



Computer Vision Based Pothole Detection under Challenging Conditions

Abstract
1. Introduction
The Importance of Pothole Detection
- Potholes begin to form when water flows into cracks and small holes in the road. These cracks and small holes are created due to road wear over time.
- The second stage is characterized by a change in temperature. When the temperature drops below freezing, the water freezes to ice and expands its volume. As a result, the road changes its shape and can rise.
- In the third stage, the road temperature rises during the day, the ice melts and the vehicles gradually disrupt the damaged road surface as they pass through.
2. Related Works
2.1. Sensors and 3D Reconstruction Techniques
2.2. Two-Dimensional Vision-Based Techniques
2.3. Road Damage Datasets
3. Materials and Methods
3.1. Dataset Development
- Vid—video frames were extracted and saved to images.
- day_ID—videos were captured on different days.
- direction—data collection was performed in both directions that are marked as Ca and Pr. The designation Ca represents images recorded in the forward direction, and the designation Pr represents images recorded in the opposite direction. The abbreviations are based on the naming of local areas.
- frame_ID—video frame identifier.
3.2. Yolo v3
3.3. Evaluation Metrics
4. Results
- Yolo v3 Tiny,
- Yolo v3,
- Yolo v3-SPP.
4.1. Yolo v3
4.2. Yolo v3-SPP
4.3. Sparse R-CNN
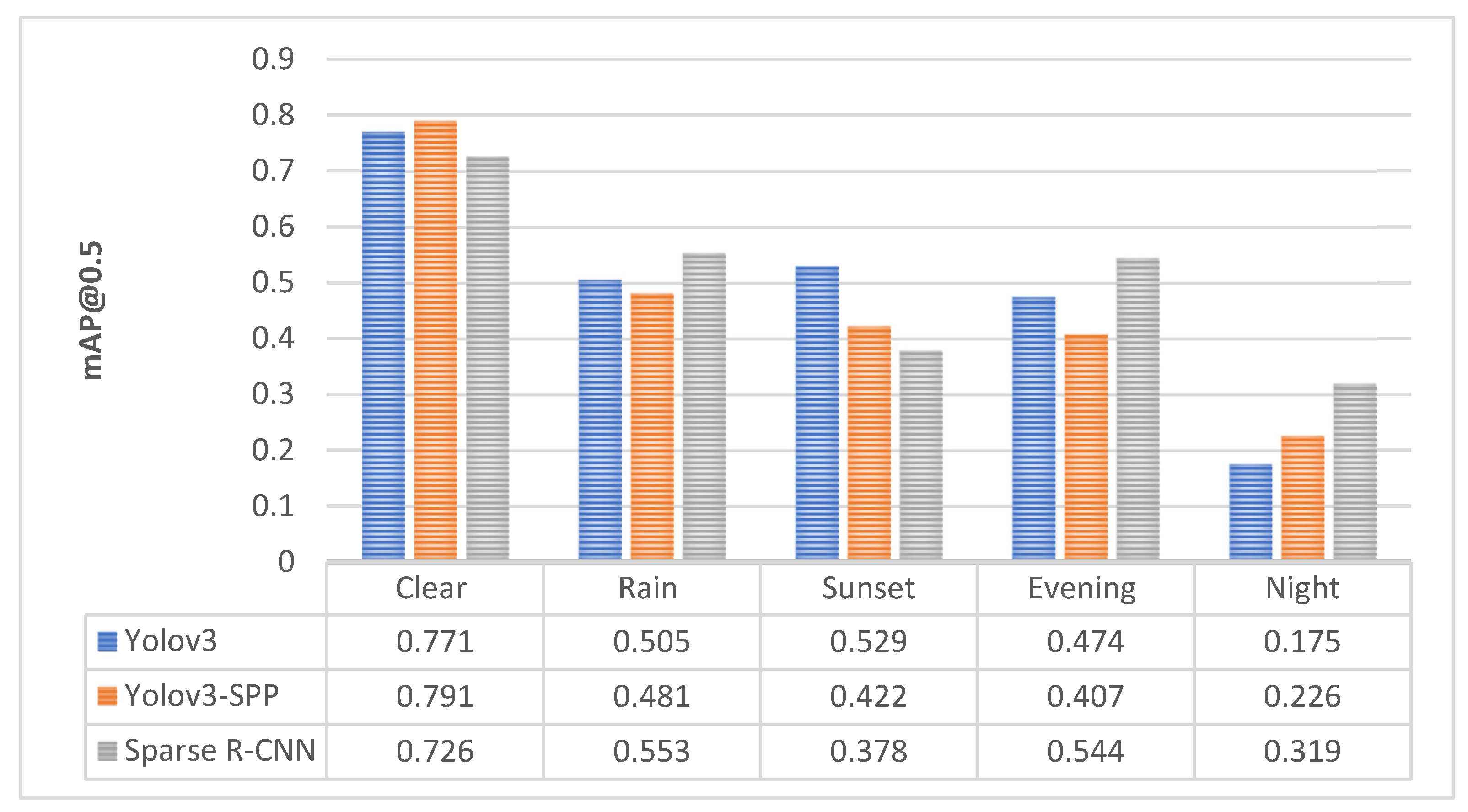
5. Discussion
6. Conclusions
Author Contributions
Funding

Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Celko, J.; Drliciak, M.; Gavulova, A. Transportation Planning Model. Commun. Sci. Lett. Univ. Zilina 2007, 9, 28–32. [Google Scholar] [CrossRef]
- Cingel, M.; Čelko, J.; Drličiak, M. Analysis in Modal Split. Transp. Res. Procedia 2019, 40, 178–185. [Google Scholar] [CrossRef]
- Safe Driving on Roads with Potholes and Avoiding Pothole Damage. Available online: https://www.arrivealive.mobi/Safe-Driving-on-Roads-with-Potholes-and-Avoiding-Pothole-Damage (accessed on 7 April 2022).
- Automotive Engineering—Fact Sheet. Available online: https://publicaffairsresources.aaa.biz/wp-content/uploads/2016/02/Pothole-Fact-Sheet.pdf (accessed on 27 September 2022).
- Lacinák, M. Resilience of the Smart Transport System—Risks and Aims. Transp. Res. Procedia 2021, 55, 1635–1640. [Google Scholar] [CrossRef]
- Guzmán, R.; Hayet, J.-B.; Klette, R. Towards Ubiquitous Autonomous Driving: The CCSAD Dataset. In Proceedings of the Computer Analysis of Images and Patterns, Valletta, Malta, 2–4 September 2015; Azzopardi, G., Petkov, N., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 582–593. [Google Scholar]
- Yu, X.; Marinov, M. A Study on Recent Developments and Issues with Obstacle Detection Systems for Automated Vehicles. Sustainability 2020, 12, 3281. [Google Scholar] [CrossRef]
- Avoiding Pothole Damage to Your Vehicle|MOOG Parts. Available online: https://www.moogparts.com/parts-matter/surviving-pothole-season.html (accessed on 29 March 2022).
- Analýza—Problematické Podnety—Opravy Miestnych Komunikácii. Available online: https://www.governance.sk/gov_publication/analyza-problematicke-podnety-opravy-miestnych-komunikacii/ (accessed on 5 April 2022).
- Ahmed, K.R. Smart Pothole Detection Using Deep Learning Based on Dilated Convolution. Sensors 2021, 21, 8406. [Google Scholar] [CrossRef]
- Pena-Caballero, C.; Kim, D.; Gonzalez, A.; Castellanos, O.; Cantu, A.; Ho, J. Real-Time Road Hazard Information System. Infrastructures 2020, 5, 75. [Google Scholar] [CrossRef]
- Ochoa-Ruiz, G.; Angulo-Murillo, A.A.; Ochoa-Zezzatti, A.; Aguilar-Lobo, L.M.; Vega-Fernández, J.A.; Natraj, S. An Asphalt Damage Dataset and Detection System Based on RetinaNet for Road Conditions Assessment. Appl. Sci. 2020, 10, 3974. [Google Scholar] [CrossRef]
- Chen, H.; Yao, M.; Gu, Q. Pothole Detection Using Location-Aware Convolutional Neural Networks. Int. J. Mach. Learn. Cybern. 2020, 11, 899–911. [Google Scholar] [CrossRef]
- Park, S.-S.; Tran, V.-T.; Lee, D.-E. Application of Various YOLO Models for Computer Vision-Based Real-Time Pothole Detection. Appl. Sci. 2021, 11, 11229. [Google Scholar] [CrossRef]
- Du, F.-J.; Jiao, S.-J. Improvement of Lightweight Convolutional Neural Network Model Based on YOLO Algorithm and Its Research in Pavement Defect Detection. Sensors 2022, 22, 3537. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Wu, Y.; Luo, X.; Yuan, Y. Automatic Defect Detection of Pavement Diseases. Remote Sens. 2022, 14, 4836. [Google Scholar] [CrossRef]
- Wang, H.-W.; Chen, C.-H.; Cheng, D.-Y.; Lin, C.-H.; Lo, C.-C. A Real-Time Pothole Detection Approach for Intelligent Transportation System. Math. Probl. Eng. 2015, 2015, e869627. [Google Scholar] [CrossRef]
- Harikrishnan, P.M.; Gopi, V.P. Vehicle Vibration Signal Processing for Road Surface Monitoring. IEEE Sens. J. 2017, 17, 5192–5197. [Google Scholar] [CrossRef]
- Li, X.; Goldberg, D.W. Toward a Mobile Crowdsensing System for Road Surface Assessment. Comput. Environ. Urban Syst. 2018, 69, 51–62. [Google Scholar] [CrossRef]
- Singh, G.; Bansal, D.; Sofat, S.; Aggarwal, N. Smart Patrolling: An Efficient Road Surface Monitoring Using Smartphone Sensors and Crowdsourcing. Pervasive Mob. Comput. 2017, 40, 71–88. [Google Scholar] [CrossRef]
- Wu, C.; Wang, Z.; Hu, S.; Lepine, J.; Na, X.; Ainalis, D.; Stettler, M. An Automated Machine-Learning Approach for Road Pothole Detection Using Smartphone Sensor Data. Sensors 2020, 20, 5564. [Google Scholar] [CrossRef]
- Aparna; Bhatia, Y.; Rai, R.; Gupta, V.; Aggarwal, N.; Akula, A. Convolutional Neural Networks Based Potholes Detection Using Thermal Imaging. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 578–588. [Google Scholar] [CrossRef]
- Palčák, M.; Kudela, P.; Fandáková, M.; Kordek, J. Utilization of 3D Digital Technologies in the Documentation of Cultural Heritage: A Case Study of the Kunerad Mansion (Slovakia). Appl. Sci. 2022, 12, 4376. [Google Scholar] [CrossRef]
- Zhang, Z.; Ai, X.; Chan, C.K.; Dahnoun, N. An Efficient Algorithm for Pothole Detection Using Stereo Vision. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; pp. 564–568. [Google Scholar]
- Brna, M.; Cingel, M. Comparison of Pavement Surface Roughness Characteristics of Different Wearing Courses Evaluated Using 3D Scanning and Pendulum. MATEC Web Conf. 2020, 313, 00013. [Google Scholar] [CrossRef][Green Version]
- Danti, A.; Kulkarni, J.Y.; Hiremath, P. An Image Processing Approach to Detect Lanes, Pot Holes and Recognize Road Signs in Indian Roads. Int. J. Model. Optim. 2012, 2, 658–662. [Google Scholar] [CrossRef]
- Nienaber, S.; Booysen, M.J.; Kroon, R. Detecting Potholes Using Simple Image Processing Techniques and Real-World Footage. In Proceedings of the 34th Annual Southern African Transport Conference SATC, Pretoria, South Africa, 6–9 July 2015. [Google Scholar]
- Arulprakash, E.; Aruldoss, M. A Study on Generic Object Detection with Emphasis on Future Research Directions. J. King Saud Univ.-Comput. Inf. Sci. 2021, 34, 7347–7365. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. aRxiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G. Yolov5. Available online: https://github.com/ultralytics/yolov5 (accessed on 5 April 2022).
- Rahman, A.; Patel, S. Annotated Potholes Image Dataset. Available online: https://www.kaggle.com/chitholian/annotated-potholes-dataset (accessed on 30 March 2022).
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection Using Deep Neural Networks with Images Captured Through a Smartphone. Comput.-Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Lin, Y.-C.; Chen, W.-H.; Kuo, C.-H. Implementation of Pavement Defect Detection System on Edge Computing Platform. Appl. Sci. 2021, 11, 3725. [Google Scholar] [CrossRef]
- Arya, D.; Maeda, H.; Ghosh, S.K.; Toshniwal, D.; Sekimoto, Y. RDD2020: An Annotated Image Dataset for Automatic Road Damage Detection Using Deep Learning. Data Brief 2021, 36, 107133. [Google Scholar] [CrossRef]
- Jo, Y.; Ryu, S. Pothole Detection System Using a Black-Box Camera. Sensors 2015, 15, 29316–29331. [Google Scholar] [CrossRef]
- Chitale, P.A.; Kekre, K.Y.; Shenai, H.R.; Karani, R.; Gala, J.P. Pothole Detection and Dimension Estimation System Using Deep Learning (YOLO) and Image Processing. In Proceedings of the 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020; pp. 1–6. [Google Scholar]
- Potholes Dataset|MakeML—Create Neural Network with Ease. Available online: https://makeml.app/datasets/potholes (accessed on 11 April 2022).
- Angulo, A.A.; Vega-Fernández, J.A.; Aguilar-Lobo, L.M.; Natraj, S.; Ochoa-Ruiz, G. Road Damage Detection Acquisition System Based on Deep Neural Networks for Physical Asset Management. In Proceedings of the Mexican International Conference on Artificial Intelligence, Xalapa, Mexico, 27 October–2 November 2019. [Google Scholar]
- RDD2022: A Multi-National Image Dataset for Automatic Road Damage Detection. Available online: https://deepai.org/publication/rdd2022-a-multi-national-image-dataset-for-automatic-road-damage-detection (accessed on 20 October 2022).
- Pothole Detection Using Computer Vision in Challenging Conditions. Available online: https://doi.org/10.6084/m9.figshare.21214400.v3 (accessed on 27 September 2022). [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the Computer Vision—ECCV, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 346–361. [Google Scholar]
- The PASCAL Visual Object Classes Challenge 2010 (VOC2010). Available online: http://host.robots.ox.ac.uk/pascal/VOC/voc2010/ (accessed on 23 May 2022).
- COCO—Common Objects in Context. Available online: https://cocodataset.org/#detection-eval (accessed on 26 July 2022).
- Jocher, G. Yolov3. Available online: https://github.com/ultralytics/yolov3 (accessed on 5 April 2022).
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals 2021. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- MMdetection. Available online: https://github.com/open-mmlab/mmdetection (accessed on 5 April 2022).
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| References | Year | Model | Image Resolution | Inference Speed | Precision | AP@ [0.5:0.95] | AP@0.5 |
|---|---|---|---|---|---|---|---|
| Maeda et al. [38] | 2018 | SSD using Inception V2 | 300 × 300 | 16 FPS | 67% | – | – |
| SSD MobileNet | 300 × 300 | 33 FPS | 99% | – | – | ||
| Pena-Caballero et al. [11] | 2020 | SSD300 MobileNetV2 | 300 × 300 | – | – | – | 45.10% |
| Yolo v2 | – | – | – | – | 90.00% | ||
| Yolo v3 | – | – | – | – | 98.82% | ||
| Chen et al. [13] | 2020 | LACNN | – | 49 FPS | 95.2% | – | – |
| Ahmed [10] | 2021 | YoloR-W6 | 1774 × 2365 | 31 FPS | – | 44.6% | – |
| Faster R-CNN: MVGG16 | 1774 × 2365 | 21 FPS | 81.4% | 45.4% | – | ||
| Yolo v5 (Ys) | 1774 × 2365 | 111 FPS | 76.73% | 58.9% | – | ||
| Faster R-CNN: ResNet50 | 1774 × 2365 | 10 FPS | 91.9% | 64.12% | – | ||
| Lin et al. [39] | 2021 | Yolo v3 | 416 × 416 | 35 FPS | – | – | 71% |
| Park et al. [14] | 2021 | Yolo v5s | 720 × 720 | – | 82% | – | 74.8% |
| Yolo v4 | 720 × 720 | – | 84% | – | 77.7% | ||
| Yolo v4-tiny | 720 × 720 | – | 84% | – | 78.7% |
| References | Year | Model | Image Resolution | Inference Speed | mAP@0.5 |
|---|---|---|---|---|---|
| Pena-Caballero et al. [11] | 2020 | SSD300 MobileNetV2 | 300 × 300 | – | 41.83% |
| Yolo v2 | – | – | 69.58% | ||
| Yolo v3 | – | – | 97.98% | ||
| Lin et al. [39] | 2021 | MobileNet-Yolo | 416 × 416 | 40 FPS | 2.27% |
| TF-Yolo | 416 × 416 | 28 FPS | 2.66% | ||
| Yolo v3 | 416 × 416 | 35 FPS | 68.06% | ||
| RetinaNet | 416 × 416 | 30 FPS | 73.75% | ||
| Yolo v4 | 416 × 416 | 35 FPS | 80.08% | ||
| Yolo v4 | 618 × 618 | 30 FPS | 81.05% | ||
| Du & Jiao [15] | 2022 | Yolo v3-Tiny | 640 × 640 | 167 FPS | 59.4% |
| Yolo v5S | 640 × 640 | 238 FPS | 60.5% | ||
| B-Yolo v5S | 640 × 640 | 278 FPS | 62.6% | ||
| BV-Yolo v5S | 640 × 640 | 263 FPS | 63.5% |
| Database | Year | Num. of Images | Num. of Instances | Num. of Classes |
|---|---|---|---|---|
| MakeML [43] | – | 665 | – | 1 |
| MIIA Pothole Dataset [27] | 2015 | 2459 | – | 1 |
| Road Damage Dataset [38] | 2018 | 9053 | 15,435 | 8 |
| Road Surface Damages [44] (Extended [38]) | 2019 | 18,345 | 45,435 | 8 |
| Pothole Detection Dataset [42] | 2020 | 1243 | – | 1 |
| RDD2020 [40] | 2020 | 26,336 | >31,000 | 4 |
| RDD2022 [45] | 2022 | 38,385 | 55,007 | 4 |
| Database | Categories of Road Damage |
|---|---|
| Road Damage Dataset [38] |
|
| RDD2020 [40] |
|
| Pena-Caballero et al. [11] |
|
| Data | Num. of Images | Num. of Instances | Potholes | Manhole Covers |
|---|---|---|---|---|
| Clear | 1052 | 2128 | 1896 | 232 |
| Rain | 286 | 458 | 383 | 75 |
| Sunset | 201 | 404 | 364 | 40 |
| Evening | 250 | 339 | 286 | 53 |
| Night | 310 | 262 | 220 | 42 |
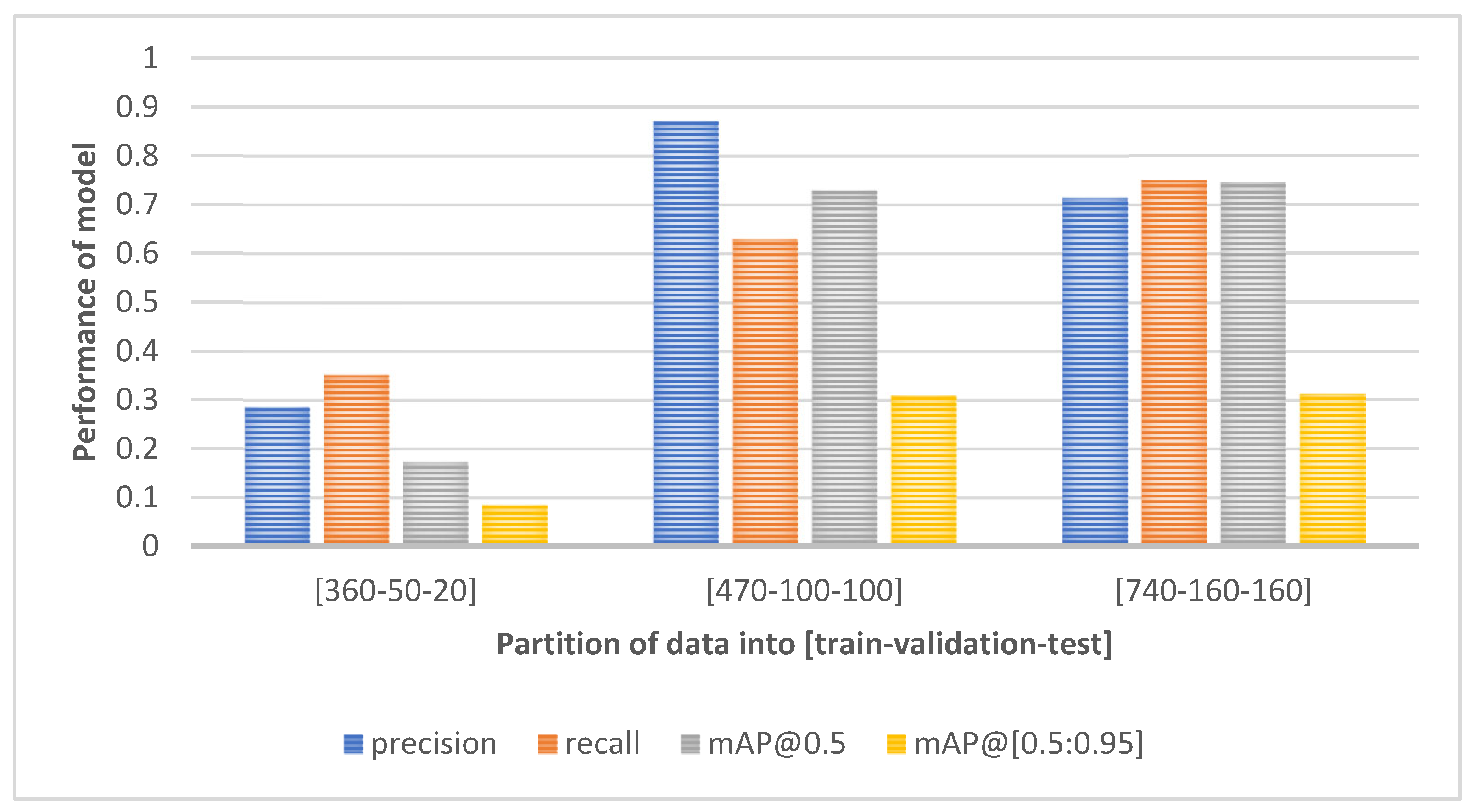
| Model | Image Resolution | Pretrained Weights | Data Augmentation | Precision | Recall | mAP@ 0.5 | mAP@ [0.5:0.95] | Inference Speed |
|---|---|---|---|---|---|---|---|---|
| Yolo v3 | 640 × 640 | ✕ | ✕ | 0.434 | 0.346 | 0.285 | 0.092 | ~35 ms |
| 640 × 640 | ✓ | ✕ | 0.789 | 0.512 | 0.563 | 0.202 | ~35 ms | |
| 640 × 640 | ✕ | ✓ | 0.708 | 0.684 | 0.681 | 0.268 | ~35 ms | |
| 640 × 640 | ✓ | ✓ | 0.713 | 0.751 | 0.747 | 0.314 | ~35 ms | |
| 1080 × 1080 | ✓ | ✓ | 0.777 | 0.771 | 0.771 | 0.330 | ~82 ms | |
| Yolo v3-SPP | 640 × 640 | ✓ | ✓ | 0.812 | 0.663 | 0.711 | 0.286 | ~36 ms |
| 1080 × 1080 | ✓ | ✓ | 0.821 | 0.700 | 0.791 | 0.354 | ~84 ms |
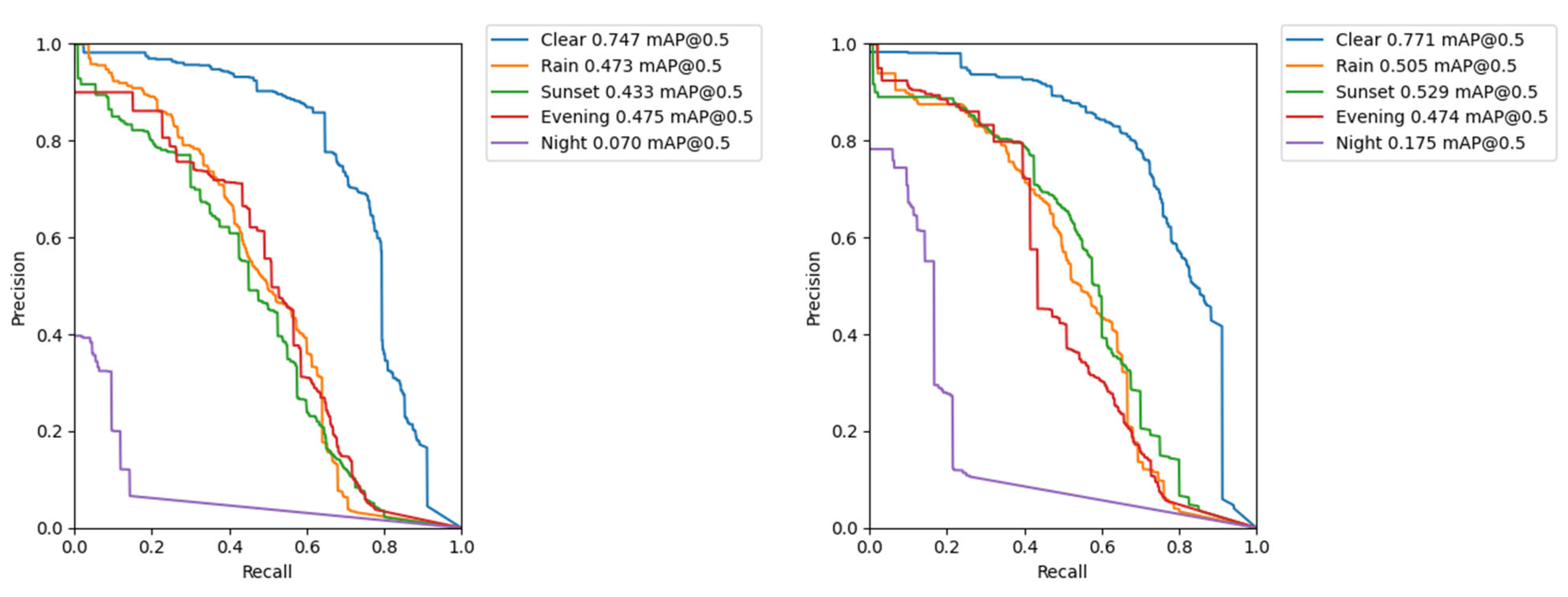
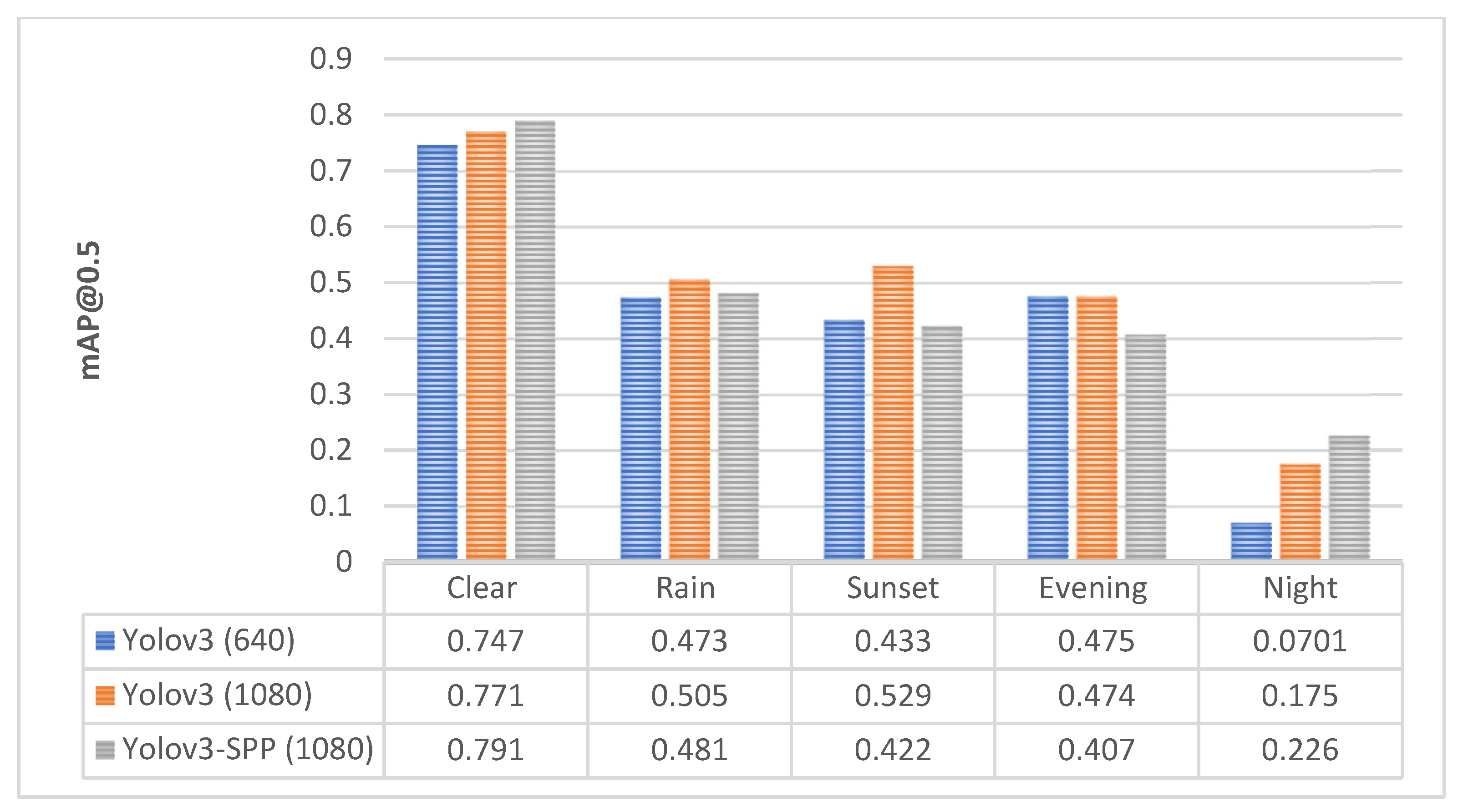
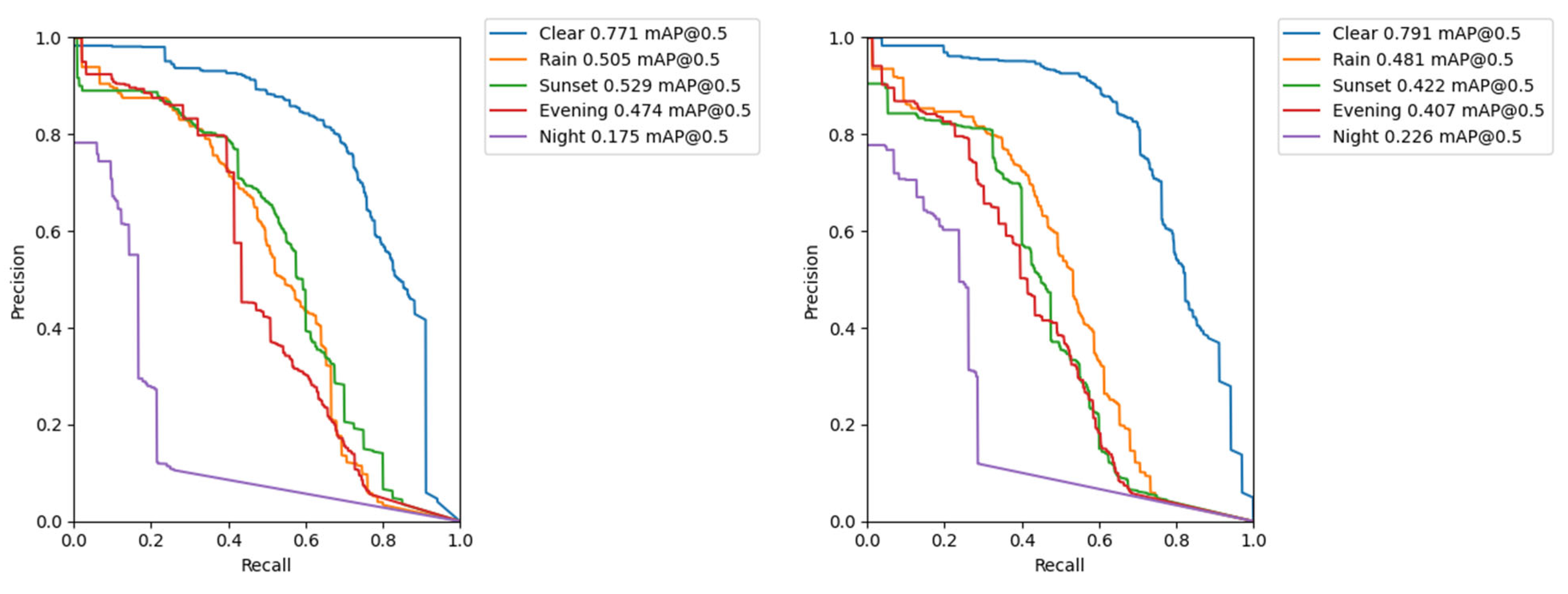
| Data Subset | Class | Image Resolution | Precision | Recall | mAP@0.5 | mAP@ [0.5:0.95] |
|---|---|---|---|---|---|---|
| Clear | All | 1080 × 1080 | 0.777 | 0.771 | 0.771 | 0.33 |
| Potholes | 0.726 | 0.69 | 0.703 | 0.262 | ||
| Covers | 0.828 | 0.852 | 0.839 | 0.398 | ||
| Rain | All | 1080 × 1080 | 0.613 | 0.519 | 0.505 | 0.199 |
| Potholes | 0.445 | 0.465 | 0.396 | 0.145 | ||
| Covers | 0.782 | 0.573 | 0.614 | 0.254 | ||
| Sunset | All | 1080 × 1080 | 0.694 | 0.496 | 0.529 | 0.194 |
| Potholes | 0.537 | 0.418 | 0.399 | 0.133 | ||
| Covers | 0.852 | 0.575 | 0.659 | 0.256 | ||
| Evening | All | 1080 × 1080 | 0.742 | 0.483 | 0.474 | 0.182 |
| Potholes | 0.609 | 0.57 | 0.518 | 0.194 | ||
| Covers | 0.874 | 0.396 | 0.429 | 0.17 | ||
| Night | All | 1080 × 1080 | 0.36 | 0.157 | 0.175 | 0.062 |
| Potholes | 0.36 | 0.1 | 0.145 | 0.0493 | ||
| Covers | 0.36 | 0.214 | 0.204 | 0.0746 |
| Model | Precision | Recall | mAP@0.5 | mAP@ [0.5:0.95] | Elapsed Time: Test | Model Size |
|---|---|---|---|---|---|---|
| Yolo v3 | 0.777 | 0.771 | 0.771 | 0.330 | 24 s | 123.7 MB |
| Yolo v3-SPP | 0.821 | 0.700 | 0.791 | 0.354 | 25 s | 125.8 MB |
| Sparse R-CNN | – | – | 0.726 | 0.321 | 31 s | 415 MB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bučko, B.; Lieskovská, E.; Zábovská, K.; Zábovský, M. Computer Vision Based Pothole Detection under Challenging Conditions. Sensors 2022, 22, 8878. https://doi.org/10.3390/s22228878
Bučko B, Lieskovská E, Zábovská K, Zábovský M. Computer Vision Based Pothole Detection under Challenging Conditions. Sensors. 2022; 22(22):8878. https://doi.org/10.3390/s22228878
Chicago/Turabian StyleBučko, Boris, Eva Lieskovská, Katarína Zábovská, and Michal Zábovský. 2022. "Computer Vision Based Pothole Detection under Challenging Conditions" Sensors 22, no. 22: 8878. https://doi.org/10.3390/s22228878
APA StyleBučko, B., Lieskovská, E., Zábovská, K., & Zábovský, M. (2022). Computer Vision Based Pothole Detection under Challenging Conditions. Sensors, 22(22), 8878. https://doi.org/10.3390/s22228878