
An Efficient End-to-End Multitask Network Architecture for Defect Inspection



Abstract
1. Introduction
- Low contrast, as shown in Figure 1a. Influenced by dust, metal surface reflection, etc., defects in the image have low contrast to the background.
- Intra-class difference, as shown in Figure 1b. As a result of the inhomogeneity of the production process, the measurement, silhouette, and other characteristics of similar defects are quite different.
- Small sample size. Because defects are not common in actual production, and fine annotation requires a lot of labor, data collection and annotation are very expensive in defect detection.
- Image-level defect classification: classify images according to defect types.
- Object-level defect detection: identify each defect on the image and label its rough range.
- Pixel-level defect segmentation: classify each pixel of the image and accurately segment defects.
- The single-stage detection network is faster and easier to meet the real-time performance than the two-stage detection network;
- Compared with the two-stage detection network, the single-stage detection network has better encoder optimization, which can give the segmented decoder better performance.
- An efficient multi-task network is proposed, which combines the advantages of both methods while saving computational costs. It achieves the best overall performance. This proves that the method has certain generality and theoretical value.
- A DDWASPP module is proposed, which is used to extract dense multi-scale features. Compared with other multi-scale feature extraction methods, this module has a significant computational advantage.
- A resDWAB module is proposed, which is used to reinforce the spatial information of the encoder’s low-level feature maps, ensuring that it can provide useful information for the final prediction. Experiments show that this method can significantly improve segmentation performance with low computation.
- A training strategy is investigated. Adopting the strategy of training the segmentation task first can improve the performance of the model, which is believed to provide a reference for other related research work.
2. Related Work
3. Methodology
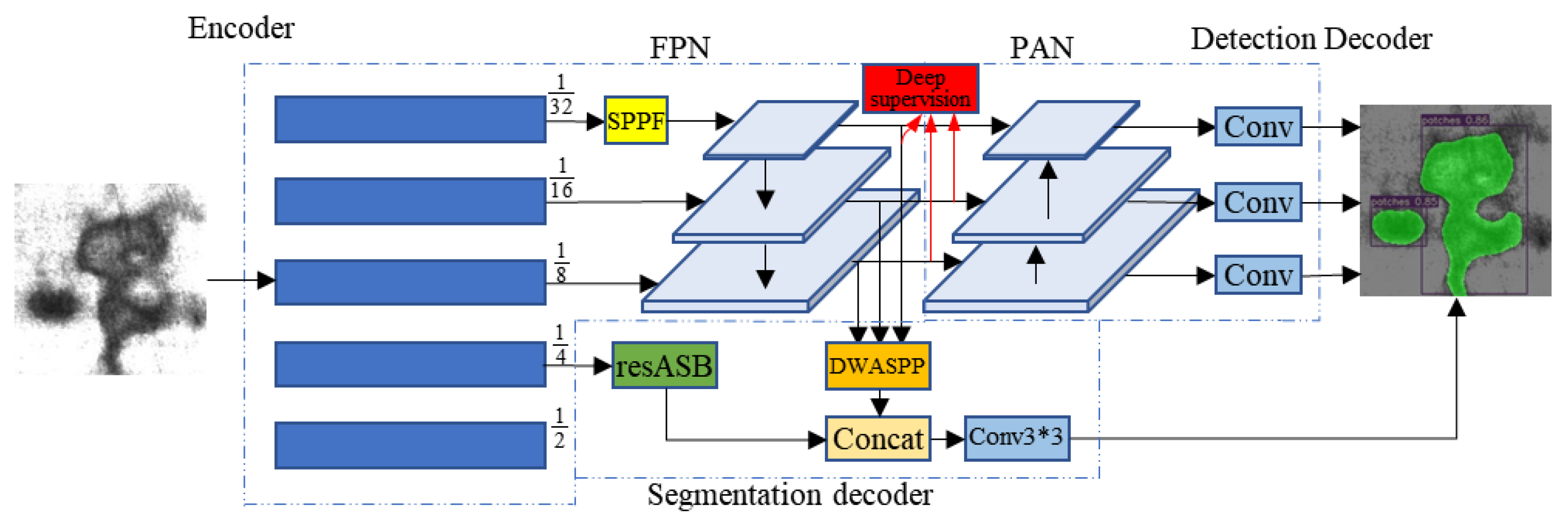
3.1. Model Structure
3.2. Object Detection Decoder
3.3. Semantic Segmentation Decoder
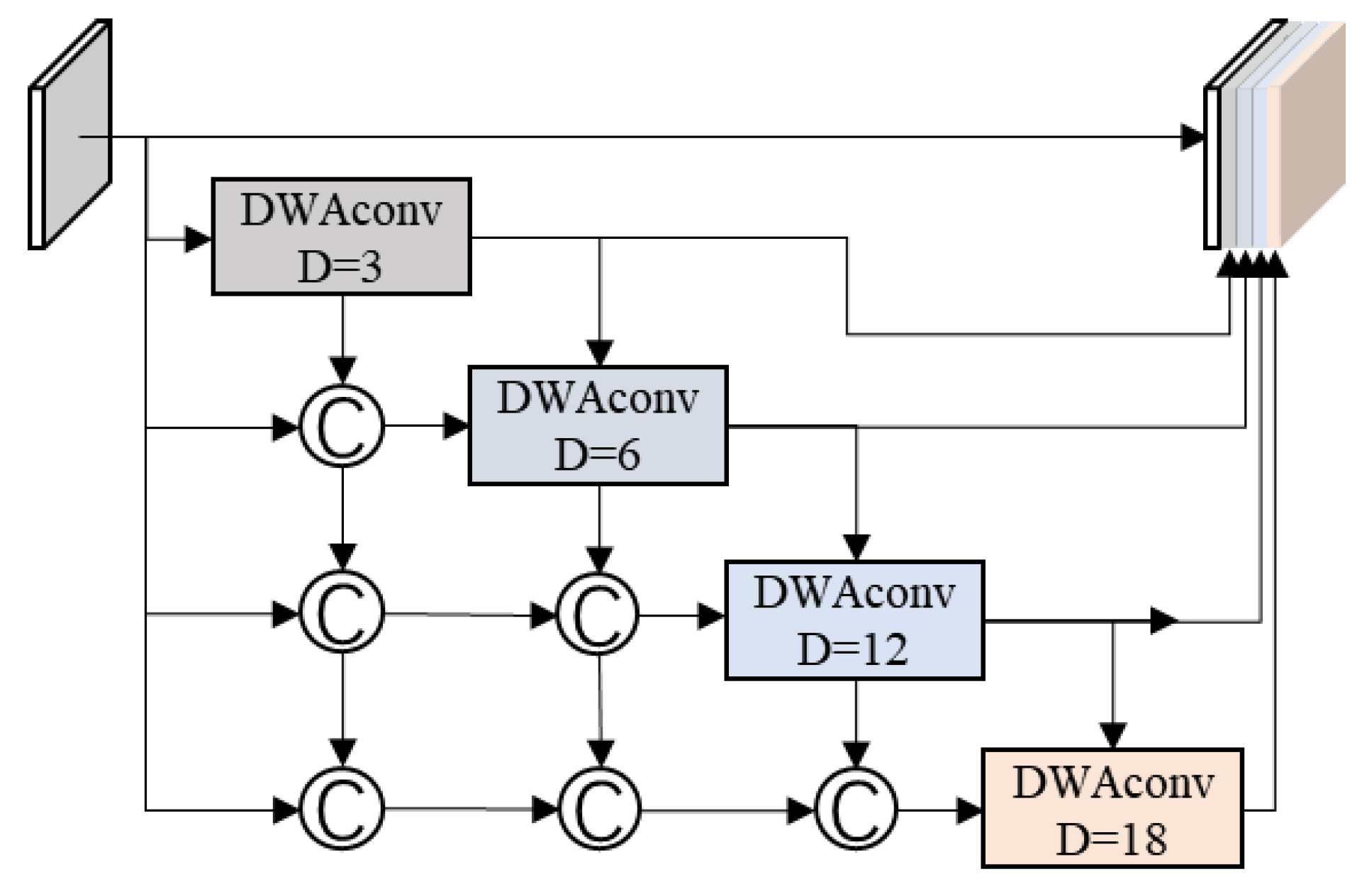
3.3.1. Densely Connected Depthwise Separable Atrous Spatial Pyramid Pooling Module
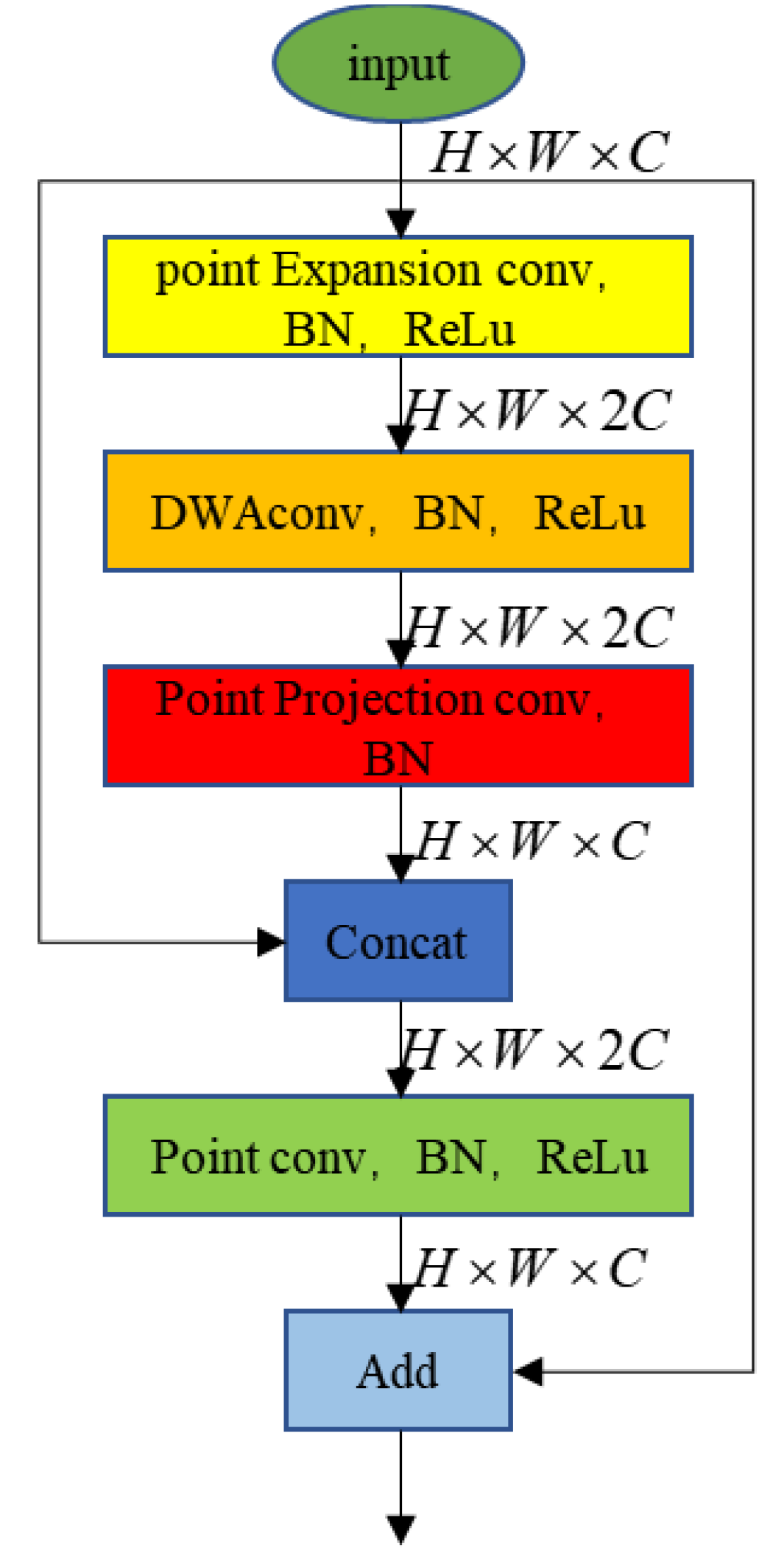
3.3.2. Residually Connected Depthwise Separable Atrous Convolutional Blocks
3.3.3. Deep Supervision
4. Loss Function and Evaluation Metrics
4.1. Loss Function
4.2. Evaluation Method
5. Experimental and Results
5.1. Dataset
5.2. Training Environment Parameters
5.3. Training Strategy
5.3.1. Training Method
5.3.2. Loss of Weight
5.4. Ablation Experiment
5.5. Comparative Experiments and Discussion of Results
5.5.1. Comparative Test
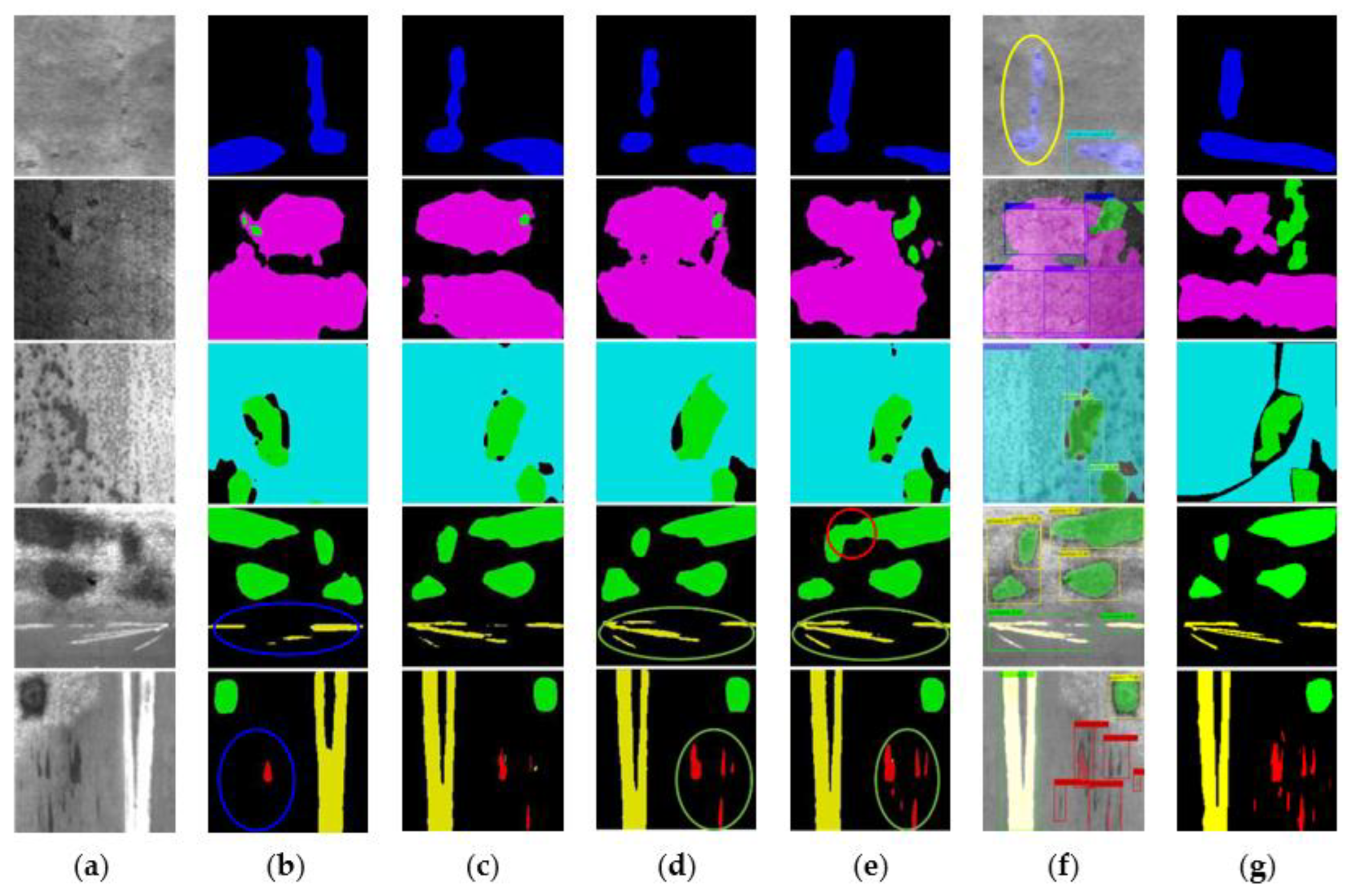
5.5.2. Failure Case Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S.; Zhang, Q.; Gu, J.; Su, L.; Li, K.; Pecht, M. Visual inspection of steel surface defects based on domain adaptation and adaptive convolutional neural network. Mech. Syst. Signal Process. 2021, 153, 107541. [Google Scholar] [CrossRef]
- Xing, F.; Xie, Y.; Su, H.; Liu, F.; Yang, L. Deep learning in microscopy image analysis: A Survey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 4550–4568. [Google Scholar] [CrossRef] [PubMed]
- Zhong, K.; Zhou, G.; Deng, W.; Zhou, Y.; Luo, Q. MOMPA: Multi-objective marine predator algorithm. Comput. Methods Appl. Mech. Eng. 2021, 385, 114029. [Google Scholar] [CrossRef]
- Huang, C.; Zhou, X.; Ran, X.J.; Liu, Y.; Deng, W.Q.; Deng, W. Co-evolutionary competitive swarm optimizer with three-phase for large-scale complex optimization problem. Inf. Sci. 2022. [Google Scholar] [CrossRef]
- Jin, T.; Xia, H.; Deng, W.; Li, Y.; Chen, H. Uncertain Fractional-Order Multi-Objective Optimization Based on Reliability Analysis and Application to Fractional-Order Circuit with Caputo Type. Circuits Syst. Signal Process. 2021, 40, 5955–5982. [Google Scholar] [CrossRef]
- Deng, W.; Zhang, L.; Zhou, X.; Zhou, Y.; Sun, Y.; Zhu, W.; Chen, H.; Deng, W.; Chen, H.; Zhao, H. Multi-strategy particle swarm and ant colony hybrid optimization for airport taxiway planning problem. Inf. Sci. 2022, 612, 576–593. [Google Scholar] [CrossRef]
- Wei, Y.Y.; Zhou, Y.Q.; Luo, Q.F.; Deng, W. Optimal reactive power dispatch using an improved slime Mould algorithm. Energy Rep. 2021, 7, 8742–8759. [Google Scholar] [CrossRef]
- Li, T.; Qian, Z.; Deng, W.; Zhang, D.Z.; Lu, H.; Wang, S. Forecasting crude oil prices based on variational mode decomposition and random sparse Bayesian learning. Appl. Soft Comput. 2021, 113, 108032. [Google Scholar] [CrossRef]
- Song, Y.; Cai, X.; Zhou, X.; Zhang, B.; Chen, H.; Li, Y.; Deng, W.; Deng, W. Dynamic hybrid mechanism-based differential evolution algorithm and its application. Expert Syst. Appl. 2022, 213, 118834. [Google Scholar] [CrossRef]
- Zhao, H.; Liu, J.; Chen, H.; Chen, J.; Li, Y.; Xu, J.; Deng, W. Intelligent Diagnosis Using Continuous Wavelet Transform and Gauss Convolutional Deep Belief Network. IEEE Trans. Reliab. 2022. [Google Scholar] [CrossRef]
- Zhou, X.; Ma, H.; Gu, J.; Chen, H.; Deng, W. Parameter adaptation-based ant colony optimization with dynamic hybrid mechanism. Eng. Appl. Artif. Intell. 2022, 114, 105139. [Google Scholar] [CrossRef]
- Chen, H.; Miao, F.; Chen, Y.; Xiong, Y.; Chen, T. A Hyperspectral Image Classification Method Using Multifeature Vectors and Optimized KELM. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2781–2795. [Google Scholar] [CrossRef]
- Jin, T.; Zhu, Y.; Shu, Y.; Cao, J.; Yan, H.; Jiang, D. Uncertain optimal control problem with the first hitting time objective and application to a portfolio selection model. J. Intell. Fuzzy Syst. 2022. [Google Scholar] [CrossRef]
- Deng, W.; Ni, H.; Liu, Y.; Chen, H.; Zhao, H. An adaptive differential evolution algorithm based on belief space and generalized opposition-based learning for resource allocation. Appl. Soft Comput. 2022, 127, 109419. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, H.; Du, C.; Fan, X.; Cui, L.; Chen, H.; Deng, F.; Tong, Q.; He, M.; Yang, M.; et al. Custom-molded offloading footwear effectively prevents recurrence and amputation, and lowers mortality rates in high-risk diabetic foot patients: A multicenter, prospective observational study. Diabetes Metab. Syndr. Obes. Targets Ther. 2022, 15, 103–109. [Google Scholar] [CrossRef]
- Yao, R.; Guo, C.; Deng, W.; Zhao, H. A novel mathematical morphology spectrum entropy based on scale-adaptive techniques. ISA Trans. 2022, 126, 691–702. [Google Scholar] [CrossRef]
- He, Z.Y.; Shao, H.D.; Wang, P.; Janet, L.; Cheng, J.S.; Yang, Y. Deep transfer multi-wavelet auto-encoder for intelligent fault diagnosis of gearbox with few target training samples. Knowl.-Based Syst. 2020, 191, 105313. [Google Scholar] [CrossRef]
- Bi, J.; Zhou, G.; Zhou, Y.; Luo, Q.; Deng, W. Artificial Electric Field Algorithm with Greedy State Transition Strategy for Spherical Multiple Traveling Salesmen Problem. Int. J. Comput. Intell. Syst. 2022, 15, 5. [Google Scholar] [CrossRef]
- Li, W.; Zhong, X.; Shao, H.; Cai, B.; Yang, X. Multi-mode data augmentation and fault diagnosis of rotating machinery using modified ACGAN designed with new framework. Adv. Eng. Inform. 2022, 52, 101552. [Google Scholar] [CrossRef]
- Zhao, H.M.; Zhang, P.P.; Zhang, R.C.; Yao, R.; Deng, W. A novel performance trend prediction approach using ENBLS with GWO. Meas. Sci. Technol. 2023, 34, 025018. [Google Scholar] [CrossRef]
- Ren, Z.; Han, X.; Yu, X.; Skjetne, R.; Leira, B.J.; Sævik, S.; Zhu, M. Data-driven simultaneous identification of the 6DOF dynamic model and wave load for a ship in waves. Mech. Syst. Signal Process. 2023, 184, 109422. [Google Scholar] [CrossRef]
- Jin, T.; Gao, S.; Xia, H.; Ding, H. Reliability analysis for the fractional-order circuit system subject to the uncertain random fractional-order model with Caputo type. J. Adv. Res. 2021, 32, 15–26. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Xu, J.J.; Gao, X.Z.; Zhao, H.M. An enhanced MSIQDE algorithm with novel multiple strategies for global optimization problems. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 1578–1587. [Google Scholar] [CrossRef]
- Zhang, Z.; Huang, W.G.; Liao, Y.; Song, Z.; Shi, J.; Jiang, X.; Shen, C.; Zhu, Z. Bearing fault diagnosis via generalized logarithm sparse regularization. Mech. Syst. Signal Process. 2022, 167, 108576. [Google Scholar] [CrossRef]
- Yu, Y.; Hao, Z.; Li, G.; Liu, Y.; Yang, R.; Liu, H. Optimal search mapping among sensors in heterogeneous smart homes. Math. Biosci. Eng. 2023, 20, 1960–1980. [Google Scholar] [CrossRef]
- Xu, G.; Dong, W.; Xing, J.; Lei, W.; Liu, J.; Gong, L.; Feng, M.; Zheng, X.; Liu, S. Delay-CJ: A novel cryptojacking covert attack method based on delayed strategy and its detection. Digit. Commun. Netw. 2022. [Google Scholar] [CrossRef]
- Chen, H.Y.; Fang, M.; Xu, S. Hyperspectral remote sensing image classification with CNN based on quantum genetic-optimized sparse representation. IEEE Access 2020, 8, 99900–99909. [Google Scholar] [CrossRef]
- Zhao, H.M.; Zhang, P.P.; Chen, B.J.; Chen, H.Y.; Deng, W. Bearing fault diagnosis using transfer learning and optimized deep belief network. Meas. Sci. Technol. 2022, 33, 065009. [Google Scholar] [CrossRef]
- Xu, G.; Bai, H.; Xing, J.; Luo, T.; Xiong, N.N. SG-PBFT: A secure and highly efficient distributed blockchain PBFT consensus algorithm for intelligent Internet of vehicles. J. Parallel Distrib. Comput. 2022, 164, 1–11. [Google Scholar] [CrossRef]
- Li, X.; Zhao, H.; Yu, L.; Chen, H.; Deng, W.; Deng, W. Feature extraction using parameterized multi-synchrosqueezing transform. IEEE Sens. J. 2022, 22, 14263–14272. [Google Scholar] [CrossRef]
- Li, T.Y.; Shi, J.Y.; Deng, W.; Hu, Z.D. Pyramid particle swarm optimization with novel strategies of competition and cooperation. Appl. Soft Comput. 2022, 121, 108731. [Google Scholar] [CrossRef]
- Yu, C.; Liu, C.; Yu, H.; Song, M.; Chang, C.I. Unsupervised domain adaptation with dense-based compaction for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 12287–12299. [Google Scholar] [CrossRef]
- Jin, T.; Yang, X. Monotonicity theorem for the uncertain fractional differential equation and application to uncertain financial market. Math. Comput. Simul. 2021, 190, 203–221. [Google Scholar] [CrossRef]
- Deng, W.; Li, Z.; Li, X.; Chen, H.; Zhao, H. Compound fault diagnosis using optimized MCKD and sparse representation for rolling bearings. IEEE Trans. Instrum. Meas. 2022, 71, 1–9. [Google Scholar] [CrossRef]
- Hao, R.; Lu, B.; Cheng, Y.; Li, X.; Huang, B. A steel surface defect inspection approach towards smart industrial monitoring. J. Intell. Manuf. 2021, 32, 1833–1843. [Google Scholar] [CrossRef]
- Yu, C.; Zhou, S.; Song, M.; Chang, C.-I. Semisupervised Hyperspectral Band Selection Based on Dual-Constrained Low-Rank Representation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 5503005. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wu, D.; Liao, M.; Zhang, W.; Wang, X. Yolop: You only look once for panoptic driving perception. arXiv 2021, arXiv:2108.11250. [Google Scholar] [CrossRef]
- Kang, Z.; Grauman, K.; Sha, F. Learning with whom to share in multi-task feature learning. In Proceedings of the The 28th International Conference on Machine Learning, Bellevue, WA, USA, 28 June 28–2 July 2011. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE conference on computer vision and pattern recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Yang, M.; Yu, K.; Zhang, C.; Li, Z.; Yang, K. Denseaspp for semantic segmentation in street scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3684–3692. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Song, K.; Yan, Y. A noise robust method based on completed local binary patterns for hot-rolled steel strip surface defects. Appl. Surf. Sci. 2013, 285, 858–864. [Google Scholar] [CrossRef]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. Multinet: Real-time joint semantic reasoning for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1013–1020. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards realtime object detection with region proposal networks. In Advances in Neural Information Processing Systems 28, Proceedings of the 29th Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: New York, NY, USA, 2016. [Google Scholar]
- Huang, W.; Song, Z.; Zhang, C.; Wang, J.; Shi, J.; Jiang, X.; Zhu, Z. Multi-source Fidelity Sparse Representation via Convex Optimization for Gearbox Compound Fault Diagnosis. J. Sound Vib. 2021, 496, 115879. [Google Scholar] [CrossRef]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; NanoCode012; Kwon, Y.; Xie, T.; Fang, J.; imyhxy; Michael, K.; et al. Ultralytics/yolov5: v6.1—TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference. 2022. Available online: https://doi.org/10.5281/zenodo.6222936 (accessed on 12 October 2021).
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 2020, 111, 300–323. [Google Scholar] [CrossRef]
- Li, N.; Huang, W.; Guo, W.; Gao, G.; Zhu, Z. Multiple Enhanced Sparse Decomposition for gearbox compound fault diagnosis. IEEE Trans. Instrum. Meas. 2020, 69, 770–781. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Future Generation Computer Systems-the International. J. Escience 2019, 97, 849–872. [Google Scholar]
- Luo, W.; Li, Y.; Urtasun, R.; Zemel, R. Understanding the effective receptive field in deep convolutional neural networks. In Advances in Neural Information Processing Systems 29, Proceedings of the 30th Annual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; Curran Associates, Inc.: New York, NY, USA, 2017. [Google Scholar]
- Nana, K.G.; Girma, A.; Mahmoud, M.N.; Nateghi, S.; Homaifar, A.; Opoku, D. A Robust Completed Local Binary Pattern (RCLBP) for Surface Defect Detection. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 1927–1934. [Google Scholar]
- Moe, W.; Bushroa, A.R.; Hassan, M.A.; Hilman, N.M.; Ide-Ektessabi, A. A Contrast Adjustment Thresholding Method for Surface Defect Detection Based on Mesoscopy. IEEE Trans. Ind. Inform. 2015, 11, 642–649. [Google Scholar]
- Ni, X.; Liu, H.; Ma, Z.; Wang, C.; Liu, J. Detection for Rail Surface Defects via Partitioned Edge Feature. IEEE Trans. Intell. Transp. Syst. 2022, 23, 5806–5822. [Google Scholar] [CrossRef]
- Gan, J.; Wang, J.; Yu, H.; Li, Q.; Shi, Z. Online Rail Surface Inspection Utilizing Spatial Consistency and Continuity. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 2741–2751. [Google Scholar] [CrossRef]
- Li, Y.; Li, J. An End-to-End Defect Detection Method for Mobile Phone Light Guide Plate via Multitask Learning. IEEE Trans. Instrum. Meas. 2021, 70, 2505513. [Google Scholar] [CrossRef]
- Xu, L.; Tian, G.; Zhang, L.; Zheng, X. Research of Surface Defect Detection Method of Hot Rolled Strip Steel Based on Generative Adversarial Network. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 401–404. [Google Scholar]
- He, Y.; Song, K.; Meng, Q.; Yan, Y. An end-to-end steel surface defect detection approach via fusing multiple hierarchical features. IEEE Trans. Instrum. Meas. 2019, 69, 1493–1504. [Google Scholar] [CrossRef]
- Zhang, H.; Song, Y.; Chen, Y.; Zhong, H.; Liu, L.; Wang, Y.; Akilan, T.; Wu, Q.J. MRSDI-CNN: Multi-Model Rail Surface Defect Inspection System Based on Convolutional Neural Networks. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11162–11177. [Google Scholar] [CrossRef]
- Tao, X.; Zhang, D.; Singh, A.K.; Prasad, M.; Lin, C.-T.; Xu, D. Weak Scratch Detection of Optical Components Using Attention Fusion Network. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 855–862. [Google Scholar]
- Dong, H.; Song, K.; He, Y.; Xu, J.; Yan, Y.; Meng, Q. Pga-net: Pyramid feature fusion and global context attention network for automated surface defect detection. IEEE Trans. Ind. Inform. 2019, 16, 7448–7458. [Google Scholar] [CrossRef]
- Zheng, Z.; Hu, Y.; Zhang, Y.; Yang, H.; Qiao, Y.; Qu, Z.; Huang, Y. Casppnet: A chained atrous spatial pyramid pooling network for steel defect detection. Meas. Sci. Technol. 2022, 33, 085403. [Google Scholar] [CrossRef]
- Zhang, Z.; Yu, S.; Yang, S.; Zhou, Y.; Zhao, B. Rail-5k: A real-world dataset for rail surface defects detection. arXiv 2021, arXiv:2106.14366. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mIOU | mAP@0.5 |
|---|---|---|
| end-to-end training | 79.21 | 77.33 |
| rotation training | 78.85 | 77.46 |
| first-train detection | 78.79 | 77.21 |
| train the segmentation first | 79.51 | 77.52 |
| mIOU | mAP | |
|---|---|---|
| 1 | 2.3 | 77.69 |
| 0.9 | 73.25 | 79.62 |
| 0.8 | 75.53 | 79.12 |
| 0.7 | 78.91 | 78.47 |
| 0.6 | 79.37 | 78.38 |
| 0.5 | 79.51 | 77.52 |
| 0.4 | 79.18 | 74.37 |
| 0.2 | 78.90 | 67.83 |
| 0.1 | 78.81 | 63.62 |
| 0 | 78.75 | 0.2 |
| Method | mIOU |
|---|---|
| Baseline | 76.51 |
| Baseline + Aspp | 77.13 |
| Baseline + DenseAspp | 78.57 |
| Baseline + DWAspp | 77.68 |
| Baseline + U-shape decoder | 73.82 |
| Baseline + v3plus decoder | 74.63 |
| Baseline + Aspp + v3plus decoder | 75.37 |
| Baseline + DWAspp + v3plus decoder | 75.84 |
| Method | mIOU |
|---|---|
| Baseline + resDWAB × 1 | 77.52 |
| Baseline + resDWAB × 2 | 78.34 |
| Baseline + resDWAB × 3 | 78.98 |
| Baseline + resDWAB × 4 | 79.37 |
| Baseline + resDWAB × 5 | 79.42 |
| Method | mIOU | Ba | In | Pa | Sc | Cr | Ri | Pt | FPS |
|---|---|---|---|---|---|---|---|---|---|
| Pspnet [41] | 75.76 | 96.03 | 64.48 | 84.07 | 73.22 | 48.11 | 74.59 | 89.83 | 26.6 |
| Unet [40] | 74.62 | 95.75 | 67.21 | 83.36 | 78.51 | 45.32 | 71.73 | 80.43 | 60.1 |
| Hrnet [42] | 75.86 | 96.15 | 69.57 | 84.78 | 79.01 | 49.55 | 71.76 | 80.18 | 24.9 |
| Deeplabv3+ [37] | 77.90 | 96.08 | 67.69 | 83.72 | 77.74 | 58.43 | 75.03 | 86.64 | 65.8 |
| Ours | 79.37 | 96.17 | 69.91 | 85.23 | 78.76 | 61.47 | 74.84 | 89.22 | 85.6 |
| Method | mAP@0.5 | In | Pa | Sc | Cr | Ri | Pt | FPS |
|---|---|---|---|---|---|---|---|---|
| Yolov5s | 77.69 | 81.15 | 96.26 | 87.91 | 52.34 | 65.66 | 82.83 | 160.5 |
| Faster-RCNN [64] | 66.12 | 72.41 | 77.77 | 84.43 | 31.46 | 58.91 | 71.48 | 10.2 |
| He [64] | 82.31 | 84.7 | 90.7 | 90.1 | 62.4 | 76.3 | 89.7 | 6.25 |
| Hao [35] | 80.38 | 85.55 | 93.01 | 88.26 | 61.39 | 63.75 | 90.33 | 43.5 |
| Ours | 78.38 | 81.58 | 91.93 | 88.75 | 50.17 | 71.80 | 86.06 | 85.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Yang, H.; Ma, J.; Chen, H. An Efficient End-to-End Multitask Network Architecture for Defect Inspection. Sensors 2022, 22, 9845. https://doi.org/10.3390/s22249845
Zhang C, Yang H, Ma J, Chen H. An Efficient End-to-End Multitask Network Architecture for Defect Inspection. Sensors. 2022; 22(24):9845. https://doi.org/10.3390/s22249845
Chicago/Turabian StyleZhang, Chunguang, Heqiu Yang, Jun Ma, and Huayue Chen. 2022. "An Efficient End-to-End Multitask Network Architecture for Defect Inspection" Sensors 22, no. 24: 9845. https://doi.org/10.3390/s22249845
APA StyleZhang, C., Yang, H., Ma, J., & Chen, H. (2022). An Efficient End-to-End Multitask Network Architecture for Defect Inspection. Sensors, 22(24), 9845. https://doi.org/10.3390/s22249845