1. Introduction
Knowing the refined electricity behaviors of household energy consumption is important to residents, by means of which energy consciousness can be awakened and energy conservation schemes can be customized [
1]. Meanwhile, it is also important to power utilities, where understanding the load components helps to model power system operations and schedule the demand response better [
2]. Furthermore, it is also meaningful to the development of the entire power industry, e.g., it is the technological base of tracking household energy carbon emissions [
3]. Therefore, insights into household electricity usage are emerging as a vital link in the energy consumption chain and are attracting more and more attention in both academic and industrial fields.
A straightforward way to realize refined electricity monitoring is to install smart sockets for target appliances and form a sensor network for household electricity monitoring [
4]. The exploration enthusiasm for such a project had lasted for a period of time, but it decreased due to the high financial costs associated with too many sockets [
5]. Besides, this method of electricity monitoring is strictly confined to socketed appliances, and it is not friendly to residents due to intrusive installations [
6]. Hence, the socket-based sensor network, considered as the intrusive way, was replaced once non-intrusive approaches achieved reliable performance.
Non-intrusive load monitoring, NILM for short, is a technology proposed by Professor Hart from MIT. The key idea of NILM is to use a disaggregation algorithm instead of sensor hardware to realize individual appliance monitoring [
7]. Thus, the original electric topology and measurements do not need to be changed, and only the service panel data are required, which can be captured by the existing electric meter [
8]. Such non-intrusive technology obviously decreases the monitoring cost, covers all appliances, and furthermore does not interfere with residents’ normal life. Therefore, it is widely accepted, and receives much attention in the field of household monitoring.
It is certainly the case that, to realize all the above advantages of NILM, the applied disaggregation approach should be reliable in the first place. Although proposed in 1990s, NILM has emerged as a potential solution only in recent years due to the development of artificial intelligence technologies [
9]. Acting as the key pillar during the early development stage of artificial intelligence, pattern recognition plays an important role in the field of non-intrusive load monitoring. Classification technologies, which reflect the essence of pattern recognition, have been widely investigated for NILM research. Considering different appliance characteristics, diverse electric features can be utilized for classification in NILM, such as wavelet-based classification [
10] and event-based classification [
11]. As to the classification algorithms, the classic k-nearest neighbors was explored in [
12] to improve the accuracy and efficiency of NILM. Further on, a support vector machine has been introduced in an early stage [
13], enhancing the classification of five nearest neighbor methods. Besides, a novel neuro-fuzzy classification approach is proposed in [
14] to address the uncertainties in NILM. Furthermore, multi-label classification was proposed in [
15] as a solution with the highest potential for NILM problems, and was widely discussed in the following years [
16,
17]. In addition to classification, other pattern recognition algorithms also draw attention in the field of load disaggregation field. For example, non-negative matrix factorization has been discussed in various works and demonstrated to be effective in revealing the hidden pattern of energy consumption monitoring, which is suitable for the non-intrusive load disaggregation of large buildings, e.g., industrial buildings [
18] and hospital buildings [
19]. A revised form of matrix factorization, namely independent-variation matrix factorization, was proposed in [
20] to recover positive sources with strong temporal dependency and independent variations, achieving a feasible NILM solution for commercial buildings.
As seen, pattern recognition approaches have already drawn wide attention and achieved considerable results in the field of NILM. However, some limitations show up as the research goes further, e.g., the recognition performance is highly dependent on the expert featured model. Such drawbacks are also observed along with the development of artificial intelligence; therefore, machine learning was developed as an effective alternative [
21,
22]. Because pattern recognition and machine learning are both implementation methods of artificial intelligence, and machine learning was developed on the basis of pattern recognition, all the approaches discussed above can be categorized into machine learning. In non-intrusive monitoring problems, machine learning is highlighted due to strong self-learning ability, such as semi-supervised learning [
23] and unsupervised learning [
24]. As a representative, clustering shows a good performance in NILM studies, while k-means clustering is able to deal with unlabeled appliances [
25] and density peak clustering improves the disaggregation remarkably [
26]. Similarly, as an important branch in machine learning, neural networks show reliable performance in NILM, where convolutional neural networks [
27], recurrent neural networks [
28], and Siamese neural networks [
29] are all demonstrated to be effective. In particular, deep neural networks can be improved for NILM by embedding a denoising autoencoder scheme, which is a new trend in NILM research [
30]. As the research progresses, researchers also find that dictionary learning models, which are another machine learning approach, exactly match the key idea of load disaggregation [
31]. Showing potential in NILM implementations, dictionary learning was proven to be an outstanding formulation, naturally applicable to NILM [
32]. Additionally, further inspired by the sparse coding principle of dictionary learning, transform learning was also explored in [
33] and was found to be well-adapted to NILM formulation.
In recent years, the practical experiences from world-leading artificial intelligence races show that the ensemble method is the most powerful approach in machine learning. Therefore, although limited, researchers have noticed the value of ensemble methods in NILM studies, and conducted some explorations. In [
34], a multiscale wavelet packet tree is applied to collect comprehensive energy consumption features, and an ensemble bagging tree is adopted as a classifier, where the performance is compared with various machine learning schemes. In [
35], an event detection and disaggregation framework based on an ensemble approach is proposed, whose disaggregation target is the water heating operation. Both of the above works focus on event-based load monitoring. Our team has established a general ensemble framework based on bagging in [
36] for the load disaggregation of steady-state data, and proved its performance robustness and model flexibility in diverse NILM scenarios.
However, to our knowledge, the current ensemble strategies applied to NILM all follow the evaluation criterion used in individual classifiers, even the probabilistic quantitative scoring method proposed in [
36]. Such implementation requires the individual classifier to be reliable and differentiated, but the bias can hardly be avoided since the combined classifier and individual classifiers are homogeneous. If the classifiers are chosen in an inappropriate way, e.g., overemphasizing a specific electrical feature, some errors may be generated and finally cause false decomposition. Since the combined classifier needs the information from individual classifiers for decision making, such disadvantages always exist in the ensemble decision system with homogeneous classifiers, only explicitly or implicitly. Based on this observation and knowledge, the idea of utilizing a heterogeneous design for ensemble-approach-based NILM is proposed and investigated in this paper. Firstly, the multidimensional heterogeneity for an NILM-oriented ensemble method is discussed. Since the individual classifiers can be naturally distinct in a traditional ensemble framework, our research is featured by investigating the heterogeneities from the following aspects, i.e., the heterogeneity between the combined classifier and individual classifiers, as well as the heterogeneity in independent evaluation committees of the combined classifier. Then, an implementation design is illustrated, where the individual classifiers are established based on dictionary learning, while the sparsity is not considered in the combined classifier. Meanwhile, multiple committees with distinguishing similarity measures are employed and coordinated in the decision-making stage, providing valid disaggregation evaluations from multi-perspective points. Through verifications on both a simulation platform and a field measurement dataset, the proposed idea and strategy are proven to be effective in enhancing NILM performance.
The major contribution of this paper is the presence of a multidimensional-heterogeneity-enhanced ensemble approach for NILM. By introducing heterogeneity, the obstacles of ensemble application, including design difficulty and computational inefficiency, are overcome. In addition to providing an effective method to improve NILM performance, this study also stimulates the explorations of applying the ensemble method to NILM for robust and reliable disaggregation. Furthermore, deep thinking of the nature of NILM problems as well as the rationality and completeness of disaggregation models is also inspired. In support of the contribution, the following aspects are highlighted:
Based on the properties of NILM problems, the heterogeneous evaluation design is utilized in an ensemble model.
Dictionary learning is deployed for basic load disaggregation, while the sparsity measures are featured in individual classifiers.
The combined classifier is free of sparsity measures, but composed of multiple decision committees with different similarity measures.
Verifications on both a simulation platform and a field measurement dataset show the effectiveness of our work.
2. Methodology
The task of non-intrusive load monitoring is to disaggregate the detailed appliances’ states via integral electrical measurements. In other words, it is to distinguish the components of monitoring signals, which can be formulated as:
where
x RS×1 is the target signal with the length of
S,
xi RS×1 is the
ith appliance selective electrical signature in length,
S, and Ω stands for the candidate appliance set.
Considering the background noise and signature fluctuations, Equation (1) can hardly be followed in practical applications. Therefore, an error term is usually considered in load disaggregation problems, i.e.,:
where
e0 RS×1 is the error term for the decomposition and also in length,
S.
Since background noise always exists in daily power consumption, and appliances’ operation states are highly dependent on manufacturing standards and electrical aging, the error term provided in Equation (2) not only exists but also plays a key role in load decomposition. The objective of the multidimensional-heterogeneity-enhanced ensemble model is to evaluate the error term from diverse perspectives and avoid the bias caused by certain evaluation approaches.
2.1. Ensemble Method Framework
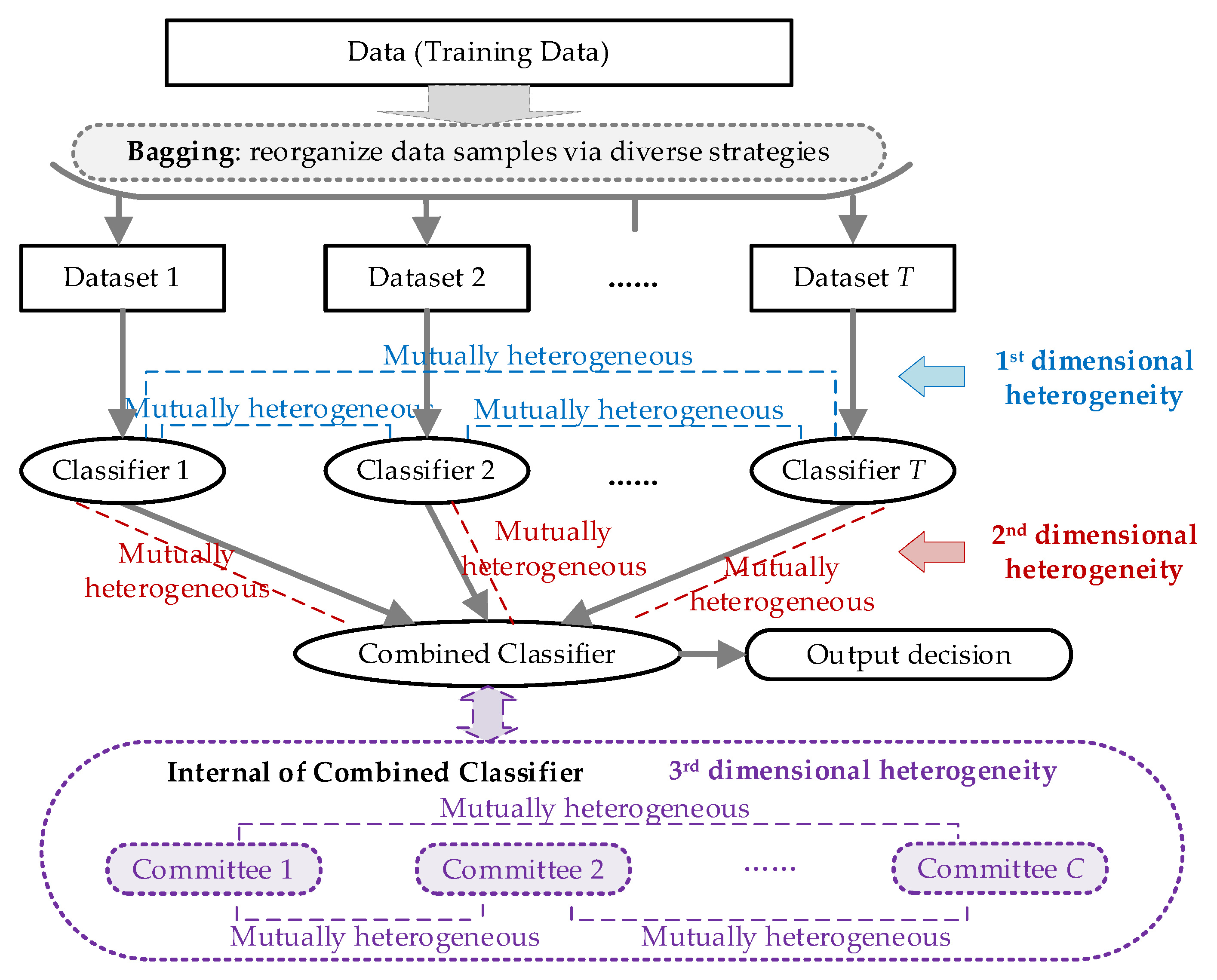
Following the load disaggregation formulation provided in Equation (2), the corresponding ensemble method framework is established in
Figure 1, while the proposed idea of multidimensional heterogeneity enhancement is highlighted in color.
As seen in
Figure 1, the NILM-oriented ensemble framework follows the bagging strategy. The proposed multidimensional heterogeneity is integrated in the architecture with the following considerations:
First: Dimensional heterogeneity in the individual classifiers. The basic idea of bagging is to establish several weak classifiers to combine into a strong classifier. For an effective combination, the weak classifiers should be distinctive from each other. Therefore, the individual classifiers may be heterogeneous according to the definition of the ensemble method. Therefore, in our following sections we do not present the detailed discussions of this point. However, considering the entirety of the description, we still illustrate this dimension in
Figure 1 for readers to understand it better.
Second: Dimensional heterogeneity between the combined classifier and individual classifiers. The individual classifiers act as the basic appliance disaggregation tool in ensemble-method-based NILM, and the combined classifier acts as the ultimate decision maker. Therefore, if these classifiers are homogeneous, the disaggregation results may be biased, following the features of the applied algorithms. Hence, we introduce heterogeneous evaluation for the combined classifier to assess the candidate solutions from diverse perspectives.
Third: Dimensional heterogeneity in the multiple committees established for the combined classifier. The combination strategy is essential for the ensemble method, which is majorly dependent on the design of the combined classifier. In order to create a valid combined classifier, we split the decision maker to be multiple committees and also introduced heterogeneity into these committees. By evaluating the candidate solutions from multi-dimensional points (these points are also distinct with individual classifiers), a more reliable result may be provided.
For a better understanding and also the verification of the proposed idea, the detailed designs and implementations are illustrated in the following sections. As mentioned above, we focus on the newly proposed schemes, i.e., the heterogeneity designs for the last two dimensions.
2.2. Heterogeneous Design for Combined Classifier and Individual Classifiers
Aiming for heterogeneity, the individual classifiers and combined classifier should follow different objective models. Since we will design multiple committees for the combined classifier, the most commonly used model in Equation (1) is reserved for the combined classifier. As to the individual classifiers, dictionary learning is employed for formulation where the sparsity is seriously considered. Therefore, whether considering the sparsity or not will be the featured heterogeneity between the combined classifier and individual classifiers.
2.2.1. Dictionary Learning Model for Individual Classifiers
The dictionary learning models tries to establish a dictionary for the target signal in Equation (1) and decompose the signal with as few dictionary atoms as possible. The basic formulation is illustrated as:
where the dictionary is defined as
D = [
d1,
d2,…,
dN]
RS×N, whose column
dk RS×1 is defined as an atom. One dictionary contains
N atoms.
α RN×1 is defined as a sparsity parameter.
For a well-established model, sparsity, α, has as an important role. On one hand, the dictionary, D, is established based on an alternative optimization for both dictionary and sparsity. On the other hand, once the dictionary is determined, sparsity becomes a key factor for problem solving.
Therefore, based on the principles of dictionary learning, it is required to determine the dictionary,
D, first. The problem is defined as:
where ||•||
F is the
F-norm calculation, measuring the differences between the target and fitting in the physical sense.
λ is the regularization parameter, indicating the proportion of sparsity in the optimization objective.
g•(•) is the unified sparsity measurement function, revealing the sparsity calculation in the objective. Since both dictionary,
D, and sparsity,
α, are unknown variables to be solved in the model, the K-SVD algorithm is utilized to solve the alternative problem [
31].
After completing the training stage, we have a feasible
D for the NILM problem in a specific house. Hence, the load disaggregation problem under normal operations is a straightforward optimization, which is free of calculation burden:
2.2.2. Heterogeneous Design for the Combined Classifier
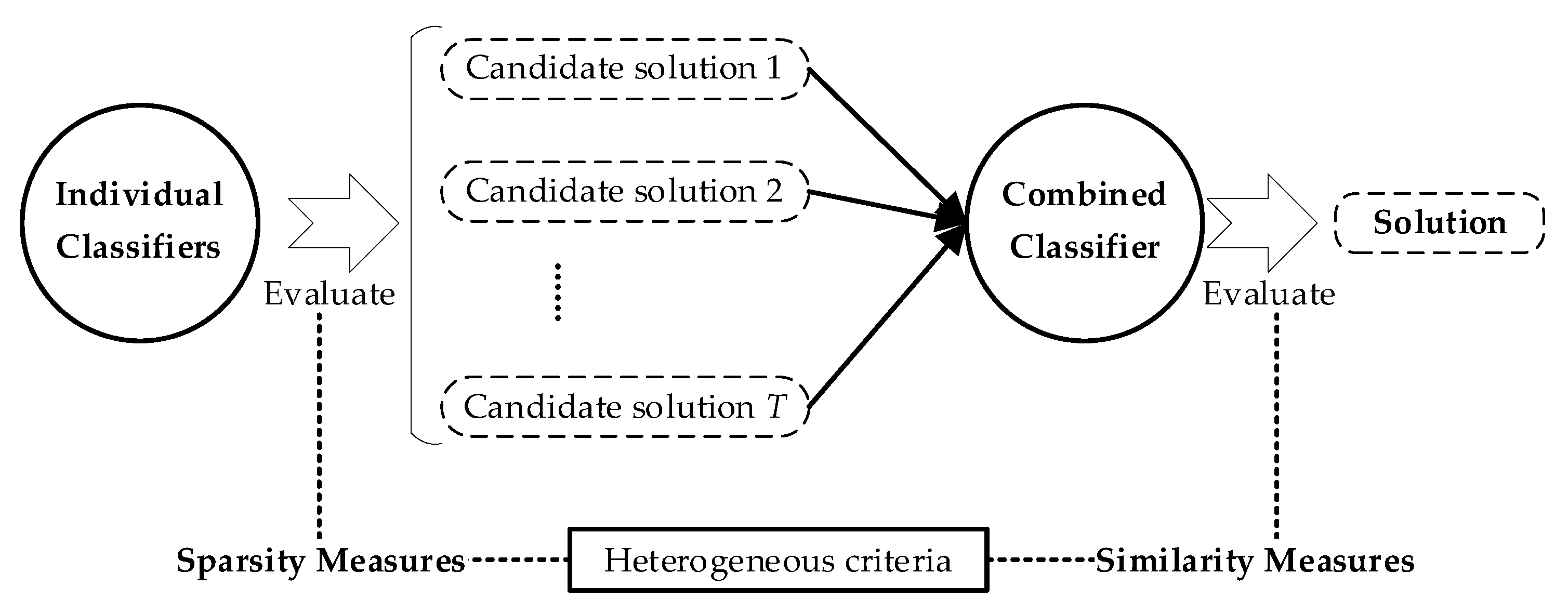
As seen from Equations (4) and (5), the role of sparsity may vary in the load disaggregation problem, but will always be considered in the model. However, back to the original problem in (1), sparsity is not tightly bounded. Therefore, in order to introduce the heterogeneous evaluation system, the design of the combined classifier considers the physical properties only, while the sparsity is totally ignored. The key to this idea is illustrated in
Figure 2.
The architecture shown in
Figure 2 provides a design sample for the heterogeneity between individual classifiers and the combined classifier. The core of this is that the evaluation criteria of individual classifiers follow sparsity measures, while those of the combined classifier follow similarity measures. The sparsity measures are calculated based on Equations (4) and (5), and diverse individual classifiers can be personalized by allocating a different regularization parameter,
λ. The similarity measures, through which sparsity is not considered, should provide an effective and justified evaluation for the candidate solutions. Therefore, a multi-committee decision-making system is designed for the combined classifier, where different committees hold different similarity measures.
2.3. Heterogeneous Design for Decision-Making Committees of the Combined Classifier
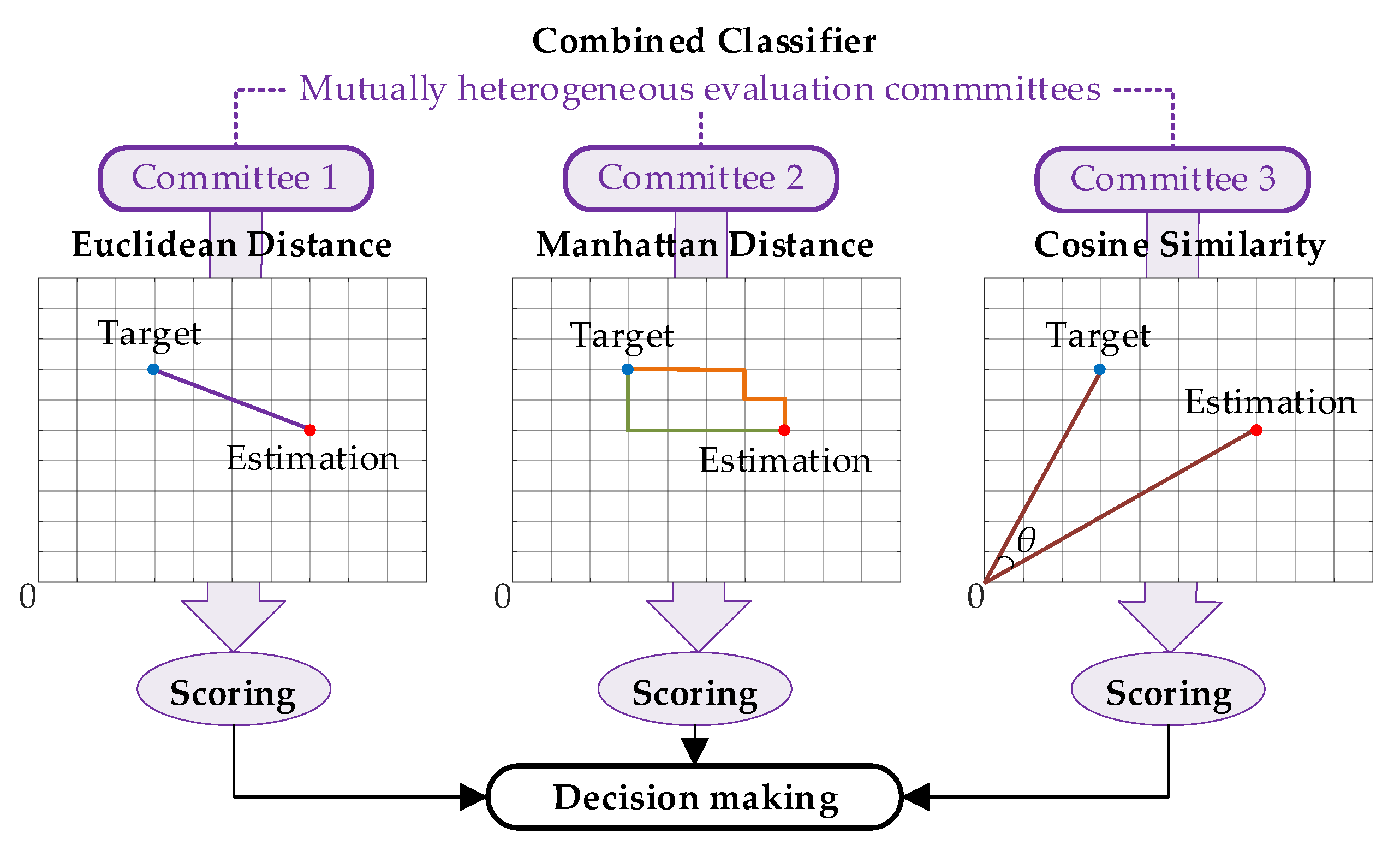
Following the heterogeneous design idea for the combined classifier discussed above, diverse similarity measures should be selected for evaluation committees of the combined classifier. Among dozens of similarity measures, three commonly used measures, i.e., Euclidean distance, Manhattan distance, and cosine similarity, are selected considering the physical features of NILM. The design of the combined classifier is illustrated in
Figure 3, where the physical meanings of heterogeneous committees are visualized. The basic ideas for choosing these three measures are listed below, while the rationality is demonstrated by case results:
Euclidean distance is the most commonly used measure to evaluate the absolute distance between two points in multidimensional space. Therefore, Euclidean distance would provide an overall assessment of the differences between the estimation and target in NILM.
Manhattan distance measures the total sum of absolute distance on each coordinate axis for a multidimensional system. Hence, Manhattan distance focuses on the fitting differences for each electric features, paying more attention to the details.
Cosine similarity utilizes the cosine value of the angle between two vectors in multidimensional space to quantify the differences. Compared with distance measures, it is more interested in the direction as opposed to the distance or length. This measure would highlight the electric feature relevance of appliances in NILM.
2.3.1. Multidimensional Space Mapping and Standardization
A vital design in similarity analysis for a multidimensional problem is how to unify the measurements of diverse dimensions together. From the view of NILM, it is essentially a trade-off problem of multi-objective fitting. This problem is quite similar to parameter tuning in many system designs, which seems insignificant but actually matters.
In practice, the unity of multiple dimensions does exist in individual classifiers, where the dictionary-learning-formulated disaggregation approach utilizes the different regularization parameters to coordinate diverse electric features together:
where norm (·) is the normalization function,
P is the target signal of real power, and
DP is the dictionary for the normalized real power analysis.
D* is the dictionary for the normalized electric feature of
*.
λ* is the regularization parameter for the electric feature of
*.
LS is the load signature features apart from real power
P, including reactive power,
Q, and different orders of harmonics,
H.
For designs with heterogeneity, the mapping and standardization for the combined classifier follows another strategy. All electric features are considered equally important, and the target is mapped to be a reference point with all dimensions equaling to unity. Consistently, the estimation is also standardized by selecting the target values as a rating base. The calculations are as follows:
where
Ptar,
Qtar, and
Htar are, respectively, the measured value of real power, reactive power, and harmonics, indicating the target.
Pest,
Qest, and
Hest are, respectively the estimation value of real power, reactive power, and harmonics through load disaggregation. The above variables are all related to the original electric feature space. Meanwhile,
tar,
tar, and
tar are, respectively, the standardized target of real power, reactive power, and harmonics.
est,
est, and
est are, respectively, the standardized estimation of real power, reactive power, and harmonics. These variables are considered in unified space, which are comparable.
Hence, by the above detailed designs, the combined classifier is completely heterogeneous with individual classifiers, which conforms to the proposals of this article.
2.3.2. Similarity Evaluation and Scoring
With comparable multidimensional objects, it is possible to evaluate and score from different views of similarity. Following the physical meanings of the selected measures shown in
Figure 3, the detailed calculations for the three committees are:
where
Score1 is the evaluated score for the candidate by the first committee of the combined classifier, following the Euclidean distance.
Score2 is the evaluated score for the candidate by the second committee of the combined classifier, following the Manhattan distance.
Score3 is the evaluated score for the candidate by the third committee of the combined classifier, following the Cosine similarity.
rpe and
rpm are, respectively, the regulation parameters for the scoring of the first and second committees. By comparing the sum of scores, the most optimal solution is determined from all candidates.
Since the candidates are generated following weighted standardization and sparsity evaluation, and selected by unified standardization and disparate measures, the decision process is totally heterogeneous. Therefore, the idea of establishing an ensemble-method-based NILM model with multidimensional heterogeneity is realized by the above implementations.




{kind=link}
{kind=link}
{kind=link}
{kind=link}