
Exploring the Potential of Machine Learning for the Diagnosis of Balance Disorders Based on Centre of Pressure Analyses




Abstract
1. Introduction
- The stability limits may vary significantly by age and height.
- There is an asymmetry in the average value representing the limit of stability for normal balance participants (approximately 7° anterior and 5° posterior sway) that is disregarded in the EQS equation.
- More than one combination of anterior and posterior sway degrees can result in the same EQS value.
- The EQS only considers the two extreme values of the sway angle in a given test condition, not the complete measurement history (2000 data points) in a trial of 20 s.
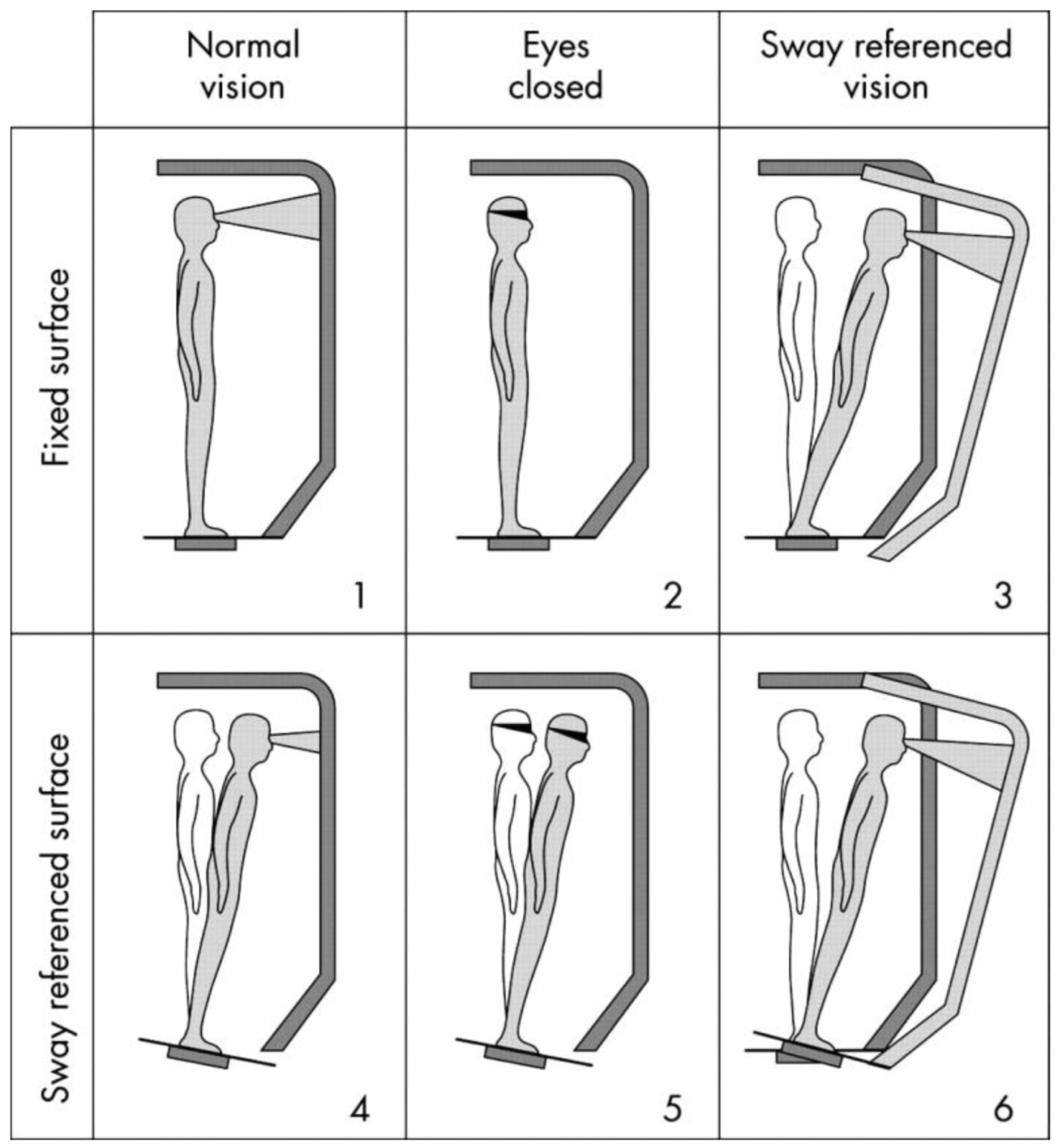
2. Materials and Methods
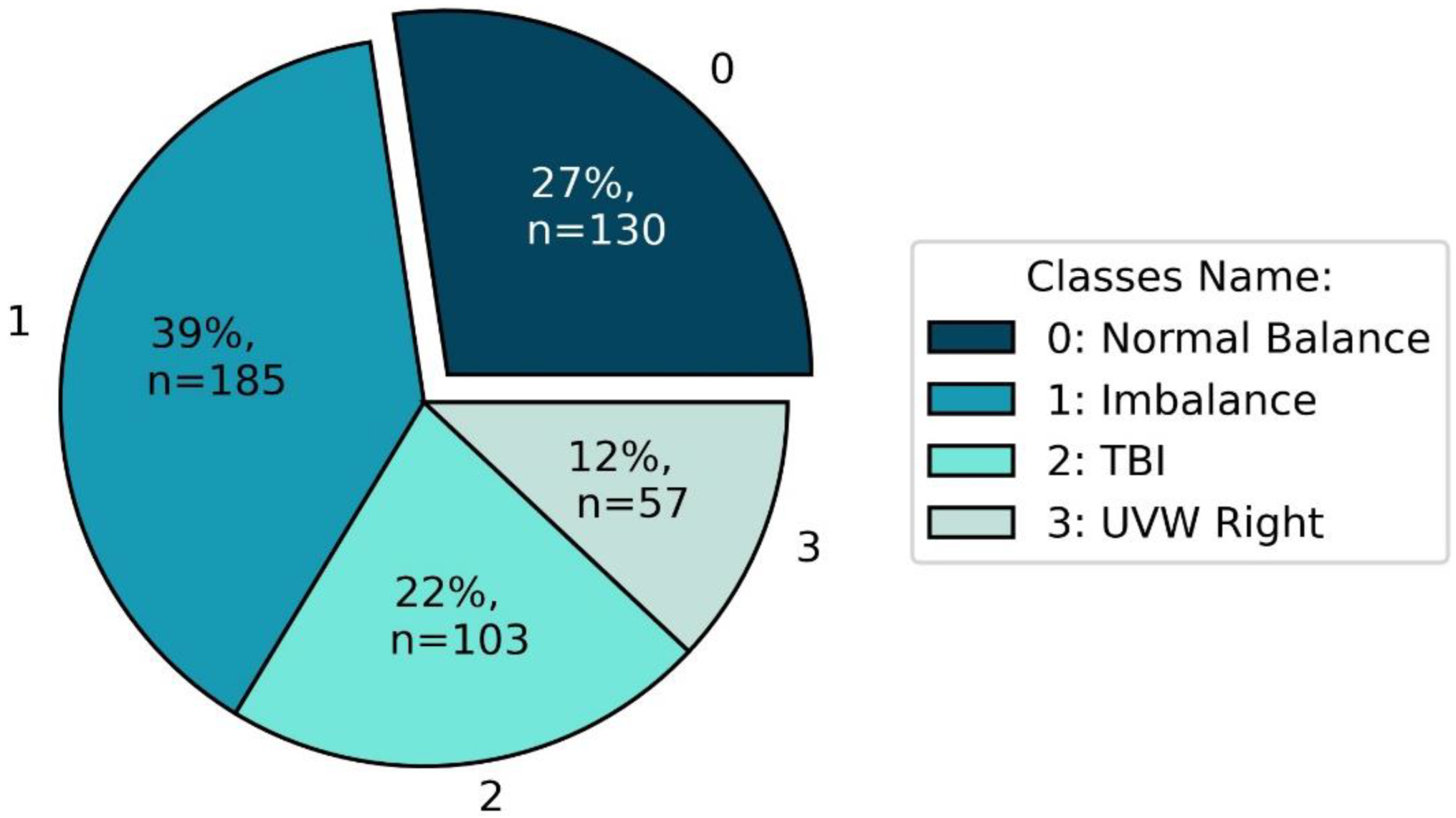
2.1. Subjects
2.2. Approximate Entropy (ApEn)
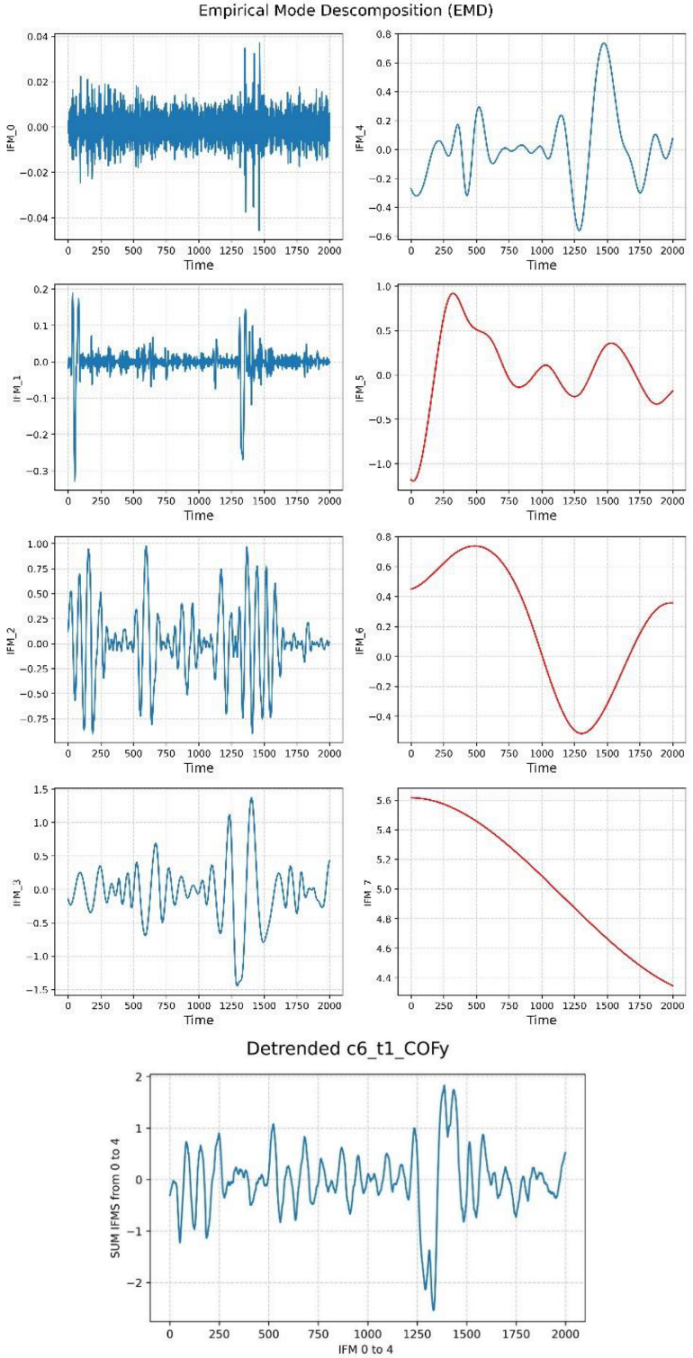
2.3. Empirical Mode Decomposition (EMD)
- Identify all extrema of the signal x(t).
- Fit the maxima and minima to an individual envelope and .
- Compute the average:
- Extract the detail:
- Check the stopping criterion:
- If d(t) does not satisfy the stopping criterion, another iteration from steps 1 to 5 using d(t) in step 1 is undertaken until the stopping criterion is fulfilled.
- When the stopping criterion is fulfilled, only then is the d(t) considered as an IFM. After that, the original x(t) is updated by subtracting the IFM, and the loop starts again at step 1.
- The decomposition stops when d(t) approaches a monotonic function where is it not possible to extract any extrema.
2.4. Machine Learning Methods
- Random Forest (RF) is a general purpose regression and classification machine learning algorithm. Its approach generates several randomised decision trees and aggregates their votes for a final prediction. RF has shown good performance in datasets where the dimensional feature space is greater than the number of observations [24].
- Linear Discriminant Analysis (LDA) is a technique for data classification and dimensionality reduction. It works by maximising the distances between the means of the categories and minimising the variability within them. After fitting the training data, the method generates a linear decision boundary to classify unlabelled observations [25].
- Support Vector Machine (SVM) is an algorithm that looks for a particular line or decision boundary, termed hyperplane, which efficiently separates classes and avoids extra overfitting. This decision boundary is created using a soft margin which is a method that allows misclassification. After fitting the data, the algorithm arranges the hyperplane in such a way that results in better predictions. SVM is capable of performing linear and non-linear classification. For non-linear classification, SVM uses a Kernel function that helps to map the data to high dimensional space. This allows SVM to create non-linear boundaries for classifications [26].
- Logistic Regression (LR), regardless of its name, is a linear model for classification rather than regression. It has its basis in taking the natural logarithm of the odds as a regression function of the predictors. LR can handle both binary and multiclass classification. Unlike statistics approaches, in the machine learning, this approach commonly applies regularisation methods to avoid overfitting [27,28].
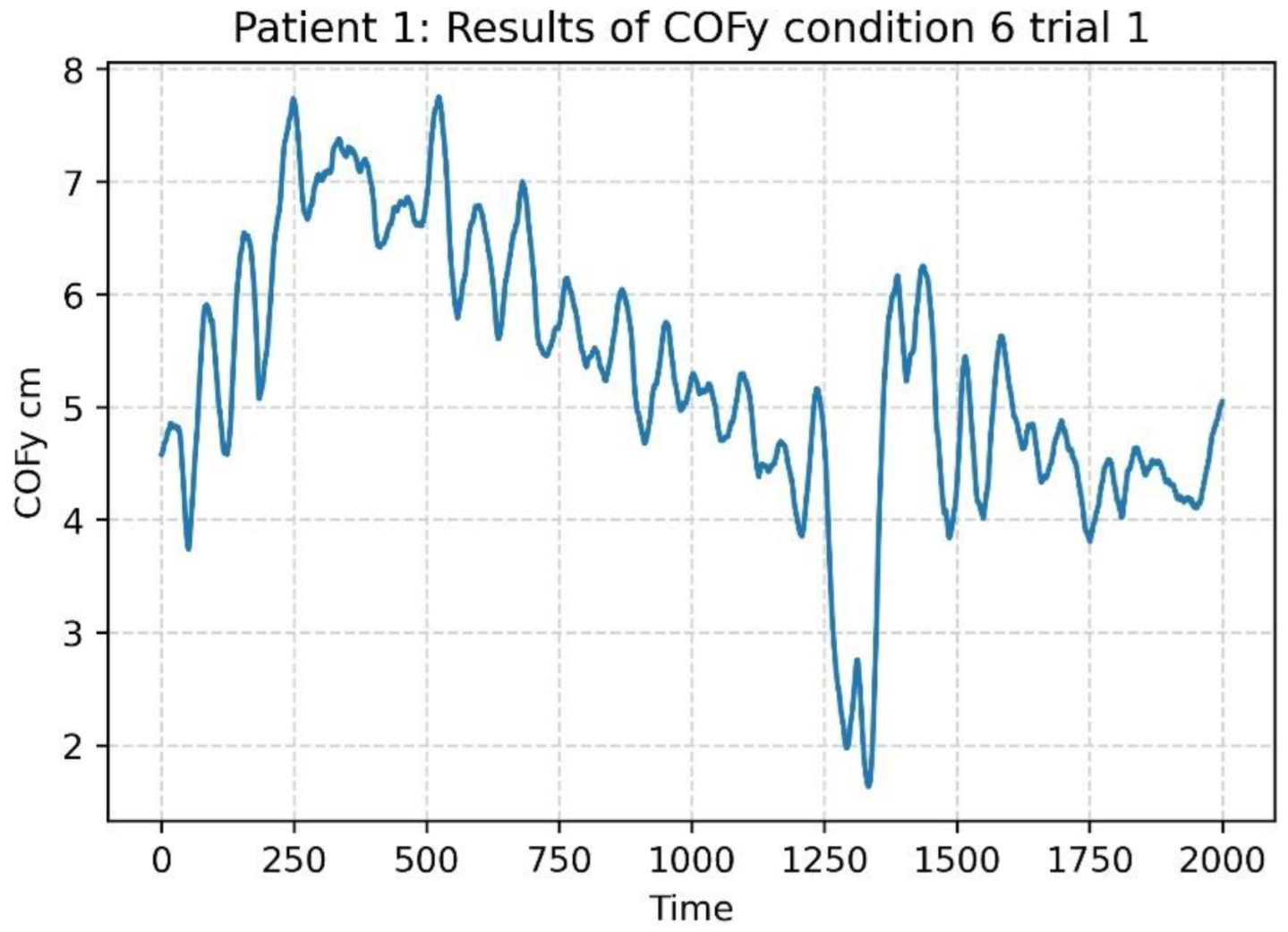
2.5. COP Time Series Pre-Processing
2.6. Testing Normality of ApEn Values
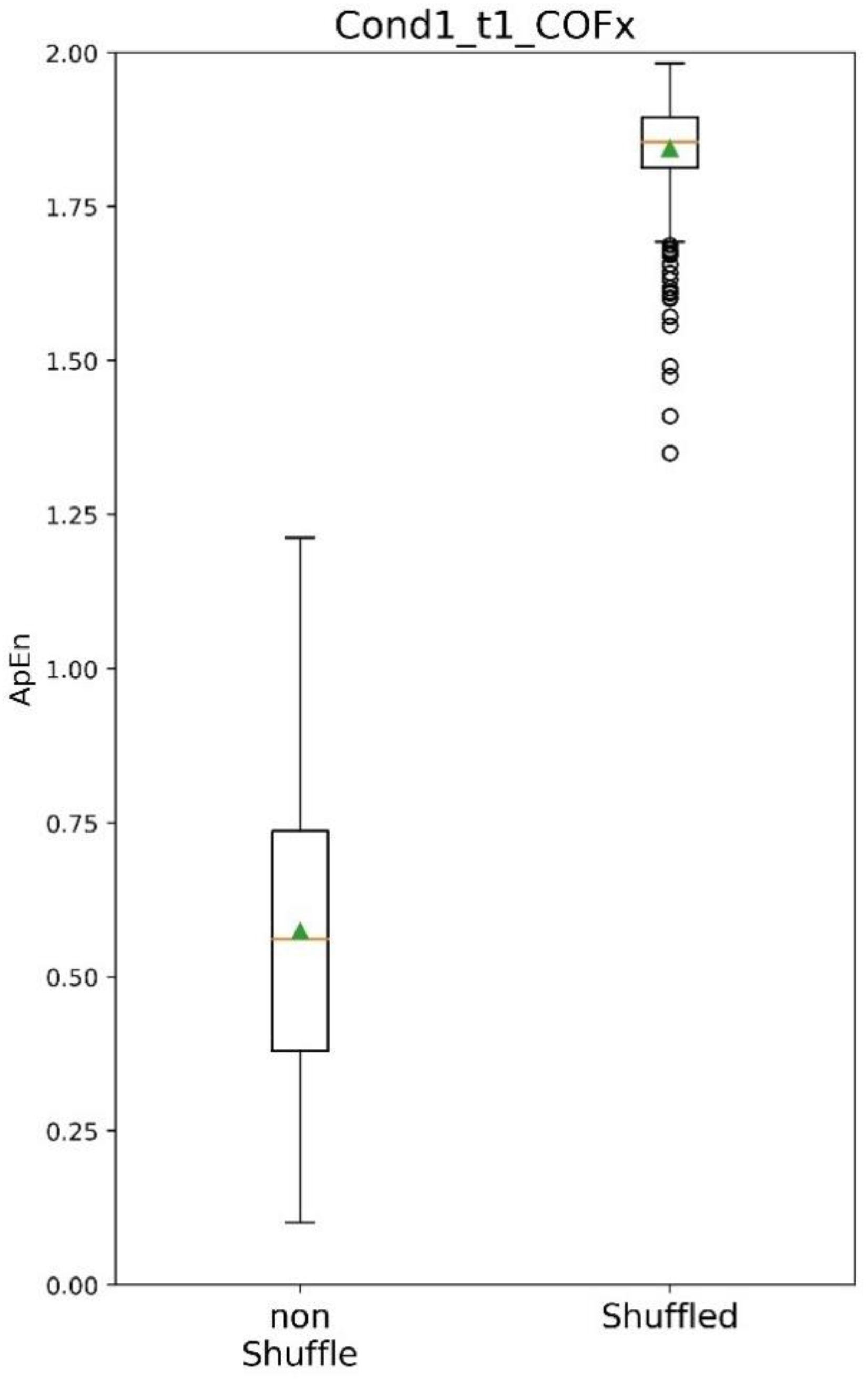
2.7. Finding the Two Classes with Significant Differences
3. Results
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| COFx—Patients ≤ 47 years old | COFx—Patients > 47 years old | ||||||||
| Class 0: N | Class 1: I | Class 2: T | Class 3: U | Class 0: N | Class 1: I | Class 2: T | Class 3: U | ||
| n | 71 | 64 | 46 | 7 | n | 59 | 121 | 57 | 50 |
| Cond1 | 0.442 | 0.0424 | 0.5162 | 0.0602 | Cond1 | 0.2637 | 0.0001 | 0.0086 | 0.2465 |
| Cond2 | 0.0085 | 0.0172 | 0.0221 | 0.5669 | Cond2 | 0.0358 | 0.0000 | 0.0000 | 0.0015 |
| Cond3 | 0.0288 | 0.0226 | 0.0137 | 0.3386 | Cond3 | 0.0643 | 0.0000 | 0.0318 | 0.0007 |
| Cond4 | 0.5113 | 0.0067 | 0.0001 | 0.7692 | Cond4 | 0.0002 | 0.0182 | 0.0037 | 0.0002 |
| Cond5 | 0.9594 | 0.161 | 0.0001 | 0.9073 | Cond5 | 0.7898 | 0.2995 | 0.128 | 0.0333 |
| Cond6 | 0.1344 | 0.5797 | 0.0024 | 0.2274 | Cond6 | 0.1682 | 0.0501 | 0.0252 | 0.0348 |
| COFy—Patients ≤ 47 years old | COFy—Patients > 47 years old | ||||||||
| Class 0: N | Class 1: I | Class 2: T | Class 3: U | Class 0: N | Class 1: I | Class 2: T | Class 3: U | ||
| n | 71 | 64 | 46 | 7 | n | 59 | 121 | 57 | 50 |
| Cond1 | 0.0004 | 0.0002 | 0.0048 | 0.0039 | Cond1 | 0.0016 | 0.0047 | 0.0000 | 0.0001 |
| Cond2 | 0.0000 | 0.0000 | 0.0000 | 0.1991 | Cond2 | 0.0127 | 0.0003 | 0.0000 | 0.0018 |
| Cond3 | 0.0000 | 0.0000 | 0.0000 | 0.2693 | Cond3 | 0.0000 | 0.0001 | 0.0000 | 0.0000 |
| Cond4 | 0.016 | 0.0051 | 0.0727 | 0.9099 | Cond4 | 0.0633 | 0.242 | 0.0015 | 0.7876 |
| Cond5 | 0.3549 | 0.098 | 0.0206 | 0.6259 | Cond5 | 0.3491 | 0.0343 | 0.0197 | 0.0905 |
| Cond6 | 0.0726 | 0.2741 | 0.1112 | 0.7791 | Cond6 | 0.1924 | 0.0192 | 0.0276 | 0.0067 |
| COFx—Patients ≤ 47 years old | COFx—Patients > 47 years old | ||||||||
| Class 0: N | Class 1: I | Class 2: T | Class 3: U | Class 0: N | Class 1: I | Class 2: T | Class 3: U | ||
| n | 71 | 64 | 46 | 7 | n | 59 | 121 | 57 | 50 |
| Cond1 | 0.60 ± 0.23 I | 0.71 ± 0.26 N,TT | 0.52 ± 0.21 II | 0.66 ± 0.27 | Cond1 | 0.60 ± 0.23 I,T | 0.55 ± 0.26 N | 0.47 ± 0.27 N | 0.53 ± 0.23 |
| Cond2 | 0.52 ± 0.24 T | 0.53 ± 0.26 T | 0.40 ± 0.19 N,I | 0.49 ± 0.21 | Cond2 | 0.47 ± 0.20 TT | 0.44 ± 0.24 TT | 0.28 ± 0.16 NN,II,UU | 0.41 ± 0.18 TT |
| Cond3 | 0.58 ± 0.25 TT | 0.56±0.28 TT | 0.43 ± 0.24 NN,II | 0.50 ± 0.25 | Cond3 | 0.51 ± 0.23 TT | 0.48 ± 0.25 TT | 0.33 ± 0.17 NN,II,UU | 0.47 ± 0.20 TT |
| Cond4 | 0.42 ± 0.14 TT | 0.44 ± 0.23 TT | 0.33 ± 0.16 NN,II | 0.46 ± 0.23 | Cond4 | 0.42 ± 0.19 TT | 0.34 ± 0.15 | 0.28 ± 0.14 NN,U | 0.39 ± 0.17 T |
| Cond5 | 0.30 ± 0.10 TT | 0.29 ± 0.12 | 0.25 ± 0.13 NN | 0.28 ± 0.09 | Cond5 | 0.30 ± 0.11 TT | 0.26 ± 0.12 TT | 0.20 ± 0.11 NN,II,UU | 0.27 ± 0.14 TT |
| Cond6 | 0.40 ± 0.13 I,TT | 0.33 ± 0.15 N,T | 0.30 ± 0.14 NN,I | 0.40 ± 0.14 | Cond6 | 0.32 ± 0.16 TT | 0.28 ± 0.14 T | 0.24 ± 0.13 NN,I,U | 0.29 ± 0.14 T |
| COFy—Patients ≤ 47 years old | COFy—Patients > 47 years old | ||||||||
| Class 0: N | Class 1: I | Class 2: T | Class 3: U | Class 0: N | Class 1: I | Class 2: T | Class 3: U | ||
| n | 71 | 64 | 46 | 7 | n | 59 | 121 | 57 | 50 |
| Cond1 | 0.43 ± 0.23 | 0.44 ± 0.23 | 0.37 ± 0.21 | 0.39 ± 0.29 | Cond1 | 0.42 ± 0.20 TT | 0.39 ± 0.19 TT | 0.31 ± 0.20 NN,II,U | 0.38 ± 0.17 T |
| Cond2 | 0.25 ± 0.12 | 0.23 ± 0.15 | 0.2 ± 0.12 | 0.21 ± 0.11 | Cond2 | 0.27 ± 0.12 TT | 0.28 ± 0.13 TT | 0.17 ± 0.08 NN,II,UU | 0.24 ± 0.12 TT |
| Cond3 | 0.34 ± 0.16 II,TT | 0.28 ± 0.19 NN | 0.24 ± 0.13 NN | 0.32 ± 0.18 | Cond3 | 0.33 ± 0.15 TT | 0.34 ± 0.17 TT | 0.24 ± 0.12 NN,II,UU | 0.32 ± 0.14 TT |
| Cond4 | 0.25 ± 0.11 I | 0.21 ± 0.1 N | 0.21 ± 0.1 | 0.22 ± 0.13 | Cond4 | 0.28 ± 0.10 TT | 0.28 ± 0.12 TT | 0.20 ± 0.12 NN,II,UU | 0.27 ± 0.09 TT |
| Cond5 | 0.20 ± 0.07 | 0.19 ± 0.07 | 0.17 ± 0.09 | 0.20 ± 0.08 | Cond5 | 0.23 ± 0.09 TT | 0.21 ± 0.11 | 0.18 ± 0.11 NN,II | 0.22 ± 0.12 |
| Cond6 | 0.27 ± 0.10 II,TT | 0.22 ± 0.11 NN | 0.20 ± 0.1 NN | 0.23 ± 0.13 | Cond6 | 0.26 ± 0.12 | 0.26 ± 0.13 | 0.23 ± 0.12 | 0.27 ± 0.12 |
References
- Cohen, H.; Heaton, L.G.; Congdon, S.L.; Jenkins, H.A. Changes in sensory organization test scores with age. Age Ageing 1996, 25, 39–44. [Google Scholar] [CrossRef] [PubMed]
- Virk, S.; McConville, K.M.V. Virtual reality applications in improving postural control and minimizing falls. In Proceedings of the 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 2694–2697. [Google Scholar]
- Derebery, M.J. The diagnosis and treatment of dizziness. Med. Clin. N. Am. 1999, 83, 163–177. [Google Scholar] [CrossRef] [PubMed]
- Bloem, B.R.; Visser, J.E.; Allum, J.H. Posturography. In Handbook of Clinical Neurophysiology; Elsevier: New York, NY, USA, 2003; Volume 1, pp. 295–336. [Google Scholar]
- Yeh, J.R.; Hsu, L.C.; Lin, C.; Chang, F.L.; Lo, M.T. Nonlinear analysis of sensory organization test for subjects with unilateral vestibular dysfunction. PLoS ONE 2014, 9, e91230. [Google Scholar] [CrossRef] [PubMed]
- Sosnoff, J.J.; Broglio, S.P.; Shin, S.; Ferrara, M.S. Previous mild traumatic brain injury and postural-control dynamics. J. Athl. Train. 2011, 46, 85–91. [Google Scholar] [CrossRef]
- Yeh, J.R.; Lo, M.T.; Chang, F.L.; Hsu, L.C. Complexity of human postural control in subjects with unilateral peripheral vestibular hypofunction. Gait Posture 2014, 40, 581–586. [Google Scholar] [CrossRef] [PubMed]
- Zammit, G.; Wang-Weigand, S.; Peng, X. Use of computerized dynamic posturography to assess balance in older adults after nighttime awakenings using zolpidem as a reference. BMC Geriatr. 2008, 8, 5–15. [Google Scholar] [CrossRef]
- Chaudhry, H.; Findley, T.; Quigley, K.S.; Bukiet, B.; Ji, Z.; Sims, T.; Maney, M. Measures of postural stability. J. Rehabil. Res. Dev. 2004, 41, 713–720. [Google Scholar] [CrossRef]
- Chaudhry, H.; Bukiet, B.; Ji, Z.; Findley, T. Measurement of balance in computer posturography: Comparison of methods—A brief review. J. Bodyw. Mov. Ther. 2011, 15, 82–91. [Google Scholar] [CrossRef]
- Doyle, R.J.; Hsiao-Wecksler, E.T.; Ragan, B.G.; Rosengren, K.S. Generalizability of center of pressure measures of quiet standing. Gait Posture 2007, 25, 166–171. [Google Scholar] [CrossRef]
- Cavanaugh, J.T.; Guskiewicz, K.M.; Stergiou, N. A nonlinear dynamic approach for evaluating postural control. Sports Med. 2005, 35, 935–950. [Google Scholar] [CrossRef]
- Van Emmerik, R.E.; Hamill, J.; McDermott, W.J. Variability and coordinative function in human gait. Quest 2005, 57, 102–123. [Google Scholar] [CrossRef]
- Apthorp, D.; Nagle, F.; Palmisano, S. Chaos in balance: Non-linear measures of postural control predict individual variations in visual illusions of motion. PLoS ONE 2014, 9, e113897. [Google Scholar] [CrossRef] [PubMed]
- Ivanenko, Y.; Gurfinkel, V.S. Human postural control. Front. Neurosci. 2018, 12, 171. [Google Scholar] [CrossRef] [PubMed]
- Torres, B.D.L.C.; López, M.S.; Cachadiña, E.S.; Orellana, J.N. Entropy in the analysis of gait complexity: A state of the art. Br. J. Appl. Sci. Technol. 2013, 3, 1097. [Google Scholar] [CrossRef]
- Cavanaugh, J.T.; Guskiewicz, K.M.; Giuliani, C.; Marshall, S.; Mercer, V.S.; Stergiou, N. Recovery of postural control after cerebral concussion: New insights using approximate entropy. J. Athl. Train. 2006, 41, 305. [Google Scholar]
- Delgado-Bonal, A.; Marshak, A. Approximate entropy and sample entropy: A comprehensive tutorial. Entropy 2019, 21, 541. [Google Scholar] [CrossRef]
- Pincus, S.M.; Goldberger, A.L. Physiological time-series analysis: What does regularity quantify? Am. J. Physiol. Heart Circ. Physiol. 1994, 266, H1643–H1656. [Google Scholar] [CrossRef]
- Gow, B.J.; Peng, C.K.; Wayne, P.M.; Ahn, A.C. Multiscale entropy analysis of center-of-pressure dynamics in human postural control: Methodological considerations. Entropy 2015, 17, 7926–7947. [Google Scholar] [CrossRef]
- Flandrin, P.; Goncalves, P.; Rilling, G. Detrending and denoising with empirical mode decompositions. In Proceedings of the 2004 12th European Signal Processing Conference, Vienna, Austria, 6–10 September 2004; pp. 1581–1584. [Google Scholar]
- Costa, M.; Priplata, A.; Lipsitz, L.; Wu, Z.; Huang, N.; Goldberger, A.L.; Peng, C.K. Noise and poise: Enhancement of postural complexity in the elderly with a stochastic-resonance–based therapy. EPL Europhys. Lett. 2007, 77, 68008. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning; Lulu Press: Morrisville, NC, USA, 2020. [Google Scholar]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Izenman, A.J. Linear discriminant analysis. In Modern Multivariate Statistical Techniques; Springer: New York, NY, USA, 2013; pp. 237–280. [Google Scholar]
- Somvanshi, M.; Chavan, P.; Tambade, S.; Shinde, S. A review of machine learning techniques using decision tree and support vector machine. In Proceedings of the 2016 International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 12–13 August 2016; pp. 1–7. [Google Scholar]
- LaValley, M.P. Logistic regression. Circulation 2008, 117, 2395–2399. [Google Scholar] [CrossRef] [PubMed]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Shapiro, S.S.; Wilk, M.B. An analysis of variance test for normality (complete samples). Biometrika 1965, 52, 591–611. [Google Scholar] [CrossRef]
- Raucci, U.; Vanacore, N.; Paolino, M.C.; Silenzi, R.; Mariani, R.; Urbano, A.; Reale, A.; Villa, M.P.; Parisi, P. Vertigo/dizziness in pediatric emergency department: Five years’ experience. Cephalalgia 2016, 36, 593–598. [Google Scholar] [CrossRef] [PubMed]
- Reneker, J.C.; Cheruvu, V.; Yang, J.; Cook, C.E.; James, M.A.; Moughiman, M.C.; Congeni, J.A. Differential diagnosis of dizziness after a sports-related concussion based on descriptors and triggers: An observational study. Inj. Epidemiol. 2015, 2, 22. [Google Scholar] [CrossRef] [PubMed]
- Staibano, P.; Lelli, D.; Tse, D. A retrospective analysis of two tertiary care dizziness clinics: A multidisciplinary chronic dizziness clinic and an acute dizziness clinic. J. Otolaryngol. Head Neck Surg. 2019, 48, 11. [Google Scholar] [CrossRef] [PubMed]
- Szczupak, M.; Hoffer, M.; Murphy, S.; Balaban, C. Posttraumatic dizziness and vertigo. Handb. Clin. Neurol. 2016, 137, 295–300. [Google Scholar]





| Models | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Patients > 47||Normal Balance vs. TBI | ||||
| LR | 72.74% | 72.22% | 81.25% | 76.47% |
| RF | 72.41% | 78.57% | 68.75% | 73.33% |
| LDA | 62.06% | 60.87% | 87.50% | 71.79% |
| SVM | 65.51% | 61.54% | 100.00% | 76.19% |
| All Patients || Normal Balance, Imbalance, TBI, UVW Right | ||||
| LR | 43.69% | 36.04% | 34.73% | 32.28% |
| RF | 40.34% | 32.50% | 31.28% | 30.31% |
| LDA | 42.86% | 34.44% | 33.85% | 32.07% |
| SVM | 39.49% | 32.06% | 31.29% | 29.91% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rojas, F.; Niazi, I.K.; Maturana-Russel, P.; Taylor, D. Exploring the Potential of Machine Learning for the Diagnosis of Balance Disorders Based on Centre of Pressure Analyses. Sensors 2022, 22, 9200. https://doi.org/10.3390/s22239200
Rojas F, Niazi IK, Maturana-Russel P, Taylor D. Exploring the Potential of Machine Learning for the Diagnosis of Balance Disorders Based on Centre of Pressure Analyses. Sensors. 2022; 22(23):9200. https://doi.org/10.3390/s22239200
Chicago/Turabian StyleRojas, Fredy, Imran Khan Niazi, Patricio Maturana-Russel, and Denise Taylor. 2022. "Exploring the Potential of Machine Learning for the Diagnosis of Balance Disorders Based on Centre of Pressure Analyses" Sensors 22, no. 23: 9200. https://doi.org/10.3390/s22239200
APA StyleRojas, F., Niazi, I. K., Maturana-Russel, P., & Taylor, D. (2022). Exploring the Potential of Machine Learning for the Diagnosis of Balance Disorders Based on Centre of Pressure Analyses. Sensors, 22(23), 9200. https://doi.org/10.3390/s22239200