
The Impact of Attention Mechanisms on Speech Emotion Recognition


Abstract
:1. Introduction
- To explore the influence of difference Attention Mechanisms on different models: We set up Sequential Networks and Parallel Networks respectively, to explore the influence of difference Attention Mechanisms on different models. As for the forms of the attention mechanism, we used Self-Attention and Global-Attention.
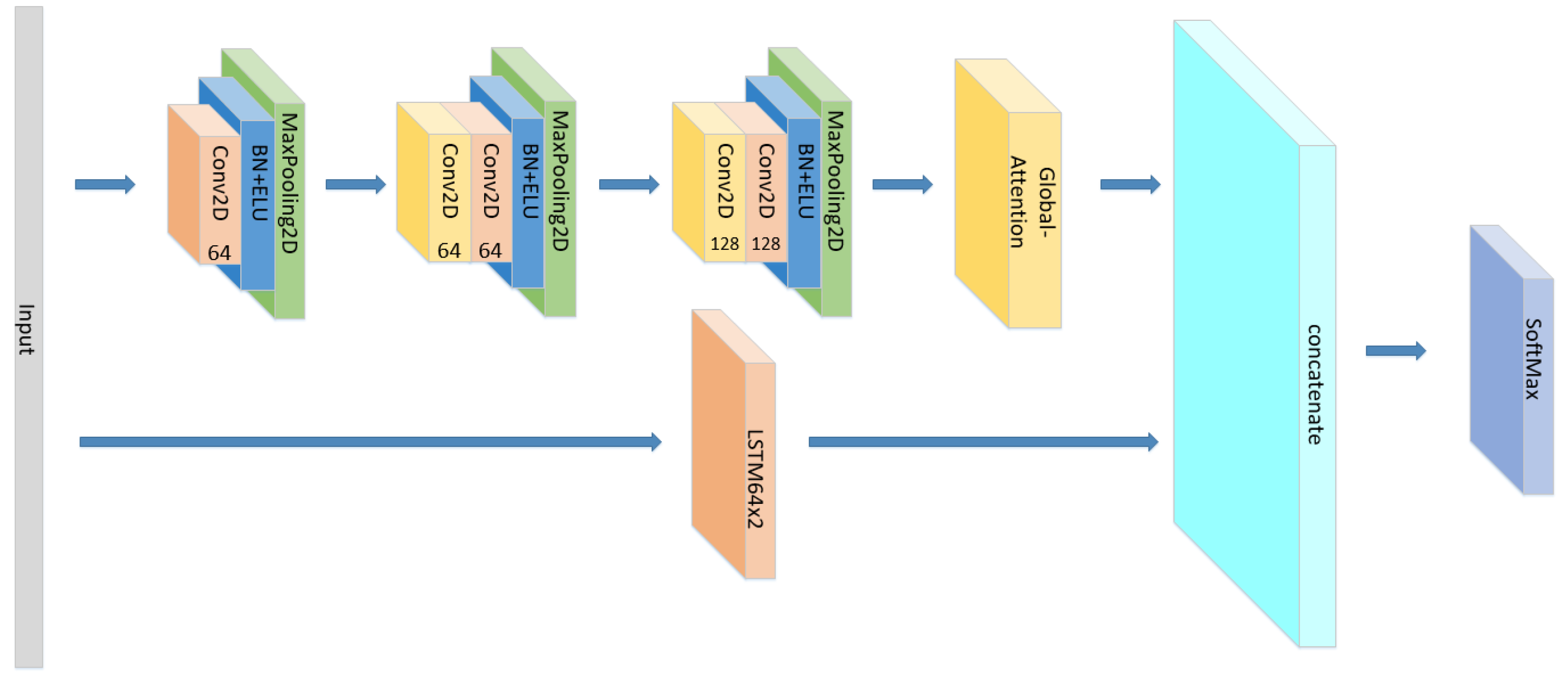
- To propose a CNN-LSTM×2+Global-Attention model: By comparing the training convergence speed, accuracy, and generalization ability of different models, we proposed a CNN-LSTM×2+global-attention model and conducted experiments on the EMO-DB dataset, which achieved an accuracy of 85.427%.
2. Related Work
3. Proposed Method
3.1. Feature Introduction
3.2. Feature Extraction
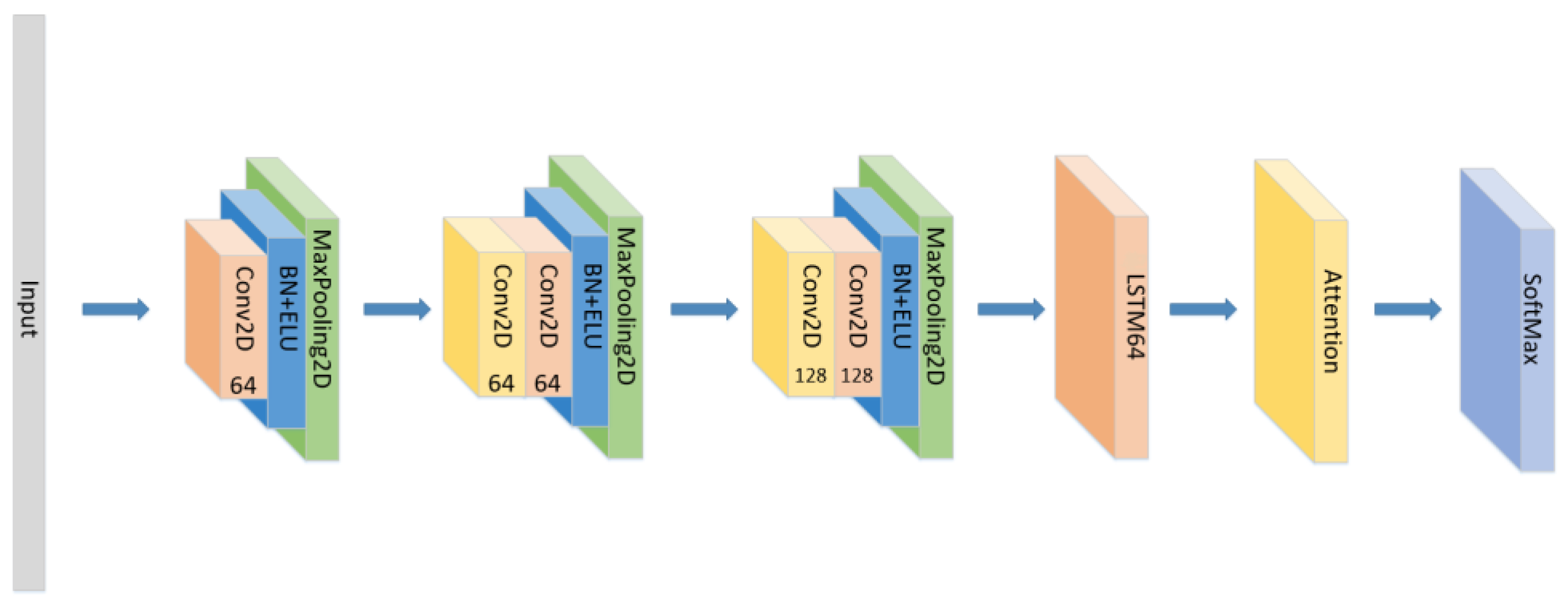
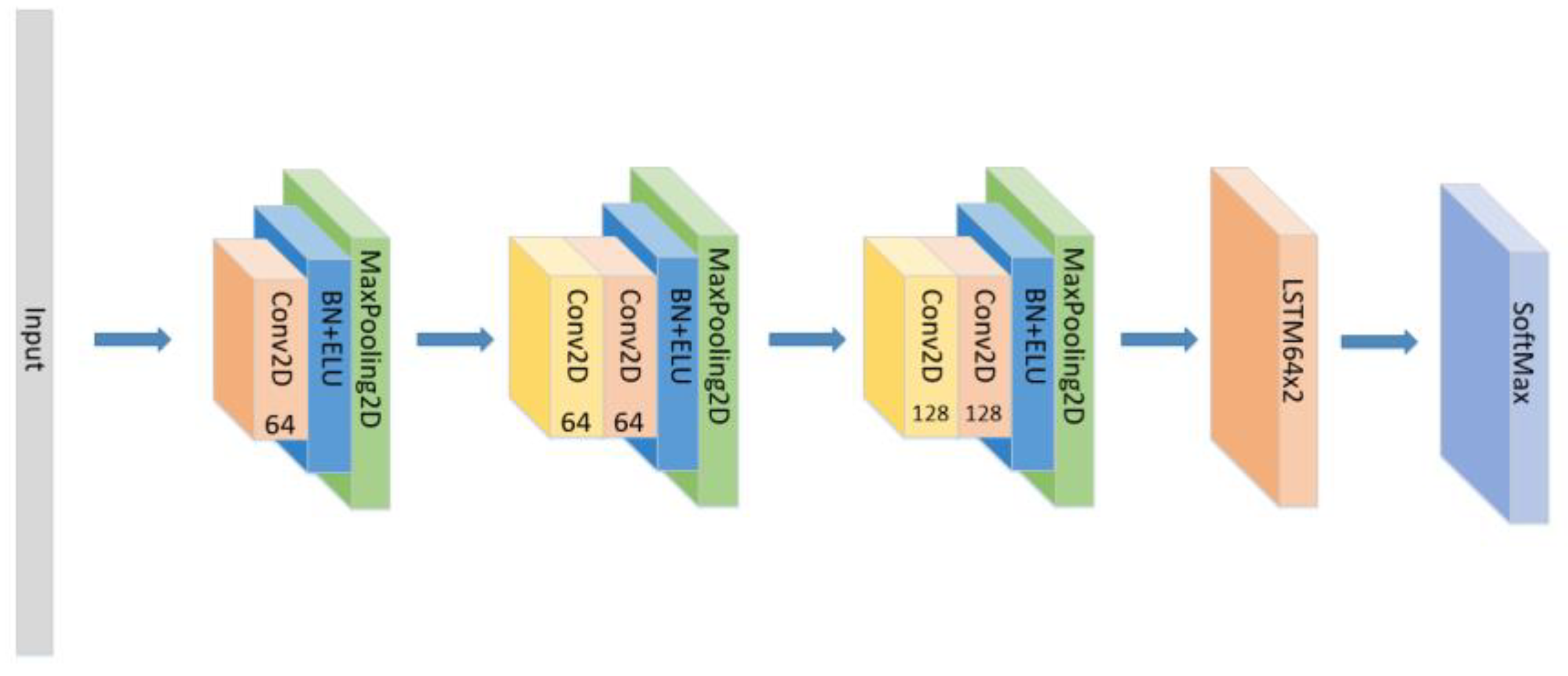
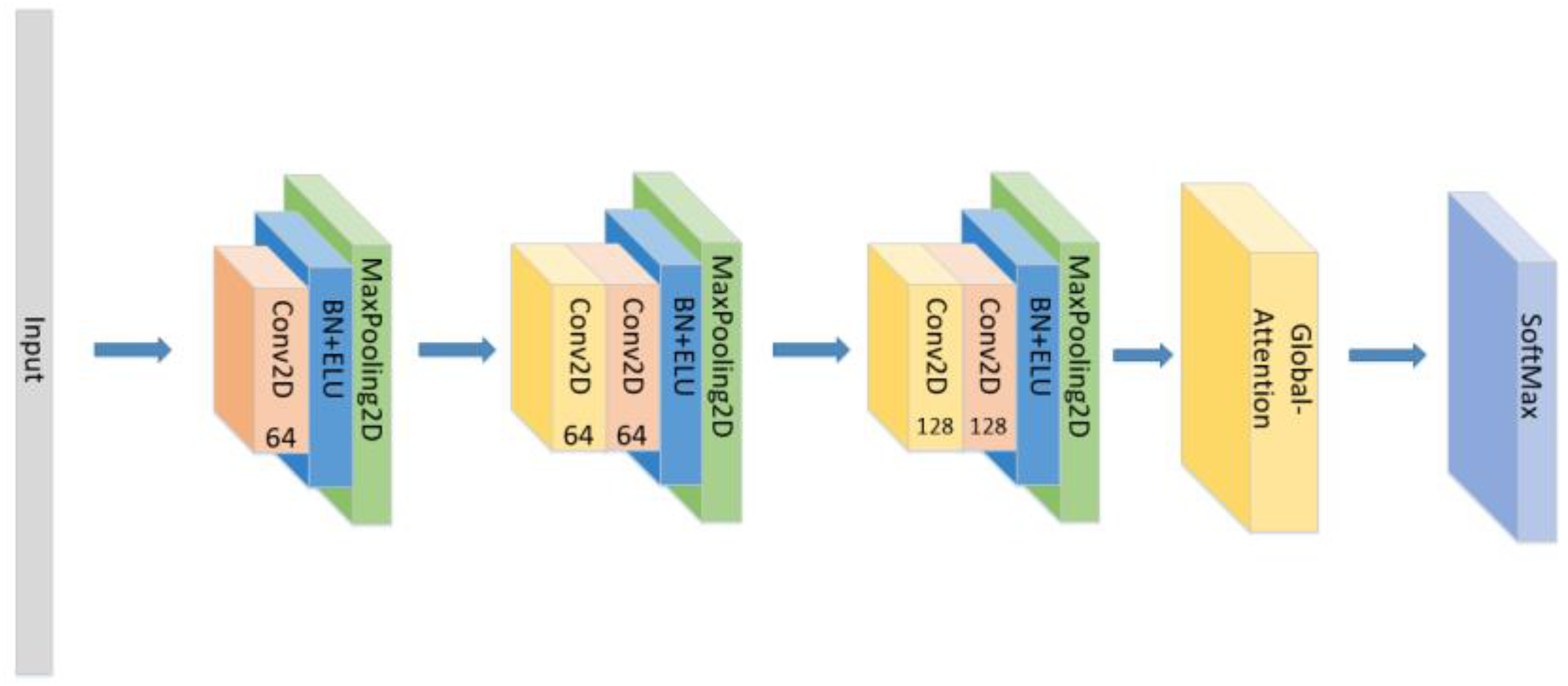
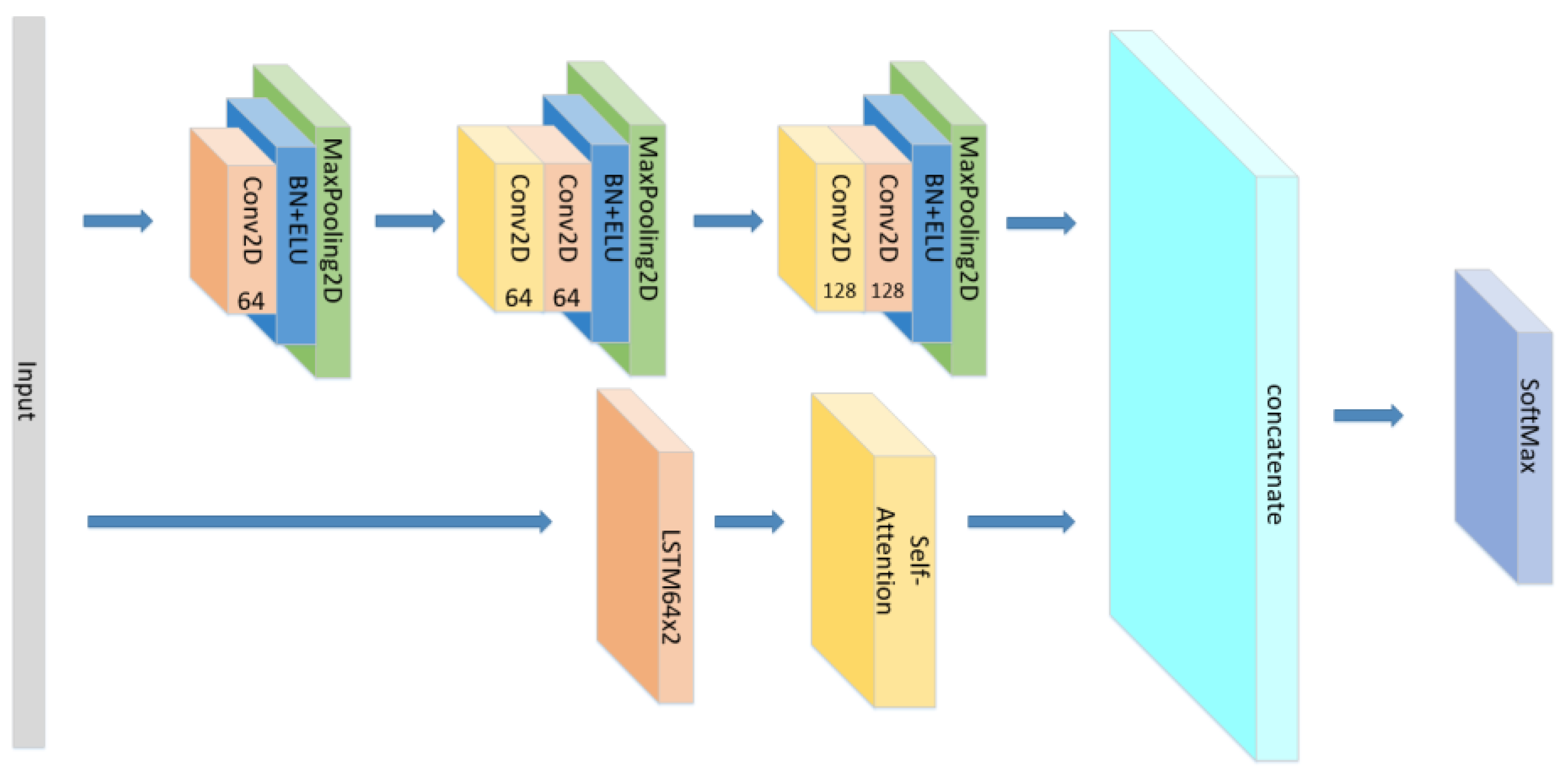
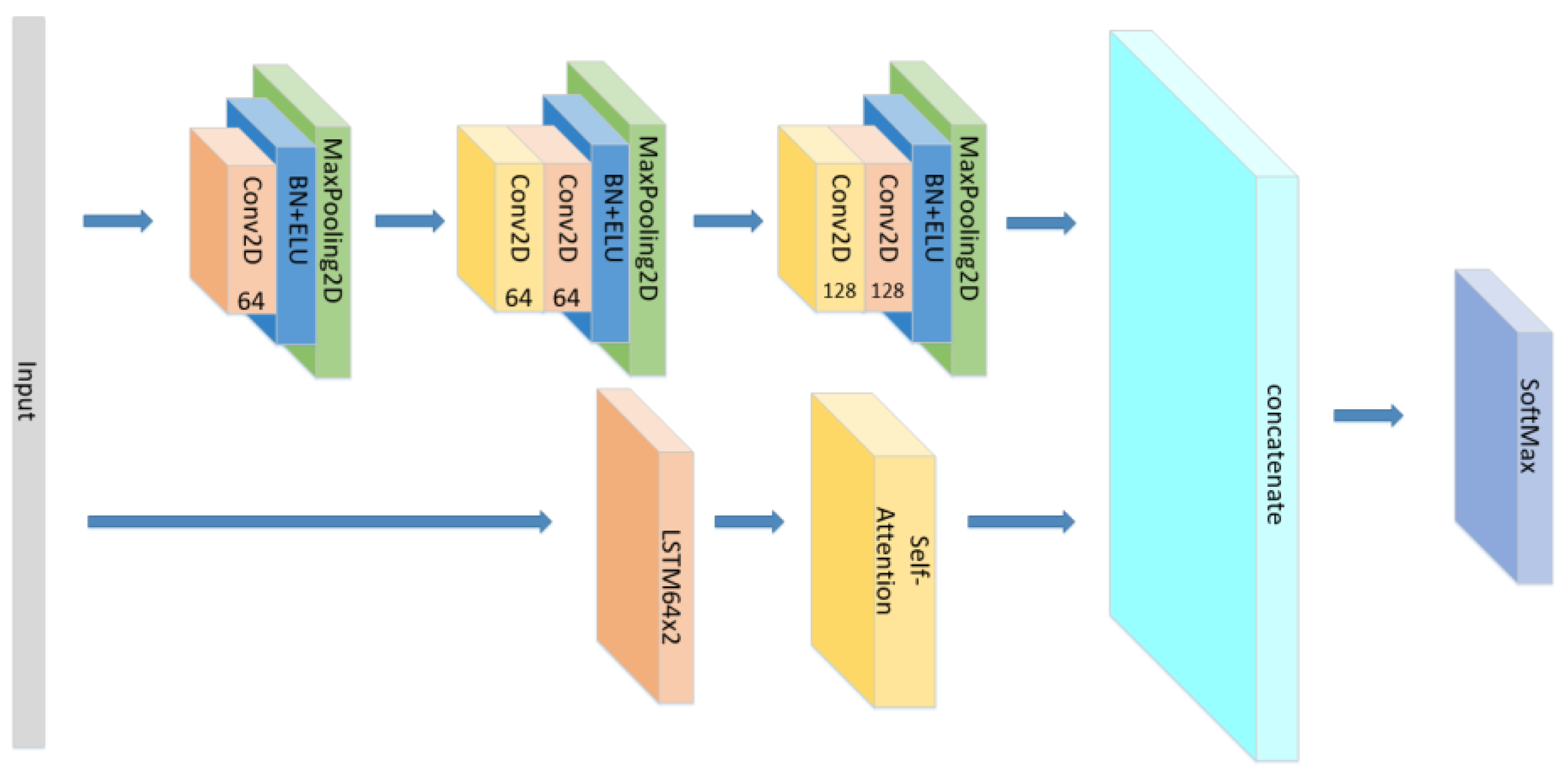
3.3. Model Construction
- (1)
- Set the CNN network with the same parameters and the same number of layers as the original model without the LSTM layer and attention block as seen in Figure 5, and compare the experimental results.
- (2)
- Set the CNN network with the same parameters and the same number of layers as the original model, add the LSTM layer as seen in Figure 6 and compare the experimental results without using the attention block.
- (3)
- The position of the attention mechanism was changed as seen in Figure 7, and the CNN+LSTM+Global-Attention+LSTM network with the same parameters as the original model was set to explore the influence of the position of attention on the accuracy of the model.
- (4)
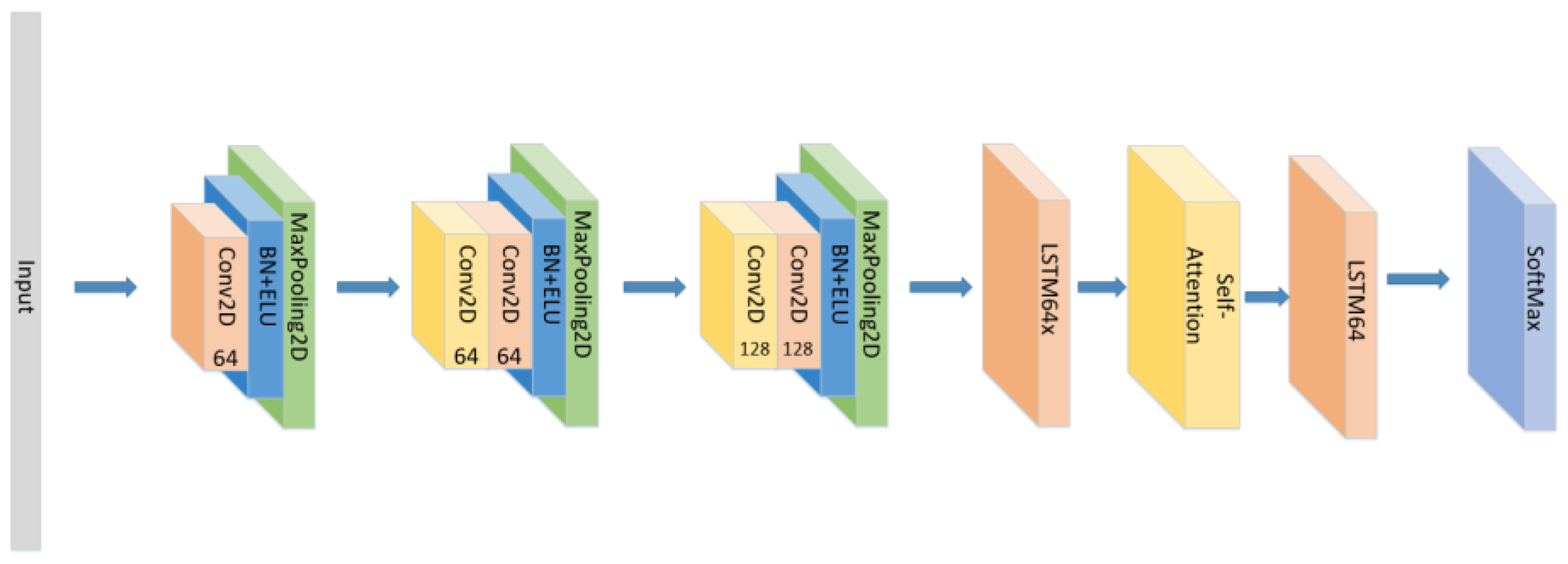
- Change the form of the attention mechanism as seen in Figure 8 and set the CNN+ LSTM×2+Self-Attention network with the same parameters as the original model to explore the influence of the form of attention on the accuracy of the model.
- (5)
- The position of the attention mechanism was changed as seen in Figure 9, and the CNN+LSTM+Self-Attention+LSTM network with the same parameters as the original model was set to explore the influence of the form of attention on the accuracy of the model.
- (6)
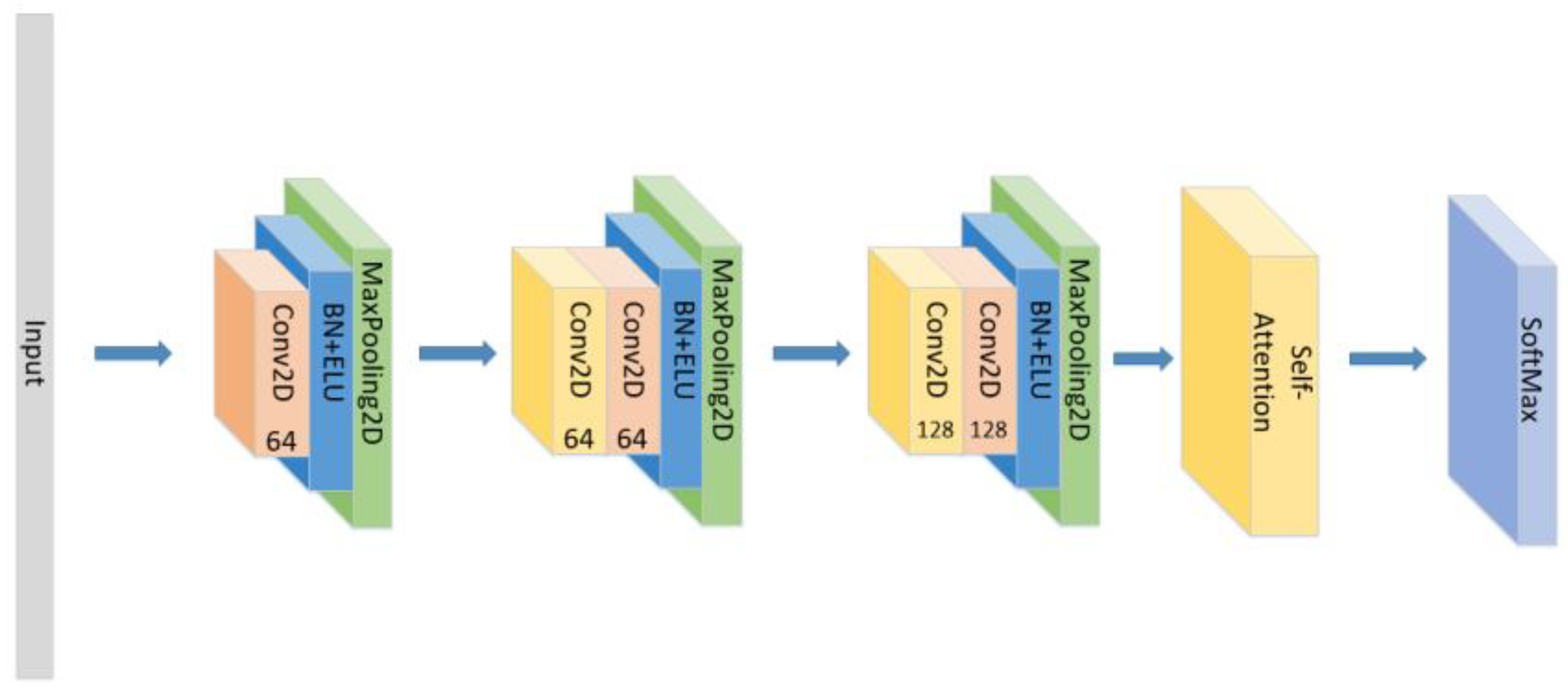
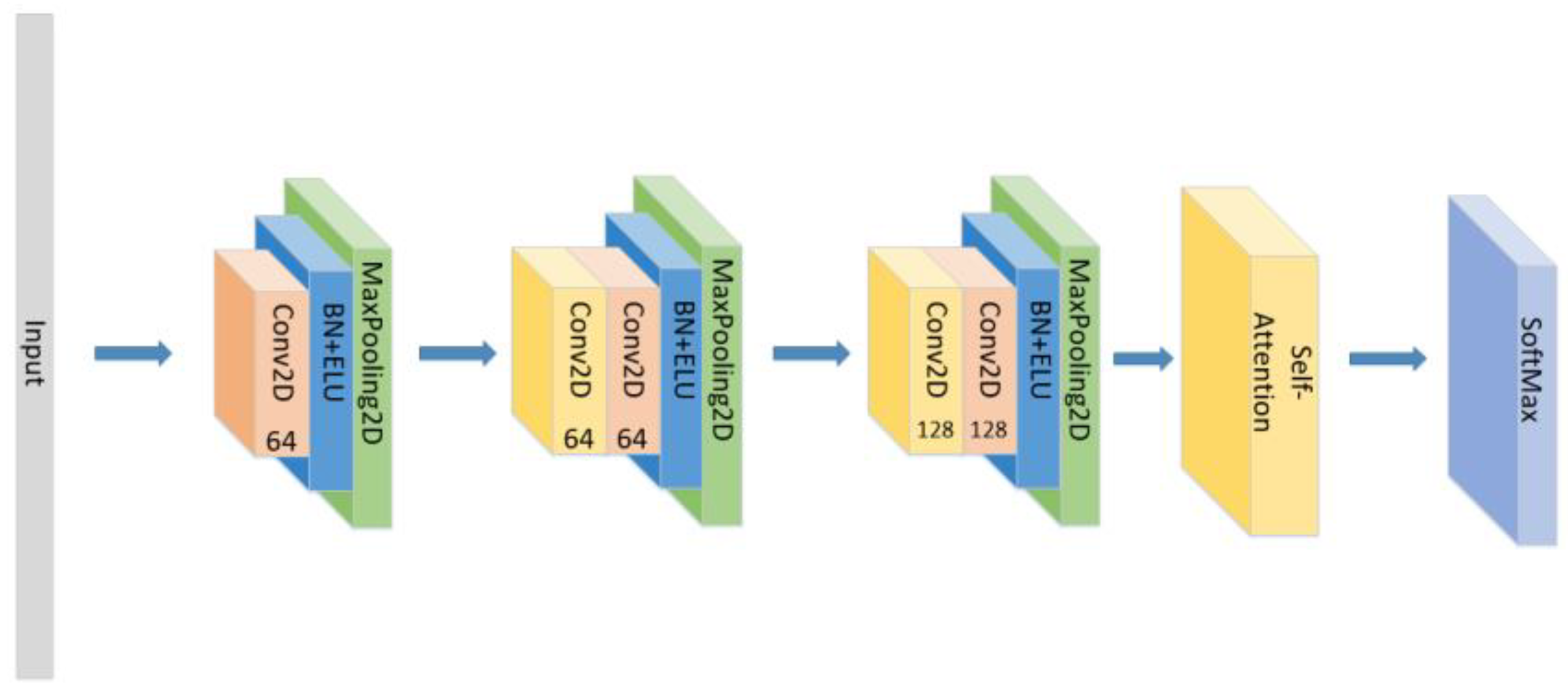
- Set the CNN network with the same parameters and the same number of layers as the original model with the Self-Attention as shown in Figure 10.
- (7)
- Set the CNN network with the same parameters and the same number of layers as the original model with the Self-Attention as shown in Figure 11.
4. Experiments and Results
4.1. Data Processing
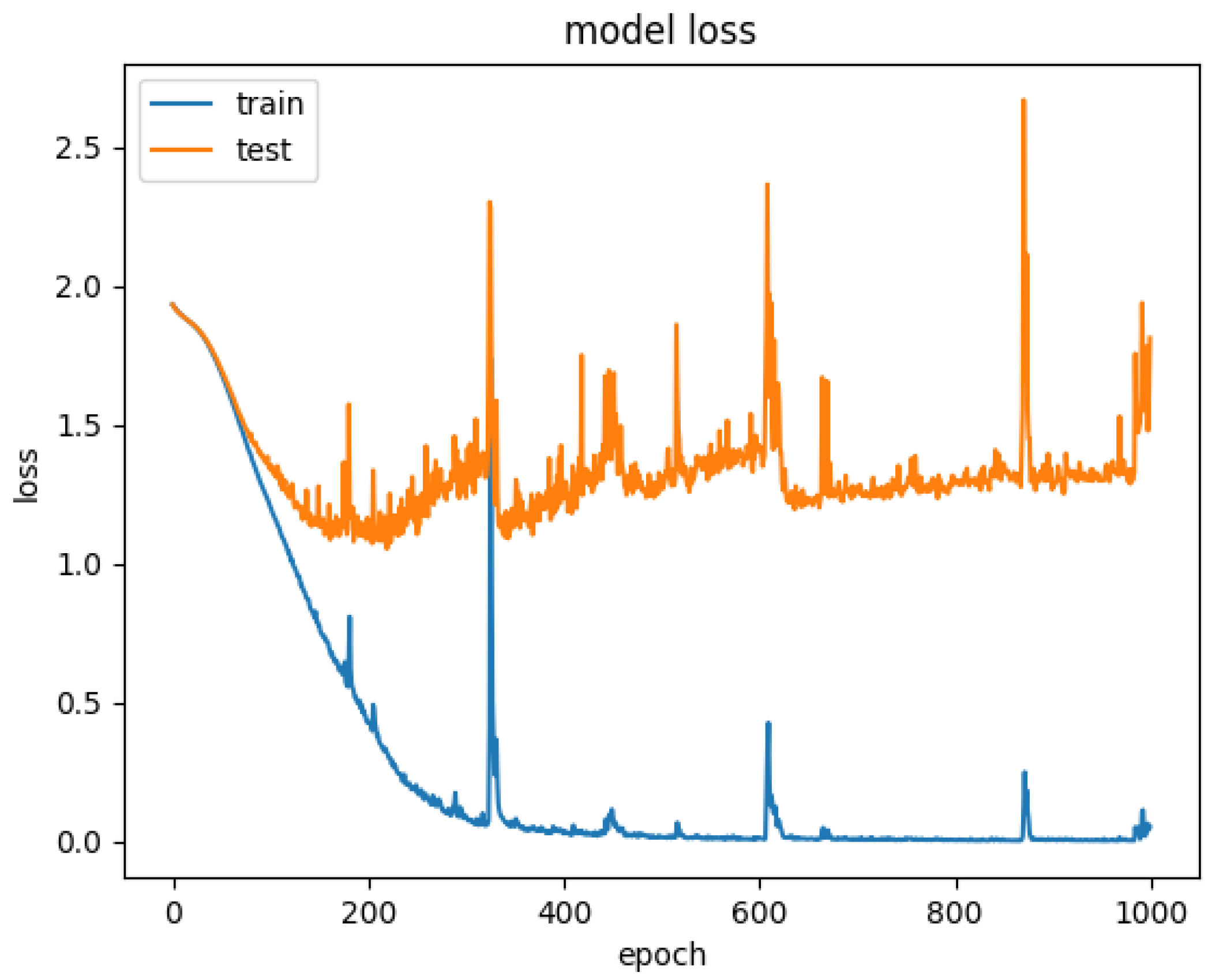
4.2. Model Fitting
4.3. Experimental Environment Configuration
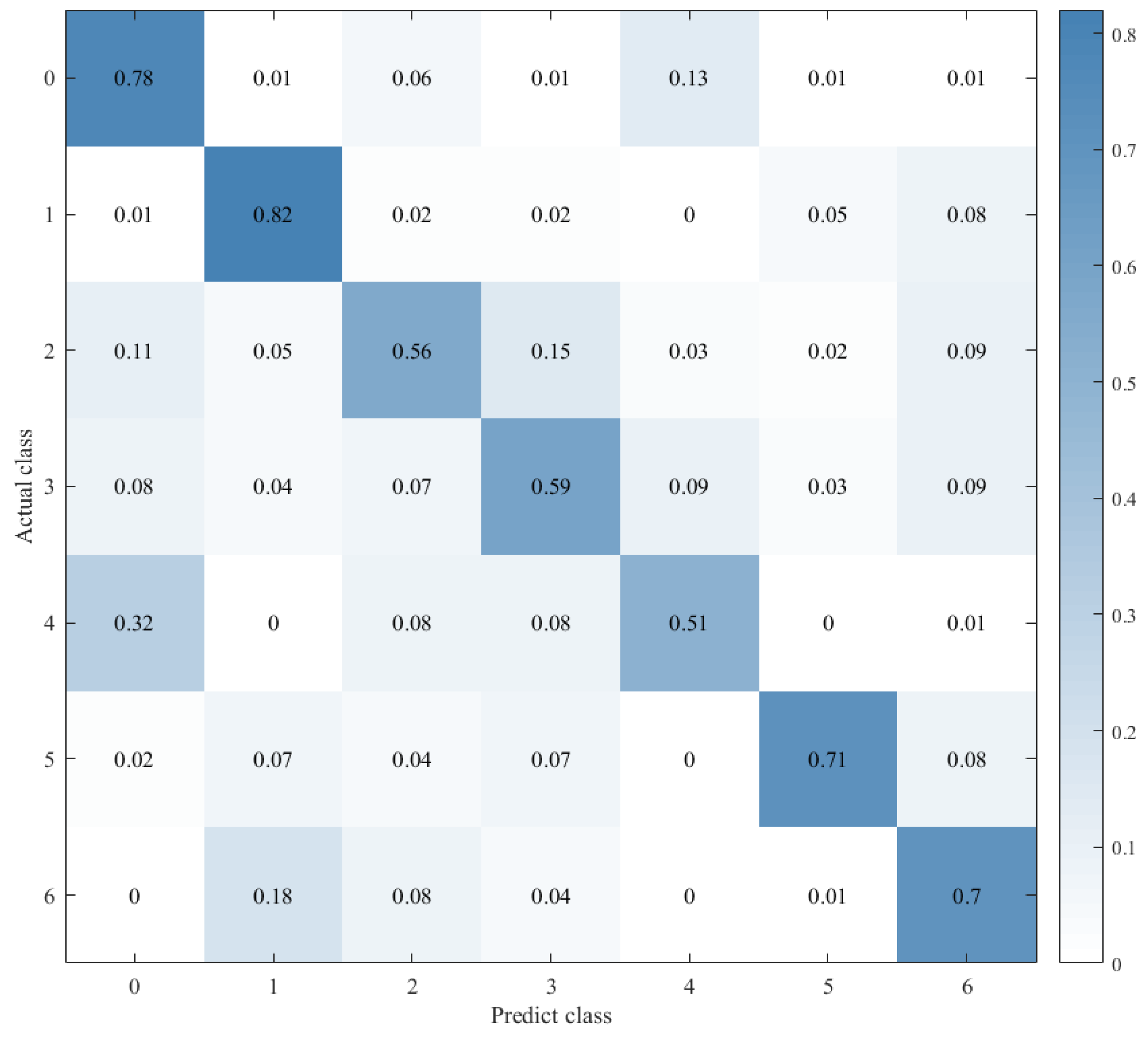
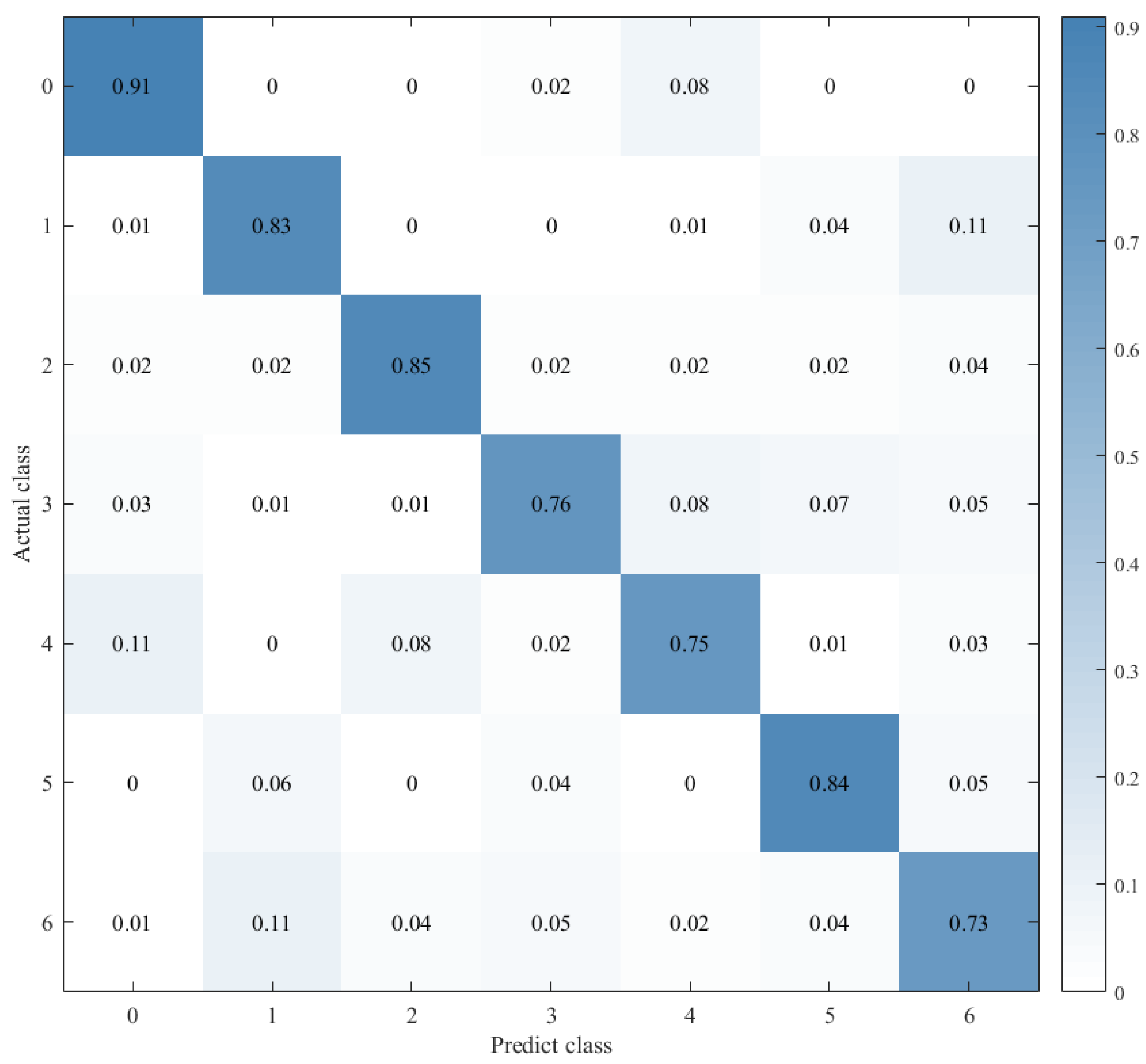
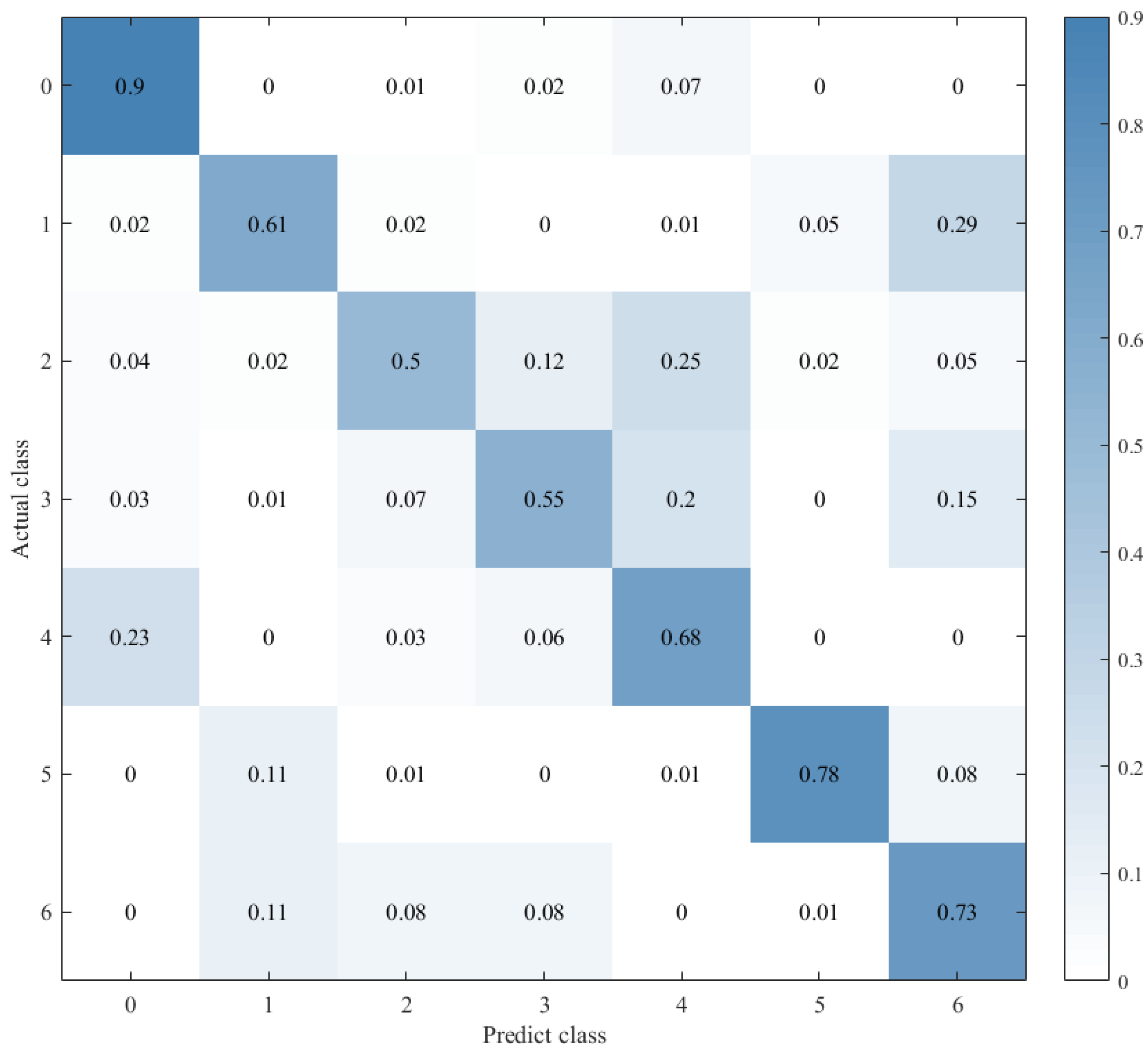
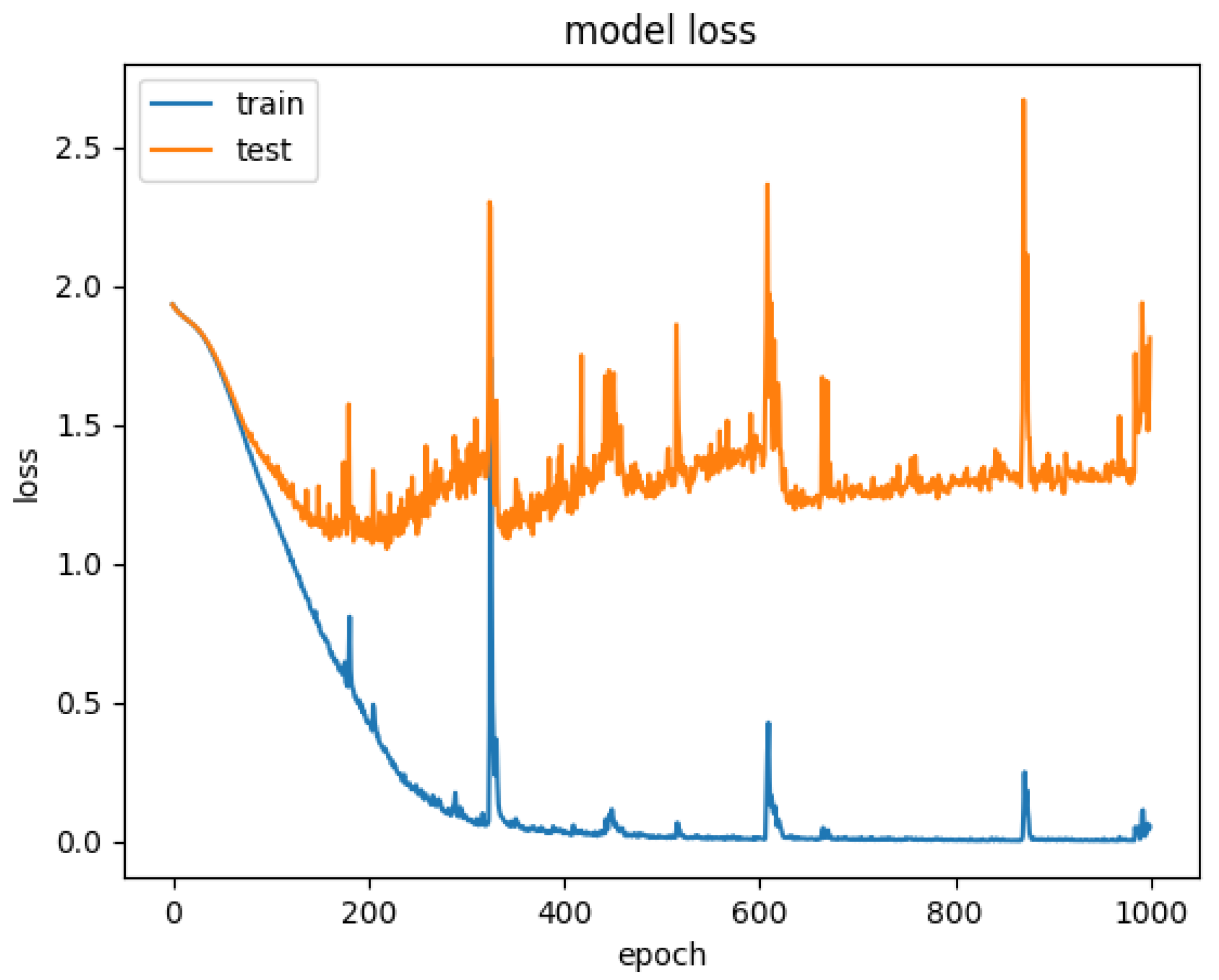
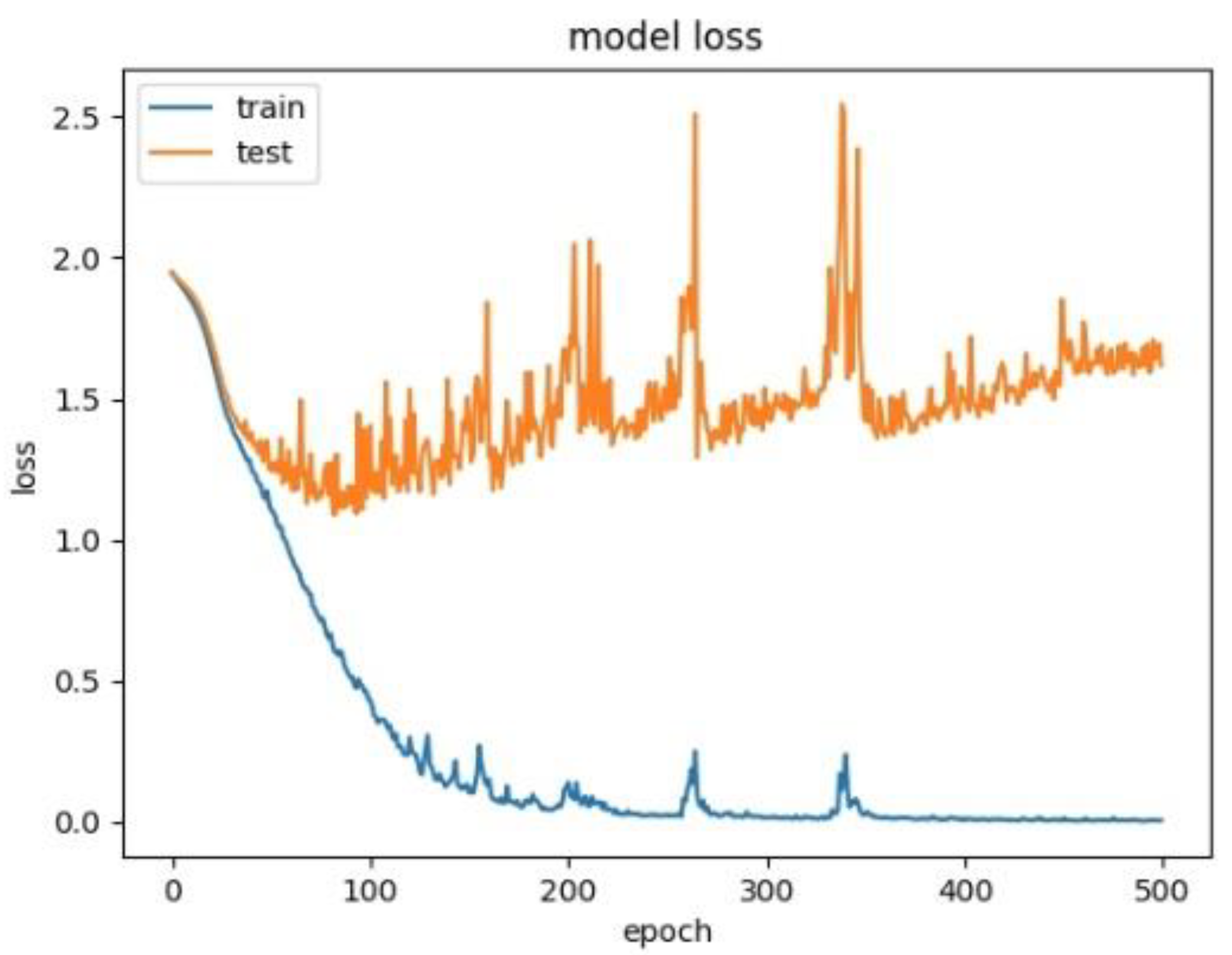
4.4. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jeong, J.; Yang, J.; Baltes, J. Robot magic show: Human-robot interaction. Knowl. Eng. Rev. 2020, 35, e15. [Google Scholar] [CrossRef]
- Issa, D.; Demirci, M.F.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]
- Zheng, K.; Xia, Z.; Zhang, Y.; Xu, X. Speech emotion recognition based on multi-level residual convolutional neural networks. Eng. Lett. 2020, 28, 559–565. [Google Scholar]
- Duan, C. A comparative analysis of traditional emotion classification method and deep learning based emotion classification method. Softw. Guide 2018, 17, 22–24. [Google Scholar]
- Anvarjon, T.; Mustaqeem; Kwon, S. Deep-Net: A Lightweight CNN-Based Speech Emotion Recognition System Using Deep Frequency Features. Sensors 2020, 20, 5212. [Google Scholar] [CrossRef] [PubMed]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control 2019, 47, 312–323. [Google Scholar] [CrossRef]
- Dangol, R.; Alsadoon, A.; Prasad, P.W.C.; Seher, I.; Alsadoon, O.H. Speech Emotion Recognition UsingConvolutional Neural Network and Long-Short TermMemory. Multimed. Tools Appl. 2020, 79, 32917–32934. [Google Scholar] [CrossRef]
- Farooq, M.; Hussain, F.; Baloch, N.K.; Raja, F.R.; Yu, H.; Bin Zikria, Y. Impact of Feature Selection Algorithm on Speech Emotion Recognition Using Deep Convolutional Neural Network. Sensors 2020, 20, 6008. [Google Scholar] [CrossRef] [PubMed]
- Zhu, L.; Chen, L.; Zhao, D.; Zhou, J.; Zhang, W. Emotion Recognition from Chinese Speech for Smart Affective Services Using a Combination of SVM and DBN. Sensors 2017, 17, 1694. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mu, Y.; Gómez, L.A.H.; Montes, A.C.; Martínez, C.A.; Wang, X.; Gao, H. Speech emotion recognition using convolutional-recurrent neural networks with attention model. In Proceedings of the 2017 2nd International Conference on Computer Engineering, Information Science and Internet Technology (CII 2017), Wuhan, China, 8–9 July 2007. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 818–833. [Google Scholar]
- Wang, Z.-Q.; Tashev, I. Learning utterance-level representations for speech emotion and age/gender recognition using deep neural networks. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5 March 2017; pp. 5150–5154. [Google Scholar]
- Zhao, Z.; Zheng, Y.; Zhang, Z.; Wang, H.; Zhao, Y.; Li, C. Exploring Spatio-Temporal Representations by Integrating Attention-based Bidirectional-LSTM-RNNs and FCNs for Speech Emotion Recognition. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018. [Google Scholar] [CrossRef] [Green Version]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient Emotion Recognition from Speech Using Deep Learning on Spectrograms. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Cummins, N.; Amiriparian, S.; Hagerer, G.; Batliner, A.; Steidl, S.; Schuller, B.W. An Image-based Deep Spectrum Feature Representation for the Recognition of Emotional Speech. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 478–484. [Google Scholar]
- Lee, J.; Tashev, I. High-level feature representation using recurrent neural network for speech emotion recognition. In Proceedings of the Interspeech 2015, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Guo, L.; Wang, L.; Dang, J.; Zhang, L.; Guan, H. A Feature Fusion Method Based on Extreme Learning Machine for Speech Emotion Recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2666–2670. [Google Scholar]
- Pascanu, R.; Gulcehre, C.; Cho, K.; Bengio, Y. How to construct deep recurrent neural networks. arXiv 2013, arXiv:1312.6026. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Du, Q.; Gu, W.; Zhang, L.; Huang, S.L. Attention-based LSTM-CNNs For Time-series Classification. In Proceedings of the 16th ACM Conference on Embedded Networked Sensor Systems, Shenzhen, China, 4–7 November 2018. [Google Scholar]
- Scherer, K. Vocal communication of emotion: A review of research paradigms. Speech Commun. 2003, 40, 227–256. [Google Scholar] [CrossRef]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Interspeech—Eurospeech, 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Badshah, A.M.; Rahim, N.; Ullah, N.; Ahmad, J.; Muhammad, K.; Lee, M.Y.; Kwon, S.; Baik, S.W. Deep features-based speech emotion recognition for smart affective services. Multimed. Tools Appl. 2019, 78, 5571–5589. [Google Scholar] [CrossRef]
- Chen, M.; He, X.; Jing, Y.; Han, Z. 3-d convolutional recurrent neural networks with attention model for speech emotion recognition. IEEE Signal Process. Lett. 2018, 25, 1440–1444. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Size | Strides | Output Shape | Param | |
|---|---|---|---|---|---|
| Input shape | (64,64,3) | 0 | |||
| CNN BLOCK1 | Conv2D(64) | (3,3) | (1,1) | (64,64,64) | 1792 |
| BN | 256 | ||||
| Activation(elu) | 0 | ||||
| Maxpooling2D | (2,2) | (2,2) | (32,32,64) | 0 | |
| CNN BLOCK2 | Conv2D(64) | (3,3) | (1,1) | (32,32,64) | 36,928 |
| Conv2D(64) | (3,3) | (1,1) | (32,32,64) | 36,928 | |
| BN | (32,32,64) | 256 | |||
| Activation(elu) | (32,32,64) | 0 | |||
| Maxpooling2D | (4,4) | (2,2) | (15,15,64) | 0 | |
| CNN BLOCK3 | Conv2D(128) | (3,3) | (1,1) | (15,15,128) | 73,856 |
| Conv2D(128) | (3,3) | (1,1) | (15,15,128) | 147,584 | |
| BN | (15,15,128) | 512 | |||
| Activation(elu) | (15,15,128) | 0 | |||
| Maxpooling2D | (4,4) | (2,2) | (6,6,128) | 0 | |
| LSTM layers | LSTM(64) | (36,64) | 49,408 | ||
| LSTM(64) | (36,64) | 33,024 | |||
| attention block | (0,64) | 4096 | |||
| SoftMax | Dense(7) | (0,7) | 455 |
| Emotion | Label | Number | One-Hot Coding |
|---|---|---|---|
| anger | W | 0 | [1 0 0 0 0 0 0] |
| boredom | L | 1 | [0 1 0 0 0 0 0] |
| disgust | E | 2 | [0 0 1 0 0 0 0] |
| anxiety/fear | A | 3 | [0 0 0 1 0 0 0] |
| happiness | F | 4 | [0 0 0 0 1 0 0] |
| sadness | T | 5 | [0 0 0 0 0 1 0] |
| neutral version | N | 6 | [0 0 0 0 0 0 1] |
| Group Number | Model | Accuracy |
|---|---|---|
| Parallel Network | ||
| 1 | CNN//LSTM×2+Global-Attention | 63.284% |
| CNN//LSTM×2+Self-Attention | 73.031% | |
| 2 | CNN+Global-Attention//LSTM×2 | 69.025% |
| CNN+Self-Attention//LSTM×2 | 70.894% | |
| Sequential Network | ||
| 3 | CNN | 70.627% |
| CNN+LSTM×2 | 79.038% | |
| 4 | CNN+LSTM+Global-Attention+LSTM | 71.837% |
| CNN+LSTM+Self-Attention+LSTM | 71.695% | |
| 5 | CNN+LSTM×2+Self-Attention | 78.772% |
| CNN+LSTM×2+Global-Attention | 85.427% | |
| 6 | CNN+Self-Attention | 75.033% |
| CNN+Global-Attention | 58.477% | |
| Model | Features | Dataset | Accuracy | |
|---|---|---|---|---|
| Kai Zheng [3] | Multilevel residual CNN | spectrogram | EMO-DB | 74.36% |
| Jianfeng Zhao [6] | 2D CNN+LSTM | Log-Mel Spectrogram | EMO-DB | 82.42% |
| Ranjana Dangol [7] | attention-based 3D CNN and LSTM | MFCC | EMO-DB | 83.38% |
| Abdul Malik Badshah [24] | CNN | spectrograms | EMO-DB | 73.57% |
| Mingyi Chen [25] | 3-D ACRNN | MFCC | EMO-DB | 82.82% |
| CNN+LSTM×2+Global-Attention | MFCC | EMO-DB | 85.427% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, S.; Zhang, M.; Yang, X.; Zhao, Z.; Zou, T.; Sun, X. The Impact of Attention Mechanisms on Speech Emotion Recognition. Sensors 2021, 21, 7530. https://doi.org/10.3390/s21227530
Chen S, Zhang M, Yang X, Zhao Z, Zou T, Sun X. The Impact of Attention Mechanisms on Speech Emotion Recognition. Sensors. 2021; 21(22):7530. https://doi.org/10.3390/s21227530
Chicago/Turabian StyleChen, Shouyan, Mingyan Zhang, Xiaofen Yang, Zhijia Zhao, Tao Zou, and Xinqi Sun. 2021. "The Impact of Attention Mechanisms on Speech Emotion Recognition" Sensors 21, no. 22: 7530. https://doi.org/10.3390/s21227530
APA StyleChen, S., Zhang, M., Yang, X., Zhao, Z., Zou, T., & Sun, X. (2021). The Impact of Attention Mechanisms on Speech Emotion Recognition. Sensors, 21(22), 7530. https://doi.org/10.3390/s21227530