
The Challenge of Data Annotation in Deep Learning—A Case Study on Whole Plant Corn Silage



Abstract
:1. Introduction
- Present our annotation process for WPCS with respect to kernel fragmentation and stover overlengths;
- Show an analysis of the quality and consistency of the resulting annotations;
- Evaluate SSL for WPCS, showing a considerably more efficient alternative to manual annotations for supervised learning.
2. Related Work
3. Dataset Annotation
3.1. Kernel Fragmentation
3.1.1. Annotation Guideline
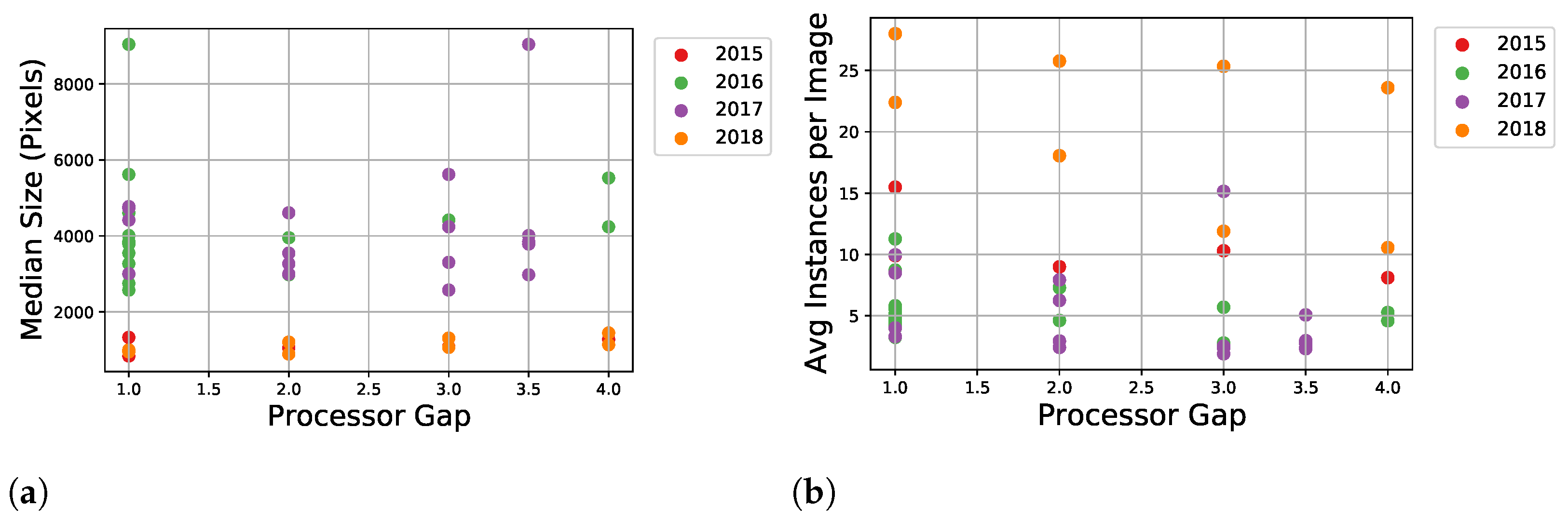
3.1.2. Statistics and Evaluation
3.2. Stover Overlengths
3.2.1. Annotation Guideline
3.2.2. Statistics and Evaluation
4. Semi-Supervised Learning
| Algorithm 1: Teacher-student training overview |
|
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| WPCS | Whole Plant Corn Silage |
| CNN | Convolutional Neural Network |
| SSL | Semi-Supervised Learning |
| PG | Processor Gap |
| TLOC | Theoretical Length of Cut |
| CSPS | Corn Silage Processing Score |
| IoU | Intersection-over-Union |
| AP | Average Precision |
| AR | Average Recall |
| p.p. | Percentage Points |
| EMA | Exponential Moving Average |
| PCC | Pearson’s Correlation Coefficient |
References
- Rasmussen, C.B.; Moeslund, T.B. Maize Silage Kernel Fragment Estimation Using Deep Learning-Based Object Recognition in Non-Separated Kernel/Stover RGB Images. Sensors 2019, 19, 3506. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rasmussen, C.B.; Kirk, K.; Moeslund, T.B. Anchor tuning in Faster R-CNN for measuring corn silage physical characteristics. Comput. Electron. Agric. 2021, 188, 106344. [Google Scholar] [CrossRef]
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; Sun, J. Objects365: A Large-Scale, High-Quality Dataset for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8429–8438. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Zhang, D.; Han, J.; Cheng, G.; Yang, M.H. Weakly Supervised Object Localization and Detection: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021; early access. [Google Scholar] [CrossRef]
- Riekert, M.; Klein, A.; Adrion, F.; Hoffmann, C.; Gallmann, E. Automatically detecting pig position and posture by 2D camera imaging and deep learning. Comput. Electron. Agric. 2020, 174, 105391. [Google Scholar] [CrossRef]
- Jiang, B.; Wu, Q.; Yin, X.; Wu, D.; Song, H.; He, D. FLYOLOv3 deep learning for key parts of dairy cow body detection. Comput. Electron. Agric. 2019, 166, 104982. [Google Scholar] [CrossRef]
- Frei, M.; Kruis, F. Image-based size analysis of agglomerated and partially sintered particles via convolutional neural networks. Powder Technol. 2020, 360, 324–336. [Google Scholar] [CrossRef] [Green Version]
- Byun, H.; Kim, J.; Yoon, D.; Kang, I.S.; Song, J.J. A deep convolutional neural network for rock fracture image segmentation. Earth Sci. Inf. 2021, 14, 1937–1951. [Google Scholar] [CrossRef]
- Lotter, W.; Diab, A.R.; Haslam, B.; Kim, J.G.; Giorgia, G.; Wu, E.; Wu, K.; Onieva, J.O.; Boyer, Y.; Boxerman, J.L.; et al. Robust breast cancer detection in mammography and digital breast tomosynthesis using an annotation-efficient deep learning approach. Nat. Med. 2021, 27, 244–249. [Google Scholar] [CrossRef]
- Marsh, B.H. A Comparison of Fuel Usage and Harvest Capacity in Self-Propelled Forage Harvesters. Int. J. Agric. Biosyst. Eng. 2013, 7, 649–654. [Google Scholar]
- Mertens, D. Particle Size, Fragmentation Index, and Effective Fiber: Tools for Evaluating the Physical Attributes of Corn Silages. In Proceedings of the Four-State Dairy Nutrition and Management, Dubuque, IA, USA, 15 June 2005; pp. 211–220. [Google Scholar]
- Heinrichs, J.; Coleen, M.J. Penn State Particle Separator. 2016. Available online: https://extension.psu.edu/penn-state-particle-separator (accessed on 10 June 2021).
- Rasmussen, C.B.; Moeslund, T.B. Evaluation of Model Selection for Kernel Fragment Recognition in Corn Silage. arXiv 2020, arXiv:2004.00292. [Google Scholar]
- Drewry, J.L.; Luck, B.D.; Willett, R.M.; Rocha, E.M.; Harmon, J.D. Predicting kernel processing score of harvested and processed corn silage via image processing techniques. Comput. Electron. Agric. 2019, 160, 144–152. [Google Scholar] [CrossRef]
- Savoie, P.; Audy-Dubé, M.A.; Pilon, G.; Morissette, R. Chopped forage particle size analysis in one, two and three dimensions. In Proceedings of the American Society of Agricultural and Biological Engineers’ Annual International Meeting, Kansas City, MO, USA, 21–24 July2013. [Google Scholar] [CrossRef]
- Audy, M.; Savoie, P.; Thibodeau, F.; Morissette, R. Size and shape of forage particles by image analysis and normalized multiscale bending energy method. In Proceedings of the American Society of Agricultural and Biological Engineers Annual International Meeting 2014, ASABE 2014, Montreal, QC, Canada, 13–16 July 2014; Volume 2, pp. 820–830. [Google Scholar]
- Gupta, A.; Dollar, P.; Girshick, R. LVIS: A Dataset for Large Vocabulary Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5122–5130. [Google Scholar] [CrossRef]
- Papadopoulos, D.P.; Uijlings, J.R.R.; Keller, F.; Ferrari, V. Extreme Clicking for Efficient Object Annotation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4940–4949. [Google Scholar]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Castrejón, L.; Kundu, K.; Urtasun, R.; Fidler, S. Annotating Object Instances with a Polygon-RNN. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Acuna, D.; Ling, H.; Kar, A.; Fidler, S. Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++. arXiv 2018, arXiv:1803.09693. [Google Scholar]
- Papadopoulos, D.P.; Weber, E.; Torralba, A. Scaling up Instance Annotation via Label Propagation. In Proceedings of the ICCV, Virtual, 11–17 October 2021. [Google Scholar]
- Li, Y.; Fan, B.; Zhang, W.; Ding, W.; Yin, J. Deep active learning for object detection. Inf. Sci. 2021, 579, 418–433. [Google Scholar] [CrossRef]
- Yuan, T.; Wan, F.; Fu, M.; Liu, J.; Xu, S.; Ji, X.; Ye, Q. Multiple Instance Active Learning for Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Sandfor, V.; Yan, K.; Pickhardt, P.J.; Summers, R.M. Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks. Sci. Rep. 2019, 9, 16884. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar] [CrossRef]
- Liu, Y.C.; Ma, C.Y.; He, Z.; Kuo, C.W.; Chen, K.; Zhang, P.; Wu, B.; Kira, Z.; Vajda, P. Unbiased Teacher for Semi-Supervised Object Detection. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, Austria, 3–7 May 2021. [Google Scholar]
- Ren, Z.; Yu, Z.; Yang, X.; Liu, M.Y.; Lee, Y.J.; Schwing, A.G.; Kautz, J. Instance-aware, Context-focused, and Memory-efficient Weakly Supervised Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020. [Google Scholar]
- Lu, Y.; Young, S. A survey of public datasets for computer vision tasks in precision agriculture. Comput. Electron. Agric. 2020, 178, 105760. [Google Scholar] [CrossRef]
- Kestur, R.; Meduri, A.; Narasipura, O. MangoNet: A deep semantic segmentation architecture for a method to detect and count mangoes in an open orchard. Eng. Appl. Artif. Intell. 2019, 77, 59–69. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Paterson, A.H.; Robertson, J.S. DeepSeedling: Deep convolutional network and Kalman filter for plant seedling detection and counting in the field. Plant Methods 2019, 15, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Hani, N.; Roy, P.; Isler, V. MinneApple: A Benchmark Dataset for Apple Detection and Segmentation. arXiv 2019, arXiv:cs.CV/1909.06441. [Google Scholar] [CrossRef] [Green Version]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. DeepFruits: A Fruit Detection System Using Deep Neural Networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, N.; Siegel, Z.D.; Zarecor, S.; Lee, N.; Campbell, D.A.; Andorf, C.M.; Nettleton, D.; Lawrence-Dill, C.J.; Ganapathysubramanian, B.; Kelly, J.W.; et al. Crowdsourcing image analysis for plant phenomics to generate ground truth data for machine learning. PLoS Comput. Biol. 2018, 14, e1006337. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bargoti, S.; Underwood, J. Deep fruit detection in orchards. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3626–3633. [Google Scholar] [CrossRef] [Green Version]
- Dias, P.A.; Tabb, A.; Medeiros, H. Multispecies Fruit Flower Detection Using a Refined Semantic Segmentation Network. IEEE Robot. Autom. Lett. 2018, 3, 3003–3010. [Google Scholar] [CrossRef] [Green Version]
- Dias, P.A.; Shen, Z.; Tabb, A.; Medeiros, H. FreeLabel: A Publicly Available Annotation Tool Based on Freehand Traces. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 21–30. [Google Scholar] [CrossRef] [Green Version]
- Skovsen, S.; Dyrmann, M.; Mortensen, A.K.; Laursen, M.S.; Gislum, R.; Eriksen, J.; Farkhani, S.; Karstoft, H.; Jorgensen, R.N. The GrassClover Image Dataset for Semantic and Hierarchical Species Understanding in Agriculture. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/Accuracy Trade-Offs for Modern Convolutional Object Detectors. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3296–3297. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 1 June 2021).
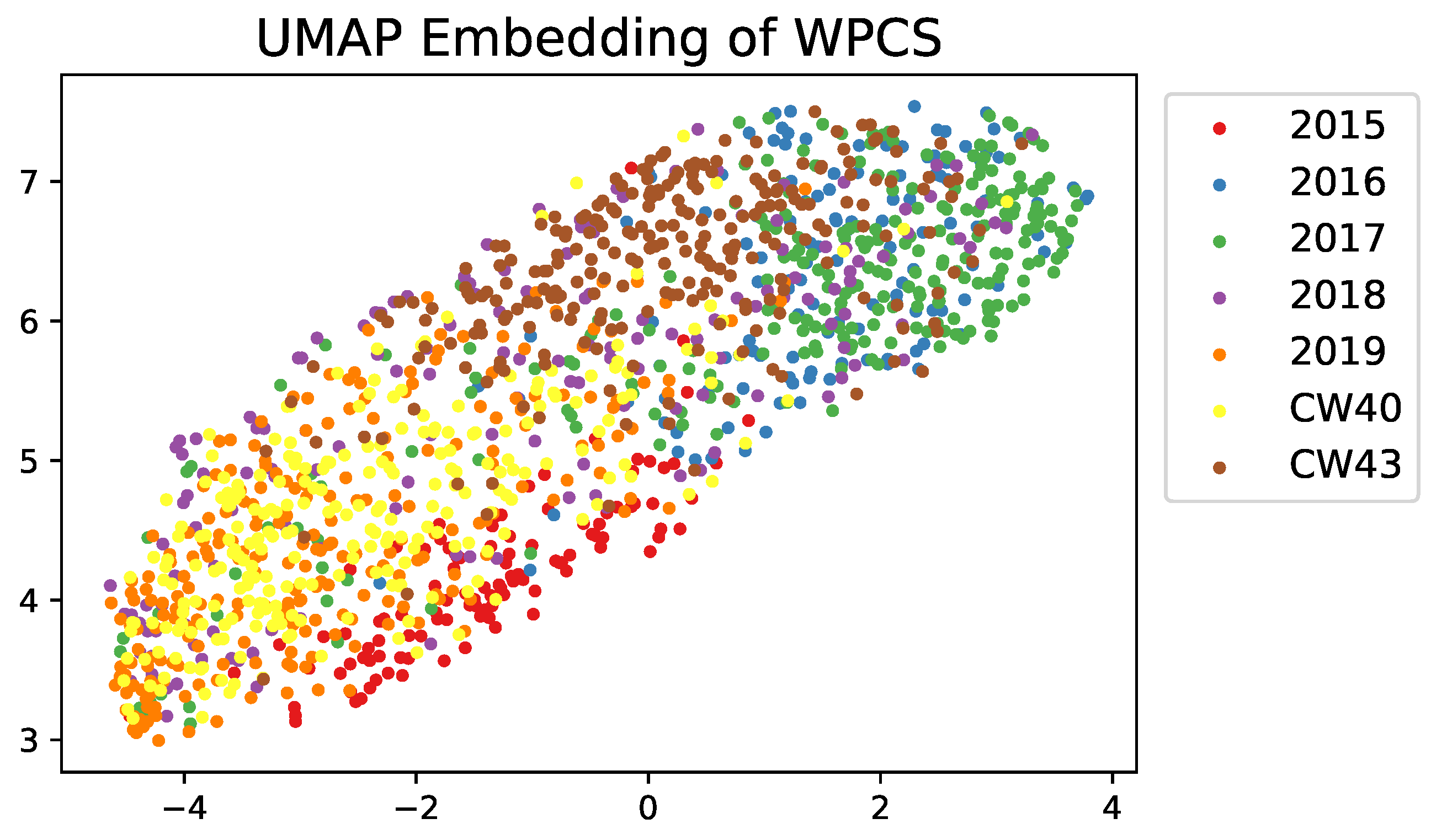
- McInnes, L.; Healy, J.; Saul, N.; Grossberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PG | TLOC | Images | Anno Insts | Insts per Img |
|---|---|---|---|---|
| 2015 | ||||
| 1 (2) | 9 | 90 | 1333 | 14.8 |
| 2 (1) | 9 | 21 | 189 | 9.0 |
| 3 (1) | 9 | 37 | 402 | 10.31 |
| 4 (1) | 9 | 39 | 300 | 8.11 |
| Total | 187 | 2224 | 11.89 | |
| 2016 | ||||
| 1 (14) | 4 | 131 | 762 | 5.82 |
| 2 (2) | 4 | 18 | 110 | 6.11 |
| 3 (2) | 4 | 19 | 82 | 4.32 |
| 4 (1) | 4 | 11 | 58 | 5.27 |
| Total | 205 | 1118 | 5.45 | |
| 2017 | ||||
| 1 (2) | 4 | 152 | 967 | 6.36 |
| 2 (2) | 4 | 127 | 458 | 3.61 |
| 3 (2) | 4 | 359 | 901 | 2.51 |
| 3.5 (2) | 4 | 126 | 442 | 3.51 |
| 1 (2) | 12 | 290 | 1200 | 4.14 |
| 2 (2) | 12 | 289 | 1909 | 6.61 |
| 3 (2) | 12 | 111 | 927 | 8.35 |
| 3.5 (2) | 12 | 171 | 435 | 2.54 |
| Total | 1972 | 8270 | 4.19 | |
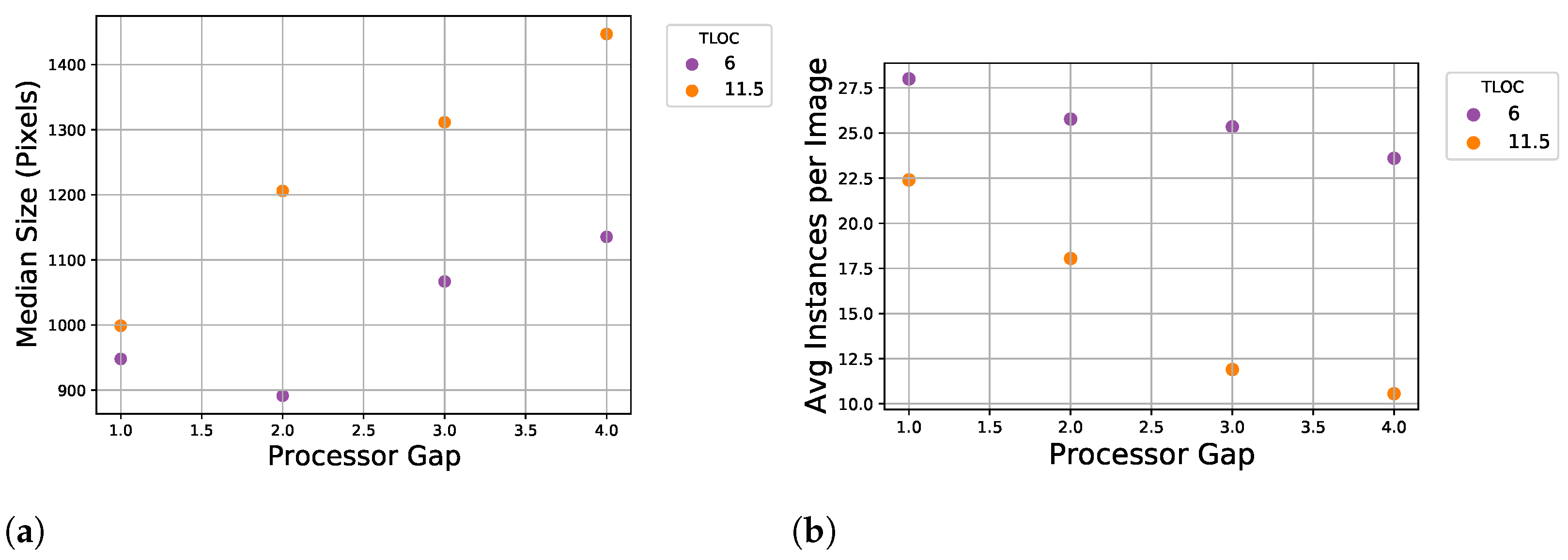
| 2018 | ||||
| 1 (1) | 6 | 20 | 616 | 28.00 |
| 2 (1) | 6 | 20 | 567 | 25.77 |
| 3 (1) | 6 | 20 | 507 | 25.35 |
| 4 (1) | 6 | 20 | 472 | 23.60 |
| 1 (1) | 11.5 | 20 | 448 | 22.40 |
| 2 (1) | 11.5 | 20 | 361 | 18.05 |
| 3 (1) | 11.5 | 20 | 238 | 11.90 |
| 4 (1) | 11.5 | 20 | 264 | 10.56 |
| Total | 169 | 3473 | 20.55 |
| TLOC | Images | Instances | A Leaves | NA Leaves | Inner Stalk | Outer Stalk | Avg. Size | Avg. Major Axis Length | Avg. Minor Axis Length |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 163 | 1233 | 520 | 419 | 75 | 209 | 14,518.9 | 216.6 | 94.3 |
| 6 | 199 | 904 | 182 | 559 | 35 | 122 | 26,315 | 294.3 | 122.7 |
| 11.5 | 113 | 263 | 51 | 172 | 1 | 38 | 61,328.2 | 485.5 | 179.9 |
| Images | Instances | Avg. Insts per Image | Avg. Size | Avg. Major Axis Length | Avg. Minor Axis Length | |
|---|---|---|---|---|---|---|
| Annotator 1 | ||||||
| Seq1 | 37 | 73 | 1.97 | 33,056.85 | 322.33 | 140.05 |
| Seq2 | 32 | 57 | 1.78 | 36,415.78 | 360.33 | 124.02 |
| Seq3 | 31 | 102 | 3.29 | 25,180.66 | 292.98 | 124.02 |
| Annotator 2 | ||||||
| Seq1 | 37 | 124 | 3.35 | 25,423.53 | 294.71 | 126.33 |
| Seq2 | 32 | 180 | 5.62 | 20,969.54 | 262.65 | 111.25 |
| Annotator 3 | ||||||
| Seq1 | 37 | 271 | 7.32 | 17,105.99 | 234.34 | 102.44 |
| Seq2 | 32 | 256 | 8.0 | 18,098.88 | 232.60 | 111.25 |
| Seq3a | 31 | 227 | 7.32 | 18,025.16 | 234.55 | 111.41 |
| Seq3b | 31 | 222 | 7.16 | 18,427.43 | 242.06 | 110.28 |
| Annotator | A Leaves | NA Leaves | I Stalks | O Stalks |
|---|---|---|---|---|
| Annotator 1 | 122 | 46 | 7 | 7 |
| Annotator 2 | 82 | 98 | 10 | 24 |
| Annotator 3 | 418 | 330 | 65 | 157 |
| Cohen Kappa | Count IoU > 0.5 | ||||
|---|---|---|---|---|---|
| A1 | A2 | A3 | Inst Cnt A1 | A2 | A3 |
| Seq1 | 0 | 0 | 25 | 1 | 0 |
| Seq2 | 0 | 0 | 6 | 0 | 0 |
| Seq3 | 0 | na | 15 | na | 15 |
| A2 | A1 | A3 | Inst Cnt A2 | A1 | A3 |
| Seq1 | 0 | 0 | 62 | 7 | 4 |
| Seq2 | 0 | 0 | 23 | 3 | 1 |
| Seq3 | na | na | na | na | na |
| A3 | A1 | A2 | Inst Cnt A3 | A1 | A2 |
| Seq1 | 0 | 0 | 78 | 9 | 6 |
| Seq2 | 0 | 0 | 37 | 4 | 3 |
| Seq3 | 0 | na | 39 | 3 | na |
| Class | AP | AP@0.5 | AP@0.75 | AR@1 | AR@10 | AR@100 |
|---|---|---|---|---|---|---|
| All (207) | 23.7 | 42.2 | 25.8 | 23.0 | 42.5 | 47.8 |
| 28.1 | 48.1 | 34.8 | 26.9 | 42.1 | 45.5 | |
| A Leaves (107) | 29.1 | 47.3 | 33.6 | 17.4 | 51.6 | 57.8 |
| 29.2 | 41.8 | 39.6 | 17.7 | 55.7 | 61.3 | |
| NA Leaves (59) | 17.9 | 34.2 | 17.4 | 19.3 | 35.3 | 44.4 |
| 20.0 | 34.2 | 21.2 | 22.8 | 30.6 | 35.6 | |
| I Stalks (11) | 31.7 | 54.7 | 31.3 | 27.3 | 50.9 | 50.9 |
| 51.7 | 76.3 | 59.2 | 34.6 | 51.8 | 55.4 | |
| O Stalks (30) | 15.9 | 32.7 | 20.8 | 28.0 | 32.3 | 38.0 |
| 10.0 | 30.6 | 19.0 | 32.3 | 23.3 | 29.7 |
| Class | AP | AP@0.5 | AP@0.75 | AR@1 | AR@10 | AR@100 |
|---|---|---|---|---|---|---|
| All (141) | 32.0 | 54.2 | 35.6 | 23.8 | 45.1 | 49.1 |
| 39.7 | 63.0 | 50.4 | 29.6 | 46.0 | 46.9 | |
| A Leaves (64) | 44.6 | 70.7 | 54.7 | 20.2 | 55.8 | 61.1 |
| 49.1 | 70.8 | 68.5 | 22.6 | 60.8 | 63.9 | |
| NA Leaves (43) | 23.5 | 45.0 | 19.6 | 17.2 | 35.6 | 43.5 |
| 27.8 | 48.7 | 25.5 | 23.7 | 29.3 | 34.4 | |
| I Stalks (10) | 37.4 | 64.5 | 36.9 | 30.0 | 56.0 | 56.0 |
| 60.5 | 97.5 | 69.0 | 38.0 | 68.0 | 61.0 | |
| O Stalks (24) | 22.5 | 36.6 | 31.3 | 27.9 | 32.9 | 35.8 |
| 21.1 | 35.1 | 38.5 | 34.1 | 25.8 | 28.3 |
| Train Set | Unsup. Set | Bbox Thresh | Unsup Images | Unsup Weight | AP | AP@0.5 | AP@0.75 | PCC CW40 | PCC CW43 | PCC CW40+43 |
|---|---|---|---|---|---|---|---|---|---|---|
| 151617 [2] | NA | NA | NA | NA | NA | NA | NA | 0.95 | 0.79 | 0.81 |
| 151617 | NA | NA | NA | NA | 17.20 | 32.15 | 15.96 | 0.94 | 0.75 | 0.68 |
| 151617 | 2019 | 0.1 | 1 | 0.5 | 15.57 | 27.73 | 16.16 | 0.88 | 0.73 | 0.72 |
| 151617 | 2019 | 0.1 | 1 | 4 | - | - | - | - | - | - |
| 151617 | 2019 | 0.1 | 4 | 0.5 | 17.49 | 31.36 | 17.40 | 0.86 | 0.76 | 0.71 |
| 151617 | 2019 | 0.1 | 4 | 4 | - | - | - | - | - | - |
| 151617 | 2019 | 0.3 | 1 | 0.5 | 17.85 | 31.92 | 17.78 | 0.93 | 0.72 | 0.75 |
| 151617 | 2019 | 0.3 | 1 | 4 | 19.93 | 36.02 | 19.64 | 0.81 | 0.74 | 0.67 |
| 151617 | 2019 | 0.3 | 4 | 0.5 | 17.95 | 32.32 | 17.66 | 0.92 | 0.71 | 0.72 |
| 151617 | 2019 | 0.3 | 4 | 4 | 19.73 | 35.15 | 20.47 | 0.85 | 0.69 | 0.65 |
| 151617 | 2019 | 0.5 | 1 | 0.5 | 19.79 | 35.86 | 20.32 | 0.90 | 0.79 | 0.70 |
| 151617 | 2019 | 0.5 | 1 | 4 | 17.78 | 34.85 | 15.45 | 0.83 | 0.73 | 0.62 |
| 151617 | 2019 | 0.5 | 4 | 0.5 | 19.66 | 36.45 | 18.54 | 0.88 | 0.72 | 0.65 |
| 151617 | 2019 | 0.5 | 4 | 4 | 20.75 | 38.35 | 19.99 | 0.88 | 0.72 | 0.63 |
| 151617 | 2019 | 0.7 | 1 | 0.5 | 15.56 | 27.82 | 15.36 | 0.88 | 0.63 | 0.63 |
| 151617 | 2019 | 0.7 | 1 | 4 | 15.36 | 28.13 | 15.13 | 0.77 | 0.58 | 0.59 |
| 151617 | 2019 | 0.7 | 4 | 0.5 | 15.47 | 28.48 | 14.84 | 0.86 | 0.60 | 0.58 |
| 151617 | 2019 | 0.7 | 4 | 4 | 13.58 | 24.37 | 13.22 | 0.77 | 0.55 | 0.56 |
| Train Set | Unsup. Set | Bbox Thresh | Unsup Images | Unsup Weight | AP | AP@0.5 | AP@0.75 | PCC CW40 | PCC CW43 | PCC CW40+43 |
|---|---|---|---|---|---|---|---|---|---|---|
| 2016 | NA | NA | NA | NA | 4.97 | 7.39 | 6.05 | 0.70 | 0.54 | 0.56 |
| 2016 | 1517+2019 | 0.1 | 1 | 0.5 | 11.95 | 24.02 | 9.65 | 0.72 | 0.65 | 0.63 |
| 2016 | 1517+2019 | 0.1 | 1 | 4 | - | - | - | - | - | - |
| 2016 | 1517+2019 | 0.1 | 4 | 0.5 | 14.24 | 28.51 | 11.51 | 0.70 | 0.76 | 0.59 |
| 2016 | 1517+2019 | 0.1 | 4 | 4 | 12.00 | 22.43 | 11.32 | 0.74 | 0.66 | 0.65 |
| 2016 | 1517+2019 | 0.3 | 1 | 0.5 | 13.67 | 27.15 | 10.89 | 0.70 | 0.57 | 0.52 |
| 2016 | 1517+2019 | 0.3 | 1 | 4 | - | - | - | - | - | - |
| 2016 | 1517+2019 | 0.3 | 4 | 0.5 | 13.28 | 27.90 | 9.35 | 0.85 | 0.55 | 0.62 |
| 2016 | 1517+2019 | 0.3 | 4 | 4 | 13.53 | 24.15 | 13.31 | 0.84 | 0.66 | 0.70 |
| 2016 | 1517+2019 | 0.5 | 1 | 0.5 | 15.05 | 29.60 | 12.30 | 0.73 | 0.64 | 0.56 |
| 2016 | 1517+2019 | 0.5 | 1 | 4 | - | - | - | - | - | - |
| 2016 | 1517+2019 | 0.5 | 4 | 0.5 | 16.98 | 33.60 | 13.98 | 0.83 | 0.70 | 0.71 |
| 2016 | 1517+2019 | 0.5 | 4 | 4 | 16.62 | 32.75 | 14.16 | 0.79 | 0.65 | 0.58 |
| 2016 | 1517+2019 | 0.7 | 1 | 0.5 | 12.34 | 21.14 | 13.52 | 0.82 | 0.55 | 0.64 |
| 2016 | 1517+2019 | 0.7 | 1 | 4 | 13.92 | 27.88 | 11.91 | 0.85 | 0.61 | 0.58 |
| 2016 | 1517+2019 | 0.7 | 4 | 0.5 | 9.67 | 16.23 | 10.59 | 0.74 | 0.59 | 0.64 |
| 2016 | 1517+2019 | 0.7 | 4 | 4 | 17.66 | 33.91 | 16.24 | 0.90 | 0.61 | 0.64 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rasmussen, C.B.; Kirk, K.; Moeslund, T.B. The Challenge of Data Annotation in Deep Learning—A Case Study on Whole Plant Corn Silage. Sensors 2022, 22, 1596. https://doi.org/10.3390/s22041596
Rasmussen CB, Kirk K, Moeslund TB. The Challenge of Data Annotation in Deep Learning—A Case Study on Whole Plant Corn Silage. Sensors. 2022; 22(4):1596. https://doi.org/10.3390/s22041596
Chicago/Turabian StyleRasmussen, Christoffer Bøgelund, Kristian Kirk, and Thomas B. Moeslund. 2022. "The Challenge of Data Annotation in Deep Learning—A Case Study on Whole Plant Corn Silage" Sensors 22, no. 4: 1596. https://doi.org/10.3390/s22041596
APA StyleRasmussen, C. B., Kirk, K., & Moeslund, T. B. (2022). The Challenge of Data Annotation in Deep Learning—A Case Study on Whole Plant Corn Silage. Sensors, 22(4), 1596. https://doi.org/10.3390/s22041596