
Scalable Fire and Smoke Segmentation from Aerial Images Using Convolutional Neural Networks and Quad-Tree Search



Abstract
:1. Introduction
2. Related Works
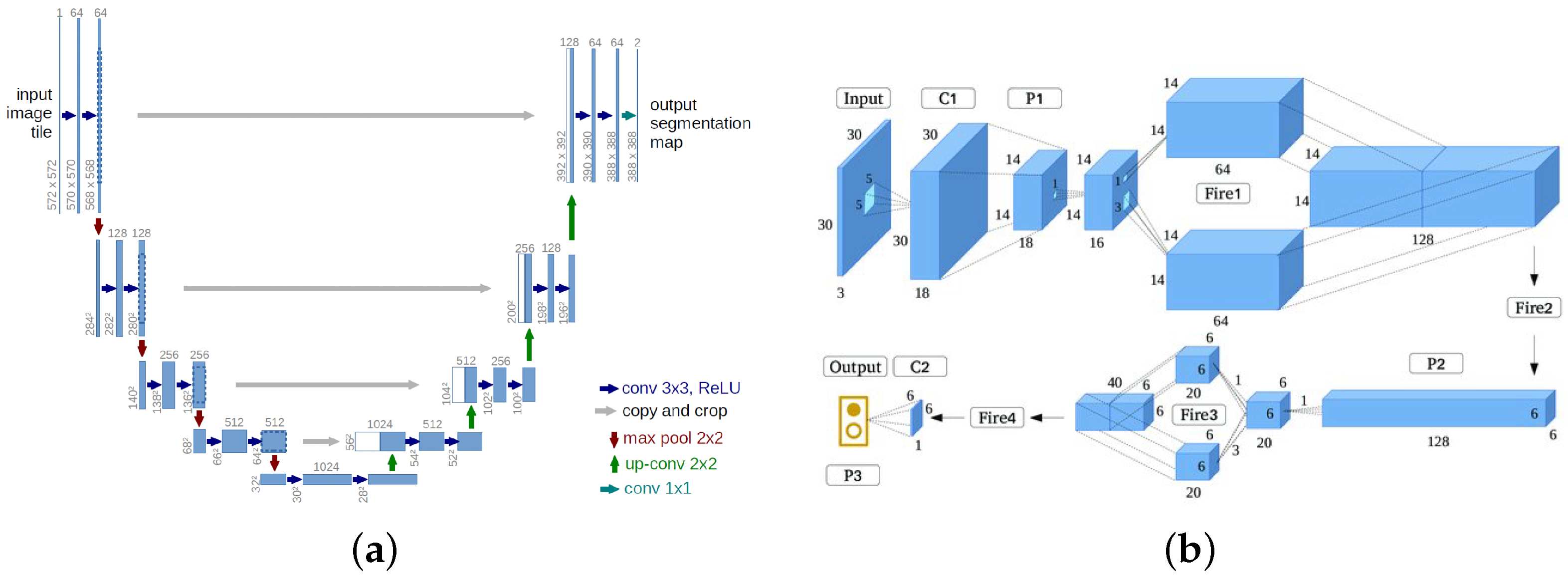
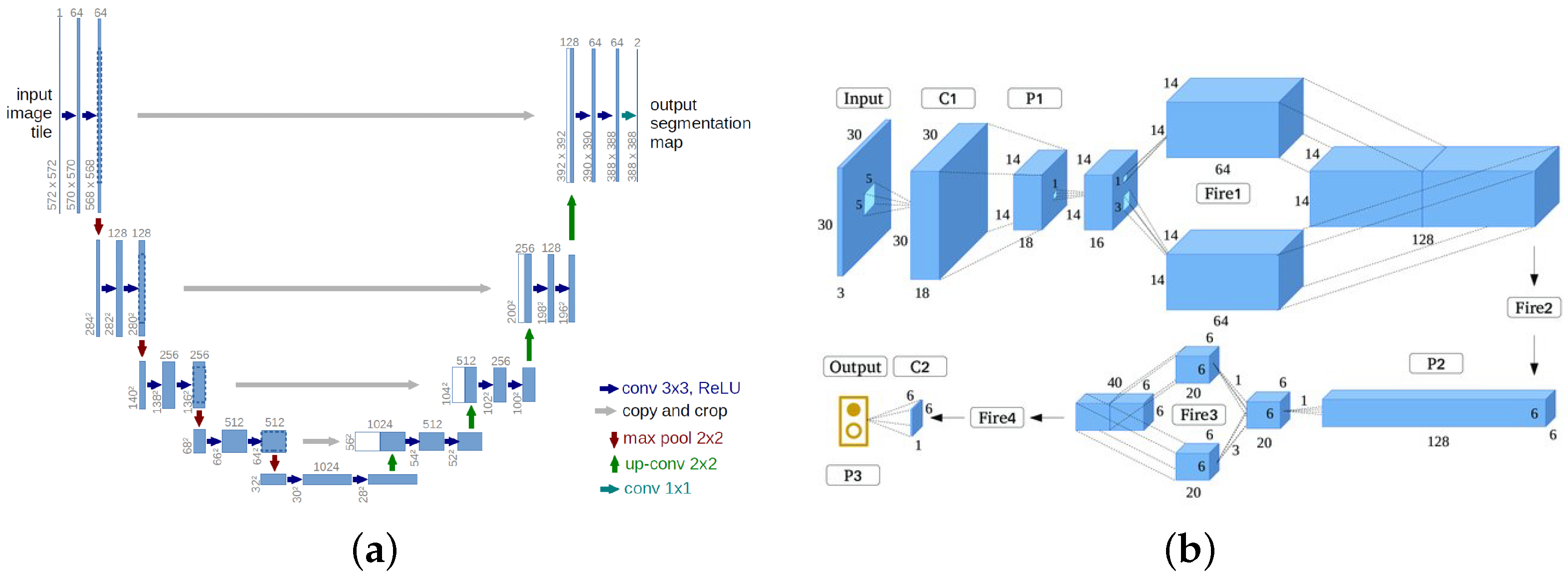
3. Methodology
| Algorithm 1: Quad_Tree Algorithm. |
 |
- computes the ratio between the number of segmented pixels divided by the total number of pixels in the patch;
- is the threshold value for the previous ratio, below which the algorithm continues the ’zooming’ process;
- is the maximum value of the patch sizes for which we rely on the negative classification output;
- is the minimum value of patch size for the zoom-in process. This is actually the minimum size of patch the algorithm can reach.
4. Implementation and Results
4.1. Dataset
4.2. Networks Training
- Optimizer: Adam()
- Learn. Rate: 0.001
- : 0.9;
- : 0.999;
- : 1e-7;
- Loss: Binary Crossentropy;
- Batch Size: 32;
- Patience: 20;
- Epochs: 150;
- Monitor: Val. Loss;
- Optimizer: Adam()
- Learn. Rate: 0.002
- : 0.9;
- : 0.999;
- : 1e-7;
- Loss: Binary Crossentropy;
- Batch Size: 32;
- Patience: 20;
- Epochs: 150;
- Monitor: Val. Loss;
- Optimizer: Adam()
- Learn. Rate: 0.0001
- : 0.9;
- : 0.999;
- : 1e-5;
- Loss: Binary Crossentropy;
- Batch Size: 32;
- Patience: 30;
- Epochs: 200;
- Monitor: Val. Loss;
- Optimizer: Adam()
- Learn. Rate: 0.0005
- : 0.9;
- : 0.999;
- : 1e-5;
- Loss: Binary Crossentropy;
- Batch Size: 32;
- Patience: 50;
- Epochs: 200;
- Monitor: Val. Loss;
4.3. Results
- 1. Q + C + S: This model corresponds to the complete proposed algorithm. It uses all the components explained earlier, the QuadTree algorithm, the classification stage, and the segmentation stage;
- 2. Q + S: This model removes the classification component from the algorithm, and QuadTree assumes the classification to always be positive;
- 3. C + S: In this model, QuadTree methodology is removed. It divides the image into patches of minimum size (). It then processes all patches by first classifying them and then segmenting them.
- 4. S: This final model consists only of the segmentation stage with the input image resized to the network input size. This corresponds to conventional semantic segmentation methods (in our case with Deeplab-v3).
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Batista, M.; Oliveira, B.; Chaves, P.; Ferreira, J.C.; Brandão, T. Improved Real-time Wildfire Detection using a Surveillance System. In Proceedings of the World Congress on Engineering, London, UK, 3–5 July 2019. [Google Scholar]
- Lindner, L.; Sergiyenko, O.; Rivas-López, M.; Hernández-Balbuena, D.; Flores-Fuentes, W.; Rodríguez-Quiñonez, J.C.; Murrieta-Rico, F.N.; Ivanov, M.; Tyrsa, V.; Básaca-Preciado, L.C. Exact laser beam positioning for measurement of vegetation vitality. Ind. Robot. Int. J. 2017, 44, 532–541. [Google Scholar] [CrossRef]
- Sotnikov, O.; Kartashov, V.G.; Tymochko, O.; Sergiyenko, O.; Tyrsa, V.; Mercorelli, P.; Flores-Fuentes, W. Methods for Ensuring the Accuracy of Radiometric and Optoelectronic Navigation Systems of Flying Robots in a Developed Infrastructure. In Machine Vision and Navigation; Springer: Berlin/Heidelberg, Germany, 2020; pp. 537–577. [Google Scholar]
- Yuan, C.; Zhang, Y.; Liu, Z. A Survey on Technologies for Automatic Forest Fire Monitoring, Detection and Fighting Using UAVs and Remote Sensing Techniques. Can. J. For. Res. 2015, 45, 783–792. [Google Scholar] [CrossRef]
- Celik, T.; Demirel, H. Fire detection in video sequences using a generic color model. Fire Saf. J. 2009, 44, 147–158. [Google Scholar] [CrossRef]
- Chen, T.H.; Wu, P.H.; Chiou, Y.C. An early fire-detection method based on image processing. In Proceedings of the 2004 International Conference on Image Processing, Singapore, 24–27 October 2004; pp. 1707–1710. [Google Scholar]
- Habiboğlu, Y.H.; Günay, O.; Çetin, A.E. Covariance matrix-based fire and flame detection method in video. Mach. Vis. Appl. 2012, 23, 1103–1113. [Google Scholar] [CrossRef]
- Dunnings, A.J.; Breckon, T.P. Experimentally defined convolutional neural network architecture variants for non-temporal real-time fire detection. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1558–1562. [Google Scholar]
- Barmpoutis, P.; Dimitropoulos, K.; Kaza, K.; Grammalidis, N. Fire Detection from Images Using Faster R-CNN and Multidimensional Texture Analysis. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar] [CrossRef]
- Chaoxia, C.; Shang, W.; Zhang, F. Information-guided flame detection based on faster r-cnn. IEEE Access 2020, 8, 58923–58932. [Google Scholar] [CrossRef]
- Harkat, H.; Nascimento, J.M.; Bernardino, A. Fire Detection using Residual Deeplabv3+ Model. In Proceedings of the 2021 Telecoms Conference (ConfTELE), Leiria, Portugal, 11–12 February 2021; pp. 1–6. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Finkel, R.A.; Bentley, J.L. Quad trees a data structure for retrieval on composite keys. Acta Inform. 1974, 4, 1–9. [Google Scholar] [CrossRef]
- Toulouse, T.; Rossi, L.; Akhloufi, M.; Celik, T.; Maldague, X. Benchmarking of wildland fire color segmentation algorithms. IET Image Process. 2015, 9, 1064–1072. [Google Scholar] [CrossRef] [Green Version]
- Cruz, H.; Eckert, M.; Meneses, J.; Martínez, J.F. Efficient Forest Fire Detection Index for Application in Unmanned Aerial Systems (UASs). Sensors 2016, 16, 893. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dung, N.M.; Ro, S. Algorithm for Fire Detection Using a Camera Surveillance System. In Proceedings of the 2018 International Conference on Image and Graphics Processing, New York, NY, USA, 24–26 February 2018. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. In The Handbook of Brain Theory and Neural Networks; The MIT Press: Cambridge, MA, USA, 1998; pp. 255–258. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lehr, J.; Gerson, C.; Ajami, M.; Krüger, J. Development of a Fire Detection Based on the Analysis of Video Data by Means of Convolutional Neural Networks; Springer: Berlin, Germany, 2019; pp. 497–507. [Google Scholar]
- Verlekar, T.T.; Bernardino, A. Video Based Fire Detection Using Xception and Conv-LSTM. In Proceedings of the International Symposium on Visual Computing, San Diego, CA, USA, 5–7 October 2020; pp. 277–285. [Google Scholar]
- Harkat, H.; Nascimento, J.; Bernardino, A. Fire segmentation using a SqueezeSegv2. In Proceedings of the Image and Signal Processing for Remote Sensing XXVII, Online, 21–25 September 2020; pp. 82–88. [Google Scholar]
- Yuan, F.; Zhang, L.; Xia, X.; Wan, B.; Huang, Q.; Li, X. Deep smoke segmentation. Neurocomputing 2019, 357, 248–260. [Google Scholar] [CrossRef]
- Shusterman, E.; Feder, M. Image compression via improved quadtree decomposition algorithms. IEEE Trans. Image Process. 1994, 3, 207–215. [Google Scholar] [CrossRef] [PubMed]
- D’Angelo, A. A Brief Introduction to Quadtrees and Their Applications. In Proceedings of the 28th Canadian Conference on Computational Geometry, Vancouver, BC, Canada, 3–5 August 2016. [Google Scholar]
- Cordonnier, J.B.; Mahendran, A.; Dosovitskiy, A.; Weissenborn, D.; Uszkoreit, J.; Unterthiner, T. Differentiable Patch Selection for Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2351–2360. [Google Scholar]
- Katharopoulos, A.; Fleuret, F. Processing megapixel images with deep attention-sampling models. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 18–23 January 2019; pp. 3282–3291. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50× fewer parameters and <0.5 MB model size. In Proceedings of the 19th International Conference Medical Image Computing and Computer-Assisted Intervention MICCAI1, Athens, Greece, 17–21 October 2016. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the 18th International Conference Medical Image Computing and Computer-Assisted Intervention MICCAI1, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Toulouse, T.; Rossi, L.; Campana, A.; Celik, T.; Akhlouf, M. Computer vision for wildfire research: An evolving image dataset for processing and analysis. Fire Saf. J. 2017, 92, 188–194. [Google Scholar] [CrossRef] [Green Version]
- Baidya, A.; Olinda. Smoke Detection via Semantic Segmentation Using Baseline U-Net Model and Image Augmentation in Keras. 2019. Available online: https://github.com/rekon/Smoke-semantic-segmentation (accessed on 12 November 2020).
- Smoke Dataset. 2016. Available online: http://smoke.ustc.edu.cn/datasets.htm (accessed on 20 November 2020).
- The MathWorks, Inc. Computer Vision Toolbox. 2018. Available online: https://www.mathworks.com/products/computer-vision.html (accessed on 27 December 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification | Fire | Positive | 800 |
| Negative | 520 | ||
| Smoke | Positive | 500 | |
| Negative | 300 | ||
| Segmentation | Fire | Containing fire | 700 |
| Negative | 450 | ||
| Smoke | Containing fire | 300 | |
| Negative | 60 |
| Fire Dataset | Smoke Dataset | |
|---|---|---|
| Training set accuracy | 98.56 | 96.10 |
| Validation set accuracy | 95.98 | 91.01 |
| Predicted Fire | Predicted Non-Fire | |
|---|---|---|
| True fire class | 0.951 | 0.049 |
| True non-fire class | 0.041 | 0.959 |
| Predicted Smoke | Predicted Non-Smoke | |
|---|---|---|
| True smoke class | 0.902 | 0.098 |
| True non-smoke class | 0.087 | 0.913 |
| Model | Mean IoU % | SD (of IoU) | Pixel Acc. | Process. Time (per Pixel) |
|---|---|---|---|---|
| Q + C + S | 88.3 | 0.10 | 95.8 | |
| Q + S | 88.01 | 0.15 | 95.8 | |
| C + S | 88.51 | 0.10 | 95.9 | |
| S | 83.49 | 0.22 | 91.3 |
| Model | Mean IoU % | SD (of IoU) | Pixel Acc. | Process. Time (per Pixel) |
|---|---|---|---|---|
| Q + C + S | 83.37 | 0.133 | 91.6 | |
| Q + S | 82.81 | 0.149 | 91.5 | |
| C + S | 83.25 | 0.144 | 91.6 | |
| S | 77.21 | 0.215 | 87.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perrolas, G.; Niknejad, M.; Ribeiro, R.; Bernardino, A. Scalable Fire and Smoke Segmentation from Aerial Images Using Convolutional Neural Networks and Quad-Tree Search. Sensors 2022, 22, 1701. https://doi.org/10.3390/s22051701
Perrolas G, Niknejad M, Ribeiro R, Bernardino A. Scalable Fire and Smoke Segmentation from Aerial Images Using Convolutional Neural Networks and Quad-Tree Search. Sensors. 2022; 22(5):1701. https://doi.org/10.3390/s22051701
Chicago/Turabian StylePerrolas, Gonçalo, Milad Niknejad, Ricardo Ribeiro, and Alexandre Bernardino. 2022. "Scalable Fire and Smoke Segmentation from Aerial Images Using Convolutional Neural Networks and Quad-Tree Search" Sensors 22, no. 5: 1701. https://doi.org/10.3390/s22051701
APA StylePerrolas, G., Niknejad, M., Ribeiro, R., & Bernardino, A. (2022). Scalable Fire and Smoke Segmentation from Aerial Images Using Convolutional Neural Networks and Quad-Tree Search. Sensors, 22(5), 1701. https://doi.org/10.3390/s22051701