
Integration of Multi-Head Self-Attention and Convolution for Person Re-Identification


Abstract
:1. Introduction
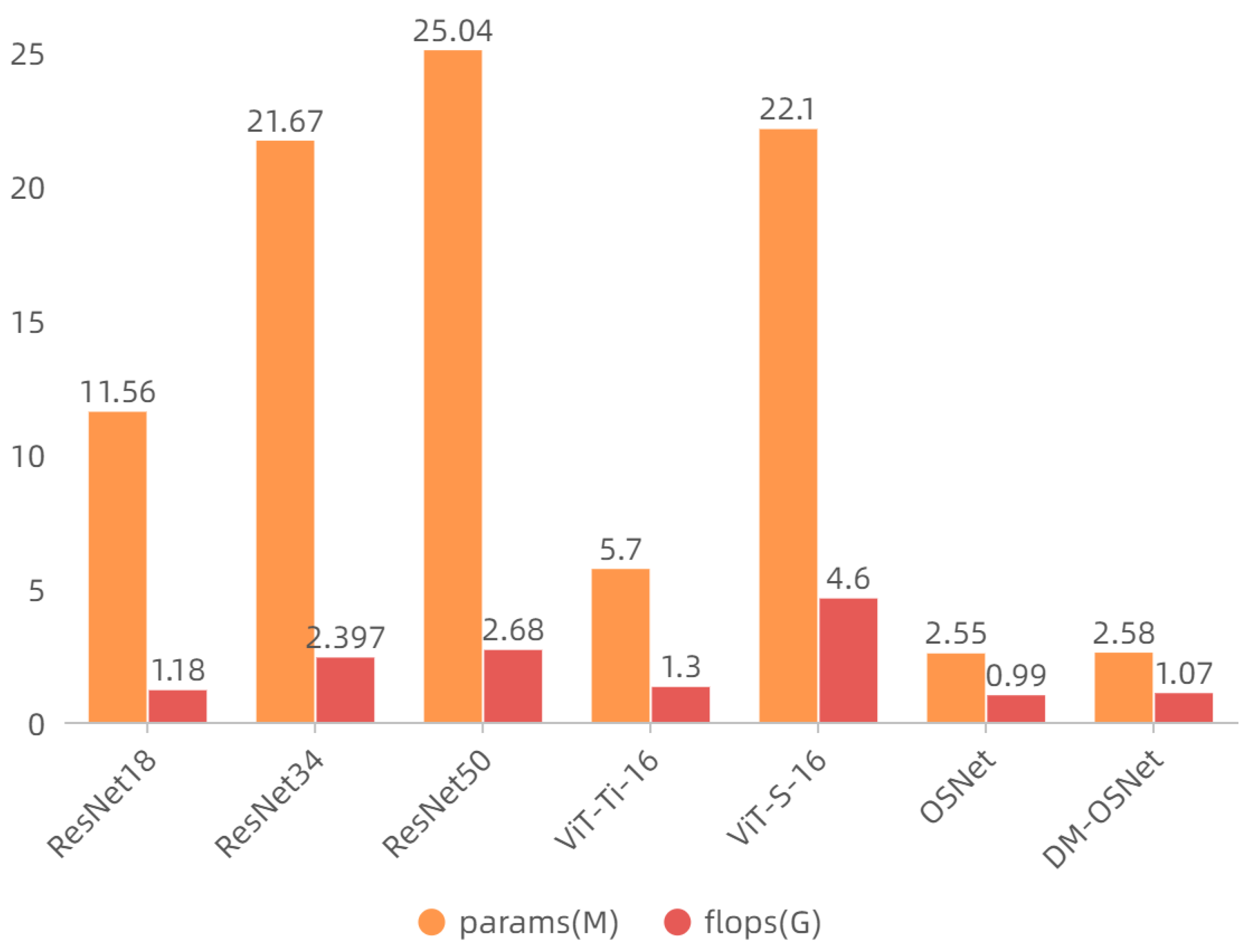
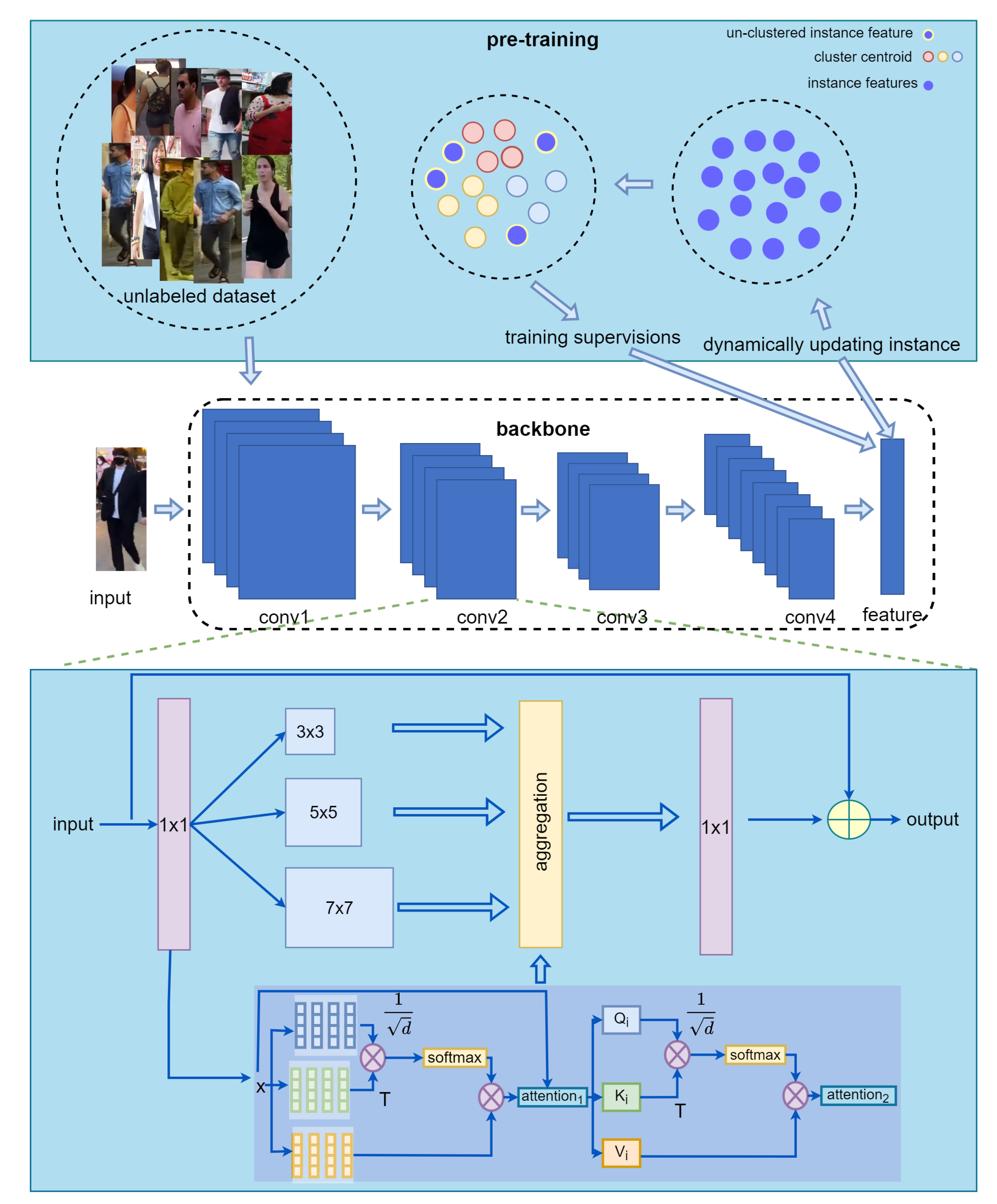
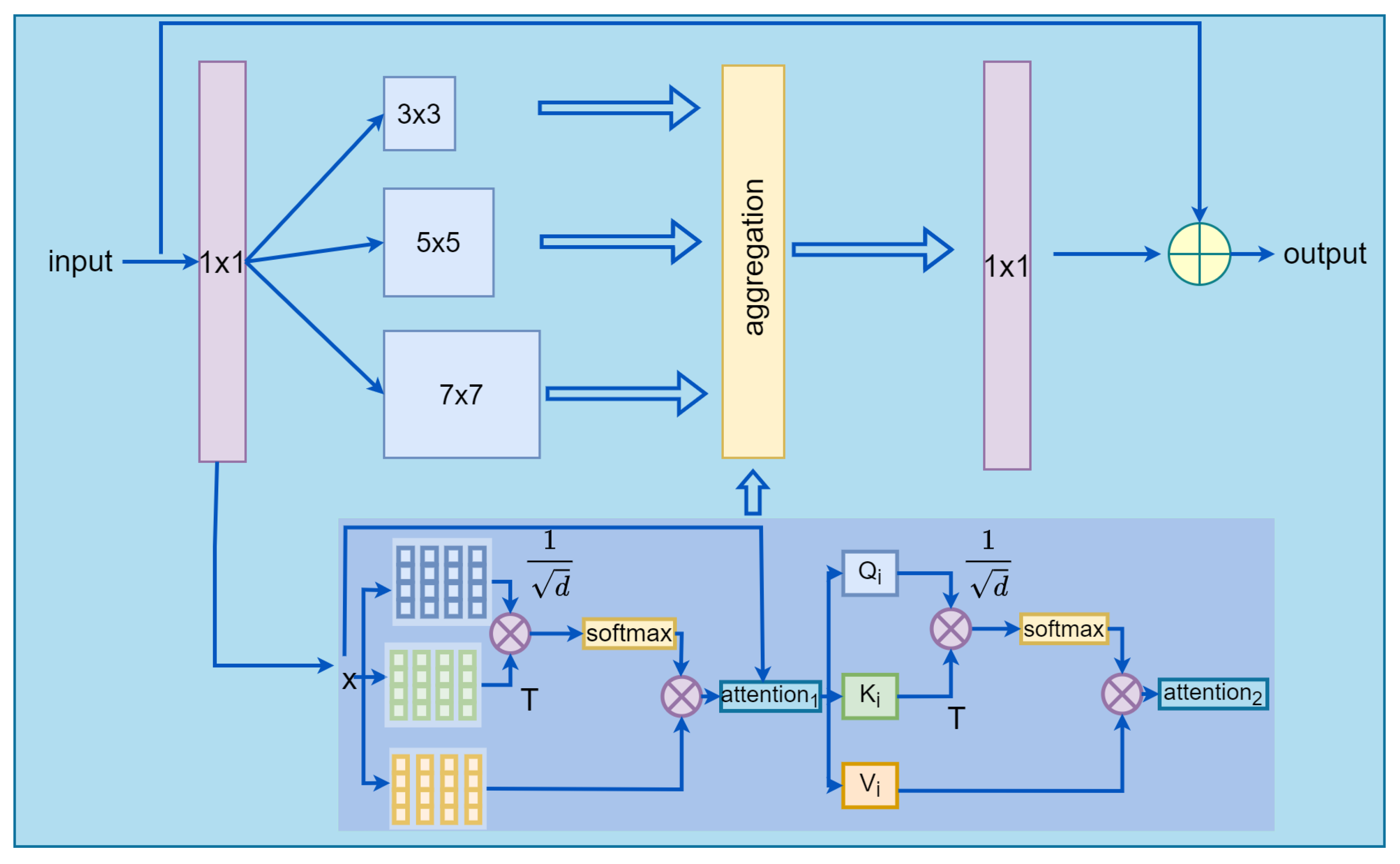
- We propose DL-MHSA based on MHSA, which reduces the computational complexity of MHSA with a small increase in the number of parameters. We replace the convolutional flow of OSNet with our DL-MHSA, which not only improves the model performance, but also maintains the light weight of OSNet.
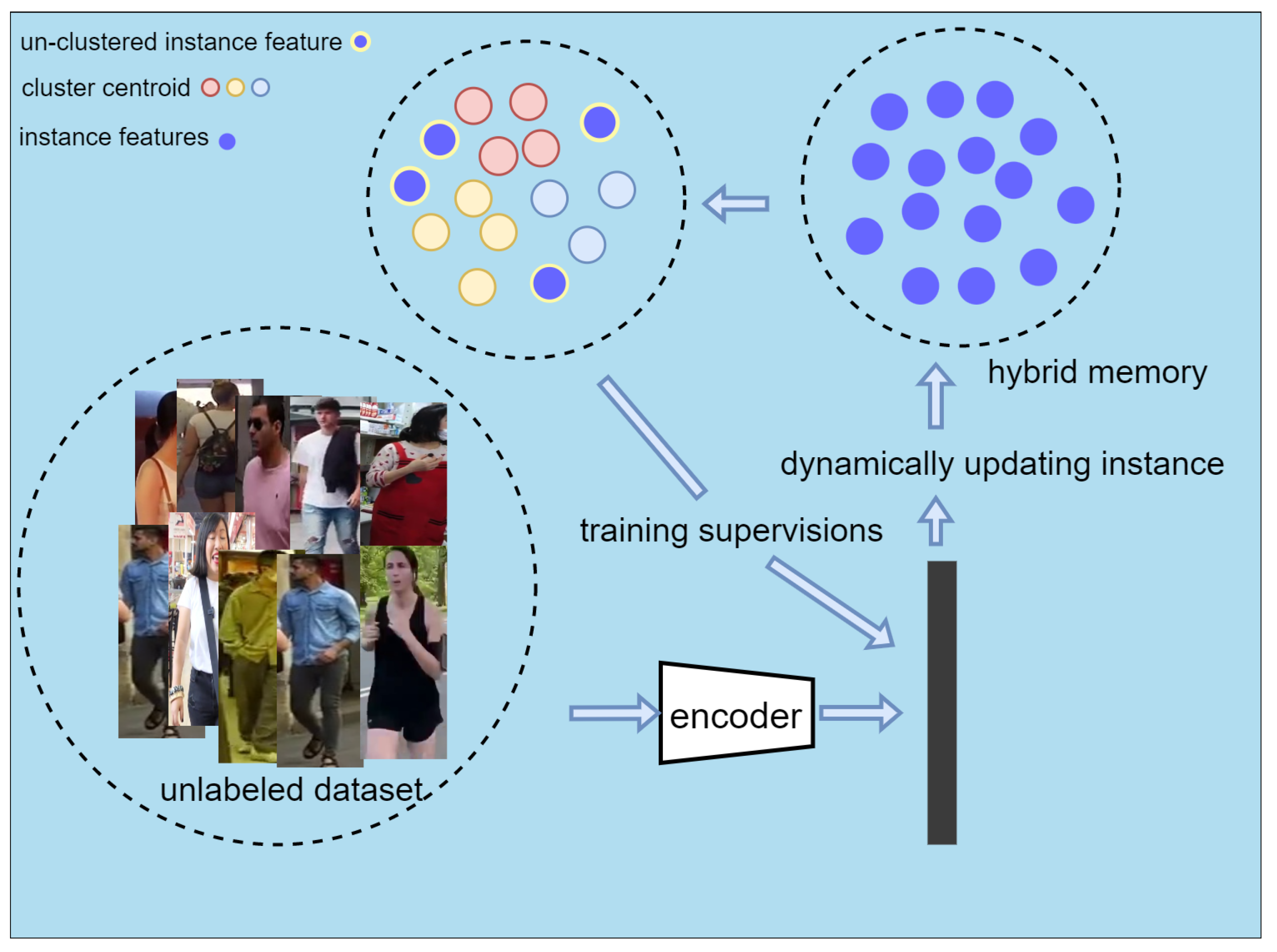
- We use a large-scale unlabeled pedestrian dataset, LUPerson, instead of ImageNet for pre-training. Given that it is an unlabeled dataset, we sort and filter it with the help of the catastrophic forgetting score (CFS) [8] and, then, use SpCL to produce pseudo-labels for pre-training. The pre-trained model using this approach is tuned on the labeled dataset, and the model performance is further improved.
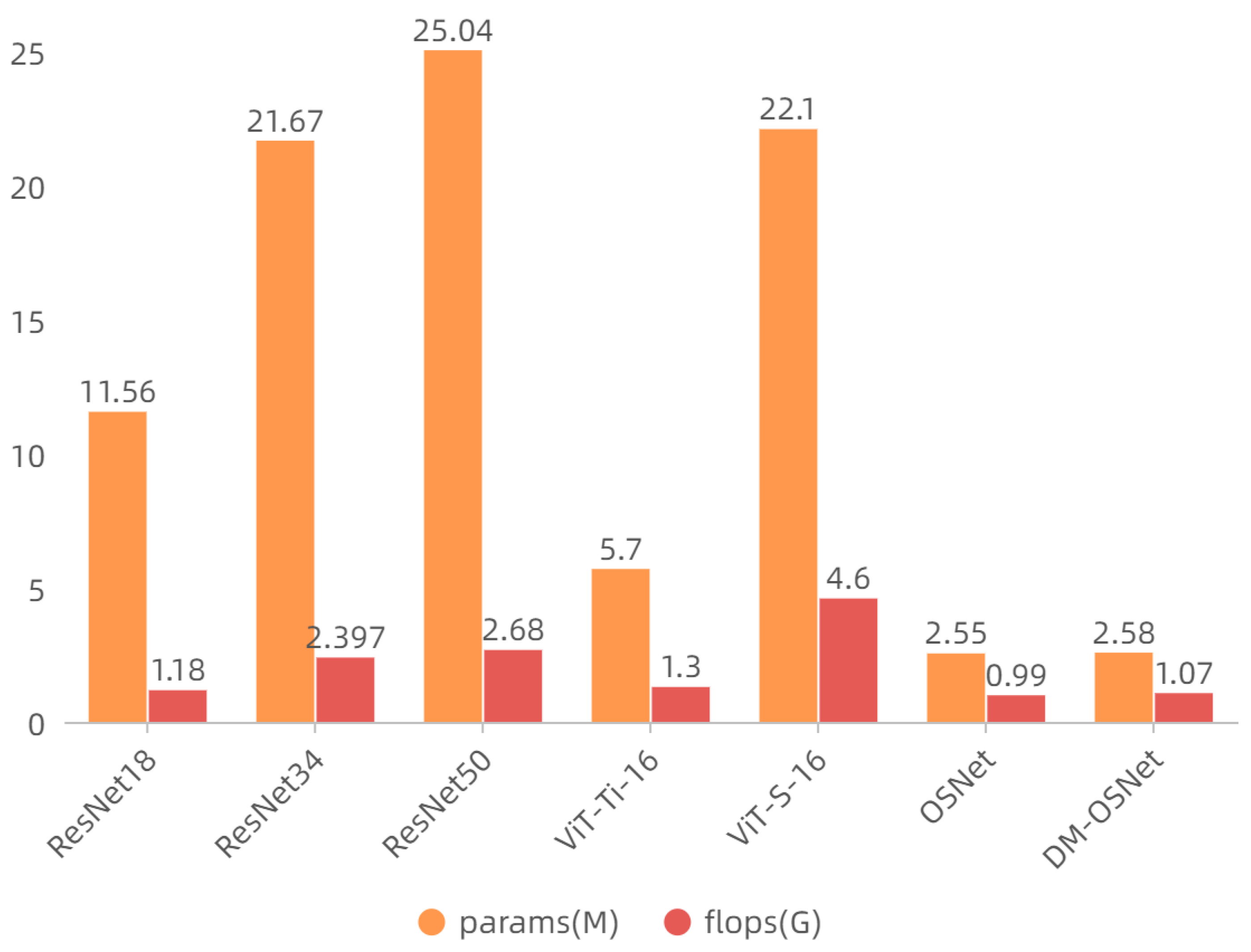
- Our proposed method is comparable to most re-ID methods in the case of a lower number of parameters and FLOPs. More importantly, it is lightweight enough to facilitate deployments.
2. Related Work
2.1. Re-ID Based on Convolutional Neural Networks
2.2. Transformer in Visual Recognition
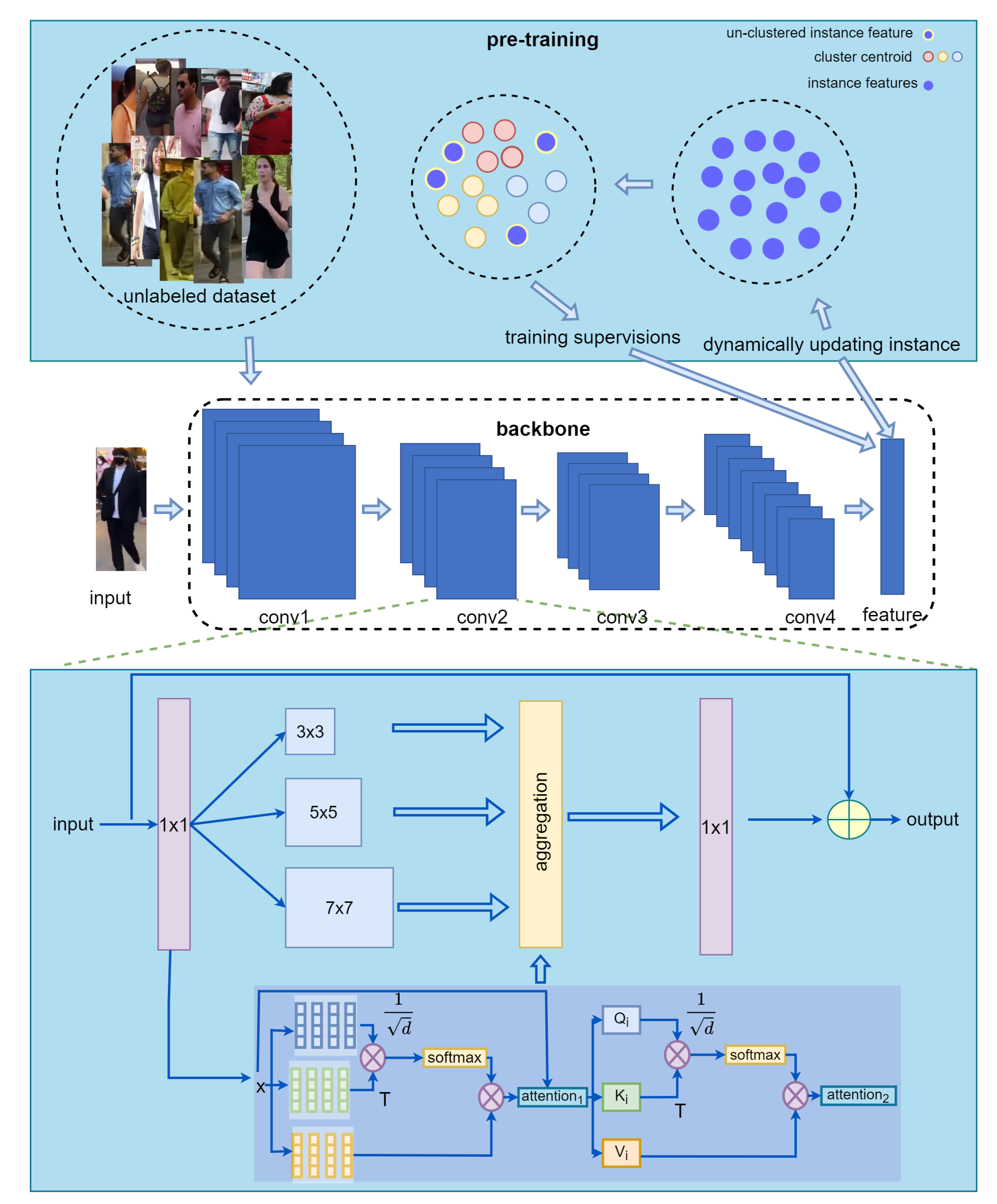
3. Methods
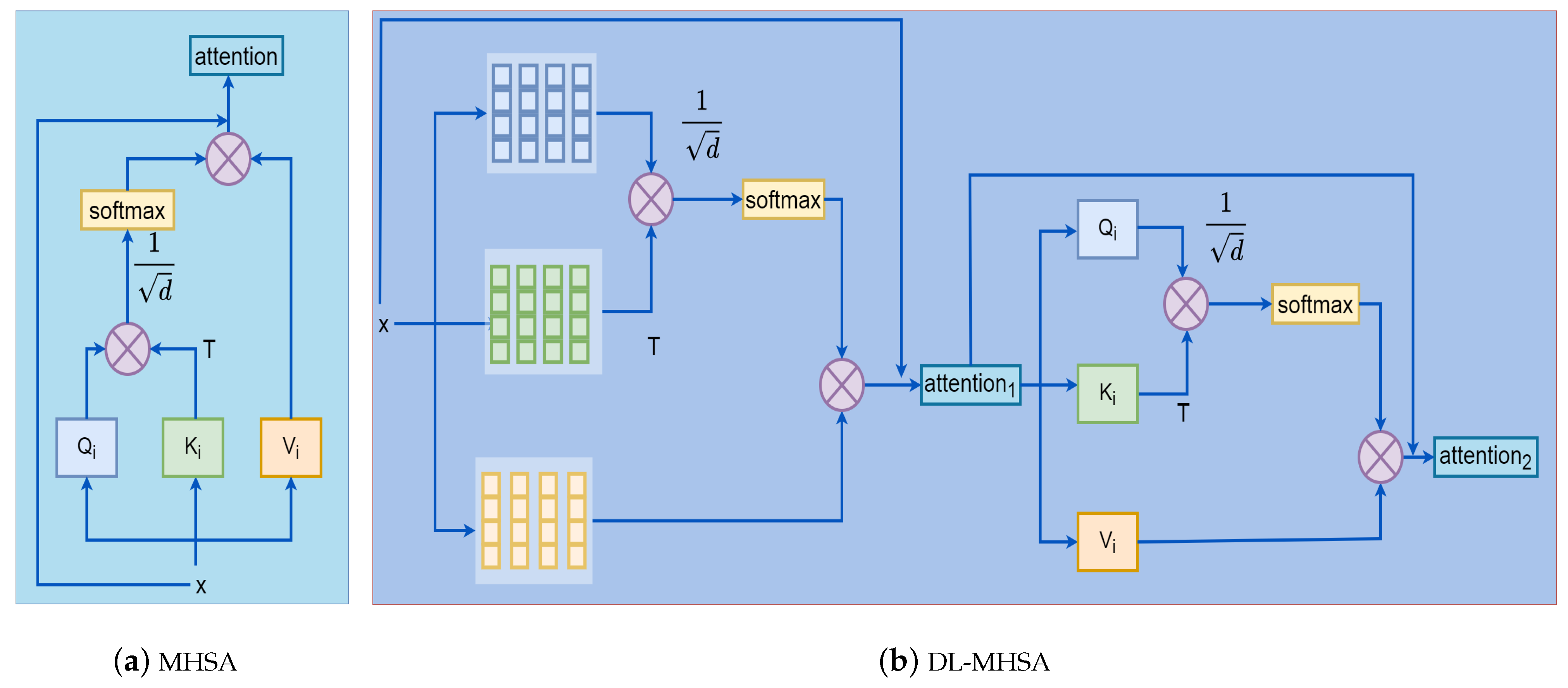
3.1. Double-Layer Multi-Head Self-Attention
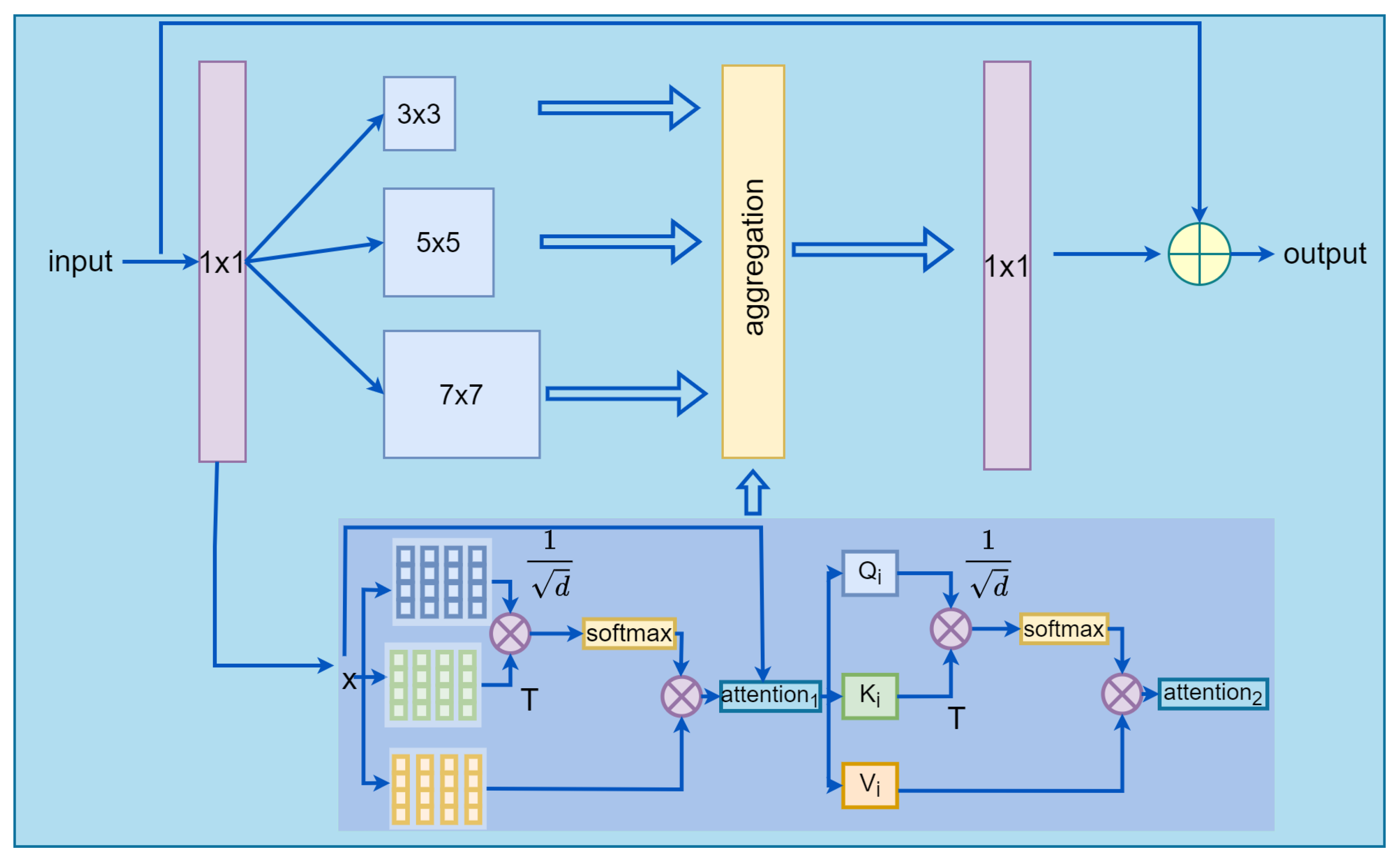
3.2. OSNet Adds Self-Attention Transformer Stream
3.3. Large-Scale Unlabeled Dataset for Pre-Training
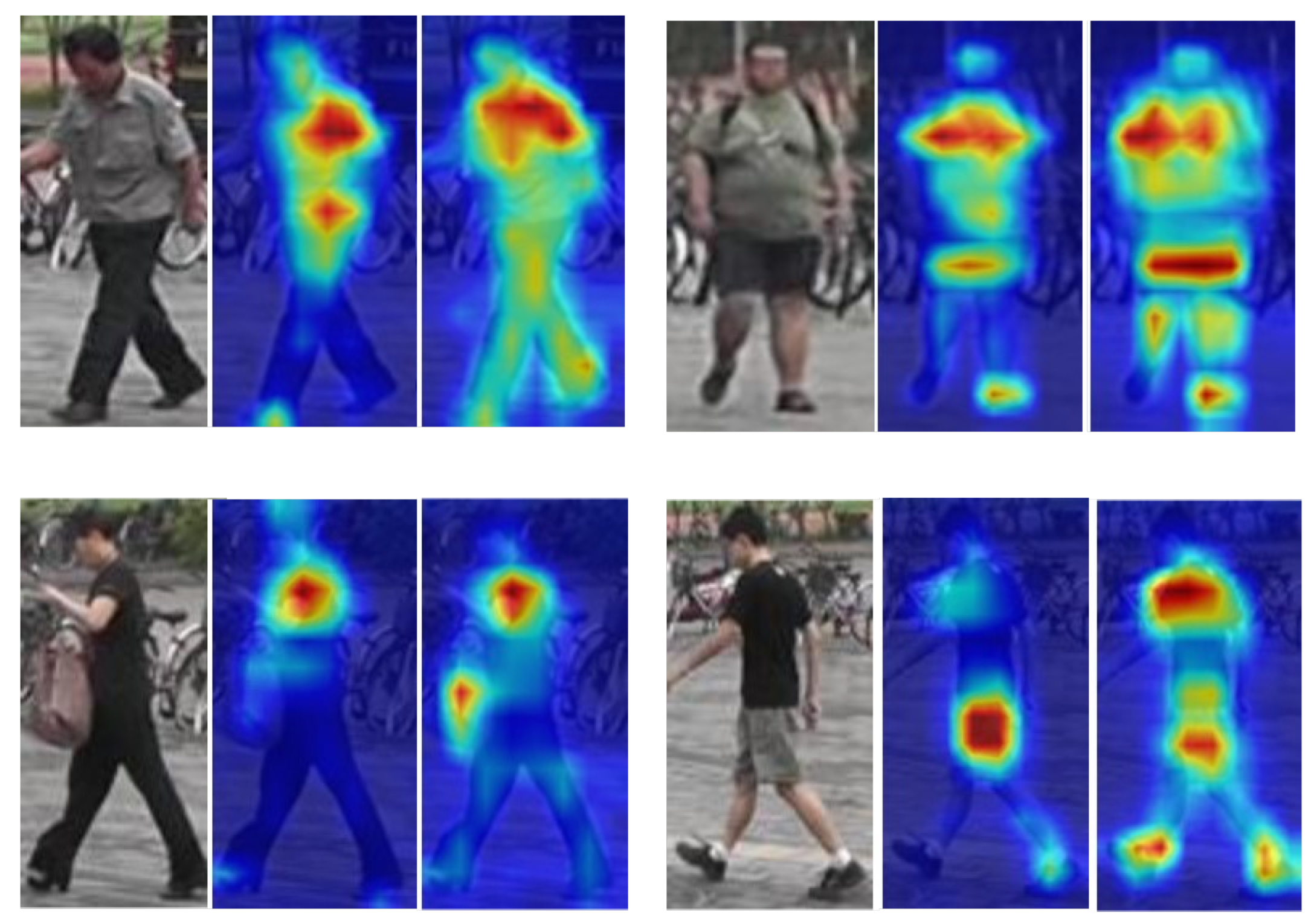
4. Experiments and Analysis of Results
4.1. Datasets and Evaluation Protocol
4.2. Implementation Details
4.3. Ablation Experiments Using DL-MHSA in Different Locations
4.4. Comparison of Different Pre-Training Methods
4.5. Comparison with Other Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zheng, L.; Yang, Y.; Hauptmann, A.G. Person Re-identification: Past, Present and Future. arXiv 2016, arXiv:1610.02984. [Google Scholar]
- Zhao, L.; Li, X.; Wang, J.; Zhuang, Y. Deeply-Learned Part-Aligned Representations for Person Re-Identification. arXiv 2017, arXiv:1707.07256v1. [Google Scholar]
- Suh, Y.; Wang, J.; Tang, S.; Mei, T.; Lee, K.M. Part-Aligned Bilinear Representations for Person Re-identification. arXiv 2018, arXiv:1804.07094v1. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929v2. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030v2. [Google Scholar]
- Zhou, K.; Yang, Y.; Cavallaro, A.; Xiang, T. Omni-Scale Feature Learning for Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Fu, D.; Chen, D.; Bao, J.; Yang, H.; Yuan, L.; Zhang, L.; Li, H.; Chen, D. Unsupervised pre-training for person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14750–14759. [Google Scholar]
- Luo, H.; Wang, P.; Xu, Y.; Ding, F.; Zhou, Y.; Wang, F.; Li, H.; Jin, R. Self-Supervised Pre-Training for Transformer-Based Person Re-Identification. arXiv 2022, arXiv:2111.12084. [Google Scholar]
- Jin, X.; He, T.; Yin, Z.; Shen, X.; Liu, T.; Wang, X.; Huang, J.; Hua, X.S.; Chen, Z. Meta Clustering Learning for Large-scale Unsupervised Person Re-identification. arXiv 2022, arXiv:2111.10032. [Google Scholar]
- Ge, Y.; Zhu, F.; Chen, D.; Zhao, R.; Li, H. Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID. Adv. Neural Inf. Process. Syst. 2022, 33, 11309–11321. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zheng, L.; Zhang, H.; Sun, S.; Chandraker, M.; Yang, Y.; Tian, Q. Person Re-identification in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017. [Google Scholar]
- Cheng, D.; Gong, Y.; Zhou, S.; Wang, J.; Zheng, N. Person Re-identification by Multi-Channel Parts-Based CNN with Improved Triplet Loss Function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, D.; Chen, X.; Zhang, Z.; Huang, K. Learning Deep Context-aware Features over Body and Latent Parts for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017. [Google Scholar]
- Zhao, H.; Maoqing, T.; Sun, S.; Shao, J.; Yan, J.; Yi, S.; Wang, X.; Tang, X. Spindle Net: Person Re-identification with Human Body Region Guided Feature Decomposition and Fusion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Chen, Z. Densely Semantically Aligned Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Guo, J.; Yuan, Y.; Huang, L.; Zhang, C.; Yao, J.G.; Han, K. Beyond Human Parts: Dual Part-Aligned Representations for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sun, Y.; Zheng, L.; Yang, Y.; Tian, Q.; Wang, S. Beyond Part Models: Person Retrieval with Refined Part Pooling. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning Discriminative Features with Multiple Granularities for Person Re-Identification. In Proceedings of the 26th ACM International Conference on Multimedia, Yokohama, Japan, 11–14 June 2018. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Vanhoucke, V.; Rabinovich, A.; Erhan, D. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017. [Google Scholar]
- Chang, X.; Hospedales, T.M.; Xiang, T. Multi-level factorisation net for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lake City, UT, USA, 18–22 June 2018; pp. 2109–2118. [Google Scholar]
- Qian, X.; Fu, Y.; Jiang, Y.G.; Xiang, T.; Xue, X. Multi-scale deep learning architectures for person re-identification. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5399–5408. [Google Scholar]
- Chen, Y.; Zhu, X.; Gong, S. Person re-identification by deep learning multi-scale representations. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 2590–2600. [Google Scholar]
- Li, Y.; Liu, L.; Zhu, L.; Zhang, H. Person re-identification based on multi-scale feature learning. Knowl.-Based Syst. 2021, 228, 107281. [Google Scholar] [CrossRef]
- Huang, Z.; Qin, W.; Luo, F.; Guan, T.; Xie, F.; Han, S.; Sun, D. Combination of validity aggregation and multi-scale feature for person re-identification. J. Ambient. Intell. Humaniz. Comput. 2021, 1–16. [Google Scholar] [CrossRef]
- Wu, D.; Wang, C.; Wu, Y.; Wang, Q.C.; Huang, D.S. Attention deep model with multi-scale deep supervision for person re-identification. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 70–78. [Google Scholar] [CrossRef]
- Huang, W.; Li, Y.; Zhang, K.; Hou, X.; Xu, J.; Su, R.; Xu, H. An Efficient Multi-Scale Focusing Attention Network for Person Re-Identification. Appl. Sci. 2021, 11, 2010. [Google Scholar] [CrossRef]
- Perwaiz, N.; Fraz, M.M.; Shahzad, M. Stochastic attentions and context learning for person re-identification. PeerJ 2021, 7, e447. [Google Scholar] [CrossRef]
- Li, W.; Zhu, X.; Gong, S. Harmonious Attention Network for Person Re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Liu, H.; Feng, J.; Qi, M.; Jiang, J.; Yan, S. End-to-End Comparative Attention Networks for Person Re-identification. IEEE Trans. Image Process. 2016, 26, 3492–3506. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Ding, S.; Xie, J.; Yuan, Y.; Chen, W.; Yang, Y.; Ren, Z.; Wang, Z. ABD-Net: Attentive but Diverse Person Re-Identification. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, G.; Lin, C.; Ren, L.; Lu, J.; Zhou, J. Self-Critical Attention Learning for Person Re-Identification. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Bryan, B.; Gong, Y.; Zhang, Y.; Poellabauer, C. Second-Order Non-Local Attention Networks for Person Re-Identification. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zhou, S.; Wang, F.; Huang, Z.; Wang, J. Discriminative Feature Learning With Consistent Attention Regularization for Person Re-Identification. In Proceedings of the International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. Neural Inf. Process. Syst. 2017, 30, 3058. [Google Scholar]
- Zhu, K.; Guo, H.; Zhang, S.; Wang, Y.; Huang, G.; Qiao, H.; Liu, J.; Wang, J.; Tang, M. AAformer: Auto-Aligned Transformer for Person Re-Identification. arXiv 2021, arXiv:2104.00921. [Google Scholar]
- He, S.; Luo, H.; Wang, P.; Wang, F.; Li, H.; Jiang, W. TransReID: Transformer-based Object Re-Identification. arXiv 2021, arXiv:2102.04378. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention Augmented Convolutional Networks. In Proceedings of the Computer Vision and Pattern Recognition, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhang, G.; Zhang, P.; Qi, J.; Lu, H. HAT: Hierarchical Aggregation Transformers for Person Re-identification. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021. [Google Scholar]
- Li, Y.; He, J.; Zhang, T.; Liu, X.; Zhang, Y.; Wu, F. Diverse Part Discovery: Occluded Person Re-identification with Part-Aware Transformer. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Liu, Y.; Sun, G.; Qiu, Y.; Zhang, L.; Chhatkuli, A.; Gool, L.V. Transformer in Convolutional Neural Networks. In Proceedings of the Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Zhang, L.; Wu, X.; Zhang, S.; Yin, Z. Branch-Cooperative OSNet for Person Re-Identification. arXiv 2020, arXiv:2006.07206. [Google Scholar]
- Herzog, F.; Ji, X.; Teepe, T.; Hörmann, S.; Gilg, J.; Rigoll, G. Lightweight Multi-Branch Network for Person Re-Identification. In Proceedings of the 2021 IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2020. [Google Scholar]
- Zheng, L.; Shen, L.; Tian, L.; Wang, S.; Wang, J.; Tian, Q. Scalable Person Re-identification: A Benchmark. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ristani, E.; Solera, F.; Zou, R.S.; Cucchiara, R.; Tomasi, C. Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Li, W.; Zhao, R.; Xiao, T.; Wang, X. DeepReID: Deep Filter Pairing Neural Network for Person Re-identification. In Proceedings of the CVPR, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Wei, L.; Zhang, S.; Gao, W.; Tian, Q. Person Transfer GAN to Bridge Domain Gap for Person Re-Identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017. [Google Scholar]
- Zhong, Z.; Zheng, L.; Cao, D.; Li, S. Re-ranking Person Re-identification with k-Reciprocal Encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 26 July 2017. [Google Scholar]
- He, L.; Liao, X.; Liu, W.; Liu, X.; Cheng, P.; Mei, T. FastReID: A Pytorch Toolbox for General Instance Re-identification. arXiv 2020, arXiv:2006.02631. [Google Scholar]
- Tay, C.P.; Roy, S.; Yap, K.H. AANet: Attribute Attention Network for Person Re-Identifications. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Yu, Z.; Zheng, L.; Yang, Y.; Kautz, J.; Yang, X.; Zheng, Z. Joint Discriminative and Generative Learning for Person Re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Quan, R.; Dong, X.; Wu, Y.; Zhu, L.; Yang, Y. Auto-ReID: Searching for a Part-aware ConvNet for Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, S.; Gu, X.; Dai, Z.; Tan, P.; Chen, M. Batch DropBlock Network for Person Re-identification and Beyond. In Proceedings of the International Conference on Computer Vision, Perth, Australia, 2–6 December 2018. [Google Scholar]
- Hou, R.; Ma, B.; Chang, H.; Gu, X.; Shan, S.; Chen, X. Interaction-And-Aggregation Network for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, S.; Huang, H.; Huang, K.; Zhang, Z.; Yang, W.; Chen, X. Towards Rich Feature Discovery With Class Activation Maps Augmentation for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Deng, W.; Chen, B.; Hu, J. Mixed High-Order Attention Network for Person Re-Identification. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Label | Images | ID | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Total | Train | Query | Gallery | Total | Train | Query | Gallery | ||
| Market1501 | labeled | 32,668 | 12,936 | 3368 | 15,913 | 1501 | 751 | 750 | 751 |
| DukeMTMC-reID | labeled | 36,411 | 16,522 | 2228 | 17,661 | 1852 | 702 | 702 | 1110 |
| CUHK03(D) | labeled | 14,097 | 7365 | 1400 | 5332 | 1467 | 767 | 700 | 700 |
| CUHK03(L) | labeled | 14,096 | 7368 | 1400 | 5328 | 1467 | 767 | 700 | 700 |
| MSMT17 | labeled | 126,441 | 30,248 | 11,659 | 82,161 | 4101 | 1041 | 3060 | 3060 |
| LUPerson | unlabeled | 4,180,243 | - | - | - | 46,260 | - | - | - |
| Method | Market1501 | DukeMTMC-reID | CUHK03(D) | CUHK03(L) | MSMT17 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | rank-1 | mAP | rank-1 | mAP | rank-1 | mAP | rank | mAP | rank-1 | |
| [0,0,0] | 84.9 | 94.8 | 73.5 | 88.6 | 67.8 | 72.3 | - | - | 52.9 | 78.7 |
| [1,0,0] | 86.76 | 95.26 | 76.87 | 89.45 | 68.81 | 71.50 | 71.56 | 74.00 | 55.96 | 80.25 |
| [0,1,0] | 86.68 | 95.01 | 76.65 | 89.54 | 68.90 | 71.20 | 70.73 | 72.71 | 55.29 | 80.03 |
| [0,0,1] | 86.42 | 95.06 | 76.58 | 89.68 | 69.09 | 71.36 | 70.86 | 73.57 | 54.03 | 79.26 |
| [1,1,0] | 86.07 | 94.83 | 75.87 | 88.7 | 67.79 | 70.57 | 70.43 | 72.57 | 54.47 | 79.71 |
| [1,0,1] | 85.57 | 94.12 | 75.38 | 88.24 | 69.02 | 71.93 | 70.47 | 72.86 | 54.17 | 79.38 |
| [0,1,1] | 85.42 | 94.18 | 75.21 | 88.73 | 68.11 | 70.57 | 71.12 | 73.64 | 53.45 | 78.78 |
| [1,1,1] | 84.93 | 93.88 | 75.03 | 87.75 | 66.90 | 68.70 | 69.89 | 71.79 | 52.23 | 77.37 |
| Models | Pre-Training | Market1501 | DukeMTMC-reID | CUHK03(D) | CUHK03(L) | MSMT17 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Methods | Data | mAP | rank-1 | mAP | rank-1 | mAP | rank-1 | mAP | rank-1 | mAP | rank-1 | |
| ResNet50 | Supervised | ImageNet | 81.95 | 92.55 | 72.66 | 83.80 | 63.11 | 65.07 | 65.83 | 67.79 | 44.39 | 68.73 |
| SpCL | LUPerson | 83.23 | 93.17 | 76.00 | 86.12 | 65.71 | 67.14 | 68.23 | 69.07 | 47.62 | 71.28 | |
| OSNet | Supervised | ImageNet | 84.9 | 94.8 | 73.5 | 88.6 | 67.8 | 72.3 | - | - | 52.9 | 78.7 |
| SpCL | LUPerson | 86.16 | 95.1 | 76.62 | 88.29 | 68.99 | 71.67 | 70.87 | 72.86 | 55.78 | 80.23 | |
| Method | Market1501 | DukeMTMC-reID | CUHK03(D) | CUHK03(L) | MSMT17 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| mAP | rank-1 | mAP | rank-1 | mAP | rank-1 | mAP | rank-1 | mAP | rank-1 | |
| PCB [20] | 81.6 | 93.8 | 69.2 | 83.3 | 57.5 | 63.7 | - | - | 40.4 | 68.2 |
| AANet [56] | 83.4 | 93.9 | 74.3 | 87.7 | - | - | - | - | - | - |
| DGNet [57] | 86.0 | 94.8 | 74.8 | 86.6 | - | - | - | - | 52.3 | 77.2 |
| OSNet [6] | 84.9 | 94.8 | 73.5 | 88.6 | 67.8 | 72.3 | - | - | 52.9 | 78.7 |
| Auto-ReID [58] | 85.1 | 94.5 | - | - | 69.3 | 73.0 | 73.0 | 77.9 | 52.5 | 78.2 |
| BDB [59] | 86.7 | 95.3 | 76.0 | 89.0 | 69.3 | 72.8 | 71.7 | 73.6 | - | - |
| IANet [60] | 83.1 | 94.4 | 73.4 | 87.1 | - | - | - | - | 46.8 | 75.5 |
| CAMA [61] | 84.5 | 94.7 | 72.9 | 85.8 | 64.2 | 66.6 | 66.5 | 70.1 | - | - |
| MHN [62] | 85.0 | 95.1 | 77.2 | 89.1 | 65.4 | 71.7 | 72.4 | 77.2 | - | - |
| SCAL [36] | 89.3 | 95.8 | 79.6 | 89.0 | 68.6 | 71.1 | 72.3 | 74.8 | - | - |
| MGN [21] | 86.9 | 95.7 | 78.4 | 88.7 | 66.8 | 66.0 | 68.0 | 67.4 | 52.1 | 76.9 |
| OSNet+DL-MHSA | 86.76 | 95.26 | 76.87 | 89.45 | 68.81 | 71.50 | 71.56 | 74.00 | 55.96 | 80.25 |
| OSNet++LUperson | 86.16 | 95.1 | 76.62 | 88.29 | 68.99 | 71.57 | 70.87 | 72.86 | 55.78 | 80.23 |
| OSNet+DL-MHSA+LUperson (DM-OSNet) | 87.36 | 95.61 | 78.26 | 89.18 | 70.59 | 73.0 | 72.96 | 74.57 | 57.13 | 80.96 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Liu, P.; Cui, Y.; Liu, C.; Duan, W. Integration of Multi-Head Self-Attention and Convolution for Person Re-Identification. Sensors 2022, 22, 6293. https://doi.org/10.3390/s22166293
Zhou Y, Liu P, Cui Y, Liu C, Duan W. Integration of Multi-Head Self-Attention and Convolution for Person Re-Identification. Sensors. 2022; 22(16):6293. https://doi.org/10.3390/s22166293
Chicago/Turabian StyleZhou, Yalei, Peng Liu, Yue Cui, Chunguang Liu, and Wenli Duan. 2022. "Integration of Multi-Head Self-Attention and Convolution for Person Re-Identification" Sensors 22, no. 16: 6293. https://doi.org/10.3390/s22166293
APA StyleZhou, Y., Liu, P., Cui, Y., Liu, C., & Duan, W. (2022). Integration of Multi-Head Self-Attention and Convolution for Person Re-Identification. Sensors, 22(16), 6293. https://doi.org/10.3390/s22166293