
Computer Vision-Based Path Planning for Robot Arms in Three-Dimensional Workspaces Using Q-Learning and Neural Networks



Abstract
:1. Introduction
- Although many applications require 3D movement, the scope of work was limited to the 2D workspace.
- Finding a start, an obstacle, and a target point through their colors may negatively affect image processing accuracy depending on the ambient light. Obstacle detection based on shapes would be preferable.
- Because the KNN algorithm was used in this study, a start, an obstacle, and a target cell were required to have distinct colors.
- Only one obstacle could be located in the workspace unless distinct colors were used for each obstacle.
2. Related Works
3. Methods
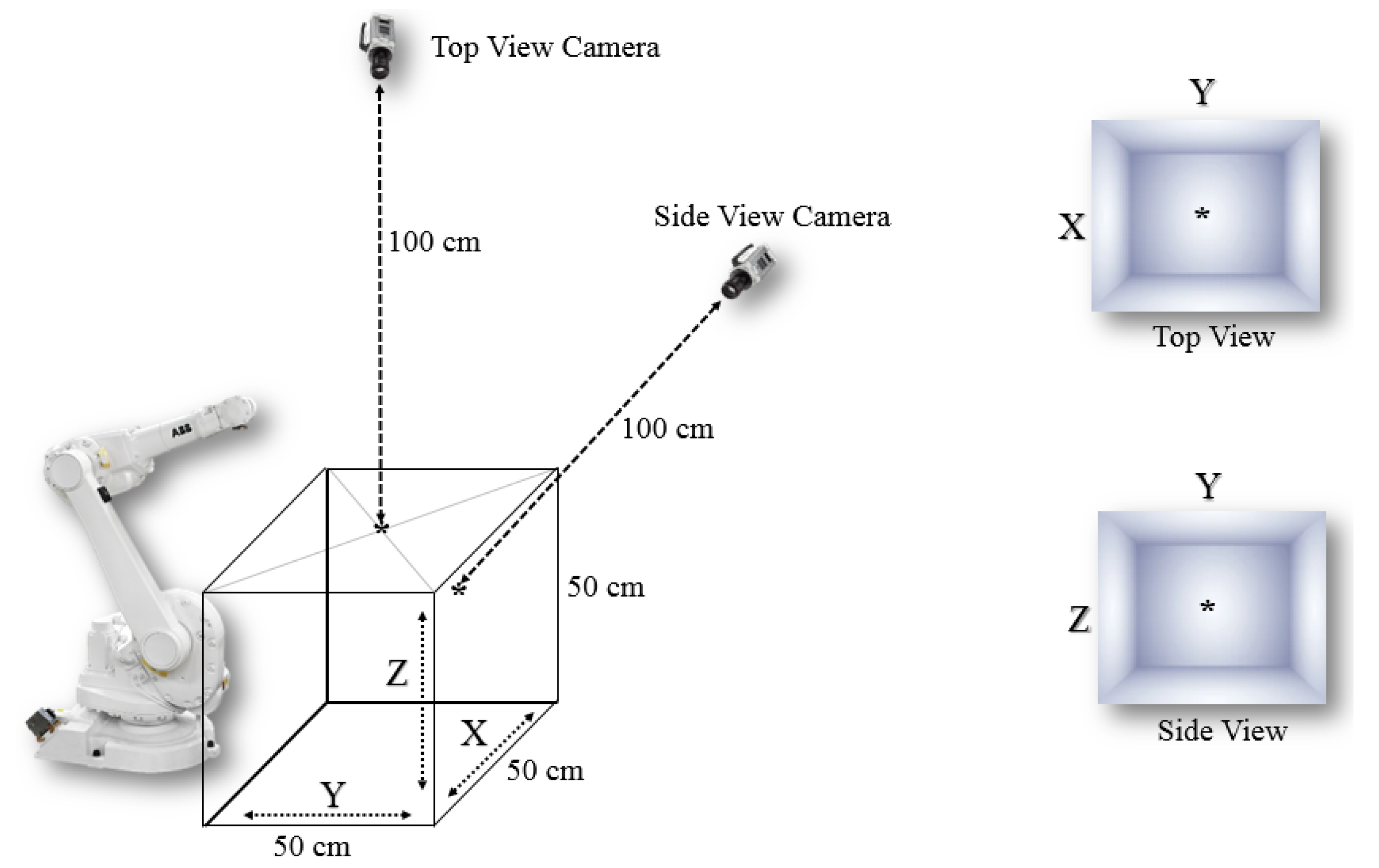
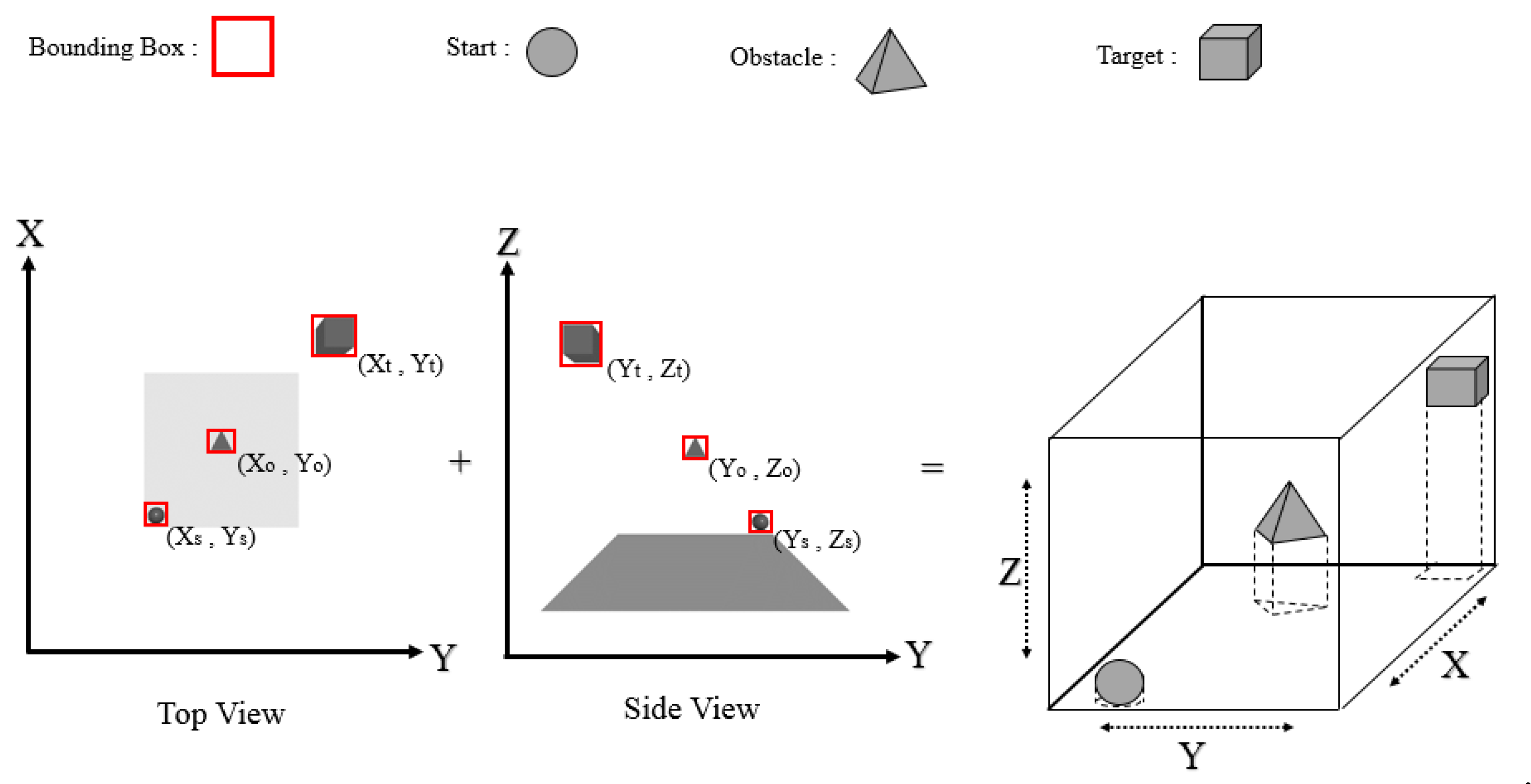
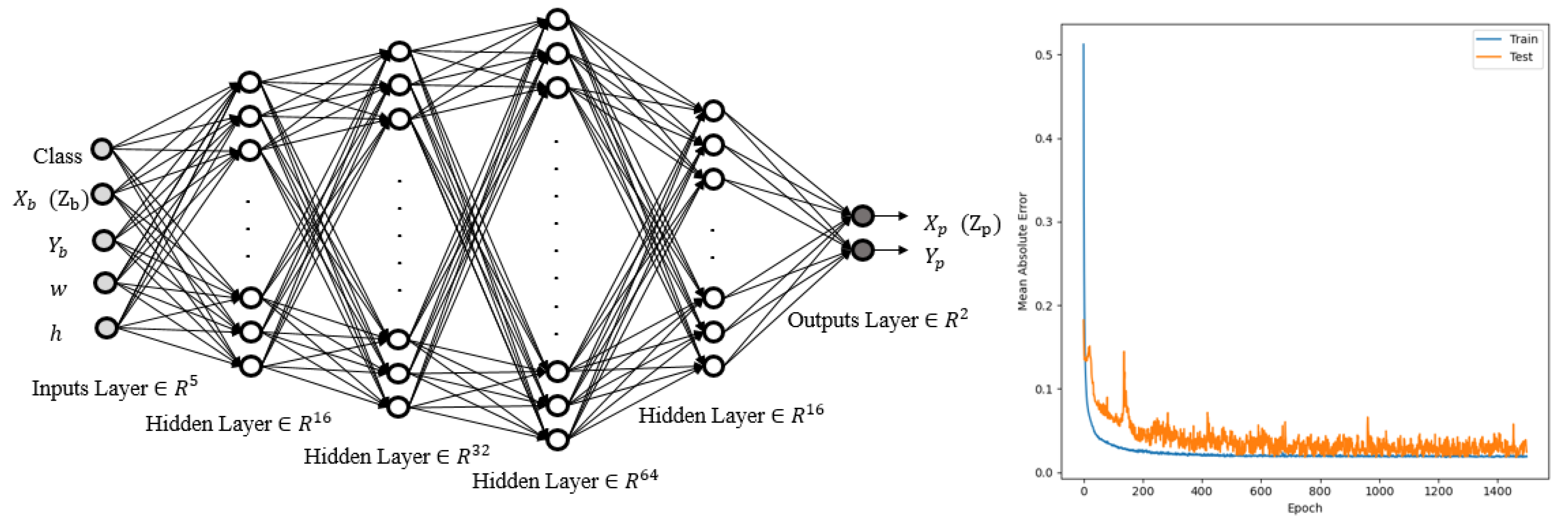
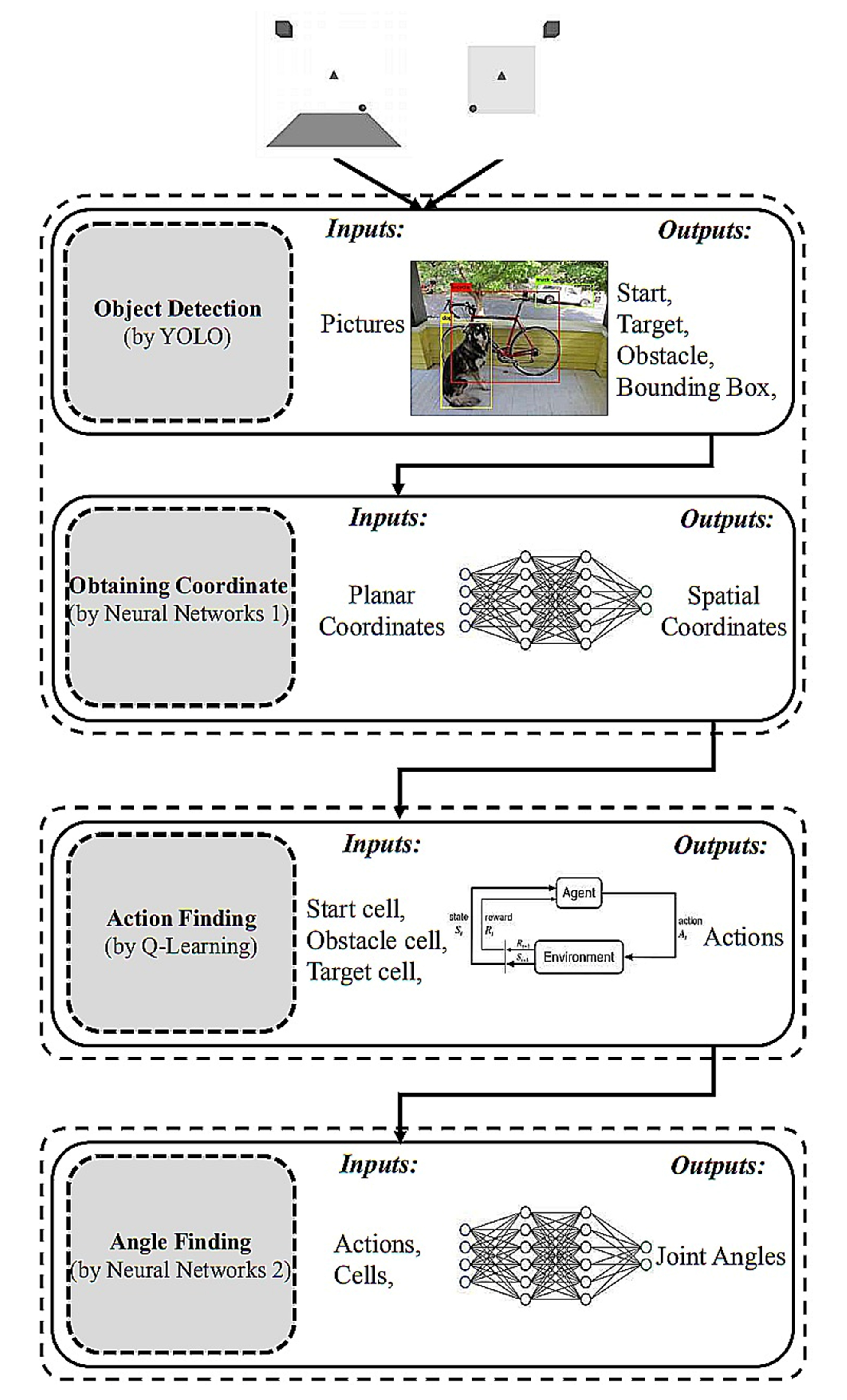
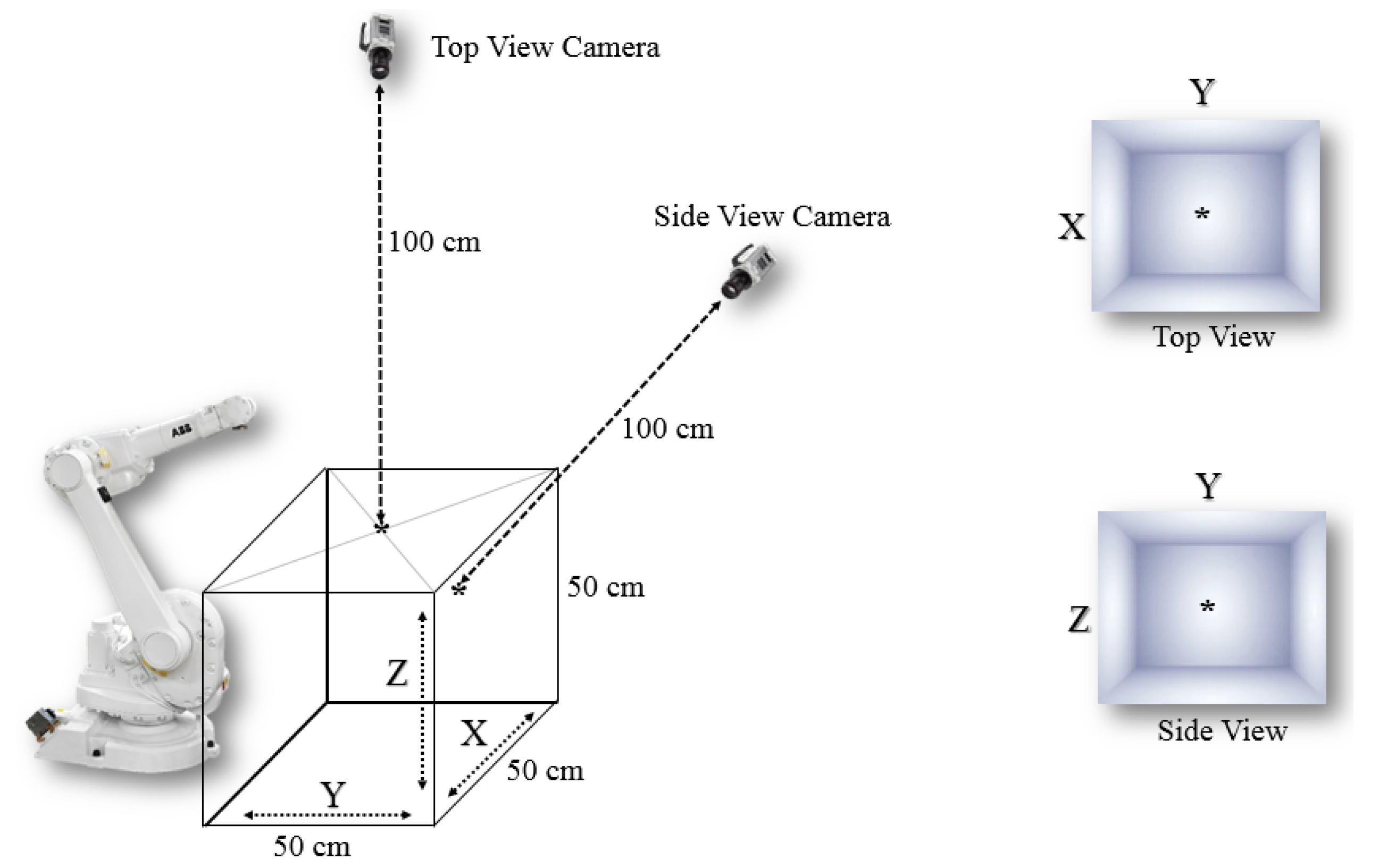
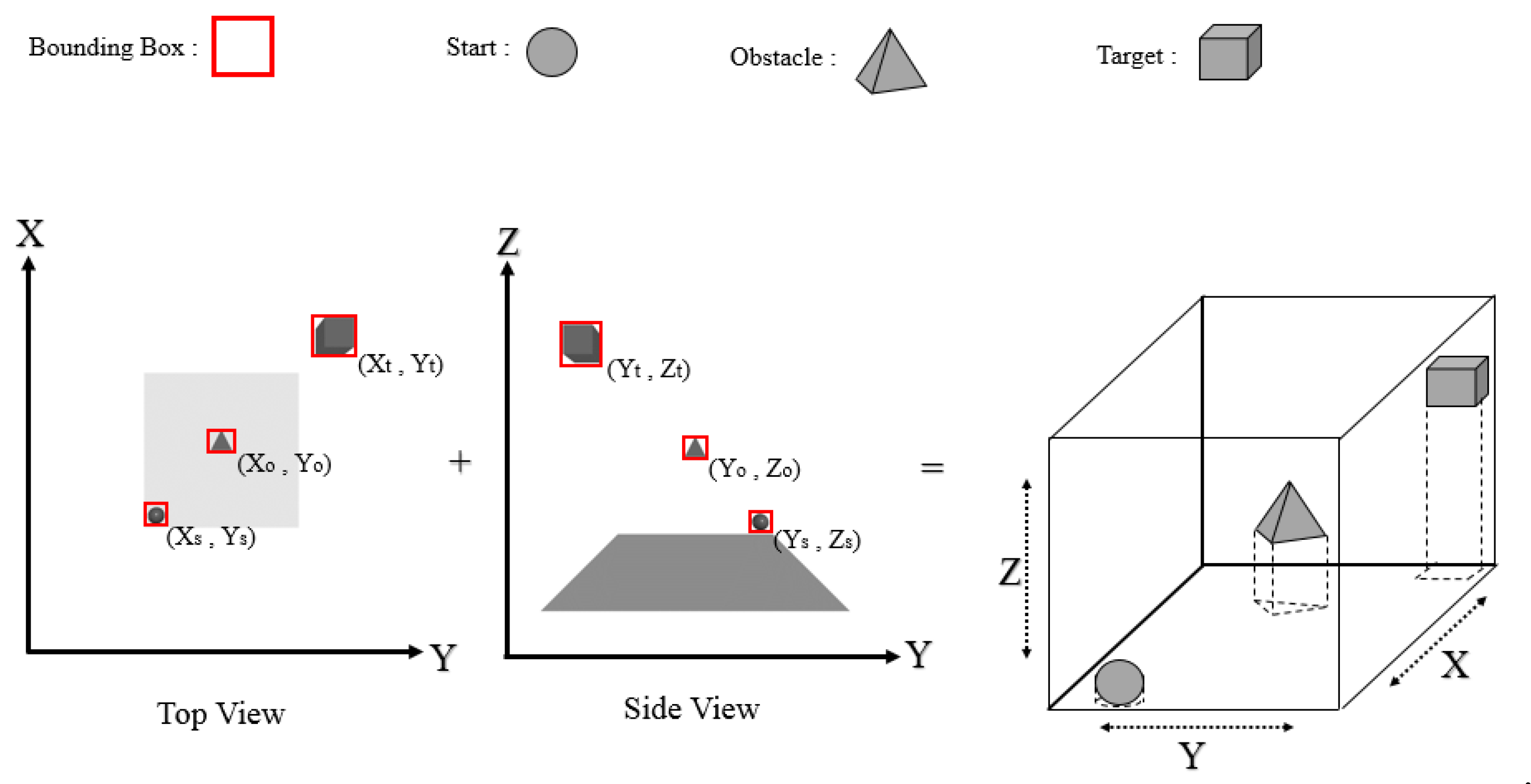
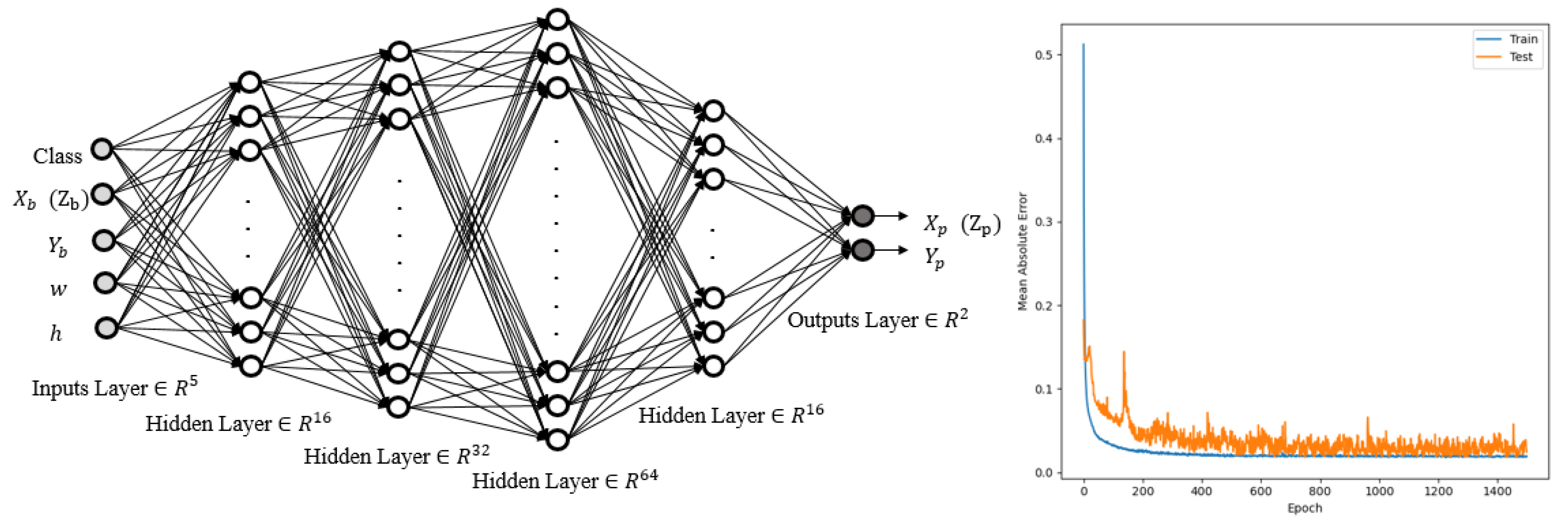
3.1. Object Detection and Spatial Coordinates (Combined YOLO-Neural Networks 1)
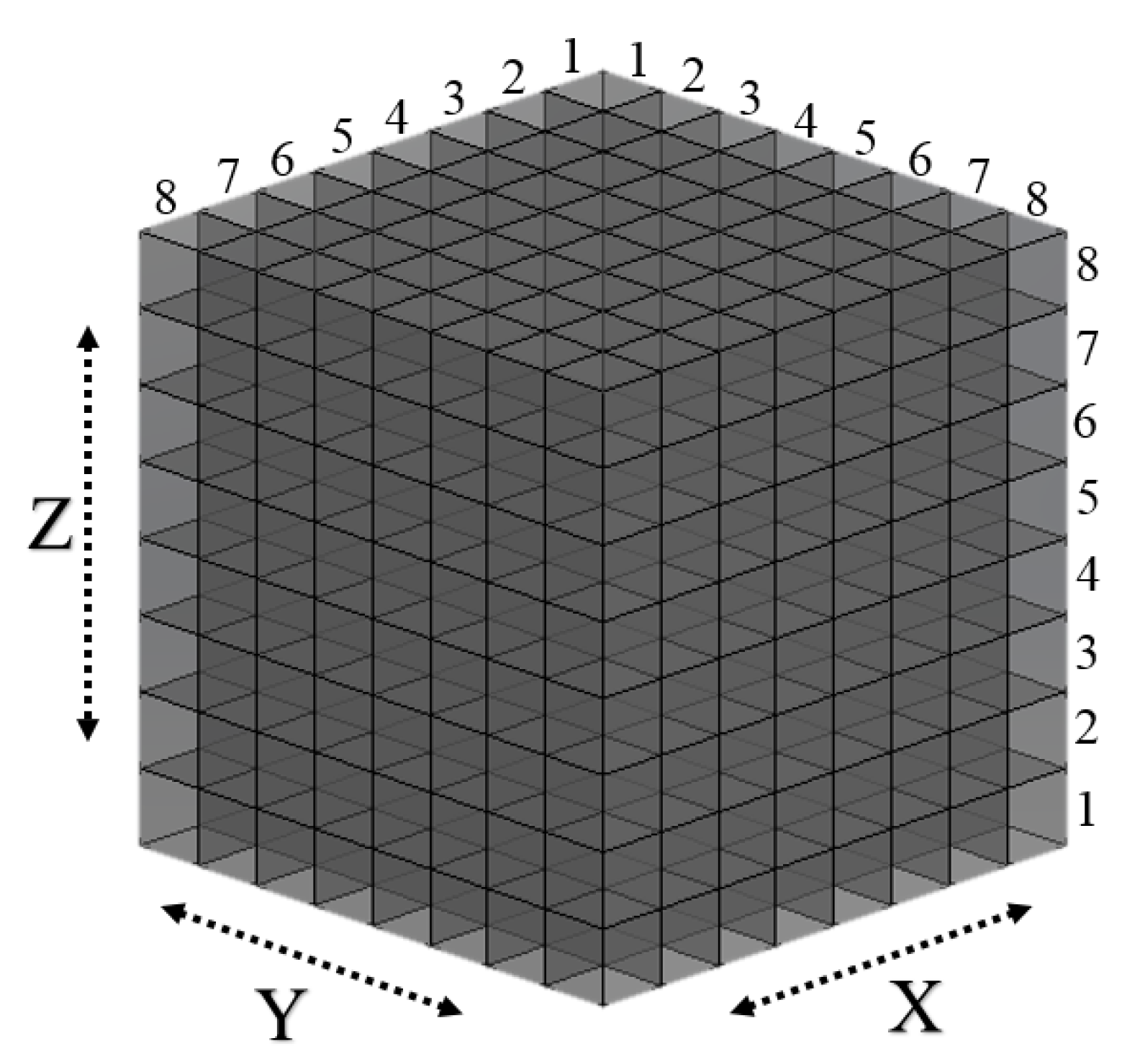
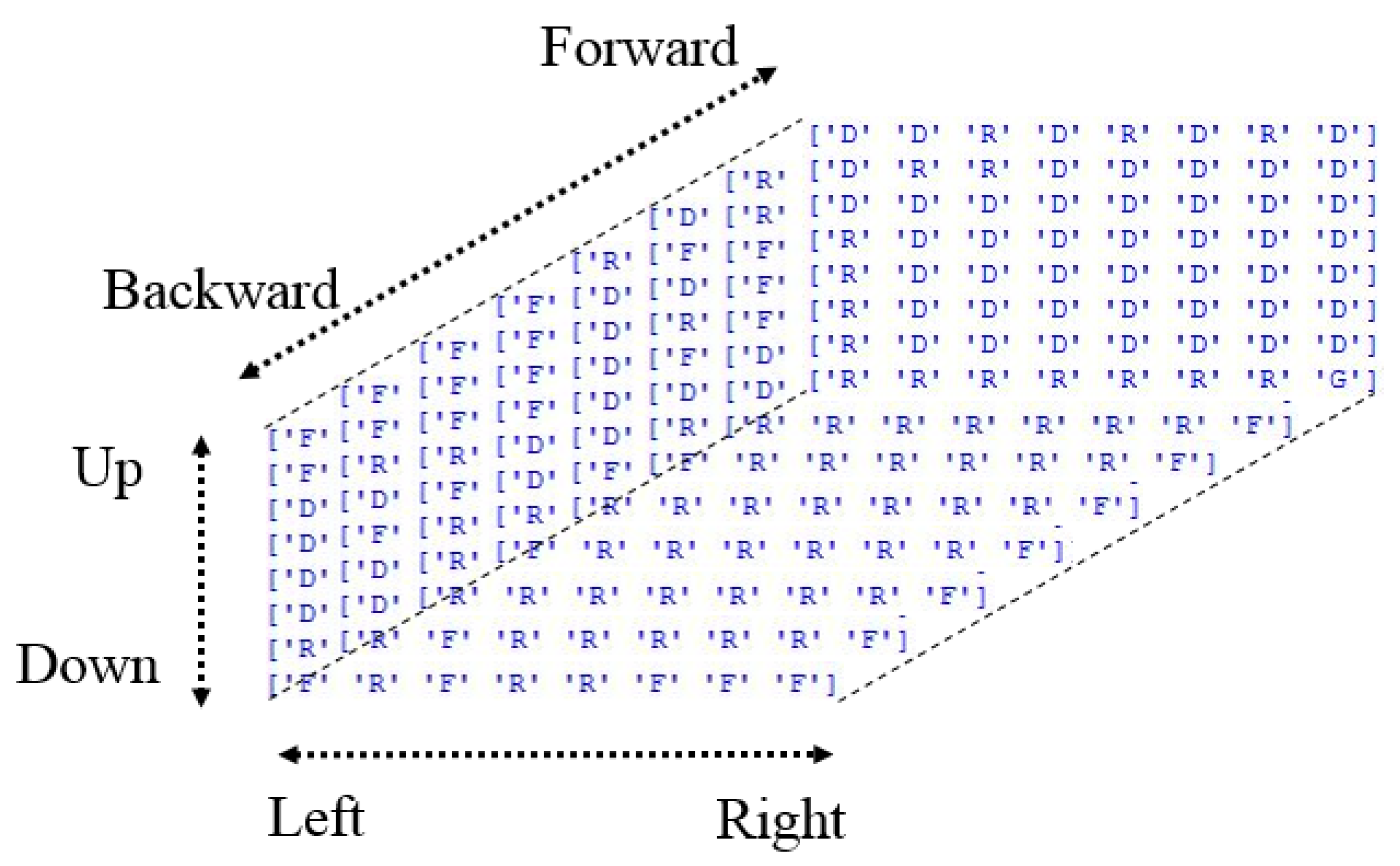
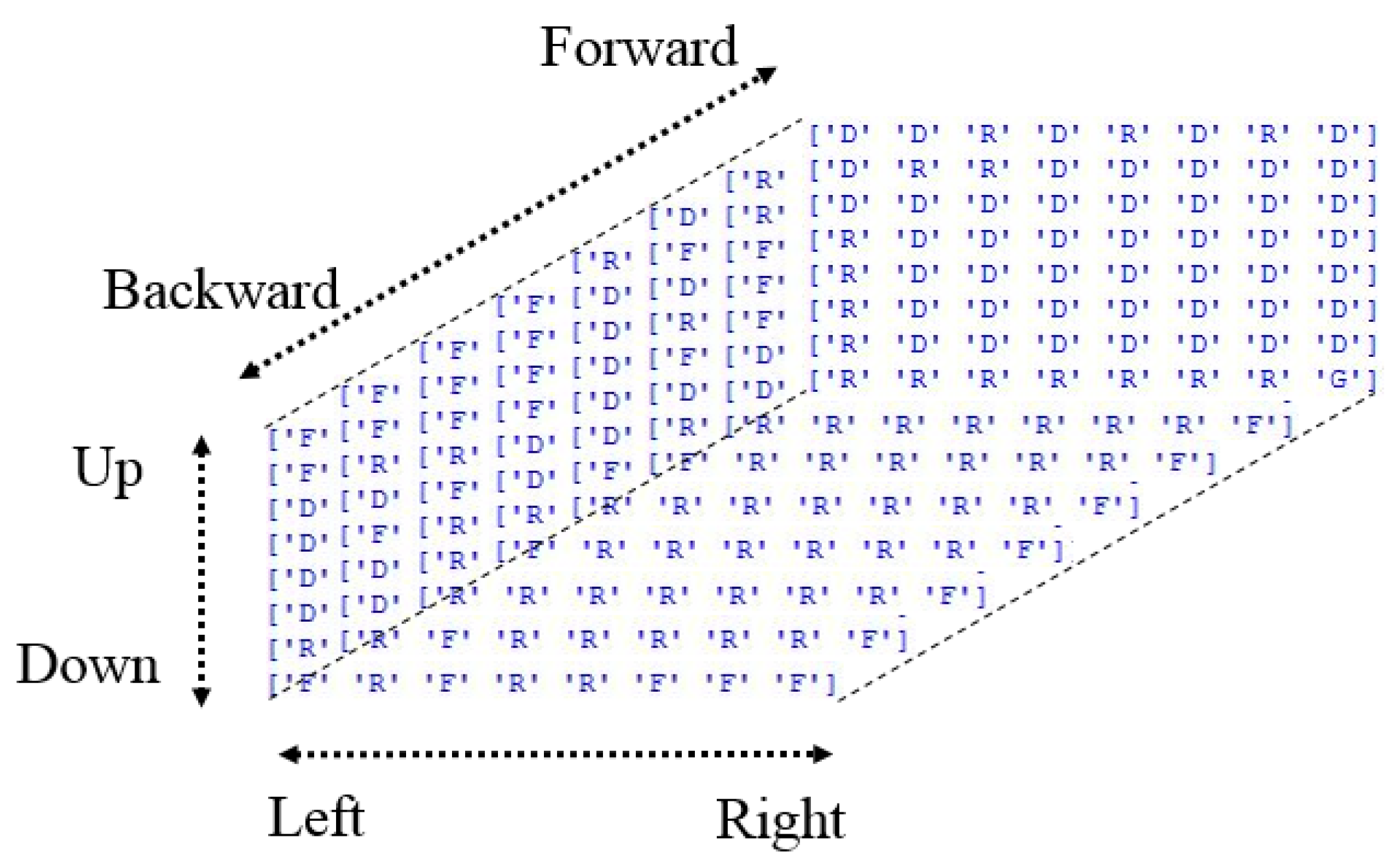
3.2. Action Finding (Q-Learning)
- In an 8 × 8 × 8 3D grid workspace, six possible actions, namely forward, backward, up, down, left, and right, were considered.
- An agent starts from a randomly located start state and receives a reward of 50 points for reaching a randomly located target state.
- An agent receives a penalty of −100 points for reaching a randomly located obstacle cell.
- All other actions cause a penalty of −1 point.
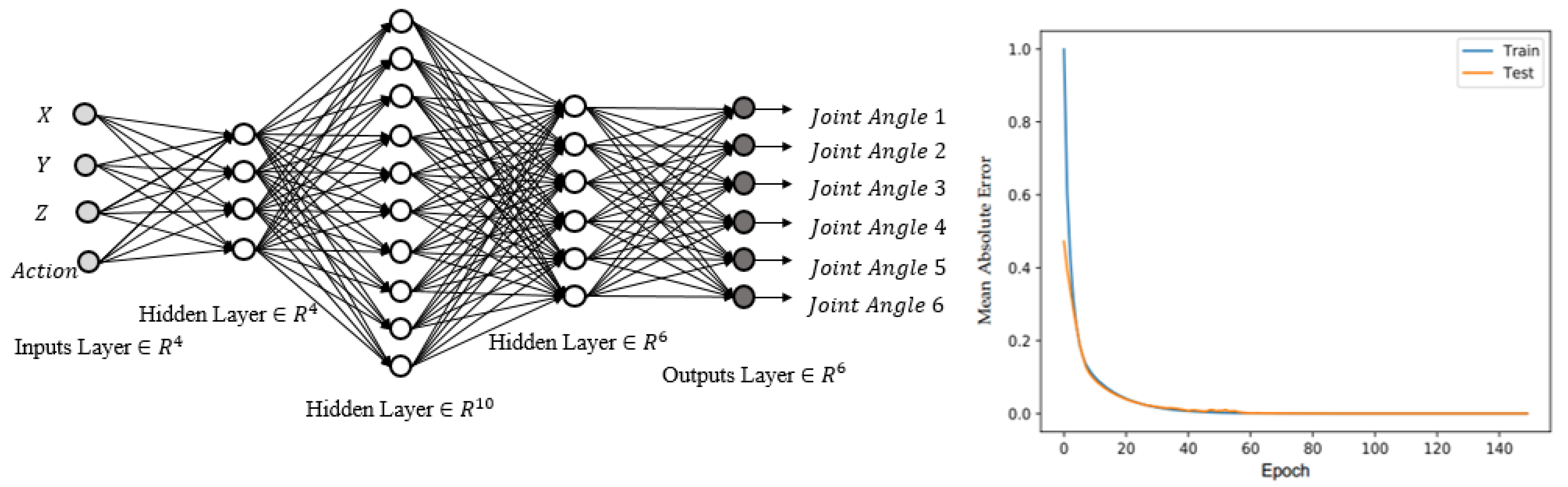
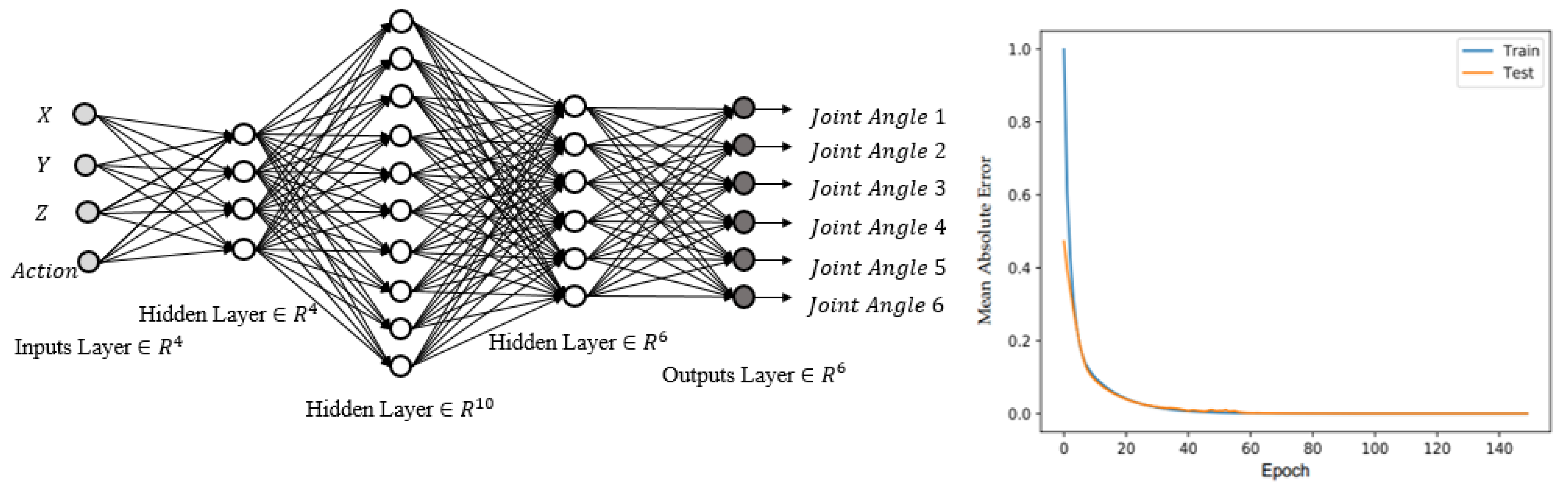
3.3. 6-DOF Angle Finding (Neural Networks 2)
- Capturing a snapshot of the 3D workspace with the two cameras;
- Detecting a start, target, and obstacle cell using the YOLO object-detection algorithm
- Obtaining the spatial coordinates of three objects using the first neural networks;
- Using the Q-learning method to determine an optimal route from a starting point to a target point while avoiding obstacle collision.
- Finding the joint angles of the discovered actions using the trained neural network;
- Implementation in the actual or simulated world of the acquired joint angle sequence on the robot arm.
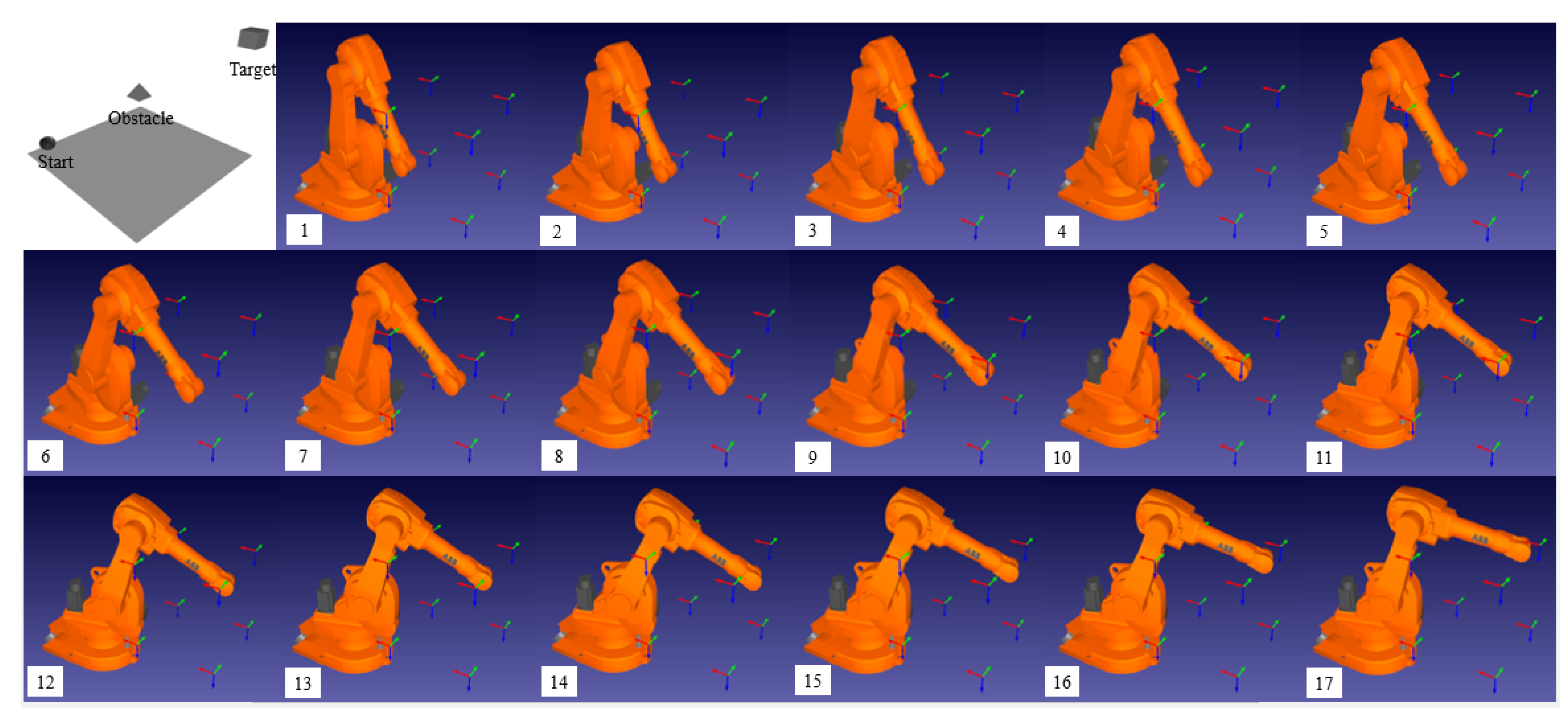
3.4. Simulation
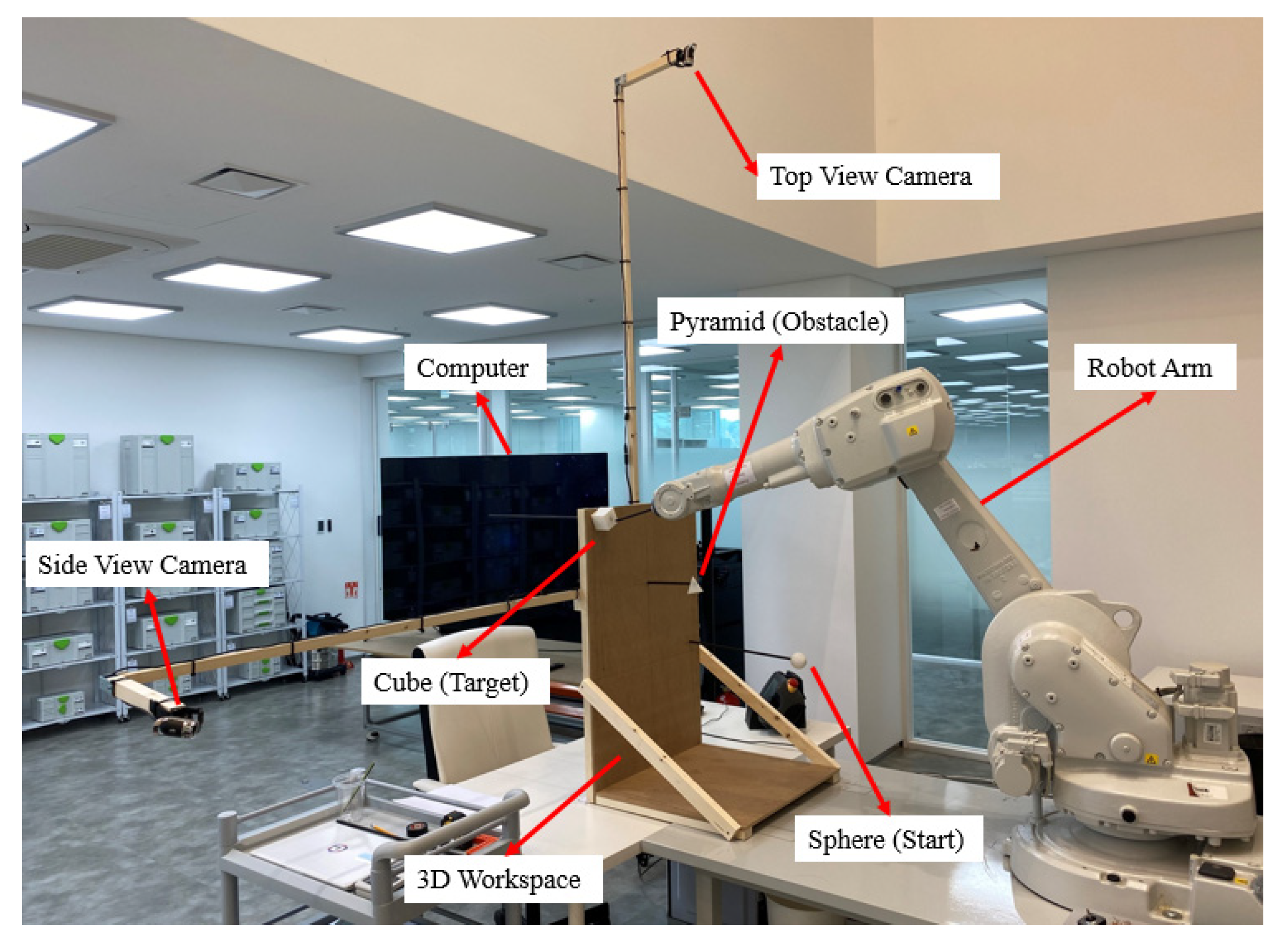
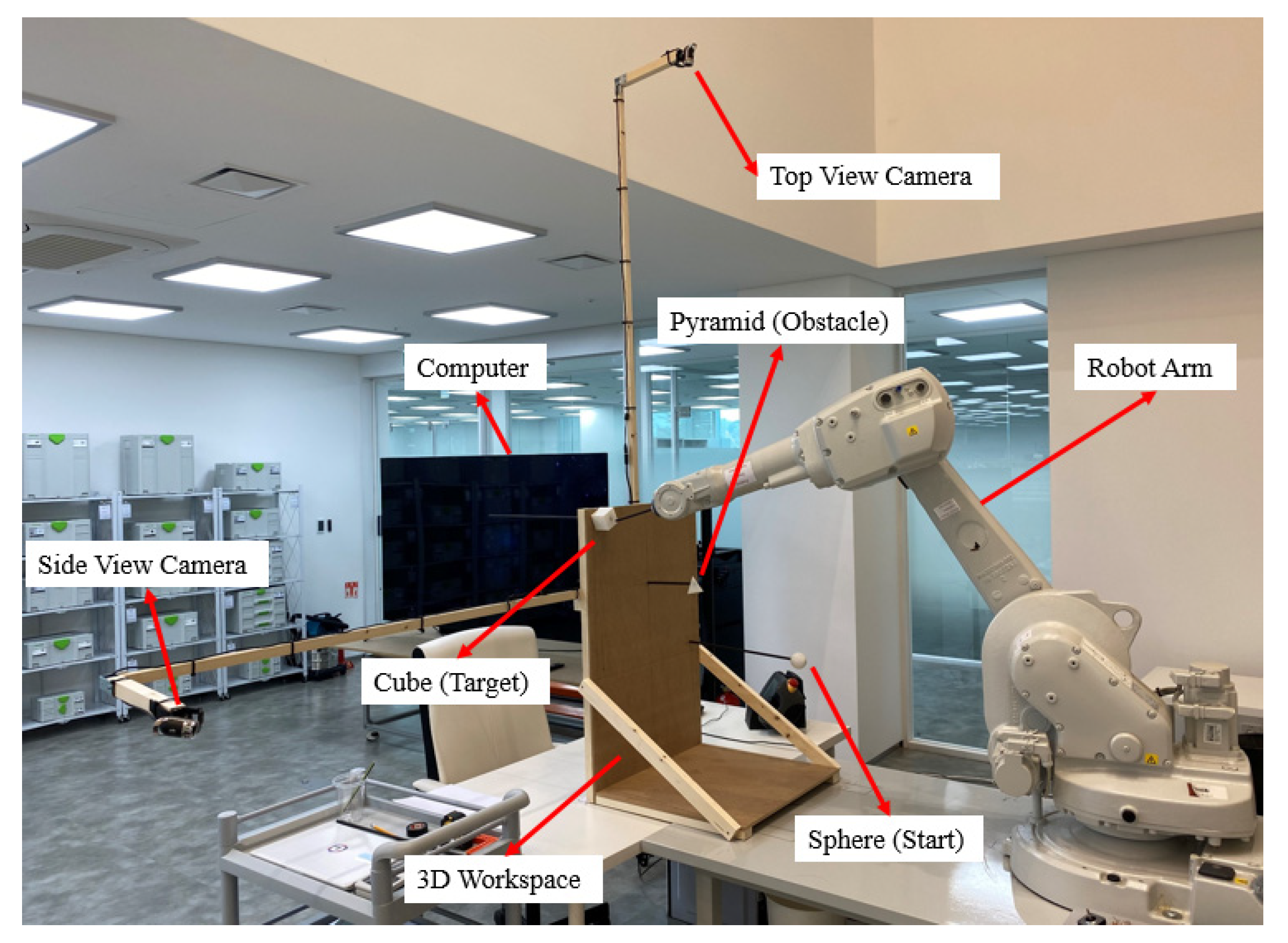
4. Experiment Results
5. Discussion
- Although we tested the method using a physical robot arm, the physical setup was not exactly identical to the simulation because levitating multiple objects in the air and the middle of the workspace is difficult due to the use of fixtures and wood structures. Certain parts of a robot arm, such as the end-effector, may collide with fixtures. Therefore, in the future, the feasibility of using augmented reality (AR) for virtual test setup in physical robot tests should be considered. Furthermore, the efficacy of using a virtual sphere, pyramid, and cube instead of using physical objects that require fixtures should be evaluated. Such augmented tests can considerably reduce expenses and facilitate the rapid implementation of complex settings. Moreover, a more comprehensive analysis is possible than in an experimental test.
- In future studies, trained deep Q-learning can also be incorporated into the proposed method to learn additional possible pathfinding to increase the speed of the action finding section. To use a deep Q-learning technique, a large dataset is required, which is currently not possible. This approach can drastically reduce the inference time, but concerns regarding high computing costs remain.
- We used two cameras in two views which made our method less practical, especially for those applications that need a portable robot arm. One suggestion is that we use a single perspective picture taken by deep cameras then generate a path.
- Our invention just takes shots at the beginning and a robot moves following a generated path. In order to be a realistic application, it should take many pictures (one per sec) and re-generate a path. Therefore, the system could be an intelligent real-time system.
- We used a combined object detection-neural network method to calculate its spatial coordinates. It is suggested using 3D reconstruction methods to calculate objects’ position.
- To make the method more practical, further study may use actual objects such as a cup, pen, monitor, book, etc.
- It could be used for a harvesting robot to collect fruits from trees avoid obstacles.
- It could be used for a recycling robot to pick up bottles, cans, batteries, or other particular objects in a recycling factory in real-time.
- It could be used for warehouse robots to pick selected items from shelves or totes and place them into shipping containers to fulfill orders.
- It could be used for assembly line robots to pick components and place them at an appropriate location.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviation
| APF | artificial potential field |
| PRM | probabilistic road maps |
| RRT | rapidly-exploring random tree |
| RL | reinforcement learning |
| DOF | degrees of freedom |
References
- Bugday, M.; Karali, M. Design optimization of industrial robot arm to minimize redundant weight. Eng. Sci. Technol. Int. J. 2019, 22, 346–352. [Google Scholar] [CrossRef]
- Korayem, M.; Madihi, M.; Vahidifar, V. Controlling surgical robot arm using leap motion controller with Kalman filter. Measurement 2021, 178, 109372. [Google Scholar] [CrossRef]
- Park, H.C.; Ahn, K.H.; Min, J.K.; Song, J.-B. 5 DOF Home Robot Arm based on Counterbalance Mechanism. J. Korea Robot. Soc. 2020, 15, 48–54. [Google Scholar] [CrossRef]
- Chen, L.; Yang, H.; Liu, P. Intelligent robot arm: Vision-based dynamic measurement system for industrial applications. In International Conference on Intelligent Robotics and Applications; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Sharma, A.; Singh, P.K.; Hong, W.-C.; Dhiman, G.; Slowik, A. Introduction to the Special Issue on Artificial Intelligence for Smart Cities and Industries. Scalable Comput. Pract. Exp. 2021, 22, 89–91. [Google Scholar] [CrossRef]
- Jezia, Y.; Samir, L.; Abdelmajid, B.A. Image-based 3D reconstruction precision using a camera mounted on a robot arm. Int. J. Nonlinear Sci. Numer. Simul. 2021, 22, 1–11. [Google Scholar] [CrossRef]
- Sawangsri, W.; Suppasasawat, P.; Thamphanchark, V.; Pandey, S. Novel approach of an intelligent and flexible manufacturing system: A contribution to the concept and development of smart factory. In Proceedings of the 2018 International Conference on System Science and Engineering (ICSSE), New Taipei City, Taiwan, 28–30 June 2018. [Google Scholar]
- Cheng, C.; Lv, X.; Zhang, J. Robot Arm Path Planning Based on Improved RRT Algorithm. In Proceedings of the 2021 3rd International Symposium on Robotics & Intelligent Manufacturing Technology (ISRIMT), Changzhou, China, 24–26 September 2021. [Google Scholar]
- Abdi, A.; Adhikari, D.; Park, J.H. A novel hybrid path planning method based on q-learning and neural network for robot arm. Appl. Sci. 2021, 11, 6770. [Google Scholar] [CrossRef]
- Ka, H.; Ding, D.; Cooper, R.A. Three dimentional computer vision-based alternative control method for assistive robotic manipulator. Symbiosis 2016, 1, 1–6. [Google Scholar]
- Rai, N.; Rai, B.; Rai, P. Computer vision approach for controlling educational robotic arm based on object properties. In Proceedings of the 2014 2nd International Conference on Emerging Technology Trends in Electronics, Communication and Networking, Surat, India, 26–27 December 2014. [Google Scholar]
- Hsu, Y.H.; Hsu, H.-Y.; Lin, J.-S. Control design and implementation of intelligent vehicle with robot arm and computer vision. In Proceedings of the 2015 International Conference on Advanced Robotics and Intelligent Systems (ARIS), Taipei, Taiwan, 29–31 May 2015. [Google Scholar]
- Chen, X.; Huang, X.; Wang, Y.; Gao, X. Combination of augmented reality based brain-computer interface and computer vision for high-level control of a robotic arm. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 3140–3147. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Li, H.; Zhang, X. Construction waste recycling robot for nails and screws: Computer vision technology and neural network approach. Autom. Constr. 2019, 97, 220–228. [Google Scholar] [CrossRef]
- Tebbe, J.; Gao, Y.; Sastre-Rienietz, M.; Zell, A. A table tennis robot system using an industrial kuka robot arm. In German Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Sadhu, A.K.; Konar, A.; Bhattacharjee, T.; Das, S. Synergism of firefly algorithm and Q-learning for robot arm path planning. Swarm Evol. Comput. 2018, 43, 50–68. [Google Scholar] [CrossRef]
- Wen, S.; Chen, J.; Wang, S.; Zhang, H.; Hu, X. Path planning of humanoid arm based on deep deterministic policy gradient. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Kuala Lumpur, Malaysia, 12–15 December 2018; pp. 1755–1760. [Google Scholar]
- Ji, M.; Zhang, L.; Wang, S. A path planning approach based on Q-learning for robot arm. In Proceedings of the 2019 3rd International Conference on Robotics and Automation Sciences (ICRAS), Wuhan, China, 1–3 June 2019. [Google Scholar]
- Huadong, Z.; Chaofan, L.; Nan, J. A path planning method of robot arm obstacle avoidance based on dynamic recursive ant colony algorithm. In Proceedings of the 2019 IEEE International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 12–14 July 2019. [Google Scholar]
- Das, S.D.; Bain, V.; Rakshit, P. Energy optimized robot arm path planning using differential evolution in dynamic environment. In Proceedings of the 2018 Second International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 14–15 June 2018. [Google Scholar]
- Raheem, F.A.; Sadiq, A.T.; Abbas, N.A.F. Robot arm free Cartesian space analysis for heuristic path planning enhancement. Int. J. Mech. Mechatron. Eng. 2019, 19, 29–42. [Google Scholar]
- Chang, W.-Y.; Lin, S.-Y.; Hsu, J.-W.; Hsu, B.-Y. Automatic path planning of robot for intelligent manufacturing based on network remoted controlling and simulation. In Proceedings of the 2019 4th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Tianjin, China, 1–3 July 2019. [Google Scholar]
- Sugiura, H.; Gienger, M.; Janssen, H.; Goerick, C. Real-time self collision avoidance for humanoids by means of nullspace criteria and task intervals. In Proceedings of the 2006 6th IEEE-RAS International Conference on Humanoid Robots, Genova, Italy, 4–6 December 2006. [Google Scholar]
- Martínez, C.; Jiménez, F. Implementation of a Potential Field-Based Decision-Making Algorithm on Autonomous Vehicles for Driving in Complex Environments. Sensors 2019, 19, 3318. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kavraki, L.E.; Latombe, J.-C.; Motwani, R.; Raghavan, P. Randomized query processing in robot path planning. J. Comput. Syst. Sci. 1998, 57, 50–60. [Google Scholar] [CrossRef] [Green Version]
- Hsu, D.; Latombe, J.-C.; Kurniawati, H. On the probabilistic foundations of probabilistic roadmap planning. Int. J. Robot. Res. 2006, 25, 627–643. [Google Scholar] [CrossRef]
- Liu, Y.; Zuo, G. Improved RRT Path Planning Algorithm for Humanoid Robotic Arm. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020. [Google Scholar]
- Karaman, S.; Frazzoli, E. Sampling-based algorithms for optimal motion planning. Int. J. Robot. Res. 2011, 30, 846–894. [Google Scholar] [CrossRef]
- Prianto, E.; Kim, M.; Park, J.-H.; Bae, J.-H.; Kim, J.-S. Path planning for multi-arm manipulators using deep reinforcement learning: Soft actor–critic with hindsight experience replay. Sensors 2020, 20, 5911. [Google Scholar] [CrossRef] [PubMed]
- Panov, A.I.; Yakovlev, K.S.; Suvorov, R. Grid path planning with deep reinforcement learning: Preliminary results. Procedia Comput. Sci. 2018, 123, 347–353. [Google Scholar] [CrossRef]
- Low, E.S.; Ong, P.; Cheah, K.C. Solving the optimal path planning of a mobile robot using improved Q-learning. Robot. Auton. Syst. 2019, 115, 143–161. [Google Scholar] [CrossRef]
- Yu, J.; Su, Y.; Liao, Y. The path planning of mobile robot by neural networks and hierarchical reinforcement learning. Front. Neurorobotics 2020, 14, 63. [Google Scholar] [CrossRef] [PubMed]
- Lai, T.-C.; Xiao, S.-R.; Aoyama, H.; Wong, C.-C. Path planning and obstacle avoidance approaches for robot arm. In Proceedings of the 2017 56th Annual Conference of the Society of Instrument and Control Engineers of Japan (SICE), Kanazawa, Japan, 19–22 September 2017. [Google Scholar]
- Wu, B.; Wan, A.; Iandola, F.; Jin, P.H.; Keutzer, K. Squeezedet: Unified, small, low power fully convolutional neural networks for real-time object detection for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- He, K. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- CV-Tricks.com. Available online: https://cv-tricks.com/object-detection/faster-r-cnn-yolo-ssd/ (accessed on 12 December 2021).
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Van Seijen, H.; van Hasselt, H.; Whiteson, S.; Wiering, M. A theoretical and empirical analysis of Expected Sarsa. In Proceedings of the 2009 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, Nashville, TN, USA, 31 March–1 April 2009. [Google Scholar]
- Werbos, P. New Tools for Prediction and Analysis in the Behavioral Sciences. Ph.D. Thesis, Harvard University, Cambridge, MA, USA, 1974. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shape | Number of Data | Class |
|---|---|---|
| Pyramid | 200 | 0 |
| Sphere | 200 | 1 |
| Cube | 200 | 2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdi, A.; Ranjbar, M.H.; Park, J.H. Computer Vision-Based Path Planning for Robot Arms in Three-Dimensional Workspaces Using Q-Learning and Neural Networks. Sensors 2022, 22, 1697. https://doi.org/10.3390/s22051697
Abdi A, Ranjbar MH, Park JH. Computer Vision-Based Path Planning for Robot Arms in Three-Dimensional Workspaces Using Q-Learning and Neural Networks. Sensors. 2022; 22(5):1697. https://doi.org/10.3390/s22051697
Chicago/Turabian StyleAbdi, Ali, Mohammad Hassan Ranjbar, and Ju Hong Park. 2022. "Computer Vision-Based Path Planning for Robot Arms in Three-Dimensional Workspaces Using Q-Learning and Neural Networks" Sensors 22, no. 5: 1697. https://doi.org/10.3390/s22051697
APA StyleAbdi, A., Ranjbar, M. H., & Park, J. H. (2022). Computer Vision-Based Path Planning for Robot Arms in Three-Dimensional Workspaces Using Q-Learning and Neural Networks. Sensors, 22(5), 1697. https://doi.org/10.3390/s22051697