1. Introduction
Traffic accidents have been around since Karl Benz invented the car. With the development of society and economy, the number of cars is increasing, which has led to the increase in traffic congestion and traffic accidents. The research suggests that more than 90% of traffic accidents are caused by human factors [
1]. Among them, a survey of the AAA Foundation for Traffic Safety shows that about 55.7% of fatal traffic accidents were associated with aggressive driving behavior (ADB) [
2], and there is a positive correlation between ADB and the probability of traffic accidents [
3,
4]. As one of the main causes of traffic accidents, ADB is affected by situational factors such as traffic congestion [
5,
6] and personal factors such as negative emotions [
7]. Due to the increasingly crowded traffic system and the accelerated pace of life, it is easier for drivers to exhibit ADB, so it is urgent to accurately recognize ADB. However, there is no uniform definition of ADB. ADB was mostly defined from the perspective of traffic psychology in existing studies as a syndrome of frustration-driven instrumental behaviors, that is, deliberately dangerous driving to save time at the expense of others [
8]; the driving behavior that is likely to increase the risk of collision, and is motivated by impatience, annoyance, hostility, and/or an attempt to save time [
9]; or any driving behavior that intentionally (whether fueled by anger or frustration or as a calculated means to an end) endangers others psychologically, physically, or both [
10]. The above definition based on traffic psychology is beneficial for people to understand the causes of ADB, but it is difficult to be directly applied to the recognition of ADB. Therefore, for the accurate recognition of ADB, we define ADB as driving behaviors where a driver intentionally harms another driver in any form, which are typically manifested as abnormal acceleration, abnormal deceleration, abnormal lane change, and tailgating.
In recent years, some studies were conducted on the recognition of ADB, which can be divided into studies based on simulated driving datasets [
11,
12,
13,
14] and studies based on naturalistic driving datasets [
15,
16,
17,
18,
19,
20,
21,
22,
23], according to the different datasets utilized. The simulated driving experiment is commonly used in studies on ADB due to its high level of safety. Wang et al. used a semi-supervised support vector machine to divide the driving style between aggressive driving style and normal driving style based on the vehicle dynamic parameters collected in simulated driving experiments [
11]. Danaf et al. proposed a hybrid model for aggressive driving analysis and prediction based on the state-trait anger theory, which was verified using simulated driving experiment data [
12]. Fitzpatrick et al. studied the influence of time pressure on ADB based on simulated driving experiments [
13]. Kerwin et al. concluded that people with high trait anger tend to view many driving behaviors as aggressive, based on the ratings of the videos taken by 198 participants on a driving simulator [
14]. Compared with the naturalistic driving experiment, the simulated driving experiment is safer and provides easier control of the experimental conditions. However, there is a certain difference between the data collected through the simulation driving experiment and those collected in the actual traffic environment, which may lead to the problems of low recognition accuracy and high miss rate when the relevant recognition methods are applied to the actual environment. With the development and popularization of vehicle sensor technology and computing platforms, the research on ADB based on naturalistic driving datasets has gradually increased. Ma et al. developed an online approach for aggressive driving recognition using the kinematic parameters that were collected by the in-vehicle recorder under naturalistic driving conditions [
15]. Feng et al. verified the performance of the vehicle jerk for recognizing ADB through naturalistic driving data [
16].
Both naturalistic driving and simulated driving can provide considerable datasets, which provide the conditions for the studies of ADB recognition based on data-driven methods. Compared with the theory-driven methods, the data-driven methods [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26] are naturally suitable for accurately recognizing the complex behaviors in the actual environment because of their capacity to explore the inherent correlations of the captured data warning [
27,
28] and have been applied in the studies of ADB recognition [
17,
18,
19,
20,
21,
22,
23]. Zylius used time and frequency domain features extracted from accelerometer data to build a random forest classifier to recognize aggressive driving styles [
17]. Ma et al. used the vehicle motion data collected by the smartphone sensors to compare the recognition performance of the Gaussian mixture model, partial least squares regression, wavelet transformation, and support vector regression on ADB [
18]. Carlos et al. used the bag of words method to extract features from accelerometer data and built the models of ADB recognition based on multilayer perceptron, random forest, naive Bayes classifier, and K-nearest neighbor algorithm [
19]. Although the recognition of ADB can be realized based on the above methods, a large number of data preprocessing and feature engineering are required in the modeling of time series. In recent years, many deep learning methods have proved to be an effective solution to time series modeling due to their capacity to automatically learn the temporal dependencies present in time series [
29]. These deep learning methods have already been applied in the research of ADB recognition [
20,
21,
22,
23]. Moukafih et al. proposed a recognition method of ADB based on long short-term memory full convolutional network (LSTM-FCN), and the results showed that the performance of this method is better than some traditional machine learning methods [
20]. Matousek et al. realized the recognition of ADB based on long short-term memory (LSTM) and replicator neural network (RNN) [
21]. Shahverdy et al. recognized normal, aggressive, distracted, drowsy, and drunk driving styles based on convolutional neural networks (CNN) [
22]. Khodairy achieved the recognition of ADB based on stacked long short-term memory (stacked-LSTM) [
23].
Although the methods used in the above studies have realized the recognition of ADB, there are still some disadvantages. These methods usually assume that the distribution of the classes in the dataset is relatively balanced and the cost of misclassification is equal. Therefore, these methods cannot properly represent the distribution characteristics of the classes when dealing with class imbalance datasets, which leads to poor recognition performance [
30,
31,
32,
33]. Unfortunately, the samples of ADB are usually less than the samples of normal driving behavior (NDB) in the naturalistic driving datasets, which leads these methods to focus on correctly predicting NDB, while ignoring ADB as a minority class. Ensemble learning refers to the methods of training and combining multiple classifiers to complete specific machine learning tasks, which is considered as a solution to the class imbalance problem of machine learning [
34]. By combining multiple classifiers, the error of a single classifier may be compensated by other classifiers. Therefore, the recognition performance of the ensemble classifier is usually better than that of a single classifier [
34].
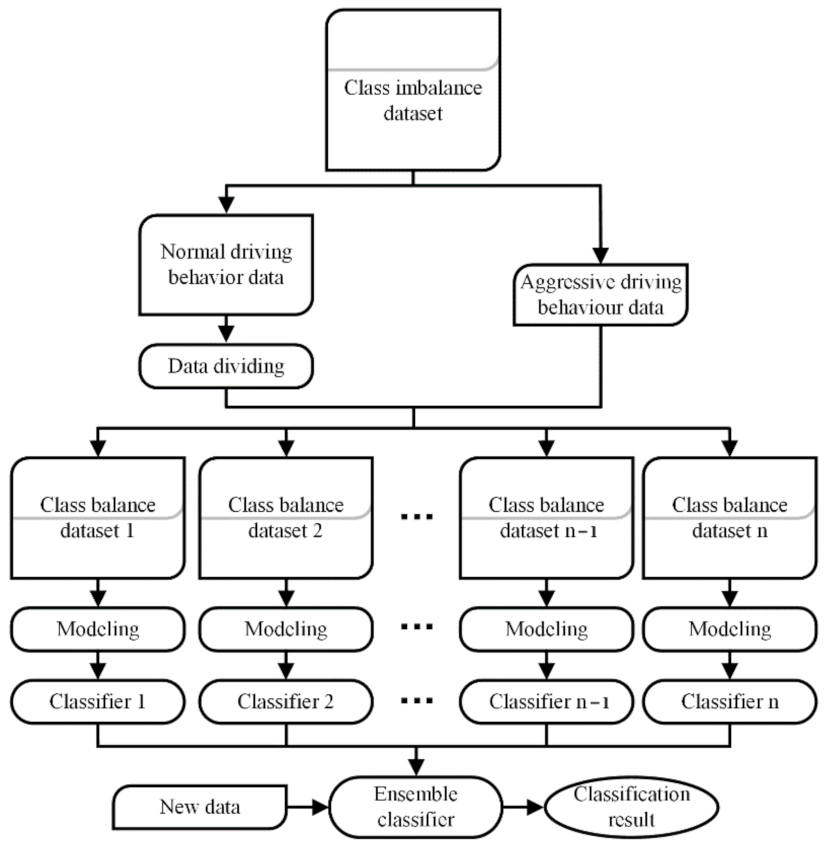
According to the above analysis, we propose a recognition method of ADB based on ensemble learning. In this method, the majority class data in the dataset is first divided into multiple groups, and each group of data is combined with the minority class data to construct the class balance dataset; next, the base classifiers are built based on the class balance datasets; finally, the base classifiers are combined based on different ensemble rules to build ensemble classifiers. The salient contributions of our work to the research of ADB recognition can be summarized as follows:
The acquisition of multi-source naturalistic driving data: combined with the development status of intelligent and connected technology, an integrated experimental vehicle for driving behavior and safety based on the multi-sensor array is constructed. Based on this integrated experimental vehicle, a real vehicle experiment is designed and completed, and a naturalistic driving dataset containing ADB data is acquired;
The research of the recognition performance of ensemble classifiers: to solve the problem of the poor recognition performance of machine learning method for the ADB data as a minority class in the dataset, a recognition method of ADB based on ensemble learning is proposed.
The rest of this paper is organized as follows.
Section 2 introduces the composition of the integrated experimental vehicle for driving behavior and safety, the scheme of the real vehicle experiment, and the method of the data processing.
Section 3 introduces the recognition method of ADB based on ensemble learning.
Section 4 introduces the comparison results and discussion of the performance of the established ADB identification method and three typical deep learning methods.
Section 5 presents the conclusion of this research.
2. Data Acquisition and Processing
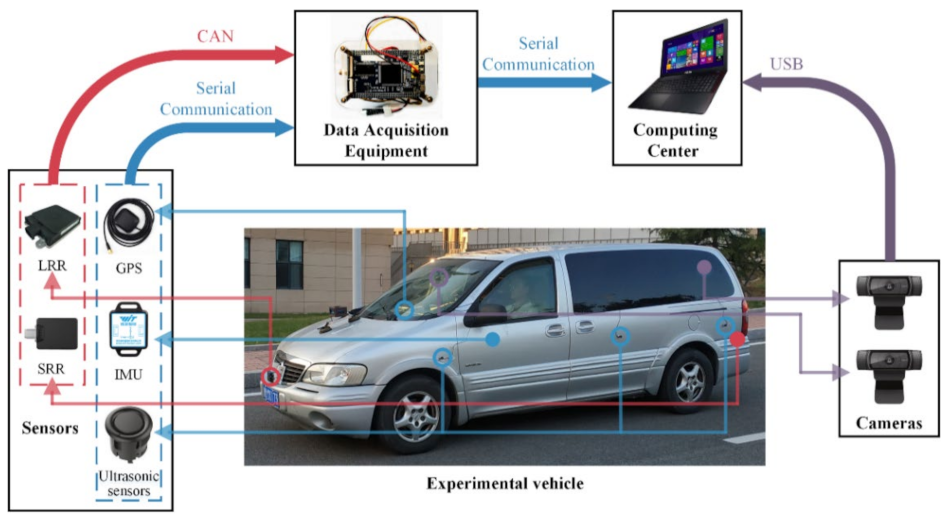
In order to acquire the dataset suitable for the training and verification of the ADB recognition method based on ensemble learning, an integrated experimental vehicle for driving behavior and safety was constructed. As shown in
Figure 1, the integrated experimental vehicle consists of the sensors, the data acquisition device, the cameras, the computing center, and the experimental vehicle. The functions of each component of the integrated experimental vehicle are shown in
Table 1. The sensors used in the integrated experimental vehicle include long range radar (LRR), short range radar (SRR), inertial measurement unit (IMU), global positioning system (GPS), and an ultrasonic sensor. The functions and installation positions of the above sensors are shown in
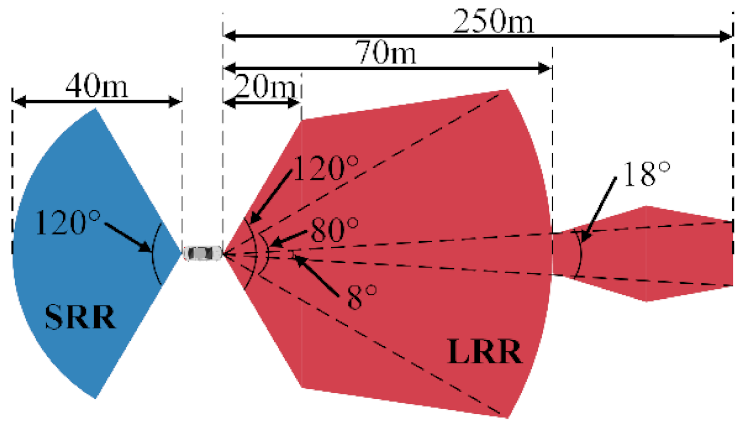
Table 2. The detection range of the LRR and SRR are shown in
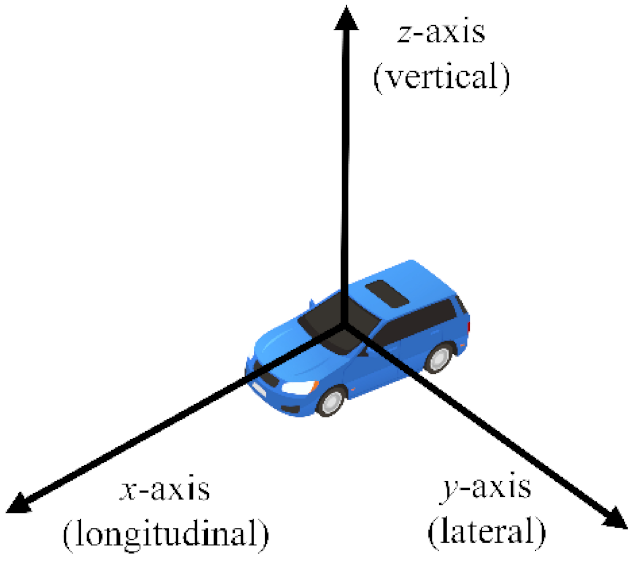
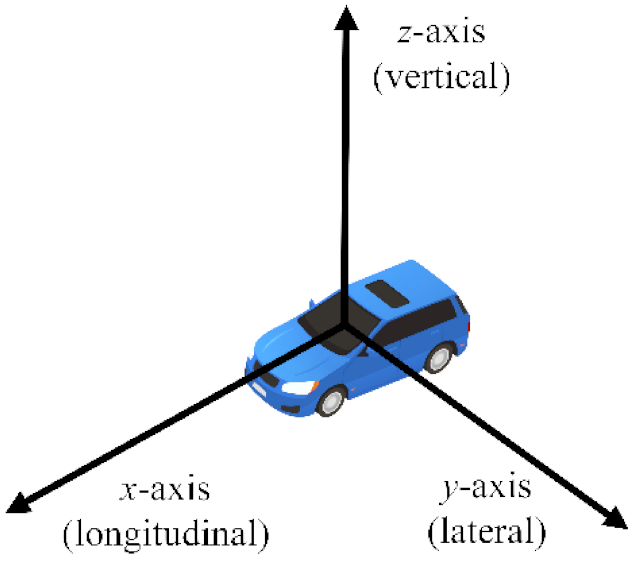
Figure 2. The coordinates of the IMU are shown in
Figure 3.
The vehicle motion parameters and the driving environment parameters are collected at 10 Hz through the integrated experimental vehicle. The vehicle motion parameters include speed, acceleration, yaw rate, etc. Driving environment parameters include the distance and the relative speed between the integrated experimental vehicle and the objects, etc.
Six consecutive weeks of real vehicle experiment was conducted based on the integrated experimental vehicle for driving behavior and safety. The real vehicle experiment was conducted on one working day and one non-working day every week, and the data acquired every day included the data in rush hour and non-rush hour. Sixteen drivers were selected, including thirteen males and three females, to take part in the experiment. The age distribution of the drivers was between 23 and 50 years, and the average age was 28.9 years old. The driving age distribution was between 2 and 20 years, and the average driving age was 5.3 years. As shown in
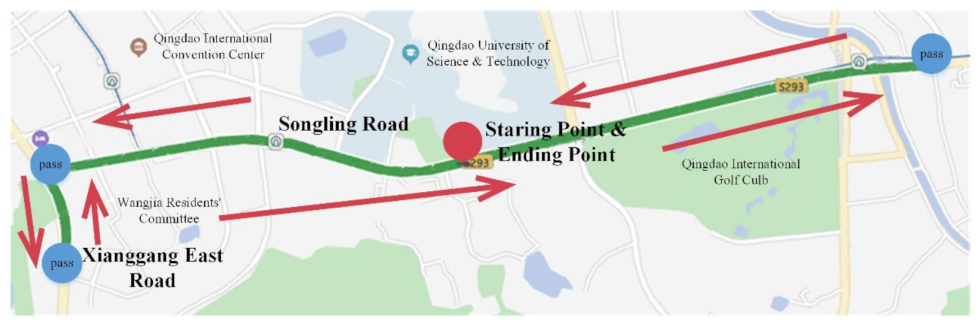
Figure 4, the road sections of Songling Road-Xianggang East Road in Laoshan, Qingdao were selected as the real vehicle experimental route. The route is a two-direction six-lane urban road with a total length of about 12 km.
According to the aforementioned definition of ADB and previous studies, the longitudinal acceleration, lateral acceleration, yaw rate, distance between the experimental vehicle and the front vehicle, and relative speed between the experimental vehicle and the front vehicle were selected as the features of ADB. The above features are listed in
Table 3. Among them,
is related to abnormal acceleration and deceleration, because the abnormal acceleration and deceleration are usually manifested as large longitudinal acceleration and deceleration;
and
are related to abnormal lane changes because abnormal lane changes are usually manifested as large lateral accelerations and the large yaw rate; and
and
are related to the tailgating.
The essence of ADB recognition is a problem of the time series classification. Therefore, before building the model, a sliding window of fixed length is utilized to segment the data into overlapping series [
23,
35,
36]. The length of the sliding window should be longer than the duration of the four abnormal driving events recorded in our experiment. However, the difference between the ADB series and the NDB series may be reduced if the sliding window is too long, which will lead to an increase in the miss rate and a decrease in the recognition accuracy. To balance the recognition and real-time performance of the recognition method of ADB, a sliding window with 50 time steps and 80% overlap is selected to process the raw data after several iterations of experiments.
Because the features we selected have different scales, the z-score is used to standardize the features, and the definition is shown in Equation (1).
where
is the unstandardized data,
is the mean of the feature vector,
is the standard deviation of the feature vector, and
is the standardized data.
After the above processing steps, a class imbalance dataset consisting of 31,506 standardized driving behavior series was obtained, which contained 28,908 NDB series and 2598 ADB series.
4. Results and Discussion
The validation set is composed of 300 NDB samples and 300 ADB samples, which are randomly selected from NDB samples and ADB samples, respectively. The training set is composed of the remaining 28,608 NDB samples and 2298 ADB samples. After the training is completed, the accuracy (
), precision (
), recall (
), and F
1-score (
) of each classifier are calculated. The F
1-score is the harmonic mean of precision and recall, which is closer to the smaller of the two; a high F
1-score can ensure that both the precision and recall are high [
30]. Therefore, the performance of the classifiers in recognizing ADB is evaluated by F
1-score as the main evaluation metric and accuracy, precision, and recall as the supplementary evaluation metrics. The definition of F
1-score is shown in Equation (16):
The definitions of accuracy, precision, and recall are as follows:
where
is true positive,
is true negative,
is false positive, and
is false negative.
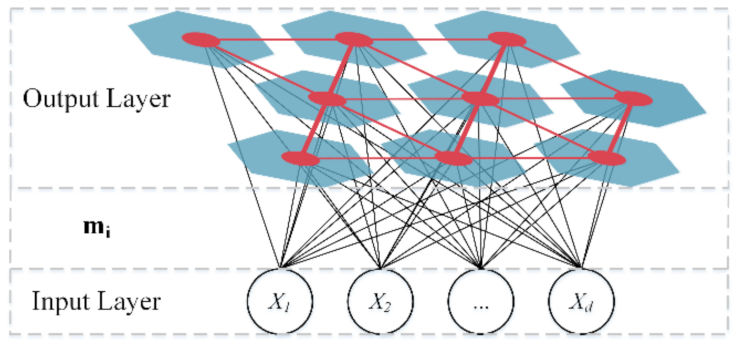
In the dataset balancing, the NDB samples in the training set are divided into multiple groups, and the number of NDB samples in each group should be as close as possible to the number of ADB samples in the training set. Therefore, according to the ratio of the ADB samples to the NDB samples in the training set, the number of SOM neurons is set as 12, and the mapping size is set to 4 × 3 after several tests. After the clustering, the NDB data in the training set are divided into 12 groups. As shown in
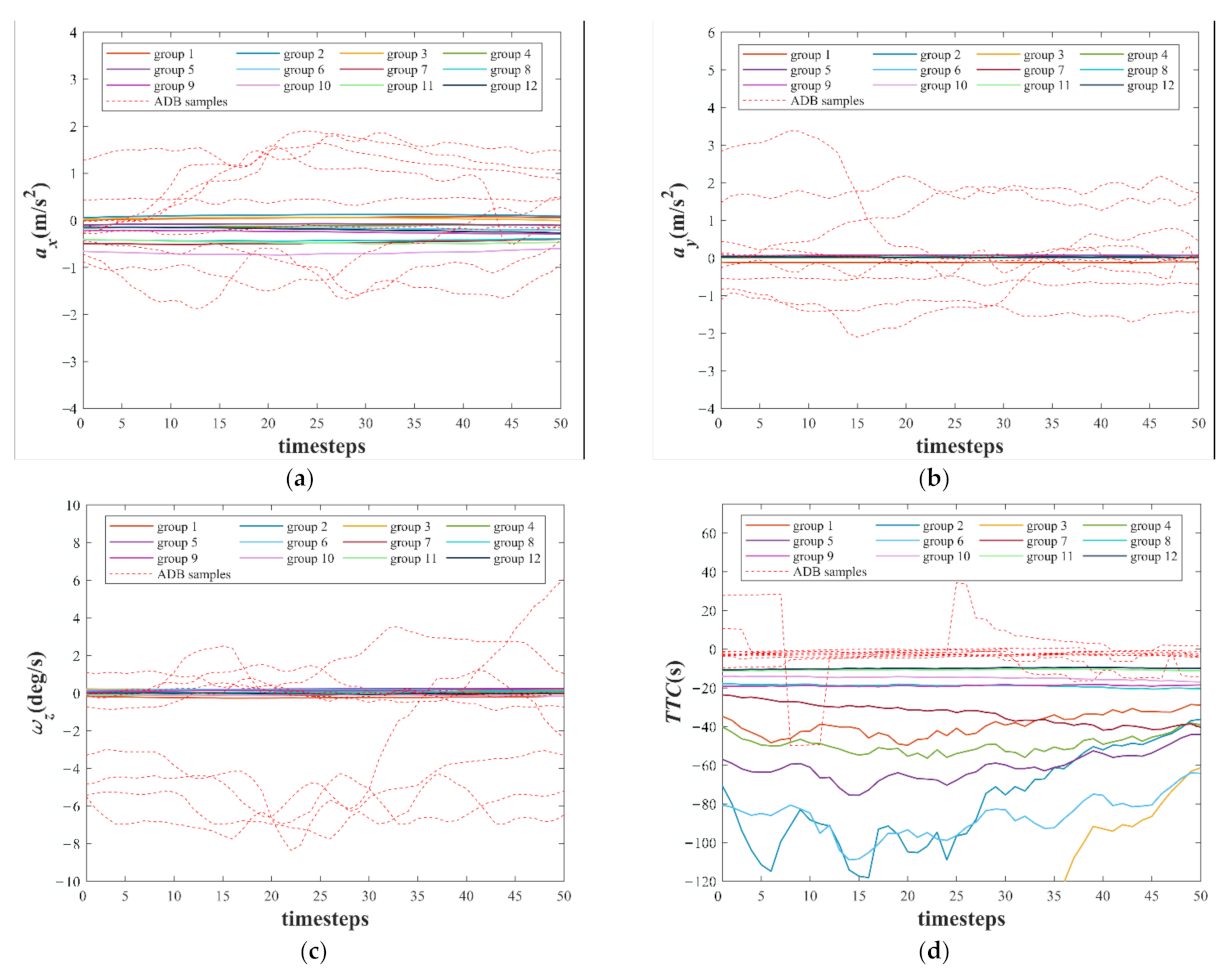
Figure 10, the white numbers in grids represent the number of NDB samples in the group. The size of the purple shape in the grid is proportional to the number of NDB samples in this group. By combining the 12 groups of the NDB samples with the ADB samples in the training set, 12 groups of class relative balance datasets are obtained.
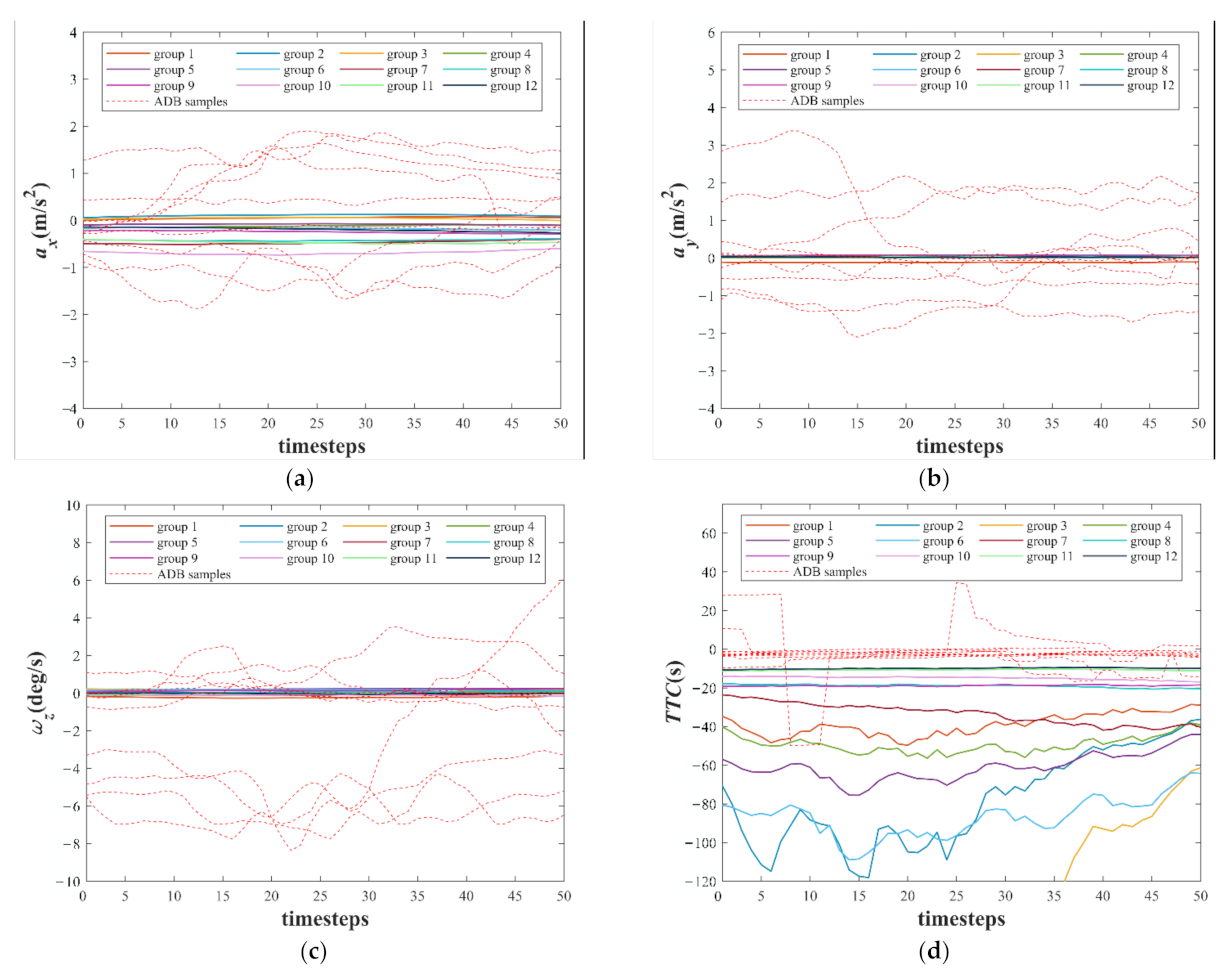
The weight vectors of 12 neurons after training are shown in
Figure 11. To show the characteristics of the 12 weight vectors more intuitively, they are compared with several randomly selected ADB samples. As shown in
Figure 11a–c, the values and the fluctuations with time steps of the
, the
, and the
of the 12 weight vectors are small, whereas the values and the fluctuations with time steps of the
, the
, and the
of most ADB samples are large. Because the difference between
and
of the 12 weight vectors and the ADB samples is difficult to be directly observed, the time to collision (
) is calculated based on
and
. The definition of
is shown in Equation (20), and the negative value of
means that the experimental vehicle is approaching the vehicle in front. As shown in
Figure 11d, the
of the 12 weight vectors and some ADB samples is less than 0. However, the
of these ADB samples is closer to 0, which means a higher risk of collision.
After the dataset balancing, all the methods, including CNN, LSTM, and GRU, are used to build 12 base classifiers with the 12 groups of class balance datasets, respectively, and the 12 base classifiers are combined into the ensemble classifiers based on the 10 different ensemble rules shown in
Table 4. In addition, CNN, LSTM, and GRU are used to directly build the classifiers on the class imbalance dataset without ensemble learning. The main parameters of CNN, LSTM, and GRU are shown in
Table 5, which are selected after several tests. The number of layers in
Table 5 indicates the number of convolutional layers, LSTM layers, or GRU layers in the models. The CNN is designed with a single convolutional layer. LSTM is designed with a single LSTM layer with 128 hidden units. GRU is designed with a single GRU layer with 128 hidden units. In addition, the “/” in
Table 5 indicates that the parameter is not utilized in the models.
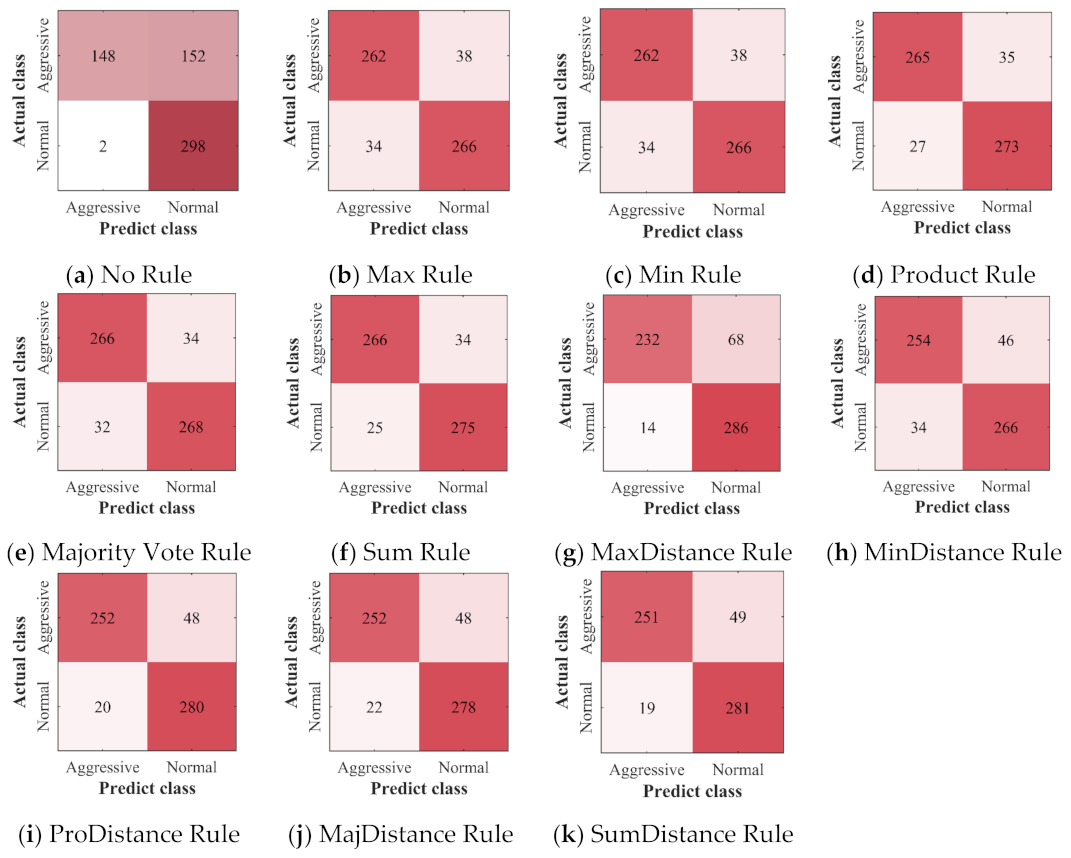
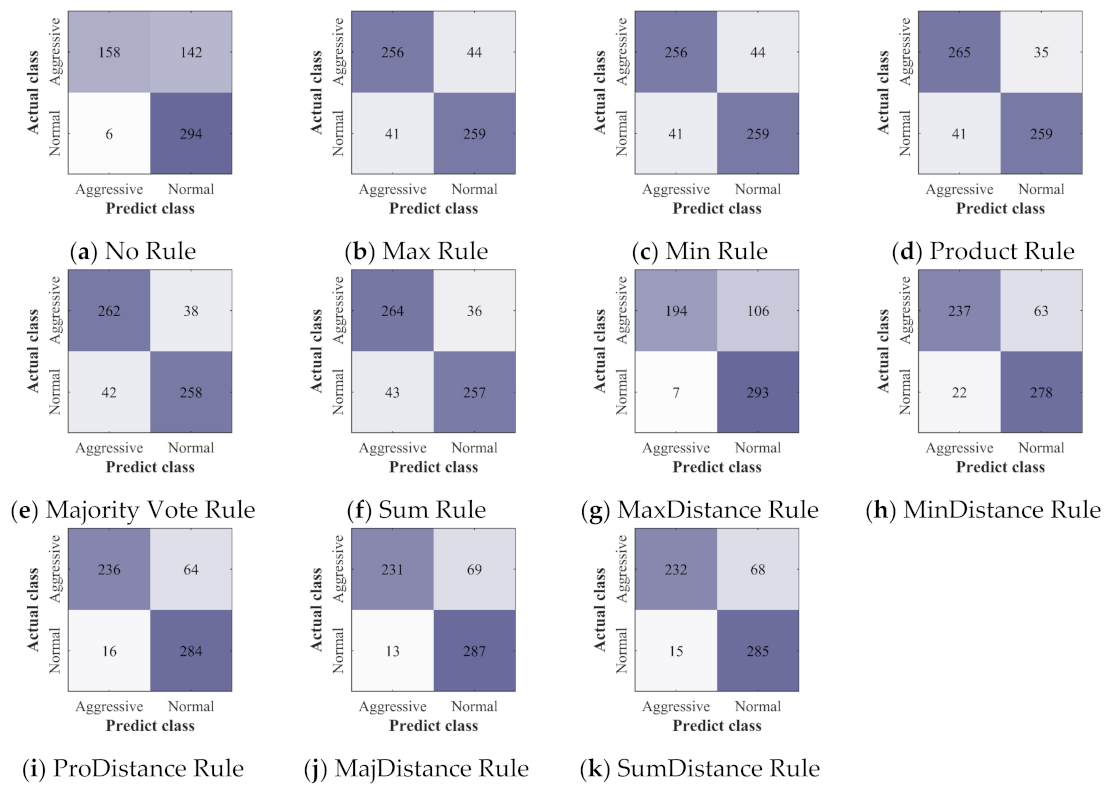
The confusion matrices of all the classifiers and ensemble classifiers obtained by verification are shown in
Figure 12,
Figure 13 and
Figure 14. The results obtained by the three deep learning methods before and after the application of ensemble learning have similar characteristics. Compared with the classifier built without ensemble learning, the ensemble classifier built with ensemble learning has a slight increase in the misclassification of NDB samples, but it greatly improves the accuracy of the classification of ADB samples. For the ensemble classifiers, the ones built with the ensemble rules based on classification probability have obtained similar results, and they have fewer misclassification of ADB samples. However, after the ensemble rules based on classification probability are combined with the distance weighting mechanism, they have more misclassification of ADB samples and fewer misclassification of NDB samples.
In order to express the performance of each classifier more intuitively, the accuracy, precision, recall, and F
1-score of each classifier are calculated and listed in
Table 6,
Table 7 and
Table 8.
As shown in
Table 6,
Table 7 and
Table 8, the ensemble classifiers achieve higher accuracy, recall, and F
1-score, which shows that compared with classifiers built without ensemble learning, the ensemble classifiers can recognize ADB more accurately. Classifiers built without ensemble learning achieve higher precision and lower recall, which reflects the problem that some machine learning methods are more likely to misclassify minority classes. Compared with the ensemble rules based on classification probability, the ensemble rules combined with the distance weighting mechanism achieve higher precision and lower recall, which means that they have more misclassification of ADB samples. This may be caused by the high dimension of time series data because the distance difference between different data points gradually decreases with the increase of dimension [
58]. Therefore, the ensemble classifiers built without distance weighting mechanism are more suitable for the recognition of ADB.
Among the classifiers built without ensemble learning, the one based on the GRU achieves the highest accuracy of 75.33%, recall rate of 52.67%, and F1-score of 68.10%, whereas the one based on the CNN achieves the highest precision of 98.66%. Therefore, among the three classifiers built without ensemble learning, the one based on the GRU with the highest F1-score achieves the best performance in the recognition of ADB.
Among the ensemble classifiers, the one based on the LSTM and the Product Rule achieves the highest accuracy of 90.50%, which indicates that only 9.50% of the samples are misclassified. The one based on the LSTM and the Majority Vote Rule achieves the highest recall of 90.00%, which indicates that only 10.00% of ADB samples are misclassified. The one based on the LSTM and the MaxDistance Rule achieves the highest precision of 96.54%, which indicates that only 3.46% of the samples classified as ADB are misclassified. The one based on the LSTM and the Product Rule achieves the highest F1-score of 90.42%.
Ensemble learning has the greatest improvement to the LSTM, which makes the LSTM ensemble classifiers perform the best in the recognition of ADB. The performance of the CNN ensemble classifiers in the recognition of ADB is second only to the LSTM ensemble classifiers, and the GRU ensemble classifiers have the worst performance.
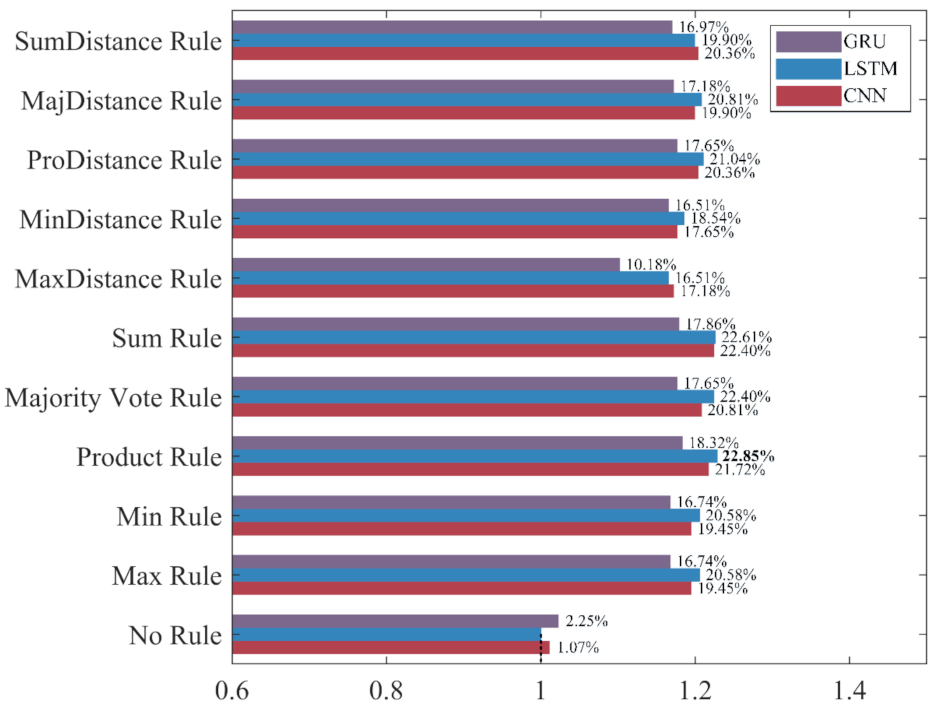
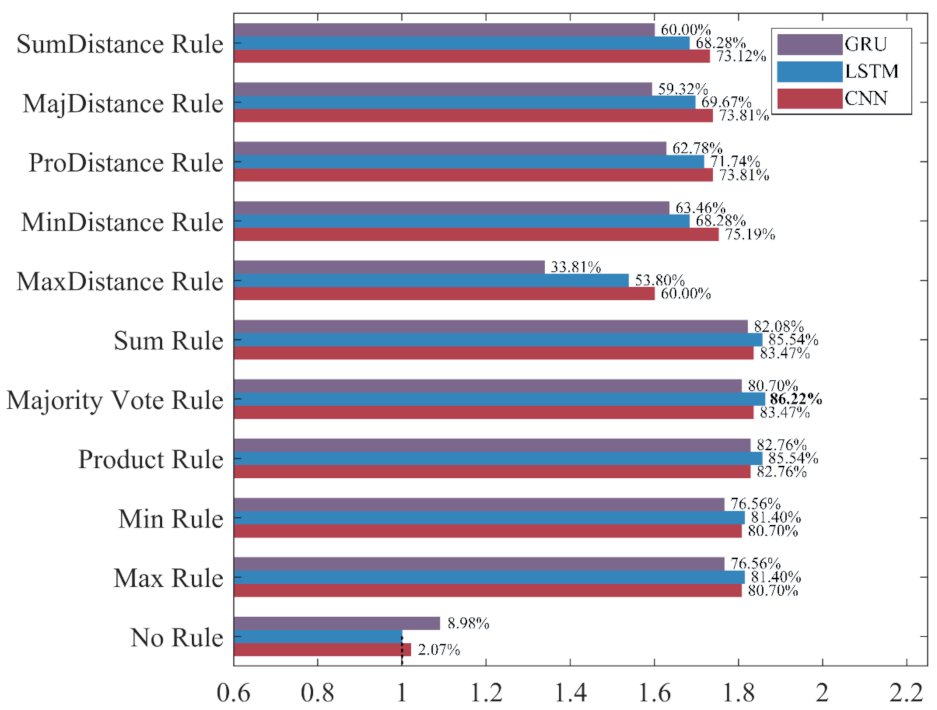
To intuitively compare the influence of different ensemble rules on the recognition performance under different evaluation metrics, the classifier built without ensemble learning, which has the worst performance in each evaluation metric, is used as the benchmark “1” to calculate the increase rate and decrease rate of the evaluation metrics for ensemble classifiers. The results are shown in
Figure 15,
Figure 16,
Figure 17 and
Figure 18.
As shown in
Figure 15,
Figure 16,
Figure 17 and
Figure 18, the accuracy, recall, and F
1-score of the three deep learning methods are significantly improved by ensemble learning. As shown in
Figure 15, the increase rate of the accuracy for each ensemble classifier is more than 10%, among which the one based on the LSTM and the Product Rule achieves the highest increase rate of 22.85%, followed by the one based on the LSTM and the Sum Rule. This means that although the ensemble learning method increases the misclassification of NDB samples, it reduces the misclassification of more ADB samples. As shown in
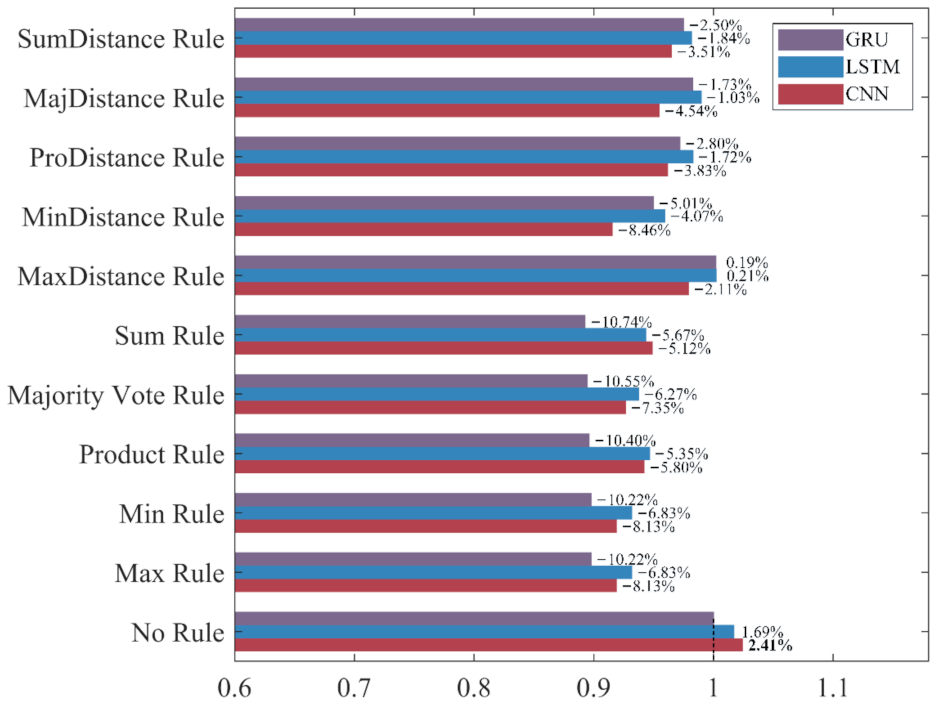
Figure 16, the precision of most ensemble classifiers has slightly decreased, among which the one based on the GRU and the Sum Rule achieves the highest decrease rate of 10.74%. Although only the ensemble classifiers based on the MaxDistance rule have increased precision, their increase rates of other evaluation metrics are the lowest. Therefore, we consider that the ensemble classifiers based on the MaxDistance Rule have the worst performance. As shown in
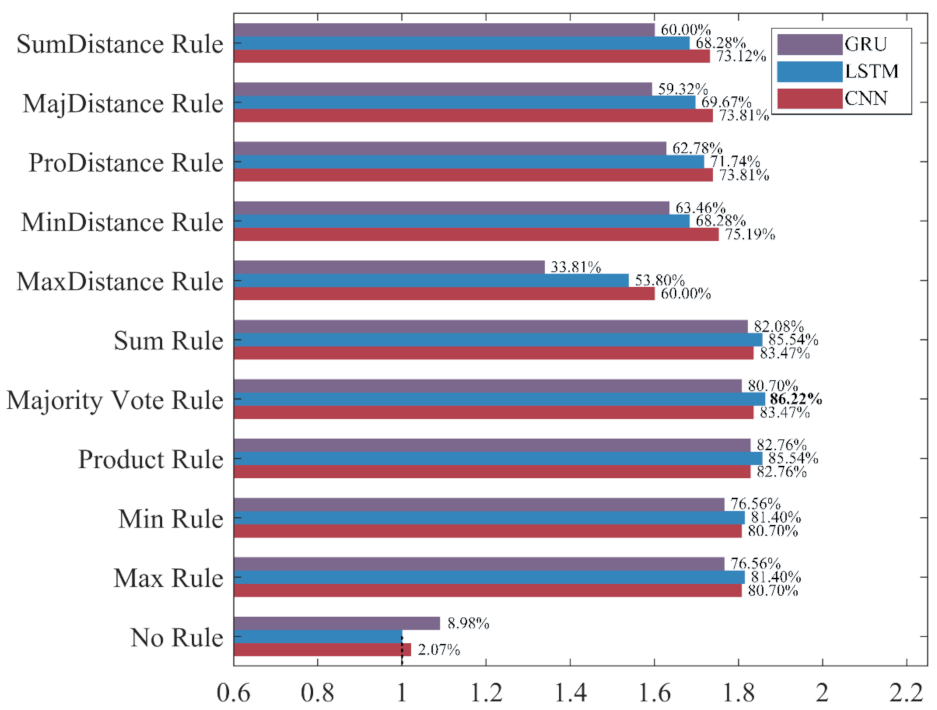
Figure 17, the increase rate of the recall for each ensemble classifier is more than 33%, among which the one based on the LSTM and the Majority Vote Rule achieves the highest increase rate of 86.22%, followed by the one based on the LSTM and the Product Rule and the Sum Rule. The recall has been significantly improved, which shows that the misclassification of minority class samples is substantially reduced after the application of the ensemble learning method. As shown in
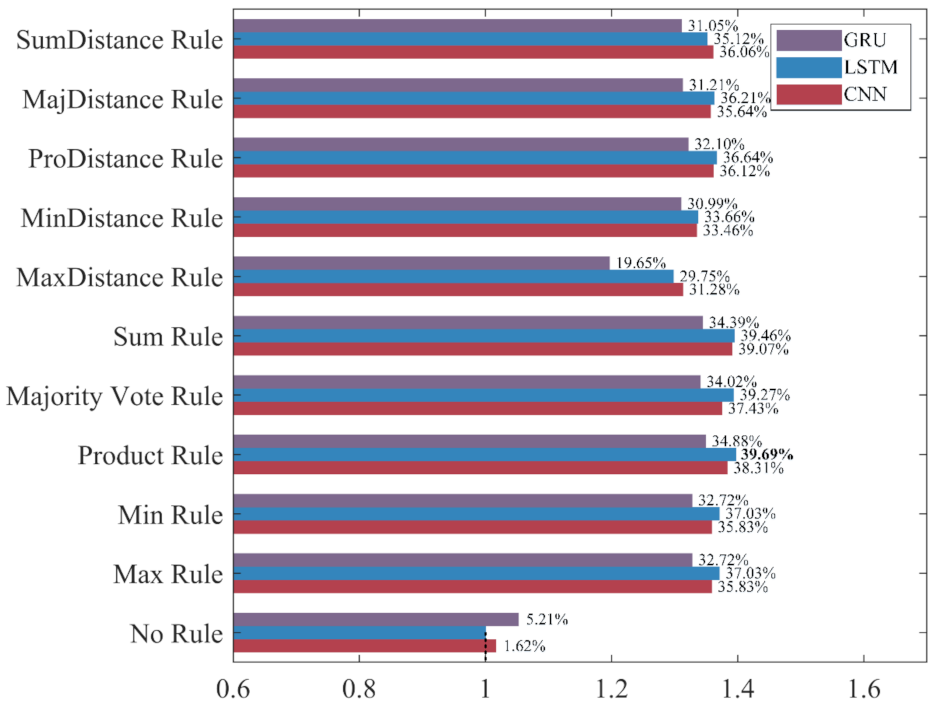
Figure 18, the increase rate of the F
1-score for each ensemble classifier is more than 19%, among which the one based on the LSTM and the Product Rule achieves the highest increase rate of 39.69%, followed by the one based on the LSTM and the Sum Rule. The F
1-score of most ensemble classifiers is about 30%, which shows that the ensemble learning method effectively improves the recognition performance of three deep learning methods for ADB.
Among the 10 ensemble rules, the Product Rule has the highest improvement to the LSTM and the GRU. Compared with the LSTM and the GRU classifiers built without ensemble learning, the increase rate of the F1-score for the LSTM and the GRU ensemble classifier based on the Product Rule are 39.69% and 34.88%, and the LSTM ensemble classifier based on the Product Rule achieves the highest F1-score of 90.42%. The Sum Rule achieves the highest improvement to the CNN. Compared with the CNN classifier built without ensemble learning, the increase rate of the F1-score for the CNN ensemble classifier based on the Sum Rule is 39.07%. Compared with the other ensemble classifiers, CNN, LSTM, and GRU ensemble classifiers based on the MaxDistance Rule achieves higher precision and lower accuracy, recall, and F1-score, and have the worse performance in the recognition of ADB. Overall, ensemble learning significantly improves the recognition performances of the three deep learning methods for ADB. The LSTM ensemble classifier based on the Product Rule with the highest F1-score of 90.42% achieves the best performance for ADB recognition, followed by the LSTM ensemble classifier based on the Sum Rule. However, most of the ensemble classifiers built based on ensemble learning have a slight decrease in precision, which means that their recognition performance for NDB has decreased.
In the research, the recognition of ADB is realized based on the motion parameters of vehicles. However, ADB is not only reflected in the four abnormal driving behaviors specified in this research, it is also reflected in behaviors such as frequent whistles and disregard of traffic rules. Therefore, the research on the recognition of aggressive driving behavior that integrates existing parameters and other behavior-related parameters is the focus topic of further work. In addition, verifying the application of other methods in this ensemble learning framework is also the focus of future work, such as applying other clustering methods or directly dividing the majority class samples in the dataset balancing and the application of other deep learning methods in the base classifiers building. Moreover, we will also focus on the application of unsupervised learning and semi-supervised learning methods in the research of aggressive driving behavior recognition.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}