, K. Performance of Deep Learning Models in Forecasting Gait Trajectories of Children with Neurological Disorders. Sensors 2022, 22, 2969. https://doi.org/10.3390/s22082969
Kolaghassi R, Al-Hares MK, Marcelli G, Sirlantzis K. Performance of Deep Learning Models in Forecasting Gait Trajectories of Children with Neurological Disorders. Sensors. 2022; 22(8):2969. https://doi.org/10.3390/s22082969
Chicago/Turabian StyleKolaghassi, Rania, Mohamad Kenan Al-Hares, Gianluca Marcelli, and Konstantinos Sirlantzis. 2022. "Performance of Deep Learning Models in Forecasting Gait Trajectories of Children with Neurological Disorders" Sensors 22, no. 8: 2969. https://doi.org/10.3390/s22082969
APA StyleKolaghassi, R., Al-Hares, M. K., Marcelli, G., & Sirlantzis, K. (2022). Performance of Deep Learning Models in Forecasting Gait Trajectories of Children with Neurological Disorders. Sensors, 22(8), 2969. https://doi.org/10.3390/s22082969