
Synthetic Source Universal Domain Adaptation through Contrastive Learning


Abstract
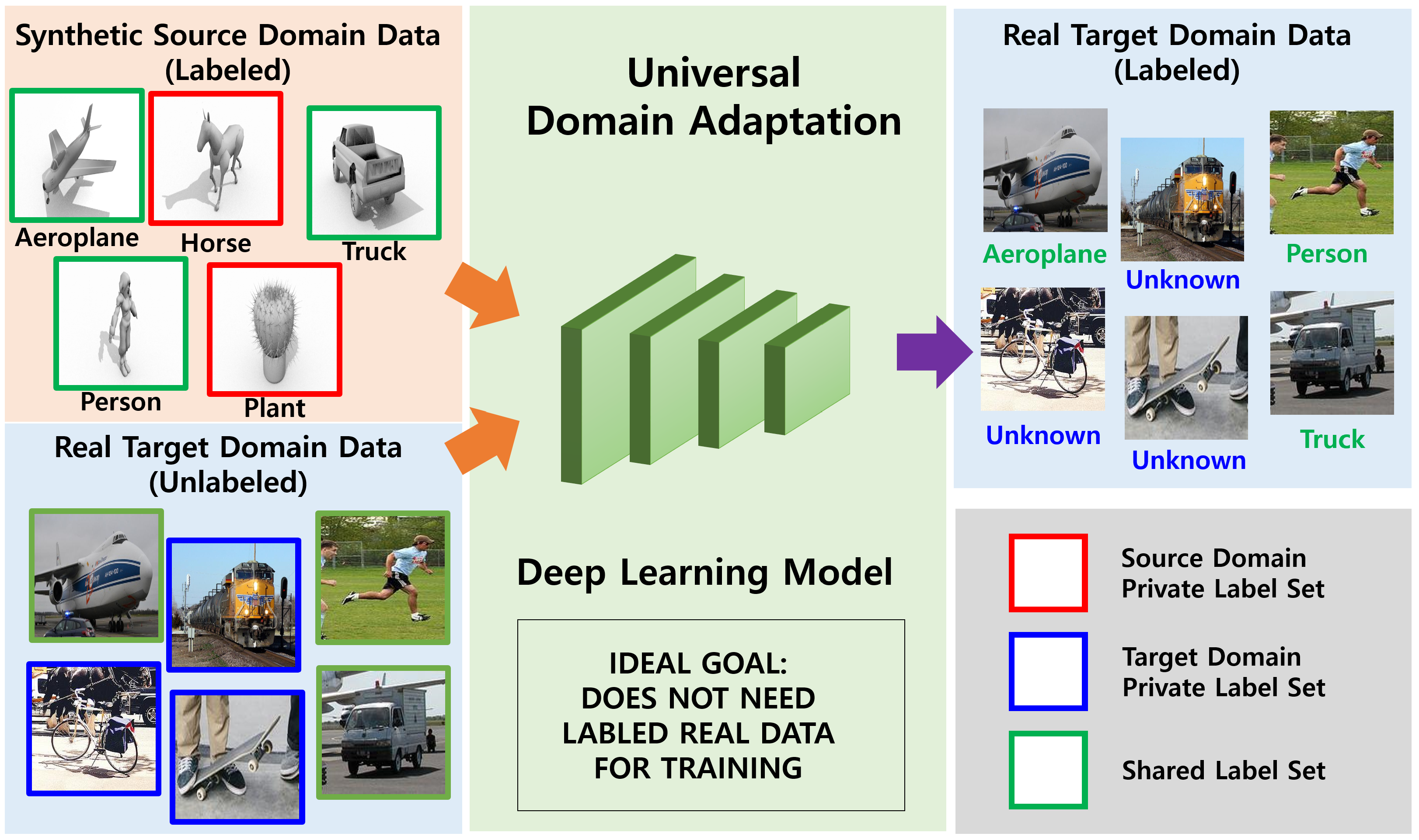
:1. Introduction
- In this case, owing to the limitations of data synthesis, the source domain has different characteristics from the real data in the target domain. Thus, the target domain information should be fully utilized to learn the feature representation. I used contrastive learning [27] to extract discriminative features from the target domain.
- For contrastive learning, the target domain feature extraction network is not separately constructed. The source and target domains share a common feature extraction network, thus avoiding unnecessary computation surges.
- The experiments conducted on the VisDa-2017 dataset and MNIST to SVHN dataset indicate that the proposed method significantly outperforms baselines by 2.7% and 5.1%, respectively.
2. Related Work
2.1. Domain Adaptation
- Closed-set domain adaptation, if . The main challenge in closed-set domain adaptation is to mitigate the domain gap between the source and target domains.
- Partial domain adaptation, if . This does not assume that label sets are identical across domains, but that the source label set subsumes the target label set. The mismatched label set in the source domain presents a new challenge for domain adaptation.
- Open-set domain adaptation, if . To avoid the unrealistic assumptions of closed-set domain adaptation, open-set domain adaptation assumes that the target domain contains unknown labels in the source domain.
2.1.1. Close-Set Domain Adaptation
2.1.2. Partial Domain Adaptation
2.1.3. Open-Set Domain Adaptation
2.2. Contrastive Learning
3. Approach
3.1. Notation
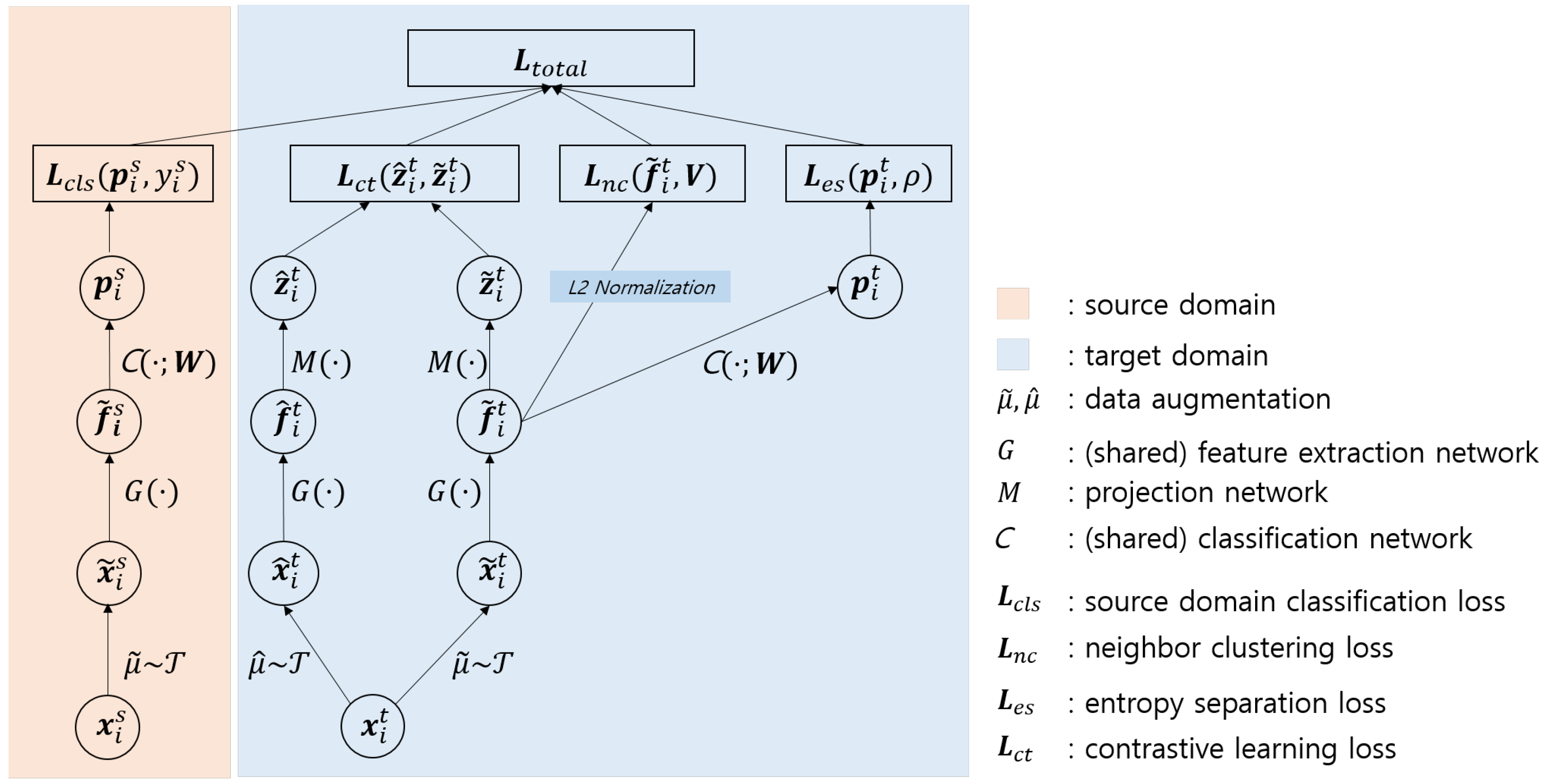
3.2. Architecture
3.2.1. Target Domain Contrastive Loss
- Generate different perspectives based on the same target sample:Randomly selected data augmentations and are applied sequentially to a target domain sample , obtaining two augmented samples and . As a result, two sets of minibatches are obtained: and . The size of each minibatch is equal, i.e., .
- Extract features from augmented target samples: The augmented target samples are fed into a feature extraction network G to generate feature representations and . The feature extraction network is shared for the source-domain classification task. Although any network is freely available, I use [6,27], i.e.,
- Obtain target projection features for contrastive learning: Projection feature representations and are obtained via a projection network M, and contrastive learning loss is applied to them. I use a shallow multilayer perceptron () for projection networks M, i.e.,
- Minimize contrastive learning loss in the target domain: Given two augmented minibatches and , contrastive learning aims to identify using or vice versa. The loss function is defined using the projection representation of the target samples as follows:where is the temperature parameter [34]., and is the similarity function. I used the cosine similarity for this as .
3.2.2. Neighbor Clustering (NC) Loss
3.2.3. Entropy Separation Loss
3.2.4. Total Loss
4. Experiments
4.1. Implementation Details
4.2. Evaluation and Data Augmentation
4.3. Datasets and Results
4.3.1. VisDA-2017 Dataset
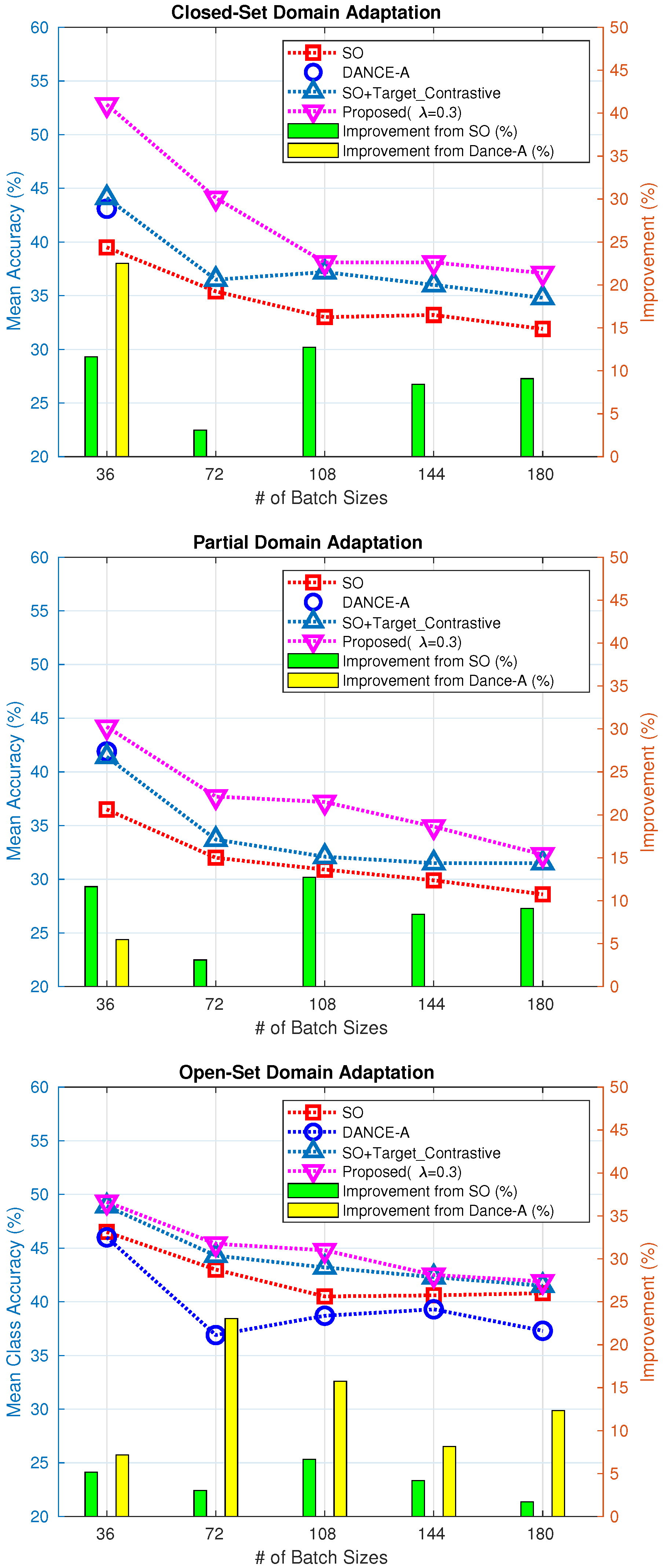
4.3.2. Digit Datasets: MNIST → SVHN
4.3.3. Analysis of the Target Domain Contrastive Loss Function
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Xiao, B.; Wu, H.; Wei, Y. Simple baselines for human pose estimation and tracking. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yun, K.; Park, J.; Cho, J. Robust human pose estimation for rotation via self-supervised learning. IEEE Access 2020, 8, 32502–32517. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Lee, G.; Yun, K.; Cho, J. Improved Human-Object Interaction Detection Through On-the-Fly Stacked Generalization. IEEE Access 2021, 9, 34251–34263. [Google Scholar] [CrossRef]
- Vo, D.M.; Nguyen, D.M.; Le, T.P.; Lee, S.W. HI-GAN: A hierarchical generative adversarial network for blind denoising of real photographs. Inf. Sci. 2021, 570, 225–240. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Stateline, NV, USA, 3–8 December 2012. [Google Scholar]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Pereira, F. Analysis of representations for domain adaptation. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Cho, J.; Lee, M. Building a compact convolutional neural network for embedded intelligent sensor systems using group sparsity and knowledge distillation. Sensors 2019, 19, 4307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ben-David, S.; Blitzer, J.; Crammer, K.; Kulesza, A.; Pereira, F.; Vaughan, J.W. A theory of learning from different domains. Mach. Learn. 2010, 79, 151–175. [Google Scholar] [CrossRef] [Green Version]
- Sun, S.; Shi, H.; Wu, Y. A survey of multi-source domain adaptation. Inf. Fusion 2015, 24, 84–92. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 4068–4076. [Google Scholar]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; Marchand, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 2096–2030. [Google Scholar]
- Long, M.; Zhu, H.; Wang, J.; Jordan, M.I. Unsupervised Domain Adaptation with Residual Transfer Networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Cao, Z.; Ma, L.; Long, M.; Wang, J. Partial adversarial domain adaptation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Cao, Z.; You, K.; Long, M.; Wang, J.; Yang, Q. Learning to transfer examples for partial domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Zhang, J.; Ding, Z.; Li, W.; Ogunbona, P. Importance weighted adversarial nets for partial domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Panareda Busto, P.; Gall, J. Open set domain adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22-29 October 2017. [Google Scholar]
- Saito, K.; Yamamoto, S.; Ushiku, Y.; Harada, T. Open set domain adaptation by backpropagation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, Y.; Liu, T.; Long, M.; Jordan, M. Bridging theory and algorithm for domain adaptation. In Proceedings of the International Conference on Machine Learning, Long, Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- You, K.; Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Universal domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Saito, K.; Kim, D.; Sclaroff, S.; Saenko, K. Universal Domain Adaptation through Self Supervision. In Proceedings of the Advances in Neural Information Processing Systems, Virtual-only, 6–12 December 2020. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Xi’an, China, 10 August 2020. [Google Scholar]
- Haeusser, P.; Frerix, T.; Mordvintsev, A.; Cremers, D. Associative domain adaptation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Long, M.; Cao, Z.; Wang, J.; Jordan, M.I. Conditional adversarial domain adaptation. arXiv 2018, arXiv:1705.10667. [Google Scholar]
- Oord, A.v.d.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.H.; Buchatskaya, E.; Doersch, C.; Pires, B.A.; Guo, Z.D.; Azar, M.G.; et al. Bootstrap your own latent: A new approach to self-supervised learning. arXiv 2020, arXiv:2006.07733. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. In Proceedings of the NIPS 2017 Workshop Autodiff Submission, Long Beach, CA, USA, 28–29 October 2017. [Google Scholar]
- Peng, X.; Usman, B.; Kaushik, N.; Hoffman, J.; Wang, D.; Saenko, K. Visda: The visual domain adaptation challenge. arXiv 2017, arXiv:1710.06924. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–17 December 2011. [Google Scholar]
- Liu, H.; Cao, Z.; Long, M.; Wang, J.; Yang, Q. Separate to adapt: Open set domain adaptation via progressive separation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]


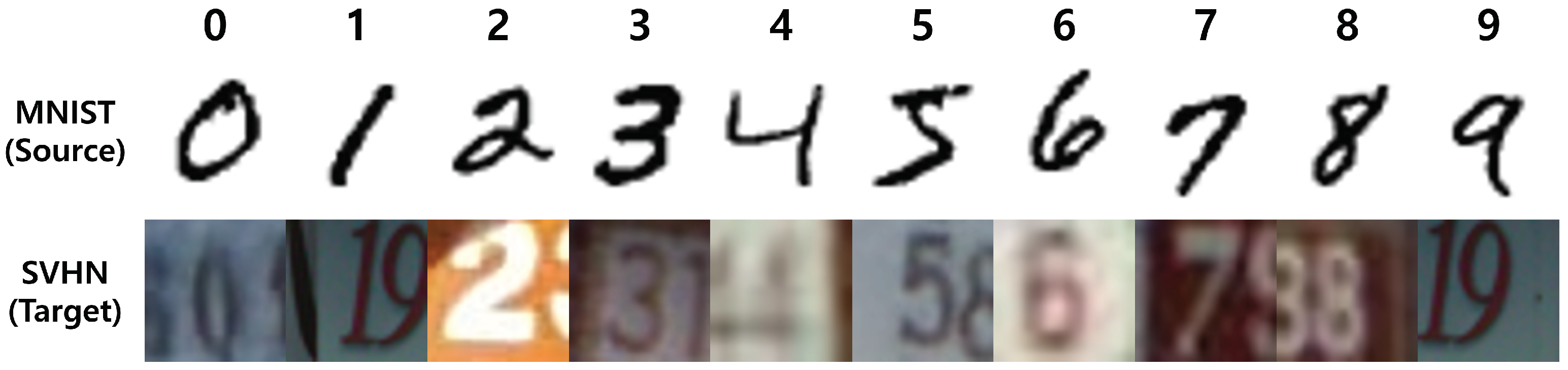


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Method | Feature Extraction (G) | Classification (C) | Projection (M) | Total |
|---|---|---|---|---|---|
| Params | Baseline | 23.5 M | 0.01 M | - | 23.5 M |
| Proposed | 23.5 M | 0.01 M | 8.4 M | 31.9 M | |
| GFLOPs | Baseline | 4.1 × 2 | 0.0004 × 2 | - | 8.2 |
| Proposed | 4.1 × 3 | 0.0004 × 2 | 0.6 × 2 | 13.5 |
| Method (Split) | Closed-Set (12/0/0) | Partial (6/6/0) | Open-Set (6/0/6) | Avg. |
|---|---|---|---|---|
| SO [26] | 46.3 | 46.3 | 43.3 | 45.3 |
| DANN [17] | 69.1 | 38.7 | 48.2 | 52.0 |
| ETN [20] | 64.1 | 59.8 | 51.7 | 58.5 |
| STA [39] | 48.1 | 48.2 | 51.7 | 49.3 |
| UAN [25] | 66.4 | 39.7 | 50.0 | 52.0 |
| DANCE [26] | 70.2 | 73.7 | 65.3 | 69.7 |
| DANCE-R | 71.3 | 76.6 | 64.2 | 70.7 |
| DANCE-A | 73.0 | 80.1 | 63.8 | 72.3 |
| Proposed ( = 0.1) | 73.7 | 82.6 | 66.7 | 74.3 |
| Proposed ( = 0.03) | 74.0 | 83.0 | 67.9 | 75.0 |
| Method (Split) | Closed Set (10/0/0) | Partial (5/5/0) | Open Set (5/0/5) | Avg. |
|---|---|---|---|---|
| SO-R | 22.7 | 25.2 | 30.2 | 26.0 |
| SO-A | 39.5 | 36.5 | 46.5 | 40.8 |
| DANCE-R | 25.6 | 29.1 | 28.8 | 27.8 |
| DANCE-A | 43.1 | 41.9 | 46.0 | 43.7 |
| Proposed ( = 0.1) | 53.0 | 42.2 | 48.3 | 47.8 |
| Proposed ( = 0.03) | 52.8 | 44.2 | 49.3 | 48.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, J. Synthetic Source Universal Domain Adaptation through Contrastive Learning. Sensors 2021, 21, 7539. https://doi.org/10.3390/s21227539
Cho J. Synthetic Source Universal Domain Adaptation through Contrastive Learning. Sensors. 2021; 21(22):7539. https://doi.org/10.3390/s21227539
Chicago/Turabian StyleCho, Jungchan. 2021. "Synthetic Source Universal Domain Adaptation through Contrastive Learning" Sensors 21, no. 22: 7539. https://doi.org/10.3390/s21227539
APA StyleCho, J. (2021). Synthetic Source Universal Domain Adaptation through Contrastive Learning. Sensors, 21(22), 7539. https://doi.org/10.3390/s21227539