The results obtained from the experiments performed were evaluated in terms of accuracy (A), precision (P), recall (R), specificity (S) and Matthews correlation coefficient (MCC) [
51] (The used image databases and the developed codes are available at:
https://git.io/JOCYu (accessed on 1 March 2021)). Because the new layers were trained from randomly initialised weighs, five runs were performed to compute mean and standard deviation of the evaluation metrics. The results were compared against those of the eight state-of-the-art methods, including standard feature extraction methods for colour, shape and texture [
6], and CNN-based methodologies [
22]. All experiments were carried out on a PC with a 3.6 GHz Intel
®Xeon
™processor, 24 GB of RAM, and a NVIDIA TITAN XP 12 GB graphics card.
4.1. Models and Fine-Tuning Evaluation
An ablation study was conducted to define the base architecture of the proposed model and the training methodology. Through validation by LODOCV, the development set was evaluated along the experiments using the ALL-IDB 1 and ALL-IDB 2 datasets. As already mentioned, this validation methodology was selected because it provides a more critical evaluation than k-fold cross-validation, simulating the actual training and testing conditions.
In the following experiments, the hyperparameters were empirically defined, following literature standards for training CNNs, and maintained constant in all experiments. The defined learning rate was 0.001, while the weight decay was 0.0001. The size of the mini-batch was defined as 32, and the binary cross-entropy was used as the loss function.
Table 3 presents the results obtained using the VGG-16 architecture. All fine-tuning approaches archived accuracy over 79% in the ALL-IDB1 dataset. However, among them, it was observed that the mDFT approach achieved the best results for both datasets.
During the training phase, it was verified that the lower loss does not always lead to the best accuracy, as well as the opposite. We obtained lower results in the ALL-IDB 2 dataset relative to the ALL-IDB 1 dataset. This ALL-IDB performance was due to the type of image classified: this dataset contained only one leukocyte per image, while ALL-IDB 1 has several. The presence of numerous leukocytes in the slide may denote the existence of the disease, thus facilitating its classification.
The results obtained by the VGG-19 architecture are presented in
Table 4. From the data shown in this table, one can verify that DFT archived better accuracy, recall and MCC rates. However, mDFT, as in the VGG-16 case, obtained high rates compared with the other approaches, with 96.95% and 96.30% precision and specificity, respectively.
The results obtained using InceptionV3 and Xception are presented in
Table 5 and
Table 6, respectively. From these tables, one can realise that the mDFT technique was more effective than the mSFT technique. When comparing the accuracy obtained by the two architectures, Xception achieved better results in both datasets. However, when we compared those outcomes with the ones obtained using sequential architectures, there was a decrease in performance. Therefore, we concluded that this was because these architectures deal better with greater complexity in terms of the amount of data and classes than the other ones.
Finally,
Table 7 presents the results obtained using ResNet50. This architecture did not originally have convolutional layers, so for fine-tuning, fully connected layers were added at the end of their structure. The achieved results were superior to the ones obtained by the Inception architecture. It is possible to observe that in the ALL-IDB 2 experiments, this architecture obtained an accuracy of 69.46% and a MCC of 40.65%, which are higher than the ones obtained by InceptionV3 and Xception. Similar to other architectures, the mSFT technique was still inferior to the mDFT. Therefore, we believe that both ResNet and other Inception-type architectures work best when fully retrained. Note that from the results obtained with mSFT with ALL-IDB1, it was possible to conclude that ResNet50 could not correctly generalise the classes, classifying all the examples in just one class. This caused a decrease in the average accuracy and recall, and a value of 0 (zero) as to the MCC metric.
LeukNet was designed after analysing the previously described results, where VGG-16 and VGG-19 architectures achieved the best outcomes, with similar values for the mDFT approach in the ALL-IDB2 dataset. Therefore, the Student’s
t-test [
52] was performed to statistically compare the results at a significance level of 5%. From the test performed, it was possible to conclude that the results were equivalent. Therefore, VGG-16 was selected due to its smaller number of trainable parameters.
According to Kornblith et al. [
25], the best-performing architectures on ImageNet can provide better feature extraction and fine-tuning. However, the authors observed this fact only in photographic datasets. In datasets with fine-grained images, the effects of pre-training with ImageNet were considered small. The current study indicated that the features obtained from ImageNet are not adequately transferred to such datasets. According to Sipes et al. [
53], leukaemia images are considered fine-grained images. This fact explains why the results achieved by VGG-16 and VGG-19 were superior to the ones obtained by the other CNNs.
Additionally, a running time analysis as to the CNNs training and classification of an image was conducted.
Table 8 presents the results obtained for the evaluated architectures. This analysis was limited to refined models through mDFT because these models presented the best results in the classification.
Regarding the training time, the Inception V3 network was the fastest (32 min) and Xception the slowest (over 40 min). The running time to classify a single new image was in the order of 0.01 s or less for all the networks under comparison. In practice, all running times can be considered similar as a training under one hour and a classification under 0.01 s mean no restriction as to the practical application of the proposed methodology.
4.2. Proposed Model: LeukNet
The final LeukNet model uses a VGG-16 convolutional backbone, with new dense layers with lower dimensionality, and a training strategy based on transfer learning with mDFT. Experiments varying the size of the fully connected layers were also performed to find the best compromise between accuracy and loss (
Table 9), which showed that the highest accuracy was achieved with 1024 and 256 neurons.
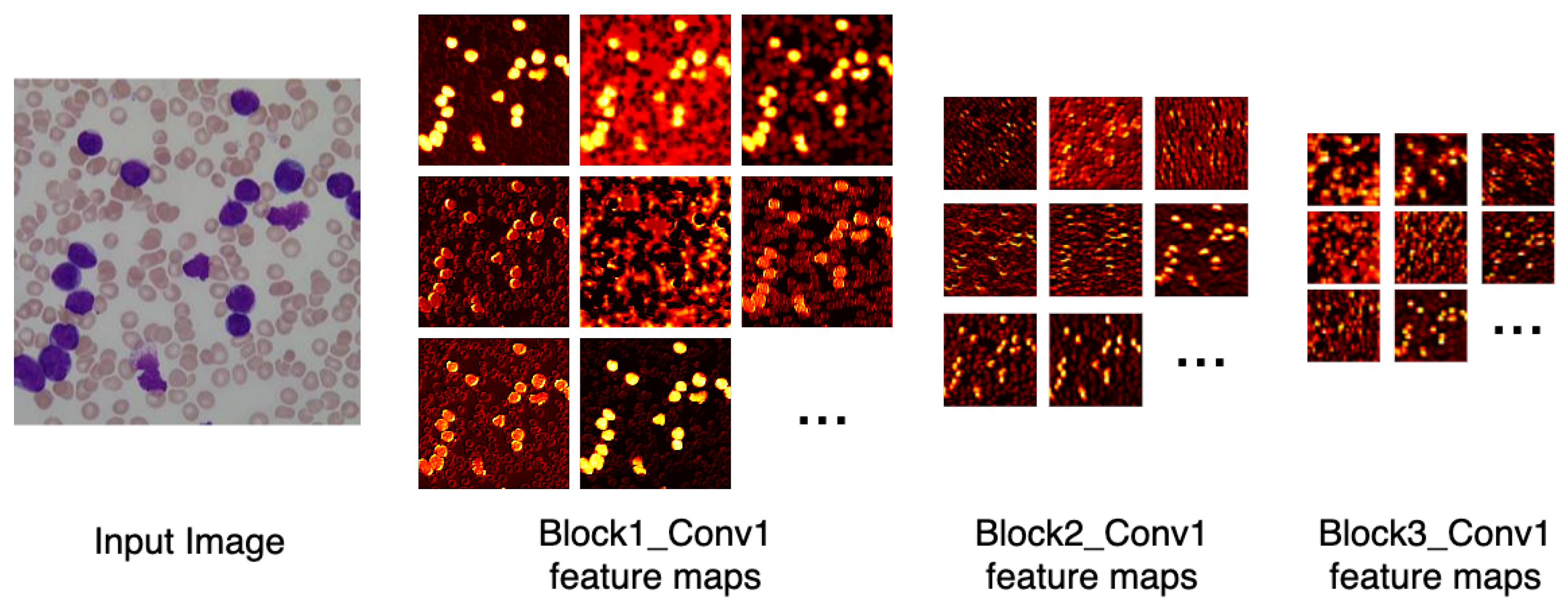
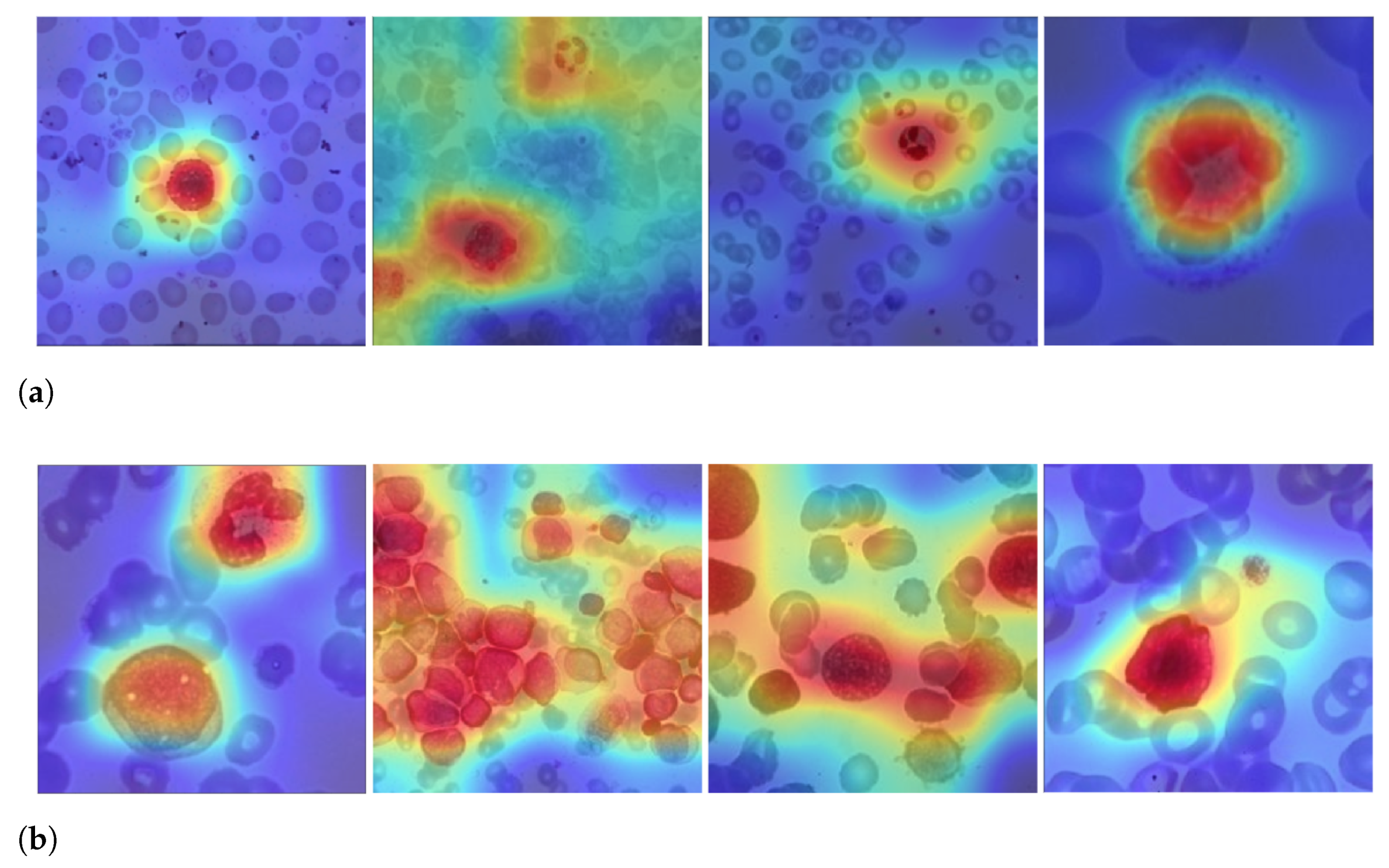
Figure 6 depicts the output of some of LeukNet’s convolutional filters as heat maps. It can be seen in this figure that the CNN excludes the background and defines the cytoplasm and leukocyte nucleus as regions of interest. However, the nuclei region (regions in yellow tone in the figure) is considered to be the most crucial region for classification in the application addressed here.
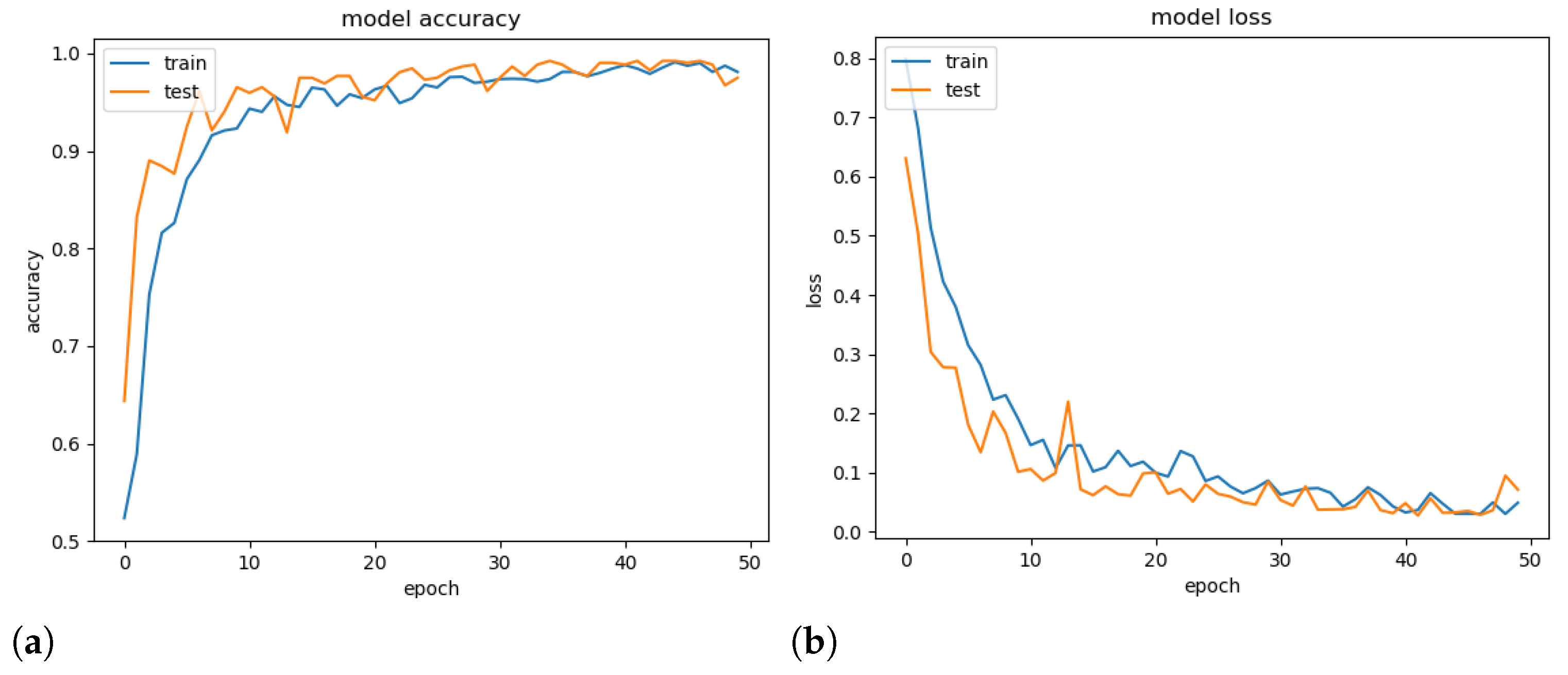
To demonstrate the generalisation ability of the proposed model, a validation experiment was conducted using a random set containing 25% of the available images, and its accuracy and loss throughout the epochs were computed. Note that models tend to overfitting when they cannot generalise for a new set.
Figure 7 presents the obtained accuracy and loss ratio of the training and validation sets over the training epochs. One can observe that the results achieved in the validation set decrease with training, which characterises a good generalisation capacity [
36]. From the results, it is possible to conclude that there was no overfitting during training. We attribute this fact to the decrease in complexity provided by the mDFT and data augmentation techniques.
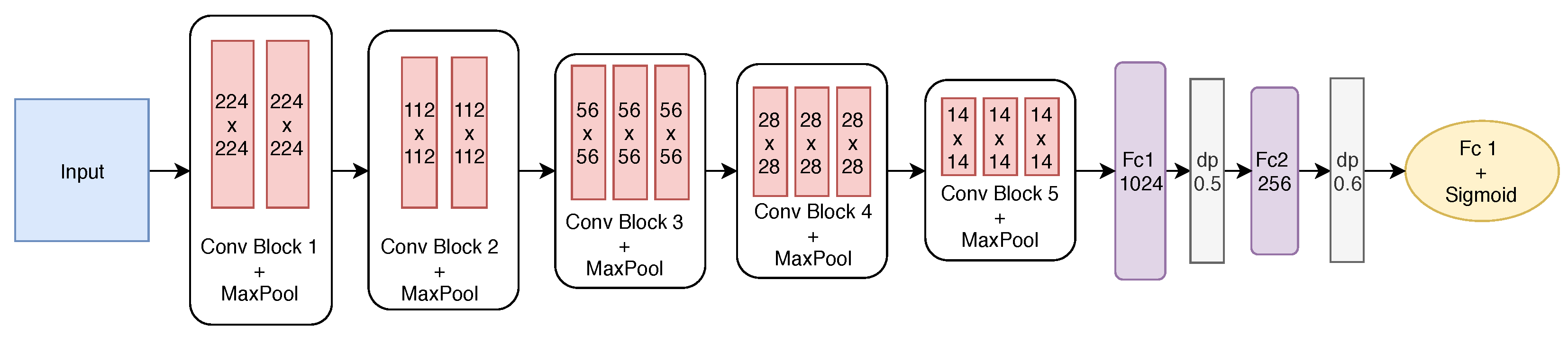
The best-built model has five convolutional blocks and two fully connected layers. After each convolutional block, max pooling is employed. The first two blocks have only two convolutional layers, while the remaining ones have three layers. The first block has 64 filters with size
. From the second block on, the number of filters is doubled to 128, and after the convolution, the pooling operation reduces the filter size. Finally, the last two convolutional blocks have the same number of filters.
Figure 8 shows the final structure of the proposed model.
To define the size of the two fully connected (FC) layers, the effect of the number of neurons was investigated, varying from 1024 to 256 at FC1 and FC2. To avoid overfitting, dropout (dp) was also employed after each fully connected layer with rates of 0.5 and 0.6, respectively. As we are dealing with a binary classification problem, the output layer has one neuron with the sigmoid activation function.
The stochastic gradient descent (SGD) optimisation algorithm was employed with a batch size of 32 and for a total of 50 epochs. Therefore, we used 0.001 and 0.8 for the learning rate and the momentum, respectively. The loss function used during fine-tuning was the binary cross-entropy to allow computing the gradients at each iteration.
Figure 9 shows examples of LeukNet activation maps for the two classes under study. In this figure, it is possible to identify which regions are used to differentiate healthy images from those with leukemia. In the shown activation maps, blue tones mean low activation and indicate that the correspondent regions are of little importance for the final classification; in contrast, red tones are associated to the most critical regions for the final classification.
The number of leukocytes varies in the input images, causing LeukNet to generate different activation map patterns as shown in
Figure 9. Furthermore, as it is trained using different datasets, the proposed model can adapt to different characteristics.
Interpretation is still a challenge in CNNs, but activation maps indicate that LeukNet gives more importance to regions containing disease patterns, as one can see, especially, in
Figure 9a. From
Figure 9, note that leukocytes and lymphoblasts are highlighted in the activation regions. Additionally, note that the number of leukocytes and their shape are considered essential aspects in detecting leukemia.
4.3. Beyond CNN Results with a Features Space Analysis
In order to go beyond the results obtained by fine-tuning the CNNs, we carried out two additional analyses using the features spaces formed by two models. In particular, the goal was to compare the models in terms of the linear separability of the feature spaces generated by the layer before the network classifier (output layer). Because we employed a linear SVM, which has strong learning guarantees, better results would favour models with better generalisation capabilities [
24].
The analyses were performed according to two scenarios. The first scenario consisted of validation with LODOCV using feature extraction with pre-trained VGG-16 on ImageNet and fine-tuned VGG-16. The second one used databases tested in LODOCV (ALL-IDB 1 and ALL-IDB 2) individually as input for the k-fold cross-validation with a k value equal to 5. Both experiments used the same pre-trained models for feature extraction.
For the model pre-trained with ImageNet and those refined with DFT and SFT techniques, the output vector had 4096 features. Therefore, to analyse the intrinsic dimensionality in the data, a principal component analysis (PCA) was applied to reduce the vector to its 100 principal components.
Table 10 presents the results obtained by the two performed analyses.
From the results in
Table 10, it is possible to realise that in experiments with multiple datasets (LODOCV experiment), mDFT provided a superior linear separability of the data. However, for only one dataset (
k-fold cross-validation experiment), the DFT showed better results. The advantage of mDFT in the first experiment was that it restricts dense layers in dimensionality (from 4096 in the original model to 256 in the proposed model), making the model robust to images from different datasets. The DFT uses a larger output, and it consequently has more “degrees of freedom” in the pre-trained model, which can cause overfitting in datasets used for fine-tuning, reducing the accuracy in an experiment with multiple datasets.
This analysis confirms previous findings which indicate that models with a more restricted bias, i.e., in terms of their space of admissible functions, may transfer better for different domains [
4] in comparison to the same domain, which in the case of the widely used ImageNet dataset are mostly natural images and photographic data [
25]. Furthermore, it is clear how a high
k-fold cross-validation measure obtained by using an off-the-shelf CNN model, e.g., trained in ImageNet, is severely impacted when using a more realistic scenario concerning the different source and target datasets, which indicates the importance of transfer learning [
54].
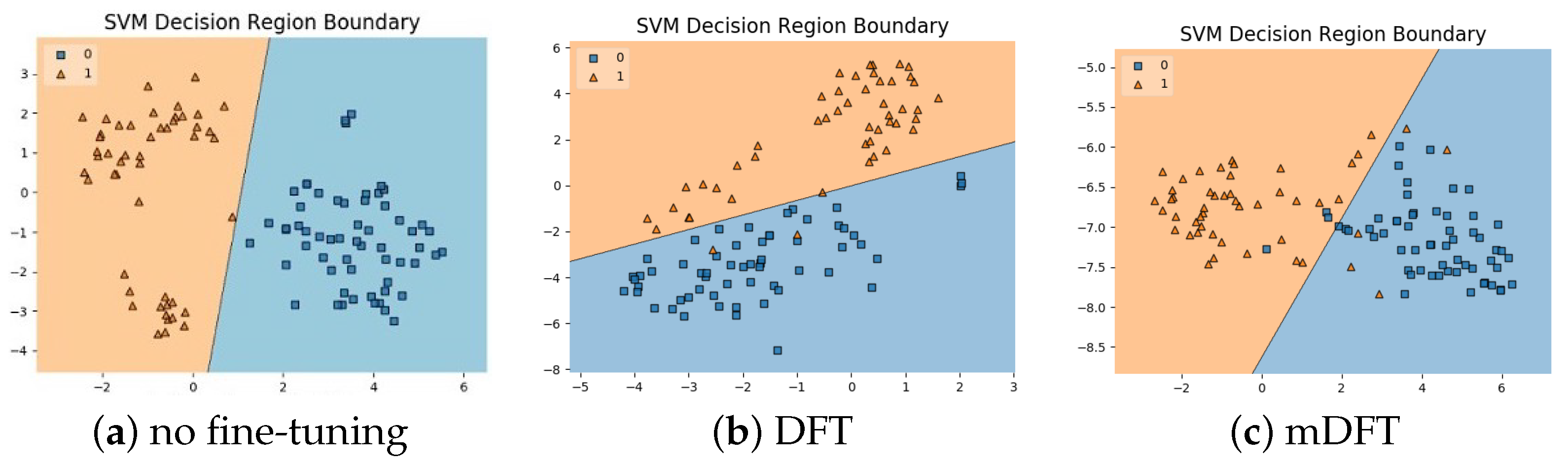
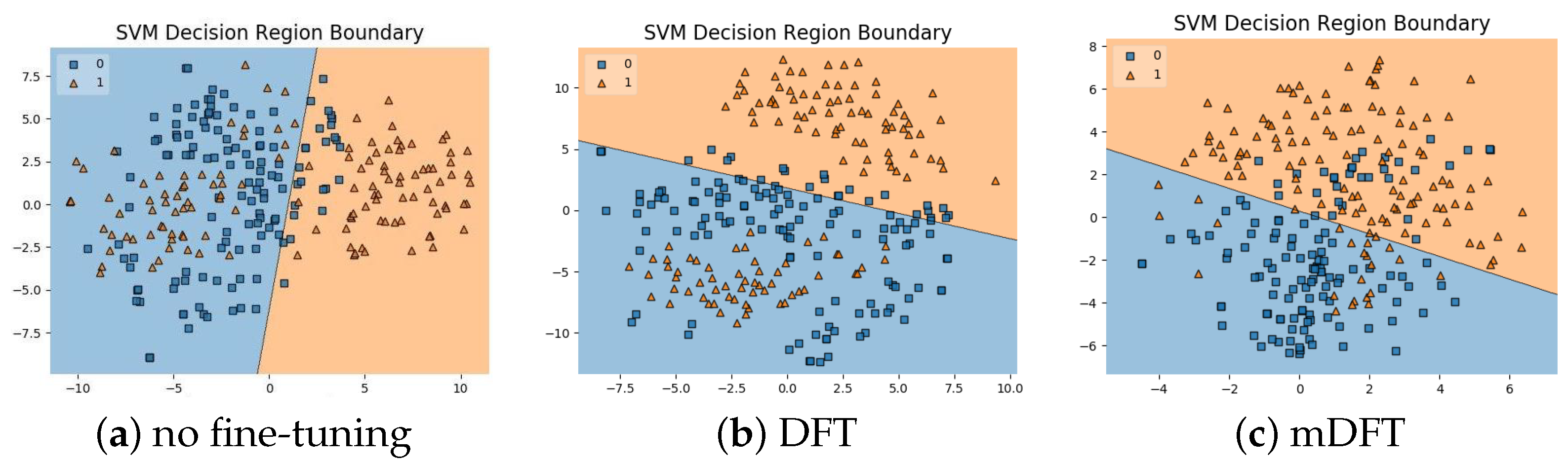
In addition to the classification experiments, we also visualised the feature spaces using a t-SNE projection, with the respective decision boundaries estimated to the 2D case, both for ALL-IDB 1,
Figure 10, and ALL-IDB 2,
Figure 11. From these figures, it is possible to note how the decision boundaries show good feature spaces with good discrimination capability. Furthermore, it is clear how ALL-IDB2 is a more challenging dataset, and that the mDFT tends to produce a space that better separates the classes compared to the greater classes overlap shown in DFT and spaces without fine-tuning,
Figure 11.
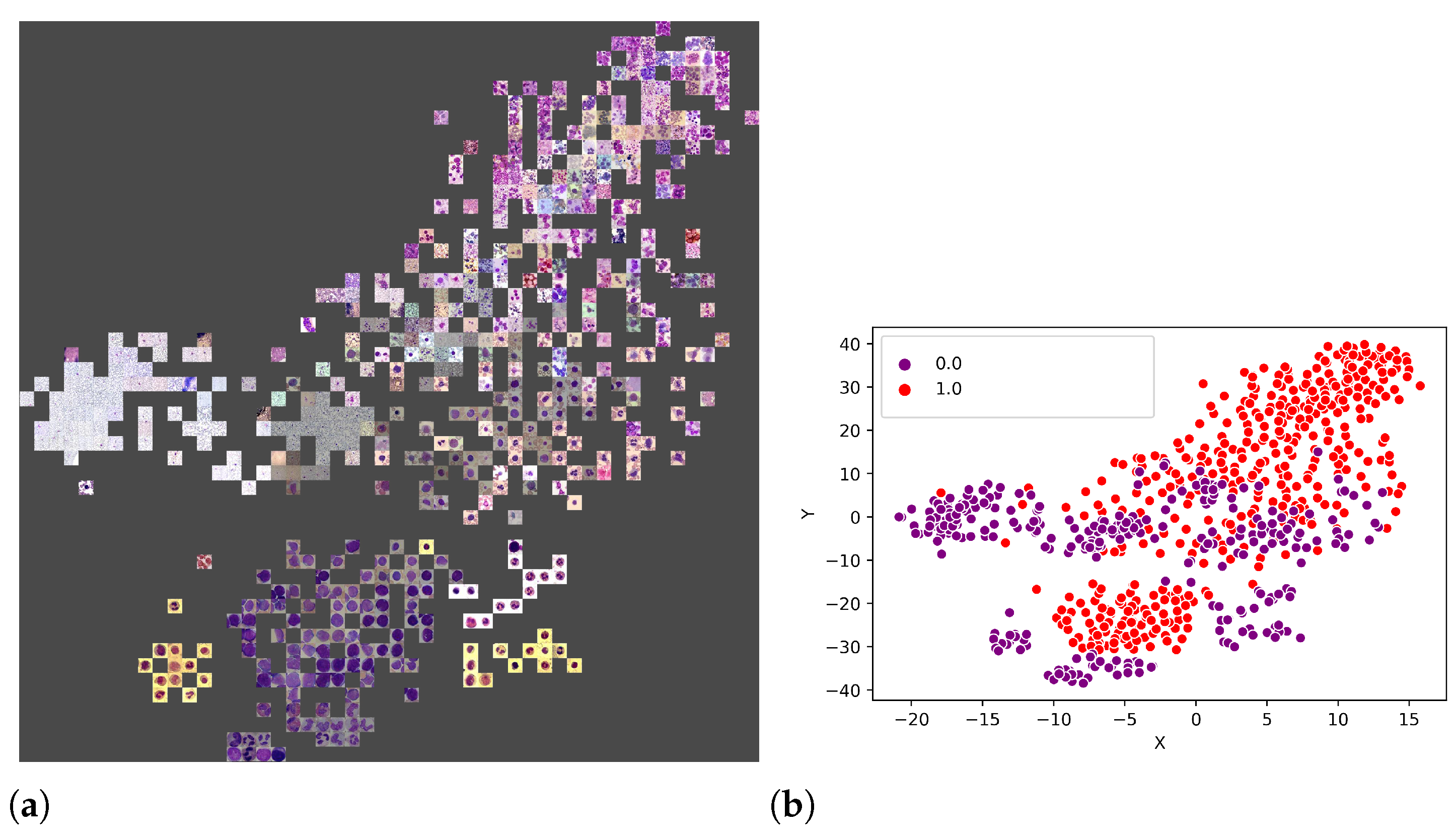
An additional experiment was performed to better understand which features were used by the CNNs to separate the classes. Thus, from the union of the 18 datasets (totalling 3536 images), 80% of the images were randomly selected to form a training set, and the remaining 20% were used as the test set.
Figure 11a illustrates the visual attributes that contributed to the classification using the t-SNE. Some of these attributes are the number of leukocytes per slide, the colour and zoom. However, in
Figure 12b, one can also observe that it is impossible to separate the set linearly, requiring a more sophisticated prediction function, such as that provided by LeukNet.
4.4. Discussion
An interesting discussion in the classification and segmentation of medical pathology images is related to colour normalisation. In [
55], the authors evaluated the influence of colour normalisation in the classification of lymphoma images and concluded that the best classification rate was obtained with features extracted from the images, i.e., without colour normalisation. Another study [
56] evaluated the impact of colour normalisation in convolutional neural network-based nuclei segmentation in blood smear images, and it was concluded that, despite the colour variability in the original images, the used CNN model could effectively segment the nuclei presented in the original images. Thus, in this study, we chose not to apply colour normalisation strategies.
The results presented in
Section 4.1 were obtained using the LODOCV strategy; however, other studies do not use this validation strategy. Thus,
k-fold cross-validation, with
k = 5 in all of the 3536 images from the available 18 datasets, was applied to compare the results of the proposed approach with the ones obtained by state-of-the-art methods.
Table 11 presents the results achieved by the approaches under comparison; the indicated accuracy values for the state-of-the-art methods were gather from their original articles.
First, from
Table 11, it is possible to verify that the number of images used in all competing methods is inferior to those presented in our experiments. Several authors used feature extraction techniques based on texture, shape and colour [
6,
7,
8,
9]. These methods achieved accuracies of 93.63, 97.7, 93.75 and 93.80%. The use of a single dataset and the accuracy obtained in the experiments proposed by these methods expose the lack of robustness compared with other state-of-the-art approaches.
Among the works based in deep learning techniques, Shafique et al. [
16], Rehman et al. [
17] and Pansombut et al. [
19] proposed solutions for the classification of leukaemia subtypes. With the use of shallower and less complex CNNs, the authors were able to deal with small databases without compromising the CNN training as they did not use data augmentation techniques.
Thanh et al. [
14], Ahmed et al. [
20] and Loey et al. [
18] tackled the classification between leukaemia and healthy images, as in this work. According to the results obtained by the proposed model using the image development set, it can be concluded that more complex architectures, i.e., with a higher number of parameters, produced better success rates in tests like LODOCV, and are more challenging than
k-fold cross-validation and holdout. Among the previously mentioned studies, only Thanh et al. [
14] presented an architecture with high complexity. However, in terms of architecture depth, LeukNet presents a more extensive set of convolutional filters, which allows the extraction of more feature maps.
Among the mentioned studies, Vogado et al. [
22] presented experiments in more than two datasets: eight of the 14 that were used in this work. Among the best results, we observed that both Loey et al. [
18] and Vogado et al. [
22] obtained results superior to LeukNet. However, we must emphasise that Loey et al. [
18] performed tests where the classes are represented by two homogeneous databases, which justifies the high accuracy obtained. Because Vogado et al. [
22] was the only group to use the
k-fold method for cross-validation, we compared our method with theirs in more detail below.
Table 12 presents the comparative result of the proposed method and the one of Vogado et al. [
22]. In this experiment, we performed twenty
k-fold cross-validation executions (
k = 5) on 3415 images from 17 image datasets (the UFG dataset was separated for a second experiment). For comparison purposes, an experiment of training the VGG-16 from random weights is described.
Vogado et al. [
22] used eight of the seventeen datasets used in this study. Comparing the results presented in
Table 11 and
Table 12, the competing method shows lower accuracy after inclusion of new images. In particular, the ASH, Bloodline and ONKODIN datasets are composed of images with distinct resolutions, textures and different colour characteristics. According to the results shown in
Table 12, one can observe that using the Student’s
t-test with a significance level of 5%, the results of VGG-16 and LeukNet can be considered equivalent, and both are superior to the competing method.
To demonstrate the generalisation capacity of LeukNet,
Table 13 shows average results of applying the models generated by the previous experiment in an external dataset as a test set. The UFG set is a novel dataset, which was never used in previous studies, and is particularly challenging for three reasons: (1) the dataset is formed up of images acquired by different microscopes, and according to different resolutions and lighting conditions (2) has complete slide images and images with only one leukocyte, and (3) among all the datasets used in this study, the UFG dataset is the one with the highest diversity within the leukemia class, since it has examples of images with ALL, AML, CLL and CML subtypes.
From
Table 13, one can conclude that the three approaches obtained lower results when compared to those obtained by the
k-fold cross-validation. However, the decay of the proposed model was more moderate (from 98.61 to 70.24%) than that of VGG-16 (98.64 to 65.94%) and that in [
22] (from 92.79 to 52.06%). This result suggests that LeukNet can generalise better than the methods in the literature. Thus, it can be concluded that this superior generalisation is due to the use of larger data and the precise definition of the convolutional neural network parameters as was conducted in this study.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}