
DTS-Net: Depth-to-Space Networks for Fast and Accurate Semantic Object Segmentation


Abstract
:1. Introduction
- Rather than a pixel-wise classification problem, we treat the semantic segmentation problem as an image-to-image translation problem through regression using the DTS layer, and construct segmentation maps using the higher-resolution image reconstruction approach of the super-resolution task;
- We propose DTS-Net, a deep model that uses Xception architecture as a feature extractor for high-accuracy critical applications, as well as a small lightweight model, DTS-Net-Lite, for high-speed critical applications that uses MobileNetV2 architecture as a feature extractor;
- We reduce the typical decoding stage complexity for segmentation mask construction to that of the DTS image construction layer and show that this layer can construct segmentation masks with far lower computational cost and much higher precision than conventional CNN-based decoding architectures.
- We propose a new segmentation improvement technique namely nearest label filtration (NLF) to improve the segmentation by correcting the wrong predicted pixels by DTS-layer in the segmentation mask.
2. Related Work
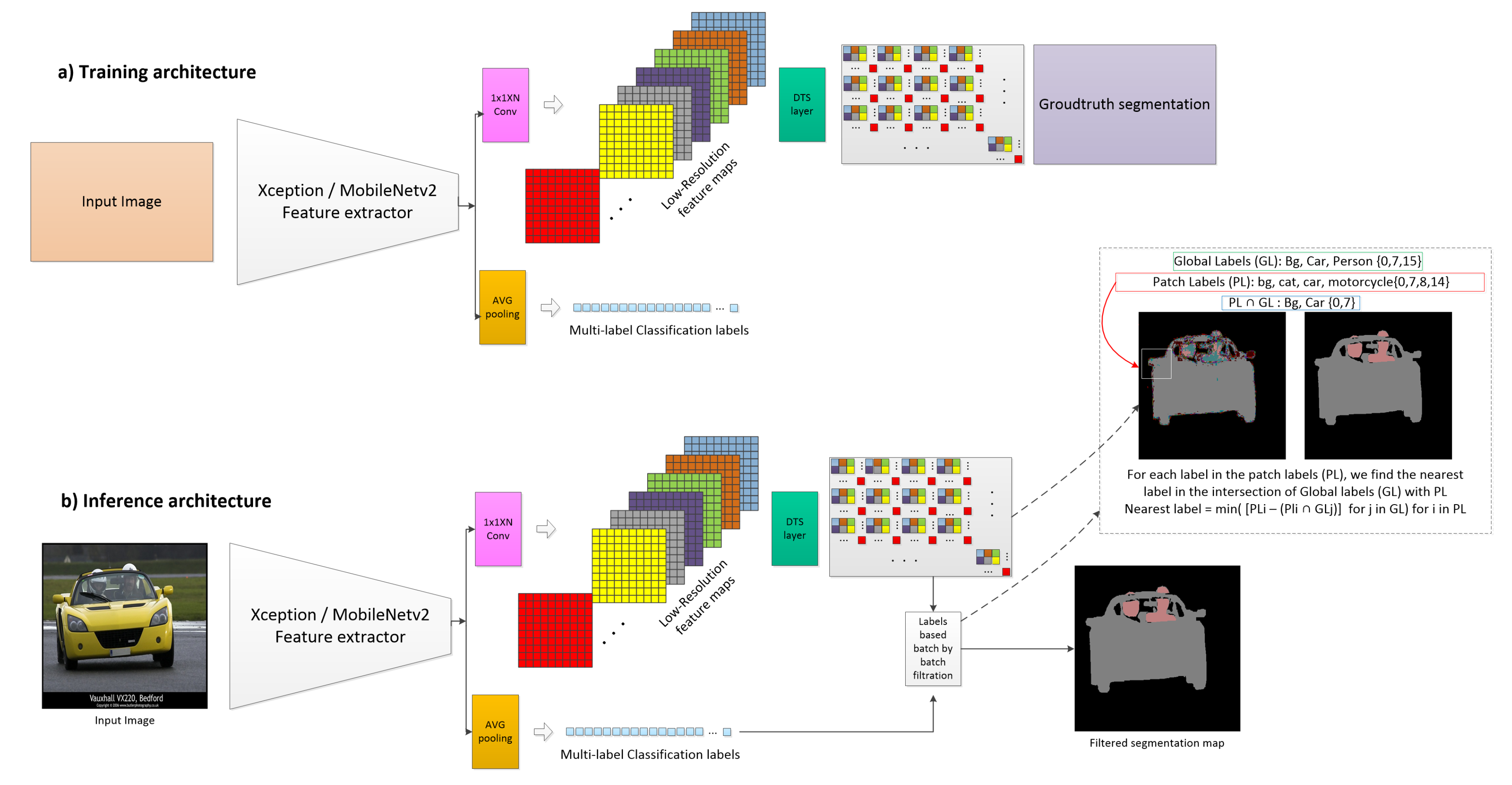
3. Proposed Method
- The feature extractor CNNs: These CNNs extract the image semantics and deliver deep feature maps. Both proposed architectures, DTS-Net and DTS-Net-Lite, are presented in this section. We also discuss our reasons for choosing depth-wise separable convolution-based architectures.
- DTS layer: This layer aggregates the small feature maps to form a higher-resolution segmentation map (or depth map).
- The nearest label filtration (NLF): This filtration employs multi-label classification labels to filter the segmentation mask patch by patch.
3.1. Feature Extractor Architectures
3.2. Efficient Sub-Pixel Convolutional Neural Networks
3.3. Nearest Label Filtration
3.4. Loss Function
4. Experiments
4.1. Semantic Segmentation Evaluation Metrics
4.2. DTS-Net and DTS-Net-Lite
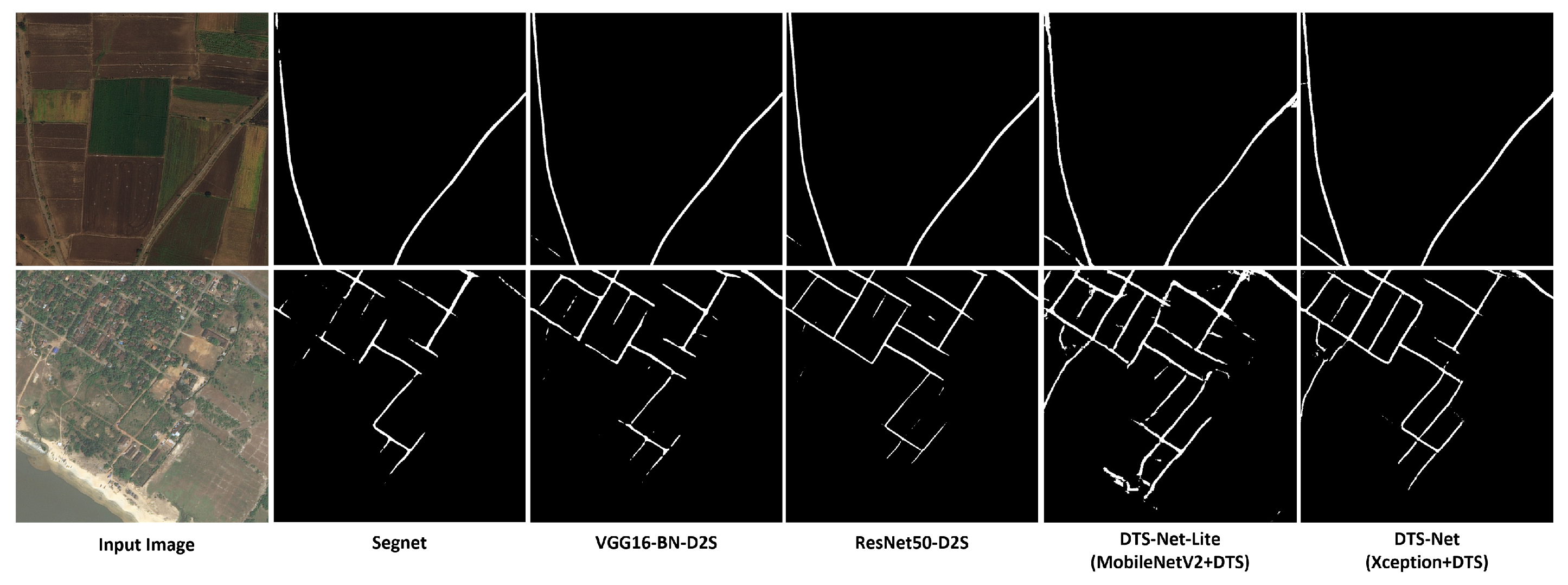
4.3. Benchmarks
4.4. Training and Testing Configuration
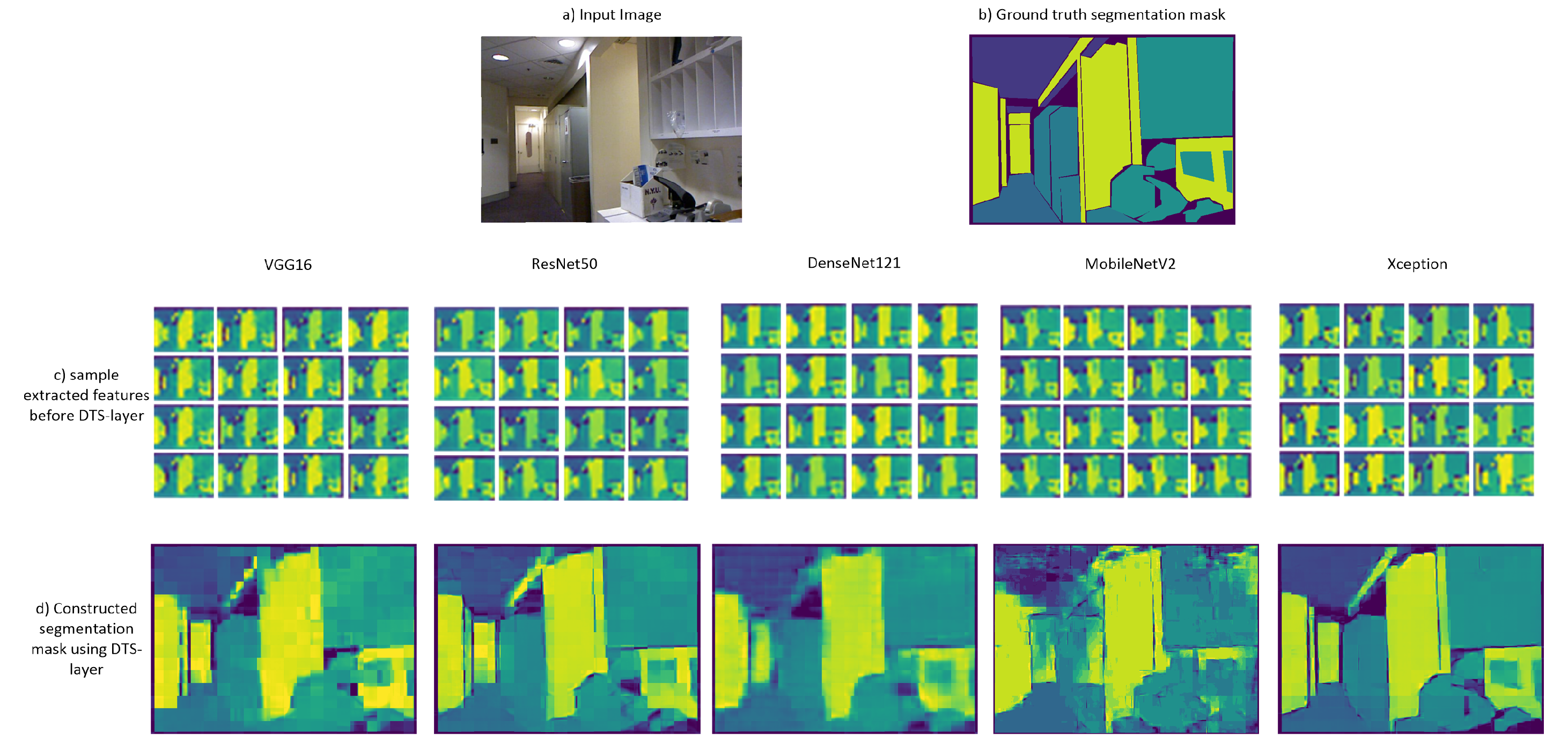
4.5. Quality Comparison between Different CNN Backbones
4.6. Joint Semantic Segmentation and Depth Estimation
5. Results
5.1. Semantic Segmentation mIOU Results
5.2. Semantic Segmentation Speed Results
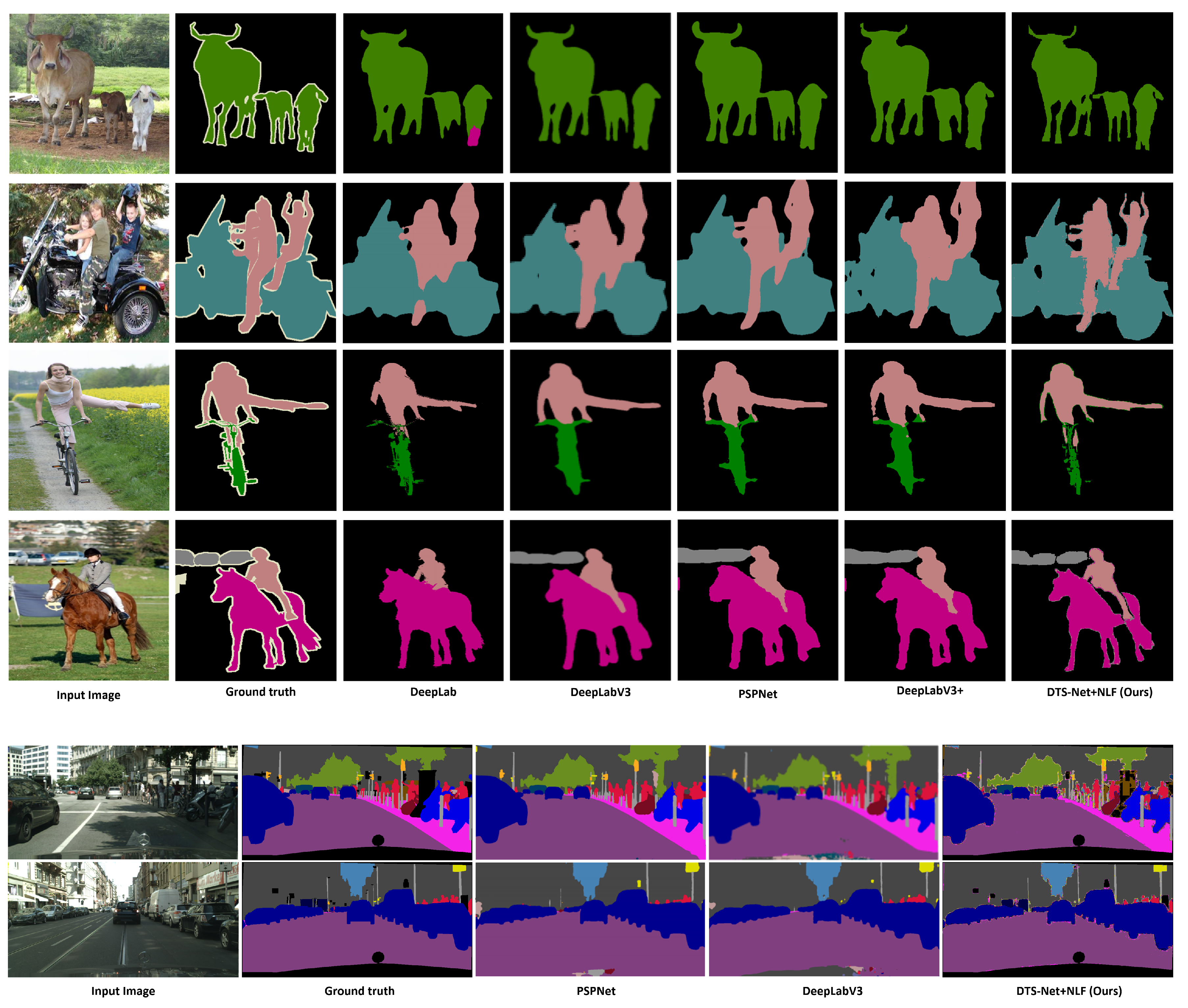
5.3. Comparison with SOTA Semantic Segmentation Methods
5.4. DTS-Net for Joint Depth Estimation and Semantic Segmentation
- the absolute relative error (REL): ;
- the relative difference squared (Sq_REL): ;
- the root mean squared error (RMSE): ;
- the disparity error (px): ;
- the threshold accuracy of : for the commonly used threshold values ,
6. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar] [CrossRef] [Green Version]
- Everingham, M.; Gool, L.V.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor Segmentation and Support Inference from RGBD Images. In Proceedings of the European Conference on Computer Vision (ECCV) 2012, Florence, Italy, 7–13 October 2012. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834848. [Google Scholar] [CrossRef]
- Liu, S.; Deng, W. Very deep convolutional neural network based image classification using small training sample size. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 730–734. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. ICNet for Real-Time Semantic Segmentation on High-Resolution Images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Muller, J.; Manmatha, R.; et al. Resnest: Splitattention networks. arXiv 2020, arXiv:2004.08955. [Google Scholar]
- Shi, H.; Li, H.; Meng, F.; Wu, Q.; Xu, L.; Ngan, K.N. Hierarchical Parsing Net: Semantic Scene Parsing From Global Scene to Objects. IEEE Trans. Multimedia 2018, 20, 2670–2682. [Google Scholar] [CrossRef]
- Chen, T.; Xie, G.; Yao, Y.; Wang, Q.; Shen, F.; Tang, Z.; Zhang, J. Semantically Meaningful Class Prototype Learning for One-Shot Image Segmentation. IEEE Trans. Multimedia 2021. [Google Scholar] [CrossRef]
- Zoph, B.; Ghiasi, G.; Lin, T.-Y.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q.V. Rethinking pre-training and self-training. arXiv 2020, arXiv:2006.06882. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Rashwan, A.; Du, X.; Yin, X.; Li, J. Dilated spinenet for semantic segmentation. arXiv 2021, arXiv:2103.12270. [Google Scholar]
- Bai, S.; Kolter, J.Z.; Koltun, V. Deep Equilibrium Models. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Termritthikun, C.; Jamtsho, Y.; Ieamsaard, J.; Muneesawang, P.; Lee, I. EEEA-Net: An Early Exit Evolutionary Neural Architecture Search. Eng. Appl. Artif. Intell. 2021, 104, 104397. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13733–13742. [Google Scholar]
- Aich, S.; van der Kamp, W.; Stavness, I. Semantic Binary Segmentation Using Convolutional Networks without Decoders. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–1824. [Google Scholar] [CrossRef] [Green Version]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Kang, B.; Lee, Y.; Nguyen, T.Q. Depth-Adaptive Deep Neural Network for Semantic Segmentation. IEEE Trans. Multimedia 2018, 20, 2478–2490. [Google Scholar] [CrossRef] [Green Version]
- Gu, Z.; Niu, L.; Zhao, H.; Zhang, L. Hard Pixel Mining for Depth Privileged Semantic Segmentation. IEEE Trans. Multimedia 2020, 23, 3738–3751. [Google Scholar] [CrossRef]
- Mousavian, A.; Pirsiavash, H.; Košecká, J. Joint Semantic Segmentation and Depth Estimation with Deep Convolutional Networks. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 611–619. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Cui, Z.; Xu, C.; Jie, Z.; Li, X.; Yang, J. Joint Task-Recursive Learning for Semantic Segmentation and Depth Estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 235–251. [Google Scholar]
- Lin, X.; Sánchez-Escobedo, D.; Casas, J.R.; Pardàs, M. Depth Estimation and Semantic Segmentation from a Single RGB Image Using a Hybrid Convolutional Neural Network. Sensors 2019, 19, 1795. [Google Scholar] [CrossRef] [Green Version]
- He, L.; Lu, J.; Wang, G.; Song, S.; Zhou, J. SOSD-Net: Joint semantic object segmentation and depth estimation from monocular images. Neurocomputing 2021, 440, 251–263. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Hu, W.; Zhao, H.; Jiang, L.; Jia, J.; Wong, T.-T. Bidirectional Projection Network for Cross Dimension Scene Understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 14373–14382. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P.H. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhang, X.; Peng, C.; Xue, X.; Sun, J. ExFuse: Enhancing Feature Fusion for Semantic Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–284. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.-Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple Copy-Paste Is a Strong Data Augmentation Method for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Handa, A.; Patraucean, V.; Badrinarayanan, V.; Stent, S.; Cipolla, R. Understanding Real World Indoor Scenes with Synthetic Data. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4077–4085. [Google Scholar]
- Hermans, A.; Floros, G.; Leibe, B. Dense 3D semantic mapping of indoor scenes from RGB-D images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2631–2638. [Google Scholar]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. Semanticfusion: Dense 3dsemantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Niessner, M. Scannet: Richly annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in Network. arXiv 2014, arXiv:1312.4400. [Google Scholar]
- Dai, A.; Nießner, M. 3DMV: Joint 3D-multi-view prediction for 3D semantic scene segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Mehta, S.; Hajishirzi, H.; Rastegari, M. DiCENet: Dimension-wise Convolutions for Efficient Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 14, 1–10. [Google Scholar] [CrossRef]
- Poudel, R.P.K.; Bonde, U.; Liwicki, S.; Zach, C. ContextNet: Exploring Context and Detail for Semantic Segmentation in Real-time. In Proceedings of the British Machine Vision Conference BMVC 2018, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Nekrasov, V.; Shen, C.; Reid, I. Template-Based Automatic Search of Compact Semantic Segmentation Architectures. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 1980–1989. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Scalable Image Recognition. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Gong, X.; Liu, X.; Zhang, Q.; Li, Y.; Wang, Z. FasterSeg: Searching for Faster Real-time Semantic Segmentation. In Proceedings of the ICLR, Simien Mountains, Ethiopia, 27–30 April 2020. [Google Scholar]
- Shaw, A.; Hunter, D.; Landola, F.; Sidhu, S. SqueezeNAS: Fast Neural Architecture Search for Faster Semantic Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27–28 October 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extractor | Params (M) | MACs (G) | Pix.acc. % |
|---|---|---|---|
| VGG16 | 138.3 M | 62.1 G | 42.1 |
| DenseNet121 | 8 M | 11.1 G | 51.3 |
| ResNet50 | 25.6 M | 15.4 G | 62.5 |
| MobileNetV2 | 3.5 M | 1.2 G | 66.7 |
| Xception | 22.4 M | 18.5 G | 79.4 |
| Model | Img Size | Dataset | mIOU% | Pix acc.% | Speed (FPS) |
|---|---|---|---|---|---|
| DTS-Net | 480 × 480 | VOC2012 | 27.66 | 90.07 | 22 |
| DTS-Net | 640 × 480 | NYUV2 | 33.92 | 79.4 | 18.1 |
| DTS-Net | 1024 × 512 | CITYSCAPES | 47.7 | 85.1 | 9.5 |
| DTS-Net-Lite | 256 × 256 | VOC2012 | 14.72 | 87.0 | 24 |
| DTS-Net-Lite | 320 × 256 | NYUV2 | 24.5 | 66.76 | 21.3 |
| DTS-Net-Lite | 512 × 256 | CITYSCAPES | 35.3 | 82.8 | 14.7 |
| DTS-Net+ NLF | 480 × 480 | VOC2012 | 91.1 | 98.8 | 15.5 |
| DTS-Net+NLF | 640 × 480 | NYUV2 | 62.77 | 84.73 | 12.8 |
| DTS-Net+NLF | 1024 × 512 | CITYSCAPES | 80.72 | 93.1 | 6.6 |
| DTS-Net-Lite+NLF | 256 × 256 | VOC2012 | 83.8 | 96.1 | 19.2 |
| DTS-Net-Lite+NLF | 320 × 256 | NYUV2 | 48.46 | 73.3 | 14.2 |
| DTS-Net-Lite+NLF | 512 × 256 | CITYSCAPES | 61.5 | 82.06 | 11.7 |
| Method | Backbone | mIOU (%) |
|---|---|---|
| DeepLab-CRF [9] | ResNet-101+CRF | 77.69 |
| DeepLabv3 [12] | ResNet-101 | 76.5 |
| DeepLabv3+Res2Net [40] | Res2Net-101 | 79.3 |
| DeepLabv3+ [13] | Aligned Xception | 84.56 |
| PSPNet [15] | RestNet-152 | 85.4 |
| SpineNet-S143 [24] | Dilated SpineNet | 85.64 |
| HPN [19] | ResNet-101 | 85.8 |
| ExFuse [41] | ResNeXt-131 | 85.8 |
| Eff-B7 NAS-FPN [42] | EfficientNet-B7+NAS+FPN | 86.6 |
| EfficientNet-L2+NAS-FPN [21] | EfficientNet-B7+NAS+FPN | 90.0 |
| bf DTS-Net-Lite+NLF | MobileNetV2+DTS | 83.8 |
| DTS-Net+NLF | Xception+DTS | 91.1 |
| Method | Backbone | Pix.acc.% |
|---|---|---|
| SceneNet [43] | VGG16 | 52.5 |
| Hermans et al. [44] | RDF+CRF | 54.3 |
| SemanticFusion [45] | VGG16 | 59.2 |
| ScanNet [46] | NiN [47] | 60.7 |
| 3DMV [48] | Enet [49] | 71.2 |
| BPNet [39] | U-Net | 73.5 |
| DTS-Net-Lite+NLF | MobileNetV2+DTS | 73.3 |
| DTS-Net+NLF | Xception+DTS | 84.7 |
| Method | Backbone | mIOU (%) | Speed (FPS) |
|---|---|---|---|
| DICENet [50] | ShuffleNetV2 | 63.4 | 17.2 |
| ContextNet [51] | Shallow+deep CNN | 65.9 | 18.3 |
| Template-Based NAS-arch1 [52] | NAS-Net [53] | 69.5 | 97.0 |
| HPN [19] | ResNet-101 | 71.7 | 4.0 |
| FasterSeg [54] | NAS-Net [53] | 73.1 | 6.1 |
| SqueezeNAS [55] | NAS-Net [53] | 75.2 | 0.0065 |
| Dilated-ResNet [11] | Dilated ResNet-101 | 75.7 | - |
| EEEA-Net-C2 [26] | NAS-Net [53] | 76.8 | 11.6 |
| MDEQ-large [25] | MDEQ | 77.8 | - |
| DeepLabv3 [12] | Dilated ResNet-101 | 78.5 | 2.0 |
| DeepLabv3+ [13] | Dilated Xception-71 | 79.6 | 4.2 |
| PSPNet [15] | Dilated ResNet-101 | 79.7 | 1.6 |
| MDEQ-XL [25] | MDEQ | 80.3 | - |
| RepVGG-B2 [27] | VGG-like | 80.57 | 4.5 |
| DTS-Net-Lite+NLF | MobileNetV2+DTS | 61.5 | 11.7 |
| DTS-Net+NLF | Xception+DTS | 80.72 | 6.6 |
| Method | Dataset | REL | Sq Rel | RMSE | px | |||
|---|---|---|---|---|---|---|---|---|
| SemDepth+CRF [32] | NYUV2 | 0.158 | 0.121 | 0.641 | 0.769 | 0.950 | 0.988 | - |
| TRL-ResNet50 [33] | NYUV2 | 0.144 | - | 0.501 | 0.815 | 0.962 | 0.992 | - |
| HybridNet A2 [34] | CS | 0.240 | 4.27 | 12.09 | 0.597 | 0.822 | 0.929 | - |
| NYUV2 | 0.202 | 0.186 | 0.682 | 0.613 | 0.892 | 0.974 | - | |
| ESOSD-Net [35] | NYUV2 | 0.145 | - | 0.514 | 0.805 | 0.962 | 0.992 | - |
| CS | - | - | - | - | - | - | 2.41 | |
| DTS-Net+NLF | NYUV2 | 0.102 | 0.503 | 0.310 | 0.946 | 0.997 | 0.999 | - |
| CS | 0.098 | 1.093 | 7.627 | 0.905 | 0.956 | 0.971 | 1.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ibrahem, H.; Salem, A.; Kang, H.-S. DTS-Net: Depth-to-Space Networks for Fast and Accurate Semantic Object Segmentation. Sensors 2022, 22, 337. https://doi.org/10.3390/s22010337
Ibrahem H, Salem A, Kang H-S. DTS-Net: Depth-to-Space Networks for Fast and Accurate Semantic Object Segmentation. Sensors. 2022; 22(1):337. https://doi.org/10.3390/s22010337
Chicago/Turabian StyleIbrahem, Hatem, Ahmed Salem, and Hyun-Soo Kang. 2022. "DTS-Net: Depth-to-Space Networks for Fast and Accurate Semantic Object Segmentation" Sensors 22, no. 1: 337. https://doi.org/10.3390/s22010337
APA StyleIbrahem, H., Salem, A., & Kang, H.-S. (2022). DTS-Net: Depth-to-Space Networks for Fast and Accurate Semantic Object Segmentation. Sensors, 22(1), 337. https://doi.org/10.3390/s22010337