
Wildfire Smoke Classification Based on Synthetic Images and Pixel- and Feature-Level Domain Adaptation

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Pixel-Level Based Domain Adaptation
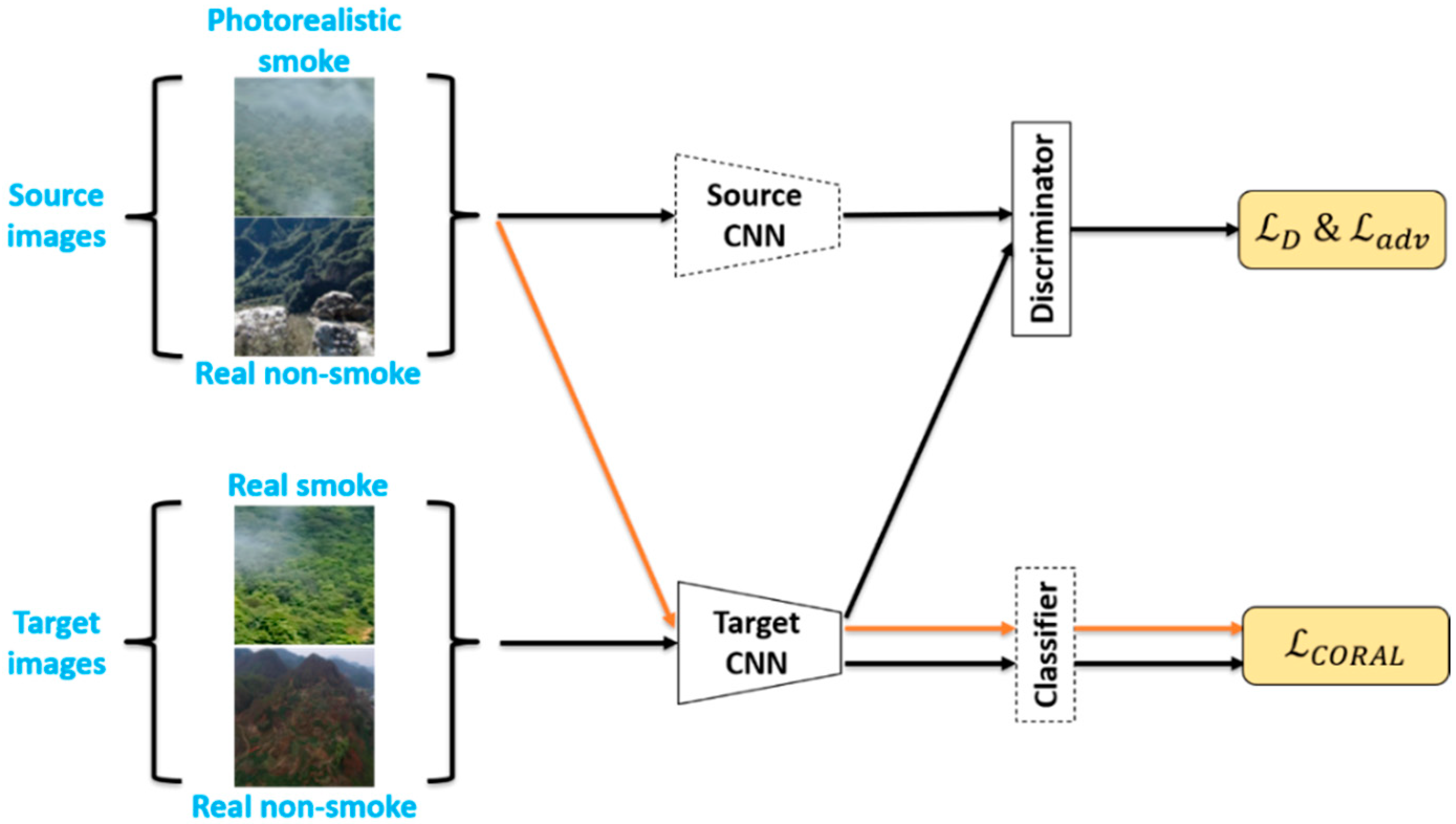
2.3. Feature-Level Based Domain Adaptation
3. Experiments and Discussion
3.1. Dataset
3.2. Implementation Details
3.3. Evaluation Metrics
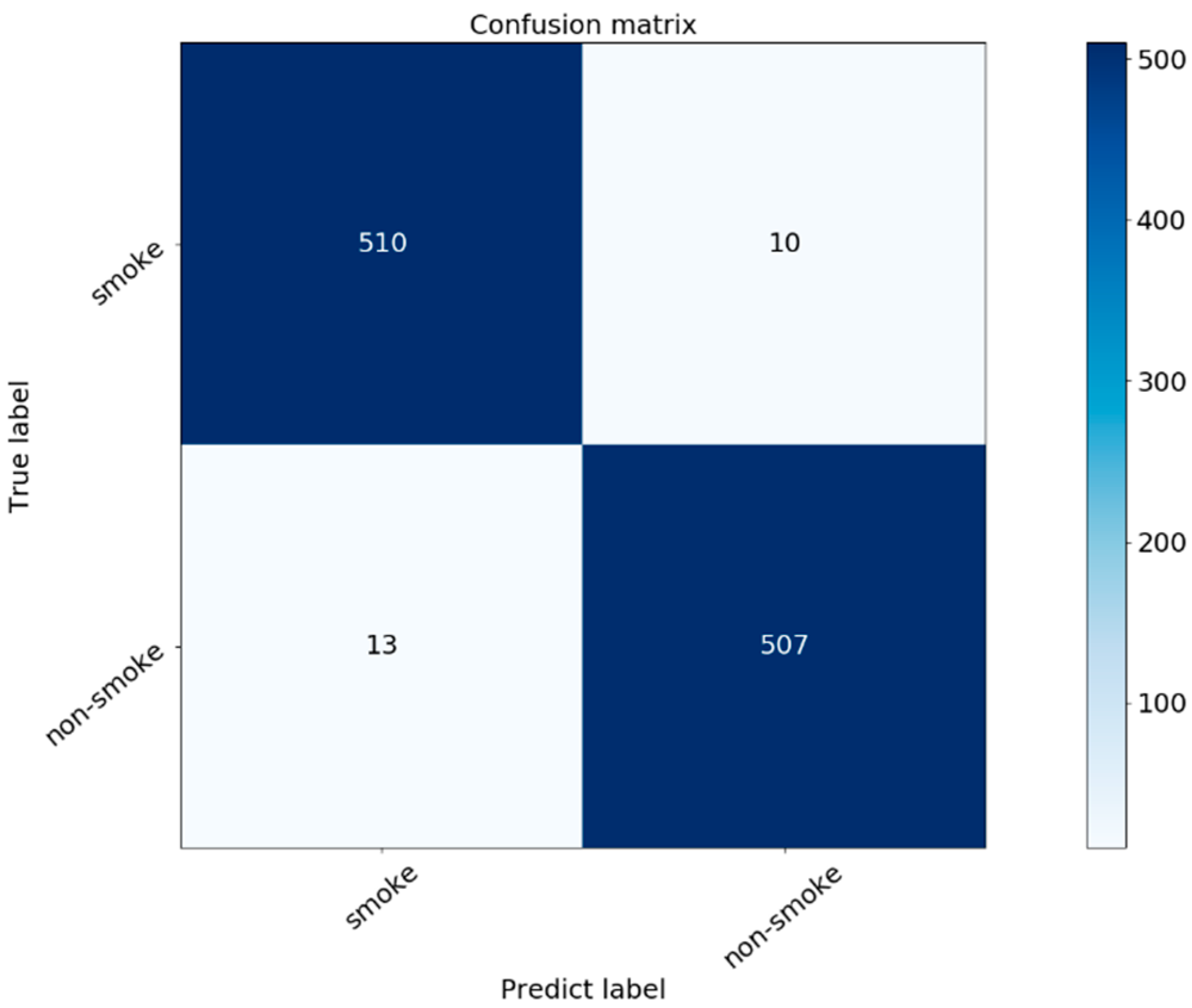
3.4. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A Review on Early Forest Fire Detection Systems Using Optical Remote Sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef] [PubMed]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, Z.; Jia, Y.; Wang, J. Video smoke detection based on deep saliency network. Fire Saf. J. 2019, 105, 277–285. [Google Scholar] [CrossRef] [Green Version]
- Gomes, P.; Santana, P.; Barata, J. A Vision-Based Approach to Fire Detection. Int. J. Adv. Robot. Syst. 2014, 11, 149. [Google Scholar] [CrossRef]
- Sun, X.; Sun, L.; Huang, Y. Forest fire smoke recognition based on convolutional neural network. J. For. Res. 2020, 32, 1921–1927. [Google Scholar] [CrossRef]
- Zhang, F.; Qin, W.; Liu, Y.; Xiao, Z.; Liu, J.; Wang, Q.; Liu, K. A Dual-Channel convolution neural network for image smoke detection. Multimed. Tools Appl. 2020, 79, 34587–34603. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Sanakoyeu, A.; Khalidov, V.; McCarthy, M.S.; Vedaldi, A.; Neverova, N. Transferring Dense Pose to Proximal Animal Classes. arXiv 2020, arXiv:2003.00080. Available online: https://arxiv.org/abs/2003.00080 (accessed on 5 November 2021).
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Xu, C.; Yang, X.; Tao, D. Attention-GAN for Object Transfiguration in Wild Images. Lect. Notes Comput. Sci. 2018, 167–184. [Google Scholar] [CrossRef] [Green Version]
- Song, G.; Luo, L.; Liu, J.; Ma, W.-C.; Lai, C.; Zheng, C.; Cham, T.-J. AgileGAN. ACM Trans. Graph. 2021, 40, 1–13. [Google Scholar] [CrossRef]
- Namozov, A.; Cho, Y.I. An Efficient Deep Learning Algorithm for Fire and Smoke Detection with Limited Data. Adv. Electr. Comput. Eng. 2018, 18, 121–128. [Google Scholar] [CrossRef]
- Park, M.; Tran, D.; Jung, D.; Park, S. Wildfire-Detection Method Using DenseNet and CycleGAN Data Augmentation-Based Remote Camera Imagery. Remote Sens. 2020, 12, 3715. [Google Scholar] [CrossRef]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.-X.; Lin, G.-H.; Zhang, Y.-M.; Xu, G.; Wang, J.-J. Wildland Forest Fire Smoke Detection Based on Faster R-CNN using Synthetic Smoke Images. Procedia Eng. 2018, 211, 441–446. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Q.; Liu, D.; Lin, G.; Wang, J.; Zhang, Y. Adversarial Adaptation from Synthesis to Reality in Fast Detector for Smoke Detection. IEEE Access 2019, 7, 29471–29483. [Google Scholar] [CrossRef]
- Xu, G.; Zhang, Y.; Zhang, Q.; Lin, G.; Wang, J. Deep domain adaptation based video smoke detection using synthetic smoke images. Fire Saf. J. 2017, 93, 53–59. [Google Scholar] [CrossRef] [Green Version]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Wang, M.; Deng, W.; Wang, M.; Deng, W.; Wang, M.; Deng, W.; Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]
- Wang, J.; Lan, C.; Liu, C.; Ouyang, Y.; Qin, T. Generalizing to Unseen Domains: A Survey on Domain Generalization. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence Survey Track, Montreal, QC, Canada, 19–27 August 2021; Volume 5, pp. 4627–4635. [Google Scholar] [CrossRef]
- Jiang, W.; Gao, H.; Lu, W.; Liu, W.; Chung, F.-L.; Huang, H. Stacked Robust Adaptively Regularized Auto-Regressions for Domain Adaptation. IEEE Trans. Knowl. Data Eng. 2018, 31, 561–574. [Google Scholar] [CrossRef]
- Jiang, W.; Liu, W.; Chung, F.-L. Knowledge transfer for spectral clustering. Pattern Recognit. 2018, 81, 484–496. [Google Scholar] [CrossRef]
- Qi, G.-J.; Liu, W.; Aggarwal, C.; Huang, T. Joint Intermodal and Intramodal Label Transfers for Extremely Rare or Unseen Classes. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1360–1373. [Google Scholar] [CrossRef]
- Hoffman, J.; Tzeng, E.; Park, T.; Zhu, J.Y.; Isola, P.; Saenko, K.; Efros, A.; Darrell, T. CyCADA: Cycle-Consistent Adversarial Domain Adaptation. Int. Conf. Mach. Learn. 2018, 80, 1989–1998. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial Discriminative Domain Adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2962–2971. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Lin, J.; Ding, Y.; Liu, Z.; Zhu, J.-Y.; Han, S. GAN Compression: Efficient Architectures for Interactive Conditional GANs. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2020, Seattle, WA, USA, 14–19 June 2020; pp. 5283–5293. [Google Scholar] [CrossRef]
- Sun, B.; Saenko, K. Deep CORAL: Correlation Alignment for Deep Domain Adaptation. Lect. Notes Comput. Sci. 2016, 443–450. [Google Scholar] [CrossRef] [Green Version]
- Blender, version 2.90; Software For 3D Modeling; Blender Institute: Amsterdam, The Netherlands, 2020.
- State Key Laboratory of Fire Science, USTC. Research Webpage about Smoke Detection for Fire Alarm. 2021. Available online: http://smoke.ustc.edu.cn (accessed on 10 October 2021).
- Yuan, F. Smoke and Non-Smoke Image Databases Created by Dr. YUAN Feiniu. 2019. Available online: http://staff.ustc.edu.cn/~yfn/ (accessed on 5 November 2021).
- Shan, Y.; Lu, W.F.; Chew, C.M. Pixel and Feature Level based Domain Adaptation for Object Detection in Autonomous Driving. Neurocomputing 2019, 367, 31–38. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Synthetic Images | Real Images | |
|---|---|---|
| Smoke images | 2000 | 1800 |
| Smoke Images | Non-Smoke Images | |
|---|---|---|
| Source images | 5000 | 5000 |
| Target images | 5000 | 5000 |
| Real Smoke Images | Real Non-Smoke Images | |
|---|---|---|
| Test set | 520 | 520 |
| CD | ED | MD | |
|---|---|---|---|
| ResNet-50 w/source images | 0.6348 | 0.3371 | 0.4712 |
| ResNet-50 w/target images | 0.6597 | 0.1988 | 0.5420 |
| ResNet-50 w/PDA | 0.7042 | 0.2989 | 0.2764 |
| ResNet-50 w/FDA(only Deep CORAL) | 0.7918 | 0.1053 | 0.1291 |
| ResNet-50 w/FDA(only ADDA) | 0.8569 | 0.1765 | 0.1138 |
| ResNet-50 w/FDA(ADDA+DeepCORAL) | 0.9242 | 0.0815 | 0.0655 |
| ResNet-50 w/PDA+FDA(ADDA+DeepCORAL) | 0.9739 | 0.0386 | 0.0304 |
| CD | ED | MD | |
|---|---|---|---|
| ResNet-50 | 0.6598 | 0.2812 | 0.2157 |
| ResNet-50 w/PDA+FDA(ADDA+DeepCORAL) | 0.9382 | 0.0477 | 0.0534 |
| Average Recognition Time (s) | Average Recognition Time (s) | Average Recognition Time (s) | |
|---|---|---|---|
| GPU | 0.0041 | 0.0039 | 0.0038 |
| CPU | 0.0595 | 0.0586 | 0.0580 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mao, J.; Zheng, C.; Yin, J.; Tian, Y.; Cui, W. Wildfire Smoke Classification Based on Synthetic Images and Pixel- and Feature-Level Domain Adaptation. Sensors 2021, 21, 7785. https://doi.org/10.3390/s21237785
Mao J, Zheng C, Yin J, Tian Y, Cui W. Wildfire Smoke Classification Based on Synthetic Images and Pixel- and Feature-Level Domain Adaptation. Sensors. 2021; 21(23):7785. https://doi.org/10.3390/s21237785
Chicago/Turabian StyleMao, Jun, Change Zheng, Jiyan Yin, Ye Tian, and Wenbin Cui. 2021. "Wildfire Smoke Classification Based on Synthetic Images and Pixel- and Feature-Level Domain Adaptation" Sensors 21, no. 23: 7785. https://doi.org/10.3390/s21237785
APA StyleMao, J., Zheng, C., Yin, J., Tian, Y., & Cui, W. (2021). Wildfire Smoke Classification Based on Synthetic Images and Pixel- and Feature-Level Domain Adaptation. Sensors, 21(23), 7785. https://doi.org/10.3390/s21237785