1. Introduction
The growth of the Internet in recent years has produced a wide variety of services and improved the convenience of our daily lives. However, this has also resulted in increased numbers of cyberattacks. Intrusion detection systems (IDSs) are one mechanism for detecting such attacks. Such systems can be broadly divided into two categories depending on the detection method used. The first, signature-based IDS, performs detection based on rules that are defined in advance. The second is an anomaly-based IDS that detects abnormal states as anomalies. However, a signature-based IDS cannot detect attacks for which it has no rules, which imposes an extremely large burden on designers by requiring new rules to be added in response to the ever more diverse range of new cyberattacks. Consequently, anomaly-based IDSs that can detect unknown cyberattacks, particularly methods that use machine learning (ML) and deep learning (DL), have attracted significant attention and are now being widely researched [
1,
2,
3].
Autoencoders, which are a core technology among the anomaly detection models that use DL, generally have smaller intermediate layers than their same-sized input and output layers. Because autoencoders are normally trained to reconstruct the input, the input data are compressed into lower dimensionality by the intermediate layer. Hinton et al. [
4] described steps up to the intermediate layer as a non-linear generalization of principal component analysis (PCA). When an autoencoder is trained to reconstruct the training data, it experiences difficulty when encountering unfamiliar data that were not present during training. In the security field, attempts have been made to detect such attacks as anomalies by using autoencoders [
5,
6,
7,
8]. Furthermore, there are reports of attempts to use convolutional neural networks (CNNs) for intrusion detection, which are used primarily in the image recognition field [
9,
10,
11]. Specifically, CNNs have been proposed as a method for utilizing the relationships between data by learning the features that determine data shapes, arranging and visualizing data in two dimensions, and transforming packet byte arrays into integers.
However, many of these methods are difficult to implement for various reasons. For example, it is necessary to make the feature values used in detection capable of discriminating between normal and abnormal traffic based on network packets, requiring complicated network packet processing during the extraction of the designed feature values. Furthermore, when a supervised learning method is used, labeled data must be obtained and/or created. These difficulties can impose obstacles in the research and practical application of anomaly-based IDSs. Accordingly, our study proposes an anomaly detection method that can perform automatic feature extraction without requiring specially labeled data for each use case.
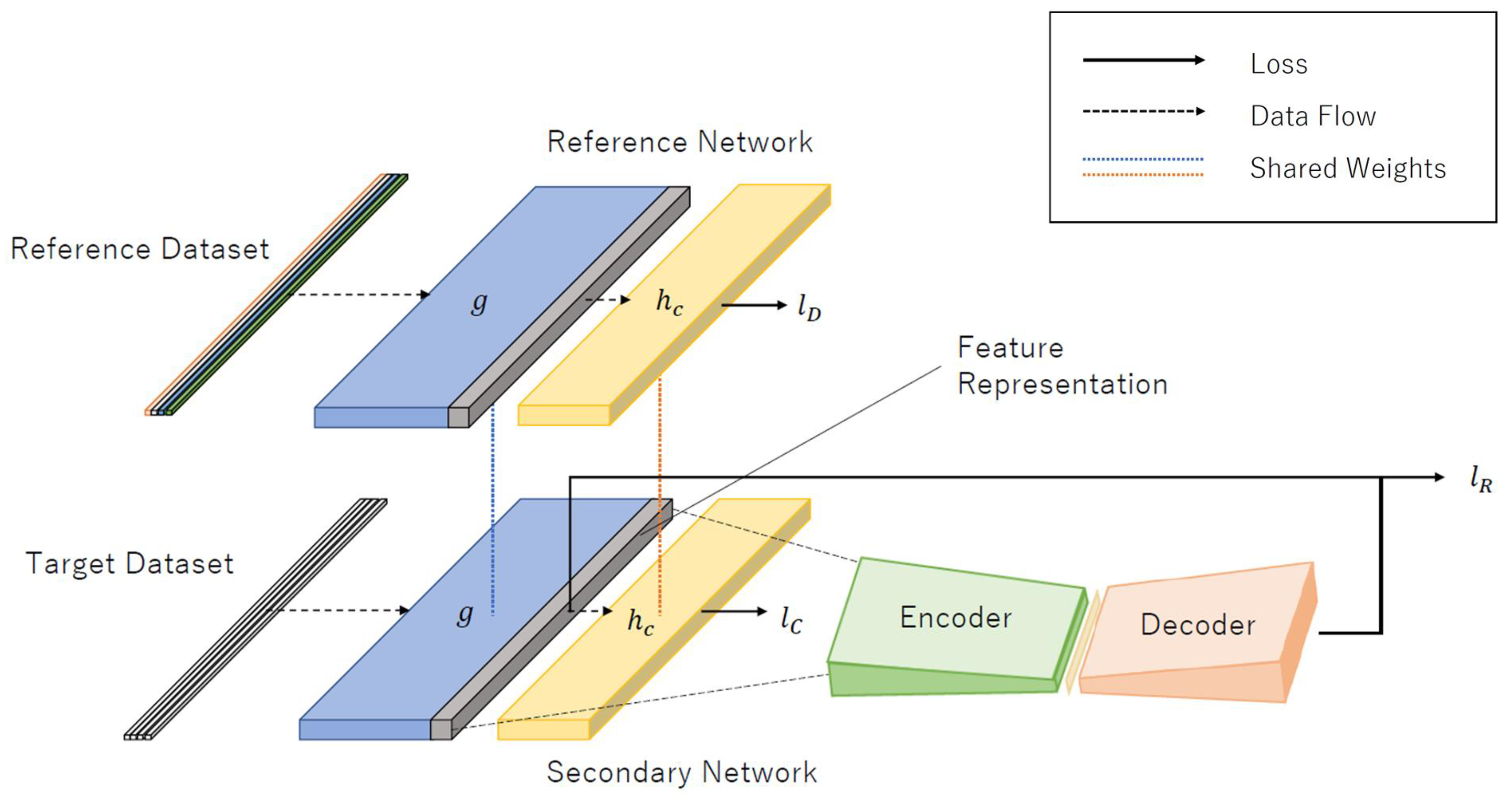
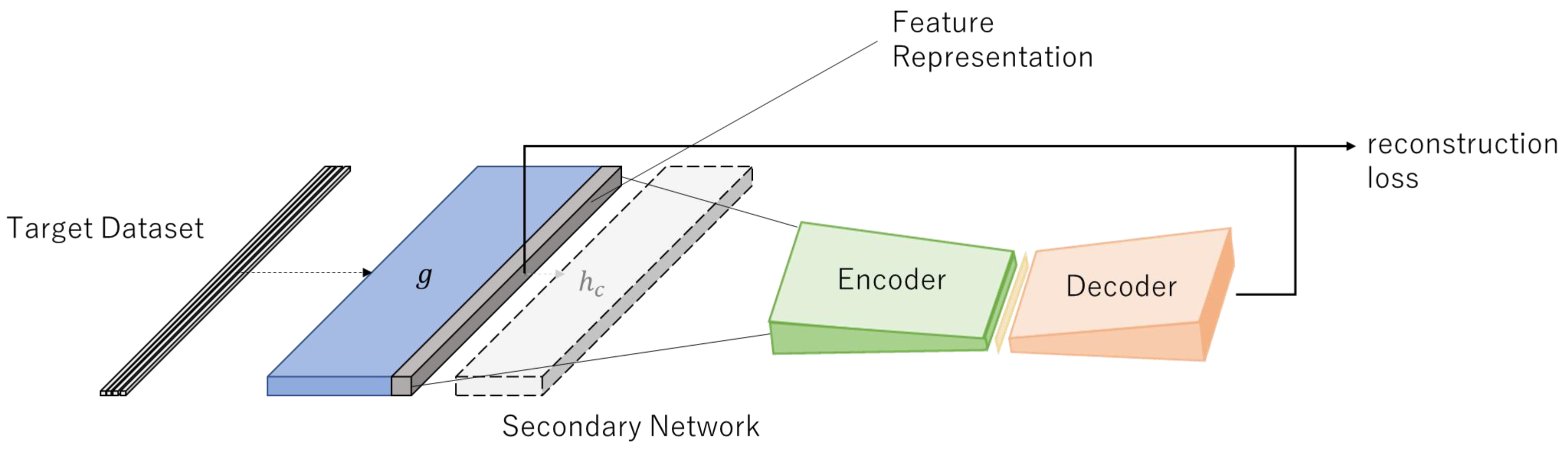
The DOC-IDS proposed herein is a feature extraction and anomaly detection method that uses a two-input DL model and employs a deep one-class classification (DOC) [
12] feature extraction method for one-class classification, which is normally used in the computer vision field, to extract features from network packets. The DOC-IDS consists of a pair of identical one-dimensional (1D) CNNs, one of which is connected to an autoencoder via the intermediate layer. In operation, the DOC-IDS uses these 1D CNNs to extract features that reveal the relationship between bytes in traffic data. During training, an existing labeled multi-class dataset is input in addition to the single class normal traffic. Two loss types are used to improve the discriminative ability among the data, whereas another loss type is used for anomaly detection. The model trained in this manner acquires feature representations with a highly enhanced ability to discriminate between normal and abnormal traffic that did not appear in the training process and is also able to perform anomaly detection. The results of the evaluation experiments using multiple datasets showed that the DOC-IDS has a higher detection accuracy than existing methods, it is particularly effective for detecting communication with command and control (C2) servers, and its processing speed delivers sufficient performance for practical applications.
The contributions of this study can be summarized as follows:
We apply a feature extraction method for one-class classification, which has high anomaly detection performance in the computer vision field, to traffic data. We then demonstrate a method of obtaining feature representations with a highly enhanced ability to discriminate between normal and abnormal traffic. Furthermore, we reduce the burden of designing and extracting feature values.
We have simultaneously trained the CNN for feature extraction and the autoencoder for anomaly detection by implementing those processes using a single DL model.
We show through evaluation experiments that our DOC-IDS method can detect anomalous traffic with high accuracy levels, particularly when handling communications with C2 servers.
The remainder of this paper is organized as follows.
Section 2 introduces the related work.
Section 3 introduces closely related research, and
Section 4 presents the architecture, training method, and anomaly detection method for the proposed DOC-IDS.
Section 5 describes the datasets used in the experiments, and
Section 6 and
Section 7 describe two experiments conducted using the datasets. Finally,
Section 8 summarizes the study.
2. Related Works
With the growing diversity of cyberattacks in recent years, there is the new burden of creating rules for signature-based IDSs that cannot detect attacks for which they have not learned the correct rules. Research is now focusing on anomaly-based IDSs that can detect unknown attacks using ML and DL [
1,
2,
3].
Numerous methods that use feature values extracted from flows provided by open datasets have been proposed, such as NSL-KDD [
13] and CIC-IDS2017 [
14]. For example, Zavrak et al. [
7] trained an autoencoder, variational autoencoder (VAE), and one-class support vector machine (SVM) using normal traffic flow data contained in the CIC-IDS2017 dataset to perform abnormal traffic detection. Separately, Khan et al. [
15] proposed a hybrid convolutional recurrent neural network intrusion detection system (HCRNNIDS) that uses a convolutional recurrent neural network (CRNN) for the flow data contained in the CSE-CIC-IDS2018 dataset. In the HCRNNIDS, feature value engineering is performed on the flow data, and a classifier is trained using flow data labels. Hence, the HCRNNIDS can extract spatial and temporal features using a convolutional layer combined with a recurrent layer. Su et al. [
16] proposed the BAT-MC detection model that combined bidirectional long short-term memory with an NSL-KDD convolutional layer. In that study, the authors converted the category variables among the NSL-KDD to a one-hot representation and used the obtained numerical data converted to an image as an input. BAT-MC training was performed by classifying the NSL-KDD labels.
Some existing studies using flows have focused on feature selection. For example, Gül et al. [
17] proposed a feature selection algorithm for the NSL-KDD that adopted an attribute evaluator to evaluate each feature and a search method to find feature combinations. The proposed algorithm achieved detection with less execution time, which was almost the same as using all the features. In [
18], Alani et al. performed preprocessing such as the binarization of classes into malicious and benign, balancing of data, removal of missing values, and encoding of categorical variables. For feature selection, they proposed a method of classification that employed a random forest and repeated the process of removing features with low contribution rates, starting with 48 features after preprocessing and repeating until five features were selected. Gharaee et al. [
19] proposed a feature selection method using a genetic algorithm (GA), in which features obtained by GA were used to train an SVM and classify communications until the maximum number of iterations was reached or the termination criteria were met. They also proposed a fitness value for the GA that multiplies the true positive rate (TPR), false positive rate (FPR), and the number of features by their respective weights.
In methods that use the flow data contained in these datasets, the features are extracted in advance so we can focus on the detection model design. Although there are also many methods that perform feature value engineering to select only the most useful feature values from those provided [
20], there have been no studies showing that feature value extraction processing needs to be implemented during actual operations and that labeling is required for detecting attacks when using supervised learning.
Methods that do not use the flow data provided by open datasets have also been proposed to extract features from network packets. For example, Mirsky et al. [
5] proposed the Kitsune anomaly detection framework that uses an ensemble of autoencoders. This method also tallies the statistical quantities from the network packets using an incremental method, and it performs feature value extraction based on the obtained statistical quantities. Specifically, the feature values are allocated to the autoencoder ensemble, and anomaly detection is performed by incorporating the reconstruction error for each autoencoder.
Yu et al. [
8] extracted features useful for anomaly detection using dilated convolutional autoencoders (DCAEs). The authors accomplished this by extracting information from the header information and network packet payloads and then training the DCAEs by inputting the obtained information arranged in two dimensions. The output from the intermediate layers of the DCAEs provides the feature representation of the traffic data, and a communication classifier is obtained by connecting a fully connected layer to the intermediate layer and then performing fine tuning using labeled data.
Among the methods for extracting features from network packets, some proposals are related to significantly reducing packet processing. For example, the D-PACK method proposed by Hwang et al. [
6], which is similar to our proposed method, implements feature extraction from raw packets and abnormal traffic detection using a combination of a CNN and autoencoder. In the D-PACK training process, a set of normally labeled traffic is input, and the CNN classification and autoencoder reconstruction errors are used.
However, even in methods that perform feature extraction from packets, feature value designs, complicated packet processing, and labeled data for supervised learning are required, all of which can be obstacles to the research and practical application of anomaly-based IDSs. Accordingly, when these problems are addressed, the amount of labor involved in the research and practical application of anomaly-based IDSs can be reduced. Thus, programmers can focus on more important problems, such as anomaly detection model design.
With these points, the present study proposes the DOC-IDS method as a feature extraction and anomaly detection method using a two-input DL model. Specifically, the DOC-IDS employs the DOC [
12] feature extraction method, commonly employed in the computer vision field, to acquire feature values using a highly enhanced ability to discriminate between normal and abnormal traffic. Although a labeled multi-class dataset is required to improve discriminative ability during DOC-IDS training, DOC-IDS uses existing data from open datasets, which implies that it does not require labeling of the detected network traffic. The primary advantage of this method is that it resolves the problems that have hindered the research and practical application of anomaly-based IDSs in existing studies [
5,
6,
7,
8,
9,
10,
11,
15,
16] that are related to the burden of designing and extracting feature values and creating labels. Furthermore, the DOC-IDS model can simultaneously train feature extraction and anomaly detection networks using a single DL model.
7. Time Efficiency
Then, the processing performance of the DOC-IDS was evaluated using the CIC-IDS2017 dataset.
Table 11 lists the performance of the hardware and software used in the experiments.
In this experiment, the model trained using the Monday traffic file, which does not contain attack traffic, was used to evaluate the time required for anomaly detection. The time measurement was performed for each file contained in CIC-IDS2017, and the time taken for the entire execution, the times taken for both flow sampling, and detection times were investigated.
In terms of implementation, the scapy [
36] sniffer method was used to parse the packets. Furthermore, TCP and user datagram protocol (UDP) traffic was processed in parallel to the flow sampling, and the DOC-IDS anomaly detection (divided into five parallel processes) was performed.
7.1. Results
Table 12 shows the time taken for the entire execution, whereas
Table 13 shows the time taken for detection in the experiments. The experimental results showed that the DOC-IDS processing performance is approximately 5152 packets per second (pps).
Table 13 also shows that the majority of the processing time resulted from packet parsing, which depended on the performance of the Scapy library. For flow sampling, the average was approximately 21,964 pps for TCP and 14,435 pps for the UDP. These flow samplings indicated that processing at a maximum of approximately 36,399 pps is possible. Furthermore, because the five above-mentioned detection processes were executed in parallel, the processing could eventually reach 1917 flows per second, and that speed might even be further improved by increasing the degree of parallelism.
7.2. Discussion
From the experimental results, we can observe that if we regard the flow sampling processing performance as the bottleneck, the DOC-IDS should be able to process traffic at several tens of megabits per second (Mbps) in an experimental environment, indicating that it can process medium-sized networks. Methods for further speed increases could include using a high-speed parser, using higher-performance hardware, and implementation using a high-performance language, such as C++.
8. Conclusions
This paper proposed the DOC-IDS method to reduce the obstacles to the implementation of anomaly-based IDS, which is a method that has been attracting significant attention in recent years. Our method alleviates the difficulties of designing feature values, the complexity of processing in feature value extraction, and the labor required to create labeled data in supervised learning. In our experiments, the DOC-IDS was able to perform processing from feature extraction to anomaly detection without requiring labeling by inputting pre-labeled traffic from an open dataset and the traffic from the target network into the model.
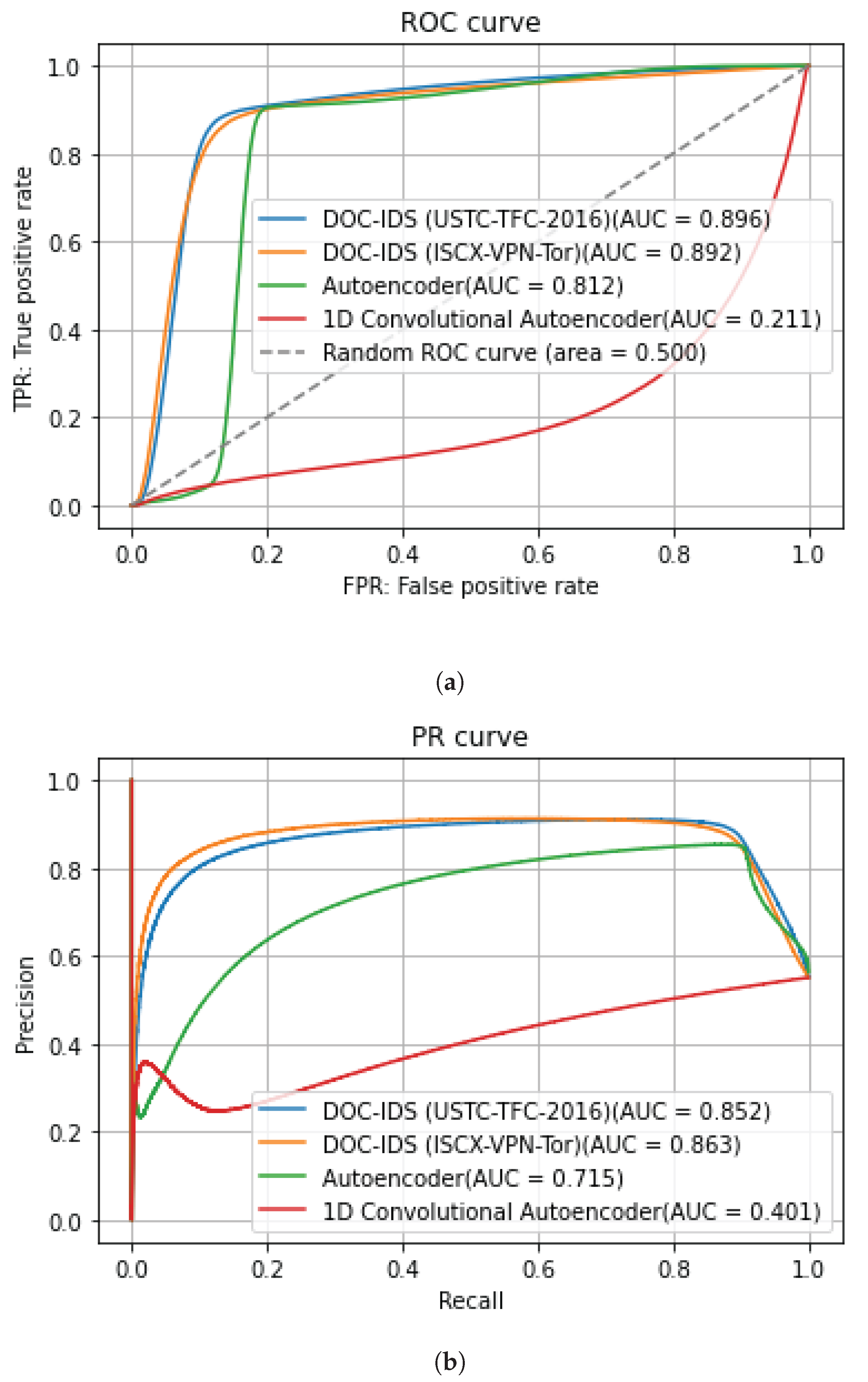
Our experimental results showed that the anomaly detection performance of the DOC-IDS exhibited a maximum AUC for the ROC and PR curves of 0.996 and 0.889, respectively, which surpasses the comparison methods. Furthermore, the processing performance levels are sufficient for practical use. In addition, the DOC-IDS addresses the obstacles in conventional anomaly-based IDS methods using ML and DL by eliminating the need to create specially labeled data or process network packets. Thus, this paper provides interesting implications for future research and practical applications.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}