
Real-Time Analysis of Hand Gesture Recognition with Temporal Convolutional Networks †




Abstract
:1. Introduction
- Analysis of the real-time performance of the proposed TCN models using a simulation experiment;
- Improved offline accuracy compared to our previous study [31] as a result of the optimized hyperparameter values.
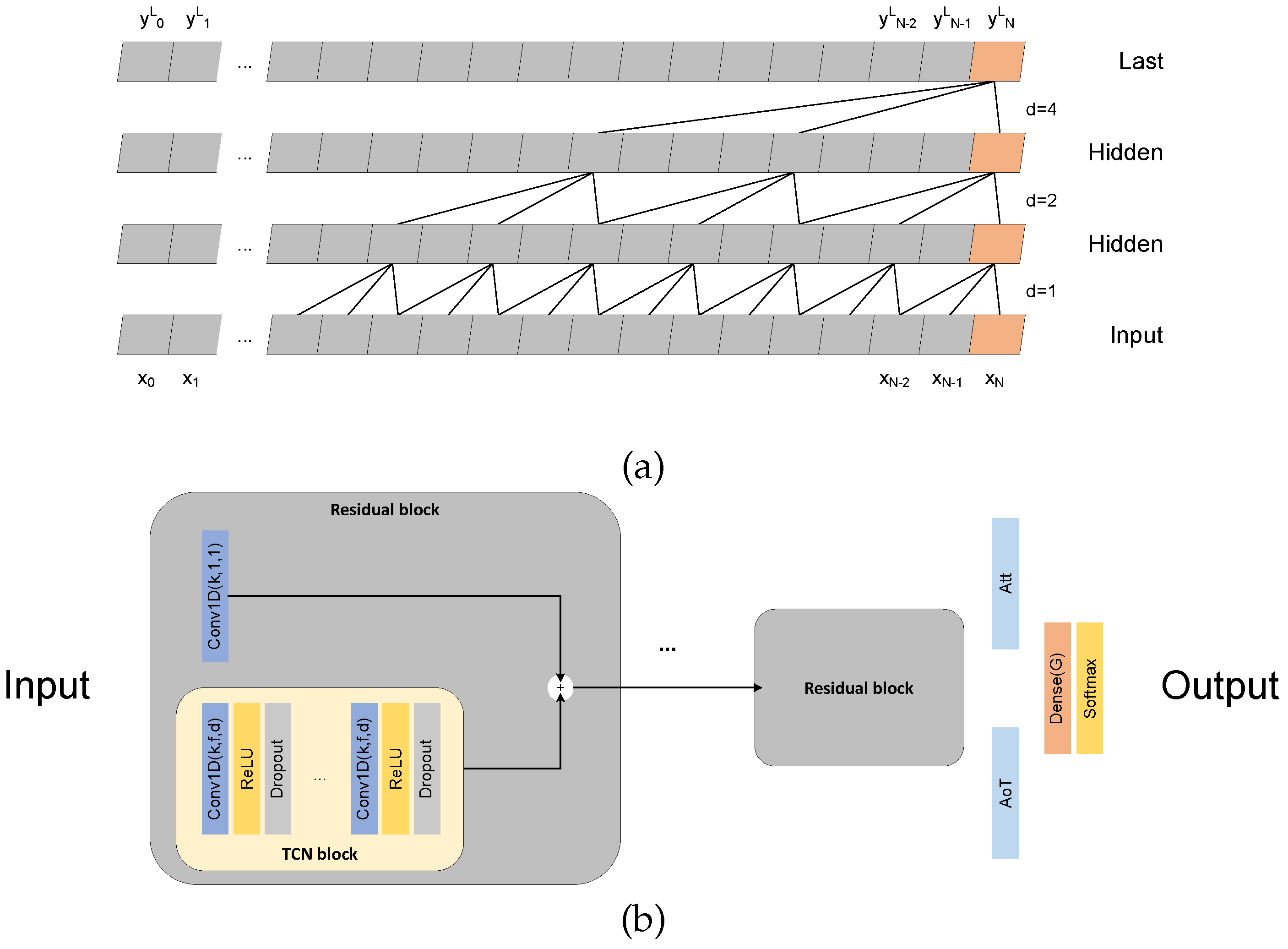
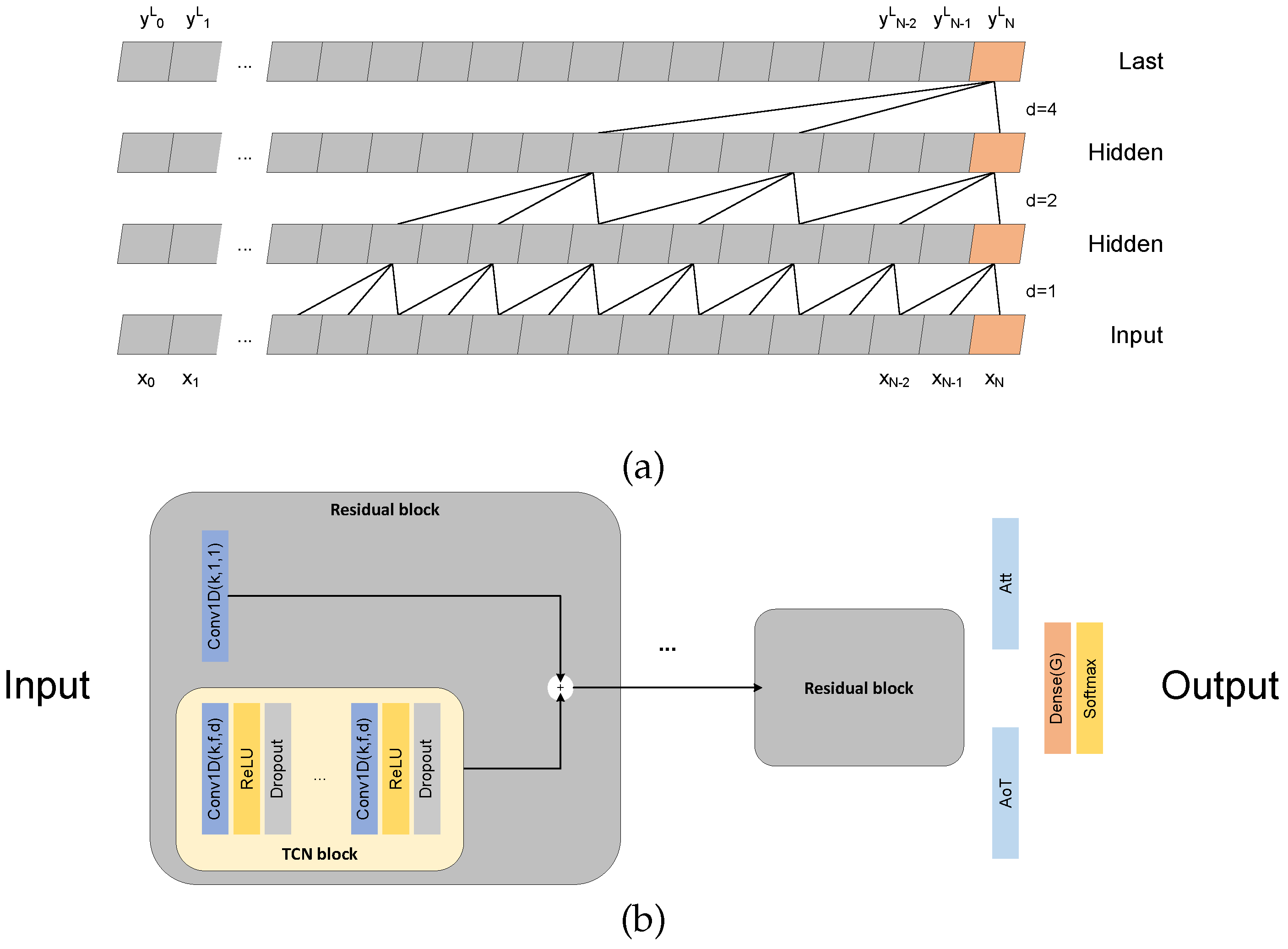
2. Materials and Methods
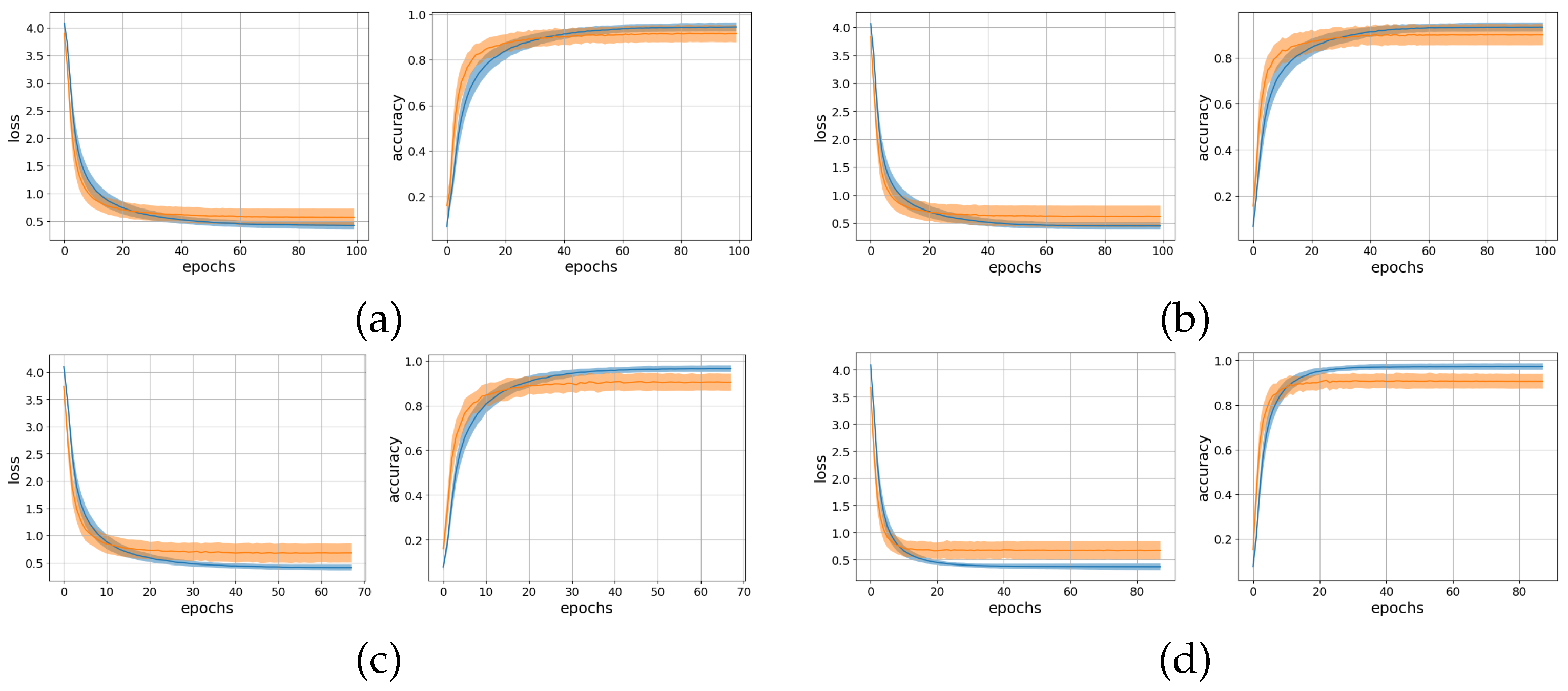
3. Results and Discussion
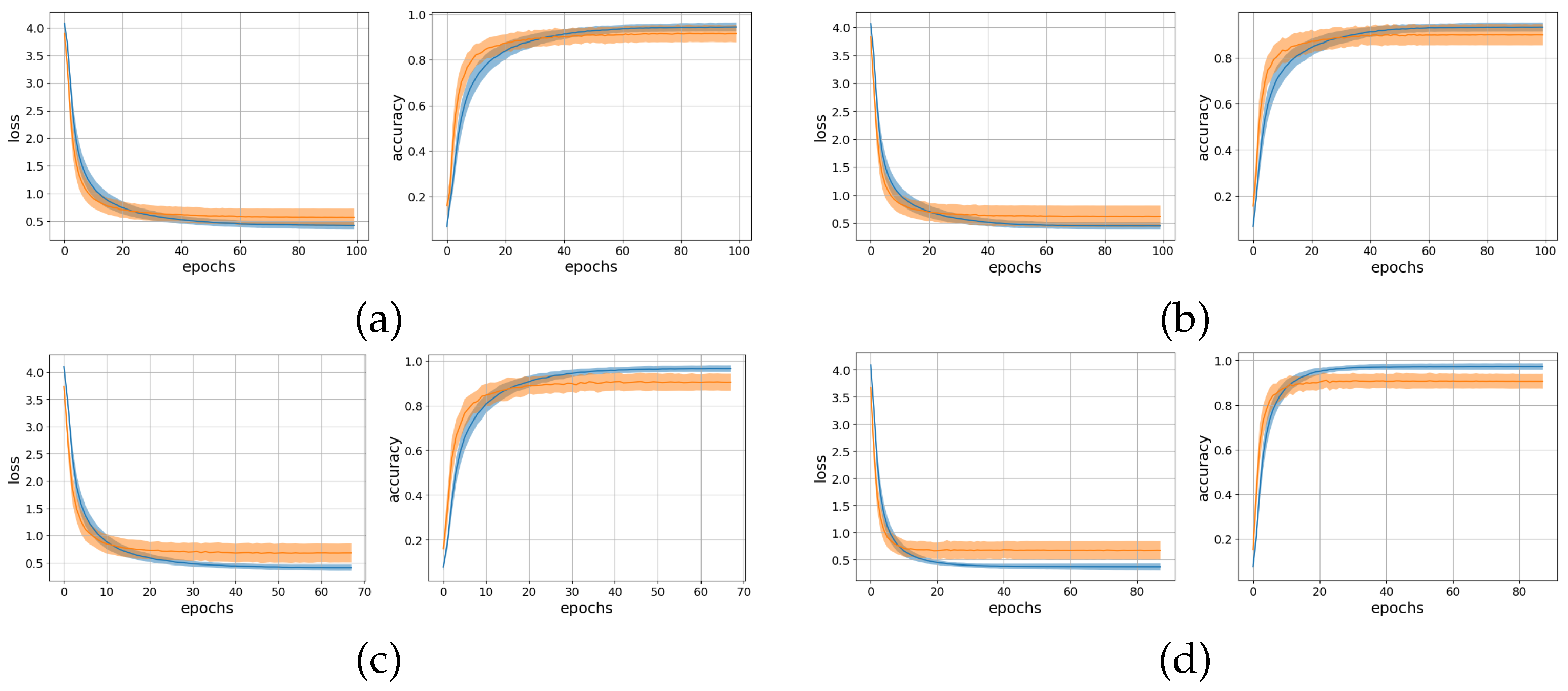
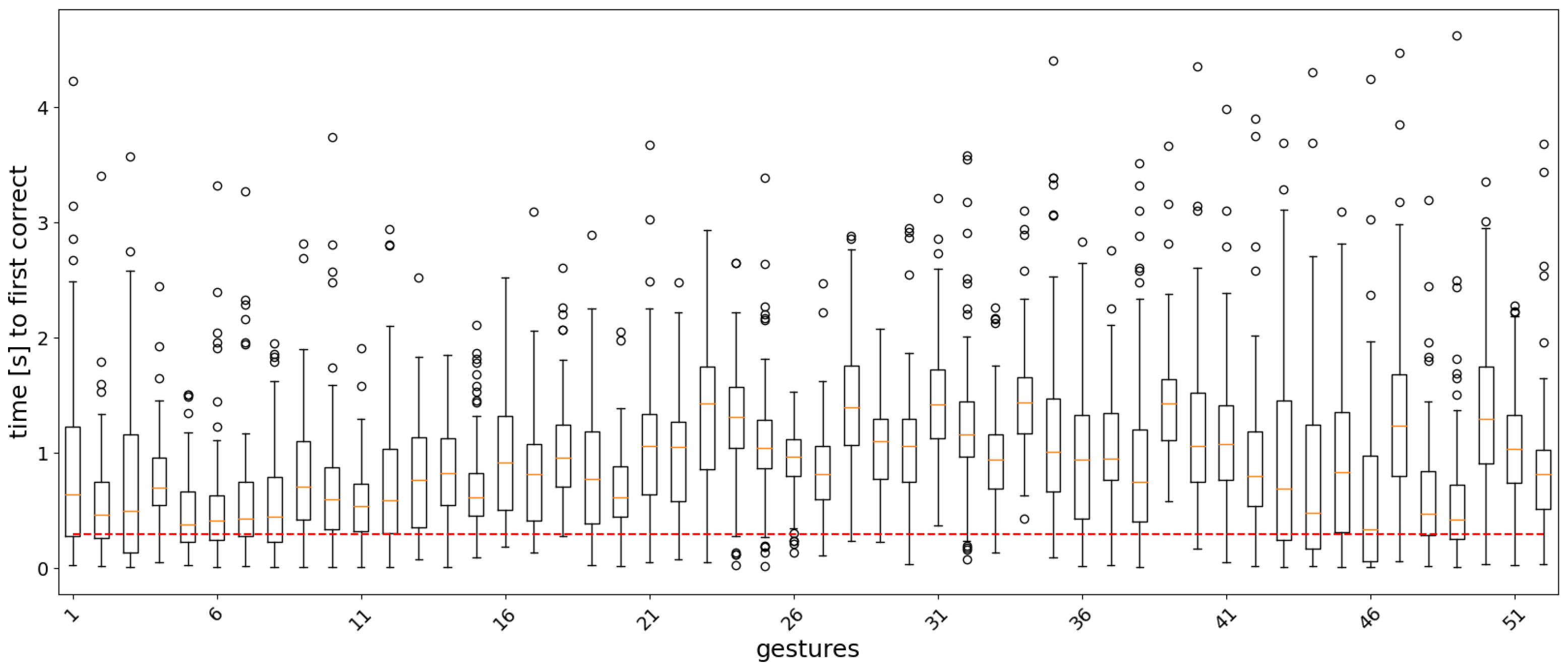
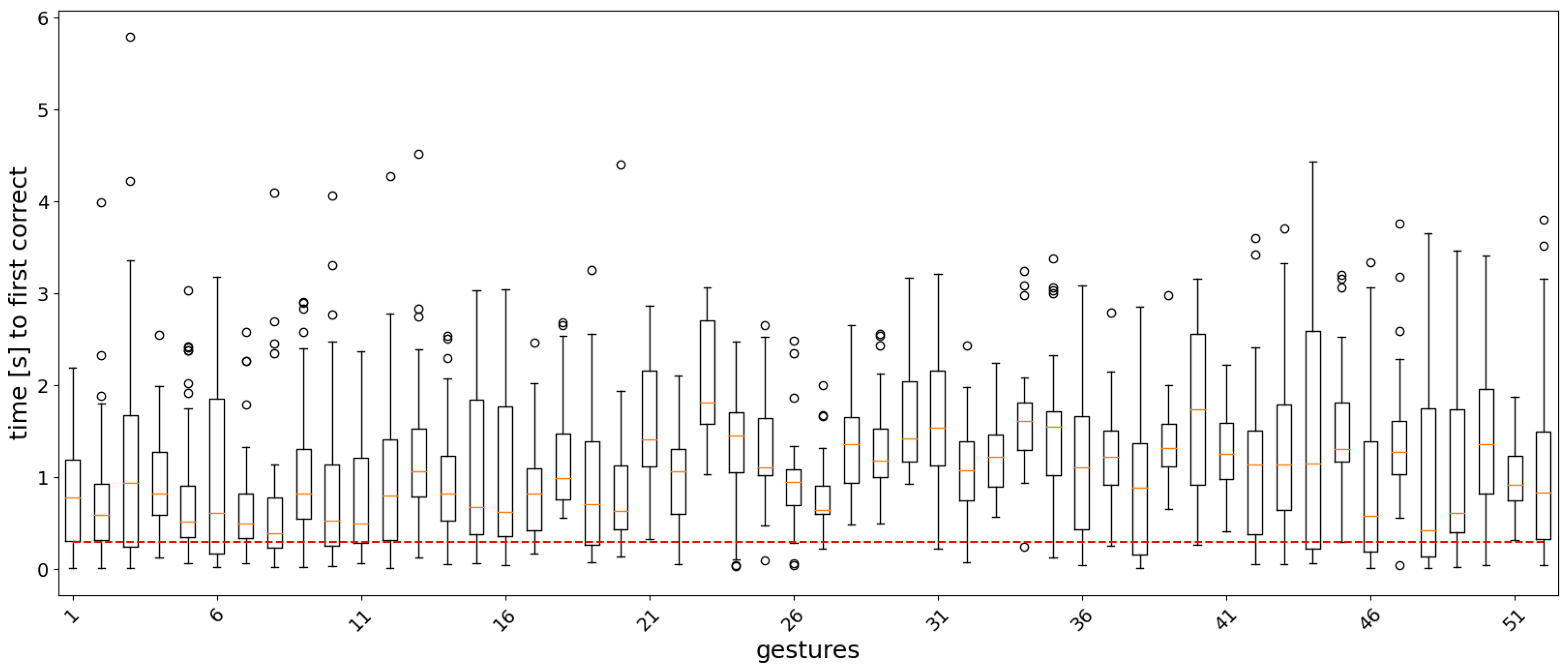
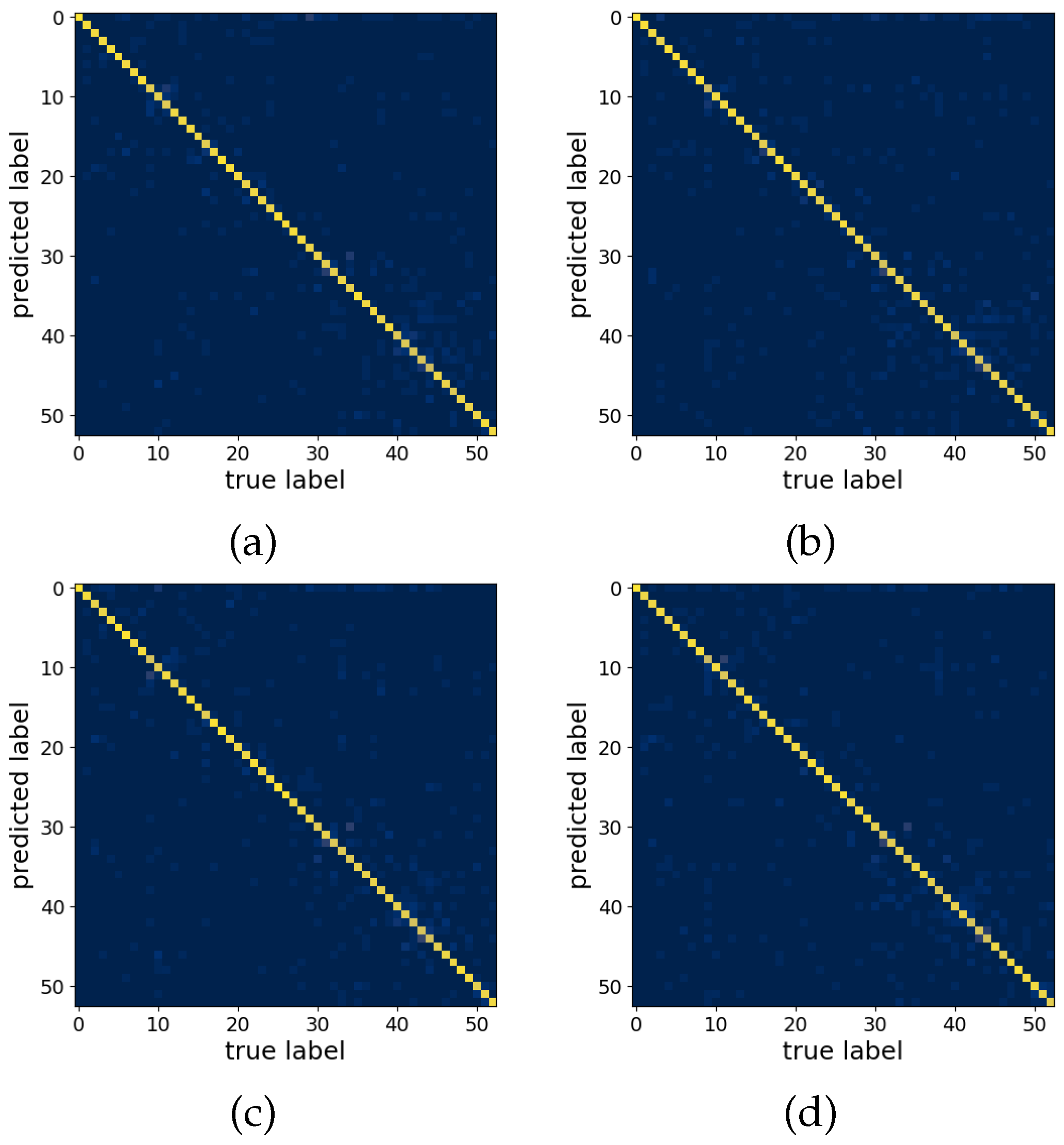
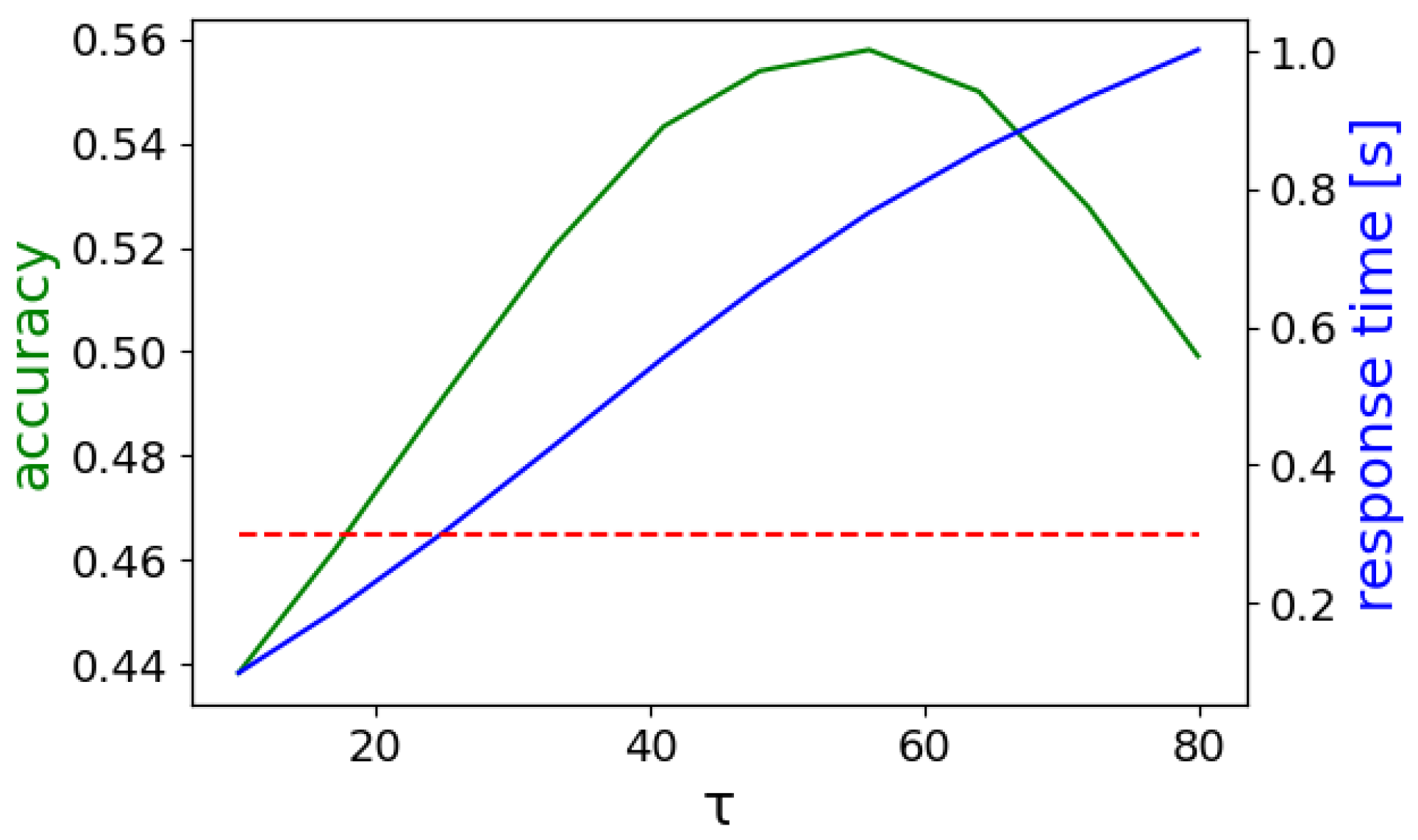
3.1. Offline Analysis
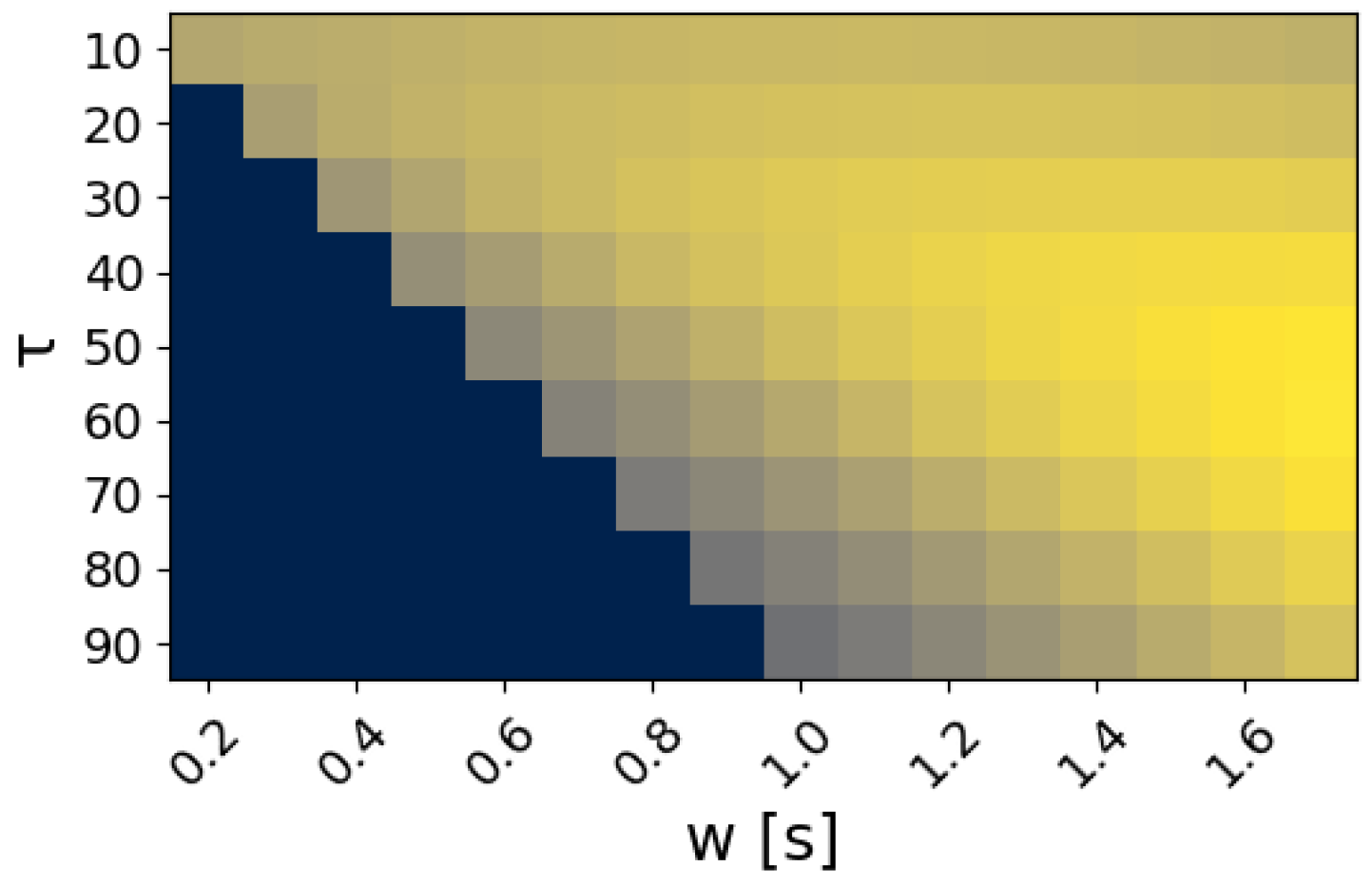
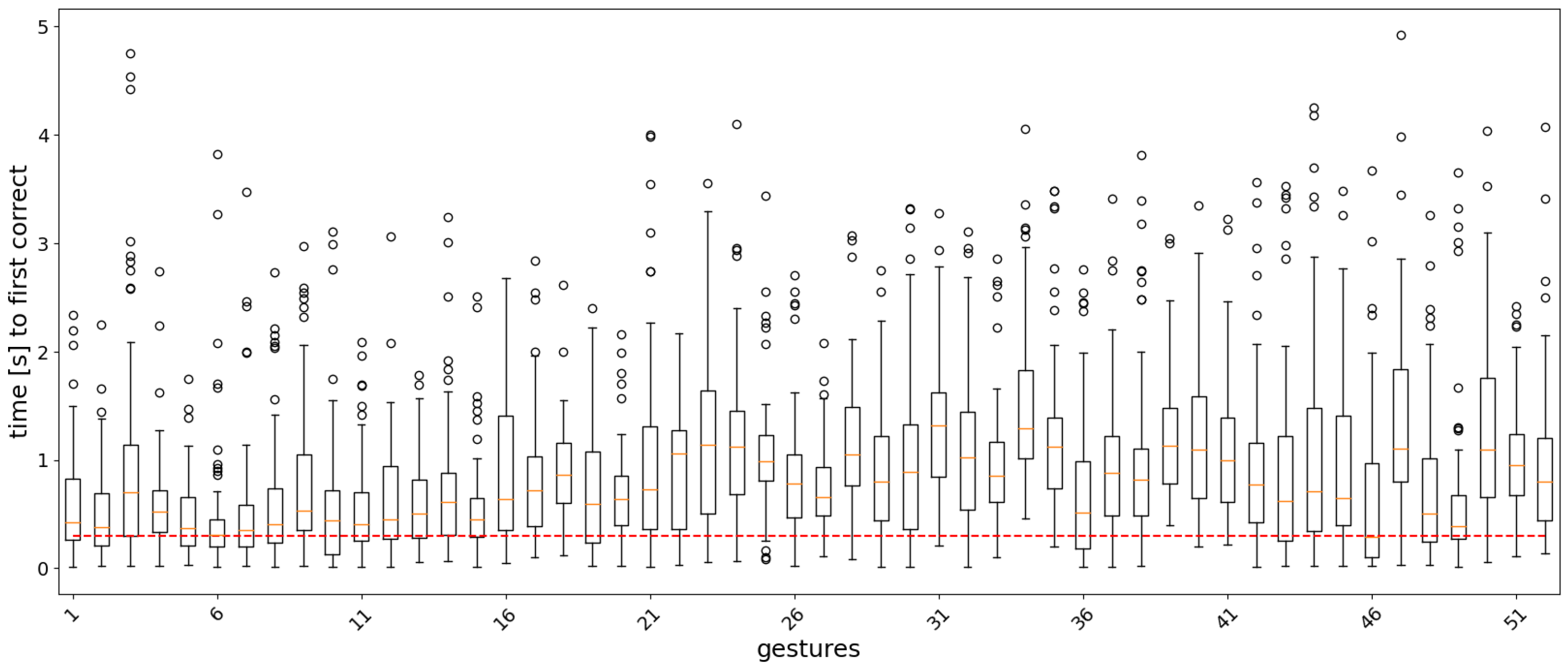
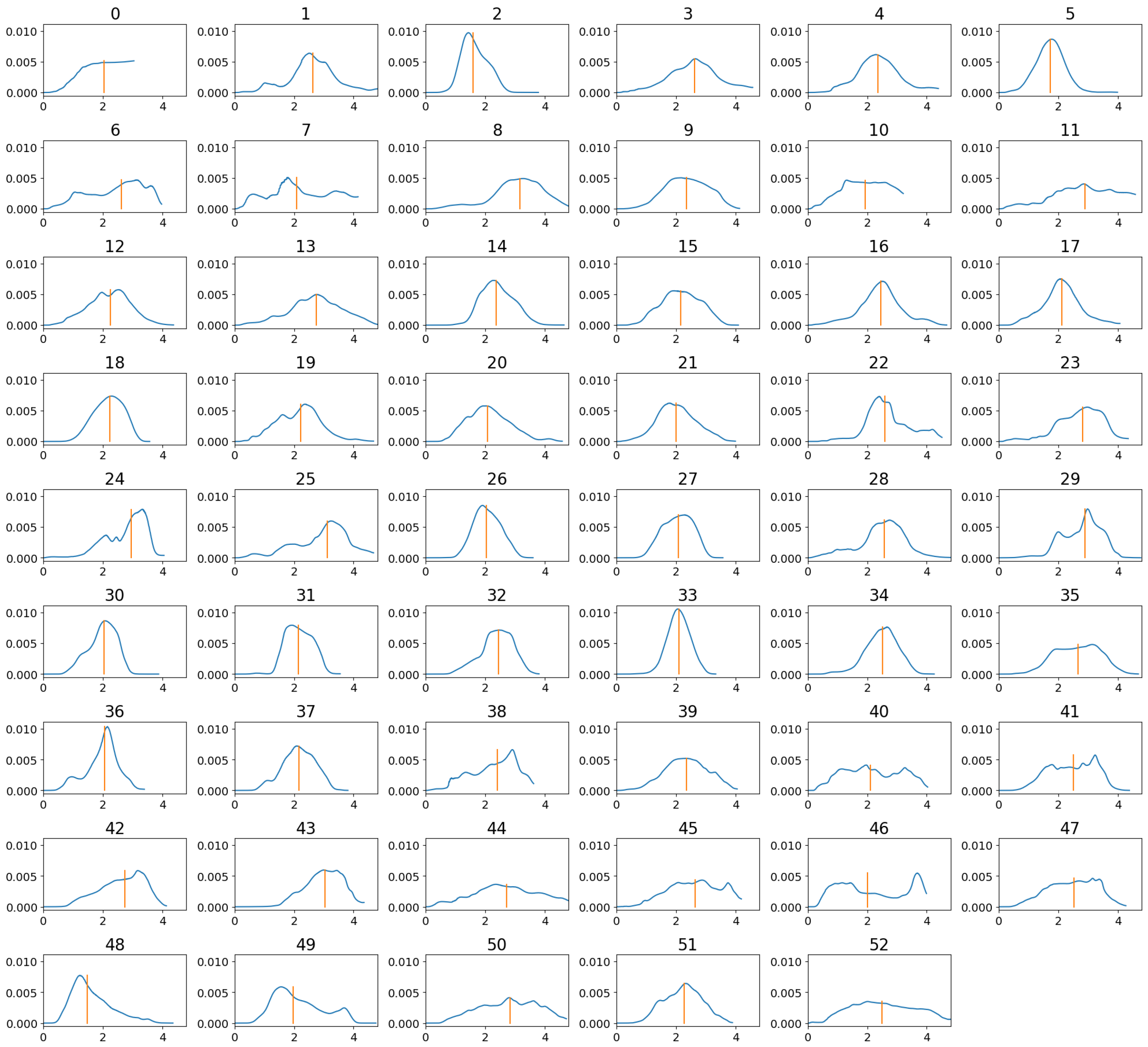
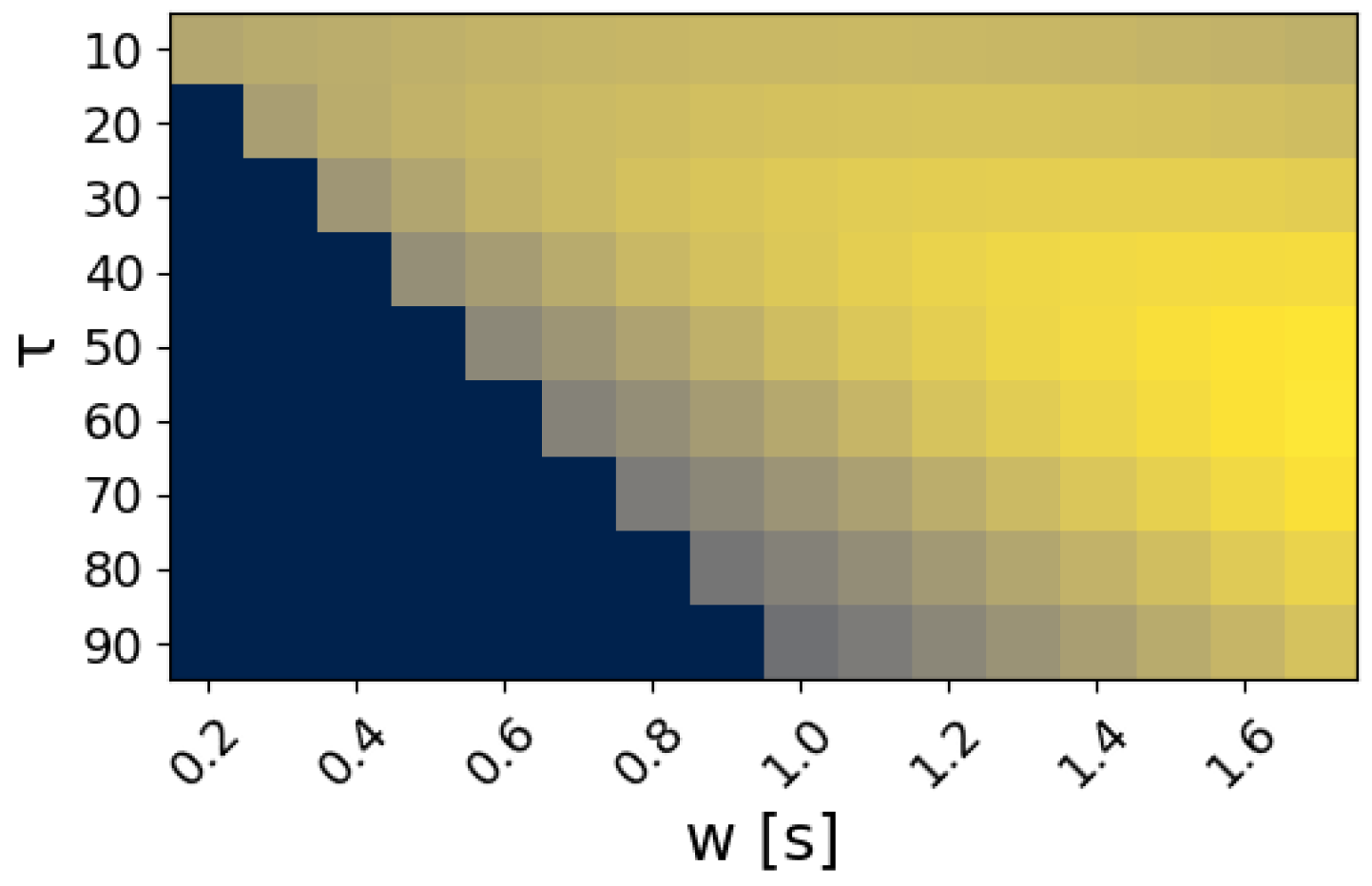
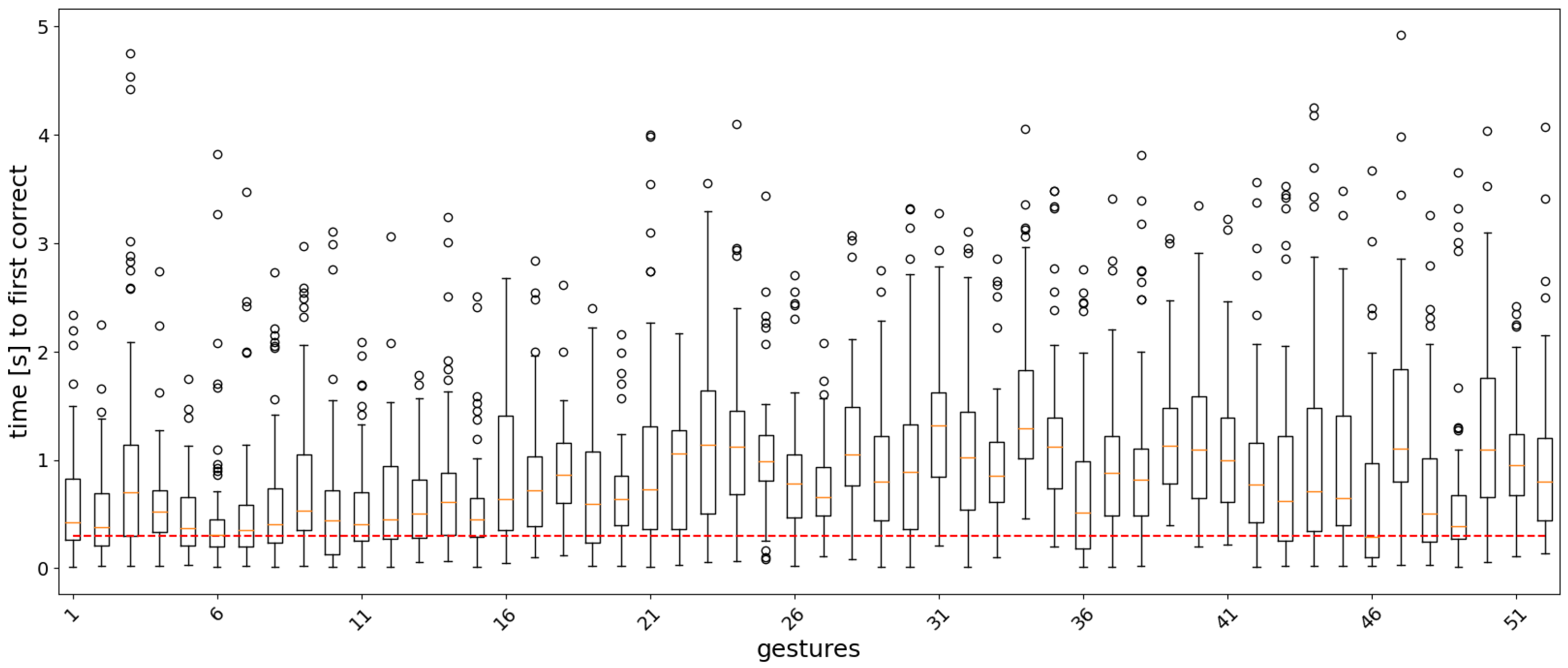
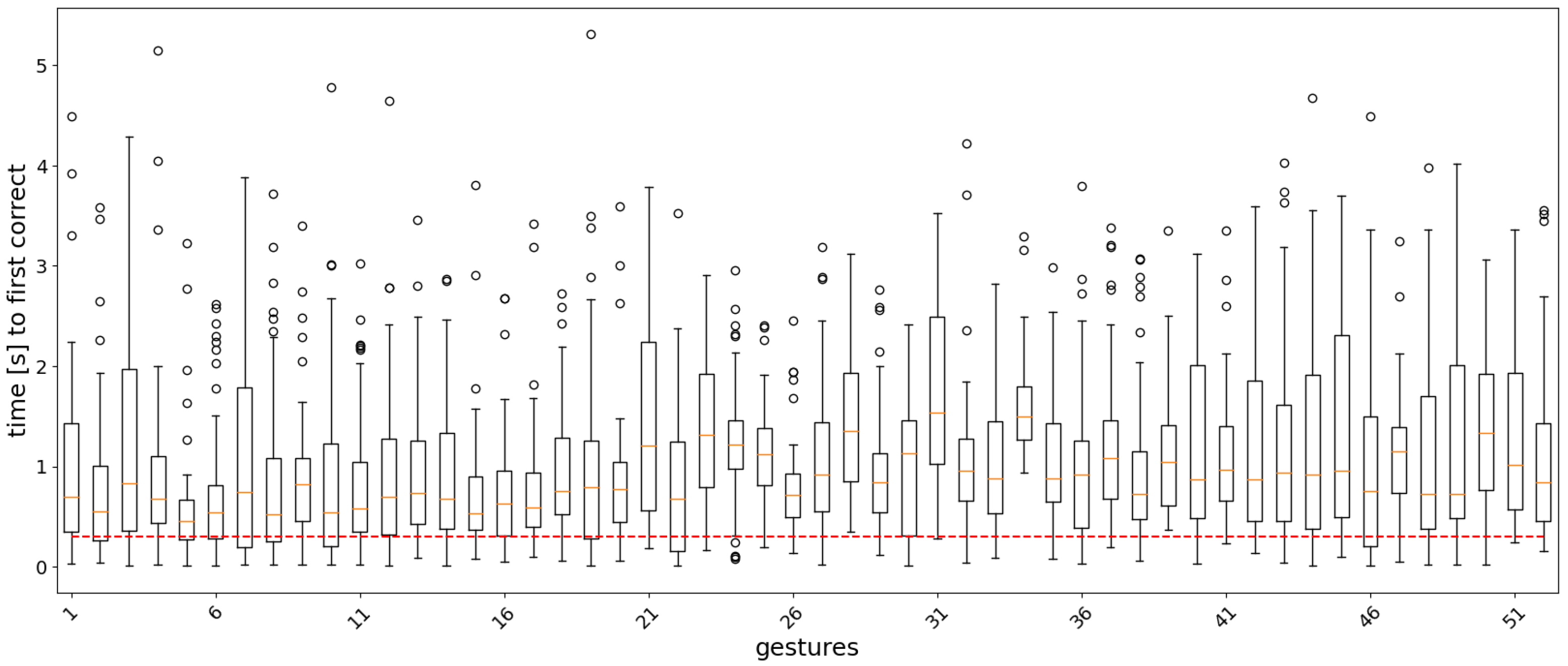
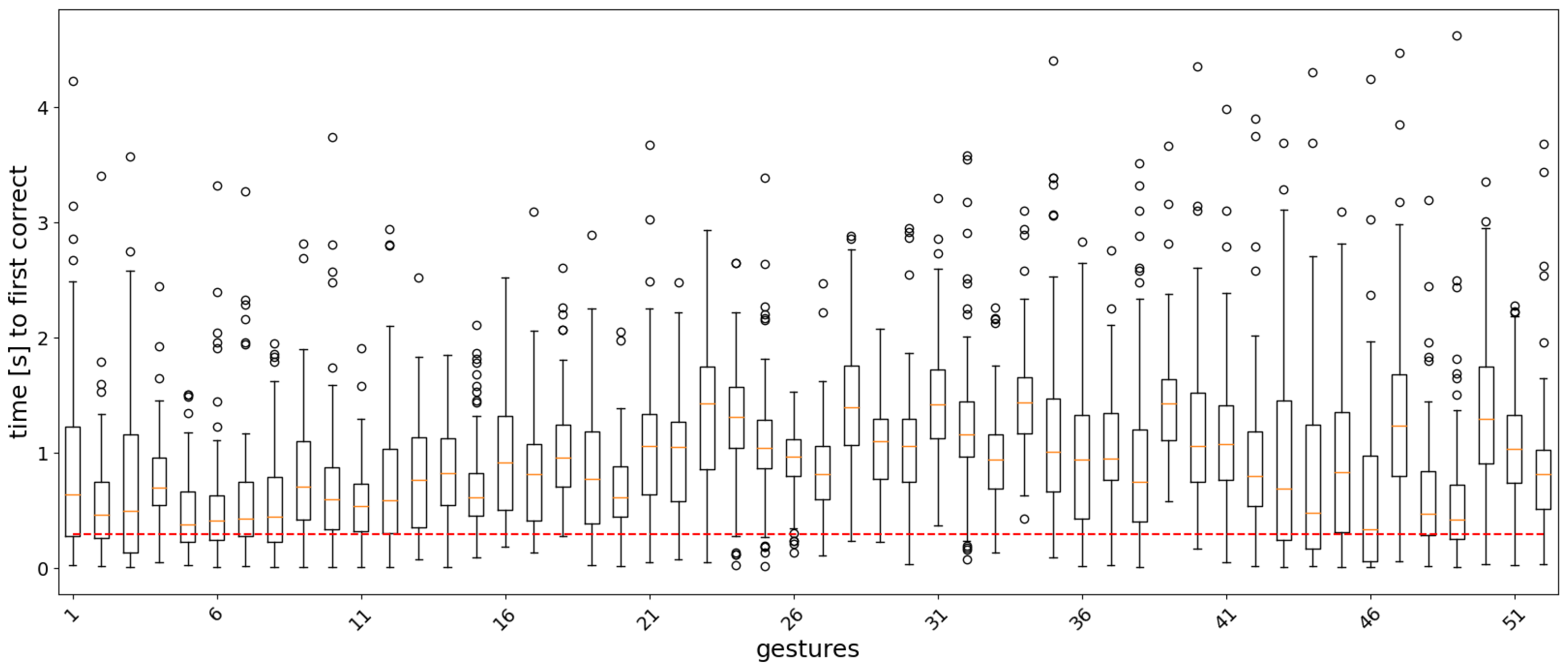
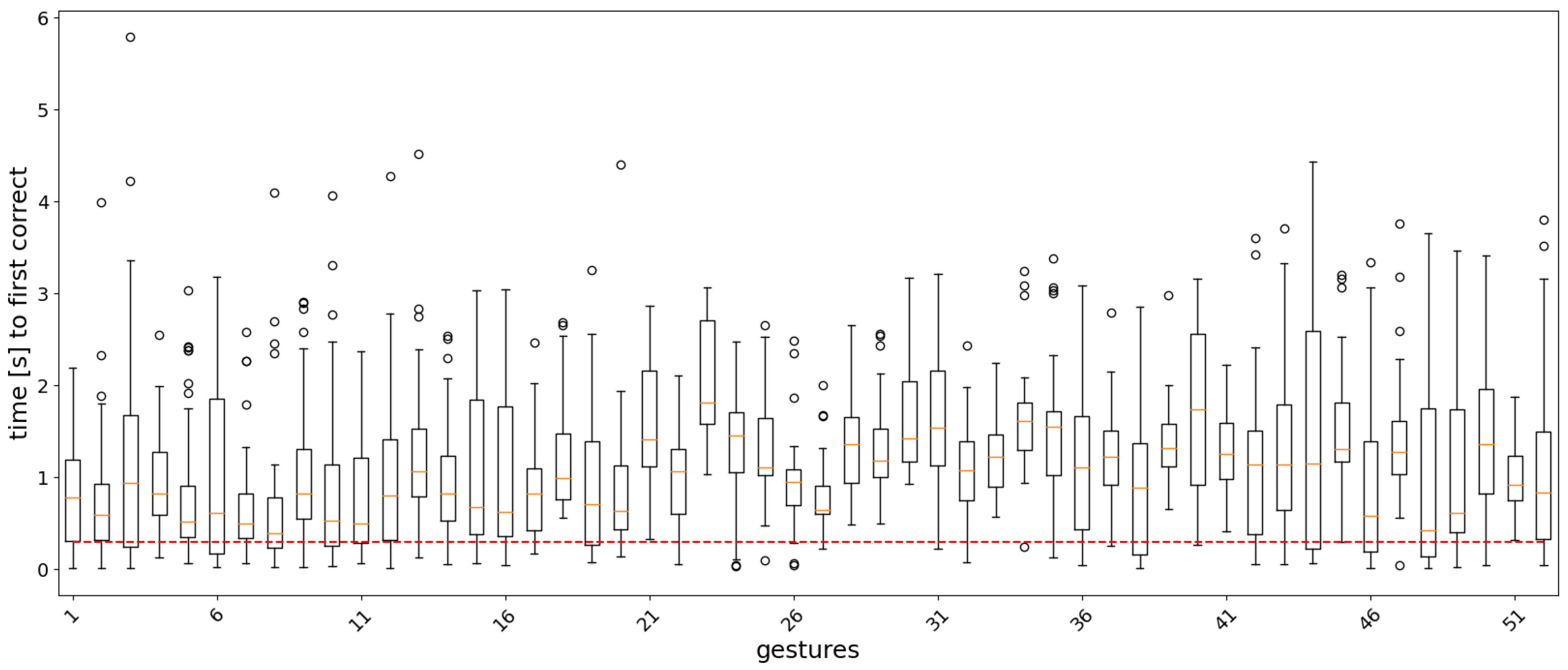
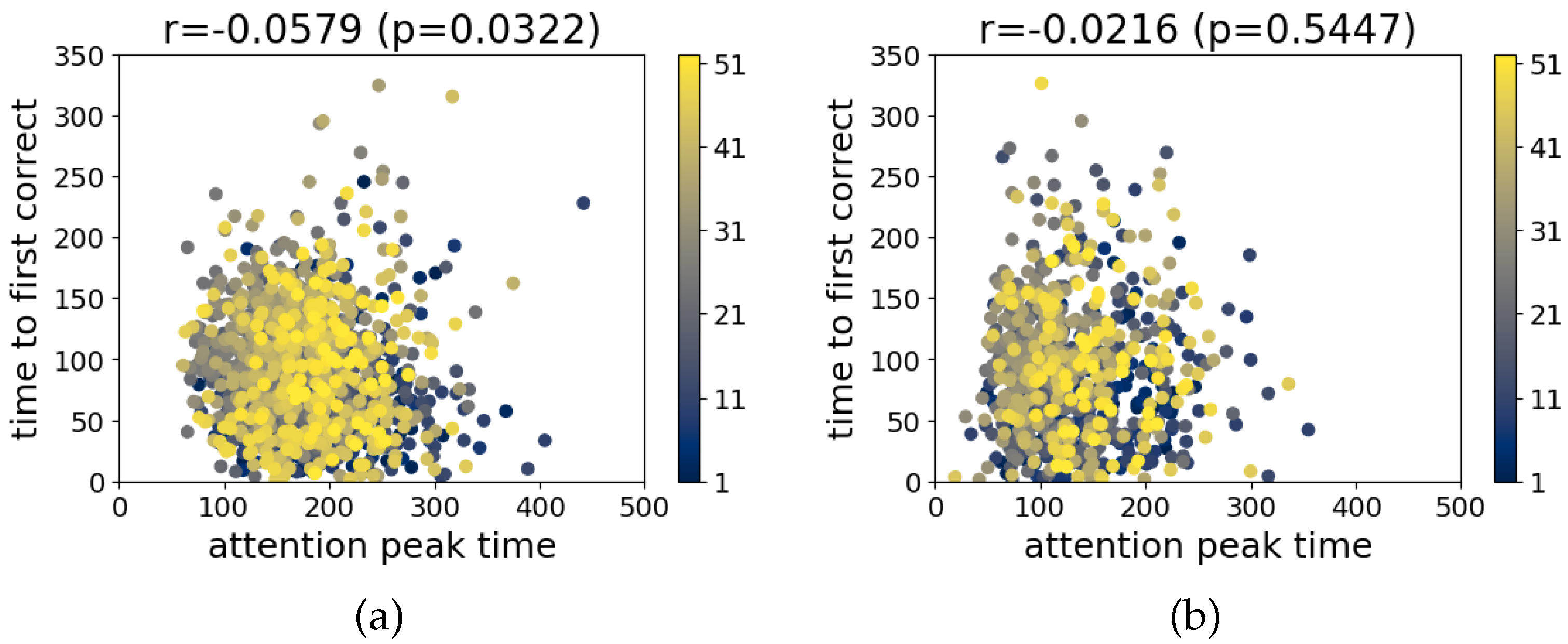
3.2. Real-Time Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AoT | average over time |
| Att | attention mechanism |
| CNN | convolutional neural network |
| DL | Deep Learning |
| ML | Machine Learning |
| RF | receptive field |
| RMS | Root Mean Squared |
| sEMG | surface electromyography |
| TCN | temporal convolutional neural network |
References
- Rautaray, S.S.; Agrawal, A. Vision based hand gesture recognition for human computer interaction: A survey. Artif. Intell. Rev. 2015, 43, 1–54. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, X.; Zhao, Z.Y.; Yang, J.H.; Lantz, V.; Wang, K.Q. Hand Gesture Recognition Research Based on Surface EMG Sensors and 2D-accelerometers. In Proceedings of the 2007 11th IEEE International Symposium on Wearable Computers, Boston, MA, USA, 11–13 October 2007; pp. 1–4. [Google Scholar] [CrossRef]
- Chang, Y.J.; Chen, S.F.; Huang, J.D. A Kinect-based system for physical rehabilitation: A pilot study for young adults with motor disabilities. Res. Dev. Disabil. 2011, 32, 2566–2570. [Google Scholar] [CrossRef]
- Omelina, L.; Jansen, B.; Bonnechère, B.; Van Sint Jan, S.; Cornelis, J. Serious games for physical rehabilitation: Designing highly configurable and adaptable games. In Proceedings of the 9th International Conference on Disability, Virtual Reality & Associated Technologies, Laval, France, 10–12 September 2012; pp. 195–201. [Google Scholar]
- Scheme, E.; Englehart, K. Electromyogram pattern recognition for control of powered upper-limb prostheses: State of the art and challenges for clinical use. J. Rehabil. Res. Dev. 2011, 48, 643. [Google Scholar] [CrossRef]
- Simão, M.; Neto, P.; Gibaru, O. EMG-based online classification of gestures with recurrent neural networks. Pattern Recognit. Lett. 2019, 128, 45–51. [Google Scholar] [CrossRef]
- Li, Z.; Zuo, J.; Han, Z.; Han, X.; Sun, C.; Wang, Z. Intelligent Classification of Multi-Gesture EMG Signals Based on LSTM. In Proceedings of the 2020 International Conference on Artificial Intelligence and Electromechanical Automation (AIEA), Tianjin, China, 26–28 June 2020; pp. 62–65. [Google Scholar] [CrossRef]
- Azhiri, R.B.; Esmaeili, M.; Nourani, M. Real-time EMG signal classification via recurrent neural networks. arXiv 2021, arXiv:2109.05674. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 156–165. [Google Scholar]
- Hudgins, B.; Parker, P.; Scott, R.N. A new strategy for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 1993, 40, 82–94. [Google Scholar] [CrossRef]
- Castellini, C.; Fiorilla, A.E.; Sandini, G. Multi-subject/daily-life activity EMG-based control of mechanical hands. J. Neuroeng. Rehabil. 2009, 6, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Kuzborskij, I.; Gijsberts, A.; Caputo, B. On the challenge of classifying 52 hand movements from surface electromyography. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 4931–4937. [Google Scholar] [CrossRef] [Green Version]
- Atzori, M.; Gijsberts, A.; Castellini, C.; Caputo, B.; Hager, A.G.M.; Elsig, S.; Giatsidis, G.; Bassetto, F.; Müller, H. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci. Data 2014, 1, 140053. [Google Scholar] [CrossRef] [Green Version]
- Gijsberts, A.; Atzori, M.; Castellini, C.; Müller, H.; Caputo, B. Movement Error Rate for Evaluation of Machine Learning Methods for sEMG-Based Hand Movement Classification. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 735–744. [Google Scholar] [CrossRef]
- Atzori, M.; Gijsberts, A.; Heynen, S.; Hager, A.G.M.; Deriaz, O.; Van Der Smagt, P.; Castellini, C.; Caputo, B.; Muller, H. Building the Ninapro database: A resource for the biorobotics community. In Proceedings of the IEEE RAS and EMBS International Conference on Biomedical Robotics and Biomechatronics, Rome, Italy, 24–27 June 2012; pp. 1258–1265. [Google Scholar] [CrossRef] [Green Version]
- Park, K.H.; Lee, S.W. Movement intention decoding based on deep learning for multiuser myoelectric interfaces. In Proceedings of the 2016 4th International Winter Conference on Brain-Computer Interface (BCI), Gangwon, Korea, 22–24 February 2016; pp. 1–2. [Google Scholar] [CrossRef]
- Atzori, M.; Cognolato, M.; Müller, H. Deep Learning with Convolutional Neural Networks Applied to Electromyography Data: A Resource for the Classification of Movements for Prosthetic Hands. Front. Neurorobot. 2016, 10, 9. [Google Scholar] [CrossRef] [Green Version]
- Tsinganos, P.; Cornelis, B.; Cornelis, J.; Jansen, B.; Skodras, A. Deep Learning in EMG-based Gesture Recognition. In Proceedings of the 5th International Conference on Physiological Computing Systems, Seville, Spain, 19–21 September 2018; pp. 107–114. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Geng, W.; Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Li, J. Gesture recognition by instantaneous surface EMG images. Sci. Rep. 2016, 6, 36571. [Google Scholar] [CrossRef]
- Wei, W.; Wong, Y.; Du, Y.; Hu, Y.; Kankanhalli, M.; Geng, W. A multi-stream convolutional neural network for sEMG-based gesture recognition in muscle-computer interface. Pattern Recognit. Lett. 2019, 119, 131–138. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Jiang, N.; Vujaklija, I.; Rehbaum, H.; Graimann, B.; Farina, D. Is Accurate Mapping of EMG Signals on Kinematics Needed for Precise Online Myoelectric Control? IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 549–558. [Google Scholar] [CrossRef]
- Muceli, S.; Jiang, N.; Farina, D. Extracting Signals Robust to Electrode Number and Shift for Online Simultaneous and Proportional Myoelectric Control by Factorization Algorithms. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 623–633. [Google Scholar] [CrossRef]
- Stango, A.; Negro, F.; Farina, D. Spatial Correlation of High Density EMG Signals Provides Features Robust to Electrode Number and Shift in Pattern Recognition for Myocontrol. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 189–198. [Google Scholar] [CrossRef]
- Tsinganos, P. Multi-Channel EMG Pattern Classification Based on Deep Learning. Ph.D. Thesis, University of Patras, Patras, Greece, 2021. [Google Scholar]
- Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Geng, W. Surface EMG-Based Inter-Session Gesture Recognition Enhanced by Deep Domain Adaptation. Sensors 2017, 17, 458. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Wang, N.; Shi, J.; Liu, J.; Hou, X. Revisiting Batch Normalization For Practical Domain Adaptation. arXiv 2016, arXiv:1603.04779. [Google Scholar]
- Côté-Allard, U.; Fall, C.L.; Drouin, A.; Campeau-Lecours, A.; Gosselin, C.; Glette, K.; Laviolette, F.; Gosselin, B. Deep Learning for Electromyographic Hand Gesture Signal Classification Using Transfer Learning. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 760–771. [Google Scholar] [CrossRef] [Green Version]
- Tsinganos, P.; Cornelis, B.; Cornelis, J.; Jansen, B.; Skodras, A. Improved Gesture Recognition Based on sEMG Signals and TCN. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 1169–1173. [Google Scholar] [CrossRef]
- Tsinganos, P.; Cornelis, B.; Cornelis, J.; Jansen, B.; Skodras, A. Data Augmentation of Surface Electromyography for Hand Gesture Recognition. Sensors 2020, 20, 4892. [Google Scholar] [CrossRef]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. In Proceedings of the 2016 International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Zhang, Z.; Yang, K.; Qian, J.; Zhang, L. Real-Time Surface EMG Pattern Recognition for Hand Gestures Based on an Artificial Neural Network. Sensors 2019, 19, 3170. [Google Scholar] [CrossRef] [Green Version]
- Englehart, K.; Hudgins, B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 2003, 50, 848–854. [Google Scholar] [CrossRef]
- Betthauser, J.L.; Krall, J.T.; Bannowsky, S.G.; Levay, G.; Kaliki, R.R.; Fifer, M.S.; Thakor, N.V. Stable Responsive EMG Sequence Prediction and Adaptive Reinforcement With Temporal Convolutional Networks. IEEE Trans. Biomed. Eng. 2020, 67, 1707–1717. [Google Scholar] [CrossRef]
- Zanghieri, M.; Benatti, S.; Burrello, A.; Kartsch, V.; Conti, F.; Benini, L. Robust Real-Time Embedded EMG Recognition Framework Using Temporal Convolutional Networks on a Multicore IoT Processor. IEEE Trans. Biomed. Circuits Syst. 2020, 14, 244–256. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | RF [ms] | Size | Layers |
|---|---|---|---|
| AoT | 300 | 60 K | 4 |
| AoT | 2500 | 70 K | 7 |
| Att | 300 | 75 K | 4 |
| Att | 2500 | 85 K | 7 |
| Augmentation | Hyperparameters |
|---|---|
| WD | wavelets = [‘sym4’], levels = [2, 3, 4], b = [0, 2.5, 5], p = 0.75 |
| MW | sigma = 0.2, p = 0.75 |
| GN | snrdb = 30, p = 0.25 |
| Model | Offline Top-1 Accuracy [31] | Offline Top-1 Accuracy | Offline Top-3 Accuracy | Real-Time Accuracy | Response Time (ms) |
|---|---|---|---|---|---|
| AoT300 | 0.8951 (0.0343) | 0.9189 (0.0366) * | 0.9832 (0.0157) | 0.4293 (0.0415) | 122.83 (0.89) |
| AoT2500 | 0.8929 (0.0380) | 0.9147 (0.0402) * | 0.9788 (0.0177) | 0.2022 (0.0439) | 121.29 (0.84) |
| Att300 | 0.8967 (0.0350) | 0.9067 (0.0443) | 0.9790 (0.0170) | 0.4188 (0.0429) | 122.51 (0.94) |
| Att2500 | 0.8976 (0.0349) | 0.9100 (0.0365) | 0.9774 (0.0165) | 0.1772 (0.0435) | 120.76 (1.34) |
| Model | Offline Top-1 Accuracy | Offline Top-3 Accuracy | Real-Time Accuracy | Response Time [ms] |
|---|---|---|---|---|
| AoT300 | 0.7442 (0.0548) | 0.9019 (0.0349) | 0.7527 (0.0582) | 118.54 (1.56) |
| AoT2500 | 0.7619 (0.0618) | 0.9079 (0.0383) | 0.7696 (0.0667) | 117.61 (1.50) |
| Att300 | 0.7062 (0.0531) | 0.8825 (0.0314) | 0.7481 (0.0630) | 120.24 (1.56) |
| Att2500 | 0.7800 (0.0528) | 0.9169 (0.0314) | 0.7867 (0.0561) | 119.31 (1.72) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsinganos, P.; Jansen, B.; Cornelis, J.; Skodras, A. Real-Time Analysis of Hand Gesture Recognition with Temporal Convolutional Networks. Sensors 2022, 22, 1694. https://doi.org/10.3390/s22051694
Tsinganos P, Jansen B, Cornelis J, Skodras A. Real-Time Analysis of Hand Gesture Recognition with Temporal Convolutional Networks. Sensors. 2022; 22(5):1694. https://doi.org/10.3390/s22051694
Chicago/Turabian StyleTsinganos, Panagiotis, Bart Jansen, Jan Cornelis, and Athanassios Skodras. 2022. "Real-Time Analysis of Hand Gesture Recognition with Temporal Convolutional Networks" Sensors 22, no. 5: 1694. https://doi.org/10.3390/s22051694
APA StyleTsinganos, P., Jansen, B., Cornelis, J., & Skodras, A. (2022). Real-Time Analysis of Hand Gesture Recognition with Temporal Convolutional Networks. Sensors, 22(5), 1694. https://doi.org/10.3390/s22051694