
Domain Adaptation with Augmented Data by Deep Neural Network Based Method Using Re-Recorded Speech for Automatic Speech Recognition in Real Environment
Abstract
1. Introduction
- A domain adaptation approach independent of the ASR model is proposed by preparing speech data which contain target domain characteristics. Experiments are conducted on two of the state-of-the-art approaches, and the effectiveness of the proposed method on both of them is proved.
- To prepare speech data with target domain characteristics at low cost, the following approaches are adopted:
- Use an already existing corpus.
- Re-recording the corpus data by playing them in a real environment for only a limited short period of time.
- Performing post-processing on them to adapt them for ASR model training.
- It is proved that by involving a simple regression model for transforming, it is possible to obtain data with target domain characteristics from clean data if only a small amount of target domain data (duration of less than 1 h) is acquired to improve the performance of ASR to a great extent.
2. Materials and Methods
2.1. ASR Models for Domain Adaptation
2.1.1. DNN-HMM-Based Speech Recognition
2.1.2. End-to-End (E2E)-Based Speech Recognition
2.2. Re-Recorded Data Acquisition
2.2.1. Re-Recording of Clean Data in Real Environment
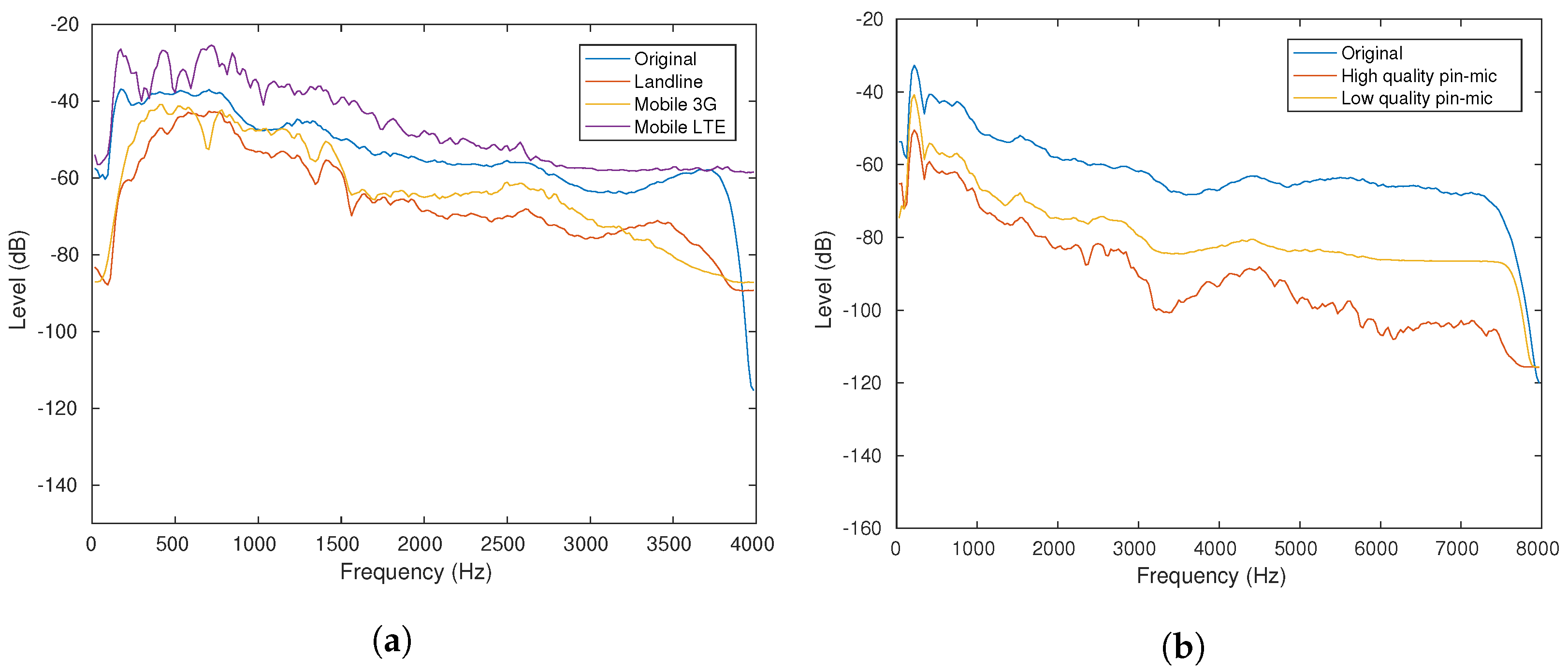
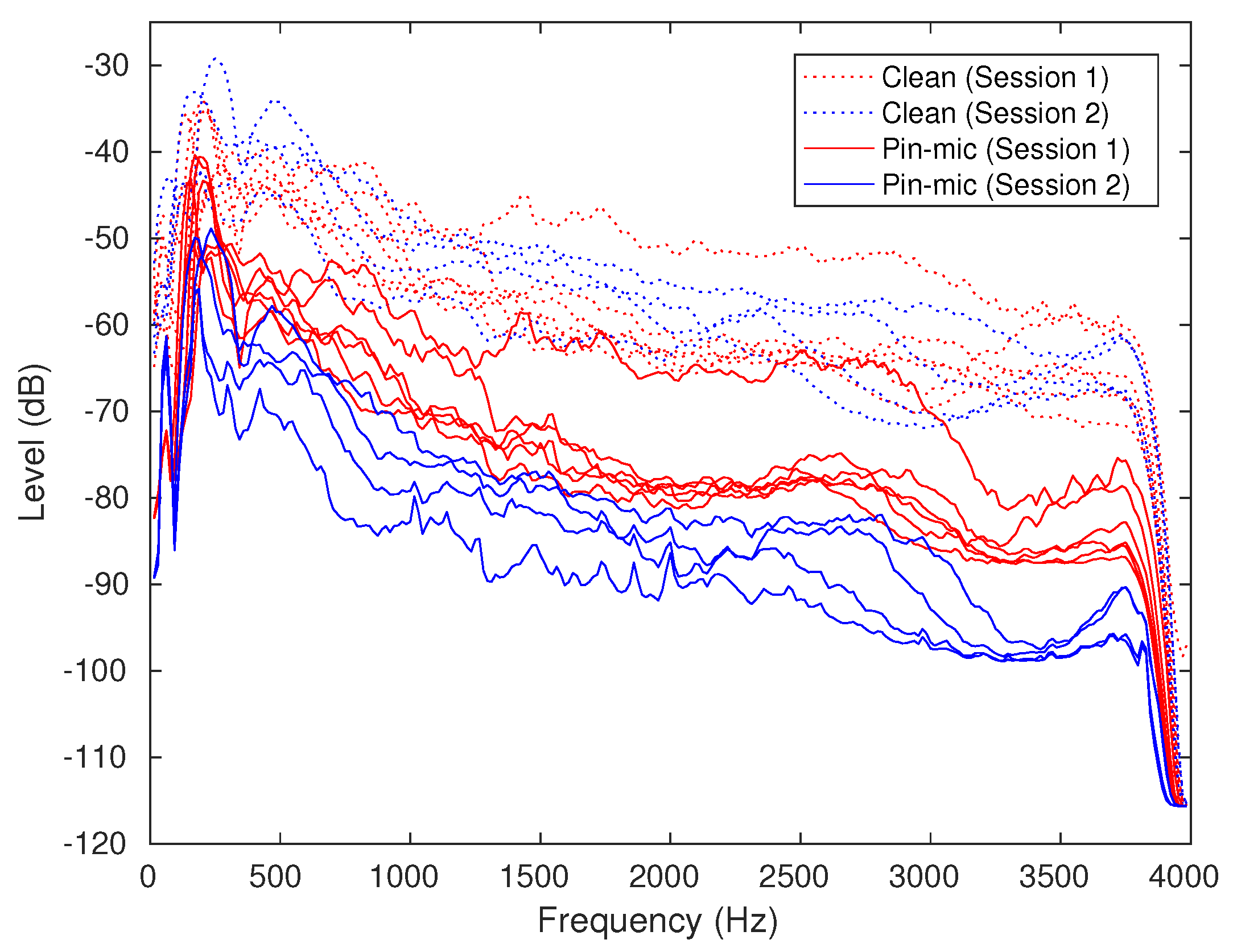
2.2.2. Spectral Analysis on Re-Recorded Speech
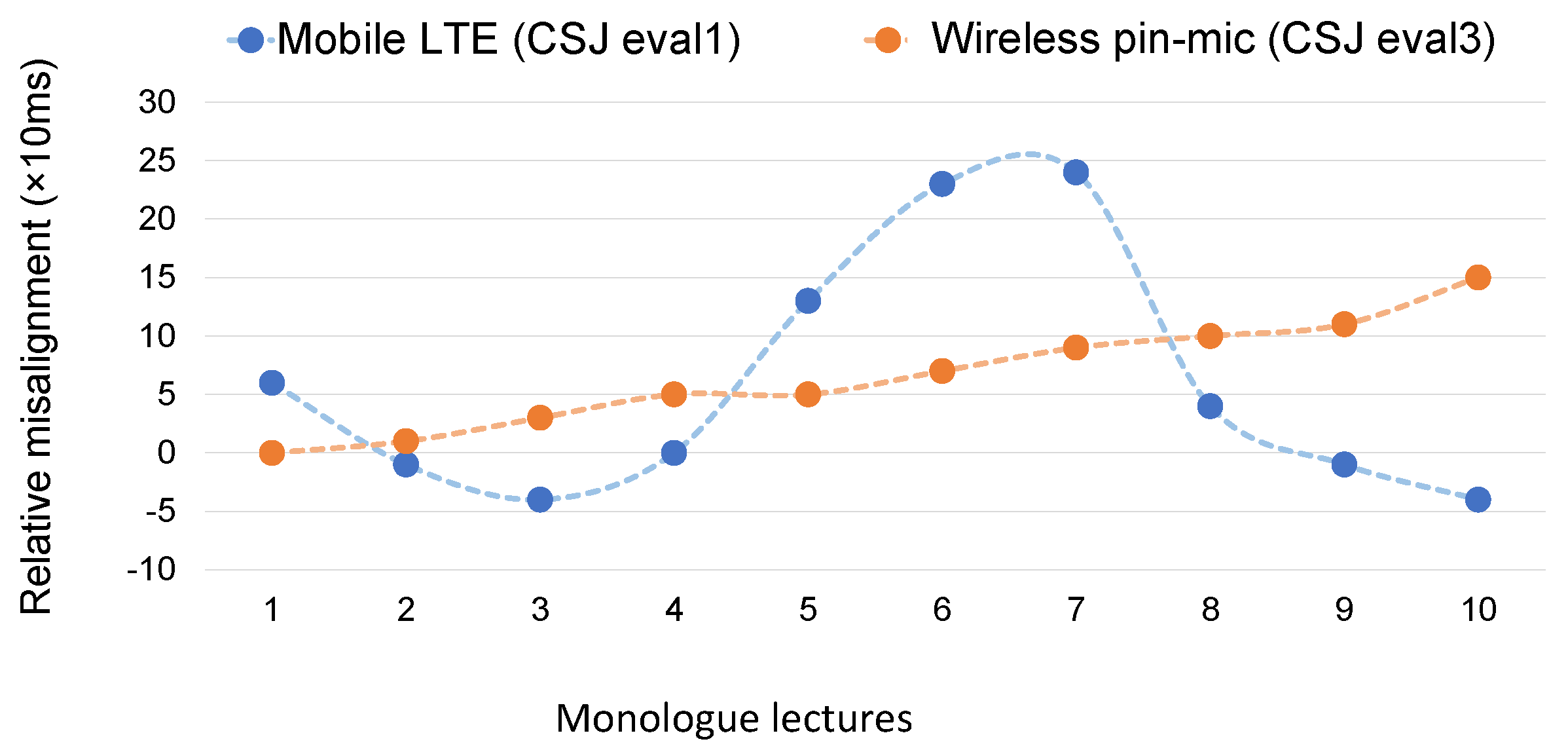
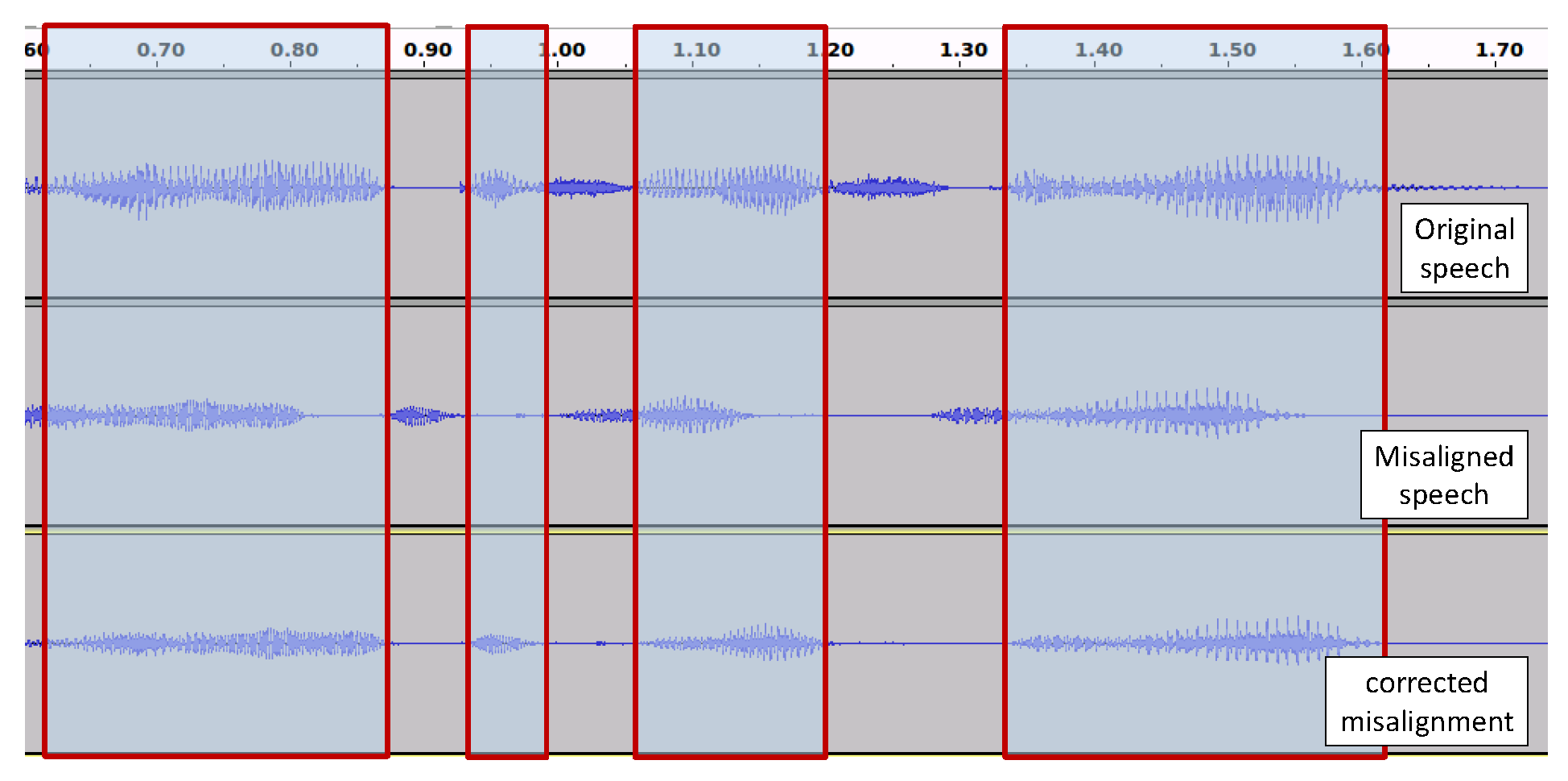
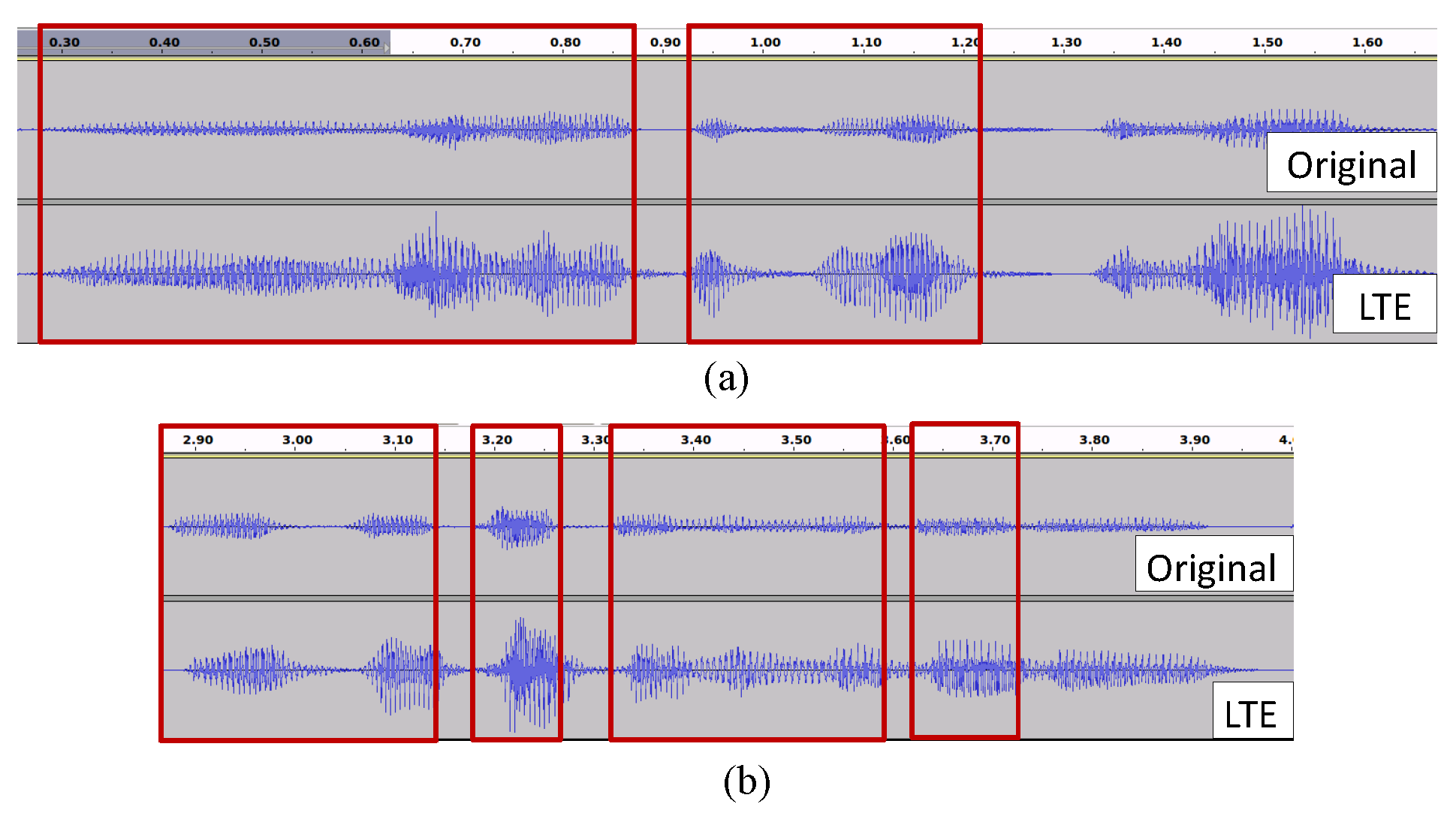
2.3. Problems Regarding Re-Recorded Speech: Temporal Misalignment
2.3.1. Proposed Misalignment Correction Method Based on Segment-Level Matching with Euclidean Distance
2.3.2. Filtering of Re-Recorded Speech
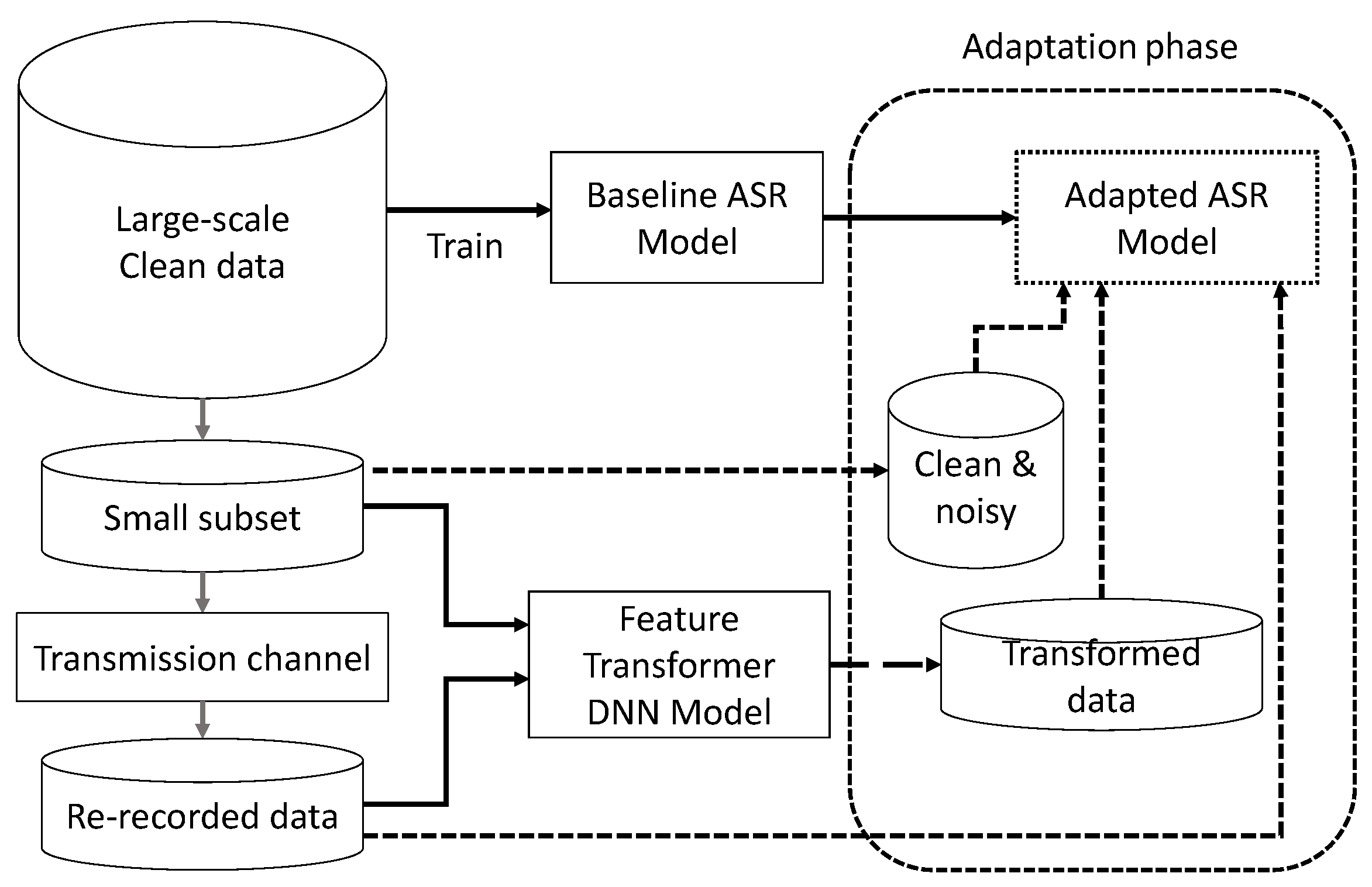
2.4. Domain Adaptation Using Re-Recorded Speech and DNN-Based Data Augmentation
2.4.1. Task Setting
2.4.2. DNN-Based Data Augmentation Using Feed-Forward Network Architecture
2.4.3. Data Augmentation Approaches
3. Experimental Setup
3.1. Datasets
3.1.1. Datasets for Training Baselines
3.1.2. Dataset for Fine-Tuning
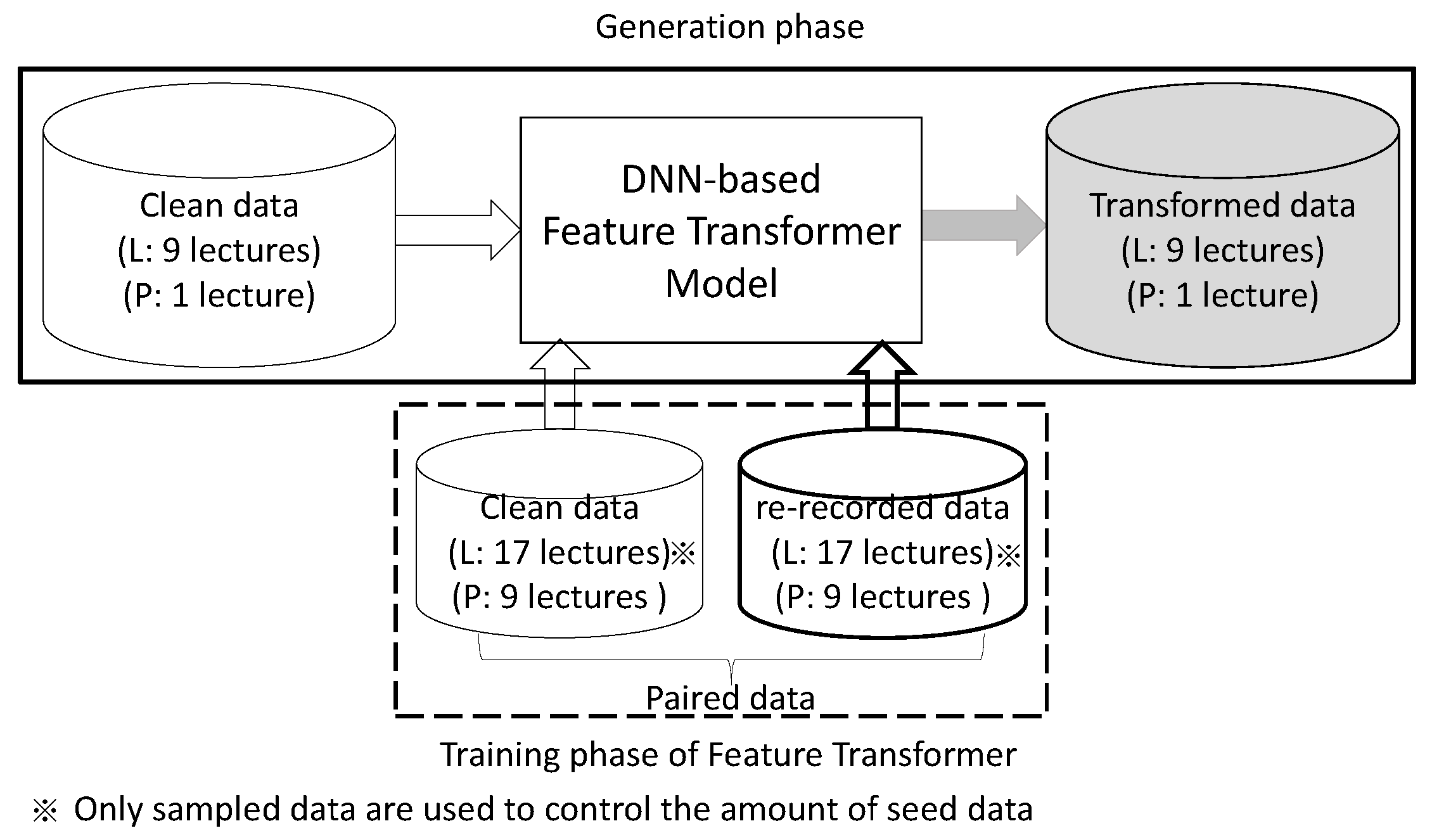
3.1.3. Dataset for Training Feature Transformer Model
3.2. Evaluation Tasks
3.3. Explanation of Models
3.3.1. DNN-Based Feature Transformer Model
3.3.2. DNN-HMM ASR Model
3.3.3. End-to-End ASR Model
3.4. Evaluation Metrices
4. Results and Discussion
4.1. Results of Domain Adaptation for LTE and Pin Mic Channel When the Largest Amount of Data Are Used
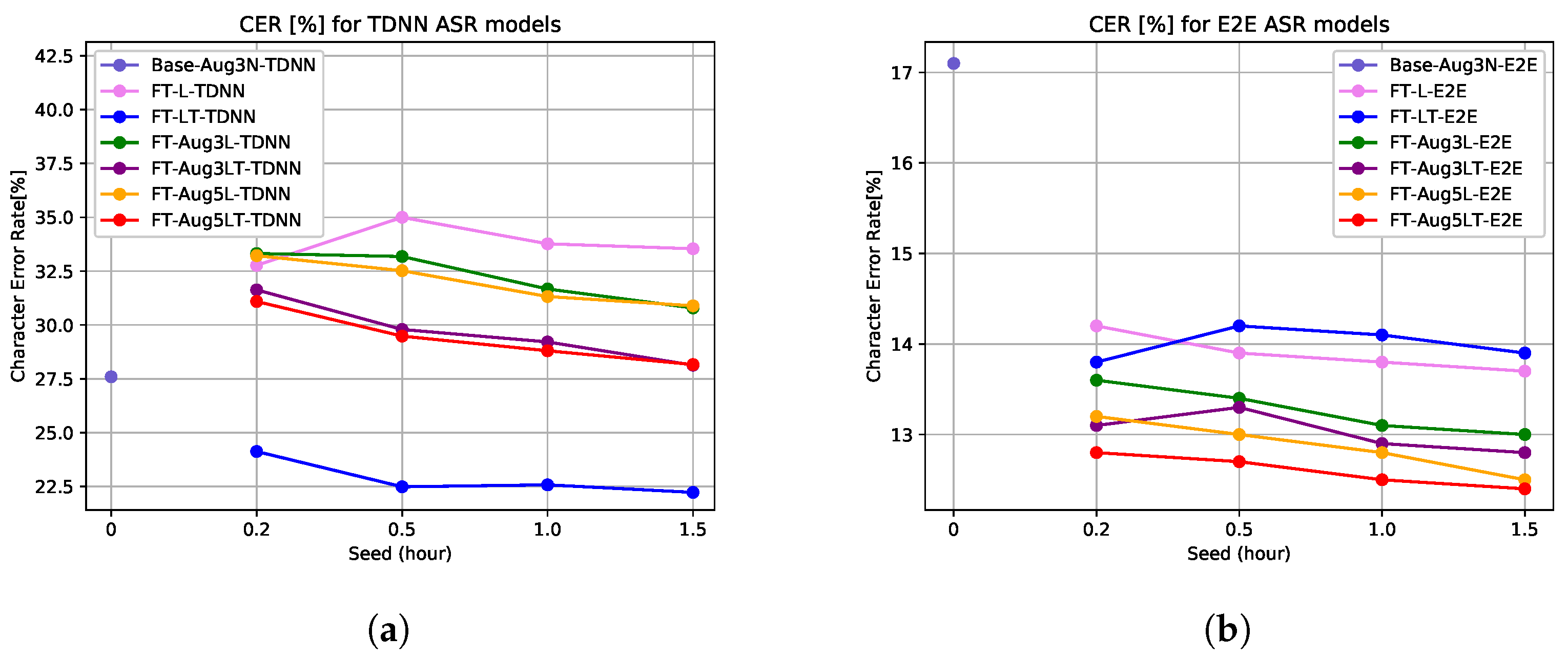
4.2. Effect of Variability in Recording Quality
4.3. Validation Experiments for mobile LTE Channel with Limited Re-Recorded Data
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ko, T.; Peddinti, V.; Povey, D.; Khudanpur, S. Audio augmentation for speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3586–3589. [Google Scholar]
- Hsiao, R.; Ma, J.; Hartmann, W.; Karafiát, M.; František, G.; Burget, L.; Szöke, I.; Černocký, J.H.; Watanabe, S.; Chen, Z.; et al. Robust speech recognition in unknown reverberant and noisy conditions. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 533–538. [Google Scholar]
- Ko, T.; Peddinti, V.; Povey, D.; Seltzer, M.L.; Khudanpur, S. A study on data augmentation of reverberant speech for robust speech recognition. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5220–5224. [Google Scholar]
- Cui, X.; Goel, V.; Kingsbury, B. Data augmentation for deep neural network acoustic modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 1469–1477. [Google Scholar]
- Khokhlov, Y.; Zatvornitskiy, A.; Medennikov, I.; Sorokin, I.; Prisyach, T.; Romanenko, A.; Mitrofanov, A.; Bataev, V.; Andrusenko, A.; Korenevskaya, M.; et al. R-vectors: New Technique for Adaptation to Room Acoustics. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 1243–1247. [Google Scholar]
- Mohamed, A.; Dahl, G.E.; Hinton, G. Acoustic Modeling using Deep Belief Networks. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 12–22. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, G.; Deng, L.; Acero, A. Context-dependent Pre-trained Deep Neural Networks for Large Vocabulary Speech Recognition. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 30–42. [Google Scholar] [CrossRef]
- Hinton, G.; Yu, D.; Dahl, G.E.; Mohamed, A.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; Kingsbury, B. Deep Neural Network for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Hinton, G.; Osindero, S.; Teh, Y.W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1557. [Google Scholar] [CrossRef] [PubMed]
- Christensen, H.; Cunningham, S.; Fox, C.; Green, P.; Hain, T. A comparative study of adaptive, automatic recognition of disordered speech. In Proceedings of the INTERSPEECH, Portland, OR, USA, 9–13 September 2012; pp. 1776–1779. [Google Scholar]
- Hsu, W.-N.; Zhang, Y.; Glass, J. Unsupervised domain adaptation for robust speech recognition via autoencoder-based data augmentation. In Proceedings of the 2017 IEEE Automatic Speech Recognition and Understanding Workshop, Okinawa, Japan, 16–20 December 2017; pp. 16–23. [Google Scholar]
- Ueda, Y.; Wang, L.; Kai, A.; Ren, B. Environment-dependent denoising autoencoder for distant-talking speech recognition. EURASIP J. Adv. Signal Process 2015, 92, 1–11. [Google Scholar] [CrossRef]
- Zhang, Y.; Qin, J.; Park, S.D.; Han, W.; Chiu, C.C.; Pang, R.; Le, V.Q.; Wu, Y. Pushing the Limits of Semi-Supervised Learning for Automatic Speech Recognition. arXiv 2020, arXiv:2010.10504. [Google Scholar]
- Graves, A.; Fernandez, S.; Gomez, F.; Huber, J.S. Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 25–29. [Google Scholar]
- Chorowski, J.; Bahdanau, D.; Cho, K.; Bengio, Y. End-to-end Continuous Speech Recognition using Attention-based Recurrent NN: First Results. arXiv 2014, arXiv:1412.1602. [Google Scholar]
- Watanabe, S.; Hori, T.; Kim, S.; Hershey, J.R.; Hayashi, T. Hybrid CTC/Attention Architecture for End-to-End Speech Recognition. IEEE J. Sel. Top. Signal Process. 2017, 11, 1240–1253. [Google Scholar] [CrossRef]
- Nakamura, A.; Saito, T.; Ikeda, D.; Ohta, K.; Mineno, H.; Nishimura, M. Automatic Detection of Chewing and Swallowing. Sensors 2021, 21, 3378. [Google Scholar] [CrossRef] [PubMed]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the INTERSPEECH, Dresden, Germany, 6–10 September 2015; pp. 3214–3218. [Google Scholar]
- Waibel, A.; Hanazawa, T.; Hinton, G.; Shikano, K.; Lang, K. Phoneme recognition using time-delay neural networks. IEEE Trans. Acoust. Speech Signal Process. 1989, 37, 328–339. [Google Scholar] [CrossRef]
- Waibel, A. Modular construction of time-delay neural networks for speech recognition. Neural Comput. 1989, 1, 39–46. [Google Scholar] [CrossRef]
- Jankowski, C.; Kalyanswamy, A.; Basson, S.; Spitz, J. NTIMIT: A phonetically balanced, continuous speech, telephone bandwidth speech database. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; Volume 1, pp. 109–112. [Google Scholar]
- Brown, K.L.; George, E.B. CTIMIT: A speech corpus for the cellular environment with applications to automatic speech recognition. In Proceedings of the 1995 International Conference on Acoustics Speech, and Signal Processing, Detroit, MI, USA, 9–12 May 1995; pp. 105–108. [Google Scholar]
- Garofolo, J.; Lamel, L.; Fisher, W.; Fiscus, J.; Pallett, D.; Dahlgren, N. DARPA, TIMIT Acoustic-Phonetic Continuous Speech Corpus CD-ROM; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1990. [Google Scholar]
- Gray, R.M.; Buzo, A.; Gray, A.; Matsuyama, Y. Distortion measures for speech processing. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 367–376. [Google Scholar] [CrossRef]
- Corpus of Spontaneous Japanese. Available online: https://clrd.ninjal.ac.jp/csj/en/index.html (accessed on 1 September 2022).
- Report: “Construction of the Corpus of Spontaneous Japanese”, Chapter 2: Transcriptions. Available online: https://clrd.ninjal.ac.jp/csj/en/document.html (accessed on 1 September 2022).
- Electronic Noise Database. Available online: http://www.sunrisemusic.co.jp/database/fl/noisedata01_fl.html (accessed on 1 September 2022). (In Japanese).
- ITU Recommendation G.712. Transmission Performance Characteristics of Pulse Code Modulation Channels. 1996.
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.-C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic speech Recognition. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 2613–2617. [Google Scholar]
- Watanabe, S.; Hori, T.; Karita, S.; Hayashi, T.; Nishitoba, J.; Unno, Y.; Enrique Yalta Soplin, N.; Heymann, J.; Wiesner, M.; Chen, N.; et al. ESPnet: End-to-End Speech Processing Toolkit. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 2207–2211. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
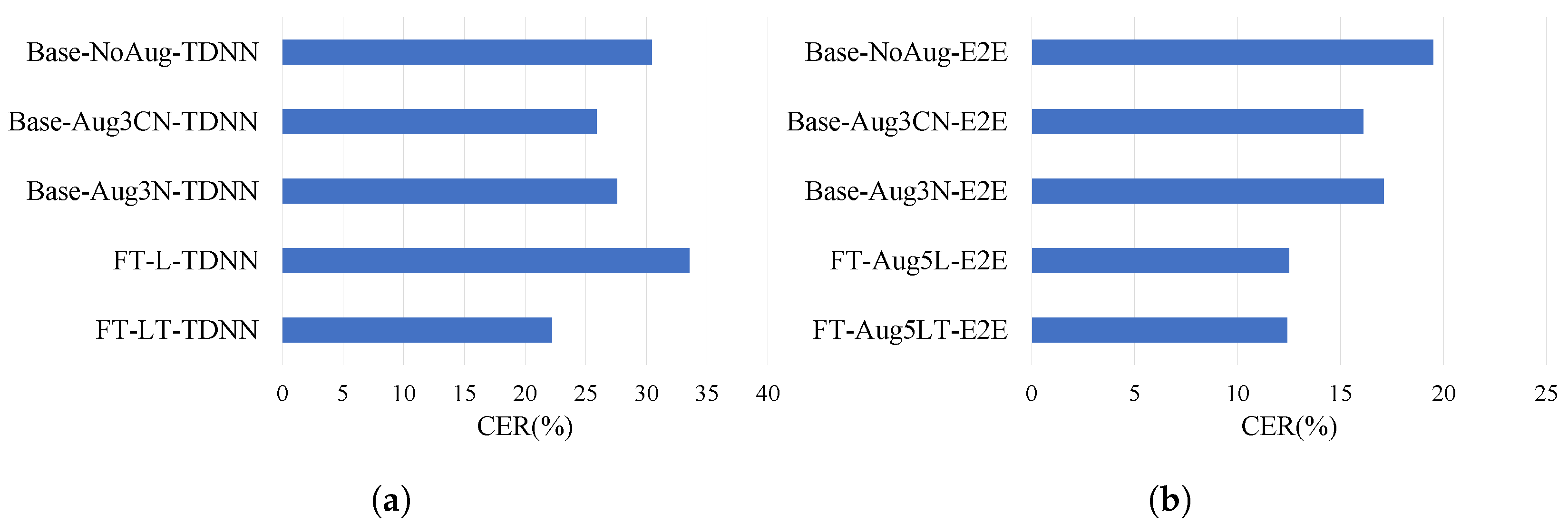{kind=link}
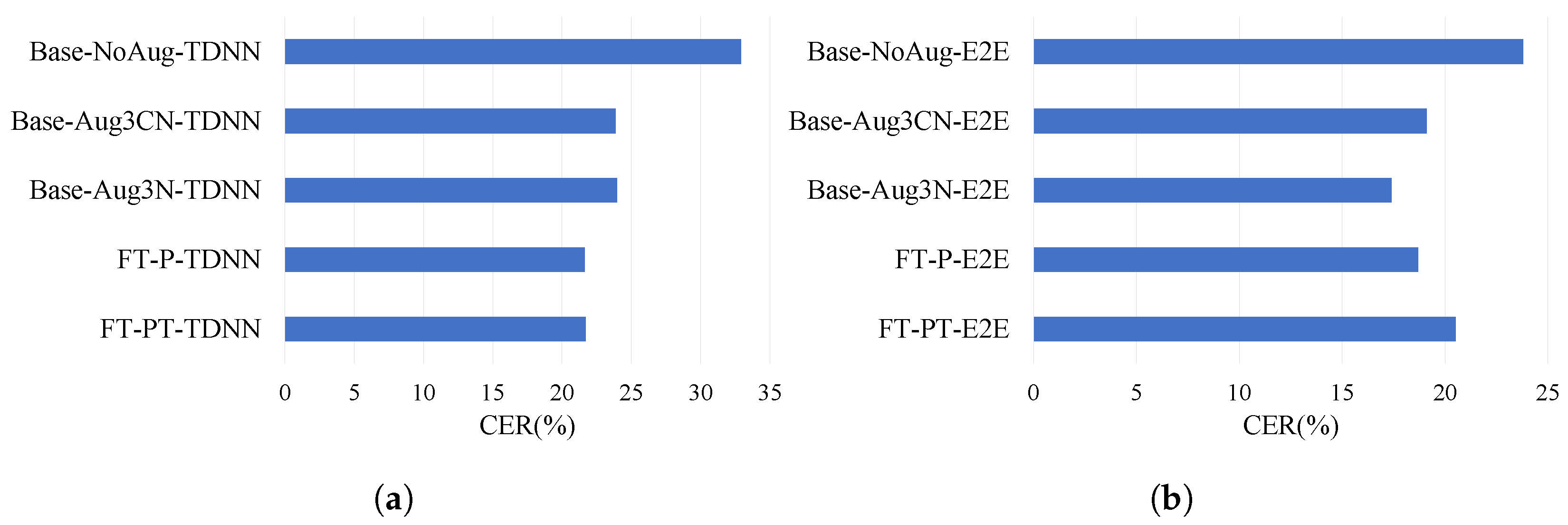{kind=link}
{kind=link}
{kind=link}
| Re-Recorded Dataset | Recording Device (mic) | Channel | |
|---|---|---|---|
| Caller | Receiver | ||
| Landline | Landline | Landline | Landline |
| Mobile 3G | Mobile | SoftBank 3G | SoftBank 3G |
| Mobile LTE | SoftBank LTE | Landline | |
| Classroom | High-quality pin mic | 2.4 GHz digital wireless | |
| ( wireless pin mic) | Low-quality pin mic | 800 MHz analog wireless | |
| Model | Clean | Noisy | Total Size (×233 h) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| -Law Encoding | Speed Pert. | Vol Pert. | Size | -Law Encoding | Speed Pert. | Vol Pert. | Size | ||
| Base-NoAug-ASR | ✓ | - | - | 1 | - | - | - | 0 | 1 |
| Base-Aug3CN-ASR | ✓ | S1 | ✓ | 3 | ✓ | - | - | 1 | 4 |
| Base-Aug3N-ASR | - | - | - | 0 | ✓ | ✓ | ✓ | 3 | 3 |
| Model | Clean (-Law, S1, V) | Noisy (-Law, F) | Re-Recorded (-Law) | Trans. | Total Size (×Seed) | |||
|---|---|---|---|---|---|---|---|---|
| Size | Size | SP. | Vol. | Size | T | Size | ||
| FT-L-ASR | 3 | 1 | - | - | 1 | - | 0 | 5 |
| FT-LT-ASR | 3 | 1 | - | - | 1 | ✓ | 1 | 6 |
| FT-Aug3L-ASR | 3 | 1 | S1 | ✓ | 3 | - | 0 | 7 |
| FT-Aug3LT-ASR | 3 | 1 | S1 | ✓ | 3 | ✓ | 1 | 8 |
| FT-Aug5L-ASR | 3 | 1 | S2 | ✓ | 5 | - | 0 | 9 |
| FT-Aug5LT-ASR | 3 | 1 | S2 | ✓ | 5 | ✓ | 1 | 10 |
| FT-P-ASR (no -law & F) | 3 | 1 | - | - | 1 | - | 0 | 5 |
| FT-PT-ASR (no -law & F) | 3 | 1 | - | - | 1 | ✓ | 1 | 6 |
| Model | -Law Encoding | Test Dataset (CSJ eval1) | |||
|---|---|---|---|---|---|
| Clean | Re-Recorded | ||||
| Landline | Mobile 3G | Mobile LTE | |||
| Base-NoAug-TDNN | × | 9.5 | 11.1 | 24.4 | 31.5 |
| Base-NoAug-TDNN | ✓ | 9.4 | 11.0 | 23.6 | 30.6 |
| Base-NoAug-E2E | × | 6.2 | 6.8 | 15.3 | 20.6 |
| Base-NoAug-E2E | ✓ | 6.3 | 7.0 | 14.4 | 19.5 |
| Model | Data Size for Training/ Adaptation (Seed) (h) | Test Dataset (CSJ eval1) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Clean | Re-Recorded | ||||||||
| Landline | Mobile 3G | Mobile LTE | |||||||
| CER | CERR | CER | CERR | CER | CERR | CER | CERR | ||
| Base-NoAug-TDNN | 233 (233) | 9.4 | - | 11.0 | - | 23.6 | - | 30.4 | - |
| Base-Aug3CN-TDNN | 933 (233) | 8.8 | 6.2 | 9.7 | 11.5 | 18.5 | 21.6 | 25.9 | 27.8 |
| Base-Aug3N-TDNN | 700 (233) | 9.6 | −1.8 | 9.9 | 10.2 | 17.1 | 27.8 | 27.6 | 9.4 |
| FT-L-TDNN | 7.5 (1.5) | - | - | - | - | - | - | 33.6 | −10.2 |
| FT-LT-TDNN | 9 (1.5) | - | - | - | - | - | - | 22.2 | 27.0 |
| FT-Aug3L-TDNN | 10.5 (1.5) | - | - | - | - | - | - | 30.8 | −1.1 |
| FT-Aug3LT-TDNN | 12 (1.5) | - | - | - | - | - | - | 28.1 | 7.6 |
| FT-Aug5L-TDNN | 13.5 (1.5) | - | - | - | - | - | - | 30.9 | −1.5 |
| FT-Aug5LT-TDNN | 15 (1.5) | - | - | - | - | - | - | 28.2 | 7.5 |
| Model | Data Size for Training/ Adaptation (Seed) (h) | Test Dataset (CSJ eval1) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Clean | Re-Recorded | ||||||||
| Landline | Mobile 3G | Mobile LTE | |||||||
| CER | CERR | CER | CERR | CER | CERR | CER | CERR | ||
| Base-NoAug-E2E | 233 (233) | 6.3 | - | 7.0 | - | 14.4 | - | 19.5 | - |
| Base-Aug3CN-E2E | 933 (233) | 5.8 | 6.2 | 6.2 | 11.5 | 11.7 | 18.8 | 16.1 | 15.1 |
| Base-Aug3N-E2E | 700 (233) | 6.5 | −3.2 | 6.7 | −4.5 | 11.5 | 20.1 | 17.1 | 12.3 |
| FT-L-E2E | 7.5 (1.5) | - | - | - | - | - | - | 13.7 | 29.7 |
| FT-LT-E2E | 9 (1.5) | - | - | - | - | - | - | 13.9 | 28.7 |
| FT-Aug3L-E2E | 10.5 (1.5) | - | - | - | - | - | - | 13.0 | 33.3 |
| FT-Aug3LT-E2E | 12 (1.5) | - | - | - | - | - | - | 12.8 | 34.4 |
| FT-Aug5L-E2E | 13.5 (1.5) | - | - | - | - | - | - | 12.5 | 35.9 |
| FT-Aug5LT-E2E | 15 (1.5) | - | - | - | - | - | - | 12.4 | 36.4 |
| Model | Data Size for Training/ Adaptation (Seed) (h) | Test Dataset (CSJ eval3) | |||
|---|---|---|---|---|---|
| Clean | Re-Recorded | ||||
| Wireless pin mic | |||||
| CER | CERR | CER | CERR | ||
| Base-NoAug-TDNN | 233 (233) | 10.6 | - | 30.8 | - |
| Base-Aug3CN-TDNN | 933 (233) | 10.1 | 6.2 | 22.1 | 2.8 |
| Base-Aug3N-TDNN | 700 (233) | 11.2 | -9.4 | 22.5 | 26.7 |
| FT-P-TDNN | 6 (1.2) | - | - | 21.6 | 29.7 |
| FT-PT-TDNN | ≈7 (1.2) | - | - | 21.7 | 29.4 |
| Model | Data Size for Training/ Adaptation (Seed) (h) | Test Dataset (CSJ eval3) | |||
|---|---|---|---|---|---|
| Clean | Re-Recorded | ||||
| Wireless pin mic | |||||
| CER | CERR | CER | CERR | ||
| Base-NoAug-E2E | 233 (233) | 10.8 | - | 23.8 | - |
| Base-Aug3CN-E2E | 933 (233) | 10.0 | 7.4 | 19.1 | 19.7 |
| Base-Aug3N-E2E | 700 (233) | 11.4 | -5.3 | 17.4 | 26.9 |
| FT-P-E2E | 6 (1.2) | - | - | 18.7 | 21.4 |
| FT-PT-E2E | ≈7 (1.2) | - | - | 20.5 | 13.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nahar, R.; Miwa, S.; Kai, A. Domain Adaptation with Augmented Data by Deep Neural Network Based Method Using Re-Recorded Speech for Automatic Speech Recognition in Real Environment. Sensors 2022, 22, 9945. https://doi.org/10.3390/s22249945
Nahar R, Miwa S, Kai A. Domain Adaptation with Augmented Data by Deep Neural Network Based Method Using Re-Recorded Speech for Automatic Speech Recognition in Real Environment. Sensors. 2022; 22(24):9945. https://doi.org/10.3390/s22249945
Chicago/Turabian StyleNahar, Raufun, Shogo Miwa, and Atsuhiko Kai. 2022. "Domain Adaptation with Augmented Data by Deep Neural Network Based Method Using Re-Recorded Speech for Automatic Speech Recognition in Real Environment" Sensors 22, no. 24: 9945. https://doi.org/10.3390/s22249945
APA StyleNahar, R., Miwa, S., & Kai, A. (2022). Domain Adaptation with Augmented Data by Deep Neural Network Based Method Using Re-Recorded Speech for Automatic Speech Recognition in Real Environment. Sensors, 22(24), 9945. https://doi.org/10.3390/s22249945