1. Introduction
The construction site environment is complex; objects, as well as operators may fall from a height at any time. Injuries due to accidents can be effectively decreased by wearing safety helmets. However, tragedies resulting from inadequate supervision of the construction system and insufficient safety awareness of the workers occasionally occur. Therefore, supervising the wearing of safety helmets through a helmet wearing detection algorithm has high practical value.
The early studies primarily used manual feature extraction to detect the wearing of helmets. The mainstream research idea is to locate the position of the pedestrian using the HOG feature, C4 algorithm, and other methods [
1,
2,
3,
4] and then identify the characteristics of the helmet in the head area, such as the color, contour, and texture [
5,
6,
7]. Finally, SVM and other classifiers were used to complete helmet detection [
8,
9].
Figure 1 shows the four main implementation steps of this kind of algorithm: pre-processing, Region Of Interest (ROI) selection, feature extraction and detection or classification. Because of the simple structure of the algorithm, the traditional algorithm has less computational requirements and a faster detection speed.
However, there is still a gap between the detection effect of the traditional algorithm and the practical application requirement of high precision. The effectiveness of helmet wearing detection is poor under the traditional algorithm, especially when the frames are under the influence of illumination and angle variability. Convolutional neural networks are frequently employed in target detection in various disciplines [
10] due to their great feature extraction capabilities with the emergence of deep learning methods [
11,
12,
13,
14]. Scholars have successively applied RCNN, fast RCNN, SSD, YOLO, and other algorithms to the research of helmet wearing detection [
15,
16,
17,
18,
19,
20]. Among them, the SSD and YOLO algorithms have higher accuracy as one-stage algorithms, while YOLO has a higher detection rate on this basis, which makes the YOLO algorithm stand out in the research and application of helmet wearing detection [
21,
22,
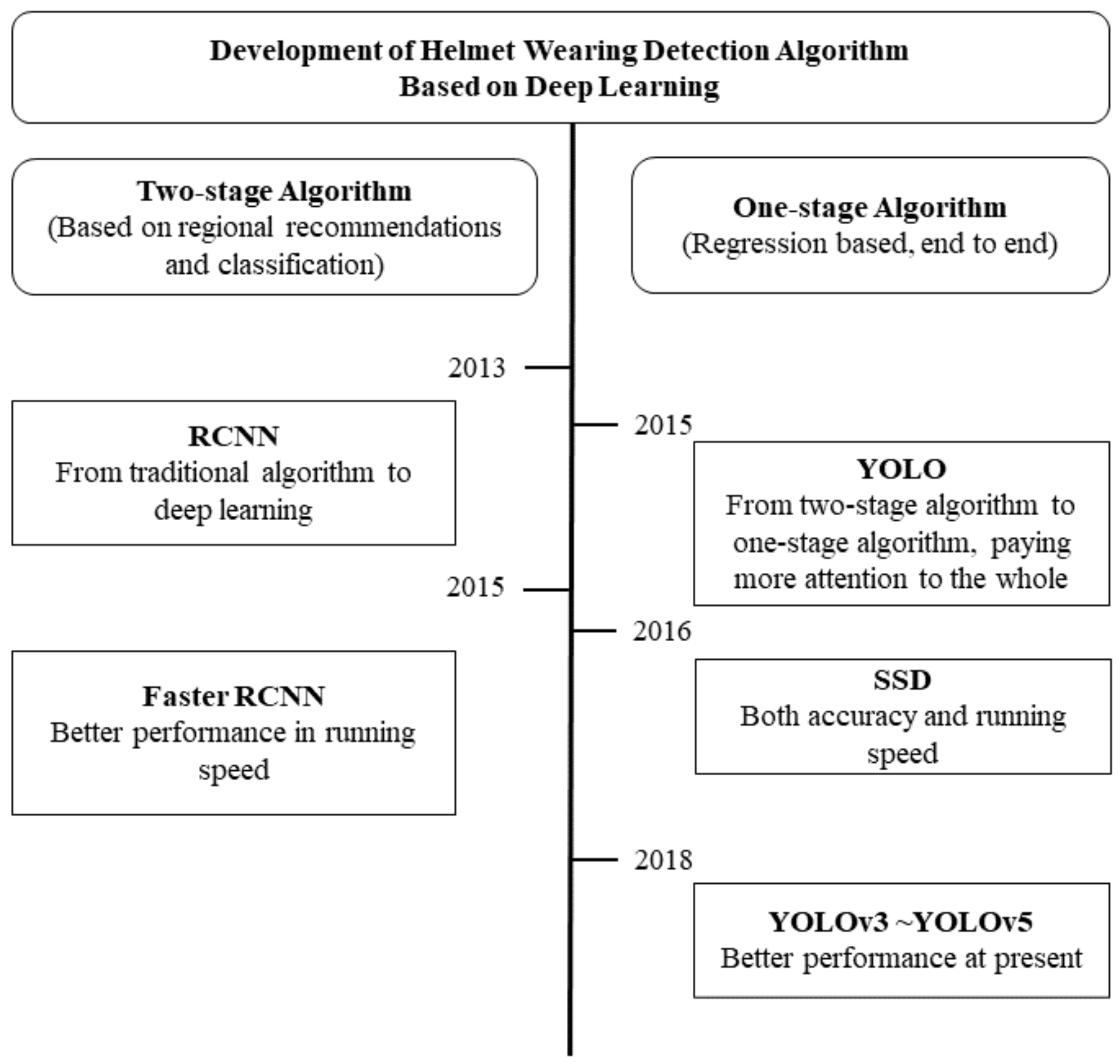
23]. In order to better explain the optimization process of the helmet wearing detection algorithm, we provide
Figure 2.
However, the majority of the YOLO series of algorithms for detecting helmet wearing perform two-class tests on the dataset SHWD, which merely determines whether a helmet is being worn or not. It is difficult for those algorithms to meet the comprehensive helmet wearing state detection under complex conditions, and there is little space for further research.
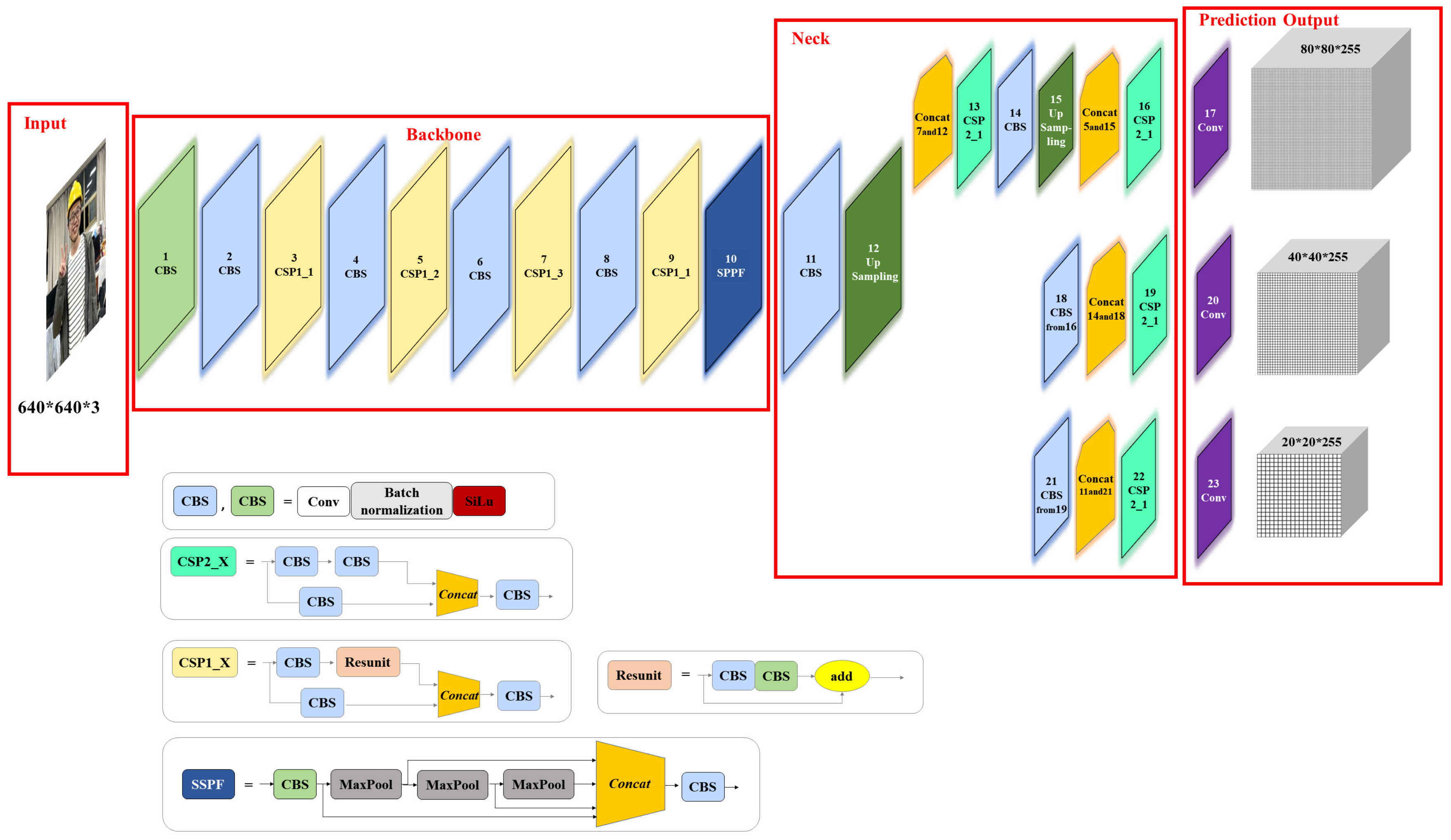
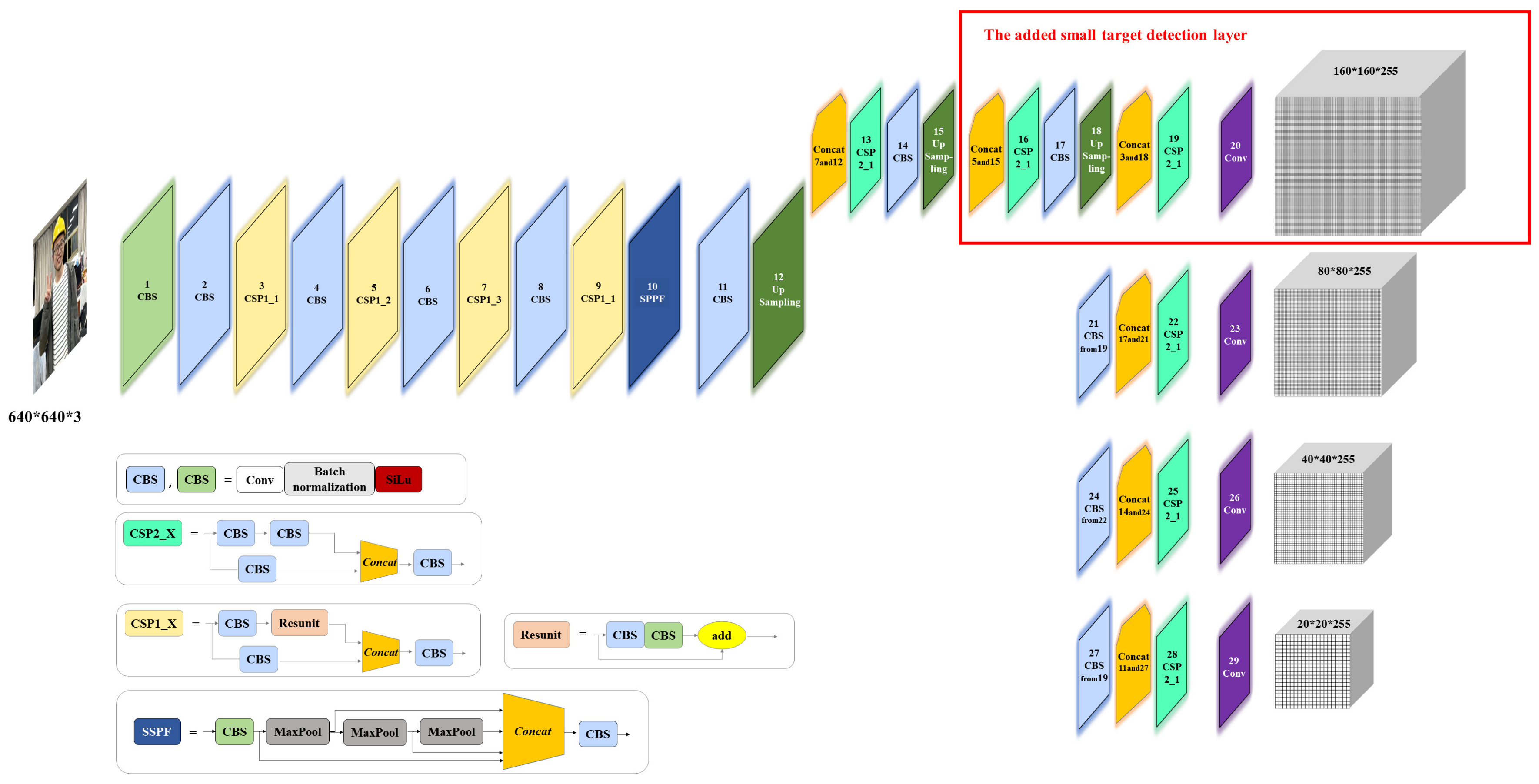
In this paper, an algorithm based on the improved YOLOv5s algorithm is proposed for detecting the wearing states of safety helmets. The specific contributions are as follows: (1) Different from the existing datasets, we construct a six-class helmet wearing dataset, which aims to distinguish the different states of helmets in the construction scene and improve the feature extraction accuracy and detection performance of the whole model. (2) A small target detection layer is added to the YOLOv5 network, and the anchor size is revised in accordance with the new detection layer and the dataset we constructed. In addition, the attention mechanism is introduced to the backbone network of YOLOv5s, and its initial CIOU_Loss is replaced with the EIOU_Loss function. (3) Using our dataset to train the improved YOLOv5 algorithm, we can obtain a model that can accurately identify the wearing of safety helmets.
This paper is organized as follows:
Section 2 presents the YOLOv5s algorithm and some improved techniques of this paper. The experimental process and analysis of the improved YOLOv5s algorithm are elaborated in
Section 3, such as the experimental setup, dataset acquisition, training and test results, and ablation experiment.
Section 3 also compares the improved algorithm with some current helmet wearing detection algorithms to further show the experimental effect. The research of this paper is finally concluded in
Section 4, which also suggests the future work.
3. Experiment and Analysis
3.1. Experimental Setup
In our experiments, the operating system was Linux, the CPU was a AMD Ryzen 9 5950X 16-Core Processor 3.40 GHz, the GPU was a Tesla v100-sxm2-16GB, the framework was Pytorch, the batch size was set to 16, the epoch was set to 300 (the early stopping mechanism was also enabled), and the image size was 640 × 640.
3.2. Dataset
At present, there are few datasets on helmet wearing. The public dataset named SHWD only includes two cases of helmet wearing and pedestrians, which cannot reflect the various states of the helmet in the real construction scene completely. Therefore, this paper collected 8476 images using dataset selection, web crawling, and self-shooting, and then we annotated them by labelImg to build a dataset of six categories which includes not wearing a helmet (person), only wearing a helmet (helmet), just wearing a hat (hat_only), having a helmet, but not wearing it (helmet_nowear), wearing a helmet correctly (helmet_good), and wearing a helmet without the chin strap (not_fastened). A wide range of construction scenarios were included in the dataset created for this study, which can accurately reflect real construction scenarios. However, in the early images of helmet wearing, most helmets were only attached to the head, and there was no design for the chin strap. In addition, it is difficult to judge whether a person is wearing a helmet correctly when he/she has a head covering or we have a remote view of his/her back. Therefore, the classification of “wearing a helmet (helmet)” in our dataset is more like a “suspicious” classification.
The dataset was split into a training set and a validation set at a 7:3 ratio.
Table 6 lists the total number of target box annotations of each category in the dataset.
The sample of the six categories is shown in
Figure 5. It is worth noting that a six-class dataset was constructed to better distinguish and recognize the use of helmets in the construction scene, and finer classification can also better improve the detection performance of the model. For example, the class “hat_only” can distinguish some situations better that interfere with the wearing of safety helmets (such as a worker wearing a baseball cap that is very similar to a safety helmet, as well as police and nurses at the construction site); the class “helmet_nowear” is intended to detect the situation where the helmet is held in the hand or there is a helmet in the environment, but it is not being worn. The above research can also pave the way for further image description research on this subject.
It is worth mentioning that the images in our test set were collected from a recent construction site, completely independent of the training set and validation set, which makes the test results more convincing.
Figure 6 represents some samples of the training set and test set.
3.3. Training Results
The improved YOLOv5s algorithm and the original algorithm used the same dataset for 300 epochs of training under the same experimental environment mentioned in
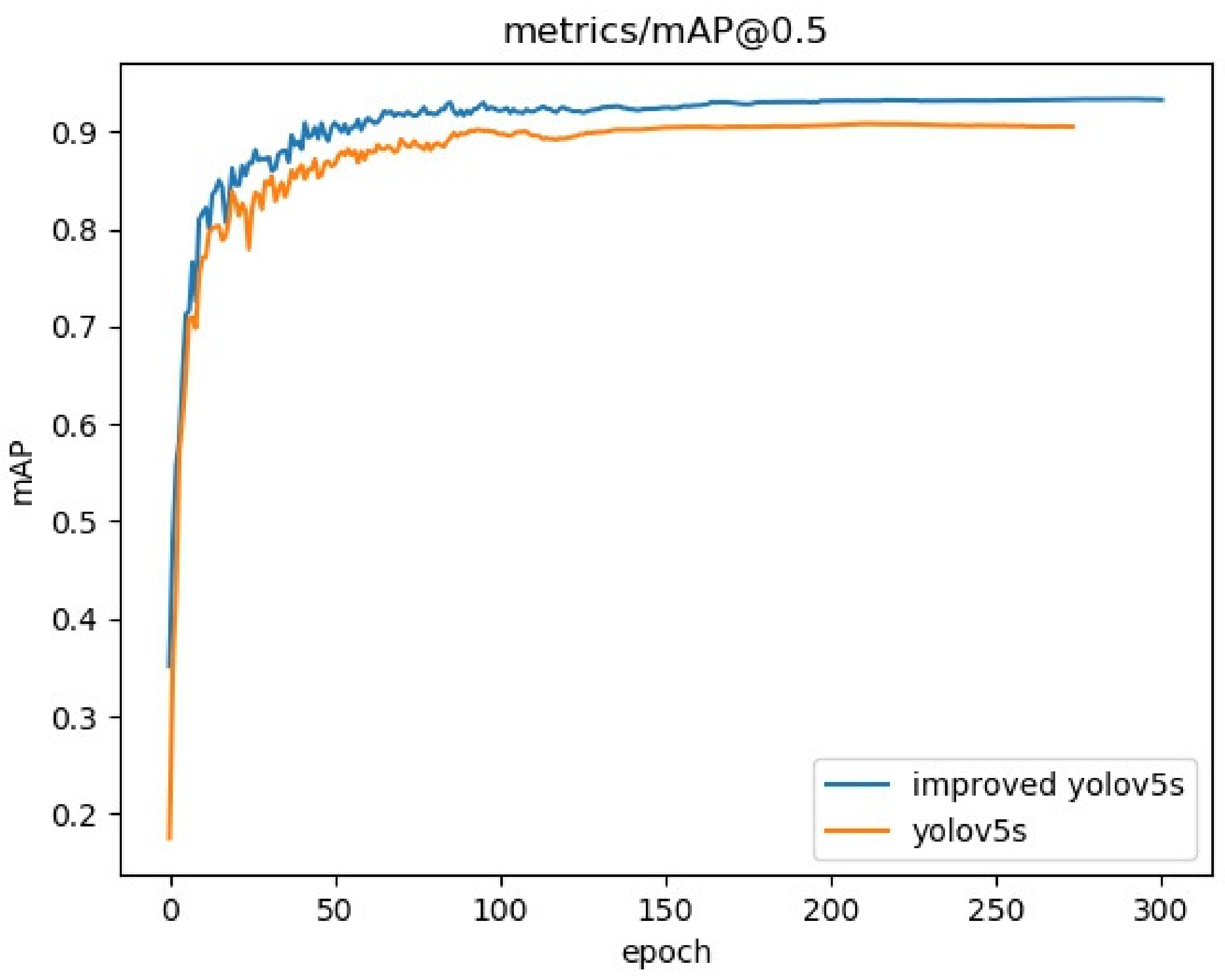
Section 3.1. The mean Average Precision (mAP) comparison curve of the experiments is shown in
Figure 7.
As can be seen from
Figure 7, after 50 epochs of training, both algorithms converged rapidly, and the improved YOLOv5s algorithm converged faster than the original algorithm. Additionally, the enhanced YOLOv5s method significantly improves the average accuracy when compared to the original algorithm.
3.4. Test Results
3.4.1. Qualitative Analysis
In order to better show the detection results of the algorithm for the six classifications, we tested on the example diagram in
Section 3.2. The detection results of the yolov5s algorithm before and after improvement are shown in
Figure 8.
We can see from
Figure 8 that, for the six states of helmet wearing in this research, the detection results of the original YOLOv5 algorithm missed the detection of
helmet_nowear and falsely detected
helmet_good, while the improved YOLOv5 algorithm could accurately detect the six states, and the confidence level was mostly higher than the original YOLOv5 algorithm. After many tests, it was found that the improved YOLOv5 algorithm had strong robustness.
In addition, in order to better test the detection effect of our algorithm on helmet wearing in a real construction scene, we selected distant and small targets, mesoscale targets, and dense targets from the test set for helmet wearing status detection. The detection results of the yolov5s algorithm before and after improvement in the real scene are shown in
Figure 9.
The improved YOLOv5s algorithm had an excellent detection impact for targets at all scales and dense targets, reducing many missed and false detections, as can be observed in
Figure 9. In particular, some long-distance targets at the construction site can be detected accurately, which makes the model more practical.
3.4.2. Quantitative Analysis
We used the
Precision and
Recall, which are respectively defined in Equations (6) and (7), to quantitatively assess the performance of the model in terms of detection, and the PR curves of various categories under the YOLOv5s algorithm model before and after improvement are drawn, respectively.
Figure 10 demonstrates that the enhanced YOLOv5s algorithm improved the detection performance of each classification, with the mAP improved by 3.9%.
where
TP denotes the number of samples that predict the correct category as positive,
FP indicates the number of samples that incorrectly predict the category as positive, and
FN represents the number of samples that identify the correct category as negative.
From the comparison of the PR curves, it can be shown that the improved model greatly improved the detection performance of the helmet wearing state, and the improved model was particularly accurate at detecting the classes helmet_nowear and hat_only. However, due to its fine features, the class not_fastened is not significantly different from the classes helmet and helmet_good, and the detection performance needs to be improved. In view of the low detection accuracy of this classification, in the dataset preparation stage, we focused on supplementing and enhancing it, but the detection effect was not significantly improved. We will consider fusing the fine-grained algorithms in further research.
3.5. Ablation Experiment
In this research, the ablation experiments based on the YOLOv5s algorithm were designed to demonstrate the impact of each modification on the effectiveness of helmet wearing state identification more clearly. In
Table 7, the experimental findings are shown.
Table 7 details the experimental results of the four improved methods mentioned in
Section 2 under different combinations. Overall, the combination of various improvement methods improved the performance of helmet wearing status detection, and the four improvements together had the best effect. In the two mixed experiments for improvement, the combination of redesigning the anchor and introducing an attention mechanism had the best effect, while the combination of adding a small target layer and modifying the loss function had the worst effect. In the three mixed experiments for improvement, the combination of redesigning the anchor, adding a small target layer, and introducing an attention mechanism had the best effect, while the combination of redesigning the anchor, adding a small target layer, and modifying the loss function had the worst effect.
3.6. Comparative Experiment
To demonstrate the performance of the improved YOLOv5s algorithm better, we tested some highly evaluated target detection algorithms in the field of deep learning on our dataset.
Table 8 shows the Average Precision (AP) of each algorithm on our six-class dataset.
Table 9 compares the mAP (both IOU = 0.5 and IOU = 0.5:0.95, area = small), Frames Per Second (FPS), and the file size of each algorithm from a more macro perspective.
It can be seen from
Table 8 that the improved YOLOv5s algorithm performed best in the detection of the wearing states of
helmets,
hat_only,
helmet_good, and
not_fastened; the original YOLOv5 algorithm was the top performer in the detection of
person and
helmet_nowear. The SSD-VGG16 algorithm performed as well as the improved YOLOv5s algorithm in detecting
not_fastened.
Table 9 shows that the improved YOLOv5s algorithm performed best in the mAP with an IOU of 0.5 and small target evaluation indicators; for the FPS, the YOLOv5s algorithm before and after the improvement had little difference, but both were much higher than the other algorithms. In addition, although the file size of the improved YOLOv5s method was 1.4 MB larger than the initial algorithm, it was still less than other competing algorithms. This feature makes the YOLOv5s algorithm have greater hardware portability and practical value.
4. Conclusions and Future Works
In order to solve the problem in which most of the existing helmet wearing detection algorithms only deal with whether the helmet is worn or not and do not pay attention to the various states of the helmet in the actual scene, this paper constructed a dataset with finer classification and proposed a helmet wearing state detection algorithm based on an improved YOLOv5s algorithm.
For the dataset, compared with existing datasets, the quality of the six-category dataset we built is higher, especially the added class hat_only, which can distinguish some cases that can be confused with class helmet and the class helmet_nowear enriches the detection capability of the model and helps in the preparation of future research. Furthermore, we made four improvements to the YOLOv5s algorithm. By adapting to the annotation of this dataset, the size of the prior box was redesigned, and a small target detection layer was added for the situation where the actual construction scene is far away and the target objects are dense. Furthermore, we introduced the attention mechanism CoordAtt to the algorithm and used the EIOU_Loss function to replace the original CIOU_Loss in the YOLOv5s algorithm.
According to the experiments in
Section 3, the improved algorithm’s false detection and missed detection rates were lower than those of the present helmet wearing detection methods. Moreover, its detection precision and small target detection capability were greatly improved. However, our current algorithm still has some shortcomings, mainly reflected in the lack of detection accuracy of the class
not_fastened with small differences between classes. In this study, we performed data augmentation and improved the YOLOv5s algorithm’s structure, but this did not completely solve the problem. Next, we will consider using a fine-grained algorithm to solve this problem [
34,
35,
36]. In addition, in view of the richness and strong expression ability of our dataset, the idea for further research is to study the description of the construction images to further assist the safety monitoring of construction sites through image description.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}