Asymmetric Adaptive Fusion in a Two-Stream Network for RGB-D Human Detection


Abstract
1. Introduction
1.1. Based Only on RGB Data
1.2. Based Only on Depth Data
1.3. Based on Combined RGB-D Data
- (1)
- We propose an asymmetric two-stream network for RGB-D human detection, which reduces the complexity of typical symmetric two-stream networks while helping to overcome the partial loss of significant depth features in deeper layers and the insufficient representation of RGB features in shallow layers.
- (2)
- We propose a multiscale fusion structure (Depth-FPN) for the depth stream, which can effectively fuse multilevel features from depth images.
- (3)
- We introduce an adaptive channel weighting module (ACW module) for multimodal data fusion, which helps to select more valuable multimodal RGB-D feature channels for weighted fusion.
2. Method
- (1)
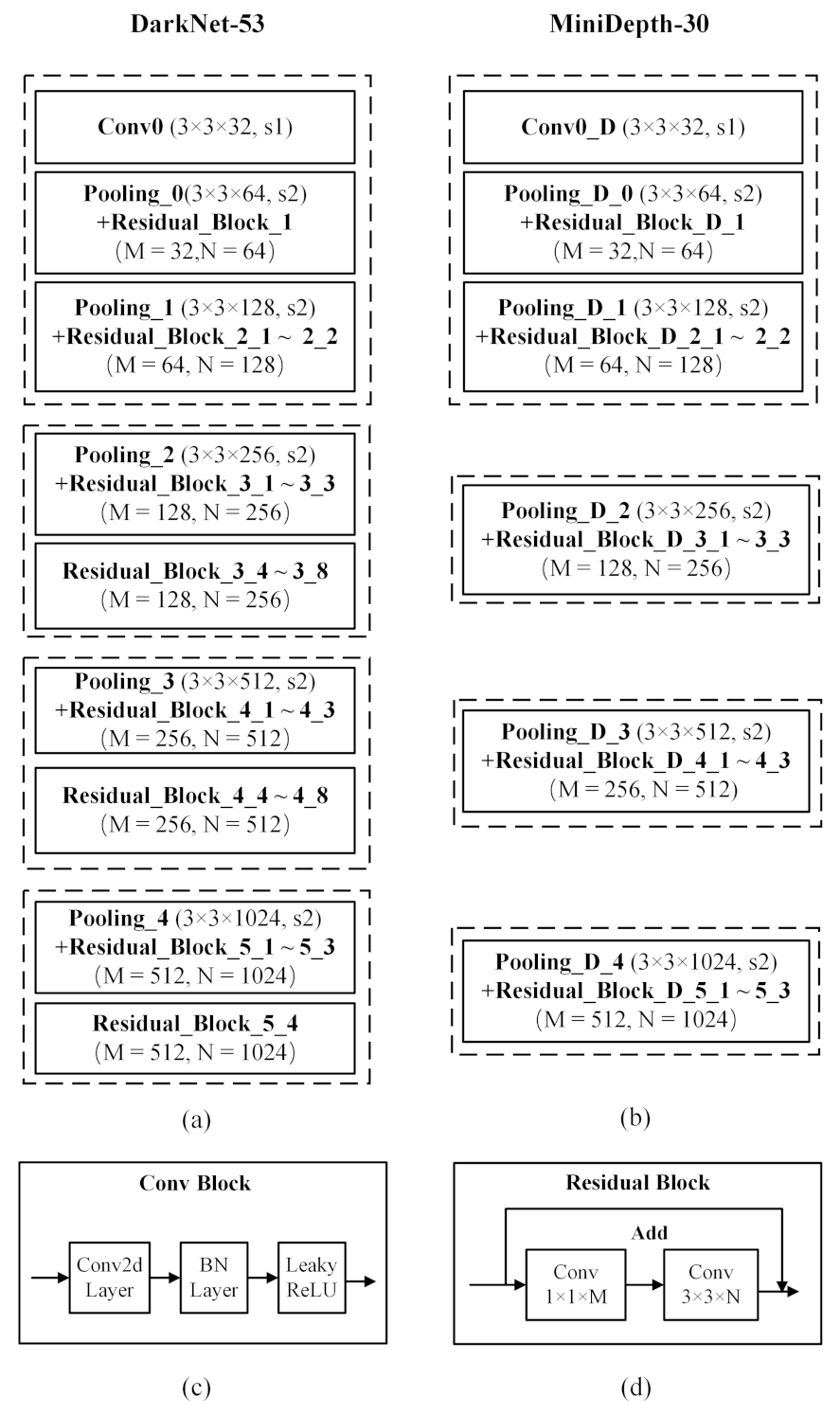
- Asymmetric two-stream network: The network structure consists of two parallel branches, an RGB branch and a depth branch. The RGB branch is based on Darknet-53 from YOLOv3, which consists of 53 convolutional layers for extracting features from RGB images. For the depth stream, a pruned version of DarkNet-53 is adopted based on depth features; this architecture, which retains 30 of the original convolutional layers, is called MiniDepth-30.
- (2)
- Depth-FPN: Following MiniDepth-30, we also introduce a feature pyramid structure called Depth-FPN, which can effectively combine deep semantic features and shallow detail features from depth images by means of an upsampling operation. The multiscale depth features are enhanced and extracted so as to exhibit a one-to-one correspondence with the YOLOv3 feature hierarchy on prediction branches of three different resolutions.
- (3)
- ACW: Inspired by the design of the Squeeze-and-Excitation (SE) block [34], an adaptive channel weighting module called the ACW module is proposed for multimodal data fusion. This module assigns weights obtained through adaptive network learning to each multimodal RGB-D channel to realize the efficient selection and fusion of multimodal features on the three prediction branches. Multimodal RGB-D feature maps of different resolutions (high, medium, and low) are input into the classification and regression layers of the corresponding prediction branches to generate the confidence values and coordinates of the predicted bounding boxes.
2.1. Asymmetric RGB-D Two-Stream Network
2.2. Feature Pyramid Structure Following MiniDepth-30 (Depth-FPN)
2.3. RGB-D Adaptive Channel Weighting (ACW)
- (1)
- The ACW module takes an RGB feature map and a depth feature map as inputs, both from the same pyramid level and with the same resolution. First, the two feature maps are concatenated in the channel dimension. The concatenated multimodal feature map is denoted by , where .
- (2)
- X is sent to the branch network to adaptively learn the weight values for each multimodal channel. Since each feature channel in X has been generated by a convolution kernel, the output response of each cell reflects only the local receptive field and does not consider context information outside of this range. Therefore, a global average pooling layer, , is introduced in the branch network. The global spatial information of each feature channel is aggregated into a channel descriptor, as shown in Equation (1). In this equation, the statistic represents the output response after aggregation, represents channel C of input feature map X, and represents channel C of the output response.
- (3)
- To limit the complexity of the model, a bottleneck is added after to learn a nonlinear mapping. This bottleneck consists of a 1 × 1 convolution with a reduction ratio of , a ReLU activation, and a 1 × 1 convolution with an expansion ratio of s. Then, the sigmoid function is used to introduce a gating mechanism for learning the nonlinear interactions among channels, generating a total of C channel activation values between 0 and 1. Equation (2) describes the gating function , where and represent the sigmoid and ReLU functions, respectively; describes the convolutional response before activation; and represent the parameters of the first and second convolutional layers, respectively; and the elements of are the C channel weight values.
- (4)
- The final output of the ACW module, , is obtained as shown in Equation (3). First, the scalar values are multiplied by the feature map , thus mapping the input feature map X to a unique set of channel weights S. The greater the channel weight value, the more prominent that channel’s contribution to the human detection process. Finally, the output feature map Y for each prediction branch are sent to the classification layer and coordinate regression layer of YOLOv3 for final detection.
3. Experiment
3.1. Datasets
- (1)
- CLOTH: This dataset was provided by Liu et al. [27]. It was acquired using a Kinect in a clothing store. The Kinect was placed 2.2 meters above the ground and at an angle of 30 degrees from the ground. For this study, 496 pairs of RGB-D images were selected from the original dataset.
- (2)
- OFFICE: The OFFICE dataset was shot in an office environment and was provided by Choi et al. [35]. We selected 12 representative video sequences for use in this study, retaining 2209 pairs of RGB-D images.
- (3)
- MOBILE: This dataset is also from Choi et al. [37]. It mainly collected images from scenes such as meeting rooms, corridors and restaurants. The challenges for human detection that are represented in this dataset include horizontal shooting angles, dynamic backgrounds, overlapping people, and changes in distance and lighting. For this study, we selected 8 video sequences of the MOBILE dataset where contains a total of 691 pairs of RGB-D images.
- (4)
- DARK: This dataset was captured at night by Zhang et al. [17] and consists of 275 RGB-D images. In this scene, the people and backgrounds cannot be distinguished based on the low-light RGB images alone. We chose to use DARK to evaluate the human detection performance of our method in low-light or even dark conditions.
- (5)
- MICC (Media Integration and Communication Center) people counting dataset(MICC): The MICC dataset provided by Bondi et al. [38] mainly consists of video surveillance images collected in crowded indoor conditions. This dataset contains three recorded video sequences: FLOW, QUEUE and GROUPS. It contains 1128 pairs of images. The entire MICC dataset consists of 3193 pairs of RGB-D images.
- (6)
- EPFL (EPFL Laboratory) Pedestrian Dataset(EPFL): This dataset is provided by Bagautdinov et al. [39] and consists of two scenarios. EPFL-LAB was shot in a laboratory and contains a total of 250 pairs of images. EPFL-CORRIDOR was captured in the corridor of a school building and contains 8 video sequences comprising a total of 1582 pairs of RGB-D images. Severe occlusion and human scale changes are the greatest challenges presented by this dataset. For the current study, this dataset was selected to evaluate human detection performance under occlusion conditions.
3.2. Implementation Details
- (1)
- Data preprocessing: We integrated the selected data from CLOTH, OFFICE, MOBILE, DARK and MICC into a large RGB-D human detection dataset called RGBD-human, which contains 6,864 pairs of RGB-D images. We randomly divided the data into training, evaluation and test sets at a ratio of 6:2:2, corresponding to 4118, 1373 and 1373 image pairs, respectively. In addition, we evaluated the performance of AAFTS-net under occlusion conditions on the EPFL dataset. We randomly divided the EPFL dataset into a training set and a test set at a ratio of 6:4, corresponding to 1099 and 733 image pairs, respectively. Data augmentation was applied to the training samples using color jitter, random translation and rotation, and horizontal flipping. The ground-truth coordinates were also correspondingly modified at the same time. The original depth images often contain many holes of missing data. The depth values at these holes are ’none’, resulting in large black patches in the depth images. In this study, the hole-filling method proposed by Zhang et al. [40] was used to repair the depth images. The restored depth images were preprocessed using HHA [30] encoding.
- (2)
- Network details: In AAFTS-net, the RGB stream is initialized using the parameters of Darknet-53 pretrained on the ImageNet dataset. For MiniDepth-30 and the remaining layers, Gaussian random initialization is used. The scales and matching strategy for the anchors are consistent with those of YOLOv3. For human detection, we need to label ‘person’ objects; therefore, the number of categories in the classification layer is 1.
- (3)
- Hyperparameters: AAFTS-net was implemented using PyTorch1.0 and trained for 20 hours on a system running Ubuntu 18.04 with an NVIDIA GTX 1080Ti GPU. The number of training epochs was set to 100, and the batch size was 8. The initial learning rate was 0.001, which was reduced to 0.0001 after 30 epochs and further reduced to 0.00001 after 80 epochs, with a momentum of 0.9 and a weight decay of 1 . The confidence threshold was set to 0.3, and the NMS threshold was set 0.4.
3.3. Evaluation and Analysis
3.3.1. Performance Metrics
3.3.2. Comparisons with YOLOv3
- (1)
- Comparison results on RGBD-Human. The experimental results are compared in Table 1. The AAFTS-net model proposed in this paper achieved FPPI and MR values that were lower than those of YOLOv3 by 0.13 and 0.12, respectively, which shows that our algorithm can effectively reduce the false detection rate and missed detection rate. Additionally, the F1 measure increased by almost 2% and the precision increased by 3.7%, which confirmed that AAFTS-net is better than YOLOv3 at detecting accuracy. Compared to the original YOLOv3, we obtained the abovementioned significant performance improvement at the cost of only 0.003 ms inference time. The real-time speed of the AAFTS-net algorithm on NVIDIA 1080Ti reached 47 FPS. This improvement is closely related to the characteristics of the depth features. Depth images show strong anti-interference capabilities and robustness to occlusion. It also confirms with an appropriate feature construction mechanism, the information provided by depth features can be used to supplement and strengthen the information provided by RGB features, thus obtaining a more robust multimodal feature representation.
- (2)
- Comparison results on OFFICE, DARK and MICC. In the RGBD-Human, each subset represented a different indoor detection scene. Different data distributions of each subset could affect algorithm performance. Therefore, we compared the results of AAFTS-net and YOLOv3 on OFFICE, DARK and MICC to analyze the influence of the metadata from different scenes and different levels of data quality on the detection results. The experimental results are shown in Table 2.
3.3.3. Comparisons with Other Existing Methods
3.3.4. Occlusion Performance
3.3.5. Ablation Study
- (1)
- Selection of the asymmetric network structure: We used the same pruning strategy used for MiniDepth-30 to construct MiniDepth-22 and MiniDepth-40, which retain 22 and 40, respectively, of the convolutional layers in Darknet-53. In this study, MiniDepth-22, MiniDepth-30, MiniDepth-40 and Darknet-53 were each used as the basis of the depth stream in the RGB-D two-stream network, and the corresponding networks were all trained and tested on the RGB-human dataset. The results obtained with these different network structures are compared in Table 4. It can be seen from this table that MiniDepth-30 yielded the best results, while the results of the symmetric Darknet-53-based network were the worst. This finding also confirms our previous hypothesis that depth images and RGB images contain unbalanced amounts of information that can aid in human detection. Compared with MiniDepth-22 and MiniDepth-40, the optimal network depth achieved in MiniDepth-30 overcomes the lack of shallow feature extraction ability while ensuring the complete validity of the depth features.
- (2)
- Component contributions: The individual contributions of the various components of AAFTS-net were evaluated through additional ablation experiments. The investigated components mainly include Depth-FPN, the ACW module and the use of HHA depth coding. The corresponding experimental results are shown in Table 5. The introduction of Depth-FPN results in a 1.2% improvement in the F1 measure performance of AAFTS-net, thus demonstrating that multiscale feature fusion enhances the detector’s adaptability to human targets of different sizes. HHA coding provides a small improvement in the performance of the algorithm, with an increase of only 0.7%. Its main benefit is related to the enhancement of the edges of human targets in the depth images. The ACW module gives AAFTS-net a 3.5% performance boost, showing that our exploration of the intrinsic correlations between the RGB and depth feature channels leads to an obvious performance improvement. Our simple and efficient feature selection strategy can improve the fusion efficiency for multimodal data and generate a high-quality feature representation for RGB-D human detection.
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, S.; Huang, D. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Mateus, A.; Ribeiro, D.; Miraldo, P.; Nascimento, J.C. Efficient and robust pedestrian detection using deep learning for human-aware navigation. Robot. Auton. Syst. 2019, 113, 23–37. [Google Scholar] [CrossRef]
- Cheng, E.J.; Prasad, M.; Yang, J.; Khanna, P.; Chen, B.-H.; Tao, X.; Young, K.-Y.; Lin, C.-T. A fast fused part-based model with new deep feature for pedestrian detection and security monitoring. Measurement 2020, 151, 107081. [Google Scholar] [CrossRef]
- Tesema, F.B.; Wu, H.; Chen, M.; Lin, J.; Zhu, W.; Huang, K. Hybrid channel based pedestrian detection. Neurocomputing 2020, 389, 1–8. [Google Scholar] [CrossRef]
- Wang, X.; Xiao, T.; Jiang, Y.; Shao, S.; Sun, J.; Shen, C. Repulsion loss: Detecting pedestrians in a crowd. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7774–7783. [Google Scholar]
- Yang, P.; Zhang, G.; Wang, L.; Xu, L.; Deng, Q.; Yang, M.-H. A Part-Aware Multi-Scale Fully Convolutional Network for Pedestrian Detection. IEEE Trans. Intell. Transp. Syst. 2020, 1–13. [Google Scholar] [CrossRef]
- Xie, J.; Pang, Y.; Cholakkal, H.; Anwer, R.M.; Khan, F.S.; Shao, L. PSC-Net: Learning Part Spatial Co-occurence for Occluded Pedestrian Detection. arXiv 2020, arXiv:2001.09252. [Google Scholar]
- Saeed, A.; Khan, M.J.; Asghar, M.A. Person Detection by Low-rank Sparse Aggregate Channel Features. In Proceedings of the 7th International Conference on Communications and Broadband Networking, Nagoya, Japan, 12–15 April 2019; pp. 58–62. [Google Scholar]
- Balta, D.; Salvi, M.; Molinari, F.; Figari, G.; Paolini, G.; Croce, U.D.; Cereatti, A. A two-dimensional clinical gait analysis protocol based on markerless recordings from a single RGB-Depth camera. In Proceedings of the 2020 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Bari, Italy, 1 June–1 July 2020; pp. 1–6. [Google Scholar]
- Xiao, Y.; Kamat, V.R.; Menassa, C.C. Human tracking from single RGB-D camera using online learning. Image Vis. Comput. 2019, 88, 67–75. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, G.; Tian, L.; Chen, Y.Q. Real-time human detection with depth camera via a physical radius-depth detector and a CNN descriptor. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 1536–1541. [Google Scholar]
- Zhang, G.; Tian, L.; Liu, Y.; Liu, J.; Liu, X.A.; Liu, Y.; Chen, Y.Q. Robust real-time human perception with depth camera. In Proceedings of the Twenty-Second European Conference on Artificial Intelligence, The Hague, The Netherlands, 29 August–2 September 2016; pp. 304–310. [Google Scholar]
- Wetzel, J.; Laubenheimer, A.; Heizmann, M.J.I.A. Joint Probabilistic People Detection in Overlapping Depth Images. IEEE Access 2020, 8, 28349–28359. [Google Scholar] [CrossRef]
- Fujimoto, Y.; Fujita, K. Depth-Based Human Detection Considering Postural Diversity and Depth Missing in Office Environment. IEEE Access 2019, 7, 12206–12219. [Google Scholar] [CrossRef]
- Tian, L.; Li, M.; Hao, Y.; Liu, J.; Zhang, G.; Chen, Y.Q. Robust 3-d human detection in complex environments with a depth camera. IEEE Trans. Multimed. 2018, 20, 2249–2261. [Google Scholar] [CrossRef]
- Sun, S.; Akhtar, N.; Song, H.; Zhang, C.; Li, J.; Mian, A. Benchmark data and method for real-time people counting in cluttered scenes using depth sensors. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3599–3612. [Google Scholar] [CrossRef]
- Huang, W.; Zhou, B.; Qian, K.; Fang, F.; Ma, X. Real-Time Multi-Modal People Detection and Tracking of Mobile Robots with A RGB-D Sensor. In Proceedings of the 2019 IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM), Toyonaka, Japan, 3–5 July 2019; pp. 325–330. [Google Scholar]
- Shah, S.A.A. Spatial hierarchical analysis deep neural network for RGB-D object recognition. In Lecture Notes in Computer Science, Proceedings of the Pacific-Rim Symposium on Image and Video Technology, Sydney, NSW, Australia, 18–22 November 2019; Springer: Cham, Switzerland, 2019; pp. 183–193. [Google Scholar]
- Essmaeel, K.; Migniot, C.; Dipanda, A.; Gallo, L.; Pietro, E.D.G.D. A new 3D descriptor for human classification: Application for human detection in a multi-kinect system. Multimed. Tools Appl. 2019, 78, 22479–22508. [Google Scholar] [CrossRef]
- Lian, D.; Li, J.; Zheng, J.; Luo, W.; Gao, S. Density map regression guided detection network for rgb-d crowd counting and localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 1821–1830. [Google Scholar]
- Mahalakshmi, M.; Kanthavel, R.; Hemavathy, N. Real-Time Human Detection and Tracking Using PEI Representation in a Dynamic 3D Environment. In Advances in Intelligent Systems and Computing, Proceedings of the International Conference on Intelligent Computing and Applications; Springer: Singapore, 2019; pp. 179–195. [Google Scholar]
- Liu, J.; Liu, Y.; Zhang, G.; Zhu, P.; Chen, Y.Q. Detecting and tracking people in real time with RGB-D camera. Pattern Recognit. Lett. 2015, 53, 16–23. [Google Scholar] [CrossRef]
- Tian, L.; Zhang, G.; Li, M.; Liu, J.; Chen, Y.Q. Reliably detecting humans in crowded and dynamic environments using RGB-D camera. In Proceedings of the 2016 IEEE International Conference on Multimedia and Expo (ICME), Seattle, WA, USA, 11–15 July 2016; pp. 1–6. [Google Scholar]
- Ophoff, T.; Beeck, K.V.; Goedemé, T. Exploring RGB + Depth fusion for real-time object detection. Sensors 2019, 19, 866. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S.; Girshick, R.; Arbeláez, P.; Malik, J. Learning rich features from RGB-D images for object detection and segmentation. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 345–360. [Google Scholar]
- Zhang, G.; Liu, J.; Liu, Y.; Zhao, J.; Tian, L.; Chen, Y.Q. Physical blob detector and Multi-Channel Color Shape Descriptor for human detection. J. Vis. Commun. Image Represent. 2018, 52, 13–23. [Google Scholar] [CrossRef]
- Zhang, G.; Liu, J.; Li, H.; Chen, Y.Q.; Davis, L.S. Joint human detection and head pose estimation via multistream networks for RGB-D videos. IEEE SIgnal Process. Lett. 2017, 24, 1666–1670. [Google Scholar] [CrossRef]
- Zeng, H.; Yang, B.; Wang, X.; Liu, J.; Fu, D. RGB-D Object Recognition Using Multi-Modal Deep Neural Network and DS Evidence Theory. Sensors 2019, 19, 529. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, W.; Tran, D.; Feiszli, M. What Makes Training Multi-Modal Classification Networks Hard? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 12695–12705. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Lecture Notes in Computer Science, Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Choi, W.; Pantofaru, C.; Savarese, S. A general framework for tracking multiple people from a moving camera. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1577–1591. [Google Scholar] [CrossRef] [PubMed]
- Bondi, E.; Seidenari, L.; Bagdanov, A.D.; Bimbo, A.D. Real-time people counting from depth imagery of crowded environments. In Proceedings of the 2014 11th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Seoul, Korea, 26–29 August 2014; pp. 337–342. [Google Scholar]
- Bagautdinov, T.; Fleuret, F.; Fua, P. Probability occupancy maps for occluded depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2829–2837. [Google Scholar]
- Zhang, Y.; Funkhouser, T. Deep depth completion of a single rgb-d image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 175–185. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FPPI | MR | Precision | Recall | F1 Measure | Inference Time |
|---|---|---|---|---|---|---|
| YOLOv3 (Only RGB) | 0.378 | 0.095 | 0.913 | 0.905 | 0.908 | 0.020 ms |
| AAFTS-net (Ours) | 0.259 | 0.083 | 0.940 | 0.917 | 0.928 | 0.023 |
| Dataset | Num | Method | FPPI | MR | Precision | Recall | F1 Measure |
|---|---|---|---|---|---|---|---|
| OFFICE | 881 | YOLOv3 | 0.363 | 0.124 | 0.878 | 0.876 | 0.877 |
| AAFTS-net | 0.270 | 0.121 | 0.906 | 0.879 | 0.893 | ||
| DARK | 95 | YOLOv3 | 1.210 | 0.406 | 0.686 | 0.594 | 0.637 |
| AAFTS-net | 0.827 | 0.169 | 0.817 | 0.831 | 0.824 | ||
| MICC | 1301 | YOLOv3 | 0.356 | 0.038 | 0.939 | 0.962 | 0.950 |
| AAFTS-net | 0.233 | 0.037 | 0.959 | 0.963 | 0.961 |
| Method | FPPI | MR | Precision | Recall | F1 Measure |
|---|---|---|---|---|---|
| YOLOv3 (Only RGB) | 1.190 | 0.133 | 0.803 | 0.867 | 0.834 |
| AAFTS-net (Ours) | 0.664 | 0.108 | 0.870 | 0.892 | 0.880 |
| MiniDepth-22 | MiniDepth-30 (Ours) | MiniDepth-40 | Darknet-53 | |
|---|---|---|---|---|
| FPPI | 0.284 | 0.259 | 0.301 | 0.285 |
| Miss rate | 0.099 | 0.084 | 0.093 | 0.097 |
| Precision | 0.924 | 0.941 | 0.919 | 0.915 |
| Recall | 0.901 | 0.916 | 0.907 | 0.903 |
| F1 measure | 0.914 | 0.928 | 0.912 | 0.909 |
| HHA + ACW | PN + ACW | HHA + FPN | AAFTS-Net | |
|---|---|---|---|---|
| Depth-FPN? | ✓ | ✓ | ✓ | |
| ACW? | ✓ | ✓ | ✓ | |
| HHA? | ✓ | ✓ | ✓ | |
| F1 measure | 0.916 | 0.920 | 0.893 | 0.928 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Guo, X.; Wang, J.; Wang, N.; Chen, K. Asymmetric Adaptive Fusion in a Two-Stream Network for RGB-D Human Detection. Sensors 2021, 21, 916. https://doi.org/10.3390/s21030916
Zhang W, Guo X, Wang J, Wang N, Chen K. Asymmetric Adaptive Fusion in a Two-Stream Network for RGB-D Human Detection. Sensors. 2021; 21(3):916. https://doi.org/10.3390/s21030916
Chicago/Turabian StyleZhang, Wenli, Xiang Guo, Jiaqi Wang, Ning Wang, and Kaizhen Chen. 2021. "Asymmetric Adaptive Fusion in a Two-Stream Network for RGB-D Human Detection" Sensors 21, no. 3: 916. https://doi.org/10.3390/s21030916
APA StyleZhang, W., Guo, X., Wang, J., Wang, N., & Chen, K. (2021). Asymmetric Adaptive Fusion in a Two-Stream Network for RGB-D Human Detection. Sensors, 21(3), 916. https://doi.org/10.3390/s21030916