
Operational State Recognition of a DC Motor Using Edge Artificial Intelligence




Abstract
1. Introduction
- An architecture design of the EDGE-AI implementation and the frequency analysis of an audio dataset [7] for a DC motor’s operational states. We show, in detail, how the sound signal is digitally processed and interfaced with the deep learning (DL) algorithm.
- Two design methodologies for the implementation of CNNs on microcontroller units (MCUs). We evaluate the utilization of HW resources, along with the model training and validation processes.
- The simulation of a stress test experimental setup, which included slight variations in the environmental noise gain, so as to evaluate the performance of our EDGE-AI solutions in conditions close to a real industrial environment. More concretely, the inference performance is measured with respect to the resulting speed and accuracy, two criteria crucial for the stringent real-time conditions of an industrial environment.
2. Related Work
3. Methods and Materials
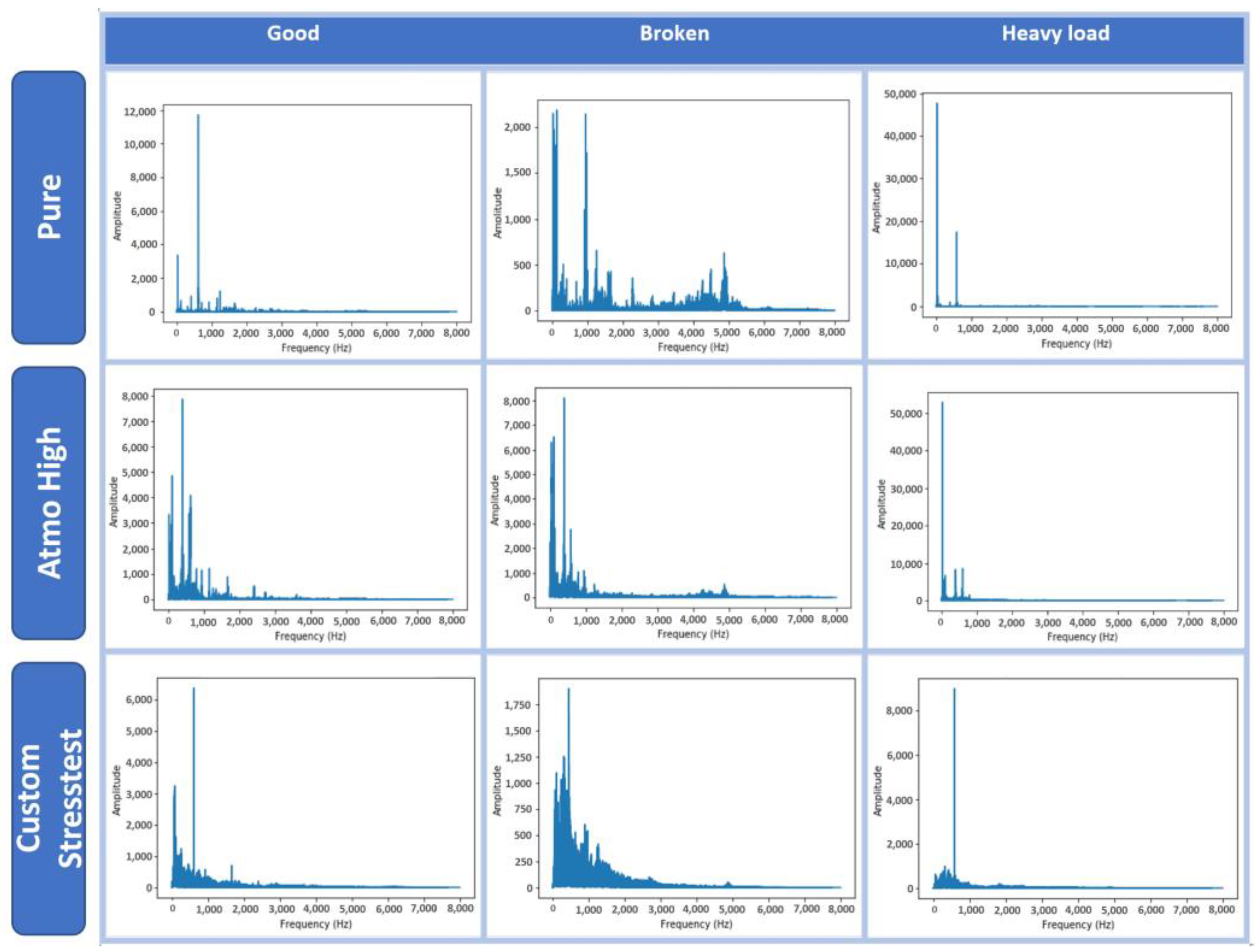
3.1. DC Motor Dataset
- Pure—recordings without the presence of other sounds or noise.
- Talking—recordings with the presence of sounds from people talking outside the case surrounding the device.
- White noise—recordings in the presence of white noise played by speakers outside the case surrounding the device.
- Atmo—recordings with the presence of sounds from a factory environment in three volume levels (low, medium, high) that were reproduced using speakers.
- Stress test—recordings with slightly changed gains at the input, simulating variations in the setup.
3.2. Basic Definitions
3.2.1. Mel-Scale
3.2.2. Convolutional Neural Networks (CNN)
3.2.3. Softmax
3.2.4. Rectified Linear Unit (ReLU)
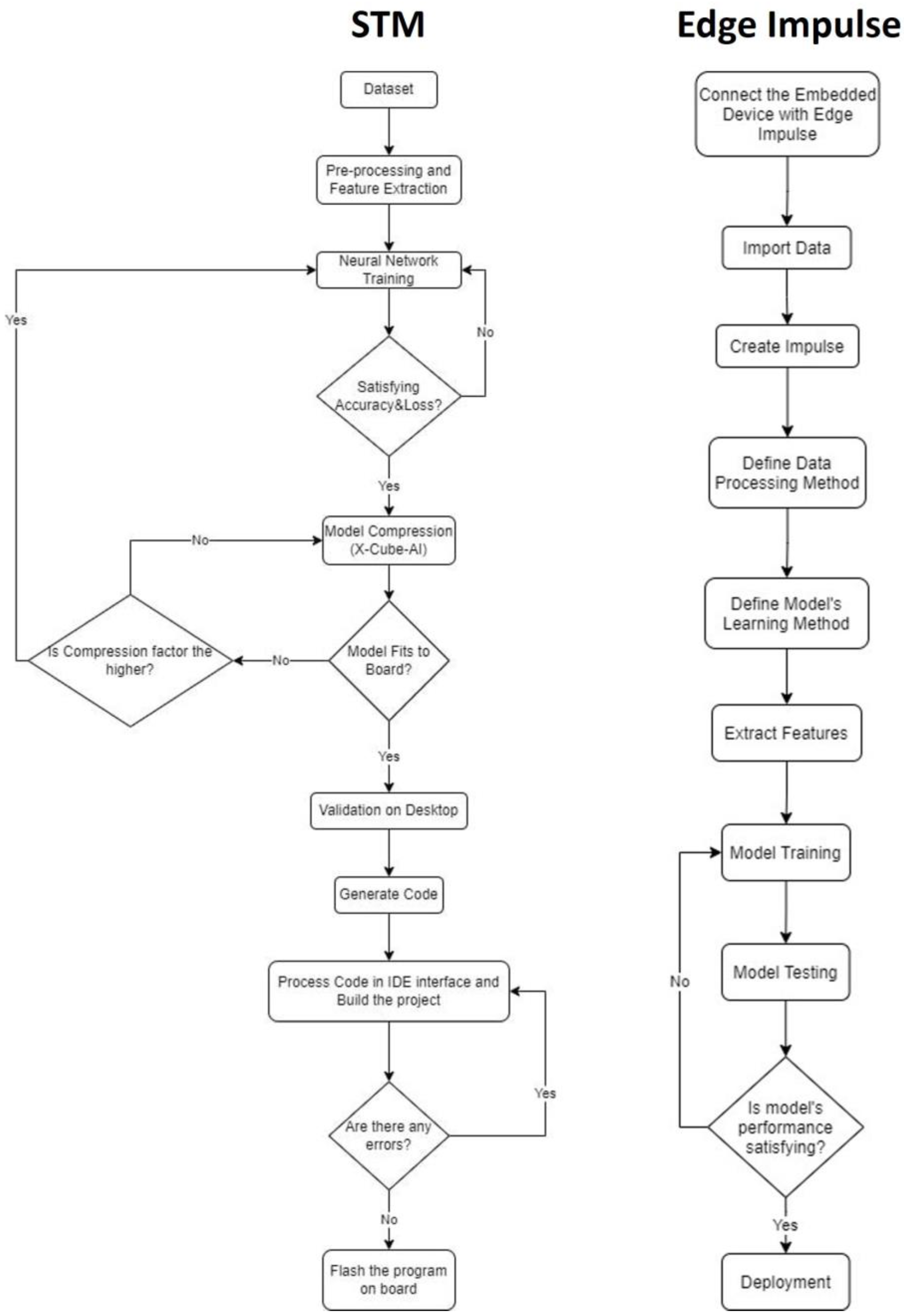
3.3. Design Methodology for Artificial Intelligence Implementation on Edge and IoT Devices
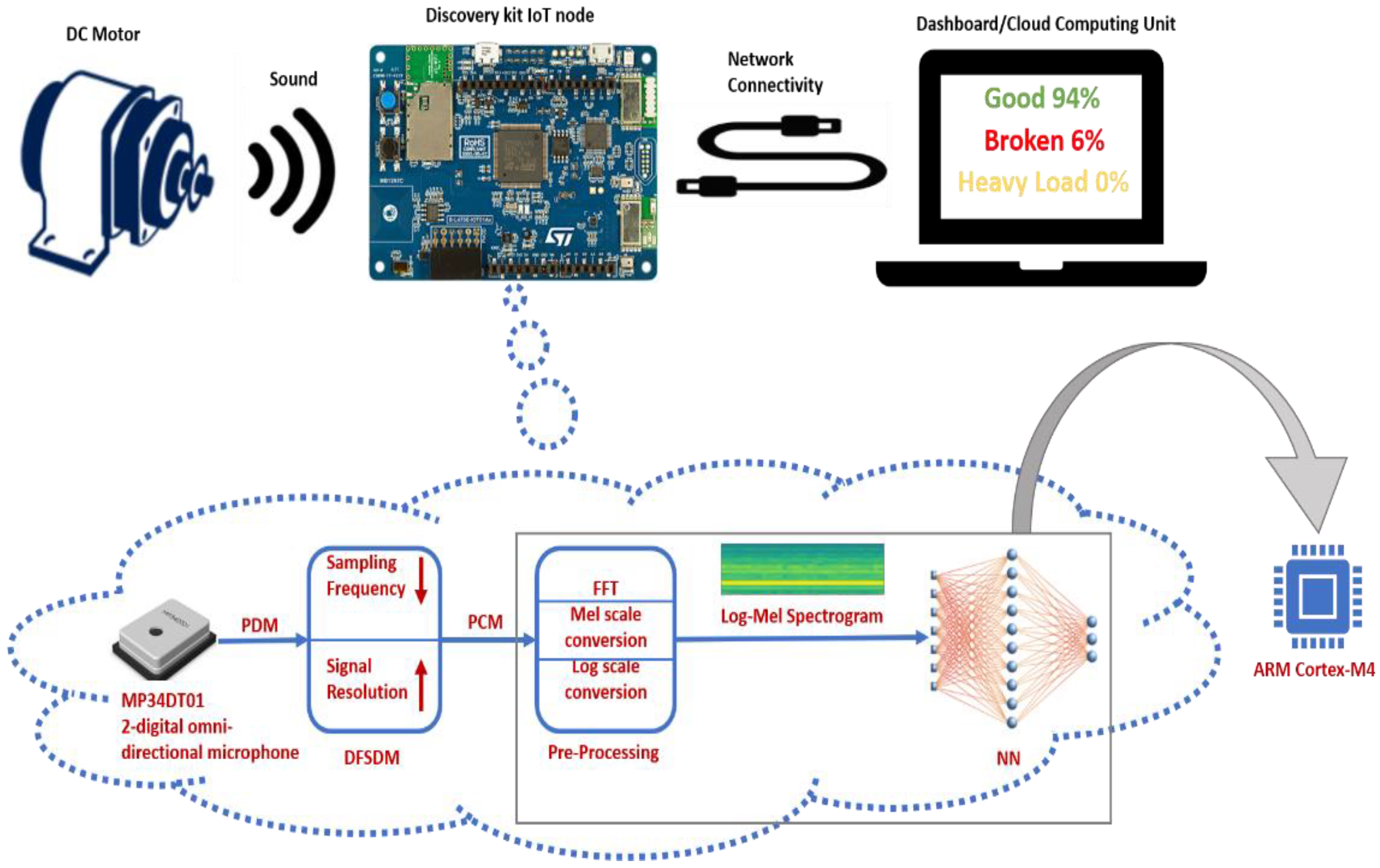
4. EDGE-AI Node Architecture and Operating Process
5. Methodological Approaches—Results
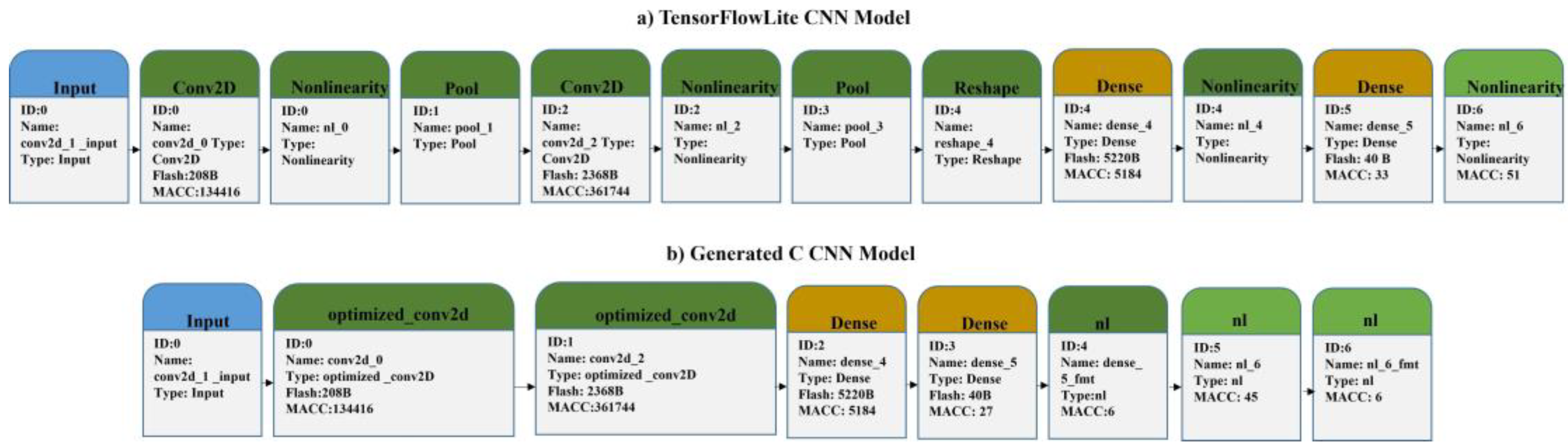
5.1. EDGE-AI Implementation Based on STM’s Tools
5.2. EDGE-AI Implementation Based on Edge Impulse Environment
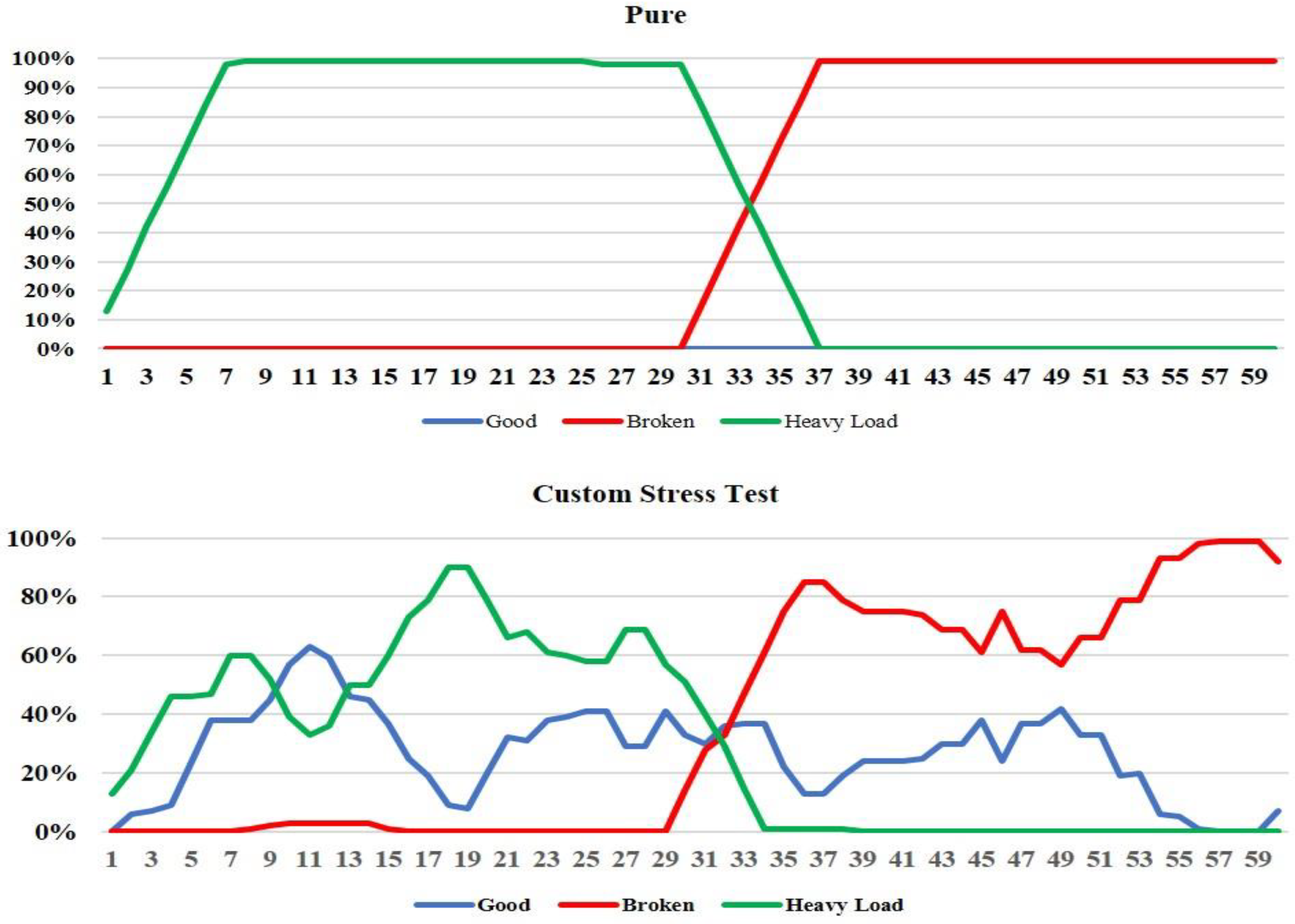
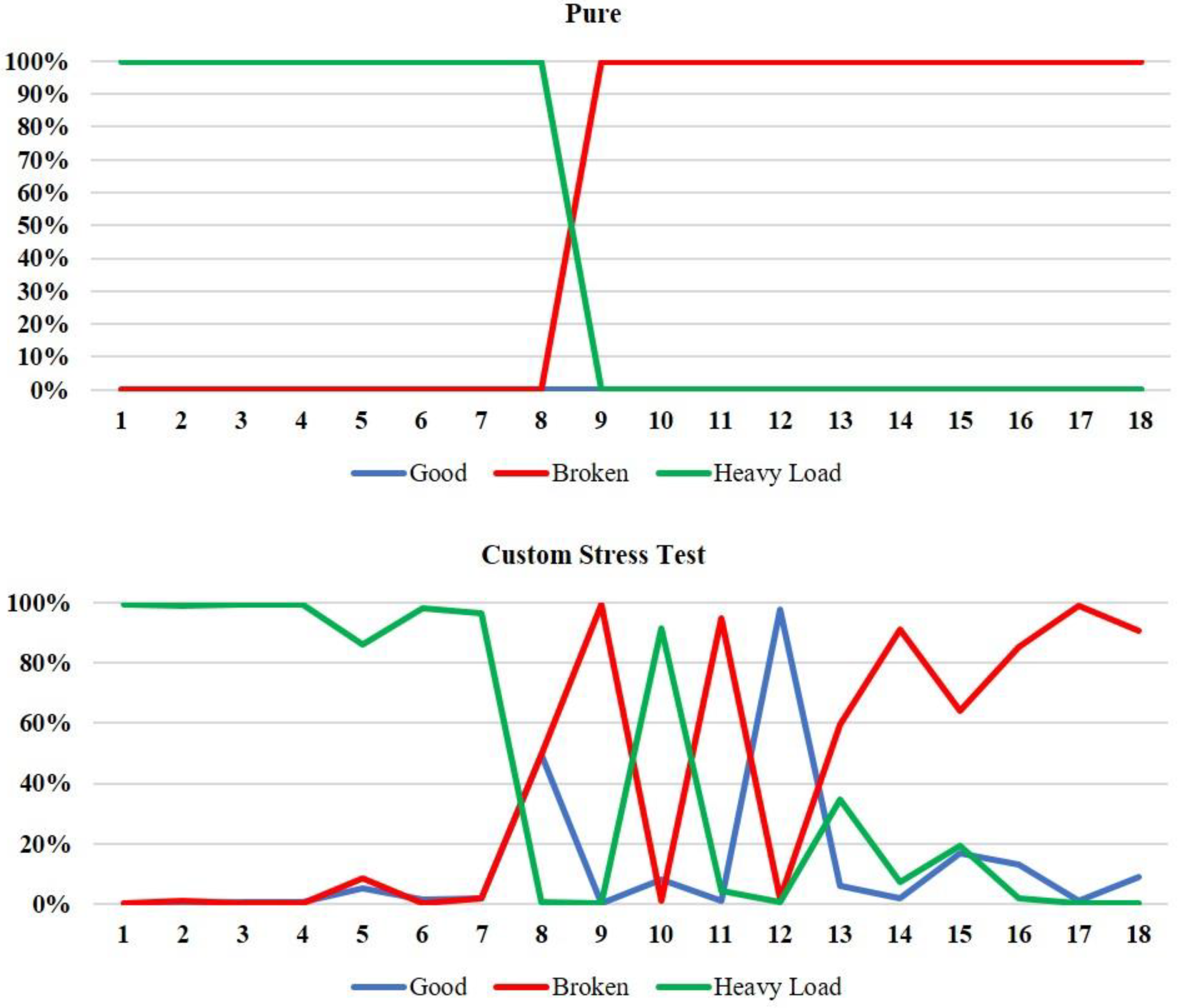
5.3. Real-Time Performance Monitoring and Test Results
5.4. Models’ Performance Analysis and Evaluation of Test Results
6. Discussion—EDGE AI Implementation vs. Cloud Computing for Predictive Maintenance
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Merenda, M.; Porcaro, C.; Iero, D. Edge Machine Learning for AI-Enabled IoT Devices: A Review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing. Proc. IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef]
- Akhtari, S.; Pickhardt, F.; Pau, D.; Di Pietro, A.; Tomarchio, G. Intelligent Embedded Load Detection at the Edge on Industry 4.0 Powertrains Applications. In Proceedings of the 5th IEEE International forum on Research and Technology for Society and Industry (RTSI), Florence, Italy, 9–12 September 2019; pp. 427–430. [Google Scholar] [CrossRef]
- Nourse, D. Electric Motor Failure—A Comparative study of its causes. In Proceedings of the 8th Electrical Insulation Conference, Los Angeles, CA, USA, 9–12 December 1968; pp. 142–143. [Google Scholar] [CrossRef]
- Azurto, A.; Quispe, E.; Mendoza, R. Causes and failures classification of industrial electric motor. In Proceedings of the 2016 IEEE ANDESCON, Arequipa, Peru, 19–21 October 2016; pp. 1–4. [Google Scholar] [CrossRef]
- Portos, J.; Dean, K.; Parker, B.; Cannon, J. Most common mechanisms and reasons for electric motor failures in industry. In Proceedings of the 2019 IEEE IAS Pulp, Paper and Forest Industries Conference (PPFIC), Jacksonville, FL, USA, 23–28 June 2019; pp. 1–11. [Google Scholar] [CrossRef]
- Grollmisch, S.; Abesser, J.; Liebetrau, J.; Lukashevich, H. Sounding industry: Challenges and datasets for industrial sound analysis. In Proceedings of the 27th European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019; pp. 1–5. Available online: https://new.eurasip.org/Proceedings/Eusipco/eusipco2019/Proceedings/papers/1570526697.pdf (accessed on 22 October 2022).
- IoT Use Case Adoption Report 2021. Available online: https://iot-analytics.com/top-10-iot-use-cases/ (accessed on 22 October 2022).
- Waswani, R.; Pawar, A.; Deore, M.; Patel, R. Induction motor fault detection, protection and speed control using arduino. In Proceedings of the 2017 International Conference on Innovations in Information, Embedded and Communication Systems (ICIIECS), Coimbatore, India, 17–18 March 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Munikoti, S.; Das, L.; Natarajan, B.; Srinivasan, B. Data-Driven Approaches for Diagnosis of Incipient Faults in DC Motors. IEEE Trans. Ind. Informatics 2019, 15, 5299–5308. [Google Scholar] [CrossRef]
- He, Z.; Ju, Y.; Liu, Y.; Zhang, B. Cloud-Based Fault Tolerant Control for a DC Motor System. J. Control Sci. Eng. 2017, 2017, 5670849. [Google Scholar] [CrossRef]
- Aravazhi, A.; Arjun, K.V.; Deepak, S.; Karthick, V.; Muthusamy, S. Machine learning based fault diagnosis of rotating machinery using sound signal. In Proceedings of the India National Conference on Recent Trends in Mechanical Engineering (RTIME 2011), Chennai, India, 20–21 April 2011; Available online: https://www.researchgate.net/publication/325313722_Machine_learning_based_fault_diagnosis_of_rotating_machinery_using_sound_signal (accessed on 22 October 2022).
- Glowacz, A.; Głowacz, Z. (Recognition of rotor damages in a DC Motor using Acoustic Signals. Bull. Polish Acad. Sci. Tech. Sci. 2017, 65, 187–194. [Google Scholar] [CrossRef]
- Grebenik, J.; Zhang, Y.; Bingham, C.; Srivastava, S. Roller element bearing acoustic fault detection using smartphone and consumer microphones comparing with vibration techniques. In Proceedings of the 2016 17th International Conference on Mechatronics—Mechatronika (ME), Prague, Czech Republic, 7–9 December 2016; pp. 1–7. [Google Scholar]
- Matlab—Mathworks—Matlab and Simulink. Available online: https://www.mathworks.com/products/matlab.html (accessed on 22 October 2022).
- Glowacz, A. Acoustic-Based Fault Diagnosis of Commutator Motor. Electronics 2018, 7, 299. [Google Scholar] [CrossRef]
- Wu, C.; Jiang, P.; Ding, C.; Feng, F.; Chen, T. Intelligent fault diagnosis of rotating machinery based on one-dimensional convolutional neural network. Comput. Ind. 2019, 108, 53–61. [Google Scholar] [CrossRef]
- X-CUBE-AI: AI Expansion Pack for STM32 CUBEMX. Available online: https://www.st.com/en/embedded-software/x-cube-ai.html (accessed on 22 October 2022).
- Keras: The Python Deep Learning API. Available online: https://keras.io/ (accessed on 22 October 2022).
- Montino, P.; Pau, D. Environmental Intelligence for Embedded Real-time Traffic Sound Classification. In Proceedings of the 2019 IEEE 5th International forum on Research and Technology for Society and Industry (RTSI), Florence, Italy, 9–12 September 2019; pp. 45–50. [Google Scholar] [CrossRef]
- Sensortile Development Kit. Available online: https://www.st.com/en/evaluation-tools/steval-stlkt01v1.html (accessed on 22 October 2022).
- Xu, M.; Duan, L.Y.; Cai, J.; Chia, L.T.; Xu, C.; Tian, Q. HMM-Based Audio Keyword Generation. In Advances in Multimedia Information Processing—PCM 2004; Lecture Notes in Computer Science; Aizawa, K., Nakamura, Y., Satoh, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3333, pp. 566–574. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning. MIT Press. 2016. Available online: http://www.deeplearningbook.org (accessed on 22 October 2022).
- Machine Learning for All STM32 Developers with STM32Cube.AI and Edge Impulse. Available online: https://www.edgeimpulse.com/blog/machine-learning-for-all-stm32-developers-with-stm32cube-ai-and-edge-impulse (accessed on 22 October 2022).
- B-L475E-IOT01A, STM32L4 Discovery Kit IoT Node. Available online: https://www.st.com/en/evaluation-tools/b-l475e-iot01a.html (accessed on 22 October 2022).
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Audio and Music Signal Analysis in Python. In Proceedings of the 14th Python in Science Conference (SCIPY 2015), Austin, TX, USA, 6–12 July 2015; pp. 18–24. [Google Scholar] [CrossRef]
- Valenti, M.; Diment, A.; Parascandolo, G.; Squartini, S.; Virtanen, T. Acoustic scene classification using convolutional neural networks. In Proceedings of the Detection and Classification of Acoustic Scenes and Events Workshop (DCASE 2016), Budapest, Hungary, 3 September 2016; pp. 1–5. Available online: https://www.eurecom.fr/~evans/papers/pdfs/4982.pdf (accessed on 22 October 2022).
- Importance of Feature Scaling. Available online: https://scikit-learn.org/stable/auto_examples/preprocessing/plot_scaling_importance.html (accessed on 22 October 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Work | Monitoring Variable | Diagnosis Algorithm | Computation Unit | Cloud Support |
|---|---|---|---|---|
| [9] | Speed, temperature, current, and voltage | Simple Heuristic | Arduino and Local PC | No |
| [10] | Current | SVM, CNN, and LSTM | Local PC | No |
| [11] | armature winding current, resistance, input voltage and inductance, rotor angular speed, and torque constant | Output feedback approximate dynamic programming | Cloud Connectivity | Yes |
| [12] | Audio signals | Decision tree learning | Local PC | No |
| [13] | Acoustic signal | Linear discriminant analysis, NN, and NM | Local PC | No |
| [14] | Acoustic signal and Vibration | SVM | Local PC, microphone, and smartphone | No |
| [16] | Acoustic signal | NN, NM, SOM, and BNN | Local PC | No |
| [17] | Vibration signal | 1-DCNN | Local PC | No |
| [18] | Acoustic signal | ANN | Local PC | No |
| [3] | Vibration | DNN | MCU | No |
| [19] | Acoustic signal of car engines | ANN, CRNN | MCU | No |
| This Work | Audio signal | CNN | MCU | No |
| Type of Audio Recordings | Duration (min) |
|---|---|
| Pure | 15 |
| Talking | 18 |
| Atmo (High) | 9 |
| Atmo (Medium) | 9 |
| Atmo (Low) | 9 |
| White Noise | 9 |
| Stress Test | 6 |
| Good | Broken | Heavy Load | |
|---|---|---|---|
| Good | 10,637 | 1 | 2 |
| Broken | 0 | 10,587 | 8 |
| Heavy load | 32 | 0 | 10,635 |
| Good | Broken | Heavy Load | |
|---|---|---|---|
| Good | 664 | 0 | 0 |
| Broken | 0 | 574 | 0 |
| Heavy load | 0 | 0 | 633 |
| Metrics | Values |
|---|---|
| Accuracy (%) | 97.8 |
| Loss (%) | 0.06 |
| Peak RAM Usage (Kbytes) | 7.0 |
| ROM Usage (Kbytes) | 38.2 |
| Inference Time (ms) | 16 |
| Good | Broken | Heavy Load | |
|---|---|---|---|
| Good | 504 | 5 | 4 |
| Broken | 4 | 479 | 0 |
| Heavy load | 13 | 7 | 512 |
| Pure | Atmo Medium | White Noise | Custom Stress Test | |
|---|---|---|---|---|
| Good-to-Broken DC Motor State Transition | ||||
| Good class average percentage (%) | 92 | 89 | 84 | 82 |
| Broken class average percentage (%) | 89 | 89 | 91 | 61 |
| Transition response time between classes (s) | 4.46 | 4.61 | 4.25 | 5.22 |
| Good to Heavy Load DC Motor State Transition | ||||
| Good class average percentage (%) | 90 | 90 | 89 | 89 |
| Broken class average percentage (%) | 87 | 79 | 84 | 58 |
| Transition response time between classes (s) | 5.43 | 4.86 | 4.63 | 9.07 |
| Heavy Load to Broken DC Motor State Transition | ||||
| Good class average percentage (%) | 89 | 83 | 78 | 56 |
| Broken class average percentage (%) | 89 | 88 | 89 | 72 |
| Transition response time between classes (s) | 3.68 | 4.16 | 3.97 | 4.54 |
| Pure | Atmo Medium | White Noise | Custom Stress Test | |
|---|---|---|---|---|
| Good to Broken DC Motor State Transition | ||||
| Good class average percentage (%) | 87.2 | 87.1 | 80.4 | 54.9 |
| Broken class average percentage (%) | 99.6 | 85.7 | 99.6 | 92.5 |
| Transition response time between classes (s) | 3.31 | 3.94 | 2.13 | 2.62 |
| Good to Heavy Load DC Motor State Transition | ||||
| Good class average percentage (%) | 95.9 | 95.8 | 96.4 | 72.6 |
| Broken class average percentage (%) | 99.6 | 99.2 | 99.6 | 84.6 |
| Transition response time between classes (s) | 2.92 | 5.17 | 3.96 | 5.8 |
| Heavy Load to Broken DC Motor State Transition | ||||
| Good class average percentage (%) | 99.6 | 99.5 | 97.7 | 84.9 |
| Broken class average percentage (%) | 99.6 | 85.8 | 99.6 | 68.7 |
| Transition response time between classes (s) | 3.23 | 5.31 | 3.69 | 2.31 |
| Good | Broken | Heavy Load | |
|---|---|---|---|
| Good | 100% | 0% | 0% |
| Broken | 5.90% | 89.26% | 4.84% |
| Heavy load | 11.16% | 0% | 88.84% |
| Good | Broken | Heavy Load | |
|---|---|---|---|
| Good | 89.06% | 0% | 10.94% |
| Broken | 2.63% | 94.74% | 2.63% |
| Heavy load | 3.65% | 0.73% | 95.62% |
| Data Processing Mode | Data Size Processed During Inference | Latency of Data Processing | Data Transmitted Over the Network |
|---|---|---|---|
| EDGE-AI | 8.4575 Kbytes | 1064.767 ms | 32 bytes |
| Cloud Computing | 2 Kbytes | 1024 ms | 1.9844 Kbytes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Strantzalis, K.; Gioulekas, F.; Katsaros, P.; Symeonidis, A. Operational State Recognition of a DC Motor Using Edge Artificial Intelligence. Sensors 2022, 22, 9658. https://doi.org/10.3390/s22249658
Strantzalis K, Gioulekas F, Katsaros P, Symeonidis A. Operational State Recognition of a DC Motor Using Edge Artificial Intelligence. Sensors. 2022; 22(24):9658. https://doi.org/10.3390/s22249658
Chicago/Turabian StyleStrantzalis, Konstantinos, Fotios Gioulekas, Panagiotis Katsaros, and Andreas Symeonidis. 2022. "Operational State Recognition of a DC Motor Using Edge Artificial Intelligence" Sensors 22, no. 24: 9658. https://doi.org/10.3390/s22249658
APA StyleStrantzalis, K., Gioulekas, F., Katsaros, P., & Symeonidis, A. (2022). Operational State Recognition of a DC Motor Using Edge Artificial Intelligence. Sensors, 22(24), 9658. https://doi.org/10.3390/s22249658