
CACLA-Based Trajectory Tracking Guidance for RLV in Terminal Area Energy Management Phase



Abstract
:1. Introduction
- (i)
- An intelligent trajectory tracking guidance strategy is proposed based on CACLA for RLV in terminal area energy management phase.
- (ii)
- The guidance strategy is a data-based guidance method with the ability to learn online, with no need to know the accurate system model.
- (iii)
- The guidance strategy has good adaptability and robustness, and can be used to track the reconstructed reference trajectory.
2. Problem Formulation
2.1. Dynamics of RLV
2.2. Markov Decision Processes
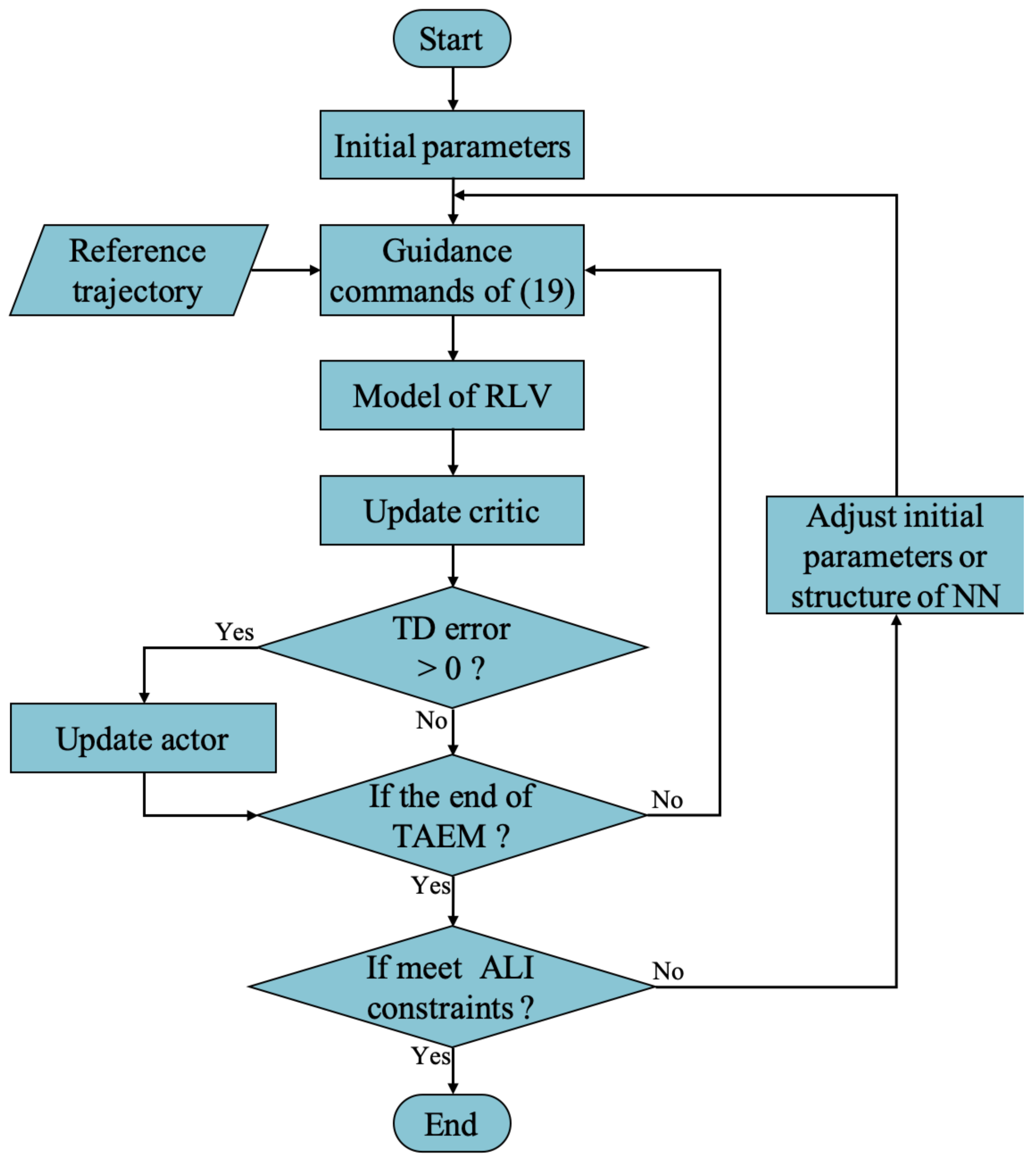
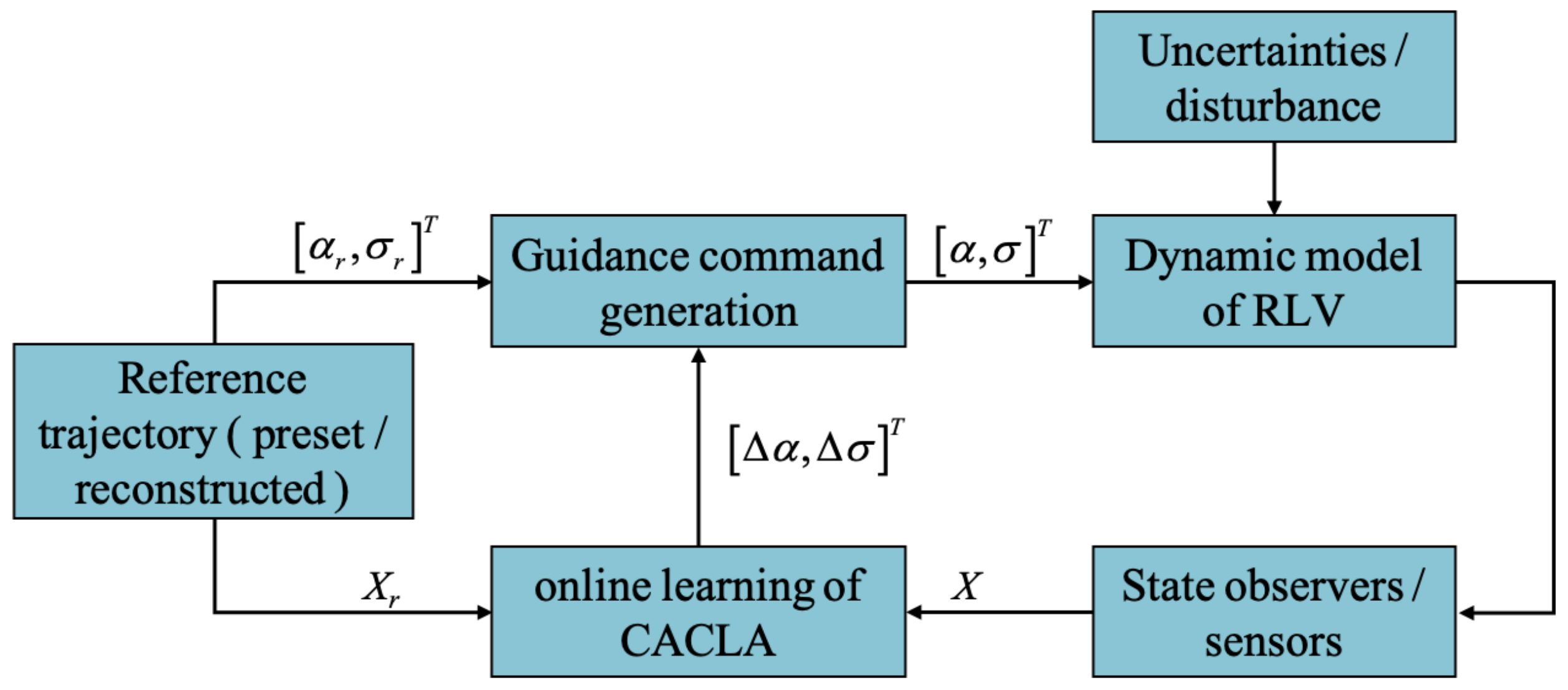
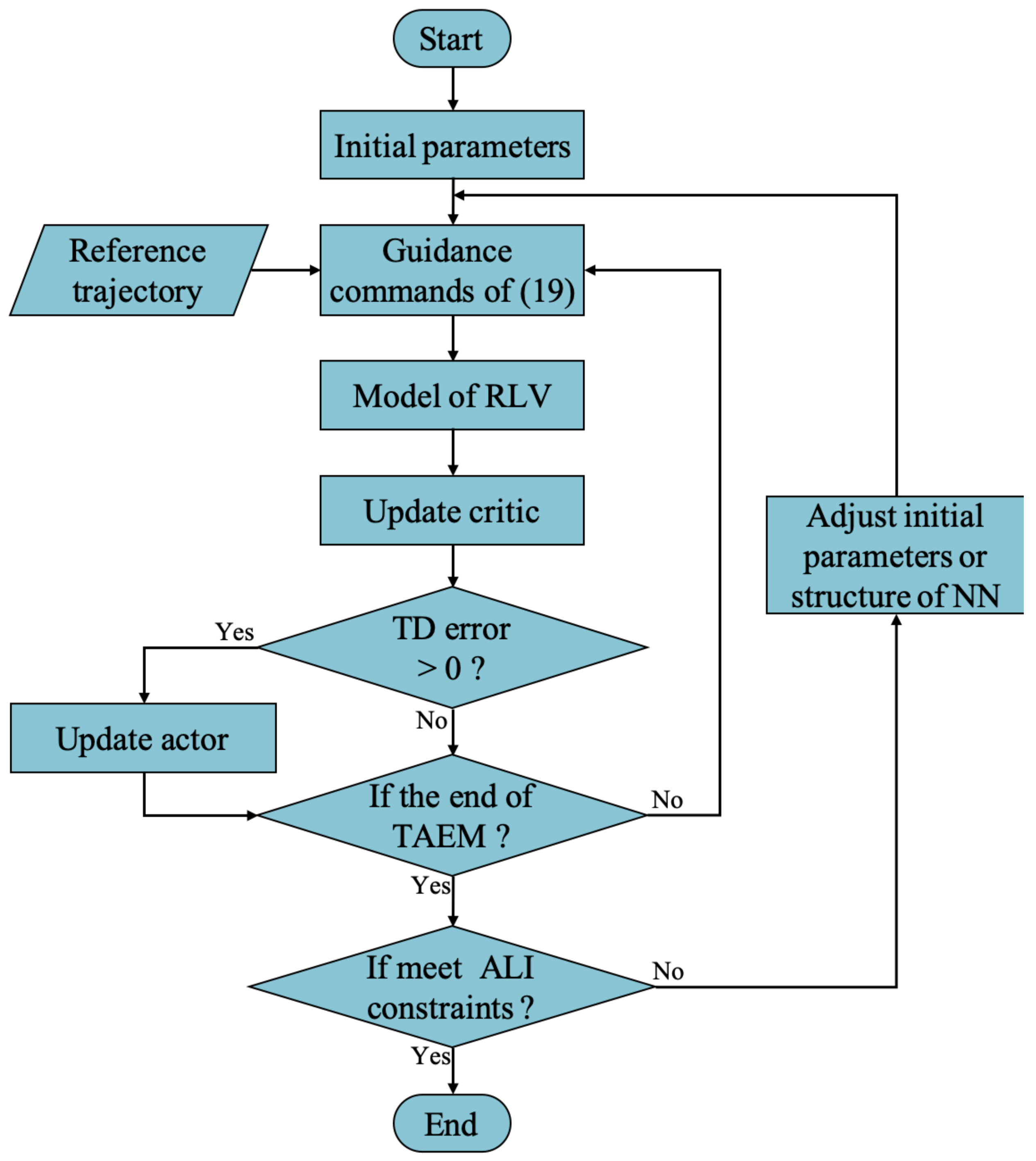
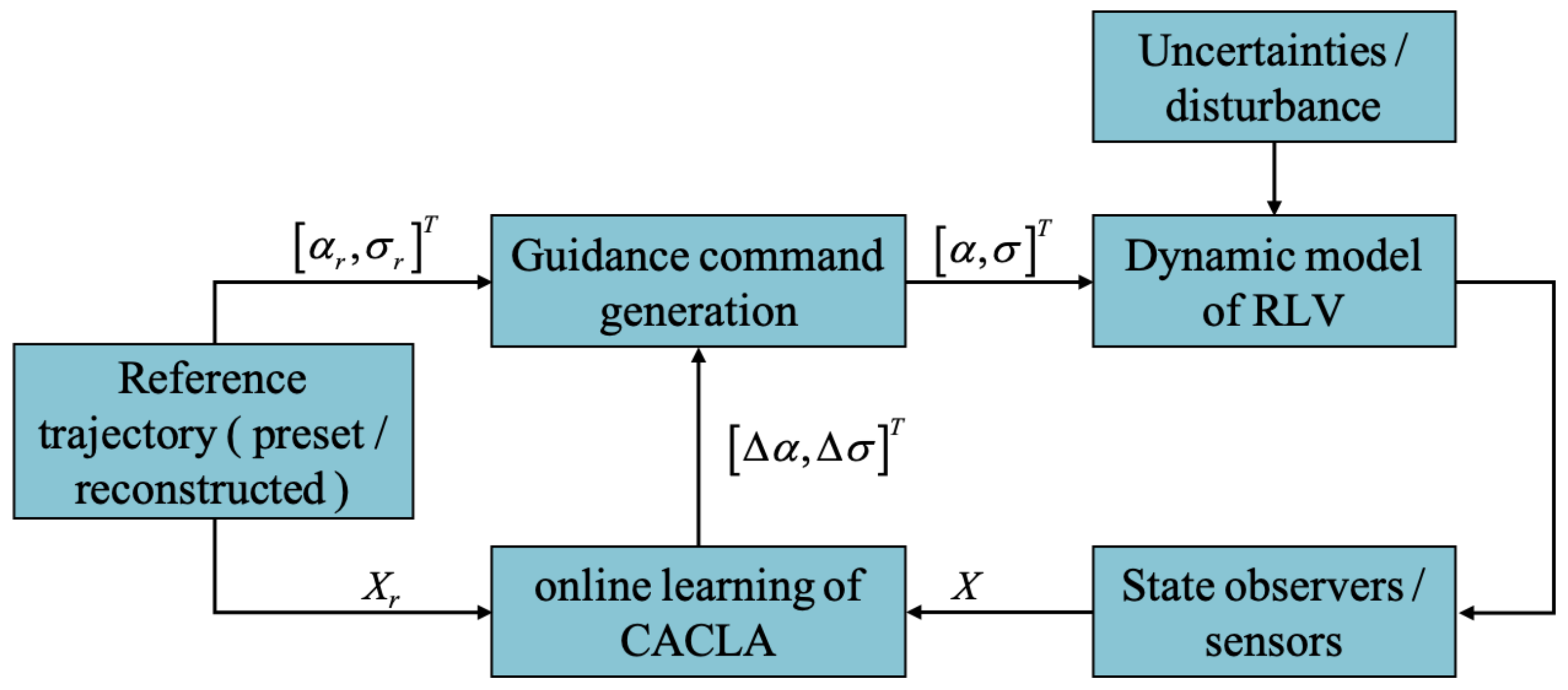
3. CACLA-Based Guidance Strategy
3.1. CACLA Algorithm for Trajectory Tracking
3.2. Application of Guidance Strategy
4. Simulation Results
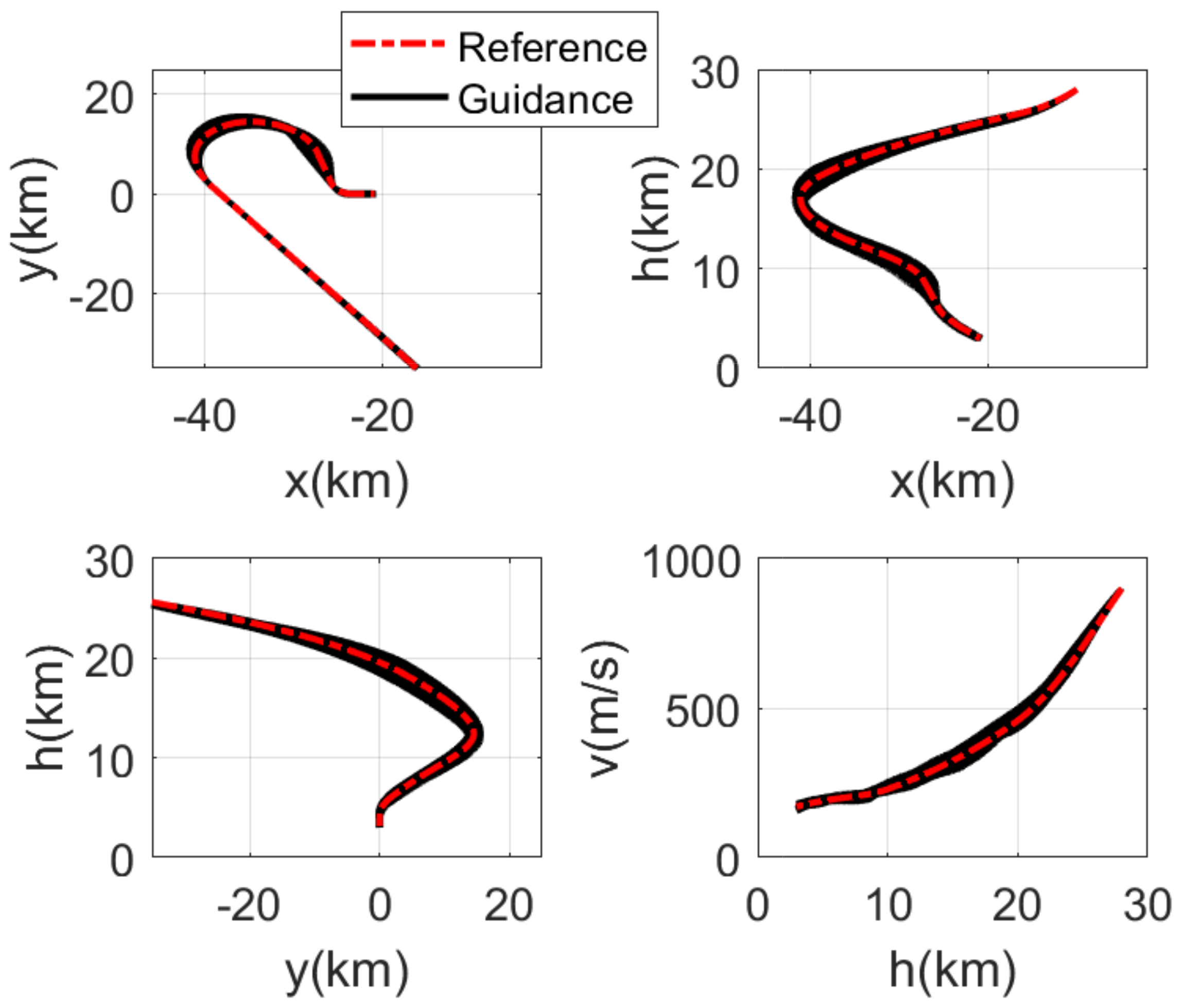
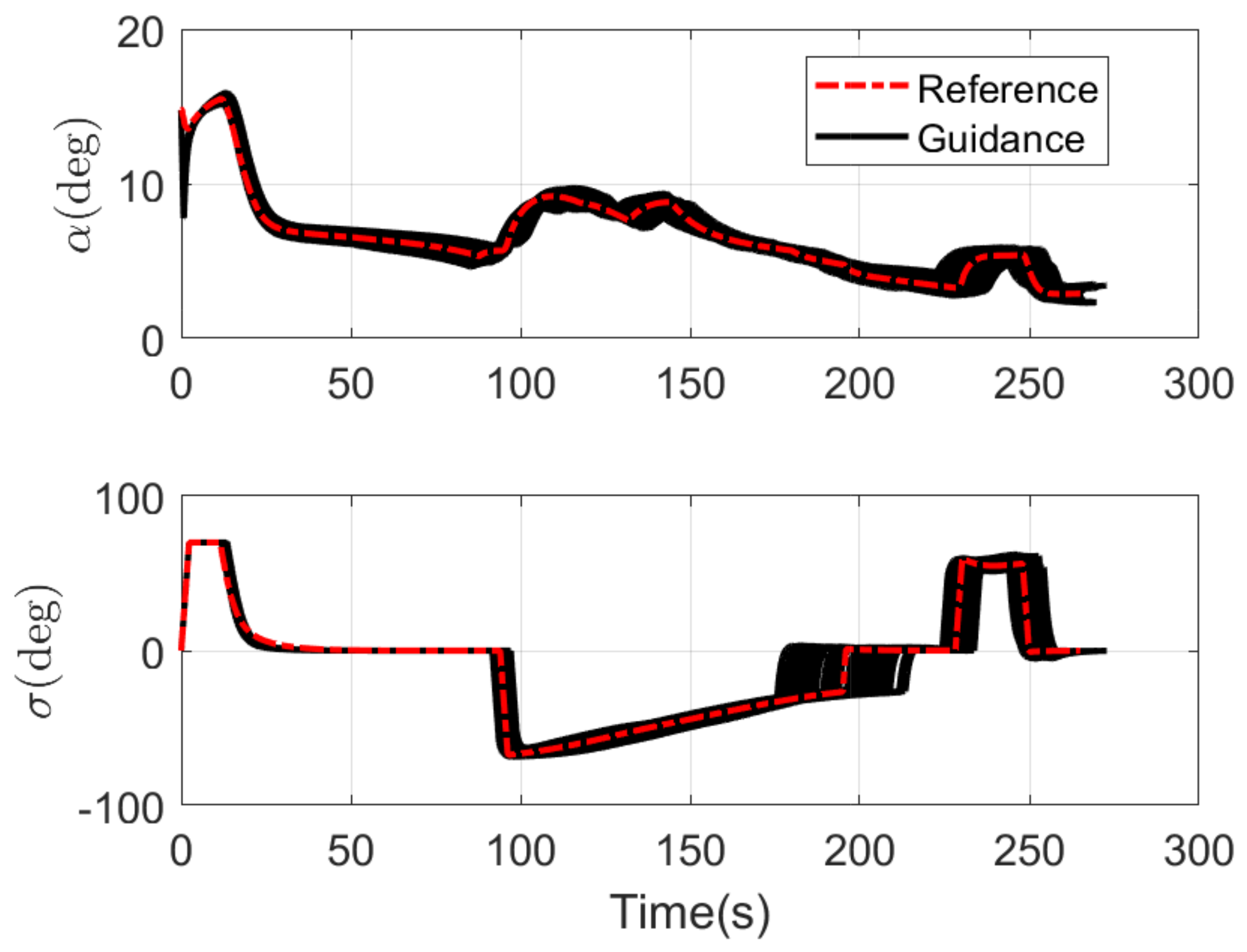
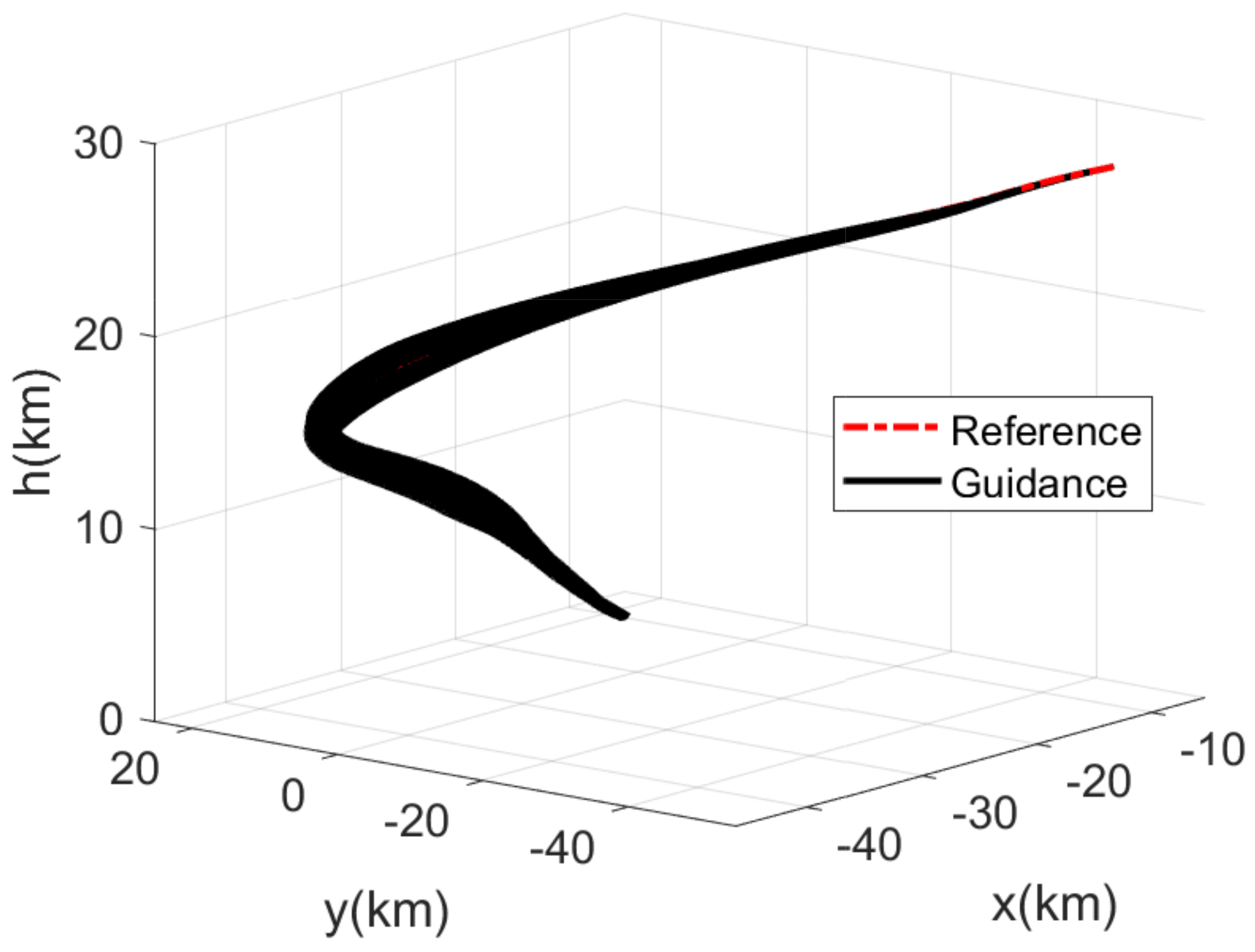
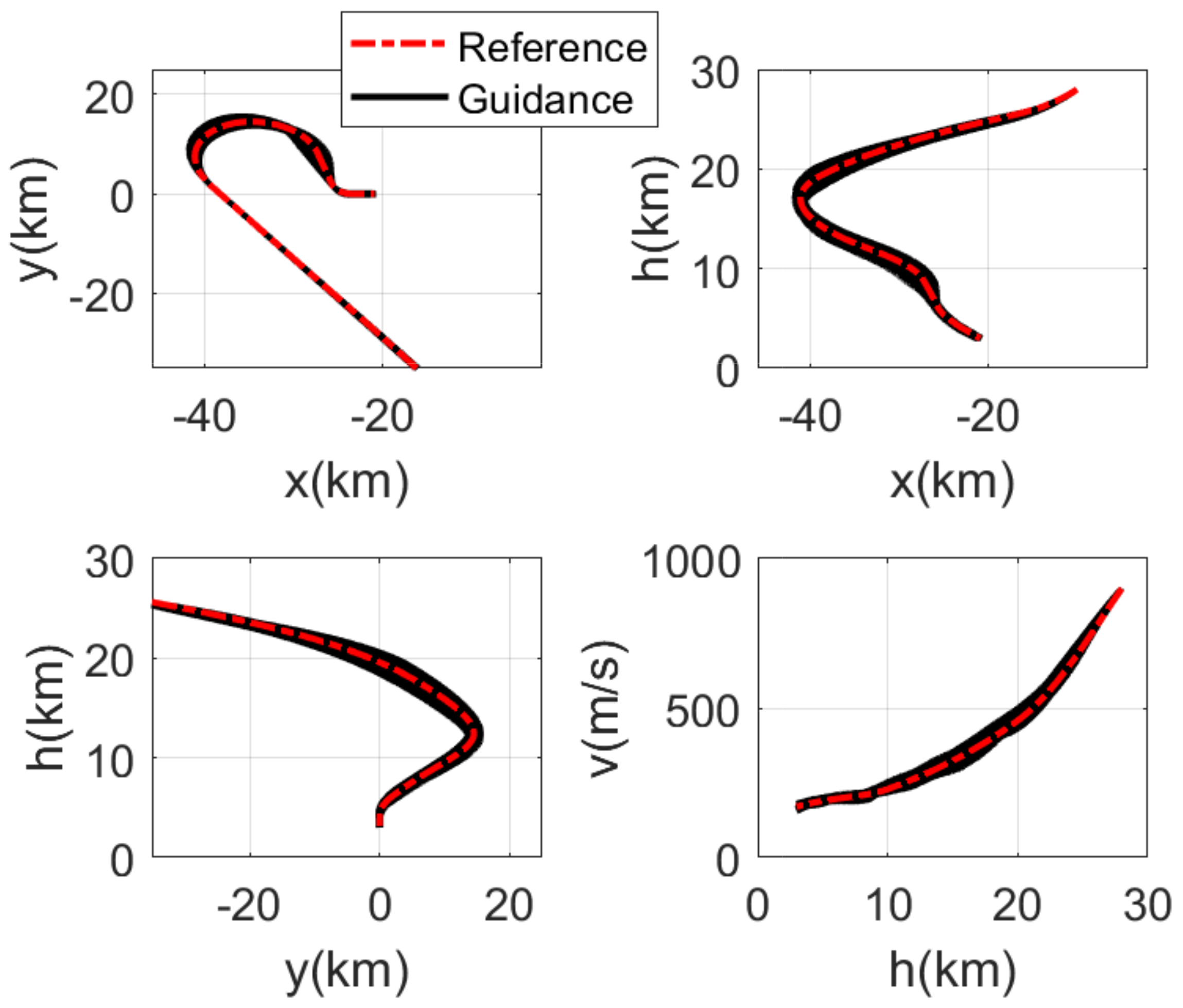
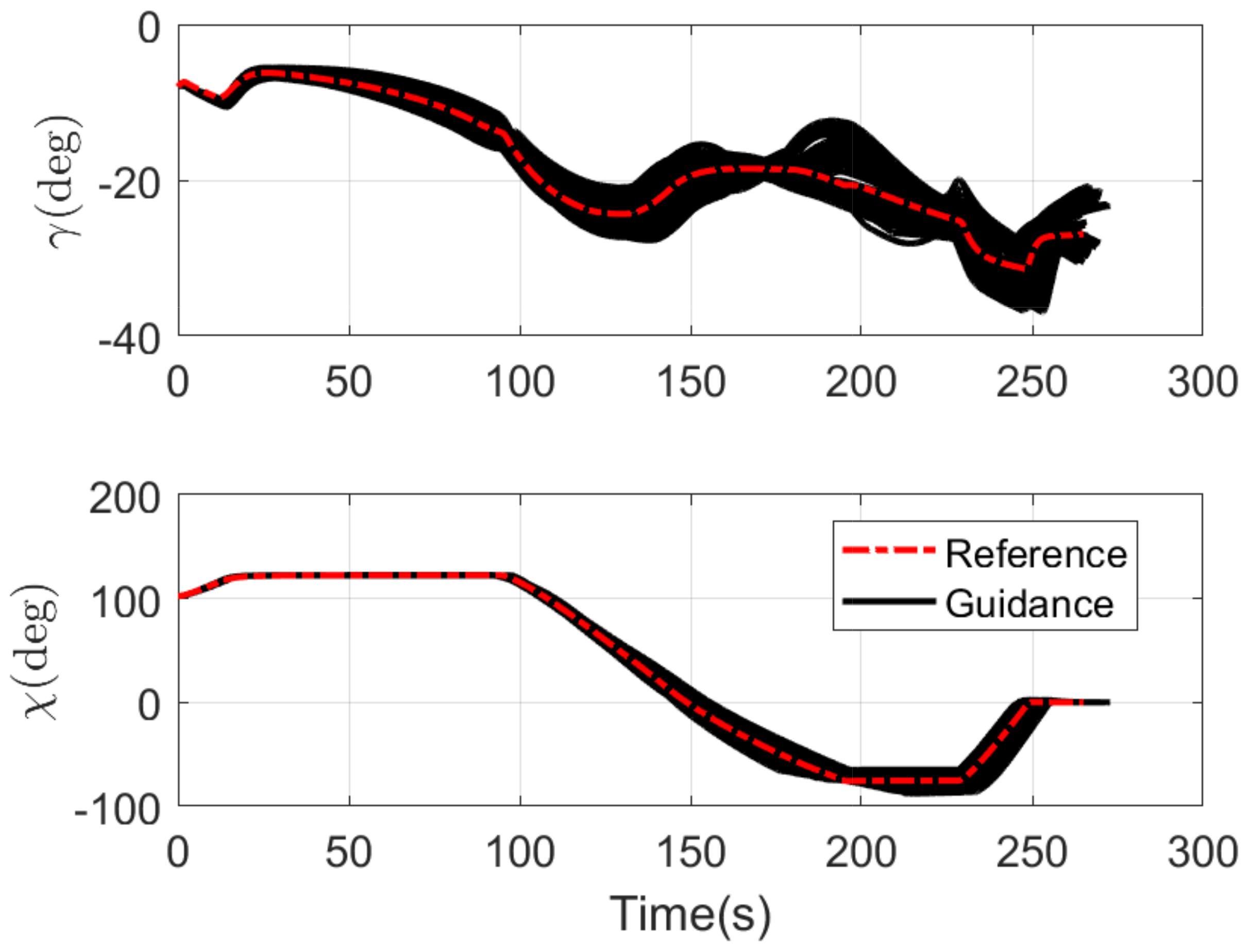
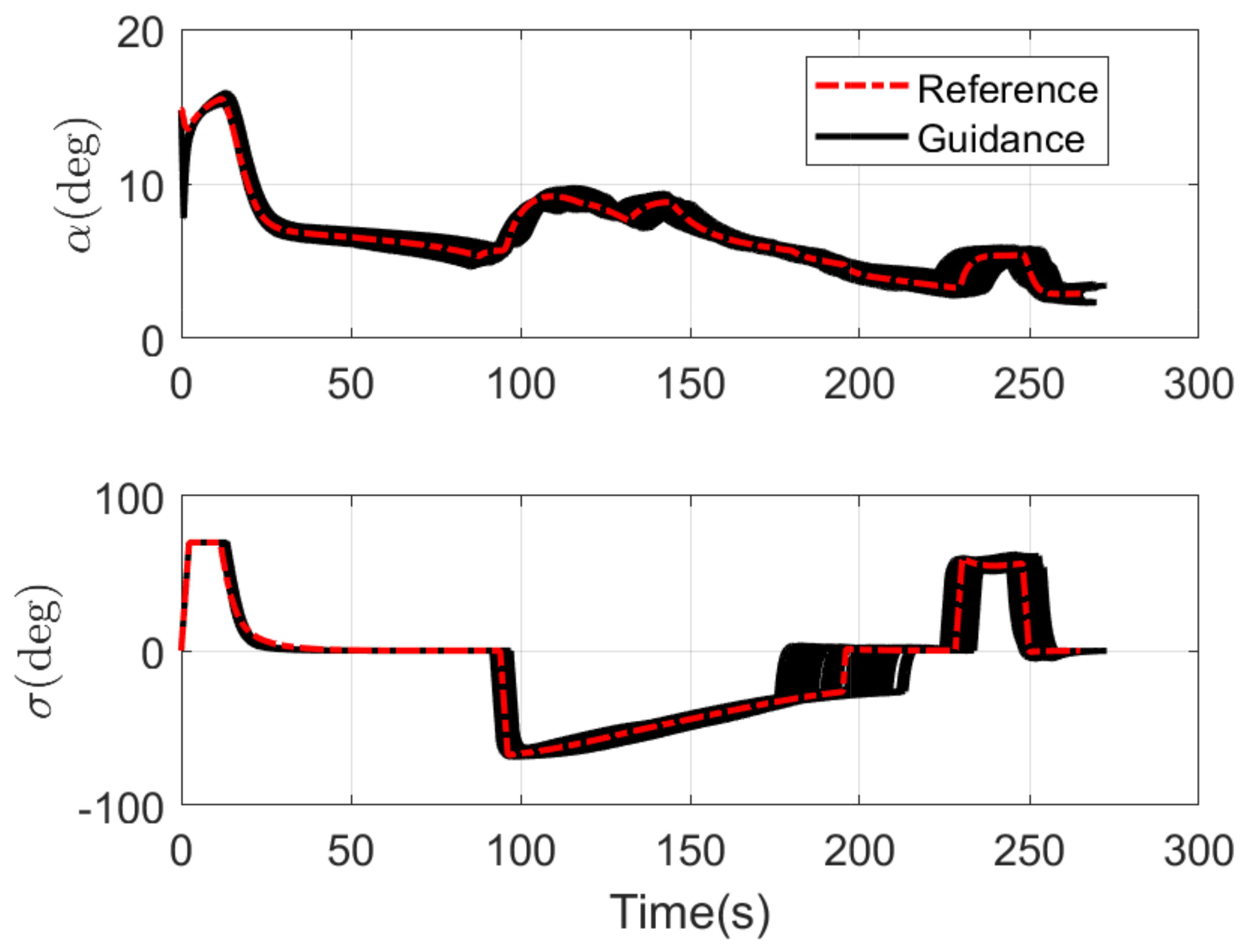
4.1. Monte Carlo Simulation
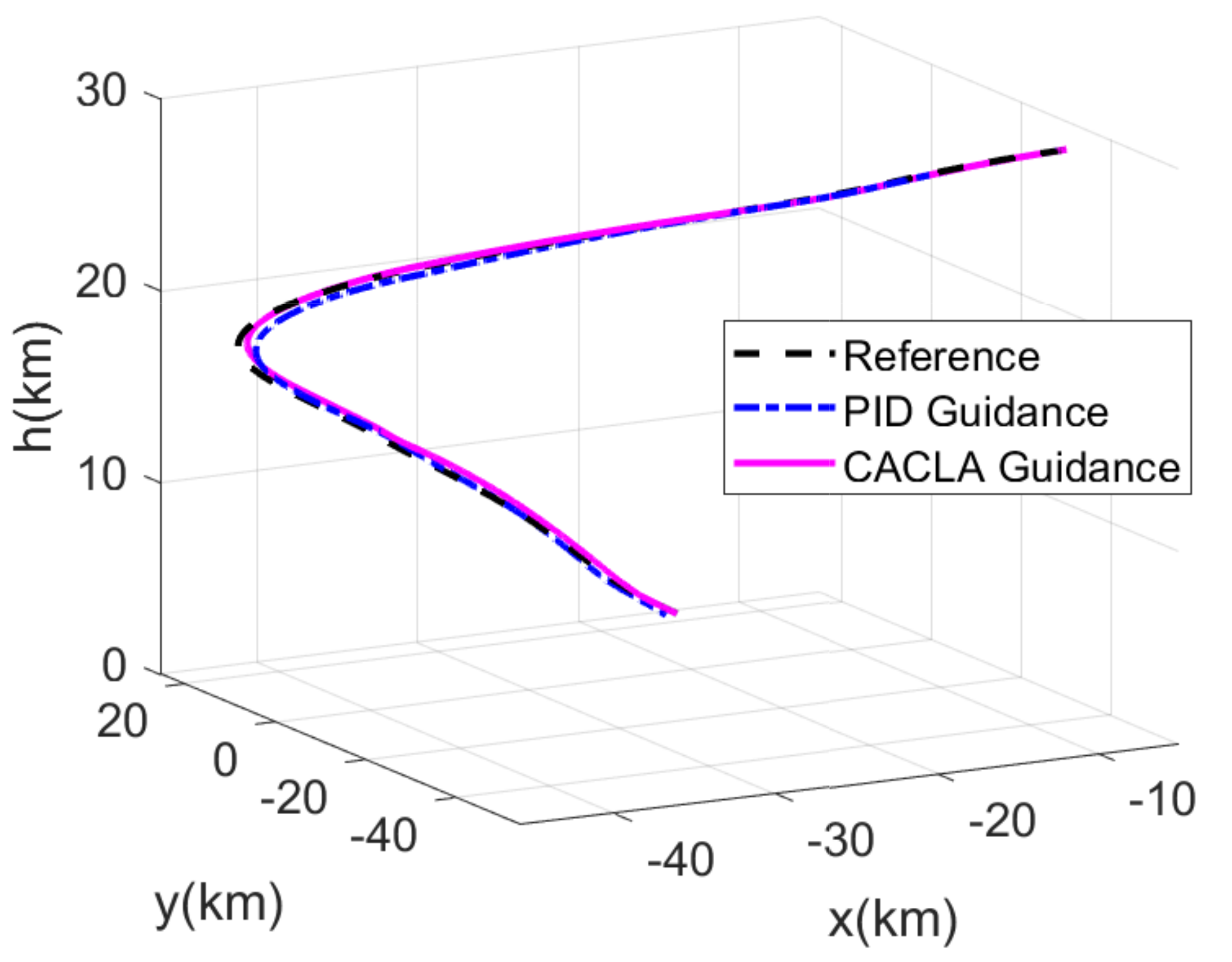
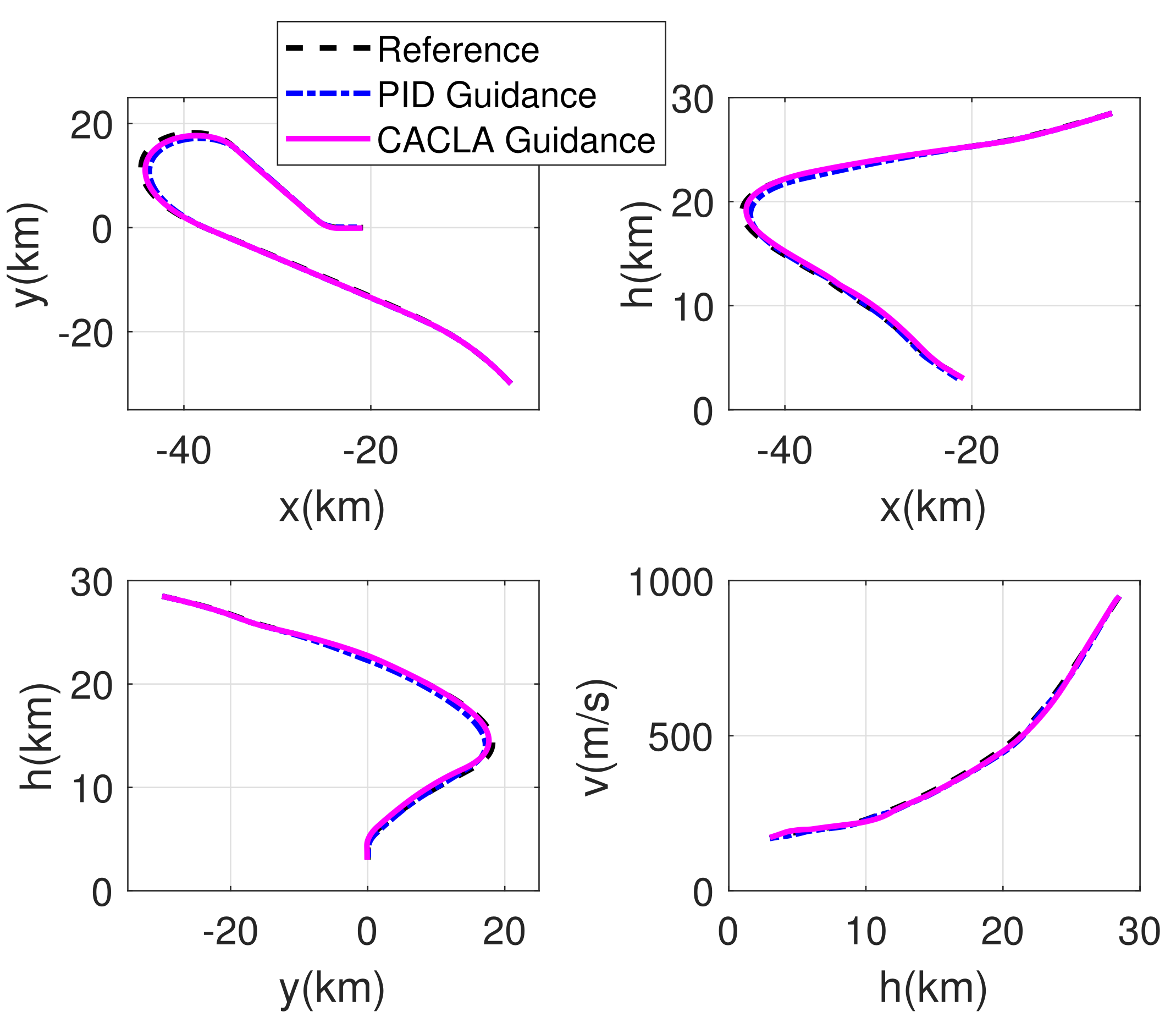
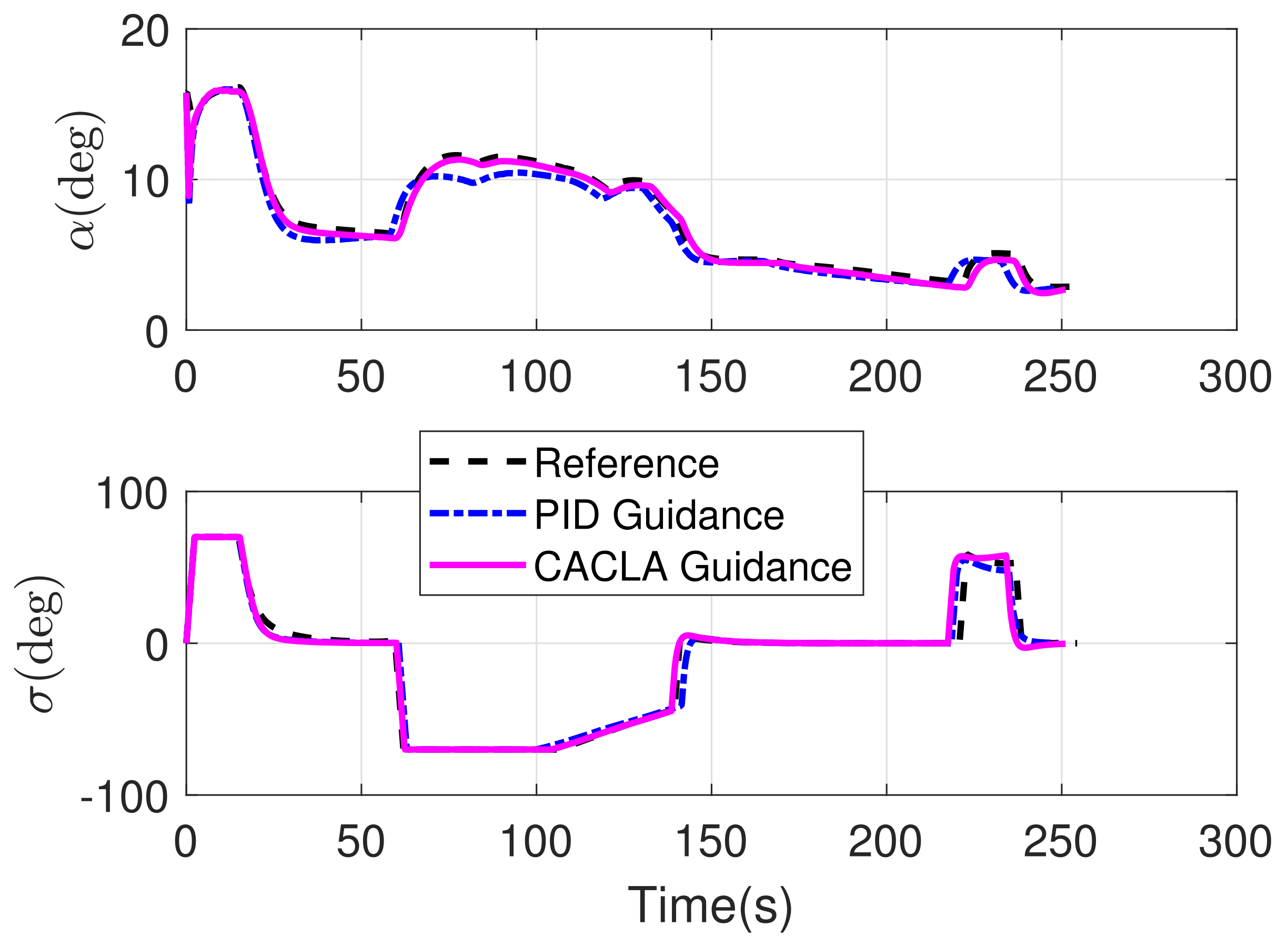
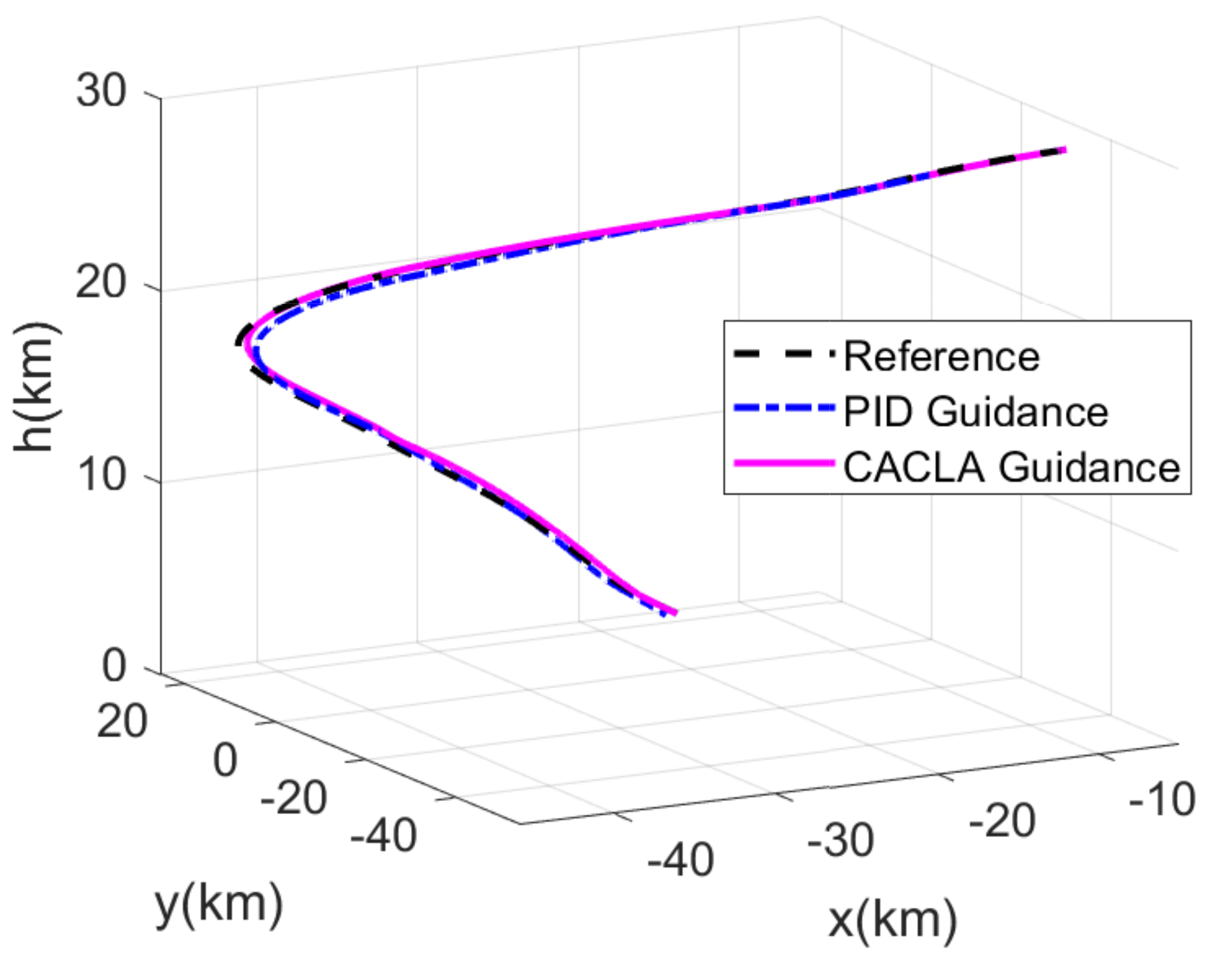
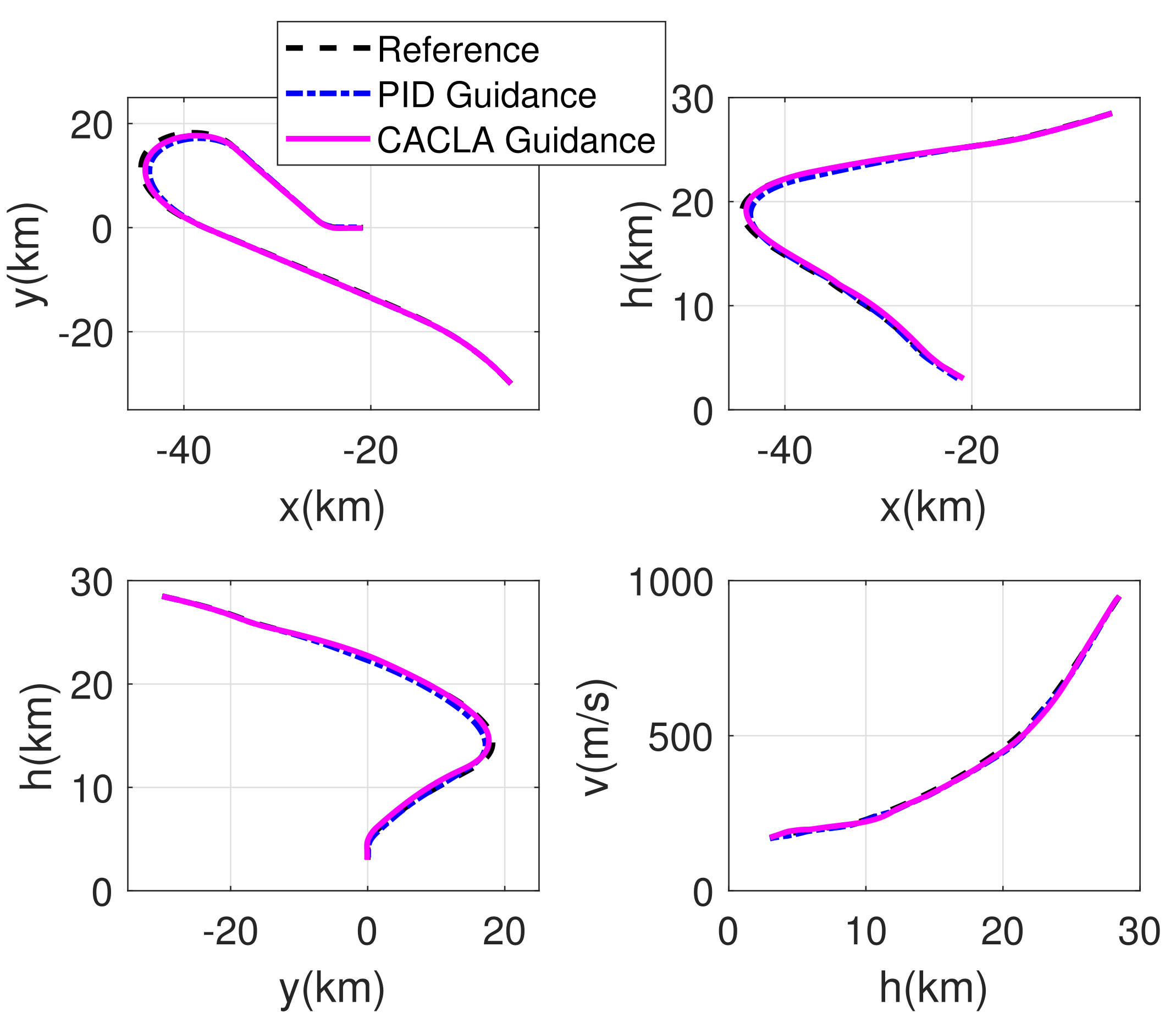
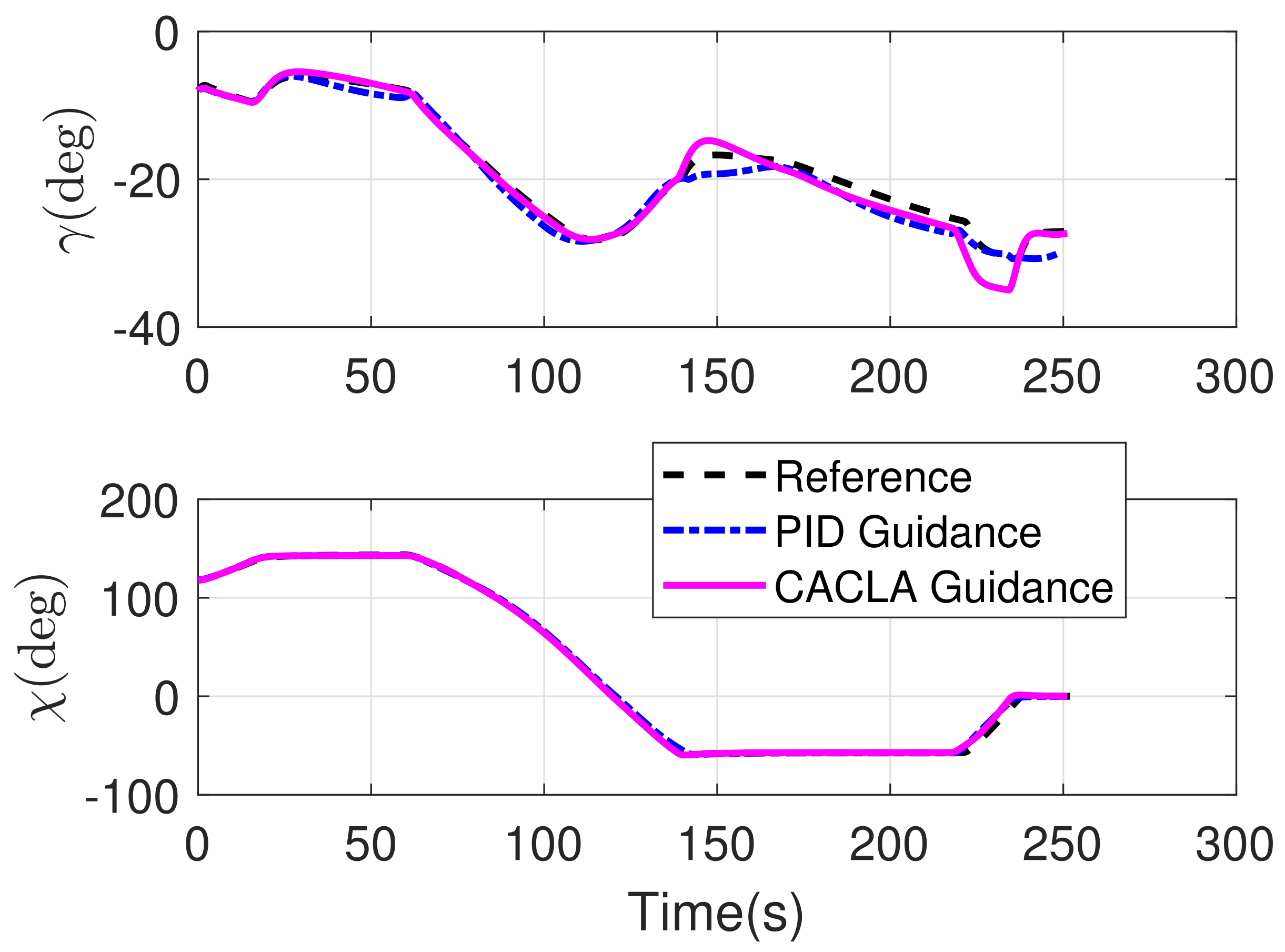
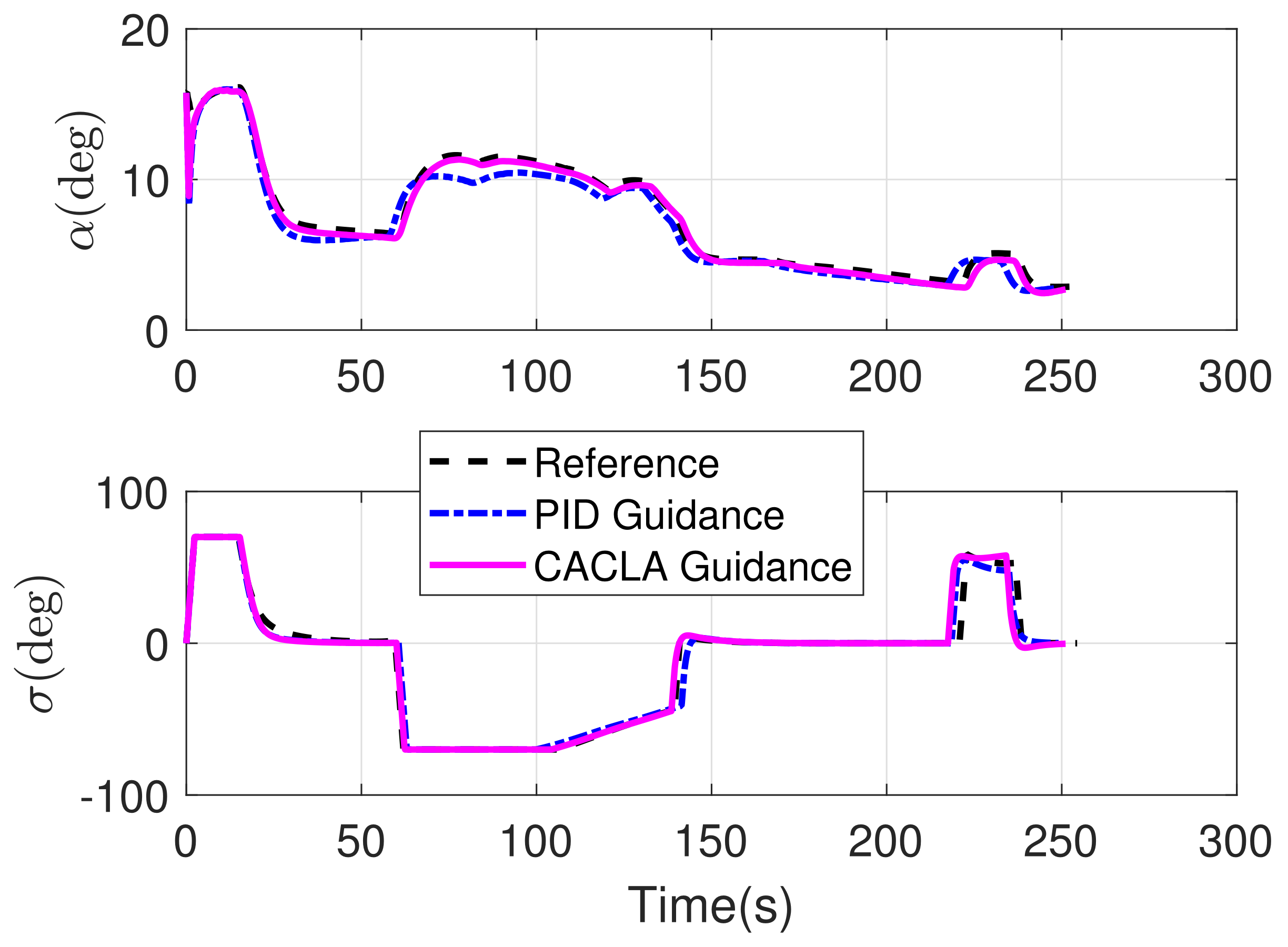
4.2. Comparison Simulation
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Joshi, A.; Sivan, K. Reentry Guidance for Generic RLV Using Optimal Perturbations and Error Weights. In Proceedings of the AIAA Guidance, Navigation, and Control Conference and Exhibit, Honolulu, HI, USA, 18–21 August 2012; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2012; pp. 1979–2014. [Google Scholar]
- Liang, Z.; Hongbo, Z.; Wei, Z. A three-dimensional predictor–corrector entry guidance based on reduced-order motion equations. Aerosp. Sci. Technol. 2018, 73, 223–231. [Google Scholar]
- Hilton, S.; Sabatini, R.; Gardi, A.; Ogawa, H.; Teofilatto, P. Space traffic management: Towards safe and unsegregated space transport operations. Prog. Aerosp. Sci. 2019, 105, 98–125. [Google Scholar] [CrossRef]
- Tomatis, C.; Bouaziz, L.; Franck, T.; Kauffmann, J. RLV candidates for European Future Launchers Preparatory Programme. Acta Astronaut. 2009, 65, 40–46. [Google Scholar] [CrossRef]
- Hanson, J. A Plan for Advanced Guidance and Control Technology for 2nd Generation Reusable Launch Vehicles. In Proceedings of the AIAA Guidance, Navigation, and Control Conference and Exhibit, Honolulu, HI, USA, 18–21 August 2012; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2012; pp. h1979–h1989. [Google Scholar]
- He, R.; Liu, L.; Tang, G.; Bao, W. Entry trajectory generation without reversal of bank angle. Aerosp. Sci. Technol. 2017, 71, 627–635. [Google Scholar] [CrossRef]
- Mao, Q.; Dou, L.; Zong, Q.; Ding, Z. Attitude controller design for reusable launch vehicles during reentry phase via compound adaptive fuzzy H-infinity control. Aerosp. Sci. Technol. 2017, 72, 36–48. [Google Scholar] [CrossRef] [Green Version]
- Zang, L.; Lin, D.; Chen, S.; Wang, H.; Ji, Y. An on-line guidance algorithm for high L/D hypersonic reentry vehicles. Aerosp. Sci. Technol. 2019, 89, 150–162. [Google Scholar] [CrossRef]
- Wei, X.; Lan, X.; Liu, L.; Wang, Y. Rapid trajectory planning of a reusable launch vehicle for airdrop with geographic constraints. Int. J. Adv. Robot. Syst. 2019, 16, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Wang, X.; Cui, N. A Novel Reentry Trajectory Generation Method Using Improved Particle Swarm Optimization. IEEE Trans. Veh. Technol. 2019, 68, 3212–3223. [Google Scholar] [CrossRef]
- Wang, X.; Guo, J.; Tang, S.; Qi, S.; Wang, Z. Entry trajectory planning with terminal full states constraints and multiple geographic constraints. Aerosp. Sci. Technol. 2019, 84, 620–631. [Google Scholar] [CrossRef]
- Li, M.; Hu, J. An approach and landing guidance design for reusable launch vehicle based on adaptive predictor–corrector technique. Aerosp. Sci. Technol. 2018, 75, 13–23. [Google Scholar] [CrossRef]
- Hameed, A.S.; Bindu, D.G.R. A Novel Flare Maneuver Guidance for Approach and Landing Phase of a Reusable Launch Vehicle. In Advances in Science and Engineering Technology, Proceedings of the International Conferences (ASET), Dubai, United Arab Emirates, 26 March–11 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Ridder, S.D.; Mooij, E. Optimal Longitudinal Trajectories for Reusable Space Vehicles in the Terminal Area. J. Spacecr. Rocket. 2011, 48, 642–653. [Google Scholar] [CrossRef]
- Corraro, F.; Morani, G.; Nebula, F.; Cuciniello, G.; Palumbo, R. GN&C Technology Innovations for TAEM: USV DTFT2 Mission Results. In Proceedings of the 17th AIAA International Space Planes and Hypersonic Systems and Technologies Conference, San Francisco, CA, USA, 11–14 April 2012; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2012; pp. 2004–2013. [Google Scholar]
- Horneman, K.; Kluever, C. Terminal Area Energy Management Trajectory Planning for an Unpowered Reusable Launch Vehicle. In Proceedings of the AIAA Atmospheric Flight Mechanics Conference and Exhibit, Minneapolis, MN, USA, 13–16 August 2012; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2012; pp. 36–38. [Google Scholar]
- Mayanna, A.; Grimm, W.; Well, K. Adaptive Guidance for Terminal Area Energy Management (TAEM)of Reentry Vehicles. In Proceedings of the AIAA Guidance, Navigation, and Control Conference and Exhibit, Honolulu, HI, USA, 18–21 August 2012; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2012; pp. 1–11. [Google Scholar]
- Kluever, C.A. Terminal Guidance for an Unpowered Reusable Launch Vehicle with Bank Constraints. J. Guid. Control. Dyn. 2007, 30, 162–168. [Google Scholar] [CrossRef]
- Fonseca, J.; Dilão, R. Dynamic guidance of orbiter gliders: Alignment, final approach, and landing. CEAS Space J. 2019, 11, 123–145. [Google Scholar] [CrossRef]
- Pengfei, F.; Fan, W.; Yonghua, F.; Jie, Y. In-flight Longitudinal Guidance for RLV in TAEM Phase. In Proceedings of the 2018 IEEE 4th International Conference on Control Science and Systems Engineering (ICCSSE), Wuhan, China, 24–26 August 2019; pp. 296–303. [Google Scholar]
- Baek, J.H.; Lee, D.W.; Kim, J.H.; Cho, K.R.; Yang, J.S. Trajectory optimization and the control of a re-entry vehicle in TAEM phase. J. Mech. Sci. Technol. 2008, 22, 1099–1110. [Google Scholar] [CrossRef]
- Cazaurang, F.; Falcoz, A.; Morio, V.; Vernis, P. Robust terminal area energy management guidance using flatness approach. IET Control Theory Appl. 2010, 4, 472–486. [Google Scholar]
- Zheng, B.; Liang, Z.; Li, Q.; Ren, Z. Trajectory tracking for RLV terminal area energy management phase based on LQR. In Proceedings of the 2014 IEEE Chinese Guidance, Navigation and Control Conference, Yantai, China, 8–10 August 2015; pp. 2520–2524. [Google Scholar]
- Grantham, K. Adaptive Critic Neural Network Based Terminal Area Energy Management/Entry Guidance. In Proceedings of the 41st Aerospace Sciences Meeting and Exhibit, Reno, NV, USA, 6–9 January 2012; American Institute of Aeronautics and Astronautics: Reston, VA, USA, 2012; pp. 4–6. [Google Scholar]
- Mu, L.; Yu, X.; Wang, B.; Zhang, Y.; Wang, X.; Li, P. 3D gliding guidance for an unpowered RLV in the TAEM phase. In Proceedings of the 2018 33rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanjing, China, 18–20 May 2018; pp. 409–414. [Google Scholar]
- Kluever, C.; Horneman, K.; Schierman, J. Rapid Terminal-Trajectory Planner for an Unpowered Reusable Launch Vehicle. In Proceedings of the AIAA Guidance, Navigation, and Control Conference, Chicago, IL, USA, 10–13 August 2009. [Google Scholar]
- Lan, X.J.; Liu, L.; Wang, Y.J. Online trajectory planning and guidance for reusable launch vehicles in the terminal area. Acta Astronaut. 2016, 118, 237–245. [Google Scholar] [CrossRef]
- Lan, X.; Xu, W.; Wang, Y. 3D Profile Reconstruction and Guidance for the Terminal Area Energy Management Phase of an Unpowered RLV with Aerosurface Failure. J. Aerosp. Eng. 2020, 33, 04020003. [Google Scholar] [CrossRef]
- Busoniu, L.; Ernst, D.; De Schutter, B.; Babuska, R. Approximate reinforcement learning—An overview. In Proceedings of the IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning (ADPRL), Paris, France, 11–15 April 2011; pp. 1–8. [Google Scholar]
- Wei, Q.; Liu, D.; Shi, G. A Novel Dual Iterative Q-Learning Method for Optimal Battery Management in Smart Residential Environments. IEEE Trans. Ind. Electron. 2014, 62, 2509–2518. [Google Scholar] [CrossRef]
- Tampuu, A.; Matiisen, T.; Kodelja, D.; Kuzovkin, I.; Korjus, K.; Aru, J.; Aru, J.; Vicente, R. Multiagent Cooperation and Competition with Deep Reinforcement Learning. arXiv 2015, arXiv:1511.08779v1. [Google Scholar] [CrossRef]
- Yang, C.; Chen, C.; Wang, N.; Ju, Z.; Wang, M. Biologically Inspired Motion Modeling and Neural Control for Robot Learning From Demonstrations. IEEE Trans. Cogn. Dev. Syst. 2018, 11, 281–291. [Google Scholar] [CrossRef] [Green Version]
- Yang, C.; Chen, C.; He, W.; Cui, R.; Li, Z. Robot Learning System Based on Adaptive Neural Control and Dynamic Movement Primitives. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 777–787. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Chen, C.; Yang, C. A Robot Learning Framework based on Adaptive Admittance Control and Generalizable Motion Modeling with Neural Network Controller. Neurocomputing 2019, 390. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, Z. Finite-Time Convergence Disturbance Rejection Control for a Flexible Timoshenko Manipulator. IEEE/CAA J. Autom. Sin. 2021, 8, 161–172. [Google Scholar]
- Al-Talabi, A.A.; Schwartz, H.M. Kalman fuzzy actor-critic learning automaton algorithm for the pursuit-evasion differential game. In Proceedings of the IEEE International Conference on Fuzzy Systems, Vancouver, BC, Canada, 24–26 July 2016; pp. 1015–1022. [Google Scholar]
- Gerken, A.; Spranger, M. Continuous Value Iteration (CVI) Reinforcement Learning and Imaginary Experience Replay (IER) for learning multi-goal, continuous action and state space controllers. arXiv 2019, arXiv:1908.10255v1. [Google Scholar]
- Zimmer, M.; Weng, P. Exploiting the Sign of the Advantage Function to Learn Deterministic Policies in Continuous Domains. arXiv 2019, arXiv:1906.04556v2. [Google Scholar]
- Lan, X.; Liu, Y.; Zhao, Z. Cooperative control for swarming systems based on reinforcement learning in unknown dynamic environment. Neurocomputing 2020, 410. [Google Scholar] [CrossRef]
- Leuenberger, G.; Wiering, M.A. Actor-Critic Reinforcement Learning with Neural Networks in Continuous Games. In Proceedings of the International Conference on Agents and Artificial Intelligence (ICAART), Funchal, Portugal, 16–18 January 2018. [Google Scholar]
- Jiang, X.; Yang, J.; Tan, X.; Xi, H. Observation-based Optimization for POMDPs with Continuous State, Observation, and Action Spaces. IEEE Trans. Autom. Control 2018, 1–8. [Google Scholar] [CrossRef]
- Lan, X.; Liu, L.; Wang, Y. ADP-Based Intelligent Decentralized Control for Multi-Agent Systems Moving in Obstacle Environment. IEEE Access 2019, 7, 59624–59630. [Google Scholar] [CrossRef]
- Van Hasselt, H. Reinforcement Learning in Continuous State and Action Spaces. In Reinforcement Learning; Springer: Berlin/Heidelberg, Germany, 2012; pp. 207–251. [Google Scholar]
- Comsa, I.S.; Aydin, M.; Zhang, S.; Kuonen, P.; Wagen, J.F.; Yao, L. Scheduling policies based on dynamic throughput and fairness tradeoff control in LTE-A networks. In Proceedings of the 39th Annual IEEE Conference on Local Computer Networks, Edmonton, AB, Canada, 8–11 September 2014; pp. 418–421. [Google Scholar]
- Hafez, M.B.; Weber, C.; Wermter, S. Curiosity-driven exploration enhances motor skills of continuous actor-critic learner. In Proceedings of the 7th Joint IEEE International Conferences on Development and Learning and Epigenetic Robotics (ICDL-Epirob), Lisbon, Portugal, 18–21 September 2017; pp. 39–46. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Mean | Three Standard Deviations |
|---|---|---|
| Atmospheric density | 0.0 | |
| Aerodynamic lift coefficient | 0.0 | |
| Aerodynamic drag coefficient | 0.0 |
| Conditions | Maximum | Minimum | Mean | Variance | Desired Value |
|---|---|---|---|---|---|
| (m/s) | 178.8269 | 159.3518 | 167.9724 | 4.654 | <180 |
| (km) | −20.7174 | −21.2804 | −20.9724 | 0.15224 | |
| (km) | 0.0934 | −0.0862 | 0.0043 | 0.0479 | |
| (deg) | 0.1533 | −0.0237 | 0.0638 | 0.0365 |
| Conditions | Reference | CACLA Guidance | PID Guidance | Desired Value |
|---|---|---|---|---|
| (m/s) | 169.9194 | 171.6748 | 168.3108 | <180 |
| (km) | −20.8309 | −20.8800 | −21.5007 | |
| (km) | 0.0148 | −0.0863 | 0.0712 | |
| (deg) | 0.0075 | 0.0828 | −0.0414 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, X.; Tan, Z.; Zou, T.; Xu, W. CACLA-Based Trajectory Tracking Guidance for RLV in Terminal Area Energy Management Phase. Sensors 2021, 21, 5062. https://doi.org/10.3390/s21155062
Lan X, Tan Z, Zou T, Xu W. CACLA-Based Trajectory Tracking Guidance for RLV in Terminal Area Energy Management Phase. Sensors. 2021; 21(15):5062. https://doi.org/10.3390/s21155062
Chicago/Turabian StyleLan, Xuejing, Zhifeng Tan, Tao Zou, and Wenbiao Xu. 2021. "CACLA-Based Trajectory Tracking Guidance for RLV in Terminal Area Energy Management Phase" Sensors 21, no. 15: 5062. https://doi.org/10.3390/s21155062
APA StyleLan, X., Tan, Z., Zou, T., & Xu, W. (2021). CACLA-Based Trajectory Tracking Guidance for RLV in Terminal Area Energy Management Phase. Sensors, 21(15), 5062. https://doi.org/10.3390/s21155062