Abstract
The ever-growing ecosystem of the Internet of Things (IoT) integrating with the ever-evolving wireless communication technology paves the way for adopting new applications in a smart society. The core concept of smart society emphasizes utilizing information and communication technology (ICT) infrastructure to improve every aspect of life. Among the variety of smart services, eHealth is at the forefront of these promises. eHealth is rapidly gaining popularity to overcome the insufficient healthcare services and provide patient-centric treatment for the rising aging population with chronic diseases. Keeping in view the sensitivity of medical data, this interfacing between healthcare and technology has raised many security concerns. Among the many contemporary solutions, attribute-based encryption (ABE) is the dominant technology because of its inherent support for one-to-many transfer and fine-grained access control mechanisms to confidential medical data. ABE uses costly bilinear pairing operations, which are too heavy for eHealth’s tiny wireless body area network (WBAN) devices despite its proper functionality. We present an efficient and secure ABE architecture with outsourcing intense encryption and decryption operations in this work. For practical realization, our scheme uses elliptic curve scalar point multiplication as the underlying technology of ABE instead of costly pairing operations. In addition, it provides support for attribute/users revocation and verifiability of outsourced medical data. Using the selective-set security model, the proposed scheme is secure under the elliptic curve decisional Diffie–Hellman (ECDDH) assumption. The performance assessment and top-ranked value via the help of fuzzy logic’s evaluation based on distance from average solution (EDAS) method show that the proposed scheme is efficient and suitable for access control in eHealth smart societies.
1. Introduction
The transformative effect of eHealth on smart society (shown in Figure 1) enables wearable medical devices for a vast number of applications, such as wearable fitness trackers, smart health watches, electrocardiogram (ECG) monitors, blood presser monitors, biosensors, etc. On the other front, advances in wireless communication lead to the emergence of the solidified and specialized wireless area network for these worn-on or implanted devices; the wireless body area network (WBAN). A WBAN typically consists of tiny biosensors or sensors (wearable and/or implanted) to collect/forward vital signs to the mobile or fixed gateway. It was developed to enable around-the-clock availability of a patient’s medical data to healthcare professionals. This unremitting availability of data will efficiently utilize healthcare resources and makes in-home monitoring for patients having chronic diseases [1]. Unlike conventional sensor networks, a WBAN operates on more critical and sensitive patient information that demands significant security and privacy preservation from the practical aspect of this technology. This concern leads to the desire for more control of their data from the data owner end. This self-contradicting aspect results in severe security challenges for its practical adaptation. In the presence of its underlying Internet of Things (IoT) infrastructure, conventional encryption techniques preclude its adaption for WBAN security. Specifically, public-key encryption suffers from high computation, certificate, and key management overhead issues. The dynamic secret key management hinders the application of symmetric encryption as well. Considering the nature of WBAN healthcare systems, it is inevitable to provide this crucial data to its concerned healthcare professionals. Hence, traditional role-based access control and identity-based encryption (IBE) cannot guarantee fine-grained and one-to-many data transfer. Recently, attribute-based encryption (ABE) has gained popularity for secure access control mechanisms to confidential data because of its inherent support for fine-grained access and one-to-many transfer. ABE is a particular type of IBE; the user’s ID is described by the set of attributes, in which the data is encrypted for all those users who are the possessors of that specific set of attributes. The ABE schemes are categorized into two variants: ciphertext policy (CP-ABE) and key-policy (KP-ABE). Using CP-ABE, the data owner embeds access policy inside ciphertext and the private key of the end user is attached to the attribute set. Anyone can perform the decryption operation if his/her attributes matched with the specified access policy. While in KP-ABE, private keys are attached with the access control policy and ciphertext are attached with the attribute set [2]. In the context of WBAN, ciphertext policy ABE (CP-ABE) is more appropriate because it provides more control to the data owners (patient in WBAN) over the recipients [3] (medical stuff in WBAN) as opposed to its other type, i.e., key-policy ABE (KP-ABE) [4]. The only series concern for most contemporary ABE schemes is that they rely heavily on expensive bilinear pairing and exponentiation operation in the encryption and decryption algorithm. This intense computation hinders its deployment for WBAN resource-constrained sensors [3,5]. This leads to the development of non-pairing ABE schemes in the research community. As a result, the most recent work equips the ABE with the elliptic curve cryptography (ECC) algorithms, which have much stronger bit security and also replace the ten times more expensive bilinear pairing operation with scalar point multiplication on an elliptic curve [3]. At the same time, because of underlying ABE technology, linearity properties entrust the ECC algorithm with heavy operations. As we know, the number of operations linearly increases with the number of attributes and hence incurs a heavy load on WBAN sensors. Therefore, a secure and efficient management mechanism is needed, which stands this operation to an acceptable and minimum constant range for WBAN sensors nodes. In this paper, by utilizing Hu et al.’s [4] secure framework for WBAN, we have proposed an efficient and secure ECC-based CP-ABE scheme for WBAN.

Figure 1.
eHealth in smart societies.
Our Contribution
The primary contribution of our work is as follows:
- Considering the resource-scarce nature of WBAN, we have proposed an efficient and secure ABE scheme with outsourcing intense encryption and decryption operations without revealing the secret key/data content to the WBAN data sink node and cloud server digital signal processing (DSP), respectively.
- Our proposed scheme is based on elliptic curve point scalar multiplication instead of costly bilinear pairing operations to address the resource-constrained nature of WBAN, especially the sensors. This feature makes it more appealing to smart healthcare.
- Our proposed scheme supports indirect attribute/users revocation without the need for maintaining a private channel between the trusted attribute authority and the non-revoked users for disseminating updated decryption keys.
- The proposed scheme inherently supports the integrity check, thus increasing the security and reliability of medical data.
- The proposed scheme is secure under the elliptic curve decisional Diffie–Hellman (ECDDH) assumption using the selective-set security model.
- The performance assessment of our scheme shows a significant overall efficiency in storage, computation, and communication.
2. Related Work and Background Knowledge
This section presents a brief overview of existing work and all the cryptographic primitives used to construct our proposed scheme.
2.1. Related Work
With the emerging use of e-healthcare systems, patients are not only concerned for the security of their personal information but also worry for the privacy of their biological characteristics [6,7]. To improve the performance, early approaches utilized cloud computing models for e-healthcare systems. For example, in [8] they have proposed a patient-oriented four-layer cloud-based e-healthcare system. With the emergence of edge computing and its proximity to resource-constrained devices, many edge-based e-healthcare systems [9,10] are proposed. In [11], the author developed a first-aid service to provide emergency aid to the patients rapidly. However, the early approach lacks the much-needed security requirements. For the realization of security in smart healthcare, the author in [12] utilizes fully homomorphic encryption (FHE) to encrypt the data. For better security, Cai et al. [13] create a novel medical record based on the mobile cloud without compromising too much performance. Still, the above system does not devise any proper access control mechanism for these medical records. So, to better protect data privacy, some schemes equipped with access control were proposed [14,15]. For example, in [15], the author suggests a role-based access control with the capability of origin tracing and further scrutinizing the authorization of access made to the system resources. However, fine-grained access control is needed for better and flexible access, which requires the exposure of specific portions of data to the relevant medical professionals. Attributed to its inherent expressiveness and fine-grained access support, attribute-based encryption (ABE) has emerged. Sahi and waters [16] were the first to interpret the identity of users as a set of attributes and were able to propose a fuzzy variation of identity-based encryption (IBE). Attributed to the placement of access policy, ABE has two variations, namely key-policy ABE (KP-ABE) [17] and ciphertext policy ABE (CP-ABE) [18]. Li et al. [19] propose the outsourcing of encryption with MapReduce to relieve local computation overhead. Li et al. [20] construct a novel ABE scheme which outsourced both the key-issuing and decryption with the verification of the results returned from the cloud server. Asim et al. [21], with the help of a semi-trusted proxy, outsourced the computation of message encryption by utilizing the El-Gamal cipher. However, the scheme is proven in the generic group model. Zong et al. [22] utilize the edge-enabled environment for outsourcing part of encryption and decryption to the edge node for the smart healthcare system. Zhidan et al. [23] propose the construction of an ABE scheme with verifiable delegation both for encryption and decryption to an untrusted encryption service provider (ESP) and a decryption service provider (DSP), respectively. Khan et al. [24] propose an online/offline-aided attribute-based multi-keyword search (OOABMS) scheme to delegate most heavy computation operations to the offline phase before acquiring the attribute-based access control policy or keywords. However, all of these ABE schemes were heavily dependent on a costly bilinear pairing operation [25]. Later, in [26], the author proposed a free-pairing lightweight KP-ABE scheme using ECC for resource constraint of IoT infrastructure. Consequently, Tan et al. [27] introduces the concept of key out-sourcing property in [26] for better efficiency without compromising its security. Several body sensor network (BSN) [28,29], are proposed for the cloud environment that exhibits their usability and favorability for the key-policy type of ABE in different scenarios. KP-ABE transferred the computation overhead of access policy formulation to the medical attribute authority (MAA) from the patient but at the same time offered no control over it. CP-ABE offers complete control over who has access to the sensitive medical data, making it conceptually similar to the role-based access control [30] model.
These appealing characteristics for WBAN resulted in the basis for many proposed [18] schemes with various features such as policy update, hidden access policy, traceability, and revocability. These schemes mainly utilized costly pairing operations. Considering the resource constraint nature of a WBAN, pairing-free ABE schemes should be the first choice of a WBAN. In this direction, Ref. [31] proposed a pairing-free ECC-based CP-ABE scheme. However, similar to most of the schemes, this also suffers from the inherent linearity property of ABE. For the sake of practical deployment, we have designed a pairing-free CP-ABE scheme based on ECC with a minimal constant number of scalar point multiplication.
Basar et al. [32] present an image segmentation method based on pulse coupled neural network (PCNN) and local binary pattern (LBP) components. The proposed method is robust because the presented model’s parameters can be modified for different situations. The proposed algorithm has been tested on a dataset that consists of 1000 defocused images. The results show that the proposed algorithm outperforms contemporary algorithms on different evaluation metrics such as accuracy and precision. A fuzzy logic-based ranking based on EDAS has been used for ranking. The experimental results and evaluation show that the proposed scheme outperforms contemporary schemes in terms of time complexity and accuracy.
Mehmood et al. [33] developed a trust-based energy-efficient and reliable communication scheme named trust-based ERCS for remote patient monitoring in eHealth applications. A cooperative communication strategy is used in the proposed scheme to ensure trust and reliability. Furthermore, privacy preservation and a fuzzy-logic rank-based method have been used in the proposed scheme. The detailed experimental results and ranking demonstrated that the proposed scheme outperforms the available contemporary schemes.
Similarly, Basar et al. [34] present a method for an RGB histogram-based K-means clustering initialization for unsupervised color image segmentation. In this method, an adaptive initialization approach has been used to determine the number of clusters and initial central points of each cluster to solve the segmentation issues of color images. The proposed method is compared with well-known unsupervised segmentation methods on various segmentation parameters. Furthermore, the EDAS (evaluation based on distance from average solution) technique is used to rank segmentation integrity. The experimental results show that the proposed method outperformed the contemporary methods. However, due to classification errors, the proposed method is not recommended for healthcare medical applications.
2.2. Background Knowledge
This section presents all the cryptographic primitives used for the construction of our proposed ECC-based ABE scheme, including elliptic curve cryptosystem, lagrange interpolation for secret reconstruction, and access control structure.
2.3. Elliptic Curve Cryptosystem and Its Related Complexity Assumptions
An elliptic curve E over a prime finite field is defined by a cubic equation
while the set of parameters can be used for its description, where , and . All the point operations in ECC must be define to form a cyclic group over E.
Definition 1
(Elliptic curve discrete logarithm problem (ECDLP)). Given points P and Q on the curve, i.e., , it is intractable for a polynomial time algorithm to get the random chosen value such that .
Definition 2
(Elliptic curve computational Diffie–Hellman problem (ECCLP)). For generator G of and randomly chosen values , given it is intractable for a polynomial time algorithm to get .
Definition 3
(Elliptic curve decisional Diffie–Hellman problem (ECDLP)). Given randomly chosen values and generator G and any point Z of , it is impossible to distinguish between the two probability distributions and .
Definition 4
(Access tree). Access tree [17]. Let a tree represent an access structure. Each non-leaf node of is identified by a threshold gate, associated by its corresponding threshold value and its children. In this case, if is the threshold value of node x and is its number of children, then . When , the threshold gate is an AND gate, and when , it is an OR gate. Each leaf node x of is identified by a threshold value and an attribute. Further, definitions and notations can be obtained from [35].
In ABE, the lagrange interpolation is used for secret reconstruction. The lagrange coefficient for a random number in and a set of random elements corresponding to each element in is given by .
3. System and Security Model
Figure 2 depicts the main components of our proposed scheme, namely the medical attribute authority (MAA), cloud service provider (CSP), body area network (BAN), data sink (DS), and medical data user (MDU). This section presents an overview of the roles played by each component.
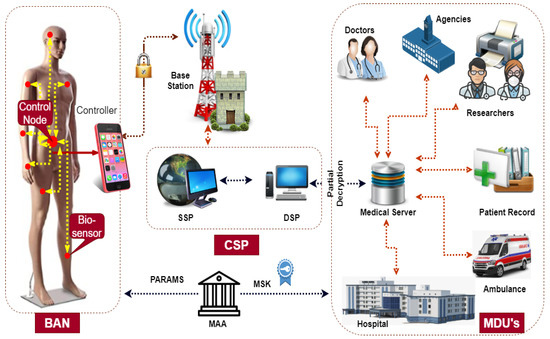
Figure 2.
System model.
MAA: The MAA acts as a key generation center (KGC) and the only fully trusted entity in the system model. KGC is responsible for the registration of all system users [36]. Through the initialization phase, it produces public parameters (PARAMS), a system master key (SMK), and secret key components (SK) against a set of attributes specific to each user.
CSP: This entity is providing services for storage and partial decryption via sub-entities storage service provider (SSP) and decryption service provider (DSP), respectively. The SSP stores the encrypted health-related data for each registered patient and serves as a repository for all the uploaded data. DSP performs partial decryption service to the interested MDU’s without knowing the actual data contents.
BAN: Body area network is a wireless network consisting of small biosensors. It could be implanted (placed inside the human body), wearable (on the body), or carried based on its specific use. Its deployment aims to persistently measure and notice the abnormal changes in the vital body parameters. Subsequently, consult in real time the healthcare professional for life support. Sensors are suffering from a scarcity of vital resources in memory, battery power, and computation power. In the traditional framework, these [31] resource-constrained sensors are entrusted with the expensive secret distribution mechanism for access formulation along with its prime tasks of sensing, processing, and transmission. Moreover, because of the ABE linearity property, the encryption complexity grows with the size of the access policy. Exploiting the delegation property of the CP-ABE mode of encryption, we offload most of the computation to the gateway. More specifically, retaining part of the secret for little processing locally while exposing part of it to the gateway for most processing still ensures information-theoretical security of a secret.
DS: DS acts as a gateway for aggregation and dissemination of its corresponding sensor data to the MAA. It could be a mobile device such as a smartphone or a specialized BAN controller. Hence, it has significantly more memory, processing, and transmission capacity as opposed to the sensors. These features make us compel in our proposed framework to delegate most of the processing overhead from sensors to the DS. The traditional framework [31] devotes this unit to the function of forwarding only, which is not a judicious use of this entity considering its resources.
MDU: It could be a doctor, nurse, or any other healthcare expert. To be registered into the system, each MDU must prove its credentials and affiliation in a set of attributes to the KGC. The KGC needs to verify the validity of these claimed attributes, subsequently computes its corresponding secret key components, and sends it via a secure channel to its concerned user. These secret key components are uniquely generated to prevent collision attacks by associating a random number to them. As long as the MDU poses the required set of attributes, it can access any patient’s encrypted data. MDU is usually a device, such as a mobile phone, with limited resources. In our framework, we shift most of the decryption overhead to the DSP of MAA. As a result, after retrieving the partially encrypted data from the DSP, it needs to perform a minor operation on its full decryption.
In our threat model, we take the CSP honest-but-curious, adapted by most of the ABKS schemes, which means they will honestly run the algorithm and infer privacy information based on the available data. The medical attribute authority and the data owner (DO) are fully trusted entities in our system model. Corrupted data users (DU) may also collide with each other. To prove the security of an ABE scheme, the selective-set security model generally makes use of a game between the challenger and an attacker . In this game, the attacker faces challenges posed by the challenger to solve the underlying security assumption. Following are the six steps defined in our security game for our proposed scheme against a chosen-plaintext attack [35].
Initialization: declares the encryption attribute set in the form of an access structure that he wants to be challenged upon.
Setup: To generates the system parameters, runs the setup algorithm, keeps the SMK to itself and sends the public parameter PARAMS to adversary .
Phase 1: The adversary is allowed to adoptively ask for a set of secret key components of attribute sets such that all the attribute sets associated to the corresponding secret key components do not satisfy the .
Challenge: Now, submits two equal length messages and to with . flips binary coin b to encrypt under and sends the generated ciphertext to .
Phase 2: Both adversary and challenger adoptively repeat the same steps as they did in phase 1.
Guess: outputs a guess of b to .
The advantage gained by in the above game is defined by .
Table 1 lists all the notations used in this work.

Table 1.
Notations.
4. Proposed Model
In this section, a detail description of our proposed scheme algorithms (i.e., , , , , , ) is presented.
Setup (: Run by , the Algorithm 1 takes EEC domain parameters as an implicit security parameter as input. Define the universal attribute set for attribute space in the system. A secure hash function is chosen to map global identity . for each attribute , chooses uniformly at random. The public key components corresponding to each system attribute is given by . Moreover, it chooses uniformly at random to be the master secret key . Thereafter, setting accordingly, the master public key is . Finally, the algorithm sets the and .
| Algorithm 1: Setup . |
Input Implicit security parameter . Output System secret key and public parameter.
|
Encryption: To preserve the data privacy and delegate most of the computation of encryption, this algorithm specifies the access control policy tree in the form of , where and are two subtrees of connected by an AND logical operator ⋀. This division of access control tree leads to two algorithms: local encryption (Algorithm 2) and outsource encryption (Algorithm 3).
For optimal efficiency, the attaches only one virtual attribute, as shown in Figure 3. The algorithm randomly specify a 1-degree polynomial and set , and , where .
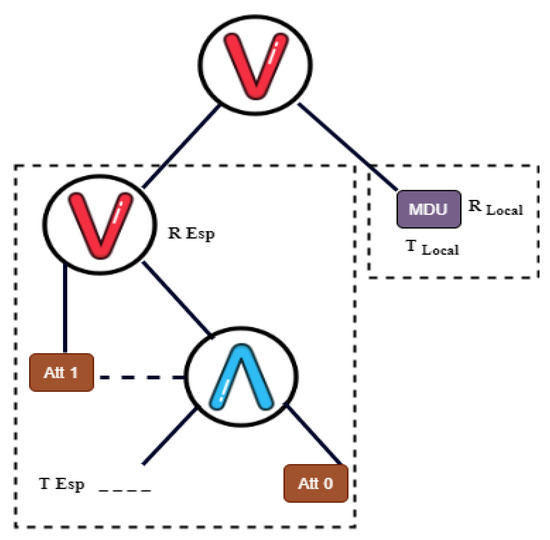
Figure 3.
Access policy with subtree.
Let be the set of leaf nodes in . This algorithm encrypts M by computing such that . Let serve as the encryption key and be the integrity key for M, then and can be computed and , respectively. Finally, the algorithm outputs temporal ciphertext
Let be the set of leaf nodes in . Beginning at the root node of the subtree , this algorithm chooses a polynomial of degree for each node v. Note that the value for root node has been set as . The value of the inner node x is calculated by the equation as and randomly chooses coefficients to build the polynomial . Then, the algorithm generates the temporal ciphertext . Combining the above generated ciphertext with the received ciphertext from , the whole ciphertext is given as:
Key Generation The Algorithm 4 runs by , and is used to generate the secret key under the valid attribute set by the corresponding . More specifically, upon receiving the claimed attribute set, the needs to check its validity and assign a unique global identity to this . It selects a random and computes local private key . This algorithm for each attribute generates its corresponding key components, a delegate key given by . Here, is the inverse of element chosen in setup phase.
| Algorithm 2:. |
Input Access structure , the message M and public parameters . Output Local version of ciphertext .
|
| Algorithm 3:. |
Input Access structure , and public parameters . output.
|
| Algorithm 4:. |
Input claimed attribute set , system master key Output keys: and .
|
Finally, the algorithm via a secure channel submits the secret keys and to its concerned .
Decryption: Realizing a CP-ABE scheme via scalar point multiplication instead of bilinear pairing operations still faces a deployment challenge for lightweight devices, especially for sensors. The scheme makes use of threshold secret sharing for secret distribution. Subsequently, the reconstruction makes use of polynomial interpolation, a heavy computation operation. MDU is usually a device such as a mobile phone with limited resources. Hence, this phase delegates most of the decryption load to the . This phase makes use of two algorithms (Algorithm 5) and (Algorithm 6).
This algorithm is run by , which makes use of a recursive function . If y is leaf node, let , is defined as:
which states that the output of must be an element in group or null.
For a leaf node , the function proceeds as follows:
For a non-leaf node y, it calls for each child x and stores the result as in sized set of child node x. To reconstruct the value of at nodes y using lagrange interpolation, the algorithm proceeds as follows:
where and is the lagrange coefficients
Accordingly, the recursive function at root node R returns . Finally, the temporal ciphertext set as: .
. After receiving the intermediate ciphertext calculates . Here, and are the recovered keys for decryption and integrity of message M, respectively. Therefore, after decrypting we can confirm, whether to assure that the M is correctly received and not being tempered. Hence, the proposed scheme provides confidentiality, authenticity, and integrity of encrypted data, which is the top most priority of any health-related application.
| Algorithm 5:. |
Input Delegate key component , system public parameter and . Out Put Temporal ciphertext .
|
| Algorithm 6:. |
Input local secret key , and temporal ciphertext . Output Message M.
|
5. Security Analysis
This section, along with security proof, also assesses the proposed scheme’s collision resistance and attribute/user revocation features.
5.1. Security Proof
The security proof of our scheme in the selective security model is presented as a game between the challenger and an attacker . In this game, the attacker confronts challenges posed by the challenger to break the underlying hardness assumption. Since our scheme is based on ECC, hence, the attacker’s goal is to reduce the hardness of the elliptic curve decisional Diffie–Hellman (DDH) assumption.
Theorem 1.
If an adversary in the selective-set model successfully attacks our proposed scheme with, at most, advantage ϵ, then it can also build a simulator that can distinguish an elliptic curve DDH tuple with non-negligible advantage .
Proof.
Let there exist an adversary , in the particular set security model that in polynomial time with non-negligible advantage can break our scheme, then we can build a simulator to play the ECDDH with advantage in polynomial time.
Firstly, the challenger generates an EC group with order q and sets over the finite field having a base point G. Then, challenger takes a fair binary coin , flips it outside of ’s view for some random choices a, b, z . Now, the choices for is given as:
- -
- Case 1. if , then ECDDH challenge instance as,, and sent to .
- -
- Case 2. if , then ECDDH challenge instance as,, and sent to .
Initialization: The simulator runs adversary , to gets an access structure that the adversary wants to be challenged upon.
Setup: The simulator needs to send the public parameters to adversary as follows:
- at first sets the system parameters .
- Then, for , sets according to the following condition:
- If it sets and where is randomly chooses from .
- If , it sets , where is randomly chooses from .
- Sends the system public parameters to and keeps the secret parameter as secret.In the above scenario, does not observe any change as and are analogous to and of the proposed scheme.
Phase 1: adoptivily calls for a number of secret key components of attribute sets such that all the attribute sets associated to the corresponding secret key components do not satisfy the . Now, sends the secret key components to as follows:
Case 1. if , it sets as
Case 2. if , it sets as
The distribution for both the terms in Equations (1) and (2) is uniform, thus, in ’s perspective, the key components generated by are the same as the basic scheme.
Challenge: submits two equal length messages and to . First sets and then sends to the DO. It randomly selects and sets for root node R according to the proposed scheme. is also sent along with to ESP (i-e sink node) to distribute it for the remaining attributes in randomly selects a bit to encrypt and generates the ciphertext as follows:
Hence, and represent the encryption and integrity K for message M, respectively. Afterwards, computes .
after computing and transmits below ciphertext to adversary .
The challenger flips coin , thus the following cases arises:
- If satisfies case 1, which is identical to our original encryption, then . Therefore, if S is set to d, there should be , and , where .
- If satisfies case 2, which is different from our proposed scheme, then . Therefore, if S is set to z, it turns out that , and .
Phase 2: Both and follow the same steps as they did in Phase 1.
Guess: output a guess of b to .
- If , output , which indicates a valid ECDDH instance, .
- If , output , which indicates a random instance, .
Now, according to the security game, where , the adversary cannot predict the , thus we have
Since outputs when , it gives
When , the adversary can predict the correct , thus we have
Since outputs when , we have
According to the selective set security model of our proposed scheme, the overall advantage using Equations (8) and (10) of in this game is
or,
or,
or,
Hence, it conflicts with our assumption, which proves the security of our proposed scheme under the ECDDH assumption. □
5.2. Secure against Collusion Attack
One of the most anticipated attacks on any attribute-based system is a collision attack. Therefore, it is required of the designers of such a system to implicitly avoid it in their proposed scheme. Let us assume that multiple users possess some secret key components, where no individual secret key has access to the message. If they play the role of an attacker to launch a collision attack (i.e., a combination of their secret keys) by trying to decrypt a message that is encrypted under the intersects (common attributes) of their attributes sets. It is assumed that they constitute secret key components labeled to their common attribute set in the form of
Even after collectively generating secret keys among themselves, still, they are unable to decrypt the message because of the random selection of for each user to satisfy the equation
Hence, the association of the secret key component with attributes along with a unique global identity and a random number for each user makes the proposed scheme resistant to collusion attack.
5.3. Attribute/User Revocation
Nowadays, revocation is a desirable property on the part of an ABE-based scheme. Considering the following aspects, equipping the ABE scheme with revocation is not a simple task: First, the attribute authority labeled each user secret key from a universal set of attributes instead of a unique user-specific attribute. As a result, a malicious user cannot simply be singled out on an attribute or set of attributes; second, after the revocation of a misbehaving user, the system must avoid the collusion attack even if there exists the overlapping of attributes with non-revoked users. The ABE scheme supports two types of revocation, direct revocation and indirect revocation, to address these issues. Indirect revocation incurs the liability on TAA to update and distribute the non-revoked users’ secret key with every revocation event. In direct revocation, we do not need to perform updation on the secret key of non-revoked users. All contemporary direct revocation schemes require system users to maintain an updated and long list of revoked users, which must be labeled to ciphertext. This computation and storage overhead linearly increases with the increase in revoked users in the encryption and decryption algorithms system.
Given the resource-constrained and medical-centric characteristics of our proposed scheme MAA, the indirect revocation fits aptly into our ehealth practical scenario. The computation and storage cost of our scheme is independent of the number of revoked users. The KGC of MAA explicitly maintains the list of global IDs GID and its associated attribute lists for each registered user. To revoke the system attribute from its universal set of attributes, the KGC deletes the associated system attribute’s public key. Similarly, to revoke the user-specific attribute, the KGC must delete the corresponding secret key component for that specific user. Further, KGS deletes the entire attribute set and the GID assigned to that user to revoke a user. For all of these revocation scenarios, the MAA needs to update the delegated key with the help of MSK and the revoked of the revoked attribute and produces a new delegate key of the revoked attribute . Furthermore, our proposed scheme avoids the need for maintaining a private channel between the MAA and the non-revoked user for the dissemination of the updated delegated key .
6. Performance Analysis
In this section, we compare our proposed scheme with five related schemes in [19,20,21,22,23], in terms of its features, communication overhead, and computation overhead. Moreover, for the sake of fair comparison, we set n = 20 and m = 10 representing attributes in universal set and encryption, respectively.
6.1. Features Analysis
Table 2 depicts the comparison of various features of our scheme with related schemes for a WBAN from four perspectives: encryption delegation, decryption delegation, integrity check, and attribute revocation. Additionally, our proposed scheme lacks time-based access control and hierarchical access control support. In some practical scenarios, it is inevitable to provide access control for a specific time interval. For instance, a medical document may have different privacy requirements for a different period. More specifically, fewer medical experts have access to the medical record at an early time, while more experts can get access to it at a later time point. Similarly, the hierarchical access permission ensures access to the corresponding documents based on the specific role of the data users. For example, the hospital president can access all the information of the patients and doctors, while the medical experts can access his/her patient information only.
Table 2.
Features comparison.
6.2. Communication Overhead
Communication overhead relates to the transfer of the message. In the most commonly adopted architectures of ABE, the least number of messages that should be transmitted are of the public key, private key, and ciphertext. For the sake of analysis, we take the length of these messages as a metric to determine and compare the relative communication overhead. Most contemporary ABE schemes use bilinear pairing; a map involves two groups . Because of the underlying modular exponentiation, these are termed RSA-based ABE schemes. Accordingly, we call our scheme an ABE ECC-based scheme.
As we know, ECC has much stronger hit security; we considered 160-bit, i.e., secp160r1 elliptic curve, which has up to 1024-bit RSA security strength. Based on the above-stated assumptions, the size of both public and private keys in the ABE RSA-based scheme is 1024-bit, while the size of an element in and is 1024 bits and 2048-bits. Accordingly, the size of an elliptic curve point is 320 bits, corresponding to both its coordinates. As a result, the 160 bits and 320 bits constitute the private key and public key size, respectively, in ABE ECC-based schemes. For comparison, the communication overhead is identical for each ABE RSA-based scheme. Therefore, we compute the [23] overhead for illustration purposes. The ciphertext in [23] scheme is given by , where m represents the maximum number of attributes attached to the ciphertext. According to the setup phase of this scheme, g and e(g,g) belong to the group and , respectively. As a result, the size of each ciphertext component and is 2048, 1024, (2m × 1024) and (m × 1024) bits, respectively. In this way, the length of ciphertext CT is (3m + 3) × 1024 ≈ 33,792 bits. Here, the public key is set to , so its length is 4 × 1024 ≈ 4096 bits. In addition, the private key is given by where S represents the user set of attributes associated to the key K. Therefore, the length of the private key of scheme [23] computes to (m + 3) × 1024 ≈ 13,312 bits.
Similarly, we compute the public key, private key, and ciphertext length in our scheme. According to the encryption process of our proposed scheme, the ciphertext is . The size of attribute set T is taken constantly for all schemes and, hence, rolled out of the total ciphertext size. Here, and are the single coordinates on the elliptic curve, each having 160 bits in length. Similarly, consists of 320 bits, a single point on the elliptic curve. Thus, the length of the ciphertext in our proposed scheme computes to (m + 1) × 320 ≈ 3520 bits. The public key components in our scheme are , and consists of (n + 1) × 320 ≈ 6720 bits, as each of its components is a single point on the elliptic curve. The private key of our scheme is , . Hence, its length computes to (m + 1) × 160 ≈ 1760 bits.
We can see from Table 3 that the ciphertext and private key sizes of our proposed scheme are significantly lower than those of all other schemes. We can observe from Table 3 that only the length of the public key in our proposed scheme is higher than the scheme with a constant-size public key [19,23]. However, overall communication overhead for the private key, the public key, and ciphertext size in our scheme is significantly lower than that of [19]. Moreover, the scheme in [23] is based on KP-ABE as opposed to our CP-ABE-based scheme, which provides more control to the patient over the recipient of its sensitive medical data. Moreover, the generation of the public key is a one-time process in the lifetime of the system.
Table 3.
Parameters size (bits).
6.3. Computation Overhead
The computation overhead is mainly caused by the ABE scheme operations, including bilinear pairing, ECC-based scalar point multiplication, exponentiation, hashing, basic arithmetic, and logical operations. We have considered the most expensive exponentiation operations, bilinear pairing, and elliptic curve base scalar point multiplications. Comparatively, the cost of other least costly operations can be ignored [3]. For the sake of simplicity, Table 4, based on [37], is constructed, which shows the execution time (in millisecond) required by each group operation. According to work in [37], single bilinear pairing and modular exponentiation operation is about 10 and 2 times ECC-based scalar point multiplication, respectively.
Table 4.
Execution time for cryptographic operations.
To evaluate the computation overhead of the proposed scheme, we need the individual computation overhead of users and service providers on both the encryption and decryption sides. Therefore, in Table 5, we compare the computation overhead incurred on MDO and ESP in the encryption offloading and the MDU and DSP in the decryption offloading. As our scheme is free from costly pairing operations, all matrices’ execution time is comparatively less than other schemes. We can also see from Table 5 that the unwanted linearity property of ABE is shifted to comparatively resource-rich server providers (DSP and ESP). Hence, the data users are left with a significantly less and constant number of operations. Thus, based on the performance assessments, our scheme demonstrates more efficiency and the best solution for a WBAN in terms of communication, computation, and security.
Table 5.
Computational overhead (ms).
6.4. Rank-Based Evaluation of Performance Matrices
In this research work, a fuzzy logic-based evaluation, which is constructed on the method distance from average solution (EDAS), is used for calculating the ranking of the proposed scheme with state-of-the-art algorithms in terms of computational cost operations, such as KeyGen, Enc, Enc, Dec, and Dec, on both the sides of the sender and receiver to find the top rank efficiency of these schemes. The above-stated performance matrices/operations are compared with existing state-of-the-art schemes, including the proposed scheme in this section.
In this evaluation, the authors use the EDAS approach to collect the cross-efficient values of numerous parameters of five schemes, including the proposed scheme. The aggregate of appraisal scores can be measured for ranking of given schemes to compute the positive distance from the average solution, which is represented in the equation as () and the negative distance from the average solution is represented by the symbol ().
In Table 6 below, the performance matrices are deliberated as the criteria of state-of-the-art schemes.
Table 6.
Analysis results of average.
The above steps define the performance matrices as benchmarks of various schemes. The calculation of aggregate in Equations (7) and (8) can be gained as the average value () for each calculated benchmark value against each given value in Table 7.
Table 7.
Cross-efficient values.
Step 2: In this step of the EDAS method, the positive distance from the average is denoted as , and is calculated as shown in Equations (9)–(11) as given below:
If the th criterion is more beneficial, then
and if non-beneficial, then the given equation will be changed as follows below:
The results replicate in Table 8 following as:
Table 8.
Analysis results of average ).
Step 3: In this step of the EDAS, the negative distance from the average is denoted as ), and is calculated using Equations (12), (13) and (15) as follows:
If the criterion is more beneficial, then
and if non-beneficial, then the given equation will be changed as follows below:
In the above equations, and stand for the positive distance and negative distance of appraised algorithms from the average value concerning rating performance parameters, respectively.
The results reproduced are shown in Table 8 as:
Step 4: In this step, the the weighted sum of for the rated algorithms in Table 9 is shown below:
Table 9.
Analysis results of the aggregate .
Step 5: In this step, the weighted sum of for the rated algorithms in Table 10 is shown below in Equation (16):
Table 10.
Analysis results of the aggregate .
The results obtained are reflected in Table 10 as shown:
Step 6: In this step, the normalized scores of and for the rated algorithms are calculated as presented in Equations (17) and (18):
Step 7: In this step, the scores of and to receive an appraisal score (AS) is calculated, which is equal to for the rated algorithms given in Equation (19).
where .
The is determined by the aggregate score of and .
Step 8: In this step, measurement of the appraisal scores in terms of decreasing order and then concluding of the ranking of rated algorithms is performed. The paramount ranking algorithms have the higher . Thus, in Table 11 below, the proposed algorithm has the highest .
Table 11.
Analysis results of five state-of-the-art schemes.
The final results of the overall ranking are represented in Table 11:
The ranking shows that the proposed algorithm is the best out of five total state-of-the-art algorithms in the stated research domain.
7. Conclusions and Future work
In summary, we present a secure and efficient ABE architecture with outsourcing intense encryption and delegation operations. Further, leverage on the lightweight features of ECC and the primitive syntax of CP-ABE, our scheme reduces the computation cost of both encryption and decryption on the user side into a constant. Our solution enables the resource-scarce and lightweight WBAN sensors to securely upload and retrieve sensitive medical data in public clouds with a minimum constant cost. The inherent features of attribute/user revocation and verifiability of outsourcing data further strengthen the security of our scheme. The proposed scheme is found to be secured under the ECDDH assumption using the selective-set security model. The performance assessment of our scheme shows a significant overall efficiency in terms of storage, computation, and communication. Further, for better clarification and evaluation, the final outputs of the EDAS ranking method show that the proposed approach is on the top rank that noticeably reported the proposed scheme’s outperformance than the other reference schemes. We will investigate the incorporation of time-based access control and hierarchical access control in our research work as future work.
Author Contributions
Formal analysis, S.K. (Shahzad Khan), A.W., G.M. and S.K. (Shawal Khan); funding acquisition, M.Z. and R.R.B.; investigation, G.M.; methodology, S.K. (Shahzad Khan), W.I. and S.K. (Shawal Khan); project administration, R.R.B.; supervision, W.I.; writing—original draft, S.K. (Shahzad Khan); writing—review and editing, A.W. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the School of Engineering and Sciences at Tecnologico de Monterrey.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ali, S.T.; Sivaraman, V.; Ostry, D. Zero reconciliation secret key generation for body-worn health monitoring devices. In Proceedings of the Fifth ACM conference on Security and Privacy in Wireless and Mobile Networks, Tucson, AZ, USA, 16–18 April 2012; pp. 39–50. [Google Scholar]
- Khan, S.; Khan, S.; Zareei, M.; Alanazi, F.; Kama, N.; Alam, M.; Anjum, A. ABKS-PBM: Attribute-Based Keyword Search With Partial Bilinear Map. IEEE Access 2021, 9, 46313–46324. [Google Scholar] [CrossRef]
- Yao, X.; Chen, Z.; Tian, Y. A lightweight attribute-based encryption scheme for the Internet of Things. Future Gener. Comput. Syst. 2015, 49, 104–112. [Google Scholar] [CrossRef]
- Hu, C.; Li, H.; Huo, Y.; Xiang, T.; Liao, X. Secure and efficient data communication protocol for wireless body area networks. IEEE Trans. Multi-Scale Comput. Syst. 2016, 2, 94–107. [Google Scholar] [CrossRef]
- Belguith, S.; Jemai, A.; Attia, R. Enhancing data security in cloud computing using a lightweight cryptographic algorithm. In Proceedings of the 11th International Conference on Autonomic and Autonomous Systems, Rome, Italy, 24–29 May 2015; pp. 98–103. [Google Scholar]
- Li, Y.; Wang, G.; Nie, L.; Wang, Q.; Tan, W. Distance metric optimization driven convolutional neural network for age invariant face recognition. Pattern Recognit. 2018, 75, 51–62. [Google Scholar] [CrossRef]
- Nogueira, R.F.; de Alencar Lotufo, R.; Machado, R.C. Fingerprint liveness detection using convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1206–1213. [Google Scholar] [CrossRef]
- Zhang, Y.; Qiu, M.; Tsai, C.W.; Hassan, M.M.; Alamri, A. Health-CPS: Healthcare cyber-physical system assisted by cloud and big data. IEEE Syst. J. 2015, 11, 88–95. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge computing: Vision and challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhang, Q.; Shi, W.; Zhong, H. Distributed collaborative execution on the edges and its application to amber alerts. IEEE Internet Things J. 2018, 5, 3580–3593. [Google Scholar] [CrossRef]
- Zhang, Q.; Sun, H.; Wu, X.; Zhong, H. Edge video analytics for public safety: A review. Proc. IEEE 2019, 107, 1675–1696. [Google Scholar] [CrossRef]
- Sun, X.; Zhang, P.; Sookhak, M.; Yu, J.; Xie, W. Utilizing fully homomorphic encryption to implement secure medical computation in smart cities. Pers. Ubiquitous Comput. 2017, 21, 831–839. [Google Scholar] [CrossRef]
- Cai, Z.; Yan, H.; Li, P.; Huang, Z.a.; Gao, C. Towards secure and flexible EHR sharing in mobile health cloud under static assumptions. Clust. Comput. 2017, 20, 2415–2422. [Google Scholar] [CrossRef]
- Green, M.; Hohenberger, S.; Waters, B. Outsourcing the decryption of abe ciphertexts. In Proceedings of the USENIX Security Symposium, San Francisco, CA, USA, 8–12 August 2011; Volume 2011. no.3. [Google Scholar]
- Chen, L.; Hoang, D.B. Novel data protection model in healthcare cloud. In Proceedings of the 2011 IEEE International Conference on High Performance Computing and Communication, Banff, AB, Canada, 2–4 September 2011; pp. 550–555. [Google Scholar]
- Waters, B. Efficient identity-based encryption without random oracles. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, 22–26 May 2005. [Google Scholar]
- Goyal, V.; Pandey, O.; Sahai, A.; Waters, B. Attribute-based encryption for fine-grained access control of encrypted data. In Proceedings of the 13th ACM Conference on COMPUTER and Communications Security, Alexandria, VA, USA, 30 October 30–3 November 2006; pp. 89–98. [Google Scholar]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-policy attribute-based encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy (SP’07), Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Li, J.; Jia, C.; Li, J.; Chen, X. Outsourcing encryption of attribute-based encryption with mapreduce. In Proceedings of the International Conference on Information and Communications Security, Chongqing, China, 17–19 September 2012; pp. 191–201. [Google Scholar]
- Li, J.; Huang, X.; Li, J.; Chen, X.; Xiang, Y. Securely outsourcing attribute-based encryption with checkability. IEEE Trans. Parallel Distrib. Syst. 2013, 25, 2201–2210. [Google Scholar] [CrossRef]
- Asim, M.; Petkovic, M.; Ignatenko, T. Attribute-based encryption with encryption and decryption outsourcing. In Proceedings of the 12th Australian Information Security Management Conference, Perth, Australia, 1–3 December 2014. [Google Scholar]
- Zhong, H.; Zhou, Y.; Zhang, Q.; Xu, Y.; Cui, J. An efficient and outsourcing-supported attribute-based access control scheme for edge-enabled smart healthcare. Future Gener. Comput. Syst. 2021, 115, 486–496. [Google Scholar] [CrossRef]
- Li, Z.; Li, W.; Jin, Z.; Zhang, H.; Wen, Q. An efficient ABE scheme with verifiable outsourced encryption and decryption. IEEE Access 2019, 7, 29023–29037. [Google Scholar] [CrossRef]
- Khan, S.; Zareei, M.; Khan, S.; Alanazi, F.; Alam, M.; Waheed, A. OO-ABMS: Online/Offline-Aided Attribute-Based Multi-Keyword Search. IEEE Access 2021, 9, 114392–114406. [Google Scholar] [CrossRef]
- Pang, L.; Yang, J.; Jiang, Z. A survey of research progress and development tendency of attribute-based encryption. Sci. World J. 2014, 2014, 193426. [Google Scholar] [CrossRef]
- Catarinucci, L.; De Donno, D.; Mainetti, L.; Palano, L.; Patrono, L.; Stefanizzi, M.L.; Tarricone, L. An IoT-aware architecture for smart healthcare systems. IEEE Internet Things J. 2015, 2, 515–526. [Google Scholar] [CrossRef]
- Tan, S.Y.; Yeow, K.W.; Hwang, S.O. Enhancement of a lightweight attribute-based encryption scheme for the internet of things. IEEE Internet Things J. 2019, 6, 6384–6395. [Google Scholar] [CrossRef]
- Tan, Y.L.; Goi, B.M.; Komiya, R.; Tan, S.Y. A study of attribute-based encryption for body sensor networks. In Proceedings of the International Conference on Informatics Engineering and Information, Kuala Lumpur, Malaysia, 14–16 November 2011. [Google Scholar]
- Tian, Y.; Peng, Y.; Peng, X.; Li, H. An attribute-based encryption scheme with revocation for fine-grained access control in wireless body area networks. Int. J. Distrib. Sens. Netw. 2014, 10, 259798. [Google Scholar] [CrossRef]
- Coyne, E.J.; Feinstein, H.; Sandhu, R.; Youman, C.E. Role-based access control models. IEEE Comput. 1996, 29, 38–47. [Google Scholar]
- Sowjanya, K.; Dasgupta, M. A ciphertext-policy Attribute based encryption scheme for wireless body area networks based on ECC. J. Inf. Secur. Appl. 2020, 54, 102559. [Google Scholar] [CrossRef]
- Basar, S.; Ali, M.; Ochoa-Ruiz, G.; Waheed, A.; Rodriguez-Hernandez, G.; Zareei, M. A Novel Defocused Image Segmentation Method based on PCNN and LBP. IEEE Access 2021, 9, 87219–87240. [Google Scholar] [CrossRef]
- Mehmood, G.; Khan, M.Z.; Waheed, A.; Zareei, M.; Mohamed, E.M. A trust-based energy-efficient and reliable communication scheme (trust-based ERCS) for remote patient monitoring in wireless body area networks. IEEE Access 2020, 8, 131397–131413. [Google Scholar] [CrossRef]
- Basar, S.; Ali, M.; Ochoa-Ruiz, G.; Zareei, M.; Waheed, A.; Adnan, A. Unsupervised color image segmentation: A case of RGB histogram based K-means clustering initialization. PLoS ONE 2020, 15, e0240015. [Google Scholar] [CrossRef] [PubMed]
- Sahai, A.; Waters, B. Fuzzy identity-based encryption. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Aarhus, Denmark, 22–26 May 2005. [Google Scholar]
- Cao, Q.; Li, Y.; Wu, Z.; Miao, Y.; Liu, J. Privacy-preserving conjunctive keyword search on encrypted data with enhanced fine-grained access control. World Wide Web 2020, 23, 959–989. [Google Scholar] [CrossRef]
- Karati, A.; Amin, R.; Biswas, G. Provably secure threshold-based abe scheme without bilinear map. Arab. J. Sci. Eng. 2016, 41, 3201–3213. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).